
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
The quality of fish pre-treatment processing directly affected the production competitiveness of the fish industry. The removal of heads and tails is one of the key technologies in the fish processing. This study proposed an identification method of fish head and tail, and the original YOLOV3 model was improved by replacing the backbone feature extraction network of the YOLOV3 model with the lightweight neural network MobileNetv3. Firstly, a freshwater fish image dataset was created and divided into the training, validation and test sets with the assigned ratio of 6:2:2. Next, the freshwater fish dataset was trained using the target detector YOLOV3. Finally, the average accuracy mAP (mean of Average Precision) and the average image detection time were used as the accuracy and speed indexes to evaluate the detection effect of the model. In addition, the SSD-MobileNetv3 and SSD-VGG16 were introduced into present study and they were compared with the improved algorithm. The experimental results showed that the detection speed of the YOLOV3 model with MobileNetV3 was significantly improved. The mAP of YOLOV3-MobileNetv3 model was 98.36%, the inference speed was 28.2 ms, which was 5.09%, 4.24% and 2.07% higher than the mAP of other three models (SSD-VGG16, SSD-MobileNetv3 and YOLOV3-Darknet-53), and the average detection time shortened by 86%, 9.99% and 29%, respectively. Therefore, this experimental method of head and tail of freshwater fish could achieve real-time detection and recognition of various kinds of freshwater fish, which had the great advantages of high detection accuracy and fast detection speed.
Introduction
China is the world’s largest aquaculture producer, and the output of freshwater fish is nearly four fifths of the world’s total.[Citation1] The freshwater fish mainly include silver carp, herring, grass carp, etc., which grow and reproduce fast, contain rich protein and low-fat content, and are the most commonly consumed domestic fish in China.[Citation2] However, at present, the slaughter of fish including the removal of the head and tail is still mainly manual processing in most fish processing enterprises, and the research of automation technology is still in the initial stage in China. [Citation3] - [Citation4] The traditional manual processing has the disadvantages of low production efficiency, difficult quality assurance and increased production cost.[Citation5] Therefore, it is of great practical significance to develop a device for automatically cutting off the head and tail of fish, among which it is an important prerequisite to judge its position accurately and quickly. The accurate and rapid determination of the position of the head, tail and viscera is an important prerequisite for the automatic slaughter of fish.[Citation6]
In recent years, the partial reported methods in the research of automatic segmentation of fish head and tail are mostly based on the combination of image processing and machine learning to extract the features presented by the fish head and tail in the image. The fish head and tail are extracted according to the features (the outline, regional center coordinates, color, etc.) presented in the images, and then these features are used to construct a classifier in a machine learning manner.[Citation7] Li et al. designed a head and tail matching positioning algorithm based on the image invariant moment theory, and then applied a programmable logic controller (PLC) to achieve accurate knife alignment and automatic completion of the head and tail removal operation, and the detection algorithm was used to detect the head and tail of bighead carp with an efficiency of more than 86%.[Citation8] Zhang et al. used machine vision technology to obtain the length and width of the conveyor belt mackerel contour size, transferred the data to the computer and obtained the length of the required section, so as to control the parameters in the required parts to achieve automatic continuous cutting, and the minimum value of fish head cutting force was 186.7 N.[Citation9] Zhang et al. extracted the color characteristics of common silver carp, crucian carp, bream and carp, and distinguished the species of freshwater fish by the red, green and blue color components, and the recognition accuracy rate could reach 94.97%.[Citation10] Zhang et al. collected images of four kinds of freshwater fish using machine vision technology and processed the images using digital image processing technology.[Citation11]
