
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In this study, a computer vision system was developed for the identification of paddy varieties based on the morphological features. Artificial neural networks and linear discriminant analysis methods were utilized for identification of the paddy seeds. Seven varieties of paddy (Tarom Hashemi, Tarom Molaei, Fajr, Neda, Kados, Sahel, and Shiroudi) were used in this research. The results showed that the identification with an artificial neural network classifier achieved over 91.5% prediction accuracy. It was evident that the predictive accuracy of artificial neural network model was higher than that evaluated with the linear discriminant analysis method. The values of error obtained from artificial neural network analysis ranged from 1.5 to 32.0% according to number of morphological features analyzed.
INTRODUCTION
Rice (Oryza sativa L.) is a staple food for a large part of the world’s human population and is the most consumed cereal grain.[Citation1] Rice variety is one of the most important factors which contribute to the yield and overall quality of the seeds. Therefore, the identification and classification of rice varieties are of substantial scientific and feasible significance in precise agronomy. Various identification systems for the classification of different cereal grains and varieties have been reported in literature. The DNA, enzymes, and chemical analysis technologies have proven to be the most precise and useful tools for identification of crop varieties.[Citation2,Citation3] However, these methods are hampered by the very high expense for inspection.
Direct identification and classification of different cereal grains and varieties is still performed mainly by human-based observation. The variables which commonly used in visual inspection of crop variety are color, morphological, and texture properties of seeds. Such data are bulky, non-linear, and complex, showing noise, redundancy, internal relations, and outliers.[Citation4] There is also wide variability in the variables and complex interactions between explanatory and response variables. Therefore, the visual inspection method that is extremely laborious, requires trained personnel, has low reproducibility, and results in an unacceptable level of misclassification.[Citation5] To overcome the difficulty of human high-dimensional data analysis, computer systems have been widely employed.[Citation6] A computer vision technology (CVT) provides an alternative to the manual inspection of grain sample properties by integrating an image acquisition device and a computer.[Citation7] It stimulates human eyes to distinguish the seed varieties and is considered to be more accurate and consistent than subjective methods. Most of the kernel features employed in grain identification can be rapidly measured using machine vision.
Classifier plays an important role in a machine vision system performance. Statistical and artificial neural network (ANN) classifiers are widely used in grain classification.[Citation8] Different statistical pattern recognition techniques were also employed to analyze the size, shape, and color properties of seeds and to identify different grain species, varieties, and impurities.[Citation9–Citation13] Guevara-Hernandez and Gomez[Citation14] used a machine vision system for identification of wheat and barley grain kernels. Traditional statistical techniques such as principal component analysis (PCA) and linear discriminant analysis (LDA) were also employed for seeds identification purposes.[Citation15,Citation16] The features extracted from the properties of pixels inside an object are called internal image features. The most important internal features are color, morphological, and image texture. Some investigations dealing with the use of different color features were conducted for the purpose of classifying different cereal grains and their varieties.[Citation17–Citation20] Golpour et al.[Citation7] developed an algorithm based on color features for the classification of Bulk Paddy, Brown, and White Rice Cultivars. Azizi et al.[Citation21] also developed a method for identifying and discriminating 10 potato varieties by combining machine vision and ANN methods using color, textural, and morphological features. They found that classification accuracy of neural network is more than LDA’s classification accuracy to identify potato varieties.
The morphological parameters were reported to be important parameters for seeds variety identification.[Citation22] They also determined that the morphological features had a better discriminating power for weed species comparing to color and texture image descriptors.[Citation23] Substantial works dealing with the use of different morphological features for statistical classification of different cereal grains and varieties have been reported.[Citation24–Citation28]
In order to achieve the highest wheat classification accuracy, an optimum set of different textural features was selected using stepwise discriminant analysis method and employed in a LDA classifier.[Citation29] LDA is linear transformation that is well suited for separating multidimensional data for different objects or class.[Citation30] Linear transform methods typically extract information only from the second-order correlations in the data (covariance matrix) and ignore higher-order correlations (covariance matrix) in the dataset. Many researchers have reported that multidimensional datasets in the real world are inherently non-symmetric.[Citation31,Citation32]
PCA and LDA methods were not very accurate in a non-linear and complex dataset of crop varieties. However, a non-linear analysis performed better in this case.[Citation33] ANN is a non-linear classification method, which can be considered as a potential approach for a pattern recognition application with a higher and faster performance comparing to the standard statistical algorithms back-propagation (BP) ANNs are the most commonly used supervised networks because of their ability to generalize. The generalization ability of the ANNs is measured by the classification accuracy on a validation set of unseen examples. Some of the studies on ANN application in computer vision system (CVS) include grading of cereal grains and vegetables, classification of fruits, nuts, and some other foods such as meat and fish.[Citation34]
Reliable, cost effective, consistent, accurate, and fast identification/classification of seeds is of major technical and economical importance for the seed production industry. These parameters can be achieved by using a vision based and ANN-assisted identification system. Automated identification approaches (such as machine vision) had undergone substantial growth in the industry because of its infrastructures availability. However, the processing speed and accuracy were two major problems for identification of paddy cultivars.
