Abstract
Digital terrain models (DTM) are created increasingly often on the basis of data recorded automatically. In the processing of such sets, there is often a need to organize the measured values and present them in the form of a specific GRID (a regular grid of nodes: the points forming the DTM are located in the corners of squares with a specified side length) or TIN (triangulated irregular network) structure. The correct setting of processing criteria and the proper selection of the structural parameters of a given structure are important factors influencing terrain model accuracy. The GRID structure not only allows data to be organized, but also increases the efficiency of data processing in LIS/GIS (land information systems/geographical information systems). If a large volume of measurement data is acquired, using the GRID structure reduces its volume and eliminates redundancies. To maintain proper DTM quality, it is necessary to set correct processing parameters during the construction of the network forming the GRID structure. This paper analyzes the effect of measurement point distribution on the selection of the structural parameters of a regular square grid used to create the digital bottom model.
1. Introduction
The digital terrain model (DTM) is currently an essential component of land information systems (LIS, GIS) (Carlisle Citation2002; Gallant and Wilson Citation2000; Longley et al. Citation2005). It allows users to generate and visualize a specific terrain or sea bottom surface. However, the role of LIS is not limited to digital surface representation. An important advantage of information systems is the possibility of performing comprehensive quantitative and qualitative analysis (Mahmood and Gloaguen Citation2011; Heuvelink, Burrough, and Stein Citation2006; Longley and Batty Citation2003; Masser Citation2005). Among the requirements set by the users of these systems, besides the accuracy and reliability of the obtained results, particular emphasis is also placed on the information-processing dynamics and the possibilities of conducting real-time comparative analysis (Shary, Sharaya, and Mitusov Citation2002; Shi, Fisher, and Goodchild Citation2004; Worboys and Duckham Citation2004). The performance of these tasks often requires initial data preparation for their proper and economical processing by the information system. The most reliable and accurate data-feeding information systems come from direct measurements (Aerts, Goodchild, and Heuvelink Citation2003; Gosciewski Citation2012; Maguire Citation2005; Zandbergen Citation2010). Modern measuring devices (LiDAR, multi-beam sounders, laser measurement stations) allow the automatic recording of a large volume of data over a relatively short time (Aruga, Sessions, and Akay Citation2005; Axelsson Citation2000; Cobby, Mason, and Davenport Citation2001; Lee et al. Citation2010). However, the information recorded this way is usually unorganized, contains repeated (redundant) information and the sequential manner of its archiving additionally impedes processing and analysis. Because of this situation, measurement data are most often not used directly. Triangulated irregular network (TIN) or GRID (a regular grid of nodes: the points forming the DTM are located in the corners of squares with a specified side length) structures are used for the digital representation of surface models in information systems (Raaflaub and Collins Citation2006; Wechsler Citation2003). The advantage of the former is the construction of models based directly on measurement points. Such an assumption allows users to create an irregular network of triangles on which the generation of the surface model is based. However, this does not rid the model of data and other redundancies.
Because the points forming a TIN model are distributed irregularly, the GRID structure-based model is more advantageous for dynamic spatial analysis in different measurement epochs. It allows information redundancy reduction and, due to a decreased number of points describing the surface, a substantial reduction in the volume of sets stored in system databases (Ehlschlaeger Citation2002; Schabenberger and Gotway Citation2005). This structure (due to the use of mathematically defined points in space) also enables comprehensive comparative analysis of the same objects in different measurement epochs, with different densities of the measured points. The simplification of the recording structure also allows faster access to information, data transmission acceleration, and the application of efficient compression and archiving algorithms, which favors higher information processing dynamics (Cressie and Pavlicova Citation2002; MacEachren et al. Citation2004; Stefanik et al. Citation2011).
Surface representation by the GRID structure requires the interpolation of the values at the nodal points forming the regular square grid, uniformly covering a given measurement area. The proper selection of the parameters taken into account during grid creation based on the measured points is essential to maintain the proper quality of the DTM generated on the basis of the GRID. GRID resolution and measurement point density are important elements influencing the quality of the created terrain model. In the presented paper, for practical reasons, two terms are used to specify the number of points per unit of area (1 m2): “resolution”, which is applied for the GRID's nodal points, and “density”, which is applied for the measurement points. The selection of the proper location of measurement points with their specific density influences the number of generated nodal points and, consequently, the GRID resolution. The possibility of using the maximally complete grid of nodes increases the quality of the generated DTM and determines the accuracy of GRID structure-based spatial analysis. Improper selection of processing parameters relative to the GRID resolution and measurement point density may lead to loss of the quality of the generated model, which is presented in the selected examples.