By extracting the characteristic values of each color component and the ratio of the long and short axes, they established a model for the recognition of freshwater fish species and found that the recognition rate of silver carp, crucian carp, paraben and carp reached 96.67%.[Citation11] And the digital image processing and BP (Back Propagation) algorithm were also used to extract the morphological and texture features of whitefish, osmanthus, crucian carp and Parabramis, and the recognition rate reached 75%. Although the above techniques have obtained good experimental results for the identification of different fish species and the recognition and localization of fish head and tail, the traditional machine learning recognition also has some drawbacks.[Citation12] First of all, traditional machine learning requires the accumulation of thousands of training data for each field, and such sample data sets are required to be used during the learning process, which will consume a lot of manpower and energy. Secondly, traditional machine learning may have a great learning effect on the processing of a small number of samples, but its generalization ability is not high, and it cannot achieve an ideal effect on the processing of more large-scale samples.[Citation13,Citation14]
With the continuous progress of related technologies, deep learning has emerged to solve the above problems caused by traditional machine learning. Many excellent deep learning-based target detection methods have been developed, and the deep learning-based target detection algorithms mainly include two categories.[Citation15] The first type is a two-stage detector that is used to classify and regression candidate regions, representing Faster-RCNN and Mask-RCNN. The other type is the single-stage detector that does not need to generate candidate regions and directly conducts target classification and regression based on the idea of regression, such as YOLO series and SSD series. Moreover, these algorithms related to deep learning also get good results in the object detection experiments.[Citation16] Guo et al. applied the deep learning model to the group behavior research of zebrafish.[Citation17] In order to solve the problem that the traditional whole fish detection would be ineffective when the fish is cross-blocked, they proposed to use the fish head and tail instead of the whole fish detection method. The YOLOV4 model was applied in their actual test experiment, and the mAP result reached 79.80%. In the aspect of target detection, when the target occlusion rate is 42.72%, the recall rate of 82.0% and the occlusion detection rate of 58.02% are obtained by this algorithm.[Citation17] In addition, based on the hourglass Net-based deep learning network model, Fang et al. realized the catfish body length of rapid measurement, error can be reduced to less than 4%.[Citation18] Wang et al. studied the image classification and recognition problem of marine microalgae using YOLOv3 objective detection algorithm, and the results showed that the average mean accuracy of YOLOv3 objective detection algorithm for marine microalgae was 88. 22%.[Citation19] Liu et al. adopted the YOLOv3 target detection algorithm to achieve rapid and accurate detection of the species and location of tomato diseases and pests in natural environment, with the detection accuracy reaching 92.39%.[Citation20] Zhu et al. selected Mobilenetv3-Small neural network to classify the feeding state of sea bass and the accuracy of the trained network model reached 99.60% in the test set, which provided a key reference for efficient intelligent feeding of sea bass.[Citation21] In summary, deep learning models did not require to select the features of detection objects carefully, they also have a large sample dataset with high generalization ability. Therefore, compared with machine learning models, deep learning models can obtain higher accuracy.
The deep learning-based target detection algorithm has been widely applied in poultry and agricultural products and has achieved many satisfactory experimental results, proving that the application of deep learning will bring more convenience to the automatic processing of aquatic products.[Citation22] Therefore, based on the YOLOV3 deep learning model, we proposed a precise identification method for freshwater fish head and tail, which was used to achieve accurate localization and identification of fish head and tail, and also provided technical support for the substitute processing of freshwater fish on the assembly line.[Citation23–28]
Materials and methods
Image data acquisition and classification
Some common freshwater fish were randomly selected in this study, and the fish image samples were collected on the production line. Image acquisition equipment was Hikvision gigabit network interface industrial surface array camera and webcam was commercial Hikvision cameras. The camera (MV-CA050-20 GM) has a resolution of 3968 × 2976 pixels with RGB color space and JPG storage format. Photographs of freshwater fish on a conveyor belt were taken under a specific light source. The same kind of fish was photographed from multiple angles to improve the generalization ability when training the model. In order to ensure the diversity and comprehensiveness of the samples, the different species of fish were collected at the same time. The image acquisition device is shown in , examples of images are shown in . There are many kinds of freshwater fish collected in this study, among which the main representative fish are perch, bighead carp, silver carp and carp.
Figure 1. Schematic diagram of the acquisition device. 1- Camera, 2- Freshwater, 3- Conveyor Belt.
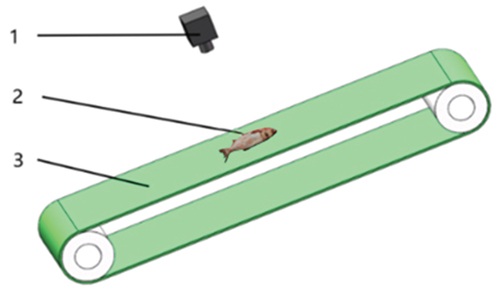
Figure 2. Four fish images. (a) silver carp. (b) Carp. (c) Perch. (d) Bighead carp.

