
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In real decision-making problems, decision makers (DMs) usually select the most potential project from several ones. However, they unconsciously show different confidence levels in decision-making process because they come from various backgrounds and have different experiences, etc., which affects the decision results. Moreover, the probabilistic linguistic term set, which not only includes the linguistic expressions used by DMs in their daily life but also contains the probability for each linguistic term, can well portray the real perceptions of DMs for the projects. Furthermore, large-scale consensus has gradually been a popular way to effectively solve complex decision-making problems. To sum up, in this paper, we are dedicated to constructing a large-scale consensus model considering the confidence levels of DMs under probabilistic linguistic circumstance. Firstly, the endo-confidence is defined and measured by DM’s probabilistic linguistic information. Then, the DMs are clustered according to the similarities of both evaluation information and the endo-confidence levels. Both evaluation of the non-consensus cluster and evaluation integrated by the clusters with higher endo-confidence level than this non-consensus cluster are used as the reference to adjust its evaluation information. Then, a case study and the comparative analysis are carried out. Finally, some conclusions and future work are given.
1. Introduction
In our daily life, decision makers (DMs) often evaluate the available projects, which is the main part in the decision-making process. Sometimes, there are many aspects which should be considered due to the complexity of the decision objects (Tian et al., Citation2021). In order to comprehensively evaluate the projects, DMs need to master different types of knowledge. However, with the development of economy, the social division of labor has been increasingly refined, and the professional knowledge and skills continue to be strengthened. Thus, the single DM can be only specialised in one major and be proficient in a special field. Then, group decision making (GDM) has become a general way to conquer the disadvantages caused by the professionalisation in real decision-making situations.
In GDM process, the DMs come from various professional fields and have different backgrounds. And thus, they may have different opinions for the same project. Sometimes, those opinions may have large difference. If those evaluations with large difference are used to make decisions, the decision results may be unreasonable and distorted. Therefore, reaching consensus is the precondition to make a reasonable decision in GDM. Moreover, for complex decision-making problems, the large number of DMs need to be invited to participate in decision making. Considering the situation above, large-scale consensus has been a hot topic in recent years.
In real decision-making cases, some attributes are not suitable to be expressed as numerical form, and nature languages are the usual form used by DMs in their evaluation processes. In order to deal with natural languages, linguistic expression (Zadeh, Citation1975) is developed and widely adopted as the basic evaluation information in decision-making methods. As experts may hesitate among several values to assess a project in decision-making process, hesitate fuzzy linguistic term set (HFLTS) has been proposed by Rodriguez et al. (Citation2012) to handle the uncertain environments. However, according to HFLTS, all possible values provided by the DMs have equal importance or weight which may lead to unreasonable decision results (Pang et al., Citation2016). That is because (1) the occurrence frequencies of evaluation values are likely to be different for a group of DMs, and (2) for a single DM, the reliabilities or the preference degrees on evaluation values are also probably different (Xu, He, et al., Citation2019). As a result, the probabilistic linguistic term set (PLTS) (Pang et al., Citation2016), which is a widespread description tool in the existing decision-making method (Wei et al., Citation2020), can solve the above problem. It not only includes the hesitant linguistic representation but also reflects the different preference degree for each piece of linguistic representation. Hence, in this paper, we will use PLTSs to represent the evaluation information of DMs.
Moreover, DMs are professional individuals in their special fields, and they may have different perceptions for the same aspect of the projects. Then, the confidence levels of their evaluation information are also different. Thus, considering the effect of confidence on the decision-making results is essential. Consensus models with self-confidence have been presented and Ding et al. (Citation2019) alleged that the self-confidence level indeed affect the consensus reaching process. According to Liu et al. (Citation2017) and Liu et al. (Citation2018) proposed an iteration-based consensus with self-confidence multiplicative preference relations. Gou, Xu, Wang, et al. (Citation2021) introduced self-confidence factor into the double hierarchy linguistic preference relations and presented a consensus model based on the priority ordering theory. Zhang et al. (Zhang et al., Citation2021) introduced self-confidence factor into comparative linguistic expressions and gave an optimisation consensus model with minimum information loss. Liu, Xu, Montes, and Herrera (Citation2019) focussed on the self-confidence-based consensus model and proposed a novel feedback mechanism that chooses the expert with minimal self-confidence to adjust his/her evaluation information.
Consistency of preference relation in consensus model should also be considered (Gou et al., Citation2019). It is easy to notice that some researches based on preference relations with self-confidence neglect the consistency of the preference relations, which has a direct influence on the results of final decision (Liu, Xu, Montes, Dong, et al., Citation2019). To solve this problem, Liu, Xu, Montes, Dong, et al. (Citation2019) gave a novel method to measure the additive consistency level by considering both the fuzzy preference values and the self-confidence levels. However, additive consistency sometimes cannot capture the consistency of a fuzzy preference relation (Zhang, Kou, et al., Citation2020). Zhang, Kou, et al. (Citation2020) proposed two algorithms to improve the multiplicative consistency level. Bashir et al. (Citation2018) defined the hesitant fuzzy preference relation with self-confidence and the hesitant multiplicative preference relation with self-confidence in their paper, and also the corresponding additive consistency and multiplicative consistency.
As the development of technology, large-scale decision making has been more and more popular. Based on Xu, Du, et al. (Citation2019), the combination of the levels of both rationality and non-cooperation is used to measure the confidence level, which is utilised as adjustment coefficient to modify the evaluation value. According to Liu et al. (Citation2017), Liu, Xu, and Herrera (Citation2019) studied the large-scale consensus which considers the overconfidence behaviours of DMs. The grey clustering algorithm was used to distinguish the experts by combining the similarities of both fuzzy preference values and self-confidence levels. An overconfidence measurement was given to detect the experts’ overconfidence behaviours in the consensus model. Also, a dynamic weight punishment mechanism was implemented to manage overconfidence behaviour. However, the clustering method in Liu, Xu, and Herrera (Citation2019) causes the problem that the experts with lower similarities of fuzzy preference values will be classified into one cluster because they have the higher similarities of self-confidence levels. Then, these experts with large differences in fuzzy preference will be used to calculate the weights together and further to obtain the overall preference value, which may lead to unreasonable decision-making results.
As far as we know, in the existing literature, self-confidence level is directly given by DMs and there are not any consensus researches considering to measure the confidence from the evaluation information. Because there are not any consensus researches considering the confidence of DMs with PLTS, our research targeted at consensus with PLTS for multi-attribute large-scale GDM (LSGDM) problems typically has four main goals:
In order to give the DMs’ confidence level more accurately and objectively, and distinguish the self-confidence given by DM in the existing studies, one aim is to define the endo-confidence, which is measured by DM’s evaluation information rather than the existing self-confidence given by the DM aforehand.
To solve the problem of confidence-based clustering that DMs with lower similarities of evaluations may be classified into one cluster, one purpose is to define a novel clustering procedure based on both the evaluation information and the endo-confidence level.
In the decision-making process, the DMs with higher level of endo-confidence may influence the opinions of others whose confidence levels are lower than themselves. Also, those DMs with higher endo-confidences tend to have a greater impact on the final results than those DMs with lower endo-confidences. Hence, one objective is to simulate the above phenomenon and present a new feedback adjustment mechanism.
