
Abstract
The ensemble Kalman filter (EnKF) is a reliable data assimilation tool for high-dimensional meteorological problems. On the other hand, the EnKF can be interpreted as a particle filter, and particle filters (PF) collapse in high-dimensional problems. We explain that these seemingly contradictory statements offer insights about how PF function in certain high-dimensional problems, and in particular support recent efforts in meteorology to ‘localize’ particle filters, i.e. to restrict the influence of an observation to its neighbourhood.
1. Introduction
Many applications in geophysics require that one updates the state of a numerical model by information from sparse and noisy observations, see, e.g. van Leeuwen (Citation2009), Bocquet et al. (Citation2010), Fournier et al. (Citation2010) and van Leeuwen et al. (Citation2015) for recent reviews in geophysics. Particle filters (PF) are sequential Monte Carlo algorithms that solve such a ‘data assimilation’ problem as follows (Doucet et al., Citation2001; Arulampalam et al., Citation2002). One draws samples from a proposal density, and then attaches weights to the samples such that the weighted samples form an empirical estimate of a posterior density. The samples are often called ‘particles’ in the PF literature, or ‘ensemble members’ in the geophysics literature. The empirical estimate approximates the posterior density in the sense that weighted averages over the samples converge to expected values with respect to the posterior density. The PFs in the literature differ in their choice of proposal density, and therefore in their weights. Several particle filters can be found, e.g. in Zaritskii and Shimelevich (Citation1975), Gordon et al. (Citation1993), Liu and Chen (Citation1995), Doucet (Citation1998), Doucet et al. (Citation2000), Chorin and Tu (Citation2009), Weare (Citation2009), Chorin et al. (Citation2010), Morzfeld et al. (Citation2012) and Vanden-Eijnden and Weare (Citation2012).
The variance of the weights determines the efficiency of a PF. If this variance is large, then a PF ‘collapses’, i.e. the weights of all but one sample are near zero. The collapse of particle filters has been described in Snyder et al. (Citation2008); Bickel et al. (Citation2008);Bengtsson et al. (Citation2008); Snyder (Citation2011); Chorin and Morzfeld (Citation2013); Snyder et al. (Citation2015). It is argued that an effective dimension defines the ensemble size required to prevent collapse. While there are various definitions of effective dimensions, we explain in Section 2.4 that the huge state dimension of global weather models (hundreds of millions of state variables) and the vast number of observations (millions) cause any effective dimension to be large, which in turn implies that particle filters would require huge ensemble sizes in meteorological problems.
It is interesting however that the ensemble Kalman filter (EnKF, Tippet et al., Citation2003; Evensen, Citation2006), used routinely with ensembles of 50 to a few hundred members in meteorological problems, can in fact be interpreted as a particle filter. Specifically, as shown by Papadakis et al. (Citation2010), one can view the EnKF ensemble members as draws from a proposal density and attach weights to each ensemble member, interpreting the EnKF as a particle filter. It follows from the optimality result of Snyder et al. (Citation2015) that the particle filter interpretation of the EnKF collapses in the same way as other particle filters. The goal of this paper is to clarify this situation: Why does the EnKF do so well in meteorological problems in which its particle filter interpretation collapses? Resolving this apparent contradiction reveals the significance of a certain type of particle filter collapse, and suggests improvements of particle filters for meteorological applications.
2. Preliminaries
We consider linear Gaussian data assimilation problems because we can make our points in this simplified setting. Moreover, linear problems are standard in the context of the collapse of particle filters and have been used by Snyder et al. (Citation2008), Bickel et al. (Citation2008), Bengtsson et al. (Citation2008), Snyder (Citation2011), Chorin and Morzfeld (Citation2013), Snyder et al. (Citation2015). Specifically, we consider(1)
(2)
where the state, , is a real
-dimensional vector, the linear model,
, is an
matrix, the observation,
, is a real
-dimensional vector,
is a
matrix and where
is discrete time. We further assume that the initial condition
is Gaussian distributed, and that no observations are available at time
. Throughout this paper, we use subscripts for time indexing and superscripts for indexing samples of random variables. For example,
is the jth sample of the state
at time k. We write
for a set of vectors
. The random variables
and
in Equations (Equation1
(1) ) and (Equation2
(2) ) represent model errors and errors in the observations, respectively, and we assume that
and
are independent identically distributed Gaussians with mean zero, which we write as
,
. The covariances
and
are
, respectively,
symmetric positive definite matrices. We exclude data assimilation problems with a deterministic model for which
, but many of our results hold for data assimilation problems with deterministic models as well by simply setting
in equations. We explain which results generalize in Section 6.
2.1. Filtering and smoothing densities
The goal of data assimilation is to update the state of the model (Equation1(1) ) in view of the noisy observations in (Equation2
(2) ). Model and observations jointly define the conditional random variable
, which describes the state trajectory up to time k, given the observations up to time k. This random variable is specified by the ‘smoothing density’
(3)
The ‘filtering density’ is a marginal of the smoothing density,(4)
and describes the state at observation time, conditioned on all observations up to now, but it does not describe how the system got to that state. In practice, the filtering density may be more important. Forecast models, for example, require initial conditions sampled from the filtering density; samples from the smoothing density, i.e. descriptions of past weather, are not required. On the other hand, smoothing algorithms have recently received more and more attention, especially in the context of re-analyses.
2.2. The localized EnKF
The EnKF uses a Monte Carlo step within the Kalman filter formalism, and recursively approximates the filtering density by an ensemble (Kalman, Citation1960; Kalman and Bucy, Citation1961; Tippet et al., Citation2003; Evensen, Citation2006). Specifically, let ,
, be samples of the filtering density
at time
. The collection of
samples is called the ensemble, and each sample is an ensemble member;
is the ensemble size. The ensemble is evolved to time k using the model (Equation1
(1) ) to generate the forecast ensemble
where is a sample of
. Let
(5)
be the forecast covariance, where is the forecast mean. The forecast covariance is usually localized and inflated, see, e.g. Houtekamer and Mitchell (Citation2001) and Hamill et al. (Citation2001). During localization, one decreases long-range correlations in the error covariances, typically by Schur (entrywise) multiplication of the forecast covariance with a specified
localization matrix
:
In atmospheric applications, localization matrices as described by Gaspari and Cohn (Citation1999) are commonly used. During inflation, one increases the localized forecast covariance, e.g., by multiplying the forecast covariances by a number slightly larger than one, e.g. ,
. Combined, localization and inflation are known to be key factors in making the EnKF a practical tool for meteorological data assimilation, see, e.g. Houtekamer et al. (Citation2005), Wang et al. (Citation2007) and Raeder et al. (Citation2012). Here, ‘practical’ means that an EnKF with a small ensemble (
) yields a small mean square error (MSE), and a comparable ensemble ‘spread’, defined by the trace of the posterior covariance divided by the system dimension
(see Section 4).
The localized and inflated forecast covariance defines the Kalman gain(6)
which is used to compute the analysis ensemble(7)
where , is a perturbed observation and where
is a sample of
. The sample mean and sample covariance of the analysis ensemble approximate the mean and covariance of the filtering density
. This is the ‘perturbed observations’ implementation of the localized EnKF. Other implementations of the EnKF are also available, see, e.g. Anderson (Citation2001), Bishop et al. (Citation2001) and Tippet et al. (Citation2003).