Sample pre-processing and generation of dataset
Because deep learning is driven by large datasets, we need to increase the number of samples required for training as much as possible. The large datasets not only can increase the accuracy of the model and allow the model to perform greatly on the test set, but also reduce overfitting to increase the stability of the network. Therefore, we performed image broadening on the acquired freshwater fish images to expand the training dataset. We chose freshwater fish weighing 1 kg − 2 kg as the test sample, and the average length of the head was about 107 mm and the average length of the tail was about 72 mm. Since rotating and flipping a fish does not change its part characteristics, both rotation and flipping are adopted for dataset enlargement. In this study, we use Ladling image annotation tool to label image samples with reference to the VOC (Visual Object Classes) data format. The tags of the head and tail of freshwater fish are set for “head” and “wei.” The completed dataset contains a total of 2000 images, and according to the common dataset partitioning principle in deep learning tasks, 1200 images are manually selected as the training set, 400 images are set as the test set and 400 images were set as the validation set.[Citation29] The information on the number of various fish that contained in each dataset is shown in .
Table 1. Category and quantity of Freshwater fish datasets.
Freshwater fish target detection model and evaluation index
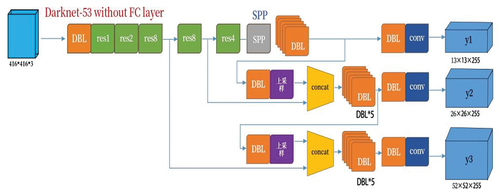
YOLOV3 model: The YOLOV3 model is a type of single-stage target detection algorithm that uses a single neural network acting on the image. This algorithm divides the image into multiple regions and predicts the bounding box and probability of each region. Finally, the target localization and classification are performed based on the non-maximum suppression algorithm.[Citation30] Although YOLOV3 is not the most accurate algorithm, its overall performance is relatively good while balancing accuracy and detection speed, so it was used to train on the freshwater fish dataset. YOLOV3, designed with Darknet-53 as the backbone network, consists of two parts: (i) Multi-scale detection network, YOLOV3 model can detect objects of different sizes, the detection scales are 13*13, 26*26, 52*52 respectively for large, medium and small objects. This can be applied to target objects of different sizes, (ii) (ii)Forward propagation CNN-based feature extraction network Darknet-53.[Citation31] DarkNet-53 is composed of convolutional and residual layers. When training the classification task on ImageNet dataset, we use DarkNet-53 as the backbone for extracting image features in YOLOv3. The first 52 layers out of the total 53 layers are used for feature extraction, and the last three layers Avgpool, Connected and Softmax are used for training the classification task on the ImageNet dataset. The last layer is used for the output results, the prediction of the object category does not use softmax, instead of using the logistic output for prediction. This can support multi-label objects. The YOLOV3 network structure is shown in .
Figure 3. Structure diagram of YOLOV3.
YOLOV3 has three anchor boxes that predict three bounding boxes per cell, and the anchor boxes are the a priori of the bounding boxes. The border prediction formula of YOLOV3 uses logistic regression, while the predicted center coordinates are determined by a sigmoid function that forces the values to be restricted between 0 and 1. Instead of predicting the center coordinates of the bounding box, YOLOV3 predicts its offset, relative to the upper left corner of the grid cell of the prediction object, with the dimension normalized by the feature graph cell.[Citation31] The prediction formula is as following:
,
represents the offset of the grid cell, the specific value is the coordinate of the upper left corner of the grid cell,
,
is the pre-defined anchor box size and
,
,
,
are the four predicted values in the YOLOV3 convolution module,
,
,
,
is the center coordinates and size of the predicted bounding box.
is calculated as:
The allocation applies larger a priori frame (116 × 90), (156 × 198), (373 × 326) on the smallest 13 × 13 feature map, suitable for detecting larger objects. Medium priori frame (30 × 61), (62 × 45), (59 × 119) is applied on the medium 26 × 26 feature map, which is suitable for detecting medium-sized objects. Smaller priori frame (10 × 13), (16 × 30), (33 × 23) is applied on larger 525 × 525 feature maps, which is suitable for detecting smaller objects.
