
ABSTRACT
Humankind is facing unprecedented global environmental and social challenges in terms of food, water and energy security, resilience to natural hazards, etc. To address these challenges, international organizations have defined a list of policy actions to be achieved in a relatively short and medium-term timespan. The development and use of knowledge platforms is key in helping the decision-making process to take significant decisions (providing the best available knowledge) and avoid potentially negative impacts on society and the environment. Such knowledge platforms must build on the recent and next coming digital technologies that have transformed society – including the science and engineering sectors. Big Earth Data (BED) science aims to provide the methodologies and instruments to generate knowledge from numerous, complex, and diverse data sources. BED science requires the development of Geoscience Digital Ecosystems (GEDs), which bank on the combined use of fundamental technology units (i.e. big data, learning-driven artificial intelligence, and network-based computing platform) to enable the development of more detailed knowledge to observe and test planet Earth as a whole. This manuscript contributes to the BED science research domain, by presenting the Virtual Earth Cloud: a multi-cloud framework to support GDE implementation and generate knowledge on environmental and social sustainability.
1. Introduction
Humankind is facing unprecedented global environmental and social challenges in terms of food, water and energy security, resilience to natural hazards, population growth and migrations, pandemics of infectious diseases, sustainability of natural ecosystem services, poverty, and the development of a sustainable economy (Nativi, Mazzetti, and Craglia Citation2021). Addressing these challenges is crucial for our planet preservation and the future development of human society. To this aim, international organizations have defined a list of policy actions to be achieved in a relatively short and medium-term time framework. Notably, the United Nations (UN) defined 17 Sustainable Development Goals (SDGs)Footnote1 along with an implementation agenda. Such an effort is supported by other relevant international initiatives and programmes, including the UNFCCC Process-and-meetingsFootnote2 (see for example the Conference of Parties 2015 on Climate: COP21)Footnote3 and the Sendai Framework for Disasters Risk ReductionFootnote4 overseen by the United Nations Office for Disaster Risk Reduction (UNDRR). Most of these frameworks require the development and use of a knowledge platform, which must build on the recent and next coming digital technologies that have transformed society – including the science and engineering sectors. Having this in mind, for example, the EU developed a European growth model underpinned by the ‘twin transitions’,Footnote5 i.e. the green transition must go hand in hand with the digital one (Muench, et al. Citation2022).
A knowledge platform supports policy makers to take significant decisions (providing the best available knowledge) and avoid potentially negative impacts on society and the environment – also considering the connections between the local and global processes (Mazzetti et al. Citation2022; Guo et al. Citation2020; Nativi, Mazzetti, and Craglia Citation2021). A sustainable development must be guided by a science that transitions from focusing on one-problem-at-one-scale at a time, to truly exploring the complexity and systemic nature of the simultaneous and mutually interacting cause-and-effect chains in the interdependent human – nature and people – planet reality of the twenty-first century (Rockström, Bai, and deVries Citation2018).
Understanding the impacts and interrelationships between humans as a society and natural Earth system processes requires a significant effort in collecting, analyzing, and sharing relevant information at different spatial and temporal scales. With the advent of the Digital Transformation, the interconnection between the physical and the digital world has become almost complete: economic, industrial, and social relationships have been moved to the ‘cyber-physical’ world (i.e. the realm where digital and physical hybrid systems operate, thanks to transformative technologies for managing the interconnection between their physical assets and computational capabilities operate (Lee and Kao Citation2015)), where all the relevant stakeholders are included more easily and can intensively cooperate in generating the knowledge required for addressing a given purpose (Nativi, Mazzetti, and Craglia Citation2021). The Digital Earth concept (Gore Citation1998), represents an overarching effort in that direction to address the scientific and technological challenges which must be faced to enhance our understanding of the Earth system. As recognized by the International Society on Digital Earth (ISDE), ‘Digital Earth is a multidisciplinary collaborative effort that engages different societies to monitor, address and forecast natural and human phenomena’ (ISDE Citation2019).
In this context, Big Earth Data (BED) science (Guo et al. Citation2020) aims to provide the methodologies and instruments to generate knowledge from numerous, complex, and diverse data sources, which are essential to develop a sustainable society and preserve the planet Earth. BED science requires the development of Geoscience Digital Ecosystems (GDEs) (Nativi and Mazzetti Citation2020), which bank on the combined use of: Big Data, AI data-driven instruments, and online highly scalable computing platforms to observe and test planet Earth as a whole (Guo et al. Citation2020; Nativi, Mazzetti, and Craglia Citation2021). For GDEs, the fundamental technology units (i.e. big data, learning-driven artificial intelligence, and network-based computing platform) enables the development of more detailed knowledge.
A key tool for transforming the huge amount of data currently available into knowledge is represented by scientific models, either theory-driven or data-driven. This manuscript contributes to the BED science research domain, by presenting a multi-cloud framework to support GDE implementation and execute scientific models for the generation of knowledge on environmental and social sustainability. Next section (2) introduces the concept of GDE as defined by (Nativi and Mazzetti Citation2020). Section 3 presents the resources that must be handled by a GDE. In section 4, the concept of Virtual Earth Cloud is defined and a possible architecture is presented. Section 5 describes a proof-of-concept, implemented in an international framework. Finally, section 6 draws some conclusions and discusses the future work.
2. Geosciences digital ecosystems
A Geoscience Digital Ecosystem (GDE) is defined in (Nativi and Mazzetti Citation2020) as a ‘tsystem of systems that applies the digital ecosystem paradigm to model the complex collaborative and competitive social domain dealing with the generation of knowledge on the Earth plane’.
The Digital Ecosystem (DE) paradigm stems from the concept of natural ecosystems (Blew Citation1996). DEs focus on a holistic view of diverse and autonomous entities (i.e. the many heterogeneous and autonomous online systems, infrastructures, and platforms that constitute the bedrock of a digitally transformed society) which share a common environment. In search of their own benefit, such entities interact and evolve, developing new competitive or collaborative strategies, and, in the meantime, modifying the environment (Nativi, Mazzetti, and Craglia Citation2021).
In the geosciences domain, DEs are called to enable the coevolution (i.e. the complex interplay between competitive and cooperative business strategies) of geosciences public and private organizations around the new opportunities and capacities offered by the digital transformation of society – Internet, big data, and computing virtualization processes represent some of the main engines of innovation, rising an entirely new type of geosciences ecosystems (Nativi and Mazzetti Citation2020).
It is worth to note that the Digital Ecosystem (and therefore the Geosciences Digital Ecosystem) approach differs from the approach adopted by currently available cloud platforms for geospatial data processing (e.g. Google Earth Engine (Google Citation2022), Microsoft Planetary Computers (Microsoft Citation2022), etc.). Such platforms are highly optimized tools for developing and executing scientific models on top of geospatial data made available on the platform itself, and utilizing the computational resources of the underlying cloud platform. Google Earth Engine is built on top of a collection of enabling technologies that are available within the Google data center environment (Gorelick et al. Citation2017) – a similar approach is implemented by Microsoft Planetary Computers. The advantages of this approach are well-known and essentially stem from the control of the entire (end-to-end) technological stack which makes up the platform. A Digital Ecosystem approach, instead, focuses on how to build added-value services on top of existing and autonomous systems (i.e. systems which are operated and governed autonomously from the others) without being able to control the end-to-end technological stack. To this aim, as far as Geosciences Digital Ecosystems are concerned, a set of principles, development patterns, and governance styles were recognized for an effective GDE implementation framework (Nativi and Mazzetti Citation2020):
Evolvability and Resilience: a GDE operates in a highly dynamic environment in which technology, policies, and use needs are in constant evolution.
Emergent Behavior of GDE as a whole: for the enterprise systems belonging to an ecosystem, the aim is to create a value that is greater than (or different from) the value that they would have without being part of the ecosystem.
Enterprise Systems Dispersion: The enterprise systems, constituting a GDE, are generally disperse (i.e. geographically distributed and heterogeneous) and cope with big data. Therefore, the resulting ecosystem must deal with the challenges characterizing the ‘big data’ cyber-physical realm and implement appropriate strategies to manage volume, velocity, variety, and value of data from multiple sources in a scalable way.
Governance: The enterprise systems constituting a GDE are existing and autonomous structures, managed by different organizations. The governance of a GDE must define and apply the set of rules and principles that will help steer the ecosystem evolution and effectiveness through the many changes occurring at the political, social, cultural, scientific, and technological environment where it operates.
