
Abstract
A gene encoding putative β-carbonic anhydrase gene (CA) from cowpea (Vigna unguiculata L. Walp.) was characterized and designated as VuCA1 (GenBank ID: JQ429799). While the genomic sequence of CA was found to be 1470 bp long with 4 introns, the open reading frame was 990 bp in length. The deduced amino acid sequence of CA contained two characteristic conserved domains, i.e. CSDSRV and EYAVLHLKVSNIVVIGHSACG, which showed high degree of homology with other β-CA genes of angiosperms. We have reported three-dimensional model of VuCA1 and quality of the predicted model was analysed with PROCHECK. Molecular docking of modeled VuCA1 revealed similar binding pockets for different substrates and products. The expression of VuCA1 transcripts was detected in different parts of the cowpea plant, with highest level observed in leaves, followed by flower buds, weak expression in stems, and the weakest in roots. The expression of VuCA1 transcripts of leaves was downregulated by zinc deficiency but upregulated by salt and dehydration stress.
Introduction
Carbonic anhydrase (CA; carbonate dehydratase, EC 4.2.1.1) is a zinc-containing enzyme which catalyzes the reversible hydration of CO2. CA is a ubiquitous enzyme present in both prokaryotes as well as eukaryotes and is one of the most abundant soluble proteins in the leaves and green tissue (Reed & Graham Citation1981). It catalyzes the reversible hydration of . In eukaryotes, the enzyme participates in various physiological functions, which include the interconversion of CO2 and HCO3− during photosynthesis and intermediary metabolism, facilitated diffusion of CO2, pH homeostasis, photomorphogenesis (Wang et al. Citation2012), and transportation of ions (Badger & Price Citation1994; Sly & Hu Citation1995). It mediates the transport of inorganic carbons to actively photosynthesizing cells or away from actively respiring cells (Badger & Price Citation1994). Six different evolutionarily unrelated CA families have been identified and designated as α, β, γ, δ, ε, and ζ CAs, which have originated independently as a convergent evolution to perform same catalytic function of reversible hydration of CO2. Higher plants, algae, and cyanobacteria possess three major families of CAs, namely α, β, and γ, and the active sites of these CAs contain Zn2 + as cofactor that catalyzes the reversible interconversion of CO2 and HCO3 (Liljas & Lauberg Citation2000). Although CA genes from several different plants had been isolated and characterized (Kim et al. Citation1994; Bracey & Bartlett Citation1995; Ignatova et al. Citation2011; Kaul et al. Citation2011; Wang et al. Citation2012), yet, it is not reported from cowpea plant.
Cowpea (Vigna unguiculata L. Walp.) is an important leguminous crop that is used for livestocks as feed, as green vegetables, as well as dry beans for human consumption (Murillo-Amador et al. Citation2006; Goenaga et al. Citation2008). In India, cowpea is grown in an area of 3.9 million hectares with a production of 2.21 million tons annually (www.impact.cgiar.org). Because of its high nutrition, versatility, and self-pollinating nature, cowpea is apt for catch crop, mulch crop, intercrop, mixed crop, and green crop (Nelson et al. Citation2008). Calcareous soils, where cowpea is often grown, account for more than 25% of the earth's soil surface (Marschner Citation2003). When grown at pH greater than 7.5 in calcareous soils, it develops severe leaf chlorosis caused by deficiencies of micronutrient such as Fe and Zn. To the best of our knowledge, there is no commercial cowpea cultivar possessing soil zinc deficiency tolerance; however, genotypic differences of pod zinc content had been observed (Boukar et al. Citation2011). Thus, cloning and subsequent transfer of the CA gene may increase the zinc-use efficiency in cowpea in future.
Zn is an essential catalytic component of over 300 enzymes, including CA. Recently, Zn deficiency in diet especially of young children below 5 years of age registered 453,207 deaths in Asia. Diseases due to zinc deficiency in infants and children are diarrhea, pneumonia, stunted growth, weak immune system, and retarded mental growth. Zn deficiency in pregnant women can lead to these problems and even mortality in infants. Although Zn deficiency to some extent can be cured by Zn supplementation and improvement in dietary composition, it is better to increase the Zn content in staple foods or forage crops. A positive correlation between CA transcript expression with high zinc content was found (Hacisalihoglu et al. Citation2003) and hence this correlation can be translated to establish the marker/trait relationship or to develop high zinc-accumulating genotype by ectopic expression of CA gene in plant. Nevertheless, the prerequisite for the same is to clone and characterize CA gene. Therefore, in the present study, we have characterized the CA gene and studied its expression under different abiotic stresses.
