
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
With recent technological advances, the efficient extraction and utilization of valuable information from large-scale data sources have become increasingly important. The development of knowledge graphs (KGs) based on logical relationships between data has garnered attention from various location-related services. To provide results that satisfy the diverse preferences of individuals, explicit attributes and implicit semantic context must be considered during the retrieval of places of interest (POIs). Most POI retrievals often involve not just examining detailed information about places but also specifying places for intended visits. Therefore, spatial knowledge regarding the surroundings of POIs, such as proximity and accessible routes, should be incorporated to support decision-making. In this study, we propose a comprehensive framework for constructing a KG for POI retrieval (PKG), which adeptly integrates the place attributes, semantic features, and spatial context of locations. The core objective of this framework is to acquire suitable data for facilitating POI retrieval that effectively considers diverse user preferences for places. After constructing a PKG of Orlando (FL, USA), we verified the practical applicability of the proposed framework by conducting 10 types of distinct POI retrieval queries catering to a range of user preferences. The graph queries returned a list of POIs that precisely aligned with the requirements of users on not only the explicit attributes of places but also the spatial and semantic features while providing detailed travel route information to these destinations. In conclusion, the PKG enabled POI retrieval that satisfied user preferences and diversified the retrieved places and the information provided. As the PKG offers flexibility in data integration without physical constraints, it can be expanded by incorporating information from various sources.
Introduction
With the increasing volume of data, efficient methods of identifying and using it are increasingly important. Recently, the use of knowledge graphs (KGs) has garnered attention in various services such as information retrieval, recommendation, and question-answering (QA) services (X. Chen, Jia, and Xiang Citation2020; Guo et al. Citation2022; Ma Citation2022; Zou Citation2020). Such enormous datasets contain a diverse array of useful information bearing logical relationships (Li et al. Citation2017; H. Wang et al. Citation2019; Yu et al. Citation2014), as well as the various types of information which can be integrated, managed, and utilized based on these logical relationships. Although the description of logical relationships between various types of data can be inherently challenging, KGs can be an optimal alternative for this purpose (H. Wang et al. Citation2019).
However, when it comes to the retrieval of places of interest (POI), existing KG models face specific challenges. Traditional POI retrievals have largely focused on objective attributes such as the type of places, services offered, and operational hours. While these factors are essential, they overlook the subjective dimensions of user experience. In searching for POIs and deciding on the relevant POIs among the retrieved results, various factors must be considered. Most decision-making factors are influenced by the popularity and reputation of the given place (Kefalas and Manolopoulos Citation2017; Yin et al. Citation2017; Zhang, Hu, and Li Citation2015). Specifically, the subjective evaluations and opinions of other visitors regarding the POI – such as the ambiance, quality of service, and cost-effectiveness – are crucial factors for selecting places to visit (F. Wang et al. Citation2017; Yin et al. Citation2017). In this respect, unstructured data – such as descriptions and visitor reviews containing useful information related to the query – are important knowledge associated with the POI (Mai et al. Citation2018). Consequently, this gap highlights the need for a more comprehensive approach that integrates both explicit attributes and implicit features about places.
As POIs are designated with physical locations, POI retrieval inherently involves the user’s intention to visit, which can vary from a general keyword search mechanism. The decision to visit a place is not based solely on its attributes but also on its spatial context. For instance, even if a user searches for a reasonably priced restaurant, they tend to avoid it if it is situated in a difficult-to-visit location. In this context, the knowledge of places – such as the route to the POI, travel duration, and geographical features of the POI (e.g., located in the city center) – is important for POI retrieval, necessitating consideration of their spatial context. Consequently, the factors influencing the selection of the best places in POI retrieval can be summarized into three categories – that is, explicit attributes based on factual information (e.g., category, operation duration, and offerings), implicit features and relationships associated with places (such as “friendly staff” and “relaxed ambiance”), and spatial knowledge of the places (e.g., routes, connectivity, and centrality).
Results cannot be retrieved by combining factual, semantic, and spatial contexts using traditional information retrieval approaches that simply search for the names of places. To this end, integrated data compatible with retrieval tasks are required. Introducing a KG based on the logical relationships between the factual, semantic, and spatial knowledge related to POIs enables the development and utilization of such integrated data. Previously, several KGs have been developed for POI (POI-KG) applications in retrieval and recommendation services (W. Chen et al. Citation2022; B. Hu et al. Citation2022; S. Hu et al. Citation2019; Ounoughi et al. Citation2021; Tang et al. Citation2021; Yuan, Zhou, and Lam Citation2020). Hu et al. (Citation2019) proposed a KG comprising POIs, services, and user entities, wherein the relationships between the POIs and user entities were created based on sentiment analysis of user emotions toward the POIs or services. The users were linked to their visited POIs, which were further linked to the provided services, and connections were established between semantically similar users and service nodes. However, the spatial context of the POIs was not considered.
As users’ interest in POIs varies with geographical characteristics (Tang et al. Citation2021), considering spatial contexts becomes crucial in POI retrieval and recommendation. Based on the fact that people prefer places that are geographically close to previously visited places, several studies, such as Acharya and Mohbey (Citation2023) and Acharya et al. (Citation2023), introduced the concept of spatial neighbors in POI recommendation; however, the “neighbors” focuses on the positional relationships among users rather than the locational and topological context of the POIs. In particular, the spatial context has been combined with KGs. Cabrera R et al. (Citation2015) reflected spatial factors – such as walking distance – for POI recommendations. However, they only used factual attributes of POIs and addressed limited spatial operations based on absolute locations, leaving expandability for the more complex semantic and spatial context of POIs. In contrast, Tang et al. (Citation2021) proposed a semantic spatial graph considering category similarity and regional features of POIs. The geographical influence of POIs was specified by creating nearby relationships when distances between POIs were below a set threshold (e.g., 50 m). Subsequently, Hu et al. (Citation2022) constructed a POI-KG using check-in data based on the number of visits, visitors, and geographic categories of POIs. However, their KGs utilized predefined spatial relationships. Consequently, prompt adaptation to changes in the POI location was challenging, and inference of the spatial relationships beyond the predefined relationships (e.g., proximity and geographic category) was limited. Chen et al. (Citation2022) took a different approach by modeling a spatial-temporal knowledge graph (STKG) comprising users and POIs based on check-in sequences from user movement trajectories. The STKG concentrated primarily on movement patterns without incorporating the external attributes of the POIs. Similarly, Wang et al. (Citation2022) leveraged the check-in sequence of users, adopting distance-based and transition-based graphs. However, their model did not account for the complexity of the road topology for traveling between POIs.
Most of the previous POI-KGs have been proposed for recommendation purposes – that is, they have been characterized as user-centric models emphasizing the representation of the relationships between users and POIs. Moreover, certain studies have focused only on identifying the semantic associations between POIs and users based on user-generated reviews and ratings, whereas others have concentrated only on the geographical features of POIs and users’ visits, failing to capture the distinctive context associated with places. In essence, these models focus on the relationship between users and POIs, emphasizing where specific users have visited and how they rated these places; consequently, they often lack contextual information about the “place” where POIs are located. This approach tends to miss the broader context of the POIs, failing to fully capture the unique aspects that represent each place. By focusing on the relationships between places and combining the detailed spatial and topological knowledge of a place with its attributes and characteristics, the usability of POI-KGs can be improved.
To address the emerging need for integrating geospatial information with KGs, several geospatial KGs have been developed – including the GeoKG (S. Jiang et al. Citation2019; S. Wang et al. Citation2019), Yago2geo (Karalis, Mandilaras, and Koubarakis Citation2019), and WorldKG (Dsouza et al. Citation2021). Nonetheless, most geospatial KGs focus on fact-based geographic information regarding the physical entities and events to be utilized in GeoQA systems. Although these KGs contain various POI entities, they lack detailed contextual information regarding places to support decision-making in POI retrieval. They effectively represent geographic features and facilitate understanding of real-world objects and events. However, they fall short of encompassing knowledge about POIs from the perspective of places where activities occur and which individuals visit. With more focus on POIs, the spatial-semantic integrated knowledge graph (SSIKG) was developed for indoor environments (Park and Lee Citation2022). The SSIKG is a double-layered graph comprising a spatial layer representing indoor navigable paths, alongside a semantic layer representing inherent place characteristics derived from visitor reviews. Although the SSIKG can accurately reflect the spatial context of indoor places, it cannot be directly applied to outdoor environments owing to the differences in spatial characteristics. In particular, since indoor spaces are constrained by objects such as walls, the spatial layer of an SSIKG includes key objects (e.g. openings, elevators, etc.) as entities; however, in outdoor environments, intersections can become key entities based on road connectivity. Moreover, unlike indoor graphs that primarily concentrate on pedestrian movement, outdoor graphs necessitate accounting for vehicular transportation.
In summary, the efficacy of a POI-KG can be significantly enhanced by integrating contextual information from various perspectives for modeling knowledge regarding the place. It is well known that considering contextual information can improve the performance of recommendation systems, providing more appropriate and meaningful results (Iqbal et al. Citation2019; S. Wang et al. Citation2017). To obtain a comprehensive understanding of places, it is imperative to incorporate both the semantic and spatial context of POIs, along with factual information. However, existing POI-KGs are predominantly user-centric and deficient in capturing the intrinsic and unique characteristics of the places. There is a need for a place-centric modeling approach, which defines the characteristics of each place based on how it is commented on by all users who have visited it. Furthermore, the geographic features involved in POI-KGs are confined to addresses and coordinates. Thus, user convenience and satisfaction can be significantly enhanced by providing more detailed geographic information related to the places – for example, the path costs and optimal routes via multiple transportation modes – along with retrieval results. Ultimately, a database adopting a place-centric approach and integrating the aforementioned factors based on the spatial and topological characteristics of places is a vital prerequisite for effective POI retrieval.
