
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
We consider a Markovian SIR-type (Susceptible → Infected → Recovered) stochastic epidemic process with multiple modes of transmission on a contact network. The network is given by a random graph following a multilayer configuration model where edges in different layers correspond to potentially infectious contacts of different types. We assume that the graph structure evolves in response to the epidemic via activation or deactivation of edges of infectious nodes. We derive a large graph limit theorem that gives a system of ordinary differential equations (ODEs) describing the evolution of quantities of interest, such as the proportions of infected and susceptible vertices, as the number of nodes tends to infinity. Analysis of the limiting system elucidates how the coupling of edge activation and deactivation to infection status affects disease dynamics, as illustrated by a two-layer network example with edge types corresponding to community and healthcare contacts. Our theorem extends some earlier results describing the deterministic limit of stochastic SIR processes on static, single-layer configuration model graphs. We also describe precisely the conditions for equivalence between our limiting ODEs and the systems obtained via pair approximation, which are widely used in the epidemiological and ecological literature to approximate disease dynamics on networks. The flexible modeling framework and asymptotic results have potential application to many disease settings including Ebola dynamics in West Africa, which was the original motivation for this study.
1. Introduction
A fundamental issue in disease dynamics is that contact patterns change in response to infection. This is particularly salient in the study of disease dynamics on contact networks: infected individuals curtail contacts with their regular community due to illness (e.g. being too sick to go to school or work) but increase their contacts with other segments of the population, such as healthcare workers or caretakers in the home. The recent Ebola outbreak in West Africa provides a stark example. The array and severity of symptoms, including high fever, diarrhea, vomiting, and hemorrhaging, make symptomatic individuals too ill to engage their regular community contacts and, instead, cause individuals to seek care in the home, hospital, or other facility. This coupling of evolution of network structure to disease status is basic, but a theoretical understanding of how this affects disease dynamics is currently lacking.
Disease dynamics on networks has been an extremely active area of research in the past 20 years, typically within the SIR-type (Susceptible → Infected → Recovered) modeling framework [Citation17,Citation25,Citation42,Citation65,Citation71,Citation75,Citation100]. This has been stimulated in part by the explosion of data on networks of various sorts [Citation6,Citation14,Citation16,Citation21,Citation30,Citation72,Citation89,Citation91,Citation105] and the recognition that network structure can have a dramatic impact on disease dynamics. Theoretical findings include applications of percolation theory to static networks [Citation39,Citation71]. Less theory has been developed for networks that change over time, with much work in this area focusing on concurrent partnerships forming and breaking independent of disease status [Citation1,Citation2,Citation9,Citation29,Citation54,Citation55,Citation98]. The study of adaptive networks, where the contact structure changes in response to disease progression, is an emerging area, as reviewed by Funk et al. [Citation33]. One popular approach is to assume that susceptible individuals break connections to avoid infection [Citation31,Citation40,Citation88,Citation109]. Related works examine behavioural changes due to awareness of infection [Citation33,Citation38]. As these studies indicate, evolving network structure may lead to rich dynamics that are of practical importance for disease forecasting and evaluating public health interventions [Citation40,Citation85,Citation88].
A challenge for understanding disease dynamics on networks is their high dimensionality – for example, a modest-sized network or graph (here, and elsewhere in the paper, we use these terms interchangeably) may have tens of thousands of nodes and over a hundred thousand edges. Various approaches have been developed for deriving simpler models to approximate the full network dynamics including grouping vertices by degree [Citation11,Citation12,Citation74] or ‘effective degree’ [Citation7,Citation57,Citation59] and considering stationary degree distributions for dynamic graphs [Citation2,Citation54,Citation55]. Two approaches particularly relevant to this work are the pairwise approach (e.g. early work includes [Citation45,Citation46,Citation78]) and the edge-based approach of Volz and Miller that is applicable to graphs with a specified degree distribution [Citation69,Citation70,Citation97]. Both approaches naturally lead to consideration of the disease dynamics in the large graph limit, i.e. when the number of nodes tends to infinity. Whereas Volz and Miller derived their results heuristically, recent mathematical work has rigorously shown that a deterministic edge-based system of equations is the large graph limit of an SIR continuous-time Markov process on a static random graph [Citation24,Citation43].
Multilayer networks, which allow for more complex disease dynamics, have also received much attention recently, as reviewed by Kivelä et al. [Citation48]. In particular, multilayer networks where the interconnected layers can represent different populations have been considered [Citation18,Citation81,Citation99,Citation108,Citation110]. The effect of degree correlation on two-layer networks has also been studied [Citation84] with each layer being an Erdos–Rényi or Barabási-Albert random graph. Other models involving two-layer graphs were also considered where one layer corresponded to information-spreading and the second to disease transmission [Citation34,Citation35,Citation38,Citation44] or where two competing pathogens spread on the two layers [Citation82,Citation102]. Multilayer networks have also recently been employed to model temporal networks as sequences of static networks [Citation92,Citation93]. The particular class of multilayer networks studied here are those in which the set of nodes is identical in each layer (i.e. node-aligned [Citation48]) with distinct edge types corresponding to each layer. These are often referred to as multiplex (or multi-relational) networks [Citation13,Citation19,Citation23,Citation107] and can be represented as a graph with edges colored according to type.
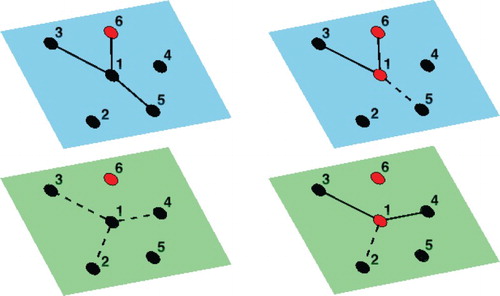
In this work, we consider the problem of modeling an epidemic with different modes of disease transmission on a dynamic contact network. Specifically, we formulate an SIR continuous-time stochastic process on a multilayer graph, with specified degree distribution, where nodes represent individuals and edges represent potentially infectious contacts. Each layer contains the same set of nodes but corresponds to a different transmission mechanism (i.e. a multiplex network). In addition, we allow edges to be active or dormant with transmission occurring only along an active edge. The network structure is dynamic in that edges can activate or deactivate over the course of infection. This approach allows us to incorporate behavioural changes due to infection while keeping the total edges (active plus dormant) given by the degree distribution fixed. A simple example is a two-layer network with one layer corresponding to community contacts and the other to healthcare contacts where we assume that infected individuals deactivate their community edges, for example due to decreased mobility or isolation, while their healthcare edges are being activated as they seek care (Figure ).
Figure 1. (Left) Neighborhood of a susceptible vertex (labeled 1) with an infected (red) neighbour. Community (top/blue) and healthcare (bottom/green) contacts are shown as active (solid) or deactivated (dashed). (Right) After infection of vertex 1, two of its healthcare contacts are activated and one community contact is dropped.
The main result of this work, Theorem 3.1 in Section 3, describes the large graph limit for the stochastic SIR process on the dynamic multilayer network. According to the theorem, the scaled counts of different edge and node types converge uniformly in probability to the solution of a deterministic system of equations. Thus, we obtain a relatively simple limiting model in the setting where network connectivity changes with the evolution of the disease process. In particular, it follows that for a certain class of random graphs the large graph limit coincides with the model obtained using either the pairwise [Citation45] or the edge-based [Citation98] approximation approach. As we demonstrate with the two-layer network example, the limiting systems are amenable for mathematical analysis, allowing us to gain biological insight into how changing network structure influences disease dynamics. Moreover, Theorem 3.1 extends previous results on edge-based models [Citation24,Citation43].
This paper is organized as follows. Section 2 introduces the stochastic model that is considered along with the necessary notation. Section 3 presents our main result, a law of large numbers for the stochastic process on the dynamic multilayer network, and considers several important special cases, which relate our result to edge-based and pairwise models. The two-layer community-healthcare network model and its analysis is given in Section 4. We conclude with a discussion in Section 5. The proof of our main theorem is given in Appendix 2 which also provides further mathematical details along with a summary of notation for the main body of the paper.
2. Stochastic model
Recent advances in computational methods and the ever-increasing power of modern computers have made it possible to consider stochastic versions of the classical ODE epidemic models. Such models not only provide the overall trend of an epidemic across a population but also inform about the stochastic fluctuations around the mean and, hence, about the intrinsic noise in the system (see, for instance [Citation106] and references therein). Some visual examples are provided in the next section. The stochastic models are typically formulated as continuous time Markov processes with discrete state space (see, e.g. [Citation1,Citation43,Citation97]), which is also the framework we adopt in this paper.
We start by introducing some notation and relevant definitions for dynamic multilayer networks. The class of random graphs considered here will be an extension of the configuration model to the multilayer setting. In the following section we will precisely define the layered configuration model, and extend the notions of degree and excess degree to the multilayer setting. Then, we introduce the stochastic process considered in this work, which is the appropriately modified version of the SIR process.
2.1. Layered configuration model
Let r denote the number of layers and, for any vectors in
, denote
. The probability generating function (pgf) of the multivariate degree distribution is given by
(1)
(1) where
is the probability of a node being of (multi-)degree
, i.e. having
neighbours in layer i.
Given a realization of the degree distribution on n nodes, we construct a multilayer graph as follows. Each node is assigned a collection of half-edges in each layer corresponding to its degree, and then half-edges within each layer are paired uniformly at random. We assume that the pairing is done independently in each layer. Thus, restricted to the jth layer, the resulting graph is a realization of a configuration model (see, Chapter 13 in [Citation72]) with the degree distribution given by the jth marginal of ψ (also see, for instance, Section 2.2.4 in [Citation69]). We refer to the collection of such realized graphs as the layered configuration model (LCM) and denote it by .
Excess degree distribution
In a single-layer graph, the excess degree of a node u is calculated by following an edge to u from a neighbour v and counting the number of other neighbours (not including v) of u (see, Chapter 13 in [Citation72]). It will be convenient to extend the notion of an excess degree distribution to the multilayer setting. Let denote the probability that a randomly selected i-neighbour (i.e. neighbour in layer i) of a node u has j-degree (i.e. degree in layer j) equal to l. Then, by LCM construction,
is given as
where
is the average i-degree,
denotes the partial derivative with respect to
, and
is the vector of ones in
. Correspondingly, let
denote the pgf of the excess j-degree distribution of a node randomly selected as a i-neighbour. Then,
where
is the vector of ones with the jth coordinate replaced by
. The average excess j-degree of an i-neighbour is then given by
Finally, we define the normalized average excess j-degree of an i-neighbour as
(2)
(2) Note that, for the univariate (i.e. single layer) case when r=1,
, which is the well-known distribution of the degree of a neighbour (also referred to as the size-biased distribution [Citation96] and corresponding to the excess degree distribution
[Citation72]), and κ is the ratio of the average excess degree to average degree.
2.2. SIdaR process
Assume that we have a realization of an LCM specifying the contact network for a population of size n. The disease modeling framework adopted is the standard Markovian SIR compartmental model where individuals are classified based on their infection status [Citation47]. S, I and R correspond, respectively, to susceptible, infected, and recovered (or removed) individuals. We assume that edges within layers represent potentially infectious contacts of a certain type and we allow the network to be dynamic in response to infection. That is, we assume that infected nodes will either activate or deactivate their edges, depending on edge type. An infectious node drops (resp. activates) edges in layer j at rate
(resp.
