
Abstract
Too often operational atmospheric dispersion models are evaluated in their ability to replicate short-term concentration maxima, when in fact a valid model evaluation procedure would evaluate a model's ability to replicate ensemble-average patterns in hourly concentration values. A valid model evaluation includes two basic tasks: In Step 1 we should analyze the observations to provide average patterns for comparison with modeled patterns, and in Step 2 we should account for the uncertainties inherent in Step 1 so we can tell whether differences seen in a comparison of performance of several models are statistically significant. Using comparisons of model simulation results from AERMOD and ISCST3 with tracer concentration values collected during the EPRI Kincaid experiment, a candidate model evaluation procedure is demonstrated that assesses whether a model has the correct total mass at the receptor level (crosswind integrated concentration values) and whether a model is correctly spreading the mass laterally (lateral dispersion), and assesses the uncertainty in characterizing the transport. The use of the BOOT software (preferably using the ASTM D 6589 resampling procedure) is suggested to provide an objective assessment of whether differences in model performance between models are significant.
Implications:
Regulatory agencies can choose to treat modeling results as “pseudo-monitors,” but air quality models actually only predict what they are constructed to predict, which certainly does not include the stochastic variations that result in observed short-term maxima (e.g., arc-maxima). Models predict the average concentration pattern of a collection of hours having very similar dispersive conditions. An easy-to-implement evaluation procedure is presented that challenges a model to properly estimate ensemble average concentration values, reveals where to look in a model to remove bias, and provides statistical tests to assess the significance of skill differences seen between competing models.
Introduction
For more than 30 years the following conclusions regarding air quality models have been known and are still accepted today (e.g., CitationVenkatram, 1979; CitationFox, 1984; CitationWeil, 1985; CitationWeil et al., 1992; CitationStein and Wyngaard, 2001). Most operational atmospheric simulation models are deterministic. They provide estimates of the average time and space variations in the conditions (e.g., a mesoscale meteorological model), or they provide estimates of the average effects of such time and space variations (e.g., a dispersion model). The observations used to test the performance of these models are individual realizations (which can be envisioned as coming from some ideal ensemble), and are affected by stochastic variations unaccounted for within the simulation model. Air-quality dispersion models predict the mean concentration for a given set of conditions (i.e., an ensemble average), whereas observations are individual realizations drawn from various ensembles.
The comparison of short-term (1 hr or less) model predictions with observations, taken under supposedly the same conditions, will reveal large deviations between that which is predicted and that which is observed. The deviations have a mean (or model bias) and a variance. Given unbiased model inputs, the bias is due solely to internal model errors (e.g., physics, parameterizations, etc.), whereas the variance is due to four factors: (1) uncertainty in model input variables, (2) errors in the concentration measurements, (3) internal model errors, and (4) natural or inherent variability (see CitationWeil, 1985; CitationFox, 1984, CitationVenkatram, 1979). Bias in the model inputs might occur and thereby bias the model estimates if the meteorology or emissions are consistently mischaracterized, but biased model inputs are unlikely when using intensive tracer field experiment data, as discussed and used in this paper.
If we believe dispersion models provide estimates of the ensemble average concentration values, then it makes sense to ask the models to replicate average patterns seen in the observations, but it does not make sense to ask the models to replicate exactly what is seen in any one observation period, which contains the effects of stochastic variations unaccounted for within the simulation model (maxima, minima, or total variance as seen in the observations, etc.). Thus, we are faced with two basic tasks in order to develop a performance evaluation strategy: In Step 1 we should analyze the observations to provide average patterns for comparison with modeled patterns, and in Step 2 we should account for the uncertainties inherent in Step 1 so we can tell whether differences seen in a comparison of performance of several models are statistically significant.
Within the American Society for Testing and Materials (ASTM), a standard guide, D6589 (2010), was developed to address these two steps to foster development of objective statistical procedures for comparing air quality dispersion simulation modeling results with tracer field data. In contrast to a direct comparison of observations and modeling results, D6589 recommends that comparisons be made of some average characteristic of the observed and modeled concentration pattern. To illustrate how this might work, an example procedure was provided for evaluating performance of models to estimate the average maximum ground-level centerline concentration. In the example procedure, evaluation data having similar meteorological and physical conditions are grouped together. Grouping the data together provides a way for us to compute an average centerline maximum concentration for the group for comparison with what the model simulates (on average) for the same group. Comparison of these averages over a series of groups provides a means for assessing modeling skill (Step 1). In order to place confidence bounds on conclusions reached, bootstrap sampling was used (Step 2).
The example procedure outlined in D6589 is nontrivial to implement, and, as discussed in the following, may not be that informative. The goal is to compare some feature (or features) that (1) informs us as to how well the model is doing in estimating the ensemble average centerline concentration values and (2) reveals trends in model bias in such a manner that we have clues to where to look in the modeling algorithms to improve model performance. It can be easily shown that the modeled centerline concentration value, Cmax, is:
There are three ways to estimate the correct value for Cmax: (1) estimate the correct values for Cy and σy, (2) overestimate the values of Cy and σy by the same amount, and (3) underestimate the value of Cy and σy by the same amount, and only one of these ways is accomplished by good model performance. This suggests that the comparison of observed and modeled average centerline concentration values as promoted by D6589 may reveal overall model performance, but will not reveal whether the model is providing the correct values of Cmax by properly estimating Cy and σy. So, why structure a model evaluation strategy on Cmax? We suggest that a starting point for a better evaluation strategy is to compare observed and estimated group averages values of Cy and σy.
