
Abstract
A review is presented of the most effective methods for the computation of Sommerfeld integral tails. Such integrals, which are often oscillatory, singular and divergent, commonly arise in layered media Green functions. The mathematical foundations of various pertinent methods are discussed in detail and their performance is illustrated by relevant numerical examples. The associated algorithms are given in pseudocode for their easy computer implementation.
1. Introduction
In a variety of applications of new and well-established technologies a need arises to compute electromagnetic fields of time-harmonic dipoles embedded in plane-stratified media. In most cases these fields may be expressed in terms of the Sommerfeld integrals (also known as Fourier–Bessel or Hankel transforms [Citation1, p.20], [Citation2]) of the form(1)
where the kernel comprises the appropriate spectral-domain Green function, [Citation3,Citation4] z and
are the vertical (perpendicular to the stratification) coordinates of the field- and source-point, respectively,
is the lateral (in the plane of the stratification) distance between these points, and
denotes the Bessel function. [Citation5, Section 10.2]
is an even (odd) function of
for even (odd)
. Note that the second-order transform can always be expressed in terms of the transforms of orders 0 an 1, using the recurrence relations for the Bessel functions. [Citation5, Section 10.6] In certain loop antenna and aperture problems the driving current is not a point source, but is distributed over a circular region of radius
, which leads to a more general Sommerfeld-type integral of the form [Citation4,Citation6–Citation9]
(2)
where the order may be integer or half-integer. Note that the (cylindrical) Bessel function of order
is related to spherical Bessel function of order n. [Citation5, Section 10.47] The integration path in (Equation1
(1) )–(Equation2
(2) ) follows the positive-real axis of the complex
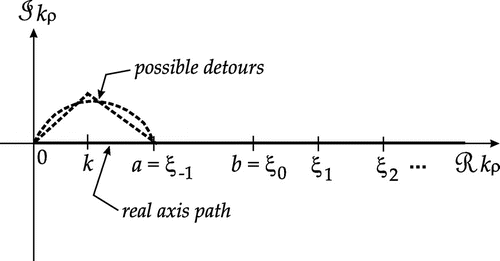
-plane, as illustrated in Figure . It is understood that this path should be indented to pass above any branch-point or pole singularities that may lie on or close to the positive-real axis, which may be accomplished by a path detour into the first quadrant, as also indicated in Figure . [Citation9–Citation15] Although the shape of this detour is not critical, its height is restricted by the exponential growth of the Bessel function off the real axis and the concomitant loss of accuracy when large numbers are subtracted to produce a small net result. Alternatively, one may first extract the poles [Citation16] and keep the integration path on the real axis as
(3)
and similarly for (Equation2(2) ), where k is the branch point associated with the upper halfspace and
is a suitably selected break point – for example, we may set
. If the second branch point is also located on or near the real axis, the corresponding break point should be inserted between k and a. The finite-range integrals
and
in (Equation1
(1) ) may readily be evaluated by the Gauss–Jacobi quadrature, [Citation17], [Citation18–Citation21] or by a suitable local change of the variable of integration on both sides of the singular point, [Citation22–Citation25] The computation of the tail integral S poses a much greater challenge, owing to the fact that
typically behaves as [Citation12]
(4)
Figure 1. Real axis integration path in the complex -plane, with possible detours.
where C is a constant and is a parameter related to z and
– for example, in a homogeneous medium
. In the above and elsewhere in this paper we utilize the “big-oh” and “little-oh” Landau symbols. [Citation26, p.9] Hence, as long as
, the integrand in (Equation3
(3) ) is oscillatory and – depending on the values of
and
, may be slowly convergent or may even diverge. The oscillations are only absent in the
“zero offset” case. [Citation27–Citation29] This is why evaluating Sommerfeld integrals has been characterized as “a standard nightmare for many electromagnetic engineers”, [Citation30] and it should not be surprising that a multitude of papers have been published – and still continue to be published – devoted to this topic. [Citation12,Citation15,Citation31,Citation45]
The purpose of the present review is to present in detail the most effective techniques and algorithms for the computation of Sommerfeld integrals along the real axis, with emphasis on the Sommerfeld tails. The mathematical foundations of the various methods are discussed in detail, with references to the relevant literature, and their performance is illustrated by representative numerical examples. In most cases algorithms are given in pseudocode for easy computer implementation. We exclude from consideration methods based on path deformation into the complex plane. [Citation46,Citation47] (applicable when ), as well as the complex-image and similar approximate methods. [Citation48–Citation51] The advantage of using the real-axis integration path is that the exact location of the poles intercepted on the proper and improper Riemann sheets need not be determined and that only Bessel functions of real arguments arise in the integral tail. The method is generally applicable, but is not recommended when the lateral distance
exceeds about a hundred wavelengths, in which case the Bessel function undergoes an excessive number of oscillations in the initial interval (0, a) of the path in Figure . Hence, when far-zone fields are of interest, other techniques – such as numerical integration along the steepest descent path or along vertical branch cuts [Citation52–Citation55] – are more appropriate.
The contents of the remainder of this paper is as follows. In Section 2, we describe the DE rules and their adaptive implementation. In Section 3, we discuss sequence acceleration by extrapolation and describe and compare the performance of the most effective algorithms. In Section 4, we discuss the partition-extrapolation method for the oscillatory Sommerfeld tails and describe its efficient implementation. This method relies on the DE rules and extrapolation techniques introduced in the previous sections. In Section 5, we describe another type of DE rule applicable to oscillatory tails. In Section 6, we include sample numerical results for Sommerfeld integral tails evaluated by different methods. Finally, we end with conclusions in Section 7. Throughout the paper, we include algorithms in pseudocode, which may easily be translated into any higher level computer language, such as modern Fortran. [Citation56]
2. Double-exponential (DE) rules
In this section, we describe efficient methods for the numerical integration over a finite or semi-infinite range of analytic functions that may be singular at one or both of the endpoints, which arise in Sommerfeld integrals. The DE rules of Takahasi and Mori [Citation19] presented here are competitive in terms of efficiency with Gaussian quadratures, [Citation57, Section 8.4], [Citation58, Chapter 3] but are more versatile – as they are quite insensitive to endpoint behavior – and simple to program, since the weights and nodes (abscissae) are easily generated. Furthermore, the DE rules can be implemented in a progressive manner, with the step size halved each time the rule level is raised and reusing the function values computed on previous levels. The integral values generated at consecutive levels can be used to monitor the convergence of the quadrature. As with any other quadrature rule, singularities of the integrand near the integration path adversely affect the convergence and should preferably be extracted prior to the integration. However, any singularities on the integration path are easily treated by splitting the integration range, so that the singularities are placed at the endpoints. The development of the DE rules was motivated by the discovery by Goodwin [Citation59] that the primitive trapezoidal rule,(5)
where is the mesh size, gives remarkably accurate results for certain functions that are analytic in a strip about the real axis. This paradox can be explained by the fact that bell-shaped functions
that fall off rapidly as
are well approximated by the sinc expansion, the integral of which gives exactly the rule (Equation5
(5) ) [Citation18, p.178]. In fact, it can be shown by contour integration in the complex plane that the discretization error in (Equation5
(5) ) is
as
, where w is the distance from the real axis to the nearest singularity of the integrand. [Citation60] The convergence being exponential, halving the step h doubles the number of correct figures in the result for sufficiently small values of h.
2.1. Finite intervals
To apply this method to finite-range integrals, we map the infinite interval onto
using a suitable monotonic function
, such that
(6)
where is the Jacobian of the transformation. As indicated, the infinite sum must in practice be terminated after a finite number of terms, thus introducing a truncation error, in addition to the discretization error. The high accuracy of the rule (Equation6
(6) ) is predicted by the Euler-Maclaurin sum formula, [Citation61, p.24], [Citation62, p.247], [Citation63] if the transformation results in a bell-shaped function whose derivatives all vanish at
. This formula is basically a trapezoidal quadrature rule with an error term in a form of an asymptotic series, whose terms comprise the derivatives of the integrand evaluated at the endpoints of the interval of integration. Hence, a transformation that forces these endpoint derivatives to vanish results in a great enhancement of the accuracy of the trapezoidal rule. The required mapping may be effected by choosing [Citation20]
(7)
where g(t) is an odd function, which leads to the trapezoidal rule approximation(8)
with the nodes and weights
defined as
(9)
where we have introduced(10)
It is important to code the abscissae and weights as indicated in (Equation9(9) )–(Equation10
(10) ), since a more direct implementation of (Equation7
(7) ) would result in overflows. Using the fact that
,
, and
, we may also express (Equation8
(8) ) in the more convenient form
(11)
Although we assume in the above the standard integration interval , an arbitrary interval [a, b] may be mapped onto
by the linear transformation
with
and
, which leads to [Citation57, p.367]
(12)
Hence, for an arbitrary interval [a, b] the nodes and weights become and
, respectively, and (Equation11
(11) ) is transformed to
(13)
We have not yet specified the function g(t) appearing in the argument of the transformation (Equation7
(7) ). Perhaps the simplest odd function choice,
(14)
generates the th order tanh rule [Citation20] which for
reduces to the classical tanh rule, [Citation64–Citation67], whereas choosing
(15)
where is a positive parameter, generates the tanh-sinh rule [Citation19]. The Jacobians
of the tanh and tanh-sinh transformations exhibit exponential and double-exponential decay, respectively, as
, resulting in the desired rapid fall-off of the integrands in most cases. These Jacobians also introduce singularities in the complex plane, so that the half-width of the strip of analyticity
for the tanh rule, as well as the tanh-sinh rule, provided that
. The performance of the tanh-sinh rule tends to be insensitive to values of
in the neighborhood of unity, hence the convenient value of
has been suggested as a good practical choice [Citation20]. Setting
is counterproductive, as this causes w to decrease rapidly, with the concomitant deterioration of the convergence rate. With
, the discretization error of these rules is
, whereas the truncation error for a given truncation index n may be estimated as
[Citation20] For a fixed n, the truncation error grows with diminishing h, while the discretization error decreases. One can therefore estimate the optimum value of h by making the two errors equal, which leads to
and
for the (classical) tanh and tanh-sinh rules, respectively, assuming
in the latter, and the corresponding total errors are found to be
and
, respectively [Citation20]. The estimates for the higher order tanh rule are more elaborate and are also given in [Citation20], while a more refined step size estimate for the tanh-sinh rule may be found in [Citation63]. Although these are only crude estimates based on the assumption that the integrand function itself makes no appreciable contribution to the decay rate, they are nevertheless indicative of the performance of the two methods. In particular, we note that with a growing truncation index n the double-exponential (DE) tanh-sinh rule converges faster that the single-exponential (SE) tanh rule. One might thus expect that a triple-exponential rule would offer further improvement. It turns out, however, that beyond the double-exponential, the poles of the Jacobian come nearer to the real axis, so that the discretization error gets worse, not better [Citation18,Citation19,Citation68,Citation69]. We should mention that, from the classical point of view, the rule (Equation13
(13) ) is a strange quadrature method indeed, as it is not exact for any polynomials – not even a constant – for any h and finite n [Citation67]. Nevertheless, it is remarkably accurate!
