
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Group satisfaction is a trending issue in large-scale group decision-making (LSGDM) but most existing studies maximize the group satisfaction of LSGDM from the perspective of consensus. However, the clustering algorithm in LSGDM also has an impact on group satisfaction. Hence, this paper proposes a density-based spatial clustering of applications with noise (DBSCAN)-based LSGDM approach in an intuitionistic fuzzy set (IFS) environment. The DBSCAN algorithm is used to identify experts with outlier ratings that can reduce the time consumption and iterations of the LSGDM process and maximize the satisfaction of the group decision. An easy-to-use function is then provided to estimate group satisfaction. Finally, a numerical example of data centre supplier evaluation and comparative analysis is constructed to validate the rationality and feasibility of the proposed DBSCAN-based LSGDM approach in an IFS environment. The results demonstrate that the proposed method can effectively identify outliers in expert ratings and improve group satisfaction in the LSGDM process.
1. Introduction
In recent years, the study of large-scale group decision-making (LSGDM) has received extensive attention and many scholars have proposed and applied various decision-making methods to multiple aspects of economic and management sciences (Choi & Chen, Citation2021; Lu et al., Citation2022; Rodríguez et al., Citation2021; Li, Citation2022; Mardani et al., Citation2015). Generally, LSGDM refers to a problem wherein at least 20 experts participate in the decision-making process (Liu et al., Citation2014) and mainly includes four processes: clustering, weighting, consensus reaching, and alternative ranking (Ding et al., Citation2020; Li et al., Citation2021). Among them, the clustering process refers to clustering of experts with the same preference information into one subcluster; the weighting process refers to calculating the weights of subclusters, experts, and criteria; the consensus-reaching process focuses on adjusting the consensus degree of each subcluster to achieve the maximum consensus; and the alternatives-ranking process is performed by MULTIMOORA (Multi-Objective Optimization on the basis of a Ratio Analysis plus the full Multiplicative form) (Zhang et al., Citation2019; Brauers & Zavadskas, Citation2010), VIKOR (VIse Kriterijumska Optimizacija kompromisno Resenje) (Büyüközkan & Göçer, Citation2021), TOPSIS (Technique for Order Performance by Similarity to Ideal Solution) (Li & Chen, Citation2015; Kazancoglu et al., Citation2021), and other Multi-Criteria Decision Making (MCDM) methods to select optimal alternatives (Huang et al., Citation2021).
In LSGDM, clustering algorithms are mainly used to reduce the dimensions of decision makers (Ding et al., Citation2020) that improves the satisfaction and consensus of subclusters. Existing research on clustering algorithms for LSGDM includes three categories: partition-based (Tang et al., Citation2019; Wu & Xu, Citation2018; Petchrompo et al., Citation2021), hierarchical-based (Zhu et al., Citation2016; Hong et al., Citation2021), and model-based methods (Tang & Liao, Citation2021; Azadnia et al., Citation2012). For instance, Wu and Xu (Citation2018) used the K-means method to group DMs with fuzzy preference relations; Li et al. (Citation2019) used the fuzzy c-means (FCM) algorithm to cluster personalized individual semantics in linguistic LSGDM; Ozcalici and Bumin (Citation2020) used a self-organized map (SOM) that is an artificial neural network-based method to cluster high-dimensional data in MCDM.
However, these clustering algorithms have some limitations in LSGDM with respect to the following: first, partition-based approaches identify the initial clustering centres subjectively, which means that different clustering centres may lead to diverse results. In addition, partition-based approaches are restricted to datasets with convexity, which presents limited application. Second, both the partition-based and hierarchical-based approaches are sensitive to outliers, which means that if outlier samples exist in the dataset, the clustering results may become biased and affect the stability of the subclusters. Third, model-based approaches such as fuzzy C-Means consider the membership between samples and subclusters but they are not very practical because of the tedious calculation process that may be time consuming for LSGDM. These problems may affect the consensus reaching of the group, leading to biased decision results and further reducing the group satisfaction of LSGDM. This means that it fails to yield optimal decisions. More objective and precise clustering algorithms with fewer parameters, reasonable clustering standards, and rigorous logic in the clustering process are required for LSGDM problems (Ding et al., Citation2020).
Additionally, the main purpose of LSGDM is to maximize group satisfaction; therefore, improving group satisfaction has received wide attention in the LSGDM problem research (Fu et al., Citation2020). Group satisfaction is the extent to which decision experts are satisfied with the decision process and results (Huang et al., Citation1999; CitationGreen & Taber, 1980). However, most existing research is based on group consensus, wherein many researchers consider group consensus to be equivalent to group satisfaction but there exists a difference between them. For example, if a decision process reaches a high degree of group consensus, it requires multiple rounds of iterative computation, resulting in a longer and time-consuming process. Furthermore, some decision experts may be dissatisfied, resulting in lower group satisfaction.
DBSCAN (density-based spatial clustering of applications with noise) is a density-based clustering algorithm that identifies noise contained in data sets with arbitrary numbers and cluster shapes. The kernel of the algorithm, without prior information, divides the regions with sufficient densities into subclusters based on the given global density parameters and
(Zhu et al., Citation2021). Because the DBSCAN algorithm does not require a prespecified number of clusters and can detect arbitrarily-shaped clusters in a spatial database with noise (Hu et al., Citation2021), it has been widely used in different domains such as student behaviour pattern recognition and management (Li et al., Citation2021), heterogeneous text data detection (Nguyen & Shin, Citation2019), and industrial fault detection (Li et al., Citation2018).
In the decision-making process, expert preferences often contain a considerable amount of vague or uncertain information; therefore, IFS is widely used to express the preference of a decision maker for support, opposition, and hesitation towards alternatives by means of membership, non-membership, and hesitation (Pan & Deng, Citation2022). Because IFS can more delicately and flexibly describe the fuzziness of the objective world, it has become a trending research domain in route management (Hao et al., Citation2021), Industry 4.0 evaluation (Mahdiraji et al., Citation2020), and drug assessment (Xue & Deng, Citation2021).