In the following discussion, we demonstrate how dispersion model performance can be assessed using group average values of Cy and σy. The procedure is fairly easy to implement, makes good use of full-scale intensive tracer field data, and seems to provide insight into a model's performance.
Field Data and Analyses
The site of the Kincaid plant is approximately 15 miles southeast of Springfield, IL and is surrounded generally by flat farmlands. The surface roughness varies from 7 cm to 15 cm, depending on time of year and wind direction. During two periods (April 20–August 29, 1980, and May 9–June 1, 1981), Sulfur hexafluoride (SF6) tracer gas was injected into the ductwork of the 187-m stack, and 1-hr samples were collected. Approximately 200 sampling sites were activated for a period of 6 to 9 hr in a sector chosen on the basis of the expected meteorological conditions. The network design consisted of concentric circles at average radial distances of 0.5, 1, 2, 3, 5, 7, 10, 15, 20, 30, 40, and 50 km from the power plant, using the existing roadway network, and the downwind distance to an arc varied as much as 20% of the mean distance (CitationBowne et al., 1983; CitationLiu and Moore, 1984; CitationHanna and Paine, 1989). An analysis of the Kincaid data determined there were 676 arcs with at least 5 or more nonzero concentration values, and with a maximum concentration within the middle third of the nonzero receptors. Of the 676 arcs, we selected initially the 546 arcs at downwind distances of 3, 5, 7, 10, 15, and 20 m, as there were almost 60 or more arcs for analysis at each downwind distance. Of these 546 arcs, we lost 78 arcs for lack of meteorological data to drive the models or one of the models assumed the plume rise had punched through the elevated unstable mixing height, resulting in simulating zero concentrations at the surface. This left 478 Kincaid arcs for analysis.
The steps in the analysis of the observations consisted of (1) selecting receptors for analysis with concentration values that were greater than or equal to zero (i.e., ignoring receptors with missing values); (2) computing the lateral dispersion, σy, as
, where Ci is the concentration at the ith receptor, and yi is the distance along the arc in a clockwise sense from the first receptor with a valid concentration value; (3) computing the crosswind integrated concentration, Cy, by trapezoidal integration; and (4) computing the Gaussian-fit centerline concentration using σy, Cy, and Equationeq 1. In listing out the results, Cy and Cmax were converted to micrograms per cubic meter and then the values were divided by the assumed emission rate of 1000 g/s.
Model Simulations and Analyses
We used model simulation results from two dispersion models (ISCST3 version 02035 and AERMOD version 12345).
The Industrial Source Complex Short-Term model (ISCST3) has a long history of use in the United States, as it was designated by the U.S. Environmental Protection Agency (EPA) as preferred model for use for State Implementation Plan (SIP) revisions for existing sources and for New Source Review (NSR) and Prevention of Significant Deterioration (PSD) programs (U.S. EPA, 1978). ISCST3 is a steady-state Gaussian plume model for continuous source emissions to compute ground-level concentration from stack, volume and area sources. The Briggs equations are used to compute plume rise as a function of stack emission characteristics, stack top wind speed, and downwind distance. The wind speed is adjusted using a stability-dependent power law. The vertical and lateral dispersion are estimated using the Pasquill–Gifford curves (U.S. EPA, 1995).
In 1991, the American Meteorological Society (AMS) and the U.S. Environmental Protection Agency (EPA) initiated a formal collaboration with the designated goal of introducing recent advances in boundary layer meteorology into regulatory dispersion models. A working group (AMS/EPA Regulatory Model Improvement Committee, AERMIC) was formed with a goal to provide a complete replacement for ISCST3 by (1) adopting ISCST3’s input/output computer architecture; (2) updating antiquated ISCST3 model algorithms with newly developed or current surface-layer and planetary boundary layer modeling techniques; and (3) insuring that all processes then modeled by ISCST3 would be handled by the AERMIC Model (AERMOD). Relative to ISCST3, AERMOD currently contains new or improved algorithms for (1) dispersion in both the convective and stable boundary layers; (2) plume rise and buoyancy; (3) plume penetration into elevated inversions; (4) computation of vertical profiles of wind, turbulence, and temperature; (5) the urban nighttime boundary layer; (6) the treatment of receptors on all types of terrain from the surface up to and above the plume height; (7) the treatment of building wake effects; (8) an improved approach for characterizing the fundamental boundary layer parameters; and (9) the treatment of plume meander (U.S. EPA, 2004; U.S. EPA, 2012a; CitationCimorelli et al., 2005; CitationPerry et al., 2005).
The meteorology for each model was generated with the AERMET version 12345 (U.S. EPA, 2012b) meteorological processor, using the Springfield, IL, hourly National Weather Service (NWS) weather observations, and Peoria, IL, twice daily NWS upper air observations, to characterize the meteorological conditions for the tracer dispersion site. The AERMET meteorology and mixing heights were used by both models. For ISCST3, the AERMOD Monin–Obukhov length, L, was converted to a Pasquill stability category by assuming a surface roughness that varied by season and wind direction but was generally on the order of 15 cm, and using the CitationGolder (1972) relationships listed in CitationIrwin (1979).
Receptors were generated for each experiment, where we had observation results, assuming the wind was coming from the west, covering a 150-degree sector with receptors spaced at 0.5 degree. In default mode, AERMOD's plume meander will compute nonzero concentrations essentially in all directions, which does not realistically replicate the coherent plumes seen in all of the Kincaid intensive field experiments. So we used the nondefault model option LOWWIND1 to turn off AERMOD's plume meander. All AERMOD input files contained the following statement:
MODELOPT BETA CONC NOCHKD FLAT LOWWIND1. The modeled concentrations along each arc were analyzed in the same way as the observations, and Cy and Cmax were divided by the assumed emission rate of 1000 g/s.