Model evaluation indexes
MAP is usually applied in target detection tasks and is also used as an evaluation index of model detection accuracy in this study. MAP is related to AP and accuracy P, recall R,[Citation32] the accuracy and recall can be expressed by Equationequation (6)(6)
(6) (7):
where TP indicates the number of samples correctly judged as positive, FP indicates the number of samples incorrectly judged as positive, and FN indicates the number of samples incorrectly judged as negative. AP represents the detection accuracy of a category, obtained by integrating the accuracy-recall curve. The mAP is the mean value of the detection accuracy AP of all categories, it can be expressed by Equationequation (8)(8)
(8) :
In the equation, M is the number of all classes, and AP (k) represents the detection accuracy of the class K of objects. In addition to the detection accuracy, the detection speed of the model is equally important; therefore, the average time taken by the model to process a single image is chosen as the second index to judge the goodness of the model in present study.
Loss function
YOLOV3 replaces the classification prediction with regression prediction, and the classification loss function is replaced with a binary cross-entropy loss function. The loss function is the central coordinate error function (dist_xy), width and height coordinate error function (dist_wh), Confidence error (dist_C), and Classification error function (dist_p) mean value of the sum, the function Equationequation (9)(9)
(9) is as follows:
The evaluation index function uses the IOU loss function, IOU is the intersection ratio of the prediction frame and the rear frame can reflect the detection effect of the formula as follows:
Fish head and fish tail detection based on YOLO3
In this study, the detection and identification of fish head and tail based on improved YOLOV3 were performed in 4 steps: (1) Building a freshwater fish dataset. (2) Building and training of YOLOV3 model. (3) Two target detection models, SSD-VGG16 and SSD-MobileNetv3 were introduced to conduct comparison experiments with YOLOV3 model for freshwater fish dataset. (4) The feature extraction network of the YOLOV3 model was changed to MobileNetV3, and its influence on the detection accuracy and average detection speed of the model was detected, and compared with the original model Yolov3-Darknet53.[Citation27] The flow is shown in .
Figure 4. Flow chart of fish head and fish tail detection.

Experimental platforms
The experiments in this study were based on the TensorFlow deep learning framework, and the YOLOV3 model was built and trained by Python language for validation. The specific computer parameters are set as showing in below.
Table 2. Parameters related to the experimental environment.
Model Training
The introduction of transfer learning in the process of model training can not only accelerate the model convergence speed, but also improve the model training effect. Therefore, we loaded pre-training weight before training the dataset and added an SGD optimizer to make the gradient less turbulent and smoother in the descent process. The initial learning rate was set to 0.001, the momentum factor was 0.9, the batch size was set to 4, and the learning rate decay factor was set to 0.1. The number of training rounds was set to 100, and the parameters were continuously adjusted during the training process to achieve the optimal model. shows the change of the loss function curve during the training process. The loss function curve decreased significantly in the early stage of training. After training rounds reached 20 rounds, it started to slowly decline and level off.
Figure 5. YOLOV3-Darknet53 detection effect.

Results and discussion
Validation of fish head and tail detection results for YOLOV3-Darknet-53 model
The optimal YOLOV3-Darknet-53 model based on the training output is tested for the fish-head and fish-tail verification set. The detection accuracy mAP of the model and the average detection time of a single image were obtained to judge the detection performance of the model. The test results are shown in and in .
Table 3. Comparison table of detection accuracy and time of the four models.
According to 1) and , we can find that the YOLOV3-Darknet model for fish head and tail detection accuracy is still relatively high, and the average detection speed is still relatively fast. At the same time, the model can completely and accurately mark the location of the target for the frame of the fish head and tail, indicating that this model has a great detection accuracy for the head and tail of the fish. The test results show that the mAP and single-image detection time of theYOLOV3-Darknet-53 model were 96.29% and 57.20 ms, respectively. The Darknet-53 network has a large number of network parameters, which increases the model inference time, but the detection accuracy can meet the requirements of production line.[Citation33,Citation34]
Performance comparisons of different target detection methods
With the development and progress of technology, the development pace of deep learning is very fast, and the change speed of model and feature extraction network is also extremely fast. Different models and feature extraction networks show different performance when executing different target detection tasks. Therefore, in order to verify the effectiveness of the model for fish head and tail target detection, we add the SSD-VGG16 model for comparative experiment. Meanwhile, in order to increase contrast, the backbone networks of SSD-VGG16 and YOLOV3-Darknet53 were replaced with the lightweight neural network MobileNetv3 respectively. The mAP and average detection time for the freshwater fish dataset SSD-VGG16 and SSD-MobileNetv3 are shown in , the loss curve of the freshwater fish dataset are shown in , and the actual detection results of the three models are shown in .
