
Abstract
This article presents the results of discrimination of 11 wheat grain varieties. The statistical analysis included reduction of variables to a set of 49 textures with the highest discriminating strength and multidimensional analysis. Reduction of variables was performed by the following methods: genetic algorithms (sequential forward floating search [SFFS] method) as well as the Class Ranker and Class RankersSearch methods. Furthermore, the multidimensional analysis was performed by methods employing the following classifiers: Bayes, Lazy, Meta, Decision trees, and Discriminatory analyses. The classification of individual varieties, regardless of the year of cultivation, was between 98 and 100%.
INTRODUCTION
The use of computer visualising systems in the food industry has been growing. They are used, for example, to evaluate product quality, to control processing, and to identify varieties. These methods can help identify such features of an object as colour, geometry, and surface texture. An image may be acquired with a video camera, a digital camera, or scanners.Citation1–3 Citation Citation3] In recent years, devices for taking 21/2 and 3D images have been used increasingly often. Typical image analysis is based on acquisition of photographs taken in the electromagnetic radiation whose wavelength ranges from 400 to 700 nm. Owing to the development of digital camera technology, it is now possible to take ultraviolet (below 400 nm) and infrared (above 700 nm) photographs. The latest trends in visualising techniques include hyperspectral photography—photographs of an object are taken in several or even in several dozen spectral channels. Any visualising system must include software for photograph analysis (object identification and separation from the background), the object measurement, and statistical analysis of the results (multidimensional analyses, reduction of variables).
With a tool like this, researchers can develop visualising systems, which can be used for such purposes as evaluation of food product quality and sorting and identification of varieties of various crops, including grains. Variety identification is important as varieties are usually intended for a specific use. For example, wheat grain can be used for either fodder or food production. Traditional methods of variety identification are still costly, but also time consuming. Therefore, studies should be conducted aimed at constructing a cheap and quick system, which could identify varieties with the smallest possible error. Such conditions can be met by a visualising system based on a flat scanner and en masse grain analysis.
Such research has been carried out for several years.Citation4–7 Citation Citation Citation7] The authors have employed the technique of digital image recording with a CCD camera to identify different grain species. They isolated three groups of features that determine the physical properties of caryopses, i.e., geometric features, colour, and surface texture, and they identified 25 different indexes. Subsequently, they used neural networks to develop a system of identification of grain species. The final recognition effectiveness ranged from 95.7 (wheat) to 92.5% (rice). AuthorsCitation8–13 Citation Citation Citation Citation Citation13] used a flat scanner to identify different species of Indian wheat. Out of the 45 indexes of geometric dimensions and shapes, they isolated 5 indexes that can be used to identify varieties. UtkuCitation[14] made an attempt at developing a system to recognise 31 wheat varieties with a CCD camera. There are systems to perform quality evaluation of agricultural products.Citation15–18 Citation Citation Citation18] Such a system can identify lentil varieties with an accuracy of 99.8% and beans with an accuracy of 99.0% and varieties of wheat and wheat products with a similar accuracy.
However, those reports do not provide any information about the effectiveness of the statistical models in identifying variety in successive years of cultivation. Developing a model based on data from only one specific year, using neural networks or multidimensional analyses, brings very good results and scientists can build such models. But would such a model—developed for one year—prove useful when used in classification in subsequent years? Another question is whether a model based on varieties harvested in a specific climate and weather conditions would be useful in other conditions. Therefore, the author developed a statistical model to identify varieties that would be effective in classification of varieties in successive years of study. The model is based on measuring the texture of en masse images of caryopses. In order to reduce the number of variables, several methods of feature space reduction were employed as well as several discriminatory methods to achieve the best classification model.