Grouping Data
It was suggested in the introduction that comparison of averages of a group of observations and modeled values might provide a more meaningful comparison. In this section we outline our reasoning for this conclusion.
The observed concentrations can be envisioned as (CitationVenkatram, 1988):
The modeled concentrations, , are envisioned as:
A comparison of the observed maximum concentration along an arc (often called arc-maxima) with the modeled centerline concentration is suggesting that “good model performance” occurs when Equationeq 2 equals Equationeq 3, which can only happen fortuitously if the random effects and
happen to equal
and
. If anything, we should expect from Equationeq 3 that a model with no bias, f
, and negligible input uncertainty,
, will consistently underestimate the ‘arc-maxima.’ So why are such comparisons in the literature? The answer is likely that various regulatory agencies use the model (inappropriately) as if they can simulate “arc maxima.” Such comparisons reveal how well the model performs an “inappropriate” task, but do not tell us much about how well the model is performing its true tasks, namely, simulating ensemble average concentration values. If we truly wish to model short-term observed concentration values, then we would need to add to Equationeq 3 a term to simulate the stochastic effects of
, and such a model would then express its estimates in a probabilistic fashion.
One way to perform a valid evaluation of modeling skill is to separately average the observations and modeling results over a series of nonoverlapping limited ranges of α. Averaging the observations provides an empirical estimate of what the model is attempting to simulate, . A comparison of the respective averages over a series of α-groups provides an empirical estimate of the combined deterministic error associated with input uncertainty and formulation errors. These averages can consist of any definable feature or characteristic in the concentration pattern (e.g., lateral extent, centerline concentration maximum, variance of centerline concentrations). This process is not without problems. The variance due to natural variability is of order of the magnitude of the ensemble averages (CitationHanna, 1993; CitationIrwin and Hanna, 2005; CitationIrwin et al., 2007), and hence small sample sizes in the groups can lead to large uncertainties in the estimates of the ensemble averages. The variance due to input uncertainty could be quite large—see CitationIrwin et al. (1987)—and hence small sample sizes in the groups can lead to large uncertainties in the estimates of the deterministic error in each group. Grouping data together for analysis requires large data sets, of which there are few.
In spite of the problems noted, this process does avoid making physically inappropriate comparisons to determine modeling skill. From Equationeqs 2 and Equation3, we can conclude that the modeled and observed concentrations (unaveraged) have different sources of variance. Therefore, unless one happens to be working with one of the very few models that attempts to simulate the total variability, any agreement in the upper (or lower) percentile values of the respective cumulative frequency distributions (or Quantile–Quantile plots) can be attributed to happenstance—that is, the effects of Δα’ and f(α) are compensating for the lack of any characterization of C’(α,β) in the modeling. So it is concluded that grouping the data for determination of average patterns has merit, but it comes at the price of developing grouping and analysis strategies.
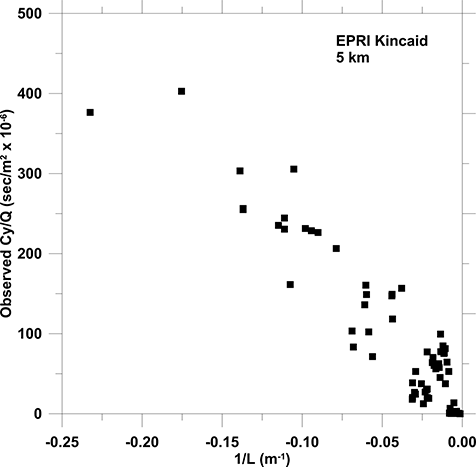
Generally, concentration values decrease as the distance downwind increases and stability effects are seen at a fixed distance downwind (). Thus, the distance downwind and surface-layer atmospheric stability are two obvious criteria for sorting observed and modeled values into groups for analysis and comparison. For each downwind arc, the observed and modeled Cy, σy, and Cmax values were sorted by stability (AERMOD 1/L values, where L is the Monin–Obukhov length). Ten values to a group were defined going from most unstable towards stable, until we did not have sufficient data to form a 10-value group. Initially we computed arithmetic averages for each group. It was discovered that the computed Cmax using Equationeq 1 and arithmetic averages for Cy and σy did not agree with the 10-value arithmetic average Cmax. It was then determined that the computed Cmax using Equationeq 1 and geometric averages for Cy and σy, did agree with the 10-value geometric average Cmax.
Figure 1. Kincaid 5-km observed crosswind integrated concentration values versus AERMOD 1/L values.
Step 1: Comparison of Group Averages
The numbers of arcs to sort into 10-value groups for analysis at each Kincaid distance were 3 km (58), 5 km (90), 7 km (105), 10 km (82), 15 km (79), and 20 km (54), so the numbers of groups for each distance were 5, 9, 10, 8, 7, and, 5 respectively, and the stability ranges are unique for each distance.
In the following analyses, we have chosen to place the observations on the y-axis, as least-square fits assume that random noise effects are most apparent in the y-values. In the plots to be shown, the dotted line is a least-square fit with the intercept forced through the origin (which usually provides a first-order estimate of overall bias). The open symbols denote daytime unstable/neutral conditions, and the solid symbols denote daytime neutral conditions. The first number in the symbol label indicates downwind distance (1 being nearest to the release) and the decimal number indicates stability (1 being most unstable). A symbol label of 1.1 indicates a result for 3 km downwind for the most unstable group, and a label of 1.5 indicates a result for the 3 km downwind for the most stable group.