). We assume that a layer cannot be both activating and deactivating, i.e. at most one of
and
are nonzero, and we also assume that all deactivating layer edges are initially activated and all activating layer edges are initially deactivated. Note that both active and deactivated edges are counted in a node's degree, which is therefore constant throughout the course of an epidemic (see Section 2.3.1 in [Citation69] for a similar approach). Let
denote the deactivating layers (with
) and let
denote the activating layers (with
). Then, 2r+1 event types may occur: infection (I) along an edge of any of the r types, drop (d) of a deactivating edge or activation (a) of an activating edge, and recovery (R). The timings of all events are assumed to follow independent exponential clocks with the following rates:
For a susceptible node u, let and
denote, respectively, the number of infectious (i.e. infected, not yet recovered) and susceptible active j-neighbours of u. Similarly, let
and
denote the number of deactivated j-neighbours of u. Also, for an infected node u, let
and
denote the number of susceptible active and deactivated, respectively, j-neighbours of u. We consider aggregate variables that are the total number of nodes or pairs of neighbouring nodes (i.e. dyads) with a given disease status. For example, the total number of j-edges between susceptible and infectious individuals is denoted
and is given by
. We regard the aggregate dyad counts as vectors in
, e.g.
and likewise for
,
, and
. Note that
and
count the edges twice. We let
denote the state of the aggregate stochastic process at time t>0 where
and
denote the number of susceptible and infectious nodes, respectively. Note that the number of recovered individuals is given by
and so, for the sake of simplicity, we ignore the equation for
throughout. In addition, we do not keep track of
or the dyads of recovered individuals since the evolutions of the main quantities of interest, S and I, are not affected by these variables. The transitions for the aggregate process are listed in Table . We refer to such a process as
in order to emphasize the activation and deactivation events. The analysis of this process is complicated, partially due to the aggregation of the nodes that destroys the Markov property (see, e.g. [Citation2]).
Table 1. Transitions for the  process according to the 2r+1 possible event types with corresponding rates. Network arrangements corresponding to the transitions are also given with and denoting, respectively, active and deactivated edges of type j between nodes (denoted u, v and w). Here, denotes the set of l-neighbours of node u with disease status Y .
process according to the 2r+1 possible event types with corresponding rates. Network arrangements corresponding to the transitions are also given with and denoting, respectively, active and deactivated edges of type j between nodes (denoted u, v and w). Here, denotes the set of l-neighbours of node u with disease status Y .
Note that the dyad (e.g. ) is understood throughout as a (row) vector in
. Also, with a slight abuse of notation we take multiplication, division, integration and ordering of vectors to be coordinatewise. The state variables depend on n but we do not explicitly acknowledge this in our notation.
Consider the process
on the LCM
with transitions as outlined in Table . The Doob-Meyer decomposition theorem [Citation64] guarantees the existence of a zero-mean martingale
such that
(3)
(3) where the integrable function
is given by
(4)
(4) for
.
We now define two more variables that will help us describe the evolution of the process in the large graph limit. Let where
is the number of j-edges (active and deactivated) belonging to susceptible nodes at time t. We partition the collection of susceptible nodes S by their degree
so that
, which corresponds also to
Note
(5)
(5) We also define
by
(6)
(6) where
. We may interpret
as the probability of no infection along a j-edge by time t in a susceptible node of j-degree one, given that the node was susceptible at t=0. That is,
is the probability that a susceptible node of (multi-)degree
has not been infected through any layer by time t, given that the node was susceptible at t=0. Note also that we may equivalently write
(7)
(7) where
and
(8)
(8) As shown in Theorem 3.1 below,
plays a key role in describing the evolution of
in the large graph limit. The use of such a variable was pioneered by Volz [Citation97] and Miller [Citation66] in their edge-based approach. In fact, as shown in Section 3.2, in the single-layer, static network case, the large graph limit of
corresponds to the variable in the standard SIR edge-based model [Citation70].
3. Large graph limit theorems
The stochastic process defined in Section 2.2 is complex and difficult to analyze directly. In this section we present a limit theorem (Theorem 3.1) that shows, under mild technical assumptions, that the stochastic process converges to a relatively simple system of ODEs as the number of nodes tends to infinity. The limiting ODEs retain key features of the epidemic process while being amenable to analysis. In the case of a finite but large population, analysis of this deterministic system provides a good approximation to disease dynamics, in the sense that fluctuations around the mean due to intrinsic noise in the system shrink as the graph size grows. The study of such large volume limits for stochastic processes of the type discussed here was originated by Kurtz in [Citation50] in the context of chemical reaction models. His work has subsequently inspired multiple large volume results on the stochastic SIR-type models (see, e.g. Chapter 5 in [Citation4]). Among others, Andersson [Citation3] derived limit theorems for a discrete-time random graph epidemic model under rather restrictive assumptions on the degree sequence of the random graph, such as finiteness of a th moment for some
. Using a heuristic argument, Volz [Citation97] presented scaling limits for an SIR model on random graphs in the form of ODEs. Decreusefond et al. [Citation24] later proved Volz's results rigorously by summarizing the epidemic dynamics on a configuration model random graph using certain measure-valued process. Several similar law of large numbers-type scaling limits under varying sets of technical assumptions surfaced afterwards. For example, Bohman and Picollelli [Citation15] and Barbour and Reinert [Citation10] assumed uniformly bounded degrees. Janson, Luczak and Windridge [Citation43] assumed the degree of a randomly chosen susceptible vertex to be uniformly integrable and the maximum degree of initially infected nodes to be
, a condition slightly less restrictive than our condition (A3) below. However, none of these previous works have considered multiple layers in the random graph or allowed for activation/deactivation events.
We start by formulating our assumptions in the general case when evolution of the quantities of interest, , involves a function of the variable
defined in the preceding section. In Section 3.2, we state corollaries that relate our result to edge-based models in the special case of static graphs (that is, in the absence of activation or deactivation) [Citation69]. Finally, in Section 3.3 we show that, for a particular class of degree distributions, the evolution of
decouples from
. This fact reveals an interesting connection between our limiting system and the one obtained via pair approximation. While others have recently investigated the conditions for exactness of local network moment closures [Citation76,Citation87], we are able to obtain the condition for exactness of a population-level network moment closure. We confirm that, as suggested in [Citation76,Citation86], such a condition depends on the network structure (i.e. degree) heterogeneity. Indeed, in Section 3.3, we employ Theorem 3.1 to prove that the pair approximation approach may or may not give the correct large graph limiting ODEs for the class of LCM stochastic processes described here. In particular, we provide a necessary and sufficient condition on the degree distribution for the two limiting systems to coincide.
3.1. General case
All limits considered below, unless otherwise noted, are with respect to the number of nodes . We use
to denote convergence in probability in the product space of the right-continuous with finite left limits (càdlàg) stochastic processes and the space of all random configurations drawn according to an LCM
. We say that a sequence of random variables
with high probability (w.h.p.) if
for any k>0. Let
. We make the following assumptions:
For
The fractions of initially susceptible, infected, and recovered nodes converge, respectively, to some
The assumption (A1) implies that, for large graphs, some proportion of the individuals remain susceptible on and, hence,
is well-defined in (Equation6
(6)
(6) ). Furthermore, it implies that the average j-degree of a randomly chosen node, i.e.
, is positive since
.
Assumption (A2) implies that the initial conditions for the dyads, scaled by n, also converge in probability, i.e.
(9)
(9) where, for the deactivating layers
,
and, for the activating layers
,
To illustrate the above consider, for example, the initial condition
for
as follows. By assumption, all deactivating layer edges are initially activated and all activating layer edges are initially deactivated. Then, according to (A2), the limiting probability of selecting a random node that is susceptible is
. The average number of j-edges a node has is
, and the limiting probability that a given edge connects to an infected node is
. Therefore,
. The other dyad initial conditions are obtained similarly. We denote
in what follows.
The assumption (A3) implies that for
(i.e. the second moments of the marginal degree distributions are finite) and consequently also that, in each layer, the multigraph constructed by matching half-edges uniformly at random is a simple graph with positive probability (see Section 2 in [Citation43]). Therefore (A3) also guarantees that there is a positive probability of generating a simple LCM graph, i.e. a multilayer graph with a simple graph in each layer.
Before stating the main result, we define a quantity that plays a key role in describing how the network structure affects the large graph limit. For , let
be defined by
(10)
(10) As we discuss in Section 3.3.3,
can be interpreted as the ratio of the average excess j-degree of a susceptible node chosen randomly as an l-neighbour of an infectious node to the average j-degree of a susceptible node.
We now define the function that in Theorem 3.1 below describes the evolution of in the large graph limit. Let
and define
where
and
are given by
(11)
(11) for
.
Theorem 3.1
Strong law of large numbers
Assume conditions (A1)–(A3) for the LCM . Then, for any
where
is the solution of
(12)
(12) with initial conditions
and
Theorem 3.1 specifies the large graph limit of the aggregated process on
under conditions (A1)–(A3). It says that
converges uniformly in probability on any finite interval
to the solution
of the deterministic set of equations given by (Equation12
(12)
(12) ). Proof of Theorem 3.1 is provided in Appendix 2. The argument largely follows the standard large volume analysis [Citation50]. The main difficulty is in showing that the terms corresponding to ‘empirical moments’ in system (Equation4
(4)
(4) ) (i.e. those summing over susceptible nodes in the graph and counting exact numbers of neighbours of certain type) can be replaced in the large graph limit (Equation11
(11)
(11) ) with the corresponding
terms encapsulating a population-level average over the heterogeneity in the degrees and excess degrees of susceptible nodes. This may be done due to the properties of the LCM construction with the help of the representation introduced in Remark A.1 in Appendix 2.
3.2. Edge-based limiting systems
We consider two special cases of the large graph limit theorem for multilayer networks. First, we consider a static network, i.e. the case where for
. Corollary 3.2 below states that in this case our system (Equation12
(12)
(12) ) is equivalent to an edge-based model with multiple modes of transmission. This model is the one proposed by Miller and Volz [Citation69] but with a modification to allow for a large number of initially infected nodes (following [Citation67] where Miller modifies the standard SIR edge-based model for such a scenario). In the case that the initially infected nodes are randomly chosen (which we assume in (A2)), the model is given by
(13)
(13) The statement of Corollary 3.2 is as follows. Its proof is given in Appendix 3.
Corollary 3.2
Assume for
and the conditions of Theorem 3.1 hold. Then, the conclusions of Theorem 3.1 hold where
is equivalent to the solution of the edge-based model with multiple modes of transmission (Equation13
(13)
(13) ).
We further consider the special case of a static, single layer graph (i.e. r=1 and ). In the case r=1, (Equation13
(13)
(13) ) reduces to the well-known edge-based SIR model of Volz and Miller et al. [Citation70,Citation97], which has been proven to be the large graph limit of the SIR stochastic process on a static configuration model graph [Citation24,Citation43]. By taking r=1 in Corollary 3.2 we have provided an alternative proof of this fact.
Corollary 3.3
Assume
and the conditions of Theorem 3.1 hold. Then, the conclusions of Theorem 3.1 hold where
is equivalent to the solution of the edge-based SIR model(Equation13
(13)
(13) ) with r=1.
3.3. Pairwise limiting systems
In this section we consider a certain class of LCMs where as defined by Equation (Equation10
(10)
(10) ) is constant. This affords a substantial simplification to the limiting system (Equation11
(11)
(11) ) and, in fact, the system of differential equations defining the large graph limit will coincide with the model derived via the pairwise approach.
