
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
We study the full-waveform inversion (FWI) problem for the recovery of velocity model/image in acoustic media. FWI is formulated as a typical nonlinear optimization problem, many regularization techniques are used to guide the optimization process because the FWI problem is strongly ill-posed. Recently, sparsity regularization has attracted considerable attention in the field of inverse problems. In addition, the nonlocal similarity is also an inherent property of many subsurface images themselves. In this paper, we present a novel computational framework for FWI based on joint local sparsity and nonlocal self-similarity. First, principal component analysis (PCA)-based dictionary learns from noisy approximation images (the estimated results from certain local optimization method) and the learned dictionary is used to guide similar patch grouping. Second, the sparse representation and the nonlocal similarity are introduced as the regularization term. At last, the relative total variation (RTV) algorithm is used to further eliminate the residual artefacts in the reconstructed model more thoroughly. In our inversion strategy, the external optimization knowledge, and the intrinsic local sparsity and nonlocal self-similarity prior of model are used jointly for FWI. Computational results demonstrate the proposed method is obviously superior to existing inversion methods both qualitatively and quantitatively, including total variation FWI method in model-derivative domain and sparsity promoting FWI method in the curvelet domain.
1. Introduction
Full-waveform inversion (FWI) is an important imaging modality to retrieve high-resolution velocity model (see [Citation1,Citation2] for a review). FWI relies on a nonlinear least squares optimization problem that attempts minimizing the misfit between recorded and calculated seismic data. The misfit function can be defined in the time domain [Citation3–6] or the frequency domain[Citation7–9] (for further details, please see [Citation10]). Although frequency-domain FWI implementations have various advantages, the insufficiency of the low-frequency information in seismic data, the nonlinearity of the forward model and the ill-posed nature of the formulation all lead to a pressing need for an effective regularization techniques to increase the robustness of FWI and improve inversion quality.
In order to obtain an accurate approximate solution of FWI, the classical Tikhonov regularization is known as one of the most commonly employed methods [Citation11]. However, it leads inversion results to suffer from the over-smoothing effect and be more difficult to recover some small-scale features [Citation12]. Total variation (TV) regularization has been successfully introduced in many different imaging applications, such as image deblurring [Citation13], CT image reconstruction [Citation14], and recovering the salt body through FWI [Citation15,Citation16], because it is able to preserve sharp interfaces and capture some sparsely important information in model-derivative domain. Nevertheless, TV regularization assumes that the model is piecewise smooth, which usually smears out model details and produces staircase artifacts. This effect is due to the fact that TV regularization requires the gradient be sparse and only sharp boundaries be preserved.
Sparsity is a major tool for extracting useful information from indirect measured data, which can provide a more easily interpretable and parsimonious model. Recently, sparsity regularization has attracted great interest in the field of geophysical inverse problems. Successful examples include seismic tomography with the sparsity constraint by using the -norm to the model wavelet expansion coefficients [Citation17,Citation18], sparsity constrained FWI using the curvelet or seislet transform [Citation19–22], and the multiple sparsity constraints for FWI [Citation23].
The above mentioned transform domains or dictionaries are analytical and cannot accurately capture the specific structure characteristics of the desired model. In fact, it is very difficult to find a suitable sparse representation for the unknown velocity model with any concise analytical dictionaries because of complicated subsurface structures. A novel, popular, and heart-stirring approach for solving FWI problems is to find the sparse representation of model parameter by using a learned dictionary. Compared with the analytic bases or frames, the learned dictionaries may provide better sparse approximation properties [Citation24], and adapt to patterns in specific problems. Different dictionary learning approaches have already been applied to the sparsity-promoting FWI problem [Citation25–27]. As expected, by learning a set of training data/patches, such dictionaries can provide a more sparse representation of subsurface model parameters.
Based on this and another impressive property called nonlocal similarity, Li and Harris [Citation28] have developed a novel adaptive sparsity-promoting regularization in the model-derivative domain, which unifies the local sparsity and the nonlocal similarity into a variational framework for FWI. In [Citation29], by exploiting nonlocal similarity Shi and Wang presented a novel reverse time migration strategy in seismic imaging. Nonlocal similarity posits that a local patch often has many geometrically similar patches across the model. In the field of image processing, a non-locally centralized sparse representation (NCSR) framework proposed by Dong et al. [Citation30] is very competitive. They exploited the nonlocal similarity to obtain good estimate of the sparse coding coefficients of the clean natural images.
In this paper, to benefit both from the sparsity-based regularization and the nonlocal similarity nature of subsurface model, we propose a new regularization strategy for FWI. Here, the dictionary is trained from PCA transformation, and the PCA-subspace Euclidean distance is used to guide similar patches grouping results, so that the reconstructed model coded by the sub-dictionaries learned from the classified patches can be more sparse. Then, we introduce a nonlocal similarity prior into the sparse representation-based FWI framework. At last, the RTV algorithm is used to further reduce the residual artifacts in the reconstructed model more thoroughly.