2.3. Particle filters
Particle filters are sequential importance sampling methods that construct an empirical estimate of the smoothing density (Equation3(3) ), see, e.g. Doucet et al. (Citation2001). The empirical estimate consists of a collection of weighted samples, such that expected values of functions of
can be approximated by weighted averaging over the samples, see, e.g. Kalos and Whitlock (Citation1986) and Chorin and Hald (Citation2013). In particular, particle filters make use of a recursion of the smoothing density,
(8)
and draw samples from a proposal density which is a similar product of functions,(9)
Thus, only the most recent product needs to be updated when a new observation is collected. At each step k, the update is used to propose samples
, which are appended to the samples of
to extend the trajectory to time k. The weights satisfy the recursion
(10)
and account for the fact that one draws samples sequentially from the proposal density , rather than directly from the smoothing density. After each step, the weights are normalized such that their sum is one, and the ensemble is ‘resampled’ (Arulampalam et al., Citation2002), i.e. ensemble members with a small weight are deleted, and ensemble members with a large weight are repeated. Various choices for the updates
lead to the various particle filters developed over the past years, each with different weights, e.g. Gordon et al. (Citation1993), Doucet (Citation1998), Chorin and Tu (Citation2009), Weare (Citation2009), Chorin et al. (Citation2010), Morzfeld et al. (Citation2012) and Vanden-Eijnden and Weare (Citation2012).
More specifically, the ‘standard particle filter’ (Gordon et al. (Citation1993)) uses the proposal density , i.e. the ensemble is generated by running the numerical model (Equation1
(1) ). The weights are the ratio of target and proposal density and, thus, are proportional to the likelihood,
. Note that the standard particle filter does not make use of the most recent observation when generating the ensemble. A particle filter with proposal density
however does make use of the most recent observation when generating the ensemble. The weights of this particle filter are given by
, and it can be shown that these weights have minimum variance over all particle filters with a proposal density of the form (Equation9
(9) ) (Snyder et al. (Citation2015)). For that reason, this particle filter is called the ‘optimal particle filter’ (see, e.g. Zaritskii and Shimelevich, Citation1975; Liu and Chen, Citation1995; Doucet et al., Citation2000). There are, however, more general particle filters that make use of more complicated proposal densities than the ones described by Equation (Equation9
(9) ). For example, one can use ‘tempering’, i.e. techniques that ensure a more gradual transition from a proposal density to a posterior density (see, e.g. Beskos et al., Citation2014 and Kantas et al., Citation2014). Such filters may have lower variance weights than the ‘optimal’ particle filter described above. For the remainder of this paper, however, we only consider ‘classical’ particle filters with proposal densities of the form (Equation9
(9) ).
2.4. The collapse of particle filters and effective dimensions
A particle filter collapses if only one ensemble member carries a significant weight. The collapse occurs when the variance of the weights is large, and avoiding the collapse can require huge ensemble sizes. Indeed, it is often said that particle filters require ensemble sizes that are exponential in the ‘dimension’. However, the situation is more delicate. It was argued by Chorin and Morzfeld (Citation2013) that there are several mechanisms that can cause particle filters to collapse, not merely a large state dimension. These mechanisms are described by the theory of the collapse of particle filters and effective dimensions: when the effective dimension is large, an even larger ensemble size is needed to avoid collapse. We briefly review this theory here because it is needed to identify the cause for the collapse of particle filters in meteorological problems.
The collapse of the ‘standard particle filter’ with proposal density is described by Snyder et al. (Citation2008), Bickel et al. (Citation2008) and Bengtsson et al. (Citation2008). Specifically, in Snyder et al. (Citation2008), it is shown that the collapse of this particle filter depends on the variance
where is the jth element of the observation
, and where
are the eigenvalues of the covariance matrix in observation space, normalized by the observation covariance matrix,
. Asymptotic statements about the collapse of the standard particle filter can be made for large state dimensions and large number of observations (
), when
.
In this case, collapse occurs if , i.e. the ensemble size must be exponential in
to avoid the collapse. Similar arguments hold for the optimal particle filter, with a slightly different definition of
(Snyder, Citation2011); SBM2015. The exponential scaling of the ensemble size
with
suggests that the ensemble’s size required to avoid collapse may be too large to be feasible in numerical weather prediction, where
is so large – typically millions – that even moderate eigenvalues
lead to large
.
Effective dimensions are quantities related to , which describe how difficult it is to solve a given data assimilation problem by a particle filter. There are several definitions of effective dimensions in the literature, some of which are reviewed by Agapiou et al. (Citation2016). For example, in Bickel et al. (Citation2008), an effective dimension is defined by
(11)
Note that this effective dimension is a property of the data assimilation problem and the standard particle filter algorithm. In Chorin and Morzfeld (Citation2013), effective dimensions for the standard and optimal particle filter are defined by Frobenius norms, rather than traces of covariances. The Frobenius norm of a matrix is the square root of the sum of the squares of the singular values. For the symmetric covariance matrices we consider, this is the same as the square root of the sum of the squares of the eigenvalues. For example, an effective dimension of the standard particle filter is defined by
All effective dimensions above depend on the covariance of and on the data assimilation algorithm one uses. In Chorin and Morzfeld (Citation2013), the covariance of
is calculated during steady state of a linear and Gaussian data assimilation problem, so that the effective dimension does not vary over time. Note that the trace of the prior and posterior covariance matrices often oscillates about a steady-state value in non-linear problems as well. Indeed, the Frobenius norm, or the trace, of a (steady state) posterior covariance matrix
is a natural candidate for an effective dimension of a data assimilation problem, independently of the particle filter one applies to solve it:
(12)
Here, are the eigenvalues of
, and the Frobenius norm depends on all aspects of the data assimilation problem, including the number of observations, the number of state variables, as well as the covariances that define model and observation error (
and
).
It was pointed out in Chorin et al. (Citation2016) that none of the effective dimensions are in fact ‘dimensions’. The effective dimensions above rather describe ‘effective variance’, and one can define more effective dimensions, for example, by(13)
where is a predetermined small parameter (Chorin et al., Citation2016). Similar ideas were used in the context of ‘partial noise’ by Morzfeld and Chorin (Citation2012). However, it is not yet clear which effective dimension will ultimately be most useful. Nonetheless, all effective dimensions have in common that they describe that ‘if the effective dimension is large, an even larger ensemble size is needed to avoid collapse’.
2.5. The collapse of particle filters in meteorology
We are interested in the collapse of particle filters as it may occur in meteorological problems. Meteorological problems are characterized by
| (a) | large state dimension | ||||
| (b) | large spatial domains, in the sense that there are many correlation lengths of a prior density contained within the overall system domain; | ||||
| (c) | the matrix | ||||
To understand why the above conditions imply large effective dimensions, recall that the Frobenius norm of a matrix is equal to the square root of the sum of the squares of all of its elements, . Thus, if
is huge, the effective dimension
is large unless each entry of
is tiny.