A high-level architecture for a GDE according to the above principles is designed in (Nativi and Craglia Citation2021). This high-level architecture recognizes the need to leverage the existing heterogeneous and autonomous systems, which provide the necessary functionalities/resources needed by the digital ecosystem to fulfill its objective. That is, the GDE implementation should apply a System of Systems (SoS) approach to connect and orchestrate the contributing systems in order to provide added-value services and functionalities.
depicts the ecosystem engineering view, adapted from (Nativi and Craglia Citation2021).
Figure 1. GDE Engineering Model, adapted from (Nativi and Craglia Citation2021).
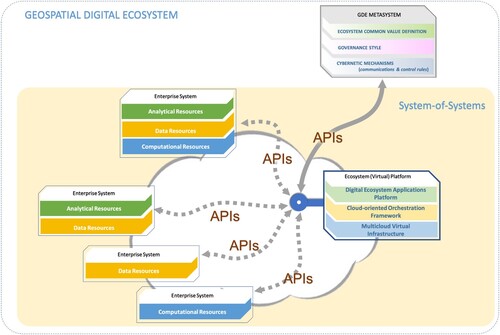
The diagram shows a set of enterprise systems – large complex computing systems which handle large volumes of data and enable organizations to integrate and coordinate their business processes (IGI Global Citation2022); these are the actual digital ecosystem components. Each enterprise system can share resources (data resources, analytics resources, and computational resources – see section Geosciences Digital Ecosystem Resources) utilizing Web APIs (see next subsection) to interact with the other components of the distributed environment, which is implemented by the ecosystem. The emerging (virtual) platform of the digital ecosystem connects to the enterprise systems to exploit their resources; this is where new components and functionalities are implemented to provide digital ecosystem added-value services. Finally, shows the metasystem – i.e. the governance and cybernetic framework; this is included here for completeness but is out of the scope of this work.
This work focuses on the analysis of the emerging (virtual) platform of the digital ecosystem. In particular, we capture and analyze the requirements and the solutions (conceptual and technological) to enable execution of heterogeneous analytical software (models) in a GDE framework.
2.1. Ecosystem elements: enterprise systems and their interoperability mechanisms
Digital ecosystems must leverage existing heterogeneous and autonomous systems. These provide their functionalities/resources utilizing the Web technologies which are more suitable for their own mandates (they are autonomous). For the objective of this work, the key feature characterizing the enterprise systems contributing to the digital ecosystem is that they expose their resources and functionalities utilizing Web technologies, rather than the specific utilized technology (e.g. Web APIs, Web Services, or Microservices).
Web APIs stem from the notion of APIs, which (Shnier Citation1996) defines ‘the calls, subroutines, or software interrupts that comprise a documented interface an application program can use the services and functions of another application, operating systems, network operating system, driver, or another low-level software program’. From a software engineering point of view, APIs constitute the interfaces of the various building blocks that a developer can assemble to create an application (Santoro et al. Citation2019; Vaccari et al. Citation2021). The expression Web APIs indicates the APIs operating over the Web. In the reminder of this paper, the terms Web APIs and APIs are used generically to refer to the mechanisms an enterprise system implements to expose its resources and functionalities on the Web.
Several definitions exist for a Web service, essentially describing it as a service that is offered over the web, irrespective of the usage of specific protocols and message formats (Santoro et al. Citation2019; OASIS Citation2006; IBM Citation2020). The main difference between a Web Service and a Web API stems from their offering. A Web Service provides a service interface (i.e. an interface aimed at offering access to ‘high-level’ functionalities for end-users). A Web API offers a programming interface (i.e. a set of low-level functionalities that can be used and combined by software developers to deliver a higher-level service). Thus, Web Services and Web APIs differ at the design level but not necessarily at the technological level (Santoro et al. Citation2019).
Microservices deal specifically with how an application is structured internally; the National Institute of Standards and Technology (NIST) (Karmel, Chandramouli, and Iorga Citation2016) defines a microservice as ‘a basic element that results from the architectural decomposition of an application’s components into loosely coupled patterns consisting of self-contained services that communicate with each other using a standard communications protocol and a set of well-defined APIs, independent of any vendor, product or technology’. Microservices can be described as a way of structuring a Web application into loosely coupled, independently deployable components that communicate over the web utilizing lightweight interfaces (Santoro et al. Citation2019; Karmel, Chandramouli, and Iorga Citation2016; Newman Citation2015).
3. Geosciences digital ecosystem resources
As outlined in section 2, the main objective of a GDE is the generation of knowledge about the Earth planet. A key tool for transforming the huge amount of data currently available into knowledge is represented by scientific models, either theory-driven or data-driven. The former, also referred to as physical models, encode the mathematical model of a scientific theory, e.g. numerically solving the set of equations that represent alleged physical laws (Prada et al. Citation2018). The latter, also termed empirical models, aim at building a model of data by raw data reduction and fitting, with the only objective of empirical adequacy. With the increased availability of data and the development of advanced modeling techniques like Machine and Deep Learning, data-driven modeling is gaining importance (Hofmann et al. Citation2019; Nisbet, Elder, and Miner Citation2009).
In order to execute a scientific model (implemented as an analytical software), there is the need to discover and utilize different types of resources, which can be classified into three broad categories: data resources, infrastructural resources, and analytical resources. Such resources are provided by the different enterprise systems belonging and contributing to a digital ecosystem and are shared utilizing different APIs, according to the specific implementations of each enterprise system. It is worth to note that an enterprise system can share resources belonging to different categories (e.g. it can share both data and infrastructural resources). Providing such APIs enables an enterprise system to contribute to the overall digital ecosystem, allowing the implementation of new components which utilize the APIs to offer added-value services exploiting the shared resources.
The following sections describe the different categories of resources and their main characteristics.
3.1. Data resources
Data to be processed or generated by computational models (e.g. model input and output) belong to this category. Geospatial datasets are characterized by a high level of variety in terms of spatial and temporal characteristics, coordinate reference systems, encoding formats, etc. The resulting landscape is therefore highly heterogeneous. Traditionally, several (standard) data schemas and data access protocols exist for data sharing (Santoro et al. Citation2018; Craglia et al. Citation2011) – including metadata and data typologies, access service interfaces, and APIs. This heterogeneity addresses the need of handling a great variety of data resources, and generates a high complexity for working with multi-disciplinary data, requiring specific expertise. Often, domain scientists (including modelers) but also application developers, do not have such expertise. Typically, a domain expert (or application developer) works with a limited set of data types and protocols, belonging to her/his realm.
An enterprise system sharing data resources must provide one or more Web APIs, possibly complying with FAIR principles (Wilkinson et al. Citation2016), allowing the discovery and access of shared data, at least. In the reminder of this manuscript, such APIs are referred to as Data APIs.
3.2. Infrastructural resources
This category of resources includes networking, storage, computing, and other fundamental infrastructural resources, which are commonly used to execute a scientific model/workflow. Often, a scientific model run requires infrastructure scalability – i.e. heavy computing capabilities and substantial data storage. Even when a single execution does not require a significant amount of resources, the opportunity to invoke multiple parallel executions might need that.
Today, empowered by the digital transformation technologies, different solutions exist to provide scalable infrastructure resources. Although such solutions differ in terms of technical capabilities and philosophical approaches (e.g. resources availability, costs, privacy, and property rights conditions), they can all be characterized as IaaS (Infrastructure as a Service) solutions (Mell and Grance Citation2011).
An enterprise system sharing infrastructural resources must provide one or more Web APIs, which allow the discovery and instantiation of the resources, at least. In the reminder of this manuscript, such APIs are referred to as IaaS APIs.
3.3. Analytical resources
These resources represent the implementation(s) and encoding of scientific models to process one or more datasets. In general, three different approaches for scientific model sharing can be recognized, according to three implementation traits: (a) openness, (b) digital portability, and (c) client-interaction style (Nativi, Mazzetti, and Craglia Citation2021):
Model-as-a-Tool (MaaT): users interact with a software tool internally exploiting scientific models, but they cannot interact directly with the models themselves.
Model-as-a-Service (MaaS): a given implementation of the scientific model runs on a specific server, but this time, APIs are exposed to interacting with the model.
Model-as-a-Resource (MaaR): the source code (or the executable binary) of a scientific model is shared and can be accessed through a resource-oriented interface, i.e. API.
In the case of MaaT, the user utilizes a dedicated Graphical User Interface to configure and launch the model execution, which then is run on a specific computational resource. A high level of control is ensured in this case as far as how the model is used and executed; however, this methodology is essentially not interoperable (no machine-to-machine interaction is possible). Besides, due to the limitations of the computational resource where the model is executed, scalability of the model is strongly limited as well. Finally, with MaaT it is not allowed to automatically move the model to different computational resources.