2. Selection of the GRID's structural parameters
The proper selection of structural parameters is an important problem during the creation of a GRID-type network. Depending on measurement point density and the terrain morphology, the created square grid should ensure proper model accuracy. The interpolation of the value at a nodal point, based on the measurement points surrounding the node, can be conducted by different methods (Heo Citation2003; Pitas Citation2000; Sulebak Citation2000). The accuracy of the determination of this value depends mainly on the distribution of measurement points and their distance from the node. Fully reliable interpolation results are obtained when the points (on whose basis the value at the node is computed) meet a specific criterion. They should lie within the assumed search radius, closest to the nodal point, and simultaneously form a surrounding figure with the node situated within its field. Such an assumption eliminates cases of nodal point value extrapolation and allows precise value determination. The simplest figure surrounding a node is the triangle. The use of the minimal number of found points to determine a node is particularly important for the processing speed for a large volume of measured data.
a presents two cases of H value determination at two nodal points on the basis of the nearby found measurement points P1, P2, and P3. In the first case, when the nodal point (A′w) is inside the triangle formed by the measurement points (P′1, P′2, P′3), interpolation occurs and the height HAw is determined. The value at the nodal point (HAw) can be determined, in this case, by any (even simplified) interpolation method because the node Aw lies within the interpolation space formed by the points P1, P2, and P3. In the second case, when the nodal point (B′w) is outside the field of the triangle (P′1, P′2, P′3), extrapolation occurs where the node Bw does not lie within the interpolation space formed by the points P1, P2, and P3 and the HBw value can be determined inaccurately. The precise determination of the value at a nodal point should, therefore, be preceded by finding properly located measurement points.
Figure 1. Criteria for the selection of measurement points in GRID node determination.
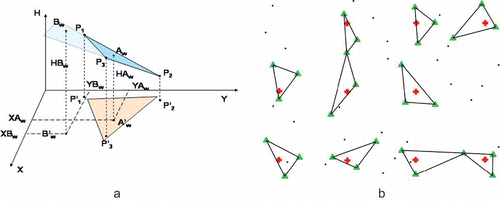
The location of the found measurement points is crucial for DTM quality because it allows a specific number of GRID nodes to be generated. Selected found measurement points participating in the interpolation of the values at specific nodal points (red cross) are shown in , with a green triangle. Because all nodes determined this way are computed by interpolation, the DTM created on their basis is reliable and accurate. The number of found nodes depends mainly on measurement point density and the setting of the proper search radius around a nodal point. The resolution of the created GRID structure should also be taken into account when setting this search radius.
The distances between the nodes forming a terrain model depend mainly on the number of measurement points per unit of area. If a large measurement point density is available (as in the discussed case), these distances can be small, which gives a higher GRID resolution and increases model accuracy.
An object forming a sea bottom fragment, forming a rectangle with the sides: 114 m × 144 m and a surface area of 16,416 m2, was selected for the research. A total of 197,626 measurement points were measured with a multi-beam echo sounder in this area, which obtained a density of 12 mp/1 m2 (100% mp). To conduct analysis with different densities, appropriate numbers of measurement points were selected at random from the whole spectrum, creating different cases: 10 mp/1 m2 (80% mp); 7 mp/1 m2 (60% mp); 5 mp/1 m2 (40% mp); 2 mp/1 m2 (20% mp); 1 mp/1 m2 (10 % mp); and 0.5 mp/1 m2 (5% mp). A regular GRID was also generated in the same area with different base square sizes (different resolution): 0.2 m × 0.2 m (25 n/1 m2); 0.5 m × 0.5 m (4 n/1 m2); 1 m × 1 m (1 n/1 m2); 2 m × 2 m (0.2 n/1 m2); and 5 m × 5 m (0.04 n/1 m2). The proper interpolation was preceded by finding the appropriate location of measurement points around the node within a specific radius, so that the node lay within the field of the triangle formed by the measurement points ( and 1b). The interpolation was carried out by several methods and the results were presented for the plane and straight line method, where the value at the node was determined as the result of the solution of the following system of equations: of the plane passing through the three nearest measurement points situated in the corners of the triangle surrounding the node and the line perpendicular to the plane XY passing through the node. A number of analyses were then performed on the effect of GRID resolution selection on DTM quality (depending on measurement point density and specific search radius) and the most representative examples were presented.