A salient feature of the tanh and tanh-sinh transformations is that the uniform sampling on the t-axis results in the clustering of nodes near the endpoints of the integration interval, which – in view of the rapid decrease of the weights
– permits the suppression of any endpoint singularities of
. This node clustering is also responsible for a pitfall in the computer implementation of (Equation13
(13) ), which may have been responsible for the initially slow rate of acceptance of the DE rules [Citation69]. Namely, since
can become very small, the round off errors in computing
and
may give rise to overflows as the singularities at a and b are approached. To remedy this, the function
should be programmed as a two-parameter procedure f(c, d), where
,
or b, and
, so that the singular part may be computed using d directly [Citation20,Citation68], [Citation18, p.175]. For example, if the integrand comprises a term
with
and
, this procedure should compute it as
when
, and as
when
.
In view of the indeterminate nature of the error estimates, reliance cannot be placed on a calculation of (Equation13(13) ) for a single value of the truncation index n, and if the optimum values of the mesh size h were employed, the earlier function evaluations would usually be lost when n is increased. Hence, here we adopt the following strategy, due to Evans et al. [Citation20]. First, with the selected starting (zero-level) mesh size h, the initial truncation index n is determined from the condition
(16)
where denotes the kth term in the rule (Equation13
(13) ) and
is a specified truncation error. Note that this empirical determination of the truncation index takes into account any endpoint singularities of the integrand function. In the process of computing n, the zero-level quadrature estimate is also obtained. Next, higher level estimates are computed with the number of points systematically doubled and the mesh size halved each time the level is raised, always re-utilizing in (Equation13
(13) ) the previously computed function values. The successive quadrature estimates are monitored until convergence to a specified tolerance
is achieved. Since the number of correct digits approximately doubles with each iteration once the method starts converging, the actual error of the computed integral will typically be the square of the requested
value [Citation70], [Citation18, p.178]. Accordingly, one can set
to the square root of the desired precision. A posteriori error bounds for DE rules are also available, but require the computation of two derivatives of the integrand function at the sampling points [Citation71,Citation72].
A pseudocode implementing an automatic and progressive tanh-sinh rule is given in Algorithm 1, which comprises the main procedure and two subsidiary procedures
and
, as well as an auxiliary function
. This algorithm closely follows the steps described above and is for the most part self-explanatory. The procedure
computes the initial truncation index n and the initial quadrature estimate using the condition (Equation16
(16) ), and the procedure
evaluates higher level partial sums, skipping the nodes of all previous levels. Finally, the function
computes the kth term of the rsule (Equation13
(13) ). Note that the transformation (Equation15
(15) ) is implemented as
(17)
with . After some experimentation, the initial mesh size was set to
and the truncation threshold in (Equation16
(16) ) to
. The user-provided integrand function f should be coded as a two-parameter procedure with overflow mitigation in the case of endpoint singularities, as discussed above. Implementations of the tanh-sinh rule are also given in [Citation73, p.312], [Citation74,Citation75], and [Citation18, p.176]. The tanh rule can similarly be implemented, but the algorithm is not listed in the interest of brevity.
We now illustrate the application of the tanh-sinh rule to the integral in (Equation3
(3) ), where the integrand exhibits an inverse-square-root singularity at the upper interval end, which may be set to unity without loss of generality, since the integration variable can be normalized to the wavenumber k. Hence, we consider the integral
(18)
where the integrand is singular at and also oscillatory with the frequency proportional to the parameter
. Applying Algorithm 1 to compute
, we obtain the results listed in Table , where m denotes the rule level and N the cumulative number of function evaluations. A rapid convergence is observed, with the number of correct digits, which are underlined, approximately doubled each time the rule level is raised. In the last column, we include the results of the Gauss–Jacobi quadrature [Citation17]. using the same number of nodes as in the corresponding tanh-sinh rule. The Gauss–Jacobi quadrature delivers unsurpassed accuracy, but unlike the tanh-sinh rule, is non-progressive, i.e. it cannot reuse the previously evaluated functions when the quadrature level is raised to check for convergence. For the same integral, in Tables and , we include results obtained by the classical and fifth-order tanh rules, respectively. It is seen that although the fifth-order tanh rule requires much fewer function evaluations than the classical one, it is still inferior to the DE tanh-sinh rule.
Table 1. DE tanh-sinh rule applied to .
Table 2. Classical tanh rule applied to .
Table 3. 5th-order tanh rule applied to .
Next, to examine the performance of the tanh-sinh rule in the case of highly oscillatory integrands, we evaluate with the parameter
increased over fiftyfold. The results for this case are listed in Table , where rapid convergence is observed, but only beginning with the fourth level, after a number of nodes has been reached, sufficient to capture the oscillations of
. In the last column, we again include for comparison the corresponding Gauss–Jacobi quadrature results.
Table 4. DE tanh-sinh rule applied to .
To gain further insight into the performance of the tanh-sinh rule, in Figure (a) we plot the original integrand function of
, as given by (Equation18
(18) ), and the transformed integrand
.
Figure 2. Plots of the original integrand and the transformed integrand
for (a)
using the tanh-sinh transformation and (b)
using the mixed transformation.
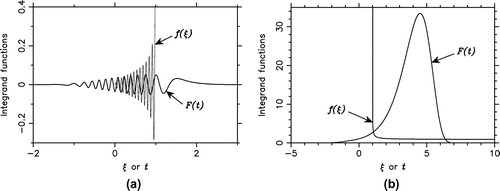
Note the singular inverse-square-root behavior of near
, modulated by the oscillations of the Bessel function. In the transformed integrand, this singularity has been moved to
and suppressed by the double-exponential decay of the Jacobian
. Although still oscillatory, F(t) is well behaved with a rapid decay at both ends, which explains the high accuracy of the trapezoidal rule.
2.2. Semi-infinite intervals
For a semi-infinite interval , the appropriate DE transformation is [Citation19]
(19)
which yields the quadrature rule(20)
with the abscissas and weights given as(21)
However, this transformation is not optimal if exhibits an exponential decay at infinity, in which case a more appropriate choice is [Citation19]
(22)
Note that this is a mixed DE–SE transformation – DE at , but only SE for
[Citation18, p.176]. However, the exponential decay of
at infinity results in a DE behavior at the upper integration limit also. For the mixed transformation (Equation22
(22) ), the abscissae and weights in (Equation20
(20) ) become
(23)
Note that, due to the lack of symmetry in the transformations (Equation19(19) ) and (Equation22
(22) ), the sum in (Equation20
(20) ) cannot be folded with respect to the
element – as in (Equation13
(13) ), and the partial sums for negative and positive k must be evaluated separately.
A pseudocode implementing an automatic and progressive mixed rule is given in Algorithm 2, which comprises the main procedure MixedQuad and two subsidiary procedures TruncIndex and PartSum, as well as an auxiliary function Term. This algorithm is very similar to Algorithm 1 – in fact, it shares the procedures TruncIndex and PartSum with the latter. The function Term is of course different, as it implements the kth term in (Equation20(20) ), with the abscissae and weights given by (Equation23
(23) ). The other difference is that the partial sums for negative and positive indices k must be treated separately – hence the two calls to TruncIndex and, at each level, two calls to PartSum. Note that changing
to k is tantamount to the replacement
. The initial truncation indices
and
for the negative and positive ranges of k are determined based on a condition similar to (Equation16
(16) ). As in the case of the tanh-sinh rule, the user-provided function
should be coded as a two-parameter procedure
, where
, to facilitate overflow mitigation for integrands that have an algebraic singularity at the lower end a of the integration range.
As an example of the application of the mixed rule, consider the integral(24)
where the integrand is singular at the lower limit and exhibits exponential decay at infinity. Applying Algorithms 2 to compute for
, we obtain the results listed in Table . Here again, once the method starts converging, approximate doubling of the number of correct digits is observed each time the rule level is raised. In this example, we specified the small value of z in order to make the integrand slowly-convergent at infinity and thus the problem more challenging. The summation limits in (Equation20
(20) ) (as determined by TruncIndex) were in this case
and
. It is found that increasing z ten-fold to
reduces
to 6 and the number of function evaluations from 57 to 45.
Table 5. Mixed rule applied to .
To get more insight into the performance of the mixed rule, in Figure (b) we plot the original integrand function of
, as given by (Equation24
(24) ), and the transformed integrand
. Note the inverse-square-root singularity of
at
and its very slow exponential decay for large
. In contrast, the transformed integrand F(t) is a smooth hat-like shaped function, with rapid decay at both ends. The singularity of the original integrand at the lower integral limit has been sent to
and suppressed by the double-exponential decay of the Jacobian, and its exceedingly slow decay for
has also been spectacularly accelerated, which explains the remarkable accuracy of the trapezoidal rule in this case.
The DE rules for semi-infinite ranges discussed above are not recommended in the case of slowly decaying and oscillating functions [Citation76]. For such integrands, a special DE rule has been developed based on a different principle, which we describe in Section 5.
3. Sequence acceleration by extrapolation
Extrapolation is a powerful tool frequently employed in the efficient computation of Sommerfeld integral tails [Citation12]. The objective of extrapolation is to accelerate the rate of convergence of a series(25)
or, equivalently, of a sequence of partial sums(26)
The sequence element may be partitioned as
(27)
where is the truncation error, commonly referred to as the remainder. To accelerate the convergence of (Equation26
(26) ), we seek a transformation
, such that the new sequence converges faster, i.e.