With the MaaS approach the level of interoperability is increased due to the availability of APIs to configure and launch the model execution, i.e. MaaS enables a machine-to-machine interaction. However, also in this case, scalability limitations described for MaaT still apply and it is not possible to automatically moving the model to different computational resources.
Finally, in the case of MaaR, the interoperability level can be considered the same as for any other shared digital resource, e.g. data. With MaaR it is possible to automatically move the model and launch its execution on different computational resources, e.g. allowing to select the most appropriate according to the specific needs of the single run. While the scalability and interoperability benefits are clear in this case, this approach requires addressing some challenges in particular as far as automatically executing all necessary steps for the configuration of the execution environment and the triggering of the model.
This manuscript will consider the MaaS and MaaR approaches, which allow a machine-to-machine (M2M) interaction for the execution of a given scientific model. In the reminder of this manuscript, the expression Model APIs refers to the APIs utilized to share a model resource, according to either the MaaR or MaaS approach (in those contexts where the difference is relevant, MaaR or MaaS qualification is explicitly stated).
4. Virtual earth cloud architecture
Virtual Cloud can be defined as a ‘customized cloud by aggregating resources and services of different clouds and aims to provide end users with a specific cloud working environment’ (An et al. Citation2017). The use of different clouds is beneficial for several reasons, including cost efficiency, avoidance of vendor lock-in, performance optimization, service outages resilience, diversity of geographical locations, etc. It is worth noting that the provided definition of Virtual Cloud does not imply any specific approach for the use of different clouds, focusing instead on the fact that the end user is provided with a specific cloud working environment, i.e. the underlying use of different clouds is transparent for the user.
Since short time after the emergence of Cloud Computing and different Cloud Service Providers, the issue of how to enable the use of different clouds emerged as a central topic in the field of Cloud Computing research, also considering that despite tremendous development of Cloud Computing, it still suffers from the lack of standardization (Chauhan et al. Citation2019). Many papers address this topic, analyzing, discussing and classifying the different architectural approaches which can be applied to obtain an effective use of multiple clouds (often referred to as Inter-Cloud), according to different use cases, needs and constraints. In (Grozev and Buyya Citation2014) the first broad level of architectural classification differentiates between Independent and Volunteer Inter-Cloud environments, defining the concept of Multi-Cloud as ‘the usage of multiple, independent clouds by a client or a service’, whereas a (cloud) Federation ‘is achieved when a set of cloud providers voluntarily interconnect their infrastructures to allow sharing of resources among each other’. The Multi-Cloud strategy fits with the Digital Ecosystem approach, where autonomy of the enterprise systems (including cloud providers) is key.
In the Multi-Cloud approach, cloud brokering plays an important role. Already in 2011, the NIST Cloud Computing Reference Architecture lists the Cloud Broker as one of the five major actors of the architecture (Liu et al. Citation2011) and defines it as ‘An entity that manages the use, performance and delivery of cloud services, and negotiates relationships between Cloud Providers and Cloud Consumers’. Several organizations active in the cloud technology area have identified cloud service brokerage as an important architectural challenge and a key concern for future cloud technology development and research (Fowley, Pahl, and Zhang Citation2014). A classification of cloud brokering solutions is proposed in (Fowley et al. Citation2018) and a list of cloud broker capabilities is provided. Particularly relevant for this manuscript is the Broker Integration Capability, defined as ‘building independent services and data into a combined offering – often as an integration of a vertical cloud stack or data/process integration within a layer through transformation, mediation and orchestration’ (Fowley et al. Citation2018).
We define Virtual Earth Cloud as a Multi-Cloud integration brokering framework for Big Earth Data analytics. It is possible to identify different types of users interacting with Virtual Earth Cloud, directly or indirectly, according to the following roles:
Resource Provider: the person/organization providing resources (data, infrastructural, analytical) to Virtual Earth Cloud;
Application Developer: the intermediate user developing applications for end-users, exploiting the functionalities made available by Virtual Earth Cloud.
End-users: an end-user interacts indirectly with Virtual Earth Cloud, through an application created by an Application Developer; examples of end-users include: policy-makers, decision-makers, and citizens.
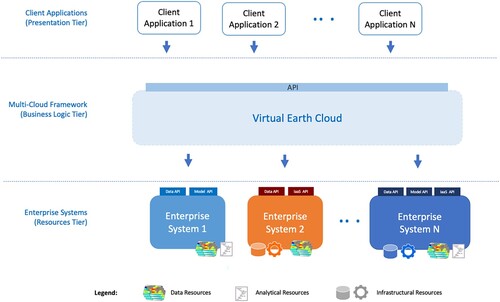
depicts the high-level system architecture of the Virtual Earth Cloud framework. Based on the well-known layered architecture style (Richards Citation2015), the architecture includes three functional layers (which can be implemented as a three-tiers architecture):
Presentation layer – that is responsible for handling all user interface components (i.e. Client Applications). The Virtual Earth Cloud does not provide any user interface for end-users, instead it provides APIs which can be invoked by user interfaces for exploiting its functionalities (see section Use-cases).
Business Logic layer – that is responsible for implementing all necessary functionalities to satisfy requests from Client Applications, exploiting the available digital resources shared by the enterprise systems, which belong to the ecosystem. This layer provides the actual Multi-Cloud Framework functionalities and is comprised of several components (see section Main Components of the Virtual Cloud), which form a Virtual Earth Cloud. This, based on the virtual cloud paradigm (An et al. Citation2017), creates another level of abstraction providing users (Client Applications) with a unified perspective on services from a range of heterogeneous providers (the enterprise systems constituting the ecosystem).
Digital Resources: – that provides all the required resources to define and execute scientific models (see section Geosciences Digital Ecosystem Resources). Different and autonomous enterprise systems (represented by different colors) contribute their resources. The set of contributing enterprise systems is dynamic; i.e. it is possible for new enterprise systems to join the Virtual Earth Cloud (providing their resources) as well as for contributing enterprise systems to leave the Virtual Earth Cloud.
Figure 2. Virtual Earth Cloud High-level System Architecture.
4.1. Virtual Earth Cloud requirements
The main goal of the Virtual Earth Cloud infrastructure is to allow the execution of analytical software (e.g. scientific models) on the most appropriate of the different underlying enterprise systems, in a seamless way for the requester (i.e. users via Client Applications). To this aim, the Virtual Earth Cloud must provide a common entry-point (e.g. a set of Web APIs), which can be used to request the execution of a scientific model, along with a set of input data. Model is then executed on one or more of the available infrastructures; the infrastructures selection is the result of an optimization metrics, which consider parameters such as computational resources availability, latency time, data availability, legal obligations, and execution cost. Finally, results are returned to requesters via the Virtual Earth Cloud Web APIs.
To achieve its goal, the Virtual Earth Cloud infrastructure must provide the following high-level functionalities:
Implementation of the workflow required for model execution: configuring the environment (programming languages, software libraries, etc.), ingesting input data, etc.;
Provisioning of computational resources from the available underlying enterprise systems;
Discovery of and access to the necessary data and model resources, from the available underlying enterprise systems;
Optimization of the model execution, e.g. based on availability of computational resources, latency time, and required data.
Considering the multi-disciplinary domain characterizing the geosciences domain, the Virtual Earth Cloud must address the high heterogeneity which characterizes each of the resource types to be utilized (e.g. dataset schemas and metadata, scientific models description and code, and computing and storage infrastructures) by supporting the diverse resource and service protocols and APIs, exposed by the different enterprise systems, which constitute the digital ecosystem.
To support the MaaR approach, for scientific models sharing, the Virtual Earth Cloud must be able, not only to discover and access model implementations, but also to execute the implementing code. For a given model, where several model implementations exist (developed in different software environments or simulation frameworks). Avoiding to impose constraints on model providers is key to keep interoperability requirements as minimum as possible (Santoro, Nativi, and Mazzetti Citation2016; Bigagli et al. Citation2015). Therefore, the Virtual Earth Cloud must be able to supply the appropriate execution environment for the model, rather than pushing a change in the utilized software environment or simulation framework.
4.2. Conceptual approach for Virtual Earth Cloud design
This section introduces the three conceptual approaches the Virtual Earth Cloud design is based on, namely: containerization, orchestration, and brokering.