In the next section, we briefly review the background of acoustic FWI, and basic optimization algorithms. Section 3 introduces the theoretical details for the proposed method and corresponding numerical scheme. Experimental results are given in Section 4 to demonstrate the advantages of our inversion strategy over FWI with conventional regularization schemes including the TV regularization and sparsity promotion regularization using curvelet transform. Finally, Section 5 presents concluding remarks.
2. Full waveform inversion
The purpose of FWI is to obtain high resolution and precision seismic imaging via minimization of the misfit between observed and forward modeling data. The observed data is acquired by receiver arrays and denoted as . In the discrete case,
denotes the unknown subsurface model, where
and
are the number of grid points in z- and x- directions, respectively. In this work,
(
is the discrete velocity model,
, and
) represents the squared-slowness value in a 2D grid. Let
be the mathematical expression of the forward modelling problem that describes the calculation process from model to data. Therefore, FWI seeks to find a model
that minimizes the following discrete nonlinear least squares misfit function
(1)
(1) where
is the Frobenius norm.
In the frequency domain, the forward modeling operator can be obtained by solving the following constant-density Helmholtz equation
(2)
(2) where
is the discretized Helmholtz operator
with perfectly matched layer (PML) boundary conditions for the frequency ω and the model
, the solution
is the pressure wavefield and
denotes the source. Let P be a measurement operator that projects the solution
onto the receiver locations, then the operator
can be formally written as
.
When a local optimization technique (such as the conjugate gradient method, steepest-descent method or quasi-Newton method) is used to minimize the misfit function in (Equation1(1)
(1) ), the gradient of Ψ is required. In this paper, we adopt the L-BFGS algorithm [Citation31], a popular quasi-Newton strategy, which can achieve a much faster convergence speed at minimal computational cost. More specifically, the L-BFGS algorithm iteratively updates the model
by setting
(3)
(3) where
is the misfit gradient, it can be calculated by the adjoint-state method [Citation32,Citation33], which specific steps for complex-valued fields can refer to Barucq et al. ([Citation34], Appendix A). Furthermore, the L-BFGS method does not need the complete storage of
(an approximation of the inverse Hessian), which is prohibitive for large-scale model. The step length
is chosen by a line search that satisfies the Wolfe conditions [Citation31,Citation35].
3. The proposed method
As mentioned above, we need to add sufficient complete prior knowledge of desired model parameters to guide the inversion process to obtain a satisfactory solution. Recently, sparsity-based regularization and nonlocal self-similarity method are becoming more popular in image processing community. In this study, we propose a novel FWI strategy to recover unknown medium parameters properly, aiming to exploit the local sparsity and the nonlocal self-similarity of model parameters simultaneously in a unified framework. The proposed method exploits the PCA sub-dictionaries for adaptive sparse representation and suppresses the sparse coding noise by computing the weighted average of the sparse representation coefficients for nonlocal similar patches to enhance the image quality. We call this method Adaptive Sparse constrained Nonlocal self-Similarity FWI method or ASNS-FWI method for short.
The proposed ASNS-FWI method mainly consists of two loops: In the inner loop, we adopt the L-BFGS algorithm to solve the nonlinear optimization problem (Equation1(1)
(1) ), which yields a noisy inversion result. And the outer loop is to obtain an artifact-reduced result using the Adaptive Sparse constrained Nonlocal self-Similarity (ASNS) method. Most of undesirable artifacts in the target model are removed after performing the above steps, but there are still some residual streak artifacts . To further remove the residual streak artifacts , the RTV method is introduced as a post-processing step. The following subsections give detail formulation and numerical scheme of the newly proposed ASNS-FWI.
3.1. Sparse representation modeling
While medium parameters are generally not sparse in the ambient domain, most model parameters have a concise representation in the transform domain. Mathematically, the model can be sparsely represented as
, by solving the following optimization problem:
(4)
(4) where
is the dictionary, α is a sparse coefficient vector,
denotes the
-norm of α, i.e., the number of non-zero components in α, the second term
is the
-norm fidelity term, and
is a small constant.
A crucial question in sparse representation is the choice of the dictionary. Possible choices include various static dictionaries such as discrete cosine transform (DCT), wavelet, and curvelet. Generally, the performance of sparse representation depends on the dictionary used, and most importantly its suitability for the desired model and the problem at hand. In this work, we employ the K-means clustering technique to categorize the extracted image patches into K groups, and use PCA technique to learn a sub-dictionary of each group.