This study proposes a framework for constructing an integrated KG for POI retrieval (PKG) by combining three types of place-related knowledge – that is, explicit attributes, implicit characteristics, and spatial contexts. First, the attributes commonly provided in existing POI-related services were extracted as mandatory information. Thereafter, the semantic features and relationships were identified from reviews reflecting visitors’ subjective evaluations or opinions on places. Moreover, a method for deriving the relationship weights was presented to leverage the PKG in services such as POI retrieval and recommendations. Finally, spatial networks were employed to combine the spatial context while preserving the detailed topology between places. The major contributions of this study include:
We proposed a conceptual KG model for POI retrieval by integrating explicit and objective attributes, implicit and subjective semantic features, and geographic and topological knowledge. Accordingly, the proposed graph included three subgraphs – namely, the attribute, semantic, and spatial graphs for POIs.
The proposed PKG combined the detailed topological relationships between POIs to provide enriched place-related information and increase the diversity of the retrieval results. The route information could be provided along with retrieved places that satisfied the semantic preferences; concurrently, the spatial context of visiting situations could be reflected as user requirements in POI retrieval.
We proposed a PKG construction framework using open datasets such as Yelp and OpenStreetMap (OSM) based on a case study in Orlando, FL, USA, wherein we detailed the process of exploring the constructed PKG to search for suitable POIs in response to ten types of queries.
The proposed PKG was constructed as a property graph database with a flexible schema, allowing for its expanded use through integration with other data. Specifically, we retrieved POIs without considering the spatial extent constraints by combining them with a prebuilt indoor KG. Furthermore, the PKG could be used for recommending POIs through integration with user history data.
Places-of-interest knowledge graph (PKG)
The property graph (PG) model is a labeled graph representing entities and their relationships across diverse domains using nodes and edges with attributes (Angles, Thakkar, and Tomaszuk Citation2020). Unlike the RDF – which has limitations in traversal and analytical algorithm implementation (Chiba, Yamanaka, and Matsumoto Citation2020) – the PG allows straightforward traversal of relationships for querying data. Moreover, in the PG, each node can be uniquely identified using globally unique identifiers. Since the primary purpose of the PKG is to retrieve user-preferred POIs through queries, we adopted the PG model for constructing the PKG. Additionally, as road topology – which is used to extract the spatial context of places – follows a graph structure, it can be intuitively and easily modeled utilizing the PG. Given that the PG exhibits good performance for relationship-based queries, we considered it to be a suitable model for POI retrieval based on spatial topology.
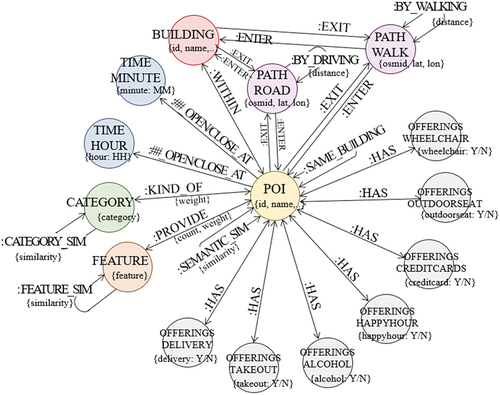
The PKG is a graph integrating three types of subgraphs to represent the contextual information of places – that is, subgraphs for attributes, place semantics, and spatial contexts (hereinafter, referred to as the attribute graph, semantic graph, and spatial graph, respectively). In particular, the attribute graph represents objective information related to POIs (e.g. the operating hours, services provided), the semantic graph captures implicit subjective information (e.g. a pleasant ambiance, friendly staff) in the PKG, and the spatial graph describes the locational and topological details of POIs (e.g. navigable paths between places, location within a building, road connections) based on road topology. The three subgraphs were linked through a common POI entity.
Definition 1.
PKG = <,
,
> is a labeled property graph with direction, configured using PE and PR, a set of labeled entities and typed relationships with various properties – that is,
and
denote the head and tail entities, respectively; all nodes and edges are indexed using labels.
Information describing the characteristics of places can be classified into explicit/objective information from tabular attributes and implicit/subjective information based on visitors’ opinions and evaluations. For instance, “parking available/unavailable” pertains to the first category of information, whereas “easy/hard to park” pertains to the second category. Conversely, the semantic graph comprises the inherent place features based on visitors’ reviews, where knowledge in this graph is subjective and relevant to user preferences.
Furthermore, as selecting the optimal POI among retrieved results implies an intention to visit, the route cost for visiting is a crucial factor in this selection. Consequently, the spatial graph incorporates knowledge regarding the geographic location of places, topological relationships between them, and travel routes. By preserving the geographic locations and topology based on the spatial networks, this subgraph reflects the various navigable paths depending on the transportation modes, whether via walking or driving. A conceptual model of the proposed PKG is illustrated in to ensure graph data consistency. All entities and relationships are detailed in the following sections.
Figure 1. Conceptual graph model for the PKG.
Model definitions
Entities
The PKG involves seven entities – namely, POI, CATEGORY, OFFERINGS, TIME, PATH, BUILDING, and FEATURE, wherein TIME, OFFERINGS, and PATH include two, seven, and two sub-entities, respectively. The entities of the PKG can be defined as follows:
POI : Places with physical existence in the real world are defined as POI entities, which include all places from various categories. The POI entity contains objective attributes – such as name, category, business hours, and available services (e.g., delivery, card payment). Additionally, the POI entity comprises several subjective characteristics – known as place semantics – based on the visitors’ opinions. Users can express their preferences by reviewing the offered services or the surrounding environment. Spatially, the POI entity contains geographical location information and is connected to the nearest road or walkway segment in the proposed PKG.
CATEGORY : All places are classified into a specific category, depending on the purpose of the visit or the type of service. The CATEGORY entity represents the category of the place based on its classification (e.g., restaurants, shopping, leisure, tours). Reflecting the hierarchical structure of categories, it is feasible to establish multiple relationships between POI and CATEGORY nodes. The web-based POI retrieval services often classify POIs into multiple categories. For example, several POIs might be categorized as “Calabrian,” which falls under the broader category of “Italian” cuisine; further, “Italian” itself is nested within the even more general category of “Restaurant.” In such cases, a POI node can be linked to each relevant CATEGORY node at every level of this hierarchy; that is, a single POI could simultaneously hold relationships with “Calabrian,” “Italian,” and “Restaurant” CATEGORY nodes.
TIME : The PKG expresses the temporal availability of the places based on the categorical time modeling, where the available time t satisfies the “open time < t < closed time” condition. The TIME entity includes the sub-entities of HOUR and MINUTE, represented by dual-labeled nodes.
OFFERINGS : The various services offered by a POI can be defined as the OFFERINGS entity, which refers to the objective attributes provided by a POI to its visitors. Information commonly provided by multiple services is regarded as essential; thus, we reviewed the offering lists defined by Yelp, FourSquare, and Google Maps to identify the common objective features among popular POI-search services. Thereafter, the seven features consistently offered across all three services were defined as the sub-entities of OFFERINGS—that is, ALCOHOL, HAPPYHOUR, CREDITCARDS, DELIVERY, TAKEOUT, OUTDOORSEAT, and WHEELCHAIR (). Notably, additional types of offerings could be added as the source data for constructing the PKG expands.
Table 1. Offered items common across Yelp, FSQ, and Google Maps and sub-entities of OFFERINGS.
PATH : A PATH entity is defined as a set of intersections configuring the navigable paths, by car and walking, to a given POI. Depending on the transportation mode, the PATHs can be classified into the sub-entities of WALK and ROAD; thus, all PATH entities include two or more labels.
BUILDING : The BUILDING entity is defined as a physical building object in the real world, while the POI refers to individual places. A building can be abstracted as a single node of the BUILDING entity, marked by its geometric centroid, and multiple POIs can exist within a single building (e.g. various shops within a shopping mall). In such cases, the BUILDING entity is associated with those multiple POIs. However, the POIs do not necessarily exist on a per-building basis; thus, there may be POI nodes not connected to any BUILDING nodes.
FEATURE : The FEATURE entity pertains to a keyword extracted from user reviews. This entity denotes the characteristics of a POI extracted from the implicit and subjective information contained in the textual data. During place retrieval, searching for FEATURE nodes is associated with user preferences presented in the query, followed by exploring the connected POIs, enabling the return of optimal places that incorporate the user preferences. The FEATURE entity can be structured in the form of bi- or tri-grams, comprising nouns or gerunds extracted from reviews.
Relationships
The PKG was organized into 14 types of relationships connecting the head () and tail (
) entities – that is, four types for place attributes, four types for semantic context, and six types for spatial context. These relationships were bi- (
) or uni-directional (
), based on their definitions and usage. The PKG relationships can be described as follows:
KIND_OF: Subgraph can be defined as
= <
, KIND_OF,
>. The relationships between all the categories and their associated POIs can then be constructed. Accordingly, a weight is assigned if the POI is connected to two or more categories.
DAY*_OPEN_AT, DAY*_CLOSE_AT: As per Park and Lee (Citation2022), the subgraphs and
denote the temporal availability of places – that is,
= <
, DAY_OPEN_AT,
>,
= <
, DAY_CLOSE_AT,
>. By adjusting the DAY* portion, relationships can be created for each day of the week if the place can be visited (e.g. MON_OPEN_AT). Unlike previous studies, these relationships can connect the POI to HOUR and to MINUTE.
HAS: Subgraph can be defined as
= <
, HAS,
>. This indicates connections with OFFERINGS having the property of Y/N based on their availability.
