?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
We consider the question of language diffusion and examine the latest attempt to popularize the Ukrainian language. This effort has been undertaken by the Ukrainian government since 1991. While sociological studies report positive dynamics in Ukrainian language dissemination, in practice, the language adoption progress might be slower than reported. We test this hypothesis using google trends web search data. We apply a Bayesian beta regression model and show that the proposed model is appropriate. The results suggest that the Ukrainian language popularization policy is successful and that the 2022 Russian invasion has considerably intensified the usage of the Ukrainian language.
Introduction
The Russian Federation has enormous military power. According to the global fire power rankingFootnote1, its army is placed second on our planet. Moscow also possesses a powerful cultural weapon that is frequently overlooked – the Russian language (Decker Citation2021). The Russian language has an enormous unifying power for 193 ethnic groups that live in Russia, with more than 95% speaking Russian (Gladkova Citation2015). Despite the dissolution of the Soviet Union, which led to the creation of many new independent states, Moscow is more than willing to use both cultural and linguistic ties with a view to promoting its geopolitical interests (Decker Citation2021; Feklyunina Citation2016; Forsberg and Smith Citation2016). The usage of this (soft) power is especially applicable (but is not limited) to a range of former Soviet republics including Ukraine, Belarus, and Kazakhstan. In this study, we examine the case of Ukraine, and in particular the most recent Ukrainization attempt that followed the 2014 Euromaidan revolution. Since 1991, the Ukrainian government has opposed the promotion of Russian cultural and linguistic establishments on Ukrainian territory. These attempts have become more comprehensive since 2014. The extensive Ukrainization policy (see Kiss Citation2022) was perceived by Donetsk and Luhansk regions as an effort to prohibit the Russian language. This could be an important element that contributed to the development of separatist movements in eastern Ukraine. In addition, this situation was a perfect opportunity for Russian president Vladimir Putin to pursue his geopolitical aims. The Ukrainian case gives us a chance to rigorously examine the effect of de-Russification policies in the post Soviet space; the latter being the main objective of this study.
Several studies suggest that language is an important aspect of society’s self-identification (Arel Citation2002; Kulyk Citation2011; Poses and Revilla Citation2021; Reznik Citation2018; Ushchyna Citation2020). An implementation of Ukrainization policy implies increasing the usage of the Ukrainian language, promoting the local culture in various domains, and discouraging both Russian cultural influence and the Russian language. For a comprehensive historical overview of Ukrainian language development, we refer to Flier and Graziosi (Citationn.d.). While such policy can be beneficial for Ukrainian identity and selfhood, it is important to remember that for some regions, especially for those that share a border with the Russian Federation, the corresponding ties to Russia are extremely strong. In addition, many people who live in these regions consider Russian as their native language and have (historically) held pro-Russian views (Bureiko and Moga Citation2018). Such a regional diversity effect has often been exploited by politicians. As Reetta Toivanen (Citation2007) observes, “Language boundaries, real or imagined, can easily become exploited politically.” Not surprisingly, Ukrainian politicians have also capitalized on linguistic and cultural differences to accumulate electoral support (Kulyk Citation2011).
Language planning development as part of Ukrainization policy has always been an important concern in Ukraine (Kiss Citation2022). In 1989, the Ukrainian Soviet Socialist Republic adopted the Law of Languages; this law declared the Ukrainian language as the only official language in the state. It is convenient to divide the 1991–2021 time frame into three periods: the early independence years (1991–2004); the Orange revolution, which took place in 2004; and the post-Euromaidan era, which started in 2014. Under President Leonid Kravchuk (1991–1994), a de-Russification of schools was begun. President Viktor Yushchenko (2005–2010) started to de-Russify the media landscape. However, only mild Ukrainization attempts were made by president Yushchenko’s government. One example of such actions is the requirement that television and radio should have a quota of 75% minimum Ukrainian-language programs, and that there should be an audio-dubbing in Ukrainian for programs that were originally broadcast using other languages. In 2010, when the election was won by Viktor Yanukovych, Ukrainization policy implementation experienced a significant slowdown. A law sponsored by Kivalov and Kolesnichenko (both members of the Verkhovna Rada), called Principles of State Language Policy from 2012, granted the Russian language the status of a regional language. Effectively, the law allowed the usage of minority languages (and Russian in particular) in government institutions such as schools and courts in regions where national minorities exceeded 10% of the population (Elder Citation2012). The most important event that happened in 2014 on the linguistic front was when parliament repealed (February 23, 2014) the Principles of State Language Policy law. Although President Oleksandr Turchynov (February 23, 2014–June 7, 2014) and President Petro Poroshenko (2014–2019) refused to sign the removal of the law (so the law remained in force until February 2018), the parliament’s decision provided a pretext for Moscow to militarily annex Crimea and promote separatist movements in the east (Reznik Citation2018).
After the Euromaidan events, Ukrainian society experienced major changes. The loss of Crimea and the war in the eastern Ukraine led to a dramatic increase in national identity and influenced the growing usage of the Ukrainian language. For example, in 2018, the Kivalov–Kolesnichenko language law was declared unconstitutional by the Constitutional Court of Ukraine. According to the Ukrainian Center for Economic and Political Studies (Centr Razumkova Citation2016), 69%, 27%, and 2% of Ukrainians consider the Ukrainian language, the Russian language, or another language, respectively, as their native language. Nevertheless, certain care should be taken when discussing the “native language” term (Hentschel and Palinska Citation2022; Zeller Citation2021). Specifically, it does not necessarily mean that this language is used in practice but instead, it might correspond to nationality, heritage, or the country of residence.