When assigning the missing probabilities to linguistic terms for the incomplete PLTSs, the total probability for linguistic terms from DMs should be considered. Moreover, the original preference among linguistic terms of DMs should also be considered when normalising the PLTSs. In order to reflect the opinions of DMs more accurately and avoid the loss of information, the other goal is to provide a suitable method to normalise the PLTSs.
To sum up, in this paper, we will construct the large-scale consensus model with probabilistic linguistic information considering the confidence behaviours (which is named as endo-confidence level in this paper) of DMs derived from PLTS itself. Although there already exists large-scale consensus models considering the self-confidence behaviours, it is different according to our above review. The innovations of this paper can be summarised as follows:
In this paper, the endo-confidence is defined and it can be obtained from three aspects: (a) the probabilistic information in the original evaluation given by DMs; (b) DMs’ hesitation in the original evaluation information; and (c) DMs’ preference among linguistic terms in the original evaluation information.
Inspire by the similarity-based clustering algorithm, we give a new bi-clustering process considering both the evaluation information and the endo-confidence level. The optimal classification threshold is determined by both the similarities and the threshold given by DMs.
We consider the evaluation information of both the cluster itself and the clusters with higher endo-confidence levels than itself as the reference to adjust the evaluation information of this cluster. Meanwhile, an endo-confidence-based method to determine weights is proposed. In this method, we give a function to obtain the weights.
We proposed a new method to normalise the PLTSs, which considers both the certainty degree of probabilistic information and the preference among the linguistic terms in it.
The outline of this paper is listed as follows: Section 2 shows the preliminaries including the form of basic evaluation information and its operators. Consensus reaching process is given in Section 3, including how to determine the endo-confidence level, how to normalise the PLTSs and the weights of DMs, clustering process, consensus measurement, feedback mechanism and the selection process. Then, a case study and comparative analysis are shown in Section 4. Finally, Section 5 ends with some conclusions.
2. Preliminaries
In this section, we will introduce the basic knowledge proposed in previous studies, such as the linguistic term set, the probabilistic linguistic term set and its score function, distance and similarity measurements, etc., which will be used in this paper.
2.1. The probabilistic linguistic term set
Linguistic is generally used in our daily life to express DMs’ opinions. The linguistic variable (Zadeh, Citation1975) is closer to the natural or artificial language and has been widely used in the decision-making field. Let be a linguistic term set (LTS), where
represents the
-th linguistic term in
and
is the cardinality of the LTS
Then, the PLTS (Pang et al., Citation2016) with probability of each linguistic term is defined as:
(1)
(1)
where
is a linguistic term
associated with the probability
and
is the number of all different linguistic terms in
When
we should normalise it to be
before the aggregation processes. In this paper, we will give a new normalised method in Section 3.2.
In order to reflect the assessments of experts with PLTSs and make a comparison among different PLTSs, Pang et al. (Citation2016) defined the score function of
as:
(2)
(2)
where
and
means the subscript of linguistic term
If
it is named as virtual linguistic term (Xu, Citation2004). For two PLTSs
and
if
then
is superior to
denoted by
if
then
is inferior to
denoted by
if
then there is
2.2. The distance and the similarity between PLTSs
Distance is a general tool used to reflect the relationship of PLTSs. Pang et al. (Citation2016) and Zhang et al. (Citation2016) defined two methods to obtain the distance among PLTSs. However, both of those two methods need to add linguistic terms to a shorter PLTS, which may lead to biased results (Wu et al., Citation2018). To solve this problem, Wu et al. (Citation2018) introduced a novel method to adjust the linguistic terms with different probability distributions into those with the same probability distribution. The method effectively avoids the problem of information loss by the unchanged linguistic terms and the sum of their probabilities. Hence, this method (Wu et al., Citation2018) is used in this paper to make two PLTSs have the same length, so that we can measure the distance between them. Here, we give a brief description of this method.
Let and
be two normalised PLTSs and the subscripts of the linguistic terms in them are ranked as ascending/descending order. Suppose that the rearranged probabilistic distributions of
and
are the same as
Then, we can obtain the rearranged PLTSs of
and
denoted as
and
by the following steps:
Step 1. Let
Step 2. Then we can calculate
If
then
If
Step 3. Obtain by using the following rules:
If
If
If
If
Step 4. We can calculate other rearranged probability distributions by the above rules.
Notes:
We can find that
The length of the rearranged PLTSs is equal, that is
It should be satisfied that
The subscripts of the linguistic terms in the rearranged PLTSs are ranked as non-ascending/non-descending order.
In order to use data more efficiently and express the semantics flexibly, Wang et al. (Citation2014) proposed the linguistic scale function which is a monotonically increasing function, where
Then, it is represented by:
(3)
(3)
Wu and Liao (Citation2019) introduced the linguistic scale to measure the distance by EquationEquation (4)(4)
(4) :
(4)
(4)
According to Wu et al. (Citation2018), we can obtain the similarity of the PLTSs based on their distance
(5)
(5)
3. Consensus decision making with endo-confidence based on the probabilistic linguistic information
In this section, we will give a new procedure to reach consensus considering the endo-confidence levels of DMs. Firstly, we will show how to determine the endo-confidence level of each DM from his/her evaluation information. Then, a new method to normalise the PLTSs is given. After that, a similarity-based clustering algorithm is used to distinguish the DMs into several clusters with bi-clustering. The weight of each DM is an important issue in decision making, and we will define a method to measure the weight of DM based on his/her endo-confidence level. Subsequently, a consensus measurement is carried out and the identification and adjustment procedures are designed to achieve consensus. Finally, when the consensus level is reached, the selection process is presented. Please see Table A1 for the meaning of notations used in the proposed model.
3.1. How to determine the endo-confidence level of each DM
As afore-mentioned, the experts’ confidence levels greatly influence the final decision-making results and it should be considered in the decision-making process. As a key step, the measurement of confidence level should be further discussed. However, few studies measure the confidence level according to the evaluation information (Guha & Chakraborty, Citation2011), especially through probabilistic linguistic information. As a result, in this paper, we propose a method to determine experts’ original confidence levels which are named endo-confidence levels based on probabilistic linguistic information from those three aspects:
(1) The probabilistic information in the original evaluation given by experts
The original probabilities given by experts can reflect their endo-confidence levels. It is not difficult to find that the greater the total probability of the original assessment from an expert is, the higher the expert’s endo-confidence level for the corresponding assessment. For instance, if an expert () gives his/her assessment as
while another expert (
) gives his/her assessment as
we can find that the expert
gives more information than the expert
That is, the expert
is more confident for his/her evaluation information than the expert
Hence, we can calculate endo-confidence level from the perspective of total probability by
The first part of endo-confidence level of expert
/
is denoted as
/
(2) Experts’ hesitation in the original evaluation information
Experts may express various degrees of hesitation when facing a decision-making problem. The greater degree of hesitation means that the experts are less confident. Furthermore, endo-confidence level should be related to the number of the linguistic terms in PLTS. For instance, if there are two PLTSs and
given by experts
and
respectively. Intuitively, the expert
is more hesitant than the expert
That is,
is less confident about his/her evaluation information than
Hence, the endo-confidence level based on hesitation is defined as:
1. When
2. When
3. In other cases, the value of endo-confidence level of the expert is somewhere between the above two cases, that is,
(3) Experts’ preference among linguistic terms in the original evaluation information
One of the most important characteristics of probabilistic linguistic information is that it can reflect the preferences of DMs among the linguistic terms in PLTSs. We can get another part of the expert’s endo-confidence level from the probability distribution in different linguistic terms.