3. Analysis of nodal point resolution
Because of the direct effect of node resolution on the accuracy of the created model, the crucial structural parameter of the GRID is to have properly selected spacing between the nodes forming the model. presents the same sea bottom surface fragment generated for different nodal point resolutions (a – 5 m × 5 m, b – 2 m × 2 m, c – 1 m × 1 m).
Figure 2. Bottom models created with different nodal point resolutions.

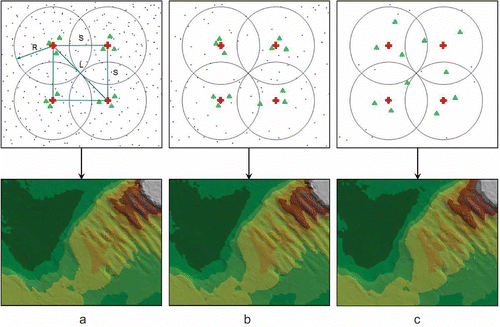
A higher resolution of the points forming a surface model should lead to increased model accuracy. However, the automation of measurement data processing in interpolation algorithms does not always increase this accuracy. In most algorithms, the distance between nodal points determines the size of the measurement point search radius around a node. Assuming the analysis of the full measurement spectrum, a search radius (R) equal to half the diagonal (L) of the square (S × S) forming the grid (R = ½ L) is most often adopted (a). With proper selection of the spacing between nodes, such an assumption allows (in most cases) correct value interpolation for different measurement point densities.
shows examples of finding the location of measurement points according to the described principles. The determined values at selected nodal points of the GRID generate the presented bottom models. With assumed low nodal point resolution (2 m × 2 m; 0.2 n/1 m2), appropriate systems of measurement points (marked with a green triangle and situated in the corners of surrounding triangles with nodes inside) are found for each density. This allows the correct interpolation of the values at the nodes in most cases and the number of nodal points is sufficient to generate an accurate DTM. The surface models generated based on the computed nodal points are similar for high measurement point density (12 mp/1 m2) (a), medium density (7 mp/1 m2) (b), and low density (2 mp/1 m2) (c). Moreover, these models are characterized by similar accuracy for both areas with low and strong morphological diversity. Constant selection of the search radius size for different measurement point densities enables the obtaining of good model quality, but is not justified economically. With the selected search parameters, the processing time for data sets increases considerably because the number of points analyzed with a high density is equal for each node. For a low GRID resolution and a high measurement point density, the search radius can be decreased without impairing DTM quality, while shortening the processing time.
Figure 3. Low nodal point resolution for different measurement point densities.
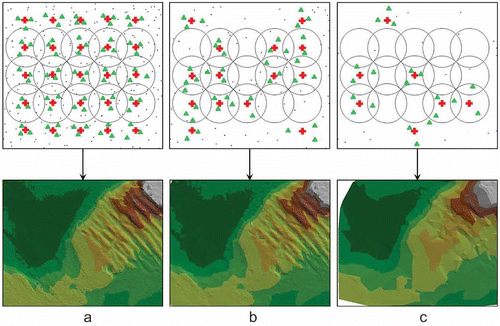
The application of the same principle of point search around a node (the search radius is equal to half the diagonal of the square forming the grid R = ½ L), in a situation when the parameter of distance between nodes is selected incorrectly relative to measurement point density, may lead to a reduction in the number of found points. With a high nodal point resolution (0.5 m × 0.5 m; 4 n/1 m2) and decreasing measurement point density, a diminishing number of nodes are found. For a high measurement point density (12 mp/1 m2), based on the three found surrounding points (marked with a green triangle), interpolation can be conducted for most nodal points (marked with a red cross), and an accurate bottom model can be created (a). In situations of a medium measurement point density (7 mp/1 m2), the number of nodes for which the correct location of measurement points has been found decreases and, as a result, the bottom model is less accurate (b). The latter example illustrates a situation in which few values were determined at nodal points because of a low measurement point density (2 mp/1 m2), which resulted in the creation of a bottom model with the worst quality (c). Consequently, leaving a constant search radius for a decreasing measurement point density causes deterioration of the created surface model, despite using a higher nodal point resolution. The bottom model created on the basis of a limited number of nodes is clearly less accurate, especially for morphologically diverse areas.
