
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
This paper deals with a generalization of the Bass model for the description of the diffusion of innovations. The generalization keeps into account heterogeneity of the interactions of the consumers and is expressed by a system of several nonlinear differential equations on complex networks. The following contributions can be singled out: first, explicit algorithms are provided for the construction of various families of assortative scale-free networks; second, a method is provided for the identification of the takeoff time and of the peak time, which represent important turning points in the life cycle of an innovation/product; third, the emergence of specific patterns in connection with networks of the same family is observed, whose tentative interpretation is then given. Also, a comparison with an alternative approach is given, within which adoption times of different communities are evaluated of a network describing firm cooperations in South Tyrol.
1. Introduction
The findings described in this paper are related to the identification of the time at which the adoption rate of new products in a community of variously interconnected individuals reaches its maximum and of the takeoff time, another quantity of interest in the marketing perspective. The investigation of this problem is carried out here within a framework which extends on complex networks the classical Bass model.
Since its first appearance in the Sixties, the Bass model [Citation1] for the description of the innovation diffusion process has been extensively applied (the reviews [Citation2] and [Citation3] provide several references in this connection). Also, during the course of time, several versions of this model have been formulated, which provide generalizations in a variety of directions (see, e.g. [Citation4,Citation5]). The original version is expressed by a single ordinary differential equation, in fact a Riccati one, which is, albeit non-linear, analytically solvable. Its solution describes the evolution in time of the number of adopters of new products within a population, as a consequence of two basic factors, innovation and imitation. An aggregate perspective is taken, in that only the cumulative fraction of adopters is considered and, for a fixed product, the two parameters appearing in the equation, the ‘innovation’ and the ‘imitation’ coefficient, are the same for the whole population.
It is, however, to be expected that a thorough investigation keeps into account heterogeneity of the individuals. This can be done in different ways, among whose a significant one is to consider the network of interpersonal connections. Indeed, especially in regard to the imitation aspect of the process, it can make a big difference whether individuals who have already adopted have a few or several contacts [Citation6]. Driven by this motivation, we have introduced in [Citation7,Citation8] a network structure into the model. Specifically, we have considered networks whose nodes have at most a fixed number of links. A first statistical attribute of networks is given by the so-called degree distribution
, which carries information on the fraction of nodes having
links. Further and central importance in relation to the network topology have the degree correlations
, with
expressing the conditional probability that an individual with
links is connected to one with
links. In [Citation7,Citation8], following the approach developed for the study of epidemic spreading on complex networks [Citation9–Citation11], we have reformulated the Bass equation
(in which is the cumulative adopter fraction at the time
, and
and
are the innovation and the imitation coefficient, respectively) into a system of
ordinary differential equations, one for each admissible number of links, of the form
The quantity in (2) represents for any
the fraction of potential adopters with
links that at the time
have adopted the innovation. More precisely, denoting by
the fraction of the total population composed by individuals with
links, who at the time
have adopted, and admitting that, in the end, all individuals will adopt (in analogy with the fact that the solution
of (1) tends to
as
tends to infinity), we set
.
In principle, one could consider at this point different kinds of networks. We dealt with scale-free ones, having degree distribution of the form where
, because it is into this category and with power-law exponent into this range that many real-world networks fall [Citation12,Citation13]. We explored various features of the different link classes for both correlated and uncorrelated networks, comparing results of numerical simulations relative to system (2) with results relative to Equation (1). In particular, to perform this task, we devised an algorithm for the construction of both assortative and disassortative networks.
In this paper, in view of the foreseen application and of the fact that networks in the social sciences are found to be typically assortative [Citation14,Citation15], we further restrict attention to their category. Yet, we observe en passant that in the modelling of diffusion and innovation also networks falling beyond the group of the social ones, notably collaboration networks among firms, may play a part. And in fact, we deal with such a network, disassortative indeed, in Section 5, where an approach alternative to that one based on Equation (2) is discussed.