The de-Russification efforts of the Ukrainian government included Ukrainian language quotas for television and radio broadcasting (Ogarkova Citation2018) and a de-communization law under which the majority of geographical names with reference to Soviet era were changed. To further support de-Russification laws, in February 2017 the Ukrainian government banned the commercial importation of books from Russia. According to Ukrainian sources, the Ukrainization policy is very fruitful. The 2021 sociological service poll of the Ilko Kucheriv Democratic Initiatives Foundation and Razumkov Center (Citation2021), which considered 2,019 respondents aged 18 and older, showed that 78% of Ukrainians identify the Ukrainian language as their native language as opposed to 18 who stated that their native language is Russian. As expected, Russia-oriented media sources like Russia Today (RT) report that the majority of the population in Ukraine is actively using the Russian language and in fact prefers to use Russian. For example, based on polls from the Social Monitoring Center, RT reports that more than 50% of Ukrainian citizens are willing to consume books and media that are delivered in Russian. Moreover, they also report that less than a third of the population supports the usage of the Ukrainian language only. RT thus arrives at the conclusion that the “forceful” Ukrainization of the population, which started in 2014, is not effective overall (for details, please see Latyshev, Onischuk, and Medvedeva Citation2021). We would like to note that we could not independently verify the Social Monitoring Center poll, since this resource is no longer available.
In this work, we do not intend to make any political claims in favor of Ukrainization or Russification of Ukraine. We do want to note that due to different polls, there is a considerable lack of clarity and uncertainty about the actual usage of the Ukrainian and Russian languages in Ukraine. In addition, some responders might be reluctant about stating their true preferences in both the controlled and the uncontrolled territories. With this in mind, we aim to rigorously investigate the hypothesis that the usage of the Ukrainian language is actually growing by examining an independent and self-sufficient data source. In order to accomplish this, we utilize the google trend data from 2011 to 2021 in order to study the dynamic of change in percentage of Ukrainian language usage. In order to understand the effect of Ukrainization on different regions – namely, regions that are geographically (historically and culturally) closer to Russia or those having such proximity to the “West”Footnote2 – we apply a Bayesian beta regression model which can take into account the effect of regions (noting that significant parts of two regions were annexed by Russian Federation in 2014). We verify that the model fits the data well and that the Ukrainization policy is successful in all regions (except for Crimea and Sevastopol). However, we also show that in practice, Ukrainian language adoption by the Ukrainian population might be slower than reported.
In addition, we provide several conceptual and methodological contributions. First, we show that the annexed regions of Crimea and Sevastopol should have experienced a severe deterioration in Ukrainian language usage. A possible reason for this decline is the fact that usage of the Ukrainian language is discouraged and that many Ukrainians, including Crimean Tatars, have fled from Crimea since 2014. (For additional details about linguistic conflicts, refer to Müller and Wingender Citation2021; in particular, see “Characterisation of the Language Situation in the Republic of Crimea from the Perspective of Geolinguistics” by Yuri Dorofeev, in Müller and Wingender Citation2021, Part III, where the situation in Crimea is discussed.) Regions that are under the control of the Ukrainian government show a statistically significant increase of Ukrainian language usage. Our model also suggests that some regions (Donetsk and Luhansk), in Ukraine will show very slow adoption of the Ukrainian language, which is not very surprising since Donetsk and Luhansk regions have a strong pro-Russian agenda and are partly controlled by separatists. Moreover, with respect to these regions, the question of multiethnicity of Ukraine is raised. The question of Ukraine being a multiethnic country was recently examined by Volodymyr Kulyk (Citation2022b), where the author focuses on the disappearing differentiation between the two largest population groups in Ukraine, Ukrainians and Russians, in Soviet times.
The rest of the paper is organized as follows. In the next section, we formally define the methods used in this paper. We show that one can use the Bayesian beta regression models to fit a language usage data extracted from google trends, and also validate the model and perform efficient prior selection. The results are discussed in the following section. The next section is dedicated to the full-scale Russian invasion in 2022, where we show that the proposed model can be easily adjusted to account for large-scale changes. In the final section we summarize our findings and discuss both the limitations of the proposed method and the possible directions for future research.
Methods
Data Collection
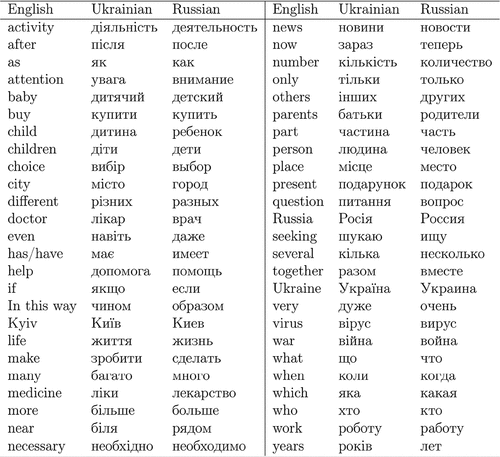
Google and other media companies collect useful data about their customers’ preferences. Here, we take advantage of publicly available Google trends data and, in particular, of the interest by sub-region option which is attainable for specific search terms. Under our setting, a search term is translated into two languages – Ukrainian and Russian – while making sure that these terms are written differently, in order to distinguish between them. Effectively, we now have two search terms that have the same meaning but, are treated as different search labels by Google. Then, the sub-region data provide the percentage of queries recorded for these two terms for a specific region and for a given time frame. Using the Leipzig Corpora Collection (Quasthoff, Goldhahn, and Eckart Citation2014)Footnote3, a list of 50 popular terms was created (for the full list, see Appendix A). The recorded terms are associated with the News, Web, and Wikipedia domains. To ensure a fair comparison, frequent Russian and Ukrainian words were recorded. Finally, for each term, region, and time frame (year), the data from the google trends website was extracted. Eventually, for each region and for years from 2011 to 2021, we calculated the average proportion of searches in the Ukrainian language. Formally, we are working with a quantity:
For the rest of the paper we refer to (1) as the proportion. In order to ensure that the sample of size 50 is indeed representative, we took several random samples (without replacement), of sizes 30 and 40 out of 50. Using these reduced data-sets, we performed a statistical analysis. The obtained results were similar to the ones presented in this manuscript.