Figure 6. The loss curve of the freshwater fish dataset. (1) SSD-VGG16; (2) SSD-MobileNetV3.
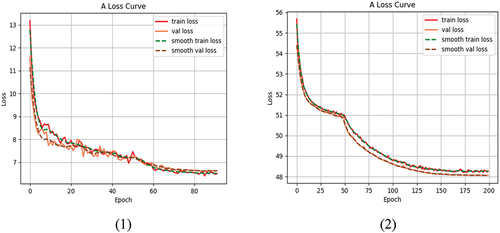
Figure 7. The actual test result for the freshwater fish dataset. (a) The test results of YOLOv3-MobileNetv3. (b) The test results of SSD-MobileNetv3. (c) The test results of SSD-VGG16.
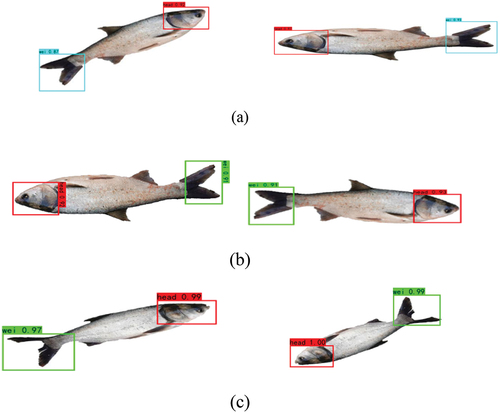
The final experimental detection results showed that the three models, YOLOV3-MobileNetV3, SSD-VGG16 and SSD-MobileNetv3, were accurate in the identification and detection of freshwater fish head and tail, without missing or wrong detection. The boundary frames of the three models coincide with the actual positions, ever for freshwater fish with a certain angle of inclination, these algorithms can also detect the exact position of the head and tail of the fish, and provide a reference for the orientation of the fish in the subsequent processing. However, there are differences in the detection accuracy among them. SSD-MobileNetv3 has better detection performance than SSD-VGG16, and the detection time and accuracy are also better. The main reason may be that MobileNetv3 has added SE module, which makes the identification of fish head and tail features to be identified more accurate. In addition, in terms of activation function, V3 version uses swish function instead of ReLU6 activation function, which can improve the accuracy of network. The VGG16 performed poorly in the detection task, and its disadvantages were also evident in the training process, as it took too long to train and was difficult to adjust the parameters. YOLOv3-Darkne53 achieved a recognition accuracy of 96.29% for fish head and tail, and performed well for target detection. It was mainly because the Darkne53 network had deeper layers and more network parameters, so it could extract deeper abstract features of the image, which was helpful in improving the model detection accuracy. Meanwhile, Darkne53 introduced residual modules, each of which consisted of two convolutional layers and one shortcut connection, solving the problem of gradient disappearance in deep neural networks. YOLOV3 enhanced the detection of small targets by the idea of multiple down sampling feature fusion, which makes the detection accuracy of YOLOV3-DarkNet53 higher.[Citation35] Although the feature pyramid structure adopted by SSD model enhances the multi-scale target detection capability of SSD, but the detection of SSD-VGG16 in this experiment is unsatisfactory.
Generally, the SSD-MobileNetv3 and SSD-VGG16 could achieve the recognition and detection of fish head and tail. However, due to the different structure of feature extraction network, the detection performance of the above both of methods was still different. The experimental results of the SSD-MobileNetv3 and SSD-VGG16 are shown in .
As shown in , YOLOV-Darknet53 had the best detection accuracy with 96.29% mAP, followed by the best SSD-MobileNetv3 over SSD-VGG16, but the feature extraction network using MobileNetv3 made the detection speed of the images greatly improved. The detection speed of SSD-MobileNetv3 was improved by 76.01 ms compared to SSD-VGG16. In summary, Darknet53 and VGG16 had an advantage over MobileNetv3 in ensuring that the model has high accuracy, but the lightweight neural network MobileNetv3 could significantly improve the detection speed.
Effect of different feature extraction networks on the model classification detection effect
The above results show that the classification results of models with different feature extraction networks often show different detection results. There are various kinds of feature extraction networks, which are roughly divided into heavyweight and lightweight. Heavyweight feature extraction networks perform well in the face of complex classification problems, while lightweight feature networks with a smaller number of parameters are more suitable for mobile terminal. MobileNeV3 is a lightweight dept-deep neural network, which uses dept-separable convolution instead of traditional convolution, greatly reducing the number of network parameters and training calculation, so that it is more suitable for mobile terminal or embedded devices. Therefore, considering the actual situation and the unique needs of the production line machine, the feature extraction network of YOLOv3 was replaced by MobileNetV3 in this study, and the classification detection effect experiment was compared with that of Yolov3-Darkne53. The experimental results are shown in and .