Therefore, the main purpose of this study was to classify the paddy kernel using a machine vision approach. The specific objectives included (1) to develop an image analysis technique for extracting 17 morphological features of paddy kernels images; (2) to develop BP ANNs for identification of seven varieties of paddy based on the morphological features; and (3) to compare the classification accuracies using BP ANNs and specialist statistical classifiers.
MATERIALS AND METHODS
Paddy Sample Procurement
The grain samples were collected from the Rice Research Institute in Amol, Iran. Seven varieties of paddy kernels named as follows: Tarom Hashemi, Tarom Molaei, Fajr, Neda, Kados, Sahel, and Shiroudi. Three kilograms of paddy kernel were selected randomly from each variety and were kept in double sealed polythene bags at 5°C in a refrigerator during the experiment. All broken grains were removed manually and only head rice was used for the experiment. Moisture contents of the samples were monitored and kept between 7–9% (dry basis). Moisture content was measured using a standard air oven method. In this method, 5 g of seeds were kept in an oven at 103°C for 48 h and then the weight loss was measured and used to calculate the moisture content.[Citation35]
Image Acquisition and Segmentation
Image acquisition was conducted using a digital camera (PowerShot G7, Canon, Tokyo, Japan) with resolution of 1200 × 1600 pixels. A lens (ANB847, Panasonic, Osaka, Japan) with 50 mm focal length was mounted on the camera using an adapter rings (ANB848, Panasonic, Osaka, Japan). The camera was fixed on a stand which provided easy vertical movement and stable support. Clear focused images of paddy seed were obtained at the distance of 140 mm between the lens and the sample platform. The seeds were placed in a random orientation and position within the camera’s field-of-view. A white board was used as the background on the imaging platform. Two hundred paddy seeds were selected randomly from each variety for image acquisition. Digital images were stored in uncompressed JPEG format. A database of 1400 images of paddy seeds in seven varieties was created. shows an example image of a paddy seed in each variety. At the second step, the paddy seeds were segmented in the images from the background. MATLAB (version 2012, MathWorks, Natick, MA, USA) software was used to develop the required algorithms for image segmentation and texture feature extraction. A detailed illustration of the image acquisition, segmentation, and classification processes are given in the flow chart shown in .
FIGURE 1 Sample images of the paddy seeds in seven varieties.

FIGURE 2 Flowchart of the image analysis algorithm and main steps of the developed program.
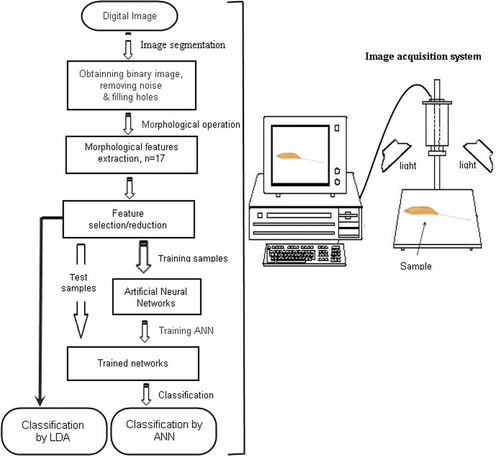
Segmentation was performed in several steps. An edge detection was conducted as the first step using Canny’s edge detector method. Once the edges were detected, the images were scanned from left to right in each row, and the areas belonging to the background were removed. A segmented image of a paddy seed is shown in . At the next step, the images resolutions were reduced from 1200 × 1600 pixels to 600 × 800 pixels, using a 4–1 pixel averaging method to facilitate the analysis process. This approach significantly reduces the computational burden with minimal loss of textural information. Afterward, morphological features were extracted from binary images.
FIGURE 3 Image of a paddy kernel after background removal.

Feature Extraction
An algorithms was developed in MATLAB to extract the following morphological features from individual paddy seeds:
Major axis length: The longest line that can be drawn through the object. It was determined by searching for the pair of pixels on the border which have the maximum distance (mm).
Minor axis length (mm): The longest line that can be drawn in a perpendicular direction to the major axis through the object.
Length (L; mm): The length of the rectangle bounding the seed.
Width (W; mm): The width of the rectangle bounding the seed.
Aspect ratio (K): The ratio of length to width.