Materials and methods
Plant treatment and RNA extraction
Seeds of cowpea (Vigna unguiculata L. Walp.) cultivar, ‘Pusa Komal,’ were surface sterilized with 0.1% HgCl2 (w/v) and grown for three weeks in paper towel. After 21 days, 10 seedlings were taken for each treatment. For salinity treatment, seedlings were treated with 150 mM NaCl for 24 h. For zinc deficiency treatment, seedlings were watered for 21 days with 1/10 strength of MS medium (Murashige & Skoog Citation1962) but without ZnCl2, which was a component of MS medium. Similarly for dehydration, 10 seedlings 21 days old were air dried for 6 h on a blotting paper. The treatment procedure reported in this paper was based upon report in the literature (El-Mashad & Mohamed Citation2012; Mukhopadhyay et al. Citation2013). All the harvested tissues (third mature leaf, young flower bud of 1 cm long, second internode young stems, and young roots) were collected and immediately frozen in liquid nitrogen and stored at −80°C until nucleic acid extraction.
RACE PCR for cloning of full-length cDNA
RNA was extracted from 100 mg leaf tissues using TriZol reagent (Invitrogen, Carlsbad, CA, USA) following the manufacturer's instructions. The yield and quality of DNAase (Promega Life Sc, India) treated RNA were determined by Nanodrop 1000 (M/S Thermo Scientific Corporation, USA) and 2% agarose denaturing gel electrophoresis in MOPS {3-(N-morpholino) propanesulfonic acid)} buffer, respectively. The cDNA was synthesized using 1 µg of RNA with 200 U l−1 reverse transcriptase Superscript III (Invitrogen, USA), 10 mM dNTPs, and 250 ng oligo (dT). For designing the forward and reverse primers of CA gene, nucleotide sequence of different legume species of angiosperm CAs were downloaded and aligned. Accordingly two degenerate primers, i.e. D-FP and D-RP were used (). The amplification product was gel purified with Gel Extraction Kit (Qiagen) and cloned into pGEM-T easy vector (Promega, USA) in Escherichia coli strain DH5α for sequencing. The forward and reverse contigs were joined to make a complete sequence which was used for in silico analysis. Based on amplified fragment of the cDNA, the primers were designed to perform 5′ and 3′ RACE with the SMART RACE cDNA Amplification Kit (Clontech, USA) following the user manual (). From this sequence, end-to-end primer pair was designed to amplify the entire codon region. For identification of introns, cowpea genomic DNA was isolated (Murray & Thompson Citation1980) and amplified using same end-to-end forward and reverse primer of CA gene which was sequenced as mentioned above.
Table 1. The primers used in the present study.
In silico analysis of VuCA1
Nucleotide and deduced amino acid sequences were analyzed using BLAST tool of NCBI (www.ncbi.nlm.nih.gov). For phylogenetic analysis, all the CA genes with CA domains (Pfam: PF00194) of rice and Arabidopsis were downloaded from Phytozome (www.phytozome.net) and were aligned using CLUSTAL W2 online (www.ebi.ac.uk) (Thompson et al. Citation1994) to exclude overlapping genes. Phylogenic tree was obtained by the neighbor-joining method (Saitou & Nei Citation1987) using a bootstrap for 1000 replicates. The domain of the protein was determined by SMART (smart.emblheidelberg.de), MOTIF search, and PROSITE database (prosite.expasy.org). Secondary structure of deduced amino acid sequence of VuCA1 was analyzed by SOPMA (Combet et al. Citation2000). Sequence logos of alignments were generated with WebLogo (Crooks et al. Citation2004). The folding state of VuCA1 was predicted by Fold Index program (bioportal.weizmann.ac.). Analyses of transmembrane domain was performed by TMHMM Server v. 2.0 (www.genome.cbs) and signal peptide was determined by SignalP 4.1 Server (www.cbs.dtu.dk) as well as Chloroplast Localization Prediction or PCLR (www.andrewschein.com/pclr).
