
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
The present paper introduces a mathematical model for analysing dynamic grain growth. In particular, we show how the characteristic measurements grain volumes, centroids, and central second-order moments at discrete moments in time can be quickly turned into a continuous description of the grain growth process in terms of geometric diagrams (which largely generalize the well-known Voronoi and Laguerre tessellations). We give a theoretical analysis of common optimization-free heuristics in terms of discriminant analysis and evaluate the computational behaviour of our algorithm on real-world data.
1. Introduction
Grain growth is an important field of study in materials science as the resulting grain structures strongly influence the mechanical and physical properties of metals, ceramics, and other polycrystalline materials [Citation1, Citation2]. Although, starting with works of Smith, von Neumann, and Mullins in the 1950s [Citation3–5], a number of different models have been introduced over the years, understanding and controlling grain growth remains challenging, both in theory and practice. For instance, the recent empirical study [Citation6] demonstrates that neither the classical Hillert model [Citation7] nor the MacPherson–Srolovitz model [Citation8] capture anisotropic grain growth adequately. Even more drastically, [Citation9] concludes that ‘a new model for grain boundary migration is needed to predict microstructure evolution’; see also [Citation10–13].
The present paper introduces and analyses a novel tool which, when applied to real data, provides an empirical grain growth representation that can be used to analyse physical models and simulate grain growth. More precisely, we develop a mathematical interpolation/extrapolation model for quickly turning grain information acquired at discrete moments in time into a continuous description of the grain growth process. It employs diagram representations of grain maps (which will be formally introduced in Section 2) based on measured (or simulated) estimates of the grain volumes, centroids, and, if available, central second-order moments. Such characteristics can be obtained, for instance, by utilizing tomographic techniques [Citation1, Citation14] or from otherwise available grain maps.
The diagram representations considered in this paper are anisotropic generalizations of previously used (isotropic) Laguerre and Voronoi tessellations [Citation15–17] and allow for curved boundaries and non-convex grains. While these representations are based on a phenomenological model whose physical foundation is still not fully understood, they have consistently been reported to capture the grain boundaries in polycrystalline materials quite accurately; see [Citation18–25].
Several sophisticated optimization algorithms are available for computing or approximating such diagrams with high accuracy, [Citation18, Citation20], but they require relatively large computational cost. This can be a bottleneck, particularly in dynamic 3D studies. We therefore focus in the present paper on extremely fast optimization-free heuristics for fitting diagrams to measured data. Methods for the related but generally different task of generating synthetic grain structures that follow a given distribution are discussed in [Citation26–30].
First, we use discriminant analysis to interpret, for the first time in literature, a heuristic (subsequently referred to as H1) which was introduced in [Citation15] for the isotropic case and extended in [Citation25] to the anisotropic case. Our analysis leads naturally to an even simpler and faster heuristic H2, proposed in [Citation19], which, again for the first time, can now be explained to perform equally well under certain conditions. Also, the comparison of H1 and H2 and, in particular, our interpretation of the so-called size parameters, suggests that diagram parameters may provide additional insight into the stage of the growth process, and this will be used later on in the paper. Our theoretical foundation of the heuristics is then empirically verified. In fact, we apply H1 and H2 to real-world 3D grain map data in order to compare their quality. Then, we introduce an interpolation/extrapolation model to obtain a continuous description of the grain growth process based on measurements at only a few moments in time. Finally, we evaluate the computational behaviour of our algorithm on a real-world data set yielding an empirical grain growth model. Our study indicates that the growth process converges towards particularly simple diagrams, which seem to be energetically favourable.
The paper is organized as follows. Section 2 introduces the relevant diagrams and formalizes the concept of grain scans. Sections 3 and 4 address optimization-free heuristics, both, in terms of a theoretical analysis and a practical evaluation on real-world data. Section 5 introduces the interpolation/extrapolation model which is capable of extending measurements at a few time steps to a continuous grain growth model very quickly. Further, the results of our empirical study on practical grain data are presented. Section 6 concludes with some final remarks.
2. Diagrams and grain scans
Adequate representations of grain maps can be valuable tools for understanding the physical principles of grain growth and the properties of the resulting material. In fact, the diagram representations studied in this paper require only a few parameters per grain and are thus relatively easy to process. As they exhibit geometric and combinatorial features of grain maps which are not readily available otherwise, such representations may contribute to predicting and, potentially, even controlling the forming of new materials.
Some or all parameters which specify a diagram can be estimated from certain tomographic measurements, and optimizing the remaining ones then constitutes an inverse problem; see [Citation31]. Previous studies [Citation18–25] indicate that, in particular, grain volumes, centroids, and central second-order moments govern decisive properties of grain maps.
