Abstract
Traditional prior-knowledge-based region of interest (ROI) detection methods for processing high-resolution remote sensing images generally use global searching, which largely leads to prohibitive computational complexity. As an attempt to solve this problem, in the present study, a faster, more efficient ROI detection algorithm based on an adaptive spatial subsampling visual attention model (ASS-VA) is proposed. In the ASS-VA model, a visual attention mechanism is used to avoid applying image segmentation and feature detection to the entire image. The adaptive spatial subsampling strategy is formulated to decrease the computational complexity of ROI detection. A discrete moment transform (DMT) feature is extracted to provide a finer description of the edges. In addition, a region growing strategy is employed to obtain more accurate shape information of ROIs. Experimental results show that the time spent on detection using the new algorithm is only 2-4% of that expended in the traditional visual attention model and the detection results are visually more accurate.
Introduction
In the development of remote sensing technology, the resolution of remote sensing images has reached a high level. The IKONOS satellite launched in 1999 was able to take spatial resolution of remote sensing images to within a meter. The recent GeoEye-1 satellite further increased the spatial resolution to 0.41m. Compared with traditional low-spatial-resolution remote sensing images, whose spatial resolution is usually over 10 m, high-spatial-resolution images have the following properties:
| 1. | The amount of data in an image is extraordinarily large. A high-spatial- resolution remote sensing image contains complicated spatial information, clear details, and well-defined geographic features. | ||||
| 2. | The intensity, structure, shape, and texture information in a high-spatial-resolution remote sensing image is abundant and clear. The background information becomes much more complex. | ||||
All of these properties allow people to observe the earth in detail and at a larger scale. In traditional low-spatial-resolution remote sensing images, one pixel contains miscellaneous information about a larger area. The separation of the information is usually complicated and may lead to disappointing results, so high-spatial-resolution remote sensing images are increasingly coming into wider use. Thus there is a need for a more efficient information processing technology for high-spatial-resolution remote sensing images (Mei, Citation2004; Z. Zhang, Citation2005).
Target detection is one of the most popular applications applied to remote sensing images. Traditional approaches to detect targets in remote sensing images commonly include procedures of classification and segmentation (Congalton Citation2010). The classification procedure includes supervised and unsupervised classifiers (Jensen and Lulla Citation1987; Li et al., Citation2007) such as neural networks (Pei and Tan Citation2008; García-Balboa et al., Citation2012), support vector machines (SVM) (Inglada Citation2007), C-means (Fan et al., Citation2009), nearest neighbor classification (Zhang et al., Citation2012), and ISODATA (Rozenstein and Karnieli Citation2011). The segmentation procedure usually involves edge detection (Heath et al., Citation1998), contour modeling (Kass et al., Citation1988), morphologic methods (Lee et al., Citation1987), and edge growing (Yu et al., Citation1992). However, most of the classification methods need an a priori knowledge model that is highly influential to detection results and hard to build (Guo et al., Citation2007). In addition, global searching is an essential part of both classification and segmentation procedures, which is time consuming and storage expensive (P. Zhang and Wang, Citation2005; Sun, Citation2010; G. Zhang, Citation2010).
Considering that targets usually stand out from their surroundings and make up only small parts of the entire image, it is unnecessary to equally treat every pixel in a high-spatial -resolution remote sensing image. If we can pretreat the original image to find certain regions that may contain the targets, namely regions of interest (ROIs), the amount of data needed for further classification will be greatly reduced, which is of great value in real-time image processing.
The study of the human visual system (HVS) provides a valuable perspective. To deal with the overwhelming excess of input, the visual system has attention mechanisms for selecting a small subset of possible stimuli for more extensive processing while relegating the rest to only limited analysis (Wolfe and Horowitz Citation2004). A region that draws people's attention is defined as a focus of attention (FOA), which is considered to be a ROI or a target. In recent years, several computational models have been developed to simulate the HVS visual attention. Inspired by feature integration theory, Itti and colleagues (Itti et al., Citation1998; Itti and Koch, Citation2001) proposed a model in which multi-scale features, including intensity, color, and orientation, are extracted to generate a grayscale “saliency map” that results in the generation of attention regions through center-surround differences. Itti et al.’s model has had a significant influence in the study of the visual attention mechanism and many improvements have been made since it was first proposed (Le Meur et al., Citation2006; Frintrop et al., Citation2007). All of these models mentioned above have one thing in common, that is, they all try to simulate the visual attention mechanism on the basis of the HVS's biological constitution.