Therefore, this paper proposes a DBSCAN-based LSGDM approach in an IFS environment. The DBSCAN clustering algorithm is used to cluster experts; the criteria importance through intercriteria correlation (CRITIC) weighting method is utilized to calculate the objective weight of the criteria. The MULTIMOORA approach, which contains the ratio system, reference point approach, and full multiplicative form, is used to rank the alternatives. The final ranking is determined by the dominance theory. Finally, an illustrative example is constructed for data centre supplier selection and a comparative analysis is conducted to verify the performance of the proposed DBSCAN-based LSGDM approach in an IFS environment.
The main contributions of this paper are summarized as follows:
The DBSCAN clustering algorithm is used to effectively identify the outliers of rating experts. It can not only maximize the group consensus and satisfaction but also provide new insight for clustering in the LSGDM process.
The CRITIC method is used for determining the objective weights of criteria. It incorporates both the contrast intensity of each criterion and the conflict between criteria to obtain the weights of the criteria (Diakoulaki et al., Citation1995).
An easy-to-use group satisfaction calculation function is provided to characterize the satisfaction of an expert with the complete LSGDM process based on the group consensus and iterations during the LSGDM process.
The remainder of this paper is organized as follows: Section 2 presents the preliminaries; Section 3 details the methodology proposed in this paper; Section 4 further demonstrates the methodology through a case illustration. Section 5 presents a comparative analysis. Section 6 concludes the paper with a summary of the results and provides an in-depth discussion of the subsequent research.
2. Preliminaries
2.1. DBSCAN clustering
DBSCAN clustering is a density-based algorithm proposed by Ester et al. (Citation1996) that identifies noise contained in datasets having arbitrary numbers and shapes of clusters. The relevant concepts in DBSCAN include the following.
Definition 1
(Zhu et al., Citation2021). -neighbourhood: For
the
-neighbourhood contains the samples from sample set
whose distance from
is not greater than
that is,
and the number of samples in this subcluster is denoted as
Definition 2
(Zhu et al., Citation2021). Core point: For
is defined as a core point if its
-neighbourhood
contains at least
samples, that is,
Definition 3
(Zhu et al., Citation2021). Directly density-reachable: A sample is directly density-reachable from
if it satisfies (1)
and (2)
Definition 4
(Zhu et al., Citation2021). Density-reachable: A sample is density-reachable from a sample
if there exists a sequence of samples
and
such that
is directly density-reachable from
Definition 5
(Zhu et al., Citation2021). Density connected: and
are density-connected if there exists a core sample
such that both
and
are reachable by the
density.
The specific procedure of the DBSCAN clustering algorithm is described in Algorithm 1.
Algorithm 1:DBSCAN Clustering Algorithm
INPUT:initial sample set neighbourhood parameters (
).
OUTPUT: subclusters
BEGIN
Initialize the set of core points
the number of clusters
For
If
If
Calculate the pairwise distance between the core points and find the reachable density core points in
Cluster these core objects with their subsamples in the
Iterate until no new clusters are created during Step 5.
Return
END
Source: Summarized based on previous studies
2.2. Intuitionistic fuzzy sets
The fuzzy sets (FS) theory was first proposed by Zadeh (Citation1965) and utilized to characterize the fuzzy attitude of the decision maker in the decision-making process by means of membership. However, since it fails to portray the neutral state, Atanassov (Citation1986) extended the FS and proposed the intuitionistic fuzzy sets (IFS) theory.
Definition 6
(Atanassov, Citation1986). Let be a nonempty set; then the fuzzy set can be expressed as:
(1)
(1)
where
is the membership of the element
in
belonging to
that is,
and
Definition 7
(Atanassov, Citation1986). Let be a nonempty set; then the intuitionistic fuzzy set can be expressed as:
(2)
(2)
where
and
are the membership and nonmembership of element
in
belonging to
respectively and
Furthermore, for
(3)
(3)
where
represents the hesitation or uncertainty of element
in
belonging to
Definition 8
(Atanassov, Citation1986). Let and
be any two intuitionistic fuzzy numbers; then the distance between them can be expressed as:
(4)
(4)
Further, let and
be intuitionistic fuzzy sets. Then, their weighted distance can be expressed as:
(5)
(5)
Definition 9
(Atanassov, Citation1986). Let be a set of intuitionistic fuzzy numbers and
If
(6)
(6)
then
is called an intuitionistic fuzzy weighted average operator.
is the exponential weight vector of
that satisfies
and
It is worth noting that if
then the
operator degenerates to the intuitionistic fuzzy average (
) operator as:
(7)
(7)
Definition 10
(Liu & Wang, Citation2007). Given the intuitionistic fuzzy number the intuitionistic fuzzy score function can be defined as:
(8)
(8)
The higher the value of the better the corresponding alternative will meet the expectations of the decision-maker.
2.3. MULTIMOORA
The MULTIMOORA approach, which is based on MOORA, was proposed by Brauers and Zavadskas (Citation2010). This method considers the additive utility function, multiplicative utility function, and reference point method, which means that the MULTIMOORA method has the advantages of several MCDM methods simultaneously. It is assumed that there are alternatives
and
criteria
represents the rating of the decision maker on alternative
with respect to criteria
The ratio system, reference point approach, and full multiplicative form in the MULTIMOORA approach are elaborated upon in the following subsections.
