
ABSTRACT
Algorithms are an increasingly important element of internet infrastructure in that they are used to make decisions about everything from mundane music recommendations through to more profound and oftentimes life changing ones such as policing, health care or social benefits. Given algorithmic systems’ impact and sometimes harm on people’s everyday life, information access and agency, awareness of algorithms has the potential to be a critical issue. We, therefore, ask whether having awareness of algorithms or not corresponds to a new reinforced digital divide. This study examines levels of awareness and attitudes toward algorithms across the population of the highly digitized country of Norway. Our exploratory research finds clear demographic differences regarding levels of algorithms awareness. Furthermore, attitudes to algorithm driven recommendations (e.g., YouTube and Spotify), advertisements and content (e.g., personalized news feeds in social media and online newspaper) are associated with both the level of algorithm awareness and demographic variables. A cluster analysis facilitates an algorithm awareness typology of six groups: the unaware, the uncertain, the affirmative, the neutral, the sceptic and the critical.
Introduction
Whether through search engines, social media, or music streaming services, algorithms have become imperative to the internet’s infrastructure. On one hand, algorithms are technological prescriptions and logical instructions created by data engineers, mathematicians and programmers. On the other, algorithms are invisible infrastructure for internet users who consciously or unconsciously follow their instructions. Insofar as algorithms increasingly influence information and content delivery, internet users’ algorithm awareness becomes an issue of agency, public life, and democracy.
Many scholars, belonging to ‘critical algorithm studies’, have argued a need for more insight on algorithms due to their informational and content impact on what people encounter online (Beer, Citation2017; Diakopoulos, Citation2015; Gillespie, Citation2013; Gillespie & Seaver, Citation2016; Kitchin, Citation2017; Oakley, Citation2009; Seaver, Citation2017; Wilson, Citation2017). While algorithms and data-driven models currently underpin the operation of most online platforms, previous research suggests that many people are not necessarily aware that platforms like Facebook use algorithms to filter their feeds (Eslami et al., Citation2015; Smith, Citation2018).
In selecting what information is considered individually relevant, algorithms play a crucial role in providing the condition for information, consumption and participation in public life (Gillespie, Citation2013). Moreover, we are entering a day and age where algorithms assist and are fundamentally embedded in crucial decision-making processes in most sectors of society, including public administration, the media, health care and politics. This fundamental democratic role suggests the need for knowing more about people’s level of knowledge and awareness, not least because algorithms are far from neutral devices but often work to perpetuate structural inequalities and historical bias in sometimes unforeseen ways.
Another theoretical tradition, so-called ‘digital divides studies’, has focused on inequality concerning access to internet infrastructure and computers, as well as divides related to different motivations, skills, user patterns and the broader benefits of digital skills in everyday life (Dutton & Reisdorf, Citation2019; Lutz, Citation2019; van Deursen & Helsper, Citation2015; van Deursen & van Dijk, Citation2014; Zillien & Hargittai, Citation2009). Until now, this tradition has yet to measure awareness of algorithms as part of the digital divide on a national level, focusing more on practical to-do-skills (browse, navigate, make content etc.) and concrete usage (e-mails, social media, entertainment etc.). In line with Hargittai and Micheli’s (Citation2019) identification of algorithm awareness as a variable factor among internet users, we aim to incorporate algorithm awareness and attitudes in digital divide studies.
Working with a representative sample (N = 1624) of the Norwegian population, we examine algorithm awareness, attitudes to specific algorithm-driven functions on the internet, and whether these attitudes are influenced by the level of awareness. Awareness is compared against demographic variables to investigate whether it follows traditional demographic divides (Lutz, Citation2019; van Deursen & Helsper, Citation2015; van Deursen & van Dijk, Citation2014). Via cluster analysis, we develop a typology of algorithm awareness and attitudes among internet users. Finally, we reflect on the implications of our findings for internet users, public life, democracy and digital divides.
Algorithm awareness: related work
Beyond its simple definition, as step-by-step instructions for solving a computational problem, algorithms can be understood as infrastructure for a variety of actions, including business models, commercial transactions and communicative interactions.
From business (Chung et al., Citation2016), journalism (Anderson, Citation2013; Dörr, Citation2016), finance (Lenglet, Citation2011; Pasquale, Citation2015), security (Amoore, Citation2009) and juridical systems (Christin, Citation2017), social scientists have documented how algorithms are restructuring the ways in which key democratic institutions and organizations work and operate. As Diakopoulos (Citation2015, p. 398) argues: ‘We are now living in a world where algorithms, and the data that feed them adjudicate a large array of decisions in our lives […] even how social services like welfare and public safety are managed’. Despite the pervasive role that algorithmic systems are now playing as part of the digital infrastructure of many countries, not much is yet known about the extent to which the general public is aware of their workings or the potentially disruptive changes enforced by algorithmic decision-making.
While there is a growing body of scholarship assembled under the title of ‘critical algorithm studies’ (Gillespie & Seaver, Citation2016), most studies are of largely qualitative or exploratory nature, focusing on thick descriptions of specific sites of algorithmic production, maintenance and decision-making (Geiger, Citation2017; Mackenzie, Citation2015), case studies, for example of algorithmic governance (Introna, Citation2016; Lenglet, Citation2011), or more theoretically-oriented critiques of the power and politics of algorithmic systems (Bucher, Citation2012, Citation2018; Gillespie, Citation2013; van Dijck, Citation2013). A common thread in the burgeoning literature is the notion that algorithms have become powerful information brokers with potentially ‘transformative effects’ (Kitchin, Citation2017, p. 2).