Since the norm is NP-hard problem, it is usually replaced by the convex norm
. For a given dictionary
, we formulate this
-norm minimization as the following regularization form:
(5)
(5)
In fact, after an estimated result is obtained by the L-BFGS algorithm, we try to minimize the following optimization problem:
(6)
(6) To reconstruct the unknown clean model
based on
, some basic notations needed in following analysis are provided.
3.2. PCA dictionary learning
First, we divide the estimated image from L-BFGS into n overlapped patches of size
, where
represents the image patch at the spatial location i,
. To remove block artifacts, overlapping patches with a sliding distance of one pixel are used in this paper. Using an extraction matrix
to build the connection between
and
, there holds
These image patches form a matrix
given by
where
is the vectorized model patch. The mean vector of
is denoted as
Then, we subtract the mean vector
from
, and
updates to
The covariance matrix of
can be calculated as
Because
is symmetrical, its eigenvalue decomposition (EVD) can be written as
(7)
(7) where
is a diagonal matrix whose diagonal elements
are the eigenvalues in decreasing order, that is,
. The columns of matrix
are the corresponding eigenvectors of the covariance matrix
. The energy captured by each eigenvector can be computed as [Citation36]
(8)
(8) As aforementioned, we adopt PCA to learn the adaptive dictionary. Before that, we can find a proper number d to satisfy
. Then, we obtain a PCA dictionary
decided by
(9)
(9) And using the dictionary
, we can now project the image patch
onto this low-dimensional PCA subspace to obtain
,
. By applying the K-means clustering algorithm, all patches
can be divided into K groups
. The algorithm requires a similarity metric defined in the sample space, and the Euclidean distance is a usual choice. Recent research [Citation28] has shown that the patch-wise Euclidean distance tends to produce poor results. In our algorithm, we adopt the Euclidean distance in a lower dimensional space determined by PCA to measure the similarity between two image patches. Related concepts are also employed in [Citation37]. For given two image patches
and
, the PCA subspace Euclidean distance is calculated as
(10)
(10) In the work of [Citation37], the theoretical and experimental results for benchmark applications demonstrate that the similarity measure in a low-dimensional subspace described by PCA can capture the intrinsic characteristics of image patches more precisely than in the full space. A major reason for this is that the front few PCA eigenvectors contain important information about the edges or texture of the image patch. For each patch group
, PCA (as shown in formula (Equation9
(9)
(9) )) is applied to learn a dictionary
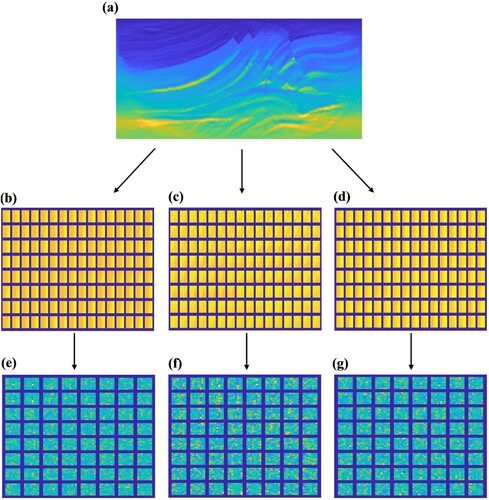
called PCA sub-dictionaries. Thanks to the patches in a group are similar to each other, so we construct a set of compact PCA sub-dictionaries for clustered patches rather than an over-complete dictionary. Usually, a compact dictionary will contribute to the decrease of computational cost of the sparse coding for a given image patch [Citation30]. Meanwhile, these K PCA sub-dictionaries construct a large over-complete dictionary to capture all the possible local characteristics of subsurface model. Figures and show examples of three classes of training patches and their corresponding dictionaries.
Figure 1. Three classes of training patches and corresponding dictionaries: (a) the true Marmousi model; (b)–(d) 128 patches from three clusters; (e)–(g) dictionaries trained from corresponding patch clusters.
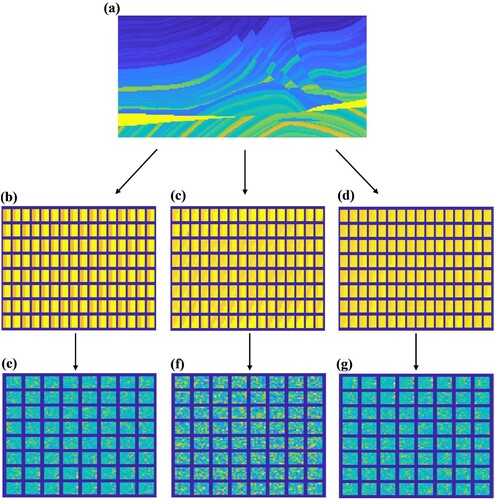
Figure 2. Three classes of training patches and corresponding dictionaries: (a) the inversion result obtained at the end of the first inner loop; (b)–(d) 128 patches from three clusters; (e)–(g) dictionaries trained from corresponding patch clusters.