2.3.1. Ratio system
The ratio system defines a standardized rating matrix wherein the standardized rating
of each alternative
with respect to each criterion
is calculated as follows:
(9)
(9)
Considering two types of criteria, namely benefit-based and cost-based, the standardized formula for assessing value is
(10)
(10)
where
is the benefit criterion,
is the cost criterion, and
represents the standardized rating of alternative
for all criteria. The final preferences for the alternatives are obtained by ranking
The larger the value of
the higher is the ranking of
2.3.2. Reference point approach
The preference point is obtained based on the standardized matrix
If
is a benefit criterion, then
and if
is a cost criterion, then
The final ranking is obtained by calculating the deviation of the standard value relative to the reference point by
(11)
(11)
where
denotes the maximum deviation of the standard value of the alternative
under all criteria with respect to the reference point. Therefore, the smaller the value of
the lower is the ranking of alternative
2.3.3. Full multiplicative form
The utility function of the full multiplicative form for alternative ranking is
(12)
(12)
where
is the benefit criterion,
is the cost criterion, and
is the utility value of
The final alternative preference is obtained by sorting the
Therefore, the larger the
the higher is the ranking of
2.4. CRITIC
CRITIC is an objective weighting method first proposed by Diakoulaki et al. (Citation1995). This weighting method determines the objective weights through both the contrast strength and conflicting nature of the indicators. The contrast strength refers to the difference between the values of different samples on the same indicator that can be expressed by calculating the standard deviation; the larger the standard deviation, the greater is the strength of contrast. The conflict of indicators is expressed by the correlation between different indicators; the stronger the correlation, the smaller is the conflict of indicators (Krishnan et al., Citation2021). The weight coefficients of each evaluation index are determined by combining the comparative strengths and conflicting aspects of each index. The CRITIC method is calculated using the following formula:
(13)
(13)
where
is the value of the weight coefficient and
is the standard deviation of the
evaluation index, respectively, and
represents the correlation coefficient between the two indices.
indicates the conflicting nature of the
evaluation indicator and other evaluation indicators. Therefore, the greater the value of
the higher is the value of
The weights corresponding to each indicator are obtained by normalizing
as:
(14)
(14)
3. DBSCAN-based LSGDM method in an IFS environment
3.1. Framework of the proposed DBSCAN-based LSGDM approach
To solve the applicability problem of clustering algorithms in the LSGDM process, this paper proposes a DBSCAN clustering-based LSGDM method in an IFS environment. This method includes the following four components, shown in .
Figure 1. Framework of the proposed LSGDM model.
Source: Self-formulated.
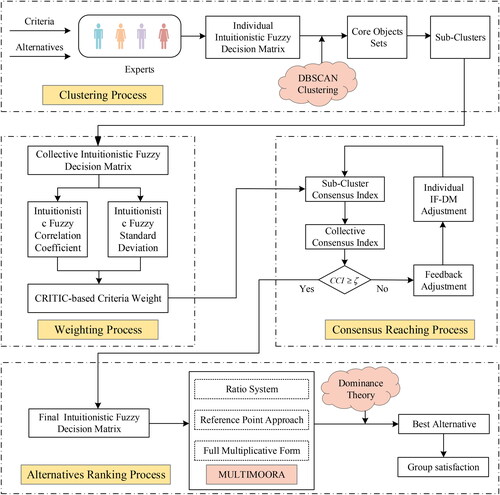
Clustering process. The DBSCAN clustering algorithm is used to cluster the experts. The advantage of this algorithm is that it can automatically identify outliers among experts, thus maximizing the degree of consensus and satisfaction of the subclusters.
Weighting process. Considering that the weight of the criterion is unknown in LSGDM, the CRITIC method is applied to calculate the criterion weights. This assignment method determines the objective weights mainly through two aspects: comparison intensity and conflicting nature of the indicators.
Consensus-reaching process. The degree of consensus within the subclusters as well as the overall degree of consensus is measured, such that the result of the group decision is maximal consensus.
Alternative ranking process. The MULTIMOORA method is used to rank alternatives. It consists of three parts: ratio system, reference point approach, and full multiplication form, each of which yields the ranking results of the alternatives. The final ranking of the alternatives is combined with the dominance theory to determine the best group decision alternative.
3.2. Proposed DBSCAN-based LSGDM approach in an IFS environment
Let be the set of alternatives,
the set of experts, and
the set of criteria. The vectors of criteria weights
and expert weights
remain unknown but they satisfy
and
The intuitionistic fuzzy decision matrix
of the
expert for the set of alternatives can be expressed as:
(15)
(15)
where
is the intuitionistic fuzzy number of expert
under the
criterion of the
alternative. The calculation steps of the proposed DBSCAN-based LSGDM approach in the IFS environment in this study are elaborated upon in the following subsections.
3.2.1. Clustering process
The DBSCAN algorithm is used to cluster the experts. The advantage of DBSCAN is that it can automatically identify outliers using simple calculations and fewer iterative processes. Subsequently, the decision preference information of the group is integrated using the agglomerative operator; thus, the intuitionistic fuzzy decision preference matrix of the group can be obtained.
Step 1. Construction of an intuitionistic fuzzy distance matrix. According to EquationEq. (5)
where and
are the intuitionistic fuzzy ratings of experts
and
respectively, with respect to alternative
under the criterion
Based on this, the intuitionistic fuzzy distance matrix can be obtained as:
(17)
(17)
Step 2. Clustering of experts. According to Algorithm 1, the DBSCAN algorithm is used to cluster the experts, given the clustering initialization parameters
Step 3. Calculation of the weights of experts and subclusters. The weight of expert
Further, the weights of subcluster can be represented by:
(19)
(19)
where
denotes the number of experts in the subcluster
Step 4. Construct the intuitionistic fuzzy decision matrix of the group. Let
Therefore, the intuitionistic fuzzy decision matrix of the subcluster after integration can be obtained as:
(21)
(21)
where
denotes the intuitionistic fuzzy number of subcluster
Further, based on EquationEq. (20)(20)
(20) , the collective intuitionistic fuzzy decision matrix is obtained by combining the weights of the subcluster
(22)
(22)
3.2.2. Weighting process
The weights of the criteria are calculated using the IF-CRITIC method that combines both comparative strength and conflicting nature of each criterion to calculate its weight.