Let us now formally introduce the appropriate class of diagrams. Let denote the dimension of space. Here, we are mainly interested in the 3 dimensional case. However, our approach works for general d, and, in fact, planar sections or surfaces of polycrystals are also relevant in practice. Further, let
denote the number of different grains in the underlying grain map. An anisotropic power diagram is specified by the following data for each
:
a positive definite symmetric matrix
,
a site
size
For simpler reference, we collect these parameters in the two families and
, where repetitions of elements are permitted, and the set
. The sites specify the positions of the grains while the matrices in
describe characteristics of their shapes. In fact, each grain is equipped with its own ellipsoidal norm
given through
by
The sizes
are used to control the grain volume.
Given , S, and
, the anisotropic power diagram (in the following often simply referred to as diagram)
is a decomposition of
into cells
defined by
In particular, two different cells do not share interior points, i.e.
for
. See [Citation32, Citation33] for examples and further properties of different classes of diagrams.
Diagrams can be viewed as continuous (or resolution-independent) representations of polycrystalline samples. Conventionally, the samples are represented as voxel-based digital images at some resolution, called grain maps. More generally, given a set of points in the sample and labels, i.e.
, with
denoting again the number of different grains in the sample, we will call the labeled data set
a grain scan or polycrystal scan. In the following, we refer to it as
with the understanding, that the indices of the labels in the family
correspond to the indices of the points in X. A grain scan therefore provides a partitioning of X into
, the (discretizations of the) grains.
We can measure the fit of the diagram in terms of the symmetric difference of and
for all
. (Points on the boundary of two or more cells are assigned according to some preference criterion or, conservatively, can be viewed as classification error, but are essentially irrelevant in our context and hence generally discarded.)
Usual grain maps are special grain scans where the sample is assumed to be in the range and points of X are identified with the points of
in the grid
for some resolution
. Note that, with
, the term
can be regarded as an approximation of the volume
of the ith grain.
If a grain scan is available the computation of a best fitting diagram requires the optimization of all three characteristics , S, and
. While this can indeed be done, see [Citation20, Citation31], it is, however, too time-consuming, given current optimization technology, for dynamic 3D applications. Hence, we will in the following assume that
and S are available through measurements and
will be determined by a heuristic which may, additionally, use grain volume information, i.e. (approximations of)
. As such heuristics abstain from any optimization, they are computationally fast but potentially result in a higher misclassification error.
3. Optimization-free heuristics
This section considers two heuristics that derive all characteristic parameters for an anisotropic power diagram directly from given measurements. These heuristics, introduced in [Citation15, Citation19, Citation25], avoid optimization routines altogether, are fast and, as we will see, already provide a reasonable classification accuracy. More specifically, we provide a new interpretation of the heuristics within the framework of discriminant analysis.
3.1. Choices for and S
Discriminant analysis is a popular classification technique in statistics and provides a different perspective on the a priori choices for the characteristic parameters ); see e.g. [Citation34]. Within its realm, the grain scan is regarded as a sample of the multivariate random variable
where
specifies a point in
and
gives the index
of the corresponding grain. Discriminant analysis estimates the distribution of the multivariate random variable from samples and assigns a point to the class with the highest probability p. Hence, the decision boundary between two classes
consists of those points x that have an equal conditional probability of lying in either class, i.e.
For its estimation, discriminant analysis applies the maximum likelihood principle under the assumption that the members from each class are normally distributed. As each normal distribution
is fully determined by its d-dimensional mean vector
and its
-covariance matrix
, it is these characteristics that need to be estimated. It is well known that the maximum likelihood principle results in the choices of the sites S as the centroids and the matrices
as the inverse of the covariance matrices of the sample, i.e. more precisely,
for
. Note that the latter requires that the matrices
have full rank d. This can be assumed here as, in the underlying model, grains that are degenerate to volume 0 do not matter. The above maximum likelihood setting is precisely the choice for
and S suggested in [Citation18], and subsequently also used in [Citation25]. Also, estimates for these parameters are available through tomographic measurement.
Let us point out that, in practice, discriminant analysis is often applied even when the underlying assumption of a normal distribution is only met approximately (as is the case here). This is justified as the procedure is generally reported to be quite robust; see, e.g. [Citation35].
3.2. Choices for Γ
We will now turn to the third set of characteristics, i.e. the sizes . We show first that the choice of
in heuristic H1 can also be interpreted within the paradigm of discriminant analysis with a specific prior. Building on this interpretation, a different natural choice will lead to H2.
To begin with, let us briefly recall the volume argument of [Citation15] and (in its anisotropic generality) [Citation25] that leads to the specific choice for in heuristic H1.
Let be positive definite and symmetric. As A can be diagonalized there exist an orthogonal matrix
and a diagonal matrix
with
such that
. Then, using the abbreviation
, we have for the unit ball
and
Hence, the volume
of this ellipsoid is given by
Regarding the ellipsoid
as an approximation of the ith grain, it is now natural to choose
according to the volume condition
involving the available approximation
for the volume of the ith grain. A simple computation yields
For d = 3, and with the specific setting of
, this yields the choice
from [Citation15, Citation25] (the heuristic H1). In order to interpret this choice via discriminant analysis, we determine which probability distribution, called prior, will lead to the same decision boundaries between the classes. So, let
Then
specifies the a priori ‘belief’ about the prior probability
that a point (regardless of its position) belongs to cluster i, i.e.