Besides these biologically based models, valuable achievements have been obtained by other researchers from other perspectives. Achanta et al. (Citation2009) proposed a complete computational model that computes the saliency map in the frequency domain and can produce a saliency map of the original size. Hou and Zhang (Citation2007) constructed a saliency map using the log-spectrum of an image. Ki Tae et al. (Citation2012) put forward a visual saliency detection method in the discrete cosine transform domain. Harel et al. (Citation2007) advocated a model similar to Itti et al.’s, which uses feature vectors to create “activation maps” to build the saliency map both on a biological basis and computationally. In addition to all these models, significant advances have also been made on quality assessment of visual saliency models (Gide and Karam Citation2012) and feature selection for visual saliency computation (Pal et al., Citation2011).
In the present study, an adaptive spatial subsampling visual attention (ASS-VA) model is presented. The input image is preprocessed to decrease the amount of data. Multiple visual features, a feature competition strategy, and region growing methods are combined to achieve a satisfying detection result. Experimental results show that the proposed model is time efficient and accurate.
The remainder of this paper is organized as follows. The description of the Itti et al. model, the Achanta model, and the new ASS-VA model are presented in the following section. The proposed methodology is illustrated a third section, and a fourth focuses on the research findings. A final section provides conclusions.
Background of the visual attention models
The Itti et al. model
Figure 1 illustrates the framework of the Itti et al. model. In this model, the early visual features are extracted from the input image, including intensity, color, and orientation. For each feature, nine spatial scales are created using a dynamic Gaussian pyramid. A linear “center-surround difference” operation, denoted as “Θ,” including interpolating the coarser to a finer scale and point-by-point subtraction, is used between different levels of the pyramid to compute the multi-scale feature maps as follows:
1. Framework of the Itti et al. model.
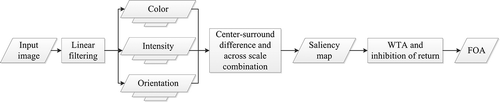
Let r, g, and b be the red, green, and blue channels of the input image. The intensity image I is obtained as:
The corresponding Gaussian pyramid is obtained as I(σ) where σ ∈ [0 … 8]. Then the center-surround difference operation is applied with c ∈ {2,3,4} and s = c + δ, δ ∈ {3,4} to generate six intensity feature maps:
As for the color feature, the r, g and b channels are first normalized by I to eliminate the fluency of intensity. Then four broadly tuned color channels are generated:
R, G, B, and Y refer to red, green, blue, and yellow colors, respectively (negative values are set to zero). Four Gaussian pyramids are generated for these color channels, R(σ), G(σ), B(σ), and Y(σ). The center-surround difference is computed according to a so-called “color double-opponent” system: the neurons in the center of the receptive fields of a human's retina are excited by one color and inhibited by another, while the converse is true in the surround. Such spatial and chromatic opponency exists for the red/green, green/red, blue/yellow, and yellow/blue color pairs (Engel et al., Citation1997):
The orientation feature is obtained by using the Gabor pyramids (Greenspan et al., Citation1994), where σ ∈ [0...8] refers to the scale and θ ∈ {0°, 45°, 90°, 135°} represents the preferred orientation. Orientation feature maps are computed as follows:
The feature maps are globally prompted using the normalization operation N (•) and added using the across-scale combination operation “⊕”. It includes reducing each map to scale four and point-by-point addition to generate the conspicuity maps, I for intensity, _C for color, and _O for orientation:
The final saliency map S is computed by the addition of these conspicuity maps as follows:
The search for the ROIs is established on the saliency map under the “winner-take-all” network (Koch and Ullman Citation1985; Tsotsos et al. Citation1995) and “inhibition of return” mechanisms (Posner Citation1984). The global maximum is selected, and the disk region around it with a fixed radius is regarded as the ROI. The ROI previously detected is inhibited before the new search procedure.
The Achanta et al. model
In 2009, Achanta et al. introduced a method for salient region detection that outputs full-resolution saliency maps with well-defined boundaries of salient objects. These boundaries are preserved by retaining substantially more frequency content from the original image than other existing techniques. This method, which exploits features of color and luminance, is simple to implement and computationally efficient. Compared with the Itti et al. model, this method is purely computational and discards the biological mechanism of HSV.