Figure 8. The loss curve of the freshwater fish dataset. (1) YOLOV3-Darknet-53; (2) YOLOV3-MobileNetV3.
According to , the mAP and average detection time of the YOLOV3-MobileNetV3 model were 98.36% and 28.2 ms. Compared with the original model, the detection accuracy is only improved by 2.07%, indicating that replacing the feature extraction network with MobileNetV3 has little impact on the detection accuracy of the model. However, in terms of single-image detection time, YOLOV3-MobileNetV3 reduced 29 ms compared with YOLOv3-Darkne53, indicating that the lightweight neural network MobileNetv3 could significantly improve the average detection speed of the YOLOV3 model. In addition, as shown in , the target locations and categories predicted by the YOLOV3-MobileNetV3 model are very accurate, indicating that the model has a great classification effect.
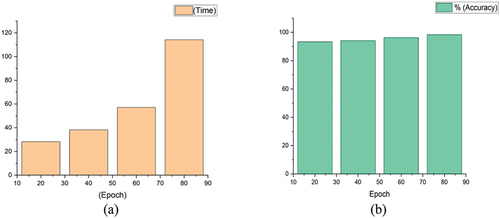
By comparing the classification detection effects of four deep learning target detection models on freshwater fish data sets, we further compared the detection accuracy and average detection time of each model. As shown in , the mAP of YOLOV3-MobileNetV3 model was improved by 5.09%, 2.07% and 4.24% compared to SSD-VGG16, YOLOv3-DarkNet53 and SSD-MobileNetv3, respectively, and the average detection time was reduced by 86 ms, 29 ms and 9.99 ms, respectively. Therefore, the comprehensive detection performance of the YOLOV3-MobileNetV3 model had obvious advantages over the other three models. Moreover, the method in this paper is more accurate and faster than the method used by Kai-Mo Lee et al. for locating the fish head and fish tail, and consumes less human and material resources in the preliminary preparation work.[Citation8]
Figure 9. The comparison of four deep learning-based target detection models. (a) Time comparison. (b) Accuracy comparison.
Conclusion
The deep learning-based target detection model YOLOV3-Darknet53 could achieve accurate detection of fish head and tail, and has certain real-time performance. For the verification set, the detection accuracy and average detection speed of the model are 96.29% and 57.2 ms respectively, which is 2.17% and 3.02% higher than that of SSD-MobileNetV3 and SSD-VGG16. This study adopted the lightweight neural network MoilbeNetV3 as the feature extraction network of the YOLOV3 model, which could significantly improve the detection speed of the model and make up for the disadvantage of longer average detection time of the YOLOv3-DarkNet53. The test results showed that the detection accuracy and average detection speed of the YOLOV3-MobileNetV3 model were 98.36% and 28.2 ms, which were 2.07% better than the YOLOv3-DarkNet53 detection accuracy and 9.99% shorter than SSD-MobilNetV3 average detection time. The fish head and tail detection method based on YOLOV3-MobileNetV3 had the best comprehensive detection performance, which could quickly and accurately obtain the position of fish head and tail on the production line. Moreover, this experimental method also had higher detection accuracy, real-time characteristics and certain multi-scale detection capability, which provided more technical reference for realizing automatic sorting of production line.[Citation1]
Acknowledgments
Authors extend their gratitude to Shida Zhao and Shucai Wang for her technical assistance to this study. The authors declare that there is no conflict of interests regarding the publication of this article.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Zhang, T.; Chen, E.; Xiao, W. A Fast Target Detection Method for Improving MobileNet_yolov3 Network. Small Mcom. Sys. 2021, 42(5), 7. DOI: 10.3969/j.issn.1000-1220.2021.05.018.
- Hu, F. Establishment of a Comprehensive Evaluation System for Freshwater Fish Nutrition[d]. HZ. Agric. Univ. 2011. DOI: 10.7666/d.y2004238.