Example 1.
If the experts
and
give their assessments as
and
respectively, we can find that the expert
does not know which of the linguistic terms
and
is better, while the expert
thinks that the linguistic term
can better describe his/her perception than
Motivated by the concept of standard deviation in depicting the degree of dispersion, we can find that a smaller standard deviation level of probabilities means that the probabilities are closer, and endo-confidence level of the expert is lower, while a larger standard deviation indicates that the expert has a stronger preference for some linguistic terms, which shows that the expert is more confident. Hence, the standard deviation of probabilities should be used as a measure of endo-confidence level. It is worth noting that the expert
and the expert
have the same preference for the terms
and
but the standard deviation levels of probabilities are different due to the difference in total probabilities. The standard deviation of the probabilities in
is 0.05, while the standard deviation of the probabilities in
is 0.15.
In order to solve this problem, inspired by Pang et al. (Citation2016), we first adjust the total probability to 1 according to the given information. In particular, the associated PLTS is defined by
where
We can further calculate standard deviation level
of probabilities
(6)
(6)
and
is the number of all different linguistic terms in
Specially, for the PLTS with only one term, we add a term to it and define the corresponding probability as zero. Then, the standard deviation of probabilities is 0.5.
Then, if there is a finite set of experts (
) and the evaluation information of an expert
is shown as PLTS, the endo-confidence level
of
from the perspective of preference among linguistic terms can be obtained by EquationEquation (7)
(7)
(7) :
(7)
(7)
where
means that the minimum standard deviation level of probabilities given by all the experts and
denotes the corresponding maximum one.
Example 2.
According to Example 1, there is
and
for the experts
and
respectively. Then, we utilise EquationEquation (6)
(6)
(6) to calculate the standard deviation level
and
Finally, we get the endo-confidence level
and
After giving the calculation methods of
and
we can obtain the endo-confidence level
of the expert
as:
(8)
(8)
and
are two parameters determined by the DM.
Let (
) be a finite set of potential alternatives and
(
) be a finite set of attributes. Suppose that the decision-making matrix from the expert
is given as:
(9)
(9)
where
(
) is represented by the PLTS
which is a piece of probabilistic linguistic information for the alternative
on the attribute
given by the expert
Then, we can get the endo-confidence matrix of the expert
as:
(10)
(10)
where
can be calculated by EquationEquation (8)
(8)
(8) .
3.2. How to normalise the PLTSs
Many scholars have proposed some methods to execute the normalisation of PLTSs. Mi et al. (Citation2020) divided these methods into five categories according to different methods of assigning unknown information, that is, (1) average assignment, (2) full-set assignment, (3) pow-set assignment, (4) envelope assignment, and (5) attitude-based assignment. Furthermore, Zhang, Liao, et al. (Citation2020) gave a new method to normalise the incomplete PLTS into the complete one by assigning the unknown probabilities evenly to all the linguistic terms in
Although previous researches have given various methods to assign the ignorance of probabilistic information, there are some unreasonable points in these methods. For example, the average assignment method assumes that if a linguistic term does not appear in
then it should not appear in the normalised PLTS
However, experts cannot accurately know the linguistic terms associated with the ignorance of probabilistic information. As a result, this assumption imposes too many restrictions on the ignorance of probabilistic information. The full-set assignment method (Fang et al., Citation2020) and the method proposed by Zhang, Liao, et al. (Citation2020) assign the unknown probabilities to all the linguistic terms which can avoid the problem of too strict restrictions mentioned above. For
if we use average assignment method, there is
while if we use full-set assignment method, there is
and if we use the method proposed by Zhang, Liao, et al. (Citation2020), there is
Compared with the average assignment method, the latter two methods assign the unknown information to more terms of the PLTSs. However, those methods do not consider the attitude of DMs. Although the attitudes of DMs (such as optimistic, pessimistic and neutral) are considered in the attitude-based assignment method (Song & Li, Citation2019), it is not easy to judge the attitudes of DMs in real decision-making process. As a result, inspired by the score function
of
we propose a novel method to normalise the incomplete PLTSs.
Since the limitation of knowledge and ability, some DMs will give less assessment which lead to the ignorance of probabilistic information in the decision-making process. It is clear that the more unknown assessment is, the less accurate the information provided by DMs will be. For instance, there are two PLTSs and
Both of the experts deem that the assessment should be between
and
but the corresponding probabilities show that the certainty of the assessment
reaches 0.9, while the certainty of
is only 0.3. It is clear that different normalisation methods should be adopted according to the ignorance of probabilistic information. If the total probability of the PLTS is at a higher level, we tend to believe that experts are more certain about their assessments, thus the remaining probabilities are also distributed around the original information. If the total probability of the PLTS is at a lower level, the assessments may not be accurate. In other words, the remaining probabilities should be assigned to more linguistic terms which are far from the original linguistic information. Hence, we use the values of the ignorance of probabilities to determine the terms that appear in the normalised PLTSs. The specific method is shown as follows:
We can calculate the lower and upper bounds of the normalised PLTS, which is denoted as and
respectively, where
and
are obtained by EquationEquations (11)
(11)
(11) and Equation(12)
(12)
(12) :
(11)
(11)
(12)
(12)
Notice that:
When
When
Specifically, if the bounds of the normalised PLTS exceed the definition of the LTS, then we set
Subsequently, we fill in all integer terms between and
to get the normalised LTS
Then, we get the corresponding expanded original probabilities
according to EquationEquation (13)
(13)
(13) and obtain the PLTS
(13)
(13)
where
is the number of all different linguistic terms in
When normalising the probabilistic linguistic information, we should consider the original opinions of experts. The term which is closer to the score is more in line with the original opinion of the expert, and we should assign a greater probability to this term. When
(see EquationEquation (2)
(2)
(2) ), the proportion of the probability distribution
should be maximised. In this paper, we use the exponential function to obtain
(14)
(14)
EquationEquation (15)(15)
(15) is used to get the normalised proportion
of the probability distribution:
(15)
(15)
Then, we can obtain the normalised probabilities
(16)
(16)
where
is the number of all different linguistic terms in the normalised PLTS
In order to facilitate readers to understand the proposed normalisation method, in this paper, we give the corresponding calculation process by Example 3 in Appendix.
3.3. The clustering procedure of the large-scale experts
Clustering analysis, which can not only reduce the complexity of LSGDM problems and the cost of decision making but also help us find common opinion patterns to identify a spokesman who represents the cluster (Tang & Liao, Citation2021) has attracted much attention and become the most commonly used method in LSGDM problem.
Some traditional clustering algorithms (i.e., K-means, fuzzy C-means) have been used to distinguish participants into different subgroups. Since the results of these two clustering methods are affected by the number of clusters determined by DMs, other clustering methods including similarity measure-based clustering and fuzzy equivalence clustering are introduced into LSGDM problem recently. The similarity-based clustering, which is one of the most widespread methods used by the researchers to distinguish the DMs into different clusters, is utilised in this paper (Gou et al., Citation2018).