The online protein structure prediction tool PS2 (Protein Structure Prediction Server) (http://www.ps2.life.nctu.edu.tw/) was used for the prediction of three-dimensional (3D) structure of VuCA1 (Chen et al. Citation2006). The models were analyzed based on the DOPE score, and the stereochemical quality of the model was analyzed with PROCHECK analysis using Ramachandran plot on SAVES server (Laskowski et al. Citation1993). The active sites of preferred target proteins were searched using Q-site Finder, where a putative ligand could bind and optimize its van der Waals interaction energy (Laurie & Jackson Citation2005). Chemical structures of ligands such as CO2, bicarbonate, and metal zinc were retrieved from Pubchem compound database (http://www.ncbi.nlm.nih.gov/search). The retrieved ligand structures in.sdf format were converted to.pdb format using Pymol. The docking analysis was carried out using SWISSDOCK server, a protein small-molecule docking web service based on EADock DSS (Grosdidier et al. Citation2011).
Expression analysis of VuCA1 by Q-PCR
Expression of VuCA1 transcripts was analyzed by Q-PCR, using gene-specific forward (GSP-F) and reverse (GSP-R) primers (). The expression of each gene in various samples was normalized with actin (GenBank ID: FR839671) reference gene as an internal control to quantify the expression level of the transcripts (). Total RNA extraction and cDNA synthesis were done from the third leaf as described above. The resulting cDNA samples were diluted 20 times (1:20) in RNase-free water and 2 µl of the diluted cDNA was used as template in a total reaction volume of 25 µl using QuantiFast SYBR Green PCR Master Mix (Qiagen, India). Real-time PCR analysis was performed in a 96-well plate using Roche 454 Q-PCR system (Roche, USA). The thermal cycling conditions of 95°C for 5 min followed by 45 cycles of 95°C for 15 s, 60°C for 30 s, and 72°C for 30 s were used. The Q-PCR amplifications were performed with at least two independent biological replicates and two technical replicates for each biological replicate. The specificity of the PCR reactions was confirmed by melting curve analysis of the amplicons. The comparative 2−Δct [ΔCT = CT, gene of interest − CT, actin] method was used to calculate the normalized fold changes of each transcript in the samples (Schmittgen & Livak Citation2008). Statistical analyses were conducted using the SAS software (SAS Institute Inc., NC, USA).
Results and discussion
Isolation and characterization of VuCA1 gene
Initially, we used the degenerate primers which could amplify a 360 bp of VuCA1 from the cDNA of cowpea cultivar, ‘Pusa Komal.’ After sequencing and subsequent BLASTn search, we confirmed it as a tag of CA gene of the other plants. This sequence was then used to design the primers for 5′ as well as 3′ RACE PCR which was used to amplify the full-length cDNA. The isolated full-length cDNA of VuCA1 has 1323 nucleotides consisting of a 3′-UTR (untranslated region) of 73 bp and a 5′-UTR of 250 bp. Further, we identified VuCA1 open reading frame (ORF) which was 990 bp in length () and corresponded to a size of 329 amino acids long peptide. The complete ORF was termed as cowpea carbonic anhydrase gene 1 (VuCA1) and registered in GenBank (Accession No. JQ429799). To find out the structural organization, this same primer pair was used to clone the 1.37-kb genomic DNA () which revealed the existence of four introns namely intron-I (53 bp), intron-II (270 bp), intron-III (106 bp), and finally intron-IV (314 bp) (). Comparison of peptide sequence of VuCA1 indicated the highest of 92.42% conservation with Pisum sativum CA protein. The prediction of secondary structure indicated that VuCA1 protein contained 111 α-helices, 29 β-turns, 63 extended strands, and 126 random coils (). A similar secondary structure for MstCA had been documented for Medicago sativa (Coba de la Pena et al. Citation1997) that comprised 113 α-helices, 28 β-turns, 61 extended strands, and 116 random coils suggesting that VuCA1 could be a functional gene. However, we did not register any transmembrane domain. Further, we found that the percentage of amino acid-disordered residue was 20.7% and distributed in two segments of VuCA1 protein structure (). The value of disordered residues in VuCA1 peptide was in close comparison to earlier reported for MstCA (20%) (Coba de la Pena et al. Citation1997) in which the disordered residues were also distributed in two segments.