Exploratory Analysis
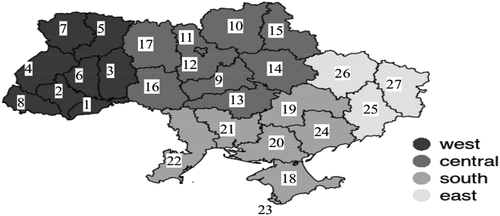
depicts the map of Ukraine divided into administrative districts (regions); the detailed region mapping is given in .
Table 1. 27 Ukrainian Administrative Divisions; The Peninsula and the City of
Were Annexed in 2014 by Russian Federation; The Regions of
and
are Partially Controlled by Separatists
Figure 1. Ukraine map with regions divided into western, central, southern, and eastern regions. The western part of Ukraine consists of regions that are geographically close to “Western” counties, namely, to Poland, Slovakia, Hungary, and Roumania. The eastern part of Ukraine contains regions that are geographically close to the Russian Federation.
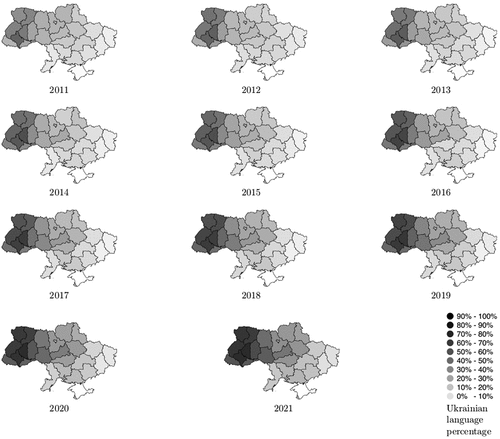
The average proportion of Ukrainian language usage for each region between 2011 and 2021 is depicted in . While shows positive dynamics for the Ukrainian language, it is important to rigorously investigate the phenomena using an appropriate regression analysis. With a view to modeling proportions and in order to allow a natural interpretation of the obtained results, we propose to utilize the beta regression model (Ferrari and Cribari-Neto Citation2004; Figueroa-Zúñiga, Arellano-Valle, and Ferrari Citation2013), which is discussed below.
Figure 2. The dynamic of the proportion of the Ukrainian language used from 2011 to 2021.
The Proposed Beta Regression Model
A continuous random variable is said to have a
distribution if its probability density function is given by
where α > 0, β > 0, and is the beta function (Grimmett and Stirzaker Citation2001). For
, it holds that
, and therefore, for convenience, we consider the reparametrisation:
.
Under this reparametrisation, we write , and arrive at
. We further assume that the Ukrainian language proportion in region
and year
is
, and that
. In order to ensure that
and with a view to providing a natural interpretation via odds ratios, we utilize the logit link function and define:
where the effect is the intercept that characterizes baseline state of proportion, and
is the baseline rate of proportion growth. The regional effects
and
are associated with region
, and
is the covariate, specifically,
is a function of a year
. Under the proposed model, the slopes
, have an appealing interpretation as the change of log-odds that corresponds to a one unit increase in
, namely
For computational efficiency, we center the year covariate and define , where 2016 is the mean of the {2011,…,2021} set. The available data size is not large, and thus we believe that the latter justifies the usage of the Bayesian approach. In addition, we aim to explore a general machinery for future research, which might include a good prior knowledge about the model parameters. Specifically, we propose to use a Bayesian model which is defined via:
The proposed model can be potentially extended to include change-points (regime switching), with a view to specifying different behaviors of the proportion time series, and by specifying distinct parameters , instead of the single parameter
. Our experiments imply that the model in (2) (with σ = 1 parameter for the
for
coefficients prior), fits the data well. A more detailed discussion regarding the choice of the σ parameter (prior sensitivity) and the goodness of fit is provided below. We proceed with the computational aspects.
Computation and Validation
Computation
Using No U-Turn Sampling scheme (Carpenter, Andrew Gelman, and Hoffman et al. Citation2017), we generated three chains with 10,000 iterations per chain, where the first 5,000 iterations were used as a warm-up. The 5,000 remaining samples for each chain were thinned by a factor of 10. Therefore, we had the total of 1,500 samples to perform inference. The Gelman-Rubin diagnostics (Brooks and Gelman Citation1998; Gelman and Rubin Citation1992) shows good convergence characteristics with the corresponding statistic values around 1.0 for all model parameters.
Convergence Diagnostics
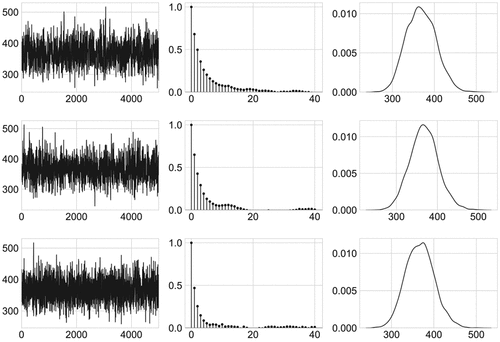
The MCMC sampler shows good convergence results. shows the convergence of the GelmanRubin statistic (Brooks and Gelman Citation1998; Gelman and Rubin Citation1992) of three independent MCMC runs of the No U-Turn sampler and depicts a graphical summary. The first, the second, and the third column of correspond to trace, sample auto correlation function, and density plots, respectively. The first, the second, and the third row of , correspond to the first, the second and the third independent MCMC run, respectively. For additional typical convergence results, please see Online Appendix B.