3.3. Adaptive regularization by nonlocal similarity
Once we obtain the learned dictionary (
, M denotes the number of contained atoms in
), each patch
can be sparsely represented as
, and the sparse vector
can be obtained via solving the following problem:
(11)
(11) for some
.
Then the model image is reconstructed as
where
denotes the concatenation of all
, and the notation ° is used to simplify the operation of
. That is, we can express the entire model
by averaging each recovery patch of
.
Now, the optimization formulation (Equation6(6)
(6) ) can be rewritten as
(12)
(12) Obviously, the sparsity regularization minimization (Equation12
(12)
(12) ) exploits the local statistics in each image patch. On the other hand, there are usually many repetitive patterns throughout the subsurface model. Such nonlocal redundancy (similarity) is very helpful to increase the quality of reconstructed images. As complementary, by considering redundancy of image patches, a nonlocal similarity is introduced into the minimization problem (Equation12
(12)
(12) ), in order to make the sparse representation coefficients
close to the true sparse coefficients
as possible. The sparse coding error (SCN)
expresses the variation of
from the true sparse coefficients
, which is basically the sparse coding error that obeys the Laplacian distribution [Citation30,Citation37,Citation38]. In practice,
is unavailable.
Fortunately, there are many similar patterns or structures in the model. First for each local patch , search Q patches whose PCA-subspace Euclidean distance to its the first-Q smallest compared with all image patches in a large window
centered at location i. Then, using the selected PCA sub-dictionaries to sparsely represent all patches in
, which includes the patch
itself, i.e.
, and the corresponding sparse coefficients can be calculated as
(13)
(13) Thus a prediction
of
can be calculated by the weighted average of
, i.e.,
(14)
(14) where
, ζ is a predetermined constant, and W is a normalization factor.
By incorporating the nonlocal similarity regularization term, the sparsity regularization minimization (Equation12(12)
(12) ) can be rewritten as
(15)
(15) where λ is a regularization parameter. In addition, the sparse coefficient α in equation (Equation15
(15)
(15) ) can be calculated by the PCA sub-dictionaries. The elements of α are zero on
sub-dictionaries except for the related one and the sparsity is ensured implicitly. Hence, by removing the second term, we can obtain
(16)
(16) Mathematically, the choice of the regularization parameter is critical, and we determine λ by empirical formula as in [Citation38]
(17)
(17) in which, let
,
denote the
element of
, and
be the standard deviation of
, and σ be the standard deviation of the noise
[Citation37,Citation39]. Even though the true model
is unknown, according to the above analysis, we can adopt
.
Now for fixed , we solve the following minimization problem:
(18)
(18) By utilizing the surrogate algorithm in [Citation40] for solving (Equation18
(18)
(18) ), we have
(19)
(19) where
is the
element of
in the
th iteration,
is the well-known soft-thresholding operator,
, and c is a pre-determined parameter to guarantee the soft-thresholding algorithm convergent. Therefore, the entire model can be reconstructed by
(20)
(20)
3.4. The RTV postprocessing step
The artifacts of the reconstructed model are greatly removed after implementing the above operator steps, but there are still some residual streak artifacts . In order to remove these artifacts more thoroughly, the RTV method [Citation41] is used as a postprocessing step. RTV is defined as follows:
(21)
(21) where ϵ is a small constant to avoid division by zero. The windowed total variations
and
in two directions for pixel p are expressed as follows:
where
represents a rectangular region whose central pixel is the pth pixel of model
, the weighting function
is expressed as
, and ρ controls the spatial scale of the window.
In addition, the windowed inherent variation (WIV) and
of the pth pixel are defined as
Generally, the WIV values in a rectangular window with more textures are smaller than those in a window with more structures [Citation42]. Therefore, the objective function of RTV regularization is expressed as
(22)
(22) where η is a trade-off parameter. In practice, the value of η typically varies in a small interval
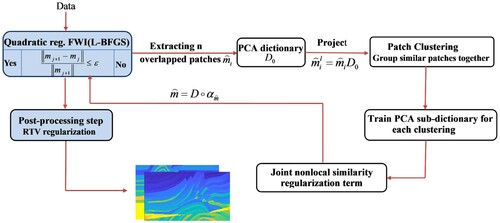
[Citation41]. So far, the ASNS-FWI method is summarized in the flowchart shown in Figure and the pertinent details of algorithm are given in Algorithm 1.
Figure 3. Flowchart of the ASNS-FWI algorithm.