4.2.1. Containerization
Scientific models are developed in many different programming environments (e.g. Python, Java, R, MATLAB) or simulation frameworks (e.g. NetLogo, Simulink). Therefore, to be able to execute a model, it is not sufficient accessing its source code. The retrieved code must be executed in an environment that supports the required programming language and the software libraries utilized by the model source code.
Today, containerization (or container-based virtualization) (Soltesz et al. Citation2007) is commonly used to address this requirement. Essentially, containerization is the packaging together of software code with all its necessary components (e.g. libraries, frameworks, and other dependencies). This creates a container, i.e. a single fully packaged and portable executable, which can be run on any infrastructure compatible with the specific containerization technology (i.e. container engine). With respect to traditional virtualization approaches based on the creation of full Virtual Machines (VMs), containerization offers several benefits. In particular, containers are typically lighter than VMs and require less start-up time. The result is that containerization allows to use the same type of computational resources for any software (i.e. model implementation). The only requirement is the availability of the specific container engine, since all other model-specific dependencies are packaged in the container itself.
4.2.2. Orchestration
Orchestration is the automated configuration, management, and coordination of computer systems, applications, and services (Red Hat Citation2021c). The Virtual Earth Cloud infrastructure must provide orchestration functionalities at three different levels: scientific model, container, and computational resources.
Model orchestration coordinates the execution of the necessary steps which compose the execution workflow of a given scientific model. The high-level steps for this orchestration include:
Management of input data access/ingestion.
Configuration of model execution.
Triggering of model execution.
Storage of the generated output.
Container orchestration automates the deployment, management, scaling, and networking of containers (Red Hat Citation2021b). In the case of Virtual Earth Cloud, this orchestration is needed when a container is submitted for execution to an enterprise system belonging to the ecosystem. The orchestration:
takes care of selecting which computing node to use, according to the capacities (memory, CPU, etc.) required by the container;
executes all container-level configurations (e.g. links to persistent storage if requested);
triggers the container;
monitors the resource allocations and the state of the containers.
Computational resources orchestration deals with all aspects related to the instantiation/removal of computational resources in an enterprise system. When new computational resources are requested on a specific enterprise system, it is necessary to coordinate and invoke the instantiation of the processing, storage, networks, and other fundamental computing resources. Finally, the newly instantiated computational resources must be properly configured to support the containerized execution of models.
4.2.3. Brokering approach for System of Systems
The notion of ‘System of Systems’ (SoS) and ‘System of Systems Engineering’ (SoSE) emerged in many fields of applications. ‘Systems of systems are large-scale integrated systems that are heterogeneous and consist of sub-systems that are independently operable on their own, but are networked together for a common goal’ (Jamshidi Citation2008).
In the brokered approach (Nativi, Craglia, and Pearlman Citation2013) no common model is defined to be part of a SoS. Participating systems can adopt or maintain their preferred interfaces, metadata and data models. Interoperability is implemented by dedicated components (the brokers) that oversee connecting to the participant systems, by implementing all the required mediation and harmonization artifacts. The only interoperability agreement is the availability of documentation describing the published interfaces, metadata, and data models – i.e. openness. The brokered approach was successfully applied to develop SoS in contexts characterized by a high level of heterogeneity, e.g. the Global Earth Observation System of Systems (GEOSS) (Nativi et al. Citation2015) (Craglia et al. Citation2017), CODATA system (International Science Council Citation2021), and the WMO Hydrology Observing System (WHOS) (WMO Citation2021).
4.3. Main components of the Virtual Cloud
The main software components of the Virtual Earth Cloud infrastructure are discussed in this section. For each component, the main requirements and functionalities are described.
depicts the internal components of the Virtual Earth Cloud and their interaction with the enterprise systems participating to the ecosystem (for simplicity only one enterprise system is depicted in the figure). also depicts a set of Ancillary Services. These are generic services that modern cloud infrastructures offer to developers, generally. Such services provide general-purpose functionalities, which can be used by application developers according to the SaaS (Software as a Service) paradigm (Mell and Grance Citation2011). The Web Storage service allows providers the possibility to store and retrieve a large amount of data in a web-accessible storage system. The Message Queue provides a cloud-based hosting of message queues, which lets to create and interact with a message queue, from different distributed components.
Figure 3. Virtual Earth Cloud Internal Components.
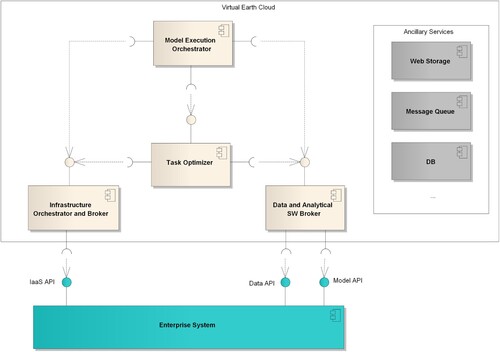
4.3.1. Data and analytical SW broker
This component enables the discoverability and access of data and analytical resources (models), which are provided by the enterprise systems participating the digital ecosystem. It provides a unique entry point to discover and access such resources by the other Virtual Earth Cloud components; i.e. it exposes a set of APIs which can be used to discover and access the (data and models) resources from the different enterprise systems.
Based on the brokering approach (Nativi, Craglia, and Pearlman Citation2013), the Data and Analytical SW Broker implements all the interoperability arrangements that are necessary to interoperate with the heterogeneous Data and Model APIs, utilized by the ecosystem enterprise systems to share their resources. To provide a harmonized view of the shared resources, this broker component must implement three main functionalities: mediation, distribution and harmonization. Mediation allows to interconnect different components by adapting their technological (protocol), logical (data model), and semantic (concepts and behavior) models (Nativi, Craglia, and Pearlman Citation2013). Distribution permits to ‘view’ all contributing enterprise systems as if they were a single provider. Harmonization allows consumer applications (generally clients, in this case the other Virtual Earth Cloud internal components) to discover and access available resources according to the same protocol and data model.
Based on the above functionalities, four main operations are provided by Data and Analytical SW Broker APIs: data discovery, data access, model discovery, and model access. While the first three operations are quite straightforward in terms of what they mean, the model access operation is worth to be further detailed, in fact two separate use cases must be considered, depending on the model sharing approach (MaaS or MaaR). Although both approaches enable a machine-to-machine interaction, accessing a model using the MaaS approach requires different functionality than using the MaaR approach – the distinction stems from the different paradigms they apply: SOA (Service Oriented Architecture) versus ROA (Resource Oriented Architecture). In the MaaS approach, the exposed service is the model execution. With ROA, the provider exposes the model as a digital resource, i.e. a logical entity that is exposed for direct interactions (Overdick Citation2007). Thus, with MaaR, the exposed resource is a given model implementation (e.g. the source code or a binary executable). In both MaaS and MaaR use cases, the broker component must implement typical mediation and distribution functionalities to interoperate with the different MaaS/MaaR APIs and distribute the access request, properly. However, in the MaaS case the broker access request triggers an actual model execution. While, in the MaaR case, the access request simply retrieves the model implementation; then, the model execution must be handled separately.
4.3.2. Infrastructure Orchestrator and Broker
This component is in charge of connecting to the enterprise systems which share computational resources in order to discover and allocate the required computational resources needed for the execution of the model.
To this aim, this component acts as a computational resource broker interacting with the specific and heterogeneous IaaS (Infrastructure as a Service) APIs exposed by the enterprise systems. Therefore, it must implement all required interoperability arrangements to interoperate with them. Besides, this component implements orchestration functionalities at two different levels: computational resources and container executions (see section Orchestration).
Through the Infrastructure Orchestrator and Broker component, the discovery of computational resources is provided to the other Virtual Earth Cloud components. The discovery functionality must provide different levels of granularity: enterprise systems, and computational resources. The first one, enterprise systems, enables the discovery of enterprise systems which are currently (i.e. at the moment of the request being received) connected to the Virtual Earth Cloud and share computational resources. The second level of granularity (computational resources) provides more details about computational resources availability from each enterprise system. At this level, the component provides information about the current availability of computational resources of an enterprise system. This includes, at least, the following items:
Total resources: this represents the maximum resources instantiable for the system.
Instantiable units: although modern cloud solutions enable the instantiation of computational resources according to combinations of CPU and RAM, not all enterprise systems will support all combinations; this information must provide the list (or the range) of possible combinations supported by the enterprise system.
Available resources: these are the currently instantiated resources (and their units) which are not in use.
Resources in use: these are the currently instantiated resources (and their units) which are inuse.