Figure 3. Gelman-Rubin diagnostic for parameter ϕ.
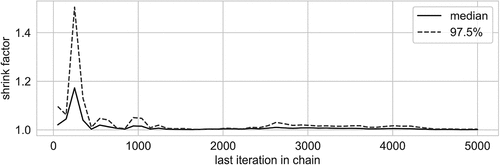
Figure 4. Summary of three Markov Chain Monte Carlo runs for the parameter ϕ.
Prior Sensitivity Analysis for Models with Same Parameter Vector
Note that since our attention is restricted to models with priors , and
for
, for different values of σ, all competitive models have the same parameter vector
. Let
and
be two models that have the same parameter vector. Then, the Bayesian Factors (BF) for models
and
, is given by:
Under the same parameter vector assumption, it holds that
Therefore,
Suppose further that for any two models, and
and for any
, it holds that
Note that this condition corresponds to the beta regression model in the manuscript, since the only difference between two models is the prior parameter . In this case (3), simplifies to
If one has access to samples from the posterior distribution that corresponds to the model, it is possible to compare
to any model
without even fitting the
model. Specifically, it holds that
where are samples from the posterior distribution that corresponds to
.
For the proposed model in the manuscript, let and
be two competitive models. Then, an estimator
for
, can be obtained via
where are samples from the posterior distribution that corresponds to
, and
is the joint prior distribution that corresponds to model
(Chan and Eisenstat Citation2015). We used posterior samples that correspond to two models,
and
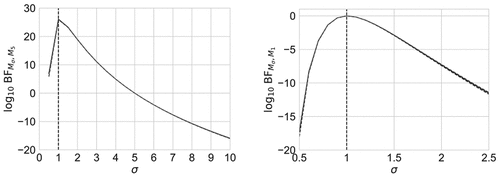
to produce . The left panel of , shows the logarithm of Bayes factor
as a function of σ and one can observe that the largest
is located around σ = 1. The right panel of depicts the logarithm of Bayes factor
as a function of σ. Combining the observations from the left and the right panel with BF interpretation (see Kass and Raftery Citation1995 for details), we conclude that
, namely σ = 1, constitutes an appropriate prior.
Figure 5. Logarithms of Bayes factors as a function of σ.
Remark 1 (A hierarchical model) As an alternative, it is possible to consider a hierarchical model:
The obtained results are similar to the ones reported above; please see Online Appendix C for additional details. For example, the posterior summary for ,
,
, and σ parameters that are associated with the hierarchical model (7) provided in Table C1. Indeed, the σ parameter is around 1.0 as expected. Figure C1 shows the slopes and the intercept of the hierarchical model.
Goodness of Fit
In order to validate that the proposed model fits the data, we use the extension of the classical test proposed by Johnson (Johnson Citation2004). Johnson showed that if one draws parameters samples from the posterior distribution and evaluate the Parson’s goodness-of-fit statistic at these values, then, regardless of the dimension of the parameter vector, the Parson’s goodness-of-fit statistic is asymptotically distributed as a
random variable with K – 1 degrees of freedom.
Let be a scalar-valued, continuous, identically distributed, conditionally independent observations drawn from probability density function
(
is a multidimensional parameter vector). Let
be the posterior density of
based on the data
and let
be a sample from the posterior distribution, namely, from
. The procedure of constructing the Bayesian
test for goodness of fit is as follows.
Let
be (user-predefined), quantiles from a uniform distribution. In addition, let
Define the vector
where F is the cumulative distribution function which corresponds to .
(3) Using the definition in (5), let:
(4) Finally, we define
where is the expected number of points that should lend in bin j.
Theorem 2.1. Under some regularity conditions (Johnson Citation2004), converges to the
distribution with K – 1 degrees of freedom as
.
Under this setting, the null hypothesis is that there is no significant difference between the observed and the expected values.
Practical considerations: It was shown that the number of bins works well in practice. In principle, it is preferred to base the goodness-of-fit statistic on more than a single sampled value from the posterior distribution. This means that in practice we should aim to calculate an average with respect to samples from the posterior distribution, namely, we use
where for
are N samples from the posterior distribution.
In order to test the adequacy of the proposed model, we perform the Bayesian goodness-of-fit test (Johnson Citation2004). Following Johnson’s recommendation (Johnson Citation2004), we define the number of bins
, where n is the sample size. In our case, there are 27 regions with 11 observations for each district and thus K = 10. The corresponding
test statistic estimator
for goodness of fit, was calculated based on 1,500 posterior samples. For the σ = 1 model, the point estimator
is 12.649 and the corresponding 95% confidence interval is (12.734,13305). Since it holds that
, we conclude that
, so this suggests that the proposed model indeed provides an adequate fit to the data.
Results
As mentioned above, the inference is based on 1,500 posterior samples. In this section, all the results are reported with respect to σ = 1 prior parameter. For the posterior distribution summary tables with respect to σ = 5 prior parameters, please refer to Online Appendix D. , show the full posterior distribution summaries associated with model (2) and with respect to σ = 1 prior parameter.
Table 2. Posterior Distribution Summaries for and Baseline Effects
and
; the Summary is with Respect to
Prior Parameter
Table 3. Posterior Distribution Summaries for Intercepts; the Summary is with Respect to Prior Parameter
Table 4. Posterior Distribution Summaries for Slopes; the Summary is with Respect to Prior Parameter
depicts interval estimates from posterior draws associated with model (2).
Figure 6. Left panel shows the regional intercepts and right panel shows the regional slopes.