A large implies that the effective dimensions
and
are also large (see Chorin and Morzfeld, Citation2013). The same arguments apply to effective dimensions defined for the optimal particle filter (Chorin and Morzfeld, Citation2013; Snyder, Citation2011; Snyder et al., Citation2015). The effective dimension
is large since, by property (b), far away variables de-correlate, so that the overall system can be thought of as a collection of loosely coupled lower dimensional ‘sub-systems’. Since the correlation lengths are small compared to the overall system domain, the overall system contains a large number of subsystems. Thus, the effective dimension
is large. In fact, it increases with the number of loosely coupled subsystems.
We emphasize that the above statements about the collapse of particle filters in meteorology only apply to particle filters of a certain kind (see Section 2.3). The collapse may be avoided, even for meteorological problems, by a next generation of particle filters that make use of more general approach, e.g. using techniques to transition more smoothly from a proposal density to a posterior density. Indeed, some of these algorithms have already been proven to scale algebraically, rather than exponentially with (effective) dimension (see, e.g. Beskos et al., Citation2014; Kantas et al., Citation2014).
3. The collapse of the particle filter interpretation of the EnKF
The EnKF performs well in high-dimensional meteorological applications in which particle filters are expected to collapse. On the other hand, it was shown by Papadakis et al. (Citation2010) that the EnKF can be interpreted as a particle filter (PF-EnKF), and, thus, can be expected to collapse under the same conditions as other particle filters. We study this apparent contradiction and in particular the mechanisms that cause the collapse of the PF-EnKF in meteorological problems. This approach allows us to combine what we know about the performance of EnKF in real meteorological problems with what we know about the collapse of particle filters. In this context, we first consider the PF-EnKF as a particle filter for the smoothing density, and then make connections to the filtering density using ideas similar to marginal particle filters introduced by Klaas et al. (Citation2005).
3.1. Collapse of the PF-EnKF for the smoothing density
It was pointed out by Papadakis et al. (Citation2010) that the EnKF ensemble members can be viewed as draws from the proposal density(14)
where
with the Kalman gain defined in (Equation6
(6) ). This proposal density is of the form (Equation9
(9) ) so that the EnKF can be interpreted as a particle filter. A related construction using Kernel density estimation at each step is discussed in Khlalil et al. (Citation2015). The weights that can be attached to the EnKF ensemble are the ratio of the smoothing and proposal densities
(15)
The theory for the collapse of particle filters reviewed in Section 2.4 applies to these weights, and their variance governs the collapse of the PF-EnKF. This variance is at least as large as the corresponding variance of the optimal PF (Snyder et al., Citation2015). Thus, the PF-EnKF collapses whenever the optimal PF collapses. As a specific example, we will demonstrate in Section 4 that the ensemble size required to avoid the collapse of the PF-EnKF scales exponentially with the dimension in the canonical system studied in Snyder et al. (Citation2008), Bickel et al. (Citation2008), Bengtsson et al. (Citation2008), Snyder (Citation2011), Chorin and Morzfeld (Citation2013) and Snyder et al. (Citation2015).
While covariance localization and inflation of EnKF will modify the mean and covariance of the proposal density (Equation14(14) ), these mechanisms will not avoid the collapse when sampling from the smoothing density. The reason is that, even with tuned localization and inflation, the proposal density defined by the EnKF ensemble cannot improve on the performance of the optimal proposal and must collapse in the same way as the optimal particle filter. Thus, using even a localized EnKF that is operating correctly by tracking the truth to within the ensemble variance to define a proposal density cannot prevent the collapse for small ensemble sizes in meteorological problems.
3.2. Collapse of the PF-EnKF for the filtering density
The particle filter interpretation of the EnKF defines a sequential importance sampler for the smoothing density. However, the EnKF ensemble can also be viewed as draws from a proposal density for the filtering density. Indeed, the idea of designing particle filters directly for the filtering density, rather than the smoothing density, was explored by Klaas et al. (Citation2005) via ‘marginal particle filters’. We connect these ideas to the EnKF and study the conditions for the collapse of the particle filter interpretation of the EnKF for the filtering density. The reason is that it may be possible that the PF-EnKF collapses as a sampler for the smoothing density, but performs well as a sampler for the filtering density, and that sampling the filtering density is sufficient in meteorology. Below we argue that this is not the case, i.e. the collapse of the PF-EnKF occurs, under the same conditions, for filtering and smoothing densities, unless the ensemble size is huge.
As before, we interpret the EnKF ensemble members as draws from a suitable proposal density . We wish to compute the weights,
(16)
such that the weighted ensemble approximates the filtering density, not the smoothing density as before. Note that the EnKF proposal density for the smoothing density in (Equation14(14) ) is conditioned on the previous analysis state but the EnKF proposal density for the filtering density in (Equation16
(16) ) is not. Thus, the EnKF proposal density for the filtering density is not the same as the EnKF proposal density for the smoothing density. The weights (Equation16
(16) ), are difficult to compute in general because the filtering density and the EnKF proposal density are not known up to a multiplicative constant (see the Appendix and literature about marginal particle filters, e.g. Klaas et al. (Citation2005), for more detail). However, for the linear Gaussian problems we consider, the filtering density is also Gaussian and we write
. The proposal density generated by the EnKF ensemble is the Gaussian,
(17)
where is the mean of the analysis ensemble and where
(18)
Under our assumptions, the weights are(19)
Asymptotically, for large ensembles, the sample mean converges to the posterior mean and the sample covariance converges to the posterior covariance, so that the variance of the PF-EnKF weights for the filtering density goes to zero asymptotically (see, e.g. Burgers et al., Citation1998).
We are interested in the collapse of the particle filter interpretation of a localized EnKF with small ensemble sizes, and study this situation by making simplifying assumptions. Specifically, we neglect errors in the ensemble mean, i.e. we set , and assume that errors in the ensemble covariance matrix are small, i.e.
, where
is a small number. One could also consider perturbations of the form
, but, in the context of importance sampling, perturbations as above are more favourable, and we wish to study a ‘best-case-scenario’ for EnKF. The reason why
is favourable is that importance sampling requires that the support of the proposal density contains the support of the target density, i.e. one wants to use proposal densities with variances larger than those of the target densities.
While drastic, the above simplifications do lead to useful expansions that can accurately describe the behaviour of the weights of a localized EnKF with small ensembles (see also Section4.3). Those simplifications require that the EnKF mean and covariance are close to correct. In typical large geophysical problems, this can be achieved for small ensemble size () only when using covariance localization. Without localization, ensemble sizes substantially larger than
would be necessary. Thus, the subsequent arguments in this section hold only for a localized EnKF and an EnKF with large ensembles. We further assume, for simplicity, that the posterior covariance
is full rank, so that all its eigenvalues are positive. While the rank of
may not be equal to the state dimension
, conditions (a)–(c) in Section 2.5 imply that the rank of
is large (we discuss what happens when some eigenvalues are zero below). In the context of the localized EnKF, our above assumption that the EnKF covariance is close to correct implies that
has the same rank as the posterior covariance.
