
Abstract
Propositional attitude generics such as “Experts think early humans ate grass” report an epistemic state (e.g., think, believe, say) that is generalised to a wider community (e.g., Experts, Scientists, Academics). These generics are often used in place of quantified claims (e.g., “Some experts think…”) but three pre-registered experiments (N = 4891) indicate that this lexical choice risks misrepresenting the true degree of scientific consensus. Relative to “Some experts think…” the generic “Experts think…” was more likely to be understood as “All Experts” or “Possibly all Experts” and less likely to invite the scalar inference “Not all Experts.” Consistent with this, the choice to use generic language became increasingly likely as expert consensus approached unanimity. Propositional attitude generics can imply a high degree of consensus and keep open the possibility of universal agreement. To avoid overgeneralisation, they should be used with caution where the objective degree of consensus is unknown.
Introduction
Most mainstream scientific claims are backed by some degree of expert consensus. The consensus may be overwhelmingly in favour of one conclusion (e.g., humans have contributed to climate change) or may be less than unanimous. When scientific work is reported in the media, there is often explicit or implicit reference to the degree of expert consensus. Consider the example headlines below, taken from four mainstream media outlets.
95% consensus of expert economists: cut carbon pollution (The Guardian)Footnote1
Most experts agree: Walking is good exercise (CNN)Footnote2
Many experts say to keep masks on, as pushback to CDC guidance intensifies (LA Times)Footnote3
Experts think early humans ate grass (BBC)Footnote4
Headlines 1-4 each imply some degree of expert consensus. Perceived consensus matters. This is because the perceived degree of expert consensus supporting a claim may be used by lay people as a heuristic to inform their own beliefs (Van der Linden et al., Citation2015; Van der Linden et al., Citation2019); if most experts believe humans have caused climate change, then who am I to argue? Headline 1 provides a direct estimate of consensus based on a sample of relevant experts. Headlines 2-3, on the other hand, are less precisely quantified and open to interpretation; “Most experts agree” and “Many experts say…” imply an unspecified majority. Headline 4 is different, as it avoids using a quantifier altogether and generically states “Experts think….” This final type of headline is perhaps the most common, as it has properties that headline writers’ desire: it is short, easy to understand and appealing (Dor, Citation2003). Despite its apparent simplicity, Headline 4 is also the most ambiguous. Does “Experts think…” mean “All experts think”? “Possibly all experts”? or “Not all experts”? “How people interpret the degree of expert consensus implied by such generic generalisations is the focus of three experiments reported below.
Generic generalisations (or simply generics) are common (e.g., “Ravens are black,” “Ducks lay eggs,” “Men enjoy DIY”) and have been considered extensively by linguists, philosophers and more recently by psychologists (Leslie & Lerner, Citation2022). The prototypical generic is of the form “Ks are F” where K refers to a kind (e.g., ravens) and F refers to a property of that kind (e.g., black feathers). They make broad, enduring claims that gloss over individual variability. This results in generics having an unusual property: they are typically judged as true even in the face of obvious exceptions. Male ducks do not lay eggs and some men do not enjoy DIY, but few would question the truth of the generic claims above. In other words, generics are readily accepted as true, but difficult to prove false. Cimpian et al. (Citation2010) found that generics are often judged true even when the prevalence of a trait is well below 50%. For example, a novel generic such as “Lorches have purple feathers” was widely accepted as true even when participants were informed that prevalence was low (e.g., 10% of Lorches have purple feathers). Paradoxically, the same generics imply that the property (purple feathers) occurs in over 90% of group members (Lorches). Extrapolated to Headline 4, this implies that the headline writer could have truthfully asserted “Experts think early humans ate grass” even if only a minority of relevant experts held this belief, all the while implying to readers that a large majority of experts share this belief. It is this flexibility in the use and interpretation of generics that has led researchers to focus on the implications of using generic language to report scientific conclusions (e.g., DeJesus et al., Citation2019, Citation2021, Citation2024; Haigh et al., Citation2020; Haigh & Birch, Citation2021; Lemeire, Citation2024; Peters et al., Citation2022; Bowker, Citation2023). Collectively, this work warns us that generic language can lead to overgeneralised conclusions about groups such as “Men,” “Women,” “Humans,” “Introverts” or “Experts.”
In this paper we focus on the use of generics to communicate the beliefs of experts. Generics attributing beliefs to experts are particularly common in news headlines (Haigh et al., Citation2020; Haigh & Birch, Citation2021); as such they are a fundamental linguistic device for communicating science to the public. Three genuine examples are listed below (emphasis added).
Experts believe Aladdin may actually be based on a real person (New York Post)Footnote5
Scientists say bees can do basic math (CNN)Footnote6
Broccoli slows arthritis, researchers think (BBC)Footnote7
What these examples have in common is that they generalise a propositional attitude (e.g., believe, say, think) to a community of individuals (e.g., “Experts,” “Scientists,” “Researchers”). For this reason, we classify them as propositional attitude generics. Propositional attitude verbs describe an epistemic state or speech act such as believe, say, or think (Richard, Citation2006). These verbs accept a subordinate clause beginning with ‘that’ (e.g., Experts think that x) although this conjunction is often omitted for brevity (e.g., Experts think x). The focus here is specifically on the propositional attitudes of experts, but this type of generic could also be used more broadly to report the epistemic states or attitudes of other groups (e.g., “Men think…,” “Children say…”).
Philosophers and linguists have written extensively about sentences that describe propositional attitudes. These sentences are known as propositional attitude reports (e.g., Nelson, Citation2000) or propositional attitude ascriptions (e.g., Richard, Citation2006). A typical feature of existing work on propositional attitude reports is the focus on the epistemic states of specific individuals (e.g., Harry thinks…,). In contrast, what we refer to as propositional attitude generics focus on the epistemic states of communities (e.g., Experts think…). It is this feature that makes propositional attitude generics interesting; they imply a degree of consensus among that community. Previous research looking at phrases fitting the definition of a propositional attitude generic (e.g., Scientists believe…) showed that numerical estimates of consensus were highly variable (Haigh et al., Citation2020). On average, phrases such as Scientists believe… were judged to apply to just over 50% of scientists. What this does not reveal is the type of pragmatic inferences that inform our perception of consensus. When people encounter a generic such a “Experts think…” it is unlikely that they produce a fine-grained numerical estimate (e.g., 54% of experts think), instead it is more plausible that they make a coarser natural language inference, such as “some experts” or “all experts” (Haigh & Birch, Citation2021). Better understanding the nature of this inference is important if perceived consensus is used as a heuristic for updating personal beliefs (Van der Linden et al., Citation2019).
