
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We fit an SARS-CoV-2 model to US data of COVID-19 cases and deaths. We conclude that the model is not structurally identifiable. We make the model identifiable by prefixing some of the parameters from external information. Practical identifiability of the model through Monte Carlo simulations reveals that two of the parameters may not be practically identifiable. With thus identified parameters, we set up an optimal control problem with social distancing and isolation as control variables. We investigate two scenarios: the controls are applied for the entire duration and the controls are applied only for the period of time. Our results show that if the controls are applied early in the epidemic, the reduction in the infected classes is at least an order of magnitude higher compared to when controls are applied with 2-week delay. Further, removing the controls before the pandemic ends leads to rebound of the infected classes.
1. Introduction
Mathematical models have been widely implemented to study the spread and interventions aimed to mitigate the impact of the COVID-19 pandemic. Model complexity has varied significantly, from the simple Susceptible, Exposed, Infected, Recovered (SEIR) model involving a few parameters to more elaborate models with many more parameters that incorporate testing efforts, contact tracing and social distancing protocols [Citation8,Citation12,Citation26,Citation29,Citation31,Citation38,Citation40,Citation41]. For instance, Tang et al. [Citation29] showed that intensive contact tracing followed by quarantine and isolation was effective for reducing the reproduction number and risk of transmission in a model that incorporated clinical progression of disease. In an extended SEIR model, Zou et al. considered testing and under-reporting of COVID-19 cases, which was later trained by machine learning algorithms [Citation41]. Lu et al. illustrated some of the limitations of model fitting based on confirmed cases alone in the absence of information about testing efforts overt time [Citation19]. Researchers have used the cumulative number of cases, quarantined population [Citation29], number of confirmed and fatality cases [Citation41], at early stages of the pandemic. However, the ability to accurately forecast epidemics is highly dependent on (i) amount and type of data, whether there exists sufficient data to identify the model parameters, and (ii) model structure, whether the model is structured to reveal its parameters from the ideal noise free data [Citation33,Citation34].
Insights from mathematical models that incorporate features of disease transmission, incubation period, and other features of a virus can be used to improve our understanding of the spread of diseases and investigate optimal intervention strategies. We are often challenged with the decision of implementing models that are simple enough to provide meaningful inference given the limited data but also models that realistic enough to capture key underlying virus dynamics and epidemiological states. The implementation of more complex features often involves models with large number of unknown parameters and epidemiological states that while important are often not observed or captured. The variability and lack of accuracy in the projections based on some mathematical models have raised concern among public health officials, specially during the early phase of the COVID-10 pandemic. Therefore, it is important that modelling studies of COVID-19 investigate the question of parameter identifiability [Citation21]. A model is said to be (structurally) identifiable, if its parameters can be determined uniquely from the observations such as daily cases and fatalities. If a model is unidentifiable, then infinitely many parameters would give the same observation. In that situation, multiple parameter combinations satisfying the parameter correlations would fit the same data sets, which will result in misleading and inaccurate predictions. Formally studying the parameter identifiability for COVID-19 models will be valuable for several reasons. First, it will provide some guidance about the limitations of the models themselves being proposed in providing valuable predictions and inferences based on data that is currently available. Findings of studies on parameter identifiability are also essential for increasing awareness about the importance of timely access to data that are instrumental for improving estimates and projections.
In this study, we propose a model to study the spread of SARS-CoV-2 and assess the effect of social intervention measures to curtail the spread of the COVID-19 pandemic during the early phase of the outbreak. The findings of this study are most relevant to understanding the spread of the pandemic as it unfolds initially. To our knowledge, this is the first study that has considered the question of both structural and practical identifiability of a COVID-19 model, but the structural identifiability of several COVID-19 models has been recently considered in [Citation21]. Structural and practical identifiability of epidemic models for Ebola, Cholera, Dengue, Rift Valley Fever and Zika have been studied before [Citation5,Citation9,Citation10,Citation32–35]. Even though, it is not possible to identify individual parameters of the epidemic model from the observations, two independent studies confirmed that it is possible to accurately estimate the basic reproduction number from the epidemic data [Citation9,Citation33]. In this study, we investigate the structural and practical identifiability of a COVID-19 model that considers six epidemic states. Susceptible (S) individuals can be transitioned into a latency period (E), become infectious with no symptoms and not being tested (), or can move into symptomatic infectious and tested state (
), symptomatic isolated and treated (
), and recovered individuals (R).
In Section 2, we consider a COVID-19 model with no infection control measures (e.g. social distancing), derive the basic reproductive number, and investigate parameter identifiability using daily COVID-19 cases and deaths data. In Section 3, we discuss structural and practical identifiability of the model. We determine structural identifiability using the Differential Algebra approach given its ability to eliminate the unobserved state variables. Using data on daily incidence of cases and deaths, we establish that the proposed model is not structurally identifiable but we improve its structural identifiability by fixing some of the parameters from external information. We further investigate parameters practical identifiability by performing Monte Carlo simulations on a constrained minimization problem numerically from noisy observations. This approach is local and is similar in nature to approaches with derived 95% confidence intervals, bootstrapping or sensitivity analysis. Although Monte Carlo Simulations (MCS) are not a novel approach, the novelty in our approach is that we are applying MCS only after we have determined that the parameter estimation problem is well-posed. This framework is expected to lead to much more reliable solutions. A subset of two parameters were deemed practically unidentifiable. Given that shelter-in-place order were initiated in March 19, 2020, Section 4 incorporates an optimal control with control variables of reduction in transmission rates for exposed and asymptomatic infected individuals, as well as self-isolation for symptomatic infected individuals. The forward–backward sweep method is used to approximate the solution of the model with controls. Section 5 provides a discussion of the findings described in this study.
Structural non-identifiability arises from excessive parametrization of the proposed model or by choice of a completely wrong model structure [Citation22,Citation32]. This problem can often be resolved by reformulating the model to reduce the number of states and parameters or fix parameter values that are less relevant to model predictions of interest. Lack of practical identifiability can be remedied by employing an alternative model of lower complexity, collecting more data about model states to better characterize the system dynamic features, increasing spatial–temporal resolution of the data to better constrain the model parameters, and/or reducing the number of parameters that are jointly estimated.