BY_WALKING, BY_DRIVING: Subgraphs and
denote the navigable paths between the places based on their topological relationships – that is,
= <
, BY_WALKING,
> and
= <
, BY_DRIVING,
>. Sequential WALK nodes on the pedestrian routes can be connected through the BY_WALKING relationship, while the ROAD nodes on vehicle routes can be connected through the BY_DRIVING relationship. For driveways, a unidirectional relationship can be defined for a specified direction of travel, whereas a bidirectional relationship can be defined as walkways permitting free bidirectional passage. Notably, the
and
relationships can be used to derive the route and cost of visiting the retrieved places from the user’s current location (or designated location) along with the accessibility of the place, which is critical for recommending and selecting places.
WITHIN, SAME_BUILDING: Subgraphs and
denote the association between POIs and BUILDINGs—that is,
= <
, SAME_BUILDING,
>,
= <
, WITHIN,
>. The POI nodes located within a building can be connected to BUILDING nodes through the WITHIN relationships, with the SAME_BUILDING relationships linking the POI nodes located within the same building. This relationship can filter the potential places to recommend for subsequent POIs. For instance, based on this relationship, a user who earlier visited a restaurant inside a particular shopping mall can be recommended a café located within the same shopping mall.
ENTER, EXIT: Subgraphs and
denote the paths for accessing a place:
= <
, KIND_OF,
>,
= <
, KIND_OF,
>. The POI or BUILDING nodes are connected to PATH via ENTER and EXIT relationships within the shortest distance. Moreover, these relationships are unidirectional – that is, the ENTER relationship follows the direction of the entrance to the place, and the EXIT relationship considers the direction of the exit from the place.
PROVIDE: Subgraph can be defined as
= <
, PROVIDE,
> and is established between the POIs and all the provided FEATUREs. As the FEATURE nodes are generated using implicit information from user reviews, they can be deemed to be semantic relationships between the POIs and FEATUREs. The relationships include the properties of “weight” and “count” representing the relative significance of FEATUREs with an associated POI.
CATEGORY_SIM: Subgraph can be defined as
= <, CATEGORY_SIM,
>. The CATEGORY_SIM relationship is created between CATEGORY nodes. Thereafter, “similarity” between the two nodes can be assigned as a property.
FEATURE_SIM: Subgraph can be defined as
= <
, FEATURE_SIM,
>. FEATURE_SIM denotes the semantic relationship between the FEATURE entities involving a “similarity” property representing how similar two FEATURE nodes are.
SEMANTIC_SIM: Subgraph can be defined as
= <, SEMANTIC_SIM,
>. This semantic relationship between the POI entities, SEMANTIC_SIM, includes a property representing the “similarity” between two entities.
Construction of PKG
The construction process comprises four stages – first, creating POI nodes by extracting the place information from the Yelp dataset. POI nodes are created according to unique business ID in Yelp, including the geographical coordinates (latitude and longitude) of the actual location; attributes such as the name are stored in POI nodes.
Second, creating the attribute graphs based on the place attributes (category, opening hours, acceptable payment modes, and available services such as delivery). This includes creating 24 HOUR nodes and 60 MINUTE nodes and generating two nodes for each of the seven predefined OFFERINGS (Y/N). Each POI’s operation hours and service information are then used to find the corresponding nodes, which are linked to the POI using the appropriate type of relationship as defined in the model (e.g. HAS, DAY*_OPEN_AT, DAY*_CLOSE_AT). Categories to which each POI belongs are created as nodes and linked to associated POI nodes using a KIND_OF relationship. If a CATEGORY node already exists, it is reused instead of creating a new one, thereby connecting the POI to the existing CATEGORY node.
Third, creating the semantic graph based on weight-matrices generated from similarity computations between entities (i.e. between POIs, CATEGORYs, and FEATUREs, respectively) after generating FEATURE nodes from the review texts. Detailed explanations of the creation of FEATURE nodes and similarity computations will be addressed in subsequent subsections.
Lastly, creating the spatial graph using the previously generated POI nodes and OSM networks. In particular, the WALK and ROAD nodes are created from the intersections within the OSM walkway and driveway networks, respectively, and the PATH label is assigned to the nodes of both entities. Since the OSM way elements contain information on two spatially linked node elements – namely, the “from” and “end” node elements—, BY_WALKING and BY_DRIVING relationships are established by locating these elements in the PATH nodes. Subsequently, the network-based distance is assigned as a property of the relationships, and an overlay analysis between the OSM building polygons and the POI points is performed to identify the POIs associated with each BUILDING node and form WITHIN relationships. POIs are linked to PATH nodes based on the buildings to which they are connected; however, POIs not associated with any building are directly connected to the PATH nodes. Furthermore, POIs located within the same building are linked via the SAME_BUILDING relationship.
The following subsections will describe the method for extracting FEATURE entities from place reviews, followed by a detailed description for determining the values of properties within diverse relationships, which function as weights in the query executions.
FEATURE entity extraction method
Unsupervised techniques – such as term frequency-inverse document frequency (TF-IDF) (Spärck Jones Citation1972), rapid automatic keyword extraction (RAKE) (Rose et al. Citation2010), and yet another keyword extractor (YAKE!) (Campos et al. Citation2020), have been employed for keyword extraction from unstructured texts. However, these methods are limited as they do not capture the semantic context of a document because they rely solely on statistical features for keyword identification. Consequently, various methods have been proposed to address this limitation, including keyBERT (Grootendorst Citation2020) which leverages the bidirectional encoder representations from the transformer (BERT) model to embed documents or words and extract keywords based on cosine similarity. KeyBERT returns semantically similar keywords relative to the input document by extracting the most similar n-grams from the embedded representation of the document.
Consequently, this study employed keyBERT to extract keywords representing the meaning of user reviews. To this end, we had to select models for word embedding and keyword extraction from the keyBERT Python package. For the word embedding model, we employed pre-trained encoders from sentence-BERT (SBERT) (Reimers and Gurevych Citation2019), a modified version of BERT to obtain sentence embedding. Among several pre-trained encoders,Footnote1 we selected the all-MiniLM-L6-v2 model (Citation2023), a general-purpose model offering speedy execution and adequate quality. For the keyword extraction model, we employed the maximal marginal relevance (MMR) method to extract the bi- or trigram keywords, ensuring that the extracted keywords were diverse and non-overlapping. To perform part-of-speech (POS) tagging, we used the Stanford POS tagger, which is known for its high performance.
When extracting keywords using keyBERT, numerous keywords may be generated depending on various parameters (e.g., top_n, diversity), including certain irrelevant keywords. Consequently, irrelevant keywords were removed, and relevant ones were retained. Additionally, through experimental iterations applying various thresholds to keywords, it was evident that selecting keywords that appeared 50 or more times yielded reasonable results. Since nouns represent major topics or concepts in a text, only keywords containing nouns were extracted to explicitly capture the features describing visitors’ opinions. Considering these points, the following deletion rules were established:
Rule 1: Delete keywords repeated more than once (e.g., “food food” and “love love love”).
Rule 2: Delete keywords appearing less than 50 times.
Rule 3: Delete keywords that do not contain nouns (e.g., NN, NNS, or VBG) after POS tagging.
Computation of relationships’ properties
Weight of KIND_OF 
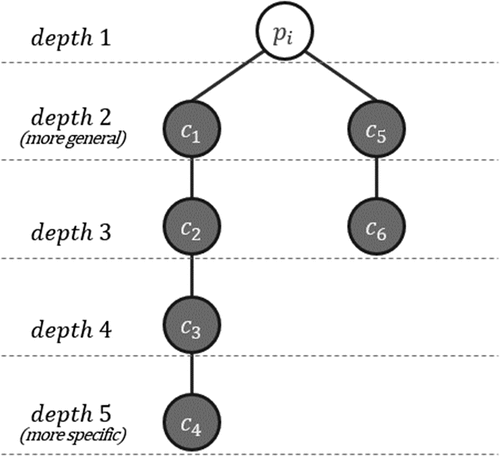
POIs are commonly categorized into several categories in the hierarchy. In a PKG, the POI entity is associated with multiple CATEGORY entities through a relationship. In case a POI and CATEGORYs are related to multiple KIND_OF relationships, a weight is required to determine the relative importance of each. In Park and Lee (Citation2022), the weight was calculated only for categories with a depth of
. In this study, we proposed an improved method for calculating the weight (
) that did not restrict the value of depth. The proposed method replaced the POI and CATEGORY relationships with a node-link structure and assigned weights based on the number of nodes from the POI node to each CATEGORY node. In a hierarchical structure, higher depths represent more general concepts, whereas lower depths represent more specific information. Consequently, categories with lower depths are assigned higher weights and those with the same depth are designated equal weights (). Notably, the sum of the weights associated with all the categories linked to each POI is equal to 1. The weight of the KIND_OF relationship
, representing the relative significance of the category associated with the POI, can be evaluated as follows:
Figure 2. Method of calculating based on the hierarchical structure of categories.
where and
denote the POI and CATEGORY entities, respectively, and
denotes the depth of nodes from
to
. However, here we treat
as depth 1 ().
denotes the total number of
units related to
, which satisfies
. The value of
increases as the depth of the category deepens, indicating that it contains more detailed information – that is, it can be inferred that a higher value of
indicates a stronger correlation between the given POI and CATEGORY.
Distance of BY_WALKING and BY_DRIVING
Generally, BY_WALKING and BY_DRIVING have a property of the spatial network-based distance, which can be used as a cost for spatial queries. This feature can be employed as a weight to find the optimal routes and travel durations for selecting POIs, such as determining the adjacent places or evaluating the travel duration required for a visit.