To better understand the types of inference that might be made from propositional attitude generics, we turn to the Experimental Pragmatics literature which focuses heavily on the interpretation of sentences quantified with “some” (Noveck & Reboul, Citation2008). This is relevant because a propositional attitude generic such as “Experts think early humans ate grass” is consistent with the same possibilities as “Some experts think early humans ate grass.” The standard semantic or logical meaning of “some” is “at least some and possibly all” (Van Tiel & Schaeken, Citation2017) or simply “more than one” (Holtgraves & Bray, Citation2022). It is therefore acceptable to assert that “Some experts think….” when only a subset of experts are known to hold this belief. It is also logically sound to assert “Some experts think…” when in fact all experts are known to hold this belief. Importantly, the same possibilities are true of propositional attitude generics; “Experts think early humans ate grass” can be asserted if all experts hold that belief and it can also be asserted if only a small subset of experts hold that belief. Both “Experts think…” and “Some experts think…” contain a regular plural noun, making them true in situations when more than one expert holds that belief. They are also compatible with situations in which all experts hold that belief.
While the logical interpretation of “some” is “at least some and possibly all” the typical pragmatic interpretation is different. On hearing a statement such as “Some guests have arrived” adults typically make the pragmatic inference that “not all” the guests have arrived (Noveck & Reboul, Citation2008). By extension, we would expect that the typical interpretation of “Some experts think early humans ate grass” would be “some but not all” experts hold this belief. This “not all” inference is not based on the semantic meaning of some, but on what the speaker or writer is believed to be implying. It is generally assumed that speakers or writers are motivated to be maximally informative (Grice, Citation1975), so if the writer knows that “All experts believe x” then we would expect them to say as much. When they choose a weaker term such as “some experts” it is typically inferred that stronger terms on the same scale (e.g., “All”) are not true or not known to be true. The failure to assert “all x” leads us to infer “not all x.” This type of pragmatic inference is known as a scalar inference or scalar implicature (Levinson, Citation1983). While the semantic scope of “some” is very wide (i.e., “At least some and possibly all”) its typical pragmatic interpretation is much narrower (“Some but not all”).
Given that the generic “Experts think…” is consistent with the same prevalence possibilities as “Some experts think…” does it follow that they have the same narrow pragmatic interpretation (“Some but not all experts”)? Or is it the case that generic claims are more often interpreted in a logical wide scope manner, keeping open the possibility of “All” (i.e., “Some and possibly all experts”)? In Experiment 1 we sought to answer this question. We presented participants with a generic phrase such as “Experts think…” or a quantified phrase such as “Some experts think…” and asked them to select the most appropriate paraphrase from three choices 1) “All experts think…” (universal interpretation) 2) “Some and possibly all experts think…” (wide scope interpretation) 3) “Some but not all experts think…” (narrow scope pragmatic interpretation). We also asked them to provide numerical estimates of the lowest and highest degree of consensus that the phrase could imply. Based on the scalar inference literature, we expected that most participants who saw a quantified phrase such as “Some experts think…” would select “Some but not all experts think…” as the most appropriate paraphrase (Noveck & Reboul, Citation2008). This is the narrow scope, pragmatic interpretation of “some” rather than a wider scope logical interpretation. In line with this, we also expected that the median upper consensus estimate would be well below 100% (consistent with a “not all” interpretation). The primary aim of Experiment 1 was to determine whether propositional attitude generics produce the same pattern of responses, or whether the generic phrasing is more likely to encourage a wider scope “some and possibly all” inference.
Both the narrow scope (“not all”) and the wide scope (“possibly all”) accounts are plausible interpretations of a propositional attitude generic. First, there is reason to expect some people will take the narrow “not all” interpretation. From a pragmatic point of view, the decision by a speaker to use a generic (“Experts think…”) and avoid using a more precise universal quantifier (“All experts think…”) suggests that the speaker does not believe (or does not know) that the universal quantifier holds. If one assumes that the speaker is being maximally informative (Grice, Citation1975), then their failure to explicitly assert “All” may be sufficient to trigger the scalar implicature “not all” (Noveck & Reboul, Citation2008). Indeed, it is rare that all relevant experts agree on anything, so “not all” is a reasonable default assumption when the speaker fails to assert universal agreement.
Alternatively, some people may choose the wider scope “possibly all” interpretation of a propositional attitude generic. The decision by the speaker or the writer to make a generic claim (“Experts think…) rather than a quantified claim (e.g., “Some experts think…”) keeps open the possibility of universal agreement. This is what Cimpian et al. (Citation2010) described as an inverse scalar implicature. If the speaker means to pick out a subset of the community, it would be maximally informative to do this explicitly (e.g., by stating “Some experts think…”). When they fail to use a quantifier, it keeps open the possibility of a stronger interpretation (“Some and possibly all experts think…”). In the absence of any background knowledge, there is evidence that the default prevalence implied by generics may be very close to “All.” Cimpian et al. (Citation2010) found that when participants were presented with the novel information that “Lorches have purple feathers,” the average prevalence implied by this generic was 95.8% (i.e., 95.8% of Lorches have purple feathers). Keeping open the possibility of “all” is also reasonable, given that generics are frequently used in place of universals (e.g., “Humans breathe oxygen” rather than “All humans breathe oxygen”; “Dogs are mammals” rather than “All dogs are mammals” etc.) and in situations where “possibly all” is a plausible conclusion (e.g., “Professional swimmers are physically fit”).
A propositional attitude generic such “Experts think early humans ate grass” is consistent with the same possibilities as “Some experts think early humans ate grass.” It is well known that statements quantified with “some” invite the strong scalar inference “some but not all.” The purpose of Experiment 1 is to determine whether propositional attitude generics are more likely to invite an inverse scalar inference that keeps open the possibility of universal agreement.
Experiment 1 method
In Experiment 1 participants were presented with a decontextualised Generic phrase (i.e., “Experts believe…,” “Experts say…” or “Experts think…”) or a decontextualised Quantified phrase (i.e., “Some experts believe…,” “Some experts say…,” or “Some experts think…”) alongside examples of this phrase used in context (see ). We varied the propositional attitude verb (“believe,” “say,” “think”) simply to improve the generalisability of our findings and always planned to collapse the three versions within each condition, as outlined in the pre-registration. One the next page of the survey participants were shown three paraphrases and asked to select the one that was most consistent with the decontextualised phrase they head seen earlier. The three options were: “All experts believe [say/think]…,” “Some and possibly all experts believe [say/think]….” and “Some but not all experts believe [say/think].….” The task instructions were clear that judgments should be made about the “general meaning” of the phrase (rather than focusing on a specific example). Finally, participants estimated the lowest and highest percentage of relevant experts the statement could refer to. This was done using a sentence completion task in which participants entered their lower-bound and upper-bound prevalence estimates. The pre-registered protocol, materials, raw data and analysis scripts can be found on the OSF.
Figure 1. Example of the task completed by participants in Experiment 1. Participants were randomly allocated to one of six versions of this task (“Experts believe…,” “Experts say…,” “Experts think…”/“Some experts believe…,” “Some experts say…” or “Some experts think…”). Only the phrasing (generic vs quantified) and the verb (“believe,” “say,” “think”) differed between versions. The position of page breaks used in the online survey are indicated.