Elongation (
): The ratio of minor axis to major axis.
Area (A; mm2): The number of pixels in the inner region of the seed multiplied by the calibration factor.
Perimeter (P; mm): The mathematical sum of the Euclidean distances between all the successive pairs of pixels around the circumference of the kernel.
Roundness (R): Describes the sharpness of the object at the corners and edges which was calculated using Eq. (1).
where A and P, are area and perimeter, respectively.
Length of awn (mm): The distance between the end points of the longest line that could be drawn through the awn.
Feret (Equivalent) Diameter (F; mm): The diameter of a circle having the same area as the object as is shown in Eq. (2).
Convex area (mm2): The number of pixels in the smallest convex polygon that can contain the paddy seed region multiplied by the calibration factor (mm2/pixel).
Solidity: The proportion of the pixels in the seed region that are also in the convex hull.
Extent: The proportion of the pixels in the bounding box that are also in the seed region.
Compactness (C): The compactness provides a measure of the object’s roundness and is the ratio of the Feret diameter to the object’s length as is shown Eq. (3).
where C, F, and L are compactness, ferret, and length, respectively.
Sphericity: The index of the object roundness (measured using a Matlab function).
As well as the morphological features, mass of every single paddy was measured manually by an electronic balance with 0.01 g precision.
Statistical Analysis
Once the morphological feature extraction was completed, the classification data file was obtained. The file had 1400 rows, representing 200 samples from each of the seven classes of paddy kernels. Each row had 17 columns representing the 17 morphological features extracted for a particular paddy grain. Each row had a unique number (1, 2, 3, 4, 5, 6, and 7) representing which class the particular row of data belongs. “1” represented Fajr variety, “2” represented Tarom Molaei, etc. The training and test file for each of the classification models were obtained from this original data file. In order to determine the level of contribution (for each feature) in the classification process, a PROC STEPDISC function from SAS software (SAS Institute Inc., Cary, NC, USA) was employed.
However, some of the 17 morphological features used for classification of paddy varieties may not contribute significantly to the classifier. Sometimes, the classifier performance declines if there are too many redundant features. To optimize the number of features that contributed significantly to the classification, SAS statistical analysis of PROC STEPDISC was used. PROC STEPDISC is used to reduce the number of features by a stepwise selection process. The “stepwise” selection procedure begins with no variables in the classification model.[Citation36] At each step of the process, the variables within and outside the model are evaluated. The variables within the model, which contributes least to the model as determined by the Wilks’ Lambda method is removed from the model. Likewise, the variable outside the model that contributes most to the model and passes the test to be admitted is added. When no more steps can be taken, the number of variables in the model is reduced to its final form. Because there are a substantial number of features, not counting conventional features, not included in the analysis, we decided to select those paddy features that are most relevant to the classification. The number of features was reduced by a backward-stepping selection using SYSTAT. In this selection, non-candidate features are removed based on their tolerance. A low tolerance value is an indication that a variable may be redundant or highly correlated with another variable. Once the candidate variables were selected, classification was performed using two classifiers. The supervised feed-forward ANN, and LDA was compared in their ability to discriminate seven varieties of paddy. The classification analysis was conducted on original and reduced data.
Identification/Prediction Process
Supervised ANN
Classifying seven paddy cultivars was done using ANN based on morphological features by means of Matlab Artificial Neural Networks Toolbox. A multi-layer perception (MLP) network which is commonly utilized to solve classification problems was tested. The classification study was carried out using different types of feature sets. Training of the networks was started with all the 17 morphological features as inputs. Therefore, the ANN model consisted of 17 input neurons, the number of input nodes is equal to number of used input features (). The output parameter was the paddy variety (unary encoded by seven output nodes).
FIGURE 4 A typical multilayer feed forward network.
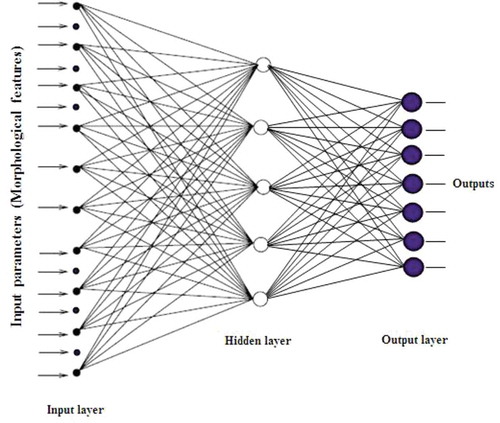
The whole data set (1400 patterns) was divided randomly into three datasets consisting of 462 patterns for training, 469 patterns for testing, and 469 patterns for verificton. Training was performed to minimize the mean square error (MSE) between targets and outputs. Trained network was saved as a mat file for further applications. Test set data was used to test the ability of the system in classifying the seven paddy varieties, after successful training of the network. Outputs of the network were rounded to the nearest integer to obtain outputs (notation) of the classes. Models with the highest correlation index calculated on the test set were considered to be the best models.