It is now worth recalling that some procedures designed to construct correlated networks, in fact, exist in the literature. For instance [Citation16], and [Citation17] suggest different rewiring-based algorithms which generate assortatively mixed networks and assortative mixing to a desired degree; in [Citation18] a network model which encompasses addition of both new nodes and new links, meant to mimic a real growing network (a preprint-archive) is introduced; besides [Citation19], and [Citation20] propose models for (assortative and disassortative) complex networks with weighted links. However, precise explicit (not only approximate) expressions for the correlations , suitable to be employed in calculations, can be hardly found in these or other papers. And the numerical solutions of our differential Equation (2) require the knowledge of a set of values of
defined for each
and
and satisfying as well suitable conditions of normalization and network closure, see Section 2. For this reason, we start providing in the next section a few ‘recipes’ towards building correlation matrices of assortative networks. In Section 3 we focus on the identification in the present analytical context of two specific times (takeoff time and peak time) which play a significant role in the life cycle of an innovation/product. Then, we calculate these times for several networks belonging to the families devised in Section 2. A comparison between the degree correlation matrices pertaining to different networks of the same family for each of three families reveals the existence of unexpected patterns, which call for explanation. This is the subject of Section 4, where also a possible interpretation is proposed. Elements of an approach alternative to that based on a mean-field approximation dealt with in Sections 2–4 are discussed in Section 5. In that section also the calculation is done of adoption times of different communities in a network model of firms in South Tyrol. We want to stress however that the purpose of this paper is to construct an analytical framework for the evaluation of the mentioned times, rather than to treat experimental data. Finally, in Section 6, a summary of the results and our conclusions are given.
It may be of interest before continuing to point out how lively and vivid the interest in innovation dynamics and spreading phenomena still is. As the following few but indicative recent references show, research related to these topics keeps growing and branching out into a manifold of novel paths. For example, an agent-based model for the description of the Skype technology large-scale adoption process is proposed in [Citation21]. An analysis and a discussion of the diverse roles of rational strategic approaches and serendipity towards the development of innovations are carried out in [Citation22]. An evolutionary game model with interacting innovators and developers is suggested in [Citation23] to investigate to which extent a system is able to maintain innovators. In [Citation24] a model for the emergence of innovations is devised which involves random walks on networks whose nodes represent concepts and ideas. A simple model, inspired by the Lotka-Volterra one regarding competition for common resources occurring among species is employed in [Citation25] to ‘measure the pace’ of collective attention through the inflationary information flows of popular topics and cultural items. Further articles on the subject can be found in the collection [Citation26].
2. Families of assortative networks
We start here by suggesting a practical way for the construction of different families of assortative networks (namely, such that high degree nodes tend to be linked to other high degree nodes, whereas low degree nodes tend to be linked to other low degree nodes). We consider for any fixed natural number a scale-free network with degree distribution
for
(
), with
. We aim at building the
matrices, whose elements are the correlation coefficients
. The reason why this is a delicate task is that the
and
must satisfy, besides the normalizations
and the positivity requirements
also the Network Closure Condition (NCC)
We recall here that the assortativity of a network can be established by looking at the average nearest neighbour degree function
Indeed, if is increasing in
, the network is assortative. Alternatively, one can calculate the Newman assortativity coefficient
(Pearson correlation coefficient) as defined in [Citation14] (see also [Citation27]).
We propose next the construction of three different matrices (in fact, matrix families), starting from a first requirement that their largest elements are on the diagonal, whereas their other elements become smaller and smaller the more apart from the diagonal they are. Notice first that the NCC condition (3) provides a constraint on the correlation matrix elements expressed by
‘Power-like’ family. A first natural choice is that of taking the elements on and above the diagonal as
for some , and the elements under the diagonal, i.e. with
, defined through the formula (5).
Since the normalization has to hold true, we compute for any
the sum
and call
the greatest of these sums:
At this point, we re-define the correlation matrix by setting the elements on the diagonal equal to
and leaving the other elements unchanged. For any the column sum
is then equal to
Finally, we normalize the entire matrix by setting
A number of numerical simulations in correspondence to different values of and
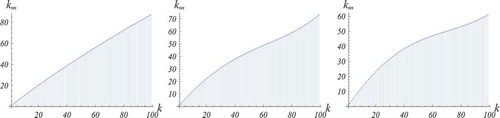
show that the function
is increasing. A graphical representation (for the case in which ,
and
) is given in the left panel of . We then conclude that these correlation matrices define a one-parameter family (
being the parameter) of assortative networks.