Participants
Participants were recruited via Prolific.com. Pre-screening ensured the study was only advertised to those aged 18 years and older, spoke English as their first language and had not taken part in related studies by the same research team. To determine a minimum sample size, we conducted a prospective power analysis for a 2 × 3 chi-squared test (2 conditions x 3 choices). This was conducted in R using the pwr package (Champely, Citation2020). A minimum of 964 participants were required to detect a small effect (w = 0.1) 80% of the time with α = .05. A total of 980 participants consented to take part. Participants were excluded if they did not complete the survey (n = 4) or self-declared they had not completed the survey seriously (n = 2). Duplicate responses were also excluded (e.g., if a participant started the experiment a second time the second response was excluded, n = 6). This left 968 participants (344 male, 618 female, 6 preferred not to say or did not answer) aged 18 - 79 (M age = 36, SD = 12.4). Participants were paid £0.3.
Materials
Stimuli
Participants were presented with a decontextualised phrase that either attributed a belief to “Experts” (Generic condition) or to “Some experts” (Quantified condition). The subject (“Experts”) was paired with one of three propositional attitude verbs that implied some degree of scientific consensus (“believe,” “say,” “think”) resulting in six versions (“Experts believe…,” “Experts say…,” “Experts think…”, “Some experts believe…,” “Some experts say…” or “Some experts think…”). The three verbs selected were previously identified by Haigh et al., (Citation2020) as common collocates of “Experts.” Five contextualised examples of the phrase were also provided. The example headlines were the same in each of the six versions (with the verb edited to match the decontextualised phrase).
Measures
The paraphrase choice task and consensus range task can be seen in . Participants completed the paraphrase task by selecting one of the three options (All experts believe…; Some and possibly all experts believe…; Some but not all experts believe…). The numerical consensus estimate task required participants to complete a sentence by selecting percentage values from two dropdown boxes.
Procedure
The experiment was conducted online using Qualtrics. Participants were randomly assigned to either the Generic condition (one of three versions) or Quantified condition (one of three versions). They then completed the task illustrated in . Page breaks were inserted between different sections of the survey and there was no ‘back’ button. Finally, participants were asked if they responded seriously (Aust et al., Citation2013). To encourage honesty, participants were informed that they would still be paid even if they declared a non-serious response. All questions required a response. Mean completion time was 1.89 min.
Experiment 1 results
Analysis was conducted using R version 4.0.3 (R Core Team, Citation2023). Chi-squared analysis was conducted using the gmodels package (Warnes et al., Citation2018). There were no missing data as all questions required a response.
Paraphrase choice
As expected, the choice of paraphrase was not associated with the verb used in the headline (i.e., “believe,” “say,” “think”) X2 (4, N = 968) = 3.14, p = .535 so all subsequent analysis was collapsed across the three verbs as planned (i.e., responses to “Experts believe,” “Experts say” and “Experts think” were combined as “Generic” and responses to “Some experts believe,” “Some experts say” and “Some experts think” were combined as “Quantified”).
A pre-registered 2 × 3 chi-squared test of independence was conducted to determine whether condition (Generic or Quantified) was associated with the choice of paraphrase (“All experts”/“Some and possibly all experts”/“Some but not all experts”). The association between condition and choice of paraphrase was statistically significant X2 (2, N = 968) = 151.13, p < .001. This indicates that the proportion of participants choosing each paraphrase was not the same in the Generic and Quantified conditions. indicates that those in the generic condition were more likely to select the ‘All’ paraphrase than those in the quantified condition. They were also more likely to select ‘Some and possibly all’ paraphrase. Those in the quantified condition were more likely to select the ‘some but not all’ paraphrase than those in the generic condition.
Figure 2. Frequency of paraphrase choice by experimental condition in Experiment 1.
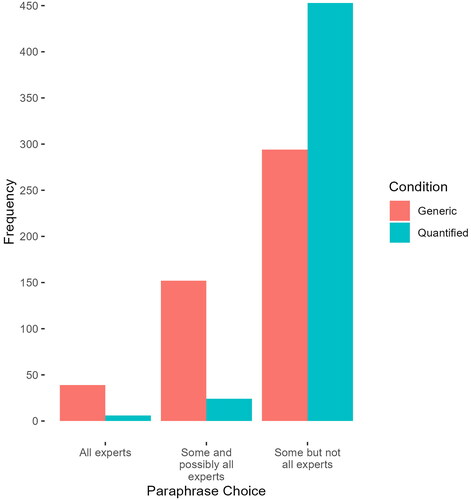
To interpret this significant omnibus test, we followed our pre-registered analysis plan and compared column proportions based on the Adjusted Standardised Residuals (see Sharpe, Citation2015). Adjusted Standardised Residuals with a positive value indicate more participants than expected in that cell. A negative value indicates fewer participants than expected in that cell. Adjusted Standardised Residual values > +/-1.96 are significant at the 0.05 significance level. To account for multiple testing, we used the Bonferroni corrected alpha of .00833 (see Sharpe, Citation2015). Adjusted Standardised Residual values > +/-2.64 are significant at the Bonferroni adjusted significance level of .0083.
The Adjusted Standardised Residuals indicate that the “All Experts” paraphrase was chosen by more participants than expected in the Generic condition (and fewer than expected in the Quantified condition) (Adjusted Standardised residual = 5.02, p<.0083) The “Some and possibly all experts” paraphrase was also chosen by more participants than expected in the Generic condition (and fewer than expected in the Quantified condition) (Adjusted Standardised residual = 10.64, p<.0083). The “Some but not all experts” paraphrase was chosen by more participants than expected in the Quantified condition (and fewer than expected in the Generic condition) (Adjusted Standardised residual = 12.29, p<.0083). In other words, those who chose the “All experts” or “Some and possibly all experts” paraphrases were more likely to be in the Generic condition. Those who chose the “Some but not all experts” paraphrase were more likely to be in the Quantified condition. Additional pre-registered analysis focusing on paraphrase choice within each of the experimental conditions can be found in the supplemental online material.
Paraphrase choice summary
Regardless of whether participants saw a generic (e.g., “Experts believe…”) or a quantified phrase (e.g., “Some experts believe…”), the most frequent paraphrase chosen was “Some but not all experts believe.” However, the pattern of paraphrase choices differed between conditions. Relative to “Some experts believe…” the generic “Experts believe…” was 6.5 times more likely to be understood as “All Experts” and 6.3 times more likely to be understood as “Possibly all Experts.” The generic was much less likely (0.65 times) to invite the scalar inference “Not all Experts.”
Numerical estimates
Participants were also asked to estimate the lowest (lower-bound) and highest (upper-bound) percentage of relevant experts that the phrase could refer to. The lower-bound and upper-bound estimates in each condition are plotted in . The degree of consensus implied by Generic phrases had a lower-bound median value of 10 (mode = 1) and an upper-bound median value of 90 (mode = 100). The degree of consensus implied by Quantified phrases had a lower-bound median value of 2 (mode = 1) and upper-bound median value of 50 (mode = 50).
Figure 3. Median upper-bound and lower-bound consensus estimates for the generic and quantified phrases used in Experiment 1. Blue circles represent individual data points (jittered to avoid overlap). The density of these data points is represented by violin plots. Box plots show the median (black vertical line) and interquartile range.
