Abstract
Abstract: In observational studies, selection bias will be completely removed only if the selection mechanism is ignorable, namely, all confounders of treatment selection and potential outcomes are reliably measured. Ideally, well-grounded substantive theories about the selection process and outcome-generating model are used to generate the sample of covariates. However, covariate selection is more heuristic in actual practice. Using two empirical data sets in a simulation study, we investigate four research questions about bias reduction when the selection mechanism is not known but many covariates are measured: (1) How important is the conceptual heterogeneity of the covariate domains in the data set? (2) How important is the number of covariates assessing each domain? (3) What are the joint effects of this conceptual heterogeneity and of the number of covariates per domain? (4) What happens to bias reduction when the set of covariates is deliberately impoverished by removing the covariates most responsible for selection bias, thus ensuring a slightly smaller but still heterogeneous set of covariates? The results indicate: (1) increasingly more bias is reduced as the number of covariate domains and the number of covariates per domain increase, though the rate of bias reduction is diminishing in each case; (2) sampling covariates from multiple heterogeneous covariate domains is more important than choosing many measures from fewer domains; (3) the most heterogeneous set of covariate domains removes almost all of the selection bias when at least five covariates are assessed in each domain; and (4) omitting the most crucial covariates generally replicates the pattern of results due to the number of domains and the number of covariates per domain, but the amount of bias reduction is less than when all variables are included and will surely not satisfy all consumers of causal research.
ACKNOWLEDGMENTS
This research was supported in part by the Institute of Education Sciences, U.S. Department of Education, through Grants R305D100033 (Peter M. Steiner and Thomas D. Cook) and R305D120005 (Peter M. Steiner). The opinions expressed are those of the authors and do not represent views of the Institute or the U.S. Department of Education.
Notes
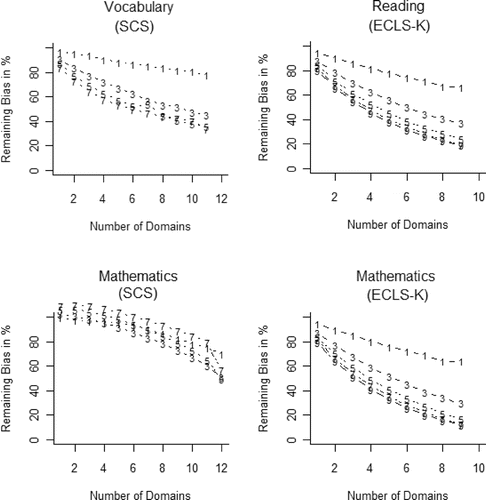
If a domain contained less than n covariates (not all domains of both data sets actually consist of at least 7 or 9 covariates), all covariates were sampled. Thus, sampling 7 or 9 covariates does not necessarily mean that 9 covariates were actually available for each covariate domain. In fact, the real average numbers of covariates drawn from each domain are n* = 1, 3, 4.6, 5.8, 7 at the designated levels of n = 1, 3, 5, 7, 9 for the SCS data, and n* = 1, 3, 5, 6.9, 8.4, for n = 1, 3, …, 9 for the ECLS-K data, indicating that the deviations from the designated levels are minor.
For the SCS data, the initial bias in the vocabulary outcome amounts to.82 points (.24 SD), the standard error of the benchmark estimate from the randomized experiment is.39 points and.49 points for the PS-adjusted treatment effect when all covariates are considered for inclusion in the PS model. The math outcome has an initial bias of.95 points (.30 SD) and the corresponding standard error for the benchmark estimate and the PS-adjusted estimate are.36 and.39 points, respectively.
For the ECLS-K reading outcome, the initial bias with respect to the model where all covariates were considered amounts to –10.6 points (–.79 SD), the standard error of the benchmark estimate is 1.09 points. For the math outcome, the initial bias is –6.6 points (–.74 SD), the standard error of the benchmark estimate is.85.
With the exemption of math outcome of the SCS data, removing the critical covariates reduces the number of domains by one because some of the covariates actually form an entire domain.