MATERIALS AND METHODS
Grain Samples
The experimental material was comprised of treated grain of common spring and winter wheat of four quality classes (elite wheat, prime quality wheat, bread wheat, and forage wheat). The elite wheat (E) includes varieties of a very good milling and baking quality as well as those resistant to overgrowth. Flour from such grain may be used to upgrade bread flour (B). Wheat of A quality features good milling quality and a very good baking quality, it is also resistant to overgrowth. It can be used to improve mixes of wheat grain of poorer quality, however, it should be added in larger volumes than E quality wheat. Bread wheat grain (B) may be used for milling and baking, however, it should usually be mixed with E or A quality wheat. Bread wheat features an average baking value. Wheat varieties that did not qualify to any of the groups (A, B, or E) are classified as group C, which comprises all the remaining varieties, including forage wheat. Grain kernel samples were supplied by the Plant Cultivation Centre in Strzelce Sp. z o.o. near Kutno and were cultivated in central Poland.
The study covered three cultivation years (2005, 2006, 2007) and 11 varieties (seven winter and four spring varieties; elite wheat: Torka*, prime quality wheat: Nawra*, Koksa*, Zyta, Sukces, Tonacja, Fregata; bread wheat: Cytra*, Soraja, Nutka; forage wheat: Symfonia) were analyzed each year at three moisture content levels—12, 14, and 16%. Initial moisture content was determined in two replications using the drying method according to Polish standard PN-71A-75101. The samples were ground and placed in a laboratory dryer at a temperature of 100°C for 4 h. Samples characterized by low initial moisture content values were hydrated. Water was added, grain was stirred for 24 h, it was placed in tight plastic containers and stored for 48 h at room temperature to ensure equal moisture distribution through the sample. Initial moisture content values were determined after the applied hydration treatment.
Image Analysis
The image acquisition workstation consisted of an Epson Perfection 4490 Photo flat scanner (Seiko Epson Covp., Nagano, Japan). Connected with a graphic station based on an Intel Pentium D 830 processor and a scanner using SilverFast Epson v 6.4.3 software (LaserSoft Imaging, Inc.). Before each series of images was acquired, the scanner was calibrated with an IT8.7/2 template, supplied with the scanner software. This enabled control of the image quality, which is of key importance in image texture measurement. The images were analysed with modified MaZda v 4.3 software (Institute of Electronics, Technical University of Ledz, Poland).[26] As compared to the original software, its modification involved a module for automatic image segmentation, which can be used to define the type of ROI (region of interest), to set the channel to be analysed, and the type textures measured. The caryopses on the measurement scene were put randomly in a layer whose thickness prevented the scanner light from passing through it (a layer of approx. 20 mm). Before the textures were measured, 16 ROI were randomly superimposed on an image fed into the software (). Each variety was described by textures from 384 ROI (24 scans * 16 ROI).
Figure 1 An image of kernel setting with ROI. (Colour figure available online.)

Statistical Analysis
The statistical analysis of results involved an unsupervised selection of data, followed by multidimensional analysis of the selected data in order to test the possibility of variety classification. The aim of the selection of variables was to reduce the set of 1960 variables, which describe a single ROI, to a set of the best 49 variables. Such a large number of variables resulted from the calculation of 280 variables from a single channel. Such a great number was initially produced since seven channels were taken into account. The data for further multidimensional analyses were selected from those available for the 2006 grain. It was assumed that the variables obtained for the year would be used to perform classification of 2005, 2006, and 2007 grain. If satisfactory discrimination is achieved for three subsequent years of harvest based on the same set of textures, it will confirm the good quality of the statistical model developed for discrimination of wheat grain varieties.
