
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
For the purpose of exploring strategies for multimedia learning object (LO) suggestion in customizable language learning support systems, particularly suggestion for learners with visual and verbal cognitive style preferences, a learning style based experiment was conducted in a Japanese grammar course. The support system under examination offers two learner modes: Open mode, which provides learners with both visual and verbal LOs, and Style-Matching mode, which provides visual learners with only visual LOs and verbal learners with only verbal LOs. Ninety students were assigned to three groups on the basis of their visual/verbal learning styles preferences and their previously measured learning achievement. Experimental group A studied with Open mode; experimental group B studied with Style-Matching mode; and the control group studied with verbal LOs from the course textbook. Learning performance differences among the three groups were examined in terms of (a) learning perception (including technology acceptance measures, cognitive load and satisfaction with learning mode) and (b) achievement differences. The control group had significantly lower scores on visual tasks than experimental groups, but no significant differences in scores were found on verbal tasks among these three groups. Moreover, despite the learners’ report of significantly higher distraction in Open mode, the learning motivation of learners with stronger visual style preference improved more in Open mode than in Style-Matching mode.
1. Introduction
The personalization of learning scenarios remains a complicated task for e-learning systems. A number of personalized or adaptive systems/models (Castillejo, Almeida, & López-de-Ipiña, Citation2014; Chen Sherry & Macredie Robert, Citation2004; Essalmi, Ben Ayed, Jemni, Kinshuk, & Graf, Citation2010; El Bachari, Abdelwahed, & El Adnani, Citation2012; Filippidis & Tsoukalas, Citation2009; Haseyama & Ogawa, Citation2013; HWang, Mendori, & Xiong, Citation2013) have been developed to support customizable learning in response to learner characteristics and have proven effective. The designs of these systems/models incorporate various learner attributes, such as knowledge level, learning preference, and learning styles.
In our previous work, a customizable language learning support system (CLLSS) was developed with consideration of learner knowledge structure and media preferences (Wang et al., Citation2013). On the one hand, ontology-based CLLSS provides a visualization “knowledge comparison” environment intended to support understanding of knowledge points (KP) by comparing each KP with related KPs. Here, a KP is defined as “a minimum learning item which can independently describe the information of one certain piece of knowledge in a specific course”; a KP can be acquired by practice or can be understood from its expression. For system evaluation, an “individual-class-individual” ontology design was applied to the construction of a course-centered ontology for an existing Japanese grammar course (referred to here as COJG). A KP in the target grammar course is referred to as a grammar point (GP). In addition to GP construction (in total 205 GPs), COJG also defines all the relations (such as similarities, contrasts, and so on) between GPs inside the target grammar course (Wang, Mendori, & Xiong, Citation2014). On the other hand, multimedia learning styles and preferences for the language course are also adopted in CLLSS as learning object (LO) metadata. In this study, each LO was designed either to provide an explanation of one GP or one relation between two GPs, or to provide practice to encourage learners to apply some grammar rules involving one or more GPs.
However, in our previous study (Wang et al., Citation2014), a significant number of the experimental group participants, who studied with both visual and verbal LOs in CLLSS, reported confusion regarding making choices while confronted with both LO styles. In response, in this article we explore the effects of existing LO recommendation strategies, especially from the perspective of cognitive load.
Cognitive load theory (CLT, Sweller, Merriënboer, & Pass, Citation1998; Van Gog & Paas, Citation2008) assumes that the limitation of working memory capacity is determined by three types of cognitive load imposed by learning materials: intrinsic, extraneous, and germane cognitive load. Intrinsic load reflects the complexity of the given learning task in relation to the learners´ level of expertise, and it decreases with increasing prior knowledge. Germane load promotes learning by helping students engage in the process of schema formation and automation, whereas extraneous load hinders learning when tasks are high in intrinsic load, both are inherent in the design of the materials. A number of studies have examined individual differences, especially prior knowledge and spatial ability, in the context of multimedia and cognitive load research. The expertise reversal effect (Kalyuga, Ayres, Chandler, & Sweller, Citation2003) explains how the level of learner expertise affects the effectiveness of instructional techniques from the perspective of CLT. Many researchers (Höffler & Leutber, Citation2011; Korbach, Brünken, & Park, Citation2016; Münzer, Citation2012, Citation2015) have emphasized the notion that spatial abilities play an important role in multimedia learning. From the perspective of CLT, the “spatial ability as enhancer” hypothesis claims that because the transitivity of animation could pose extraneous cognitive load, low spatial ability learners would benefit less from static pictures due to cognitive overload; on the other hand, “spatial ability as compensator” suggests that compared to static pictures, animations can compensate for low spatial ability learners because external animation can reduce the effort required for mental visual-spatial processing. Korbach et al. (Citation2016) also discuss the moderating effect of spatial ability and prior knowledge on learning outcome in learning with seductive details.
LO recommendation strategies in multimedia learning have been explained from the perspective of CLT by many previous researches, but most of them focused only on the analysis of learning achievement differences. Few investigated and discussed learning achievement, cognitive load and learning motivation together. Motivation has been identified as one of the contributors to second language proficiency (Gardner, Citation2000; Gardner & MacIntyre, Citation1993). Learning motivation is the internal drive that enables a learner to strive to study and acquire new skills. If a learner can find a way or ways to maintain motivation, he may expend more effort on the leaning activity and have more available means to carry out his actions to the best of his abilities. Therefore, we also investigate the variation of learning motivation together with learning achievement and cognitive load under different LO recommendation strategies. We expect the learning analytics results to provide insights toward better designs for the CLLSS reasoning mechanism for suggesting LO types in response to individual profiles (mainly refers to the multimedia learning styles).