Figure 4. High nodal point resolution for different measurement point densities.
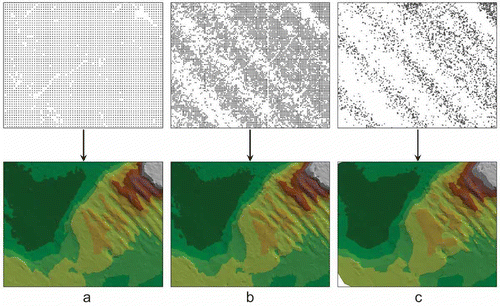
The application of the criterion in which the search radius is equal to half the diagonal of the square forming the grid leads to a situation in which the location of the found nodes closely depends on the measurement point density. If measurement points cover an area unevenly (e.g., higher point density occurs in doubled measurement zones), the location of nodal points is also characterized by varied resolutions in different areas of the measured object. illustrates the distribution of nodal points with different resolutions for the same, uneven measurement point density (12 mp/1 m2). Even distribution of nodal points on the analyzed surface is obtainable only with their relatively low resolution (5 m × 5 m; 0.04 n/1 m2) (a). With node spacing of 2 m × 2 m (0.2 n/1 m2), distinct gaps in the distribution of the found nodal points appear (b). Decreasing the spacing between nodes to 1 m × 1 m (1 n/1 m2) causes the elimination of most of them, which practically prevents the creation of a good quality surface model on this basis (c). To generate the proper number of nodes with their different resolutions and different measurement point densities, the search radius size should be set dynamically, depending on the situation.
Figure 5. Nodal point location for uneven measurement point density.
4. Analysis of measurement point density
To increase the surface model accuracy, the measurement point search radius around a node, which is independent of the distance between nodes, should be used. Additionally, for a high measurement point density, a proper search radius reduces the set search time, which considerably accelerates data processing.
presents the bottom models created based on the nodes computed using different search radii for the same measurement point density (7 mp/1 m2). A comparison of such models created with the standard surface model (created on the basis of the maximum measurement point density; 12 mp/1 m2) generated the differential graphs at the bottom of the figure. The differences (exceeding the measurement accuracy of ± 0.2 m) between the values determined at individual nodal points and the standard surface model are presented in red in the graphs. This allowed the areas where the interpolation distortions of the model were greatest to be located.
Figure 6. Bottom models created with a high measurement point density for decreasing search radii.
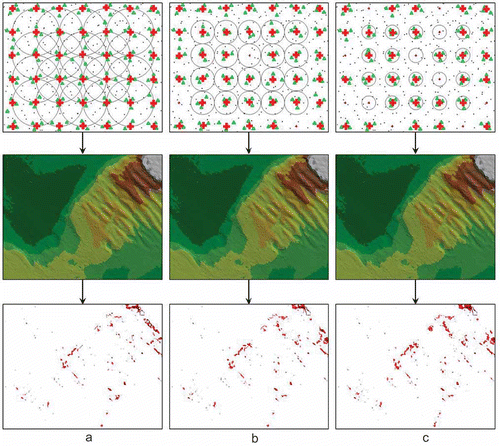
In the analyzed case, the GRID base square size was 1 m × 1 m. In the first example, the search radius was equal to the node spacing (R = 1 m) (a), which led to the situation in which the same measurement points (marked with a green triangle) could be used repeatedly to compute the values at the neighboring nodes (marked with a red square). Because the measurement point density was high in this case (12 mp/1 m2), the setting of a large search radius range did not increase model accuracy, but only the computation time was prolonged uneconomically. In the next examples, the search radius was reduced to half of the spacing between the nodes (R = 0.5 m) (b) and then to one-fourth of the spacing between the nodes (R = 0.25 m) (c). In cases of search radius reduction, the processing does not cover all measurement points, but only those which lie near a node. This allows a substantial shortening of the data processing and GRID generation times. However, in this case, the location systems of three measurement points with the node inside are not found for all the nodal points and the created grid is not complete (a and 6c). Despite this, with a high measurement point density and properly selected GRID resolution, the number of generated nodes is sufficient and an accurate DTM is created in each case. Comparing the differential graphs in , all the generated bottom models have similar accuracies, and only a slight tendency to deteriorate accuracy with search radius reduction is observable. However, this has no significant effect on the quality of the created surface models. In all the cases, lower accuracies (higher differences compared to the standard model) occur in more morphologically diverse areas and the reduction in the number of determined nodal points has the greatest effect in these places.