(28)
where are the remainders of
. Such a transformation may be viewed as an extrapolation method, since the underlying principle is to obtain better estimates from a sequence of computed values
[Citation77]. The convergence of the sequence of partial sums (Equation26
(26) ) may be characterized based on the behavior of the limits
(29)
where the second equality applies with some rare exceptions [Citation78]. If , the convergence is linear, if
, it is logarithmic, if
, it is hyperlinear, and if
, the sequence diverges. We say that the sequence is asymptotically monotone if
, and alternating if
. Alternating sequences are generally the easiest to accelerate, the logarithmic convergence being the most challenging.
The most general extrapolation procedure is based on the assumption that the remainder estimates possess the asymptotic expansion(30)
where are unknown coefficients and
are known, but otherwise arbitrary functions of n, with the property that
. To accelerate the convergence of the sequence (Equation26
(26) ), a transformation is constructed that eliminates a number of leading coefficients
from
, with the number of coefficients annihilated being the order of the transformation. For many sequences encountered in practice the remainders possess a Poincaré-type asymptotic expansion [Citation78]
(31)
where are the remainder estimates, which provide the structural information about the behavior of
for large n, and
is an auxiliary sequence of interpolation points (or nodes), such that
. Note that (Equation31
(31) ) is a specialized form of (Equation30
(30) ), with the basis functions
. The most powerful convergence accelerators exploit the information contained in the remainder estimates, which are obtained either numerically from the elements of the sequence, or derived analytically, based on their known asymptotic behavior. The choice of the auxiliary sequence
also affects the properties of the sequence transformation. If equispaced nodes are appropriate, we may use
(32)
where n is a natural number and the shift parameter is either dictated by the problem considered, or otherwise is set to 1.
3.1. The Levin transformation and the W-algorithm of Sidi
The Levin transformation is based on the remainder expansion (Equation31(31) ) using the explicit remainder estimates
. Hence, upon combining (Equation31
(31) ) and (Equation27
(27) ) and truncating the resulting asymptotic expansion after k terms, where k is the transformation order, we obtain the so-called model sequence
(33)
where the remainder estimates and the interpolation points
are assumed specified. The Levin transformation is constructed to be exact for this model sequence, which has
unknowns, viz., the limit S and the coefficients
. Thus, given a sequence of partial sums
, we may use (Equation33
(33) ) to set up a system of
linear equations and solve it for S using Cramer’s rule, which gives S as a ratio of two
determinants. Upon expanding the numerator and denominator determinants by minors of the first column, one then finds [Citation79, Section 10.5]
(34)
where(35)
In this section, we adopt the convention that the subscript of the transformation symbol refers to the sequence element index and the superscript denotes the transformation order. This notation is not always followed in the literature, where the subscripts and superscripts may have the opposite meaning, or the superscripts are dispensed with in favor of two subscripts. In the case of equispaced nodes, with given by (Equation32
(32) ), the last expression may be further specialized as
(36)
where we have omitted the j-independent terms that cancel in the quotient (Equation34(34) ), but inserted the scaling factor
in the denominator to prevent overflows [Citation18, p.214]. With properly selected reminder estimates
, the values obtained from (Equation34
(34) ) with
will be much closer to the limit S than the last computed partial sum
. The transformation (Equation34
(34) ), which was derived by Levin [Citation80], [Citation5, p.94] in the special case of equispaced nodes with
, will be referred to as the general Levin (GL) transformation.
The properties of the GL transformation critically depend on the choice of the remainder estimates . If the latter do not invoke the sequence elements
, the transformation is linear; otherwise, it is nonlinear. For example, setting
results in the Richardson extrapolation scheme [Citation78], [Citation77, p.72], in which case, assuming equispaced nodes
, the denominator sum in (Equation34
(34) ) can be evaluated by the identity [Citation81, p.4]
(37)
thus reducing (Equation34(34) ) to the Salzer summation formula [Citation82], [Citation79, p.35], which is a linear transformation effective for certain logarithmically convergent sequences
that are well approximated by rational functions of n [Citation83]. However, the following remainder estimates:
(38)
introduced by Levin [Citation80] and (in the case of the d-transformation, which may be considered as a modified t-transformation) by Smith and Ford [Citation84], give rise to the most effective extrapolation methods. There is no agreed-upon name for the modified t-transformation, which has been variously referred to as d-, -, and
-transformation [Citation18,Citation12,Citation78,Citation85]. The acceleration properties of the original and modified t-transformations are similar, but the latter requires the computation of one extra term of the series for the same transformation order. Note that we may write
, where
denotes the forward difference operator. Hence, with the remainder estimates (Equation38
(38) ), the GL transformation is nonlinear, because
depends explicitly on at least one element of
. Numerical experiments [Citation84,Citation86] supported in some cases by rigorous analysis [Citation79, Section 10.5], [Citation78] indicate that the t-transformation accelerates linear convergence and is well suited for alternating series, but fails to accelerate logarithmic convergence, whereas the u- and v-transformations are more versatile, as they accelerate both logarithmic and linear convergence. The u-transformation has been pronounced “the best available across-the-board method” [Citation84].
The GL transformation (Equation34(34) ) is non-recursive, i.e. it has to be computed from scratch each time the order k is increased. This drawback was remedied by Fessler et al. [Citation87], who derived a recursive scheme for the computation of (Equation34
(34) ) in the case of equidistant nodes. In the general case, the GL transformation can be efficiently computed by the recursive W-algorithm of Sidi, which utilizes the properties of the divided difference operator
, defined as
(39)
with [Citation88], [Citation89, Section 3.8], [Citation77, Section 2.7], [Citation90, Chapter 7]. To derive this algorithm, we rewrite (Equation33
(33) ) as
(40)
and observe that the right-hand side member is a polynomial of degree in the variable
. Hence, if we consider
and
as functions of the continuous variable x evaluated at
and apply
to both sides of (Equation40
(40) ), we obtain
(41)
because the divided difference operator of order k annihilates polynomials of degree or less. Finally, invoking the linearity of
, we may express the solution S as
(42)
where, in view of (Equation39(39) ), both the numerator and the denominator can be computed by the same recurrence formula
(43)
with the staring values and
, respectively. The elements connected by (Equation43
(43) ) form a triangle
(44)
which suggests their arrangement in the two-dimensional table, where the subscript n is the row index and the superscript k is the column index. Assuming, for simplicity, that the acceleration commences with , the table corresponding to the transformation order k has the form
(45)
where the first column comprises the starting values and the computations proceed along counterdiagonals, which are added to the table as k is increased. Since the sum of the row and column indices of the kth counterdiagonal is constant and equal to k, it is convenient to rewrite the recurrence formula (Equation43(43) ) as [Citation78]
(46)
This recursion is performed twice, to update the numerator and the denominator of (Equation42(42) ) using the appropriate starting values, and the accelerated sequence elements are returned as
. In computer implementation, the counterdiagonals can be processed in a one-dimensional array of expandable length.
A pseudocode for the GL transformation implemented via the W-algorithm is given in Algorithm 3. Here, the arrays ,
, and
, where kmax is the maximum transformation order, store the interpolation points
and the numerator and denominator counterdiagonals, respectively.
3.2. The Shanks transformation and the  -algorithm of Wynn
-algorithm of Wynn
The Shanks transformation [Citation91] results from the choice in (Equation30
(30) ), which leads to the model sequence
(47)
Essentially, this means that the limit S of the series (Equation25(25) ) is approximated by the partial sum
plus a weighted sum of the next k terms
[Citation78]. As in the case of the Levin transformation, we may use (Equation47
(47) ) to set up a system of
linear equations with the limit S and the coefficients
as unknowns and solve it for S using Cramer’s rule. This solution, given as a ratio of determinants, defines the Shanks transformation
, which is strongly nonlinear. It follows from the model sequence (Equation47
(47) ) that the sequence elements
are needed to form this solution, hence
is a transformation of order 2k. The determinantal form of the Shanks transformation is computationally expensive and is never used. Instead,
is computed by the so-called
-algorithm of Wynn [Citation92], which is a recursive scheme given as
(48)
with the starting values and
. The elements connected by the recursion (Equation48
(48) ) form a rhombus
(49)
which suggests an arrangement of in a two-dimensional
-table similar to (Equation45
(45) ). Wynn [Citation92] proved that the table elements with even superscripts give the Shanks transformation, whereas the elements with odd superscripts are only auxiliary quantities. Consequently, for even
, our transformation is
(50)
whereas for odd , we use
(51)
assuming that the extrapolation commences with the term of the sequence. The recursion (Equation48
(48) ) proceeds along the counterdiagonals of the
-table, with a new counterdiagonal added when the transformation order k is incremented by one and a new sequence element (starting value)
becomes available. Since the elements of the kth counterdiagonal are given as
,
,
, it is convenient to rewrite the recurrence formula (Equation48
(48) ) as [Citation78]
(52)
Here too, the counterdiagonals can be processed in an expandable one-dimensional array. However, because (Equation52(52) ) is a rhombus, rather than a triangle scheme, two auxiliary variables are also needed to store the table elements that are required in the processing of the next counterdiagonal, but would otherwise be overwritten during the computation of the current counterdiagonal [Citation78], [Citation18, p.213].
A pseudocode for the Shanks transformation implemented via the -algorithm of Wynn is given in Algorithm 4. Here, the array
, where kmax is the maximum transformation order, stores the counterdiagonals, and a and b are the auxiliary variables referred to above. The zero divide referred to in the comment line may occur if the algorithm is not stopped after convergence has been reached.
The Shanks transformation, or equivalently the -algorithm, is effective for alternating and linear convergence, but is unable to accelerate logarithmic convergence [Citation86]. Since no remainder estimates are required, this algorithm is user-friendly and is implemented in some standard software libraries, such as QUADPACK [Citation93]. Also, when applicable, the
-algorithm is known to be robust in the presence of noise or irregularities in the sequence elements, and is thus frequently used as a reference benchmark method for other extrapolation techniques. Hence, a good extrapolation method should perform at least as well as the
-algorithm.