4. Numerical results
We now present some numerical results to evaluate the performance of the proposed ASNS-FWI method compared to FWI with total variation regularization (TV-FWI) and FWI with curvelet-domain sparsity promotion (CS-FWI) [Citation21]. By adding a regularization term, the misfit function (Equation1(1)
(1) ) becomes
(23)
(23) where
is a regularization parameter determined by noise level. Note that if the matrix C represents a discrete gradient operator, the equation (Equation23
(23)
(23) ) leads to the well-known TV regularization by using
-norm term. And if the matrix C is the curvelet transform, the equation (Equation23
(23)
(23) ) leads to sparsity promotion regularization by using
-norm term. To give the best image quality, we have made a lot of numerical experiments. The specific regularization parameter
is manually determined in the following example.
In practice, the collected data is often polluted by random noise, so we create a noisy seismic dataset by adding
white Gaussian noise. The parameter setting is as follows: the model patch size is
, the number of similar patches is set to Q = 13, the size of local searching window is
, and
; c = 0.3;
. For the ASNS-FWI method, the stopping criteria for the inner loop (L-BFGS iteration) is J = 15 or the objective function (Equation1
(1)
(1) ) decreases sufficiently small (
). To save computation time,
outer iterations are performed. The L-BFGS algorithm is used to solve (Equation23
(23)
(23) ). Moreover, the L-BFGS algorithm stops if the maximum number
of iterations is reached, or the misfit function (Equation1
(1)
(1) ) decrease is small enough (
), which helps to ensure a fair comparison between the proposed ASNS-FWI, TV-FWI and CS-FWI methods. For the CS-FWI method, the fast discrete curvelet transform based on a public code distributed is used [Citation43]. To mitigate the cycle-skipping problem, the inversions are carried out sequentially in 12 overlapping frequency windows on the interval 2–26 Hz.
All the experiments were performed in MATLAB 2018a on a PC equipped with an Intel Core i7-7700 Eight-core (8 Core) 3.60 GHz Processor and 16 GB of RAM. To quantitatively evaluate the performance of different FWI methods, the peak signal-to-noise ratio (PSNR) is commonly used to evaluate the objective image quality, three more powerful reference metrics, the structural similarity index (SSIM), the feature similarity index (FSIM) and the root mean square error (RMSE) are also adopted to evaluate the inversion quality (See Tables and ).
Table 1. Quantitative results of overthrust model. The brackets represent results without RTV.
Table 2. Quantitative results of Marmousi model. The brackets represent results without RTV.
First, the true model (see Figure (a)) is a sedimentary part from the Overthrust model. The dimensions of the model are , with grid spacings of 10 m. The initial velocity model is shown in Figure (b). We employ 67 sources and 201 receivers located near the surface and distributed uniformly over the horizontal coordinate. In this experiment, the number of clusters is set to be K = 33. The value of the regularization parameters
for the TV-FWI and CS-FWI methods is
. All final inversion results are shown in Figure (c)–(f). A direct comparison along vertical logs (as depicted with black dotted line of Figure (a)) between the true velocity, the initial and the final velocity models in Figure . Clearly, our proposed ASNS-FWI method leads to a more accurate reconstruction in this example. Compared with other two FWI methods, the ASNS-FWI method generates the best visual effect and the structural details of model are better maintained (see red rectangle in Figure (c)–(f). The quantitative evaluation of Overthrust model is given in Table . Both subjective visual effects and objective evaluation (except time) criteria clearly show the capability of the proposed ASNS-FWI approach for building high-resolution velocity model.
Figure 4. Inversion results of the Overthrust model: (a) the true velocity model; (b) the initial velocity model; (c) the ASNS-FWI result; (d) the ASNS-FWI result without RTV; (e) the TV-FWI result; (f) the CS-FWI result.
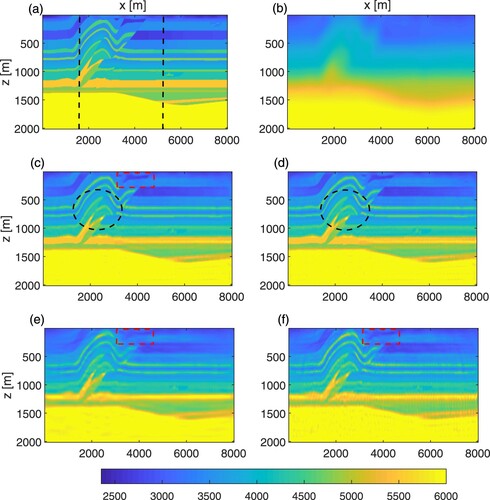
Figure 5. The vertical velocity profiles extracted from the Overthrust model.