Furthermore, we introduce the endo-confidence factor into the similarity-based clustering. Although Liu, Xu, and Herrera (Citation2019) utilised the grey clustering algorithm to classify the experts, they combined the similarity of fuzzy preference values and self-confidence level to cluster the experts. However, this algorithm may cause the problem that the experts with lower similarities of fuzzy preference values will be distinguished into one cluster because they have the higher similarities of self-confidence levels, which may lead to unreasonable decision results. As a result, we utilise the similarity-based clustering algorithm twice to reduce the dimensionality of the decision information according to their assessments and endo-confidence levels respectively. Firstly, we will get the clusters of DMs based on the similarities of evaluation information, which is recorded as In this process, the similarities of PLTSs (EquationEquation (5)
(5)
(5) ) are used. Then, we will get the clusters of DMs based on the similarities of endo-confidence levels (EquationEquation (18)
(18)
(18) ) among DMs, which are represented as
The intersection of the clusters should be the final result, that is
The specific clustering steps are shown as follows:
Clustering the experts based on the similarities of evaluation information
Step 1. Establish the similarity matrix of the evaluation information between each expert based on the alternative
over the attribute
The similarities of the evaluation information are given as (17):
(17)
(17)
where
is calculated by EquationEquation (5)
(5)
(5) and it expresses the similarity degree between the evaluation information
and
from the corresponding experts
and
based on the alternative
over the attribute
According to EquationEquation (5)
(5)
(5) , there is
Step 2. Choose the classification threshold. Due to that the similarity matrix is a symmetric matrix with its diagonal elements equal to 1, we can choose the classification threshold by ranking the value of the upper triangular elements of the similarity matrix (except the diagonal elements) as and denote the threshold as
where
Step 3. Determine the optimal classification threshold and obtain the clustering results. Gou et al. (Citation2018) determined the threshold in their paper according to the rate of threshold change which may cause problems that some experts are not distinguished into any cluster. To solve the above problem, we can define
as the classification threshold, that is produced when each expert is involved in one cluster. That is to say, we record the maximum value of the similarity between each expert and other
experts, and then take the minimum value of these
values as the threshold
Notice that, in some real decision-making processes, some DMs may want to set the threshold by themselves. This threshold has a function to artificially limit the lowest threshold level to avoid the incomplete dimensionality reduction of large-scale experts. As a result, if the similarity
is less than a parameter
given by DMs, we can say that the similarity is at such a low level that the clustering procedure can be terminated. It is worth noting that the value of the threshold is related to the degree of difficulty in clustering process. The larger the threshold is, the stricter the classification of experts will be, and vice versa. Hence, we define the optimal classification threshold
If the similarity of the experts
and
for the
-th alternative over the attribute
is not less than the optimal threshold
that is
then the experts
and
are divided into one cluster. We get the clusters
Furthermore, if there exists common experts such as
in more than one cluster, in other words,
we combine these clusters into one cluster and get the final clustering results namely
In this paper, we set
(
).
2. Clustering the experts based on the similarities of their endo-confidence levels
The similarities of DMs’ endo-confidence levels are used in the clustering process. In this paper, the similarities of endo-confidence levels for the alternative over the attributes
between the experts
and
can be calculated by (18):
(18)
(18)
According to the definition, there is and
Similar to the steps mentioned above, we first obtain the similarity matrix of the endo-confidence levels between each pair of the experts
and
based on the alternative
over the attribute
The similarities of endo-confidence of the
-th alternative over the attribute
are given as:
(19)
(19)
Then, we choose the optimal classification threshold and obtain the clustering results. We can define the parameter
and obtain the threshold
and then the optimal classification threshold
can be calculated by
We get the clusters
and combine the clusters with common experts. We can obtain the final clustering results, which are denoted as
In this paper, we set
(
).
When the experts give similar evaluation information and endo-confidence levels, then we think that the experts have similar characteristics and should be distinguished into one cluster. In other words, we take the intersection of the above clustering results and
and use the results of the intersection as the new clustering results. Then, we can obtain the final clustering results
where
is the number of clusters
and it is obvious that
To better express the clustering mechanism, we provide the clustering process by Example 4 in Appendix.
3.4. Weight determination with endo-confidence
The weights of the DMs indicate the importance levels of the DMs in the group, which have a strong effect on the final decision-making results (Zha et al., Citation2019). Hence, a lot of weights-determining methods in GDM are developed. In most circumstances, scholars determine the weights based on the majority principle, which may ignore the differences of inner characteristics (Tang & Liao, Citation2021). Confidence level is an important inner characteristic of DM. The higher the confidence level of an expert is, the more reliable he/she believes his/her assessment will be (Hinsz, Citation1990). Then, a greater degree of importance should be assigned to him/her. Thus, the confidence should be considered to determine the weight of DM. Some researchers calculate experts’ weights by using the proportion of DMs’ self-confidence levels to the collective one (Liu, Xu, Ge, et al., Citation2019; Liu, Xu, Montes, Dong, et al., Citation2019; Ureña et al., Citation2015). With this method, the weight linearly changes with the self-confidence level. However, it is obvious that under different confidence levels, the speeds of weight change should be different. Ding et al. (Citation2019) gave a weight determination model that the weight changes non-linearly with the self-confidence level. However, if the experts’ weights are calculated in this way, only the evaluations provided by the experts with high self-confidence levels will be considered, while the weights of other experts are very low and the influence of their opinions on the decision-making results will be ignored. As a result, the weight determination mechanism should be further discussed.
In this paper, we assume that if the expert’s endo-confidence level is close to the average level, as the endo-confidence level rises, the weight increases slowly. When the expert’s endo-confidence level is large or small, the weight changes rapidly as the endo-confidence level increases. Motivated by hyperbolic sine functionFootnote1 which can well portray the above phenomenon, we use EquationEquation (20)(20)
(20) to simulate the relationship between weight and endo-confidence level. And the weight determination method with endo-confidence level in this paper is indicated below:
First, we can get the weight of the expert in the cluster
namely
by using the following two steps:
Step 1. The weight of the expert in the cluster
can be simulated by EquationEquation (20)
(20)
(20) :
(20)
(20)
where
(21)
(21)
Step 2. Normalise the weight in the cluster
by EquationEquation (22)
(22)
(22) and get
(22)
(22)
where
represents the number of experts in the cluster
Then, we can obtain the weight of the cluster
by using the number of experts in the cluster
(23)
(23)
where
is the number of clusters
Example 5 in Appendix shows the weight determining method with endo-confidence level.
3.5. Consensus measurement
Consensus measurement is a crucial part in consensus reaching process. A significant point of consensus definition is to select an appropriate distance or similarity measure to obtain the consensus index among experts (Wang et al., Citation2020). In this paper, we give the steps to calculate the overall consensus index. The specific calculation steps are shown as follows:
First, we get the rearranged PLTSs of the expert
in the cluster
according to the method in Section 2.2, where
is the number of all different linguistic terms in
The collective evaluation information
of the cluster
can be calculated by EquationEquation (24)
(24)
(24) (Wu & Liao, Citation2019):
(24)
(24)
where
(25)
(25)
is the number of all different linguistic terms in
and it is obvious that
is the weight of the expert
in the cluster
according to Section 3.4, and
means to sum the terms at the same position
in the rearranged PLTS.