Properties of PROVIDE
The PROVIDE relationship comprises two properties – that is, count () and weight (
) – wherein
denotes the frequency of the corresponding FEATURE appearing as a keyword in the reviews of a given POI, and
denotes the relative significance of the FEATURE associated with the POI. To calculate
, the entire text of the review for each POI is considered to be a single document and is embedded using KeyBERT to obtain a POI vector.
can be measured using the cosine similarity between the POI and FEATURE entities, as follows:
where and
denote entities, and
and
denote
-dimensional vectors of
and
, respectively.
Here, and
denote POI and FEATURE entities, respectively. The cosine similarity calculated using EquationEq. (2)
(2)
(2) represents the correlation between a POI and FEATURE, which is defined as
. The value of
ranges from −1 to 1, where a value proximate to 1 indicates that the FEATURE is a representative characteristic of the POI and 0 means that the two entities are unrelated. If the value is negative, the POI has the opposite characteristic to the corresponding FEATURE. Furthermore,
is an integer value greater than or equal to 1; a higher value of
indicates the more frequent appearance of the FEATURE as a keyword in the reviews of the associated POI. Consequently, the FEATURE with a higher
is considered a representative feature of the POI. Thus,
represents the semantic relationship between POIs and FEATUREs, whereas
indicates a direct relationship between them. Using these two properties, the retrieval process can return POIs that are strongly associated with specific characteristics of user preferences.
Similarity of CATEGORY_SIM
The similarity of CATEGORY_SIM () indicates the degree of similarity between the CATEGORY entities. As per Park and Lee (Citation2022), we used an edge-based measurement (Wu and Palmer Citation1994) to calculate the similarity between the hierarchically structured categories, as follows:
where and
denote the CATEGORY entities, and
denotes the least common superclass of categories
and
, respectively.
and
denote the number of nodes on the shortest path from
to
and
to
, respectively.
denotes the number of nodes on the shortest path from
to the root node. The value of
ranges from 0 to 1, where 1 indicates identical categories and 0 indicates categories with no common parent category. This value can be used as a weight to search POIs in categories that are similar to a specific category.
Similarity of FEATURE_SIM
The similarity of FEATURE_SIM () denotes the similarity between FEATUREs. To calculate
, the cosine similarity between the embedded FEATURE vectors can be computed using EquationEq. (2)
(2)
(2) , where
and
denote the FEATURE entities, and
and
denote the n-dimensional vectors of
and
, respectively. The value of
ranges from −1 to 1, wherein a value of 1 indicates similarity and −1 represents dissimilarity. Thus, this value can be used to identify POIs with features similar to those of a user’s favorite POI.
Similarity of SEMANTIC_SIM
The similarity of SEMANTIC_SIM () can be accounted for by the similarity between POIs. Specifically, ss can be calculated using the cosine similarity (EquationEq. (2)
(2)
(2) ) between the POI vectors, which can be obtained by embedding the review text of each POI using KeyBERT. Here,
and
denote the POI entities, and
and
denote the n-dimensional vectors of
and
, respectively. Moreover,
can be used for retrieving POIs similar to the user’s preferred POI.
Implementation
Data and test area
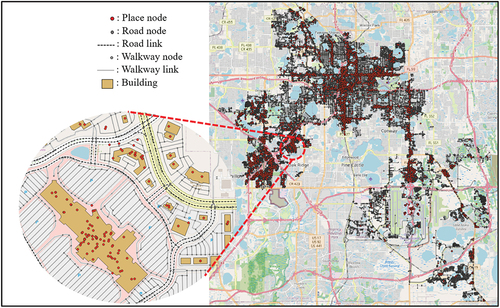
This study selected Orlando, Florida, USA, as the test area and constructed a PKG by applying the proposed framework. The spatial knowledge of the places was extracted using nodes, paths, and building features from OSM, whereas the attributes and reviews of various places in Orlando were used for semantic knowledge extraction from the Yelp dataset (Yelp Citation2023b). Since Yelp’s POI contained location coordinates, we could identify POI nodes with the nearest OSM’s PATH nodes and overlapping BUILDING entities. The buildings and spatial networks from the OSM and places from YelpFootnote2 within the test area are shown in . We downloaded two types of OSM networks – that is, drive and walk networks – from the Osmnx library (Boeing Citation2017) to construct the spatial graph representing topological knowledge between the places. The building polygons from the OSM were used for clustering the places within a building.
Figure 3. Data for the test area.
PKG of test area
Based on the graph model with labeled properties, the PKG for Orlando was constructed using the Neo4j graph database v.4.2.3. Creating, Projecting, and Querying PKG were conducted on an Intel Core i7-13700K processor with 64 GB of RAM. shows the total number of entity nodes and relationships of the PKG created for the test area. The POI “Hawkers Asian Street Food” – which was most frequently connected to various FEATURE nodes – was linked with 526 FEATUREs (such as “great food”). The “Restaurants” CATEGORY nodes contained the most POIs and were linked to 113 categories with a CATEGORY_SIM ≥0.5. Overall, no POI provided all seven offerings, and a maximum of only four offerings were simultaneously available. In addition, 3,726 POIs were associated with HOUR and MINUTE nodes with 14 *_OPEN/CLOSE_AT relationships from MON – SUN, implying their continuous operation throughout the week. However, 1,079 POIs were not connected to TIMEs displaying no operational period attribute.
Table 2. Construction results of the PKG.
As listed in , several POIs were connected with “Y” nodes for each sub-entity of OFFERINGS based on the available offerings; furthermore, POIs located within buildings were linked to PATH through the building, whereas others were directly connected to PATH nodes. Notably, the building containing the maximum number of POIs was “The Mall at Millenia,” with 97 POI nodes linked through the WITHIN relationship.
Table 3. Available POI counts for OFFERINGS.
POI retrieval using the PKG
The use of the PKG enables the provision of optimal places that reflect users’ preferences for the attributes and context of places. Moreover, it can simultaneously provide place information to fulfill the specified conditions and route information for a given location. For example, “Find a café that is semantically similar to café A and within a 10-min walk from here,” or “Where is a bar with a good atmosphere in shopping mall B? How do I get there from here?” Here, nine types of POI retrieval queries were set with specific preferences assumed, and the optimal responses were presented by exploring the PKG.
The appropriate answers to queries can be derived by identifying missing elements while traversing the entities and their relationships within the PKG. Consequently, various patterns comprising the PKG entities and relationships were presented, and several query types were defined by alternately specifying the missing elements. The following notations were used to describe the elements in the PKG – namely, po for POI, c for CATEGORY, f for FEATURE, o for OFFERINGS, t for TIME, b for BUILDING, and pa for PATH. Thereafter, we set various query types based on the combination of these elements. The notations with question marks indicate the elements to be identified through graph inference based on the present relationships. The nine types of queries can be expressed as follows:
Type1: (po?, c?, c, t): “Where are the places (po?) in a certain category (c?) similar to a specific category (c) that can be visited at (t)?”
Type2: (po?, c, po, o, t): “Which places (po?) in category (c) are semantically similar to a specific place (po) with offerings (o) and are available to visit in the timeframe (t)?”
Type3: (pa?, po, c): “What is the route from the current location (pa?) to the nearest place (po) in category (c)?”
Type4: (po?, f, po, pa): “What places (po?) contain similarities to features (f) of the preferred place (po)? and how do I get there (pa)?”
Type5: (po?, f, c, t, pa): “Which candidate place (po?) satisfies feature (f) and category (c) under the temporal condition (t) within the routing cost condition (pa)?”
Type6: (b?, po, o): “Which building (b?) has the most places (po) with specific offerings (o)?”
Type7: (po?, po, c, b): “Which place (po?) is semantically similar to a specific place (po) in category (c) within the same building (b)?”
Type8: (po?, b, po, pa): “Which place (po?) in building (b1) is most semantically similar to the place (po) in building (b2)? How long does it take to get there (pa), and which way should I go from a specific location (pa)?”
Type9: (po?, c, pa): “Which place (po?) in category (c) has the highest centrality (pa)?”
Based on the nine query types above, various queries can be set by assuming several conditions (e.g., category of “Restaurants,” offerings of “wheelchair accessible”). The POI retrieval results from the PKG for representative queries with specific conditions (second column) for each query type (first column) are shown in . Types 3, 4, 5, and 8 include spatial routing requirements. PATH nodes have the latitude and longitude as properties, and network distances are stored as properties of BY_DRIVING and BY_WALKING relationships; thus, the optimal routes presented with the retrieved places can be derived using the A* path-finding algorithm of the Neo4j Graph Data Science library v.1.8.6 (Citation2023).Footnote3 To reflect the cost condition of travel duration, the average adult walking speed and driving speed were set to 1.3 m/s and 30 km/h, respectively. Additionally, the similarity was determined as “similar” if the similarity value was at least 0.6
Table 4. POI retrieval results.
Key to the evaluation of the PKG is how well the graph data from our proposed framework encapsulates the diverse contextual information regarding POIs. Therefore, we qualitatively assessed the appropriateness of PKG’s response to various types of queries. Particularly, we examined whether the retrieved POIs satisfied the multiple conditions from queries. For our evaluation, the ground truth used to determine whether the result POIs met the query conditions was the information in the original Yelp dataset and OSM. Additionally, several route results were compared with those of Google Maps. The query conditions for the generated information during the data construction process (e.g. weight, similarity) were checked for consistency with the data stored in the database; then, they were qualitatively verified through user reviews for the corresponding POIs. Furthermore, the suitability of results for queries, which included routing cost conditions or requested optimal routes, was examined by comparing them with the OSM network. Specifically, the nodes in derived routes from the PKG included the OSM ID as a property. By mapping the sequence of the OSM IDs in the derived route to the OSM network, it could be confirmed that the returned routes were feasible.