2. A basic compartmental model for COVID-19 infection
We introduce a mathematical model of COVID-19 by splitting the total population, , into non-intersecting classes based on the disease status. In US individuals with symptoms of COVID-19 were asked to self isolate at home. We denote this class by
. If clinical symptoms were eventually developed, individuals were admitted to a hospital. We denote the hospitalized individuals who are isolated and treated by
. Individuals who were not tested but may have had COVID-19 without symptoms are denoted by
. So, the total population
is divided into sub-populations that consists of susceptible individuals
, exposed individuals
, symptomatic and infectious individuals that are tested
, asymptomatic and infectious individuals that are not tested and remain in the community
, severe symptomatic individuals who are hospitalized and isolated
, and recovered individuals
. The total population size is
. We use standard incidence but since the isolated individuals do not mix in the population, we divide by
. This implicitly assumes that the infection rate of hospital workers from the hospitalized COVID-19 individuals is relatively low and can be neglected. The model takes the form:
(1)
(1) Susceptible individuals acquire COVID-19 infection upon effective contact with an exposed individual or an infectious individual who may or may not show COVID-19 symptoms. The COVID-19 infection rate is assumed to be different for each infection class to account for the heterogeneity of the contact rates of infectious individuals with or without the clinical COVID-19 symptoms. Namely, the parameters
and
represent the transmission rates for individuals in
and
compartments respectively. It is estimated that infectiousness starts 5, 8 and 11 days before the incubation period ends [Citation14]. Recent papers have modelled the latent period and the pre-symptomatic period separately [Citation13]. In this study, to keep the model simple we lumped these two stages in a class called E, which denotes the incubation period. The average transmission rate of two stages is not zero. Hence
. Therefore, newly infected individuals that move to the incubation class E become infectious while they are still in class E. After the incubation period, which lasts for 1/k days, a fraction (
) of exposed individuals start showing clinical symptoms of COVID-19 and get tested. The remaining
fraction of the exposed individuals do not show any clinical symptoms of COVID-19. Infectious individuals might develop severe infection and get hospitalized at rate α. Infectious individuals in
,
and
classes recover at rates
and
respectively. A flow diagram of the model (Equation1
(1)
(1) ) is shown in Figure . The state variables and parameters of the model are described in Tables and , respectively.
Figure 1. Flow chart of model (Equation1(1)
(1) ) showing the transition of individuals between the classes defined by disease status.
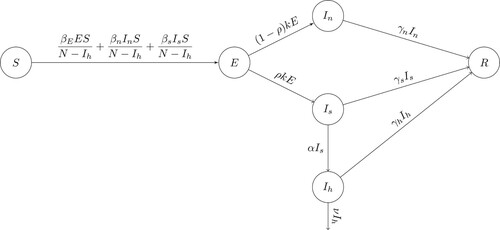
Table 1. State variables of the COVID-19 model (Equation1(1)
(1) ) and their definitions.
Table 2. Definition of the COVID-19 model parameters.
We compute the reproduction number of (Equation1(1)
(1) ) to obtain
where
is the initial total population size. The reproduction number consists of three terms, each of which corresponds to secondary cases produced by one type of infectious individuals. The first term is the number of secondary infections produced by exposed individuals in an entirely susceptible population during their lifespan as exposed, the second term is the number of secondary infections produced by asymptomatic and uncounted individuals in an entirely susceptible population during their lifespan as asymptomatic; finally, the third term corresponds to the number of secondary infections produced by symptomatic individuals during their lifespan as symptomatic and counted.
3. Identifiability analysis: can we uniquely estimate the model parameters?
In the literature, the term identifiability analysis is used to describe whether it is possible to uniquely recover model parameters from a given set of data. It is a crucial step in parameter estimation problem and is usually performed in two steps. The first step is the structural identifiability which is a theoretical property of the epidemic model. Structural identifiability explores whether the epidemic model is structured to reveal its parameters from the observations. Here we use the term observation to refer to continuous smooth output where the data is measured at the discrete time points. If a compartmental epidemic model is structurally unidentifiable, it means that different sets of parameters could produce the same output. Hence a structurally unidentifiable epidemic model should not be used to analyse epidemiological data or design intervention strategies. If an epidemic model is structurally identifiable, then the second step is the practical identifiability. Practical identifiability considers the actual epidemiological data which is contaminated with noise.
3.1. Structural identifiability analysis
To study the structural identifiability of the epidemic model, we represent the model (Equation1(1)
(1) ) in the following compact form:
(2)
(2) where
denotes the state variables and
denotes the parameters of the model of (Equation1
(1)
(1) ). The observations, such as daily incidences and deaths, are functions of the state variables. Let
denote the daily incidences and
denote daily reported deaths, then in terms of model variables the observations take the following forms;
(3)
(3) In compact form, we denote the observations as
such that
(4)
(4) Structural identifiability determines whether the model (Equation2
(2)
(2) ) is structured to reveal its parameters,
, from observations (Equation4
(4)
(4) ). Structural identifiability is a theoretical result which considers the ‘perfect’ scenario assuming that observation is given continuously for all time and is noise free. A model is said to be structurally (uniquely) identifiable if all the parameters in
can be recovered from the observations
. If even one parameter cannot be identified, the mode is said to be structurally unidentifiable. Several methods for determining structural identifiability have been introduced and studied widely [Citation10,Citation22,Citation33]. Here, we will use the Differential Algebra approach to study the structural identifiability [Citation22]. The goal of Differential Algebra approach is to eliminate the unobserved state variables using the system of differential equations in (Equation2
(2)
(2) ) and to obtain input–output equations. We obtain the input–output equations of the model (Equation1
(1)
(1) ) using the observations (Equation3
(3)
(3) ), which consist of a couple of monic differential polynomials in the observed state variables and their derivatives. The coefficients of these polynomials are rational functions of the parameters of the model. We obtain the following input–output equations using DAISY [Citation1].
(5)
(5)
(6)
(6) where
Input–output equations (Equation5
(5)
(5) ) and (Equation6
(6)
(6) ) are differential algebraic polynomials of outputs
and
whose coefficients consist of model parameters. We say that the model (Equation2
(2)
(2) ) is structurally identifiable if the mapping from parameter space to the coefficients of input–output equations (Equation5
(5)
(5) ) and (Equation6
(6)
(6) ) are one-to-one [Citation32,Citation34]. Within differential algebra approach, we define the structural identifiability as follows [Citation10,Citation34]:
Definition 3.1
Let denote the coefficients of the input–output equations (Equation5
(5)
(5) ) and (Equation6
(6)
(6) ). That is
(7)
(7) with
denoting the parameters of the model (Equation1
(1)
(1) ). Then we say that the model (Equation1
(1)
(1) ) is structured to reveal its parameters from the observations (Equation3
(3)
(3) ) if and only if
Following the definition of the structural identifiability, we set . Then solving
, we obtain the following parameter correlations:
(8)
(8) As it is evident in (Equation8
(8)
(8) ), parameters of the model (Equation1
(1)
(1) ) cannot be obtained from the observations of daily incidences and deaths. Some parameter combinations can be identified such as
or
, but individual parameters
or ν cannot be identified. Even if α is fixed to
in (Equation8
(8)
(8) ), then we can only obtain
,
and
, and the parameters
still cannot be identified. Thus we have proved the following Proposition 3.1.
