
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Facility management is an essential part of the building which encompasses multiple service areas and processes to ensuring optimum functionality of the facility. Digital twin (DT) has been increasingly introduced to the FM domain to facilitate FM tasks such as decision-making. Despite the advancements in DT-enabled FM, there still exists a problem in the disconnections between DT academics and FM practitioners. The emergence of knowledge management can act as a bridge between academics and FM practitioners. To mine knowledge in the DT-enabled FM industry for a better communication between different stakeholders and timely decisions in the case of emergency, this study proposes a natural language processing (NLP)-based approach. A detailed classification of FM-related entities is first presented, which divides the FM into five categories. The NLP model is used to extract entities and knowledge from a large volume of text data. The results indicate that an NLP-based approach can accurately extract FM-related knowledge. The findings of this study not only provide a basis for automatic DT-enabled FM-related knowledge extraction but also support the downstream tasks such as knowledge graph construction and FM-related emergency decision-making.
1. Introduction
Facility management (FM) is an essential part of the building which encompasses multiple service areas and processes to ensuring optimum functionality of the facility. According to previous studies on FM (Zhou Citation2020), the cost of building facilities has accounted for a quarter of the total expenditure of buildings, and the cost of facilities in the later operation and use stage has accounted for more than 70% of the total cost. Hence, the FM during the operation and maintenance phase is not only the longest and most expensive stage of the entire life cycle of a building but also the most important part of modern construction management.
Owing to its hotspots in real-time data collection and analysis (Pedral Sampaio, Aguiar Costa, and Flores-Colen Citation2023), the concept of DT has been increasingly introduced to the FM domain to facilitate FM tasks, such as decision-making. Building information modelling (BIM)-enabled FM has gradually transformed into DT-enabled FM. DT can be of help to FM in various ways such as efficiency gains, cost savings, and better knowledge and understanding of the building (Elyasi, Bellini, and Klungseth Citation2023; Klungseth and Tønsberg Citation2023). Despite these advancements in DT-enabled FM, there still exists a problem in the disconnections between DT academics and FM practitioners. Such a problem has also been mentioned by (Olimat, Liu, and Abudayyeh Citation2016; Pinti, Codinhoto, and Bonelli Citation2016) that academics and FM practitioners remain divided on the successful information exchange process due to interoperability being a significant challenge. Specifically, Elyasi, Bellini, and Klungseth (Citation2023) pointed out that the implementation of DT in FM requires a robust framework for information management, which can lead to better understanding of the building and more effective collaboration between the stakeholders.
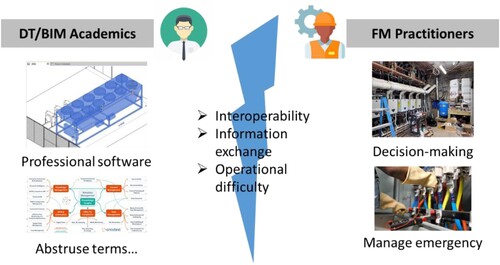
Hence, the conclusion can be drawn that while BIM and DT have brought a paradigm shift in FM development, the gaps on academics and practitioners have made DT-enabled FM face challenges, as shown in . Hopefully, the emergence of knowledge management can act as a bridge between academics and FM practitioners, which involves strategies and practices for handling information related to facility operations, maintenance and decision-making processes (Gajzler Citation2015; Lepkova and Bigelis Citation2007). In this paper, a knowledge-based approach is used to extract knowledge on DT-enabled FM to form a detailed hierarchy by which FM staff can easily understand and get access to established DTs, where the NLP-based approach is used in this study to extract knowledge on DT-enabled FM. Such knowledge of understanding as to how facilities are organized in the building is crucial for FM. First and foremost, FM staff can make timely decisions in the case of emergency with knowledge on dependencies across different building systems. They can assess the impact of the emergency and develop troubleshooting strategies quickly using knowledge on what the entire facility system comprises how different facility systems interact. Secondly, such knowledge can contribute to downstream tasks such as automatic establishment of the BIM model. Based on these, FM staff can determine the components and properties that need to be loaded into as-built BIM models (Ensafi, Harode, and Thabet Citation2022). Finally, the knowledge on FM can promote the information communication between different stakeholders and reduce the losses in the FM industry (Bouabdallaoui et al. Citation2016). This is also in line with previous findings that the main benefit of DT in FM relates to information management and the main challenge is change management (Elyasi, Bellini, and Klungseth Citation2023). Hence, the main research question this study aims to solve is how to mine knowledge in the FM industry for better communication between different stakeholders and timely decisions during emergency.
Figure 1. Gaps between DT academics and FM practitioners.