Step 5. Calculation of the correlation coefficients of the criteria. Based on the collective intuitionistic fuzzy decision matrix
where denotes the mean value of the score function after normalization of the criterion
denotes the score function of the alternative
under the criterion
represents the mean value of the score function after normalization of the criterion
and
denotes the score function of the alternative
under the criterion
Step 6. Calculation of the standard deviation of the criterion. According to the score function of each alternative under each criterion, the intuitionistic fuzzy standard deviation of criterion
where and
Step 7. Calculation of the criteria weights. Based on each criterion, let the intuitionistic fuzzy correlation coefficient be
where and
3.2.3. Consensus reaching process (CRP)
Consensus metrics are powerful tools for evaluating the consistency of individual and group preference views, and consensus measures can demonstrate the degree of preference consistency among decision makers. Generally, CRP consists of two parts: a consensus degree calculation and feedback adjustment. If the calculated consensus degree is higher than a given threshold, it indicates a high degree of consistency in group preferences; conversely, it is necessary to adjust individual preferences to satisfy the given consensus threshold.
Step 8. Calculation of the subcluster consensus index (SCCI). Calculate the consensus index of subcluster
where is the intuitionistic fuzzy score function of expert
in subcluster
with respect to alternative
under criterion
is the collective intuitionistic fuzzy score function of subcluster
under criterion
with respect to alternative
is the weight of the criterion
is the weight of the experts
in the subcluster
and
is the number of experts in the subcluster
Further, the degree of consensus for all subclusters with respect to alternative can be calculated as:
(27)
(27)
where
is the collective intuitionistic fuzzy score function for the
subcluster under the criterion
with respect to alternative
is the collective intuitionistic fuzzy score function on scheme
under criterion
where
is the weight of the
subcluster.
Step 9. Calculation of the collective consensus index (CCI).
Given a consensus degree threshold if
and
then a consensus is reached within each subcluster; otherwise, further adjustment is required. The consensus adjustment process is described in Step 12.
Step 10. Feedback adjustment. The collective average intuitionistic fuzzy preference is used to adjust the expert ratings, thereby improving the group consensus. This preference is calculated using:
where is the average intuitionistic fuzzy number of all experts in the alternative
under the criterion
3.2.4. Alternatives ranking process
IF-MULTIMOORA is used to rank the alternatives. This approach first normalizes the rating of the expert to eliminate the differences between the various criteria owing to the different dimensions. Then, the final ranking of the schemes is determined by calculating the evaluation values through the IF-ratio system, IF-reference point approach, and IF-full multiplicative form. The result is obtained based on the dominance theory.
Step 11. IF-ratio system. According to the formula of the IF-ratio System, based on the reference (Zhang et al., Citation2019), the EquationEq. (30)
Furthermore, the score function of is calculated; the higher the value of
the higher is the ranking of the solution.
Step 12. IF-reference point approach. The positive ideal alternative
The closer the alternative is to the positive ideal solution, the higher is the ranking.
Step 13. IF-Full multiplicative form. The
Step 14. Determination of the final alternative. Combined with the dominance theory, a pairwise comparison of the generalized dominance relationships in a ternary array of three sets of results obtained by IF-MULTIMOORA is performed to determine the final ranking results of each alternative and further determine the optimal alternative among them.
Step 15. Calculation of group satisfaction. The group satisfaction Sa for the complete LSGDM process is calculated as follows:
where is the collective consensus index,
is the number of iterations in the LSGDM process,
is the number of iterations in the clustering process, and
is the number of iterations in the CRP. The higher the value of
the lower is the value of
and the higher is the value of
4. Numerical example
Owing to global digital construction, the digital economy has gradually become an important engine of national economic development. According to the China Academy of Information and Communications Technology (Citation2021), the digital economy in 47 countries reached $32.6 trillion in 2020, with a nominal growth of 3.0% year-on-year, accounting for 43.7% of their total GDP. A data centre, which is the core infrastructure of digital construction, is an important carrier for the development of the digital economy. Therefore, it is crucial to select an appropriate data centre provider for the stable development of the digital economy of an enterprise.
In this chapter, a numerical example is provided to select the ideal data centre suppliers using the proposed DBSCAN-based LSGDM problem in an IFS environment. It is assumed that there are 20 experts evaluating five data centre suppliers each with the aforementioned five criteria. The results of the intuitionistic fuzzy ratings for each supplier by each expert and criterion are presented in Appendix A. For example, the rating of expert
on data centre supplier
is
4.1. Clustering process
The pairwise matrix of the intuitionistic fuzzy distance matrices between each expert can be obtained using EquationEqs. (16)(16)
(16) and Equation(17)
(17)
(17) and is listed in Appendix B. Let
and
then, based on EquationEqs. (2)–(4) and the intuitionistic fuzzy distance matrix
the set of core objects can be obtained as:
Further, the 20 experts are clustered into 3 subclusters and 3 outliers after DBSCAN clustering, where the three subclusters are
and
and the experts
and
do not belong to any subcluster; consequently, they are labelled as outliers and grouped into separate clusters, namely
and
The weight vector of the six subclusters is calculated using EquationEq. (19)
(19)
(19) , and the final clustering results are detailed in .
Table 1. Final clustering results.
Based on EquationEqs. (20)(20)
(20) and Equation(21)
(21)
(21) , the intuitionistic fuzzy decision matrix of the six subclusters can be calculated, as shown in Appendix C. Furthermore, based on the weight vectors of the subclusters, the collective group intuitionistic fuzzy decision matrix is obtained by combining it with EquationEq. (22)
(22)
(22) as:
Based on the group intuition fuzzy decision matrix, the score function for each alternative under each criterion can be obtained as follows:
4.2. Weighting process
In the weighting session of the criteria, according to EquationEqs. (23)(23)
(23) and Equation(24)
(24)
(24) , the intuition fuzzy correlation coefficient matrix
and intuitionistic fuzzy standard deviation
between the criteria can be obtained as follows:
Therefore, based on EquationEq. (25)(25)
(25) , the criterion weight is
4.3. Consensus-reaching process
In the CRP session, the consensus degree matrices within the subclusters
and
are obtained according to EquationEqs. (26)
(26)
(26) and Equation(27)
(27)
(27) ; the results are listed in . It can be concluded from these results that the consensus degree of subcluster
for each alternative is SCCIi1 = (0.9542, 0.9411, 0.9548, 0.9544, 0.9346); the consensus degree of subcluster
for each alternative is SCCIi2 = (0.9777, 0.9786, 0.9587, 0.9856, 0.9772); and the consensus degree of subcluster
for each alternative is SCCIi3 = (0.9835, 0.9937, 0.9808, 0.9795, 0.9686). Further, the consensus degree of all experts for each alternative can be obtained as SCCIi = (0.9718, 0.9711, 0.9648, 0.9732, 0.9601). Among them, all experts achieved the highest consensus degree of 0.9732 for alternative
and the lowest consensus degree of 0.9602 for alternative
Table 2. SSCI for each alternative based on FCM.