Departing from the principle which makes search radius selection dependent on the distance between nodes is particularly advantageous in cases of a low measurement point density. Increasing the search radius in such cases significantly raises the accuracy of the generated surface models. illustrates a situation in which the search radius is increased gradually to find a higher number of measurement points. In the analyzed case, the GRID base square size was 1 m × 1 m and the measurement point density was low, 2 mp/1 m2. In the first example, where the search radius is equal to half the distance between the nodes (R = 0.5 m), the number of nodes with correctly computed values (marked with a red cross) is minimal because few systems with measurement points (marked with a green triangle) meeting the required assumptions (the node within the field of the triangle) are found within the small search radius (a). This situation did not generate an accurate bottom model and low surface accuracy is also confirmed by the differential graph below (a).
Figure 7. Bottom models created with a low measurement point density for increasing search radii.
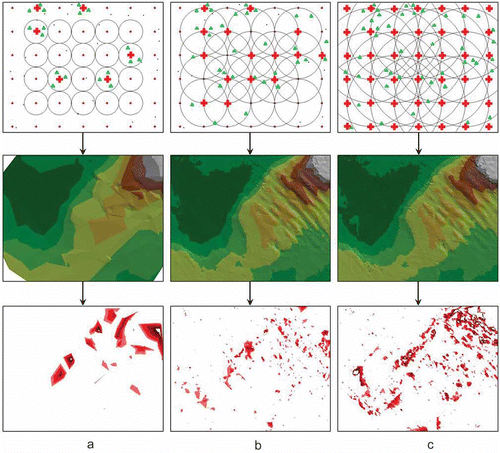
The situation improved after increasing the search radius to the value equal to the node spacing (R = 1 m) (b). The number of found measurement points around the nodes rose, which allowed the creation of a more accurate surface model, which is also confirmed by the differential graph below (b). It is comparable with the graph from , where the measurement point density was much higher. Increasing the search radius again (to a value equal to double the distance between the nodes; R = 2 m) generated an even higher number of nodal points (c). The bottom model created in this way is also of good quality, but model distortions resulting from the adoption of too remote measurement points for interpolation can already be seen in this case. This is also confirmed by the differential graph below (c). The relationship between the morphology of the studied surface and the magnitude of errors and model distortions is clearly visible. Many more errors occur in morphologically diverse areas. In the last case (c), small distortions caused by an excessive distance between measurement points and the nodal point are also observable in areas with low morphological diversity. Because of the relatively low measurement point density, increasing the search radius and repeated searching in the same areas do not significantly prolong the computational process even with a high GRID resolution.
Increasing the search radius causes a gradual rise in the number of generated nodal points and, consequently, the increased quality of the surface model created on their basis. However, an excessive increase in the search radius, with low measurement point density, leads to model distortions. Sets of sequentially recorded and archived measurement data contain many doubled measurement areas. The processing of such data with too large a search radius results in the creation of surface models in which sub-areas with a step difference in values (assigned to specific nodal point groups) are clearly visible.
Surface models affected by this defect are presented in . In the analyzed case, the GRID base square size was 1 m × 1 m and the measurement point density was low, 2 mp/1 m2. The successive examples concern a radius equal to a 5-fold distance between the nodes (R = 5 m) (a), a 10-fold distance between the nodes (R = 10 m) (b) and a 20-fold distance between the nodes (R = 20 m) (c). Gradually increasing the search radius, in this case, led to growing step bottom model distortions.
Figure 8. Sub-areas with a step difference in height caused by improper search radius selection.