As a second example, we use a modified version of the Marmousi model for numerical tests and true velocity model is shown in Figure (a). The initial velocity used to start the FWI is 1-D, which first smoothing the true velocity model with Gaussian kernel, and then averaging along the horizontal direction (Figure (b)). In this example, the model space has parameters, with a grid size of 5 m in each direction. As the velocity structure becomes more complex, the number of clusters is K = 64. We set regularization parameters
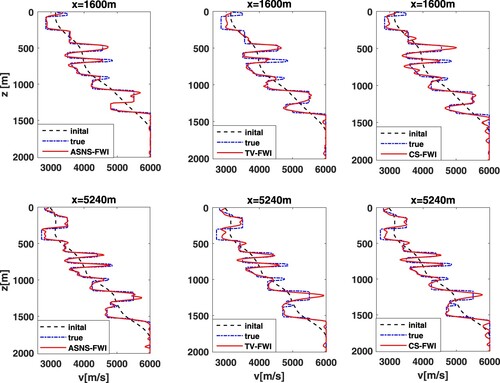
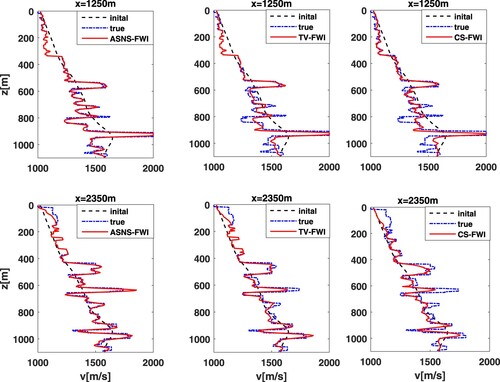
in the TV-FWI and CS-FWI methods. We use 66 equally spaced sources and 198 equally spaced receivers placed near the surface. Final inversion results are shown in Figure (c)–(f). Figure depicts two vertical cross-sections through the Marmousi model at x = 1250 m and x = 2350 m (see the black dotted line in Figure (a)). Three FWI methods can give reasonable reconstructions in this example; all main features and interfaces are identified at the correct locations. By examining the results carefully, the proposed ASNS-FWI method restores the fine structure of the model better than other methods (see red rectangles in Figure (c)–(f)). The quantitative results (except time) in Table indicate the improvements of the proposed method are impressive, which together with the visual effect verifies the superiority of the proposed method.
Figure 6. Inversion results of the Marmousi model: (a) the true velocity model; (b) the initial velocity model; (c) the ASNS-FWI result; (d) the ASNS-FWI result without RTV; (e) the TV-FWI result; (f) the CS-FWI result. Note that the total lack of lateral variation in the initial velocity.
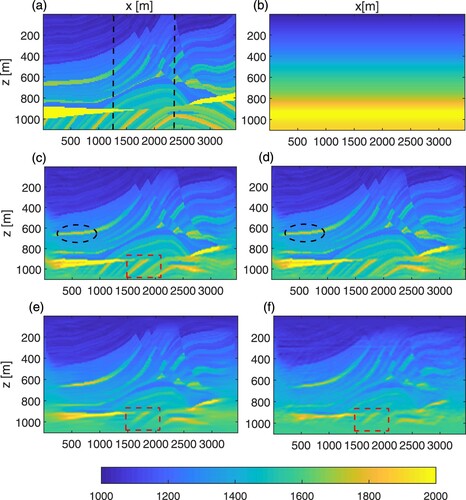
Figure 7. The vertical velocity profiles extracted from the Marmousi model.
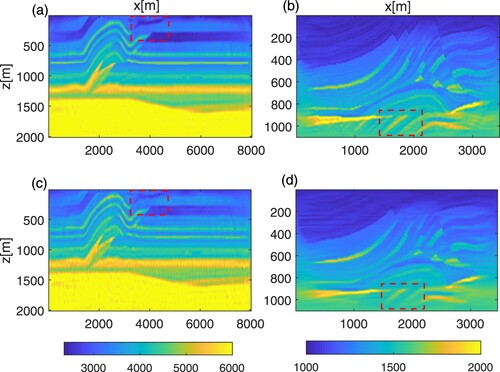
In addition, to demonstrate the impact of RTV postprocessing step on the inversion results, the calculational results of ASNS-FWI method with and without RTV postprocessing steps are presented. The comparison results show that, the residual artifacts are removed more effectively by using RTV step, which verifies the effectiveness of the RTV in the waveform inversion (see black ellipses in Figures (c),(d) and (c),(d)). To further demonstrate the robustness of our ASNS-FWI method, we add 5% white noise to the seismic data and compare the inversion results of the TV-FWI and ASNS-FWI methods. In our simulations, we take the regularization parameter in the Overthrust model and
in the Marmousi model, and the other parameters are chosen be the same as the above experiments. The reconstruction results of TV-FWI and ASNS-FWI methods are shown in Figure . In this comparison, we find that the proposed ASNS-FWI method can suppress the random noise more effectively and it helps to obtain a better inversion result (see red rectangles in Figure ).