The orchestration functionalities implemented by this component enable the provision (and removal) of the required computational resources and the execution of a containerized model. When new computational resources are requested on a specific enterprise system, different types of fundamental computing resources must be instantiated (e.g. processing, storage, networks, etc.), in the correct order, and associated with the final computational resource – usually a virtual machine ready to be used. Additionally, a newly instantiated computational resource must be properly configured for its use in the Virtual Earth Cloud framework, i.e. it must support containerization and container orchestration. Depending on the utilized technologies, this support might require additional actions to be performed. An example of such additional actions is the registration of the computational resource to the container orchestration framework. The same applies for the removal process, i.e. the fundamental computing resources must be properly eliminated, in the correct order, to become available for other instantiations. Furthermore, this component must allow the definition of a set of (configurable) rules which are used to automatically trigger the removal of unused computational resources from the underlying enterprise systems.
As far as the execution of a containerized model, this component must expose the APIs which can be used to submit the execution of a container and implement all necessary actions to configure and run the containerized model on a computational resource of the selected enterprise system. Three main phases can be identified:
Scheduling of container deployment to a particular host: based on available resources on the different hosts (e.g. CPU, memory, etc.) and/or other constraints defined in the execution request.
Provisioning of required resources: according to the definition of the container in this phase the component must provision (link) the container environment to the host environment (network connections, persistent storage, etc.).
Lifecycle management: start the container, monitor its state, etc.
4.3.3. Task Optimizer
The Task Optimizer component is responsible for selecting the optimal enterprise system for the execution of the specified model. In order to perform the selection, the Task Optimizer requires the following information to be provided by the requester:
The computational resources required for the model execution (i.e. CPU and/or RAM).
The identifiers of the input data.
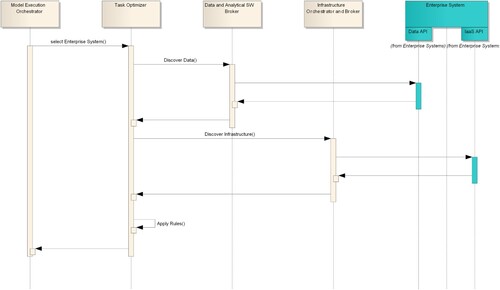
It is worth noting that the required computational resources are provided by the requester and are not retrieved automatically through Data and Analytical SW Broker model discovery operation. This is because the same model might require different computational resources depending on the specific execution (e.g. the size of the input data) or specific context of the execution (e.g. more CPU might be required for high-priority executions). Provided with this information, the Task Optimizer retrieves availability of data and computational resources from the Data and Analytical SW Broker and Infrastructure Orchestrator and Broker components respectively. After obtaining all the necessary information, first the Task Optimizer excludes the infrastructures where it is not possible to execute the task (e.g. the model requires an amount of RAM which can’t be allocated on a single node in one or more infrastructures). Finally, the remaining execution infrastructures are sorted, by applying a set of configurable rules, and returned to the requester. shows a sequence diagram of the steps which the Task Optimizer performs to work out its task.
Figure 4. Task Optimizer Sequence Diagram.
Different optimization strategies can be applied, depending on what must be optimized (e.g. data transfer, computational resource usage, etc.). The same execution request might generate different selections based on different strategies.
4.3.4. Model Execution Orchestrator
The Model Execution Orchestrator component is the main entry point of the Virtual Earth Cloud component, i.e. it publishes the APIs which can be invoked to request the execution of a model. The request must specify the identifier of the model to be executed and the list of input data identifiers.
Upon a model execution requests, this module implements the business logic needed to execute a model; that is, (i) it orchestrates the data access/ingestion, (ii) configures the model execution, (iii) invokes the execution and (iv) saves the outputs.
While the high-level steps are the same for both MaaS and MaaR approaches, their implementations and the interactions with other Virtual Earth Cloud internal components are different.
In the case of MaaS, the first step executed by the orchestrator (management of input data access/ingestion) is implemented by generating proper data access requests for each of the input data. To do this, the Data and Analytical SW Broker is queried to retrieve the metadata of each input data. The metadata provides the access information which is used to create the actual data access request for each input data. The second step (configuration of model execution) consists in generating a request for the model execution, specifying the model to be executed and the data access request for each input data. The model execution request is then submitted to the Data and Analytical SW Broker which in turn creates a proper request (according to the specific MaaS APIs utilized for the model sharing) and distributes the request to the MaaS APIs provider. This implements the third step (triggering of model execution). Finally, the fourth step (storage of the generated output) is implemented by retrieving the execution result (again via the Data and Analytical SW Broker), retrieving the generated output data and store it to the Virtual Earth Cloud Web Storage.
In the case of MaaR, the orchestrator retrieves, via the Data and Analytical SW Broker, the model description. This is used to create a proper request to the Task Optimizer, which returns the necessary information about the enterprise system selected for the execution. Then, the Model Execution Orchestration executes a data discovery request for all input data. This operation is necessary to discover if the requested input data is already available (hosted) on the enterprise system which was selected for the execution. This information is necessary for the data ingestion phase. In this phase, the Model Execution Orchestration submits a series of containerized jobs (one for each input data) via the Infrastructure Orchestrator and Broker. These jobs ingest the required data to the node where the model execution will be executed. This ingestion is achieved either via the Data and Analytical SW Broker (in case the data is not hosted on the execution enterprise system) or directly using the data hosted on the execution enterprise system (if available). After completing the data ingestion, the actual model is retrieved from the MaaR APIs via the Data and Analytical SW Broker and the model container is defined. At this time, it is possible to submit the model container execution via to the Infrastructure Orchestrator and Broker. Finally, after waiting for the completion of the execution, the generated output data is stored in the Virtual Cloud Web Storage.
5. Proof-of-concept implementation
In October 2020, the DG JRC of the European Commission, in collaboration with ESA, ECMWF, and EUMETSAT, and with the support of CNR, implemented a Proof-of-Concept (PoC) of the Virtual Earth Cloud (Nativi and Craglia Citation2021; Santoro and Rovera Citation2021).
This implementation utilizes the Docker (Docker Inc. Citation2021) technology to realize the containerization approach. The Discovery and Access Broker (Nativi et al. Citation2015) technology developed by CNR provides data brokering functionalities while the Virtual Earth Laboratory (VLab) framework (Santoro, Mazzetti, and Nativi Citation2020), also developed by CNR, provides model brokering and orchestration functionalities for MaaR. The container orchestration is provided by the well-known and widely-used Kubernetes technology (Linux Foundation Citation2021), and, finally for the computational resources orchestration the Cluster API (Kubernetes Citation2021b) and Cluster Autoscaler (Kubernetes Citation2021a) technologies are utilized.
shows the software packages which compose the Virtual Cloud PoC technological implementation. The Discovery and Access Broker and the Virtual Earth Laboratory are instances of existing technological frameworks, namely the GEO DAB (Nativi et al. Citation2015) and the VLab framework (Santoro, Mazzetti, and Nativi Citation2020). The remaining two packages, Simple Optimizer and VECloud Infrastructure Orchestrator and Broker, implement the Task Optimizer and the Infrastructure Orchestrator and Broker respectively.
Figure 5. Virtual Earth Cloud PoC Implementation Packages.

The Simple Optimizer applies the following set of rules to select the enterprise system:
Select enterprise systems where both required data and computational resources are available;
Select enterprise systems where the required computational resources are available;
Select enterprise systems where additional computational resources can be instantiated.
The VECloud Infrastructure Orchestrator and Broker () is composed of two main software components: the VECloud Core and the Multi-Cloud Agent.
Figure 6. VECloud Infrastructure Orchestrator and Broker.