Variables' Reduction
Seven methods of variables’ selection were used. The first group comprises genetic algorithms (HGA + Adaptive, HGA + Fixed), and the sequential forward floating search. The methods have been implemented in the HGA.sel software.Citation[19] Another group of methods includes those based on Class Ranker + InfoGainAttributeEva, Class Ranker + ChiSquaredAttributeEval, and Class RankersSearch + CfsSubsetEval and Class RankersSearch + ConsistencySubsetEval; in this case, the WEKA v. 3.7 software (Machine Learning Group, University of Waikato) was used.Citation[20]
Genetic Algorithms
The issue of genetic algorithm application has been presented by Pudil et al.Citation21–23 Citation Citation23] This study has applied genetic algorithms with two strategies of features’ space searching. The first of them involved seeking the best set in determination of the maximum dimension of the features’ space and the optimal dimension was established automatically (Adaptive). The other strategy was based on establishing the exact dimension of the target space (Fixed).Citation[24] Regardless of the seeking method, the algorithm operation parameters were set at: Ripple parameter—1, Population size—10, Mutation rate—0.10, Generation limit—15, Selection pressure—0.25, Cross–over points—3, Number of clusters—11, Reduced dimensionality—10.
The sequential forward floating search (SFFS)
Before the seeking was started in the method, it was necessary to declare the maximum number of features n, which was to be included in the target observation space. In initialising the SFFS procedure, all the features are placed in the Δ set, whereas the Ξ set remains empty. When the algorithm operates, subsequent significant features are found, which results in creating a collection of subsets Ξt, where 1 ≤ t ≤ n, which are the best sets with the dimension of t.Citation[19]
Class Ranker, Class RankerSearch
A detailed description and assumptions of the selection method applied has been presented by Witten and Frank.Citation[25] The study employs two methods of selection: Class Ranker and Class RankerSearch. In the first method, the selected attributes were evaluated by the InfoGainAttributeEvaluate method, which involves measuring their information gain with respect to the class. It discretizes numeric attributes first using the MDL-based discretization method (it can be set to binarize them instead). This method, along with the next three, can treat missing as a separate value or distribute the counts among other values in proportion to their frequency.Citation[25]
Another method was based on the ChiSquared statistics. ChiSquaredAttributeEvaluate evaluates attributes by computing the chi-squared statistic with respect to the class. GainRatioAttributeEval evaluates attributes by measuring their gain ratio with respect to the class.Citation[25] In the Class RankerSearch reduction method, the quality of features is evaluated by the CfsSubsetEvaluate and ConsistencySubsetEvaluate method. Application of the methods discussed above provided a set of variables with potentially the greatest discriminating power. shows the four best variables for each selection method and each colour channel.
Table 1 Listing of the best variables from different colour channels and selection methods
Finally, variables from the first place on the list were chosen for the multidimensional analysis, with the reservation that if the same texture was selected in the first place in several methods of selection, textures from the next places were selected. This provided a set of 49 variables from all the colour channels and methods of selection. It was assumed that such a procedure would ensure the best possible set of information for further analyses.
Multidimensional Analysis
The variety classification was performed with the use of seven methods of classification, i.e., Bayes, Lazy, Meta, Decision trees, and Discriminatory analyses. Discriminant analysis (stepwise regressive and progressive, as well as the Best subset) was performed using Statistica v 9.0 software (StatSoft, Inc., Tulsa, OK, USA); the other analyses were performed with WEKA v 3.7. The strategy adopted in developing the statistical model involved division of data sets into subsets according to the methods: cross-validation (k = 10), percentage split (30% of the input set), training (the test set was taken from the training set). Division of a data set in discriminant analysis was performed by the cross-validation method (k = 10). At that stage, such a method was sought which would ensure the smallest classification error for 11 wheat varieties in successive years of cultivation.