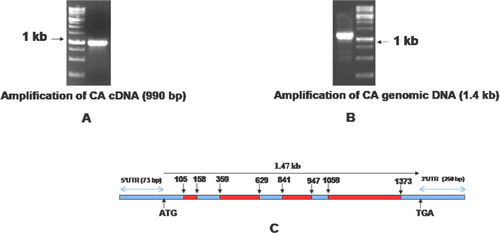

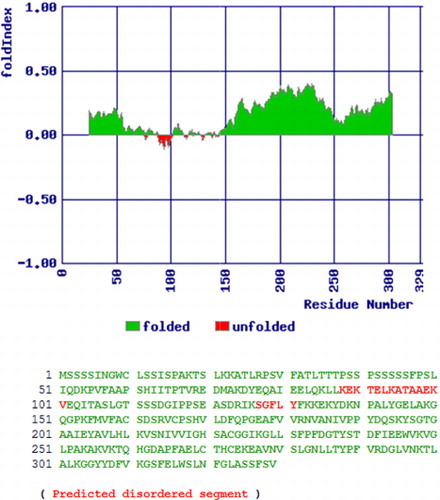
We also determined the structural properties of VuCA1 which are tabulated in . The theoretical molecular weight, extinction coefficient, and isoelectric point of the deduced amino sequence of VuCA1 were predicted using Protparam and found to be 35.5 kDa, 33265 (M−1 cm−1, at 280 nm), and 7.58 respectively. Similar isoelectric point and extinctions coefficient were also found in CA in other plant species (Cronk Citation2002). Analysis of amino acid composition showed 51.4% hydrophobic amino acids (Gly, Ala, Val, Leu, Ile, Pro, Phe, Trp, Met, Cys) and 48.6% polar amino acids (Ser, Thr, Asp, Glu, Lys, Arg, Asn, Gln, His, Tyr). Scanning the deduced protein sequence by SMART indicated following two unique signatures: (1) prokaryotic-type CA signature 1: C-[SA]-D-S-R-[LIVM]-x-[AP] CSDSRV at 160–167 amino acid position and (2) CA signature 2: [EQ]-[YF]-A-[LIVM]-x(2)-[LIVM]-x(4)-[LIVMF](3)-x-G-H-x(2)-C-G, EYAVLHLKVSNIVVIGHSACG at 204–224 amino acid position (). Sequence logos of several plant CAs generated the same sequence, and identified hydrophobic amino acid valine that appeared to be unique to CA proteins doubly confirms the signature (). Apart from that, the amino acids tyrosine, cysteine, and leucine were also found to be conserved in the motif. Catalytically important amino acid residues that actively participate as Zn+2 liganding coordinate active sites geometry of β-CA such as cys-160, asp-162, his-220, and cys-223 were found to be present in the peptide of VuCA1. The presence of this Zn+2 binding signature had been reported in several other plant CAs from angiosperms (Coba de la Pena et al. Citation1997). To identify the phylogenic relationship as well as to know the class of VuCA1 cloned in the present study, a genome-wide sequencing data were scanned from Arabidopsis and rice through Phytozom which provided a number of putative CA genes from which at least 16 CAs for Arabidopsis and 14 CAs for rice were identified. Phylogenetic study using deduced amino acid sequences of all these CA proteins from Arabidopsis and rice along with VuCA1 was performed by Clustal W (). Interestingly, it had been found that VuCA1 sequence was distinctly different from α- and γ-CA and had significant sequence identity with β-class. VuCA1 reported in this study was phylogenetically related to rice putative chloroplast β-CA (Os 01g45274).
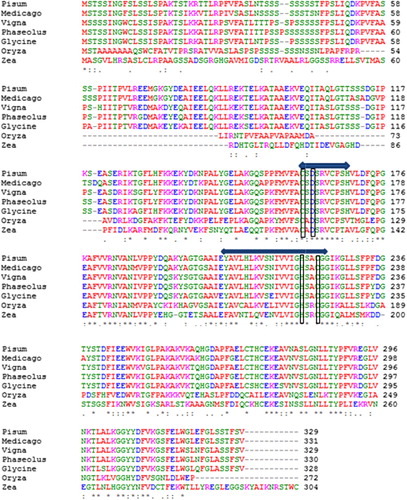
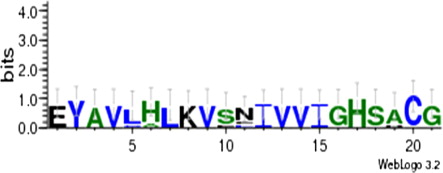

Table 2. Primary structural properties of VuCA1.