- Wu, L.; Chen, L.; Wang, L.; Cai, D.; Zhang, Z.; Zhan, G.; Fang, Y. Analysis of Fatty Acid Composition and Its Nutritional Value of ten Freshwater Fish Species. Food Ind. 2017, 38(8), 269–271. DIO: CNKI: SUN: SPGY.0.2017-08-073.
- Huang, W. Research on Fish Tail Removal Device Based on Machine Vision[d]. Wuhan Light Ind. Univ. 2021. DOI: 10.27776/d.cnki.gwhgy.2021.000028.
- Liu, Y. Research on Fish Head and Fish Tail Positioning Technology Based on Machine Vision[d]. Wuhan Light Ind. Univ. 2021. DOI: 10.27776/d.cnki.gwhgy.2021.000313.
- Li, M. Research on Head and Tail Cutting Device and Control Technology of Freshwater Fish Based on Machine Vision[d]. Wuhan Light Ind. Univ. 2021. DOI: 10.27776/d.cnki.gwhgy.2021.000117.
- Wang, H. Research on Freshwater Fish Orientation and Head-Cutting Equipment[d]. Wuhan Light Ind. Univ. 2020. DOI: 10.27776/d.cnki.gwhgy.2020.000129.
- Jia, B.; Shao, Z.; Wang, R.; Qu, Y.; Zhang, R.; Rao, K.; Jiang, A.; Liu, Y.; Guan, Y. Extraction and Analysis of Fish Behavioral Features Based on Machine Vision. J. Ecotoxicol. 2017, 12(05), 193–203. DOI: 10.7524/AJE.1673-5897.20161012001.
- Li, K.; Wen, Y. Key Technology of Vision-Guided Automatic Head and Tail Removal System for Freshwater Fish. Food Mach. 2014, 30(05), 141–143. DOI: 10.13652/j.issn.1003-5788.2014.05.030.
- Zhang, F.; Wan, P.; Zong, L.; Tan, H. Experiments and Analysis on the Mechanical Properties of the Cutting of the Head of Silver Carp. J. Huazhong Agric. Univ. 2016, 35(03), 122–127. DOI: 10.13300/j.cnki.hnlkxb.2016.03.020.
- Chen, C.; Wu, Q.; Wu, Z.; Lv, T. An Automatic Fish Classification Method Based on Image Processing. Software Eng. 2018, 21(12), 7–11. DOI: 10.19644/j.cnki.issn2096-1472.2018.12.003.
- Zhang, Z.; Niu, Z.; Zhao, S. Freshwater Fish Species Identification Based on Machine Vision Technology. J. Agric. Eng. 2011, 27(11), 388–392. DOI: 10.3969/j.issn.1002-6819.2011.11.072.
- Pi, B.; Wang, Y. A Review of Traditional Machine Learning and Deep Learning for Expression Recognition. Software Guide. 2020, 19(06), 44–47. DOI: 10.11907/rjdk.192322.
- Yao, R.; Gui, W.; Huang, Q. Freshwater Fish Species Identification Based on Machine Vision. Micro Mach. Appl. 2017, 36(24), 37–39. DOI: 10.19358/j.issn.1674-7720.2017.24.011.
- Tanveer, A.; Salman, Q.; Syed, F.; Syed, A.; Razzaq, S.; Mubashir, S.; Muzammil, A.; Amir, U.; Israr, H.; Javeria, H., et al. Machine Learning Approach for Classification of Mangifera Indica Leaves Using Digital Image Analysis. Int. J. Food Prop. 2022, 25(1), 1987–1999. DOI: 10.1080/10942912.2022.2117822.
- Fan, L.; Liu, Y.; Yu, X.; Lu, H. Computer Vision-Based Algorithm for Sport Fish Detection. J. Agric. Eng. 2011, 27(07), 226–230+394. DOI: 10.3969/j.issn.1002-6819.2011.07040.
- Song, H.; Zhang, X.; Zheng, B. Vehicle Target Detection in Complex Scene Based on Deep Learning Methods. Computer Appl. Res. 2018, 35(4), 4. DOI: 10.3969/j.issn.1001-3695.2018.04.067.
- Guo, G.; Lin, B.; Yang, X.; Zhang, X. Fish Detection Algorithm Based on Zebrafish Image Features. Appl. Opt. 2022, 43(02), 257–268. DOI: 10.5768/JAO202243.0202004.
- Fang, S. Research on Deep Learning Based Method for Measuring Fish Phenotype Data[d]. Zhejiang Univ. 2021. DOI: 10.27461/d.cnki.gzjdx.2021.002100.