Further, based on EquationEq. (28)(28)
(28) , it can be calculated that
Given a consensus threshold of
it is evident that consensus has been reached both within and between subclusters, thereby indicating that the results of group decision-making have reached a consensus.
4.4. Ranking-alternative process
In the IF-MULTIMOORA method, according to the ratio system, the collective intuitionistic fuzzy number for the five alternatives can be obtained as:
Therefore, the intuitionistic fuzzy score function of the five alternatives is Furthermore, the final ranking result of the alternatives is
According to the IF-reference point system, the intuitionistic fuzzy number of the ideal alternative can be obtained as:
Combining this with EquationEq. (31)(31)
(31) , the intuitionistic fuzzy distance between each alternative and the ideal alternative is calculated as (0.0994, 0.0701, 0.0983, 0.0917, 0.0787). The smaller the distance, the closer an alternative is to the ideal alternative. Therefore, according to the reference point system, the final ranking results of the five alternatives can be obtained as
According to EquationEq. (32)(32)
(32) of the IF full multiplicative model, the intuitionistic fuzzy numbers of the five alternatives can be obtained as:
Furthermore, the intuitionistic fuzzy score function of the five alternatives can be obtained by Therefore, the final ranking result of the alternatives can be obtained as
According to the dominance theory, the final ranking of the alternatives is Therefore, according to the IF-MULTIMOORA ranking results, the 20 experts have the highest group preference for alternative
therefore, the optimal alternative
is chosen for this case. The results are listed in .
Table 3. Ranking results of DBSCAN based LSGDM approach.
Furthermore, since and the number of iterations is 1, the group satisfaction
for the entire decision process can be calculated using EquationEq. (33)
(33)
(33) as:
From this, we can conclude that group satisfaction is 0.7231, which indicates a high level of satisfaction with the entire LSGDM process.
5. Comparative analysis
To further validate the effectiveness of the proposed DBSCAN-based LSGDM approach, we compared it with the FCM-based LSGDM approach (Xu & Wu, Citation2010) and K-means based LSGDM approach (Tang et al., Citation2019) by constructing a set of comparison experiments based on the previously-introduced simulation dataset. This means that the datasets of these comparative analyses remain consistent but a difference exists in the clustering approaches.
5.1. Comparison with FCM-based LSGDM approach
Referring to Xu and Wu (Citation2010), we used the fuzzy C-means algorithm to cluster the intuitionistic fuzzy preference information of the experts. Given the initialized clustering centres the number of clusters is
After six iterations, the distance between the cluster centres of the 6th iteration and 5th iteration is obtained as 0.049, which is less than the given distance threshold
Therefore, the clustering results obtained at this point are robust. The results are listed in .
Table 4. Information on FCM clustering parameters.
Furthermore, information on the membership of each expert in each subcluster is obtained. Given a membership threshold an expert is considered to belong to a subcluster if his or her membership in that subcluster is greater than 0.4. For example, the membership of an expert
to subclusters
and
are 0.2192, 0.6389, and 0.1418, respectively; therefore, the expert
can be considered to belong to the subcluster
The membership of the 20 experts in each subcluster is listed in .
Table 5. Membership of each expert for each subcluster based on FCM.
After aggregating the membership results for the experts, the 20 experts were divided into three subclusters:
and
The components of subclusters
and
in fuzzy C-means clustering are identical to those of the proposed DBSCAN-based LSGDM approach. The main difference between the two methods is that the components of the subcluster
vary and the subcluster
obtained by the FCM-based method contains three experts:
and
with outlier ratings. The results are listed in .
Table 6. Clustering results based on FCM.
presents the consensus degree of each subcluster with respect to each alternative according to the FCM-based approach. From this, it can be concluded that the consensus degree of subcluster for each alternative is
the consensus degree of subcluster
for each alternative is
and the consensus degree of subcluster
for each alternative is
Furthermore, the consensus degree of all experts for each alternative can be obtained as
The collective consensus index
based on fuzzy C-means clustering, is obtained using EquationEq. (28)
(28)
(28) .
Table 7. SSCI for each alternative based on FCM.
Similarly, the CRITIC method is used to calculate the objective weights of the criteria, which gives the final group decision intuitionistic fuzzy preference matrix. The final consensus vector for the group decision is(0.9172, 0.9176, 0.9229, 0.9194, 0.8943), given a consensus threshold which shows that the final group decision has reached a consensus. Furthermore, by combining the MULTIMOORA approach, the final ranking result can be obtained as
This shows that the FCM-based LSGDM approach gives the highest preference to alternative
among the 20 experts, which is also consistent with the ranking results obtained in this study. The results are listed in .
Table 8. Ranking results of the FCM-based method.
Furthermore, because and the number of iterations is 6, the group satisfaction
for the entire decision process can be calculated using EquationEq. (33)
(33)
(33) . From this, we can conclude that group satisfaction is 0.5395, which indicates a high level of satisfaction for the entire LSGDM process.
In summary, comparing the DBSCAN-based and FCM-based approaches, it can be concluded that although the final ranking results of the alternatives remain consistent, differences exist in the clustering results, group consensus, and group satisfaction. The group consensus and group satisfaction obtained using the DBSCAN-based approach were higher than those obtained using the FCM-based approach. This is primarily because the DBSCAN-based method can effectively identify the outliers among the rating experts and ensure that experts within each subcluster have consistent preference, thereby improving group consensus and group satisfaction. However, the FCM-based approach fails to identify the outliers of the rating expert, thus allowing several to be included in subcluster which reduces the consensus degree of
as well as the collective consensus index. In addition, six iterative rounds of the clustering process are performed using the FCM-based method, which is time consuming and computationally intensive. This further reduces satisfaction in the final group.