The remainder of this paper is organized as follows. Section 2 reviews the state of the art in the field of FM and DT-enabled FM, thus highlighting the necessity of this paper. In Section 3, the overview of the methodology of this study used and details of the adopted algorithm are presented . Section 4 presents the results of knowledge extraction. Section 5 discusses the results and limitations of the presented work. The final section concludes by highlighting the research contribution of the study and future work. To be specific, FM is divided into five categories and the BiLSTM-CRF model can extract FM-related entities, with a precision of 0.83, recall of 0.86 and an F1 scores of 0.84. The extracted entities and knowledge are stored in the Protégé software for visualization and interconnection.
2. Literature review
2.1. FM and its evolution
FM is a multidisciplinary field that includes the effective management and operation of a physical environment to support the primary objectives of an organization. It encompasses a wide range of activities related to the maintenance, planning, design, and operation of buildings, infrastructure, and real estate assets with the integration of people, place and process within the built environment (Lee, Irisboev, and Ryu Citation2016; Zhao et al. Citation2022). Specifically, maintenance and repairs, space management, security and safety, utilities and energy management, waste management and financial management all are included in facilities management.
With the advancement of Industry 4.0, FM-related activities have been revolutionized and gone digital with less manpower (Xu, David, and Kim Citation2018). Various tools such as the Internet of Things (IoT) and smart building technology, data-driven decision-making, predictive maintenance, energy efficiency, and remote monitoring have all been implemented into FM (Bröchner Citation2003), empowering facility managers to provide better services while reducing costs and environmental impact.
2.2. DT-enabled FM
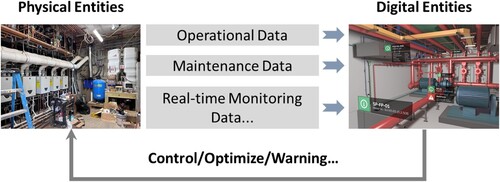
As discussed above, the concept of BIM in the early 1990s has prompted the development of a solid base for decision-making and acted as an effective source of data in FM. Emerging technologies such as IoT provide real-time data for BIM, which further advances the performance of FM. Moreover, the integration of BIM and IoT forms the core concept of DT (Olimat, Liu, and Abudayyeh Citation2016). DT refers to virtual representations of physical objects or systems which combines data describing the physical objects in a digital format. Physical entities, virtual or digital entities and the data flow between them are the three key components in DT development.
demonstrates how DT facilitates the development of FM. IoTs enable real-time monitoring or acquisition of data which reflect the operational state of the facilities. Data, including operational data, maintenance data and real-time monitoring data, can be obtained and fed back to digital facilities, which are usually BIM models. Then, after data analysis in the virtual space, advanced control, optimization orders or warning can be given and reflected in the physical space. Due to its advantages in maximizing the effectiveness of the maintenance management activities, DT-enabled FM has also attracted the attention of different researchers. Nota, Peluso, and Lazo (Citation2021) systematically summarized the contribution of DT technologies to FM and concluded that DT facilitated the planning and execution of preventive maintenance strategies.
Figure 2. Relationships between physical facilities and digital facilities under the paradigm of DT.
2.3. Necessity analysis
Academic research on DT often focuses on theoretical concepts and cutting-edge technologies, making that FM practitioners may find it challenging to translate these concepts into practical solutions for daily facility management challenges. Some examples, revealing the gap between DT academics and FM practitioners, are listed in .
Table 1. Some examples related to the gap between DT academics and FM practitioners.
As shown in different methodologies have been adopted such as literature review, survey and case study. Some studies showed that due to a limited familiarity of DT tools such as the BIM software, the maturity of FM practitioners in terms of DT execution is still in its infancy (Mayo, Giel, and Issa Citation2012; Miettinen et al. Citation2018). Some studies used literature review and found that the interoperability of DT and FM tools hampers the use of DT in FM (Mohanta and Das Citation2016; Volk, Stengel, and Schultmann Citation2014). In addition, the importance of defining the standard level of information requirements of FM decision-making was also highlighted. Dixit et al. (Citation2019) conducted a detailed literature review on DT-FM integration from the perspective of BIM tool and discussed key issues and challenges to DT-FM integration. They pointed out that software issues and interoperability between DT-FM technologies are two main challenges on DT-enabled FM. To put it simply, FM practitioners may find it difficult to use some DT tools such as Revit software which is commonly used in BIM.
In detail, DT research often involves complex mathematical models, advanced data analytics, and in-depth technical discussions. Academics may use terminology and notation that are specialized in their field, which can make it challenging for FM, who may not have the same technical background, to fully grasp the concepts. Academics may assume a certain level of background knowledge, assuming that practitioners are familiar with the fundamental concepts. Practitioners may not have the same level of expertise or may not be well-versed in the specific terminology used in academic research, which can lead to a gap in understanding. Moreover, the use of academic jargon can create a barrier to effective communication between academics and practitioners. Misunderstandings may arise due to differences in terminology and technical depth, which can further hinder collaboration and knowledge transfer. Hence, it can be seen that knowledge management is crucial in bridging the gap between DT academics and FM practitioners.