- Wang, X. Y. Design and Implementation of Image-Based Marine Microalgae Identification System[d]; Dalian Ocean University: Dalian, 2020. DOI: 10.27821/d.cnki.gdlhy.2020.000001.
- Liu, J.; Wang, X. W. Tomato Diseases and Pests Detection Based on Improved YOLOv3 Convolutional Neural Network. Front. Plant Sci. 2020, 11, 898–909. DOI: 10.3389/fpls.2020.00898.
- Zhu, M.; Zhang, Z.; Huang, H.; Chen, Y.; Liu, Y.; Dong, T. Classification of Feeding Status of Bass Based on Lightweight Neural Network MobileNetv3-Small. J. Agric. Eng. 2021, 37(19), 165–172. DOI: 10.11975/j.issn.1002-6819.2021.19.019.
- Yeh, C.; Chang, Y.; Alkhaleefah, M. YOLOv3-Based Matching Approach for Roof Region Detection from Drone Images. Remote Sens. 2021, 13(1), 127. DOI: 10.3390/rs13010127.
- Ning, Z.; Mi, Z. Research on Surface Defect Detection Algorithm of Strip Steel Based on Improved YOLOV3. J. Phys. Conf. Ser. 2021, 1907(1), 012015. DOI: 10.1088/1742-6596/1907/1/012015.
- Yang, Q.; Yu, L. Recognition of Taxi Violations Based on Semantic Segmentation of PSPNet and Improved YOLOv3. Hindawi Limited. 2021, 2021, 1–13. DOI: 10.1155/2021/4520190.
- Singh, S.; Ahuja, U.; Kumar, M.; Kumar, K.; Sachdeva, M. Face Mask Detection Using YOLOv3 and Faster R-CNN Models: COVID-19 Environment. Multimedia Tools Appl. 2021, 2021(13), 1–16. DOI: 10.1007/s11042-021-10711-8.
- Liu, X.; Wu, J. Finetuned YOLOv3 for Getting Four Times the Detection Speed. 2021. DOI: 10.1007/978-3-030-82153-1_42.
- Zhou, Y.; Chen, C.; Wu, K.; Ning, M.; Chen, H.; Zhang, P. SCTD1.0: Sonar common target detection dataset[J]. Computer Sci. 2021, 48(S2), 334–339. DOI: 10.11896/jsjkx.210100138.
- Zhao, B.; Lan, H.; Niu, Z.; Zhu, H.; Qian, T.; Tang, W. Detection and Location of Personal Safety Protective Equipment and Workers in Power Substations Using a Wear-enhanced YOLOv3 Algorithm[J]. IEEE. Access. 2021, 9, 1. DOI: 10.1109/ACCESS.2021.3104731.
- Zhang, Y.; Liu, M.; Xu, S. MobileNetv3-Large-YOLOv3 based substation fire detection[J]. 2021. DOI: 10.3969/j.issn.1007-290X.2021.011.015.
- Wang, H.; Zhang, F.; Liu, X.; Li, Q. Fruit image recognition based on DarkNet-53 and YOLOv3[J]. J. Northeast Normal Univ. (Nat. Sci. Edition). 2020, 52(4), 6. DOI: 10.16163/j.cnki.22-1123/n.2020.04.010.
- Joseph, R.; Ali, F. YOLOv3: An Incremental Improvement. Univ. Washington: Computer Vision and Pattern Recog. 2018, 4. DOI: 10.48550/arXiv.1804.02767.
- Zu, L.; Zhao, Y.; Wang, G.; Liu, P.; Yan, Y.; Zu, L. Tomato Maturity Classification Based on SE-YOLOv3-MobileNetV1 Network under Nature Greenhouse Environment[J]. Agronomy. 2022, 2022(7), 12. DOI: 10.3390/agronomy120716358.
- Jin, R.; Xu, Y.; Xue, W. An Improved Mobilenetv3-Yolov5 Infrared Target Detection Algorithm Based on Attention Distillation[C]. Springer Cham. 2022. DOI: 10.1007/978-3-030-94551-0_22.
- Deng, T.; Wu, Y. Simultaneous vehicle and lane detection via MobileNetV3 in car following scene[J]. PLoS One. 2022, 2022(3), 17. DOI: 10.1371/journal.pone.0264551.