Figure 1. The three panels in this figure display the increasing character of the function for networks of the three families introduced in this section. Specifically, the left panel refers to a network of the power-like family, the central panel refers to a network of the linear family, and the right panel refers to a network of the exponential family. In all cases, the maximum number
of links of the network is equal to
, the parameter
(the exponent of the power-law degree distribution) is equal to
Also, the parameters
and
are all equal to
.
‘Linear’ family. Another possibility is to start by defining, for
, the elements on and above the diagonal as
and the elements under the diagonal as in the formula (5).
To get the normalization , one can then apply the same procedure as for the first network family. In this case too,
turns out to be increasing in
suggesting assortativity for the
family of networks with correlations
. A graphical representation of the increasing character of
(for the case in which
,
and
) is given in the central panel of .
‘Exponential’ family. A further possibility is to start by defining the elements on and above the diagonal as
and the elements under the diagonal as in the formula (5).
Once again, the adjustment procedure necessary to get the required normalization is as for the two previous network families. And again, the increasing character of , displayed as a result of a large number of simulations, supports the assortativity of the networks associated to these correlation matrices. The increasing character of
(for the case in which
,
and
) is given in the right panel of .
2.1. Alternative assortative matrices
We briefly outline here an alternative possibility for the construction of assortative networks. It consists in starting by assigning symmetrical correlation matrices of the ‘’ type (excess-degree correlations, with
, see [Citation12,Citation13]) with larger correlation for similar degree, and derive from them the excess-degree distribution
as
and the degree distribution
as
. With suitable choices of
one can obtain, in this way, a degree distribution which is well approximated by a power law. The disadvantage of this procedure is that the degree distribution is not obtained in general in explicit form, but as the sum of a series. Still, this technique can be useful in order to enlarge the choice of the possible assortative correlations.
We recall the relations between ,
and
,
:
where . By definition,
is the fraction of links in the network joining nodes of excess degrees
and
. Therefore, it is always symmetrical. This implies that any set of
,
obtained from a given
automatically satisfy the Network Closure Condition.
As a simple example consider
where is a normalization constant depending on
and determined from the condition
. Taking for instance
,
,
and
respectively for a network with
, we obtain Newman assortativity coefficients
,
,
and
and degree distributions
behaving as
with
,
,
and
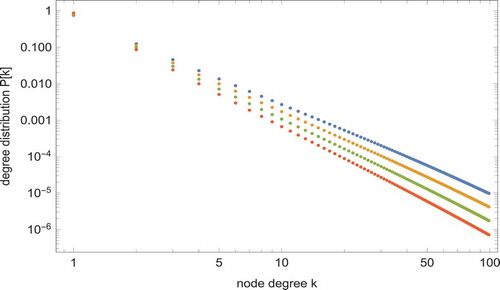
respectivelyFootnote1. shows the log-log plots of these degree distributions.
Figure 2. Log-log plots of the degree distributions obtained for networks with by assigning excess-degree correlations
, with
,
,
and
. The plots are ordered from the upper one (
) to the lower one (
). The degree distributions
behave as
with
,
,
and
respectively.
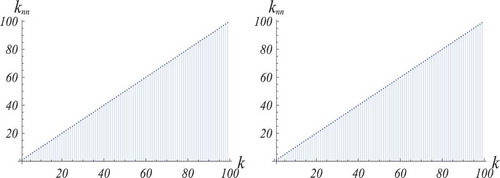
The assortativity of these networks is also evident from the increasing character of their average nearest neighbour degree functions . In those corresponding to
and
are displayed.
Figure 3. The two panels show the increasing character of the function for two networks with a maximum number
of links equal to
and excess-degree correlations as in (12) with
(left panel) and
(right panel).