Digital divide studies, which employ sociological approaches to the analysis of population samples (Lutz, Citation2019; van Deursen & Helsper, Citation2015; van Deursen & van Dijk, Citation2014; Zillien & Hargittai, Citation2009) have concentrated on three areas, and the demographic drivers (in particular age, gender and education) of these: (1) having/not having access to physical infrastructure such as broadband/wireless network and computers/mobile phones, (2) to master/not master digital skills, and patterns of internet use, and (3) whether online skills and competencies are beneficial in general. As an extension to the pure demographic explanations in digital divide studies, Dutton and Reisdorf (Citation2019) measure attitudes and beliefs toward the Internet (not algorithms in particular) and clustered them as different ‘cultures of Internet’. The authors argue that these cultures of the internet shape digital divides.
Less visible than the previously identified digital divides – access, skills, usage and general benefits – algorithmic systems affect peoples’ lives in fundamental, but unequal, ways. As information and legal scholars have shown, particularly in the US context, algorithms are used to make decisions about policing, criminal sentencing, employment, college admissions, insurance and social services that amplify and reproduce social inequalities (Eubanks, Citation2018; Noble, Citation2018; O’Neil, Citation2016). O’Neil (Citation2016) for example, argues how predictive policing sustains a disparity in law enforcement by creating ‘pernicious feedback loop’ whereby the criminalization of poverty is further amplified.
Being aware of the algorithms’ functions and impacts on platforms, in services and search engines, and being able to interact with them consciously and critically (as far as it is possible), should, therefore, be regarded as an important digital strength, which we assume is differently distributed in the population.
A small number of studies have investigated internet user awareness of algorithms (Bucher, Citation2017; Eslami et al., Citation2015; Klawitter & Hargittai, Citation2018; Proferes, Citation2017; Rader & Gray, Citation2015). For example, Eslami et al. (Citation2015) recruited 40 Facebook users for a laboratory study that sought to examine perceptions of Facebook’s News Feed algorithms using a combination of test experiments and subsequent interviews. The authors found that more than half of the study participants (62.5%) were completely unaware of the algorithm’s presence. Rader and Gray (Citation2015) employ Amazon Mechanical Turk to survey (N = 464) awareness of the extent to which Facebook curates people’s News Feed posts. In contrast to Eslami et al. (Citation2015), Rader and Gray found that most Facebook users (73%) in their sample believe they do not see every post their friends create, but also that ‘users vary widely in the degree to which they perceive and understand the behaviour of content filtering algorithms’ (Rader & Gray, Citation2015, p. 181). Using a web-based survey of a university-affiliated sample to study user and non-user beliefs about the techno-cultural and socioeconomic facets of Twitter, Proferes (Citation2017) found that a majority of the respondents could correctly identify the mechanisms behind the Trending Topics algorithm. Finally, Klawitter and Hargittai (Citation2018) undertake a qualitative study of sellers on the craft-oriented platform ‘Etsy’ to identify differences in seller skills for navigating the platform’s opaque algorithmic processes.
Still largely missing are representative studies on a national level that inform on the extent to which the general public of digitally developed countries are aware of the algorithms structuring their information and media environment. Though important work is emerging in this area, particularly some US-based studies conducted by the Pew Research Center (Smith, Citation2018), we still know much less about public attitudes and awareness towards algorithm than the enormous scholarly interest in algorithms would suggest.
Our goal is to relate a more empirically situated and quantitative approach to studying algorithm awareness, and a different digital divide, among the population of internet users in a highly digitized country. Extending existing research on both critical algorithm and digital divide studies, we believe that the survey data presented in this article provides a much-needed grounding to the broader and more general claims made about the power and politics of algorithms to date.
Research questions and method
The study responds to the following three research questions that collectively probe the qualities of algorithm awareness as a source of digital divide, and how it best be positioned with respect to dominant digital divide categories:
Is there evidence of relationships between key demographic variables and awareness and attitudes to algorithms?
To what extent is there evidence of attitudinal differences among three distinct algorithmic functions: (i) algorithm-driven recommendations (such as recommended music on Spotify and videos on YouTube, and in principle in all commercial entertainment platforms); (ii) algorithm-driven advertisements (used where ads are part of the business model; in search engines, in social media, on entertainment platforms and on websites) and; (iii) algorithm-driven content (personalized news feeds both in social media and online newspapers)?
Is there evidence of relationships between self-reported levels of algorithm awareness and attitudes towards the three algorithmic processes?
Given the lack of research investigating public awareness of algorithms beyond specific platforms, this study proceeds from an exploratory research approach. We, therefore, investigate the range of variable relationships in responding to the three questions that motivate this study. As a study of algorithmic awareness in relation to online platforms and services, we assume being online to be a prerequisite for awareness. The target audience for this study is, therefore, online participants. In a Norwegian context, where 98% of the population have access to the internet (Statistics Norway, Citation2019) and 95% have a smartphone (Schiro, Citation2019), we consider there to be only a minor difference between our target audience and the general population. The data used in this study draws from a larger web survey, conducted between 15 and 30 November 2018, designed to capture a range of information related to the usage of and attitudes towards digital cultural consumption in Norway (N = 1624). Data were then weighted by gender, age, location, and education to correct for web panel deviation from the Norwegian population. The survey, which consists of 56 open and closed-ended questions, used seven questions to measure respondents’ awareness and knowledge of algorithms (see Appendix). Other questions of potential relevance include background demographic data and questions relating to the use of social media and online participation.