3. Methodology
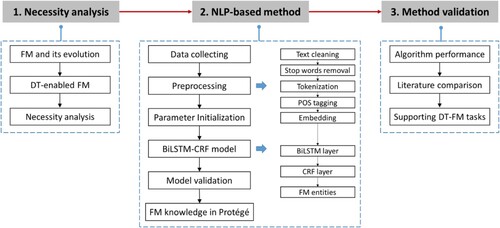
The workflow of the proposed method is shown in , which is composed of three steps. First, the necessity analysis of the proposed method is conducted to demonstrate the knowledge gap between DT academics and FM practitioners and the necessity of knowledge management in DT-enabled FM. Then, a NLP method is proposed to implement the knowledge management. Specifically, this study uses a BiLSTM-CRF model to extract FM-related knowledge based on the collected corpora. After the entities are extracted, they are integrated into the software Protégé for visualization and further analysis. At last, the method is validated through algorithm performance, literature comparison and cases where the proposed method can support DT-enabled FM tasks.
Figure 3. Overview of the proposed NLP-based method.
3.1. Corpora collecting
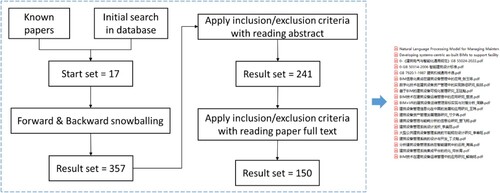
The first step of the method is to collect FM- and DT-enabled FM-related plain texts. This study uses the ‘snowball’ strategy to automatically find data sources, i.e. data sources are not limited to FM-related standards and specifications. The field of DT and FM is dynamic and rapidly evolving, with new research emerging regularly. Snowball sampling allows for the identification of seminal and recent literature through references. In addition, snowball sampling is particularly effective in identifying key references that may not be evident through traditional database searches alone. For DT-enabled FM, terms like ‘digital twin in FM,’ ‘smart buildings,’ ‘IoT in facility management,’ ‘facility data analytics,’ and related phrases are considered. FM-related academic papers are also selected as the data source. In this way, the newly extended academic papers can be found and considered as the new seed, thus the process can be repeated. The process of the ‘snowball’ strategy is shown in . The identified literature underwent a peer validation process, where two researchers independently assessed the relevance and quality of the sources, aiming to enhance the consistency and reliability of the collected data.
Figure 4. Flowchart of the snowballing literature retrieval process and part of the collected corpora.
3.2. Data preprocessing
In this step, first, all pdf files are converted into txt format, and figures and tables are converted into texts manually. Then, open-source tools for typical text preprocessing are used, and in this study Jieba is used for preprocessing of Chinese texts (Gao et al. Citation2004). Preprocessing includes several steps: removal of stop words, tokenization, part-of-speech (POS) tagging and embedding. The graphical representation of the tokenization, POS tagging and embedding process is shown in .
Figure 5. Illustration of the tokenization, POS tagging and embedding process.

Considering the corpora in this study are in Chinese, the stop words used in this study are also some common pronoun words and article words. In this step, every stop word is removed from the dataset. Tokenization refers to the process where purse strings in the text are divided into sentences or words (Zhang and El-Gohary Citation2016). In this step, Jieba is used as it provides a quick division of the sequences of words. After this step, the texts are converted into a single word, number symbol or punctuation. POS tagging is also used in this study to assign type labels to a character. Label types include different systems in the domain of FM such as the air system, cooling system, heat system, ventilation system, energy system, plumbing system and other systems.
Finally, the word embedding is used, for representing the unstructured text in a numerical form to make them computable. In this study, a 300-dimension vector is used to represent each character as a higher dimensional embedding can capture better relationships between the characters and words.
3.3. The BiLSTM-CRF model
The schematic diagram of the BiLSTM-CRF knowledge extraction model is shown in . The embedded vectors in Subsection 2.2 are firstly fed into a BiLSTM layer, and the results from the BiLSTM layer are then fed into the CRF layer to obtain the final predicted label. Details of the BiLSTM and CRF are given below.
Figure 6. Schematic diagram of the BiLSTM-CRF knowledge extraction model.