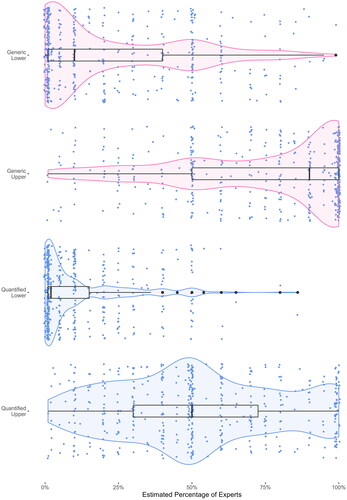
We preregistered two planned comparisons (independent t-tests) to compare the mean lower-bound values between the generic and quantified conditions and to compare the mean upper-bound values between conditions. The density plots in show that the data were not normally distributed. This was confirmed by Shapiro-Wilk tests. Because the data were not normally distributed, we used non-parametric Mann-Whitney tests (rather than t-tests). These tests revealed a significant difference between lower-bound estimates in the generic condition (median = 10) and lower-bound estimates in the quantified condition (median = 2; W = 141896, p < .001). Likewise, there was a significant difference between upper-bound estimates in the generic condition (median = 90) and upper-bound estimates in the quantified condition (median = 50; W = 173787, p < .001).
Exploratory analysis
Examination of the data points plotted in suggest that the difference in upper-bound estimates between conditions may be driven by a greater proportion of participants choosing exactly 100% consensus in the generic condition. In the quantified condition 2.5% of participants (12 out of 483) selected exactly 100% consensus for their upper-bound estimate (equivalent to “All experts”). In contrast, 34% of participants (165 out of 485) made this selection in the generic condition. An exploratory two proportion Z test indicates that a significantly greater proportion of participants chose exactly 100% consensus in the generic condition than did so in the quantified condition X2 (1) = 158.97, p < .001. The proportion choosing exactly 100% in the generic condition was 13.6 times greater than in the quantified condition.
Experiment 1 discussion
A propositional attitude generic such as “Experts think…” and its quantified equivalent “Some experts think” are both true when more than one expert holds that belief, but our data reveal important pragmatic differences in their interpretation. In both conditions “Some but not all experts” was the most selected paraphrase. Most of those in the generic condition (60.6%) made this pragmatic “not-all” scalar inference (compared to 93.8% on the quantified condition). For this subset of participants, the absence of the explicit quantifier “All” implied “not-all.” However, the pattern of paraphrase choices was strikingly different between conditions. Relative to the quantified “Some experts believe…” the generic “Experts believe…” was less likely to invite the scalar inference “Not all Experts” and more likely to be understood as “All Experts” or “Possibly all Experts.” This pattern indicates that a significant minority took the wide scope “possibly all” interpretation (inverse scalar implicature). While “Some experts believe” largely closed off the possibility of universal expert agreement, nearly 40% of those who saw a generic headline selected a paraphrase that keeps open the possibility of universal agreement. This is corroborated by the numerical estimate data, in which over one third of participants in the generic condition selected 100% consensus (i.e., universal consensus) as a plausible upper-bound estimate. A key feature of propositional attitude generics is that they have wide scope that keeps open the possibility of universal agreement; it cannot be assumed that they always invite a scalar “not-all” inference.
Experiments 2a and 2b
Experiment 1 indicates that propositional attitude generics have a wide scope. A generic such as “Experts believe” can truthfully be asserted when only a handful of experts believe, but also when the vast majority believe (see ). It could therefore be argued that a propositional attitude generic tells us nothing about the true degree of consensus—perhaps it is a catch-all term that could truthfully refer to any proportion of experts.
While propositional attitude generics do not directly tell us the degree of consensus, their use may imply something about the writer’s communicative intention. Generics do not have an explicit quantifier, but it has been suggested that they evoke an implicit quantifier known as “Gen”. Gen is an implicit, unspoken quantifier that in many cases can be paraphrased as generally (Leslie, Citation2008). As such, a speaker who utters “Experts believe…” may be implying something along the lines of “Generally experts believe….” Indeed, it would be stretching the truth to say “Experts believe…” when it is known that only 5% of experts hold that belief. Instead, it would be more informative in that context to say “some experts” or “a few experts” (see Declerck’s (Citation1991) inclusiveness principle). It seems less of stretch to use a propositional attitude generic when consensus is 70% and even less so when consensus is 90%. Consistent with this, Cimpian et al. (Citation2010) found that novel generics such as “Lorches have purple feathers” were more likely to be accepted as true as the generality increased (for example, more participants indicated that this statement was true when prevalence of purple feathers was 90% compared to 70%).
The use of a propositional attitude generic may provide some clues about the writer’s communicative intention. A simple heuristic may be to assume that if a writer has produced a propositional attitude generic then they are more likely to be expressing generalised (majority) than localised (minority) consensus. In Experiments 2a and 2b we tested this assumption.
We predicted that when an individual believes there is a high degree of expert consensus, they will be more likely to communicate this using a propositional attitude generic. If this is the case, then we would expect (for example) a greater likelihood of producing a propositional attitude generic when expert agreement is known to be 80% than if expert agreement is known to be 40%. Assuming there is such a linear relationship, we also sought to identify the degree of expert consensus at which a generic becomes the preferred (modal) way to express consensus. We addressed these questions in Experiments 2a and 2b by examining whether the likelihood of using a propositional attitude generic increases as the known degree of consensus increases. In Experiment 2a we presented participants with a news story that reported a specific degree of expert consensus (ranging from 5% to 100% consensus; see ) and asked them to select the most appropriate headline to caption the article. The choices were a quantified headline (“Some experts believe…”) or a generic headline (“Experts believe…”). We predicted that the proportion of participants choosing the generic headline would increase as the degree of expert consensus increased. Informed by the results of Experiment 2a, Experiment 2b allowed us to more precisely estimate the degree of consensus at which the majority of participants choose a generic headline.
Figure 4. Task completed by participants in Experiment 2a. Participants were randomly allocated to see one of 20 versions of this story (5% - 100% consensus in increments of five percentage points). In this specific example expert consensus was 70%. Participants were asked to select one of two headlines.

Experiment 2a method
Participants were presented with a brief description of a local news story. Each participant was randomly assigned to see one of 20 versions of this story. Each version differed in the degree of expert consensus that was described (ranging from 5% of experts to 100%). Participants were then asked to select from two headlines the one they thought most appropriate to caption the news story. One of the headlines was generic “Experts believe…” and the other was quantified “Some experts believe…” (see ). The pre-registered protocol, materials, raw data and analysis scripts can be found on the OSF.