2. Framework of the Achanta Model.
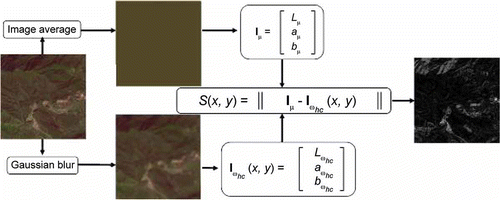
Figure 2 illustrates the framework of the Achanta et al model. In the Achanta et al. model, the original image is first transformed to CIELAB color space and each pixel location is a [L,a,b] T vector. The method of finding the saliency map S for an image I of width of W and height of H pixels can be formulated as:
An image-adaptive threshold is set to binarize the saliency map. The adaptive threshold (T a) value is determined as two times the mean saliency of a given image:
The ASS-VA model
The Itti et al. model agrees with HSV very well and it utilizes various visual features to generate the saliency map. Still, the Itti et al. model also has some drawbacks. The complicated convolution and floating point computation lead to a high computational complexity. Figure 3A shows an example of the detection results using the Itti et al. model. The low-resolution saliency map and the disk-shaped detected regions make it difficult to produce accurate detection results.
3. Detection results when applying the traditional models to high-spatial-resolution images. A. Original image. B. Detection result using the Itti et al.’s model. C. Detection result using the Achana method. The disk-shaped detected regions make it difficult to obtain accurate detection results with the Itti et al. model. The Achanta model regarded some unexpected regions as ROIs.
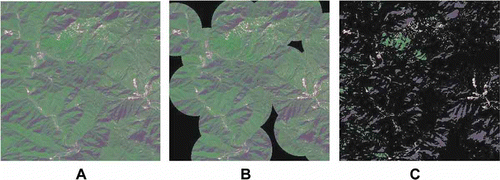
The Achanta et al. model is easy and fast to implement, and provides full-resolution saliency maps. However, this method only involves intensity and color features, regardless of some valuable characteristics of HSV. Figure 3B displays an example of the detection results using the Achanta et al. model, in which some unexpected regions are regarded as ROIs.
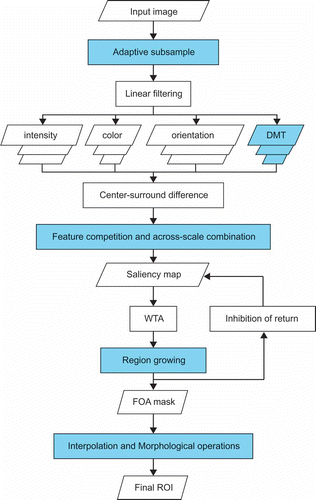
To overcome the weaknesses of the existing visual attention models and make them suitable for the processing of high-spatial-resolution remote sensing images, we focus on two aspects: low computational intensity and accuracy. All the salient regions should be detected and well described. Because of the importance of visual features and multi-scale saliency, we select the Itti et al. model as the basis for building up the ASS-VA model. Figure 4 shows the framework of the ASS-VA model. The input image is first filtered and subsampled to reduce the amount of data. Besides intensity, color, and orientation features, the discrete moment transform (DMT) feature, which reflects the intensity distribution of a small region, is extracted to represent texture information which is abundant and important in remote sensing images. A novel feature competition strategy is employed to assign different weights to different feature maps in order to generate the saliency map. Finally, the detected regions are formed through region growing to improve the accuracy in target detection.
Methodology
The ASS-VA model
The ASS-VA model is proposed to improve the computational efficiency and the accuracy of ROI detection for high-spatial-resolution remote sensing images. The methodology involves the following steps: (1) preprocessing; (2) feature extraction; (3) saliency map computation; (4) ROI description.
4. Framework of the adaptive spatial subsampling visual attention model. The key steps in the model are shown with a blue background.
Preprocessing
To decrease the amount of data to be processed, an adaptive spatial subsampling strategy is employed in our model using the Gaussian pyramid. The original image is filtered and then subsampled to a specific level of the pyramid in accordance with the original resolution.
In Eq. (16), p is the level of subsampling, M is the shorter border of the original image and N is set to 512 to balance the time complexity and the detection results. We have M ≥ 2N. The size of the subsampled image, I s, is 1/22p of the input image. The feature extraction is then done on I s.
5. Response of the DMT with different p, q Combinations. A. Original image. B. p = 0, q = 0. C. p = 0, q = 1. D. p = 1, q = 0. E. p = 1, q = 1. When p and q form an even-odd combination, the DMT responds strongly for regions with great changes of intensity in the vertical orientation. For the odd-even combination, the DMT responds strongly for the regions with great changes of intensity in the horizontal orientation. The odd-odd combination leads to a smooth result. The even-even combination produces a result similar to the input image.