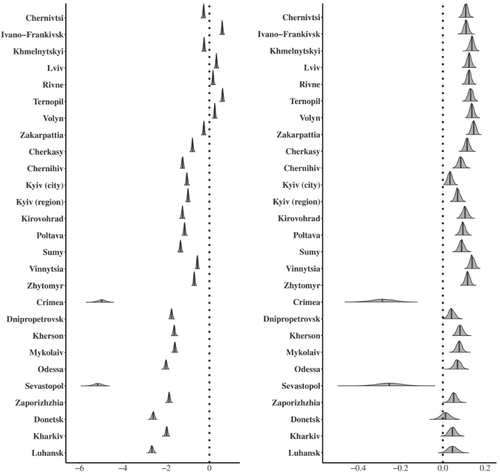
The left plot shows the intercepts. The intercepts of the western part of Ukraine are generally larger as compared to the eastern part, thus indicating that the usage of the Ukrainian language was always stronger in the western part as compared to other regions. On the other hand, the intercepts of Crimea, Sevastopol, and eastern regions such as Luhansk and Donetsk that have geographic (historical and cultural) proximity to the Russian Federation indicate a lower usage of the Ukrainian language as compared to the Russian language.
While the left panel of aligns well with our intuition, it is even more instructive to consider the right panel of . The latter corresponds to the regression slopes and thus shows the dynamics of the proportion, namely, the growth of the proportion of Ukrainian language usage. By observing the slopes, we can see that all the government-controlled territories have positive slopes (the results are statistically significant; please see for details). This indicates that the Ukrainization policy is indeed quite successful. Of course, we can also see that the slopes in Crimea and Sevastopol (two regions that were annexed by Russia in 2014) have negative slopes (this result is also statistically significant).
The mean and the corresponding 95% credible intervals (CI) for slopes in Crimea are –0.287 and (–0.396,–0.186), respectively. The situation in Sevastopol is similar: the mean and the corresponding 95% credible intervals (CI) for slopes are –0.254 and (–0.361,–0.146), respectively. Namely, we see a strong Russification of the annexed regions. On the other hand, there are regions in Ukraine that show a rapid growth of Ukrainian language usage. Two such regions are Zakarpattia and Khmelnytskyi, that introduce the slopes of 0.146, (0.125,0.165) and 0.138, (0.117,0.159), respectively. The results suggest that the effect of the Russification of Crimea is stronger than the corresponding Ukrainization effects in other Ukrainian regions.
The regional effect slopes in the Ukrainian territory indicate that the western regions in Ukraine show the biggest increase in the proportion, which is not surprising. We acknowledge that Donetsk and Luhansk are partially controlled by separatists, so negative slopes are expected there. Surprisingly enough, the Luhansk region shows slow growth, with mean slope of 0.046 and 95% CI of (0.003,0.088). However, for the Donetsk region, we observe the mean slope of 0.013 and the corresponding 95% CI of (–0.028,0.056). The latter might indicate that the situation in the Donetsk region is more radical as compared to the Luhansk region.
Overall, the obtained regression slopes indicate that the Ukrainization policy is working, although the progress might be slower than reported by Ukrainian sources. Using the posterior samples and the 2021 population estimatesFootnote4, we were able to approximate the overall population percentage that perform Google searches in Ukrainian language. Our data show that about 35% (the 95% credible interval is (32.56%, 37.48%), see ), perform their search in Ukrainian.
Table 5. Posterior Summary of the Number of People Who Perform Google Search Using Ukrainian Language. The Mean UA Search Column Corresponds to the Estimator of the Number of People that Search Using the Ukrainian Language
The posterior summary of the number of people who perform search in Ukrainian language for each region is given in . From , we arrive at the conclusion that the percentage of the Ukrainian population that performs Ukrainian language searches is about 35%; this might not align well with the reported 78% who reported that they consider Ukrainian as their native language (Tables D1–D3).
Nevertheless, our model predicts that the number of regions that will exceed the 50% usage threshold of the Ukrainian language grows. Specifically, in 2021, only 9 regions (out of 27), exceeded the 50% threshold. However, in 2026 and 2031, we predict that 11 and 15 regions will exceed this threshold. The latter is an indication of the overall success of the Ukrainization policy, at least with respect to Ukrainian language usage.
The full-scale Russian invasion in 2022 requires an additional validation of the proposed model. In the next section we examine the model and the consequences of recent events on Ukrainian language popularization. We show that the proposed model is still valid subject to the introduction of a change point that occurs in 2022.
The 2022 Russian Invasion
First, we examine how well the current 2011–2021 model fits the data when including the results from 2022. In this case, there are again 27 regions with 12 observations for each district and thus K = 11. The corresponding test statistic estimator
for goodness of fit, was calculated based on 1,500 posterior samples. For the σ = 1 model, the point estimator
is
and the corresponding 95% confidence interval is
. Since it holds that
, we conclude that
, so this suggests that the proposed model is not adequate for the 2022 data. While the
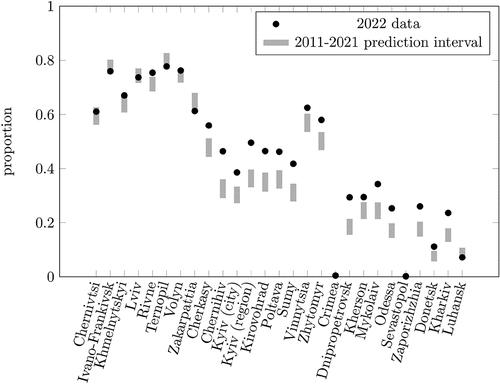
test statistic is important from the mathematical point of view, , which depicts the 2022 data and the 2011–2021 model prediction intervals for every region is quite instructive. It is interesting to note that the 2011–2021 model is adequate for the western regions. Nevertheless, the majority of data points for the central, southern, and eastern regions are above the prediction intervals. This might be due to the fact that the western regions were less exposed to military actions.
Figure 7. The 2022 data and the 2011–2021 model 95% prediction intervals for all regions.