3.3. The weighted-averages method and the Mosig–Michalski algorithm
Whereas the Levin and Shanks transformations are constructed to be exact for a certain model sequence, the weighted averages (WA) method belongs to the class of iterative sequence transformations, which are obtained by repeated application of some very simple transformation [Citation78,Citation85,Citation94,Citation95]. As the name indicates, the WA method is generated by a weighted mean of two consecutive partial sums [Citation12,Citation37,Citation96,Citation98]:(53)
where denotes the weight associated with
. In view of (Equation27
(27) ), we may also express the above as
(54)
where is the remainder of the new sequence element
. Upon introducing the weights ratio coefficient
(55)
into (Equation53(53) ) and (Equation54
(54) ), we may express them as
(56)
We now assume that the remainders possess the asymptotic expansion (Equation31
(31) ) and find
(57)
which suggests selecting the weights ratio in (Equation56(56) ) as
(58)
With this choice of , and assuming that the denominator in (Equation56
(56) ) has the asymptotic behavior
(59)
where , we find that the acceleration condition (Equation28
(28) ) is satisfied with
. It can be shown that
(and thus
) for all sequences other than those with logarithmic convergence, for which
(
). In view of (Equation56
(56) ), we conclude that the remainders
have the same asymptotic form (Equation31
(31) ) as
, except that the remainder estimates
are now scaled by the factor
. Consequently, the sequence
may again be accelerated by the transformation in (Equation56
(56) ), using the properly modified
in (Equation58
(58) ). We thus arrive at the recursive scheme
(60)
with the starting values and the coefficients
(61)
where the second expression is an asymptotic form applicable for large n. Note that with the weights ratio coefficients fixed as , (Equation60
(60) ) reduces to the so-called
-transformation [Citation99–Citation101], which for
further reduces to the classical Euler transformation [Citation102], [Citation103, p.124]. The power of WA derives from the fact that the coefficients
are not fixed, but adaptively adjusted.
The algorithm given above is equivalent to the so-called generalized WA procedure [Citation12], which is also referred to as the Mosig–Michalski algorithm [Citation85]. Although the asymptotic form of the weights ratio coefficient given in (Equation61(61) ) can hardly be justified, as the recursion is often applied beginning with
and satisfactory convergence is in many cases reached before n exceeds 10, Michalski [Citation12] observed that in practice this particular approximation results in conspicuously better performance than the exact form.
The recursion (Equation60(60) ) is a triangle scheme similar to (Equation43
(43) ), hence the elements
may be arranged in a two-dimensional table as in (Equation45
(45) ). Here again, we assume that the acceleration is applied commencing with
. The first column of this table comprises the starting values
and the recursion proceeds along the counterdiagonals, where the sum of the row and column indices is constant. The table is expanded by a new counterdiagonal for each new sequence element
and the upper-right corner element
is the best approximation of S, given the partial sums
. Since the elements of the kth counterdiagonal are given as
,
,
, we may rewrite the recurrence formula (Equation60
(60) ) in the more convenient form
(62)
Similar to the W-transformation, this recursion may be processed in an expandable one-dimensional array.
A pseudocode of the WA method, implemented by a simplified Mosig–Michalski algorithm with the asymptotic weights ratio coefficients, is given in Algorithm 5. Here, the arrays and
, where kmax is the maximum transformation order, store the nodes
and the counterdiagonals, respectively. Recall that the coefficient
should be set to 1 (for logarithmic convergence) or 2 (otherwise). The parameter
,
, is the ratio of the current and previous remainder estimates at the transformation order k – cf. (Equation58
(58) ). Note that
is not invoked by the algorithm and may be set to zero.
Since the WA method depends on the explicit remainder estimates , it may be classified as a Levin-type transformation [Citation85], and is thus expected to have similar properties as the GL transformation, if the same remainder estimates are employed.
3.4. Comparison of extrapolation methods
To illustrate the relative merits of the Levin–Sidi, Mosig–Michalski, and Shanks–Wynn algorithms, we compare their performance when applied to the following slowly convergent series(63)
(64)
(65)
which exhibit alternating, linear, and logarithmic convergence, respectively [Citation104]. As the performance measure we use plots of the number of significant digits (defined here as , where
is the relative error) in the transformed sequence vs. the number of terms evaluated. It will be recalled that the Levin–Sidi and Mosig–Michalski algorithms come in different variants – t, d, u, and v – depending on which of the numerical remainder estimates (Equation38
(38) ) is employed. We apply these methods using the equidistant interpolation points (Equation32
(32) ), with the shift parameter
and without acceleration delay, i.e. the transformation commences with the partial sum
. There is usually little or no advantage in delaying the commencement of acceleration, and increasing
much beyond 1 slows down the convergence rate.
In Figure , we compare the Levin–Sidi-t, Mosig–Michalski-t, and Shanks-Wynn extrapolation algorithms for the series ,
, and
.
Figure 3. Performance of the extrapolation methods for (a) (alternating), (b)
(monotone linear), and (c)
(monotone logarithmic).
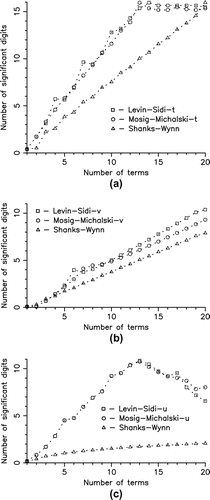
The performance of the former two methods is seen to be almost identical for the alternating series , with both reaching machine precision accuracy in under 15 iterations and outperforming the
-algorithm by a significant margin. The Levin–Sidi-d and Mosig–Michalski-d algorithms perform similarly to the respective t-variants in this case. For the monotone linear series
, we use the v-variants of the Levin–Sidi and Mosig–Michalski algorithms. Again, these methods perform similarly and both outperform the Shanks-Wynn algorithm, but the convergence is significantly slower than for the alternating case. For the monotone logarithmic series
, we use the u-variants of the Levin–Sidi and Mosig–Michalski algorithms. The performance of these two methods is again almost identical, but the curve is not monotonic in this case, as it bends down after climbing to approximately 11 significant digits in about this many iterations. This behavior can be attributed to the numerical instability of Levin-type algorithms for high transformation orders, caused by cancellation errors that are known to occur in the monotone case [Citation87]. The Shanks-Wynn algorithm performs poorly, as was to be expected for logarithmic convergence.
The above results confirm that the Levin–Sidi and Mosig–Michalski algorithms are among the most versatile and powerful extrapolation methods currently known. Since both algorithms are equally easy to implement, which one should be selected is largely a matter of personal preference. However, when approaching a new class of problems, one will be well-advised to try at least two different extrapolation methods, preferably including the Shanks-Wynn algorithm among them.
4. Partition-extrapolation method for oscillatory integral tails
We now describe a powerful technique for automatic integration of Sommerfeld integral tails, which combines the use of progressive quadratures, such as the DE rule, and the extrapolation methods discussed above. Hence, consider the tail integral(66)
over the real axis segment , where the integrand function
is oscillatory and may be slowly decaying or even divergent, as in (Equation1
(1) ). We compute S as the limit of the sequence of the partial sums
(67)
as , where
and
,
, are suitably selected break points, e.g. the consecutive zeros of
– see Figure . The finite-range integrals
are readily computed by a low-order Gauss-Legendre quadrature. For Sommerfeld integrals, the 16th-order Gauss-Legendre rule typically yields double precision machine accuracy for the partial integrals between consecutive zeros of the Bessel function [Citation105,Citation106], but for greater reliability, one can resort to Gauss-Kronrod or Patterson rules [Citation58, p.131], [Citation107], or to the progressive Clenshaw-Curtis quadrature [Citation108], which provide error estimates. The recursive DE tanh-sinh rule described in Section 2 can also be employed, even in the absence of endpoint singularities. Typically, the sequence
is slowly convergent, hence acceleration by one of the extrapolation methods discussed in Section 3 is a good strategy. The combination of the partition of the integral in (Equation67
(67) ) with extrapolation to speed the convergence of
gives rise to the partition-extrapolation (PE) method, which is the subject of many papers, including [Citation12,Citation15,Citation102,Citation109,Citation120].
In order to effectively utilize extrapolation methods to accelerate (Equation67(67) ), it is advisable to first investigate the behavior of the remainders
(68)
Here, we assume here that for , where
is a suitably selected break point, the integrand function in (Equation66
(66) ) may be expressed as
(69)
where has the asymptotic expansion
(70)
with the parameter , while
is periodic, with half-period q, such that
(71)
Consequently, we may assume equidistant break points(72)
where b is the first zero of in the range where the representation (Equation69
(69) ) is applicable. We now substitute (Equation69
(69) ) into (Equation68
(68) ) and use (Equation70
(70) ) to obtain
(73)
which upon changing the variable of integration to and using (Equation71
(71) ) becomes
(74)
Finally, upon expanding the inverse denominator of the integrand of (Equation74(74) ) in a Taylor series about
and integrating term-by-term, we arrive at the Poincaré-type expansion
(75)
where are n-independent coefficients and
are the remainder estimates, given as
(76)
The break points in (Equation75
(75) )–(Equation76
(76) ) may also be replaced by the interpolation points
given by (Equation32
(32) ) with the shift factor
.
Based on the above analysis, we may select the most appropriate extrapolation method for the sequence of partial sums (Equation67(67) ). Hence, upon using (Equation75
(75) ) and (Equation76
(76) ) in (Equation29
(29) ), we readily find that
, which indicates that the sequence (Equation67
(67) ) is linearly convergent and alternating, and thus all four variants of the Levin-type methods, corresponding to the numerical remainder estimates (Equation38
(38) ), as well as the Shanks-Wynn algorithm, are applicable. Using the analytical remainder estimates derived above with the Levin–Sidi and Mosig–Michalski algorithms gives rise to what may be called a-variants of these methods. The parameter
in the Mosig–Michalski algorithm then becomes
(77)
with , and from (Equation59
(59) ) it follows that
, and thus
. The Levin-Sidi-a algorithm is closely related to the W-transformation of Sidi [Citation111], while the Levin-Sidi-d algorithm is tantamount to his “user-friendly” mW-transformation [Citation114].