Feature extraction
The subsampled images act as an input to the visual attention (VA) portion of the model and incorporate the DMT. High-spatial-resolution remote sensing images contain abundant texture information that is useful in ROI detection, inasmuch as the ROIs usually have different texture characteristics from the background region. The DMT is a type of structural feature that reflects the intensity distribution of a small region (Belkasim et al., Citation1991). The DMT is computed as follows, where i and j are the coordinates of the corresponding pixel, and p, q = 0, 1, 2 …
The combination of p and q has a great influence on the value of the DMT (see ). When p and q perform as an even-odd combination, the DMT responds strongly to regions with large changes of intensity in the vertical orientation. For the odd-even combination, the DMT responds strongly to the regions with large changes of intensity in the horizontal orientation. The odd-odd combination leads to a smooth result. The even-even combination produces a result similar to the input image.
The ASS-VA model uses k = 1, (p, q) = (1,0), (0,1), (1,1) to obtain three DMT feature images D (p, q). The corresponding Gaussian pyramid is generated as D (p, q, σ). The feature maps are computed as:
Besides the DMT feature, the intensity, color, and orientation features are also extracted using Eqs.(1) through (9).
Saliency map computation
Before computing the saliency map, all the feature maps for each feature are combined into one conspicuity map. Because salient objects appear strongly only in a few maps, these objects may be masked by noise or by lesssalient objects present in a larger number of maps. In order to address this issue, in the traditional model, a normalization operation N(∙) is applied to each of the maps to be fused. This procedure globally promotes maps so that a small number of strong peaks of activity are present. N(∙) includes the following steps: (1) normalize the values in the map to a fixed range [0,M], to eliminate modality-dependent amplitude differences; (2) find the location of the map's global maximum Mand compute the average _m of all its other local maxima; and (3) globally multiply the map by (M - _m)2.
This operation measures how different the most salient region is from the average saliency. When the difference is significantly large, the map will be strongly highlighted. Furthermore, this operation is computationally simple. The normalization will strongly enhance the map, with only one location much more conspicuous than others. However, when there are several conspicuous locations distributed sparsely in the map, the operation will suppress the map. This is an unexpected result (Itti and Koch Citation1999).
To overcome the weakness of the traditional normalization operation, a novel feature competition strategy is proposed in our model. The ROIs in a high-spatial- resolution remote sensing image typically constitute a small part of the whole image. The salient regions in the feature maps or in the conspicuity maps should stand out strongly against the surroundings. This means that both the size of the salient regions and their average saliency should be considered when deciding the importance of a map. In the proposed model, points with a grayscale value above a pre-set threshold T are selected as “salient points,” representing the presumably selected ROIs. The associated maps are first weighted according to the number of salient points, which represent the size of the salient regions. Maps with the fewest salient points will be assigned the highest weight. Another threshold T s is set up to define “strong points” representing the regions that stand out strongly. The maps are then weighted in accordance with the number of strong points. The larger number of strong points a map has, the higher weight it will get. The weighting computation includes the following steps:
| 1. | Normalize all the maps to a fixed range [0…1], and interpolate the map to level 1 of the Gaussian pyramid. The motivation to interpolate all the maps to level 1 is to keep as much useful information as possible. | ||||
| 2. | Compute the thresholds. The traditional Otsu's method (Otsu Citation1979) is applied to each of the maps to compute a series of thresholds, whose average is the salient point threshold T. The threshold for the strong points T s is computed as follows: | ||||
| 3. | Keep track of the number of salient points and strong points for each map, namely, N i sa and N i st , i = 1, 2, 3,… is the number of the map. | ||||
| 4. | Compute the normalized coefficient w i for each map as follows: | ||||
The final DMT conspicuity map is computed as follows:
Similarly, the other three conspicuity maps are computed as follows:
The “” consists of interpolating the map to level 1 and point-by-point addition.
The final saliency map S is computed as follows:
provides an example of feature maps and the final saliency map. The coefficient for each feature map is also shown along with the image title. As is evident, the color map is almost useless and consequently it has the smallest attached weight.
Compared with the normalization operation in the Itti et al. model, our feature competition strategy mentioned above is computationally simpler. Furthermore, the feature competition has been performed across a set of maps, making the coefficient for each map correlate with others, which is consistent with the hypothesis that similar features compete strongly for saliency.