The above findings are not very surprising and are basically supported by recent studies of Rating Citation2022 and Kulyk Citation2022a. As noted by Kulyk Citation2022a, many Ukrainians tend to blame the Russian population for the war and the associated crimes of the occupying forces. Specifically, according to Kulyk’s study, Russian is now considered to be the language of the enemy and thus, many Ukrainians refuse to utilize Russian and instead try to use Ukrainian, as it is now considered to be the language of the resistance. Our findings support this claim.
The obtained results and in particular, a careful observation of , indicates that the 2011–2021 model should be adjusted. We propose to extend the original model by introducing a change point (Rizzo Citation2019, Chapter 11). The extension of the (2) is as follows.
Here, similarly to the original model, we define:
Now, for the new 2011–2022 (σ = 1) model, the point estimator is
and the corresponding 95% confidence interval is
. It holds that
, and we conclude that
, so this suggests that the proposed model fits the data well. shows a comparison of slopes for the original 2011–2021 model and the new 2011–2022 model.
Figure 8. The 2011–2021 vs 2011–2022 models slope comparison.
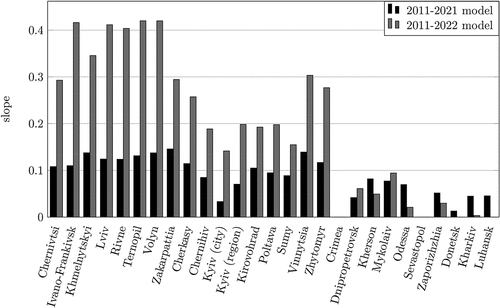
is very instructive. The majority of slopes in the 2011–2022 model are much higher when the corresponding slopes in the 2011–2021 model. This further indicates that the Russian invasion contributes to the development and the acceptance of the Ukrainian language and supports the findings of Rating Citation2022 and Kulyk Citation2022a. In Crimea and Sevastopol, the change in the slope is actually negative, namely, from –0.2871 to –0.7409 in Crimea and from –0.2537 to –0.9045 in Sevastopol.
Discussion and Conclusion
In this paper, we have demonstrated that google trend data combined with spatial information can provide important insights into language dissemination trends. The proposed beta regression model fits the data well and is able to explain spatial variations. It is important to note that the data are open and that no costly experiments are required. The proposed model combined with google trends data can potentially serve as a verification mechanism to language poll experiments.
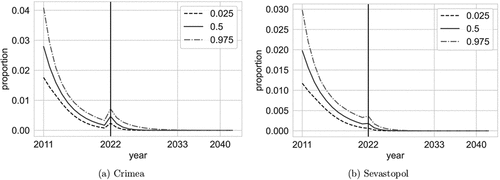
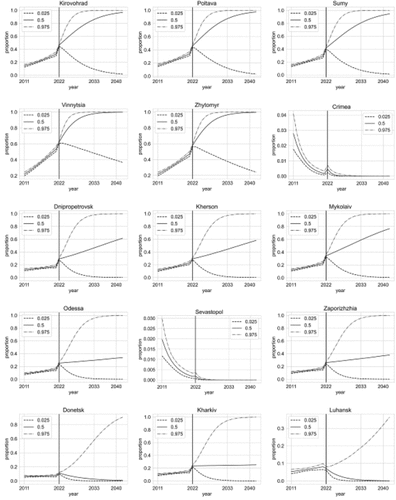
Under our model, the prediction of the proportion for the forthcoming years is straightforward. Using the posterior samples associated with the model, the prediction and confidence intervals of the proportion for region i and year j ≥ 2023 can be derived from (7). From , which shows the prediction of the Ukrainian language usage proportion in the annexed Crimea and Sevastopol, we conclude that the situation is quite distressing for the Ukrainian language.
Figure 9. Crimea and Sevastopol; proportion of Ukrainian language usage prediction until 2040. The graph shows the 0.025, 0.5, and the 0.975 quantiles of the proportion.
It is also very important to consider the situation in partly controlled territories of Donetsk and Luhansk. The prediction of the proportion for Donetsk and Luhansk is depicted in . Our analysis indicates that the situation in both regions looks dreadful for the Ukrainian language. The prediction of the Ukrainian language proportion usage for all regions is depicted in .
Figure 10. Donetsk and Luhansk; proportion of Ukrainian language usage prediction until 2040. The graph shows the 0.025, 0.5, and the 0.975 quantiles of the proportion.
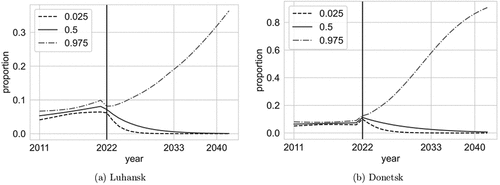
Figure 11. Prediction of Ukrainian language usage proportion until year 2040 (part 1).
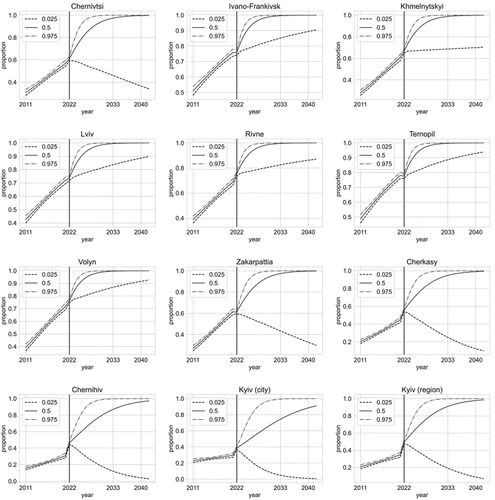
Figure 12. Prediction of Ukrainian language usage proportion until year 2040 (part 2).