2. Related theories
Felder and Henriques (Citation1995) defined learning style as “the ways in which an individual characteristically acquires, retains, and retrieves information.” It should be noted that this is not a question of category but of dimension concerning these learner characteristics. Multimedia learning style, which refer to such differences in the visual-verbal dimension, is a feature of many cognitive style models (Cooper, Citation1997; Felder & Henriques, Citation1995; Felder & Silverman, Citation1988; Kirby, Moore, & Shofield, Citation1988; Richardson, Citation1977; Riding, Citation1991), notably the widely adopted Felder-Silverman learning style model (FSLSM) (see Wang and Mendori (Citation2015a) for more details). Despite a seemingly general agreement that diagnosis of individual learning styles is essential for personalized learning support, there are two divergent groups of theories about the exploitation of styles information.
“Meshing hypothesis” (Pashler et al., Citation2009), featured in many studies, contends that information should be presented in a way that fits the learner’s learning style. This hypothesis holds that optimal instruction requires the tailoring of teaching style to match the learner’s learning style so as to achieve optimum learning attitude and consequently better achievement. Numerous adaptive systems, which integrate learning styles as a system parameter for the personalization of learning scenarios, have been designed with a deliberate emphasis on this hypothesis. The programming tutoring system “Protus” (Klašnja-Milićević, Vesin, Ivanović, & Budimac, Citation2011) forms clusters of learners based on their learning styles and then mines the behavioral patterns of each cluster to create a recommendation list for individuals. Hwang, Sung, Hung, and Huang (Citation2012) proposed a personalized game-based learning approach incorporating the sequential/global dimension of FSLSM (Felder & Silverman, Citation1988). This approach was also applied to the construction of a role-playing game for an elementary school natural science course to promote learning motivation and enhance learning achievement.
Although some experimental results suggest that learners receiving style-fit recommendation had significantly higher learning achievement than those who did not (Essalmi et al., Citation2010), support for the “meshing hypothesis” remains insufficient. The “meshing hypothesis” can only be considered validated if evidence of crossover interaction between learning styles and teaching methods is found when participants with distinct styles are randomly assigned to different methods (Pashler, McDaniel, Rohrer, & Bjork, Citation2009). Despite the extensive literature on learning styles, style-by-treatment evidence is scarcely discussed and its support is minimal. Moreover, several studies (Constantinidou & Baker, Citation2002; Massa & Mayer, Citation2006) with appropriate design (as defined by Pashler et al. (Citation2009)), found no evidence of style-by-treatment interaction. Therefore, the validation of the “meshing hypothesis” remains an open problem.
In contrast to the “meshing hypothesis,” the “balance hypothesis” (our term) holds that a balance of instructional methods is the optimal means of achieving effective learning. It has been argued (Felder & Henriques, Citation1995; Friedman & Alley, Citation1984) that learners will inevitably have to deal with problems and challenges that will require them to use a non-matching thinking mode, and that learners should regularly be given style-mismatched materials, even if that induces stress and frustration. In other words, the “balance hypothesis” suggests the provision of learning materials of all styles in order to achieve optimum learning outcomes.
The generative theory of multimedia learning (Mayer, Citation1997; Mayer & Sims, Citation1994) supports the “balance hypothesis” with regard to the visual/verbal dimension. That theory posits that effective learning is best supported when learners are able to construct and coordinate visual and verbal representations of the same material. In Mayer et al.’s experiments, the learning targets were the working principles of a bicycle tire pump and the human respiratory system. The results do identify learning performance differences strongly correlated with individual preference differences. However, the authors claim that learners built two types of retrieval cues in memory when they studied both types of LOs presented in verbal and visual form, whereas they could only build one or no type of retrieval cue when they studied only one or no forms, and that therefore, under some conditions learners who had access to both visual and verbal style information learned more effectively than those who had access to only one style of information. This multimedia learning theory work was extended to second-language learning in a study on German language learning (Plass, Chun, Mayer, & Leutner, Citation1998).
However, individual learning performance depends not only on the learning content and the task but also on the learning styles model implemented in the design (Massa & Mayer, Citation2006; Pashler et al., Citation2009). Although a number of empirical studies have examined learning styles, no consistent effects were observed. Therefore, an optimal strategy for adaptive systems has yet to be identified. In this study, we investigate learning performance in our system under strategies suggested by “meshing hypothesis” and “balance hypothesis.” We expect the learner data to point to a LO recommendation strategy which could significantly improve target course learning performance.
3. Research design
In the search for optimal strategy for multimedia LO recommendation to balance learning motivation and effectiveness, two research questions direct the design of the study.
(1) While using CLLSS, are there any learning performance differences (including learning achievement, perception, and learning motivation) among (a) participants who are provided with both visual and verbal LOs and allowed to freely choose LOs, (b) participants who are only provided with the LOs matching their learning style, and (c) participants who study a set textbook using verbal LOs?
To explore this question, two modes with two different strategies for LO suggestion, Open mode and Style-Matching mode, were provided via CLLSS. In Open mode learners were provided with both visual and verbal LOs, while in Style-Matching mode visual learners received only visual LOs and verbal learners received only verbal LOs. The learning performance of the participants in two experimental groups, who learned in these two modes of CLLSS, will be compared with that of a control group, who at the same time studied the set textbook with verbal LOs. The experimental results are expected to establish the effectiveness of CLLSS and also suggest an optimum approach to LO suggestion.