Figure 8. Inversion results under 5% white noise in seismic data: (a) the ASNS-FWI result (Overthrust model); (b) the ASNS-FWI result (Marmousi model); (c) the TV-FWI result (Overthrust model); (d) the TV-FWI result (Marmousi model).
There are two major limitations in our FWI method. First, in our experiments, the parameters are manually selected. Therefore, in practice, our method should be combined with other reasonable strategies for parameter selection. A popular machine learning algorithm is a possible solution to adaptively calculate the optimal parameters by learning from an available dataset. Second, due to the introduction of the dictionary learning and nonlocal similarity, the computational complexity of ASNS-FWI is heavier than that of conventional FWI methods. Thus, the use of parallel platforms, including distributed computing, cloud environments, and Graphics Processing Units (GPUs), is vitally important in practice.
5. Conclusion
In this paper, we present a sparsity-based regularization method for FWI that combines the nonlocal similarity prior. The proposed FWI method mainly consists of four stages such as L-BFGS iteration stage, PCA-based dictionary learning stage, nonlocal sparse regularization stage and postprocessing stage. The numerical results of the experimental data show that our inversion method has certain competitiveness compared with existing FWI algorithms. Specifically, ASNS-FWI demonstrates a superior ability to reduce most artifacts and preserve more structural details. We have also pointed out limitations of the proposed FWI method, and provided some suggestions for practical application. Although we only show FWI examples obtained by acoustic media, our ASNS-FWI can also be applied to elastic media.
Acknowledgments
The authors thank the editor and the anonymous referees for their valuable comments, suggestions and support. This work is partially supported by the National Natural Science Foundation of China (Grant No. 41474102).
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Virieux J, Stéphane O. An overview of full-waveform inversion in exploration geophysics. Geophysics. 2009;74(6):WCC1–WCC26.
- Wang YH, Rao Y. Reflection seismic waveform tomography. J Geophys Res Solid Earth. 2009;114(B3):B03304.
- Tarantola A. Inversion of seismic reflection data in the acoustic approximation. Geophysics. 1984;49(8):1259–1266.
- Bunks C, Saleck FM, Zaleski S, et al. Multiscale seismic waveform inversion. Geophysics. 1995;60(5):1457–1473.
- Shipp R, Satish CS. Two-dimensional full wavefield inversion of wide-aperture marine seismic streamer data. Geophysical Journal International. 2002;151(2):325–344.
- Han B, Fu HS, Li Z. A homotopy method for the inversion of a two-dimensional acoustic wave equation. Inverse Problems in Science and Engineering. 2005;13(4):411–431.
- Pratt RG, Shin C, Hick GJ. Gauss–Newton and full Newton methods in frequency-space seismic waveform inversion. Geophysical Journal International. 1998;133(2):341–362.
- Brossier R, Operto S, Virieux J. Seismic imaging of complex onshore structures by 2D elastic frequency-domain full-waveform inversion. Geophysics. 2009;74(6):WCC105–WCC118.
- Luo J, Xie X. Frequency-domain full waveform inversion with an angle-domain wavenumber filter. Journal of Applied Geophysics. 2017;141:107–118.
- Wang YH, Rao Y. Waveform Modeling and Tomography. In: Gupta H.K. (eds) Encyclopedia of Solid Earth Geophysics. Encyclopedia of Earth Sciences Series. Springer, Dordrecht; 2021. p. 1608–1621.
- Wang YH. Seismic inversion: theory and applications. Chichester, West Sussex, UK : John Wiley & Sons, Ltd; 2017.
- Aster RC, Borchers B, Thurber CH. Tikhonov regularization. Parameter estimation and inverse problems. 2nd edn; Elsevier Academic Press, New York; 2011. p. 93–127.
- Chan TF, Wong CK. Total variation blind deconvolution. IEEE Transactions on Image Processing. 1998;7(3):370–375.
- Ritschl L, Bergner F, Fleischmann C, et al. Improved total variation-based CT image reconstruction applied to clinical data. Physics in Medicine and Biology. 2011;56(6):1545–1561.
- Esser E, Guasch L, Van Leeuwen T, et al. Total variation regularization strategies in full-waveform inversion. SIAM Journal on Imaging Sciences. 2018;11(1):376–406.
- Peng Y, Liao W, Huang J, et al. Total variation regularization for seismic waveform inversion using an adaptive primal dual hybrid gradient method. Inverse Problems. 2018;34(4):045006.