Participants
A prospective power analysis for a 2 × 20 chi-squared test was conducted in R using the pwr package (Champely, Citation2020). This is because our design had 20 conditions and participants were asked to select one of two choices. A minimum of 2055 participants were required to detect a small effect (w = 0.1) 80% of the time with α = .05. This sample size would result in approximately 100 participants per condition. Within each of the 20 conditions we planned to conduct a binomial test to determine whether the proportion of participants choosing the generic headline differed from 0.5 (using a Bonferroni corrected alpha of 0.0025 to account for multiple testing; 0.05/20 = 0.0025). On the assumption of 100 participants per condition, these tests have power of 0.976 to detect a medium sized effect (h = 0.5) with a Bonferroni corrected alpha of 0.0025. Participants were recruited from Prolific using the same pre-screening criteria as Experiment 1 (none took part in Experiment 1). In total 2108 participants consented. As per Experiment 1, participants were excluded if they did not complete (n = 15) or declared they had not completed the survey seriously (n = 1). Duplicate responses were also excluded (e.g., if a participant started the experiment a second time the second response was excluded n = 24). The final sample included 2068 participants (845 male, 1215 female, 1 preferred not to say and 7 did not provide this information) aged 18 - 81 (M age = 35.8, SD = 13.3). They were paid £0.2.
Materials
Stimuli
News story. Participants were presented with a description of a local news story reporting that a whale had washed-up dead on a British beach. The description provided to participants is shown in . This story was chosen as it avoided potentially divisive topics such as politics or climate change (i.e., topics on which participants may have strong prior beliefs). We specifically chose a relatively obscure local news story to minimise the chance that participants had any prior beliefs or knowledge about the true degree of expert consensus. Participants were randomly assigned to one of 20 conditions (ranging from 5% to 100% consensus).
Measures
Headline choice. Participants were asked “In your opinion, which of the following headlines is most appropriate to caption the story?” The two choices were the Generic “Experts believe North Essex whale died after impact with ship” and the Quantified “Some experts believe North Essex whale died after impact with ship.” The order in which the choices were presented was randomised for each participant. The Generic option was the headline that accompanied the original news story (Bryson, Citation2020) and the Quantified option was edited to include “Some.”
Procedure
The experiment was conducted online using Qualtrics. Participants were randomly assigned to one of 20 conditions. All participants saw the same brief description of a news story. The only difference between conditions was the degree of expert consensus. Participants were then asked to select a headline to caption the story. They were then asked if they had taken part seriously. Mean completion time was 1.34 min.
Experiment 2a results
Analysis was conducted using R version 4.0.3 (R Core Team, Citation2023). Chi-squared analysis was conducted using the gmodels package (Warnes et al., Citation2018). There was no missing data as the question required a response before participants could move on.
A 2 × 20 chi-squared test of independence was conducted to determine whether the choice of headline (quantified or generic) was associated with the degree of expert consensus reported in the news article. This revealed that there was a statistically significant association X2 (19, N = 2068) = 507.98, p < .001. These data are plotted in .
Figure 5. Stacked bar chart showing the proportion of generic (“Experts believe….”) and quantified (“Some experts believe…”) headline choices at each level of expert consensus in Experiment 2a. Error bars represent 95% Confidence Intervals (N = 2068). p values are for two-tailed binomial tests, which test the null hypothesis that the proportion of those choosing the generic headline is equal to 0.5. The dashed line represents a proportion of 0.5. An asterisk indicates that the p value is <.0025.
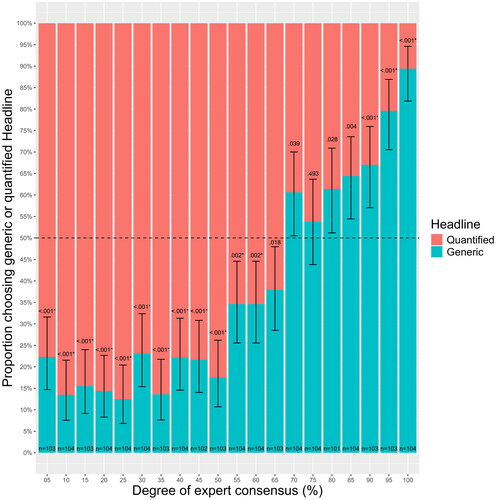
There was a strong positive correlation between the degree of expert consensus described in the article and the percentage of participants choosing a generic headline (r = 0.92). This indicates that the percentage of participants choosing a generic headline increased as the degree of expert consensus increased.
To determine whether the proportion of participants choosing the generic headline in each condition differed from 0.5 we conducted 20 binomial tests (see ). This allowed us to determine the level of consensus at which the generic headline became the modal choice (i.e., selected by more than half of participants). Because we conducted 20 tests we used Bonferroni corrected alpha of 0.0025 (0.05/20). shows the generic headline became the modal choice (selected by more than half of participants) at 70% consensus and remained the modal choice until 100% consensus. However, our Bonferroni corrected binomial tests indicate that the proportion of participants choosing a generic only became significantly greater than 0.5 (p < .0025) at 90% consensus.
Experiment 2a discussion
Experiment 2a confirms that that likelihood of producing a propositional attitude generic increases as the objective degree of consensus increases. The higher the degree of expert consensus the more likely it is that a given individual will assert “Experts believe….” This is consistent with “gen” interpretation of generics: when it is generally the case that “Experts believe” then the use of a generic is more likely. It is therefore rational to assume that if a writer has produced a propositional attitude generic they are likely to be expressing a general degree of consensus rather than localised (low) consensus. If consensus is relatively low, the likelihood is that the statement will be quantified with “some” (Declerck, Citation1991).
A propositional attitude generic can be truthfully asserted even when there is known to be a low level of consensus and also when there is a very high degree of consensus; however despite this flexibility the use of propositional attitude generics is constrained by beliefs about consensus—when a writer asserts “Experts believe…” it is more likely they understand the level of consensus to be high (generalised) than to be low (localised). Despite their wide scope, participants were generally reluctant to use propositional attitude generics when consensus was low (but increasingly likely as consensus increased). Of course, there are likely to be some boundaries to this, for example if the speaker’s motivation is to be persuasive or appealing. In such cases, a propositional attitude generic may be used in low consensus contexts precisely because it implies general consensus. Exploiting this pragmatic inference can add unwarranted weight to an argument without uttering a falsehood.
Our data also provide an insight into the degree of consensus at which most people opt to use a propositional attitude generic over a some-quantified alternative. Based the data from Experiment 2a, that tipping point is between 70% and 90% consensus. The generic headline first became the modal choice (chosen by more than half of participants) when expert consensus reached 70%. However, this preference only became statistically significant at 90% consensus. This disparity is likely due to lack of statistical power. Despite a large overall sample size which was sufficient to detect a small relationship between condition and choice, the twenty post-hoc binomial tests each had power to detect only a medium sized effect. Power was limited because each test was based on a subset of approximately 100 participants and because a conservative Bonferroni corrected alpha was used (0.05/20 = 0.0025). A retrospective power analysis revealed that these tests had power to detect a medium effect (h = 0.5) 98% of the time but power to detect a small effect (h = 0.2) only 15% of the time. To more accurately determine the point at which the generic headline first became the modal choice we conducted a partial replication of Experiment 2a with much increased statistical power.