3. Looking for the adoption peak time
An issue of considerable interest in connection with the diffusion of innovations is the identification of the peak time, which is the time corresponding to the peak of sales in marketing applications. To be more concrete, let , where
is as in the Introduction and the dot denotes the time derivative, denote the fraction of new adoptions per unit time in the ‘link class
’ i.e. in the subset of individuals having
links. And let
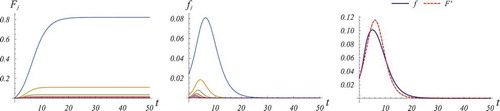
be the total number of new adoptions per unit time. The three panels in help to illustrate the concept. The left panel displays the evolution in time of the population fractions
for
. To fix ideas, an underlying network of the first family with parameters
,
and
has been chosen. The innovation and the imitation coefficients
and
are taken to be equal to
and
, respectively, which are conceivable values employed in the traditional literature on the Bass equationFootnote2. The centre panel shows the evolution in time of the nine functions
, whereas the right panel displays the evolution in time of the function
, together with that one of the function
relative to the original Bass equation. The values of
in correspondence to which the two graphs have a maximum are the peak time of the system on the network (occurring a little bit earlier) and the one of the homogeneous Bass system (occurring a little bit later on) respectively.
Figure 4. The left panel displays the evolution in time of the population fractions in the case of an underlying network of the ‘power-like’ family with parameters
,
and
. The innovation coefficient
is equal to
and the imitation coefficient
is equal to
. The graphs of the functions
, as in the centre panel those of the functions
, are ordered from the upper one (
) to the lower one (
). One may observe that the largest fraction of new adopters belongs at all times to a single link class, the link class with
, which reaches its adoption peak later than the others. The fact that more connected individuals adopt earlier is a general (and rather intuitive) phenomenon. The centre panel shows the evolution in time of the nine functions
, whereas the right panel displays the evolution in time of the function
together with that of the function
relative to the original Bass equation. The values of
in correspondence to which the two graphs have a maximum are the peak time of the system on the network and of the homogeneous Bass system, respectively.
Another time value of interest, especially for industry analysts, for managers and firms producing the innovations, is the so-called takeoff time, which represents the moment when a transition from the initial phase to a growth phase occurs. This time can be found in the context of the generalized Bass model on networks as the time at which the acceleration of the function (which expresses the fraction at time
of the population which has adopted) is maximal and, hence, the third derivative of
vanishes. Equivalently, at this point, the second derivative of
vanishes and the graph of
has an inflection point. Hence, this time also marks the point when, even if sales continue to increase, their increase increment begins diminishing. A portion of the graph of the function
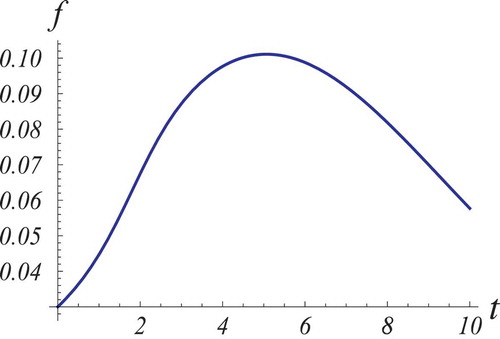
appearing in is displayed in where times have been scaled so as to make evident the existence of an inflection and of a maximum point.
Figure 5. A portion of the graph of the function of is here displayed with time scaling suitable to make evident the existence of an inflection point (the takeoff point) and of a maximum point (the peak point).
We calculated both the takeoff and the peak time for several networks belonging to three families of Section 2. Results relative to a sample of networks for each family are reported in the three , and . There, a specific network is identified by the values of the two parameters and
in the case of the ‘power-like’ family,
and
in the case of the ‘linear’ family,
and
in the case of the ‘exponential’ family. Notice that in the three tables for each network also the assortativity coefficient
is calculated. Also, to improve the readability of the results contained in the tables, is here inserted. The two panels in this figure display two surfaces, respectively, obtained through interpolation of the values of the takeoff time and of the peak time for the ‘power-like’ family in correspondence to the values of the parameters
and
mentioned in . Similar figures for the other two families are qualitatively similar and hence are not reported here.