Query 1–1 represents a request to locate the places belonging to a category similar to “Gyms” that could be visited at a specific time – that is, open before 6 am on Monday. The CATEGORY_SIM relationship with a similarity value ≥ 0.6 was used to determine the CATEGORY nodes similar to “Gyms;” the places connected to the corresponding CATEGORY nodes via KIND_OF were searched, with the condition of being connected to 1–5 HOUR nodes via MON_OPEN_AT relationship (). The number of retrieved places could be altered by adjusting the similarity value. Upon comparing the results with the POI information provided by Yelp, it was observed that one of the returned results, “Orangetheory Fitness Nona,” was categorized under “Gyms,” “Active Life,” and “Fitness & Instruction.” These categories align with the “Gyms” category specified in the query. Yelp provided the operating hours of that POI for Monday as 4:30–21:30, fitting the query conditions. Similarly, other POIs – such as “Crossfit Milk District” and “Crunch Fitness – Lake Nona” – also met the query criteria.
Figure 4. POI retrieval results using the attribute and semantic graphs; entities denoted by the following colors: retrieved place (POI) (orange), CATEGORY (purple), OUTDOORSEAT (beige), FEATURE (yellow), HOUR (light green), and MINUTE (green): (a)–(f) indicate the results to queries 1–5, respectively.
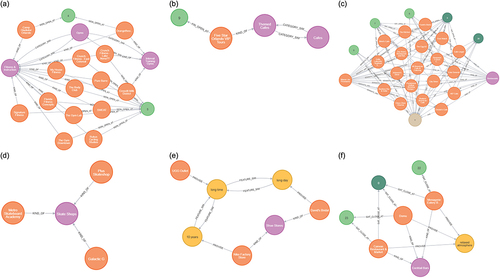
For Query 1–2, places in a category similar to “Café” which could be visited on Friday at 10 were searched. The results yielded only one similar category, “Themed Cafes,” which satisfied the category similarity of 0.6 or higher, and only one POI eventually satisfied all the conditions (). However, if the similarity criterion was decreased to 0.5, 247 POIs were retrieved. The “Five Star Orlando VIP Tours” was categorized in “Themed Cafes,” which had a similarity of 0.67 to the “Cafes” category in the database. Its Yelp-listed operating hours on Friday were “9:00–17:00,” aligning with the query requirements. As “Five Star Orlando VIP Tours” was the sole POI listed under “Themed Cafes” in the Yelp data, it was the only POI returned for this query.
Query 2 utilized semantic and temporal contexts to identify candidate POIs. The search for POIs meeting these criteria involved using HOUR and MINUTE (sub-entities of TIME), CATEGORY, and OUTDOORSEAT (sub-entity of OFFERINGS) nodes with SEMANTIC_SIM, KIND_OF, HAS, and SAT_OPEN_AT relationships. Specifically, 18 places were identified among the POI nodes connected by the SEMANTIC_SIM relationships with a similarity value of 0.6 or higher (). These places were open before 9 AM and closed after 12 PM on Saturday mornings, linked to the “Restaurants” CATEGORY nodes via KIND_OF relationships, and offered outdoor seating. Upon cross-referencing with the original Yelp data, it was confirmed that “Choo-Choo Churros” had operational hours of “6:00–22:00” on Saturdays. Additionally, it provided “Outdoor-Seating” services and was categorized under “Restaurants.” Notably, its semantic similarity with “Mason Jar Provisions” was 0.61, satisfying all query conditions. Similarly, all other POIs – including “Café Linger” and “The Egg & I” – also fulfilled all the query criteria.
Query 3 inquired about the nearest place in a specific category and the optimal route to that place from the user’s current location. As depicted in , there were three POIs classified in the “Skate shop” category, and a 1:N path-finding query was executed to select the nearest POI from the current location, “Ski World Orlando.” Among the three candidate POIs, the nearest place was “Galactic G,” located inside a building (Building ID 27,108). The optimal walkway route is shown in . Upon verification using routing services from Google Maps, it is evident that “Galactic G” was located 0.64 km from “Ski World Orlando,” “Plus Skateshop” was 2.74 km away, and “Metro Skateboard Academy” was 11.9 km away. This confirmed that among the three POIs categorized under “Skate shop,” “Galactic G” was the closest to “Ski World Orlando,” proving the accuracy of the query results.
Figure 5. POI retrieval results with optimal routes; entities are denoted by the following node colors: retrieved place (POI) (orange), START (pink), and BUILDING (sky blue). The optimal paths are represented by the directed “PATH_0” type relationships and small beige nodes: (a) query 3, (b) query 5, (c) query 8.
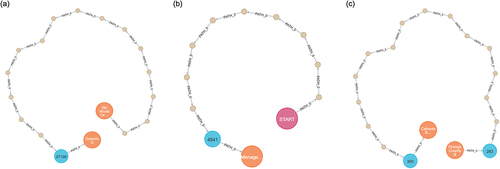
In Query 4, the FEATURE_SIM relationship was employed to identify shoe stores offering similarly featured services to the user’s preferred place (i.e., UGG Outlet), and accordingly, the path to shoe stores from a particular location (i.e., Palm Beach Atlantic University Orlando Campus) was determined. The explored places were “David’s Bridal” and “Nike Factory Store” (), and the travel routes for both walking and driving were derived from the starting point to the two POIs (). To determine the routes considering the modes of transportation, the optimal routes were explored after constructing the walkway graphs using the WALK nodes and BY_WALKING relationships, and the driveway graphs using the ROAD nodes and BY_DRIVING relationships through graph projection from the PKG. After reviewing the original data, it was evident from visitor reviews on Yelp that the features most commonly associated with the “UGG Outlet” were “brand new” and “long time.” The reviews of “David’s Bridal” contained “long day,” which had a similarity of 0.73 with “long time.” Furthermore, “Nike Factory Store” had a feature of “10 years” with a similarity of 0.6 to “long time.” Additionally, both of these POIs fell within the category of “Shoe Stores.” Due to the differences in the projected graphs for the two modes, the walking and driving paths showed slight differences in the search results, like fewer nodes and longer unit segments in the driving path. This variation corresponded with the differences in the driveway and walkway sections as per the OSM data, thereby validating the accuracy of the graphs.
Figure 6. POI retrieval results with optimal routes for query 4; entities denoted by the following node colors: retrieved place (POI) (orange), START (pink), and BUILDING (sky blue): (a) optimal walking paths represented by the directed “PATH_0” type relationships and small beige nodes; (b) optimal driving paths represented by the directed “PATH_0” type relationships and small gray nodes.
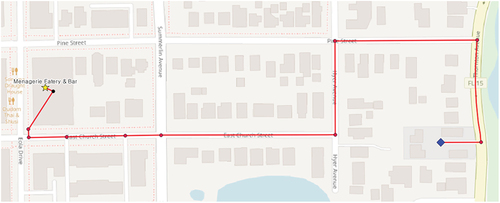
Query 5 retrieved the places under a route cost constraint. We assumed a situation in which the user searched places within a 10-min walk from their current location among “Cocktail Bars” with a relaxed atmosphere and open after 8 pm on a Saturday. The KIND_OF relationship was used to find the POIs in “Cocktail Bars” and the SAT_CLOSE_AT relationship was used to specify POIs shut after 8 pm on Saturday. Concurrently, the POI nodes connected through the PROVIDE relationship to the FEATURE nodes with a value of “relaxed atmosphere” were retrieved, discovering “Canvas Restaurant & Market,” “Domu,” and “Menagerie Eatery & Bar” (). The walking times from an arbitrary starting point to the three POIs were determined using the spatial graphs in the PKG; “Menagerie Eatery & Bar” was the most suitable POI for the query, as it could be visited via a 10-min walk (). After visualizing the returned graphs by mapping them to the OSM data (), a comparison with the routing results using OSM networks was conducted; this comparison verified that the appropriate paths had been accurately returned. However, “Canvas Restaurant & Market” was excluded from the retrieval results due to the absence of a feasible walking route in PKG; it was also corroborated by the disconnected walkway in the OSM network. Similarly, “Domu,” with a travel time of approximately 1 hour from the starting point, was not returned as a final POI. Further, upon reviewing Yelp data, it was confirmed that “Menagerie Eatery & Bar” falls under the “Cocktail Bars” category and operates on Saturdays from “11:00 am to 10:00 pm,” and the term “relaxed atmosphere” frequently appeared in its reviews.
Figure 7. Map visualization of extracted optimal walking route (fig. 5(b)) with OSM data for query 5.
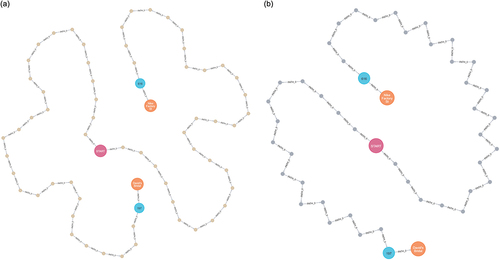
As mentioned, we assumed that a similarity of 0.6 or higher indicated that the two nodes were similar with respect to the associated relationship. shows how the retrieved POIs for Query 4 change based on the altered similarity criterion. Whether one prefers to retrieve a variety of less similar POIs or to precisely identify pairs of similar POIs, categories, and features depends on subjective preferences, making it impossible to definitively define an appropriate similarity criterion. Nevertheless, by adjusting the threshold value (raising or lowering it), users can search for POIs that are “similar” to other preferred POIs. For instance, this could involve places with similar categories or services offering similar features.