The computation of the decision boundary is then facilitated via Bayes' Theorem. As each class is assumed to be normally distributed, Bayes' Theorem involves the conditional density functions
of the k estimated normal distributions
i.e. with
In this situation, Bayes' Theorem states that
Therefore, the maximum likelihood decision boundaries between two classes
can be determined by solving the equation
Taking the logarithm, using that
, and simplifying, this condition turns into the equation
Hence, these decision boundaries coincide with that of the diagram with the parameters
if and only if
where
is an arbitrary constant. (Recall that the diagrams are invariant under such common additions to the sizes.) For the above choice of the sizes in H1, we hence obtain
Since
the first factor is proportional to the volume of the ellipsoid
. The second factor is a ‘correction term’ which increases exponentially if the measured grain volume
exceeds
. The first term seems natural while the second is quite unusual.
Within the realm of discriminant analysis it appears reasonable to simply set for all clusters i. Then we obtain the priors
which are proportional to the volumes of the ellipsoids corresponding to the covariance matrices of the grains. Thus, this simpler prior distribution encodes the assumption that the ellipsoid volumes already represent the grain volumes well. This justifies the choice
proposed in [Citation19]. We will refer to the respective heuristic as H2.
In the next section we compare the behaviour of H1 and H2 on available real-world grain scans.
4. Comparison of H1 and H2
We compare the two heuristics H1 and H2 on a real-world 3D grain scan and indicate how their difference can be interpreted. This may be of particular interest for understanding the state of a grain growth process and will be taken up in Section 5.
4.1. Experimental evaluation
We compare the methods with a data set taken from [Citation15] that has been obtained by a synchrotron micro-tomograph experiment conducted on a metastable beta titanium alloy (Ti β21S). The material was scanned with the volume of 240μm × 240μm × 420μm at a resolution corresponding to a voxel size of 0.7 μm. This scan resulted in a 3D voxel image of size composed of a total of 591 grains. All our computations are carried out in 3D, i.e. d = 3.
In the following, we assess the quality of fit by means of different measures. Let be a diagram (obtained by H1, H2, or, for that matter, any other algorithm). We set
Note that
is not a clustering of X but only of
; this is indicated by writing
rather than C.
A natural measure how well captures the grain scan
is the relative fit or accuracy
of
defined by
Let us point out that, as they are not assigned within
, all points on the cell boundaries count as misclassified.
In we will also report on the behaviour with respect to the relative cluster weight error
and the relative deviation of the centroids
and
, and the covariance matrices
and
, respectively. Formally, the relative centroid error and the relative covariance error are defined as
For the latter, we used the spectral norm. This matrix norm measures the largest singular value of the covariance differences and, thus, intuitively captures the difference in the largest singular vectors of the covariance matrices. Note that, as defined, the latter two measures depend on the original physical dimensions of the sample. We refrain from any additional normalization as we do not conduct inter-sample studies here.
Table 1. Comparison of H1 and H2.
We will also address combinatorial features. More precisely, we consider the percentage of grains with a correct neighbourhood, i.e. with all grain neighbours in the ground truth being also neighbours in the representation. Here, a grain is a neighbour of another grain if a voxel of the former grain is adjacent (face-connected, edge-connected or vertex-connected) to a voxel of the later grain. We also provide this percentage when one and, respectively, two errors in the neighbourhood are allowed, i.e. when there is either one additional or one missing voxel.
The results of our evaluation are shown in .
Let us point out that the displayed running times involve the heuristics but, for a fairer comparison, do not include the computation of the performance criteria. Hence, the entry 0 for the running time of H2 refers to the fact that all parameters defining are given upfront. Also, while we exercised appropriate care for the implementations, we do not claim that our code is fully optimized.
In terms of fit, we observe that both heuristics perform extremely well, in fact, almost identical, on the given real-world data set. We will now offer an explanation for the latter behaviour.
4.2. Similarity and difference
While both heuristics, H1 and H2, employ the same matrices and sites S, they generally differ in the sizes
of the resulting diagrams. Hence, the nearly identical performance depicted in for all applied quality criteria may come as a surprise. As observed before, the priors underlying H1 and H2 denoted
and
as before, differ by a factor that depends exponentially on the deviation of
from the measured grain volume
.
Now, let be a positive real number such that
Then, for each
,
and, expressed in terms of the sizes
used in H1, we obtain
(1)
(1) Now, suppose that all factors
are identical, i.e.
for some positive real number α independent of i. Then, of course,
Hence, the (normalized) priors for H1 and H2 coincide, which implies that the maximum likelihood decision boundaries for the two heuristics are the same. Further, since diagrams are invariant under the addition of a constant to each size, the diagrams produced by H1 and H2 are identical.