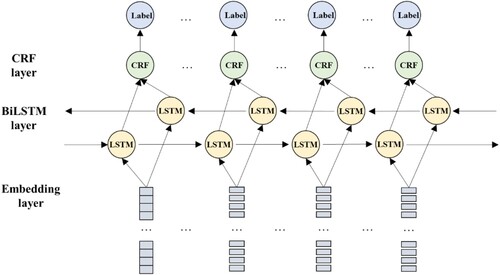
The BiLSTM layer is composed of two LSTM layers. The LSTM network is composed of four parts: input gate it, forget gate ft, output gate ot and memory cell Ct. Forgot gate determines the information to forget, as given in Equation (1) (Ding, Shang, and Mi Citation2020):
(1)
(1) where Wf is the weight of ht-1 in the forgot gate, ht-1 is the output of the hidden layer at time t-1, Uf is the weight of xt in the forgot gate, xt is the input at the current time t, bf is the bias of the forget gate.
The input gate determines how much information the LSTM network will save when it updates cells, which is determined by Equations (2)–(4):
(2)
(2)
(3)
(3)
(4)
(4) where Wi is the weight of ht-1 in the input gate, ht-1 is the output of the hidden layer at time t-1, Ui is the weight of xt in the input gate, xt is the input at the current time t, bi is the bias of i,
is the temporary cell state, Wc is the weight of ht-1 in
, Uc is the weight of xt in
, bc is the bias of
, Ct is the current cell state, ft is the vector obtained by activating the elements in f by the sigmoid function, it is the vector obtained by activating the elements in i by the sigmoid function, and
is the vector obtained by activating the elements in
by the tanh function.
The output gate determines the output of the LSTM network, which can be obtained by Equations (5) and (6):
(5)
(5)
(6)
(6) where Wo is the weight of ht-1 in the output gate, Uo is the weight of xt in the output gate, bo is the bias of the output gate, ht is the final output of LSTM, ot is the vector obtained by activating the elements in o by the sigmoid function.
As shown in , the output Ht of the BiLSTM can be calculated by Equations (7)–(9) (Xu et al. Citation2019):
(7)
(7)
(8)
(8)
(9)
(9) where
and
denote the preceding and following words’ information and can be calculated using Equations (2)–(6), Wtl and Wtr denote the weight of
and
, respectively, and bt is the bias.
The results from the BiLSTM layer will further be calculated in the CRF layer, which is a sequence tag model to compute the global optimal sequence (Lafferty, McCallum, and Pereira Citation2001). For a sequence of predictions (y1, y2, … , yn), the CRF layer is used to calculate the optimal sequence of tags. The score s(X, y) is used to denote the prediction score at the sentence level, which can be calculated by Equation (10).
(10)
(10) where Pi,yi is the output score matrix of the BiLSTM network and Tyi,yi + 1 is the transition score from the tag i to tag i + 1.
The optimal estimate yopt of all the possible outputs is given in Equation (11):
(11)
(11)
3.4. Parameter initialization
As illustrated by previous studies, hyper-parameters can affect a model’s performance and efficiency. Hyper-parameter tuning is a crucial step in developing a BiLSTM-CRF algorithm for knowledge extraction from the text. The right hyper-parameters can significantly impact your model's performance and efficiency. Specifically, the number of hidden layers, length of a hidden layer, embedding dimension, learning rate, batch size and dropout proportion are key parameters in developing the algorithm (Wu et al. Citation2021). The results of hyper-parameters’ tuning are shown in .
Table 2. Results of hyper-parameters’ tuning.
3.5. Model validation
To ensure the performance of the used BiLSTM-CRF model, the model accuracy is assessed using three performance measurements, i.e. Precision, Recall and F1-score, which are three typical evaluation criteria for NLP tasks, which can be calculated by Equations (12)–(14).
(12)
(12) where TP denotes the true-positive result and FP denotes the false-positive result.
(13)
(13) where TP is the true-positive result and FN is the false-negative result.
(14)
(14)
4. Results
The results of the study are presented from three aspects: classification of FM knowledge, extracted entities using BiLSTM-CRF method, and knowledge storage.
4.1. FM classification
An FM system is composed of numerous elements. The normal operation of the system depends on the normal functioning of each element. Hence, first, based on the collected corpora, the classifications of the FM system is done. On the one hand, a detailed classification of the FM system allows us to capture and organize categories of different systems. On the other hand, the classification of the FM system also serves as the labels which can be used in the BiLSTM-CRF model. For example, a heating system and a air system can be used two kinds of labels (see POS tagging in ).