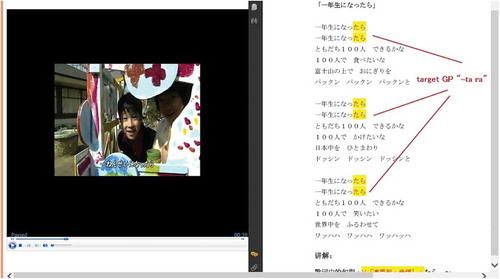
describes the types of LOs prepared in this study. For each target GP, both kinds (verbal and pictures or diagrams) of exposure with explanation and at least two verbal practice tasks and two visual practice tasks were prepared by two expert teachers. Examples of the “Cloze with pictures” LO for the GP “~ te kudasai” and “Singing Practice” LO for the GP “~ tara,” are shown in and , respectively. CLLSS displays “Fill-in-blanks with pictures” LOs as all the verbal LOs with a “reference file” button on the bottom right; as for “Singing Practice” and “Video Clips” LOs, CLLSS displays a video with Japanese subtitles on the left and the transcript of the lyrics or conversation followed by explanations of included GPs on the right. All the Japanese songs and video clips provided by CLLSS involve a target GP repeated at least twice; each appearance of target GP is highlighted and then explained. While studying with songs or video clips, learners can receive support in the form of video images depicting scenes related to the subtitles. Those images serve to illustrate and reinforce the meaning of corresponding sentences which involve target GP. Therefore, these two types of LOs are classified as visual LOs. All of the LOs in this experiment were carefully chosen to avoid the redundancy effect (Sweller, Ayres, & Kalyuga, Citation2011) and the difficulty of the practice tasks was carefully controlled.
Table 1. Types of LO provided.
Figure 1. “Cloze with pictures” LO of the GP “~ te kudasai.”

Figure 2. “Singing Practice” LO of the GP “~ tara.”
Learning performance measurement techniques in this experiment included learning achievement tests (pre-test and post-test), and questionnaires for measuring learning related perceptions (technology acceptance measures, cognitive load, and satisfaction with learning mode). Learning attitude and motivation were also measured before and after the learning activity. The design of the questionnaires, which were written in Chinese, was based on the measurement tools of other researchers (Chu, Hwang, Tsai, & Tseng, Citation2010; Davis, Citation1989; Hwang & Chang, Citation2011; Pintrich & DeGroot, Citation1990; Sweller et al., Citation1998) with some modifications.
The test sheets were developed by two experienced teachers. The pre-test, aimed at evaluating participants’ prior knowledge of Japanese, contained 10 cloze items, 25 singe-choice items, and 10 sentence-translation items, with a perfect score of 100. The post-test contained verbal aspect tasks including five cloze tasks and five sentence-transformation tasks; visual aspect tasks including five “picture cloze” tasks and five tasks involving describing pictures in Japanese. Those 20 items were designed to assess participants’ aptitude for solving verbal and visual tasks involving target content after the learning activity. The post-test perfect score was 100 (50 for verbal aspect and 50 for visual aspect). (Since the participants received very little visual explanation or practice before the experiment, visual form items were not included in the pre-test.)
In most previous studies on differences between learners with visual cognitive styles and those with verbal ones, learner aptitude for acquisition of the target knowledge after learning activity was assessed only by means of tests containing verbal tasks. For example, in the experiments of Plass et al. (Citation1998) about German language learning, the participants’ scores in the “word translation from German to English” tasks were considered “vocabulary acquisition learning achievement” and scores on the “summarizing of a story written in German” task were considered “reading comprehension learning achievement.” The post-test results represented only learning achievement in verbal aspect, not visual aspect. Therefore, in this study, participants’ aptitude for acquisition of target knowledge in both verbal and visual aspects was assessed after the learning activity.
(2) What causes the confusion phenomenon under Open mode?
In many studies the majority of learners reported feeling more comfortable while studying with style-matched materials than style-mismatched ones. This reporting of comfort in style-matched environments has been taken as evidence that style-matched environments enhance learning motivation. However, those results do not suggest that a learner tends to choose the type of LOs which match his/her learning style. Some studies have found that the choices made by learners were not in accord with their learning styles (determined by means of learning style questionnaires). Stash, Cristea, and de Bra (Citation2006) reports that the preferences settings of students are not completely in line with their ILS questionnaire (The Index of Learning Styles, Soloman & Felder, Citation2001) results in all four dimensions. HWang et al. (Citation2013) also reports that preferences in education game mode and the cognitive styles inferred from ILS questionnaire results are inconsistent in the sequential/global dimension; rather, most learners made their choices by intuition or based on personal preferences. Therefore, our study aims to examine whether learners’ behavioral multimedia preferences under Open mode are consistent with their learning styles as detected by ILS in visual/verbal dimension, and to identify the cause of confusion phenomenon under Open mode.
4. Method and Results
4.1. Participants
Ninety first-year undergraduates, all Japanese majors at three Chinese universities, participated in this study. These students, from three different classes, were taught by three different instructors, each of whom had taught Japanese grammar for more than seven years. Before the experiment, all the students had studied Japanese for six months in full verbal teaching style, i.e. with hardly any visual explanation or practice in their classroom studies.
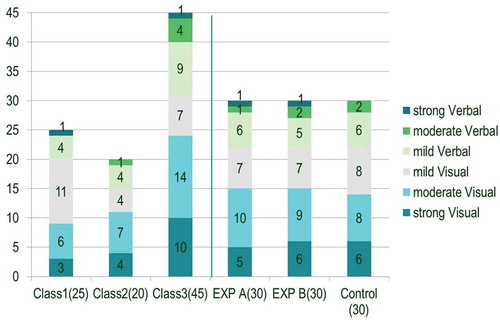
In the preparatory phase, a questionnaire was administered to determine learning style distribution. The measuring tool adopted in this phase was a 44 item ILS questionnaire translated into Chinese. ILS is a widely adopted instrument, designed on the basis of FSLSM, used to assess the cognitive styles of the learner. Its current version has been assessed as reliable, valid, and suitable for capturing learners’ behavioral tendencies (Felder & Spurlin, Citation2005). In our previous work (Wang & Mendori, Citation2015a), we discuss the internal reliability, inter-scale correlation, and construct validity of this Mandarin version ILS, based on the analysis of 198 valid questionnaires. The reliability estimate of the scores for the four scales of this Mandarin version ILS based on Cronbach alphas ranged from 0.51 to 0.65. All the participants, 14 males and 76 females, voluntarily completed the questionnaire. According to the results, 18.9% of participants were identified with strong visual cognitive style, i.e. strongly preferring that information be presented visually, and 30% were identified with moderate visual cognitive style. Only 2.2% of participants were identified with strong verbal cognitive style, i.e. strongly preferring spoken or written explanations to visual presentations, and 5.5% were identified with moderate verbal cognitive style. Meanwhile, the remaining 43.3%, with mild preferences, were evenly distributed in the Visual/Verbal dimension.
shows the distribution of learning styles among the participants in each class. In order to minimize group composition differences, students from each class were assigned to experimental groups (EXP) A and B and the control group, on the basis of both learning style in the Visual/Verbal dimension and performance on the previous semester’s final exam.