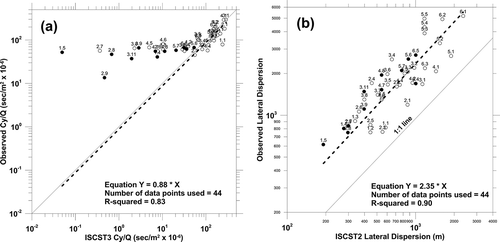
The ISCST3 results shown in show that as we go from unstable to neutral conditions, Cy is increasingly underestimated. The results shown in show that the ISCST3 model is consistently underestimating σy by over a factor of 2. As discussed in CitationPasquill (1976), the Pasquill–Gifford lateral dispersion curves have an averaging time of approximately 3 min, while the Kincaid sampling time was 1 hr. A simplistic adjustment for averaging time effects on lateral dispersion is (CitationTurner, 1970):
Figure 2. (a) Comparison of Kincaid observed and ISCST3 modeled crosswind integrated concentration values. (b) Comparison of Kincaid observed and ISCST3 modeled lateral dispersion values.
A visual inspection of AERMOD's results shown in and suggests that AERMOD is estimating Cy fairly well and is slightly underestimating σy. It would also appear that the bias in the estimates of Cy may be related to downwind distance, and the bias in the estimates of σy may be related to stability.
Figure 3. (a) Comparison of Kincaid observed and AERMOD modeled crosswind integrated concentration values. (b) Comparison of Kincaid observed and AERMOD modeled lateral dispersion values.
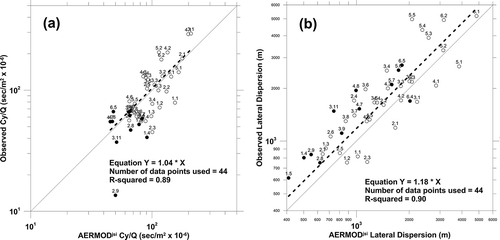
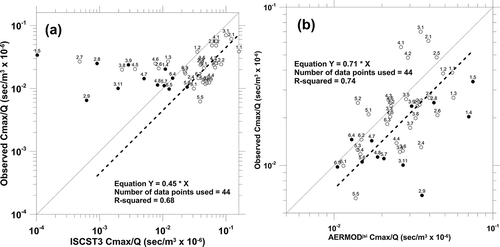
and illustrate how the biases seen in Cy and σy affect the estimates of the Gaussian-fit centerline concentration value (Cmax). From and it was seen that ISCST3 was underestimating Cy for near-neutral conditions and was nearly unbiased for unstable conditions, while ISCST3 was consistently underestimating σy by more than a factor of 2. Thus, the overestimates shown for ISCST3 Cmax in are resulting from a bias to underestimate σy. For AERMOD ( and ) it was seen that the estimates of Cy were nearly unbiased and the estimates of σy were slightly underestimated, and yet it appears AERMOD is overestimating the group-average centerline concentration values by about 40%, which we explore in the following discussion.
Figure 4. (a) Comparison of Kincaid observed and ISCST3 modeled average centerline concentration values. (b) Comparison of Kincaid observed and AERMOD modeled average centerline concentration values.
provides a way to examine whether the bias in AERMOD's Cy estimates might be related to distance downwind. The overall average and geometric mean of the ratio values shown in are nearly one. As shown in , AERMOD's estimates of Cy are larger than that observed for the 3-km and 5-km arcs. For transport beyond 7 km, it appears that AERMOD's estimates of Cy may be slightly underestimated on average. Thus, the bias in AERMOD's estimates of Cy is seen to vary in a predictable way with distance downwind. It is seen in that the bias in AERMOD's estimates of σy is mostly a function of stability, with AERMOD overestimating σy for unstable conditions and increasingly underestimating σy as conditions become more stable. If we delve a bit further for the 3-, 5-, and 7-km distances, the ratios of AERMOD estimates divided by that observed for Cmax, Cy, and σy are 1.60, 1.33, and 0.81 (geometric means of the twenty-four 10-group averages, respectively). Thus AERMOD is overestimating Cmax by overestimating Cy and underestimating σy. For the 10-, 15-, and 20-km distances, the ratios of AERMOD estimates divided by that observed for Cmax, Cy, and σy are 1.07, 0.88, and 0.80 (geometric means of the twenty 10-group averages, respectively). Thus AERMOD is very slightly overestimating Cmax by underestimating σy more so than it underestimates Cy.
Figure 5. (a) The ratio of Cy estimated by AERMOD divided by Cy observed as a function of distance downwind. (b) The ratio of σy estimated by AERMOD divided σy observed as a function of AERMOD 1/L values. The solid and dashed lines connect distance groups 1 and 3, respectively, as a function of stability.
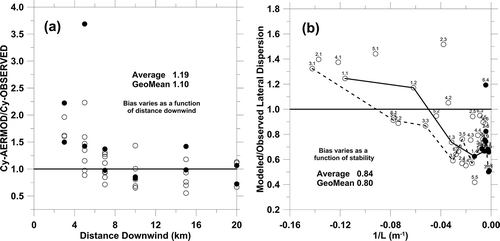
and the preceding discussion reveal how the bias in AERMOD's estimates of Cy and σy varies by distance and stability, and combined such that AERMOD's estimates of Cmax are strongly overestimated at 3, 5, and 7 km, while further downwind the Cmax estimates are nearly unbiased (through a combination of underestimates in Cy and σy). Hopefully this discussion further confirms the usefulness of using Cy and σy to discern dispersion model performance, and how difficult it is to deduce performance from only a comparison of observed and estimated centerline concentration values.