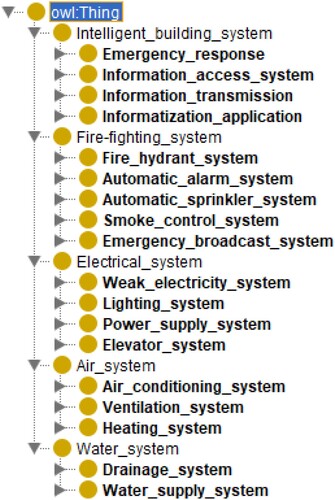
A detailed FM system classification hierarchy is given in , which is composed of different levels. The classification primarily revolved around the diverse functions and requirements of different facility management systems, giving prominence to aspects like maintenance, utilization, and operational efficiency. Different from traditional classification, which generally divides FM system into mechanical, electrical and plumbing system, this study divides the FM into five categories, i.e. the water system, air system, electrical system, fire-fighting system and intelligent building system. The subsystems of the five systems are given, as well as its composition and function. This study proposes an ‘intelligent building system’ as the advancement of information technology has made the FM systems more intelligent (Li, Han, and Ieee Citation2016).
Table 3. FM system classification.
The hierarchy in is actually a three-level classification method. System type is level 1, which is broken by subsystems based on major functions. Then, system composition further divides the subsystems into concrete entities. For example, a water system is composed of a water supply system and drainage system, while the drainage system consists of pipeline, sewage treatment facility and other facilities. The three-level hierarchy is not specific to a certain project, which is summarized based on the large volume of FM-related documents. The proposed three-level hierarchy can be expanded according to the practical FM conditions. In an underground space project such as underground metro station, a geographic information system can be listed as a subsystem of ‘intelligent building system’.
4.2. Extracted entities
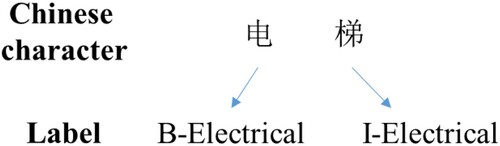
As mentioned above, the classification also serves as the label in the POS tagging process. Hence, the water system, air system, electrical system, fire-fighting system and intelligent building system are five labels that assigned to the corpora. The BIO method is used in this study for each character labelling. Taking ‘电梯’ (which means elevator) as an example, the labelling result is shown in .
Figure 7. Example of labelling.
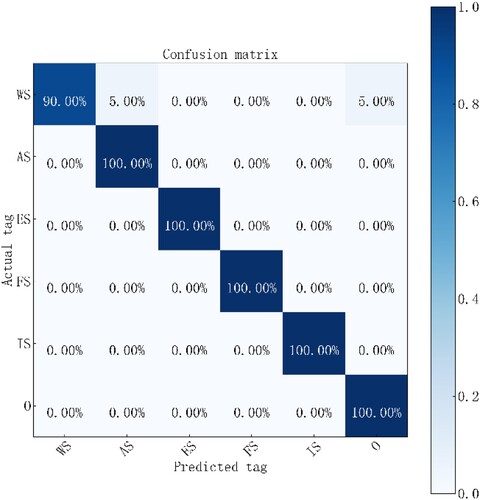
In total, 124,921 data are labelled with 5*2 + 1 = 11 labels. The processed data are then fed into the BiLSTM-CRF model for entity extraction. Previous studies have suggested some values for hyper-parameters of the BiLSTM-CRF model (Zhong et al. Citation2020), and main hyper-parameters are initialized with suggested values. The number of hidden layers, embedding dimension, number of units in LSTM and training epochs are set to 2, 200, 128 and 50, respectively, as shown in . The performance of the algorithm, i.e. model accuracy and loss, with epochs is shown in (a,b), respectively. The established BiLSTM-CRF model can well extract related entities, with an accuracy of more than 90% in the test datasets. demonstrates confusion matrices of the entity extraction in the testing dataset. All the entities almost are recognized precisely after training. The wrongly recognized entities only account for a small proportion of the data.
Figure 8. Performance of the training process: (a) Model accuracy with epochs; (b) Model loss with epochs.
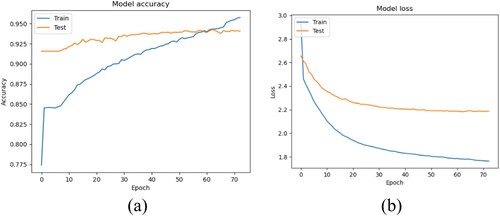
Figure 9. Confusion matrices in the testing dataset (WS: Water System, AS: Air System, ES: Electrical System, FS: Fire-fighting System, IS: Intelligent Building System).
The data are divided into training and testing datasets with an approximate proportion of 7:3. In the testing set, the BiLSTM-CRF model reaches a Precision of 0.83, a Recall of 0.86 and an F1-score of 0.84, indicating that the model can accurately extract FM-related entities. The extraction results are partially given in , which gives some extracted entities which are not shown in .
Table 4. Part of extraction results.