RESULTS AND DISCUSSION
Reduction of Variables
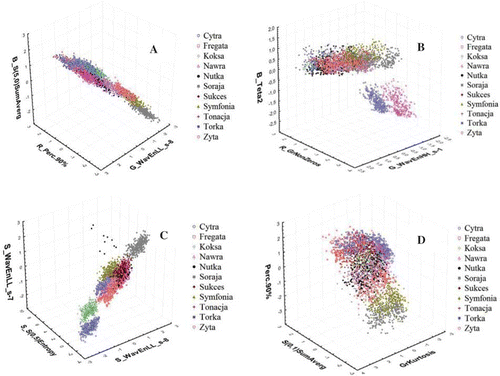
presents the results of selection of variables for all the channels under analysis. The largest group of textures for the genetic algorithms was calculated by the Co-occurrence matrix method. The selected textures in the Ranker and RankerSearch were usually calculated by the Haar wavelet transform methods, with the exception of the textures selected by the RankSearch for the U, V channel. The best discriminants in that case were the values calculated from the histogram distribution. shows the categorised diagrams of cases distribution based on selected variables (texture parameters). The discriminating power of selected “raw” variables, without the multidimensional analysis was so great that introducing variables to the model could be expected to result in an effective final classification. An example could be a case distribution presented in , where textures calculated from channel S were the grouping variables. Cases in different variables were grouped in an isolated space around its own centre. The Cytra, Koksa, and Soraja varieties were sets of points distanced from others. Moreover, the other varieties were clustered around separated space, with their centres close to one another.
Figure 2 A categorised diagram of the distribution of cases that represent 11 varieties of wheat (the year 2006, humidity 14%). (a) and (b) represent distribution of cases vs. variables from the RGB channel and the Ranker and Ranker+Fixed selection method. (c) and (d) represent distribution of cases vs. variables from channels S and Y and the HGA+Fixed, SFFS+Fixed selection methods. (Colour figure available online.)
Multidimensional Analysis
The results of multidimensional analysis are presented in . The correctness of classification depending on the method ranged from 86 to 100%, regardless of the year of cultivation. When the training and testing method was used on the same set, the percentage of exact classification was always 100%. This was caused by the fact that the discriminating power of the selected variables was very high, and mainly by the fact that classification of cases on the same set as the training set gives much better results. Therefore, further analyses used classification of sets into teaching and validation ones. In that case, the correctness
Table 2 Results of multidimensional analysis for 11 wheat varieties cultivated in the years 2005–2007, grain humidity 14%
Multidimensional Analysis—Stepwise Regressive, Progressive, and the Best Set Analysis
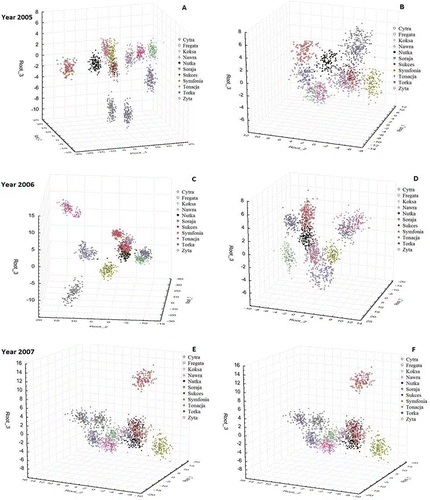
shows the results of discrimination of 11 wheat varieties in different years of cultivation. Wheat discrimination with the use of the methods under discussion was highly effective. Classification error was equal to 8% in the worst case—when the “best subset” method was used (2007). The cumulative error was only 1–2% when the stepwise progressive or regressive method was used. The error occurred only in the Sukces and Nutka varieties, when incorrect classification was performed in individual cases. Classification of the other varieties was 100% correct. In the stepwise analysis, it is possible to evaluate the effect of individual variables on the discriminant ability during the classification. This allows a decision to be made to either continue or to stop introducing variables to the model. Lambda Wilkasa is the statistic that shows the strength of the variables. The lower the value of the statistics, with a high value of statistics F, the higher the discriminating power of the variables fed into the model. shows the distribution of cases for the three best discriminating variables. The grouping of cases based on them was satisfactory; it was possible to distinguish centres for individual varieties. When only 9 variables were fed into the model, the value of the statistics was 0.000001 at F = 670, which ensured 100% of effective classification at such a low number of varieties ().