Step 2: Bootstrap Sampling
If one compares and it is obvious that ISCST3 is not performing as well as AERMOD in estimating the group-average crosswind integrated concentration values (Cy). We really do not need a statistical significance test to confirm what our eyes can see. Likewise, if you compare and , it is obvious that ISCST3 is not performing as well as AERMOD in estimating the group average lateral dispersion (σy). That said, whether the differences in performance are statistically significant in future evaluations using different models (or new versions of existing models) may not be as clear. Hence, we recommend that all model evaluations include tests to assess whether differences in performance are statistically significant.
Outline of procedure
To review, we are recommending comparison of observed and modeled group averages of some feature in the concentration pattern, so the question becomes how best to assess differences in performance when the observed and modeled averages are themselves uncertain. Standard D-6589 addressed this concern directly, and recommended a procedure that used bootstrap sampling.
Bootstrap sampling is used to generate estimates of the sampling error in the statistical metric computed, (e.g., CitationHanna and Paine, 1989; CitationCox and Tikvart, 1990; CitationEfron and Tibshirani, 1993). The distribution of some statistical metrics is not necessarily easily transformed to a normal distribution, which is desirable when performing statistical tests to see if there are statistically significant differences in the observed and modeled values computed of some concentration feature.
Following the description provided by (CitationEfron and Tibshirani, 1993), suppose one is analyzing a data set x1,x2,…xn, which for convenience is denoted by the vector x = (x1,x2,…xn). A bootstrap sample x* = (x1*,x2*,…xn*) is obtained by randomly sampling n times, with replacement, from the original data points x = (x1,x2,…xn). For instance, with n = 7 one might obtain x* = (x5,x7,x5,x4,x7,x3,x1). From each bootstrap sample one can compute some statistics (say the observed and modeled averages). By creating a number of bootstrap samples, B, one can compute the mean, , and standard deviation,
, of the statistic of interest. For estimation of standard errors, B typically is on the order of 500 or more. The bootstrap sampling procedure often can be improved by blocking the data into groups, where each group has distinctly different descriptive factors; the data within a group have similar characteristics, and the number of values within each group is similar.
When performing model performance evaluations, for each hour there are not only the observed concentration values, but also the modeling results from all the models being tested. In such cases, the individual members, xi, in the vector x = (x1,x2,…xn) are in themselves vectors, composed of the observed value and its associated modeling results (from all models, if there are more than one); thus, the selection of the observed concentration x2 also includes each model's estimate for this case. This is called “concurrent sampling.” The purpose of concurrent sampling is to preserve correlations inherent in the data (CitationCox and Tikvart, 1990). These temporal and spatial correlations affect the statistical properties of the data samples. One of the considerations in devising a bootstrap sampling procedure is to address how best to preserve inherent correlations that might exist within the data.
For assessing differences in model performance, one often wishes to test whether the differences seen in a performance metric computed between Model 1 and the observations is significantly different when compared to that computed for another model using the same observations. For testing whether the difference between statistical metrics is significant, the following procedure is recommended by D6589 and is diagramed in .
Figure 6. Diagram of bootstrap sampling procedure. In this depiction there are R regimes and each regime has Ni observed and modeled values for some feature in the concentration distribution (e.g. crosswind integrated concentration). The number Ni does not have to be the same, from one regime to the next, but it is suggested to keep the Ni values at least similar. The number of bootstrap samples (e.g., loops) is usually on the order of 500 or more.
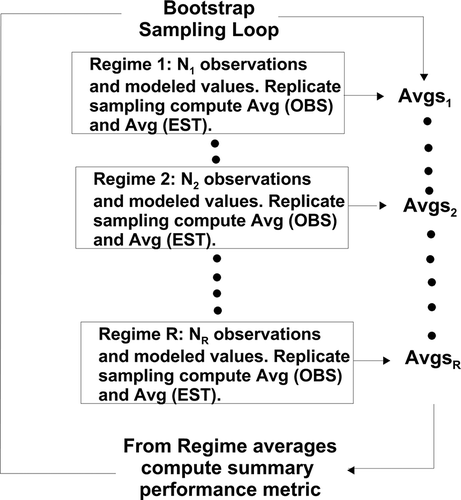
Let the results from each bootstrap (loop) be denoted, x*b, where * indicates this is a bootstrap sample and b indicates this is sample b of a series of bootstrap samples (where the total number of bootstrap samples is B). For this discussion, assume we are asking whether the geometric mean bias, , computed for one model, MG1, is significantly different from that computed for another model, MG2, where Cp and Co are the modeled and observed regime averages of say the crosswind integrated concentration values, and the overbar denotes an average over all R regimes. From each bootstrap sample, x*b, one computes the respective values for MG1
b and MG2
b. The difference ∆Δ*b = MG1
*b – MG2
*b then can be computed. Once all B samples have been processed, compute from the set of B values of Δ* = (Δ*1, Δ*2,… Δ*B) the average and standard deviation,
and
. The null hypothesis is that
is greater than zero with a stated level of confidence, η, and the t-value for use in a Student's t-test is:
For illustration purposes, assume the level of confidence is 90 % (η = 0.1). Then, for large values of B, if the t-value from eq 5 is larger than Student's t
η/2 equal to 1.645, it can be concluded with 90% confidence that is not equal to zero, and hence, there is a significant difference in the MG values for the two models being tested.