3.3.1. Poisson-type distributions
We define a multivariate Poisson-type (PT) distribution to be a distribution with a pgf that satisfies
(14)
(14) where we recall the definition of the normalized average excess degree,
, in Equation (Equation2
(2)
(2) ). At first glance, (Equation14
(14)
(14) ) may seem opaque; however, in fact it is satisfied by a broad class of distributions. For example, in the single layer case this condition is equivalent to
which is satisfied by the univariate Poisson (
), binomial (
), and negative binomial (
) distributions. Note that a k-regular graph (where all nodes have degree k) may be considered a special case of the binomial distribution and that the geometric distribution is a special case of the negative binomial distribution. Bansal et al. [Citation8] have shown that the geometric degree distribution (i.e. the discrete analog of the exponential distribution) gives the best fit for several empirical contact networks. In the multilayer case with r>1, if the marginal degree distributions in different layers are independent, i.e. the pgf
can be written as
, the PT condition (Equation14
(14)
(14) ) reduces to the degree distribution in each layer being of (univariate) Poisson-type.
3.3.2. Pairwise model
If the degree distribution is PT as defined by condition (Equation14(14)
(14) ), the limiting system (Equation11
(11)
(11) ) defining
has a particularly simple form. Indeed, substituting the constant
for
decouples
from
. We consider the resulting model in this section and introduce some new notation to do so. Let
and
denote, respectively, the number of activated and deactivated edges of type j between a node of status X (either S, I or R) and a node of status Y . Let
denote the number of triples with an active i-edge between nodes of status X and Y and an active j-edge between the node of status Y and one of status Z. Similarly,
will denote such triples where the i edge is deactivated.
Under the correlation equations approach of Rand [Citation78], triples are needed to describe the evolution of pairs, quadruples (e.g. ) are needed to describe the evolution of triples, and so forth. A pair approximation for triples is used in order to close the system at the level of pairs [Citation78]. For consideration of triples in the multilayer setting, we must take into account the edge types and the appropriate excess degrees as defined in Section 2.1. Let
denote the probability that a node u has disease status
given an edge (or triple) arrangement A for u. The pair approximation of
is then calculated as follows:
(15)
(15) with
as defined in Equation (Equation2
(2)
(2) ). Note that since alternatively we could have approximated
we must have that
.
Applying the correlation equations approach using the pair approximation (Equation15(15)
(15) ) to the
dynamics described in Section 2.2 results exactly in the same equations as the limiting system (Equation12
(12)
(12) ) in the case of a PT distribution:
(16)
(16) Here, we have derived the system (Equation16
(16)
(16) ) using absolute pair and triple counts. Notice that, if we scale all variables by the graph size n, the nondimensional quantities satisfy the same system of equations (this holds for any n and, hence by continuity of the solution, also in the limit). From here on we will consider only the scaled variables, which will be convenient when we state the law of large numbers in Corollary 3.4. Accordingly, we set the initial conditions to be
(17)
(17) so that they agree with the initial conditions in Theorem 3.1 as
.
Observe also that, in fact, we can reduce the dimension of the system (Equation16(16)
(16) ) since we only need to keep track of the deactivated edges for the activating layers, i.e.
. Also,
for an activating layer since its initial condition is zero and, hence, we only must track
for
. We refer to system (Equation16
(16)
(16) ) with its initial condition (Equation17
(17)
(17) ) as the pairwise model.
The discussion above is summarized in the following corollary.
Corollary 3.4
Assume the conditions of Theorem 3.1 hold for LCM . Then, the conclusions of Theorem 3.1 hold where
is the solution of the pairwise model (Equation16
(16)
(16) ) if and only if
has a multivariate Poisson-type degree distribution.
Furthermore, we can consider the implications of Corollary 3.4 in the static, single layer case. If r=1 and , then the pairwise model (Equation16
(16)
(16) ) reduces to the well-known correlation equations model of Rand [Citation78]:
(18)
(18)
Corollary 3.5
Assume the conditions of Theorem 3.1 hold for a static graph
i.e.
. Then, the conclusions of Theorem 3.1 hold where
is the pairwise SIR model of Rand (Equation18
(18)
(18) ) if and only if
has a univariate Poisson-type degree distribution.
Note that together Corollaries 3.2 and 3.4 imply that, in the case of a multivariate PT degree distribution on a static graph, the pairwise model (Equation16(16)
(16) ) is equivalent to the edge-based model with multiple modes of transmission (Equation13
(13)
(13) ). Likewise, Corollaries 3.3 and 3.5 indicate that the pairwise SIR model (Equation18
(18)
(18) ) is equivalent to the edge-based SIR model, (Equation13
(13)
(13) ) with r=1, when the distribution is PT. We note that the edge-based SIR model has previously been shown to be equivalent [Citation42,Citation68] to a higher dimensional pairwise model of Eames and Keeling [Citation28]. The latter model stratifies the susceptible nodes by degree and, hence, has dimension K+3 where K represents the number of distinct degrees [Citation68]. The model of dimension K+3 was derived as an approximation to an earlier well-known model of Eames and Keeling, which is of dimension
[Citation28]. We observe that, in fact, (Equation18
(18)
(18) ) can be reduced to two differential equations. Separation of variables on
(see, e.g. [Citation4] for
) gives
. Subsequent inspection of
yields a linear differential equation that can be solved to express
explicitly as a function of S:
(19)
(19) Thus, in Corollary 3.5, we have identified a condition on the degree distribution under which the dimension of a pairwise model that is equivalent to the edge-based SIR model has been reduced from K+3 to two.
3.3.3. Large-graph-consistent pair approximation
Corollary 3.4 and the derivation of the pair approximation (Equation15(15)
(15) ) motivate us to consider a more careful approximation of the triples in the general case when the distribution is not necessarily PT. Let
denote the average excess i-degree of a susceptible node chosen randomly as a j-neighbour of an infectious node and let
denote the average i-degree of a susceptible node. We now make more precise our comment in Section 3.1 that
can be interpreted as the limiting ratio of these quantities.
For the LCM with
as defined in Equation (Equation6
(6)
(6) ), we derive
and
(see Appendix 4) to be
(20)
(20) Thus, we see from the definition of
in (Equation10
(10)
(10) ) that
We note that
and
are dependent on time and differ, respectively, from
and
defined in Section 2.1. Indeed, susceptible nodes of high degree are preferentially infected [Citation62]. On the other hand, the naive approximation of a triple with
in (Equation15
(15)
(15) ) uses the average degree and excess degree over all nodes, which remain constant for all
. Note that it is only necessary to approximate triples of the form
where
. Therefore, we can more carefully derive the pair approximation using
and
(21)
(21) Note that the approximation
becomes exact in the large graph limit as the configuration model becomes locally treelike [Citation68,Citation87].
Moreover, it follows from Theorem 3.1 that uniformly on any finite interval
. We then see from (Equation21
(21)
(21) ) that, if we took the correlation equations approach for
dynamics on a general LCM but instead approximated the triples with
(22)
(22) the system of equations obtained would be exactly that given by the limiting system (Equation12
(12)
(12) ). In this sense, the pair approximation (Equation22
(22)
(22) ) is ‘correct’, i.e. it is consistent with the large graph limit.
Subsequently, we can view the pairwise system (Equation16(16)
(16) ) as resulting from the approximation
(23)
(23) For PT distributions, the above relation is exact (‘≈’ may be replace with ‘=’), and the pairwise system is consistent with the large graph limit (i.e. Corollary 3.4). However, for non-PT distributions, the approximation (Equation23
(23)
(23) ) introduces some error (see Figure ).
Figure 2. SIR epidemic simulations on static, single-layer graphs with degree distributions given by (blue), a 2-degree distribution in which
(orange), and a scale-free distribution with
for
(yellow). (Left)
(solid line) is constant and equal to κ (dashed line) for the Poisson distribution but not for the non-PT distributions. (Right) Solutions for the proportion of infected from the large graph limiting system (solid) and the pairwise system (dashed) show discrepancy for the non-PT distributions. Approximate 95% confidence intervals based on 100 stochastic simulations (shaded) and their means (dotted) show agreement with the large graph limiting systems.
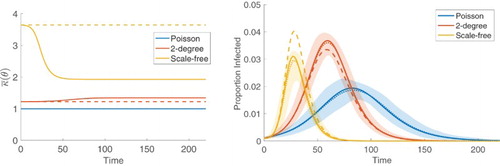
We illustrate the results of this section in Figure by simulating an SIR epidemic on three different static, single-layer graphs. The first graph has a Poisson degree distribution with (blue). In the second graph, which we refer to as a 2-degree graph, a node has either degree 2 or 9, each with probability 0.5 (orange). The final graph is a so-called scale-free graph [Citation74]; that is, the degree distribution is given by a truncated power law distribution with
for
(yellow). For each scenario, we simulate the stochastic SIR process on a graph of size
and solve the edge-based model (Equation13
(13)
(13) ) (which, by Corollary 3.3, is equivalent to the large graph limiting system (Equation12
(12)
(12) )) as well as the pairwise system (Equation16
(16)
(16) ). In Figure , we plot the quantity
(solid line) as a function of time with the starting value, κ, indicated with a dashed line. The Poisson degree distribution is a PT distribution and, therefore,
; however the latter two graphs do not have PT degree distributions and, indeed, we see a divergence of
from κ as the outbreak progresses. This corresponds to a discrepancy between the epidemic curves of the deterministic large graph limiting system (solid) and pairwise system (dashed) in Figure . Approximate 95% confidence intervals (shaded) based on 100 stochastic simulations are also shown in Figure . For the scale-free graph,
after the initial time, so using the ‘naive’ approximation (Equation15
(15)
(15) ) in the pairwise system leads to overestimating the number of triples. Figure indicates that this consequently results in an overestimate of the incidence of the epidemic (yellow, dashed). In the 2-degree network, on the other hand, κ slightly underestimates
and the disease incidence is underestimated by the pairwise system (orange, dashed), although still within the margin of error indicated by the confidence intervals. For the Poisson distribution, the two deterministic curves coincide. The means of the stochastic simulations (dotted) show good agreement with the large graph limiting systems, following Theorem 3.1.
4. Community-healthcare network example
In this section, we discuss the two-layer dynamic network model that was mentioned in the Introduction as a concrete and tractable example of the stochastic SIdaR process. We use this example to illustrate how our Theorem 3.1 can be applied to gain insight into disease dynamics, even in the quite complex setting where network dynamics are tied to infection status. One of the epidemiological issues we aim to understand is how the interplay between edge activation/deactivation and the multilayer network structure affects the ability of disease to invade. In addition, gauging the sensitivity of outbreak size to network parameters and transmissibility along the different edge types would be useful for informing interventions. We demonstrate here that analysis of the pairwise limiting system provides answers to these questions, via application of well-established techniques for analyzing compartmental ODE models of disease dynamics.
Consider the process, as described in Section 2.2, on a two-layer LCM
with multivariate PT degree distribution where the two edge types correspond to community and healthcare type contacts. We assume that infected individuals deactivate their community contacts, for example due to decreased mobility or isolation, while they activate their healthcare contacts as they seek care (Figure ). Note that the healthcare network may include both care provided by healthcare professionals at hospitals or other facilities as well as care provided in the home. This model is motivated by the recent 2014–2015 outbreak of Ebola virus in West Africa. The multitype contact features are particularly relevant for Ebola, given the disproportionate Ebola risk experienced by healthcare workers [Citation22,Citation61] and women (primary caregivers in the home in West Africa) in the 2014 West Africa outbreak as well as Ebola outbreaks in the Democratic Republic of the Congo [Citation49]. There are other aspects of Ebola that are important for transmission, such as an incubation period ranging from 2 to 21 days [Citation36] and disease transmission at funerals [Citation20,Citation36,Citation51]. For simplicity we focus here on community and healthcare transmission and the effect of illness on network structure.