Figure 3. Participant profiles from learning style (Visual/Verbal dimension) perspective.
4.2. Experimental procedures
As can be seen in , at the beginning of the experiment all participants took the pre-test and learning attitude and motivation questionnaire (Questionnaire-1), after which the purpose and objectives of the learning activity were explained to all the participants. Five GPs were chosen as target learning content: “~ te kudasai,” “~ naru,” “~ to,” “~ nara,” and “~ te morau.” These forms occur mainly in imperative expressions, expressions of change, conditional expressions, and giving and receiving expressions.
Figure 4. Experimental procedures.
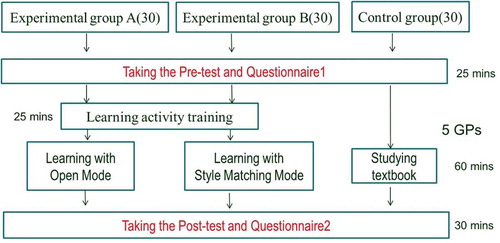
The training and the learning activity for experimental groups was performed in a computer-assisted language learning lab equipped with the Chinese version of CLLSS (Wang et al., Citation2013). During the 25 minute training, the study procedures for one GP in Open mode and in Style-Matching mode were demonstrated to experimental groups A and B, respectively; then participants in the experimental groups were encouraged to repeat the procedure for some acquired GPs so as to familiarize themselves with system operation and all types of LOs. After the training, experimental group A used Open mode while experimental group B used Style-Matching mode to study the target content. Meanwhile, in another classroom, the control group studied with verbal LOs from the set textbook. For all these three groups, the target content learning activity was of 60 minutes duration.
After the learning activity, all participants took the post-test and another questionnaire (Questionnaire-2) which involved 14 items for measuring learning attitude and motivation. Unlike the control group, the experimental groups were required to answer 13 additional questions related to learning perception on Questionnaire-2, which involved satisfaction with learning mode (Chu et al., Citation2010), technology acceptance measures (Chu et al., Citation2010; Davis, 1989), and cognitive load (Sweller et al., Citation1998).
4.3. Analysis and discussion: Focus on learning perception
System evaluation and feedback about the learning activity, provided by experimental groups A and B, are summarized in . Factor analysis of participants’ responses to the 13 items in the learning perception questionnaire (Questionnaire-2) revealed 4 distinct scales: technology acceptance measures (2 items, α = 0.630), mental effort (2 items, α = 0.790), mental load (2 items, α = 0.777), and the satisfaction with learning mode (7 items, α = 0.854). As reported in our previous work (Wang & Mendori, Citation2015c), for those who studied with Open mode, the stronger the visual preferences identified by ILS, the higher the satisfaction they perceived for the learning mode (r = 0.472); aside from satisfaction with learning mode, no significant relation between learning perception and learning style indicator was found. On the other hand, for those who studied with Style-Matching mode, no significant relation between learning perception and learning style indicator was found.
Table 2. Analytics results for learning perception items in Questionnaire-2.
In terms of “technology acceptance” measures, the “perceived ease of use” item received an average rating of 4.93 for group A and 5.17 for group B, respectively; most participants in the experimental groups reported that CLLSS was easy to operate and become familiar with. The average rating of “perceived usefulness” was 4.73 for group A and 4.97 for group B, respectively, which implies that most participants in experimental groups thought that CLLSS was useful for improving their learning performance. No significant difference (p = 0.073, p > 0.05) was found between the responses to “technology acceptance” by the two experimental groups.
In terms of “mental effort,” the average ratings of “effort required for learning the target GPs” were 3.53 and 3.47 for experimental groups A and B, respectively; this suggests that the difficulty of the learning activity was moderate (neither too easy nor too difficult) for the participants in the experimental groups. The average rating for “effort required for understanding the purpose of the learning activity” was less than 3 for both experimental groups, indicating that most participants in the experimental groups could easily understand the purpose of this activity. No significant difference (p = 0.413, p > 0.05) was found between the responses to “mental effort” by the two experimental groups.
In terms of “mental load,” the average rating for degree of distraction and degree of pressure while using CLLSS was less than 2.6 for both experimental groups; this implies that the participants felt little pressure while concentrating on learning with CLLSS. However, the MANOVA result for “cognitive load” (Wilks’ Lambda, p < 0.05) indicates a significant difference between the two experimental groups. The results of individual univariate analyses support the claim that there was a significant difference between the two groups in the rating of “distraction” (p < 0.025); this suggests that while using CLLSS, the participants who learned with Open mode experienced loss of attention more frequently than those who learned with Style-Matching mode. Further analysis was conducted to determine whether the visualizer indicator affects the effects of mode on learner distraction degree. Linear regression results (R Square = 0.95, F = 1.57, Sig. F Change > 0.05) show that the visualizer indicator is not a moderator for the effects of modes on learner distraction degree.
As can be seen in , the average rating for “satisfaction with learning mode” (by using the mean rankings for the 7 related items) was 4.63 and 4.83 for experimental groups A and B, respectively; this implies that most of the participants in both experimental groups generally were satisfied with the provided learning mode. No significant difference (p = 0.152, p > 0.05) was found between the responses to this item by the two experimental groups.