Proposition 3.1
The parameters of the model (Equation1(1)
(1) ) are not structurally identifiable from the observations of daily incidences and deaths.
In this approach, we assume that the initial conditions are given and fixed. An important advantage of using Differential Algebra approach in structural identifiability analysis is that we obtain parameter correlations as in (Equation8(8)
(8) ). These parameter correlations are then used to obtain a structurally identifiable model [Citation10,Citation32]. However, the correlations in (Equation8
(8)
(8) ) are highly complex. In an attempt to get a structurally identifiable model, we rewrite the parameter correlations into the following simpler forms;
(9)
(9) Next, we factor out
from the incidences term in model (Equation1
(1)
(1) ) as follows:
where
and
. With this setting, if we fix parameter α at
, and
at
then the parameter correlations in (Equation9
(9)
(9) ) become
(10)
(10) We can see from (Equation10
(10)
(10) ) that the parameters
and ν can be identified; parameter combinations
and
can be identified; but parameter
cannot be identified. For instance, the parameter correlation
implies that infinitely many values of the parameters
and ρ would generate the same output as long as the parameter relationship
remains constant at
. Same is true for parameters ρ and
satisfying the relationship
. In the view of these results, we obtain the following Proposition 3.2.
Proposition 3.2
If the parameters, and ρ are fixed, then solving
, we obtain
Since,
still cannot be obtained we say that the model (Equation1
(1)
(1) ) is structurally unidentifiable from the observations of daily incidences and deaths.
Remark 3.1
The model (Equation1(1)
(1) ) is not structurally identifiable, because the parameter
does not appear in the parameter relations in (Equation10
(10)
(10) ). But all the other parameters are identifiable. We use the following strategy in an attempt to make
an identifiable parameter; we use the basic reproduction number
to determine the infection rate
as
If we use estimate from the literature of
, and fix
at that value, then
will be identifiable as well.
3.1.1. Structural identifiability of COVID-19 epidemic models
We take this opportunity and study the structural identifiability of some COVID-19 models. Several models are proposed within the last year for COVID-19 infection and most of these models, including our model (Equation1(1)
(1) ), are extensions of the following Kermack–McKendrick type SEIR epidemic model without human demography.
(M$_1$)
(M$_1$) As before we assume that the observations are daily incidences and COVID-19 deaths. In terms of the state variables of the model (EquationM1
(M$_1$)
(M$_1$) ), observations becomes
We have determined the input–output equations of the model EquationM1
(M$_1$)
(M$_1$) and show that it is structurally (globally) identifiable and obtain the following result (see Appendix for details).
Proposition 3.3
The model (EquationM1(M$_1$)
(M$_1$) ) is structurally identifiable from the observations of daily incidences
, and deaths
.
In Proposition 3.3, it is assumed that all new incidences, kE are observed. However, this is not the case in reality. A key feature of COVID-19 cases is that majority of new infections are generated by individuals who do not show any clinical symptoms of COVID-19. A big portion of these asymptomatic individuals will remain undetected and only some might be detected through random testing or contact tracing. This leads to the fact that only the fraction of new incidences are reported. We continue with the identifiability analysis assuming that only fractions of daily incidences are observed, that is if we set for
then the parameter correlations for model (EquationM1
(M$_1$)
(M$_1$) ) become
(12)
(12) Assuming a much realistic scenario that only a fraction of actual incidences can be observed, makes the simple SEIR model unidentifiable. Thus we have obtained the following result for model (EquationM1
(M$_1$)
(M$_1$) ).
Proposition 3.4
The model (EquationM1(M$_1$)
(M$_1$) ) with a fraction of observed cases is not structurally identifiable from the observations of daily incidences,
, and deaths
.
Remark 3.2
From parameter correlations (Equation11(12)
(12) ), we see that if we set
, that is if we assume that the fraction of the incidences being reported daily is known, then the model (EquationM1
(M$_1$)
(M$_1$) ) becomes structurally identifiable from daily incidences and deaths.
The next model, we will study is the one where infected class I is further divided into two subclasses, as asymptomatic individuals and symptomatic individuals
. Then we obtain the following model:
(M$_2$)
(M$_2$) In this model, we assume that all the infected individuals who are showing symptoms are getting tested. That is for this model (EquationM2
(M$_2$)
(M$_2$) ), observations of daily incidences and deaths take the form
. Determining the input–output equations and then solving
, gives the following parameter correlations;
(14)
(14)
Proposition 3.5
The model (EquationM2(M$_2$)
(M$_2$) ) is not structurally identifiable from the observations of daily incidences,
, and deaths
.
If we assume both the incubation period and the fraction of infected individuals who are showing symptoms are known, and set ,
. Furthermore, if we set as before,
and
, then the following parameters of the model (EquationM2
(M$_2$)
(M$_2$) ) can be identified,
Since all the parameter but
can be identified. We use the same strategy as before and determine
from the basic reproduction number of the model (EquationM2
(M$_2$)
(M$_2$) ). We summarize the results in the following proposition.
Proposition 3.6
If the parameters k and ρ are fixed, then and ν can be identified. But the model (EquationM2
(M$_2$)
(M$_2$) ) remains structurally unidentifiable from the observations of daily incidences and deaths, since
cannot be identified.
However, the infection rate can be determined from the identifiable model parameters through basic reproduction number
,
Our intention for considering models (EquationM1(M$_1$)
(M$_1$) ) and (EquationM2
(M$_2$)
(M$_2$) ) is to find the most complex COVID-19 model which is intrinsically identifiable, that is identifiable without any restrictions on the parameters. It is worth mentioning that the models (EquationM1
(M$_1$)
(M$_1$) ), (EquationM2
(M$_2$)
(M$_2$) ) and (Equation1
(1)
(1) ) are nested models. Model (EquationM1
(M$_1$)
(M$_1$) ) is nested in model (EquationM2
(M$_2$)
(M$_2$) ), and model (EquationM2
(M$_2$)
(M$_2$) ) is nested in (Equation1
(1)
(1) ). The simplest model (EquationM1
(M$_1$)
(M$_1$) ) is the only structurally identifiable model from the observations of daily incidences and casualties. As the model gets more complex as we increase the number of infectious classes in an attempt to capture the transmission dynamics of the COVID-19 infection, the epidemic model becomes unidentifiable.