The extracted entities serve as a foundational step towards DT-enabled FM. The extracted entities form the foundation of a robust database, encompassing a wide array of FM-related information. Real-time data, generated from various FM systems and operations, can be seamlessly integrated into this database. Another example is that the extracted entities can be used for some downstream tasks such as the construction of knowledge graph and knowledge-enabled decision-making.
4.3. Knowledge storage
After the FM-related entities are extracted from the corpora, this knowledge is stored in the Protégé software, which is an ontology and knowledge management software providing rule editing, reasoner and other functions (Zhang et al. Citation2018). As shown in , a top-down establishment is constructed, which commences with the definition of the most general classes and subsequent specialization of the classes. The classes are in line with the system type and subsystem in .
Figure 10. Established hierarchy in Protégé.
Taking the power supply system as an example, different entities are listed in . It can be seen that such top-down hierarchy is convenient for searching and navigating knowledge. Moreover, it will be beneficial for FM staff to find the facilities by looking up the established knowledge tree. Besides visualization, the protégé software also supports the export of the knowledge as Ontology Wed Language (OWL) files. This means the knowledge can be transferred between different software and different stakeholders.
Figure 11. Entities of the power supply system.

By storing entities in Protégé, semantic interoperability is achieved. Protégé allows the definition of relationships and hierarchies among entities, enhancing the semantic understanding of FM-related data. This interoperability is crucial for DT, ensuring that diverse FM entities can be seamlessly integrated and interpreted. In addition, entities stored in Protégé become nodes within this representation, each with defined attributes and relationships. This organized knowledge base serves as a valuable resource for DT, offering a clear and structured understanding of the FM landscape.
5. Discussions and limitations
In this study, DT-enabled FM-related knowledge is extracted from standards (in Chinese, management standards) and academic papers and the FM-related entities are also classified. Compared to a similar study conducted by Ensafi et al. (Ensafi, Harode, and Thabet Citation2022), the classification hierarchy is more detailed, and the impact of advancements of technology on FM is also taken into consideration, i.e. addition of the intelligent building system. Thanks to the adoption of the NLP approach, several FM-related entities can be extracted, making the knowledge more comprehensive.
5.1. Contributions to DT-enabled FM
The work can contribute to the DT-enabled FM in the following ways:
Improved information management: Extracted entities can include various aspects of FM, thus supporting the development of more comprehensive DT models.
Semantic Understanding: NLP-based entity extraction enriches the semantic understanding of FM-related texts, providing a more nuanced and context-aware representation of information.
Data-Driven Decision-Making: The extracted entities serve as valuable inputs for data-driven decision-making in DT-enabled FM. The availability of structured data allows facility managers to make more informed and precise decisions especially in the case of emergency.
Predictive Maintenance: Extracted entities related to equipment, maintenance records, and operational data can support predictive maintenance efforts. By analysing these data, DT models can predict and prevent equipment failures, reducing downtime and maintenance costs.
Historical Knowledge Preservation: The entities extracted from textual data can be used to preserve historical knowledge related to FM. This knowledge repository is valuable for DT-enabled FM as it ensures that past experiences and solutions are readily available for reference.
5.2. Limitations
Although the results can be of value to the FM industry, certain limitations exist:
FM involves a wide range of knowledge; this paper focuses on the selection of standard norms and academic literature as knowledge sources, from which relevant entities are extracted and classified. However, FM-related knowledge also involves other aspects, such as the knowledge of case reports, which can be supplemented and expanded in the future.
In addition to various textual materials, FM-related knowledge carriers also include a large number of images, audio, videos, etc. This article takes text data as the starting point to study the method of extracting domain knowledge elements. When extracting knowledge from other format data sources, it is necessary to adjust the extraction method according to the characteristics of the data source.
The rich semantic information contained in FM-related knowledge can provide knowledge sources for various FM-related management decisions. The application phase involves implementing the extracted entity in collaboration with industry partners or relevant stakeholders. This process will include leveraging real-time operational data, physical asset information, and historical data, thereby creating a comprehensive dataset for the methodology’s evaluation.
It’s important to acknowledge that the categorization might not comprehensively cover all aspects related to structural and architectural systems. This limitation is a result of the deliberate choice to approach the classification primarily from a facility-centric perspective. Future research could explore additional classifications that specifically address the unique characteristics of structural and architectural components within facility management.
6. Conclusion
To bridge the research gap in knowledge extraction within the FM industry, particularly for improving communication among various stakeholders and enabling timely decision-making during emergencies, this study proposes a NLP-based approach to mine DT-enabled FM-related knowledge. The main conclusions of this study are listed as below:
A large volume of text data are collected as the corpora, and the BiLSTM-CRF model is used to extract FM-related entities. As a result, a detailed classification of FM-related entities is first presented, which divides the FM into five categories, i.e. the water system, air system, electrical system, fire-fighting system and intelligent building system.