To investigate the second research question (as to the cause of the confusion phenomenon under Open mode), Questionnaire-2 for experimental group A asked the following four questions in addition to those in the version of Questionnaire-2 used for experimental group B:
Q1: Which type (visual or verbal) of LO do you feel more comfortable with and prefer to study continuously with?
Q2: Which type (visual or verbal) of LO is more effective for your learning?
Q3: Did you have any difficulty choosing an LO from the LOs list panel, or did you sometimes get confused while choosing?
Q4: Did your behavior preference change during the learning activity?
Participants in experimental group A were required to answer these questions after studying with Open mode. Their responses to these additional items are shown in .
Figure 5. Results of Questionnaire-2 additional questions (for experimental group A).
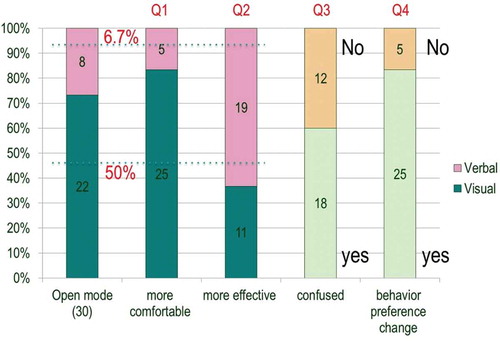
As can be seen in , 50% of the participants in experimental group A (including learners with strong and moderate visual cognitive style) were identified with stable visual cognitive style and only 6.7% of them were identified with stable verbal cognitive style. The rest, with mild style preferences, would be expected to change styles readily. Most responses to Q1 were in accord with participant learning styles, except for three learners with stable visual cognitive style who reported feeling more comfortable with verbal LOs and one stable verbal learner reported feeling more comfortable with visual. In the interview section, the three learners with stable visual cognitive style stated that unfamiliarity with the language learning materials presented in songs and videos made them less comfortable with visual LOs; the stable verbal learner, who stated a preference for visual LOs, reported that her favorite hobbies are watching Japanese movies and listening to Japanese songs, so she felt familiar and comfortable with the visual LOs. In summary, familiarity with a given LO style may positively affect comfort while interacting with that LO style.
In response to Q1, 83.3% of students in experimental group A reported feeling comfortable with visual LOs; however, in the responses to Q2, only 36.7% of those subjects reported feeling that visual LOs were more effective. Upon closer inspection of the learner data, it was found that 14 participants (46.7%) gave different responses in Q1 and Q2. Moreover, those participants (including 6 stable learners) all reported that although they felt more comfortable with the visual presentation medium, they still believed that verbal LOs were more effective. Conversely, none of the participants who reported feeling more comfortable with verbal LOs reported belief that visual LOs were more effective. Results of analysis of the data collected in the follow-up interview suggested that the inconsistent responses to Q1 and Q2 may be have been a result of the educational environment: nowadays in China the majority of Japanese Language course LOs are presented in verbal form, so most students are already used to verbal LOs no matter what learning style preference they may have. (None of the more than 200 students participating in the set of experiments in this research had used a significant amount of learning materials in visual form in regular classroom studies.) Moreover, the final exams in their curriculums include simple verbal tasks; this also encourages the students to value skill in verbal tasks more than skill in visual tasks. Consequently, given the fact that verbal form is dominant in both classroom teaching and exams, it is not surprising that most students believe that verbal LOs are more effective.
Interestingly, indicates that 60% of the participants in experimental group A struggled to choose between visual and verbal style LOs and even got confused at times. This result is consistent with that shown in , where learners who studied with Open mode reported experiencing significantly higher distraction than those who studied with Style-Matching mode. The Chi-Square test (p = 0.007) revealed that the inconsistencies between responses on Q1 and Q2 had a strong correlation with confusion over LO choice. In other words, learners can be expected to get confused easily when they do not feel comfortable with the LOs considered to be more effective. Furthermore, most of them reported that, with the strong purpose of improving learning effectiveness, they tended to choose the learning materials considered to be more effective regardless of their comfort.
It was also found that 25 participants (83.3%) changed their behavior choice during the learning activity. Chi-Square test (p = 0.046) revealed that the frequency of learner choice change had a strong positive correlation with the confusion regarding choice.
4.4. Analysis and discussion: Focus on learning motivation
In addition to the 13 items in the learning perception questionnaire (Questionnaire-2), there were another 14 items for measuring attitude/motivation. As described in our previous work (Wang & Mendori, Citation2015b), factor analysis was performed on all 120 collected responses (including those of the 90 participants in this experiment) toward the items for measuring attitude/motivation. On the basis of the results, two scales were constructed: one for attitude toward Japanese grammar learning (AJG, 7 items, α = 0.891) and one for motivation toward Japanese language learning (MJL, 7 items, α = 0.892).
As reported by Wang and Mendori (Citation2015c), there was a significant negative correlation (r = - 0.316) between the visual preferences identified by ILS for a learner and the learner’s prior learning motivation toward Japanese language learning. This situation is largely the result of the fact that all the students received only verbal types of explanation and practice in regular classes. For the visual learners, only received style-unmatched learning materials increased their frustration and lower their learning motivation. In the other hand, after the learning activity, those who studied with open mode, had a balanced motivation from learning style perceptive, especially in visual dimension (r = 0.018). However, for those who studied with Style-Matching mode, the stronger their identification as visual by ILS, the lower their learning motivation tended to be (r = -0.277). Learning attitude is not discussed in this article since no significant relation was found between learning attitude and learning style.
Despite the small amount of data, regression analyses reveal that for both groups, learner motivation was directly affected by prior motivation; however, for the Style-Matching group, perceived satisfaction with learning mode also directly affects motivation. Therefore, in this study further analyses were conducted to examine the moderating effect of visualizer indicator on the motivation of two experimental groups (by considering prior motivation as an independent variable and motivation after the learning activity as a dependent variable).