Figure 8. Result of query 4 with different similarity criteria: (a) 0.5, (b) 0.7.
Queries 6–8 are examples of using BUILDING nodes – for example, Query 6 finds the building containing the most places satisfying the given conditions; Query 7 locates places within a specific building that satisfies both the category and semantic context conditions; and Query 8 searches places in a designated building similar to a particular place in another specified building, including the route information. For Query 6, a building named “The Mall at Millenia” with 11 wheelchair-accessible POIs was identified as the most wheelchair-accessible place based on HAS relationships and WHEELCHAIR nodes with “Y” (); out of 97 POIs located within the mall, 11 offered wheelchair-accessible options, as listed in Yelp.
Figure 9. POI retrieval results using building nodes for queries 6–8; entities denoted by the following colors: retrieved place (POI) (orange), CATEGORY (purple), WHEELCHAIR (beige), and BUILDING (sky blue): (a)–(d) indicate the results to queries 6–9, respectively.
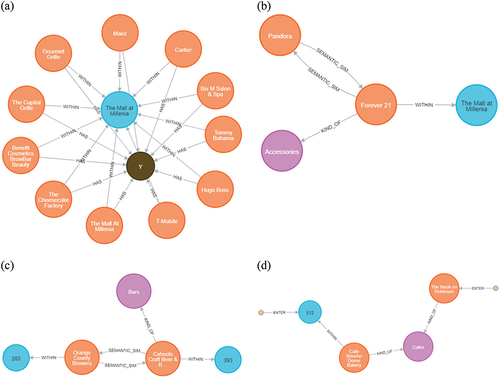
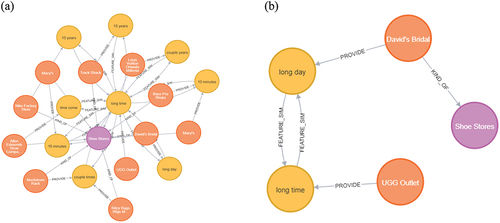
The result of Query 7, seeking accessory shops semantically similar to “Pandora” located in “The Mall at Millenia” (id:112), is shown in . The accessory shops located in the mall were searched using the WITHIN relationship, and among them, “Forever 21” was connected to “Pandora” through the SEMANTIC_SIM relationship with a similarity value of 0.6 or more. It is evident that “Forever 21” belonged to the “Accessories” category in the Yelp data. Moreover, its semantic similarity value with “Pandora” was 0.64, making it the POI linked to “Pandora” with the highest value.
Similarly, for Query 8, “Cahoots Craft Beer & Arcade Bar” was retrieved as the optimal POI after querying bars located in Building 393, which were semantically similar to “Orange County Brewers” in Building 283 (). This query also requested information on the travel duration and route to the retrieved place; by exploring the spatial graph simultaneously, it presented that the distance between “Orange County Brewers” and “Cahoots Craft Beer & Arcade Bar” could be covered in an eight-minute walk along the optimal route depicted in . Additionally, “Cahoots Craft Beer & Arcade Bar” was listed under the “Bars” category in Yelp. Its semantic similarity with “Orange County Brewers” was 0.61, marking it as the place with the highest similarity value among other “Bars” located within Building 393.
Query 9 is an example of searching for a café at an appropriate intermediate point where people living scattered in various regions can gather, using the spatial graph of the PKG. One of the graph metrics – that is, betweenness centrality—measures how often nodes appear on the shortest paths between other nodes in a network, identifying nodes that play a crucial bridging role. Nodes with high betweenness centrality scores imply greater accessibility from other nodes. By identifying cafes with high betweenness centrality as meeting points, the travel time for individuals can be optimized. In this scenario, after projecting a graph comprising WALK nodes and BY_WALKING relationships, the betweenness centrality scores of all walk nodes were determined and stored as a property. Subsequently, POIs could be identified that were connected to the “cafes” CATEGORY node and were also linked to WALK nodes with the highest betweenness centrality. Within the PKG, POIs could be located both inside and outside buildings; to provide various options, POIs for both cases were explored, considering that indoor POIs could be connected to WALK nodes through buildings. Consequently, two cafés were retrieved by considering road centrality, as depicted in .
Integration with the indoor graph
This integration can be achieved without separate scaling or transformation using properties such as distance or intersection coordinates. In addition to prebuilt indoor graph databases, node-link structured indoor networks constructed from sources like building information modeling (BIM), or floor plans can be used as sources for indoor graphs to be imported and combined into a graph database. Accordingly, POIs located within buildings such as shopping malls can be retrieved by leveraging the spatial context of intricate indoor environments. Furthermore, seamless door-to-door level routes can be offered, encompassing both indoor and outdoor areas.
Herein, a spatially unconstrained query test was performed by integrating the PKG with a prebuilt indoor KG for places – that is, the SSIKG of The Mall at Millenia in Orlando (FL, USA) – which was constructed by Park and Lee (Citation2022). As the PKG contains more up-to-date information on both place attributes and semantics, we used only the spatial layer of the SSIKG and integrated the two datasets. Regarding the CONNECTS relationship – which is the connection between each place and their associated portals in the SSIKG – we created the CONNECTS relationship with the PORTAL entity of SSIKG for the POIs of the PKG located in this mall. For POIs that did not exist in the SSIKG, relationships were created after checking the associated portal by referring to the mall guide map. The query type used for the test can be described as follows:
Type 10: (po?, pa?, f, c, b): How to go to a specific featured (f) place (po?) in a specific category (c) in a building (b) from the current location (pa?)?
We assumed the query for type 10 to be “How to go to fashion stores with good prices in the Mall at Millenia (ID:112) from IKEA?” The query results satisfying the semantic conditions are shown in along with the optimal path from the current location, “IKEA,” to the retrieved place, “H&M.” Graphs as well as the sequence of nodes were returned. Following the identification of the nodes in the spatial network that corresponded to the nodes included in the returned route, the optimal route could be visualized on a map using the derived nodes sequence () to enable users to intuitively understand the retrieved results.
Figure 10. POI retrieval results for query 9; entities denoted by the following colors: retrieved place (POI) (orange), CATEGORY(purple), FEATURE(yellow), BUILDING(sky blue). The part of the graph with small beige nodes and “PATH_0” type relationships represents the outdoor walking paths, whereas the part of the graph with green nodes and “PATH_0” type relationships represents the indoor walking paths.
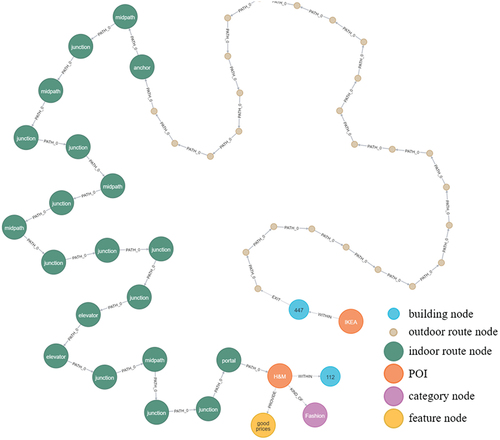
Figure 11. Visualization of the extracted optimal path for query 9 using the OSM data and 3D indoor networks.
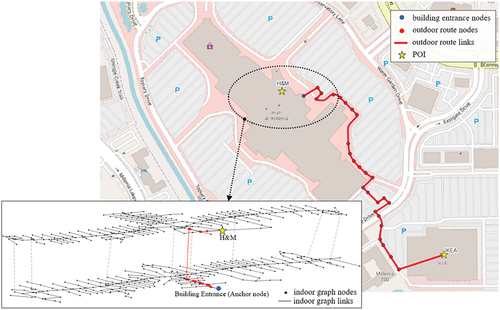
By integrating the PKG with indoor graphs, users could readily obtain information on the external pedestrian path from IKEA to the mall, which entrances to access, and the indoor travel routes to follow to reach the destination.
Discussion
The proposed PKG enabled POI retrieval that satisfied conditions based on objective facts – such as designated categories or available offerings. Leveraging the CATEGORY_SIM relationship, the search extended beyond places within the same category to include those with similar categories. Using place semantic features identified from user reviews and represented in the PKG as subgraphs comprising FEATURE nodes and SEMANTIC_SIM, FEATURE_SIM, and PROVIDE relationships, we demonstrated the retrieval of suitable places reflecting users’ subjective preferences. Furthermore, considering the location and topological conditions of places as essential factors, the PKG enabled the search for appropriate places in terms of spatial context. By capturing spatial relationships, the PKG enables complex queries encompassing not only individual POIs’ attributes but also the spatial and contextual relationships derived from their location. The PKG offers the advantage of returning a list of retrieved places while simultaneously providing optimal route information considering the transportation mode. Moreover, various graph metrics – such as centrality, connectivity, and pathfinding—can be used for spatial topology analysis, which facilitates a comprehensive spatial assessment whose results can be integrated into the place exploration process. In summary, the PKG provides comprehensive POI retrieval by taking the objective attributes, unique features, subjective evaluations, and spatial and topological characteristics of places into account. Additionally, seamless POI retrieval across indoor and outdoor environments can be accomplished through the integration of indoor graphs. Consequently, when combined with the property graph model, the PKG can excel in storing and managing multi-type and multi-format information, being particularly effective in articulating locational and topological relationships among POIs. Thus, the PKG can serve as a rich, interconnected dataset that complements existing models for POI-related tasks.