Figure 6. The panels display two surfaces, respectively, obtained through interpolation of the values of the takeoff time (left panel) and of the peak time (right panel) for the ‘power-like’ family in correspondence to the values of the parameters and
mentioned in . Similar figures for the other two families are qualitatively similar and hence are not reported here.
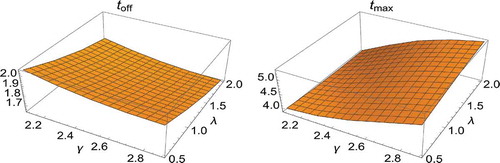
Table 1. This table provides approximate values for the takeoff time, the peak time and the assortativity coefficient of 20 networks of the ‘power-like’ family in Section 2.
Table 2. This table provides approximate values for the takeoff time, the peak time and the assortativity coefficient of 20 networks of the ‘linear’ family in Section 2.
Table 3. This table provides approximate values for the takeoff time, the peak time and the assortativity coefficient of 20 networks of the ‘exponential’ family in Section 2.
4. Emerging patterns
The patterns announced in the Introduction come out as follows: If one fixes a value of the parameter or
or
, depending on which of the three tables relative to the three network families she is considering, it is immediate to check that the peak times increase as the parameter
increases passing from
to
. As well, the takeoff times diminish as
increases. It is then tempting to try and compare the degree correlation matrices pertaining to networks with different values of
. Somehow surprisingly, it turns out that each time one subtracts the degree correlation matrix of a network with a certain
from the degree correlation matrix of a network with a greater
(keeping the other parameter fixed) one gets a matrix for which all entries below the main diagonal are negative, whereas all elements above the main diagonal are positive. For example, the difference
of the degree correlation matrices of the networks of the ‘linear’ family with
and
and
, respectively, is approximativelyFootnote3
This is an unexpected and curious phenomenon, which calls for explanation or interpretation. As a matter of fact, in a comparison of two networks belonging to a same family among the three ones defined in Section 2, the following can be observed: the correlation matrix of the network for which the takeoff time occurs earlier and the peak time occurs later (consistently with a longer period of major sales) has each entry with
greater [respectively, each entry
with
smaller] than the corresponding entry of the correlation matrix of the other network. It seems then than a greater number of individuals connected to individuals who have less connections than them and equivalently a smaller number of individuals connected to individuals who have more connections than them can have a positive effect on the length of the major sales period. Yet, it has to be stressed that this phenomenon just refers to comparisons between networks within the same family.
Notice that a first glance at , , could induce to conclude that this effect is just the consequence of a greater assortativity. But, a monotonicity character of the assortativity coefficient with respect to the parameter
does not always hold true. This can be observed by looking, for example, at the values of
for networks of the ‘power-like’ family with
. And we found a lack of monotonicity of
also in other simulations.
5. Community effects in the network Bass model
The calculations of the previous sections have been performed in the framework of the mean-field approximation, which is known to work well, under wide conditions, for diffusion processes in two-state systems, including the Bass model and several others [Citation28]. Still, it is interesting to explore the network Bass model also in certain conditions which lie outside the scope of the mean-field approximation.
In [Citation27], we have briefly reported the results of numerical solutions of the network Bass model on Barabasi-Albert networks. These were obtained computing the evolution of each single node, connected to the rest of the network according to the adjacency matrix . In principle, one has to solve a system of
coupled non-linear equations where
is the number of nodes, instead of
equations like in the mean-field approximation (
being the maximum degree present in the network). In fact, however, all the nodes with low degree, which are the overwhelming majority in a scale-free network, are coupled with few other nodes. In contrast, in the mean-field approximation, all the
variables
are completely coupled to each other in all equations, even if with coefficients
which are
In order to study diffusion on Barabasi-Albert networks, we have used in [Citation27] random realizations of the networks, obtained with a preferential attachment algorithm. We have checked that the average diffusion times of the link classes are quite close to the mean-field predictions, even though there can be significant deviations for the single nodes; for instance, considering two nodes of the same degree, one of which is connected to a hub and the other to a peripherical node with low degree, the first node always adopts earlier than the second.