In line with our objective to go beyond a platform specific study of algorithm awareness and investigate a more general awareness of algorithms in Norway, the approach to measuring algorithm awareness is of methodological importance. Hamilton et al. (Citation2014) argue that measuring awareness of algorithms is best done by presenting respondents with a specific algorithm at work, such as Facebook’s filtering of news feeds, and then ask questions that measure user perception of algorithmic processes at work. Eslami et al. (Citation2015) employ this approach to measure Facebook users’ awareness of algorithms. However, because this approach necessitates probing perceptions of algorithms at work on individual platforms (Flynn & Goldsmith, Citation1999) rather than on a more generalized basis, it is considered inappropriate for measuring the non-platform specific algorithm awareness that we seek to measure.
Instead, we adopted the approach of directly asking respondents to indicate their perceived level of awareness of algorithms from a five-point Likert scale that ranged from ‘no awareness’ to ‘very high awareness’. By being asked, ‘What kind of awareness do you have of algorithms being used to present recommendations, advertisements, and other content on the internet?’, respondents self-reported their level of algorithm awareness, and the corresponding data is best understood as a subjective measure of general awareness of algorithms. Although not without limitations, asking respondent to self-report awareness is a commonly used approach in media (Dupagne, Citation2006) and technology studies (Albert & Tedesco, Citation2010) because it remains one the most direct and cost-efficient methods for measuring exposure to media concepts in large samples (Slater, Citation2004). Adopting this approach, measuring algorithm awareness was limited to a single question due to the risk of a suggestibility effect from repeated questions relating to algorithms.
In addition to the closed-ended question on awareness and attitudes, respondents with positive/very positive or negative/very negative attitudes per algorithmic function, were asked to explain their attitudes in open comments. These comments give more detailed information about how the respondents understand and perceive the term algorithms and their diverse functions and processes. The comments were also manually coded to one of four categories based on level of algorithm awareness indicated. While demonstrating algorithm awareness in an open answer response is not a necessary condition for algorithm awareness, we nevertheless used this data to crosscheck the self-reported measure’s validity.
In interpreting the results, it should also be noted that the Norwegian term ‘kjennskap’, as used in the Norwegian language survey, occupies a space between ‘knowledge’ and ‘awareness’ in English. Due to the small knowledge element, all else equal, we would expect a population’s self-reported ‘kjennskap’ to be slightly lower than self-reported ‘awareness’ in the English language.
Data were processed using SPSS, and the analysis of relationships among the categorical data proceeded using a mixture of descriptive analytics, Pearson’s chi-square tests of significance (χ2), Cramer’s V statistic for indicating the strength of association between two variables, and Z tests for significant differences in column proportions.
Cluster analysis involves exploratory analysis of a sample to maximize within cluster homogeneity when non-homogeneity of the overall sample is assumed (Hair et al., Citation2010). A two-step cluster analysis technique was employed based on its suitability for clustering categorical data (Norušis, Citation2011), and was based on clustering respondents around four key variables: (i) self-reported assessment of algorithm awareness; (ii) attitudes to algorithm-driven recommendations; (iii) attitudes to algorithm-driven advertisements; and (iv) attitudes to algorithm-driven content. A 5% noise handling restriction was applied to the clustering procedure. The optimal cluster solution was chosen based on Schwarz’s Bayesian information criterion (Norušis, Citation2011), and then validated via three steps: ensuring the silhouette measure of cohesion and separation exceeds 0.0 (Norušis, Citation2011); checking Chi-square tests indicate significant association between the each of the four categorical variables and the cluster types; ensuring there is a similar proportion of cases spread across a not too large number of clusters (Norušis, Citation2011). Following validation, clusters were then identified via descriptive analysis against key demographic variables. In this final step, Chi-square and ANOVA tests were used to test for significant association between clusters and the relevant demographic variables.
Study limitations
Although this study provides novel findings regarding algorithm awareness in a highly digitized context, it is nevertheless subject to limitations. Potentially problematic is the use of self-reported data for measuring awareness and attitudes to algorithms. Although Hargittai (Citation2009) finds that people are generally truthful in self-reported surveys concerning online knowledge, two separate issues impact how the awareness measure is interpreted. Firstly, self-reported perception of awareness may be influenced by personality traits, such as self-confidence, as much as actual awareness (Mondak, Citation1999). Secondly, a respondent’s actual level of awareness may affect his or her understanding of the scale of awareness, meaning one’s perception of awareness need not rise with actual awareness. Finally, despite high levels of online connectivity among the Norwegian population, the survey data reflects the attitudes and options of those with ease of online access and any biases this might promote.
Findings on algorithm awareness
One of our stated aims is to determine whether there are significant differences in the level of algorithm awareness across the Norwegian population. Therefore, we begin our analysis by examining the results connected to our measure of algorithm awareness ().
Table 1. Levels of algorithm awareness among Norwegian population, 2018 (N = 1624).
Given the lack of directly comparable studies, we began with no hypotheses nor specific expectations regarding how our measure of awareness ought to be distributed. The results indicate that 41% of the Norwegian population perceive that they have no awareness of algorithms. Twenty one per cent report low awareness, 26% some awareness, 10% high awareness and only 3% indicate that they have very high awareness of algorithms. Supporting the validity of these results, we find significant and strong association (χ2 = 256.1, p < .001; Cramer’s V = 0.515) between self-reported level of algorithm awareness and the level of algorithm awareness indicated in open answer comments. Performing cross-tabulation against key demographic variables, we find significant differences in levels of algorithm awareness with respect to age, education, geographic location, and gender. Starting with age, points to a generational divide in algorithm awareness. ‘No awareness’ of algorithms is highest among the older respondents, while the two highest level of awareness is found among the youngest age groups.