As an example, consider the integral(78)
which follows from a well-known identity [Citation81, Equation 6.623.1], [Citation105] by splitting the integration range at an arbitrary point
. For
, and 2, the integrals
resemble the static forms of the tail integrals that arise in the electromagnetic field computation in layered media [Citation4]. With
and
the left-hand side integrals in (Equation78
(78) ) are formally divergent, but are defined in the sense of Abel summability [Citation77, p.381], [Citation21,Citation105]. As the finite-range integral on the right-hand side of (Equation78
(78) ) can readily be evaluated to machine accuracy by a numerical quadrature – such as the tanh-sinh rule discussed in Section 2, the infinite integral
may serve as a realistic test bed for the extrapolation methods, allowing in particular to examine the effect of changing the lower limit a. In view of the asymptotic form of the Bessel function [Citation5, p.223]
(79)
fits in the framework of the PE method with
,
, and
. The natural choice of the break points
for the partial integrals
in (Equation67
(67) ) are in this case the consecutive zeros of
(Longman partition) [Citation102,Citation117]. Since the exact Bessel function zeros can only be found by iterative procedures [Citation117,Citation121], other alternatives have been proposed, such as the asymptotic zeros based on the expansion (Equation79
(79) ) (Lyness partition) [Citation113], or just the equidistant nodes separated by the asymptotic half-period q (Sidi partition) [Citation111,Citation114,Citation122]. Still another alternative is to use the asymptotic extrema of the Bessel function, which somewhat dampens the oscillation of the partial sums and results in a modest convergence improvement of the PE method.[Citation113] The Sidi partition method is the simplest, but it has been found unreliable, as there are certain values of
for which the sequence of the partial sums (Equation67
(67) ) ceases to be strictly alternating, with the concomitant precipitous performance degradation of the PE method [Citation12]. We have observed, however, that this problem does not occur if the lower integration limit a is always placed at the first Bessel function zero that is greater than the original a. Of course, if there is no flexibility in the choice of the lower integral limit, this shift requires an extra partial integral to bridge the gap between the original and the modified values of a. Hence, if the nth zero of
is denoted by
, in the modified Sidi partition we relocate a to
, where m is the lowest zero index for which this condition is satisfied, and set the break points according to (Equation72
(72) ), with
. We adopt this modified Sidi partition in the examples that follow. For
, we use the tabulated values [Citation123, p.409] if
, and the large-n McMahon’s expansions [Citation123, p.371] otherwise.
Figure 4. The original () and accelerated (
) partial sums for the integral
, using the PE method with the modified Sidi partition and extrapolation by the Mosig–Michalski-a algorithm. Note that the scales of these two sequences are vastly different. Although
is divergent,
rapidly converges to the exact value of the integral (the antilimit),
.
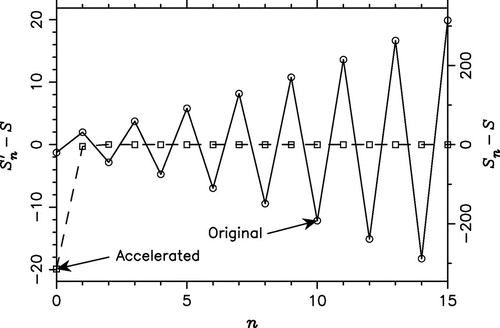
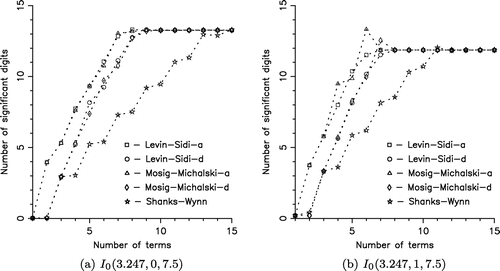
Figure 5. Performance of different PE methods for the integrals.
In Figure , we show plots of the original and accelerated partial sums for the integral , using the PE method with the Mosig–Michalski-a algorithm. Note that the chosen value of the lower limit a is the first zero of
, consistent with the modified Sidi partition. The original sequence
is divergent and alternating, while the transformed sequence
converges rapidly to the exact integral value S – in this case to the so-called antilimit [Citation78], [Citation83, p.248]. In Figure , we compare the performance of the PE methods for the integrals
and
, using the modified Sidi partition and different extrapolation algorithms. The difference between these two integrals is the strong exponential decay exhibited by the integrand of the second. Note that the chosen value
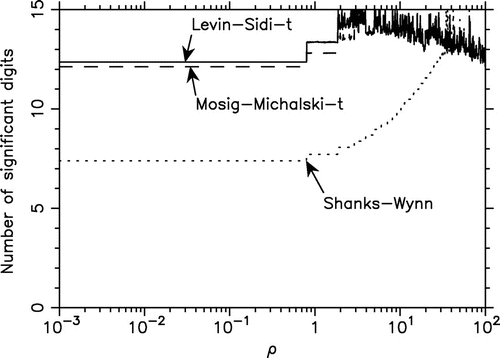
is consistent with the Sidi partition. As the performance measure we use plots of the number of significant digits vs. the number of terms (partial integrals) evaluated. All computations are done using double precision arithmetic with approximately 15 significant digits. We present plots for the a- and d-variants of the Levin-type algorithms (the other variants produce very similar results) and for the Shanks-Wynn algorithm. It is noted that the Levin–Sidi and Mosig–Michalski perform similarly and both are more effective than the Shanks-Wynn algorithm. Furthermore, the a-variants, using analytical remainder estimates, have a slight advantage over the d-variants. However, the latter are more user-friendly, as no asymptotic analysis of the integrand function is required. In Figure , we plot the number of significant digits obtained after 9 extrapolation steps (at the cost of 10 partial integrals) for the PE method using the modified Sidi partition with the Levin–Sidi-t, Mosig–Michalski-t, and Shanks–Wynn algorithms, applied to the integral
with the threshold value of
and varying
. Note that both Levin-type methods, using numerical remainder estimates, achieve at least 12 digits of accuracy over the five-decade
-range and no breakdowns are observed. The Shanks-Wynn algorithm is competitive for large
only. These plots were generated using 250 points per decade. The staircase behavior is due to the passing of the consecutive Bessel function zeros through the threshold value a and the concomitant jumps in the lower integration limit as
is increased. The growing frequency of these steps is due to the logarithmic
-scale used.
Figure 6. Accuracy of the PE method achieved after 9 extrapolation steps (10 partial integrals) for with
varying over a five-decade range. Here a depends on
consistent with the Sidi partition with the constraint
.
A pseudocode for the PE method computation of tail integrals comprising Bessel functions is given in Algorithm 6, which uses the Levin-Sidi transformation implemented via the function – see Algorithm 3 of Section 3.
It is convenient in the present context to declare the array X( : ), holding the interpolation points in Algorithm 3, to have a starting index , rather than 0, so that
may hold the lower integration limit a. For simplicity, we use the t-variant here, which is appropriate for alternating sequences (the u-variant can be implemented as easily by modifying just one line of the code). The modified Sidi partition is assumed, with the lower integral limit a set to a Bessel function zero and the asymptotic half-period
(which is accessible as a global variable). The partial integrals are evaluated by the procedure
of Section 2. Since the singularity-suppressing property of the tanh-sinh rule is not needed here, the Gauss-Legendre or Romberg quadrature may be used instead [Citation18, p.218]. For regular integrand functions, the Gaussian quadrature is typically less costly than the tanh-sinh rule.[Citation124] The transformation is applied recursively until the stopping rule, controlled by the relative error parameter tol, is satisfied. For simplicity, the implemented error estimate is computed as the difference between the current and the previous extrapolated results. However, to reduce the chance of false convergence, a much safer strategy is to use the maximum difference between the current and the previous two extrapolated results.[Citation117] A pseudocode for an alternative version of the PE method, using the Mosig–Michalski Algorithm 5 of Section 3 with analytical remainder estimates (the a-variant), is given in Algorithm 7. Note that the auxiliary function
implements the coefficient
given by (Equation77
(77) ).
The PE method can also be used to evaluate Sommerfeld integrals, such as (Equation2
(2) ), involving a product of two Bessel functions of different orders. As an example, consider the integral [Citation8]
(80)
where(81)
In the special case when , the first Bessel function in the product becomes identically 1, thus
can still be computed by the PE method described above, where
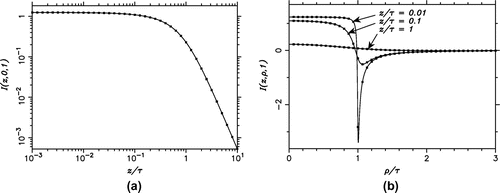
is now half-integer. To illustrate, in Figure (a) we compare the integrated and exact results for I(z, 0, 1) over a four-decade
-range, with the former computed by the PE Algorithm for
, and by the mixed quadrature rule (Algorithm of Section 2) for
(where
in the present case). The switching of the algorithms is beneficial, because in the latter range the behavior of the integrand function in (Equation80
(80) ) is dominated by the exponential decay, rather than the oscillations of the Bessel function.
Figure 7. (a) Plot of I(z, 0, 1) vs. . The integral is computed by the PE method (Algorithm 6) for
and by the mixed quadrature rule (Algorithm ) for
. (b) Plot of
vs.
, with
, 0.1, and 1, computed by the PE method (Algorithm ) with the Lucas decomposition. The integrated results are indicated by symbols and the exact results by solid lines.
In the general case, when , the integrals such as (Equation80
(80) ) are notoriously challenging to evaluate, due to the irregular oscillatory behavior of the product of the Bessel functions, which makes it difficult to devise a partition scheme that would yield a sequence of partial sums amenable to extrapolation. The method by Van Deun and Cools [Citation105] should be mentioned here, in which the tail integral is evaluated analytically, after replacing the Bessel functions by their asymptotic expansions. In the special case where the Bessel functions have the same argument, i.e.
, the modified mW-transformation of Sidi [Citation125] may be applicable. Hence, unless
, when the strong exponential decay makes the mixed rule applicable, we resort to the long-standing method of Lucas [Citation8,Citation106,Citation126,Citation127], which is based on the decomposition
(82)
with(83)
where denotes the Bessel function of the second kind and order
[Citation5]. Note the analogy with the trigonometric identity
. Since the large-argument form of
is similar to that of
, except that the cosine in (Equation79
(79) ) is replaced by a sine, it is readily found that
(84)
Thus, for , both terms in the decomposition (Equation82
(82) ) approach simple sinusoids with half-periods
, and for
,
is still asymptotically sinusoidal, but
approaches a monotonically decreasing function. The splitting (Equation82
(82) ) achieves the separation of the high- and low-frequency components in the product of the Bessel functions by adding and subtracting the term
. However, since Bessel functions of the second kind have large magnitudes for small arguments, to prevent the loss of accuracy due to catastrophic cancellation, the decomposition (Equation82
(82) ) should only be applied for
exceeding a suitable threshold value a, where the term
no longer dominates. Following Lucas [Citation126], here we set
, where
denotes the first zero of
. The initial zeros of
are tabulated for some integer and half-integer orders
[Citation123, p.410], [Citation123, p.467]. For the first zero, an asymptotic expansion valid for large orders is also available [Citation123, p.371], which yields an acceptable approximation for
as low as 1 [Citation126]. Based on these considerations, we split the integral (Equation80
(80) ) into three parts as
(85)
We evaluate the finite-range integral by the tanh-sinh DE rule and the two tail integrals
by the PE method – except in the special case
, when the integrand of
ceases to be oscillatory, and we employ the mixed quadrature rule. The use of the mixed rule is justified if the integrand has some exponential decay, i.e.