The equation system employed has the form
Such a form can be derived by a first moment closure according to the definition by [Citation29,Citation30]. Indeed, the variable can be considered as the average
(
) of the non-adoption or adoption state of node
(with
respectively equal to 0 and 1) over many stochastic evolutions of the system.
Here we report the results of the application of Equation (13) to a small real network suitable for diffusion studies, namely the network of the Top-150 companies of the year 2017 in our province, South Tyrol. The list of these companies is published annually by the Commerce Chamber of Bolzano on its website. Companies are selected according to certain listed ranking criteria and also declare their commercial partners. The structure of the connected part of the network is visible in and . It has nodes, a global clustering coefficient
and an assortativity coefficient
. The maximum degree is
and the average degree is
. Denoting by
the number of nodes with degree
, the values of
for
are equal to
, whereas the other non-zero elements are
and
. An analysis of the network communities performed with Mathematica according to the Modularity and Spectral criteria allows to spot a few communities, among which the most numerous are those of the two largest hubs, visible on the right. usually very small for high degrees.
Figure 7. The cooperation network of the Top 150 companies in South Tyrol (connected part).
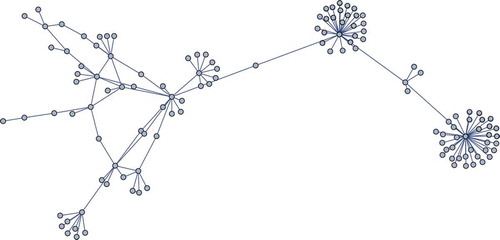
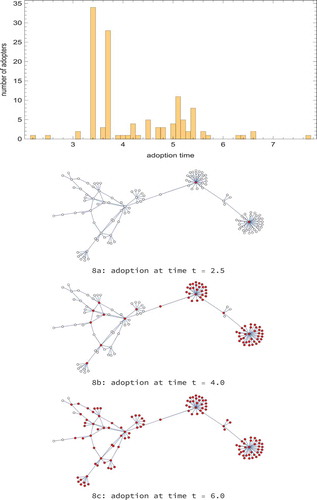
Figure 8. The top panel above shows the distribution of the peak adoption times of the nodes (companies) of the real network of , the cooperation network of the Top 150 companies in South Tyrol, according to the Bass model in the first moment closure (Equation (13)), with parameters ,
. The adoptions in the two largest clusters are clearly visible at times 3.4 and 3.7 and those of their hubs at 2.2 and 2.4. The three panels 8a, 8b, 8c correspond to snapshots of the network at time
,
and
. In each of them, the red ones in the online version (correspondent to the dark ones in the printed version) are the nodes which have adopted, whereas the white ones in the online version (light in the printed version) are the nodes which have not adopted.
Like for the Barabasi-Albert networks mentioned above, the equations system are obtained formally from a first moment closure, but in practice they give a better description of the real situation, because we can suppose that the continuous variable , with
, represents the adoption level of the innovation inside Company
; in other words, whereas in applications of the Bass model to the innovation adoption process of single individuals,
jumps from 0 to 1 in a discontinuous way, here (for companies)
evolves in a continuous way, like the average
for individuals over many realizations.
The detailed solution of the Equations (13) for our real network (depicted in ) displays some interesting features.
(1) Looking at the adoption times of the nodes of degree 1 (compare histogram in ), one finds as expected that those belonging to the same cluster adopt in the same time, since they can be regarded as identical. For instance, in the cluster of the largest hub, their adoption time is (for the hub itself,
); in the cluster of the second-largest hub, the adoption time is
(for the hub:
). What is the origin of the differences between clusters? Clearly, if the hub of a cluster is connected to the rest of the network better than the hub of another cluster, then it will adopt earlier and will consequently ‘infect’ earlier its cluster. In the SI epidemic model, which is equivalent to a Bass model with
(pure contagion, no publicity/innovation term), this would actually be the only possible explanation of the difference between the two hubs. In the Bass model, however, the publicity term plays an essential role, because each degree-1 node in a cluster has an ‘individual’ adoption probability due to the
-term and independent of the state of its neighbours. After adoption, each degree-1 node tends to infect its hub, and the hub, in turn, re-destributes the influence on the whole cluster. In the end, therefore, the largest hubs tend to adopt earlier, like parents of large families where each kid keeps bringing home new ideas or gadgets.