Table 2. Distribution of algorithm awareness by age group, 2018 (N = 1624).
Education is a very important driver of digital divides (van Deursen & van Dijk, Citation2014), so it is not surprising that education level is strongly associated with algorithm awareness. As indicates, the proportion with ‘no awareness’ or ‘low awareness’ is highest among the least educated group (68% versus 50% and 44%), while the most educated cohort disproportionally indicates ‘high’ and ‘very high’ levels of awareness (23% versus 14% and 10%).
Table 3. Distribution of algorithm awareness by education, 2018 (N = 1624).
There is a significant association between gender and the algorithm awareness measure, with men perceiving higher levels of algorithm awareness than women. Educational differences do not offer a clear explanation for this result. While the male group has a slightly higher percentage with post-graduate attainment (10% compared to 9%), data otherwise points to males having lower educational levels. Several studies have examined whether gender is a determinant of overconfidence where the self-reporting of knowledge is required. In the absence of conclusive findings (Moore & Dev, Citation2018), we are reluctant to suggest that gender-related overconfidence is an additional factor driving the results ().
Table 4. Distribution of algorithm awareness by gender, 2018 (N = 1624).
In terms of geographic location, respondents were categorized as living within (23%) or outside (77%) Norway’s five most populated urban areas. Respondents in these urban areas have a disproportionately higher percentage with ‘high’ (40%) and ‘very high awareness’ (41%). Further probing reveals significant association between location and education (p < .001), and a significantly lower average age (p = .003) for respondents in urban areas (42.3 years) compared to non-urban areas (46.1 years). While we can conclude that an internet user’s location is associated with general algorithm awareness, one should take into account the degree to which location also acts a proxy for both education and age.
In response to one of the core questions raised – Are there demographic differences with respect to awareness of algorithms? – we find clear evidence that demographic factors are strongly associated with an algorithm awareness gap.
Findings on attitude
The survey asks about users’ attitudes towards three different algorithmic-driven phenomena that users typically encounter online: (1) recommendations in digital entertainment services such as Spotify and YouTube (2) advertisements; and (3) the actual content presented (as exemplified by edited news-feeds in social media). Only respondents who indicated ‘low awareness’ of algorithms or greater were asked indicate their attitudes ().
Figure 1. Distribution of attitudes for each of algorithm-driven recommendations, advertisements, and contents (news) (N = 1048).
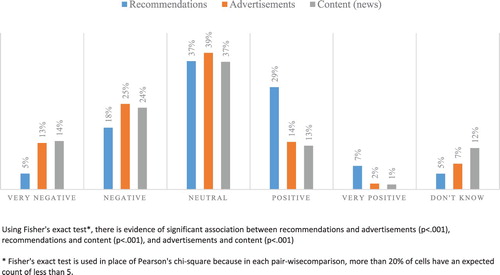
Of immediate interest is whether there is evidence of a difference in attitudes across the three algorithm-driven forms. Fisher’s exact test provides evidence of strong association between all three variables.
Comparing key demographic variables against the three algorithm attitude variables, there is mixed evidence of relationships. Gender is significantly associated with attitude towards algorithm-driven recommendations (p = .014), advertisements (p < .001), and content (p = .039). With comments such as ‘Matches my interests very well’ or ‘I do not like others to control what I find on the web’, males tend to indicate more distinct attitudes (i.e., very positive, positive, negative, very negative) while females are more likely to indicate neutral attitudes or ‘don’t know’. This difference is strongest in relation to algorithm-driven advertising and weakest in relation to algorithm-driven content.
Age is significantly associated with each of the three attitudes towards algorithms. Relative to other groups, those under 30 have a higher percentage with positive and very positive attitudes towards the three algorithm functions, and a lower percentage indicating neutral attitudes or ‘don’t know’. ‘Easier’, ‘I find new things I wouldn’t have otherwise found’, and ‘I don’t see monitoring being a problem for the average person’ are common sentiments expressed by category. The 30–49 age group is characterized by higher negative and very negative attitudes towards algorithm-driven advertisements and content. Over 50-year olds are distinguished by higher neutral or ‘don’t know’ attitudes towards the three forms of algorithm-driven information. A perceived lack of knowledge of algorithms, or a sense themselves knowing what they like and acting on it, capture many comments in this age and attitudinal category ().
Table 5. Attitudes towards algorithms by age (N = 1048, ‘<30’ = 347, ‘30 to 49’ = 413, ‘50+’ = 288).
In relation to education, we find evidence of a significant relationship between education and algorithm-driven recommendations (p = .012) and content (p = .046), but not in relation to algorithm-driven advertisements (p = .111). Those with short tertiary education display proportionally higher ‘negative’ attitudes towards recommendations, while those with long tertiary education are over-represented by ‘very negative’ attitudes toward all three algorithmic functions. While analysis of open comments reveals both educational categories to be concerned with privacy and suitability of the recommendations, the highest educated group indicates stronger concerns over censorship ().
Table 6. Attitudes towards algorithms by education level (N = 964a).
Finally, there is evidence that geographic location is related to attitude towards algorithm-driven advertisements (p = .026) and content (p = .046) but not recommendations (p = .210). Those living in the most populated urban areas hold proportionally greater ‘negative’ and ‘very negative’ attitudes towards both algorithm driven advertisements and content.