. Otherwise, the DE rule (Equation20
(20) )-(Equation21
(21) ) is more appropriate. Applying the PE method to
, we use the modified Sidi partition and Algorithm 7 with
. To find the first zero of the integrand exceeding a, we bracket it by taking a few steps of size q / 4 until a change in the sign of the function is detected, and apply the derivative-free Brent method [Citation18, p.454]. The gap between the original and modified values of a is then bridged by another application of the tanh-sinh rule. Note that
cannot be arbitrarily close to zero with this approach, as this would push the break point a towards infinity. For very small
and
, the integration range may have to be restricted, to prevent underflows.
To illustrate the performance of the PE method in conjunction with the Lucas decomposition, in Figure (b) we compare the integrated and exact results for , with varying
and
as a parameter (where
in this case). Note the excellent agreement, even in the vicinity of
, where the integral becomes singular as
. Hence, the combination of the DE quadrature and a partition method with convergence acceleration by extrapolation resulted in a powerful and efficient technique, applicable for a wide range of the parameters.
5. Application of the Ogata–Sugihara DE rule
The method of Ogata and Sugihara [Citation128–Citation130], which extends the earlier work of Ooura and Mori [Citation131–Citation133], has been successfully adopted for Sommerfeld integral tails by Golubović et al. [Citation15,Citation41]. Whereas the conventional DE transformations make the decay of the integrand double-exponential as the variable of integration approaches , the idea here is to make the nodes of the quadrature formula approach the zeros of the Bessel function in (Equation3
(3) ) double-exponentially. In applying this method to the Sommerfeld tail
(86)
we first introduce the transformation [Citation129](87)
where and
is a “mesh size” parameter, whose selection will be addressed in due course. The corresponding Jacobian is readily found as
(88)
and it clearly does not possess the rapid fall-off property of the more standard DE transformations of Section 2. The integral (Equation86(86) ) may now be expressed as [Citation41]
(89)
where we have introduced(90)
and where in the second integral we have used the fact that the integrand on the left is an odd function of t. The signum function is defined as
For later reference, we note that ,
, and
. The role of the
part of the transformation (Equation87
(87) ) is to map the lower integral limit from
into
. The influence of this term vanishes quickly as
and we find that
in those limits. Consequently, the integrand function in (Equation89
(89) ) has zeros that for large t approach the values
(91)
double-exponentially, where denotes the kth zero of the Bessel function of order
. Hence, the second integral in (Equation89
(89) ) is amenable to the DE rule of Ogata and Sugihara [Citation129], and we obtain
(92)
where(93)
and(94)
with(95)
where are the coefficients in the Laurent series expansion of
around
,
(96)
In (Equation93(93) ),
denotes the Neumann function and the second expression follows upon invoking the Wronskian of
and
[Citation5, Equation 10.5.2]. The zeros
in (Equation91
(91) ) and (Equation93
(93) ) can be obtained using available software packages [Citation134] or may be computed by a few Newton-Raphson iterations, using the asymptotic values as starting points. From (Equation94
(94) )–(Equation96
(96) ), we readily find that
and
(97)
with the higher order given by expressions rapidly increasing in complexity, which we omit to conserve space. In (Equation97
(97) ), we have used the fact that
.
We still need to address the selection of the mesh size h and the truncation index n in (Equation92(92) ). For Sommerfeld integral tails, Golubović et al. [Citation41] recommend
as the best trade-off between accuracy and computational cost. However, since it is unlikely that this particular mesh size should be suitable for all integrand functions, an algorithm for its automatic selection is desirable. If I(h) denotes the quadrature rule (Equation92
(92) ) with mesh size h, it can be shown that the discretization error
is
, where d is a constant. Consequently, if the mesh size is halved, the error of I(h / 2) will be approximately
. Hence, we may compute a sequence of approximations
, until
, where
is the desired error tolerance. Then, since the error of I(h / 2) will be approximately
, we conclude that
[Citation135]. Although this adaptive strategy is similar to that implemented for the standard DE rules in Section 2, the Ogata–Sugihara quadrature is non-progressive, i.e. it cannot reuse the previously-computed function values each time h is halved, because the Bessel function zeros are not equidistant.
The truncation error, which depends on the truncation index n, should be kept smaller than the discretization error for any value of h. Unfortunately, it does not seem possible to derive a simple a priori formula for n satisfying this condition. A simple expedient adopted here is to continue the summation in (Equation92(92) ) until the magnitude of the nth term falls below a small fraction, say
, of the already accumulated sum. We have found that double precision arithmetic (with approximately 15 significant digits) is not sufficient for some spectral domain Green functions
that grow with
, in which case, when
is small, the magnitude of
may reach a floor value before the sum in (Equation92
(92) ) converges. On the other hand, for rapidly decreasing
, its magnitude may become exceedingly small even before the first zero of the Bessel function is reached, in which case a very small mesh size h may be required to achieve the desired accuracy of the quadrature. These caveats notwithstanding, the implementation of the Ogata–Sugihara rule (Equation92
(92) ) is straightforward, hence we omit the detailed algorithm for brevity. Examples of the application of the Ogata–Sugihara rule to Sommerfeld integral tails are given in the next section.
6. Examples of automatic Sommerfeld integral tail computation
We now illustrate the application of the methods described in this paper to the automatic computation of the Sommerfeld integral tail (Equation89(89) ) with the kernels
(98)
and(99)
where(100)
with(101)
These spectral domain kernels arise in the computation of the horizontal and vertical components of the vector-potential Green functions due to a horizontal dipole radiating in air (medium 1) above a lossy halfspace (medium 2).[Citation55] In the above, and
are the reflection coefficients for TE and TM waves, respectively, looking into the lower halfspace,
is the wavenumber of medium 1 and
is the dielectric constant of medium 2. The complex square roots with negative imaginary parts should be selected in (Equation101
(101) ), to satisfy the radiation conditions at infinity. In the numerical results that follow, we use
,
, and
, where the latter is a representative value for wet soil at
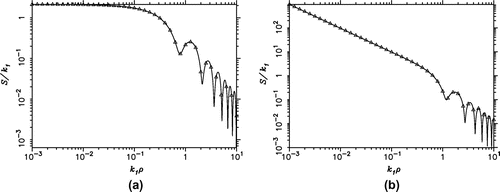
GHz. For the two kernels above, in Figure we compare the results obtained by the automatic Ogata–Sugihara quadrature of Section 5 and the Levin-Sidi partition-extrapolation (PE) method of Section 4. The maximum discrepancy of the results is
and
in the cases of (Equation98
(98) ) and (Equation99
(99) ), respectively. In the case of (Equation98
(98) ), where
is rapidly decreasing as a result of the vanishing
for
, the mesh size h as small as
was required in the Ogata–Sugihara rule near the lower
limit to satisfy the convergence criterion with
. This example illustrates that, in view of the non-progressive nature of the Ogata–Sugihara rule, many function evaluations can be wasted in some cases before the required quadrature level is reached. The PE method does not suffer from this drawback and should thus be preferred for automatic integration of Sommerfeld tails.
Figure 8. Sommerfeld tails integrated by the automatic Ogata–Sugihara quadrature (solid line) and by the PE method (triangles) for (a) the kernel given in (Equation98(98) ) and (b) the kernel given in (Equation99
(99) ).
7. Conclusion
A review has been presented of the most effective methods and algorithms for the computation of Sommerfeld integral tails that commonly arise in the Green functions for plane-stratified media. The mathematical foundations of these methods are discussed in detail and their performance is illustrated by relevant numerical examples. In the most challenging case of oscillatory tails, the partition-extrapolation method is the recommended approach for efficient and reliable computation of such integrals. We demonstrate the implementation of this method as a fully automatic procedure and present the associated algorithms in pseudocode, which even a novice can readily convert into a working computer program. Hence, the computation of Sommerfeld integral tails should no longer be a “cauchemar” of engineers and scientists engaged in various areas of applied electromagnetics.
Notes
No potential conflict of interest was reported by the authors.
References
- Tyras G. Radiation and propagation of electromagnetic waves. New York (NY): Academic Press; 1969.
- Piessens R. Chapter 9, Hankel transforms. In: Poularikas AD,editor. Transforms and applications handbook. 3rd ed. Boca Raton (FL): CRC Press; 2010. p. 719–745.
- Michalski KA, Mosig JR. Multilayered media Green’s functions in integral equation formulations (Invited review paper). IEEE Trans. Antennas Propag. 1997;45:508–519.
- Michalski KA. Electromagnetic field computation in planar multilayers. In: Chang K,editor. Encyclopedia of RF and microwave engineering. Vol. 2. Hoboken (NJ): Wiley-Interscience; 2005. p. 1163–1190.
- Olver FWJ, Lozier DW, Boisvert RF, Clark CW, editors. NIST Handbook of mathematical functions. New York (NY): Cambridge University Press; 2010.
- Singh NP, Mogi T. Electromagnetic response of a large circular loop source on a layered earth: a new computation method. Pure Appl. Geophys. 2005;162:181–200.
- Michalski KA. Spectral domain analysis of a circular nano-aperture illuminating a planar layered sample. Prog. Electromagn. Res. B. 2011;28:307–323.
- Michalski KA, Mosig JR. On the plane wave-excited subwavelength circular aperture in a thin perfectly conducting flat screen. IEEE Trans. Antennas Propag. 2014;62:2121–2129.
- Michalski KA, Mosig JR. Analysis of a plane wave-excited subwavelength circular aperture in a planar conducting screen illuminating a multilayer uniaxial sample. IEEE Trans. Antennas Propag. 2015;63:2054–2063.