The 3D structure of the VuCA1 was modeled with PS2 server using A chain of P. sativum as template (pbd id 1ekj), which shared identity, score, and e-value of 44, 407, and 1e-114, respectively (). Quality of the predicted 3D structure of VuCA1 was revealed by predicted b-factor of each residue (). The PROCHECK analysis was used to quantify the residues in available zones of the Ramachandran plot (), selecting the model of VuCA1. Procheck analysis revealed 85.4% of residues in most favored zone, 14.6% in allowed region, with no amino acid as disallowed region. Analysis of G-Factor of the modeled CuVA1 was noticed as −0.24, which revealed the quality of the predicted model (). Although there are several crystallographic structures of CA protein (Díaz Torres et al. Citation2012; Ragunathan et al. Citation2013); yet, we preferred to use P. sativum CA as a template for 3D VuCA1 protein modeling as it was one of the best characterized β-CA from C3 dicotyledonous plant (Kimber & Pai Citation2000). The amino acid sequence alignment of two sequences showed high homology of 92.42%.
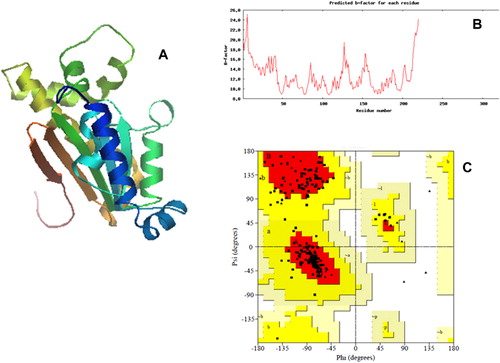
Table 3. Procheck statistics of predicted three-dimensional model of VuCA1.
Molecular docking is an important tool to understand the protein–ligand interaction (Kamaraj & Purohit Citation2013). CA does reversible hydration of . Analysis of docking pose of the CO2 and HCO3− revealed that majority of the binding site were similar to both either as substrate or a product, while the hydrogen bond length for the amino acid and ligand varied between them. The best docked pose of CO2 with VuCA1 proteins is presented in . The hydrogen bond interaction (−8.6 kcal/mol binding energy) between CO2 and the active residues of VuCA1 was Thr 199. The hydrogen bond interaction for best docked pose of HCO3 with VuCA1 proteins was found to be −8.29 kcal/mol binding energy and the active residues of VuCA1 were Val 157, Ala 159, Ser 163, Cys 166, Pro 167, and Val 170. It has been well documented that the catalytic activity of CA is more efficient through Zn hydration mechanism to form bicarbonate indicating the important role of Zn metal ion in CA. Thus, docking pose of Zn revealed tetrahydral structure with four amino acids with coordination bond. They are Cys 160, Asp162, His 220, and Cys 223 with hydrogen bond interaction (−8.13 kcal/mol binding energy) with a minimum hydrogen bond distance of 3.55°A ().
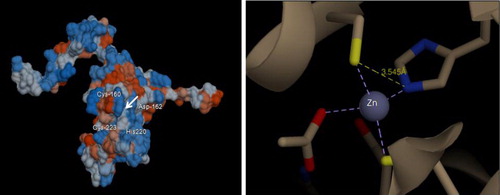
Table 4. Summary of docking details of VuCA1 with some selected ligands.
Expression analysis of VuCA1 by Q-PCR
In the present study, a quantitative comparison of CA expression was made in different tissues of 21-day-old cowpea seedlings (). It had been found that under control condition, the expression of CA transcript was the highest in young leaf followed by flower buds and then decreased in young stem and further decreased to root. This may be due to the fact that CA enzyme is highly abundant in mesophyll cells of leaves so that it accounts for 1–2% of the soluble leaf protein in C3 plants (Reed & Graham Citation1981). Similar abundance of CA transcript was also reported in pea (Majeau & Coleman Citation1994). However, upon imposition of zinc deficiency, the expression of CA transcript in leaf decreased (). Although the reason is not clear, the deficiency in zinc for 21 days may lead to a decrease of Zn content in the tissue which is otherwise required for the activity of CA enzyme. This lowering down of the Zn concentration may also decrease the demands for synthesizing the CA transcript. Increasing the CA transcript under salt stress was reported in Populus (Gu et al. Citation2004) and Rice (Yu et al. Citation2007). Additionally, under salt stress, stomatal as well as mesophyll conductance underwent changes which led to the alternation of CO2 concentration and helped the plant cell to adapt under salinity (Chaves et al. Citation2009). There was evidence for the involvement of CA in the regulation of mesophyll conductance under conditions of salinity (Gillon & Yakir Citation2000).