Awareness and attitudes – related variables
The significance of relationship between level of awareness and each of the three measures of attitude towards algorithmic function is tested using Pearson’s chi-square statistic. Doing so provides evidence that self-reported level of algorithm awareness is significantly associated with their attitude to algorithm-driven recommendations (p < 0.001), advertisements (p < 0.001), and content (p < 0.001). For each type of algorithm-driven information, those indicating ‘high’ and ‘very high’ self-perceptions of awareness tend to hold more clearly positive or negative attitudes towards recommendations, while those holding ‘don’t know’ or have ‘neutral’ attitudes is highest among respondents with low algorithm awareness.
Typology of algorithm awareness
Cluster analysis was conducted on the data corresponding to internet users who indicated low or higher levels of awareness of algorithms (N = 964), since only these respondents were prompted to state attitudes to the three algorithmic functions. Two-step clustering of the four relevant variables resulted in an optimal solution of five clusters. Ensuring the validity of the five cluster solution, the silhouette measure of cohesion and separation is 0.2, the chi-square test reveals significant association between the clusters and each of the four clustering variables (p-value < .001 in all cases), and the ratio of the largest cluster size that of the smallest is an acceptable 1.33. Given the five clusters reflect internet users with low or higher levels of awareness, an additional sixth cluster was added to capture the remaining respondents who indicated no algorithm awareness in the survey. The resulting six clusters are labelled: unaware, uncertain, affirmative, neutral, sceptic and critical.
The unaware
The ‘unaware’ (40.6% of the sample) perceives no awareness of algorithms and is, therefore, not prompted to state attitudes towards algorithm-driven recommendations, advertisements, or content. This type has the oldest average age (53.1 years), has a significantly higher percentage of women (59%), and has a significantly higher proportion of people with secondary school as highest educational attainment (77%), and in relation to the average of our sample, contains significantly higher proportion living in non-urban areas (80%) compared to those living in major urban areas.
The uncertain
The ‘uncertain’ (12.5% of the sample) predominately perceives low awareness of algorithms (82%). While they hold neutral (63%) to positive (25%) attitudes to algorithm-driven recommendations on entertainment platforms as Spotify and YouTube, this group displays more neutral attitudes towards algorithm-driven advertisements (89%), and neutral (66%), negative (13%) or don’t know (15%) attitudes towards personalized content in social media and online newspapers. ‘I don’t think they suit me very well, but sometimes something interesting comes up’ and ‘Don’t know enough on the topic’ are two commentary responses that capture reoccurring sentiments to algorithms. With an average age of 40.9 years and 32% of this group under 30, this group is younger than the average of our sample. Additionally, members of this group are significantly more likely to be male (65%). Otherwise, this type does not deviate significantly from the sample average in terms of education and geographic spread.
The affirmative
The ‘affirmative’ (11.6% of the sample) perceives low (23%) to high (28%) levels of algorithm awareness, centred around some awareness (44%). Their attitudes to algorithm-driven recommendations on entertainment platforms as Spotify and YouTube tend to be positive (79%), as is their attitude towards algorithm-driven advertisements (64% positive, 20% neutral). Slightly fewer hold positive attitudes (54%) towards personalized content in social media and online newspapers (54% positive, 23% neutral). Directed towards recommendations, but repeated across the three algorithmic functions, one respondent captures this type’s affirmative sentiment. ‘ … I feel the information they obtain cannot hurt me and thus the customized recommendations are mostly positive’. This group has the youngest average age (34.2) and is dominated by the 15–19 (27%) and 30–39 (24%) age brackets. This type is significantly more likely to be male (63%), and the group is significantly overrepresented by those living in the major urban areas (30%).
The neutral
We term this group the ‘neutral’ (10.8% of the sample) due to their perception of some awareness of algorithms (100%), yet the dominance of neutral attitudes. More specifically, they hold neutral (62%) to positive (27%) attitudes towards algorithm-driven recommendations on entertainment platforms as Spotify and YouTube, and slightly more negative attitudes towards both algorithm-driven advertisements (82% neutral, 15% negative) and content (64% neutral, 21% negative). In addition to higher levels of algorithm awareness, this group can be distinguished from the uncertain type though the reoccurrence of a more reflected yet neutral set of attitudes. One respondent neatly captures this quality in commenting, ‘There are both positive and negative aspects to this. It’s okay to get recommendations, but don’t really like the feeling of being monitored’. Compared to the sample, they are slightly younger (39.1 years) with a relatively high proportion in the 40–49 age bracket (24%) and are over-represented by those with short tertiary education (30%). Otherwise, their gender and locational attributes align with the sample averages.
The sceptic
The ‘sceptic’ (14.4% of the sample) perceives low (48%) to some (52%) algorithm awareness, and they predominately hold negative (42%) or neutral (33%) attitudes towards algorithm-driven recommendations on entertainment platforms as Spotify and YouTube. They either hold more strongly negative or undecided attitudes towards algorithm-driven advertisements (59% are negative, 24% don’t know) and algorithm-driven content in social media and online newspapers (49% are negative, 26% don’t know). Repetition of comments such as ‘not very interested in the recommendations’, ‘[I] feel there is too much tracking’, and ‘controlling’ illustrates three important sources of scepticism towards algorithms among this type. At 45.0, this group’s average age differs little from the sample average. However, this cluster contains a relatively high proportion of people in the 30–39 year old range (25%). The spread of gender and location aligns with the sample average, while the group has a significantly higher proportion with short tertiary education (29%) relative to the sample average (23%).