Figure 3 Distribution of cases based on three best variables in progressive discriminant analysis. (a) Mean values and standard deviation of texture B_WavEnLL_s-8 for the years 2005, 2006, and 2007. (Colour figure available online.)
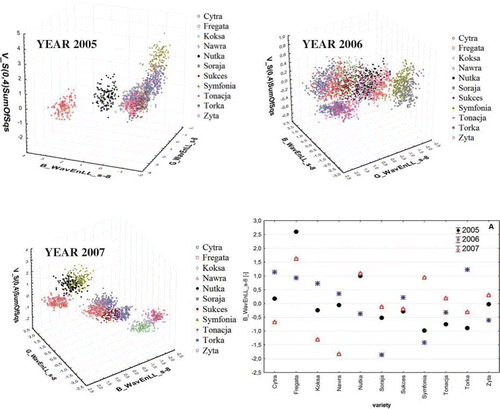
Figure 4 Classification of 11 varieties of wheat: (a, c, e) stepwise progressive method; (b, d, f) best subset method. (Colour figure available online.)
CONCLUSIONS
The method of discrimination of grain of wheat varieties provides 100% effectiveness. Based on the textures selected in 2006, it was possible to discriminate 2007 and 2005 varieties. One of the advantages of the method is its quickness. It takes about a minute to place grains on the scanner and to perform the image analysis together with the statistical analysis. These conclusions are true with the reservation that discriminant analysis is performed on variables for a specific year and applies only to that year. shows the mean values for the selected texture B_WavEnLL_s-8 for the varieties under analysis and 3 years of cultivation. The mean values for the texture for individual years were different. The differences in the parameter level exceeded 100% in most cases. The discrepancy between the parameter value for the 3 years under analysis and the 11 analysed varieties was 4.5 units, which—with small standard deviation—will make discrimination more difficult. Further studies aimed at improving the proposed method will have to produce a model, which is based on the standardised value of the texture used in classification of varieties in different years of cultivation.
ACKNOWLEDGMENTS
The author is grateful for the financial support provided by the Ministry of Scientific Research within the framework of grant no. 1089/P06/2005/29.
REFERENCES
- Seyed , M.A. , Razavia , A. and Rahbaria , R. 2010 . Computer image analysis and physico-mechanical properties of wild sage seed (Salvia macrosiphon) . International Journal of Food Properties , 13 ( 2 ) : 308 – 316 .
- Yong , H. , Xiaoli , L. and Yongni , S. 2007 . Fast discrimination of apple varieties using Vis/NIR spectroscopy . International Journal of Food Properties , 10 ( 1 ) : 9 – 18 .
- Mahmoodia , M. , Khazaeia , J. and Narjes . “ Modeling of geometric size distribution of almond ” . In International Journal of Food Properties 2010 doi: 10.1080/10942910903501872
- Majumdar , S. and Jayas , D.S. 2000 . Classification of cereal grains using machine vision: I. Morphology models . American Society of Agricultural Engineering , 43 : 1669 – 1675 .
- Majumdar , S. and Jayas , D.S. 2000 . Classification of cereal grains using machine vision: III . Texture models. Morphology models. American Society of Agricultural Engineering , 43 : 1681 – 1687 .
- Majumdar , S. and Jayas , D.S. 2000 . Classification of cereal grains using machine vision: II. Color models. Morphology models . American Society of Agricultural Engineering , 43 : 1677 – 1680 .
- Majumdar , S. and Jayas , D.S. 2000 . Classification of cereal grains using machine vision: VI . Combined morphology, color, and texture models. American Society of Agricultural Engineering , 43 : 1689 – 1694 .
- Jayas , D.S. , Paliwal , J. and Visen , N.S. 2000 . Multi-layer neural networks for image analysis of agricultural products . Journal of Agricultural Engineering Research , 77 : 119 – 128 .