The regression results for motivation of experimental group A (R Square = 0.719, F = 16.656, Sig. F Change < 0.05) show a significant curvilinear regression model with visualizer indicator as a moderator (); this suggests that the curvilinear relationship between prior motivation and post motivation is moderated by the value of the visualizer indicator with increased motivation. On the other hand, the regression results for motivation of experimental group B show no moderating effect of visualizer indicator on motivation. In summary, these results suggest that compared to Style-Matching mode, Open mode provided an environment which could more effectively improve the learning motivation of learners with higher visual style.
4.5. Analysis and discussion: Focus on learning achievement
Multivariate analysis of covariance (MANCOVA) was used to evaluate learning achievement differences (in both visual and verbal aspects) among the two experimental groups and the control group, using pre-test scores as concomitant variable and post-test scores as dependent variable. The purpose of using pre-test scores as concomitant variable in MANCOVA is to enable the use of the pre-test information to reduce the variance among learners with different prior knowledge and thus increase the chance of detecting differences between different treatments. Before MANCOVA was performed, a series of tests, including Between-Subjects Effects, the Shapiro-Wilk test, P-P plots of Standardized Residuals and Liner Regression test, were conducted to confirm that the data satisfied the MANCOVA assumption. These tests were conducted before each MANCOVA reported here. The sample data appear to conform to the assumptions of MANCOVA. It should be noted that no significant relations between learning achievement (both visual and verbal aspects) and visualizer indicator were found.
shows the descriptive data and MANCOVA results for the two experimental groups and the control group. The results of Box’s M test (p > 0.05) suggests homogeneity of variance for all groups. The results of MANCOVA (Wilks’ Lambda test, p < 0.05) indicate that there were significant learning achievement differences among the three groups. The results of individual ANCOVA analyses indicate that these significant differences were caused by differences in learning achievement on visual tasks in post-test; this suggests that learners in these three groups did have significantly different achievement on visual tasks. Meanwhile, among participants who studied with Open mode, Style-Matching mode and the set textbook, there were no significant differences in achievement on verbal tasks.
Table 3. MANCOVA results for post-test scores of the three groups.
The results of pairwise comparisons between groups further revealed that the control group had significantly lower scores on visual tasks than experimental groups A (p = 0.00007, p < 0.0001) and B (p = 0.00002, p < 0.0001). However, no significant difference in learning achievement on visual tasks (p = 0.692, p > 0.05) was found between participants who studied with Open and Style-Matching modes. It should be noted that these results may not accurately reflect the situation for learners with verbal cognitive style, given the small number of such learners (only 26.7%, 8 per group).
Also, due to the small number of verbal style learners, learning achievement differences (in both visual and verbal aspects) could only be further investigated among the visual learners in the three groups. The MANCOVA results are shown in . The results of Box’s M test (p > 0.05) suggest homogeneity of variance. The MANCOVA result (Wilks’ Lambda test, p < 0.05) indicates significant between-group learning achievement differences for the learners with visual cognitive style in the three groups. The results of individual ANCOVA indicate that these significant differences were caused by learning achievement difference on visual tasks; this in turn suggests that there were significant between-group differences for performance on visual tasks among the learners with visual cognitive style who studied with Open mode, Style-Matching mode or textbooks. Meanwhile, among the visual learners in these three groups, there were no significant between-group differences in learning achievement on verbal tasks; this suggests that the style of LO provided to visual learners did not affect their learning achievement on verbal tasks. Pairwise ANCOVA results indicate that visual learners in the control group had significantly lower scores on visual tasks than visual learners in experimental groups A (p = 0.013, p < 0.05) and B (p = 0.001, p < 0.01). However, no significant between-group difference (p = 0.428, p > 0.05) in learning achievement on visual tasks was found for visual learners in experimental groups A and B.
Table 4. MANCOVA results for post-test scores among the visualizers in the three groups.
5. Conclusion
Working from the perspective of multimedia learning style, this study conducted an experiment to evaluate the efficacy of different strategies for LO recommendation in CLLSS. Two modes were provided in CLLSS in this experiment: Open mode, which provided learners with both visual and verbal style LOs, and Style-Matching mode, which provided visual learners with only visual LOs and verbal learners with only verbal LOs.
The following discussion of the research questions described in Section 3 is based on the analysis of learner data.
(1) Learning performance differences between the two experimental groups and the control group are summarized below. On the one hand, analysis of the learning achievement of visual learners suggests that the style of LO provided to learners with visual cognitive style did not affect their learning achievement on verbal tasks. Moreover, regarding the achievement on visual tasks, those who studied with only verbal LOs from the set textbook had significantly lower scores than who studied with Open mode or Style-Matching mode, but no significant difference was found among visual style learners who studied with different modes of CLLSS. This suggests that regardless whether the learner studies with Open mode or Style-Matching mode, the short-term learning achievement of visual learners on both visual and verbal tasks was constant. Although the results of analysis of data for all the participants were consistent with the results for learners with visual cognitive style, the learning situation of the learners with verbal cognitive style may not be accurately reflected due to the small number.
On the other hand, analysis of reported learning perception suggests that learners who studied with Open mode were significantly more distracted than those who studied with Style-Matching mode. This is consistent with the finding that 60% of participants who studied with Open mode found choice of LO style difficult and even confusing at times.
In terms of the impact of learning mode on learning motivation, in a previous study (Wang & Mendori, Citation2015c) (a) although Open mode learners and Style-Matching mode learners both showed significant improvements in learning motivation, no significant difference was found between them; (b) compared to Style-Matching mode, Open mode resulted in more balanced learning motivation among learners with different learning styles; and (c) for both groups, learner motivation was directly affected by prior motivations whereas the greater the satisfaction perceived by Style-Matching mode learners, the greater was the improvement in their learning motivation. The results of the extended analysis in this article suggest that compared to Style-Matching mode, Open mode provides an environment which more efficiently improves the learning motivation of learners with higher visual style. (2) Analysis of the learning perception of participants who studied with Open mode suggests that besides learning styles, familiarity with some LO style in specific course experience may have affected comfort during interaction with the LOs of that particular course. However, the majority of both visual and verbal styles learners reported believing that verbal LOs were more effective than other LOs due to the fact that only the verbal form was presented previously in both classroom teaching and exams. Learners also reported easily becoming confused under Open mode when the style of LO considered to be more comfortable was not the style considered to be more effective.