The network design was approached empirically by a trial and error method. In order to optimize the neural network activity, the number of hidden layers, the number of hidden neurons, number of iterations, type of learning rule and transfer function were modified. The number of hidden neurons, Nn, in the hidden layers was calculated using the formula:[Citation37]
where I is the number of inputs; O is the number of outputs; and y is the number of input patterns in the training set. The number of nodes was varied to see any significant improvement in ANN performance. If no improvement was observed, the number of nodes calculated by the formula was used to train the network. For more than one hidden layer, the number of nodes calculated by the formula was equally divided among all the hidden layers. The best ANN structure was obtained by means of clustering accuracy r that is defined as:
where n is total number of objects in the dataset, k is number of clusters, and av is number of correctly assigned objects.
LDA
LDA was used to process the morphological data, employing linear combinations of the variables to distinguish the different varieties of paddy seeds. This involved presenting a set of calibration paddy seeds from which the canonical discriminant functions were generated using the MATLAB 7.2 software package. The resulting classification coefficients Ci of the discriminant functions were obtained. Ci, the classification score for variety i, was given by a linear combination of the Cijs:
where I = 1, 2 … . . n -1 (n = number of varieties of seeds), Cio is a constant, and the Q(j)s are the raw values of the variables and jmax = 17 (17 morphological variables). The mean scores were then calculated for each paddy variety. The seeds would then be sorted into the varieties whose mean was the closest. In this work, the training and test sets were same as those used for training and testing the neural networks. All statistical analyses were carried out using MATLAB software 7.2 (The MathWorks Inc., MA, USA).
RESULTS AND DISCUSSION
LDA
shows the results of linear discriminant classification for the seven paddy varieties. LDA, carried out using the 17 morphological variables, lead to the correct prediction of 691 of the 938 testing samples (73.7%). The results showed that the errors were more misclassification between Cados-Shiroudi samples, whose class boundary does not appear to be anymore linearly separable for this widened data set (). The discrimination power of the sample can be examined by studying the Mahalanobis distances which are shown canonically in . This plot demonstrates that the paddy seeds were separated into seven groups, corresponding to 17 morphological features.
TABLE 1 The results of LDA for the classification of the seven varieties of paddy based on 17 features
FIGURE 5 A canonical plot showing the discriminant separation of paddy varieties by 17 morphological features.
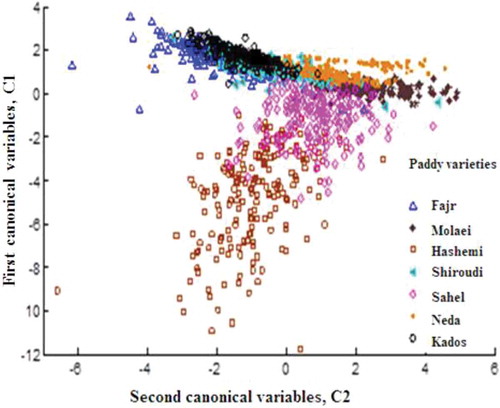
In this study, the distances between each pair of paddy group means were calculated by using the gmdist command in MATLAB 7.2 (). This commands examine the means and their distances. As evident (), the multivariate distance between Kados and Hashemi was larger than the difference between more closely spaced varieties (Kados-Fajr). This is consistent with the scatter plots, where the points seem to follow a progression as the variety changes. The small distances between group means of Kados and Fajr varieties were not surprising because even people expert in paddy classification find it very difficult to differentiate between these two species. Also these two varieties are not commercially important and are often listed as a single group in survey statistics and hence this error is unimportant.
TABLE 2 The distances between each pair of paddy group means
In general, the results of this study are agreement with those obtained by other researchers for other crops. Zayas et al.[Citation28] used six morphological features to discriminate individual kernels of different American wheat classes and varieties. For different wheat classes and varieties, the average percentages of correctly classified kernels were 77 and 85%, respectively. Sapirstein et al.[Citation38] also used multivariate discriminant analysis based on some different morphological features to classify hard red spring wheat, barley, oats, and rye. The classification error was 1% for a sample size of 580 grains.
It is evident that by using all 17 variables, results from LDA led to poor classification of paddy samples. This is because those variables without contribution to sample discrimination may also give noise to the data set. This especially occurs for the less statistically significant variables. To solve this, the selection of a small number of key variables is preferred. The criterion of the variable selection can be the Fisher weight or the discrimination power of a variable, which indicates the ability of that variable to discriminate between seven varieties.[Citation39] In this article, the nine selected features (according to the value of Fisher F-ratio) were arranged in descending order of their level of contribution to the classification model ().