Moreover, it is worth noting that the fuzzy C-means-based clustering algorithm requires initialization of the clustering centres and number of clusters. In addition, the selection of clustering and membership thresholds may also have a significant impact on the final clustering results. In contrast, the DBSCAN-based clustering algorithm is simpler, requiring only the initialization of the parameters and
to complete the clustering process and can automatically identify outliers in the sample.
5.2. Comparison with K-means based LSGDM approach
Following Tang et al. (Citation2019), the K-means algorithm was used to cluster the intuitionistic fuzzy preference information of experts. Given the initialized clustering centres, the number of clusters is
After two iterations, the distance between the samples and cluster centres was minimized, indicating that the clustering process was complete. Therefore, the clustering results obtained at this point are robust. The results are listed in .
Table 9. Information on K-means clustering parameters.
Furthermore, it can be inferred that the 20 experts are divided into three subclusters, namely
and
based on the principle of maximum membership. Compared with the DBSCAN-based approach, the K-means based method partitions experts into three subclusters and each sample is assigned to a specific subcluster. The clustering results are listed in .
Table 10. Final clustering results.
Furthermore, the weight vector of the subclusters can be obtained as (0.35, 0.35, 0.3). Combining it with EquationEq. (22)(22)
(22) , the intuitionistic fuzzy decision matrix for the population can be assembled as:
Comparing the group decision matrix obtained by the DBSCAN-based clustering algorithm with that obtained by the K-means based algorithm, it can be observed that there are some differences between the two. The primary reason is that the size, membership and weights of the subclusters obtained by the two clustering algorithms are different; therefore, the final group decision matrix is not the same.
presents the consensus degree of each subcluster with respect to each alternative according to the K-means based approach. From this, it can be concluded that the consensus degree of subcluster for each alternative is
the consensus degree of subcluster
for each alternative is
and the consensus degree of subcluster
for each alternative is
Furthermore, the consensus degree of all experts for each alternative can be obtained as
The collective consensus index
based on fuzzy C-means clustering, is obtained using EquationEq. (28)
(28)
(28) .
Table 11. SSCI for each alternative for the K-means based approach.
According to the collective decision matrix, the coefficient of the weight vector of each criterion is (0.2132, 0.2010, 0.1923, 0.2007, 0.1927). Therefore, the final ranking results of the group decisions can be obtained, as listed in . From , it can be seen that according to K-means based IF-MULTIMOORA, the final ranking result of the alternatives is which is consistent with the decision results of the proposed DBSCAN-based IF-MULTIMOORA as well as the proposed DBSCAN-based LSGDM. This is because, although there are differences in the group decision matrix and criterion weight vector, alternative
has a clear advantage over the other alternatives, followed by alternative
and then by alternatives
and
respectively, regardless of the method used to calculate the decision result.
Table 12. Ranking results for the K-means based method.
Furthermore, because and the number of iterations is 2, the group satisfaction
for the entire decision process can be calculated using EquationEq. (33)
(33)
(33) . From this, we can conclude that the group satisfaction is 0.6153, which indicates a high level of satisfaction for the entire LSGDM process.
In summary, comparing the DBSCAN-based and K-means based approaches, it can be concluded that although the final ranking results of the alternatives remain consistent, differences exist in the clustering results, group consensus, and group satisfaction. The group consensus and group satisfaction obtained by the DBSCAN-based approach were higher than those obtained by the K-means based approach. The primary reason for this is that K-means clustering is a hard clustering method through which each sample can only belong to one subcluster; therefore, it fails to identify outlier rating experts. Thus, subclusters and
also contain outlier rating experts, which reduces the subcluster consensus indices
and
as well as the collective consensus index
In addition, the K-means based method must first initialize the clustering centres and then generate subclusters by iterative computation, which further reduces the group satisfaction.
Moreover, comparing the K-means based and FCM-based methods, it can be concluded that the group consensus obtained by the FCM-based method is higher than that of the K-means based method but the group satisfaction obtained by the FCM-based method is lower than that obtained by the K-means based method because there exists no significant difference in group consensus between the two approaches. This is because the FCM-based method obtains the membership of subclusters by iterative calculation and then determines the experts of each subcluster according to the maximum membership. A total of 6 rounds of iterative calculations are performed in the clustering process, which is time-consuming and results in a low final group satisfaction. The K-means based method has fewer iterations in the clustering process, which results in higher final group satisfaction.
6. Conclusion and future work
In this study, we explored the DBSCAN clustering-based LSGDM approach in an IFS environment. First, we used the DBSCAN clustering algorithm for clustering decision experts, which has the benefit of automatically identifying outliers among experts. Second, we used the CRITIC method to calculate the objective weights of the criteria, which incorporates both contrast intensity of each criterion and the conflict between criteria to obtain the weights of the criteria. Furthermore, the MULTIMOORA approach was utilized to rank the alternatives and an easy-to-use group satisfaction calculation function was proposed to characterize the satisfaction of the expert with the complete LSGDM process based on the group consensus and iterations during the LSGDM process. Finally, the effectiveness of the proposed algorithm was verified by conducting a comparison experiment.
By comparing the DBSCAN-based, FCM-based, and K-means based approaches, it can be inferred that although the ranking results obtained by these three methods remained the same, the group consensus and group satisfaction varied. The group consensus obtained using the DBSCAN-based approach was the highest, followed by that obtained using the FCM-based approach and the lowest being the one obtained using the K-means based approach. In terms of group satisfaction, the group consensus obtained using the DBSCAN-based approach was the highest, followed by that obtained using the K-means based approach and the lowest being the one obtained using the FCM-based method. The is because the DBSCAN-based method can effectively identify the outliers among the rating experts and ensure that experts within each subcluster have consistent preference, thereby, improving the group consensus and group satisfaction. The FCM-based method obtains the membership of subclusters by iterative calculation, which is time-consuming and results in a lower group satisfaction. Although the K-means based clustering algorithm is a hard clustering algorithm wherein each sample can only belong to one subcluster, it requires fewer iterations, leading to a higher group satisfaction.