3.2. Parameter estimation
We obtain the parameter estimates of the model (Equation1(1)
(1) ) by fitting the model to the observed daily COVID-19 incidences and deaths in the USA. The time series data from March 3 to April 26, 2020, is collected [Citation36]. We are interested in estimating the epidemiologically important parameters. In particular, the parameters to be estimated from data are infection rate of S by exposed individuals (
), infection rate by individuals who are not showing any clinical COVID-19 symptoms (
), infection rate by individuals with clinical COVID-19 symptoms (
), recovery rate of individuals with clinical symptoms (
), recovery rate of hospitalized individuals (
) and death rate of hospitalized individuals (ν). Based on the structural identifiability analysis of the epidemic model (Equation1
(1)
(1) ), we fix some model parameters such as the incubation period to estimate the model parameters accurately. The literature search of peer-reviewed publications reporting the incubation period of SARS-COV-2 listed the incubation period as ranging from 2 to 18 days [Citation11]. We set the incubation period 1/k as 14 days. Mild or asymptomatic cases usually recover within 14 days [Citation2]. Since we have already set the incubation period to 14 days, we set the recovery period of the asymptomatic individuals (
) to 1 day. The mean estimated basic reproduction number of SARS-COV-2 early in the pandemic is found to vary from 1.95 to 6.47 [Citation16]. We set
for our parameter estimation problem. For the proportion of asymptomatic individuals, several studies give a wide range, namely 30–70% of individuals who have tested positive have mild or no symptoms ([Citation39] and the references therein). Due to this large uncertainty, we take the numbers in the Diamond Princess cruise ship; 712 individuals in the cruise ship Diamond Princess tested positive for COVID-19, 410 of these infected infected individuals in the cruise ship were asymptomatic. Therefore, we set the fraction of asymptomatic individuals to
[Citation27]. That is we take
. Hospitalization rate of infected individuals with clinical symptoms of COVID-19 per day (α) is not known. However, CDC reports that at an average
of infected individuals are admitted to hospitals [Citation4]. Thus we set
We use the daily US COVID-19 cases and deaths from March 3 to April 26, 2020, as the observations of the parameter estimation problem. Let
denote the discrete time when the number of US COVID-19 cases are observed, and let
denote the discrete time when the number of US COVID-19 deaths are observed. Both observations are contaminated with noise and thus
(15)
(15) We estimated the parameters of the model (Equation1
(1)
(1) )
by solving the following constrained optimization problem:
(16)
(16) where
and
are average daily US COVID-19 cases and deaths respectively from March 3 to April 26, 2020:
(17)
(17) We use the confirmed COVID-19 cases for the parameter estimation problem. However, it is worth mentioning that the due to limited (testing only individuals with moderate to severe symptoms especially early in the pandemic) and imperfect (false negative results) testing, high number of cases in the USA were undetected or under-reported [Citation39]. It is estimated that the actual COVID-19 cases is 3–20 times higher than the reported cases [Citation39]. In our modelling approach, we take this into consideration with ρ-proportion of individuals who are getting tested. Another consequence of limited testing capacities is that true initial population size
is not captured in the data. We pre-estimate the initial effective population size,
, and then fix the initial conditions, since the goal of this study is whether we can uniquely determine the epidemiologically important COVID-19 parameters such as the transmission rates of the different infectious classes. We present the estimated parameters in Table , and model (Equation1
(1)
(1) ) predictions with daily COVID-19 cases and deaths in Figure .
Figure 2. Number of COVID-19 cases and deaths in the USA from March 3 to April 26, 2020 (red dots) plotted together with the model predictions (blue curve) with the estimated values presented in Table . Pre-estimated initial conditions are .
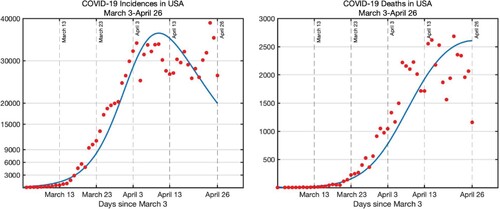
Table 3. Parameter estimation results: parameter estimates of the model (Equation1(1)
(1) ) obtained by solving the optimization problem (Equation16
(16)
(16) ).
3.3. Practical identifiability analysis
We continue the identifiability analysis by performing Monte Carlo Simulations (MCS) and study whether the parameters of the model can be estimated by solving the constraint minimization problem numerically (Equation16(16)
(16) ) from the noisy observations
(Equation15
(15)
(15) ). This type of identifiability is called practical identifiability [Citation22]. To determine the practical identifiability, first we estimate the model parameters by (Equation16
(16)
(16) ) using the reported daily incidences and deaths. Then using the estimated parameters
, we generate synthetic data sets
which are contaminated with error. We perform the MCS with two different error structures: (i) normal distribution and (ii) Poisson distribution.
(i) Error structure with normal distribution: We assume that the measurement error is proportional to data. Namely we assume that the measurement error has the following form:
where
and
are independent and identically distributed with mean zero and standard deviation
. Thus the random variables
and
have mean
and
respectively, and standard deviation
and
respectively. In particular, we generate M = 1000 data sets using normal distribution whose mean is the model predictions and standard deviations are
and
respectively. That is
(18)
(18) where
denotes the normal distribution with mean μ and standard deviation σ.
We generate M = 1000 synthetic data sets for each measurement errors, by increasing the errors gradually from , to
and
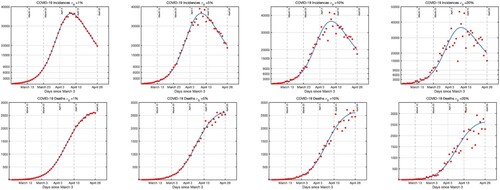
. In Figure , we present a single synthetic incidence (
) and deaths (
) for each measurement error
. Comparing Figure with the actual data in Figure , it appears the actual data has about
error.
Figure 3. Top row: A single set of incidences data generated for the Monte Carlo Simulations is presented for each measurement error. The incidence data is generated by taking the estimated parameters given in Table as true parameters and generating random incidences with normal distribution whose mean is
and the standard deviation is
. Bottom row: The simulated deaths data is generated by taking the estimated parameters given in Table and as true parameters
and generating random deaths with normal distribution whose mean is
and the standard deviation is
as in (Equation18
(18)
(18) ). First column is for
, the second column is for
, the second column is for
and the fourth column is for
. We stopped at
, because comparison with the actual data suggests that the measurement error is about
.
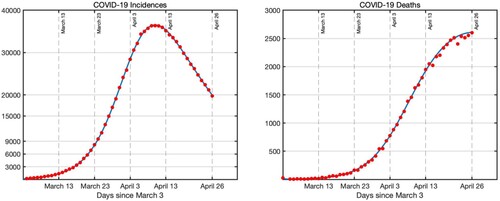
(ii) Error structure with poisson distribution: For the Poisson distribution, the mean and the standard deviation are equal.