Let C denote community edges and H denote healthcare edges. As in Section 2.2, the stochastic events are assumed to follow independent exponential clocks where the rates of infection along C- and H-edges are, respectively, and
, the rate of deactivation of a C-edge is δ, the rate of activation of an H-edge is η and the rate of recovery is γ.
The stochastic process above satisfies the conditions of Theorem 3.1 and Corollary 3.4 and, thus, converges to the following system of ODEs in the large graph limit:
(24)
(24) As in Section 3.3.2, the variables in (Equation24
(24)
(24) ) are scaled by n and the initial conditions are given by
(25)
(25) Recall that
and
are the average C- and H-degrees, respectively, of a randomly chosen node and that (Equation25
(25)
(25) ) corresponds to all community edges being active and all healthcare edges deactivated at t=0.
Figure compares trajectories of the stochastic process compared with system (Equation24
(24)
(24) ). At smaller graph size
(Figure , left), there are discrepancies between the stochastic trajectories and the limiting ODE (red versus blue curves). As the size of the graph increases, i.e. for
(Figure , right), the stochastic trajectories are tightly clustered around the ODE solution, illustrating convergence of the stochastic process to the deterministic system given in Theorem 3.1.
Figure 3. Convergence of the stochastic process for infected to its large graph limit (). The degree distribution of the C-layer is
with
and
. The degree distribution of the H-layer is regular, i.e. all nodes have equal degree, with
and
. The size of the graph is given by
(left) and
(right). The blue shaded regions indicate the approximate 95% confidence intervals based on 100 numerical simulations of the stochastic
processes, conditioned on the large outbreak. The blue lines give the mean of the stochastic simulations, and the red lines show the deterministic solutions to (Equation24
(24)
(24) ). Initially infected nodes (
,
) are randomly chosen and other parameters are given by
,
,
,
,
.
![Figure 3. Convergence of the stochastic process for infected to its large graph limit (n→∞). The degree distribution of the C-layer is NB(5,0.706) with μC=12 and κCC=1.2. The degree distribution of the H-layer is regular, i.e. all nodes have equal degree, with μH=5 and κHH=0.8. The size of the graph is given by n=104 (left) and n=105 (right). The blue shaded regions indicate the approximate 95% confidence intervals based on 100 numerical simulations of the stochastic SIdaR(2,1) processes, conditioned on the large outbreak. The blue lines give the mean of the stochastic simulations, and the red lines show the deterministic solutions to (Equation24(24) dSdt=−βC[SI]C−βH[SI]HdIdt=βC[SI]C+βH[SI]H−γId[SI]Cdt=βCκCC[SS]C[SI]CS+βHκCH[SS]C[SI]HS−βCκCC[SI]C2S−βHκCH[SI]C[SI]HS−(βC+γ+δ)[SI]Cd[SI]Hdt=−βCκCH[SI]H[SI]CS−βHκHH[SI]H2S−(βH+γ)[SI]H+η[SI~]Hd[SI~]Hdt=βCκCH[SS~]H[SI]CS+βHκHH[SS~]H[SI]HS−βCκCH[SI~]H[SI]CS−βHκHH[SI~]H[SI]HS−(η+γ)[SI~]Hd[SS]Cdt=−2βCκCC[SS]C[SI]CS−2βHκCH[SS]C[SI]HSd[SS~]Hdt=−2βCκCH[SS~]H[SI]CS−2βHκHH[SS~]H[SI]HS.(24) ). Initially infected nodes (αI=0.002, αS=0.998) are randomly chosen and other parameters are given by γ=0.08, δ=0.1, η=0.2, βC=0.009, βH=0.015.](/cms/asset/91800788-4c53-4810-850d-10e1a6768fdf/tjbd_a_1515993_f0003_c.jpg)
System (Equation24(24)
(24) ) can now be analyzed to gain insight into how the structure of the different layers of the network and their coupling through activation/deactivation of edges in response to infection affects disease dynamics. In particular, we can compute the basic reproduction number,
, which determines whether disease invasion is possible [Citation95]. Consider the disease free equilibrium
. Let
Note that
, the average excess C-degree, so we can interpret
as the average number of secondary cases transmitted through the community network in a susceptible population and, likewise,
represents the secondary cases caused by healthcare transmission. The next-generation matrix method [Citation95] gives (see Appendix A.1) the basic reproduction number as
(26a)
(26a)
(26b)
(26b) where
(27)
(27) The
term can be interpreted as the number of secondary infections created in the community contact network from an initial infection along an H edge, and
as the secondary infections created in the healthcare contact network from an initial infection along a C edge.
Let us comment about the utility of deriving from (Equation24
(24)
(24) ). The basic reproduction number is a fundamental quantity in epidemiology, and understanding the dependence of
on model parameters can be helpful for assessing different intervention strategies. For complex systems such as the stochastic process on a multilayer network considered here, deducing the form for
on heuristic grounds can be difficult. Using the next-generation matrix to compute
from the limiting system of ODEs takes the guesswork out of this process. As shown in [Citation95], the next generation matrix gives a stability criterion for the disease free equilibrium for the limiting ODEs. Theorem 3.1 shows that the threshold for when the branching process for the stochastic model is subcritical converges to the threshold for the limiting ODEs, i.e. when the
expression is equal to one.
Expression (26) is equivalent to the expression found by [Citation7,Citation56], with the difference that the edge activation and deactivation rates enter into the expression. Indeed, the presence of both
and
in
reflects the coupling of the different layers through edge activation/deactivation. In the limit of fast deactivation of community contacts (i.e.
),
and disease invasibility depends solely upon the healthcare layer. Similarly, in the limit of slow activation (i.e.
),
and the basic reproduction number is driven by the community layer. For intermediate activation and deactivation rates,
depends upon both layers and the multilayer aspect of the model plays an important role in affecting disease dynamics. Both transmission ‘within’ (e.g.
terms) and ‘between’ layers (e.g.
terms) contribute to
, as seen in (Equation26b
(26b)
(26b) ).
An important point is that (26) shows that knowledge of the reproduction numbers of the individual layers is not sufficient to determine
for the entire network. Instead,
depends upon the structure of the different layers through the parameters
. Consider the cross term in (Equation26a
(26a)
(26a) ). In the case where
(for example, independent Poisson degree distributions in each layer), the cross term vanishes and
. In general the sign of the cross term may be either positive or negative, and thus
may be either larger or smaller than
. In fact for fixed
and
it is possible for
to be either greater than or less than one, depending upon the structure of the layers. This is illustrated in Figure where we plot prevalence (i.e. infected proportion of the population) over the course of an epidemic for two different scenarios for the structure of the healthcare layer. We take the two layer-specific degrees to be independent (
) with the degree distribution of the community layer being Poisson (
) with
. We fix
and
and take the degree distribution of the healthcare layer as negative binomial with
; in the first scenario (blue) we take the healthcare layer degree as
(corresponding to
) while in the second (orange) we take the healthcare layer degree as
(corresponding to
). Figure shows, for each scenario, the deterministic solution to the limiting system (Equation24
(24)
(24) ) (solid line) as well as the approximate 95% empirical confidence interval calculated from 500 stochastic simulations of the corresponding
process with
(shaded region). The basic reproduction numbers are calculated from (Equation26a
(26a)
(26a) ) to be, respectively,
and
. Correspondingly, in the first case a large epidemic occurs while in the second case the initial infection quickly dies out. The increase in
from the first case to the second corresponds to an increase in the variance of the H degree distribution. In fact, analogous to previous results (see, e.g. [Citation56]), inspection of (Equation26b
(26b)
(26b) ) reveals that, if
and
are kept constant,
is an increasing function of the variances of the C and H degree distributions as well as their covariance.
Figure 4. Prevalence curves for two different scenarios for the structure of a community-healthcare network corresponding to large (top/blue) and small (bottom/orange) outbreaks. The degree distribution of the C-layer is . The degree distribution of the H-layer is
with
in the first case (top/blue) and
with
in the second case (bottom/orange). The solid lines show the deterministic solutions to (Equation24
(24)
(24) ) while the shaded regions indicate the approximate 95% confidence intervals based on 500 numerical simulations of the stochastic
processes with
. Initially infected nodes (
,
) are randomly chosen and
,
, and
. We fix
and
which corresponds to
and, respectively for the two scenarios,
and
.
![Figure 4. Prevalence curves for two different scenarios for the structure of a community-healthcare network corresponding to large (top/blue) and small (bottom/orange) outbreaks. The degree distribution of the C-layer is Pois(10). The degree distribution of the H-layer is NB(10,4/9) with κHH=1.1 in the first case (top/blue) and NB(1/3,0.96) with κHH=4 in the second case (bottom/orange). The solid lines show the deterministic solutions to (Equation24(24) dSdt=−βC[SI]C−βH[SI]HdIdt=βC[SI]C+βH[SI]H−γId[SI]Cdt=βCκCC[SS]C[SI]CS+βHκCH[SS]C[SI]HS−βCκCC[SI]C2S−βHκCH[SI]C[SI]HS−(βC+γ+δ)[SI]Cd[SI]Hdt=−βCκCH[SI]H[SI]CS−βHκHH[SI]H2S−(βH+γ)[SI]H+η[SI~]Hd[SI~]Hdt=βCκCH[SS~]H[SI]CS+βHκHH[SS~]H[SI]HS−βCκCH[SI~]H[SI]CS−βHκHH[SI~]H[SI]HS−(η+γ)[SI~]Hd[SS]Cdt=−2βCκCC[SS]C[SI]CS−2βHκCH[SS]C[SI]HSd[SS~]Hdt=−2βCκCH[SS~]H[SI]CS−2βHκHH[SS~]H[SI]HS.(24) ) while the shaded regions indicate the approximate 95% confidence intervals based on 500 numerical simulations of the stochastic SIdaR(2,1) processes with n=104. Initially infected nodes (αI=0.002, αS=0.998) are randomly chosen and γ=0.1, δ=0.1, and η=0.3. We fix RC=0.75 and RH=0.5 which corresponds to βC=0.0162 and, respectively for the two scenarios, βH=0.0082 and βH=0.0021.](/cms/asset/e4dc3238-759a-4afe-b3b2-225dc65637f6/tjbd_a_1515993_f0004_c.jpg)
In many situations not only determines the ability of disease to invade, but also the size of an outbreak if one occurs [Citation58]. The system of ODEs (Equation24
(24)
(24) ) obtained via Theorem 3.1 and Corollary 3.4 can similarly be analyzed to determine a relation for the final size of the epidemic, as in [Citation4,Citation5]. To illustrate, consider the special case where the degrees in community and healthcare layers are independent with Poisson degree distributions (i.e.
). Let
denote the fraction of the population that escapes infection. Analysis of a transformed model (as in [Citation4]) or, alternatively, a result of Arino et al. [Citation5] can then be used (see Appendix A.2) to derive the final size relation:
(28)
(28) which agrees with the classic result for mean-field, homogeneously mixed populations as
and
[Citation47].
We conclude our analysis of the community-healthcare network model by noting that system (Equation24(24)
(24) ) is simple enough to be amenable for practical application to outbreaks of interest, for example for parameter estimation and intervention assessment from available data (for example, medical records and contact tracing data). For a given set of parameters system (Equation24
(24)
(24) ) can be used to assess impact of different interventions on preventing outbreaks from occurring (e.g. bringing
) or decreasing the size of an outbreak if it does occur (e.g. by using (Equation28
(28)
(28) ) to compute the sensitivity of
to parameters p). Further details on statistical inference and application to specific outbreaks will be presented elsewhere. Here we briefly show how system (Equation24
(24)
(24) ) can be further reduced by finding invariants that allow for dimension reduction. Details for the following methods are provided in Appendix A.3.