The critical
The ‘critical’ (10.0% of the sample) is characterized by a perception of high algorithm awareness (43% high awareness, 29% some awareness, 19% very high awareness), predominately negative attitudes towards algorithm-driven recommendations on entertainment platforms as Spotify and YouTube, (36% negative, 24% very negative, 19% neutral), and predominately very negative attitudes towards algorithm-driven advertisements (62% very negative, 26% negative) and personalized content (59% very negative, 19% negative, 17% neutral). Capturing the dominant attitudes of this type, one respondent lists their concerns: ‘Fear of the algorithms being used to manipulate. Afraid that it may act as a form of censorship. It’s fine with everything you get to see, but what about everything you can’t see’. They are younger than population-sample average (39.1 years), and are particularly over-represented in the 30–39 age bracket (33%). This type is also over-represented by males (65%), contains a significantly higher proportion living in major urban areas (36%), and has significantly higher proportion with a long tertiary education (20%).
Discussion and conclusion
Our findings suggest a rather bleak picture. If algorithms play a crucial role in providing the conditions for participation in public life, lack of awareness seems to pose a democratic challenge. As our survey findings suggest, 61% of the Norwegian population report having no or low awareness of algorithms.
We will briefly discuss some implications of our main findings, in dialogue with both the critical algorithm perspective and digital divide studies. The notion of infrastructure is important in a critical perspective. Derived from a combination of the Latin prefix ‘infra’, meaning ‘below’ and ‘structure’, this suggests that thinking of algorithms ‘infrastructurally’ means that they do not merely enable information flows, but actively intervene and shape those very flows. In structuring the environment in important ways, emphasizing the role of infrastructure’s human elements becomes critical, for example, ‘the ways an infrastructure can structurally exclude some people (e.g., deaf, blind, or wheelchair-bound individuals)’ (Plantin et al., Citation2018, p. 4). Knowing more about the structural forces that shape the Web is not just an online navigational skill, but a necessary condition managing information as an informed citizen. While the ‘unaware type’ in our cluster analysis may be approached as a problem of digital or algorithmic literacy, the ‘critical type’ can be considered the most digitally literate.
In a Western democratic context, the digital divide is no longer primarily about access to the Internet or access to equipment such as PCs or mobile phones (first level of digital divide), but still about skills and usage (second level of digital divide), and general benefits (third level of digital divide), as shown in many studies. Where should we place users’ awareness of algorithms among these levels? It does not fit the access level; it concerns skills and usage, but awareness is not the same as practical to-do-skills and concrete usage; and it may have to do with benefits, but more indirectly. When Klawitter and Hargittai (Citation2018) use the term ‘algorithmic skills’, they refer to and analyse creative entrepreneurs’ understanding and know-how of how algorithms influence their content’s visibility. Managing visibility (and trade) through using the algorithmic infrastructure (e.g., search engines and social media) is a skill. This is what marketers and the new profession of SEO, search engine optimization, work with. Defining internet skills as a person’s ‘ability to use the Internet effectively and efficiently’, Hargittai and Micheli (Citation2019, p. 109) characterize internet skills as having both a technical and social dimension. From this perspective, Hargittai and Micheli argue that ‘awareness of how algorithms influence what people see’ is one of ten internet skills that determine levels of social and economic inclusion. Making a subtle but important deviation from their position, algorithm awareness is better understood as a meta-skill, a knowledge or understanding that may improve other digital skills and benefits in general.
Being aware of and navigating consciously on the Internet infrastructure could be seen as a new and reinforced level of digital divide. It is more subtle, more difficult to cope with than other skills, and at least as powerful as other skills and usage-based divisions. On the other hand, one might argue that algorithmic awareness and literacy, as a meta-skill, are necessary conditions for an enlightened and rewarding online life.
Lack of such awareness may also have consequences on a societal level; for public participation and democracy. With an algorithmic infrastructure that automatically amplifies existing patterns through machine-learning mechanisms, there is a greater risk of reinforcing whatever democratic deficit existed in the first place, weakening the condition for an informed public and democratic participation.
The digital gap between being algorithm aware or not, increases with machine learning algorithms and ditto infrastructure. Continually evolving ‘smart’ structures that depend on user input to grow, suggest that users are ‘complicit’ and actively involved in shaping the information environment. It seems, then, that not only does a lack of algorithm awareness pose a threat to democratic participation in terms of access to information, but that users are performatively involved in shaping their own conditions of information access. The question is how this co-responsibility that is largely hidden affects how we think of democratic participation and publics to begin with. A ‘smart’ infrastructure, which largely depends on user input, seems to place new demands on users in a way that rule-based algorithmic infrastructure did not. In the current age, the internet user can be regarded as a so-called ‘prosumer’ of the infrastructure – both producing and consuming. It is then relevant to ask: To what extent will the user also be held responsible for it – a ‘you-get-the-infrastructure-you-deserve-logic’?
Finally, peoples’ education seems to become more and more critical for online skills, usage and benefits. As underlined by van Deursen and van Dijk (Citation2014), both age and gender differences may be temporary phenomena, while the differences in education might be more permanent. As for traditional demographic characteristics, our survey findings support traditional demographic digital divides. These demographic digital divides raise the question of who gets to make informed decisions about how to navigate the digital infrastructure conditioning information flow and public participation today. Although rather small in terms of the larger findings, it is worth pondering the fact that the higher the awareness of algorithms, which correlates with the higher levels of education, the more negative are the attitudes towards them. The digital divide between the ‘sceptical type’/‘critical type’ and the ‘unaware type’ in our algorithm awareness cluster, exacerbated by smart machine learning infrastructure, may drive an even deeper digital divide than skills, usage and benefits have already done. It might not only reproduce the existing inequalities in societies, but also accelerate them in unforeseen and unanticipated ways. New divides are created based on the uneven distribution of data and knowledge, between those who have the means to question the processes of datafication and those who lack the necessary resources (Park & Humphry, Citation2019). We, therefore, agree with recent scholarly calls for ‘data justice’ that advocate developing a better understanding of how social justice is challenged and changed as a result of a data-driven arrangements (Dencik et al., Citation2016, Citation2019).