Example results
The scatter-plot comparisons previously shown used regimes defined in terms of downwind distance and stability with 10 values in each regime. The freely available BOOT software (CitationChang and Hanna, 2005) provides a means to assess whether differences in performance between two or more dispersion models are statistically significant, has been in use since 1991, and was updated in 2005 to include the ASTM D6589 resampling procedure. There are a number of performance measures one can choose from, but the geometric mean bias, MG, is easy to understand and suitable for demonstration purposes. If MG is less than 1, then the model is overestimating this feature in the concentration pattern, and if MG is greater than 1, then the model is underestimating this feature in the concentration pattern.
There were 440 values sorted into forty-four 10-value regimes (“blocks” in BOOT nomenclature). The input file to BOOT has basically two parts. The first part provides a means to define how many values, number of models, number of regimes, number of values in each regime, and names for the regimes and models. The second part is a listing of the values. The key inputs to the BOOT software were setting IMENU = 4 (which provides MG results), saying “yes” to use of the ASTM procedure, and saying “yes” to bootstrap resampling. The BOOT software uses 1000 boot samples.
For the comparisons of crosswind integrated concentration values, MG was 0.9 and 2.7 for AERMOD and ISCST3, respectively. For comparisons of lateral dispersion, MG was 1.2 and 2.5 for AERMOD and ISCST3, respectively. For AERMOD, the slight overestimation of the crosswind integrated concentration is actually amplified by the underestimation of the lateral dispersion, to result in overestimation of the regime-average centerline concentration values. ISCST3 is underestimating both the crosswind integrated concentration values and the lateral dispersion, which combine to result in over-estimation of the regime-average centerline concentration values. Not surprisingly, the differences in model performance between AERMOD and ISCST3 (as determined by MG) were determined to be statistically significant both for the crosswind integrated concentration values and the lateral dispersion values.
Transport Direction
CitationIrwin and Hanna (2005) suggested a lower bound estimate of the uncertainties associated in wind transport through an analysis of well-controlled tracer experiments from low-level releases. The lower bound uncertainty in wind speed was of the order 0.5 m/s, and the lower bound uncertainty in the wind direction was of the order 10 degrees. At Kincaid we are dealing with a tall stack with buoyant plume rise, so we might expect larger transport uncertainties.
During the Kincaid tracer experiments there was a 100-m meteorological mast 645 m east of the Kincaid stack, with hourly-averaged direction measurements at heights above ground of 10, 30, 50, and 100 m. Of the 440 arcs used in previous analyses, we had onsite wind directions for 404 arcs. summarizes the comparison of the observed transport direction (defined as the bearing from the stack to the center of mass along an arc), with the transport defined by the Springfield NWS observations and the wind directions observed by the Kincaid meteorological mast at different heights. The median and averages are similar suggesting single-mode distributions that are somewhat Gaussian. The standard deviations are so large that the average transport differences are easily shown to be not statistically significant. An F-test shows that the standard deviation in differences using NWS data (36 degrees) is significantly different (from a statistical viewpoint) as compared to the standard deviations seen in the differences using onsite wind directions; however, the transport uncertainties are sufficiently large regardless of what wind directions are used to preclude confidently simulating the plume position for any one hour.
Table 1. Summary of differences seen in simulated transport versus that deduced from sampled concentration values along arcs. The “observed” transport was defined as the center of mass of the observed concentration values along an arc. The difference was defined as the observed transport minus that simulated by NWS wind directions or Kincaid wind directions (e.g., observed onsite from the 100-m meteorological mast). All values shown are in degrees
depicts the histogram of observed transport minus simulated transport using NWS wind directions versus Kincaid 100-m wind directions. There is a shift in the transport to the right of the simulated wind directions of order 2 to 10 degrees, depending on which wind direction is used (see ). The histograms generated using 10-, 30-, and 50-m Kincaid wind directions are very similar to that depicted in for the Kincaid 100-m results.
Figure 7. Histograms of differences seen in transport observed and simulated using Kincaid 100-m versus NWS wind directions. The standard deviation of differences (StDev) is a measure of the uncertainty in simulated transport. While the difference in standard deviation values is found to be statistically significant, it is of little practical importance in helping to significantly improve model performance in locating the dispersing plume's position.
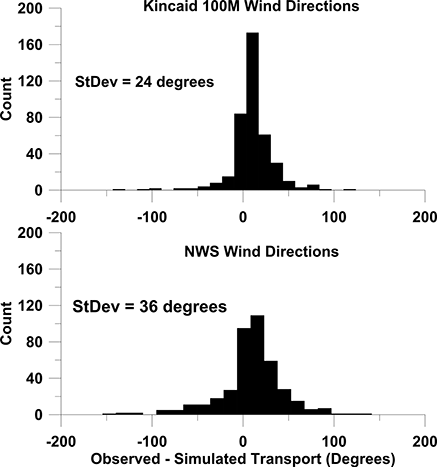
The observed average lateral dispersion was on the order of 10 degrees, hence the uncertainty in transport of at least 20 or more degrees (as suggested by the standard deviations listed in ), confirm the findings of CitationWeil et al. (1992) who analyzed nine periods from the EPRI Kincaid experiments, where each period was about 4 hr long. They concluded that for short travel times (where the growth rate of the plume's width is nearly linear with travel time), the uncertainty in the plume transport direction is of the order of one-fourth of the plume's total width. Farther downwind, where the growth rate of the plume's width is less rapid, the uncertainty in the plume transport direction is larger than one-fourth of the plume's total width.