ROI description
The traditional models define the ROIs as a disk with a fixed radius, but they have problems identifying random regions without much redundancy. To establish an accurate description, our model obtains ROIs using region growing, a simple region-based image segmentation method. This approach examines neighboring pixels of initial “seed points” and determines whether the pixel neighbors should be added to the region. The process is iterated in the same manner as by general data clustering algorithms. Region growing methods can correctly separate the regions that have the same defined properties and can provide clear-edged original images with good segmentation results. In the ASS-VA model, the region growing method includes the following steps: (1) find the location of the global maximum as the original region;
6. Examples of conspicuity maps and final saliency maps. A. Original image. B. Iintensity map. C. Color map. D. Orientation map. E. DMT map. F. Saliency map. The numbers below the images are the corresponding coefficient obtained using our feature competition strategy.

7. Flow diagram of region growing and inhibition of return.
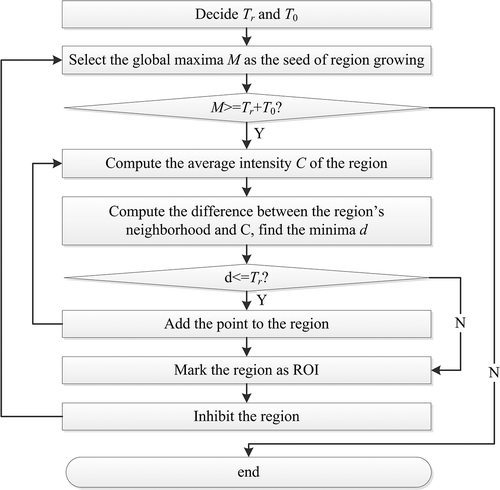
(2) check the neighborhood of the region, and find the pixel that has the least difference from the average intensity of the region; if the difference is smaller than the pre-set threshold T r , add the pixel to the region; and (3) repeat step 2 until the difference exceeds the threshold.
We choose the local maximum as the initial seed point to simulate the winner-take-all network. Once a region is generated, it is set to zero before the next searching step, according to the “inhibition of return” mechanism. A threshold is set to identify the end of the search. The traditional Otsu's (1979) method is applied to the saliency map to obtain the threshold T 0. The final threshold is set as the addition to T 0 and T r (see Fig.7).
Finally, all the detected regions are presented as a binary mask, with all the “1” values representing points in the detected regions. To eliminate the influence of noise and generate well-defined regions, some morphology operations, including dilation, hole filling, and erosion, will be carried out. The resulting mask needs to be interpolated to the original size. Then it needs to be multiplied by the original image by this mask to generate the final detection result.
Experiment
To evaluate the performance of the proposed model, several experiments were carried out on selected high-spatial-resolution remote sensing images. These images were cropped from one large image taken by the SPOT-5 satellite. Three bands were taken from the four-band image to create an approximation of the RGB color space. All the selected images were 2048 × 2048 pixels. The experiments were conducted on a computer with Intel Core 2 Quad CPU Q9400 and 8G memory.
1 Processing Time When Different Levels of Subsampling Are Applied.
Three experiments were designed to evaluate different aspects of the ASS-VA model.
A. Subsample Experiment. This experiment is designed to validate the use of adaptive spatial subsampling. The ASS-VA model with different levels of subsamples were applied to five images to compare both the detection results and the overall processing time.
B. Performance Comparison Experiment. This experiment is designed to compare the overall performance between the Itti el al. model, the Achanta et al. model, and the ASS-VA model, including comparison of detection results and processing time.
2 Processing Time of the Itti et al., Achanta et al., and the ASS-VA Modelsa.
C. DMT Validation Experiment. This experiment is designed to validate the usage of the DMT feature. The ASS-VA model and the one without DMT feature are applied to some images to compare the ability to provide well-defined edges.
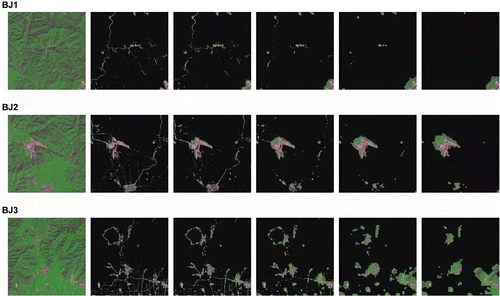
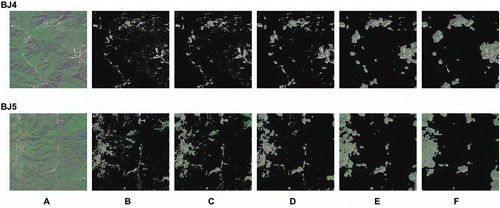
8. Detection results when applying different levels of subsampling. A. Original image. B–F. Detection results with the subsample level p = 0…4. When the subsample level increases, some tiny regions are lost and the detection results become less accurate.