As a new direction for bridging research between digital divide and critical algorithm studies, this study and its findings point to several important areas for future research. We conclude by listing several of these: (1) developing alternative survey methodologies for measuring algorithm awareness, self-reported or otherwise; (2) testing evidence of correlation between self-report algorithm awareness and internet-based skills and benefits; (3) performing other national surveys to test whether the types we identify are consistent across cultural, society, and time-based differences; (4) studying algorithm awareness and attitudes as part of internet cultures, (5) performing quantitative studies of algorithms as part of discourses and the knowledge apparatus, and; (6) further developing theoretical and methodological synergies between critical algorithm perspectives and digital divide studies.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors
Anne-Britt Gran
Anne-Britt Gran is professor of Culture and Arts Management, and director of the Centre for Creative Industries at BI Norwegian Business School. She has researched modern theatre history, postmodernism and post colonialism, cultural policy, cultural sponsorship, and digital cultural consumption and digitization. Gran lead the ‘Digitalization and Diversity’ research project [email: [email protected]].
Peter Booth
Peter Booth is postdoctoral fellow in the Centre for Creative Industries at BI Norwegian School of Management. His research covers cultural economics, theories of value, sociology of art and finance, and issues connecting arts, digitization and diversity [email: [email protected]].
Taina Bucher
Taina Bucher is Associate Professor at the Department of Media and Communication, University of Oslo. She is the author of IF...THEN: Algorithmic power and politics (OUP, 2018), and she has published extensively on the cultural and social aspects of software, and how people make sense of algorithms in their everyday lives [email: [email protected]].
References
- Albert, W., & Tedesco, D. (2010). Reliability of self-reported awareness measures based on eye tracking. Journal of Usability Studies, 5(2), 50–64.
- Amoore, L. (2009). Algorithmic war: everyday Geographies of the war on terror. Antipode, 41(1), 49–69. https://doi.org/10.1111/j.1467-8330.2008.00655.x
- Anderson, C. (2013). Towards a sociology of computational and algorithmic journalism. New Media & Society, 15(7), 1005–1021. https://doi.org/10.1177/1461444812465137
- Beer, D. (2017). The social power of algorithms. Information Communication and Society, 20(1), 1–13. https://doi.org/10.1080/1369118X.2016.1216147
- Bucher, T. (2012). Want to be on the top? Algorithmic power and the threat of invisibility on Facebook. New Media and Society, 14(7), 1164–1180. https://doi.org/10.1177/1461444812440159
- Bucher, T. (2017). The algorithmic imaginary: exploring the ordinary affects of Facebook algorithms. Information, Communication & Society, 20(1), 30–44. https://doi.org/10.1080/1369118X.2016.1154086
- Bucher, T. (2018). If..then: algorithmic power and politics. New York: Oxford University Press.
- Christin, A. (2017). Algorithms in practice: Comparing web journalism and criminal justice. Big Data & Society, 4(2), 1–14. https://doi.org/10.1177/2053951717718855
- Chung, T. S., Wedel, M., & Rust, R. T. (2016). Adaptive personalization using social networks. Journal of the Academy of Marketing Science, 44(1), 66–87. https://doi.org/10.1007/s11747-015-0441-x
- Dencik, L., Hintz, A., & Cable, J. (2016). Towards data justice? The ambiguity of anti-surveillance resistance in political activism. Big Data & Society, 3(2). https://doi.org/10.1177/2053951716679678
- Dencik, L., Hintz, A., Redden, J., & Treré, E. (2019). Exploring data justice: Conceptions, applications and directions. Information, Communication & Society, 22(7), 873–881. https://doi.org/10.1080/1369118X.2019.1606268
- Diakopoulos, N. (2015). Algorithmic accountability. Digital Journalism, 3(3), 398–415. https://doi.org/10.1080/21670811.2014.976411
- Dörr, K. N. (2016). Mapping the field of algorithmic journalism. Digital Journalism, 4(6), 700–722. https://doi.org/10.1080/21670811.2015.1096748
- Dupagne, M. (2006). Predictors of consumer digital television awareness in the United States. Communication Research Reports, 23(2), 119–128. https://doi.org/10.1080/08824090600669095
- Dutton, W. H., & Reisdorf, B. C. (2019). Cultural divides and digital inequalities: attitudes shaping internet and social media divides. Information Communication and Society, 22(1), 18–38. https://doi.org/10.1080/1369118X.2017.1353640
- Eslami, M., Rickman, A., Vaccaro, K., Aleyasen, A., Vuong, A., Karahalios, K., Hamilton, K., & Sandvig, C. (2015). I always assumed that I wasn’t really that close to [her]: Reasoning about invisible algorithms in news feeds. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems (pp. 153–162). ACM.
- Eubanks, V. (2018). Automating inequality : How high-tech tools profile, police, and punish the poor. St. Martin’s Press.
- Flynn, L. R., & Goldsmith, R. E. (1999). A short, reliable measure of subjective knowledge. Journal of Business Research, 46(1), 57–66. https://doi.org/10.1016/S0148-2963(98)00057-5
- Geiger, R. S. (2017). Beyond opening up the black box: Investigating the role of algorithmic systems in Wikipedian organizational culture. Big Data & Society, 4(2), 1–14. https://doi.org/10.1177/2053951717730735
- Gillespie, T. (2013). The relevance of algorithms. In T. Gillespie, P. Boczkowski, & K. Foot (Eds.), Media technologies: Essays on communication, materiality, and society (pp. 167–194). MIT Press.