It is concluded that although use of onsite wind directions slightly reduces the uncertainty in the transport versus using offsite NWS wind directions, the improvement is of little practical importance. Our results confirm previous findings that transport uncertainties are sufficiently large that at best we can only estimate within about 25 degrees where a plume is positioned on any given hour.
Conclusion
A missing element in past model evaluations is an accurate consideration of the fact that current dispersion models provide hourly estimates of the deterministic portion of the observed concentration time series (namely, the ensemble average). Lack of consideration of what models truly are capable of providing likely comes from various regulatory agencies erroneously treating hourly concentration estimates as if they are monitored (observed) values. Treating model estimates as if they are hourly “observations” has resulted in assessments that test a model's ability to replicate hourly maxima (sometimes referred to as “arc-maxima”), which (as discussed in the Grouping Data section) is a misinterpretation of what dispersion models provide. While regulatory agencies can accept modeling results to suit their purposes, this does not mean that useful model evaluation can be constructed by testing a model's ability to be misused.
We define a useful model evaluation procedure as one that (1) informs us as to how well the model is doing in estimating the ensemble-average concentration values; (2) reveals trends in model bias in such a manner that we have clues to where to look in the modeling algorithms to improve model performance; and (3) uses objective statistical tests to assess whether differences in performance between two or more dispersion models are statistically significant.
We have demonstrated a candidate model evaluation procedure that assesses whether a model has the correct total mass at the receptor level (crosswind integrated concentration values), is correctly spreading the mass laterally (lateral dispersion), and assesses the uncertainty in transport. We argue for the use of the BOOT software (preferably using the ASTM D6589 resampling procedure) to provide an objective assessment of whether differences in model performance between one or more models are significant.
The observed Kincaid concentration values have a 1-hr averaging time. Thus, we can attribute the underestimation of σy by ISCST3 to the fact that the averaging time of the lateral dispersion estimates by ISCST3 is 3 min versus the 1-hr averaging time associated with the Kincaid observations (CitationPasquill, 1976). AERMOD is using theoretical fits to experimental field observations to estimate the lateral and vertical turbulence, and to characterize the growth of the lateral and vertical dispersion as a function of transport downwind. Hence the averaging time to be associated with AERMOD's lateral and vertical dispersion parameters is not clear, and may deserve further investigation.
Improvements in AERMOD's estimates have been made in the past with comparisons primarily of observed arc-maxima and estimated centerline concentration values. This discussion argues that future improvements in model performance can be achieved by a forensic analysis of observed and estimated crosswind integrated concentration values and lateral dispersion values, by recognizing that models provide estimates of hourly ensemble average concentration values, and by including in all evaluations objective statistical tests to assess whether differences in performance between two or more dispersion models are statistically significant.
Acknowledgment
This paper results from Gale Hoffnagle's kind invitation to provide a luncheon presentation at the 2013 A&WMA Specialty Conference Guideline on Air Quality Models: The Path Forward. Joseph C. Chang provided me with all of his Kincaid data files, which we have come to understand were likely created by someone working for SAI, many years ago. Gary Moore provided me with all of his Kincaid data files, which are 61 archive 1-week files. Through a series of e-mails, Norman Bowne, Roger Brode, Steve Hanna, Jayant Hardikar, Russ Lee, Douglas R. Murray, Helge Olesen, Bob Paine, James Paumier, Don Shearer, and Dave Strimaitis have all tried to help me decipher the available data files. As you can see, I have had lots of help, and I am honored that so many have offered their help.
References
- American Society for Testing and Materials. 2010. Standard Guide for Statistical Evaluation of Atmospheric Dispersion Model Performance (D6589). West Conshohocken, PA: ASTM. Available at http://www.astm.org (http://www.astm.org)
- Bowne , N.E. , Londergan , R.J. , Murray , D.R. and Borenstein , H.S. 1983 . Overview, Results, and Conclusions for the EPRI Plume Model Validation and Development Project: Plains Site , Palo Alto , CA : Electric Power Research Institute . EPRI EA-3074, Project 1616-1
- Chang, J.C.S.R. Hanna. 2005. Technical Descriptions and User's Guide for the BOOT Statistical Model Evaluation Software Package, Version 2.0 http://www.harmo.org/kit/Download.asp (http://www.harmo.org/kit/Download.asp)
- Cimorelli , A.J. , Perry , S.G. , Venkatram , A. , Weil , J.C. , Paine , R.J. , Wilson , R.B. , Lee , R.F. , Peters , W.D. and Brode , R.W. 2005 . AERMOD: A dispersion model for industrial source applications. Part I: General model formulation and boundary layer characterization . J. Appl. Meteorol , 44 : 682 – 93 . doi: 10.1175/JAM2227.1
- Cox , W.M. and Tikvart , J.A. 1990 . Statistical procedure for determining the best performing air quality simulation model . Atmos. Environ , 24A:2387–95
- Efron , B. and Tibshirani , R.J. 1993 . An Introduction to the Bootstrap , New York , NY : Chapman & Hall . Monographs on Statistics and Applied Probability 57
- Fox , D.G. 1984 . Uncertainty in air quality modeling . Bull. Amer. Meteorol. Soc , 65 : 27 – 36 . doi: 10.1175/1520-0477(1984
- Golder , D. 1972 . Relations among stability parameters in the surface layer . Bound. Layer Meteorol , 3 : 47 – 58 . doi: 10.1007/BF00769106
- Hanna , S.R. 1993 . Uncertainties in air quality model predictions . Bound. Layer Meteorol , 62 : 3 – 20 . doi: 10.1007/BF00705545
- Hanna , S.R. and Paine , R.J. 1989 . Hybrid plume dispersion mopdel (HPDM) development and evaluation . J. Appl. Meteorol , 28 : 206 – 24 . doi: 10.1007/BF00705545
- Irwin , J.S. 1979 . “ Estimating plume dispersion—A recommended generalized scheme ” . In Proceedings of the 4th Symposium on Turbulence, Diffusion, and Air Pollution, Jan , 62 – 69 . Boston , MA : American Meteorological Society . 15–18, 1979, Reno, NV
- Irwin , J.S. and Hanna , S.R. 2005 . Characterizing uncertainty in plume dispersion models . Int. J. Environ. Pollut , 25 ( 1/2/3/4 ) : 16 – 24 . doi: 10.1504/IJEP.2005.007651
- Irwin , J.S. and Rosu , M.-R. 1998 . “ Comments on a draft practice for statistical evaluation of atmospheric dispersion models ” . In Proceedings of the 10th Joint Conference on the Application of Air Pollution Meteorology with the A&WMA , 6 – 10 . Phoenix : AZ .