The BiLSTM-CRF model can accurately extract FM-related entities, with a Precision of 0.83, a Recall of 0.86 and an F1-score of 0.84. The extracted entities and knowledge are stored in the Protégé software for visualization and interconnection.
The findings of this study not only provide a basis for automatic FM-related knowledge extraction but also support the downstream tasks such as knowledge graph construction, FM-related emergency decision-making and DT models’ creation.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability statement
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Additional information
Notes on contributors
Linxuan Wang
Linxuan Wang got his master degree in digital asset management in University College London.
Nanjiang Chen
Nanjiang Chen got his first master degree in Architecture from The University of Sydney and second master degree in Engineering Management from Tsinghua University.
References
- Bouabdallaoui, Yassine, Zoubeir Lafhaj, Pascal Yim, Laure Ducoulombier, and Belkacem Bennadji. 2016. “Natural Language Processing Model for Managing Maintenance Requests in Buildings.” Buildings 10 (9). https://www.mdpi.com/2075-5309/10/9/160.
- Bröchner, J. 2003. “Integrated Development of Facilities Design and Services.” Journal of Performance of Constructed Facilities 17 (1): 19–23. https://doi.org/10.1061/(ASCE)0887-3828(2003)17:1(19).
- Ding, Yu, Xuewei Shang, and Weimin Mi. 2020. “Deep Learning Based Knowledge Extraction Method for Text of Power Grid Dispatch and Control.” Automation of Electric Power Systems 44 (24): 161–168.
- Dixit, M. K., V. Venkatraj, M. Ostadalimakhmalbaf, F. Pariafsai, and S. Lavy. 2019. “Integration of Facility Management and Building Information Modeling (BIM) a Review of key Issues and Challenges.” Facilities 37 (7/8): 455–483. https://doi.org/10.1108/F-03-2018-0043.
- Elyasi, Navid, Alessia Bellini, and Nora Johanne Klungseth. 2023. “Digital Transformation in Facility Management: An Analysis of the Challenges and Benefits of Implementing Digital Twins in the use Phase of a Building.” IOP Conference Series: Earth and Environmental Science 1176 (1): 012001. https://doi.org/10.1088/1755-1315/1176/1/012001.
- Ensafi, M., A. Harode, and W. Thabet. 2022. “Developing Systems-Centric as-Built BIMs to Support Facility Emergency Management: A Case Study Approach.” Automation in Construction 133: 104003. https://doi.org/10.1016/j.autcon.2021.104003.
- Gajzler, M. 2015. “Knowledge Modeling in Construction of Technical Management System for Large Warehousing Facilities.” In Paper Presented at the 15th German-Lithuanian-Polish Colloquium / Meeting of EURO-Working-Group on Operational Research in Sustainable Development and Civil Engineering, Poznan, POLAND, Jun 19-21.
- Gao, Jianfeng, Andi Wu, Mu Li, Chang-Ning Huang, Hongqiao Li, Xinsong Xia, and Haowei Qin. 2004. “Adaptive Chinese Word Segmentation.” In Proceedings of the 42nd Annual Meeting on Association for Computational Linguistics, 462–es. Barcelona, Spain: Association for Computational Linguistics.
- Kelly, Graham, Michael Serginson, Steve Lockley, Nashwan Dawood, and Mohamad Kassem. 2013. “BIM for Facility Management: A Review and a Case Study Investigating the Value and Challenges.” In Paper presented at the Proceedings of the 13th International Conference on Construction Applications of Virtual Reality.
- Klungseth, Nora Johanne, and Conrad Wilhelm Tønsberg. 2023. “Digitally Transforming FM Standards and Their Development Process: Allowing Experts to Focus on What Matters.” In Paper presented at the IOP Conference Series: Earth and Environmental Science.
- Lafferty, John D., Andrew McCallum, and Fernando C. N. Pereira. 2001. “Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data.” In Proceedings of the Eighteenth International Conference on Machine Learning, 282–289. Morgan Kaufmann Publishers Inc.
- Lee, Jeoung Yul, Ilkhom Okmirzaevich Irisboev, and Yeon-Sik Ryu. 2016. “Literature Review on Digitalization in Facilities Management and Facilities Management Performance Measurement: Contribution of Industry 4.0 in the Global Era.” Sustainability 13 (23). https://www.mdpi.com/2071-1050/13/23/13432.
- Lepkova, N., and Z. Bigelis. 2007. “Model of Facilities Management Consulting Knowledge System.” In Paper presented at the 9th International Conference on Modern Building Materials, Structures and Techniques, Vilnius, LITHUANIA, May 16-18.