There are several limitations of this study that should be discussed. First, due to the geopolitical situation in Donetsk and Luhansk regions, we cannot distinguish between the territories that are under control of the Ukrainian government or under control of separatists. That is, the data are combined for these two regions and therefore we cannot observe the corresponding effect directly. It is also important to consider the effect of the Russian invasion of Ukraine that started on February 24, 2022. Specifically, one should keep in mind that many people died or fled these regions and a considerable number of cities and villages were devastated. Moreover, if we consider the annexed regions of Crimea and the city of Sevastopol, there might be an additional effect that is related to service availability. Namely, an individual located in Crimea and seeking, say, government assistance, will need to use the Russian language. However, this logic also applies to the territories that are under the control of the Ukrainian government. An additional limitation of this study is web content availability. Specifically, there exists more content in the Russian language. Furthermore, by using the open google trend data, we cannot distinguish between individuals with respect to say age, education, and so forth. However, this work can be potentially extended by designing appropriate experiments with human subjects; the statistical machinery would remain almost identical. Finally, it is important to note that many Ukrainian citizens use Surzhyk (Hentschel and Palinska Citation2022; Hentschel and Taranenko Citation2021), a mixed language that contains both Russian and Ukrainian words. The proposed method can not distinguish between pure Ukrainian, pure Russian, and Surzhyk speakers. However, the method can provide evidence regarding the proportion of Ukrainian and Russian words used.
Despite the above limitations, this work demonstrates the value of the spatial google trend language data availability. Moreover, it lays a foundation for various extensions and future work. For example, starting from February 2022, additional queries and keywords might become popular. It will be of interest to develop a model that both considers the available 2011–2022 data and, takes into account the new set of war-related queries. One possible direction is to consider the Beta rectangular distribution link function as suggested by Bayes et al. (Bayes, Bazán, and García Citation2012), since it can provide a more robust modeling of proportions with respect to outliers. Applying such a model will be increasingly important as time passes, and additional data from google trends becomes available. To conclude, we conjecture that the application of the proposed model is of great value since it can help to examine the effectiveness of government policies with respect to language dissemination.
Supplemental Material
Download MS Word (3 MB)Acknowledgments
We are thoroughly grateful to the editor and to anonymous reviewers for their valuable and constructive remarks and suggestions.
Disclosure Statement
No potential conflict of interest was reported by the author(s).
Supplemental data
Supplemental data for this article can be accessed on the publisher’s website at https://doi.org/10.1080/10758216.2023.2224568
Notes
2. Poland, Slovakia, Hungary, and Roumania
References
- Arel, D. 2002. “Interpreting “Nationality” and “Language” in the 2001 Ukrainian Census.” Post-Soviet Affairs 18 (3): 213–249. https://doi.org/10.2747/1060-586X.18.3.213.
- Bayes, C. L., J. L. Bazán, and C. García. 2012. “A New Robust Regression Model for Proportions.” Bayesian Analysis 7 (4): 841–866. https://doi.org/10.1214/12-BA728.
- Brooks, S. P., and A. Gelman. 1998. “General Methods for Monitoring Convergence of Iterative Simulations.” Journal of Computational and Graphical Statistics 7 (4): 434–455.
- Bureiko, N., and T. L. Moga. 2018. “Bounded Europeanisation: The Case of Ukraine.” In The European Union and Its Eastern Neighbourhood, 71–85. Manchester: Manchester University Press.
- Carpenter, B., M. D. Andrew Gelman, D. L. Hoffman, B. Goodrich, M. Betancourt, M. Brubaker, J. Guo, L. Peter, and A. Riddell. 2017. “Stan: A Probabilistic Programming Language.” Journal of Statistical Software 76 (1): 1–32. https://doi.org/10.18637/jss.v076.i01.
- Centr Razumkova. 2016. “Consolidation of Ukrainian Society: Challenges, Opportunities, Pathways.” https://razumkov.org.ua/uploads/journal/eng/NSD165-166_2016_eng.pdf.
- Chan, J. C. C., and E. Eisenstat. 2015. “Marginal Likelihood Estimation with the Cross-Entropy Method.” Econometric Reviews 34 (3): 256–285. https://doi.org/10.1080/07474938.2014.944474.
- Decker, P. K. 2021. ““We Show What Is Concealed”: Russian Soft Power in Germany.” Problems of Post-Communism 68 (3): 216–230. https://doi.org/10.1080/10758216.2020.1753082.
- Elder, M. 2012. “Ukrainians Protest against Russian Language Law.” The Guardian. https://www.theguardian.com/world/2012/jul/04/ukrainians-protest-russian-language-law.
- Feklyunina, V. 2016. “Soft Power and Identity: Russia, Ukraine and the ‘Russian World(S).’” European Journal of International Relations 22 (4): 773–796. https://doi.org/10.1177/1354066115601200.
- Ferrari, S., and F. Cribari-Neto. 2004. “Beta Regression for Modelling Rates and Proportions.” Journal of Applied Statistics, Journal of Applied Statistics 31 (7): 799–815. https://doi.org/10.1080/0266476042000214501.
- Figueroa-Zúñiga, J. I., R. B. Arellano-Valle, and S. Ferrari. 2013. “Mixed Beta Regression: A Bayesian Perspective.” Computational Statistics & Data Analysis 61:137–147. https://doi.org/10.1016/j.csda.2012.12.002.
- Flier, M. S., and A. Graziosi. n.d. “The Battle for Ukrainian: A Comparative Perspective.” Harvard Ukrainian Studies 35 (1/4): 636.
- Forsberg, T., and H. Smith. 2016. “Russian Cultural Statecraft in the Eurasian Space.” Problems of Post-Communism 63 (3): 129–134. https://doi.org/10.1080/10758216.2016.1174023.
- Gelman, A., and D. B. Rubin. 1992. “Inference from Iterative Simulation Using Multiple Sequences.” Statistical Science 7 (4): 457–472. https://doi.org/10.1214/ss/1177011136.