Consider the case where . We can then eliminate
by expressing it as a function of S and
:
(29)
(29) where
(30)
(30) In the case of independent degrees in different layers (
) neither of which has a Poisson degree distribution (i.e.
and
), we are able to find two additional invariants, Equations (Equation32
(32)
(32) ) and (Equation33
(33)
(33) ) below. The reduced system, of dimension four, is given by
(31)
(31) where
is given by (Equation29
(29)
(29) ) and
(32)
(32)
(33)
(33) In the case of independent degree layers with Poisson degree distributions (
, see Appendix A.2), we have
and
. We can further reduce the dimension of the system by one with the following invariant:
(34)
(34)
5. Discussion
The complexity of dynamic multilayer networks makes understanding the disease dynamics evolution on such structures a challenge. Working with simplified models, which are nevertheless capable of retaining most important aspects of network evolution and disease transmission, is essential for gaining biological insight into mechanisms underlying basic disease features such as invasion, persistence, and outbreak size. In this work, we have developed a framework for modeling infectious diseases with multiple modes of transmission in the setting where the network changes in response to infection. Even in this seemingly complicated scenario, it is relatively straightforward to formulate a continuous-time stochastic process by considering transitions in the states of nodes and connected pairs of nodes. However, the state space of the Markov process becomes unmanageable as the size of the network increases and analysis of the non-Markovian aggregate process is complicated. Our main result, Theorem 3.1, rigorously derives the large graph limit of the stochastic process on a layered configuration model graph and, thus, gives a simple model retaining key features of the epidemic process while being amenable to analysis. Moreover, our results extend previous ones for the SIR process on a static, single-layer configuration model network [Citation24,Citation43].
As in [Citation24,Citation43], proof of Theorem 3.1, and expression of the limiting system in the general case, require introduction of the edge-based variable (). However, in contrast to previous results, we have defined the limiting system here in terms of dyads via the function
, which also turns out to provide the large-graph-consistent approximation of triples. Consequently, we obtain a simple characterization of the class of degree distributions on random configuration model graphs for which the model obtained via ordinary pair approximation [Citation78] coincides with the limiting system described by Theorem 3.1. The characterization criterion may be formulated in terms of average and excess degrees (
) or, equivalently, in terms of the corresponding identity for the probability generating function. For the single layer case, this condition is satisfied by Poisson but also by binomial and negative binomial distributions. In the non-PT degree distribution case, as our example in Section 3.3.3 illustrates, numerical comparison of κ and
could potentially be used to quantify how well a pairwise model accurately reflects the relevant disease dynamics.
Evolving network structure in response to illness is a basic feature that is relevant for many diseases, including Ebola, which was the original motivation for this study. The importance of transmission both within the community and to care-givers for Ebola has empirical support [Citation26,Citation49,Citation80], and these different transmission routes have been incorporated into modeling studies [Citation27,Citation37,Citation51,Citation63,Citation73,Citation79,Citation90,Citation94,Citation101]. Funeral transmission of Ebola is additionally an important concern [Citation41,Citation60], and many modeling studies have incorporated Ebola transmission through unsafe burial practices [Citation51,Citation101,Citation103]. The general multi-layer framework we have presented here with activation and de-activation of edges is flexible and can be extended to include these different Ebola-specific considerations. For example, we can consider a layer corresponding to disease transmission through funerals, with activation of edges in this layer occurring following entry into a death via disease class. Similarly, the basic SIR states for the nodes presented here can be extended to incorporate additional states such an exposed (latent) class, which is important for Ebola [Citation52]. The 2014 West Africa Ebola outbreak prompted an outpouring of modeling studies, utilizing a variety of approaches including ODEs [Citation32,Citation79,Citation90], stochastic processes [Citation27,Citation73], metapopulations [Citation63,Citation94], and contact networks [Citation83,Citation104]. Our work contributes a rigorous approach to understanding how the evolution of network structure in response to infection impacts disease dynamics on layered configuration model networks.
The modeling framework we present is flexible, for example being able accommodate arbitrary joint degree distributions with finite second moment for an arbitrary number of layers. As in the single layer configuration model, however, wiring within each layer occurs at random. Empirical networks often possess features such as community structure [Citation77] or triad closure [Citation100] that are not present in configuration model networks. Despite this, the layered configuration model setting can still yield biological and epidemiological insights due to its tractability for analysis and statistical inference. As demonstrated in the two-layer community-healthcare example in Section 4, the large graph limit we have derived is indeed tractable. The basic reproduction number can be calculated, and its analysis provides insight into how the structure of the different layers and their coupling through edge dynamics affect disease invasion and the final size of the outbreak. Theorem 3.1 and Corollary 3.4 also provide reference points for examining the impact of more realistic network features such as clustering and community structure on disease spread on dynamic multilayer networks.
The general framework presented here can be adapted to diseases with multiple modes of transmission (e.g. those with sexually and non-sexually transmitted infections). Application of this framework to specific diseases, such as Ebola, will require investigation into parameter identifiability and statistical estimation methods. The large graph limit derived here will aid such analysis and, in fact, suggests a hybrid approach in which the node state transitions remain stochastic but the dyads are approximated using the limiting differential equations (or, if possible, invariants such as those found in Section 4). Even for large networks, the resulting Markov process approximation would allow for computationally inexpensive maximum likelihood estimation. Finally, we mention that interventions (e.g. vaccination) can also be incorporated into this framework. The relative simplicity of the limiting system should allow for evaluation of the impact of proposed interventions, for example via sensitivity analysis of and the final outbreak size or via methods of optimal control (e.g. optimize vaccine distribution, see [Citation53]). This could be critical for providing actionable recommendations to public health policymakers with the aim of curbing current epidemics or preventing future outbreaks.
Acknowledgements
We thank Mason Porter and KaYin Leung for their helpful comments during manuscript preparation. We also thank the Mathematical Biosciences Institute at The Ohio State University for its assistance in providing us with space and the necessary computational resources.
Disclosure statement
No potential conflict of interest was reported by the authors.
ORCID
Grzegorz A. Rempała http://orcid.org/0000-0002-6307-4555
Additional information
Funding
References
- M. Altmann, Susceptible-infected-removed epidemic models with dynamic partnerships, J. Math. Biol. 33(6) (1995), pp. 661–675.
- M. Altmann, The deterministic limit of infectious disease models with dynamic partners, Math. Biosci. 150(2) (1998), pp. 153–175.
- H. Andersson, Limit theorems for a random graph epidemic model, Ann. Appl. Probab. 8(1998), pp. 1331–1349.
- H. Andersson and T. Britton, Stochastic Epidemic Models and their Statistical Analysis, Vol. 4, Springer, New York, 2000.
- J. Arino, F. Brauer, P. Van Den Driessche, J. Watmough, and J. Wu, A final size relation for epidemic models, Math. Biosci. Eng. 4(2) (2007), p. 159–175.
- D. Balcan, V. Colizza, B. Gonçalves, H. Hu, J.J. Ramasco, and A. Vespignani, Multiscale mobility networks and the spatial spreading of infectious diseases, Proc. Natl. Acad. Sci. 106(51) (2009), pp. 21484–21489.
- F. Ball and P. Neal, Network epidemic models with two levels of mixing, Math. Biosci. 212(1) (2008), pp. 69–87.
- S. Bansal, B.T. Grenfell, and L.A. Meyers, When individual behaviour matters: Homogeneous and network models in epidemiology, J. R. Soc. Interface 4(16) (2007), pp. 879–891.
- S. Bansal, J. Read, B. Pourbohloul, and L.A. Meyers, The dynamic nature of contact networks in infectious disease epidemiology, J. Biol. Dyn. 4(5) (2010), pp. 478–489.
- A.D. Barbour and G. Reinert, Approximating the epidemic curve, Electron. J. Probab. 18(54) (2013), pp. 1–30.
- M. Barthélemy, A. Barrat, R. Pastor-Satorras, and A. Vespignani, Velocity and hierarchical spread of epidemic outbreaks in scale-free networks, Phys. Rev. Lett. 92(17) (2004), p. 178701. doi:doi: 10.1103/PhysRevLett.92.178701.
- M. Barthélemy, A. Barrat, R. Pastor-Satorras, and A. Vespignani, Dynamical patterns of epidemic outbreaks in complex heterogeneous networks, J. Theoret. Biol. 235 (2005), pp. 275–288.
- F. Battiston, V. Nicosia, and V. Latora, Structural measures for multiplex networks, Phys. Rev. E 89(3) (2014), p. 032804. doi:doi: 10.1103/PhysRevE.89.032804.
- L. Bengtsson, J. Gaudart, X. Lu, S. Moore, E. Wetter, K. Sallah, S. Rebaudet, and R. Piarroux, Using mobile phone data to predict the spatial spread of cholera, Sci. Rep. 5 (2015), p. 923. 10.1038/srep08.
- T. Bohman and M. Picollelli, Sir epidemics on random graphs with a fixed degree sequence, Random Structures Algorithms 41(2) (2012), pp. 179–214.
- D. Brockmann, Human mobility and spatial disease dynamics, in Reviews of nonlinear dynamics and complexity, vol 2, H.G. Schuster, eds., Wiley-VCH Verlag, GmbH Co, KGaA, Weinheim, Germany, 2010.
- D. Brockmann and D. Helbing, The hidden geometry of complex, network-driven contagion phenomena, Science 342(6164) (2013), pp. 1337–1342.
- C. Buono, L.G. Alvarez-Zuzek, P.A. Macri, and L.A. Braunstein, Epidemics in partially overlapped multiplex networks, PLoS ONE 9(3) (2014), p. 5.
- A. Cardillo, M. Zanin, J. Gómez-Gardeñes, M. Romance, A.J.G. del Amo, and S. Boccaletti, Modeling the multi-layer nature of the European air transport network: Resilience and passengers re-scheduling under random failures, Eur. Phys. J. Spec. Top. 215(1) (2013), pp. 23–33.
- G. Chowell and H. Nishiura, Transmission dynamics and control of ebola virus disease (evd): A review, BMC Med. 12(1) (2014), p. 196.
- V. Colizza, A. Barrat, M. Barth'elemy, and A. Vespignani, The role of the airline transportation network in the prediction and predictability of global epidemics, Proc. Natl. Acad. Sci. USA 103 (2006), pp. 2015–2020.
- C.E.M. Coltart, A.M. Johnson, and C.J.M. Whitty, Role of healthcare workers in early epidemic spread of Ebola: Policy implications of prophylactic compared to reactive vaccination policy in outbreak prevention and control, BMC Med. 13 (2015), p. 271.
- M. De Domenico, A. Solé-Ribalta, E. Cozzo, M. Kivelä, Y. Moreno, M.A. Porter, S. Gómez, and A. Arenas, Mathematical formulation of multilayer networks, Phys. Rev. X 3(4) (2013), p. 041022.
- L. Decreusefond, J.S. Dhersin, P. Moyal, and V.C. Tran, Large graph limit for an SIR process in random network with heterogeneous connectivity, Ann. Appl. Probab. 22(2) (2012), pp. 541–575.
- P.S. Dodds and D.J. Watts, Universal behavior in a generalized model of contagion, Phys. Rev. Lett. 92(21) (2004), pp. 218701(1)–218201(4).