- Li, Z. X., G. L. Han, and IEEE. 2016. “Information Management System of Public Facilities based on Internet of Things Technology.” In Paper presented at the International Conference on Smart City and Systems Engineering (ICSCSE), Zhangjiajie, PEOPLES R CHINA, Nov 25-26.
- Mayo, G., B. Giel, and Raja RA Issa. 2012. “BIM Use and Requirements Among Building Owners.” Computing in Civil Engineering 2012: 349–356. https://doi.org/10.1061/9780784412343.0044
- Miettinen, R., H. Kerosuo, T. Metsälä, and S. Paavola. 2018. “Bridging the Life Cycle: A Case Study on Facility Management Infrastructures and Uses of BIM.” Journal of Facilities Management 16 (1): 2–16. https://doi.org/10.1108/JFM-04-2017-0017.
- Mohanta, Ashaprava, and Sutapa Das. 2016. “BIM as Facilities Management Tool a Brief Review.”
- Nota, G., D. Peluso, and A. T. Lazo. 2021. “The Contribution of Industry 4.0 Technologies to Facility Management.” International Journal of Engineering Business Management 13. https://journals.sagepub.com/doi/full/10.1177/18479790211024131.
- Olimat, Hosam, Hexu Liu, and Osama Abudayyeh. 2016. “Enabling Technologies and Recent Advancements of Smart Facility Management.” Buildings 13 (6). https://www.mdpi.com/2075-5309/13/6/1488.
- Pedral Sampaio, Rodrigo, António Aguiar Costa, and Inês Flores-Colen. 2023. “A Discussion of Digital Transition Impact on Facility Management of Hospital Buildings.” Facilities 41 (5/6): 389–406. https://doi.org/10.1108/F-07-2022-0092.
- Pinti, Lidia, Ricardo Codinhoto, and Serena Bonelli. 2016. “A Review of Building Information Modelling (BIM) for Facility Management (FM): Implementation in Public Organisations.” Applied Sciences-Basel 12 (3). https://www.mdpi.com/2076-3417/12/3/1540.
- Volk, R., J. Stengel, and F. Schultmann. 2014. “Building Information Modeling (BIM) for Existing Buildings – Literature Review and Future Needs.” Automation in Construction 38: 109–127. https://doi.org/10.1016/j.autcon.2013.10.023.
- Wu, C. K., X. Y. Wang, P. Wu, J. Wang, R. Jiang, M. C. Chen, and M. Swapan. 2021. “Hybrid Deep Learning Model for Automating Constraint Modelling in Advanced Working Packaging.” Automation in Construction 127. https://www.sciencedirect.com/science/article/abs/pii/S0926580521001849.
- Xu, M., J. M. David, and S. H. Kim. 2018. “The Fourth Industrial Revolution: Opportunities and Challenges.” International Journal of Financial Research 9 (2): 95.
- Xu, Kai, Zhenguo Yang, Peipei Kang, Qi Wang, and Wenyin Liu. 2019. “Document-Level Attention-Based BiLSTM-CRF Incorporating Disease Dictionary for Disease Named Entity Recognition.” Computers in Biology and Medicine 108: 122–132. https://doi.org/10.1016/j.compbiomed.2019.04.002.
- Zhang, J. S., and N. M. El-Gohary. 2016. “Semantic NLP-Based Information Extraction from Construction Regulatory Documents for Automated Compliance Checking.” Journal of Computing in Civil Engineering 30 (2): 04015014. https://doi.org/10.1061/(ASCE)CP.1943-5487.0000346.
- Zhang, J. S., H. J. Li, Y. H. Zhao, and G. Q. Ren. 2018. “An Ontology-Based Approach Supporting Holistic Structural Design with the Consideration of Safety, Environmental Impact and Cost.” Advances in Engineering Software 115: 26–39. https://doi.org/10.1016/j.advengsoft.2017.08.010.
- Zhao, Jianfeng, Haibo Feng, Qian Chen, and Borja Garcia de Soto. 2022. “Developing a Conceptual Framework for the Application of Digital Twin Technologies to Revamp Building Operation and Maintenance Processes.” Journal of Building Engineering 49: 104028. https://doi.org/10.1016/j.jobe.2022.104028.
- Zhong, B. T., X. J. Xing, H. B. Luo, Q. R. Zhou, H. Li, T. Rose, and W. L. Fang. 2020. “Deep Learning-Based Extraction of Construction Procedural Constraints from Construction Regulations.” Advanced Engineering Informatics 43: 101003. https://doi.org/10.1016/j.aei.2019.101003.
- Zhou, Jing. 2020. “Application Research of “BIM + VR” Technology in Operation and Maintenance Management of Construction Equipment.” Master, Changchun Institute of Technology.