Then, according to weight determining method in Section 3.4, the weight of the cluster can be calculated as
We obtain the rearranged PLTSs
of the collective evaluation information
in the cluster
according to the method in Section 2.2, where
is the number of all different linguistic terms in
Similar to EquationEquations (24)
(24)
(24) and Equation(25)
(25)
(25) , we can calculate the overall evaluation as
by EquationEquation (26)
(26)
(26) :
(26)
(26)
where
(27)
(27)
is the number of all different linguistic terms in
and
Subsequently, we can calculate the similarity by EquationEquation (5)
(5)
(5) . The overall consensus index
can be calculated by EquationEquation (28)
(28)
(28) :
(28)
(28)
Obviously, the larger the value of is, the higher the similarity of evaluation information for the alternative
over the attribute
will be. If there is
for
then the consensus level is acceptable. The parameter
which is given by DM is called a consensus threshold. When the consensus level is reached, we can select the best alternative by ranking them according to the score of the overall assessment
Otherwise, some non-consensus clusters should adjust their assessments.
3.6. Feedback adjustment mechanism based on endo-confidence level
To achieve a predefined consensus level, feedback mechanism should be further discussed. Feedback mechanism can generate suggestions to help DMs adjust their evaluation information and finally reach the consensus level. Identification and direction rules are the general procedures in feedback mechanism. They are used to identify the DM who needs to revise his/her evaluation and provide the suggestions to adjust the evaluation to facilitate the group consensus. First, we should identify which clusters need to adjust the evaluation. We can rank the clusters according to their similarities
(denoted as
) as:
where
We choose group
in turn to adjust the evaluation until the consensus is reached. Notice that, in order to avoid excessive loss of original information, we stipulate that each cluster
can only adjust the evaluation once.
In our daily life, we can notice that experts’ opinions are often influenced by other experts who are more capable than himself/herself. As afore-mentioned, experts’ abilities can be reflected by their endo-confidence levels. Hence, we assume that in the adjustment process, the clusters will refer to both the original assessments of themselves and the opinions of clusters who are more confident than them to adjust their assessments. Moreover, experts with higher endo-confidence levels tend to be more difficult to be influenced by others. Thus, in the process of adjusting opinions, the degree of acceptance of others’ opinions is related to their endo-confidence levels which is obtained by EquationEquation (29)
(29)
(29) :
(29)
(29)
Then, the following adjustment rules are given:
For a cluster we can define the clusters whose endo-confidence levels are not less than
as the suggested adjustment set
where
We can calculate the collective assessment of the suggested adjustment set
and use it as an important reference part to revise evaluation information of the cluster
Firstly, using the weight determining method in Section 3.4 to calculate the weight of the cluster in
namely
Then, we can obtain the rearranged PLTSs
of the collective evaluation information
in the suggested adjustment set
according to the method in Section 2.2, where
is the number of all different linguistic terms in
Subsequently, we can utilise EquationEquation (30)
(30)
(30) to get a part of revising evaluation information
of the cluster
as:
(30)
(30)
where
(31)
(31)
is the number of all different linguistic terms in
and
and
is the number of clusters in the suggested adjustment set
Then, the updated evaluation information of the cluster
in the first adjustment round can be obtained by:
(32)
(32)
where
(33)
(33)
is the number of all different linguistic terms in
According to the method in Section 2.2,
is the rearranged PLTS of the collective evaluation information
which is obtained by EquationEquation (24)
(24)
(24) , where
is the number of all different linguistic terms in
And
is the rearranged PLTS of
which is calculated by EquationEquation (30)
(30)
(30) ,
is the number of all different linguistic terms in
and
After adjusting the evaluation information of the cluster we need to modify the endo-confidence level
of the cluster
To accomplish it, firstly, we need to calculate the average endo-confidence level (
) of the cluster
in the suggested adjustment set
according to EquationEquation (34)
(34)
(34) :
(34)
(34)
Then, the updated endo-confidence level of the cluster
in the first round which is obtained by EquationEquation (35)
(35)
(35) :
(35)
(35)
For other clusters that do not need to adjust their evaluation information and endo-confidence levels, the following rule is used:
(36)
(36)
Similar to the method presented in Section 3.4, we utilise the endo-confidence level of each cluster
to get the weight
Then, we go back to Section 3.5 to carry out the consensus process. If the consensus has been reached, then go to Section 3.7. If all the clusters have adjusted their information and the consensus has not been reached yet, the consensus fails and the decision-making process should be terminated.
3.7. Selection process with the consensus evaluation information
Once the consensus level among experts is reached, the selection process is conducted to generate the final overall ranking of alternatives with the consensus evaluation information.
Let be the consensus decision matrix after
rounds, where
(
) is represented by
which is the consensus PLTS for the alternative
over the attribute
Applying the weighted averaging operator to fuse all the evaluations in the
-th row of
the overall evaluation
of the alternative
can be generated.
We can get the rearranged PLTSs of the consensus decision information
according to the method in Section 2.2, where
is the number of all different linguistic terms in
after
rounds. We can get the overall evaluation
of the alternative
by EquationEquation (37)
(37)
(37) :
(37)
(37)
where
(38)
(38)
is the number of all different linguistic terms in
and
is the weight of the attribute
Obviously,
We can make a comparison between the overall evaluation According to the method proposed in Section 2.1, we calculate the score
of the overall evaluation
If there is
then,
is recognised as the best choice.
In summary, the detailed consensus decision-making process for LSGDM with endo-confidence level can be described as follows: First, the similarity-based cluster algorithm is utilised to distinguish experts into different clusters considering the similarities of both the evaluation information and the endo-confidence levels respectively. Then, the weights of the experts in the cluster
and the weights of the cluster
are obtained by using the method in Section 3.4. Subsequently, the consensus measurement is proposed, and if the consensus level is unacceptable, the adjustment mechanism is provided for clusters to adjust their evaluation information and endo-confidence levels. Finally, once the consensus level is reached, the decision-making process is conducted to select the best alternative. However, if the consensus level has not been reached in the end, the consensus fails. This process is presented in Algorithm I.
Algorithm I
(Decision making for LSGDM considering the endo-confidence in PLTSs)
Input: The evaluation information , where
is represented by PLTS,
,
,
,
,
and
.
Output: The score of the overall evaluation
and the ranking results of the alternatives.
Step 1. Set . We calculate the endo-confidence of
according to his/her original evaluation and establish the corresponding endo-confidence matrix (10) based on Section 3.1. Then, we normalize the evaluation information
according to Section 3.2.
Step 2. Calculate the similarities of evaluation information Eq. (17) and endo-confidence level Eq. (19), and get the final clustering results by carrying out the clustering procedure in Section 3.3.
Step 3. Obtain the weight of the expert
in each cluster
and the weight
of each cluster
by the method in Section 3.4.
Step 4. Get the overall consensus index according to Section 3.5 and judge the consensus has been reached or not. If the evaluation information from the DMs do not reach consensus, then, go to Step 5 to revise the evaluation information. If all the clusters have adjusted their evaluation information and the consensus has not been reached yet, the consensus fails and the decision-making process should be terminated; otherwise, go to Step 6.
Step 5. Find the cluster which needs to revise the evaluation information and correct it according to the suggestions in Section 3.6. Subsequently, modify the endo-confidence level of the cluster by applying Eq. (35) and utilize it to obtain the weight
according to the method proposed in Section 3.4. Then, let
and repeat Step 4.
Step 6. If the consensus among experts is reached, then we get the consensus evaluation information and obtain the overall evaluation based on (37). Further, we get the score
of the overall evaluation
. Then, rank and find the best alternative.
Step 7. End.