- Gladkova, A. 2015. “Linguistic and Cultural Diversity in Russian Cyberspace: Examining Four Ethnic Groups Online.” Journal of Multicultural Discourses 10 (1): 49–66. https://doi.org/10.1080/17447143.2015.1011657.
- Grimmett, G., and D. Stirzaker. 2001. Probability and Random Processes. 3rd ed. New York: Oxford university press.
- Hentschel, G., and O. Palinska. 2022. “The Linguistic Situation on the Ukrainian Black Sea Coast – Ukrainian, Russian and Suržyk as ‘Native Language,’ ‘Primary Code,’ Frequently Used Codes and Codes of Linguistic Socialization during Childhood.“ Russian Linguistics - International Journal for the Study of Russian and other Slavic Languages 46 (3): 259–290.
- Hentschel, G., and O. Taranenko. 2021. “Bilingualism or Tricodalism: Ukrainian, Russian and “Suržyk” in Ukraine.” Die Welt der Slaven 66 (2): 268–299.
- Ilko Kucheriv Democratic Initiatives Foundation and Razumkov Centre. 2021. “The Day of Ukrainian Writing and Language-2021: Is the Use of the State Language in the Public Sphere Increasing?” https://dif.org.ua/article/the-day-of-ukrainian-writing-and-language-2021-is-the-use-of-the-state-language-in-the-public-sphere-increasing.
- Johnson, V. E. 2004. “A Bayesian Chi(2) Test for Goodness-Of-Fit.” The Annals of Statistics 32 (6): 2361–2384. https://doi.org/10.1214/009053604000000616.
- Kass, R. E., and A. E. Raftery. 1995. “Bayes Factors.” Journal of the American Statistical Association 90 (430): 773–795. https://doi.org/10.1080/01621459.1995.10476572.
- Kiss, N. 2022. “Key Actors in the Organized Language Management of Ukraine: On the Materials of Language Legislation Development and Adoption.” In Interests and Power in Language Management, edited by M Nekula, T Sherman, and H Zawiszová, 177–201. Berlin, Bern, Bruxelles, New York, Oxford, Warszawa, Wien: Peter Lang International Academic Publishing Group.
- Kulyk, V. 2011. “Language Identity, Linguistic Diversity and Political Cleavages: Evidence from Ukraine.” Nations and Nationalism 17 (3): 627–648. https://doi.org/10.1111/j.1469-8129.2011.00493.x.
- Kulyk, V. 2022a. “Die Sprache der Widerstands. Der Krieg Und der Aufschwung Des Ukrainischen.” Osteuropa 72 (6–8): 237–248. https://doi.org/10.35998/oe-2022-0160.
- Kulyk, V. 2022b. “Is Ukraine a Multiethnic Country?” Slavic Review 81 (2): 299–323. https://doi.org/10.1017/slr.2022.152.
- Latyshev, A., E. Onischuk, and A. Medvedeva. 2021. “‘Too Strong’: Why More than Half of the Population of Ukraine Continues to Actively Use the Russian Language.” Russia Today, 1. https://russian.rt.com/ussr/article/896925-ukraina-opros-yazyk.
- Müller, D., and M. Wingender. 2021. Language Politics, Language Situations and Conflicts in Multilingual Societies. Case Studies from Contemporary Russia, Ukraine and Belarus. Wiesbaden, Germany: Harrassowitz Verlag.
- Ogarkova, T. March 12, 2018. “The Truth Behind Ukraine’s Language Policy.” Atlantic Council. https://www.atlanticcouncil.org/blogs/ukrainealert/the-truth-behind-ukraine-s-language-policy/.
- Poses, C., and M. Revilla. 2021. “Measuring Satisfaction with Democracy: How Good are Different Scales across Countries and Languages?” European Political Science Review 14 (1): 1–18.
- Quasthoff, U., D. Goldhahn, and T. Eckart. 2014. “Building Large Resources for Text Mining: The Leipzig Corpora Collection.” In Text Mining, edited by C. Biemann and A. Mehler, 3–24. Theory and Applications of Natural Language Processing. New York (NY): Springer International Publishing.
- Rating. 2022. “Seventeenth National Survey: Identity. Patriotism. Values.” https://ratinggroup.ua/research/ukraine/s_mnadcyate_zagalnonac_onalne_opituvannya_dentichn_st_patr_otizm_c_nnost_17-18_serpnya_2022.html.
- Reznik, V. 2018. “Language Policy in Independent Ukraine: A Battle for National and Linguistic Empowerment.” In Language Planning in the Post-Communist Era, edited by E. Andrews, 169–192. Eurasia and China: Palgrave Macmillan.
- Rizzo, M. L. 2019. Statistical Computing with R Maria L. Rizzo. 2nd ed. Chapman & Hall/Crc the R Series. Boca Raton, New York: CRC Press, Taylor & Francis Group.
- Toivanen, R. 2007. “Linguistic Diversity and the Paradox of Rights Discourse.” In The Language Question in Europe and Diverse Societies: Political, Legal and Social Perspectives, edited by C. Longman and D. Castiglione, 101–121. 1st ed. Oñati International Series in Law and Society. London: Hart Publishing.
- Ushchyna, V. 2020. “Corinne A. Seals Choosing a Mother Tongue: The Politics of Language and Identity in Ukraine. Bristol: Multilingual Matters, 2019. Pp. 213.” Language in Society 49 (3): 491–492. https://doi.org/10.1017/S0047404520000202.
- Zeller, J. 2021. “The Geographical and Social Distribution of Native Languages in Central Ukraine.” Linguistica Copernicana 18:105–136. https://doi.org/10.12775/LinCop.2021.006.
Appendix Appendix A.
Google trends search terms