(19)
(19) where
denotes the Poisson distribution with mean μ. We present the synthetic data generated by Poisson distribution in Figure . It is apparent from Figure , Figure and Figure that the error structure in actual data most likely has normal distribution with
.
Figure 4. Presents a single set of incidences and deaths data generated by Poisson error distribution. Data is generated by taking the estimated parameters given in Table as true parameters and generating random data with Poisson distribution.
We then fit the COVID-19 epidemic model (Equation1(1)
(1) ) to each M = 1000 data sets by solving the optimization problem (Equation16
(16)
(16) ) and then calculate the Average Relative Errors (AREs) of each parameter for each noise level. The AREs are computed as
(20)
(20) where
is the
parameter in
and
are the parameters that generate the random variables
and
. AREs of the parameters for each measurement error are presented in Table and Table . AREs give insight about the practical identifiability of the model parameters. In Table , we present the AREs of each parameter when the error structure in the data is assumed to be normal. AREs of each parameter increases as the measurement error level (
) increases. We see that two of the parameters, namely
and
have high AREs compared to other parameters. The AREs of parameters
and
are more than the 20 times the measurement error when
. On the other hand, the AREs of the parameters
and
are bounded by the measurement error at
. Based on AREs in Table , we conclude that the parameters
and
are not practically identifiable. Parameters
and
are practically identifiable.
Table 4. Monte Carlo simulation results: Average relative errors (ARE)s of parameters of the COVID-19 model (Equation1(1)
(1) ) are presented after performing parameter estimation problem (Equation16
(16)
(16) ) to M = 1000 synthetic data sets for each measurement error
.
Table 5. Monte Carlo simulation results: average relative errors (ARE)s and confidence intervals of parameters of the COVID-19 model (Equation1
(1)
(1) ) are presented after performing parameter estimation problem (Equation16
(16)
(16) ) to M = 1000 synthetic data sets with Poisson error structure.
Next we run the MCS by generating M = 1000 data sets using Poisson error structure with mean and
. We then compute the AREs and the results are presented in Table . Checking the ARE of each parameter in Table , we see that the parameters
and
have higher ARE compared to other parameters and declare these parameters to be practically unidentifiable. Comparing the ARE values in Table with ARE values in Table , regardless of the error structure assumption, Normal vs. Poisson, we see that in both cases the parameters
and
have significantly higher AREs compared to other parameters. In conclusion, error structure does not influence the parameter identifiability.
We continue with the identifiability analysis by assessing the evolution of the parameter identifiability. Thus we investigate how the parameter identifiability changes as function of time. We performed the MCS simulations at three different stages of the pandemic; (i) before it reached its peak, (ii) at the peak and (iii) after the peak. Since normal error structure is a better representation of the error structure in the actual data, we performed the MC simulations with normal error structure. We present the AREs of each parameter before the peak and at the peak in Table . AREs presented in Table are the AREs of the parameters after the peak. The AREs of the infection rate of symptomatic individuals, () decrease as the pandemic progresses, same is true for
. We do not observe the decline of the AREs for the parameter
. On the other hand, AREs of the parameters ν and
remain almost the same for all three phases of the pandemic. And AREs of the parameter
increase from before the peak to at the peak phase and then decrease again from the peak to the after the peak phase. For this practical identifiability analysis, we conclude that as the pandemic progresses, as we add more data points to the parameter estimation problem, it is not possible to say that the identifiability of the parameters improves.
Table 6. Monte Carlo simulation results: Average relative errors (ARE)s of parameters of the COVID-19 model (Equation1(1)
(1) ) are presented after performing parameter estimation problem (Equation16
(16)
(16) ) to M = 1000 synthetic data sets for each measurement error
. Error structure is assumed to be normal.
4. Forecasting multiple outbreak waves and determining control strategies
4.1. Predicting the future epidemic waves
Kermack–McKendrick type SEIR epidemic model (EquationM1(M$_1$)
(M$_1$) ) or its variations such as (EquationM2
(M$_2$)
(M$_2$) ) and (Equation1
(1)
(1) ) can only forecast a single outbreak wave. Due to their nature, these types of outbreak models cannot predict multiple epidemic waves. In this section, we give a methodology on how to use an epidemic model to predict multiple waves. We use the methodology used in sub-epidemic curves introduced in [Citation6]. Authors in [Citation6] used a single generalized-logistic growth model which describes the incidences to forecast multiple epidemic waves. Here we generalize this methodology to outbreak models. We model the epidemic wave which consist of three overlapping sub-epidemics using the COVID-19 model (Equation1
(1)
(1) ):
(21)
(21) where
for i = 1, 2, 3 with
and
. For the sub-epidemic model (Equation21
(21)
(21) ), the observation of incidences and deaths becomes respectively as follows:
To estimate the model parameters, we modified the optimization problem (Equation16
(16)
(16) ) for the sub-epidemic model (Equation21
(21)
(21) ). The estimated parameters are presented in Table . The fit is shown in Figure .
Figure 5. Blue curve is the prediction of the sub-epidemic model (Equation21(21)
(21) ) to US COVID-19 cases and deaths (bars).
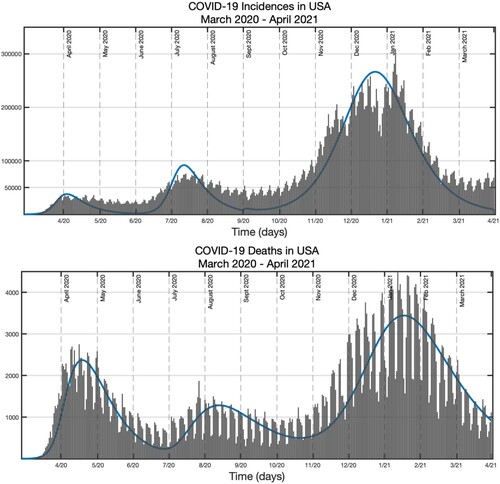
Table 7. Parameter estimation results: parameter estimates of the sub-epidemic model (Equation21(21)
(21) ).
4.2. An optimal control scenario
US states initiated various community mitigation policies in March 2020. Some of the widely implemented strategies included the issuance of orders requiring persons to stay home, schools were closed and universities transitioned to online instruction. Stay-at-home orders started from California on March 19, 2020, and ultimately were issued in all 50 states, covering 316 million people between March 19 and May 20, 2020 [Citation30]. To model the social distancing, we introduce control which effectively reduces the transmission rates for the exposed E and non-symptomatic individuals
. To model the self-isolation required from symptomatic individuals
, we introduce a control
. Although, direct correspondence between the real life controls, social distancing and self-isolation to our controls
and
is not clear, such an investigation still yields to useful observations, particularly in the extreme case, when we want to achieve maximum effect. Both controls belong to the admissible set
where T is the final time considered. The model with the controls takes the following form:
(22)
(22) The main goal of the quarantine was to reduce the total number of infected individuals over the time
. To express that we use the following cost functional:
(23)
(23) Our goal is to find an optimal control functions
such that
We do not consider isolation to be a control variable, as isolation was applied only to severe cases. Since 80–85% are mild to moderate [Citation23], hospitalizations are determined by the progression to severe symptoms and cannot be controlled.