TABLE 3 Selection of features of individual seeds of paddy using STEPDISC analysis based on their contribution to classification model
Indeed, some features were highly correlated with one another and if one of the features was selected, the rest of the features will not contribute significantly to the classification model. For example, if major axis length was selected as one of the features, the addition of length or equivalent diameter, etc., will not improve the classification accuracy significantly. According to F-values (), the awn length was the most significant feature (average squared canonical correlation; ASCC = 0.13) and the seed mass was the least significant feature (ASCC = 0.38) when other features are used in the model. With a minimum significant level of 0.15, the SAS procedure STEPDISC selected nine features from the 17 extracted morphological features and ranked thern according to their contributions to the discriminatory powers of the feature corresponding model.
All of these results indicated that there was high diversity in morphological features of seeds in different cultivars of paddy. Similar results were reported by Shouche et al.[Citation40] who quantified morphological features including geometric features, shape factors, moments and invariant moments for 15 varieties of Indian grains. These results emphasized that the features extracted by image analysis could facilitate many agricultural programs such as application of them in automated detections in machine vision systems, discrimination of cultivar seeds from each other.
The results of discriminant analysis for reduced data showed that the classification accuracy was increased in most analyzed cases (). It was observed for original data that the error of classification was considerable (26.3%). The lowest value of classification error (6.7%) was obtained using the LDA method for the Hashemi variety. It was shown that data reduction can distinguish seven varieties of paddy kernels. In general, the lower number of classification variables decreases the complexity of the classification model as it took lesser time to train.
TABLE 4 The results of testing the LDA model (n = 938) for classification of paddy seeds based on nine morphological features
Zapotoczny et al.[Citation5] also reported that the data reduction considerably improved the results of the classification of barley kernels. They found that the error of classification of two varieties of barely using the LDA and non-linear DA method was equal to zero. They have also reported that the LDA classification error of three and four varieties ranged from 0 to 6.45% according to the compared samples. According to their findings, the highest values of error were obtained for the classification of five varieties of barley kernels. The values of error obtained from LDA analysis ranged from 5.06 to 31.65% according to number of morphological features analyzed.
ANN Analysis
In this study, the supervised back propagation ANN was constructed of four layers. Training of the networks was started with all the 17 morphological features as inputs. Different ANN were trained and tested in order to find the best model, varying the number of neurons in the hidden layer, the value of the learning rate and momentum terms and the number of epochs. ANN analysis, carried out using these 17 variables, led to the correct recognition of 752 of the 938 (80.2%) testing samples (). The best model resulted a 17-23-9-7 feed forward network (including bias nodes), with learning rate = 0.43 and momentum
= 0.57, trained for 3400 epochs. Haykin[Citation46] has also reported that one or two hidden layers with an arbitrarily large number of neurons may be enough to approximate any function. Majumdar and Jayas[Citation11] used 23 morphological features for the discriminant analysis. They found that the classification accuracies of Canada Western Red Spring (CWRS) wheat, Canada Western Amber Durum (CWAD) wheat, barley, oats, and rye were 98.9, 91.6, 97.9, 100, and 91.6%, respectively, when the model was tested on the training data set.
TABLE 5 The results of testing the best ANN models for classification of paddy seeds based on both 17 and nine morphological features
It was apparent that the error scores over the training and the test set were of the same order of magnitude, thus confirming the goodness of the selection algorithm which performs a uniform mapping. Jayas et al.[Citation41] indicated that a BPN network is best suited and thus, is the most popular choice for classification of agricultural produce. However, as the predictive ability of ANN did not reach 100%, we tried to inspect other combinations of morphological variables which could lead to a better result. With nine input features (reported in ), the best results were obtained with 24 neurons in the hidden layers. The best ANN model was able to correctly recognize the 91.5% (858 out of 938) of the test set samples. In general, it was found that the values of error obtained from ANN analysis ranged from 1.5 to 32.0% according to the number of morphological features analyzed (). These results illustrate that some varieties achieved their best results using less features as it is indicated in . In order to reduce the computational process, it will be better to select the number of features based on the target variety and the required accuracy in a real classification system. Pourreza et al.[Citation29] has also reported that less features as inputs of neural network decreased computational time.