We suspect that grain structures for which the volumes of the unit balls with respect to
are nearly proportional to the grain volumes
might turn out to be energetically favourable. According to the above reasoning, the former may be quantified by the variance of the powers
computed in H1, i.e.
As an example, we will in Section 5 compute the evolution of
at different moments in time for a real-world 3D grain growth process. In terms of H1 and H2, we might expect that if the two heuristics perform differently in practice, the current grain structure will not be energetically minimal, and further growth will result in an improved structure.
We close this section with a ‘constructed’ theoretical example which sheds some additional light on the behaviour of the two heuristics. Since the general principle of the construction is the same in higher dimension and can, hence, already be illustrated in 2D we restrict the following description to the case d = 2.
As depicted in the top row of , the image consists of two grains and
; one (orange [light gray]) is the square
for different values of
, the other (blue [gray]) is its complement in
Of course, one would not expect such samples to originate from real-world grain scans. The bottom row of shows the corresponding ellipses
with respect to
.
Figure 1. A family of grain scans involving a parameter β to illustrate differences between H1 and H2. Top, from left to right: Grain scans for ,
, and
. Grain
(orange [light gray]) fills the square
,
(blue [gray]) fills the rest of the unit square. The bottom row shows the computed ellipses
with
for i = 1, 2.
![Figure 1. A family of grain scans involving a parameter β to illustrate differences between H1 and H2. Top, from left to right: Grain scans for β=0.1, β=0.5, and β=0.9. Grain G1 (orange [light gray]) fills the square [0,β]×[0,β], G2 (blue [gray]) fills the rest of the unit square. The bottom row shows the computed ellipses ci+BAi2 with Ai=(Σ(Gi))−1 for i = 1, 2.](/cms/asset/e22424c1-c71c-4d84-8438-032b0a35874b/tphm_a_2180679_f0001_oc.jpg)
As argued before, the variance of the ratios is a relevant parameter. therefore provides plots of
as a function of β.
Figure 2. Ratios of the areas of the grain and the corresponding ellipsoid for i = 1 (orange [light gray]) and i = 2 (blue [gray]) as a function of β.
![Figure 2. Ratios νi/vol(BAi2) of the areas of the grain and the corresponding ellipsoid for i = 1 (orange [light gray]) and i = 2 (blue [gray]) as a function of β.](/cms/asset/878b484e-131b-434f-b924-d82816560e71/tphm_a_2180679_f0002_oc.jpg)
Note that these ratios differ considerably for larger values of β. Hence, we would expect that the heuristics H1 and H2 behave quite differently in these cases. This is confirmed by the resulting diagrams depicted in .
Figure 3. Diagrams for the family of grain scans from obtained via H1 (top row) and H2 (bottom row).

The behaviour for suggests that H1 tries to preserve the areas of the grains, while H2 seems to favour their shapes. If the relevant volume ratios are close, as is the case for small β, both heuristics achieve both aims and perform similarly.
shows the ratios of the grain volume and the areas of the diagram cells under the two models H1 and H2, respectively.
Figure 4. Ratio of the area of the original grain and the area of the corresponding diagram cell obtained by H1 (left) and H2 (right) for i = 1 (orange [light gray]) and i = 2 (blue [gray]) as a function of β.
![Figure 4. Ratio of the area νi of the original grain and the area of the corresponding diagram cell obtained by H1 (left) and H2 (right) for i = 1 (orange [light gray]) and i = 2 (blue [gray]) as a function of β.](/cms/asset/47422b7e-9631-460c-8ee4-92c50e725ef4/tphm_a_2180679_f0004_oc.jpg)
5. Dynamic grain models
We now describe a simple interpolation/extrapolation model that is capable of quickly turning information acquired at a few moments in time into a continuous description of the grain growth process. To demonstrate the potential of the model, we then report on the results of an empirical evaluation on a real-world grain scan time series. Finally, we study for this empirical model the correlation between the diagram size parameters Γ and the disappearance of grains in the process.
5.1. The model
Since well-chosen diagrams have been demonstrated to yield high-quality representations of grain structures of many types of polycrystalline materials, it is natural to exploit their rather low-dimensional parameter space for deriving continuous models from data measured at discrete times. Recall that a diagram is fully characterized by the triple . In order to simulate the dynamic evolution of grain structures over time, we can fit a polynomial (or any other desired type of function) for each diagram parameter extracted from a discrete-time series polycrystal data set. These functions then represent the continuous change in diagram parameters during the growth process. Understanding the evolution of the diagram parameters over time may help predict changes in the material during an annealing process and may provide further insights into the material characteristics.