- Gay-Balmaz P, Mosig JR. Three dimensional planar radiating structures in stratified media. Int. J. Microwave Millimeter-Wave Comput-Aided Eng. 1997;7:330–343.
- Bunger R, Arndt F. Efficient MPIE approach for the analysis of three-dimensional microstrip structures in layered media. IEEE Trans. Microwave Theory Tech. 1997;45:1141–1153; erratum, ibid., 1998;46:202.
- Michalski KA. Extrapolation methods for Sommerfeld integral tails (Invited review paper). IEEE Trans. Antennas Propag. 1998;46:1405–1418.
- Paulus M, Gay-Balmaz P, Martin OJF. Accurate and efficient computation of the Green’s tensor for stratified media. Phys. Rev. E. 2000;62:5797–5807.
- Simsek E, Liu QH, Wei B. Singularity subtraction for evaluation of Green’s functions for multilayer media. IEEE Trans. Microwave Theory Tech. 2006;54:216–225.
- Golubovic R, Polimeridis AG, Mosig JR. Efficient algorithms for computing Sommerfeld integral tails. IEEE Trans. Antennas Propagat. 2012;60:2409–2417.
- Koufogiannis ID, Mattes M, Mosig JR. On the development and evaluation of spatial-domain Green’s functions for multilayered structures with conductive sheets. IEEE Trans. Microwave Theory Tech. 2015;63:20–29.
- Elhay S, Kautsky J. ALGORITHM 655 IQPACK: FORTRAN subroutines for the weights of interpolatory quadratures. ACM Trans. Math. Softw. 1987;13:399–415.
- Press WH, Teukolsky SA, Vetterling WT, Flannery BP. Numerical recipes: the art of scientific computing. 3rd ed. New York (NY): Cambridge University Press; 2007.
- Takahasi H, Mori M. Double exponential formulas for numerical integration. Publ. RIMS, Kyoto Univ. 1974;9:721–741.
- Evans GA, Forbes RC, Hyslop J. The tanh transformation for singular integrals. Int. J. Comput. Math. 1984;15:339–358.
- Mosig JR. Weighted averages and double exponential algorithms (Invited paper). IEICE Trans. Commun. 2013;E96-B:2355–2363.
- Johnson WA, Dudley DG. Real axis integration of Sommerfeld integrals: Source and observation points in air. Radio Sci. 1983;18:175–186.
- Katehi PB, Alexopoulos NG. Real axis integration of Sommerfeld integrals with applications to printed circuit antennas. J. Math. Phys. 1983;24:527–533.
- Mosig JR, Sarkar TK. Comparison of quasi-static and exact electromagnetic fields from a horizontal electric dipole above a lossy dielectric backed by an imperfect ground plane. IEEE Trans. Microwave Theory Tech. 1986;MTT-34:379–387.
- Tsai M, Chen C, Alexopoulos NG. Sommerfeld integrals in modeling interconnects and microstrip elements in multi-layered media. Electromagnetics. 1998;18:267–288.
- Mittra R, Lee SW. Analytical techniques in the theory of guided waves. New York (NY): Macmillan; 1971.
- Michalski KA, Butler CM. Evaluation of Sommerfeld integrals arising in the ground stake antenna problem. IEE Proc. Part H. 1987;134:93–97.
- Lambot S, Slob E, Vereecken H. Fast evaluation of zero-offset Green’s function for layered media with application to ground-penetrating radar. Geophys. Res. Lett. 2007;34:L21405-1--6.
- Slob E, Lambot S. Chapter 15, Direct determination of electric permittivity and conductivity from air-launched GPR surface-reflection data. In: Miller RD, Bradford JH, Holliger K,editors. Advances in near-surface seismology and ground-penetrating radar. Tulsa (OK): Society of Exploration Geophysicists; 2010. p. 251–261.
- Jiménez E, Cabrera FJ, Cuevas del Río JG. Sommerfeld: a FORTRAN library for computing Sommerfeld integrals. In: Digest IEEE AP-S international symposium; July; Vol. 2; Baltimore (MD): 1996. p. 966–969
- Lytle RJ, Lager DL. Numerical evaluation of Sommerfeld integrals. Livermore (CA): Lawrence Livermore Laboratory; 1974. Rep. UCRL-51688.
- Tsang L, Brown R, Kong JA, et al. Numerical evaluation of electromagnetic fields dues to dipole antennas in the presence of stratified media. J. Geophys. Res. 1974;79:2077–2080.
- Bubenik DM. A practical method for the numerical evaluation of Sommerfeld integrals. IEEE Trans. Antennas Propag. 1977;AP-25:904–906.
- Kuo WC, Mei KK. Numerical approximations of the Sommerfeld integral for fast convergence. Rad. Sci. 1978;13:407–415.
- Kuester EF, Chang DC. Evaluation of Sommerfeld integrals associated with dipole sources above earth. Scientific electromagnet lab report 43. Boulder (CO): Department of Electrical Engineering, University of Colorado; 1979.
- Mohsen A. On the evaluation of Sommerfeld integrals. IEE Proc. Part H. 1982;129:177–182.
- Mosig JR, Gardiol FE. Analytic and numerical techniques in the Green’s function treatment of microstrip antennas and scatterers. IEE Proc. Part H. 1983;130:175–182.
- Barkeshli S, Pathak PH. Radial propagation and steepest-descent path integral representations of the planar microstrip dyadic Green’s function. Radio Sci. 1990;25:161–174.
- Dvorak SL. Application of the Fast Fourier Transform to the computation of the Sommerfeld integral for a vertical electric dipole above a half-space. IEEE Trans. Antennas Propag. 1992;40:798–805.
- Firouzeh ZH, Vandenbosch GAE, Moini R, et al. Efficient evaluation of Green’s functions for lossy half-space problems. Prog. Electromagn. Res. 2010;109:139–157.
- Golubović Nićiforović R, Polimeridis AG, Mosig JR. Fast computation of Sommerfeld integral tails via direct integration based on double exponential-type quadrature formulas. IEEE Trans. Antennas Propag. 2011;59:694–699.
- Volskiy V, Vandenbosch GAE, Golubović Nićiforović R, et al. Numerical integration of Sommerfeld integrals based on singularity extraction techniques and double exponential-type quadrature formulas. In: Proceedings of 6th European conference on antennas and propagation (EUCAP); March; Prague, Czech Republic; 2012. p. 3215–3218.
- Chatterjee D, Rao SM, Kluskens MS. Improved evaluation of Sommerfeld integrals for microstrip antenna problems. In: Proceedings of 2013 URSI commission B international symposium on electromagnetic theory; May; Hiroshima, Japan; 2013. p. 981–984.
- Sainath K, Teixeira FL, Donderici B. Robust computation of dipole electromagnetic fields in arbitrarily anisotropic, planar-stratified medium. Phys. Rev. E. 2014;89:013312-1-18
- Karabult EP, Aksun MI. A novel approach for the efficient and accurate computation of Sommerfeld integral tails. In: Proceedings of international conference on electromagnetics in advanced applications (ICEAA); September; Torino, Italy; 2015. p. 646–649.
- Goldman M. Forward modelling for frequancy domain marine electromagnetic systems. Geophys. Prosp. 1987;35:1042–1064.
- Mosig JR, Melcón AA. Green’s functions in lossy layered media: Integration along the imaginary axis and asymptotic behavior. IEEE Trans. Antennas Propag. 2003;51:3200–3208.
- Kourkoulos VN, Cangellaris AC. Accurate approximation of Green’s functions in planar stratified media in terms of a finite sum of spherical and cylindrical waves. IEEE Trans. Antennas Propag. 2006;54:1568–1576.
- Yuan M, Sarkar TK. Computation of the Sommerfeld integral tails using the matrix pencil method. IEEE Trans. Antennas Propag. 2006;54:1358–1362.
- Alparslan A, Aksun MI, Michalski KA. Closed-form Green’s functions in planar layered media for all ranges and materials. IEEE Trans. Microwave Theory Tech. 2010;58:602–613.
- Kurup DG. Analytical expressions for spatial domain Green’s functions in layered media. IEEE Trans. Antennas Propag. 2015;63:1–7.
- Michalski KA. On the efficient evaluation of integrals arising in the Sommerfeld halfspace problem. In: Hansen RC, editor. Moment methods in antennas and scatterers. Boston: Artech House; 1990. p. 325–331.
- Wu B, Tsang L. Fast computation of layered medium Green’s functions of multilayers and lossy media using fast all-modes method and numerical modified steepest descent path method. IEEE Trans. Microwave Theory Tech. 2008;56:1446–1454.
- Hochman A, Leviatan Y. A numerical methodology for efficient evaluation of 2D Sommerfeld integrals in the dielectric half-space problem. IEEE Trans. Antennas Propag. 2010;58:413–431.
- Michalski KA, Mosig JR. The Sommerfeld halfspace problem revisited: from radio frequencies and Zenneck waves to visible light and Fano modes (Invited review article). J. Electromagn. Waves Appl. 2016;30:142. Available from: http://dx.doi.org/10.1080/09205071.2015.1093964
- Markus A. Modern Fortran in practice. Cambridge (UK): Cambridge University Press; 2012.
- Schwarz HR. Numerical analysis, a comprehensive introduction. New York (NY): Wiley; 1989.
- Kythe PK, Schäferkotter MR. Handbook of computational methods for integration. Boca Raton (FL): Chapman & Hall/CRC Press; 2005.
- Goodwin ET. The evaluation of integrals of the form ∫∞-∞f(x)e-x2dx. Proc. Cambridge Philos. Soc. 1949;45:241–245.
- Schwartz C. Numerical integration of analytic functions. J. Comp. Phys. 1969;4:19–29.
- Evans G. Practical numerical integration. New York (NY): Wiley; 1993.
- Krommer AR, Ueberhuber CW. Computational integration. Philadelphia (PA): SIAM; 1998.
- Trefethen LN, Weideman JAC. The exponentially convergent trapezoidal rule. SIAM Rev. 2014;56:385–458.
- Stenger F. Integration formulae based on the trapezoidal formula. J. Inst. Math. Appl. 1973;12:103–114.
- Takahasi H, Mori M. Quadrature formulas obtained by variable transformation. Numer. Math. 1973;21:206–219.
- Squire W. A quadrature method for finite intervals. Int. J. Numer. Methods Eng. 1976;10:708–712.