We use Pontryagin's Minimum Principle [Citation20] and introduce a time-varying Lagrange multiplier vector , whose elements are called the adjoint variables of the system. The Hamiltonian
is defined
by
(24)
(24) That is we set Hamiltonian as
(25)
(25) In the next theorem, we present the adjoint system and optimal control characterizations.
Theorem 4.1
Given an optimal pair , there exists adjoint variables
,
such that
with
for
. The optimal controls
are represented by
(26)
(26)
(27)
(27)
Proof.
Pontryagin minimum principle states that for the optimality of control and corresponding trajectory
with
, it is necessary that there exist a nonzero adjoint vector function
which is a solution to the adjoint system
(28)
(28) Setting
we obtain the adjoint system with
. By the optimality condition,
we obtain
Similarly,
Notice that
, and
Since,
we set
4.2.1. Numerical simulations with optimal control
We use forward–backward sweep method [Citation18] to approximate the solution of model (Equation22(22)
(22) ) with controls
. We use MATLAB built-in function ode15s to approximate the solutions of the model (Equation22
(22)
(22) ) with controls by taking initial conditions
and also use the ode15s to solve the adjoint differential differential equations backward in time by taking the value at the final time as
. We use the following forward–backward sweep algorithm to get the optimal control functions [Citation18].
Take initial guesses for
Solve for the state function differential Equation (Equation22
(22)
Solve for the adjoint function differential Equation
We update the new values of
Iterate the same process until the following convergence criteria is met for every state variable, adjoint and control functions
For the optimal control simulations, we use the parameter values obtained in the fitting as presented in Table . For the first simulation, we solve the optimal control problem with controls social distancing and self-isolation setting off at time t = 0 and effective for 75 days. Figure presents the state of infectious populations with and without social distancing and self-isolation. We see that the controls are most effective when it is applied at , that is at their upper bound of 1. We recognize that achieving 100% social distancing or isolation is not practically possible. However our results show that the higher the social distancing or isolation the lower the infection. Therefore, depending on the level of the cost parameters and our cost structure, one should aim at the maximum possible social distancing and isolation. Even if we set a realistic upper bound,
for the controls which is strictly less than 1, the optimal control will still reside at the
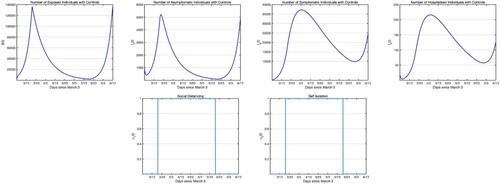
most of the time. For the next simulation, we apply the social distancing and self-isolation from March 19 till May 20, for about 2 months as this was the case for the USA. We perform the iterative process to find the optimal pair which would be only effective from March 19 till May 20 that would minimize the objective function (Equation23
(23)
(23) ) subject to the COVID-19 model (Equation22
(22)
(22) ) starting on March 3 and ending on June 23, 2020. In Figure , we only present the infectious states with controls, since the infectious populations without controls are same as in Figure second row. Comparing Figure and Figure , we see that, one of the main differences in starting the social distancing and self-isolation 2 weeks after the launch of the outbreak is that the number of infectious classes are at least 1 magnitude order higher if not more. Further, we see, comparing Figure with Figure that if we had continue to apply the controls there would not have been an uptick in cases.
Figure 6. Simulations of the COVID-19 model with control measures (Equation22(22)
(22) ). First row: Infectious populations with control. Seconfd row: Infectious populations without control. Third row: Self-isolation and social distancing controls. The weights in the objective functional are
.
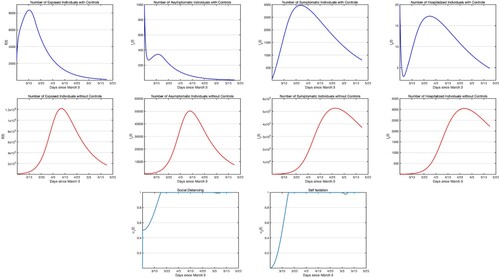
Figure 7. Simulations of the COVID-19 model with control measures (Equation22(22)
(22) ). First row: Infectious populations with control. Second row: Self-isolation and social distancing controls. Controls start on March 19 and end on May 20, last for 60 days. The weights in the objective functional are
.
5. Discussion
Mathematical compartmental models can provide valuable insight about the spread of SARS-CoV-2 in a population. In particular, they can provide guidance about the role of specific interventions in reducing the impact of an ongoing disease outbreak. All models are limited by factors that include the levels of complexity in the epidemiological states being considered, the parameters to be estimated, and the limited data that often involves delay and uncertainty. These models have the potential to provide valuable guidance for pandemic preparedness and planning to reduce the burden of an outbreak, particularly during the early phase of an outbreak. In this study, we proposed a COVID-19 epidemic model that considers six epidemic states and incorporates important phases of the coronavirus life cycle, such as incubation and latency period. Scenarios that incorporate social distancing efforts are implemented to limit the spread of SARS-CoV-2 were considered in our study. We computed the reproduction number, estimated model parameters based on daily cases and deaths, and conducted structural and practical identifiability analysis for the proposed model.
We show that parameters of the proposed model are not structurally identifiable from observations of daily incidence and deaths. We further establish that for a sequence of models, nested in the proposed model, only the SEIR model where all incidences are observed, is structurally identifiable. For our proposed model, we show that if the parameters α, , k, ρ are fixed from external information, then all parameters are structurally identifiable, except
. To identify
we use estimates of
from the literature.
We further investigated the practical identifiability of these parameters by performing Monte Carlo Simulations and found that transmission rate for exposed and symptomatic infectious
were not practically identifiable. This result largely persists even if we use outside information for the proportion of individuals who progress to hospitalization. A surprising outcome of the practical identifiability analysis was that fixing the proportion of individuals who become hospitalized in fact makes the parameters of the model practically identifiable. The practical identifiability conclusions remain the same regardless of the error structure (Poisson or Normal) chosen. We also investigated whether taking a shorter time series compared to taking a longer time series affected identifiability results. For the most part identifiability improved with the longer data set but we think that the results were not strong enough and uniform enough to be conclusive.