Suppose, that 3D-grain scans (or at least appropriate characteristic measurements) are available at the discrete times . Then we compute, for each
, the parameters of an anisotropic power diagram
which represent the grain scans. Subsequently, we select a class
of parameterized functions and determine their parameters that best fit the data
In our experimental setting we choose polynomials of a small degree to avoid overfitting, and we measure the fit in terms of least-squares deviation.
In 3D, the interpolation/extrapolation involves a class consisting of 10 functions for each grain, three for the coordinates of the diagram sites, three for the rotation part of the grain's covariance matrix, three for the length of the principal axis of the covariance matrix, and one for the size parameter. Of course, in order to set up the computation of the functions, we need to ‘track’ each grain, i.e. we need to identify which grain corresponds to which at the different moments t in time.
During the grain growth process, grains may disappear. We assume, however, that no new grains emerge. In the experimental series that will be described in more detail below, about of all initially present grains disappeared throughout the process. Hence we distinguish between such non-persistent grains and persistent grains that exist throughout the observed time interval. Of, course, for non-persistent grains, the functions are fitted only as long as the grain ‘definitely exists’. More specifically, if a previously existing grain disappears from the measurement, we choose as last diagram parameters the covariance matrix from the previous time step and compute a size parameter such that its grain volume is essentially zero. If, on the other hand, for some moment in time our prediction generates a covariance matrix and a size parameter which result in a grain volume close to zero, we exclude the grain from further consideration.
The diagrams can, in principle, be computed by any suitable method. In addition to the obvious criteria that any employed algorithm should be computationally fast and produce diagrams of appropriate accuracy, one has to pay attention to its behaviour concerning the invariances within the parameter space to avoid corruption of the interpolation/extrapolation. As we will be using the heuristic H1 described in Section 3, all parameters are, however, uniquely determined by the measurements, and we can hence, in the following, ignore this issue.
5.2. The data
For our experimental study, we use the data set from [Citation6, Citation36] (details of the data processing chain, from experiment to grain scan, can be found there and, in particular, in their supplementary materials sections). The data set, obtained by a diffraction contrast tomography (DCT) [Citation37, Citation38] experiment at beamline ID11 at the European Synchrotron Radiation Facility (ESRF), comprises 15 3D-grain scans (voxelized grain maps) of a 99.9% pure polycrystalline iron sample taken at different moments in time of an annealing process. More precisely, the material was first cold-rolled and annealed for 30 min at to fully recrystallize before it was first scanned (time
Subsequently, the sample was annealed at a constant temperature of
for 10 min leading to grain growth, cooled to stabilize, and scanned again (time
. This was repeated another 13 times with annealing periods of 5 min (time
). The effect of the growth process is already visible by the number of grains in the sample. While the first scan exhibits 1327 grains, the last one contains only 776, and the number of interior grains strictly decreases from 387 to 189; see [Citation6, Table 1] for more details. The identification of grains over the 15 moments in time is already provided by in [Citation6, Citation36].
For this data set, i.e. for each 3D-grain scan at we computed an anisotropic power diagram
representing the respective grain scan. For the computations, we used H1 as we were also interested in featuring the temporal development of the corresponding size parameters in view of the relation of H1 and H2 elaborated in Section 3.
5.3. Evaluation
We apply a cross-validation to assess the quality of the model. To compute the accuracy at time we exclude the data for
and fit the functions of
on the data for the remaining times
Then, by evaluating these functions at time
we obtain the diagram parameters
and hence the diagram
Computing
the accuracy of
representing the 3D-grain scan G at
gives us finally the accuracy (of the model) at time
In other words, we perform a leave-one-out cross validation using (in all combinations) one observation for validation and 14 observations for fitting.
The results for polynomials of degree 1, 2, and 3 are depicted in in yellow [light gray], orange [gray], and red [dark gray], respectively. Let us point out that the piecewise linear curves which connect the 15 data points for each colour are only drawn for a better perception of the trends over time.
Figure 5. Accuracy (within the cross-validation paradigm) of the interpolation/extrapolation model plotted for each using polynomials of degree 1, 2, and 3, respectively for the fit.
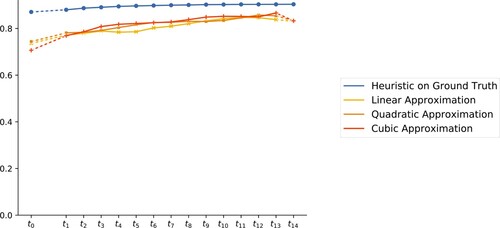
We observe that the degree of the employed polynomials does not seem to have a strong impact on the fit. It would be interesting to link this observation to the ‘uniform setup’ in terms of the actions over time of the underlying grain growth process.