Under our assumptions, the weights in Equation (Equation19(19) ) become
(20)
where ,
.
The variance of the above weights can be computed from the expected values
Indeed, one can define an ‘effective number of samples’ based on the variance of the weights (Arulampalam et al., Citation2002; Owen, Citation2013)(21)
Thus, the collapse occurs when , i.e. if
, and the ‘quality measure’ G can be used to estimate the ensemble size required to avoid collapse. Under our assumptions,
The approximation is obtained by expanding around
, i.e. for small errors
in the covariance matrix. Indeed, if we interpret
as sampling error, then G can remain constant as dimension
increases, provided that the ensemble size increases linearly with the dimension. Thus, the collapse of the PF-EnKF for the filtering density does not occur for ensemble sizes proportional to the dimension
.
A small G however is not a guarantee that a sampling scheme is ‘working well’. In particular, G may be small if the variance of the proposal density is chosen too small compared to the target density. In this case, one may find that the weights are well distributed; however, other indicators, such as MSE, will show that one is sampling too narrowly within state space.
We can relax the assumption that all eigenvalues of the posterior covariance are positive by making use of the effective dimension
in Equation (Equation13
(13) ). If some eigenvalues are zero, or if some are close to zero, then one can substitute the
dimensional approximation of this covariance matrix
into the above formulas. Using the pseudo-inverse of this matrix in (Equation20
(20) ), one obtains the same expression for G as above with
replacing
. We argued above that while
may be smaller than
in meteorological problems,
can be expected to be large in these problems (see property (b) in Section 2.5). A large
implies that the collapse of the particle filter interpretation of the EnKF can only be avoided by large ensemble sizes, in particular much larger than the 50–100 ensemble members used in practice.
4. Performance of the EnKF during the collapse of its particle filter interpretation
We have shown that the collapse of the PF-EnKF for the filtering density can be prevented by ensemble sizes that scale linearly with the dimension , or, more generally, with the effective dimension
in (Equation13
(13) ). We further argued that the large dimensions
and
in meteorological problems cause all particle filters for the smoothing density, including the particle filter interpretation of a localized EnKF, to collapse. On the other hand, localized EnKFs with small ensemble sizes (50 to several hundred) are used in meteorological problems with hundreds of millions of state variables and millions of observations and produce a MSE comparable to the normalized trace of the posterior covariance matrix, see, e.g. Houtekamer et al. (Citation2005), Wang et al. (Citation2007) and Raeder et al. (Citation2012). Thus, it seems to happen that the EnKF ensemble is ‘good’, i.e. there is sufficient spread in the ensemble and MSE is small, while at the same time, the weights are ‘bad’, i.e. all but one weight are near zero. We now demonstrate that this situation indeed occurs: localized EnKFs with small ensemble sizes yield a small MSE while their particle filter interpretation collapses.
4.1. Scaling of MSE with dimension
The MSE is defined by(22)
Here, is the ‘true’ state of the model at time k,
,
, are its
components and
is the sample mean at time k, computed from the EnKF analysis ensemble members
,
. We obtain useful scaling equations under the same assumptions as above, i.e. we consider a Gaussian filtering density
and assume that the EnKF ensemble members are draws from
, where
. As indicated above, these assumptions simplify the problem, but describe a best-case scenario for the EnKF, and in particular model the localized EnKF (see Section 3.2). Indeed, the scalings below are not valid for unlocalized EnKF, unless
is sufficiently large, and, thus, larger than ever used in practice.
Under our assumptions, the statistics of the ensemble mean are
If the true state is a sample of the filtering density, one can combine the above expression for the sample mean with the expression (Equation22(22) ) for the MSE to obtain the statistics of the MSE:
(23) If we assume that the errors in the covariance matrix are due to sampling error, we can set
, so that the mean of the normalized MSE is
(24)
Thus, even with small ensemble sizes, and even if the dimensions and
are huge, one can have that the MSE is on the order of the ‘spread’, defined by the trace of the posterior covariance matrix
divided by
. At the same time, the particle filter interpretation of the EnKF collapses for small, or even moderate ensemble sizes (see Section 3.2).
4.2. Local error and MSE vs. global error and collapse of the PF-EnKF
Note that MSE describes the error one can expect on average per dimension. Thus, MSE assesses the performance of the EnKF locally, rather than globally. This assessment of performance is useful in practice. For example, errors are usually examined locally, e.g. one might state that the data assimilation is ‘working poorly in the tropics, but well in mid-latitudes’. Similarly, an EnKF user routinely asserts that data assimilation has succeeded if average errors at stations around the globe are small.
However, when the performance of the PF-EnKF is assessed by the variance of its weights, then one does the opposite. The variance of the weights is due to differences between the posterior density and the proposal density generated by the EnKF ensemble. If the proposal and posterior densities are effectively high-dimensional (with large and
, see Sections 2.4 and 2.5), the differences, or errors, may be small in each dimension, corresponding to small
, but the errors add up to a large overall error during the weight calculation. This leads to the collapse of the PF-EnKF, and happens similarly for filtering or smoothing densities.
We have shown that it can indeed occur that localized EnKFs with small ensemble sizes can produce a small MSE while at the same time their particle filter interpretation collapses. The success of the EnKF in meteorology, where MSE is the gold standard, thus suggests that assessing errors locally is sufficient for these problems. There is no need for keeping a ‘global’ variance of the weights small: the EnKF can work well even when this variance is huge, as is illustrated by the collapse of the particle filter interpretation of the EnKF. Indeed, this collapse may occur regularly and without significant practical consequences. However, it is important to note that the particle filter interpretation of the EnKF performs poorly no matter how we evaluate its performance – by MSE or the variance of the weights. As we will describe below, this problem is caused by the fact that the PF-EnKF is not using localization during the weight calculation, which is equivalent to its ‘update’, or analysis. More specifically, localization is used for generating the ensemble, but it is not used when calculating the weights (see Section 5).
4.3. Numerical example
We illustrate that the localized EnKF with small ensemble sizes can yield a small MSE while at the same time its particle filter interpretation collapses by the canonical linear example usually studied in the context of filter collapse (Snyder et al., Citation2008; Bickel et al., Citation2008; Bengtsson et al., Citation2008; Snyder, Citation2011; Chorin and Morzfeld, Citation2013; Snyder et al., Citation2015). The example is defined by
(25)
and all effective dimensions reviewed in Section 2.4 increase with dimension . Thus, for large dimension n, any particle filter will collapse unless the ensemble size is huge. However, the localized EnKF with small ensemble sizes yields a small MSE even when its particle filter interpretation collapses. Here, we demonstrate this scenario by computing the quality measure G in (Equation21
(21) ) for various n, which is equivalent to computing the ensemble size required to avoid collapse. Specifically, if G depends exponentially on dimension n, then the required ensemble size to avoid collapse also depends exponentially on dimension. Since all effective dimensions increase with dimension n, the scaling of G also illustrates how the required ensemble size scales with effective dimensions.