The shortcoming of this study is that a simulated study was implemented to illustrate the proposed approach, which may not be very convincing; however, the main purpose was to provide a feasible way to improve group satisfaction in the LSGDM. In future research, we will further investigate the weighting approach by fusing online reviews into the LSGDM process to maximize group satisfaction.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- Atanassov, K. T. (1986). Intuitionistic fuzzy sets. Fuzzy Sets and Systems, 20(1), 87–96. https://doi.org/10.1016/S0165-0114(86)80034-3
- Azadnia, A. H., Saman, M. Z. M., Wong, K. Y., Ghadimi, P., & Zakuan, N. (2012). Sustainable supplier selection based on self-organizing map neural network and multi criteria decision making approaches. Procedia - Social and Behavioral Sciences, 65, 879–884. https://doi.org/10.1016/j.sbspro.2012.11.214
- Brauers, W. K. M., & Zavadskas, E. K. (2010). Project management by multimoora as an instrument for transition economies/Projektų Vadyba Su Multimoora Kaip Priemonė Pereinamojo Laikotarpio Ūkiams. Technological and Economic Development of Economy, 16(1), 5–24. https://doi.org/10.3846/tede.2010.01
- Büyüközkan, G., & Göçer, F. (2021). Evaluation of software development projects based on integrated Pythagorean fuzzy methodology. Expert Systems with Applications, 183, 115355. https://doi.org/10.1016/j.eswa.2021.115355
- China Academy of Information and Communications Technology. (2021). White paper on China's digital economy development. http://www.caict.ac.cn/english/research/whitepapers/202104/t20210429_375940.html
- Choi, T.-M., & Chen, Y. (2021). Circular supply chain management with large scale group decision making in the big data era: The macro-micro model. Technological Forecasting and Social Change, 169, 120791. https://doi.org/10.1016/j.techfore.2021.120791
- Diakoulaki, D., Mavrotas, G., & Papayannakis, L. (1995). Determining objective weights in multiple criteria problems: The critic method. Computers & Operations Research, 22(7), 763–770. https://doi.org/10.1016/0305-0548(94)00059-H
- Ding, R.-X., Palomares, I., Wang, X., Yang, G.-R., Liu, B., Dong, Y., Herrera-Viedma, E., & Herrera, F. (2020). Large-scale decision-making: Characterization, taxonomy, challenges and future directions from an artificial intelligence and applications perspective. Information Fusion, 59, 84–102. https://doi.org/10.1016/j.inffus.2020.01.006
- Ester, M., Kriegel, H. P., Sander, J., & Xu, X. (1996). A density-based algorithm for discovering clusters in large spatial databases with noise. KDD'96: Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, 96(34), 226–231.
- Fu, C., Chang, W., & Yang, S. (2020). Multiple criteria group decision making based on group satisfaction. Information Sciences, 518, 309–329. https://doi.org/10.1016/j.ins.2020.01.021
- Green, S. G., & Taber, T. D. (1980). The effects of three social decision schemes on decision group process. Organizational Behavior and Human Performance, 25(1), 97–106. https://doi.org/10.1016/0030-5073(80)90027-6
- Hao, Z., Xu, Z., Zhao, H., & Zhang, R. (2021). The context-based distance measure for intuitionistic fuzzy set with application in marine energy transportation route decision making. Applied Soft Computing, 101, 107044. https://doi.org/10.1016/j.asoc.2020.107044
- Hong, Y., Ezeh, C. I., Zhao, H., Deng, W., Hong, S.-H., & Tang, Y. (2021). A target-driven decision-making multi-layered approach for optimal building retrofits via agglomerative hierarchical clustering: A case study in China. Building and Environment, 197, 107849. https://doi.org/10.1016/j.buildenv.2021.107849
- Hu, L., Liu, H., Zhang, J., & Liu, A. (2021). KR-DBSCAN: A density-based clustering algorithm based on reverse nearest neighbor and influence space. Expert Systems with Applications, 186, 115763. https://doi.org/10.1016/j.eswa.2021.115763
- Huang, J., Jiang, N., Chen, J., Balezentis, T., & Streimikiene, D. (2021). Multi-criteria group decision-making method for green supplier selection based on distributed interval variables. Economic Research-Ekonomska Istraživanja, 1–16.
- Huang, W., Wei, K.-K., & Tan, B. C. (1999). Compensating effects of GSS on group performance. Information & Management, 35(4), 195–202. https://doi.org/10.1016/S0378-7206(98)00083-4
- Kazancoglu, Y., Sagnak, M., Mangla, S. K., Sezer, M. D., & Pala, M. O. (2021). A fuzzy based hybrid decision framework to circularity in dairy supply chains through big data solutions. Technological Forecasting and Social Change, 170, 120927. https://doi.org/10.1016/j.techfore.2021.120927
- Krishnan, A. R., Kasim, M. M., Hamid, R., & Ghazali, M. F. (2021). A modified CRITIC method to estimate the objective weights of decision criteria. Symmetry, 13(6), 973. https://doi.org/10.3390/sym13060973
- Li, C., Cerrada, M., Cabrera, D., Sanchez, R. V., Pacheco, F., Ulutagay, G., & Valente de Oliveira, J. (2018). A comparison of fuzzy clustering algorithms for bearing fault diagnosis. Journal of Intelligent & Fuzzy Systems, 34(6), 3565–3580. https://doi.org/10.3233/JIFS-169534
- Li, C. C., Dong, Y., & Herrera, F. (2019). A consensus model for large-scale linguistic group decision making with a feedback recommendation based on clustered personalized individual semantics and opposing consensus groups. IEEE Transactions on Fuzzy Systems, 27(2), 221–233. https://doi.org/10.1109/TFUZZ.2018.2857720
- Li, W., Li, L., Xu, Z., & Tian, X. (2021). Large-scale consensus with endo-confidence under probabilistic linguistic circumstance and its application. Economic Research-Ekonomska Istraživanja, 1–34.