Results and discussion
Subsample experiment
The processing time of each model is shown in . Compared to the results without subsampling, the processing time decreases significantly when the subsample level increases (). Adaptive spatial subsampling is quite helpful in decreasing the computational complexity. The detection results from applying different levels of subsampling are shown in , which shows that the detection results are generally acceptable. When the subsample level increases, a few tiny regions are lost, which are usually meaningless targets. The most salient regions have all been detected. At the same time, when the subsample level increases, the accuracy of detection gets worse. We chose to subsample the image to the size nearest to 512 × 512 pixels to balance the computational complexity and the detection results.
Performance comparison experiment
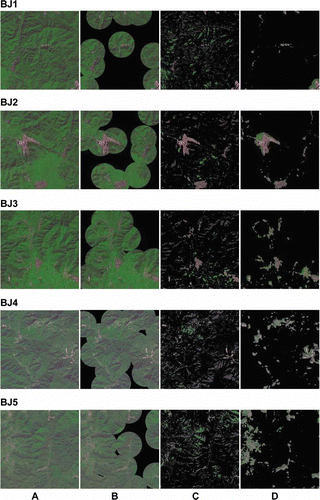
The detection results are shown in . The strength of the ASS-VA model can easily be determined. In image BJ5, the detected ROIs cover almost the entire image. In contrast to the detection results using the ASS-VA model, the Achanta et al. model produces much more accurate results, but the results contain many regions without any valuable targets. The detection results using the ASS-VA model accord very well with the salient region in the original image and contain little background information.
9. Detection results using the traditional and ASS-VA models. A. Original image. B. Itti et al. model with adaptive spatial subsampling. C. Achanta model. D. ASS-VA model.
Another noticeable result is the comparison of processing time of each part. Table 2 shows the time spent on computing saliency map and region growing for each model. When the ASS-VA model is applied, the amount of time spent on saliency map computation changes insignificantly with different images, while the time spent on region growing takes up most of the total processing time. The larger the proportion of ROIs, the longer it takes to establish the region growing. Though region growing provides a better description of the ROIs, it has become the most time-consuming part of the ASS-VA model.
Compared with the results using the traditional models, the ASS-VA model takes 10 to 20 seconds to perform the detection, which is much shorter than the amount of time taken in the Itti et al. model (more than 1000 seconds). The amount of time spent using the Achanta et al. model is about 6.7 seconds with various images, which is much shorter than that of the ASS-VA model, and almost the same length as the time spent on saliency map computation in the ASS-VA model. But the detected ROIs constitute a generally large proportion of the entire images. The threshold segmentation method used in the Achanta et al. model is much more computationally efficient than the region growing method, but produces fragmented areas as well. In other words, the ASS-VA model can also perform a rapid detection, as can the Achanta et al. model, but the detection results will be not as satisfying as before.
DMT validation experiment
compares the results from the ASS-VA model with those from the model without the DMT feature. When the DMT feature is eliminated, the model includes a small amount of background information in the detection results. However, the detection results do not always have well-defined borders. One possible reason is that the interpolations in both the center-surround difference and across-scale combination may blur the borders of the region.
10. Detection results using the ASS-VA model and model without the DMT feature. A. Fragments of the original image. B. ASS-VA model without the DMT feature. C. ASS-VA model

Conclusions
This paper has proposed and validated the ASS-VA model. The input image is adaptively subsampled to a smaller dimension by Gaussian pyramids, in order to decrease the data for further processing. In order to enhance the ability to present texture information, the DMT is used in the feature extraction step.
In computing the saliency map, a feature competition strategy is proposed. It is based on the number of “salient points” and “strong points.”
While being different from the disk region in the traditional models, the ASS-VA model uses region growing to generate the detected ROIs. This is much more accurate and brings little redundancy.
Generally speaking, the ASS-VA model can solve, to some extent, the problem of computation efficiency in high-spatial-resolution remote sensing image processing. The detection results are visually and statistically satisfying. Nevertheless, further research is still needed to obtain better performance, including an improved way of determining the level of subsampling, a better way of resolving the blurred edges, and a time-saving ROI description method.