As an additional reference the blue [black] markers give an upper ‘orientation’ for the accuracy that one may expect from the model. In fact, the blue [black] markers depict the accuracy of H1 at each of the 15 time steps. The curves are dashed at both ends to signify that the model changes from interpolation to extrapolation at these extremes. Also, note that the earlier annealing times differ from the latter ones.
shows that the accuracy of our models is generally high. With quadratic polynomials, we obtain an initial accuracy of 74%, which increases over time to approximately 86% for later time steps. Note that this is not much below the accuracy obtained by H1 on the ground truth. The general trend that accuracy increases with time (and hence prediction becomes easier) for this data set is in perfect agreement of the findings in [Citation6, Citation36], which show that over time the system approaches the self-similar regime.
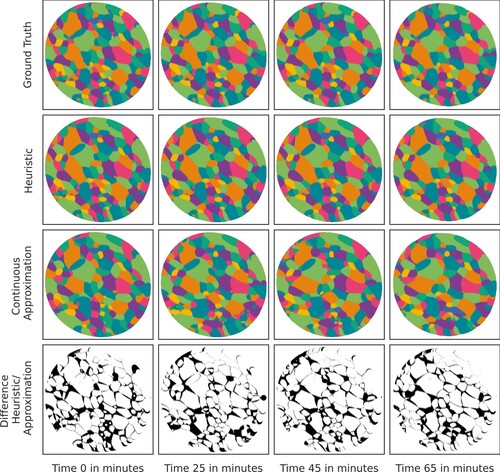
shows a fixed 2D slice of the 3D polycrystal at various moments in time and the diagrams resulting from our model (in the cross-validation scheme described above).
Figure 6. Visual comparison of diagrams obtained from full data (available for ) and the interpolation/extrapolation model that uses all data except for the respective moment in time. A fixed 2D slice through the 3D data set at times
,
,
and
(top row); the corresponding diagram representation obtained via H1 (2nd row) and, respectively, via the interpolation/extrapolation model that uses only data from the other moments in time and best-fitting quadratic polynomials (3rd row); symmetric difference between the images from the 2nd and 3rd row (bottom row).
A discussion of the question how much the fit can be further improved by optimizing over all three sets of parameters that define the anisotropic power diagrams can be found in [Citation31].
5.4. Size variation
In the remaining part of this section, we study how the growth process affects the size parameters (recall that they need not correlate with grain sizes and they should not, at this point, be confused with often similarly denoted interfacial energy terms; we have provided an interpretation in terms of scaling factors in Equation (Equation1
(1)
(1) )). As shows, the accuracy of the model increases with the duration of the process. This may be seen as an indication that the employed diagram structures are energetically favourable. Complementing the analysis of Section 4, we will now empirically study how the size parameters
of the diagrams change as the grains grow.
Let us begin by recalling the interpretation for the similarities and differences of H1 and H2. In fact, based on the analysis of Section 4 we suspected that for persistent grains the variances of the powers of the sizes chosen by H1 should be significantly smaller than for non-persistent grains (as the latter might not be energetically favourable). As and show, these variances are indeed all small and significantly smaller for the persistent grains. This means, on the one hand, that the scaling factors
from Equation (Equation1
(1)
(1) ) do not vary much, and we might as well have employed the simpler heuristic H2. On the other hand, in terms of the
non-persistent grains are less ‘regular’ than persistent grains.
Table 2. Variance of for
of persistent grains.
Table 3. Variance of for
of non-persistent grains.
A closer look at shows that, perhaps unexpectedly, the variance of does not decrease monotonously in time, not even for persistent grains. One might have anticipated that over time the behaviour of the volumes of the unit balls
with respect to
become increasingly similar to that of the grain volumes
. The actual behaviour might be explained by grain disappearance with neighbouring grains filling the newly available space such that it might require additional energy to reach a more regular mass distribution.
5.5. Grain disappearance
Next, we use a standard logistic regression model for predicting the probability of the binary response variable which signifies whether grain i disappears (response value 1) at the next observed moment t + 1 or not (response value 0). As predictor variables we use the grain's volume and its size parameter as computed by H1. Hence, we estimate three parameters, factors
and
for each of the two variables and one parameter
for the intercept, i.e. we use the regression model
Note that the parameters
and
are independent of t. Hence, the model is identical for all time steps in the sense that it depends only on the grain characteristic. Our null hypothesis is that neither the size nor volume parameter correlate with grain disappearance. As a significance level we choose 0.05.
depicts the computed coefficients and p-values. Let us, in addition, point out that the McFadden's Pseudo value is 0.322, indicating a good model fit. As it turns out, we can reject the null hypothesis at a significance level of 0.05; the small p-value for
suggests that the diagram size parameter
is statistically significant in this model for predicting grain disappearance.
Table 4. Coefficients estimated by maximum likelihood estimation and their p-values for the described logistic regression model.
We believe it is promising to investigate this further, not least because it agrees with recent experimental evidence from [Citation39, Citation40], which demonstrates that the volume parameter alone is not a good predictor of grain growth (or shrinkage).
6. Final remarks
As we have seen, measurements at discrete times of a grain growth process can be turned into a continuous description of the process using diagram representations. Our findings about the increasing fit of anisotropic diagrams, the variance of and the relevance of the
for predicting grain disappearance indicate that, in the course of the growth process, the grain scans tend towards particularly ‘simple’ diagrams with essentially uniform size parameters.