- Li, X. (2022). Big data-driven fuzzy large-scale group decision making (LSGDM) in circular economy environment. Technological Forecasting and Social Change, 175, 121285.
- Li, X., & Chen, X. (2015). Multi-criteria group decision making based on trapezoidal intuitionistic fuzzy information. Applied Soft Computing, 30, 454–461. https://doi.org/10.1016/j.asoc.2015.01.054
- Li, X., Zhang, Y., Cheng, H., Zhou, F., & Yin, B. (2021). An unsupervised ensemble clustering approach for the analysis of student behavioral patterns. IEEE Access, 9, 7076–7091. https://doi.org/10.1109/ACCESS.2021.3049157
- Liu, B. S., Shen, Y. H., Chen, X. H., Chen, Y., & Wang, X. Q. (2014). A partial binary tree DEA-DA cyclic classification model for decision makers in complex multi-attribute large-group interval-valued intuitionistic fuzzy decision-making problems. Information Fusion, 18, 119–130. https://doi.org/10.1016/j.inffus.2013.06.004
- Liu, H.-W., & Wang, G.-J. (2007). Multi-criteria decision-making methods based on intuitionistic fuzzy sets. European Journal of Operational Research, 179(1), 220–233. https://doi.org/10.1016/j.ejor.2006.04.009
- Lu, Y., Xu, Y., Huang, J., Wei, J., & Herrera-Viedma, E. (2022). Social network clustering and consensus-based distrust behaviors management for large-scale group decision-making with incomplete hesitant fuzzy preference relations. Applied Soft Computing, 117, 108373. https://doi.org/10.1016/j.asoc.2021.108373
- Mahdiraji, H. A., Zavadskas, E. K., Skare, M., Kafshgar, F. Z. R., & Arab, A. (2020). Evaluating strategies for implementing industry 4.0: A hybrid expert oriented approach of B.W.M. and interval valued intuitionistic fuzzy T.O.D.I.M. Economic Research-Ekonomska Istraživanja, 33(1), 1600–1620. https://doi.org/10.1080/1331677X.2020.1753090
- Mardani, A., Jusoh, A., MD Nor, K., Khalifah, Z., Zakwan, N., & Valipour, A. (2015). Multiple criteria decision-making techniques and their applications—A review of the literature from 2000 to 2014. Economic Research-Ekonomska Istraživanja, 28(1), 516–571. https://doi.org/10.1080/1331677X.2015.1075139
- Nguyen, M. D., & Shin, W.-Y. (2019). An improved density-based approach to Spatio-textual clustering on social media. IEEE Access, 7, 27217–27230. https://doi.org/10.1109/ACCESS.2019.2896934
- Ozcalici, M., & Bumin, M. (2020). An integrated multi-criteria decision making model with self-organizing maps for the assessment of the performance of publicly traded banks in Borsa Istanbul. Applied Soft Computing, 90, 106166. https://doi.org/10.1016/j.asoc.2020.106166
- Pan, L., & Deng, Y. (2022). A novel similarity measure in intuitionistic fuzzy sets and its applications. Engineering Applications of Artificial Intelligence, 107, 104512. https://doi.org/10.1016/j.engappai.2021.104512
- Petchrompo, S., Wannakrairot, A., & Parlikad, A. K. (2021). Pruning Pareto optimal solutions for multi-objective portfolio asset management. European Journal of Operational Research, 297(1), 203–220. https://doi.org/10.1016/j.ejor.2021.04.053
- Rodríguez, R. M., Labella, Á., Sesma-Sara, M., Bustince, H., & Martínez, L. (2021). A cohesion-driven consensus reaching process for large scale group decision making under a hesitant fuzzy linguistic term sets environment. Computers & Industrial Engineering, 155, 107158. https://doi.org/10.1016/j.cie.2021.107158
- Tang, M., & Liao, H. (2021). From conventional group decision making to large-scale group decision making: What are the challenges and how to meet them in big data era? A state-of-the-art survey. Omega, 100, 102141. https://doi.org/10.1016/j.omega.2019.102141
- Tang, M., Zhou, X., Liao, H., Xu, J., Fujita, H., & Herrera, F. (2019). Ordinal consensus measure with objective threshold for heterogeneous large-scale group decision making. Knowledge-Based Systems, 180, 62–74. https://doi.org/10.1016/j.knosys.2019.05.019
- Wu, Z., & Xu, J. (2018). A consensus model for large-scale group decision making with hesitant fuzzy information and changeable clusters. Information Fusion, 41, 217–231. https://doi.org/10.1016/j.inffus.2017.09.011
- Xu, Z., & Wu, J. (2010). Intuitionistic fuzzy C-means clustering algorithms. Journal of Systems Engineering and Electronics, 21(4), 580–590. https://doi.org/10.3969/j.issn.1004-4132.2010.04.009
- Xue, Y., & Deng, Y. (2021). Decision making under measure-based granular uncertainty with intuitionistic fuzzy sets. Applied Intelligence (Dordrecht, Netherlands), 51(8), 6224–6233.
- Zadeh, L. A. (1965). Fuzzy sets. Information and Control, 8(3), 338–353. https://doi.org/10.1016/S0019-9958(65)90241-X
- Zhang, C., Chen, C., Streimikiene, D., & Balezentis, T. (2019). Intuitionistic fuzzy MULTIMOORA approach for multi-criteria assessment of the energy storage technologies. Applied Soft Computing, 79, 410–423. https://doi.org/10.1016/j.asoc.2019.04.008
- Zhu, J., Zhang, S., Chen, Y., & Zhang, L. (2016). A hierarchical clustering approach based on three-dimensional gray relational analysis for clustering a large group of decision makers with double information. Group Decision and Negotiation, 25(2), 325–354. https://doi.org/10.1007/s10726-015-9444-8
- Zhu, Q., Tang, X., & Elahi, A. (2021). Application of the novel harmony search optimization algorithm for DBSCAN clustering. Expert Systems with Applications, 178, 115054. https://doi.org/10.1016/j.eswa.2021.115054