(2) Since the network contains, as also evident from , two large communities with different adoption times, if we plot the curves of the total adoption rates for each of these communities, their peaks are shifted. Therefore, the
curve for the entire network will have a multi-modal character; even if this does not show up in separate peaks, the consequence is that the plot of
is deformed in comparison to the standard logistic curve of the homogeneous Bass model (and also compared to the curve of the network Bass model in mean-field approximation). It is possible to check this deformation by trying, with no success, to fit
with the usual Bass logistic function
, where
. All this must be taken into account when the Bass diffusion is modelled through an agent-based simulation, like in [Citation5], where the results are fitted with the Bass logistic function.
6. Conclusion
The dynamics of diffusion of innovations and information on social networks have attracted considerable attention in the last years. From the mathematical point of view, the most distinctive feature of a social network is its assortativity, defined in terms of the Newman coefficient and of the average nearest neighbour degree function
. In this work, we have developed new techniques for the construction of assortative correlation matrices and discussed some peculiar features of these matrices. We have then employed the correlation matrices for the numerical computation of the diffusion curves of the Bass model, which is widely used in marketing analysis. The Bass model offers the advantage, in comparison to other epidemic models, that the so-called diffusion peak time and takeoff time are well defined, independently of the initial conditions; they depend only on the empirical model parameters (innovation and imitation coefficient) and on the features of the network (scale-free exponent, assortativity). We have thus been able to study relations between these quantities that can be helpful in the analysis of real diffusion data.
Disclosure statement
No potential conflict of interest was reported by the authors.
Notes
1. Of course, the value of in general changes if a different
is taken.
2. We should point out here that, as explained in [Citation7], when results relative to systems on scale-free networks with different exponents are to be compared, the coefficient
has to be normalized. And this is achieved by dividing
by the average degree of the network
.
3. Notice that several entries seem here to have the same value. In fact, this is simply due to rounding.
References
- F.M. Bass, A new product growth for model consumer durables, Management Sci 15 (1969), pp. 215–227. doi:10.1287/mnsc.15.5.215.
- V. Mahajan, E. Muller, and F.M. Bass, New product diffusion models in marketing: a review and directions for research, J. Marketing 54 (1990), pp. 1–26. doi:10.1177/002224299005400101.
- N. Meade and T. Islam, Modelling and forecasting the diffusion of innovation - a 25-year review, Int. J. Forecasting 22 (2006), pp. 519–545. doi:10.1016/j.ijforecast.2006.01.005.
- R. Guseo and M. Guidolin, Cellular automata and Riccati equation models for diffusion of innovations, Stat. Methods Appl. 17 (2008), pp. 291–308. doi:10.1007/s10260-007-0059-3.
- C.E. Laciana, S.L. Rovere, and G.P. Podestà, Exploring associations between micro-level models of innovation diffusion and emerging macro-level adoption patterns, Physica A 392 (2013), pp. 1873–1884. doi:10.1016/j.physa.2012.12.023.
- R. Pastor Satorras, C. Castellano, P. Van Mieghem, and A. Vespignani, Epidemic processes in complex networks, Rev. Mod. Phys. 87 (2015), pp. 925–979. doi:10.1103/RevModPhys.87.925.
- M.L. Bertotti, J. Brunner, and G. Modanese, The Bass diffusion model on networks with correlations and inhomogeneous advertising, Chaos Soliton Fract 90 (2016), pp. 55–63. doi:10.1016/j.chaos.2016.02.039.
- M.L. Bertotti, J. Brunner, and G. Modanese, Innovation diffusion equations on correlated scale-free networks, Phys. Lett. A 380 (2016), pp. 2475–2479. doi:10.1016/j.physleta.2016.06.003.