Since all computations are fast, and can, if necessary, generally even be speeded up by using H2 rather than H1, we believe that the described model has the potential of becoming a practical tool for simulation and further studies of grain growth in practice. A next step is to evaluate the model more extensively on various types of grain scan data. It would be desirable if a consolidating foundation of the model can be achieved based on first principles.
Finally, let us point out that the model allows for some flexibility to incorporate additional insight. It is possible, for instance, to incorporate available characteristics of grain growth into the curve fitting process.
Acknowledgments
We thank Henning Friis Poulsen for fruitful discussions and valuable comments on an earlier version of the present paper. We are also grateful to Henning Friis Poulsen and Allan Lyckegaard for providing the real-world data set used in this paper.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- H.F. Poulsen, Three-dimensional X-ray Diffraction Microscopy: Mapping Polycrystals and Their Dynamics, Springer, Berlin, 2004.
- A. Rollett, G.S. Rohrer, and J. Humphreys, Recrystallization and Related Annealing Phenomena, 3rd ed., Elsevier, Amsterdam, 2017.
- C.S. Smith, Grain shapes and other metallurgical applications of topology, in Metal Interfaces: a seminar on metal interfaces held during the 33rd National Metal Congress and Exposition, October 13-19, American Society for Metals, Detroit (Cleveland), 1952. pp. 65–108.
- J. von Neumann, Discussion of article [3] by C.S.Smith, in Metal Interfaces: a seminar on metal interfaces held during the 33rd National Metal Congress and Exposition, October 13-19, American Society for Metals, Detroit (Cleveland), 1952. pp. 108–110.
- W.W. Mullins, Two-dimensional motion of idealized grain boundaries, J. Appl. Phys. 27 (1956), pp. 900–904.
- J. Zhang, Y. Zhang, W. Ludwig, D. Rowenhorst, P.W. Voorhees, and H.F. Poulsen, Three-dimensional grain growth in pure iron. Part I. Statistics on the grain level, Acta Mater. 156 (2018), pp. 76–85.
- M. Hillert, On the theory of normal and abnormal grain growth, Acta Metall. 13 (1965), pp. 227–238.
- R.D. MacPherson and D.J. Srolovitz, The von Neumann relation generalized to coarsening of three-dimensional microstructures, Nature 446 (2007), pp. 1053–1055.
- A. Bhattacharya, Y.-F. Shen, C.M. Hefferan, S.F. Li, J. Lind, R.M. Suter, C.E. Krill III, and G.S. Rohre, Grain boundary velocity and curvature are not correlated in Ni polycrystals, Science 374 (2021), pp. 189–193.
- J. Han, S.L. Thomas, and D.J. Srolovitz, Grain-boundary kinetics: A unified approach, Prog. Mater. Sci. 98 (2018), pp. 386–476.
- J.H.X. Wang, J. Zhang, J. Luo, Z. Zhang, and Z. Shen, A general mechanism of grain growth-I. Theory, J Materiomics 7 (2021), pp. 1007–1013.
- P.R. Rios and D. Zöllner, Critical assessment 30: Grain growth – unresolved issues, Mater. Sci. Technol. 34 (2018), pp. 629–638.
- D. Zöllner, P.R. Rios, and I. Zlotnikov, Topological transitions: A topological random walk or pure geometric necessity? Comput. Mater. Sci. 166 (2019), pp. 42–56.
- H.F. Poulsen and G.B.M. Vaughan, Multigrain crystallography and three-dimensional grain mapping, in International Tables for Crystallography: Powder Diffraction. Vol. H, International Union of Crystallography, Hoboken, 2019.
- A. Lyckegaard, E.M. Lauridsen, W. Ludwig, R.W. Fonda, and H.F. Poulsen, On the use of Laguerre tessellations for representations of 3D grain structures, Adv. Eng. Mater. 13 (2011), pp. 165–170.
- H. Telley, T.M. Liebling, and A. Mocellin, The Laguerre model of grain growth in two dimensions I Cellular structures viewed as dynamical Laguerre tessellations, Philos. Mag. B 73 (1996), pp. 409–427.
- H. Telley, T.M. Liebling, A. Mocellin, and F. Righetti, Simulating and modelling grain growth as the motion of a weighted Voronoi diagram, Mater. Sci. Forum 94-96 (1992), pp. 301–306.
- A. Alpers, A. Brieden, P. Gritzmann, A. Lyckegaard, and H.F. Poulsen, Generalized balanced power diagrams for 3D representations of polycrystals, Philos. Mag. 95 (2015), pp. 1016–1028.
- H. Altendorf, F. Latourte, D. Jeulin, M. Faessel, and L. Saintoyant, 3D reconstruction of a multiscale microstructure by anisotropic tessellation models, Image Anal. Stereol. 33 (2014), p. 121.