Computing G for one time step, from to k, requires that one knows the density of the state at
. We assume that this density is Gaussian with mean
and covariance
. We thus have
We consider the following algorithms:
| (1) | an unlocalized/uninflated EnKF and its PF interpretation for the filtering density, | ||||
| (2) | a localized/inflated EnKF and its PF interpretation for the filtering density, | ||||
| (3) | a localized/inflated EnKF and its PF interpretation for the filtering density, | ||||
| (4) | a localized/inflated EnKF and its PF interpretation for the smoothing density, | ||||
| (5) | an optimal PF for the smoothing density with | ||||
4.3.1. Implementation, localization and inflation of the EnKF
We localize the forecast covariance by the identity matrix, i.e. we set all off-diagonal elements of the EnKF forecast covariance matrix to zero. Note that this is a ‘perfect’ localization for this diagonal example and therefore we are depicting a best-case scenario for the localized EnKF and its particle filter interpretation. Prior inflation is inversely proportional to the ensemble size, i.e. we multiply the forecast covariance matrix by . However, we tested our results with and without inflation and found that, for this example, the impact of inflation is insignificant compared with localization.
The weights of the PF-EnKF for the smoothing density are computed by (Equation15(15) ). Here, we assume that
, i.e. the PF-EnKF starts off with samples from the correct density, so that
. The weights of the PF-EnKF for the filtering density are computed by (Equation16
(16) ). The proposal density is given by (Equation17
(17) ), and its covariance is localized by the identity matrix as before. The filtering density is Gaussian,
, and its mean and covariance are computed by the Kalman filter formulas.
4.3.2. Results
The left panels of Fig. show the values of G for the algorithms for each experiment (dots) along with the log-linear least-squares approximations and one standard deviation confidence intervals. The right panels show the scaling of MSE with dimension, specifically the mean and two standard deviation error bars of the MSE based on the 100 experiments we perform. We observe the expected exponential scaling of G for the particle filter interpretation of the localized EnKF for the smoothing density. The optimal PF is also characterized by an exponential scaling of G, however slower the rate (see also Snyder et al. (Citation2015)). The particle filter interpretations of localized or unlocalized EnKFs for the filtering density are also characterized by an exponentially increasing G if the ensemble size is fixed at . However, the collapse of the particle filter interpretation of the localized EnKF for the filtering density can be avoided if the ensemble size is proportional to dimension, as described by our theoretical considerations above. Specifically, we observe that the PF-EnKF for the filtering density produces the same G independently of n when
.
Figure 1. Left: quality measure G as a function of the dimension for the various methods. Shown are the values of G for each experiment (dots) along with log-linear least-squares fits (straight lines) and one standard deviation confidence intervals (shaded regions). Right: normalized MSE as a function of the dimension for the various methods. Shown are the mean (dots) and confidence intervals (error bars) computed from 100 numerical experiments. Also shown (dashed lines) is the mean and two standard deviation confidence intervals of the ideal MSE (dashed green).
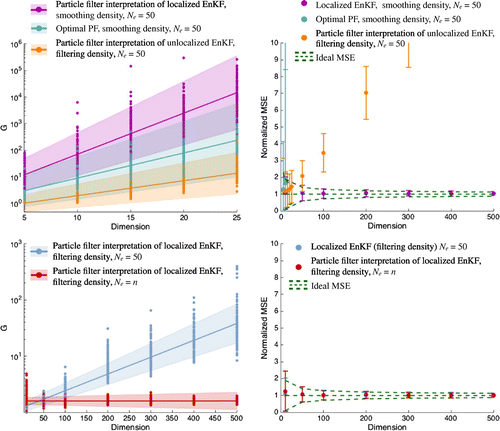
In the right panels of Fig. , we observe that the localized EnKFs give a small MSE while the unlocalized EnKF and the optimal PF cause a large MSE, which is consistent with what is reported in practice in large-dimensional problems. Specifically, the localized EnKF with gives a small MSE even when its particle filter interpretation collapses. Also shown is the mean and variance of the MSE we obtain without sampling error, i.e. by an optimal algorithm. The localized EnKFs and the optimal sampling algorithm give almost identical MSE. In summary, our numerical experiments confirm our scaling of MSE with dimension and illustrate that a localized EnKF with a small ensemble size indeed can yield a small MSE, while at the same time its particle filter interpretation collapses.
5. The importance of localization for particle filters
We argued in Section 2.5 that the collapse of particle filters in meteorology is caused by extremely large state dimensions and very large numbers of observations
, which in turn imply large effective dimensions. On the other hand, we expect that meteorological problems are characterized by correlation lengths that are short compared to the overall domain size, and that the observation operator
is ‘local’ (see Section 2.5). These assumptions imply that forecast and posterior covariances are sparse, but the PF-EnKF does not utilize this sparsity during the weight calculation, but it does use it when generating the ensemble. If one could make use of the sparsity of the data assimilation problem during weight calculation, then one may be able to avoid this type of filter collapse of the PF-EnKF, even for small ensemble sizes. The situation is perhaps analogous to numerical linear algebra, where computations with large dense matrices are expensive, but large sparse matrices can be dealt with efficiently. We now explain in more detail that ‘localization for particle filters’ means exactly that: making use of sparsity of forecast and posterior covariances. We start by discussing a diagonal problem, for which it is straightforward to define what ‘localization for particle filters’ is, and then move onto discuss more realistic cases.
5.1. Localizing particle filters for diagonal problems
In the diagonal example of Section 4.3, exploiting sparsity of covariance matrices means to make use of the fact that the system is diagonal. Since a diagonal problem uncouples into independent scalar sub-problems, one can apply scalar PF-EnKFs to each sub-problem and also compute the weights for each sub-problem independently. The ensemble size required for each scalar sub-problem is independent of dimension, so that the catastrophic scaling of the required ensemble size of the PF-EnKF with dimension disappears. In fact, this strategy of decoupling the problem applies to any particle filter (for smoothing or filtering densities) so that the scaling of the required ensemble size with dimension disappears for every particle filter (see also Rebeschini and van Handel, Citation2015).
We can connect the above localization of particle filters by decoupling to covariance localization in EnKF as follows. If the EnKF is localized by the identity matrix, which is optimal for this diagonal problem, then covariance localization is equivalent to applying n scalar EnKFs to each sub-problem. Thus, for diagonal examples, there is a one-to-one analogy between covariance localization of EnKF, and a localization of the particle filter interpretation of EnKF by decoupling of the problem.
5.2. Localizing particle filters for coupled problems
While a localization of particle filters by decoupling diagonal problems is rather intuitive, the situation is less clear in ‘real’ meteorological problems, which are not diagonal. In this context, it is important to realize that making the weights vary over space is not enough to define a localization strategy. The weights must be local and, in addition, must be used in a way to modify the ensemble locally. In the diagonal example, this is done by resampling each variable separately. In more general situations, this step may not be as straightforward and introduces bias, as highlighted in the mathematically rigorous paper by Rebeschini and van Handel (Citation2015). However, the same is true for covariance localization of EnKF. We argued that covariance localization of the EnKF and localization of particle filters by (approximate) decoupling require the same conditions and we argued that these conditions are satisfied in meteorological problems (see Section 2.5). The impressive performance of localized EnKFs in meteorology suggests that the bias introduced by the covariance localization is small. Thus, if particle filters can be localized by making use of the same properties, then the bias introduced by localization of particle filters can also be expected to be small.