The PKG can execute traditional coordinate-based spatial operations and make inferences regarding positional and topological characteristics by leveraging the coordinate properties in POI nodes. For example, assuming that POIs A and D are adjacent, the optimal path from A to C can be explored as path B using spatial graph searching in the PKG and then inferring that D can optimally reach C via path B. Furthermore, as illustrated with the centrality example in Query 9, various spatial graph metrics can be used to analyze the positional characteristics of POIs. For instance, using spatial graphs, POIs located in the city center and accessible POIs can be identified through centrality or accessibility analysis, respectively. Since the optimal routes between places correspond to subgraphs within the PKG, route similarity can be estimated by applying several graph similarity metrics, such as the node similarity index between the nodes that compose the route. Such information is expected to be meaningful in POI retrieval and recommendation tasks.
To address concerns regarding the labor-intensive nature of KG construction, we propose a semi-automated, standardized framework that builds upon preexisting open data for POIs. This approach aims to enhance the efficiency and accessibility of KG construction. Furthermore, the constructed PKG is managed as a property graph database, thus offering significant flexibility in data management. New POI, CATEGORY, and FEATURE entities can be readily added following the proposed construction methodology and, since all possible nodes have been already considered for TIME and OFFERINGS entities, the need for additional nodes is eliminated. When prebuilt nodes for entities like CATEGORY and FEATURE exist, relationships are simply established with new or updated POI nodes. If no relevant node exists, a new one is created and connected. Node properties, such as POI or CATEGORY, are not constrained by a fixed format and, hence, can be freely modified. Moreover, relationships can be efficiently added or removed to reflect updated information. For instance, if a POI discontinues delivery services, the HAS relationship with DELIVERY nodes marked “Y” would be replaced by a new HAS relationship with nodes marked “N.” Due to the inherent characteristics of graph databases, modifications and managing tasks, including additions or deletions, can be executed efficiently. This adaptability of the PKG makes it well-suited for managing the dynamic nature of POI information.
However, a limitation of the PKG is its dependency on the accuracy of the source data. In this study, POI information – such as the provided services and geographic coordinates – was extracted from a Yelp dataset, whereas semantic features of the POIs were derived from user reviews. Because Yelp gathers feedback from users and business owners to update place information and ensure content integrity, it can be considered a relatively accurate source (Yelp Citation2023a). Nonetheless, instances of outdated information or inaccurate location data might persist. Consequently, in the future, we should incorporate auxiliary sources to cross-validate data accuracy and enhance the quality of the PKG information.
The proposed PKG could benefit from integration with information from other sources. Although the fundamental graph model was outlined in this study (), not all nodes need to be connected by defined relationships. Even nodes of the same type can have different attribute items, and the same applies to relationships. Consequently, the integrated data need not conform to the presented format or encompass all the information. Enhancements to the spatial graphs of the PKG could involve reflecting predefined route information for each transportation mode, allowing users to search for more suitable places relative to their specific travel situations. Currently, the PKG model primarily addresses pedestrian and vehicular travel, but incorporating network data for buses, bicycles, and railways could significantly broaden its applicability. For instance, bicycles often share road infrastructure with cars, whereas buses typically follow preplanned routes along roads. Likewise, rail transit could be effectively integrated by adding new POIs for stations and constructing graphs to represent station sequences aligned with train routes. By considering these public transportation routes, the PKG can be expanded, either by adjusting labels and relationships within its existing road graphs or by introducing new subgraphs. This expansion would enable a more comprehensive representation of urban mobility in the graph. Furthermore, semantic graphs could be augmented by adding semantic features extracted from other review data sources (e.g. Foursquare and Google Maps) as FEATURE nodes and establishing relationships between the added FEATURE nodes and identical POI nodes in the prebuilt PKG. The PKG could be expanded not only by using more varied data sources but also by linking it to existing KGs based on matched entities. The Neo4j graph database system offers RDF import functionality, which can facilitate connections with previous KGs built in RDF format. Similarly, existing RDF-to-PG conversion algorithms (Angles, Thakkar, and Tomaszuk Citation2020; Brandizi, Singh, and Hassani-Pak Citation2018; Chiba, Yamanaka, and Matsumoto Citation2020; Matsumoto, Yamanaka, and Chiba Citation2018) could be employed. Consequently, strategies for mapping identical entities between previous ontologies and the proposed PKG model, as well as methods for translating the vocabulary of existing KGs, should be developed in the future.
Conclusions
This study proposed a framework to construct PKGs by integrating the attributes, semantic features, and spatial context of places. The PKG was based on the logical relationship of contextual information of the places extracted from heterogeneous data sources. Upon constructing a PKG for Orlando (FL, USA) using OSM and Yelp data, we conducted POI retrieval tests for 10 queries under various conditions. The test results returned the best places suited to users’ preferences along with route information for visiting these places. Although the PKG is effective for queries incorporating a complex blend of contextual information about places, it is also capable of accommodating simpler and objective requirements such as specific categories, operating hours, or availability of services like delivery; therefore, it is crucial to recognize the PKG’s potential in daily scenarios where user queries are more casual and diverse. Consequently, future enhancements of the PKG will aim to accommodate a wider range of user queries, from routine to complex, thereby expanding its applicability.
The PKG is expected to serve users seeking optimal places that encompass a blend of various contexts as well as potential users such as business owners and city planners. For example, business owners could readily access information about places offering services similar to their own, thereby aiding them in understanding their competitive landscape. Furthermore, analyzing the semantic and spatial distribution of POIs through the PKG could assist in identifying necessary facilities and services on a regional basis. Consequently, city planners could use this information to better allocate facilities and services within their jurisdiction.
Future enhancements of the PKG could involve supplementing the spatial and semantic graphs with additional information – such as detailed road attributes and various review data. Moreover, place recommendation services could be enriched by incorporating user information into the PKG. For instance, by integrating the individual profiles of users who have visited and reviewed different POIs, a USER entity could be added to the PKG encompassing information such as history and frequency of visits, preferences, and demographic details like age or gender. Thus, the rich insights provided by user interactions and behaviors could help enhance the system to accomplish more personalized and accurate POI retrieval and recommendations.
Finally, discussions should focus on strategies to enhance the PKG by utilizing user feedback, rendering it better suited to recommendation services. Specifically, introducing a method to reflect the selection of one of the many POIs returned (based on user preferences) as a weight in the PKG is expected to enhance the satisfaction of POI recommendations.
Acknowledgments
This research was supported by the Korea Agency for Infrastructure Technology Advancement (KAIA) grant funded by the Ministry of Land, Infrastructure and Transport (Grant No. RS-2022-00143336), the National Research Foundation of Korea (NRF) grant funded by the Korean government (MSIT) (Grant No. RS-2023-00209619), and the BK21 PLUS research program of the National Research Foundation of Korea.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability statement
The data that support the findings of this study are available from the corresponding author, Youngmin Lee, upon reasonable request.
Additional information
Funding
Notes
1. SBERT pretrained models. https://www.sbert.net/docs/pretrained_models.html
2. Yelp dataset. https://www.yelp.com/dataset/download
3. Neo4j GDS library. https://github.com/neo4j/graph-data-science/
References
- Acharya, M., and K. K. Mohbey. 2023. “Differential Privacy-Based Social Network Detection Over Spatio-Temporal Proximity for Secure POI Recommendation.” SN Computer Science 4 (3): 252. https://doi.org/10.1007/s42979-023-01683-7.
- Acharya, M., S. Yadav, and K. K. Mohbey. 2023. “How Can We Create a Recommender System for Tourism? A Location Centric Spatial Binning-Based Methodology Using Social Networks.” International Journal of Information Management Data Insights 3 (1): 100161. https://doi.org/10.1016/j.jjimei.2023.100161.
- Angles, R., H. Thakkar, and D. Tomaszuk. 2020. “Mapping RDF databases to property graph databases.” IEEE Access 8:86091–24. https://doi.org/10.1109/ACCESS.2020.2993117.
- Boeing, G. 2017. “OSMnx: New Methods for Acquiring, Constructing, Analyzing, and Visualizing Complex Street Networks.” Computers, Environment and Urban Systems 65:126–139. https://doi.org/10.1016/j.compenvurbsys.2017.05.004.
- Brandizi, M., A. Singh, and K. Hassani-Pak. 2018. “Getting the Best of Linked Data and Property Graphs: Rdf2neo and the KnetMiner Use Case.” In 11th International Conference Semantic Web Applications and Tools for Life Sciences, December 3–6, 2021. Antwerp, Belgium: CEUR.
- Cabrera R, L., L. M. Vilches-Blázquez, M. Torres-Ruiz, and M. A. Moreno I. 2015. “Semantic Recommender System for Touristic Context Based on Linked Data.” In Information Fusion and Geographic Information Systems, In Lecture Notes in Geoinformation and Cartography of Information Fusion and Geographic Information Systems (IF&GIS’ 2015), Cham: Springer. https://doi.org/10.1007/978-3-319-16667-4_5
- Campos, R., V. Mangaravite, A. Pasquali, A. Jorge, C. Nunes, and A. Jatowt. 2020. “YAKE! Keyword Extraction from Single Documents Using Multiple Local Features.” Information Sciences 509:257–289. https://doi.org/10.1016/j.ins.2019.09.013.
- Chen, X., S. Jia, and Y. Xiang. 2020. “A Review: Knowledge Reasoning Over Knowledge Graph.” Expert Systems with Applications 141:112948. https://doi.org/10.1016/j.eswa.2019.112948.
- Chen, W., H. Wan, S. Guo, H. Huang, S. Zheng, J. Li, S. Lin, and Y. Lin. 2022. “Building and Exploiting Spatial-Temporal Knowledge Graph for Next POI Recommendation.” Knowledge-Based Systems 258:109951. https://doi.org/10.1016/j.knosys.2022.109951.