To sum up, the findings of this article on the impact of learning mode on learning motivation are in harmony with the “balance hypothesis” which believes that a balance of instructional methods is the optimal learning mode of learning. Despite the higher distraction than found in Style-Matching mode, Open mode, which provides learners with both visual and verbal LOs, can improve the learning motivation of learners with higher visual style more efficiently. Certainly, to lower higher distraction in Open mode, a style-based mode which alternately provides style-matched LOs and a designated amount of style-unmatched LOs, is suggested.
6. Future Work
In our future work, the Style-Based mode will be developed and learning performance in that mode will be compared with the results for Style-Matching mode, so as to determine the optimal amount and frequency of presentation of style-unmatched LOs to learners. Long-term effects of learning support from CLLSS will also be explored in further experimental studies. In all the experiments of our current research, participants were required to use CLLSS to learn some chosen grammar points in an existing grammar course. We only collected and analyzed the short-term learning performance of the learners. In the next stage, we will use the same system to track long-term learning performance, i.e. the learning process throughout the course, and determine whether or not differences in learning perception resulting from different strategies for multimedia learning object recommendation will give rise to long-term learning achievement difference.
Additional information
Notes on contributors
Jingyun Wang
Jingyun Wang is currently an Assistant Professor at Kyushu University, Japan. Her current research focuses on visualization learning support systems, personalized language support, cooperative learning support, and educational big data analysis. Her work involves the integration of the traditional education methodologies with ontology technique.
Takahiko Mendori
Takahiko Mendori is currently an Associate Professor at School of Information, Kochi University of Technology, Japan. His current research interests are e-Learning Systems and its Support Systems/Services (Learning Management System, SCORM (Sharable Content Object Reference Model), Distance Learning Support System, Social Networking Service, Mentoring Support System, and so on).
Tore Hoel
Tore Hoel is a researcher at the Learning Centre and Library in OsloMet – Oslo Metropolitan University. He is working on international and European projects in the field of learning technologies. Currently, he has a research focus on learning analytics and innovative technologies for learning.
Related Research Data
References
- Castillejo, E., Almeida, A., & López-de-Ipiña, D. (2014). Ontology-based model for supporting dynamic and adaptive user interfaces. International Journal of Human–Computer Interaction, 30(10), 771–786. doi:10.1080/10447318.2014.927287
- Chen Sherry, Y., & Macredie Robert, D. (2004). Cognitive modeling of student learning in web-based instructional programs. International Journal of Human–Computer Interaction, 17(3), 375–402. doi:10.1207/s15327590ijhc1703_5
- Chu, H. C., Hwang, G. J., Tsai, C. C., & Tseng, J. C. R. (2010). A two-tier test approach to developing location-aware mobile learning systems for natural science courses. Computers & Education, 55(4), 1618–1627. doi:10.1016/j.compedu.2010.07.004
- Constantinidou, F., & Baker, S. (2002). Stimulus modality and verbal learning performance in normal aging. Brain and Language, 82, 296–311. doi:10.1016/S0093-934X(02)00018-4
- Cooper, R. (1997). Learning styles and staff development. Journal of the National Association for Staff Development, 37, 38–46.
- Davis, F. D. (1989). Perceived usefulness, perceived ease of use, and user acceptance of information technology. Mis Quarterly, 13(3), 319-340. doi:10.2307/249008
- El Bachari, E., Abdelwahed, E. H., & El Adnani, M. (2012). An adaptive teaching strategy model in e-learning using learners’ preference: LearnFit framework. International Journal of Web Science, 1(3), 257–274. doi:10.1504/IJWS.2012.045815
- Essalmi, F., Ben Ayed, L., Jemni, M., Kinshuk, & Graf, S. (2010). A fully personalization strategy of E-learning scenarios. Computers in Human Behavior, 26(4), 581–591. doi:10.1016/j.chb.2009.12.010
- Felder, R. M., & Henriques, E. R. (1995). Learning and teaching styles in foreign and second language education. Foreign Language Annals, 28(1), 21–31. doi:10.1111/flan.1995.28.issue-1
- Felder, R. M., & Silverman, L. K. (1988). Learning styles and teaching styles in engineering education. Engineering Education, 78(7), 674–681.
- Felder, R. M., & Spurlin, J. E. (2005). Applications, reliability, and validity of the index of learning styles. International Journal of Engineering Education, 21(1), 103–112.