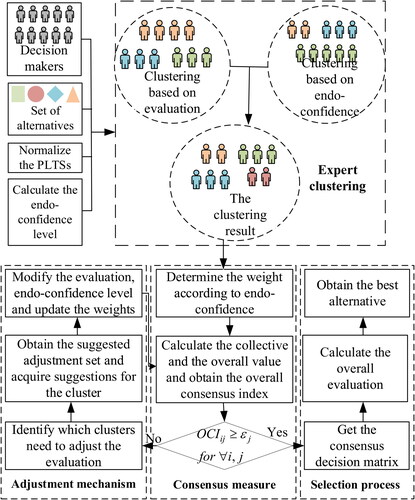
In order to intuitively reflect the consensus model based on endo-confidence, a visual procedure of the proposed model is presented in .
Figure 1. The visual procedure of consensus decision-making model with endo-confidence.
Source: calculated by the methods using the original data.
4. Case study
4.1. Decision-making process with the proposed method
In order to prove the feasibility and efficiency of the decision-making model with endo-confidence factor proposed in this paper, a case study is given. In this case, there are four alternatives for experts to make decision which are denoted as We ask experts to evaluate these alternatives from four attributes
The corresponding weights of each attribute are given as:
There are twenty experts
participated in the decision-making process, giving the corresponding probabilistic linguistic information
Then, the decision matrix
is generated randomly. In this case, we set
and
Step 1. Set We establish the endo-confidence level (
) of expert
based on Section 3.1. The endo-confidence matrixes of experts are shown as follows:
Step 2. We can obtain the normalised PLTSs by applying the method proposed in Section 3.2. We calculate the similarities of evaluation information among experts. Then, we obtain the order of the upper triangular elements of the similarity matrix (except the diagonal elements) as
The optimal classification threshold
is determined and the clustering results
are obtained. The similarities of the evaluation information are given below:
Subsequently, the similarity matrix of endo-confidence is established according to EquationEquation (18)(18)
(18) . Then, we can get the order of the upper triangular elements of the similarity matrix (except the diagonal elements)
Thus, we get the optimal classification threshold
and obtain the clustering results
The final clustering results based on the results of the above two clustering results
and
are determined. The clustering results based on the similarities of evaluation information, the clustering results based on the similarities of endo-confidence levels and the final clustering results are shown in .
Table 1. The clustering results and the corresponding weights and endo-confidence levels.
Step 3. The weight of each cluster is shown in . To save space, the results for the weight of each expert
in each cluster
are omitted here.
Step 4. We can get the collective evaluation information of the cluster and the overall evaluation
Then, the overall consensus index
has been worked out. Compared with the consensus threshold
we can see that the consensus level is not reached. Then, some clusters need to adjust their evaluation information.
Step 5. We rank the clusters according to their similarities and get
Then, we choose cluster
to adjust the evaluation information. After calculating the endo-confidence level
(see in ), we get the suggested adjustment set
and further obtain the updated evaluation information and endo-confidence level of the cluster
Step 6. Go back to Step 4. We calculate the overall evaluation and the overall consensus index, then, we compare with the consensus threshold to judge if the consensus level is reached. We get the overall consensus index for each iteration, that is
and
The renewed weights
are shown in . Due to space limitations, the results of the suggestions and the updated evaluation information are omitted.
Table 2. The results of the updated weights.
Step 7. After five iterations, the consensus for the alternative over the attribute
has been reached. After the consensus achieved for
we obtain the overall evaluation
and get the corresponding score
That is
and
Finally, we get the best alternative
4.2. The decision-making method without considering the endo-confidence of DMs
In this paper, we proposed a decision-making model for LSGDM considering the endo-confidence in PLTSs. In order to demonstrate the influence of endo-confidence factors on the decision-making process, here we give a decision-making model without endo-confidence level. The detailed steps are depicted as follows:
Step 1. Set We convert the original evaluation information into the complete PLTSs according to the method proposed in Section 3.2.
Step 2. Get the similarities of evaluation information by EquationEquation (5)(5)
(5) , and use it to distinguish the experts based on Section 3.3. We can obtain the clusters
and take it as the final clustering results, denoted as
Step 3. Based on the majority principle, we calculate the weight of the experts
in each cluster
(39)
(39)
Further, according to EquationEquation (23)(23)
(23) , we get the weight
of each cluster
Step 4. Get the collective and overall evaluation information by utilising EquationEquations (24)–(27), and we can obtain the overall consensus index Judge the consensus has been reached or not by comparing
with the threshold
If the consensus level is achieved, then, go to Step 6; otherwise, go to Step 5. If all the clusters have adjusted their evaluation information and the consensus has not been reached yet, the consensus fails and the decision-making process should be terminated.
Step 5. Rank the clusters according to the similarities
and choose the cluster with the smallest similarity to adjust the evaluation until the consensus reaches. We adjust the evaluation information according to the collective information
Notice that, each cluster
can only adjust the evaluation once.
After iterations, we obtain the rearranged PLTS
of the collective evaluation information
and the rearranged PLTS
of the overall evaluation
according to the method in Section 2.2.
Then, the updated evaluation information of the cluster can be calculated by EquationEquation (40)
(40)
(40) :
(40)
(40)
where
(41)
(41)
For other clusters that do not need to adjust their evaluation information, we can also get
(42)
(42)
We keep the weight of each cluster unchanged, that is Then, let
and repeat Step 4.
Step 6. Get the consensus evaluation information and obtain the overall evaluation based on EquationEquation (37)
(37)
(37) . Then, we calculate the score
of the overall evaluation
rank and find the best alternative.
4.3. Comparative analysis
In order to prove that the model proposed in Section 3 can reflect the influence of endo-confidence on decision-making process, we change the values of the parameters and
to reflect the effect of different importance degrees of endo-confidence measurement on the decision results. We make a comparison between the clustering results, the final weights of the cluster
the overall consensus index
and the final decision results. The same data and other parameters in Section 4.1 are utilised. We first set the parameters
and denote it as Model I with Case I. Then, the parameters become
and
which is named as Model I with Case II. We can see the detailed results of the above two cases in .
Table 3. The comparative results of Model I (case I and case II) and Model II.
Table A1. The meaning of notations used in the proposed model.
According to , we can find that in Case I, the expert is the neighbor of experts
and
while the expert
is distinguished into one cluster with the experts
and
in Case II. In the two cases, the similarities of the evaluation information have not changed. Hence, the difference in clustering results is entirely caused by the difference of the similarities of endo-confidence levels. In other words, the similarity-based clustering algorithm takes both evaluation information and endo-confidence levels into consideration, and the clustering results are more reasonable. Moreover, as we can see in , we have different updated weights
due to different clustering results and different modified endo-confidence levels of the cluster
Furthermore, the overall consensus indexes of Case I and Case II equal to
and
respectively. We can conclude that under different endo-confidence levels, there are differences in the overall consensus index due to the different collective evaluation information of each cluster and the differences in its corresponding weights. The overall consensus indexes of Case I and Case II after modification are
and
respectively. Notice that, the changes in the overall consensus index
are significantly different under Case I and Case II, that is
and
respectively. Thus, we can conclude that the feedback mechanism which considers both evaluation information and endo-confidence levels make sense. The final result of both Case I and Case II is
Although the above two cases conclude in the same result, their scores of the overall evaluation are different. We can find that the parameters
and
are sensitive to the decision result.