Experiment 2b
Experiment 2b is a partial replication of Experiment 2a designed to give a more precise estimate of when the generic headline becomes the modal choice. This was achieved by designing the experiment so that each binomial test had power to detect a “small” effect (h = 0.2) 80% of the time—an increase from 15% in Experiment 2a. We used the same protocol as Experiment 2a, but with fewer conditions (consensus conditions ranged from 60 to 85). Having fewer conditions helped to increase power in two ways. First, we could assign more participants to each condition (approximately 300 rather 100). Second, a less conservative Bonferroni corrected alpha could be used (0.008 rather than 0.0025).
Experiment 2b method
The design, materials and recruitment method were identical to Experiment 2a except for one change; we used six consensus conditions (60%,65%,70%,75%,80%,85%) rather than 20. The pre-registered protocol, materials, raw data and analysis scripts can be found on the OSF.
Participants
With a Bonferroni corrected alpha of 0.008 (0.05/6 = 0.008) and a minimum desired power of 0.8 to detect a small effect (h = 0.2) we required a minimum of 306 participants per condition. We had six conditions, so the minimum required sample size was 1836 participants. Participants were recruited from Prolific using the same pre-screening criteria as Experiments 1 and 2a. In total 1881 responses were received. Nine duplicate responses were excluded, 14 participants were excluded for non-completion and three were excluded non-serious responding. The final sample of 1855 included 1154 females and 688 males (gender data was unavailable for 13 participants). Mean age was 34.3 years (SD = 12.4).
Experiment 2b results
Analysis was conducted using the same techniques as Experiment 2a. There were no missing data.
A 2 × 6 chi-squared test of independence revealed a statistically significant association between choice of headline (quantified or generic) and degree of expert consensus X2 (5, N = 1855) = 82.1, p < .001). These data are plotted in .
Figure 6. Stacked bar chart showing the proportion of generic (“Experts believe…”) and quantified (“Some experts believe…”) headline choices at each level of expert consensus in Experiment 2b. Error bars represent 95% Confidence Intervals (N = 1855). p values are for two-tailed binomial tests, which test the null hypothesis that the proportion of those choosing the generic headline is equal to 0.5. The dashed line represents a proportion of 0.5. An asterisk indicates that the p value is <.008.
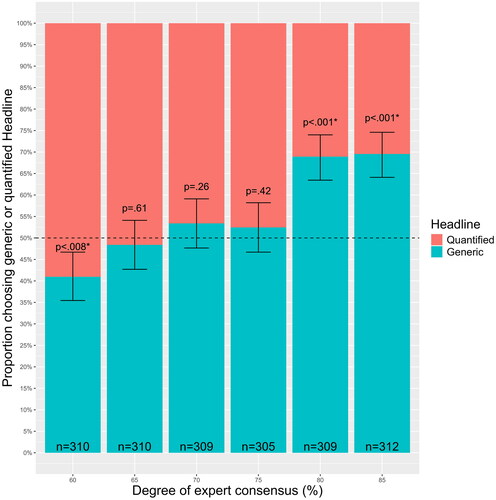
To determine whether the proportion of participants choosing the generic headline differed from 0.5 in each condition we conducted 6 binomial tests using a Bonferroni corrected alpha of 0.008 (0.05/6). This allowed us to determine the level of consensus at which the generic headline becomes the modal choice (i.e., chosen by more than half of participants). These tests are reported in . The degree of expert consensus at which participants are significantly more likely to choose the generic headline is 80% (p < .001).
Experiment 2b discussion
As with Experiment 2a the degree of expert consensus at which the generic headline first became the modal choice (chosen by more than half of participants) was when expert consensus reached 70%. However, the lower confidence interval crossed below 50% indicating that this degree of consensus may not be the modal value in the wider population. A clear and statistically significant preference for the generic headline emerged when expert consensus reached 80%. When expert consensus reached 80% a significant majority of participants (68.9%) chose to caption the news story with a generic headline. In the context of this experiment, the threshold for producing generic language was high. It would have been valid to use a generic even at very low levels of consensus, but it took at least 80% consensus for the majority of participants to show a preference for generic language.
General discussion
A propositional attitude generic implies some degree of consensus among a loosely defined group (e.g., “Experts believe…,” “Scientists think…,” “Researchers say…”). Such generics identify a specific group - in this case we focused on “Experts”—followed by a propositional attitude verb implying some degree of consensus (e.g., “believe,” “think,” “say”). Importantly they do not include a quantifier such as “some,” “many” or “most.” For this reason, the communicated degree of consensus must be inferred from a wide range of possible values. Three experiments revealed the pragmatic scope of propositional attitude generics; they imply a high degree of consensus and keep open the possibility of universal agreement.
Quantified phrases such as “Some experts think…” are typically interpreted in a narrow pragmatic sense (Some but not all experts think…) (Noveck & Reboul, Citation2008). As expected, this is what we found in Experiment 1. Nearly all of our participants (94%) paraphrased “Some experts…” as “Some but not all experts….” Consistent with this “not all” interpretation the median estimates of expert consensus implied by “Some experts…” were between 2% (median lower-bound estimate) and 50% (median upper-bound estimate). Our data revealed that propositional attitude generics are interpreted differently. Relative to “Some experts think…” the generic “Experts think…” was more likely to be understood as “All Experts” or “Possibly all Experts” and less likely to invite the scalar inference “Not all Experts.” The median degree of expert consensus was estimated at between 10% (median lower-bound estimate) and 90% (median upper-bound estimate) with the maximum upper value of 100% being chosen by over one third of participants. Propositional attitude generics are more likely to be interpreted as having a wide scope that keeps open the possibility of universal agreement. Relative to “Some experts think…” the generic “Experts think…” is less constrained by the “not all” scalar inference described in our narrow scope account. This “not all” inference is still the most common (chosen by 60.6% of participants), but a significant minority (39.4%) felt that “Experts think…” keeps open the possibility of universal agreement.
In the Introduction we set out a narrow scope (not all) interpretation of propositional attitude generics and a wide scope (possibly all) interpretation. The majority of participants made the narrow scope “not all” inference when faced with a propositional attitude generic. For those participants, the failure of the writer to explicitly assert “All experts…” was sufficient to trigger the scalar inference “Not all experts.” It may have suggested a lack of confidence or knowledge on the writer’s part that “All experts” is true. The significant minority that chose “possibly all” or “All,” felt that “Experts think…” keeps open the possibility of universal agreement (i.e., “All experts think…”). This wide scope inverse scalar inference is also a reasonable conclusion as generics are frequently used in place of universals (e.g., “Humans breathe oxygen” rather than “All humans breathe oxygen”) and is consistent with evidence that generics imply a high degree of prevalence (Cimpian et al., Citation2010).