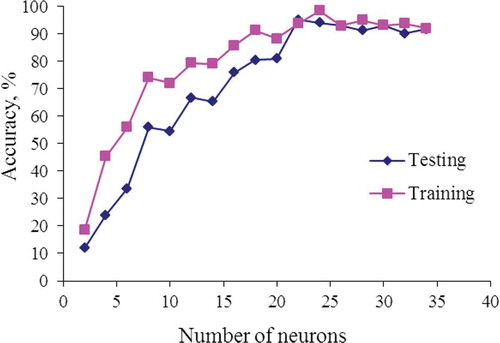
Neuman et al.[Citation27] also used digital image analysis based on kernel morphology for discrimination of Canadian wheat classes and varieties. They found that the correct classification of ANNs for a sample size of 576 kernels of 14 wheat varieties ranged from 15 to 96%. As stated previously, the objectives of MLP learning are primarily to establish the number of hidden layer and the number of neurons in each hidden layer. Investigation was performed to study the relationship between system performance and number of hidden layer. It was noticed that the MLP’s performance over selected nine morphological features did not show any significant improvement when the number of hidden layer was increased from two to three layers. Consequently, a two hidden layer MLP was designed for this application. shows the training and test accuracies for different number of neurons. It can be seen from this figure that the MLP with two hidden neurons resulted in the lowest training and test accuracies. Clearly, a single neuron in each layer could not accurately and efficiently map the relationship between morphological features and paddy varieties. The results in suggest that overall, the presence of more neurons resulted in increasing accuracy. This trend continued up to 24 hidden neurons after which, the prediction accuracy fluctuated between 89.2 and 91.5%. Therefore, the 24 hidden neurons corresponding to 91.5% test accuracy was employed for MLP identification of paddy varieties.
FIGURE 6 ANN training and testing accuracies for various numbers of neurons over nine selected features.
In particular, it was evident that the predictive accuracy of ANN model was higher than that evaluated with the LDA method. Using standard paired t-tests, the results show that the two developed ANN model were better than the LDA classifier with more than a 95% confidence level. However, the ANN classifier was selected for the online system because it is much simpler to implement and relies far less on the statistical properties of the input data than the statistical models. These results also were noted by Shahin and Symons.[Citation42] They found that and ANN models have better overall performance than the LDA classifier for grading lentils. Also Goodacre et al.[Citation43] found that supervised ANNs trained were more effective than LDA for the identification of bacteria associated with urinary tract infections.
The result of this study was a confirmation of the good generalization ability of the optimal ANNs model, which apart from being able to correctly classify paddy samples in the prediction phase. Compared to statistical classifier the classification accuracy was higher in ANN. Neethirajan et al.[Citation44] also reported higher classification accuracy using ANN than the statistical classifier for detection of sprout damaged and healthy wheat kernels using soft X-ray image analysis. ANN classifier developed from thermal images yielded classification accuracies of 99.4 and 91.7% for healthy and pre-harvest sprout damage wheat samples.[Citation45] As a result, compared to ANN and LDA classifiers used in this study, the minimum accuracy mean acquired with the all features (17 features) acquired 73.5% using LDA method for classification of paddy verities. Also the maximum accuracy mean obtained 91.5% by neural network method while nine features were used in the input of neural network ().
TABLE 6 Comparison of the classification accuracy mean of LDA and neural network
CONCLUSION
This research has demonstrated that neural network system can be used for identification of paddy seeds by morphological features. Based on the results of this study, the following conclusions can be drawn: Image processing technique may be used as an alternative system to measure different morphological features of paddy seeds. The identification with a neural classifier achieved over 91.5% prediction accuracy. In particular, it was evident that the predictive accuracy of ANN model was higher than that evaluated with the LDA method. The values of error obtained from ANN analysis ranged from 1.5 to 32.0% according to number of morphological features analyzed. The result of this study was a confirmation of the good generalization ability of the optimal ANNs model, which apart from being able to correctly classify paddy samples in the prediction phase.
ACKNOWLEDGMENT
The authors would like to thank the University of Tehran for the technical supporting of this work.
REFERENCES
- Sujatha, S.J.; Rasheed, A.; Rama Bhat, P. Physicochemical Properties and Cooking Qualities o Two Varieties of Raw and Parboiled Rice Cultivated in the Coastal Region of Dakshina Kannada, India. Food Chemistry 2004, 86, 211–216.
- Thomas, M.R.; Cain, P.; Scott, N.S. DNA Typing of Grapevine: A Universal Methodology and Database for Describing Cultivars and Evaluating Genetic Relatedness. Plant Molecular Biology 1994, 25, 939–949.
- Jongman, R.H.G.; Ter Braak, C.J.F; Van Tongerenm, O.F.R. Data Analysis in Community and Landscape Ecology; Cambridge University Press: New York, NY, 1995.
- Ye, G.N.; Soylemezoglu, G.; Weeden, N.F.; Lamboy, W.F.; Pool, R.M; Reisch, B.I. Analysis of the Relationship Between Grapevine Cultivars, Sports, and Clones Via DNA Fingerprinting. Vitis 1998, 37, 33–38.