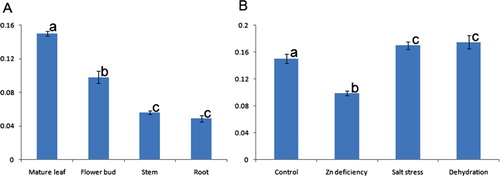
It is noteworthy to mention that CA involved in reversible hydration of CO2 was repressed in leaves/shoots under Zn deficiency (21 days). CA is involved in diverse biological processes including pH regulation, ion exchange, CO2 transfer, respiration, and photosynthetic CO2 fixation (Tiwari et al. Citation2005). Thus, its repression under this stress may have varied roles and needs further investigation. For example, its repression under Zn deficiency stress may be due to disruption of respiration/photosynthesis whilst repression under high-salinity stress may be due to regain ionic balance. On the contrary, the expression of CA transcript increased under dehydration stress as well as salt stress in the present study which corroborated with the findings of Guliyev et al. (Citation2008) as well as Gu et al. (Citation2004) who also found the upregulation of CA under dehydration in flag leaf of wheat and under salt stress of Populus euphratica, respectively.
In conclusion, we have cloned and characterized a putative β-CA gene from cowpea. Various in silico parameters were used to characterize the gene which showed high degree of similarity with other β-CAs of angiosperms and has signature domain of CSDSRV and EYAVLHLKVSNIVVIGHSACG. Having seen its downregulation under Zn deficiency, high degree of 3D structure with P. sativum β-CA, as well as its grouping with other β-CA in phylogenic tree, forced us to conclude that it belongs to beta group of CA gene of cowpea. Findings from this work will be of immense help in future to do the in vivo analysis of protein under heterologous system as well as to overexpress the gene in the knock-out line to complement its function in the Arabidopsis background. This can also be used to make the transgenic cowpea plant a better zinc-use-efficient plant for zinc-deficient soil in future.
Acknowledgments
The authors are grateful to Dr Neeta Singh, Principle Scientist, Division of Germplam Conservation, NBPGR, New Delhi, for providing the seeds and related information of cowpea to carry out the experiment. We also thank Dr K V Bhat, Head, Division of Genomic Resource, NBPGR, for his encouragement to carry out this work.
References
- Badger MR, Price GD. 1994. The role of carbonic anhydrase in photosynthesis. Annu Rev Plant Physiol Plant Mol Biol. 45:369–392. 10.1146/annurev.pp.45.060194.002101
- Boukar O, Massawe F, Muranaka S, Franco J, Maziya-Dixon B, Singh B, Fatokun C. 2011. Evaluation of cowpea germplasm lines for protein and mineral concentrations in grains. Plant Genet Resour. 9:515–522. 10.1017/S1479262111000815
- Bracey MH, Bartlett SG. 1995. Sequence of a cDNA encoding carbonic anhydrase from barley. Plant Physiol. 108:433–434. 10.1104/pp.108.1.433
- Chaves MM, Flexas J, Pinheiro C. 2009. Photosynthesis under drought and salt stress: regulation mechanisms from whole plant to cell. Ann Bot. 103:551–560. 10.1093/aob/mcn125
- Chen CC, Hwang JK, Yang JM. 2006. (PS)2: protein structure prediction server. Nucleic Acids Res. 34:152–157. 10.1093/nar/gkl187
- Coba de la Pena T, Frugier F, McKhann HI, Bauer P, Brown S, Kondorosi A, Crespi M. 1997. A carbonic anhydrase gene is induced in the nodule primordium and its cell-specific expression is controlled by the presence of Rhizobium during development. Plant J. 11:407–420. 10.1046/j.1365-313X.1997.11030407.x
- Combet C, Blanchet C, Geourjon C, Deléage G. 2000. NPS@: network protein sequence analysis. Trend Biochem Sci. 25:147–150. 10.1016/S0968-0004(99)01540-6
- Cronk JD. 2002. β-carbonic anhydrase: new insights from structural studies. In: Goyal A, Mehta SL, Lodha ML, editors. Reviews in plant biochemistry and biotechnology. New Delhi: Soc Plant Biochem Biotech. vol. I, p. 191–208.