- Haber S. The tanh rule for numerical integration. SIAM J. Numer. Anal. 1977;14:668–685.
- Mori M. Quadrature formulas obtained by variable transformation and the DE-rule. J. Comput. Appl. Math. 1985;12 &13:119–130.
- Mori M. Discovery of the double exponential transformation and its developments. Publ RIMS, Kyoto Univ. 2005;41:897–935.
- Bailey DH, Jeyabalan K, Li XS. A comparison of three high-precision quadrature schemes. Exp. Math. 2005;3:317–329.
- Bailey DH, Borwein JM. Effective error bounds in Euler-Maclaurin-based quadrature schemes. In: Proceedings of 20th international symposium on high-performance computing in an advanced collaborative environment (HPCS’06); May; St John’s (NL), Canada: IEEE Computer Society; 2006. p. 1–7.
- Koufogiannis ID, Polimeridis AG, Mattes M, et al. Real axis integration of Sommerfeld integrals with error estimation. In: Proceedings of 6th European conference on antennas and propagation (EUCAP); March; Prague, Czech Republic; 2012. p. 719–723.
- Borwein JM, Bailey DH, Girgensohn R. Experimentation in mathematics, computational path to discovery. Natick (MA): A. K. Peters; 2004.
- Ooura T. DE-quadrature package [2006 December]. Available from: http://www.kurims.kyoto-u.ac.jp/ooura/intde.html.
- Ye L. Numerical quadrature: theory and computation [master’s thesis]. Halifax, Nova Scotia: Dalhousie University, Faculty of Computer Science; 2006.
- Squire W. An efficient iterative method for numerical evaluation of integrals over a semi-infinite range. Int. J. Numer. Methods Eng. 1976;10:478–484.
- Brezinski C, Redivo Zaglia M. Extrapolation methods, theory and practice. New York (NY): North-Holland; 1991.
- Weniger EJ. Nonlinear sequence transformations for the acceleration of convergence and the summation of divergent series. Comput. Phys. Rep. 1989;10:189–371.
- Wimp J. Sequence transformations and their applications. New York (NY): Academic Press; 1981.
- Levin D. Development of non-linear transformations for improving convergence of sequences. Int. J. Comput. Math., Sect. B. 1973;3:371–388.
- Gradshteyn IS, Ryzhik IM. Table of integrals, series, and products. 7th ed. New York (NY): Academic Press; 2007.
- Salzer HE. A simple method for summing certain slowly convergent series. J. Math. Phys. 1955;33:356–359.
- Laurie D. Appendix A: convergence acceleration. In: Bornemann F, Laurie D, Wagon S, Waldvogel J, editors. The SIAM 100-digit challenge. Philadelphia (PA): SIAM; 2004. p. 225–258.
- Smith DA, Ford WF. Acceleration of linear and logarithmic convergence. SIAM J. Numer. Anal. 1979;16:223–240.
- Homeier HHH. Scalar Levin-type sequence transformations. J. Comput. Appl. Math. 2000;122:81–147.
- Smith DA, Ford WF. Numerical comparison of nonlinear convergence accelerators. Math. Comput. 1982;38:481–499.
- Fessler T, Ford WF, Smith DA. HURRY: an acceleration algorithm for scalar sequence and series. ACM Trans. Math. Software. 1983;9:346–354.
- Sidi A. An algorithm for a special case of a generalization of the Richardson extrapolation process. Numer. Math. 1982;38:299–307.
- Davis PJ, Rabinowitz P. Methods of numerical integration. 2nd ed. New York (NY): Academic Press; 1984.
- Sidi A. Practical extrapolation methods. Theory and applications. Cambridge: Cambridge University Press; 2003.
- Shanks D. Non-linear transformations of divergent and slowly convergent sequences. J. Math. Phys. 1955;34:1–42.
- Wynn P. On a device for computing the em(Sn) transformations. Math. Tables Aids Comput. 1956;10:91–96.
- Piessens R, deDoncker-Kapenga E, Überhauer CW, et al. QUADPACK: a subroutine package for automatic integration. New York (NY): Springer-Verlag; 1983.
- Bhowmic S, Bhattacharya R, Roy D. Iterations of convergence accelerating nonlinear transforms. Comput. Phys. Commun. 1989;54:31–46.
- Homeier HHH. A hierarchically consistent, iterative sequence transformation. Numer. Algorithms. 1994;8:47–81.
- Mosig JR, Gardiol FE, Hawkes PW, editors. A dynamical radiation model for microstrip structures. Vol. 59, Advances in electronics and electron physics. New York (NY): Academic Press; 1982. p. 139–237
- Mosig JR. Integral equation technique. In: Itoh T, editor. Numerical techniques for microwave and millimeter-wave passive structures. New York (NY): Wiley; 1989. p. 133–213.
- Drummond JE. Convergence speeding, convergence and summability. J. Comput. Appl. Math. 1984;11:145–159.
- Scraton RE. A note on the summation of divergent power series. Proc. Cambridge Philos. Soc. 1969;66:109–114.
- Wynn P. A note on the generalized Euler transformation. Comput. J. 1971;14:437–441.
- Scraton RE. The generalized Euler transformation. Comput. J. 1972;15:258.
- Longman IM. Note on a method for computing infinite integrals of oscillatory functions. Proc. Cambridge Philos. Soc. 1956;52:764–768.
- Goodwin ET, editor. Modern computing methods. Philosophical Library: New York (NY); 1961.
- Polimeridis AG, Golubović Nićiforović RM, Mosig JR. Acceleration of slowly convergent series via the generalized weighted-averages method. Prog. Electromagn. Res. M. 2010;14:233–245.
- Van Deun J, Cools R. Integrating products of Bessel functions with an additional exponential or rational factor. Comput. Phys. Commun. 2008;178:578–590.
- Golubović R, Polimeridis AG, Mosig JR. The weighted averages method for semi-infinite range integrals involving products of Bessel functions. IEEE Trans. Antennas Propag. 2013;61:5589–5596.
- Krogh FT, Snyder WV. Algorithm 699: A new representation of Patterson’s quadrature formulae. ACM Trans. Math. Softw. 1991;17:457–460.
- Trefethen LN, Weideman JAC. Is Gauss quadrature better than Clenshaw-Curtis? SIAM Rev. 2008;50:67–87.
- Alaylioglu A, Evans GA, Hyslop J. The evaluation of oscillatory integrals with infinite limits. J. Comp. Phys. 1973;13:433–438.
- Squire W. Partition-extrapolation methods for numerical quadrature. Int. J. Comput. Math. Sect. B. 1975;55:81–91.
- Sidi A. The numerical evaluation of very oscillatory infinite integrals by extrapolation. Math. Comput. 1982;38:517–529.
- Chave AD. Numerical integration of related Hankel transforms by quadrature and continued fraction expansion. Geophysics. 1983;48:1671–1686.
- Lyness JN. Integrating some infinite oscillating tails. J. Comput. Appl. Math. 1985;12–13:109–117.
- Sidi A. A user-friendly extrapolation method for oscillatory infinite integrals. Math. Comput. 1988;51:249–266.
- Rabinowitz P. Extrapolation methods in numerical integration. Numer. Algorithms. 1992;3:17–28.
- Espelid TO, Overholt KJ. DQAINF: An algorithm for automatic integration of infinite oscillating tails. Numer. Algorithms. 1994;8:83–101.
- Lucas SK, Stone HA. Evaluating infinite integrals involving Bessel functions of arbitrary order. J. Comput. Appl. Math. 1995;64:217–231.
- Sauter T. Computation of irregularly oscillating integrals. Appl. Numer. Math. 2000;35:245–264.
- Slevinsky RM, Safouhi H. A comparative study of numerical steepest descent, extrapolation, and sequence transformation methods in computing semi-infinite integrals. Numer. Algorithms. 2012;60:315–337.
- Mosig JR. The weighted averages algorithm revisited. IEEE Trans. Antennas Propag. 2012;60:2011–2018.
- Temme NM. An algorithm with ALGOL 60 program for the computation of the zeros of ordinary Bessel functions and those of their derivatives. J. Comput. Phys. 1979;32:270–279.
- Hasegawa T, Sidi A. An automatic integration procedure for infinite range integrals involving oscillatory kernels. Numer. Algorithms. 1996;13:1–19.
- Abramowitz M, Stegun IA, editors. Handbook of Mathematical Functions. New York (NY): Dover; 1965.
- Bailey DH, Borwein JM. Hand-to-hand combat with thousand-digit integrals. J. Comput. Sci. 2012;3:77–86.
- Sidi A. A user-friendly extrapolation method for computing infinite range integrals of products of oscillatory functions. IMA J. Numer. Anal. 2012;32:602–631.
- Lucas SK. Evaluating infinite integrals involving products of Bessel functions of arbitrary order. J. Comput. Appl. Math. 1995;64:269–282.
- Ratnanather JT, Kim JH, Zhang S. Algorithm 935: IIPBF, a MATLAB toolbox for infinite integral of products of two Bessel functions. ACM Trans. Math. Softw. 2014;40:14.1–14.12.
- Ogata H, Sugihara M. Interpolation and quadrature formulae whose abscissae are the zeros of the Bessel functions (in Japanese). Trans. Jpn. Soc. Indus. Appl. Math. 1996;6:39–66.
- Ogata H, Sugihara M. Quadrature formulae for oscillatory infinite integrals involving the Bessel functions (in Japanese). Trans. Jpn. Soc. Indus. Appl. Math. 1998;8:223–256.
- Ogata H. A numerical integration formula based on the Bessel functions. Publ. RIMS, Kyoto Univ. 2005;41:949–970.
- Ooura T, Mori M. Double exponential formulas for oscillatory functions over the half infinite interval. J. Comput. Appl. Math. 1991;38:353–360.
- Mori M, Ooura T. Double exponential formulas for Fourier type integrals with a divergent integrand. In: Agarwal RP, editor. Contributions in numerical mathematics. New York (NY): World Scientific; 1993. p. 301–308.
- Ooura T, Mori M. A robust double exponential formula for Fourier-type integrals. J. Comput. Appl. Math. 1999;112:229–241.
- Vrahatis MN, Ragos O, Skiniotis T, et al. RFSFNS: A portable package for the numerical determination of the number and the calculation of roots of Bessel functions. Comput. Phys. Commun. 1995;92:252–266.
- Ogata H. Private communication. 2015.