Furthermore, we make a comparison among Model I (with Case I and Case II) and Model II proposed in Section 4.2. In the clustering process, Model II does not consider the similarities of endo-confidence levels. Hence, the experts with different characteristic are divided into one cluster (see the experts
) which may lead to biased decision results. The weight
of Model II is always determined by the number of experts in the cluster
On the one hand, the determination of the weights does not consider the psychological factor. On the other hand, the weights could not be flexibly adjusted during the interaction process. After three iterations, the overall consensus index
and the consensus level is reached. Although Model II can reach consensus in fewer rounds, it will cause more information loss in each round of adjustment. Notice that the final result of Model II is
which is different from the result of Model I. It is obvious that endo-confidence has an impact on decision-making results. Thus, it is necessary to consider experts’ endo-confidence levels when making decisions and the model proposed in this paper has great value and practical significance.
5. Conclusions
In this paper, we propose a decision-making process under PLTSs which considers the endo-confidence levels of DMs. A method to determine the endo-confidence level of each DM from his/her evaluation information is given. We give a novel way to normalise the PLTSs which holds more original information. The similarity-based clustering algorithm is utilised to distinguish the experts into different clusters according to the similarities of both evaluation information and endo-confidence levels. Then, the relationship between endo-confidence and weight is discussed. Motivated by hyperbolic sine function, the weight determination method is proposed. Subsequently, we present the consensus measurement to calculate the overall consensus index and the feedback adjustment mechanism, which can help clusters adjust their evaluation information to reach the consensus level. Also, we give the selection process to choose the best alternative with the consensus evaluation information.
Although the proposed consensus model with endo-confidence has its advantage, sometimes, the single form of evaluation information could not properly describe all the attributes of alternatives. Hence, the consensus based on endo-confidence with heterogeneous evaluation information should be discussed in the future. Also, non-cooperative behaviour is also hot topic in the consensus problem (Gou, Xu, Liao, et al., Citation2021), and self-confidence have an influence on the degree of non-cooperative behaviour. As a result, considering the effect of endo-confidence on the non-cooperative behaviour in consensus model is another topic in our future study. Moreover, sometimes it is not easy for us to directly obtain sufficient eloquent data in the form of PLTSs. Hence, in the future, we may study the method to extract PLTSs from the natural language by using natural language processing technology, and give the applications of the decision method presented in this paper.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
Notes
1 It is worth mentioning that, the hyperbolic sine function is not the only function that satisfies these conditions.
References
- Bashir, Z., Rashid, T., & Xu, Z. S. (2018). Hesitant fuzzy preference relation based on α–normalization with self confidence in decision making. Journal of Intelligent & Fuzzy Systems, 35(3), 3421–3435. https://doi.org/10.3233/JIFS-17380
- Ding, Z. G., Chen, X., Dong, Y. C., & Herrera, F. (2019). Consensus reaching in social network DeGroot Model: The roles of the self-confidence and node degree. Information Sciences, 486, 62–72. https://doi.org/10.1016/j.ins.2019.02.028
- Fang, R., Liao, H. C., & Xu, Z. S. (2020). Probabilistic cutting method for group decision making with general probabilistic linguistic preference relation. IEEE Transactions on Systems, Man, and Cybernetics: Systems, Technical Report.
- Gou, X. J., Liao, H. C., Wang, X. X., Xu, Z. S., & Herrera, F. (2019). Consensus based on multiplicative consistent double hierarchy linguistic preferences: Venture capital in real estate market. International Journal of Strategic Property Management, 24(1), 1–23. https://doi.org/10.3846/ijspm.2019.10431
- Gou, X. J., Xu, Z. S., & Herrera, F. (2018). Consensus reaching process for large-scale group decision making with double hierarchy hesitant fuzzy linguistic preference relations. Knowledge-Based Systems, 157, 20–33. https://doi.org/10.1016/j.knosys.2018.05.008
- Gou, X. J., Xu, Z. S., Liao, H. C., & Herrera, F. (2021). Consensus model handling minority opinions and noncooperative behaviors in large-scale group decision-making under double hierarchy linguistic preference relations. IEEE Transactions on Cybernetics, 51(1), 283–296. https://doi.org/10.1109/TCYB.2020.2985069
- Gou, X. J., Xu, Z. S., Wang, X. X., & Liao, H. C. (2021). Managing consensus reaching process with self-confident double hierarchy linguistic preference relations in group decision making. Fuzzy Optimization and Decision Making, 20(1), 51–79. https://doi.org/10.1007/s10700-020-09331-y
- Guha, D., & Chakraborty, D. (2011). Fuzzy multi attribute group decision making method to achieve consensus under the consideration of degrees of confidence of experts’ opinions. Computers & Industrial Engineering, 60(4), 493–504. https://doi.org/10.1016/j.cie.2010.11.017
- Hinsz, V. B. (1990). Cognitive and consensus processes in group recognition memory performance. Journal of Personality and Social Psychology, 59(4), 705–718. https://doi.org/10.1037/0022-3514.59.4.705
- Liu, W. Q., Dong, Y. C., Chiclana, F., Cabrerizo, F. J., & Herrera-Viedma, E. (2017). Group decision-making based on heterogeneous preference relations with self-confidence. Fuzzy Optimization and Decision Making, 16(4), 429–447. https://doi.org/10.1007/s10700-016-9254-8
- Liu, X., Xu, Y. J., Ge, Y., Zhang, W. K., & Herrera, F. (2019). A group decision making approach considering self-confidence behaviors and its application in environmental pollution emergency management. International Journal of Environmental Research and Public Health, 16(3), 385. https://doi.org/10.3390/ijerph16030385
- Liu, X., Xu, Y. J., & Herrera, F. (2019). Consensus model for large-scale group decision making based on fuzzy preference relation with self-confidence: Detecting and managing overconfidence behaviors. Information Fusion, 52, 245–256. https://doi.org/10.1016/j.inffus.2019.03.001
- Liu, X., Xu, Y. J., Montes, R., Dong, Y. C., & Herrera, F. (2019). Analysis of self-confidence indices-based additive consistency for fuzzy preference relations with self-confidence and its application in group decision making. International Journal of Intelligent Systems, 34(5), 920–946. https://doi.org/10.1002/int.22081
- Liu, X., Xu, Y. J., Montes, R., & Herrera, F. (2019). Social network group decision making: Managing self-confidence-based consensus model with the dynamic importance degree of experts and trust-based feedback mechanism. Information Sciences, 505, 215–232. https://doi.org/10.1016/j.ins.2019.07.050
- Liu, W. Q., Zhang, H. J., Chen, X., & Yu, S. (2018). Managing consensus and self-confidence in multiplicative preference relations in group decision making. Knowledge-Based Systems, 162, 62–73. https://doi.org/10.1016/j.knosys.2018.05.031
- Mi, X. M., Liao, H. C., Wu, X. L., & Xu, Z. S. (2020). Probabilistic linguistic information fusion: A survey on aggregation operators in terms of principles, definitions, classifications, applications, and challenges. International Journal of Intelligent Systems, 35(3), 529–556. https://doi.org/10.1002/int.22216