- Chiba, H., R. Yamanaka, and S. Matsumoto. 2020. “G2GML: Graph to Graph Mapping Language for Bridging RDF and Property Graphs.” In International Semantic Web Conference, November 1–6, 2020. 160–175. Virtual Event: Springer.
- Dsouza, A., N. Tempelmeier, R. Yu, S. Gottschalk, and E. Demidova. 2021. “WorldKG: A World-Scale Geographic Knowledge Graph.” In 30th ACM International Conference on Information & Knowledge Management, November 1–5, 2021. 4475–4484. Virtual Event Queensland Australia: Association for Computing Machinery. https://doi.org/10.1145/3459637.3482023
- Grootendorst, M. 2020. “Keybert: Minimal Keyword Extraction with BERT.” Zenodo. [online]. https://doi.org/10.5281/zenodo.4461265.
- Guo, Q., F. Zhuang, C. Qin, H. Zhu, X. Xie, H. Xiong, and Q. He. 2022. “A Survey on Knowledge Graph-Based Recommender Systems.” IEEE Transactions on Knowledge and Data Engineering 34 (8): 3549–3568. https://doi.org/10.1109/tkde.2020.3028705.
- Hu, S., Z. Tu, Z. Wang, and X. Xu. 2019. “A Poi-Sensitive Knowledge Graph Based Service Recommendation Method.” In 2019 IEEE International Conference on Services Computing (SCC), July 8–13, 2019. 197–201. Milan, Italy: IEEE. https://doi.org/10.1109/scc.2019.00041
- Hu, B., Y. Ye, Y. Zhong, J. Pan, and M. Hu. 2022. “TransMKR: Translation-Based Knowledge Graph Enhanced Multi-Task Point-Of-Interest Recommendation.” Neurocomputing 474:107–114. https://doi.org/10.1016/j.neucom.2021.11.049.
- Iqbal, M., M. Ghazanfar, A. Sattar, M. Maqsood, S. Khan, I. Mehmood, and S. Baik. 2019. “Kernel Context Recommender System (KCR): A Scalable Context-Aware Recommender System Algorithm.” IEEE Access 7:24719–24737. https://doi.org/10.1109/ACCESS.2019.2897003.
- Jiang, B., L. Tan, Y. Ren, and F. Li. 2019. “Intelligent Interaction with Virtual Geographical Environments Based on Geographic Knowledge Graph.” ISPRS International Journal of Geo-Information 8 (10): 428. https://doi.org/10.3390/ijgi8100428.
- Karalis, N., G. Mandilaras, and M. Koubarakis. 2019. “Extending the YAGO2 Knowledge Graph with Precise Geospatial Knowledge.” Lecture Notes in Computer Science [online] Accessed March 16, 2023. https://doi.org/10.1007/978-3-030-30796-7_12.
- Kefalas, P., and Y. Manolopoulos. 2017. “A Time-Aware Spatio-Textual Recommender System.” Expert Systems with Applications 78:396–406. https://doi.org/10.1016/j.eswa.2017.01.060.
- Li, X., D. Song, P. Zhang, Y. Hou, and B. Hu. 2017. “Deep Fusion of Multi-Channel Neurophysiological Signal for Emotion Recognition and Monitoring.” International Journal of Data Mining and Bioinformatics 18 (1): 1. https://doi.org/10.1504/ijdmb.2017.086097.
- Ma, X. 2022. “Knowledge Graph Construction and Application in Geosciences: A Review.” Computers & Geosciences 161:105082. https://doi.org/10.1016/j.cageo.2022.105082.
- Mai, G., K. Janowicz, C. He, S. Liu, and N. Lao. 2018. “POIReviewQA: A Semantically Enriched POI Retrieval and Question Answering Dataset.” In 12th Workshop on Geographic Information Retrieval, November 6, 2018. 1–2. Seattle WA USA: Association for Computing Machinery.
- Matsumoto, S., R. Yamanaka, and H. Chiba. 2018. “Mapping RDF Graphs to Property Graphs.” ArXiv Preprint. [online]. Available from ht t ps://doi.org/arxiv.org/abs/1812.01801.
- Neo4j GDS library [Online]. 2023. Accessed March 16, 2023. https://github.com/neo4j/graph-data-science/.
- Ounoughi, C., A. Mouakher, M. I. Sherzad, and S. Ben Yahia. 2021. “A Scalable Knowledge Graph Embedding Model for Next Point-Of-Interest Recommendation in Tallinn City.” Research Challenges in Information Science. Accessed March 16, 2023. https://doi.org/10.1007/978-3-030-75018-3_29.
- Park, S., and Y. Lee. 2022. “SSIKG: A Framework for Spatial‐Semantic Integrated Indoor Knowledge Graph Construction.” Transactions in GIS 26 (8): 3176–3201. https://doi.org/10.1111/tgis.12973.
- Reimers, N., and I. Gurevych. 2019. “Sentence-Bert: Sentence Embeddings Using Siamese Bert-Networks.” ArXiv Preprint. [online]. h t tps://doi.o rg/arxiv.org/abs/1908.10084.
- Rose, S., D. Engel, N. Cramer, and W. Cowley. 2010. “Automatic Keyword Extraction from Individual Documents.” In Text Mining, edited by, W. B. Michael and K. Jacob. John Wiley & Sons, Ltd. https://doi.org/10.1002/9780470689646.
- SBERT pretrained models [Online]. 2023. Accessed March 16, 2023. https://www.sbert.net/docs/pretrained_models.html.
- Spärck Jones, K. 1972. “A Statistical Interpretation of Term Specificity and Its Application in Retrieval.” Journal of Documentation 28 (1): 11–21. CiteSeerX 10.1.1.115.8343. https://doi.org/10.1108/eb026526.
- Tang, J., J. Jin, Z. Miao, B. Zhang, Q. An, and J. Zhang. 2021. “Region-Aware POI Recommendation with Semantic Spatial Graph.” In IEEE 24th International Conference on Computer Supported Cooperative Work in Design (CSCWD), May 5–7, 2021. 214–219. Dalian, China: IEEE. https://doi.org/10.1109/cscwd49262.2021.9437810
- Wang, S., C. Li, K. Zhao, and H. Chen. 2017. “Learning to Context-Aware Recommend with Hierarchical Factorization Machines.” Information Sciences 409:121–138. https://doi.org/10.1016/j.ins.2017.05.015.
- Wang, F., Y. Qu, L. Zheng, C. T. Lu, and S. Y. Philip. 2017. “Deep and Broad Learning on Content-Aware POI Recommendation.” In IEEE 3rd International Conference on Collaboration and Internet Computing (CIC), October 15–17, 2017. 369–378. San Jose, CA, USA: IEEE. https://doi.org/10.1109/cic.2017.00054
- Wang, H., Z. Wang, S. Hu, X. Xu, S. Chen, and Z. Tu. 2019. “DUSKG: A Fine-Grained Knowledge Graph for Effective Personalized Service Recommendation.” Future Generation Computer Systems 100:600–617. https://doi.org/10.1016/j.future.2019.05.045.
- Wang, S., X. Zhang, P. Ye, M. Du, Y. Lu, and H. Xue. 2019. “Geographic Knowledge Graph (Geokg): A Formalized Geographic Knowledge Representation.” ISPRS International Journal of Geo-Information 8 (4): 184. https://doi.org/10.3390/ijgi8040184.
- Wang, Z., Y. Zhu, Q. Zhang, H. Liu, C. Wang, and T. Liu. 2022. “Graph-Enhanced Spatial-Temporal Network for Next POI Recommendation.” ACM Transactions on Knowledge Discovery from Data 16 (6): 1–21. https://doi.org/10.1145/3513092.
- Wu, Z., and M. Palmer. 1994. “Verb Semantics and Lexical Selection.” In 32nd Annual Meeting of the Association for Computational Linguistics, June 27–30, 1994. 133–138. Las Cruces New Mexico: Association for Computational Linguistics. https://doi.org/10.3115/981732.981751
- Yelp, Data from: Yelp dataset [dataset]. Accessed March 16, 2023b. https://www.yelp.com/dataset/download.
- Yelp, 2023a. 2022 Yelp Trust & Safety Report. Accessed August 20, 2023. https://issuu.com/yelp10/docs/2022_yelp_trust_safety_report.
- Yin, H., W. Wang, H. Wang, L. Chen, and X. Zhou. 2017. “Spatial-Aware Hierarchical Collaborative Deep Learning for POI Recommendation.” IEEE Transactions on Knowledge and Data Engineering 29 (11): 2537–2551. https://doi.org/10.1109/tkde.2017.2741484.
- Yuan, Y., J. Zhou, and W. Lam. 2020. “Point-Of-Interest Oriented Question Answering with Joint Inference of Semantic Matching and Distance Correlation.” In 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing, December 4–7, 2020. 542–550. Suzhou, China: Association for Computational Linguistics.
- Yu, X., X. Ren, Y. Sun, Q. Gu, B. Sturt, U. Khandelwal, B. Norick, and J. Han. 2014. “Personalized Entity Recommendation.” In 7th ACM International Conference on Web Search and Data Mining, February 24–28, 2014. 283–292. New York, USA: Association for Computing Machinery. https://doi.org/10.1145/2556195.2556259
- Zhang, X., X. Hu, and Z. Li. 2015. “Learning Geographical Hierarchy Features for Social Image Location Prediction.” In The 24th International Joint Conference on Artificial Intelligence, July 25–31, 2015. 2401–2407. Buenos Aires, Argentina: AAAI Press.
- Zou, X. 2020. “A Survey on Application of Knowledge Graph.” Journal of Physics Conference Series 1 (1): 012016. https://doi.org/10.1088/1742-6596/1487/1/012016.