- Zapotoczny, P.; Zielinska, M.; Nita, Z. Application of Image Analysis for the Varietal Classification of Barley: Morphological Features. Journal of Cereal Science 2008, 48, 104–110.
- Pourreza, A.; Lee, W.S.; Raveh, E.; Ehsani, R.; Etxeberria, E. Citrus Huanglongbing Disease Detection Using Narrow Band Imaging and Polarized Illumination. Transactions of the ASABE 2014, 57(1), 259–272.
- Golpour, I.; Amiri Parian, J.; Amiri Cayjan, R. Identification and Classification of Bulk Paddy, Brown, and White Rice Cultivars with Colour Features Extraction Using Image Analysis and Neural Network. Czech Journal of Food Science 2014, 32(3), 280–287.
- Siripatrawan, U.; Linz, J.E.; Bruce, R.H. Electronic Sensor Array Coupled with Artificial Neural Network for Detection of Salmonella Typhimurium. Sensors and Actuator B: Chemical 2006, 119, 64–69.
- Keefe, P.D. A Dedicated Wheat Grading System. Plant Varieties and Seeds 1992, 5, 27–33.
- Majumdar, S.; Jayas, D.S. Classification of Bulk Samples of Cereal Grains Using Machine Vision. Journal of Agricultural Engineering Research 1999, 73(1), 35–47.
- Majumdar, S.; Jayas, D.S. Classification of Cereal Grains Using Machine Vision. I. Morphology Models. Transactions of the ASAE 2000, 43(6), 1669–1675.
- Sapirstein, H.D.; Kohler, J.M. Physical Uniformity of Graded Railcar and Vessel Shipments of Canada Western Red Spring Wheat Determined by Digital Image Analysis. Canadian Journal of Plant Science 1995, 75, 363–369.
- Utku, H.; Koksel, H. Use of Statistical Filters in the Classification of Wheats by Image Analysis. Journal of Food Engineering 1998, 36(4), 385–394.
- Guevara, F.H.; Gomez, J.G. A Machine Vision System for Classification of Wheat and Barley Grain Kernels. Spanish Journal of Agricultural Research 2011, 9, 672–680.
- Granitto, P.M.; Navone, H.D.; Verdes, P.F.; Ceccatto, H.A. Weed Seeds Identification by Machine Vision. Computers and Electronics in Agriculture 2002, 33, 91–103.
- Shahin, M.A.; Symons, S.J. A Machine Vision System for Grading Lentils. Canadian Biosystems Engineering 2001, 43, 7.7–7.14.
- Neuman, M.; Sapristein, H.D.; Shwedyk, E.; Bushuk, W. Wheat Grain Color Analysis by Digital Image Processing: I. Methodology. Journal of Cereal Science 1989a, 10(3), 175–182.
- Neuman, M.; Sapristein, H.D.; Shwedyk, E.; Bushuk, W. Wheat Grain Color Analysis by Digital Image Processing: II. Wheat Class Determination. Journal of Cereal Science 1989b, 10(3), 183–188.
- Majumdar, S.; Jayas, D.S. Classification of Cereal Grains Using Machine Vision. I. Morphology Models. Transactions of the ASAE 2000a, 43(6), 1669–1675.
- Zapotoczny, P. Discrimination of Wheat Grain Varieties Using Image Analysis and Multidimensional Analysis Texture of Grain Mass. International Journal of Food Properties 2014, 17(1), 139–151.
- Azizi, A.; Abbaspour-Gilandeh, Y.; Nooshyar, M. Identifying Potato Varieties Using Machine Vision and Artificial Neural Networks. International Journal of Food Properties 2016, 19(3), 618–635.
- Granitto, P.M.; Garralda, P.A.; Verdes, P.F.; Ceccatto, H.A. Boosting Classifiers for Weed Seeds Identification. JCS&T 2003, 3(1), 34–39.
- Granitto, P.M.; Navone, H.D.; Verdes, P.F.; Ceccatto, H.A. Automatic Identification of Weed Seeds by Color Image Processing. VI Argentine Congress on Computer Science (Ushuaia, Argentina) 2000, 229–236.
- Barker, D.A.; Vouri, T.A.; Hegedus, M.R.; Myers, D.G. The Use of Ray Parameters for the Discrimination of Australian Wheat Varieties. Plant Varieties and Seeds 1992a, 5, 35–45.
- Barker, D.A.; Vouri, T.A.; Myers, D.G. The Use of Slice and Aspect Ratio Parameters for the Discrimination of Australian Wheat Varieties. Plant Varieties and Seeds 1992b, 5, 47–52.