- S.F. Dowell, R. Mukunu, T.G. Ksiazek, A.S. Khan, P.E. Rollin, and C. Peters, Transmission of ebola hemorrhagic fever: A study of risk factors in family members, kikwit, democratic republic of the congo, 1995, J. Infectious Diseases 179(Supplement 1) (1999), pp. S87–S91.
- J.M. Drake, R. Kaul, L.W. Alexander, S.M. O'Regan, A.M. Kramer, J.T. Pulliam, M.J. Ferrari, and A.W. Park, Ebola cases and health system demand in Liberia, PLoS Biol. 13(1) (2015), p. e1002056.
- K.T. Eames and M.J. Keeling, Modeling dynamic and network heterogeneities in the spread of sexually transmitted diseases, Proc. Natl. Acad. Sci. 99(20) (2002), pp. 13330–13335.
- K.T. Eames and M.J. Keeling, Monogamous networks and the spread of sexually transmitted diseases, Math. Biosci. 189(2) (2004), pp. 115–130.
- D. Easley and J. Kleinberg, Networks, crowds, and markets: reasoning about a highly connected world, Cambridge University Press, Cambridge, 2010.
- J.M. Epstein, J. Parker, D. Cummings, and R.A. Hammond, Coupled contagion dynamics of fear and disease: Mathematical and computational explorations, PLoS One 3(12) (2008), p. e3955.
- D. Fisman, E. Khoo, and A. Tuite, Early epidemic dynamics of the West African 2014 Ebola outbreak: Estimates derived with a simple two-parameter model, PLoS Currents 6 (2014), p. 1. doi:doi: 10.1371/currents.outbreaks.89c0d3783f36958d96ebbae97348d571.
- S. Funk and V.A. Jansen, Interacting epidemics on overlay networks, Phys. Rev. E81(3) (2010), p. 036118.
- S. Funk, E. Gilad, C. Watkins, and V.A. Jansen, The spread of awareness and its impact on epidemic outbreaks, Pro. Natl. Acad. Sci. 106(16) (2009), pp. 6872–6877.
- S. Funk, E. Gilad, and V. Jansen, Endemic disease, awareness, and local behavioural response, J. Theoret. Biol. 264(2) (2010), pp. 501–509.
- M. Goeijenbier, J.J.A. van Kampen, C.B.E.M. Reusken, M.P.G. Koopmans, and E.C.M. van Gorp, Ebola virus disease: A review on epidemiology, symptoms, treatment and pathogenesis, J. Med. 72(9) (2014), pp. 442–448.
- M.F. Gomes, A.P. Piontti, L. Rossi, D. Chao, I. Longini, M.E. Halloran, and A. Vespignani, Assessing the international spreading risk associated with the 2014 West African Ebola outbreak, PLoS Currents 6 (2014), p. 1. doi:10.1371/currents.outbreaks.cd818f63d40e24aef769dda7df9e0da5.
- C. Granell, S. Gómez, and A. Arenas, Dynamical interplay between awareness and epidemic spreading in multiplex networks, Phys. Rev. Lett. 111(12) (2013), p. 128701.
- P. Grassberger, On the critical behavior of the general epidemic process and dynamical percolation, Math. Biosci. 63(2) (1983), pp. 157–172.
- T. Gross, C.J.D. D'Lima, and B. Blasius, Epidemic dynamics on an adaptive network, Phys. Rev. Lett. 96(20) (2006), p. 208701.
- B.S. Hewlett and R.P. Amola, Cultural contexts of Ebola in northern Uganda, Emerg. Infect. Dis. 9 (2003), pp. 1242–1248.
- T. House and M.J. Keeling, Insights from unifying modern approximations to infections on networks, J. R. Soc. Interface 8(54) (2011), pp. 67–73.
- S. Janson, M. Luczak, and P. Windridge, Law of large numbers for the SIR epidemic on a random graph with given degrees, Random Structures Algorithms 45(4) (2014), pp. 724–761.
- H.H. Jo, S.K. Baek, and H.T. Moon, Immunization dynamics on a two-layer network model, Phys. A 361(2) (2006), pp. 534–542.
- M. Keeling, Correlation equations for endemic diseases: Externally imposed and internally generated heterogeneity, Proc. R. Soc. Lond. B 266(1422) (1999), pp. 953–960.
- M.J. Keeling, The effects of local spatial structure on epidemiological invasions, Proc. R. Soc. Lond. B 266(1421) (1999), pp. 859–867.
- W.O. Kermack and A.G. McKendrick, A contribution to the mathematical theory of epidemics, Proc. R. Soc. Lond. Ser. A 115 (1927), pp. 700–721.
- M. Kivelä, A. Arenas, M. Barthelemy, J.P. Gleeson, Y. Moreno, and M.A. Porter, Multilayer networks, J. Complex Networks 2 (2014), pp. 203–271.
- T. Kratz, P. Roddy, A.T. Oloma, B. Jeffs, D.P. Ciruelo, O. de la Rosa, and M. Borchert, Ebola Virus Disease outbreak in Isiro, Democratic Republic of the Congo, 2012: Signs and symptoms, management and outcomes, PLoS ONE 10(6) (2015), p. e0129333.
- T.G. Kurtz, Solutions of ordinary differential equations as limits of pure jump markov processes, J. Appl. Probab. 7(1) (1970), pp. 49–58.
- J. Legrand, R. Grais, P. Boelle, A. Valleron, and A. Flahault, Understanding the dynamics of ebola epidemics, Epidemiol. Infection 135(04) (2007), pp. 610–621.
- P.E. Lekone and B.F. Finkenstädt, Statistical inference in a stochastic epidemic SEIR model with control intervention: Ebola as a case study, Biometrics 62(4) (2006), pp. 1170–1177.
- S. Lenhart and J.T. Workman, Optimal control applied to biological models, CRC Press, Boca Raton, FL, 2007.
- K.Y. Leung, M. Kretzschmar, and O. Diekmann, Dynamic concurrent partnership networks incorporating demography, Theoret. Popul. Biol. 82 (2012), pp. 229–239.
- K.Y. Leung, M. Kretzschmar, and O. Diekmann, SI infection on a dynamic partnership network: Characterization of R0, J. Math. Biol. 71 (2015), pp. 1–56.
- M. Li, J. Ma, and P. van den Driessche, Model for disease dynamics of a waterborne pathogen on a random network, J. Math. Biol. 71(4) (2015), pp. 961–977.
- J. Lindquist, J. Ma, P. van den Driessche, and F.H. Willeboordse, Effective degree network disease models, J. Math. Biol. 62(2) (2011), pp. 143–164.
- J. Ma and D.J. Earn, Generality of the final size formula for an epidemic of a newly invading infectious disease, Bull. Math. Biol. 68(3) (2006), pp. 679–702.
- J. Ma, P. van den Driessche, and F.H. Willeboordse, Effective degree household network disease model, J. Math. Biol. 66 (2013), pp. 75–94.
- G.D. Maganga, J. Kapetshi, N. Berthet, B. Kebela Ilunga, F. Kabange, P. Mbala Kingebeni, V.Mondonge, J.J.T. Muyembe, E. Bertherat, S. Briand, J. Cabore, A. Epelboin, P. Formenty, G. Kobinger, L. González-Angulo, I. Labouba, J.-C. Manuguerra, J.-M. Okwo-Bele, C. Dye, and E.M. Leroy, Ebola virus disease in the Democratic Republic of Congo, New Engl. J. Med. 371(22) (2014), pp. 2083–2091.
- A. Matanock, M.A. Arwady, P. Ayscue, J.D. Forrester, B. Gaddis, J.C. Hunter, B. Monroe, S.K. Pillai, C. Reed, I.J. Schafer, M. Massaquoi, B. Dahn, and K.M. De Cock, Ebola Virus Disease cases among health care workers not working in Ebola treatment units - Liberia, June-August, 2014, Morbidity Mortality Weekly Rep. 63(46) (2014), pp. 1077–1081.
- R.M. May and A.L. Lloyd, Infection dynamics on scale-free networks, Phys. Rev. E 64(6) (2001), p. 066112.
- S. Merler, M. Ajelli, L. Fumanelli, M.F. Gomes, A.P. y Piontti, L. Rossi, D.L. Chao, I.M. Longini, M.E.Halloran, and A. Vespignani, Spatiotemporal spread of the 2014 outbreak of Ebola virus disease in Liberia and the effectiveness of non-pharmaceutical interventions: A computational modelling analysis, Lancet Infect. Dis. 15(2) (2015), pp. 204–211.
- P. Meyer, A decomposition theorem for supermartingales, Illinois J. Math. 6(2) (1962), pp. 193–205.
- L.A. Meyers, B. Pourbohloul, M.E. Newman, D.M. Skowronski, and R.C. Brunham, Network theory and SARS: predicting outbreak diversity, J. Theoret. Biol. 232 (2005), pp. 71–81.
- J.C. Miller, A note on a paper by Erik Volz: SIR dynamics in random networks, J. Math. Biol. 62(3) (2011), pp. 349–358.
- J.C. Miller, Epidemics on networks with large initial conditions or changing structure, PLoS ONE9(7) (2014), p. e101421.
- J.C. Miller and I.Z. Kiss, Epidemic spread in networks: Existing methods and current challenges, Math. Model. Nat. Phenom. 9(2) (2014), p. 4.
- J.C. Miller and E.M. Volz, Incorporating disease and population structure into models of SIR disease in contact networks, PLoS ONE 8(8) (2013), p. e69162.
- J.C. Miller, A.C. Slim, and E.M. Volz, Edge-based compartmental modelling for infectious disease spread, J. R. Soc. Interface (2011), p. rsif20110403.
- M.E. Newman, Spread of epidemic disease on networks, Phys. Rev. E 66 (2002), p. 016128. doi:doi: 10.1103/PhysRevE.66.016128.
- M. Newman, Networks: An Introduction, Oxford University Press, Oxford, 2010.
- A. Pandey, K.E. Atkins, J. Medlock, N. Wenzel, J.P. Townsend, J.E. Childs, T.G. Nyenswah, M.L.Ndeffo-Mbah, and A.P. Galvani, Strategies for containing Ebola in West Africa, Science 346(6212) (2014), pp. 991–995.
- R. Pastor-Satorras and A. Vespignani, Epidemic spreading in scale-free networks, Phys. Rev. Lett. 86(14) (2001), pp. 3200–3203.
- L. Pellis, F. Ball, S. Bansal, K. Eames, T. House, V. Isham, and P. Trapman, Eight challenges for network epidemic models, Epidemics 10 (2015), pp. 58–62.
- L. Pellis, T. House, and M.J. Keeling, Exact and approximate moment closures for non-Markovian network epidemics, J. Theoret. Biol. 382 (2015), pp. 160–177.
- M.A. Porter, J.P. Onnela, and P.J. Mucha, Communities in networks, Notices Amer. Math. Soc. 56(9) (2009), pp. 1082–1097. 1164–1166.
- D. Rand, Correlation equations and pair approximations for spatial ecologies, Adv. Ecol. Theory 1 (2007), pp. 100–142. doi:doi: 10.1002/9781444311501.ch4.
- C.M. Rivers, E.T. Lofgren, M. Marathe, S. Eubank, and B.L. Lewis, Modeling the impact of interventions on an epidemic of Ebola in Sierra Leone and Liberia, PLoS Currents 6 (2014), p. 1. doi:doi: 10.1371/currents.outbreaks.4d41fe5d6c05e9df30ddce33c66d084c.