- Pang, Q., Wang, H., & Xu, Z. S. (2016). Probabilistic linguistic term sets in multi-attribute group decision making. Information Sciences, 369, 128–143. https://doi.org/10.1016/j.ins.2016.06.021
- Rodriguez, R. M., Martinez, L., & Herrera, F. (2012). Hesitant fuzzy linguistic term sets for decision making. IEEE Transactions on Fuzzy Systems, 20(1), 109–119. https://doi.org/10.1109/TFUZZ.2011.2170076
- Song, Y. M., & Li, G. X. (2019). A large-scale group decision-making with incomplete multi-granular probabilistic linguistic term sets and its application in sustainable supplier selection. Journal of the Operational Research Society, 70(5), 827–841. https://doi.org/10.1080/01605682.2018.1458017
- Tang, M., & Liao, H. C. (2021). From conventional group decision making to large-scale group decision making: What are the challenges and how to meet them in big data era? A state-of-the-art survey. Omega, 100, 102141. https://doi.org/10.1016/j.omega.2019.102141
- Tian, X. L., Niu, M. L., Zhang, W. K., Li, L. H., & Herrera-Viedma, E. (2021). A novel TODIM based on prospect theory to select green supplier with Q-rung orthopair fuzzy set. Technological and Economic Development of Economy, 27(2), 284–310. https://doi.org/10.3846/tede.2020.12736
- Ureña, R., Chiclana, F., Fujita, H., & Herrera-Viedma, E. (2015). Confidence-consistency driven group decision making approach with incomplete reciprocal intuitionistic preference relations. Knowledge-Based Systems, 89, 86–96. https://doi.org/10.1016/j.knosys.2015.06.020
- Wang, H., Liao, H. C., Huang, B., & Xu, Z. S. (2020). Determining consensus thresholds for group decision making with preference relations. Journal of the Operational Research Society, https://doi.org/10.1080/01605682.2020.1779626
- Wang, J. Q., Wu, J. T., Wang, J., Zhang, H. Y., & Chen, X. H. (2014). Interval-valued hesitant fuzzy linguistic sets and their applications in multi-criteria decision-making problems. Information Sciences, 288, 55–72. https://doi.org/10.1016/j.ins.2014.07.034
- Wei, G. W., Lu, J. P., Wei, C., & Wu, J. (2020). Probabilistic linguistic GRA method for multiple attribute group decision making. Journal of Intelligent & Fuzzy Systems, 38(4), 4712–4721. https://doi.org/10.3233/JIFS-191416
- Wu, X. L., Liao, H. C., Xu, Z. S., Arian, H., & Francisco, H. (2018). Probabilistic linguistic MULTIMOORA: A multi-criteria decision making method based on the probabilistic linguistic expectation function and the improved Borda rule. IEEE Transactions on Fuzzy Systems, 26(6), 3688–3702. https://doi.org/10.1109/TFUZZ.2018.2843330
- Wu, X. L., & Liao, H. C. (2019). A consensus-based probabilistic linguistic gained and lost dominance score method. European Journal of Operational Research, 272(3), 1017–1027. https://doi.org/10.1016/j.ejor.2018.07.044
- Xu, X. H., Du, Z. J., Chen, X. H., & Cai, C. G. (2019). Confidence consensus-based model for large-scale group decision making: A novel approach to managing non-cooperative behaviors. Information Sciences, 477, 410–427. https://doi.org/10.1016/j.ins.2018.10.058
- Xu, Z. S., He, Y., & Wang, X. Z. (2019). An overview of probabilistic-based expressions for qualitative decision-making: techniques, comparisons and developments. International Journal of Machine Learning and Cybernetics, 10(6), 1513–1528. https://doi.org/10.1007/s13042-018-0830-9
- Xu, Z. S. (2004). A method based on linguistic aggregation operators for group decision making with linguistic preference relations. Information Sciences, 166(1–4), 19–30. https://doi.org/10.1016/j.ins.2003.10.006
- Zadeh, L. A. (1975). The concept of a linguistic variable and its application to approximate reasoning-I, II. Information Science, 8, III.
- Zha, Q. B., Liang, H. M., Kou, G., Dong, Y. C., & Yu, S. (2019). A feedback mechanism with bounded confidence-based optimization approach for consensus reaching in multiple attribute large-scale group decision-making. IEEE Transactions on Computational Social Systems, 6(5), 994–1006. https://doi.org/10.1109/TCSS.2019.2938258
- Zhang, H. J., Li, C. C., Liu, Y. T., & Dong, Y. C. (2021). Modelling personalized individual semantics and consensus in comparative linguistic expression preference relations with self-confidence: An optimization-based approach. IEEE Transactions on Fuzzy Systems, 29(3), 627–640. https://doi.org/10.1109/TFUZZ.2019.2957259
- Zhang, X. L., Liao, H. C., Xu, B., & Xiong, M. F. (2020). A probabilistic linguistic-based deviation method for multi-expert qualitative decision making with aspirations. Applied Soft Computing, 93, 106362. https://doi.org/10.1016/j.asoc.2020.106362
- Zhang, Y. X., Xu, Z. S., Wang, H., & Liao, H. C. (2016). Consistency-based risk assessment with probabilistic linguistic preference relation. Applied Soft Computing, 49, 817–833.
- Zhang, Z., Kou, X. Y., Yu, W. Y., & Gao, Y. (2020). Consistency improvement for fuzzy preference relations with self-confidence: An application in two-sided matching decision making. Journal of the Operational Research Society. https://doi.org/10.1080/01605682.2020.1748529
Appendix
In order to facilitate readers to understand the normalisation method, the clustering procedure and the weight determination method with endo-confidence, we give the following examples in Appendix.
Example 3.
Let and
be two PLTSs. According to (Equation2
(2)
(2) ), there is
and
The lower bounds of the normalised PLTS
can be calculated by
and the upper bounds of the normalised PLTS
can be calculated by
Then, the normalised LTS is denoted as
Similarly, we can obtain the normalised LTS of
as
Then, we compare each terms in PLTS
with its score, and use EquationEquation (14)
(14)
(14) to calculate the proportion of probability distribution
As
we can obtain
and
Similarly, we can find that
the proportion of probability distribution are
and
Then, we apply EquationEquation (15)
(15)
(15) to get the normalised proportion of probability distribution
which is
and
Subsequently, we use EquationEquation (16)
(16)
(16) to obtain the normalised probabilities
and
Finally, the normalised PLTS is
For
we can get the normalised PLTS in the same way as
Example 4.
Suppose that the upper matrix of similarities of five experts based on the alternative over the attribute
is:
Then,
When
all the fives experts are involved in cluster, then, the classification threshold
Then we get the optimal classification threshold
Considering this, there are two clusters as:
and
Suppose that the upper matrix of similarities of endo-confidence levels of five experts based on the alternative over the attribute
is:
Then,
We can get
Then, the optimal classification threshold
Considering this, there are three clusters as:
and
According to the above clustering results based on evaluation and endo-confidence levels, we can see that
and
As a result, we can finally acquire the final clustering results as
and
Example 5.
If there are six experts in the cluster whose endo-confidence levels are
and
First, we use EquationEquation (21)
(21)
(21) to get
and
Then, EquationEquation (20)
(20)
(20) is utilised to calculate the weights of experts
and
Finally, we apply EquationEquation (22)
(22)
(22) and get the normalised weights
We can find that when the expert’s endo-confidence level is large or small, the weight increases by 0.026 with the 0.1 increase of endo-confidence. And when the expert’s endo-confidence level is close to the average level, the weight changes by 0.023 as the 0.1 increase of endo-confidence level.