Indeed, several localization strategies for particle filters have been published recently (Reich, Citation2013; Poterjoy, Citation2015; Poterjoy and Anderson, Citation2016; Penny and Miyoshi, Citation2015; Rebeschini and van Handel, Citation2015; Tödter and Ahrens, Citation2015). Earlier work includes the study by Bengtsson et al. (Citation2003), where localization of mixture filters is considered, as well as the paper by Lei and Bickel (Citation2011). All of these strategies yield good results in numerical simulations and in one way or another exploit sparsity of the data assimilation problem by restricting the effects of an observation to its neighbourhood. Our study supports these efforts and connects localization of particle filters to real meteorological problems. Specifically, we draw attention to the fact that the successful performance of the localized EnKF in numerical weather prediction in conjunction with the collapse of its particle filter interpretation on the same problem indicates that localization schemes for particle filters may prevent particle filter collapse in meteorology at the cost of a small bias.
6. Discussion
Localizing particle filters by decoupling as described in the context of a diagonal problem applies similarly to block diagonal problems – one may apply independent particle filters to each independent block, which removes any dependence of the performance of the particle filter on dimension or the number of the blocks considered. A meteorological problem is unlikely to be block diagonal, but it may be similar to a large number of loosely coupled sub-problems (see also Section 2). This makes the localization of particle filters less straightforward, as described above, but one can anticipate that localized particle filters can only be successful if the effective dimensions of each sub-problem are small enough to prevent the collapse of particle filters. Our study does not provide any estimate for the effective dimension of each sub-problem, or the number of sub-problems or the degree to which the various blocks are ‘coupled’. Thus, we cannot provide ‘proof’ that localization will indeed make particle filters effective in meteorology. Our study merely indicates that sparsity of the data assimilation problem can be exploited by particle filters and that such strategies may prevent filter collapse in meteorology, provided that each sub-problem is manageable.
There are more analogies between covariance localization of the EnKF and localizing particle filters by (approximate) decoupling. Recall that covariance localization of the EnKF reduces or deletes long-range correlations by Schur products (see Section 2.2). The localization thus restricts the influence of an observation to its neighbourhood. The ‘localized’ weight calculation we describe for diagonal problems does precisely that. Moreover, unlocalized EnKFs with small ensemble sizes fail in high-dimensional problems, and localization makes them effective. Similarly, particle filters collapse in high-dimensional problems if the ensemble size is small; however, a localization by decoupling may make them effective.
Finally, a localization of particle filters is only useful if local errors such as MSE are of greater importance than the global errors measured by the variance of the weights. We showed in Section 4 that the MSE of a (localized) EnKF with a small ensemble can be small even when global errors, measured by the weights of the PF-EnKF, are huge. The success of EnKFs in meteorology suggests that it is sufficient to evaluate errors locally.
6.1. Extensions of our results
Our results concerning the PF-EnKF for the filtering density in Section 3.2, as well as the results concerning the MSE in Section 4 generalize to data assimilation problems with a ‘perfect’ model for which . However, the results concerning the smoothing density cannot be carried over to data assimilation problems with deterministic models by setting
. The reason is that the smoothing density
no longer exists. In the limit
, one can consider either the filtering density
, or the density
. Using the formulas and setting
, one considers methods for the latter density, i.e. the density that describes initial conditions conditioned on data collected at later times. The formulas for the optimal PF with
lead to a sampling algorithm for
, but this algorithm is not optimal. Other optimal algorithms can be obtained, as linear examples show.
Throughout our paper, we assume that the data assimilation problem is linear and Gaussian. In NWP practice, this is not the case. In fact, EnKF can struggle in non-linear problems (see, e.g. Hodyss, Citation2011; Hodyss and Campbell, Citation2013) and in these situations computing weights and using the particle filter interpretation of the EnKF may be particularly helpful. While our results do not directly extend to non-linear problems, the results we collect for linear problems indicate that weight calculations for the EnKF must be localized for non-linear problems as well or else the weights may not be useful in meteorology.
6.2. EnKF stability in time
Work towards a stability theory for the EnKF is partially done (Kelly et al., Citation2014; Kelly et al., Citation2016a) and more is underway ((Kelly et al., Citation2016b); Kelly et al., Citation2016c; Majda and Tong, Citation2016). The goal of these papers is to understand the EnKF and its approximations better by studying stability of its estimates in time. For example, Kelly et al. (Citation2014) interpret the EnKF is as a method for approximating the mean of the filtering density, and the expected distance of an ensemble member to ‘the truth’ is analysed over time. It is shown that this distance is bounded as time evolves and can become small, for large t, if the forecast covariances are inflated. We took a different perspective and address scaling of the computational requirements of the particle filter interpretation of the EnKF with dimension. We considered this scaling during a single time step, as is customary in the particle filter literature (Snyder et al., Citation2008; Bickel et al., Citation2008; Bengtsson et al., Citation2008; Snyder, Citation2011; Chorin and Morzfeld, Citation2013; Snyder et al., Citation2015). We thus neglected accumulation of variance of the weights over time due to the sequential approach, and our study complements recent papers about stability of the EnKF, as well as earlier results by Moral (Citation2004), Chopin (Citation2004) and Künsch (Citation2005) that address accumulation of variances over time.
7. Summary
We summarize the main results we have collected and derived.
| (1) | We reviewed and extended the literature about the collapse of particle filters which is caused by a large ‘effective dimension’. There are several mechanisms that can cause a large effective dimension, and, thus, lead to particle filter collapse. We describe how particle filter collapse occurs in meteorology due to huge numbers of state variables and observations, and a ‘local’ structure of the system (see Section 2). Moreover, while there are several definitions of effective dimension in the literature, we argue that every effective dimension can be expected to be large in meteorology. | ||||
| (2) | We made explicit connections between the collapse of particle filters and the EnKF. Our study and our assumptions are specific to the localized EnKF and are violated by the EnKF without localization. Specifically, we showed that the particle filter interpretation of the localized EnKF for the filtering density collapses unless the ensemble size increases linearly with dimension. This means in particular that using a localized EnKF as the proposal density does not prevent particle filter collapse in meteorology where dimension is large. | ||||
| (3) | We have demonstrated that a localized EnKF with a small ensemble size can produce a small MSE even while its particle filter interpretation collapses. The MSE is small because it is a local measure of error, and the covariance localization of the EnKF can keep local errors small. The collapse of the particle filter interpretation of the EnKF on the other hand is caused by a global weight calculation, during which small errors at various locations add up, rather than average out. We argued that the success of the EnKF indicates that a ‘global’ assessment of error may not be required in meteorology and that assessing errors locally is sufficient. | ||||
| (4) | We have described analogies between covariance localization of EnKF and ‘localization’ of particle filters. We first consider a diagonal problem and show that localization of a particle filter by decoupling the problem independent sub-problems is the equivalent to localizing the EnKF by a diagonal matrix. Relaxing the assumption of diagonality provides hints about how localization for particle filters may be implemented in more realistic, coupled problems. In particular, covariance localization for the EnKF and a localization of particle filters rely on the same assumptions of short correlation lengths within a large system domain, and local assessment of error. The impressive performance of the localized EnKF in meteorological problems indicates that these assumptions are indeed valid in meteorology, which implies that localization of particle filters may be feasible in meteorology without introducing large bias. Our collection of results thus corroborates the applicability of recently proposed localization schemes for particle filters. | ||||
Acknowledgements
We thank Prof. Alexandre J. Chorin of UC Berkeley and Berkeley National Laboratory for interesting discussion and encouragement.