- Filippidis, S. K., & Tsoukalas, L. A. (2009). On the use of adaptive instructional images based on the sequential-global dimension of the Felder-Silverman learning style theory. Interactive Learning Environments, 17(2), 135–150. doi:10.1080/10494820701869524
- Friedman, P., & Alley, R. (1984). Learning/teaching styles: Applying the principles. Theory into Practice, 23(1), 77–81. doi:10.1080/00405848409543093
- Gardner, R. C. (2000). Correlation, causation, motivation and second language acquisition. Canadian Psychology, 41, 1–24. doi:10.1037/h0086854
- Gardner, R. C., & MacIntyre, P. D. (1993). A student’s contribution to second language learning, part II: Affective variables. Language Teaching, 26, 1–11. doi:10.1017/S0261444800000045
- Haseyama, M., & Ogawa, T. (2013). Trial realization of human-centered multimedia navigation for video retrieval. International Journal of Human–Computer Interaction, 29(2), 96–109. doi:10.1080/10447318.2012.692316
- Höffler, T. N., & Leutber, D. (2011). The role of spatial ability in learning from instructional animations - Evidence for an ability-as-compensator hypothesis. Computers in Human Behavior, 27, 209–216. doi:10.1016/j.chb.2010.07.042
- Hwang, G. J., & Chang, H. F. (2011). A formative assessment-based mobile learning approach to improving the learning attitudes and achievements of students. Computers & Education, 56(1), 1023–1031. doi:10.1016/j.compedu.2010.12.002
- Hwang, G. J., Sung, H. Y., Hung, C. M., & Huang, I. (2012). Development of a personalized educational computer game based on students’ learning styles. Educational Technology Research & Development, 60(4), 623–638. doi:10.1007/s11423-012-9241-x
- Kalyuga, S., Ayres, P., Chandler, P., & Sweller, J. (2003). The expertise reversal effect. Educational Psychologist, 38(1), 23–31. doi:10.1207/S15326985EP3801_4
- Kirby, J., Moore, P., & Shofield, N. (1988). Verbal and visual learning styles. Contemporary Educational Psychology, 13, 169–184. doi:10.1016/0361-476X(88)90017-3
- Klašnja-Milićević, A., Vesin, B., Ivanović, M., & Budimac, Z. (2011). E-Learning personalization based on hybrid recommendation strategy and learning style identification. Computers & Education, 56(3), 885–899. doi:10.1016/j.compedu.2010.11.001
- Korbach, A., Brünken, R., & Park, B. (2016). Learner characteristics and information processing in multimedia learning: A moderated mediation of the seductive details effect. Learning and Individual Differences, 51, 59–68. doi:10.1016/j.lindif.2016.08.030
- Massa, L. J., & Mayer, R. E. (2006). Testing the ATI hypothesis: Should multimedia instruction accommodate verbalizer-visualizer cognitive style? Learning and Individual Differences, 16, 321–336. doi:10.1016/j.lindif.2006.10.001
- Mayer, R. E. (1997). Multimedia learning: Are we asking the fight questions? Educational Psychologist, 32, 1–19. doi:10.1207/s15326985ep3201_1
- Mayer, R. E., & Sims, V. K. (1994). For whom is a picture worth a thousand words? Extensions of a dual-coding theory of multimedia learning. Journal of Educational Psychology, 86, 389–401. doi:10.1037/0022-0663.86.3.389
- Münzer, S. (2012). Facilitating spatial perspective taking through animation: Evidence from an aptitude-treatment-interaction. Learning and Individual Differences, 22, 505–510. doi:10.1016/j.lindif.2012.03.002
- Münzer, S. (2015). Facilitating recognition of spatial structures through animation and the role of mental rotation ability. Learning and Individual Differences, 38, 76–88. doi:10.1016/j.lindif.2014.12.007
- Pashler, H., McDaniel, M., Rohrer, D., & Bjork, R. (2009). Learning styles: Concepts and evidence. Psychological Science in the Public Interest, 9(3), 105–119. doi:10.1111/j.1539-6053.2009.01038.x
- Pintrich, R. R., & DeGroot, E. V. (1990). Motivational and self-regulated learning components of classroom academic performance. Journal of Educational Psychology, 82, 33–40. doi:10.1037/0022-0663.82.1.33
- Plass, J. L., Chun, D. M., Mayer, R. E., & Leutner, D. (1998). Supporting visual and verbal learning preferences in a second-language multimedia learning environment. Journal of Educational Psychology, 90(1), 25–36. doi:10.1037/0022-0663.90.1.25
- Richardson, A. (1977). Verbalizer–Visualizer: A cognitive style dimension. Journal of Mental Imagery, 1, 109–126.
- Riding, R. J. (1991). Cognitive styles analysis. Birmingham, England: Learning and Training Technology.
- Soloman, B. A., & Felder, R. M. (2001). Index of Learning Styles Questionnaire. Retrieved March 1, 2013, from North Carolina State University March 1, http://www.engr.ncsu.edu/learningstyles/ilsweb.html
- Stash, N., Cristea, A., & de Bra, P. (2006). Adaptation to learning styles in elearning: Approach evaluation. In T. Reeves & S. Yamashita (Eds.), Proceedings of world conference on e-learning in corporate, government, healthcare, and higher education 2006. (pp.284-291) Chesapeake, VA: AACE.
- Sweller, J., Ayres, P., & Kalyuga, S. (2011). Cognitive Load Theory. Explorations in the Learning Sciences, Instructional Systems and Performance Technologies, 1, 141–154.
- Sweller, J., Merriënboer, V., & Pass, F. G. W. C. (1998). Cognitive architecture and instructional design. Educational Psychology Review, 10(3), 251–297. doi:10.1023/A:1022193728205
- Van Gog, T., & Paas, F. (2008). Instructional efficiency: Revisiting the original construct in educational research. Educational Psychologist, 43, 16–26. doi:10.1080/00461520701756248
- Wang, J. Y., & Mendori, T. (2015a). The reliability and validity of felder- silverman index of learning styles in mandarin version. Information Engineering Express, 1(3), 1–8.
- Wang, J. Y., & Mendori, T. (2015b). An evaluation of the learning attitude and motivation in a language learning support system”, Proceedings of Advanced Learning Technologies and Technology-enhanced Learning 2015, Hualien, Taiwan.
- Wang, J. Y., & Mendori, T. (2015c). A study of learning attitude and motivation under different learning object recommendation strategies from learning style perceptive. International Conference on Computers in Education 2015, Hangzhou, China.
- Wang, J. Y., Mendori, T., & Xiong, J. (2013). A customizable language learning support system using ontology-driven engine. International Journal of Distance Education Technologies, 11(4), 81–96. doi:10.4018/IJDET
- Wang, J. Y., Mendori, T., & Xiong, J. (2014). A language learning support system using course-centered ontology and its evaluation. Computer & Education, 78, 278–293. doi:10.1016/j.compedu.2014.06.009