- Visen , N.S. , Paliwal , J. , Jayas , D.S. and White , N.D.G. 2001 . Specialist neural networks for cereal grain classification . Biosystems Engineering , 82 : 151 – 159 .
- Visen , N.S. , Shashidhar , N.S. , Paliwal , J. and Jayas , D.S. 2002 . Identification and segmentation of occluding groups of grain kernels in a grain sample image . Journal of Agricultural Engineering Research , 79 : 159 – 166 .
- Paliwal , J. , Visen , N.S. and Jayas , D.S. 2001 . Evaluation of neural network architectures for cereal classification using morphological features . Journal of Agricultural Engineering Research , 79 : 361 – 370 .
- Paliwal , J. , Visen , N.S. , Jayas , D.S. and White , N.D.G. 2003 . Comparison of a neural network and non-parametric classifier for grain kernel identification . Biosystems Engineering , 85 : 405 – 413 .
- Paliwal , J. , Visen , N.S. , Jayas , D.S. and White , N.D.G. 2003 . Cereal grain and dockage identification using machine vision . Biosystems Engineering , 85 : 51 – 57 .
- Utku , H. 2000 . Application of the feature selection method to discriminate digitized wheat arieties . Journal of Food Engineering , 46 : 211 – 216 .
- Venora , G. , Grillo , O. , Ravalli , C. and Cremonini , R. 2009 . Identification of Italian landraces of bean (Phaseolus vulgaris L.) using an image analysis system . Scientia Horticulturae , 121 : 410 – 418 .
- Venora , G. , Grillo , O. and Saccone , R. 2009 . Quality assessment of durum wheat storage centres in Sicily: Evaluation of vitreous, starchy and shrunken kernels using an image analysis system . Journal Cereal Science , 49 : 429 – 440 .
- Venora , G. , Grillo , O. , Saccone , R. and Ravalli , C. June 30–July 3 2008 . “ Speck evaluation on commercial spaghetti using an imaging system ” . In From Seed to Pasta: The Durum Wheat Chain , June 30–July 3 , Bologna : International Durum Wheat Symposium .
- Venora , G. , Grillo , O. , Shahin , M.A. and Symons , S.J. 2007 . Identification of Sicilian landraces and Canadian cultivars of lentil using image analysis system . Food Research International , 40 : 161 – 166 .
- Klepaczko , A. 2006 . “ Zastosowanie algorytmów analizy skupień do selekcji cech dla zadań klasyfikacji cech dla zadań klasyfikacji wektorów danych ” . In Praca doktorska. Politechnika Łódzka, Instytut Elektroniki
- Hall , M. , Frank , E. , Holmes , G. , Pfahringer , B. , Reutemann , P. and Witten , I.H. 2009 . The WEKA data mining software: An update . SIGKDD Explorations , 11 ( 1 ) : 10 – 18 .
- Pudil , P. , Novovičova , J. and Kittler , J. 1994 . Floating search methods in feature selection . Pattern Recognition Letters , 15 : 1119 – 1125 .
- Pudil , P. and Novovičova , J. 1998 . Novel methods for subset selection with respect to problem knowledge . Intelligent Systems , 13 : 66 – 74 .
- Pudil , P. and Somol , P. 2005 . Current feature selection techniques in statistical pattern . Advances in Intelligent and Soft Computing , 30 : 53 – 68 .
- Oh , I.S. , Lee , J.S. and Moon , B.R. 2004 . Hybrid genetic algorithms for feature selection . Institute of Electrical and Electronics Engineers Transactions on Pattern Analysis and Machine Intelligence , 26 : 1424 – 1437 .
- Witten , I.H. and Frank , E. 2005 . Data Mining. Practical Machine Learning Tools and Techniques , Second , New York, USA: Elsevier .
- Szczypiński , P.M. , Strzelecki , M. , Materka , A. and Klepaczko , A. 2009 . MaZda-A software package for image texture analysis . Computer Methods and Programs in Biomedicine , 94 : 66 – 76 .