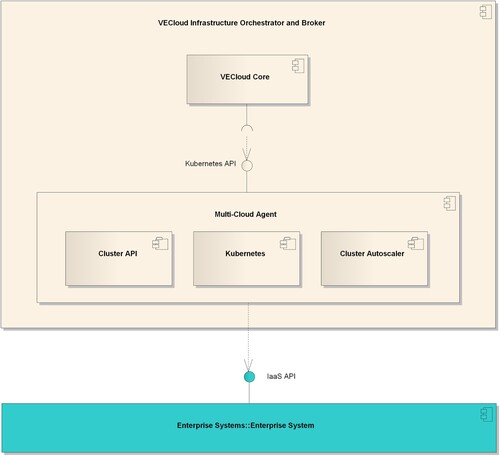
The Multi-Cloud Agent package is composed of a set of technologies which implement the orchestration functionalities at the container and computational resources levels. Specifically, container orchestration is provided by Kubernetes (Linux Foundation Citation2021). When deployed on a set of ‘nodes’ (cluster), Kubernetes provides all necessary functionalities and APIs to orchestrate the execution of containerized applications (models, in this case) and to discover available computational resources on its cluster (i.e. the nodes it is deployed on). By its own, Kubernetes does not provide any native way to automatically instantiate new nodes and add them to an existing Kubernetes cluster. To this aim, the Multi-Cloud Agent package includes the Cluster API (Kubernetes Citation2021b) framework. When utilized with Kubernetes, Cluster API is able to leverage a set of IaaS APIs to automate the task of instantiating new nodes and add them to the Kubernetes cluster. Cluster API currently supports different IaaS APIs, including: OpenStack, AWS EC2, Google Compute Engine, Azure VM, etc. If the enterprise system exposes IaaS APIs which are not supported by Cluster API, it is still possible to utilize a version of the Multi-Cloud Agent where the Cluster API framework is disabled. This results in a less flexible environment, where the number of computational resources is static and can’t be adjusted according to the needs. For the PoC implementation, the Multi-Cloud Agent was deployed by creating and utilizing a set of Ansible (Red Hat Citation2021a) scripts which automate the deployment and configuration of the technology stack composing the Multi-Cloud Agent.
The Multi-Cloud Agent package exposes the Kubernetes APIs which are utilized by the VECloud Core component. This was implemented for this PoC and is charge of collecting information about computational resources availability, current model executions and Kubernetes cluster configuration. Besides, the VECloud Core package exposes the APIs which are utilized by the other modules of the Virtual Earth Cloud component (see section Infrastructure Orchestrator and Broker).
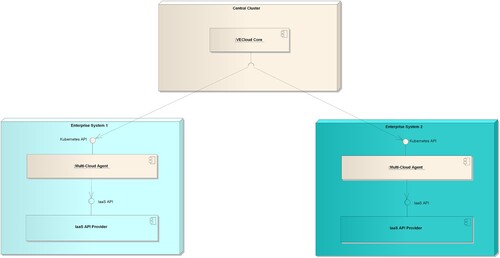
The deployment of the VECloud Infrastructure Orchestrator and Broker is depicted in . The Multi-Cloud Agent package is deployed on each enterprise system. Instead, the VCloud Core package is deployed on a Central Cloud Infrastructure, collecting all required information from the distributed instances of Multi-Cloud Agent.
Figure 7. Deployment of VECloud Infrastructure Orchestrator and Broker.
5.1. Use-cases
This section describes a couple of significant use case to exemplify how the described PoC works, i.e. to demonstrate the presented architecture is able to satisfy the identified requirements. From a user perspective, the following steps are executed in both use cases:
User discovers an analytical software (model).
User selects input data for the model execution.
User launches the model execution.
User retrieves/visualizes the output of the execution.
The first use case utilizes the Earth Observation Data for Ecosystem Monitoring (EODESM) model (Lucas and Mitchell Citation2017). It classifies land covers and changes according to the Land Cover Classification System (LCCS) of the Food and Agricultural Organization (FAO). As input data, EODESM requires two Copernicus Sentinel 2 Level 2A products covering the same area of interest at two different points in time. First, the model processes the two products for generating land cover maps. Then, it calculates the difference in the two land cover maps, generating a third output which visually captures the identified changes.
The user interacts with the Virtual Earth Cloud through a dedicated Web GUI (Graphical User Interface) which utilizes the APIs exposed by the Virtual Earth Cloud. Through the Web GUI the User discovers the model (through the VLab which in the PoC provides model discovery and access functionalities, in addition to the model orchestration ones) and the input data (through the DAB).
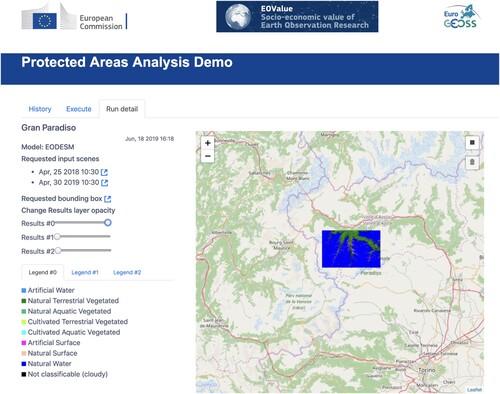
Once defined the input data, the User requests to launch the model. In turn, the GUI sends the request to VLab which essentially implements the Orchestration steps for MaaR (see section Model Execution Orchestrator), saving the output to a Web Storage. Finally, the User retrieves the output data associated with the execution via VLab (where execution information is stored, including the location of the generated outputs). shows a screenshot of the GUI, displaying the output of the computation over the Gran Paradiso protected area in Italy.
Figure 8. Output of an EODESM Computation over Gran Paradiso National Park, visualized on a dedicated GUI developed using the Virtual Earth Cloud APIs.
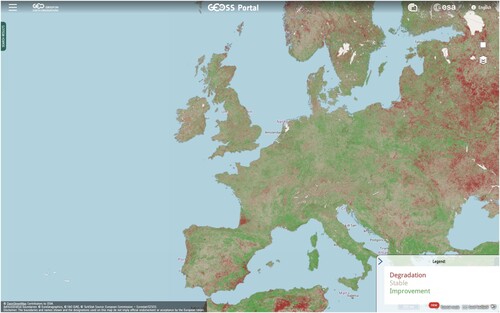
The second use case calculates the UN SDG 15.3.1 indicator (Land Degradation). One of the most widely used models for the calculation of this indicator is Trends.Earth (Gonzalez-Roglich et al. Citation2019). Originally made available as a plugin for the QGIS application, the model was published on the VLab framework (which provides provides model brokering and orchestration functionalities in the PoC) (Giuliani et al. Citation2020). For this use case a different GUI is utilized to interact with Virtual Earth Cloud APIs, the experimental version of the GEOSS Portal developed by European Space Agency (ESA). displays the calculated Land Degradation map over Europe.
Figure 9. Output of UN SDG 15.3.1 (Land Degradation) calculation over Europe, visualized on the GEOSS Test Portal using the Virtual Earth Cloud APIs.
6. Conclusions
This manuscript presented the Virtual Earth Cloud concept, a multi-cloud framework for the generation of knowledge from Big Earth Data analytics. The Virtual Earth Cloud allows the execution of analytical software to process and extract knowledge from Big Earth Data, in a multi-cloud environment, to enable a Geosciences Digital Ecosystem (GDE): a system of systems that applies the digital ecosystem paradigm.
A key tool for transforming the huge amount of data currently available into knowledge is represented by scientific models. To execute a scientific model (implemented as an analytical software), there is the need for the GDE to discover and utilize different types of resources, which can be classified into three broad categories: data resources, infrastructural resources, and analytical resources. Such resources are provided by the different enterprise systems belonging and contributing to a digital ecosystem and are shared utilizing Web technologies (e.g. Web APIs, Web Services, etc.).
To enable the GDE, the Virtual Earth Cloud provides the following high-level functionalities: (i) implementation of the workflow required for model execution, (ii) provisioning of computational resources from contributing enterprise systems, (iii) discovery of and access to the necessary data and analytical software resources, and (iv) optimization of the model execution.
The design of the Virtual Earth Cloud is based on three conceptual approaches: containerization, orchestration, and brokering. Containerization enables the execution of analytical software developed in different programming languages and environments (e.g. libraries, frameworks, and other dependencies). Orchestration (i.e. the automated configuration, management, and coordination of computer systems, applications, and services) is necessary in the Virtual Earth Cloud at three different levels: scientific model (input ingestion, model launch, etc.), container (computing node selection, container-level configuration, etc.), and computational resources (coordinate the instantiation of the processing, storage, networks, and other fundamental computing resources). Brokering allows the realization of a System of Systems by minimizing interoperability requirements for participating systems by implementing interoperability through dedicated components (the brokers) that oversee connecting to the participant systems; considering the multi-disciplinary domain charactering the geosciences domain, this approach is key to address the high heterogeneity which characterizes each of the resource types to be utilized (e.g. dataset schemas and metadata, scientific description and code, and computing and storage infrastructures) by supporting the diverse resource and service protocols and APIs, exposed by the different participating systems, which constitute the digital ecosystem.