Why do some people make a wide scope interpretation (possibly all) and some make a narrow scope (not all) interpretation? There has been little research on individual differences in the interpretation of generics. Haigh et al. (Citation2020) hypothesised that cognitive reflection (i.e., the ability to reflect on and override intuitive conclusions) might play a role. They outlined a model where generics invite an intuitive “All” conclusion that is then revised downwards on reflection. However, they found no evidence to support that prediction. Other individual differences that might explain the paraphrase preferences in Experiment 1 may include variables such as familiarity with the scientific process, level of education and critical thinking. Those who are more familiar with the scientific process would be expected to have greater appreciation that expert opinions routinely diverge and may be more inclined to make the narrow scope “not all” inference. Indeed, “Experts” often refers to only one team of experts among many and the conclusions reported may be based on only a single recent study. In contrast, those with less familiarity may be more inclined to take propositional attitude generics at face value, assuming that the claim is well established and supported by many and possibly all experts. Our sample was recruited online from a participant pool of people who ostensibly take an active interest in scientific research. Furthermore, a high proportion of those using Prolific have been exposed to higher education (either as a current or former student), so exploring the interpretation of generics among a more representative sample may be a fruitful avenue for individual differences research.
In Experiment 1 we attempted to evoke the type of generic claim that is frequently seen in the media (i.e., Experts think Y). We then asked participants to judge “the general meaning” of this decontextualised phrase. To help participants understand the task, we provided five examples of propositional attitude generics used in context (see ) that varied in form and content. For instance, they differed in terms of clause order (i.e., “Experts think X” vs. “X, experts think”) and whether the proposition applied to a group (e.g., ‘early humans’) or an individual (e.g., ‘Aladdin’). The idea was not for participants to focus on any one example, but to evoke the type of general claim that is frequently seen in the media (i.e., Experts believe Y). This evocation might also include participants’ own prior experience of encountering similar headlines. The question then explicitly asked participants to focus on “the general meaning” of a decontextualised phrase that contained only a noun (i.e., Experts) and a propositional attitude verb (e.g., believe) followed by ellipsis. We believe the instructions were sufficiently clear for participants to understand that they should focus on the general meaning of the phrase across multiple contexts, but having said this, there remains the possibility some participants focused on a specific example and made a judgement that was particular to that example. Little is known about how syntactic features of generics (e.g., clause order) affect reasoning and we encourage further research on how such variables influence judgments of truth and prevalence.
Experiments 2a and 2b focused on the production of propositional attitude generics and indicate that the use of generic language becomes increasingly likely as expert consensus approaches unanimity. Experiment 1 showed that generics have a wide scope that can that be used even when expert consensus is as low as 1% (i.e., the modal lower-bound estimate in Experiment 1 was 1%). However, participants in Experiment 2a were generally reluctant to use propositional attitude generics when consensus was low. The likelihood of using generic language increased as the objective degree of consensus increased. Only once expert consensus reached 80% did participants show a significant preference for generic language. When choosing how to describe expert consensus participants preferred to use a generic when there was generalised consensus, consistent with the unspoken quantifier “Gen” (e.g., “Generally experts think…”). In fact, when consensus was any value less than 70% the modal choice was to quantify the claim with “some.” It appears legitimate to make inferences about the speaker’s communicative intention based simply on their choice to use generic language. Speakers or writers are more likely to use generic language when they believe there is a general degree of consensus.
Of course, there are likely to be exceptions to the rule described above. Despite participants in Experiments 2a and 2b having a high threshold for using generic language, the lower-bound estimates in Experiment 1 suggest people understand that others (e.g., journalists) may have a lower prevalence threshold for using propositional attitude generics. For example, generics may be used when consensus is low, but the speaker is motivated to be appealing or persuasive. They may also be used when the degree of consensus is unknown. We predict that propositional attitude generics are more likely to be produced when the true degree of consensus is unknown or when the speaker is motivated to be appealing (e.g., a headline writer) or persuasive (e.g., as a tool for argumentation). When the degree of consensus is unknown, a propositional attitude generic can be used without fear of contradiction. The statement is true regardless of the actual degree of consensus. When a speaker or writer intends to be appealing the propositional attitude generic also offers a good option. An article captioned “Experts agree…” seems more appealing and more likely to be read than an article captioned “Some experts agree….” It presents a simpler, cleaner conclusion that may also be perceived as more relevant or important (i.e., conclusive new knowledge rather than a work in progress). We also predict that propositional attitude generics will be favoured when a speaker or writer is trying to be persuasive. In this case, the wide scope (possibly all) interpretation of propositional attitude generics can be exploited. It would be truthful to say “Experts believe…” even when that belief is held by only a small minority. Using a propositional attitude generic in this manner could strengthen an argument by implying a greater degree of consensus than really exists, taking advantage of the fact that “Experts believe” is intuitively more convincing than “Some experts believe.” These are all predictions that can be tested experimentally.
In this paper we have identified and described a use of generic language that we refer to as propositional attitude generics. This initial investigation focused on expert consensus, although we anticipate that the results will generalise to other contexts (e.g., “Men think…,” “Children say…,” “People believe…”). We consider any phrase that uses a propositional attitude verb to imply agreement (e.g., “agree,” “concur,” “accept,” “think”) among a defined group (e.g., “astronomers,” “women,” “Hungarians,” “dog owners” etc.) to be a propositional attitude generic (e.g., “Women agree…,” “Astronomers concur…,” “Hungarians think…”). The narrow focus on expert consensus was chosen because generics are common in the reporting of scientific research. One consequence of focusing on ‘experts’ is the conversational implicature that their beliefs (propositional attitudes) are likely to be perceived as true. Experts are generally expected to hold well-informed evidenced-based beliefs. A question for future research is whether the same interpretation would apply to generics in which the belief is presumed to be false (e.g., Conspiracy theorists believe…). Our conclusions only apply to ostensibly true generics, so a fuller understanding of propositional attitude generics requires further research focusing on the interpretation of ostensibly false beliefs. This could have implications for understanding how generics are used to argue for and against certain ideas (e.g., Experts believe theory X, so you should believe theory X vs. Conspiracy theorists believe theory Y, so you should not believe theory Y).
Our results indicate that the use of generic language implies a generally higher degree of consensus than a some-quantified equivalent. If the inferred degree of expert consensus is a heuristic for belief in a given claim (e.g., Van der Linden et al., Citation2019) then the choice of language used in science communication could significantly shape attitudes; “Experts believe the new vaccine is safe” is likely to be associated with more positive attitudes towards a vaccine than “Some experts believe the new vaccine is safe.” Propositional attitude generics may therefore be useful when responsibly promoting uncontroversial claims to the public. On the other hand, they pose a danger of overgeneralisation when broad consensus is not established. Generics may intentionally or unintentionally give unwarranted weight to minority opinions held by only a few experts. It would be true to state that “Experts think…” when only a handful of experts hold the belief, but it would likely lead some members of the public to overestimate scientific consensus. To avoid the risks of overgeneralisation, propositional attitude generics should be used with caution where the objective degree of consensus is unknown.
Supplemental online material.docx
Download MS Word (17 KB)Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability
The pre-registrations, materials, data and code that support the findings of this study are openly available on the Open Science Framework https://osf.io/u4yq8/.
Additional information
Funding
Notes
1 Nuccitelli, D. (2016, January 4). 95% consensus of expert economists: cut carbon pollution. The Guardian. https://www.theguardian.com/environment/climate-consensus-97-per-cent/2016/jan/04/consensus-of-economists-cut-carbon-pollution.