5. Summary
For surface models created using the GRID structure, the correct setting of processing criteria and the proper selection of the structural parameters of the square grid are an important factor, with an essential effect on analysis accuracy. Particular attention should be paid here to the correct selection of node resolution relative to measurement point density. It should be remembered that surface model accuracy is not determined only by the density of the points forming the model. An important factor in increasing DTM quality is also the proper selection of the location of the measurement points participating in GRID node determination to eliminate cases of extrapolation from the computational process. The required number of points which can create the triangle surrounding a node is found due to proper search radius selection relative to the density of both the GRID itself and the measurement points. The setting of the same search radius size for different measurement point densities is uneconomical because of long set processing times (especially when a large radius is set for a high density). With a high measurement point density, the search radius can be decreased without losing the quality of the generated model, in this way, obtaining a higher set processing speed. For a low measurement point density, a too small search radius leads to deteriorated quality of the generated surface model. However, an uncontrolled excessive increase in the radius size causes a loss of model quality by the visualization of step differences in height. The GRID size and the density and proper location of measurement points should, therefore, be taken into account when setting the search radius. The correct selection of these parameters generates an accurate DTM, while maintaining a short data processing time.
Related Research Data
References
- Aerts , J. C. , Goodchild , M. F. and Heuvelink. , G. B. M. 2003 . Accounting for Spatial Uncertainty in Optimization with Spatial Decision Support Systems . Transactions in GIS , 7 ( 2 ) : 211 – 230 . doi: 10.1007/s10109-012-0176-x
- Aruga , K. , Sessions , J. and Akay , A. E. 2005 . Application of an Airborne Laser Scanner to Forest Road Design with Accurate Earthwork Volumes.” . Journal of Forest Research , 10 ( 2 ) : 113 – 123 . doi: 10.1007/s10109-012-0176-x
- Axelsson , P. 2000 . “ DEM Generation from Laser Scanner Data Using Adaptive TIN Models.” . In International Archives of Photogrammetry and Remote Sensing Vol. 33 , 110 – 117 . B4/1 doi: 10.1007/s10109-012-0176-x
- Carlisle , B. H. 2002 . “Digital Elevation Model Quality and Uncertainty in DEM-based Spatial Modelling.” , London : PhD Thesis, University of Greenwich . doi: 10.1007/s10109-012-0176-x
- Cobby , D. M. , Mason , D. C. and Davenport , I. J. 2001 . Image Processing of Airborne Scanning Laser Altimetry Data for Improved River Flood Modelling . ISPRS Journal of Photogrammetry and Remote Sensing , 56 ( 2 ) : 121 – 138 . doi: 10.1007/s10109-012-0176-x
- Cressie , N. and Pavlicova , M. 2002 . Calibrated Spatial Moving Average Simulations . Statistical Modelling: An International Journal , 2 ( 4 ) : 267 – 279 . doi: 10.1007/s10109-012-0176-x
- Ehlschlaeger , C. R. 2002 . Representing Multiple Spatial Statistics in Generalized Elevation Uncertainty Models: Moving Beyond the Variogram.” . International Journal of Geographical Information Science , 16 ( 3 ) : 259 – 285 . doi: 10.1007/s10109-012-0176-x
- Gallant , J. C. and Wilson , J. P. 2000 . “ Primary Topographic Attributes ” . In Terrain Analysis , Edited by: Wilson , J. P. and Gallant , J. C. 51 – 85 . New York : Principles and Applications, John Wiley and Sons . doi: 10.1007/s10109-012-0176-x
- Gosciewski , D. 2012 . “ The Effect of the Distribution of Measurement Points Around the Node on the Accuracy of Interpolation of the Digital Terrain Model ” . In Journal of Geographical Systems , Springer. . doi: 10.1007/s10109-012-0176-x