The main Virtual Earth Cloud architectural components are defined in terms of their specific requirements and functionalities. The Data and Analytical SW Broker enables the discoverability and access of data and analytical resources; the Infrastructure Orchestrator and Broker connects to the enterprise systems which share computational resources in order to discover and allocate the required computational resources needed for the execution of the model; the Task Optimizer is responsible of selecting the optimal enterprise system for the execution of the specified model; finally, the Model Execution Orchestrator is the main entry point of the Virtual Earth Cloud component (i.e. it publishes the Web APIs which can be invoked to request the execution of a model) and implements the business logic needed to execute a model; that is, (i) it orchestrates the data access/ingestion, (ii) configures the model execution, (iii) invokes the execution and (iv) saves the outputs.
The described architecture is demonstrated with a Proof-of-Concept (PoC) implementation of the Virtual Earth Cloud, based on the prototype demonstrated in October 2020 by JRC (Nativi and Craglia Citation2021), in collaboration with ESA, ECMWF, and EUMETSAT, and with the support of CNR. Finally, a use case is described to show how the presented architecture and PoC work and enable a GDE.
In the present era, characterized by the digital transformation of society and the affirmation of the cyber-physical domain, there is a clear need to abandon the traditional data exchange paradigm and embrace the most effective and sustainable information and knowledge-centric approach. This key innovation is enabled by the recent technological leap linked to the ubiquitous connectivity process, the new AI spring, and the availability of public and highly scalable online computing services. On the other hand, this same innovation has brought with it a new set of issues, not only technological, but also political and social. Most relevant challenges deal with the requirement of extending interoperability from the mere domain of data (e.g. data encoding, schema, and semantic issues) to the more demanding areas of scientific modeling and cloud computing infrastructures (e.g. multi-cloud and virtual cloud services). The already complex subject of governing data system-of-systems has become much more complicated once new stakeholders must be added to provide online data analytics and computing capacities. We demonstrated that technological interoperability is possible by using open solutions. However, according to our experience, policy and governance interoperability still requires innovative styles and practices.
Future work will mainly deal with: (i) consolidation/enhancement of the presented PoC (e.g. extending the number and typology of participating enterprise systems), and (ii) extension of the presented architecture to support more advanced use cases, including:
Support of real-time capabilities: this is part of planned future development, starting with example implementations in the Hydrology modeling domain;
Knowledge Base integration: capturing scientific experts’ knowledge about a sound process for knowledge generation (e.g. the choice of appropriate datasets to be used as inputs for existing models, which model to use for a specific use-case, etc.) is a key element to build a GDE in line with Open Science principles of reproducibility, replicability and re-usability; this knowledge should be formalized and consolidated in a Knowledge Base in order to be shared and utilized in different contexts (Nativi et al., Citation2020). The presented Virtual Earth Cloud does not make use of any Knowledge Base; future work will investigate how to integrate such a component, e.g. building on existing Knowledge Base experimentations (Mazzetti et al. Citation2022).
Data quality/uncertainty: while not considered in the scope of this manuscript, data quality/uncertainty is of paramount importance; future enhancements will investigate how to include this aspect, also considering its implications in possible chaining of models.
Digital Twins of the Earth (Nativi, Mazzetti, and Craglia Citation2021): extension of the presented architecture focusing on specific support for the implementation of Digital Twins of natural environments.
Acknowledgements
The authors would like to thank Nicholas Spadaro (external collaborator of European Commission – DG JRC), Massimiliano Olivieri (CNR-IIA), and Michele Rovera (Diginova) for their contributions to the Virtual Earth Cloud development and the cloud infrastructures configuration and management. Finally, the Authors would like to thank the Reviewers for their inputs that helped to significantly improve the quality of the manuscript.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes
References
- An, B., J. Ma, D. Cao, and G. Huang. 2017. “Towards Efficient Resource Management in Virtual Clouds.” 2017 IEEE 37th International Conference on Distributed Computing Systems Workshops (ICDCSW), 320–324. doi:10.1109/ICDCSW.2017.72.
- Bigagli, L., M. Santoro, P. Mazzetti, and S. Nativi. 2015. “Architecture of a Process Broker for Interoperable Geospatial Modeling on the Web.” ISPRS International Journal of Geo-Information 4 (2). doi:10.3390/ijgi4020647.
- Blew, R. D. 1996. “On the Definition of Ecosystem.” The Bulletin of the Ecological Society of America 77 (3): 171–173. doi:10.2307/20168067.
- Chauhan, S. S., E. S. Pilli, R. C. Joshi, G. Singh, and M. C. Govil. 2019. “Brokering in Interconnected Cloud Computing Environments: A Survey.” Journal of Parallel and Distributed Computing 133: 193–209. doi:10.1016/j.jpdc.2018.08.001.
- Craglia, M., J. Hradec, S. Nativi, and M. Santoro. 2017. “Exploring the Depths of the Global Earth Observation System of Systems.” Big Earth Data 1 (1–2): 21–46. doi:10.1080/20964471.2017.1401284.
- Craglia, M., S. Nativi, M. Santoro, L. Vaccari, and C. Fugazza. 2011. “Inter-disciplinary Interoperability for Global Sustainability Research.” GeoSpatial Semantics, 1–15. doi:10.1007/978-3-642-20630-6_1.
- Docker Inc. 2021. Empowering App Development for Developers | Docker. https://www.docker.com/.
- Fowley, F., C. Pahl, P. Jamshidi, D. Fang, and X. Liu. 2018. “A Classification and Comparison Framework for Cloud Service Brokerage Architectures.” IEEE Transactions on Cloud Computing 6 (2): 358–371. doi:10.1109/TCC.2016.2537333.
- Fowley, F., Pahl, C., & Zhang, L. (2014). A Comparison Framework and Review of Service Brokerage Solutions for Cloud Architectures. In A. R. Lomuscio, S. Nepal, F. Patrizi, B. Benatallah, & I. Brandić (Eds.), Service-Oriented Computing – ICSOC 2013 Workshops (Vol. 8377, pp. 137–149). Springer International Publishing.
- Giuliani, G., B. Chatenoux, A. Benvenuti, P. Lacroix, M. Santoro, and P. Mazzetti. 2020. “Monitoring Land Degradation at National Level Using Satellite Earth Observation Time-Series Data to Support SDG15 – Exploring the Potential of Data Cube.” Big Earth Data 4 (1): 3–22. doi:10.1080/20964471.2020.1711633.
- Gonzalez-Roglich, M., A. Zvoleff, M. Noon, H. Liniger, R. Fleiner, N. Harari, and C. Garcia. 2019. “Synergizing Global Tools to Monitor Progress Towards Land Degradation Neutrality: Trends.Earth and the World Overview of Conservation Approaches and Technologies Sustainable Land Management Database.” Environmental Science & Policy 93: 34–42. doi:10.1016/j.envsci.2018.12.019.
- Google. 2022. Google Earth Engine. https://earthengine.google.com.
- Gore, A. 1998. The Digital Earth: Understanding our planet in the 21st Century. http://www.christinafriedle.com/uploads/1/8/4/7/1847486/the_digital_earth_understanding_our_planet_in_the_21st_century.pdf.
- Gorelick, N., M. Hancher, M. Dixon, S. Ilyushchenko, D. Thau, and R. Moore. 2017. “Google Earth Engine: Planetary-Scale Geospatial Analysis for Everyone.” Remote Sensing of Environment 202: 18–27. doi:10.1016/j.rse.2017.06.031.
- Grozev, N., and R. Buyya. 2014. “Inter-Cloud Architectures and Application Brokering: Taxonomy and Survey.” Software: Practice and Experience 44 (3): 369–390. doi:10.1002/spe.2168.
- Guo, H., S. Nativi, D. Liang, M. Craglia, L. Wang, S. Schade, C. Corban, et al. 2020. “Big Earth Data Science: An Information Framework for a Sustainable Planet.” International Journal of Digital Earth 13 (7): 743–767. doi:10.1080/17538947.2020.1743785.
- Hofmann, R., V. Halmschlager, M. Koller, G. Scharinger-Urschitz, F. Birkelbach, and H. Walter. 2019. “Comparison of a Physical and a Data-Driven Model of a Packed Bed Regenerator for Industrial Applications.” Journal of Energy Storage 23: 558–578. doi:10.1016/j.est.2019.04.015.
- IBM. 2020. What is a Web Service? https://www.ibm.com/docs/en/cics-ts/5.2?topic = services-what-is-web-service.
- IGI Global. 2022. What is Enterprise Systems | IGI Global. https://www.igi-global.com/dictionary/building-situational-applications-for-virtual-enterprises/10003.
- International Science Council. 2021. CODATA, The Committee on Data for Science and Technology. CODATA, The Committee on Data for Science and Technology. https://codata.org/.