- Crooks GE, Hon G, Chandonia JM, Brenner SE. 2004. WebLogo: a sequence logo generator. Genome Res. 14:1188–1190. 10.1101/gr.849004
- Díaz Torres N, González G, Biswas S, Scott KM, McKenna R. 2012. Preliminary X-ray crystallographic analysis of α-carbonic anhydrase from Thiomicrospira crunogena XCL-2. Acta Crystallogr Sect F Struct Biol Cryst Commun. 68:1064–1066. 10.1107/S1744309112031053
- El-Mashad AA, Mohamed HI. 2012. Brassinolide alleviates salt stress and increases antioxidant activity of cowpea plants (Vigna sinensis). Protoplasma. 249:625–635. 10.1007/s00709-011-0300-7
- Gillon JS, Yakir D. 2000. Naturally low carbonic anhydrase activity in C-4 and C-3 plants limits discrimination against (COO)-O-18 during photosynthesis. Plant Cell Environ. 23:903–915. 10.1046/j.1365-3040.2000.00597.x
- Goenaga R, Gillaspie V, Quiles A. 2008. Assessing yield potential of cowpea genotypes grown under virus pressure. Hort Sci. 43:673–676.
- Grosdidier A, Zoete V, Michielin O. 2011. SwissDock, a protein-small molecule docking web service based on EADock DSS. Nucleic Acids Res. 39:W270–W277. 10.1093/nar/gkr366
- Gu R, Fonseca S, Puskás LG, Hackler JRL, Zvara A, Dudits D, Pais MS. 2004. Transcript identification and profiling during salt stress and recovery of Populus euphratica. Tree Physiol. 24:265–276. 10.1093/treephys/24.3.265
- Guliyev N, Bayramov S, Babayev, H. 2008. Effect of water deficit on rubisco and carbonic anhydrase activities in different wheat genotypes. In: Allen JF, Grantt E, Golbeck JH, Osmond R, editors. Photosynthesis, energy from the sun. 14th International Congress on Photosynthesis, vol. 24. Glasgow: Springer; p. 1465–1468.
- Hacisalihoglu G, Hart JJ, Wang YH, Cakmak I, Kochian LV. 2003. Zinc efficiency is correlated with enhanced expression and activity of zinc-requiring enzymes in wheat. Plant Physiol. 131:595–602. 10.1104/pp.011825
- Ignatova LK, Rudenko NN, Mudrik VA, Fedorchuk TP, Ivanov BN. 2011. Carbonic anhydrase activity in Arabidopsis thaliana thylakoid membrane and fragments enriched with PSI or PSII. Photosynth Res. 110:89–98. 10.1007/s11120-011-9699-0
- Kamaraj B, Purohit R. 2013. In silico analysis of betaine aldehyde dehydrogenase 2 of Oryza sativa and significant mutations responsible for fragrance. J Plant Interact. 8: 321–333 10.1080/17429145.2012.758785
- Kaul T, Reddy PS, Mahanty S, Thirulogachandar V, Reddy RA, Kumar B, Sopory SK, Reddy MK. 2011. Biochemical and molecular characterization of stress-induced β-carbonic anhydrase from a C4 plant, Pennisetum glaucum. J Plant Physiol. 168:601–610. 10.1016/j.jplph.2010.08.007
- Kim HJ, Bracey MH, Bartlett SG. 1994. Nucleotide sequence of a gene encoding carbonic anhydrase in Arabidopsis thaliana. Plant Physiol. 105:449. 10.1104/pp.105.1.449
- Kimber MS, Pai EF. 2000. The active site architecture of Pisum sativum beta-carbonic anhydrase is a mirror image of that of alpha-carbonic anhydrases. EMBO J. 19:1407–1419. 10.1093/emboj/19.7.1407
- Laskowski RA, MacArthur MW, Moss DS, Thornton JM. 1993. PROCHECK – a program to check the stereochemical quality of protein structures. J Appl Crystallogr. 26:283–291. 10.1107/S0021889892009944
- Laurie AT, Jackson RM. 2005. Q-SiteFinder: an energy-based method for the prediction of protein-ligand binding sites. Bioinformatics. 21:1908–1916. 10.1093/bioinformatics/bti315
- Liljas A, Lauberg MA. 2000. Weel invented three times. The molecular structure of the three carbonic anhydrases. EMBO J. 19:16–17. 10.1093/emboj/19.1.16
- Majeau N, Coleman JR. 1994. Correlation of carbonic anhydrase and ribulose-1,5- bisphosphate carboxylase/oxygenase expression in pea. Plant Physiol. 104:1393–1399.