- Gillespie, T., & Seaver, N. (2016). Critical algorithm studies: A reading list.
- Hair, J. F., Black, W. C., Babin, B. J., & Anderson, R. E. (2010). Multivariate data analysis. Pearson custom library.
- Hamilton, K., Karahalios, K., Sandvig, C., & Eslami, M. (2014). A path to understanding the effects of algorithm awareness. In CHI ’14 extended abstracts on human factors in computing systems (pp. 631–642). ACM.
- Hargittai, E. (2009). An update on survey measures of web-oriented digital literacy. Social Science Computer Review, 27(1), 130–137. https://doi.org/10.1177/0894439308318213
- Hargittai, E., & Micheli, M. (2019). Internet skills and why they matter. In M. Graham & W. H. Dutton (Eds.), Society and the internet: How networks of information and communication are changing our lives (pp. 109–124). Oxford University Press.
- Introna, L. D. (2016). Algorithms, governance, and governmentality. Science, Technology, & Human Values, 41(1), 17–49. https://doi.org/10.1177/0162243915587360
- Kitchin, R. (2017). Thinking critically about and researching algorithms. Information, Communication & Society, 20(1), 14–29. https://doi.org/10.1080/1369118X.2016.1154087
- Klawitter, E., & Hargittai, E. (2018). “It’s like learning a whole other language”: The role of algorithmic skills in the curation of creative goods. International Journal of Communication, 12, 3490–3510.
- Lenglet, M. (2011). Conflicting codes and codings. Theory, Culture & Society, 28(6), 44–66. https://doi.org/10.1177/0263276411417444
- Lutz, C. (2019). Digital inequalities in the age of artificial intelligence and big data. Human Behavior and Emerging Technologies, 1(2), 141–148. https://doi.org/10.1002/hbe2.140
- Mackenzie, A. (2015). The production of prediction: What does machine learning want? European Journal of Cultural Studies, 18(4-5), 429–445. https://doi.org/10.1177/1367549415577384
- Mondak, J. J. (1999). Reconsidering the measurement of political knowledge. Political Analysis, 8(01), 57–82. https://doi.org/10.1093/oxfordjournals.pan.a029805
- Moore, D. A., & Dev, A. S. (2018). Individual differences in overconfidence. In V. Zeigler-Hill & T. K. Shackelford (Eds.), Encyclopedia of personality and individual differences. Springer US. http://osf.io/hzk6q
- Noble, S. U. (2018). Algorithms of oppression : How search engines reinforce racism. NYU Press.
- Norušis, M. J. (2011). IBM SPSS statistics 19 advanced statistical procedures companion. Manual Spss.
- Oakley, K. (2009). From Bohemia to Britart – Art students over 50 years. Cultural Trends, 18(4), 281–294. https://doi.org/10.1080/09548960903268105
- O’Neil, C. (2016). Weapons of math destruction : How big data increases inequality and threatens democracy. Boradway Books.
- Park, S., & Humphry, J. (2019). Exclusion by design: Intersections of social, digital and data exclusion. Information, Communication & Society, 22(7), 934–953. https://doi.org/10.1080/1369118X.2019.1606266
- Pasquale, F. (2015). The black box society: The secret algorithms that control money and information. Harvard University Press.
- Plantin, J.-C., Lagoze, C., Edwards, P. N., & Sandvig, C. (2018). Infrastructure studies meet platform studies in the age of Google and Facebook. New Media & Society, 20(1), 293–310. https://doi.org/10.1177/1461444816661553
- Proferes, N. (2017). Information flow solipsism in an exploratory study of beliefs about Twitter. Social Media + Society, 3(1). https://doi.org/10.1177/2056305117698493
- Rader, E., & Gray, R. (2015). Understanding user beliefs about algorithmic curation in the facebook news feed. In Proceedings of the 33rd annual ACM conference on human factors in computing systems - CHI ’15 (pp. 173–182). ACM Press.
- Schiro, E. C. (2019). Norsk mediebarometer 2018. Statistics Norway.
- Seaver, N. (2017). Algorithms as culture: Some tactics for the ethnography of algorithmic systems. Big Data & Society, 4(2), 1–12. https://doi.org/10.1177/2053951717738104
- Slater, B. M. D. (2004). Exposure : Foundation of media effects. Jurnalism and Mass Communication Quarterly, 81(1), 168–183. https://doi.org/10.1177/107769900408100112
- Smith, A. (2018). Many Facebook users don’t understand how the site’s news feed works.
- Statistics Norway. (2019). Bruk av IKT i husholdningene.
- van Deursen, A., & Helsper, E. (2015). The third-level digital divide: Who benefits most from being online? In L. Robinson, S. Cotten, & J. Schulz (Eds.), Studies in media and communications: Vol. 10. Communication and information technologies annual (pp. 29–52). Emerald Group Publishing Limited.
- van Deursen, A., & van Dijk, J. (2014). The digital divide shifts to differences in usage. New Media & Society, 16(3), 507–526. https://doi.org/10.1177/1461444813487959
- van Dijck, J. (2013). The culture of connectivity : A critical history of social media. Oxford University Press.
- Wilson, M. (2017). Algorithms (and the) everyday. Information Communication and Society, 20(1), 137–150. https://doi.org/10.1080/1369118X.2016.1200645
- Zillien, N., & Hargittai, E. (2009). Digital distinction: Status-specific types of internet usage. Social Science Quarterly, 90(2), 274–291. https://doi.org/10.1111/j.1540-6237.2009.00617.x