Acknowledgments
This work was sponsored by National Natural Science Foundation of China (No. 60602035, 61071103, 41072245), Fundamental Research Funds for the Central Universities (2012LYB50), National High Technology Research and Development Program of China (No. 2007AA122156), and National Science Foundation of Beijing (No. 4102029). We would like to thank the Institute of Remote Sensing Applications of Chinese Academy of Sciences, and Beijing Normal University (OFSLRSS 201001).
Related Research Data
References
- Achanta, R., S. Hemami, F. Estrada, and S. Susstrunk. 2009. “Frequency-Tuned Salient Region Detection.” Paper presented at IEEE Conference on Computer Vision and Pattern Recognition, June 20–25, 2009.
- Belkasim , S. O. , Shridhar , M. and Ahmadi , M. 1991 . Pattern Recognition with Moment Invariants: A Comparative Study and New Results . Pattern Recognition , 24 ( 12 ) : 1117 – 1138 .
- Congalton , R. 2010 . Remote Sensing: An Overview . GIScience & Remote Sensing , 47 ( 4 ) : 443 – 459 .
- Engel , S. , Zhang , X. and Wandell , B. 1997 . Colour Tuning in Human Visual Cortex Measured with Functional Magnetic Resonance Imaging . Nature , 388 ( 6637 ) : 68 – 71 .
- Fan , J. , Han , M. and Wang , J. 2009 . Single Point Iterative Weighted Fuzzy C-means Clustering Algorithm for Remote Sensing Image Segmentation . Pattern Recognition , 42 ( 11 ) : 2527 – 2540 .
- Frintrop, S., M. Klodt, and E. Rome. 2007. “A Real-Time Visual Attention System Using Integral Images.” Paper presented at the 5th International Conference on Computer Vision Systems, Bielefeld, Germany, March 21–24, 2007.
- García-Balboa , J. L. , Reinoso-Gordo , J. F. and Ariza-López , F. J. 2012 . Automated Assessment of Road Generalization Results by Means of an Artificial Neural Network . GIScience & Remote Sensing , 49 ( 4 ) : 558 – 596 .
- Gide , M. S. and Karam , L. J. 2012 . “ Comparative Evaluation of Visual Saliency Models for Quality Assessment Task. ” . In Paper presented at the International Workshop on Video Processing and Quality Metrics for Consumer Electronics , Arizona : Scottsdale .
- Greenspan, H., S. Belongie, R. Goodman, P. Perona, S. Rakshit, and C. H. Anderson. 1994. “Overcomplete Steerable Pyramid Filters and Rotation Invariance.” Paper presented at the IEEE Conference on Computer Vision and Pattern Recognition 1994, June 21–23, 1994.
- Guo , Q. , Kelly , M. , Gong , P. and Liu , D. 2007 . An Object-Based Classification Approach in Mapping Tree Mortality Using High Spatial Resolution Imagery . GIScience & Remote Sensing , 44 ( 1 ) : 24 – 47 .
- Harel , J. , Koch , C. and Perona , P. 2007 . Graph-Based Visual Saliency . Advances in Neural Information Processing Systems , 19 : 545 – 552 .
- Heath , M. , Sarkar , S. , Sanocki , T. and Bowyer , K. 1998 . Comparison of Edge Detectors: A Methodology and Initial Study . Computer Vision and Image Understanding , 69 ( 1 ) : 38 – 54 .
- Hou, X. and L. Zhang. 2007. “Saliency Detection: A Spectral Residual Approach.” Paper presented at the IEEE Conference on Computer Vision and Pattern Recognition, June 17–22, 2007.
- Inglada , J. 2007 . Automatic Recognition of Man-made Objects in High Resolution Optical Remote Sensing Images by SVM Classification of Geometric Image Features . ISPRS Journal of Photogrammetry and Remote Sensing , 62 ( 3 ) : 236 – 248 .
- Itti, L. and C. Koch. 1999. A Comparison of Feature Combination Strategies for Saliency-Based Visual Attention Systems.
- Itti , L. and Koch , C. 2001 . Computational Modelling of Visual Attention , London, UK : Nature Publishing Group .
- Itti , L. , Koch , C. and Niebur , E. 1998 . A Model of Saliency-Based Visual Attention for Rapid Scene Analysis . IEEE Transactions on Pattern Analysis and Machine Intelligence , 20 ( 11 ) : 1254 – 1259 .
- Jensen , J. R. and Lulla , K. 1987 . Introductory Digital Image Processing: A Remote Sensing Perspective . Geocarto International , 2 ( 1 ) : 65 – 65 .