- Marschner H. 2003. Mineral nutrition of higher plants. Mechanisms from whole plant to cell. Ann Bot. 103:551–560.
- Mukhopadhyay M, Das A, Subba P, Bantawa P, Sarkar B, Ghosh P, Mondal TK. 2013. Structural, physiological and biochemical profiling of tea plantlets under zinc stress. Biol Plant. 57:474–480. 10.1007/s10535-012-0300-2
- Murashige T, Skoog F. 1962. A revised medium for rapid growth and bioassays with tobacco tissue culture. Physiol Plant. 15:473–497. 10.1111/j.1399-3054.1962.tb08052.x
- Murillo-Amador B, Troyo-Diéguez E, García-Hernández JL, López-Aguilar R, Ávila-Serrano AG, Zamora-Salgado S, Rueda-Puente EO, Kaya C. 2006. Effect of NaCl salinity in the genotypic variation of cowpea (Vigna unguiculata) during early vegetative growth. Sci Hort. 108:423–431. 10.1016/j.scienta.2006.02.010
- Murray MG, Thompson WF. 1980. Rapid isolation of high molecular weight plant DNA. Nucleic Acids Res. 8:4321–4325. 10.1093/nar/8.19.4321
- Nelson M, Dempster WF, Allen JP, Silverstone S, Alling A, van Thillo M. 2008. Cowpeas and pinto beans: performance and yields of candidate space crops in the laboratory biosphere closed ecological system. Adv Space Res. 41:748–753. 10.1016/j.asr.2007.03.001
- Ragunathan P, Raghunath G, Kuramitsu S, Yokoyama S, Kumarevel T, Ponnuraj K. 2013. Crystallization, characterization and preliminary X-ray crystallographic analysis of GK2848, a putative carbonic anhydrase of Geobacillus kaustophilus. Acta Crystallogr Sect F Struct Biol Cryst Commun. 69:162–164. 10.1107/S1744309112051913
- Reed ML, Graham D. 1981. Carbonic anhydrase in plants: distribution, properties and possible physiological roles. In: Reinhold L, Harbome JB, Swain T, editors. Progress in photochemistry, vol. 7. Oxford (UK): Pergamon Press; p. 47–94.
- Saitou N, Nei M. 1987. The neighbor-joining method: a new method for reconstructing phylogenetic trees. Mol Biol Evol. 4:406–425.
- Schmittgen TD, Livak KJ. 2008. Analyzing real-time PCR data by the comparative CT method. Nat Protoc. 3:1101–1108. 10.1038/nprot.2008.73
- Sly WS, Hu PY. 1995. Human carbonic anhydrases and carbonic anhydrase deficiencies. Annu Rev Biochem. 64:375–401. 10.1146/annurev.bi.64.070195.002111
- Thompson JD, Higgins DG, Gibson TJ. 1994. CLUSTAL W: improving the sensitivity of progressive multiple sequence alignment through sequence weighting, position-specific gap penalties and weight matrix choice. Nucleic Acids Res. 22:4673–4680. 10.1093/nar/22.22.4673
- Tiwari A, Kumar P, Singh S, Ansari SA. 2005. Carbonic anhydrase in relation to higher plants. Photosynthetica 43:1–11. 10.1007/s11099-005-1011-0
- Wang Q, Fristedt R, Yu X, Chen Z, Liu H, Lee Y, Guo H, Merchant SS, Lin C. 2012. The γ-carbonic anhydrase subcomplex of mitochondrial complex I is essential for development and important for hotomorphogenesis of Arabidopsis. Plant Physiol. 160:1373–1383. 10.1104/pp.112.204339
- Yu S, Zhang X, Guan Q, Takano T, Liu S. 2007. Expression of a carbonic anhydrase gene is induced by environmental stresses in rice (Oryza sativa L.). Biotech Lett. 29:89–94. 10.1007/s10529-006-9199-z