- Heo , J. 2003 . Steepest Descent Method for Representing Spatially Correlated Uncertainty in GIS . Journal of Surveying Engineering , 129 ( 4 ) : 151 – 157 . doi: 10.1007/s10109-012-0176-x
- Heuvelink , G. B. M. , Burrough , P. A. and Stein , A. 2006 . “ Developments in Spatial Uncertainty Analysis Since 1989 ” . In Classics From IJGIS: Twenty Years of the International Journal of Geographical Information Science and Systems , Edited by: Fisher , P. F. 67 – 90 . Boca Raton, FL : CRC Press . doi: 10.1007/s10109-012-0176-x
- Lee , J. , Han , D. , Yu , K. , Heo , J. and Habib , A. F. 2010 . An Automatic Registration Method for Adjustment of Relative Elevation Discrepancies Between Lidar Data Strips. Bellwether Publishing, Ltd . GIScience & Remote Sensing , 47 ( 1 ) : 115 – 134 . doi: 10.1007/s10109-012-0176-x
- Longley , P. A. and Batty , M. 2003 . Advanced Spatial Analysis: The CASA Book of GIS , Redlands, CA : ESRI Press . doi: 10.1007/s10109-012-0176-x
- Longley , P. A. , Goodchild , M. F. , Maguire , D. W. and Rhind , D. W. 2005 . Geographical Information Systems; Principles, Techniques, Management and Applications , Hoboken, NJ : Wiley . doi: 10.1007/s10109-012-0176-x
- MacEachren , A. M. , Gahegan , M. , Pike , W. , Brewer , I. , Cai , G. , Lengerich , E. and Hardisty , F. 2004 . Geovisualization for Knowledge Construction and Decision support.” . Computer Graphic and Applications , 24 ( 1 ) : 13 – 17 . doi: 10.1007/s10109-012-0176-x
- Maguire , D. J. 2005 . “ GIS Customization ” . In Geographical Information Systems: Principles, Techniques, Management and Applications , Edited by: Longley , P. A. , Goodchild , M. F. , Maguire , D. J. and Rhind , D. W. 359 – 369 . Hoboken, NJ : Wiley . doi: 10.1007/s10109-012-0176-x
- Mahmood , S. A. and Gloaguen , R. 2011 . Analyzing Spatial Autocorrelation for the Hypsometric Integral to Discriminate Neotectonics and Lithologies Using DEMs and GIS. Bellwether Publishing, Ltd . GIScience & Remote Sensing , 48 ( 4 ) : 541 – 565 . doi: 10.1007/s10109-012-0176-x
- Masser , L. 2005 . Spatial Data Infrastructure: An Introduction , Redlands, CA : ESRI Press . doi: 10.1007/s10109-012-0176-x
- Pitas , I. 2000 . Digital Image Processing Algorithms and Applications , New York : John Wiley and Sons . doi: 10.1007/s10109-012-0176-x
- Raaflaub , L. D. and Collins , M. J. 2006 . The Effect of Error in Gridded Digital Elevation Models on the Estimation of Topographic Parameters . Environmental Modelling and Software , 21 ( 5 ) : 710 – 732 . doi: 10.1007/s10109-012-0176-x
- Schabenberger , O. and Gotway , C. A. 2005 . Statistical Methods for Spatial Data Analysis , Boca Raton,. FL : Chapman and Hall, CRC . doi: 10.1007/s10109-012-0176-x
- Shary , P. A. , Sharaya , L. S. and Mitusov , A. V. 2002 . Fundamental Quantitative Methods of Land Surface Analysis . Geoderma , 107 : 1 – 32 . doi: 10.1007/s10109-012-0176-x
- Shi , W. , Fisher , P. F. and Goodchild , M. F. 2004 . Recent Developments in Modeling Uncertainties in Geo-Spatial Data and Analysis . Photogrammetric Engineering & Remote Sensing , 70 ( 8 ) : 919 – 920 . doi: 10.1007/s10109-012-0176-x
- Stefanik , K. V. , Gassaway , J. C. , Kochersberger , K. and Abbott , A. L. 2011 . UAV-Based Stereo Vision for Rapid Aerial Terrain Mapping. Bellwether Publishing, Ltd . GIScience & Remote Sensing , 48 ( 1 ) : 24 – 49 . doi: 10.1007/s10109-012-0176-x
- Sulebak , J. R. 2000 . Applications of Digital Elevation Models DYNAMAP White paper , Oslo, Norway : Department of Geographic Information Technology, SINTEF Applied Mathematics . doi: 10.1007/s10109-012-0176-x
- Wechsler , S. P. 2003 . Perceptions of Digital Elevation Model Uncertainty by DEM Users . URISA Journal , 15 ( 2 ) : 57 – 64 . doi: 10.1007/s10109-012-0176-x
- Worboys , M. F. and Duckham , M. 2004 . GIS: A Computing Perspective , Boca Raton, FL : CRC Press . doi: 10.1007/s10109-012-0176-x
- Zandbergen , P. A. 2010 . Accuracy Considerations in the Analysis of Depressions in Medium-Resolution Lidar DEMs. Bellwether Publishing, Ltd . GIScience & Remote Sensing , 47 ( 2 ) : 187 – 207 . doi: 10.1007/s10109-012-0176-x