- Irwin , J.S. , Petersen , W.B. and Howard , S.C. 2007 . Probabilistic characterization of atmospheric transport and diffusion . J. Appl. Meteorol. Climatol , 46 : 980 – 93 . doi: 10.1175/JAM2515.1
- Irwin , J.S. , Rao , S.T. , Petersen , W.B. and Turner , D.B. 1987 . Relating error bounds for maximum concentration predictions to diffusion meteorology uncertainty . Atmos. Environ , 21 : 1927 – 37 .
- Liu , M.-K. and Moore , G.E. 1984 . Diagnostic Validation of Plume Models at a Plains Site , EA-3077. Palo Alto , CA : Electric Power Research Institute .
- Pasquill , F. 1976 . Atmospheric Dispersion Parameters in Gaussian Plume Modeling—Part III: Possible Requirements for Change in the Turner's Workbook Values , EPA-600/4-76-030B. Research Triangle Park, NC: U. S. Environmental Protection Agency .
- Perry , S.P , Cimorelli , A.J. , Paine , R.J. , Brode , R.W. , Weil , J.C. , Venkatram , A. , Wilson , R.B. , Lee , R.F. and Peters , W.D. 2005 . AERMOD: A dispersion model for industrial source applications. Part II: Model performance against 17 field study databases . J. Appl. Meteorol , 44 : 694 – 708 . doi: 10.1175/JAM2228.1
- Stein , A.F. and Wyngaard , J.C. 2001 . Fluid modeling and the evaluation of inherent uncertainty . J. Appl. Meteorol , 40 : 1769 – 74 . FMATEO>2.0.CO;2 doi: 10.1175/1520-0450(2001)040<1769
- Turner , D.B. 1970 . Workbook of Atmospheric Dispersion Estimates , NC: Office of Air Programs : Research Triangle Park . AP-26
- U.S. Environmental Protection Agency. 1978, 1986, 1987, 1995, . 2005 . Guideline on Air Quality Models , NC: U.S. Environmental Protection Agency : Research Triangle Park . EPA-450/2-78-027. [This Guideline has been updated several times: 1986 as EPA-450/2-78-027R; 1987 as EPA/450/2 78/027R SUPPL A; 1993 as EPA 450/2 78 027R B, and 1995 it was updated and incorporated into Appendix W to 40 CFR Part 51.] Office of Air Quality Planning and Standards
- U.S. Environmental Protection Agency . 1995 . Industrial Source Complex (ISC3) Dispersion Model , Research Triangle Park , NC : U.S. Environmental Protection Agency . User's Guide. EPA 454/B 95 003a (vol. I) and EPA 454/B 95 003b (vol. II)
- U.S. Environmental Protection Agency . 2004 . AERMOD: Description of Model Formulation , Research Triangle Park , NC : U.S. Environmental Protection Agency .
- U.S. Environmental Protection Agency . 2012a . Addendum User's Guide for the AMS/EPA Regulatory Model—AERMOD , Research Triangle Park , NC: U.S : Environmental Protection Agency . [Addendum to EPA-454/B-03-001 (dated September 2004)]
- U.S. Environmental Protection Agency . 2012b . Addendum User's Guide for the AERMOD Meteorological Preprocessor—AERMET , Research Triangle Park , NC: U.S : Environmental Protection Agency. . [Addendum to EPA-454/B-03-002 (dated November 2004)]
- Venkatram , A. 1979 . The expected deviation of observed concentrations from predicted ensemble means . Atmos. Environ , 11 : 1547 – 49 .
- Venkatram , A. 1988 . “ Topics in applied modeling ” . In Lectures on Air Pollution Modeling , Edited by: Venkatram , A. and Wyngaard , J.C. 267 – 324 . Boston , MA : American Meteorological Society . Ined
- Weil , J.C. 1985 . Updating applied diffusion models . J. Appl. Meteorol , 24 : 1111 – 30 .
- Weil , J.C. , Sykes , R.I. and Venkatram , A. 1992 . Evaluating air-quality models: Review and outlook . J. Appl. Meteorol , 31 : 1121 – 45 . EAQMRA>2.0.CO;2 doi: 10.1175/1520-0450(1992)031<1121