- T.H. Roels, A.S. Bloom, J. Buffington, G.L. Muhungu, W.R. MacKenzie, A.S. Khan, R. Ndambi, D.L. Noah, H.R. Rolka, C.J. Peters, and T.G. Ksiazek, Ebola hemorrhagive fever, Kikwit, Democratic Republic of the Congo, 1995: Risk factors for patients without a reported exposure, J. Infect. Dis. 179(Suppl 1) (1999), pp. S92–S97.
- M.P. Rombach, M.A. Porter, J.H. Fowler, and P.J. Mucha, Core-periphery structure in networks, SIAM J. Appl. Math. 74(1) (2014), pp. 167–190.
- F.D. Sahneh and C. Scoglio, May the best meme win!: New exploration of competitive epidemic spreading over arbitrary multi-layer networks, preprint (2013). Available at arXiv:1308.4880.
- S.V. Scarpino, A. Iamarino, C. Wells, D. Yamin, M. Ndeffo-Mbah, N.S. Wenzel, S.J. Fox, T. Nyenswah, F.L. Altice, and A.P. Galvani, et al., Epidemiological and viral genomic sequence analysis of the 2014 Ebola outbreak reveals clustered transmission, Clin. Infect. Dis. 60(7) (2015), pp. 1079–1082. doi:doi: 10.1093/cid/ciu1131.
- S. Shai and S. Dobson, Effect of resource constraints on intersimilar coupled networks, Phys. Rev. E 86(6) (2012), p. 066120. doi:doi: 10.1103/PhysRevE.86.066120.
- S. Shai and S. Dobson, Coupled adaptive complex networks, Phys. Rev. E 87(4) (2013), p. 042812. doi:doi: 10.1103/PhysRevE.87.042812.
- K.J. Sharkey, Deterministic epidemiological models at the individual level, J. Math. Biol. 57(3) (2008), pp. 311–331.
- K.J. Sharkey, I.Z. Kiss, R.R. Wilkinson, and P.L. Simon, Exact equations for SIR epidemics on tree graphs, Bull. Math. Biol. 77(4) (2015), pp. 614–645.
- L.B. Shaw and I.B. Schwartz, Fluctuating epidemics on adaptive networks, Phys. Rev. E 77(6) (2008), p. 066101. doi:doi: 10.1103/PhysRevE.77.066101.
- A.J. Tatem, Y.L. Qiu, D.L. Smith, O. Sabot, A.S. Ali, and B. Moonen, The use of mobile phone data for the estimation of the travel patterns and imported Plasmodium falciparum rates among Zanzibar residents, Malar. J. 8 (2009), p.287.
- B. Tsanou, G.M. Moremedi, R. Kaondera-Shava, J.M. Lubuma, and N. Morris, A simple mathematical model for Ebola in Africa, J. Biol. Dyn. 1(11) (2017), pp. 42–74. doi:doi: 10.1080/17513758.2016.1229817.
- J. Ugander, L. Backstrom, C. Marlow, and J. Kleinberg, Structural diversity in social contagion, Proc. Natl. Acad. Sci. USA 109(16) (2012), pp. 5962–5966.
- E. Valdano, L. Ferreri, C. Poletto, and V. Colizza, Analytical computation of the epidemic threshold on temporal networks, Phys. Rev. X 5(2) (2015), p. 021005.
- E. Valdano, C. Poletto, and V. Colizza, Infection propagator approach to compute epidemic thresholds on temporal networks: impact of immunity and of limited temporal resolution, Eur. Phys. J. B 88(12) (2015), pp. 1–11.
- L. Valdez, H.H.A. Rêgo, H. Stanley, and L. Braunstein, Predicting the extinction of Ebola spreading in Liberia due to mitigation strategies, preprint (2015). Available at arXiv:1502.01326.
- P. van den Driessche and J. Watmough, Reproduction numbers and sub-threshold endemic equilibria for compartmental models of disease transmission, Math. Biosci. 180 (2002), pp. 29–48.
- R. Van Der Hofstad, Random graphs and complex networks (2009), p. 11. Available on http://www.win.tue.nl/rhofstad/NotesRGCN.pdf.
- E. Volz, SIR dynamics in random networks with heterogeneous connectivity, J. Math. Biol. 56(3) (2008), pp. 293–310.
- E. Volz and L.A. Meyers, Susceptible–infected–recovered epidemics in dynamic contact networks, Proc. R. Soc. Lond. B 274(1628) (2007), pp. 2925–2934.
- Y. Wang and G. Xiao, Effects of interconnections on epidemics in network of networks, in 2011 7th International Conference on Wireless Communications, Networking and Mobile Computing (WiCOM), Wuhan, IEEE, 2011, pp. 1–4.
- D.J. Watts and S.H. Strogatz, Collective dynamics of ‘small-world’ networks, Nature 393(6684) (1998), pp. 440–442.
- G. Webb, C. Browne, X. Huo, O. Seydi, M. Seydi, and P. Magal, A model of the 2014 Ebola epidemic in West Africa with contact tracing, PLoS Currents 7 (2014), p. 1. doi:doi: 10.1371/currents.outbreaks.846b2a31ef37018b7d1126a9c8adf22a.
- X. Wei, N. Valler, B.A. Prakash, I. Neamtiu, M. Faloutsos, and C. Faloutsos, Competing memes propagation on networks: A case study of composite networks, ACM SIGCOMM Comput. Commun. Rev. 42(5) (2012), pp. 5–12.
- J.S. Weitz and J. Dushoff, Modeling post-death transmission of Ebola: Challenges for inference and opportunities for control, Sci. Rep. 5 (2015), p. 8751. doi:doi: 10.1038/srep08751.
- C. Wells, D. Yamin, M.L. Ndeffo-Mbah, N. Wenzel, S.G. Gaffney, J.P. Townsend, L.A. Meyers, M.Fallah, T.G. Nyenswah, F.L. Altice, K.E. Atkins, and A.P. Galvani, Harnessing case isolation and ring vaccination to control Ebola, PLoS Negl. Trop. Dis. 9(6) (2015), p. e0003794. doi:doi: 10.1371/journal.pntd.0003794.
- A. Wesolowski, N. Eagle, A.J. Tatem, D.L. Smith, A.M. Noor, R.W. Snow, and C.O. Buckee, Quantifying the impact of human mobility on malaria, Science 338(6104) (2012), pp. 267–270.
- D.J. Wilkinson, Stochastic modelling for quantitative description of heterogeneous biological systems, Nat. Rev. Genet. 10(2) (2009), pp. 122–133.
- O. Yağan and V. Gligor, Analysis of complex contagions in random multiplex networks, Phys. Rev. E 86(3) (2012), p. 036103. doi:doi: 10.1103/PhysRevE.86.036103.
- O. Yagan, D. Qian, J. Zhang, and D. Cochran, Conjoining speeds up information diffusion in overlaying social-physical networks, IEEE J. Selected Areas Commun. 31(6) (2013), pp. 1038–1048.
- D.H. Zanette and S. Risau-Gusmán, Infection spreading in a population with evolving contacts, J. Biol. Phys. 34(1–2) (2008), pp. 135–148.
- D. Zhao, L. Li, S. Li, Y. Huo, and Y. Yang, Identifying influential spreaders in interconnected networks, Phys. Scripta 89(1) (2014), p. 015203. doi:doi: 10.1088/0031-8949/89/01/015203.
Appendix 1. Summary of notation
The notation for the layered configuration model graph:
| n | = | number of nodes |
| r | = | number of layers in layered configuration model |
| = | multi-degree with degree | |
| ψ | = | probability generating function of the multivariate degree distribution |
| = | layered configuration model with n nodes, r layers and degree distribution ψ | |
| = | average i-degree | |
| = | normalized average excess j-degree of an i-neighbour | |
| = | average excess i-degree of a susceptible node | |
| = | average excess i-degree of a susceptible node chosen randomly as a j-neighbour of an infectious node |
The notation for the process:
| m | = | number of deactivating layers |
| = | rate of infection along j-edges | |
| = | rate of deactivation (drop) of j-edges | |
| = | rate of activation of j-edges | |
| γ | = | rate of recovery |
| = | number of infectious, susceptible active j-neighbours of u, for susceptible u | |
| = | number of infectious, susceptible deactivated j-neighbours of u, for susceptible u | |
| = | number of nodes (of given disease status) | |
| = | number of active edges between nodes (of given status) | |
| = | number of deactive edges between nodes (of given status) | |
| = | number of edges belonging to susceptible nodes | |
| = | quantity defined by Equation (Equation6 | |
| = | integrable function part of evolution of |
The notation for the large graph limit:
| S, I, R | = | number of nodes (of given disease status) |
| [SI], [SS] | = | number of active edges between nodes (of given status) |
| [ | = | number of deactive edges between nodes (of given status) |
| = | large graph limit of | |
| = | initial condition of | |
| = | integrable function for evolution of | |
| = | function of network structure used in large graph limit, defined by Equation (Equation10 |
Appendix 2. Proof of the limit theorem
In this section, we provide the proof of our main result, Theorem 3.1, preceded by two lemmas. The derivation of our results relies on the key observation, summarized in Remark A.1, that in a finite graph the neighbourhood of a susceptible node may be described by a certain multivariate hypergeometric distribution. Lemma A.1 shows that and
can be expressed in the limit as functions of
given by (Equation6
(6)
(6) ). Lemma A.2 shows that the dynamics of the scaled process on the finite graph converges, in the appropriate sense, to the dynamics described by the ODE system (Equation12
(12)
(12) ) involving
. Theorem 3.1 then follows from Lemma A.2 using Doob's and Gronwall's inequalities.
Recall that we take operations on vectors such as multiplication, division, integration and ordering to be coordinatewise. We first provide an important remark about the layer j neighbourhood of a susceptible node of degree , i.e.
for
. The distribution of the neighbourhood is critical when we consider the expectations of
which are mixed moments with respect to the neighbourhood distribution. Recall that we consider the evolution of the
process on a realization of the LCM random graph that has been generated by time t=0. However, we could alternatively consider an equivalent process whereby the graph is revealed dynamically as infections occur, as in [Citation24,Citation43]. In the latter process, a susceptible node
remains unpaired until it becomes infected. Equivalently we could also pair off all unpaired edges at any time t>0 (uniformly at random and independently in each layer, according to the LCM construction) in order to define the neighbourhood of node i. The following remark is perhaps most easily understood by keeping this equivalent construction in mind and recalling that the probability space considered is that of all random configurations, as described in Section 3.1.
Remark A.1
For and
, and conditionally on the process history up to time t, the vector
follows the multivariate hypergeometric distribution with probability mass function
supported on the four-simplex
. This implies
where
denotes expectation with respect to the hypergeometric distribution. We also note that, based on the LCM construction, the neighbourhoods of i in distinct layers are independent, i.e.
It follows from the above that the mixed moments are given by
(A1)
(A1) for
and
(A2)
(A2) Likewise, for any
,
Keeping in mind this remark, we proceed to prove the first lemma, which shows that and
can be expressed in the limit as functions of
.
Lemma A.1
Assume (A1) and . Then,
Proof.
. Note
where
indicates whether node i is of degree
and susceptible at time t>0. Recall from Remark A.1 that
for
. We claim that
(A3)
(A3) Indeed,
where
by (A2) and
Equation (EquationA3
(A3)
(A3) ) then implies that
is a càdlàg martingale process with mean zero and finite variation. By the triangle inequality,
The second term tends to zero by assumption (A2) and for the first term we have, by Doob's martingale inequality,
Since there are at most n jumps for
and each is of size one, it follows that the quadratic variation of
, which gives the needed result.