- Loris I, Nolet G, Daubechies I, et al. Tomographic inversion using l1-norm regularization of wavelet coefficients. Geophysical Journal International. 2007;170(1):359–370.
- Fang H, Zhang H. Wavelet-based double-difference seismic tomography with sparsity regularization. Geophysical Journal International. 2014;199(2):944–955.
- Herrmann FJ, Hanlon I, Kumar R, et al. Frugal full-waveform inversion: from theory to a practical algorithm. Geophysics. 2013;32(9):1082–1092.
- Chai X, Tang G, Peng R, et al. The linearized Bregman method for frugal full-waveform inversion with compressive sensing and sparsity-promoting. Pure Appl Geophys. 2018;175(3):1085–1101.
- Fu HS, Ma MY, Han B. An accelerated proximal gradient algorithm for source-independent waveform inversion. J Appl Geophys. 2020;177:104030.
- Xue Z, Zhu H, Fomel S, et al. Full-waveform inversion using Seislet regularization. Geophysics. 2017;82(5):1–40.
- Peters B, Smithyman BR, Herrmann FJ. Projection methods and applications for seismic nonlinear inverse problems with multiple constraints. Geophysics. 2019;84(2):R251–R269.
- Rubinstein R, Bruckstein AM, Elad M. Dictionaries for sparse representation modeling. Proc IEEE. 2010;98(6):1045–1057.
- Bao C, Cai J, Ji H. Fast sparsity-based orthogonal dictionary learning for image restoration.Sydney, NSW, AustraliaProceedings of the IEEE International Conference on Computer Vision (ICCV).2013.
- Zhu L, Liu E, Mcclellan JH, et al. Sparse-promoting full-waveform inversion based on online orthonormal dictionary learning. Geophysics. 2017;82(2):R87–R107.
- Huang X, Liu Y, Wang F, et al. A robust full waveform inversion using dictionary learning. SEG Technical Program Expanded Abstracts; 2019.
- Li D, Harris JM. Full waveform inversion with nonlocal similarity and model-derivative domain adaptive sparsity-promoting regularization. Geophys J Int. 2018;215(3):1841–1864.
- Shi Y, Wang YH. Reverse time migration of 3D vertical seismic profile data. Geophysics. 2016;18:S31–S38.
- Dong W, Zhang L, Shi G, et al. Image deblurring and super-resolution by adaptive sparse domain selection and adaptive regularization. IEEE Transactions on Image Processing. 2011;20(7):1838–1857.
- Nocedal J, Wright SJ. Numerical optimization. 2nd edn. Berlin, Heidelberg, New York: Springer Verlag; 2006.
- Chavent G. Identification of functional parameters in partial differential equations. IEEE Transactions on Automatic Control. 1974;12(12):155–156.
- Plessix RE. A review of the adjoint-state method for computing the gradient of a functional with geophysical applications. Geophysical Journal International. 2006;167(2):495–503.
- Barucq H, Chavent G, Faucher F, et al. A priori estimates of attraction basins for nonlinear least squares, with application to Helmholtz seismic inverse problem. Inverse Problems. 2019;35(11):115004.
- Metivier L, Brossier R. The seiscope optimization toolbox: a large-scale nonlinear optimization library based on reverse communication. Geophysics. 2016;81(2):F1–F15.
- Reddy SR, Freno BA, Cizmas P, et al. Constrained reduced-order models based on proper orthogonal decomposition. Comput Methods Appl Mech Eng. 2017;321:18–34.
- Wang N, Shi W, Fan C, et al. An improved nonlocal sparse regularization-based image deblurring via novel similarity criteria. Int J Adv Robot Syst. 2018;15(3):172988141878311.
- Liu Q, Zhang C, Guo Q, et al. Adaptive sparse coding on PCA dictionary for image denoising. The Visual Computer. 2016;32(4):535–549.
- Xu J, Zhang L, Zuo W. Patch group based nonlocal self-similarity prior learning for image denoising.Santiago, Chile.In International Conference on Computer Vision.2015.
- Daubechies I, Defrise M, De Mol C, et al. An iterative thresholding algorithm for linear inverse problems with a sparsity constraint. Communications on Pure and Applied Mathematics. 2004;57(11):1413–1457.
- Xu L, Yan Q, Xia Y, et al. Structure extraction from texture via relative total variation. ACM Trans Graph. 2012;31(6):139.
- Gong C, Zeng L. Adaptive iterative reconstruction based on relative total variation for low-intensity computed tomography. Signal Processing. 2019;165:149–162.
- Emmanuel C, Demanet L, Donoho D, et al. Fast discrete curvelet transforms. SIAM J Multiscale Modeling Simul. 2006;5(3):861–899.