Additional information
Funding
Notes
No potential conflict of interest was reported by the authors.
Related Research Data
References
- Agapiou, S., Papaspiliopoulos, O., Sanz-Alonso, D. and Stuart, A. (2016). Importance sampling: Computational complexity and intrinsic dimension. submitted, pre-print available on https://arxiv.org.
- Anderson, J. (2001). An ensemble adjustment Kalman filter for data assimilation. Mon. Weather Rev. 129, 2884–2903.
- Arulampalam, M., Maskell, S., Gordon, N. and Clapp, T. (2002). A tutorial on particle filters for online nonlinear/non-Gaussian Bayesian tracking. IEEE Trans. Signal Process. 50(2), 174–188.
- Bengtsson, T., Bickel, P. and Li, B. (2008). Curse of dimensionality revisited: the collapse of importance sampling in very large scale systems., IMS Collections: Probability and Statistics: Essays in Honor of David A. Freedman 2, 316–334.
- Bengtsson, T., Snyder, C. and Nychka, D. (2003). Toward a nonlinear ensemble filter for high-dimensional systems. J. Geophys. Res. 108, 8775.
- Beskos, A., Crisan, D. and Jasra, A. (2014). On the stability of sequential Monte Carlo methods in high dimensions. Ann. Appl. Probab. 24(4), 1396–1445.
- Bickel, P., Li, B. and Bengtsson, T. (2008). Sharp failure rates for the bootstrap particle filter in high dimensions., Pushing Limits Contemp. Stat.: Contrib. Honor Jayanta K. Ghosh 3, 318–329.
- Bishop, C., Etherton, B. and Majumdar, S. (2001). Adaptive sampling with the ensemble transform Kalman filter. part I: Theoretical aspects. Monthly Weather Review 129, 420–436.
- Bocquet, M., Pires, C. and Wu, L. (2010). Beyond Gaussian statistical modeling in geophysical data assimilation. Mon. Weather Rev. 138, 2997–3023.
- Burgers, G., van Leeuwen, P. J. and Evensen, G. (1998). Analysis scheme in the ensemble Kalman filter. Mon. Weather Rev. 126, 1719–1724.
- Chopin, N. (2004). Central limit theorem for sequential Monte Carlo methods and its application to Bayesian inference. Ann. Statistics 32(6), 2385–2411.
- Chorin, A. and Hald, O. (2013). Stochastic Tools in Mathematics and Science, 3rd ed., Springer, New York.
- Chorin, A., Lu, F., Miller, R., Morzfeld, M. and Tu, X. (2016). Sampling, feasibility, and priors in Bayesian estimation, Discrete Continuous Dyn. Syst. 36, 4227–4246.
- Chorin, A. and Morzfeld, M. (2013). Conditions for successful data assimilation. J. Geophys. Res. – Atmos. 118, 11522–11533.
- Chorin, A., Morzfeld, M. and Tu, X. (2010). Implicit particle filters for data assimilation. Commun. Appl. Math. Comput. Sci. 5(2), 221–240.
- Chorin, A. and Tu, X. (2009). Implicit sampling for particle filters. Proc. Nat. Acad. Sci. 106(41), 17249–17254.
- Doucet, A. (1998). On sequential Monte Carlo methods for Bayesian filtering. Technical Report. Cambridge: Department of Engineering, University Cambridge.
- Doucet, A., de Freitas, N. and Gordon, N. (eds.) (2001). Sequential Monte Carlo Methods in Practice. Springer, New York.
- Doucet, A., Godsill, S. and Andrieu, C. (2000). On sequential Monte Carlo sampling methods for Bayesian filtering. Stat. Comput. 10, 197–208.
- Evensen, G. (2006). Data Assimilation: The Ensemble Kalman Filter. Springer, New York.
- Fournier, A., Hulot, G., Jault, D., Kuang, W., Tangborn, W., co-authors. (2010). An introduction to data assimilation and predictability in geomagnetism, Space Sci. Rev. 155, 247–291.
- Gaspari, G. and Cohn, S. (1999). Construction of correlation functions in two and three dimensions. Q. J. R. Meteorol. Soc. 125, 723–757.
- Gordon, N., Salmond, D. and Smith, A. (1993). Novel approach to nonlinear/non-Gaussian Bayesian state estimation. IEEE Proc. Radar Signal Process. 140(2), 107–113.
- Hamill, T. M., Whitaker, J. and Snyder, C. (2001). Distance-dependent filtering of background covariance estimates in an ensemble Kalman filter. Mon. Weather Rev. 129, 2776–2790.
- Hodyss, D. (2011). Ensemble state estimation for nonlinear systems using polynomial expansions in the innovation. Mon. Weather Rev. 139, 3571–3588.
- Hodyss, D. and Campbell, W. (2013). Square root and perturbed observation ensemble generation techniques in Kalman and quadratic ensemble filtering algorithms. Mon. Weather Rev. 141, 2561–2573.
- Houtekamer, P. and Mitchell, H. (2001). A sequential ensemble Kalman filter for atmospheric data assimilation. Mon. Weather Rev. 129, 123–136.
- Houtekamer, P. L., Mitchell, H. L., Pellerin, G., Buehner, M., Charron, M., co-authors. (2005). Atmospheric data assimilation with an ensemble Kalman filter: Results with real observations. Mon. Weather Rev. 133, 604–620.
- Kalman, R. (1960). A new approach to linear filtering and prediction theory. Trans. ASME-J. Basic Eng. 82(Series D), 35–48.
- Kalman, R. and Bucy, R. (1961). New results in linear filtering and prediction theory. ASME J. Basic Eng. Ser. D 83, 95–108.
- Kalos, M. and Whitlock, P. (1986). Monte Carlo Methods,, 1st ed., Vol. 1. John Wiley & Sons, New York.
- Kantas, N., Beskos, A. and Jasra, A. (2014). Sequential Monte Carlo methods for high-dimensional inverse problems: A case study for the Navier-Stokes equations, SIAM/ASA. J. Uncertainty Quantification 2, 464–489.
- Kelly, D., Law, K. and Stuart, A. (2014). Well-posedness and accuracy of the ensemble Kalman filter in discrete and continuous time. Nonlinearity 27, 2579–2603.
- Kelly, D., Majda, A. and Tong, X. (2016a). Concrete ensemble Kalman filters with rigorous catastrophic filter divergence. Proc. Nat. Acad. Sci. 112(34), 10589–10594.
- Kelly, D., Majda, A. and Tong, X. (2016b). Nonlinear stability of the ensemble Kalman filter with adaptive covariance inflation. Commun. Math. Sci.