- Myers, D.G.; Edsall, K.J. The Application of Image Processing Techniques to the Identification of Australian Wheat Varieties. Plant Varieties and Seeds 1989, 2, 109–116.
- Neuman, M.; Sapirstein, H.D.; Shwedyk, E.; Bushuk, W. Discrimination of Wheat Class and Variety by Digital Image Analysis of Whole Grain Samples. Journal of Cereal Science 1987, 6, 125–132.
- Zayas, I.; Lai, Fs.; Pomeranz, Y. Discrimination Between Wheat Classes and Varieties by Image Analysis. Cereal Chemistry 1986, 63, 52–56.
- Pourreza, A.; Pourreza, H.; Abbaspour-Fard, M.H.; Sadrnia, H. Identification of Nine Iranian Wheat Seed Varieties by Textural Analysis with Image Processing. Computers and Electronics in Agriculture 2012, 83, 102–108.
- Aghaei, M.J.; Mozafari, J.; Taleei, A.R.; Naghavi, M.R.; Omidi, M. Distribution and Diversity of Aegilops Tauschii in Iran. Genetic Resources and Crop Evolution 2008, 55, 341–349.
- Scholkopf, B.A.; Smola, K.R.; Muller, A. Nonlinear Component Analysis As a Kernel Eigenvalue Problem. Neural Computation 1998, 10, 1299–1319.
- Siripatrawan, U. Self-Organizing Algorithm for Classification of Packaged Fresh Vegetable Potentially Contaminated with Foodborne Pathogens. Sensors and Actuators B: Chemical 2008, 128, 435–441.
- Blayo, F.; Demartines, P. Data Analysis—How to Compare Kohonen Neural Networks to Other Techniques? Lecture Notes in Computer Science 1991, 54, 469–475.
- Du, C.J.; Sun, D.W. Learning Techniques Used in Computer Vision for Food Quality Evaluation: A Review. Journal of Food Engineering 2006, 72, 39–55.
- Zareiforoush, H.; Komarizadeh, M.H.; Alizadeh, M.R. Effect of Moisture Content on Some Physical Properties of Paddy Grains. Research Journal of Applied Sciences, Engineering, and Technology 2009, 1(3), 132–139.
- SAS. SAS User’s Guide; Statistics Statistical Analysis System Inc.: Raleigh, NC, 1990.
- Visen, N.S.; Paliwal, J.; Jayas, D.S.; White, N.D.G. Image Analysis of Bulk Grain Samples Using Neural Networks. Canadian Biosystems Engineering 2004, 46, 7.11–7.15.
- Sapirstein, H.D.; Neuman, M.; Wright, E.H.; Shwedyk, E.; Bushuk, W. An Instrumental System for Cereal Grain Classification Using Digital Image Analysis. Journal of Cereal Science 1987, 6, 3–14.
- Marini, F.; Balestrieri, F.; Bucci, R.; Magri, A.D.; Magri, A.L.; Marini, D. Supervised Pattern Recognition to Authenticate Italian Extra Virgin Olive Oil Varieties. Chemometrics and Intelligent Laboratory Systems 2004, 73, 85–89.
- Shouche, S.P.; Rastogi, R.; Bhagwat, S.G.; Sainis, J.K. Shape Analysis of Grains Of Indian Wheat Varieties. Computers and Electronics in Agriculture 2001, 33, 55–76.
- Jayas, D.S.; Paliwal, J.; Visen, N.S. Multi-Layer Neural Networks for Image Analysis of Agricultural Products. Journal of Agricultural Engineering Research 2000, 77(2), 119–128.
- Shahin, M.A.; Symons, S.J. A Machine Vision System for Grading Lentils. Canadian Biosystems Engineering 2001a, 43, 7.7–7.14.
- Goodacre, R.; Timmins, E.M.; Burton, R.; Kaderbhai, N.; Woodward, A.M.; Kell, D.B.P.; Rooney, P. Rapid Identification of Urinary Tract Infection Bacteria Using Hyperspectral Whole-Organism Fingerprinting and Artificial Neural Networks. Microbiology 1998, 144, 1157–1170.
- Neethirajan, S.; Jayas, D.S. White, N.D.G. Detection of Sprouted Wheat Kernels Using Soft X-Ray Image Analysis. Journal of Food Engineering 2007, 81(3), 509–513.
- Vadivambal, R.; Chelladurai, V.; Jayas, D.; White, N.D.G Detection of Sprout Damaged Wheat Using Thermal Imaging. Applied Engineering in Agriculture 2010, 26(6), 999–1004.
- Haykin, S. Neural Networks: A Comprehensive Foundation, 2nd Ed; Prentice Hall: New York, NY, 1999.