- ISDE. 2019. “The 11th International Symposium on Digital Earth, Florence DECLARATION by the International Society for Digital Earth.” International Journal of Digital Earth 12 (12): 1465–1466. doi:10.1080/17538947.2019.1681645.
- Jamshidi, M. 2008. System of Systems Engineering d Innovations for the 21st Century. Wiley.
- Karmel, A., R. Chandramouli, and M. Iorga. 2016. NIST Definition of Microservices, Application Containers and System Virtual Machines. https://csrc.nist.gov/CSRC/media/Publications/sp/800-180/draft/documents/sp800-180_draft.pdf.
- Kubernetes. 2021a. Autoscaler/Cluster-Autoscaler at Master Kubernetes/Autoscaler. GitHub. https://github.com/kubernetes/autoscaler.
- Kubernetes. 2021b. Introduction—The Cluster API Book. https://cluster-api.sigs.k8s.io/.
- Lee, J., B. Bagheri, and H. Kao. (2015). A Cyber-Physical Systems Architecture for Industry 4.0-Based Manufacturing Systems. Manufacturing Letters, 3, 18–23. doi:10.1016/j.mfglet.2014.12.001.
- Linux Foundation. 2021. Production-Grade Container Orchestration. Kubernetes. https://kubernetes.io/.
- Liu, F., J. Tong, J. Mao, R. Bohn, J. Messina, L. Badger, and D. Leaf. 2011. NIST Cloud Computing Reference Architecture. 35.
- Lucas, R., and A. Mitchell. 2017. “Integrated Land Cover and Change Classifications.” In The Roles of Remote Sensing in Nature Conservation: A Practical Guide and Case Studies, edited by R. Díaz-Delgado, R. Lucas, and C. Hurford, 295–308. Springer International Publishing. doi:10.1007/978-3-319-64332-8_15
- Mazzetti, P., S. Nativi, M. Santoro, G. Giuliani, D. Rodila, A. Folino, S. Caruso, G. Aracri, and A. Lehmann. 2022. “Knowledge Formalization for Earth Science Informed Decision-Making: The GEOEssential Knowledge Base.” Environmental Science & Policy 131: 93–104. doi:10.1016/j.envsci.2021.12.023.
- Mell, P., and T. Grance. 2011. The NIST Definition of Cloud Computing. 7.
- Microsoft. 2022. Microsoft Planetary Computer. https://planetarycomputer.microsoft.com/.
- Muench, S., E. Stoermer, and K. Jensen, et al. 2022. Towards a green & digital future: Key requirements for successful twin transitions in the European Union. Publications Office of the European Union. https://data.europa.eu/doi/10.2760/977331.
- Nativi, S., and M. Craglia. 2021. Destination Earth: Ecosystem Architecture Ddescription. Publications Office of the European Union. https://data.europa.eu/doi/10.276008093
- Nativi, S., M. Craglia, and J. Pearlman. 2013. “Earth Science Infrastructures Interoperability: The Brokering Approach.” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 6 (3): 1118–1129. doi:10.1109/JSTARS.2013.2243113.
- Nativi, S., and P. Mazzetti. 2020. “Geosciences Digital Ecosystems.” In Encyclopedia of Mathematical Geosciences, edited by B. S. Daya Sagar, Q. Cheng, J. McKinley, and F. Agterberg, 1–6. Springer International Publishing. doi:10.1007/978-3-030-26050-7_458-1
- Nativi, S., P. Mazzetti, and M. Craglia. 2021. “Digital Ecosystems for Developing Digital Twins of the Earth: The Destination Earth Case.” Remote Sensing 13 (11): 2119. doi:10.3390/rs13112119.
- Nativi, S., P. Mazzetti, M. Santoro, F. Papeschi, M. Craglia, and O. Ochiai. 2015. “Big Data Challenges in Building the Global Earth Observation System of Systems.” Environmental Modelling & Software 68: 1–2126. doi:10.1016/j.envsoft.2015.01.017.
- Nativi, S., M. Santoro, G. Giuliani, and P. Mazzetti. 2020. “Towards a Knowledge Base to Support Global Change Policy Goals.” International Journal of Digital Earth 13 (2): 188–216. doi:10.1080/17538947.2018.1559367.
- Newman, S. 2015. Building Microservices: Designing Fine-Grained Systems. 1st ed. O’Reilly Media.
- Nisbet, R., J. Elder, and G. Miner. 2009. Handbook of Statistical Analysis and Data Mining Applications. Academic Press/Elsevier.
- OASIS. 2006. Reference Model for Service Oriented Architecture v1.0. http://docs.oasis-open.org/soa-rm/v1.0/soa-rm.html.
- Overdick, H. 2007. The Resource-Oriented Architecture. 2007 IEEE Congress on Services (Services 2007), 340–347. doi:10.1109/SERVICES.2007.66.
- Prada, C. D., D. Hose, G. Gutierrez, and J. Pitarch. 2018. “Developing Grey-box Dynamic Process Models.” IFAC-PapersOnLine 51 (2): 523–528. doi:10.1016/j.ifacol.2018.03.088.
- Red Hat. 2021a. Ansible is Simple IT Automation. https://www.ansible.com.
- Red Hat. 2021b. What is Container Orchestration? https://www.redhat.com/en/topics/containers/what-is-container-orchestration.
- Red Hat. 2021c. What is Orchestration? https://www.redhat.com/en/topics/automation/what-is-orchestration.
- Richards, M. 2015. Software Architecture Patterns. O’Reilly Media, Inc.
- Rockström, J., X. Bai, and B. deVries. 2018. “Global Sustainability: The Challenge Ahead.” Global Sustainability 1, e6: 1–3. doi:10.1017/sus.2018.8.
- Santoro, M., V. Andres, S. Jirka, T. Koike, U. Looser, S. Nativi, F. Pappenberger, et al. 2018. “Interoperability Challenges in River Discharge Modelling: A Cross Domain Application Scenario.” Computers & Geosciences 115: 66–74. doi:10.1016/j.cageo.2018.03.008.
- Santoro, M., P. Mazzetti, and S. Nativi. 2020. “The VLab Framework: An Orchestrator Component to Support Data to Knowledge Transition.” Remote Sensing 12 (11), Article 11.doi:10.3390/rs12111795.
- Santoro, M., S. Nativi, and P. Mazzetti. 2016. “Contributing to the GEO Model Web Implementation: A Brokering Service for Business Processes.” Environmental Modelling & Software 84: 18–34. doi:10.1016/j.envsoft.2016.06.010.
- Santoro, M., and M. Rovera. 2021. “Analysis of Conceptual and Technological Solutions for Heterogeneous Analytical Software Execution in a Multi-Cloud Environemt.” Final Report of the Study Funded by the DG JRC of the European Commission, Under Publication.
- Santoro, M., L. Vaccari, D. Mavridis, R. Smith, M. Posada, and D. Gattwinkel. 2019. Web Application Programming Interfaces (APIs): General Purpose Standards, Terms and European Commission Initiatives : APIs4DGov Study — Digital Government APIs: The Road to Value Added Open API Driven Services. Publications Office. https://data.europa.eu/doi/10.276085021.
- Shnier, M. 1996. Dictionary of PC Hardware and Data Communications Terms. O’Reilly Media, Inc.
- Soltesz, S., H. Pötzl, M. E. Fiuczynski, A. Bavier, and L. Peterson. 2007. “Container-based Operating System Virtualization: A Scalable, High-Performance Alternative to Hypervisors.” Proceedings of the 2nd ACM SIGOPS/EuroSys European Conference on Computer Systems 2007, 275–287. doi:10.1145/1272996.1273025.
- Vaccari, L., M. Posada, M. Boyd, and M. Santoro. 2021. “APIS for EU Governments: A Landscape Analysis on Policy Instruments, Standards, Strategies and Best Practices.” Data 6 (6): 59. doi:10.3390/data6060059.
- Wilkinson, M. D., Dumontier, M., Aalbersberg, Ij. J., Appleton, G., Axton, M., Baak, A., Blomberg, N., Boiten, J.-W., da Silva Santos, L. B., Bourne, P. E., Bouwman, J., Brookes, A. J., Clark, T., Crosas, M., Dillo, I., Dumon, O., Edmunds, S., Evelo, C. T., Finkers, R., … Mons, B. (2016). The FAIR Guiding Principles for Scientific Data Management and Stewardship. Scientific Data, 3(1), Article 1. doi:10.1038/sdata.2016.18
- WMO. 2021. WMO Hydrological Observing System (WHOS). https://public.wmo.int/en/our-mandate/water/whos.