- Kelly, D., Majda, A. and Tong, X. (2016c). Nonlinear stability and ergodicity of ensemble based kalman filters. Nonlinearity 29(2), 657–691.
- Khlalil, M., Sarkar, A., Adhikari, S. and Poirel, D. (2015). The estimation of time-invariant parameters of noisy nonlinear oscillatory systems. J. Sound Vib. 344, 81–100.
- Klaas, M., de Freitas, N. and Doucet, A. (2005). Towards practical N2 Monte Carlo: The marginal particle filter, Proceedings of the 21st Annual Conference on Uncertainty in Artificial Intelligence (UAI-05), Arlington, VA. pp. 308–315.
- Künsch, H. (2005). Recursive Monte Carlo filters: Algorithms and theoretical analysis. Ann. Statistics 33(5), 1983–2021.
- Lei, J. and Bickel, P. (2011). A moment matching ensemble filter for nonlinear non-Gaussian data assimilation. Mon. Weather Rev. 139, 3964–3973.
- Liu, J. and Chen, R. (1995). Blind deconvolution via sequential imputations. J. Am. Stat. Assoc. 90(430), 567–576.
- Majda, A. \ & Tong, X. (2016). Robustness and accuracy of finite ensemble Kalman filters in large dimensions. arXiv, p. 1606.09321.
- Moral, P. D. (2004). Feynman-Kac Formulae: Genealogical and Interacting Particle Systems with Applications. Springer, New York.
- Morzfeld, M. and Chorin, A. (2012). Implicit particle filtering for models with partial noise, and an application to geomagnetic data assimilation, Nonlinear Process. Geophys. 19, 365–382.
- Morzfeld, M., Tu, X., Atkins, E. and Chorin, A. (2012). A random map implementation of implicit filters. J. Comput. Phys. 231, 2049–2066.
- Owen, A. B. (2013). Monte Carlo Theory, Methods and Examples. Online at: http://statweb.stanford.edu/~owen/mc/
- Papadakis, N., Memin, E., Cuzol, A. and Gengembre, N. (2010). Data assimilation with the weighted ensemble Kalman filter. Tellus 62A, 673–697.
- Penny, S. and Miyoshi, T. (2015). A local particle filter for high dimensional geophysical systems, Nonlinear Process. Geophys. 2, 1631–1658.
- Poterjoy, J. (2015). A localized particle filter for high-dimensional nonlinear systems. Mon. Weather Rev. 144, 59–76.
- Poterjoy, J. and Anderson, J. (2016). Efficient assimilation of simulated observations in a high-dimensional geophysical system using a localized particle filter. Mon. Weather Rev. 144, 2007–2020.
- Raeder, K., Anderson, J. L., Collins, N., Hoar, T. J., Kay, J. E. and co-authors. (2012). DART/CAM: An ensemble data assimilation system for CESM atmospheric models. J. Clim. 25, 6304–6317.
- Rebeschini, P. and van Handel, R. (2015). Can local particle filters beat the curse of dimensionality? Ann. Appl. Probab. 25(5), 2809–2866.
- Reich, S. (2013). A nonparametric ensemble transform method for Bayesian inference. Mon. Weather Rev. 35(4), 1337–1367.
- Snyder, C. (2011). Particle filters, the "optimal" proposal and high-dimensional systems. Proceedings of the ECMWF Seminar on Data Assimilation for Atmosphere and Ocean, Reading, UK, 1–10.
- Snyder, C., Bengtsson, T., Bickel, P. and Anderson, J. (2008). Obstacles to high-dimensional particle filtering. Mon. Weather Rev. 136(12), 4629–4640.
- Snyder, C., Bengtsson, T. and Morzfeld, M. (2015). Performance bounds for particle filters using the optimal proposal. Mon: Weather Rev. 143(11), 4750–4761.
- Tippet, M., Anderson, J., Bishop, C., Hamill, T. and Whitaker, J. (2003). Ensemble square root filters. Mon. Weather Rev. 131, 1485–1490.
- Tödter, J. and Ahrens, B. (2015). A second-order exact ensemble square root filter for nonlinear data assimilation. Mon. Weather Rev. 143, 1337–1367.
- van Leeuwen, P. (2009). Particle filtering in geophysical systems. Mon. Weather Rev. 137, 4089–4144.
- van Leeuwen, P., Cheng, Y. and Reich, S. (2015). Nonlinear Data Assimilation. Springer.
- Vanden-Eijnden, E. and Weare, J. (2012). Data assimilation in the low noise regime with application to the Kuroshio. Mon. Weather Rev. 141, 1822–1841.
- Wang, X., Hamill, T. M., Whitaker, J. S. and Bishop, C. H. (2007). A comparison of hybrid ensemble transform Kalman filter-optimum interpolation and ensemble square root filter analysis schemes. Mon. Weather Rev. 135, 1055–1076.
- Weare, J. (2009). Particle filtering with path sampling and an application to a bimodal ocean current model. J. Comput. Phys. 228, 4312–4331.
- Zaritskii, V. and Shimelevich, L. (1975). Monte Carlo technique in problems of optimal data processing. Autom Remote Control 12, 95–103.
Appendix 1
Weights for the particle filter interpretation of the EnKF for the filtering density of non-linear problems
The weights of the PF-EnKF when sampling the filtering density are given in (Equation16(16) ) and can be re-written as
Evaluation of these weights requires integration since(A1)
and evaluating this integral is difficult unless the problem is linear and Gaussian (see above). Similarly, evaluating the density of the analysis ensemble at time k also requires integration since(A2)
where is not Gaussian. However, a basic requirement for weighted sampling (and many other sampling schemes, e.g. Markov Chain Monte Carlo) is that the target and proposal densities be known up to a multiplicative constant. This requirement is not met here so that exact weights for the PF-EnKF when sampling the filtering density are out of reach.
Using ideas of Klaas et al. (Citation2005) for marginal particle filters, one can develop approximate weights. These approximations rely on Monte Carlo for evaluating the integral (EquationA1(A1) ) and become exact as the ensemble size
goes to infinity. We demonstrate here how to use these ideas. Let
,
, be the analysis ensemble at time
, which defines an approximation to the filtering density at time
:
(A3)
which can be used in the integral (EquationA1(A1) ) to obtain
The target density can thus be approximated by(A4)
Similarly, we obtain by Monte Carlo approximation of the integral (EquationA2(A2) )
With these approximations, the PF-EnKF weights with respect to the marginal posterior are(A5)
However, the approximate weights are difficult to compute unless the model’s time stepper is in sync with the observations. The difficulties can be illustrated by considering a problem with one additional model step between two consecutive observations. In this case, the proposal density can be written as
We can use the analysis ensemble at time to approximate
as before, but we then must perform the integration over
(assuming there is no observation available at that time):
This integration is difficult in general, which complicates the computation of the weights for the PF-EnKF for the filtering density. In fact, these weights may be impractical because the observations are usually not frequently available (at least not atevery step of the model). These results can be extended to the case of deterministic models by putting , where
is the delta distribution.