- M. Boguna and R. Pastor Satorras, Epidemic spreading in correlated complex networks, Phys. Rev. E 66 (2002), pp. 047104. doi:10.1103/PhysRevE.66.047104.
- M. Boguna, R. Pastor Satorras, and A. Vespignani, Absence of epidemic threshold in scale-free networks with degree correlations, Phys. Rev. Lett. 90 (2003), pp. 028701. doi:10.1103/PhysRevLett.90.094302.
- A. Barrat, M. Barthelemy, and A. Vespignani, Dynamical Processes on Complex Networks, Cambridge University Press, Cambridge, UK, 2008.
- M.E.J. Newman, The structure and function of complex networks, SIAM Review 45 (2003), pp. 167–256. doi:10.1137/S003614450342480.
- A.-L. Barabasi, Network Science, Cambridge University Press, Cambridge, UK, 2016.
- M.E.J. Newman, Assortative mixing in networks, Phys. Rev. Lett. 89 (2002), pp. 208701. doi:10.1103/PhysRevLett.89.208701.
- M.E.J. Newman and J. Park, Why social networks are different from other types of networks, Phys. Rev. E 68 (2003), pp. 036122. doi:10.1103/PhysRevE.68.036122.
- M.E.J. Newman, Mixing patterns in networks, Phys. Rev. E 67 (2003), pp. 026126. doi:10.1103/PhysRevE.67.026126.
- R. Xulvi-Brunet and I.M. Sokolov, Reshuffling scale-free networks: from random to assortative, Phys. Rev. E 70 (2004), pp. 066102. doi:10.1103/PhysRevE.70.066102.
- M. Catanzaro, G. Caldarelli, and L. Pietronero, Assortative model for social networks, Phys. Rev. E 70 (2004), pp. 037101. doi:10.1103/PhysRevE.70.037101.
- Z. Pan, X. Li, and X. Wang, Generalized local-world models for weighted networks, Phys. Rev. E 73 (2006), pp. 056109. doi:10.1103/PhysRevE.73.056109.
- C.C. Leung and H.F. Chau, Weighted assortative and disassortative network model, Physica A 378 (2007), pp. 591–602. doi:10.1016/j.physa.2006.12.022.
- M. Karsai, G. Iñiguez, K. Kaski, and J. Kertész, Complex contagion process in spreading of online innovation, J. Roy. Soc. Interface 11 (2014), pp. 20140694. doi:10.1098/rsif.2014.0694.
- T.M.A. Fink, M. Reeves, R. Palma, and R.S. Farr, Serendipity and strategy in rapid innovation, Nat. Commun. 8 (2017), pp. 2002. doi:10.1038/s41467-017-02042-w.
- G. Armano and M.A. Javarone, The beneficial role of mobility for the emergence of innovation, Sci Rep. 7 (2017), pp. 1781. doi:10.1038/s41598-017-01955-2.
- I. Iacopini, S. Milojević, and V. Latora, Network dynamics of innovation processes, Phys. Rev. Lett. 120 (2018), pp. 048301. doi:10.1103/PhysRevLett.120.048301.
- P. Lorenz-Spreen and B.M. Mnsted, Acceleraing dynamics of collective attention, Nat. Commun. 10 (2019), pp. 1759. doi:10.1038/s41467-019-09311-w.
- S. Lehmann and -Y.-Y. Ahn, Complex Spreading Phenomena in Social Systems, Springer, Cham, CH, 2018.
- M.L. Bertotti and G. Modanese, The Bass diffusion model on finite Barabasi-Albert networks, Complexity 2019 (2019), doi:10.1155/2019/6352657.
- J.P. Gleeson, S. Melnik, J.A. Ward, M.A. Porter, and P.J. Mucha, Accuracy of mean-field theory for dynamics on real-world networks, Phys. Rev. E 85 (2012), pp. 026106. doi:10.1103/PhysRevE.85.026106.
- M.E.J. Newman, Networks. An Introduction, Oxford University Press, Oxford UK, 2010.
- M.A. Porter and J.P. Gleeson, Dynamical Systems on Networks, Springer, Cham CH, 2016.