The investigation of the optimal control problem shows that socials distancing should be practiced at 100% to reduce the disease quickly, while isolation can be practiced at more relaxed conditions, particularly as time progresses. Social distancing should be practiced at 100% for most of the time interval even if the cost of that is very high. High levels of social distancing lead to exceptionally high reduction in the number infected individuals without symptoms and hospitalized individuals which leads to quick curtailing of the pandemic and maintenance of susceptible individuals at higher level.
An important finding of our study is our investigation of social distancing and self-isolation as control measures. We investigated two scenarios: control is active during the entire studied interval of time and the control is active only when the lock down was in effect, which is a subset of time. With the first scenario both optimal controls gradually go to the maximum and stay there for the remainder of the studied duration. In this case, the epidemic states are well controlled and reach peaks at least an order of magnitude smaller than with the second scenario when the control is applied with delay. In the second scenario, the optimal controls jump to the maximum and stay there for the entire allowed duration. However, the numbers in the infected classes are much larger, and as soon as the control is stopped, these classes start growing in magnitude. The observation we make here support again the rule of thumb that control measures have to be applied as early as possible in an epidemic as strongly as possible. Our numerical simulations for each of the epidemic states of the proposed model show the critical importance of the timely implementation of control measures, particularly in reducing the number of individuals at risk of exposure and infection from the coronavirus. The implications of these findings are most relevant during the very early phase of the pandemic as the simulations are based on data captured very early-on. To further investigate the trajectories of these epidemic states and parameters as the pandemic progresses beyond its early phase, we fit overlapping epidemic waves to the data of the USA as described by [Citation6]. This allows us to investigate how the virus and epidemic characteristics of the COVID-19 pandemic have evolved over the year since it first became established in the USA. To accurately model the spread of the coronavirus and the role of specific interventions, it is important that we update modelling efforts to account for new virus information, as well as additional relevant interventions such as testing and contact tracing [Citation3,Citation12,Citation17]. It is also important to consider that morbidity and mortality associated with COVID-19 differ among individuals in the population and such trends in risk have also evolved over time [Citation7,Citation24,Citation37]. During the early phase of the COVID-19 pandemic in the USA older age individuals seemed to have experienced a higher burden while in the current months of this pandemic, younger and mid-age individuals seem to experience higher risk of infection. A consistent observation with this pandemic is that individuals of older age, and higher pre-existing comorbidities such as heart disease, diabetes and obesity have a higher risk of infection and severe COVID-19 experience [Citation15,Citation25,Citation28].
In summary, this study presents a COVID-19 model that investigates the spread of SARS-CoV-2 and the role control interventions play to reduce the burden associated with the COVID-19 pandemic. In particular, our study of the structural and practical identifiability of the proposed model highlights the importance of parameter identifiability and the limitations inherent to uncertainty in data available, particularly during the early phase of a novel pandemic. We have presented some unique methodology for turning unidentifiable into identifiable parameters. Using a mixed approach to the problem of parameter identifiability, we are able to provide specific guidance about the identifiability of a subset of parameters that can be useful in guiding some of the model predictions. We further investigate the relevance of control measures through social distancing efforts and self-isolation. We show that the timely implementation of control measures can be extremely valuable to reduce the burden of this novel pandemic.
We present all Matlab code for parameter estimation and Monte Carlo Simulations at https://github.com/NecibeTuncer/Idenitifiability_COVID-19_Early_in_Pandemic together with the DAISY and Mathematica results for the identifiability analysis.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- G. Bellu, M.P. Saccomani, S. Audoly, and L. D'Angio, Daisy – differential algebra for identifiability of systems, Available at https://daisy.dei.unipd.it.
- H.R. Bhapkar, P.N. Mahalle, N. Dey, and K.C. Santosh, Revisited covid-19 mortality and recovery rates: Are we missing recovery time period?, J. Med. Syst. 44 (2020), pp. 1–5.
- A. Bilinski, F. Mostashari, and J.A. Salomon, Modeling contact tracing strategies for covid-19 in the context of relaxed physical distancing measures, JAMA network open 3(8) (2020), pp. e2019217.
- CDC, Severe outcomes among patients with coronavirus disease 2019 (covid-19) –united states, february 12–march 16, 2020, MMWR 69 (2020), pp. 343–346.
- K. Roosa and G. Chowell, Assessing parameter identifiability in compartmental dynamic models using a computational approach: application to infectious disease transmission models, Theoretical Biol. Med. Model. 16 (2019), pp. 1–15.
- G. Chowell, A. Tariq, and J.M. Hyman, A novel sub-epidemic modeling framework for short-term forecasting epidemic waves, BMC. Med. 17 (2019), pp. 1–18.
- R.M. Colombo, M. Garavello, F. Marcellini, and E. Rossi, An age and space structured sir model describing the covid-19 pandemic, medRxiv 10 (2020), pp. 1–20.
- R. Dandekar and G. Barbastathis, Quantifying the effect of quarantine control in covid-19 infectious spread using machine learning, medRxiv2020
- M.C. Eisenberg and Y-H. Kao, Practical unidentifiability of a simple vector-borne disease model: Implications for parameter estimation and intervention assessment, Epidemics 25 (2018), pp. 89–100.
- M.C. Eisenberg, S.L. Robertson, and J.H. Tien, Identifiability and estimation of multiple transmission pathways in cholera and waterborne disease, J. Theor. Biol. 324 (2013), pp. 84–102.
- C. Elias, A. Sekri, P. Leblanc, M. Cucherat, and P. Vanhems, The incubation period of covid-19: A meta-analysis, Int. J. Infect. Dis. 104 (2021), pp. 708–710.
- G. Giordano, F. Blanchini, R. Bruno, P. Colaneri, A. Di Filippo, A. Di Matteo, and M. Colaneri, Modelling the covid-19 epidemic and implementation of population-wide interventions in italy, Nat. Med. 26 (2020), pp. 855–860.
- G. González-Parra and A.J. Arenas, Qualitative analysis of a mathematical model with presymptomatic individuals and two sars-cov-2 variants, Computational and Applied Mathematics 40 (2021), pp. 1–25.
- X. He, E. Lau, P. Wu, X. Deng, J. Wang, X. Hao, Y.C. Lau, J. Wong, Y. Guan, X. Tan, X. Mo, Y. Chen, B. Liao, W. Chen, F. Hu, Q. Zhang, M. Zhong, Y. Wu, L. Zhao, F. Zhang, B. Cowling, F. Li, and G. Leung, Temporal dynamics in viral shedding and transmissibility of covid-19, Nat. Med. 26 (2020), pp. 672–675.