2 Hansen, A. (2018, May 14). Most experts agree: Walking is good exercise. CNN. https://edition.cnn.com/2018/05/14/health/walking-exercise-partner/index.html.
3 Rong-Gong, L. (2021, May 17). Many experts say to keep masks on, as pushback to CDC guidance intensifies. Los Angeles Times. https://www.latimes.com/california/story/2021-05-17/many-experts-say-keep-masks-on-cdc-ruling-backlash.
4 Experts think early humans ate grass (2012, November 12). BBC. https://www.bbc.co.uk/newsround/20302443.
5 Perez, C. (2019, May 23). Experts believe Aladdin may actually be based on a real person. New York Post. https://nypost.com/2019/05/23/experts-believe-aladdin-may-actually-be-based-a-real-person/.
6 Landrum, L. (2019, February 8). Scientists say bees can do basic math. CNN. https://edition.cnn.com/2019/02/08/health/honeybees-learn-math-study-trnd/index.html.
7 Roberts, M. (2013, August 28). Broccoli slows arthritis, researchers think. BBC. https://www.bbc.co.uk/news/health-23847632.
References
- Aust, F., Diedenhofen, B., Ullrich, S., & Musch, J. (2013). Seriousness checks are useful to improve data validity in online research. Behavior Research Methods, 45(2), 527–535. https://doi.org/10.3758/s13428-012-0265-2
- Bowker, M. (2023). A problem for generic generalisations in scientific communication. Journal of Applied Philosophy, 40(1), 123–132. https://doi.org/10.1111/japp.12616
- Bryson, R. (2020, May 30). Experts believe North Essex whale died after impact with ship. Daily Gazette. https://www.gazette-news.co.uk/news/18486157.experts-believe-north-essex-whale-died-impact-ship/
- Champely, S. (2020). pwr: Basic functions for power analysis. R package version 1.3-0. https://CRAN.R-project.org/package=pwr
- Cimpian, A., Brandone, A. C., & Gelman, S. A. (2010). Generic statements require little evidence for acceptance but have powerful implications. Cognitive Science, 34(8), 1452–1482. https://doi.org/10.1111/j.1551-6709.2010.01126.x
- Declerck, R. (1991). The origins of genericity. Linguistics, 29(1), 79–102. https://doi.org/10.1515/ling.1991.29.1.79
- DeJesus, J. M., Callanan, M. A., Solis, G., & Gelman, S. A. (2019). Generic language in scientific communication. Proceedings of the National Academy of Sciences, 116(37), 18370–18377. https://doi.org/10.1073/pnas.1817706116
- DeJesus, J. M., Callanan, M. A., Umscheid, V. A., & Gelman, S. A. (2024). Generic language and reporting practices in developmental journals: Implications for facilitating a more representative cognitive developmental science. Journal of Cognition and Development, 25(2), 273–295. https://doi.org/10.1080/15248372.2023.2290504
- DeJesus, J. M., Umscheid, V. A., & Gelman, S. A. (2021). When gender matters in scientific communication: The role of generic language. Sex Roles, 85(9-10), 577–586. https://doi.org/10.1007/s11199-021-01240-7
- Dor, D. (2003). On newspaper headlines as relevance optimizers. Journal of Pragmatics, 35(5), 695–721. https://doi.org/10.1016/S0378-2166(02)00134-0
- Grice, H. P. (1975). Logic and conversation. In Speech acts (pp. 41–58). Brill. https://doi.org/10.1163/9789004368811_003
- Haigh, M., & Birch, H. A. (2021). When ‘scientists say’ coffee is good for you one day and bad for you the next: Do generic attributions to ‘scientists’ and ‘experts’ amplify perceived conflict? Collabra: Psychology, 7(1), 23447. https://doi.org/10.1525/collabra.23447
- Haigh, M., Birch, H. A., & Pollet, T. V. (2020). Does ‘scientists believe…’ Imply ‘all scientists believe…’? Individual differences in the interpretation of generic news headlines. Collabra: Psychology, 6(1), 17174. https://doi.org/10.1525/collabra.17174
- Holtgraves, T., & Bray, K. (2022). US liberals and conservatives live in different (linguistic) worlds: Ideological differences when interpreting business conversations. Journal of Applied Social Psychology, 53(7), 674–683. https://doi.org/10.1111/jasp.12930
- Lemeire, O. (2024). Why use generic language in science? The British Journal for the Philosophy of Science. In press. https://doi.org/10.1086/730387
- Leslie, S.-J. (2008). Generics: Cognition and acquisition. The Philosophical Review, 117(1), 1–47.https://doi.org/10.1215/00318108-2007-023
- Leslie, S.-J., & Lerner, A. (2022). Generic generalizations. In E. N. Zalta & U. Nodelman (Eds.), The Stanford encyclopedia of philosophy (Fall 2022 Edition) Stanford University. https://plato.stanford.edu/entries/generics/
- Levinson, S. C. (1983). Pragmatics. Cambridge University Press.
- Nelson, M. (2000). Propositional attitude report. In E. N. Zalta & U. Nodelman (Eds.), The Stanford encyclopedia of philosophy (Spring 2023 Edition). https://plato.stanford.edu/archives/spr2023/entries/prop-attitude-reports/
- Noveck, I. A., & Reboul, A. (2008). Experimental pragmatics: A Gricean turn in the study of language. Trends in Cognitive Sciences, 12(11), 425–431. https://doi.org/10.1016/j.tics.2008.07.009
- Peters, U., Krauss, A., & Braganza, O. (2022). Generalization bias in science. Cognitive Science, 46(9), e13188. https://doi.org/10.1111/cogs.13188
- R Core Team. (2023). R: A Language and Environment for Statistical Computing. Vienna, Austria: R Foundation for Statistical Computing.
- Richard, M. (2006). Propositional attitude ascription. In M. Devitt & R. Hanley (Eds.), The Blackwell guide to the philosophy of language (1st ed., pp. 186–211). Blackwell Publishing. https://doi.org/10.1002/9780470757031.ch10
- Sharpe, D. (2015). Chi-square test is statistically significant: Now what? Practical Assessment, Research, and Evaluation, 20(1), 8. https://doi.org/10.7275/tbfa-x148
- Van der Linden, S. L., Leiserowitz, A. A., Feinberg, G. D., & Maibach, E. W. (2015). The scientific consensus on climate change as a gateway belief: Experimental evidence. Plos One, 10(2), e0118489. https://doi.org/10.1371/journal.pone.0118489
- Van der Linden, S., Leiserowitz, A., & Maibach, E. (2019). The gateway belief model: A large-scale replication. Journal of Environmental Psychology, 62, 49–58. https://doi.org/10.1016/j.jenvp.2019.01.009
- Van Tiel, B., & Schaeken, W. (2017). Processing conversational implicatures: Alternatives and counterfactual reasoning. Cognitive Science, 41(S5), 1119–1154. https://doi.org/10.1111/cogs.12362
- Warnes, G. R., Bolker, B., Lumley, T., & Johnson, R. C. (2018). Gmodels: Various R programming tools for model fitting. https://cran.r-project.org/web/packages/gmodels/