(b). By Equation (Equation5(5)
(5) ), we can write
Consider arbitrarily large N and
. By Markov's inequality, we have
since
for n sufficiently large,
, and we may apply the Monotone Convergence Theorem. So the tail of the sum is negligible since N is arbitrary and, by assumption,
. The result then follows since in
we showed convergence for fixed
.
Before proceeding with the next lemma, we give a brief remark on boundedness of our variables and define some useful functions.
Remark A.2
We note that and, for sufficiently large n,
(and likewise for
). By (A1),
is bounded away from 0 on
for finite T and, thus so is
. Furthermore, by Lemma A.1(b), we can take the same lower bound for
. Let
be a uniform lower bound for
,
and
. We will use the notation
and hence may write
.
Let and
be defined as in (Equation4
(4)
(4) ) and (Equation8
(8)
(8) ) and
as in (Equation11
(11)
(11) ). Define
where
and
are given by
(A4)
(A4) and
(A5)
(A5) Lemma A.2 shows that
and
tend to zero uniformly in probability. The convergence of
to zero will follow easily from Lemma A.1. The convergence of
to zero is less obvious and its proof involves consideration of the empirical hypergeometric mixed moments, i.e.
and
. We will use the facts that, in the limit, the hypergeometric mixed moments are approximately multinomial and we can replace
with a function of
by Lemma A.1. Therefore, it will be convenient to define the following compensators.
Let be given by
(A6)
(A6) and
(A7)
(A7) so that the hypergeometric mixed moment in Equation (EquationA1
(A1)
(A1) ) is given by
(A8)
(A8) We also define a function related to the multinomial distribution,
, which is given by
(A9)
(A9) and
(A10)
(A10) (Note that if quantities
and
were actual probabilities then
would be a mixed moment of the multinomial distribution.) Observe that there exists L>0 such that
(A11)
(A11) for any j,l (and uniformly in n) sinsce the domain of z is bounded away from 0 and
,
are uniformly bounded above by Remark A.2. It also follows that
is Lipschitz continuous in
.
Lemma A.2
Assume (A1)–(A3). Then,
Proof.
. Define
given by
. By Remark A.2 and (A1),
and
are in the domain of
for
. By definition of
in (EquationA5
(A5)
(A5) ),
Since
is Lipschitz continuous in
,
for some
. The result then follows from Lemma A.1(b) since (A3) implies
.
Regarding part note that, by definition in (EquationA4
(A4)
(A4) ),
. We will show that
as it follows similarly for
,
and
and together these imply
. In fact, we observe that
and so it suffices to show
(A12)
(A12) for
.
Let . We can rewrite
as
Thus, we define
so that
. Hence, it suffices to show
(A13)
(A13) This is done in what follows in two separate steps. Consider an arbitrary pair
We first show that as
(A14)
(A14) To this end, observe that
(A15)
(A15) for some
since
for n sufficiently large. From the bound on
in (EquationA11
(A11)
(A11) ), we also have
(A16)
(A16) Then (EquationA14
(A14)
(A14) ) follows from (EquationA15
(A15)
(A15) ) and (EquationA16
(A16)
(A16) ) together with (A3).
Next we show that for any
. We write
(A17)
(A17)
(A18)
(A18)
(A19)
(A19)
(A20)
(A20) and we will show that each of these terms tends to zero uniformly in probability.
By Remark A.1 and Equation (EquationA8(A8)
(A8) ), the process
is a zero-mean, piecewise-constant càdlàg martingale that jumps only if infection/recovery of a node of degree
(or a neighbour of a node of degree
) occurs or activation/drop of a j-edge or l-edge belonging to a node of degree
occurs. Recall that, for each layer, either activation or drops are possible, not both. Consider events impacting a node
. For infection or recovery events, of which there are at most
corresponding to infection and recovery of u itself or one of its j- or l-neighbours), the jump size is at most
. For deactivation and activation events of an l or j-edge, of which there are at most
affecting u, the jump size is also at most
. Recall that the number of nodes of degree
is approximately
for large n. The quadratic variation of
is the sum of its squared jumps (see, e.g. [Citation4] Chapter 9) and, thus, satisfies
for
and some
. Since
, Doob's martingale inequality implies
i.e. the term in (EquationA17
(A18)
(A18) ) tends to zero uniformly in probability.
In consideration of the term in (EquationA18(A19)
(A19) ), we note that
and
for
. For the case l=j, we have
for some
and since
is non-increasing on
. Thus, the term in (EquationA18
(A18)
(A18) ) tends to zero uniformly in probability by (A1).
For the term in (EquationA19(A19)
(A19) ), we observe
by the bound on
in (EquationA11
(A11)
(A11) ) and Lemma A.1(a).
Finally, since is Lipschitz continuous in
, we have
for some
and so the term in (EquationA20
(A20)
(A20) ) tends to zero uniformly in probability by Lemma A.1(b). Therefore, recalling also (EquationA14
(A14)
(A14) ) we conclude that (EquationA13
(A13)
(A13) ) holds and hence (EquationA12
(A12)
(A12) ) follows.
We may now complete the derivation of Theorem 3.1 via Gronwall's inequality (see, e.g. [Citation4]).
Proof of Theorem 3.1.Remove!
Proof of Theorem 3.1
Recall the definition of from Equations (EquationA4
(A4)
(A4) ) and (EquationA5
(A5)
(A5) ). Note that, by Equations (Equation3
(3)
(3) ) and (Equation7
(7)
(7) ),
where
where
. Note that each coordinate of
is a pure jump, càdlàg, zero mean, martingale process. Consider the process
which, by Equation (Equation3
(3)
(3) ), jumps only if infection of a node, recovery of a node or a j-edge drop/activation occurs at time s. Recall that, for each j, either activations or drops are possible, not both. Consider events corresponding to a node of degree
. For infection and recovery events the jump size,
, is not greater than that node's j-degree, and for activation and deactivation events, of which there are at most
affecting that node, the jump size is one. Since the number of nodes of degree
is approximately
for large n, the corresponding quadratic variation process satisfies
by (A3). Consequently, Doob's martingale inequality implies
. A similar argument applies also to
,
, and
as well as
and
, both of which make only unit jumps. Since by Lemma A.2 we have
, this implies
.
Note that is a (vector valued) Lipschitz continuous function on its domain, which we can take to be
by Remark A.2. Together with Gronwall's inequality, this implies
for some L>0, since the first term in the parenthesis tends to zero by (A2) and (Equation9
(9)
(9) ). The assertion follows when we take
.
Appendix 3. Equivalence with edge-based multiple modes of transmission model (Proof of Corollary 3.2)
We provide in this section the proof of Corollary 3.2, i.e. equivalence of the system (Equation12(12)
(12) ) with the edge-based model with multiple modes of transmission given by system (Equation13
(13)
(13) ). We will use bar notation to denote the variables of the edge-based model.
First, we observe that and
i.e.
satisfies the same differential equation as S. Therefore, by the uniqueness of the ODE solution,
(A21)
(A21) Secondly, we claim that
(A22)
(A22) Indeed,
and
which is the same differential equation as that satisfied by
, which proves (EquationA22
(A22)
(A22) ).
We define
Then,
. Moreover,
We now show that
satisfies the same differential equation:
where we have used (EquationA21
(A21)
(A21) ) and (EquationA22
(A22)
(A22) ). Since
it follows from the uniqueness of the ODE solution that
Hence,
, i.e.
which is the same differential equation as that for
in (Equation13
(13)
(13) ). Furthermore,
which implies that
It subsequently follows from (Equation13
(13)
(13) ) and Equation (EquationA21
(A21)
(A21) ) that S, I and R are also equivalent for the two models.
Appendix 4. Derivations of and
We provide here the derivations for and
as given in Equation (Equation20
(20)
(20) ). Recall that
is the average i-degree of a susceptible node. By Equation (EquationA3
(A3)
(A3) ), the probability that a node u is susceptible and of degree
is given by
. We can then calculate
as follows:
Recall that
is the average excess i-degree of a susceptible node chosen randomly as a j-neighbour of an infectious node. That is, we randomly select a j-edge between a susceptible node and an infectious node, and we calculate the excess i degree of the susceptible node. Let
denote the set of j-edges between susceptible nodes and infectious nodes and let
denote the set of j-edges between susceptible nodes of degree
and infectious nodes, so that
. Recall that
is the number of infectious j-neighbours of a susceptible node u. Also recall from Remark A.1 that, given
, the neighbourhood of u has a hypergeometric distribution and
. We first assume
and calculate
If j=i, we likewise get
Therefore, Equation (Equation20
(20)
(20) ) follows.
Alternatively, we recall the equivalent model with dynamic graph construction mentioned in Section 2 and consider a j-half edge of an infectious node that is forced to pair with a j-half edge of a susceptible node, which we denote by e, at time t. Let denote the set of j-half edges belonging to susceptible nodes and let
denote those belonging to susceptible nodes of degree
. We first assume
and calculate
as follows:
The case i=j follows likewise as above.
Appendix 5. Calculations for community-healthcare model
A.1. Basic reproduction number,
We use the next-generation matrix method (and corresponding notation) from [Citation95] to calculate . We consider I,
,
, and
to be the infective compartments (m=4). We consider the disease-free equilibrium for the system (Equation24
(24)
(24) ) given by
. The matrix corresponding to terms for new infections, F, is then given by
and the matrix corresponding to terms from all other transitions, V , is
Therefore,
and the next-generation matrix is given by
Then,
is the spectral radius of the next-generation matrix, i.e. the largest absolute value of an eigenvalue. We see that
has two zero eigenvalues, and the other two eigenvalues are determined by the characteristic polynomial:
Let
We solve
to determine
A.2. Independent Poissons case
We derive an invariant and a final size relation in the case of independent layers with Poisson distributions (i.e. ). First, we observe that, in this case,
which implies that
. Likewise,
.
We then transform the system (Equation24(24)
(24) ) using
which gives:
(A23)
(A23) Observe that (EquationA23
(A23)
(A23) ) fits the form of Arino et al. [Citation5]. Matching their notation, we ignore the decoupled I equation and let the infected compartments be
, the susceptible compartment y=S, the transmission row vector
,
, and
The system can then be written as
(A24)
(A24)
(A25)
(A25) Recall that
,
and from Equation (26) we have
Observe that
which implies that
Then, from integrating Equation (EquationA25
(A25)
(A25) ), we have
Transforming back to our original variables, this gives the invariant (Equation34
(34)
(34) ):
Let
denote the fraction of the population that escapes infection. Taking the limit
gives the final size relation (Equation28
(28)
(28) ):
A.3. Model reduction
Let σ and λ be as defined by Equation (Equation30(30)
(30) ). We will derive relation (Equation29
(29)
(29) ) to demonstrate our method of finding invariants. Suppose we have a function f which satisfies
Let
,
, and
. Then,
which by system (Equation24
(24)
(24) ) implies
Thus,
if the following system of equations is satisfied:
For a given C, the solution to this system is:
We choose
which implies
for some function g. Therefore,
from which separation of variables gives
for some function h. Hence,
which gives
from which separation of variables gives
for any constant K. Therefore,
is satisfied by any f of the form:
Substituting the initial conditions (Equation25
(25)
(25) ) into f=0 gives
Hence, the invariant is
i.e. relation (Equation29
(29)
(29) ).
The derivations of relations (Equation32(32)
(32) ) and (Equation33
(33)
(33) ), the additional invariants in the independent layers case, are similar. For (Equation32
(32)
(32) ), we look for an invariant of the form
. Likewise, for (Equation33
(33)
(33) ) we consider an invariant of the form
. The analysis follow analogously to above.