- Kass , M. , Witkin , A. and Terzopoulos , D. 1988 . Snakes: Active Contour Models . International Journal of Computer Vision , 1 ( 4 ) : 321 – 331 .
- Ki Tae, P., P. Min Su, L. Jeong Ho, and M. Young Shik. 2012. “Detection of Visual Saliency in Discrete Cosine Transform Domain.” Paper presented at the IEEE International Conference on Consumer Electronics, January 13–16, 2012.
- Koch , C. and Ullman , S. 1985 . Shifts in Selective Visual Attention: Towards the Underlying Neural Circuitry . Human Neurobiology , 4 ( 4 ) : 219 – 227 .
- Le Meur , O. , Le Callet , P. , Barba , D. and Thoreau , D. 2006 . A Coherent Computational Approach to Model Bottom-up Visual Attention . IEEE Transactions on Pattern Analysis and Machine Intelligence , 28 ( 5 ) : 802 – 817 .
- Lee , J. , Haralick , R. and Shapiro , L. 1987 . Morphologic Edge Detection . IEEE Journal of Robotics and Automation , 3 ( 2 ) : 142 – 156 .
- Li , C. , Zeng , S. and Xu , L. 2007 . Intelligent Remote Sensing Image Processing , Beijing, China : Electronics Industry Press (in Chinese) .
- Mei , J. 2004 . “ Study on Object Detection for High Resolution Remote Sensing Images Based on Support Vector Machines. ” . In PhD thesis, Wuhan University , China (in Chinese) : Wuhan .
- Otsu , N. 1979 . A Threshold Selection Method from Gray-Level Histogram . IEEE Transactions on Systems, Man, and Cybernetics , 9 : 62 – 66 .
- Pal, R., P. Mitra, and J. Mukhopadhyay. 2011. “Suitable Features for Visual Saliency Computation in Monochrome Images.” Paper presented at the 4th International Congress on Image and Signal Processing, October 15–17, 2011.
- Pei , L. and Tan , Y. 2008 . The Neural Network Classification of Remote Sensing Image Supplemented by Texture Characteristic . Geomantic & Spatial Information Technology , 31 ( 4 ) : 66 – 67 .
- Posner , M. I. 1984 . Components of Visual Orienting . Attention and Performance , X ( 32 ) : 531 – 556 .
- Rozenstein , O. and Karnieli , A. 2011 . Comparison of Methods for Land-Use Classification Incorporating Remote Sensing and GIS Inputs . Applied Geography , 31 ( 2 ) : 533 – 544 .
- Sun , N. 2010 . “ Research on Target Recognition Methods for Building Detection in High Spatial Resolution Remote Sensing Images. ” . In Master's thesis, Zhejiang University , China (in Chinese) : Hangzhou .
- Tsotsos , J. K. , Culhane , S. M. , Kei Wai , W. Y. , Lai , Y. , Davis , N. and Nuflo , F. 1995 . Modeling Visual Attention via Selective Tuning . Artificial Intelligence , 78 ( 1–2 ) : 507 – 545 .
- Wolfe , J. M. and Horowitz , T. S. 2004 . What Attributes Guide the Deployment of Visual Attention and How Do They Do It? . Nature Review Neuroscience , 5 ( 6 ) : 495 – 501 .
- Yu, X., J. Yla-Jaaski, O. Huttunen, T. Vehkomaki, O. Sipila, and T. Katila. 1992. “Image Segmentation Combining Region Growing and Edge Detection.” In Proceedings of the 11th International Conference on Pattern Recognition. Vol. III. Conference C: Image, Speech and Signal Analysis.
- Zhang , D. , Zhang , C. , Cromley , R. , Travis , D. and Civco , D. 2012 . An Object-Based Method for Contrail Detection in AVHRR Satellite Images . GIScience & Remote Sensing , 49 ( 3 ) : 412 – 427 .
- Zhang , G. 2010 . “ Researches on Object Detection in Remote Sensing Image with Complicated Scenes. ” . In PhD thesis, National University of Defense Technology , China (in Chinese) : Changsha .
- Zhang , P. and Wang , R. 2005 . An Approach to Remote Sensing Image Analysis Based on Visual Attention . Journal of Electronics & Information Technology , 27 ( 12 ) : 1855 – 1860 .
- Zhang , Z. 2005 . “ Feature Extraction and Recognition of Important Targets in Remote Sensing Imagery. ” . In PhD thesis , Changsha (in Chinese) : National University of Defense Technology .