- C. Huang, Y. Wang, X. Li, L. Ren, J. Zhao, Y. Hu, L. Zhang, G. Fan, J. Xu, X. Gu, and Z. Cheng, Clinical features of patients infected with 2019 novel coronavirus in wuhan, china, The lancet 395(10223) (2020), pp. 497–506.
- G.G. Katul, A. Mrad, S. Bonetti, G. Manoli, and A.J. Parolari, Global convergence of covid-19 basic reproduction number and estimation from early-time sir dynamics, PLoS. ONE. 15 (2020), pp. e023980.
- A.J. Kucharski, P. Klepac, A. Conlan, S.M. Kissler, M. Tang, H. Fry, J. Gog, and J. Edmunds, CMMID COVID-19 Working Group: et al. Effectiveness of isolation, testing, contact tracing and physical distancing on reducing transmission of sars-cov-2 in different settings, medRxiv 20 (2020), pp. 1151–1160.
- S. Lenhart and J.T. Workman, Optimal control applied to biological models, CRC press, 2007.
- F.S. Lu, A.T. Nguyen, N.B. Link, J.T. Davis, M. Chinazzi, X. Xiong, A. Vespignani, M. Lipsitch, and M. Santillana, Estimating the cumulative incidence of covid-19 in the united states using four complementary approaches, medRxiv2020
- M. Martcheva, An introduction to mathematical epidemiology, Springer, Vol. 61, 2015.
- G. Massonis, J.R. Banga, and A.F. Villaverde, Structural identifiability and observability of compartmental models of the covid-19 pandemic, Annu. Rev. Control. 51 (2020), pp. 441–459.
- H. Miao, X. Xia, A.S. Perelson, and H. Wu, On identifiability of nonlinear ode models and applications in viral dynamics, SIAM. Rev. Soc. Ind. Appl. Math. 53 (2011), pp. 3–39.
- N.J.M. Michelen and C. Stavropoulou, In patients of covid-19, what are the symptoms and clinical features of mild and moderate cases? - cebm, preprint (2020 Apr). Available at http://www.cebm.net/covid-19/in-patients-of-covid-19-what-are-the-symptoms-and-clinical-features-of-mild-and-moderate-case/, [cited 31 Oct 2020].
- R. Omori, R. Matsuyama, and Y. Nakata, The age distribution of mortality from novel coronavirus disease (covid-19) suggests no large difference of susceptibility by age, Sci. Rep. 10(1) (2020), pp. 1–9.
- G. Onder, G. Rezza, and S. Brusaferro, Case-fatality rate and characteristics of patients dying in relation to covid-19 in italy, Jama 323(18) (2020), pp. 1775–1776.
- J.M. Read, J.R.E. Bridgen, D.A.T. Cummings, A. Ho, and C.P. Jewell, Novel coronavirus 2019-ncov: early estimation of epidemiological parameters and epidemic predictions, MedRxiv. 2020.
- A. Sakurai, T. Sasaki, and S. Kato, et al Natural history of asymptomatic sars-cov-2 infection, N. Engl. J. Med. 383 (2020), pp. 885–886.
- Y-J. Sun, Y-J. Feng, J. Chen, B. Li, Z.-C. Luo, and P.-X. Wang, Clinical features of fatalities in patients with covid-19, Disaster. Med. Public. Health. Prep. 15 (2020), pp. e9–11.
- B. Tang, X. Wang, Q. Li, N.L. Bragazzi, S. Tang, Y. Xiao, and J. Wu, Estimation of the transmission risk of the 2019-ncov and its implication for public health interventions, J. Clin. Med. 9(2) (2020), pp. 462.
- The New York Times, See which states and cities have told residents to stay at home - the new york times, Available at https://www.nytimes.com/interactive/2020/us/coronavirus-stay-at-home-order.html. [cited 31 Oct 2020].
- C. Tsay, F. Lejarza, M.A. Stadtherr, and M. Baldea, Modeling, state estimation, and optimal control for the us covid-19 outbreak, preprint (2020). Available at arXiv:2004.06291.
- N. Tuncer, H. Gulbudak, V. Cannataro, and M. Martcheva, Structural and practical identifiability issues of immuno-epidemiological vector-host models with application to rift valley fever, Bull. Math. Biol. 78 (2016), pp. 1796–1827.
- N. Tuncer, B. Labarre, S. Payoute, and M. Martcheva, Structural and practical identifiability analysis of zika epidemiological models, Bull. Math. Biol. 80 (2018), pp. 2209–2241.
- N. Tuncer and T. Le, Structural and practical identifiability analysis of outbreak models, Math. Biosci. 299 (2018), pp. 1–18.
- N. Tuncer, C. Mohanakumar, S. Swanson, and M. Martcheva, Efficacy of control measures in the control of ebola, liberia 2014–2015, J. Biol. Dyn. 12(1) (2018), pp. 913–937.
- United states coronavirus, 9, 332, 958 cases and 235, 420 deaths - worldometer, preprint (2020 Oct). Available at https://www.worldometers.info/coronavirus/country/us/, [cited 31 Oct 2020].
- B. Wilder, M. Charpignon, J.A. Killian, H.-C. Ou, A. Mate, S. Jabbari, A. Perrault, A.N. Desai, M. Tambe, and M.S. Majumder, Modeling between-population variation in covid-19 dynamics in hubei, lombardy, and new york city, Proceedings of the National Academy of Sciences 117(41) (2020), pp. 25904–25910.
- J.T. Wu, K. Leung, and G.M. Leung, Nowcasting and forecasting the potential domestic and international spread of the 2019-ncov outbreak originating in wuhan, china: a modelling study, The Lancet 395(10225) (2020), pp. 689–697.
- S.L. Wu, A.N. Mertens, A. Crider, S. Yoshika, N.N.N. Pokpongkiat, S. Djajadi, A. Seth, M.S. Hsiang, J.M. Colford, A. Reingold, B.F. Arnold, A. Hubbard, and J. Benjamin-Chung, Substantial underestimation of sars-cov-2 infection in the united states, Nat. Commun. 11 (2020), pp. 1–10.
- Z. Yang, Z. Zeng, K. Wang, S-S. Wong, W. Liang, M. Zanin, P. Liu, X. Cao, Z. Gao, and Z. Mai, et al Modified seir and ai prediction of the epidemics trend of covid-19 in china under public health interventions, J. Thorac. Dis. 12(3) (2020), pp. 165.
- D. Zou, L. Wang, P. Xu, J. Chen, W. Zhang, and Q. Gu, Epidemic model guided machine learning for covid-19 forecasts in the united states, medRxiv, 2020.
Appendix
A.1. SEIR model
Input–output equations for the SEIR model (EquationM1(M$_1$)
(M$_1$) ), where
(A1)
(A1)