- L. Petrich, O. Furat, M. Wang, C.E. Krill III, and V. Schmidt, Efficient fitting of 3D tessellations to curved polycrystalline grain boundaries, Front. Mater. 8 (2021), Article ID 760602.
- O. Šedivý, T. Brereton, D. Westhoff, L. Polívka, V. Beneš, V. Schmidt, and A. Jëger, 3D reconstruction of grains in polycrystalline materials using a tessellation model with curved grain boundaries, Philos. Mag. 96 (2016), pp. 1926–1949.
- O. Šedivý, J. Mullen Dake, C.E. Krill III, V. Schmidt, and A. Jäger, Description of the 3D morphology of grain boundaries in aluminium alloys using tessellation models generated by ellipsoids, Image Anal. Stereol. 36 (2017), p. 5.
- A. Spettl, T. Brereton, Q. Duan, T. Werz, C.E. Krill III, D.P. Kroese, and V. Schmidt, Fitting laguerre tessellation approximations to tomographic image data, Philos. Mag. 96 (2016), pp. 166–189.
- K. Teferra and L. Graham-Brady, Tessellation growth models for polycrystalline microstructures, Comput. Mater. Sci. 102 (2015), pp. 57–67.
- K. Teferra and D.J. Rowenhorst, Direct parameter estimation for generalised balanced power diagrams, Philos. Mag. Lett. 98 (2018), pp. 79–87.
- J. Barker, G. Bollerhey, and J. Hamaekers, A multilevel approach to the evolutionary generation of polycrystalline structures, Comput. Mater. Sci. 114 (2016), pp. 54–63.
- D.P. Bourne, P.J.J. Kok, S.M. Roper, and W.D.T. Spanjer, Laguerre tessellations and polycrystalline microstructures: A fast algorithm for generating grains of given volumes, Philos. Mag. 100 (2020), pp. 2677–2707.
- J. Guilleminot, A. Noshadravan, C. Soize, and R.G. Ghanem, A probabilistic model for bounded elasticity tensor random fields with application to polycrystalline microstructures, Comput. Methods Appl. Mech. Eng. 200 (2011), pp. 1637–1648.
- M. Kühn and M.O. Steinhauser, Modeling and simulation of microstructures using power diagrams: Proof of the concept, Appl. Phys. Lett. 93 (2008), Article ID 034102.
- T. Xu and M. Li, Topological and statistical properties of a constrained Voronoi tessellation, Philos. Mag. 89 (2009), pp. 349–374.
- A. Alpers, M. Fiedler, P. Gritzmann, and F. Klemm, SIAM J. Imaging Sci. 16 (2023), pp. 223–249.
- A. Brieden, P. Gritzmann, and F. Klemm, Constrained clustering via diagrams: A unified theory and its application to electoral district design, Eur. J. Oper. Res. 263 (2017), pp. 18–34.
- P. Gritzmann and V. Klee, Computational convexity, in CRC Handbook on Discrete and Computational Geometry, J.E. Goodman, J. O'Rourke, and C.D. Toth, eds., 3rd extended ed., 2017, pp. 937–968.
- T. Hastie, R. Tibshirani, and J. Friedman, The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed., Springer, New York, 2009.
- P.A. Lachenbruch and M. Goldstein, Discriminant analysis, Biometrics 35 (1979), p. 69.
- J. Zhang, W. Ludwig, Y. Zhang, H.H.B. Sørensen, D.J. Rowenhorst, A. Yamanaka, P.W. Voorhees, and H.F. Poulsen, Grain boundary mobilities in polycrystals, Acta Mater. 191 (2020), pp. 211–220.
- W. Ludwig, S. Schmidt, E.M. Lauridsen, and H.F. Poulsen, X-ray diffraction contrast tomography: A novel technique for three-dimensional grain mapping of polycrystals. I. Direct beam case, J. Appl. Crystallogr. 41 (2008), pp. 302–309.
- G. Johnson, A. King, M.G. Honnicke, J. Marrow, and W. Ludwig, X-ray diffraction contrast tomography: a novel technique for three-dimensional grain mapping of polycrystals. II. The combined case, J. Appl. Crystallogr. 41 (2008), pp. 310–318.
- A. Bhattachary, Y.-F. Shen, C.M. Hefferan, S. Fai Li, J. Lind, R.M. Suter, and G.S. Rohrer, Three-dimensional observations of grain volume changes during annealing of polycrystalline Ni, Acta Mater. 167 (2019), pp. 40–50.
- V. Muralikrishnan, H. Liu, L. Yang, B. Conry, C.J. Marvel, M.P. Harmer, G.S. Rohrer, M.R. Tonks, R.M. Suter, C.E. Krill III, and A.R. Krause, Observations of unexpected grain boundary migration in SrTiO3, Scr. Mater. 222 (2023), Article ID 115055.