
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Green food is well-known for its health benefits, environmental-friendliness, and safety. Current recommender systems used by e-commerce websites usually recommend products based on products' popularity or customers' ratings. However, users' reviews could be more representative of consumers' preferences. In addition, users' review time is not utilized. To reduce the recommendation bias, this study proposes a hybrid recommendation algorithm based on green food reviews and review time. The proposed algorithm combines a content-based recommendation algorithm with a user-based collaborative filtering approach, where affective values of reviews replace ratings and a time impact factor is considered. With the two classical evaluation indices of F1 and Mean Absolute Error (MAE), the experiments show that considering both reviews’ sentiments and dynamic changes of individuals’ preferences could improve recommendation effectiveness over three other algorithms, which provides a new reference direction for improving existing recommender systems on green food.
1. Introduction and literature review
Green food is classified as a high-quality, contaminants-free, and organic food (Zhu et al., Citation2013), which refers to edible products produced in a sustainable ecological environment that follow national production standards, and have the Green Food Mark certification. In recent years, there has been a significant amount of discussion on food-related topics, such as “melamine powdered milk”, “hormone chicken”, “water-filled meat”, “Tukeng Sauerkraut” and “Shuanghui ham”. As an issue closely related to the physical and mental health of the public, food safety has received widespread attention. Because of its stringent production process, green food has become an excellent choice for the public to avoid food safety risks.
Consumption willingness of green food is clearly increasing. From the China Green Food Statistics Annual Report, during the twenty years from 2000 to 2019, the annual sales of domestic green food in China increased from 38.34 billion yuan to 465.66 billion yuan (L. Li, Citation2021). Meanwhile, the Internet has developed by leaps and bounds. By January 2021, the number of Internet users worldwide exceeded 4.66 billion (WeAreSocial, Citation2021). By December 2021, the number of domestic Internet users in China exceeded 1 billion and the Internet penetration rate had exceeded 70% (China Internet Network Information Center [CNNIC], Citation2022). Many green food brands such as Beidahuang, Qi Yunshan and Ganzhu Brand are gradually entering e-commerce platforms, which open a new buying channel for people who pursue healthy consumption.
In the era of big data, it is particularly important that users can quickly find their favorite green food in an e-commerce website with less time and efforts. The application of recommender systems could support this objective. Existing e-commerce recommendation systems rely on the popularity of products and users’ scores, obtain information about user’s preference, interests, and characteristics of each product, with the help of recommendation algorithms, to predict products consumers’ preference.
Usually, users’ scores of general shopping websites are simply categorized as 1–5 stars, which only reflects a rough emotion tendency of a customer. The reliability of ratings is further reduced by the phenomenon of fake 5-star ratings, where merchants pay “water army” (paid posters) for high ratings. In contrast, analyzing the sentiment of users’ post-purchase reviews could provide more accurate and realistic feedback on their preference.
Many scholars have discussed and provided theoretical supports for it. In the view of the scholars, users’ sharing of consumption experience on websites in multiple forms such as graphics and texts provides a rich information source for merchants to understand consumers’ preference. Scholars have conducted a large number of research studies on online reviews and preference measurement.
S. Xiao et al. (Citation2015) proposed a modified ordered choice model (MOCM) to extract the complete consumers’ preferences from online product reviews. The superiority of the model is supported by experiments. Then, A. Wang et al. (Citation2020) constructed an inconsistent ordered choice model (IOCM) to obtain consumers’ preferences based on review data and their sentiment polarity. After that, a sentiment-based importance performance-analysis (SIPA) model was further established to make product improvement more consistent with the preferences. It had successfully improved the quality of consumer preference measurement. Chen et al. (Citation2021) determined the six most significant needs of passengers by analyzing online reviews related to high-speed rail and constructed a satisfaction evaluation index system. The results provided unique insights on improving cabin services and increasing passenger satisfaction. L. Xiao et al. (Citation2022) studied the impact of online consumer reviews on dual-channel closed-loop supply chain. The result showed that online consumer reviews were beneficial to the manufacturer only if they were sufficiently positive. Z. S. Chen et al. (Citation2022) considered individual opinions and then proposed an expertise-structure and risk-appetite-integrated two-tiered collective opinion generation framework. As a result, a group preference was accurately constructed and a reliable collective opinion was generated.
Furthermore, He et al. (Citation2020) stated that consumers’ post-purchase comments represented an explicit preference for products. Based on the Amazon dataset and the preference theory, the authors found that the impact of post-purchase review ratio on product sales exceeded the impact of average ratings, which could better reflect consumers’ preferences and provide reference for future consumers. This result provided a strong support that the users’ post-purchase reviews were more representative.
In addition, consumers’ preferences could change over time. Therefore, considering how the time affects recommendation might theoretically lead to more accurate results. Green food is becoming increasingly popular; however, time costs are increasing. It is useful to further make a personalized recommendation for green food on e-commerce platforms based on information about the review text and time.
1.1. Text sentiment analysis
Currently, there are three main approaches for text sentiment analysis, including deep learning, other machine learning methods, and methods based on emotion dictionaries. The machine learning approaches rely on classifiers for sentiment recognition and require bigger datasets (W. Li, Citation2010; Pang et al., Citation2002).
Deep learning uses artificial neural networks to achieve sentiment recognition. L. Zhang et al. (Citation2018) provided a comprehensive review of the application of deep learning in sentiment analysis. Alharbi and de Doncker (Citation2019) proposed an improved model based on Convolutional Neural Network (CNN), which increased the model’s analyzing ability on tweets’ sentiment. Ullah et al. (Citation2020) applied Long Short-term Memory (LSTM) and CNN to sentiment analysis of airline reviews on Twitter in the context of combined text and emoji data, obtaining 89% and 81% classification accuracy, respectively. Dashtipour et al. (Citation2021) presented a combined context-aware, deep learning-driven sentiment analysis method for Persian movie reviews, in which both CNN and LSTM algorithms were compared with a manual feature-engineering-driven approach. The result showed that LSTM had better classification performance.
As for other machine learning methods, there are some common algorithms such as Naive Bayes (NB), Decision Tree and Support Vector Machine (SVM) (Jiang et al., Citation2016). For example, Goel et al. (Citation2016) improved the sentiment classification of Twitter messages by applying SentiWordNet and NB. Kim et al. (Citation2020) used AdaBoost and Decision Tree to identify residents’ sentiment polarity on flat rents, and made a comparative performance analysis for different algorithms. Rahim et al. (Citation2021) compared Logistic Regression (LR), NB, and SVM, and found that SVM was optimal in identifying patients’ sentiments. Machova et al. (Citation2022) built two detection models based on a dictionary and machine learning, respectively, to identify typical sentiment of online reviews from suspicious commenters.
The first two approaches are more scalable and have higher accuracy rates in some specific contexts; however, they require more training data and are mostly only applicable to sentiment classification. Compared to machine learning techniques, the method using an emotion dictionary has outstanding advantages when the sentiment needs to be quantified or the annotated datasets are limited. The accuracy of the algorithm based on emotion dictionaries is directly influenced by the constructed dictionary.
In addition, sentiment analysis based on emotion dictionaries generally involves semantic text similarity measure to extend the emotion dictionary and then achieve higher accuracy. In this regard, Zhang et al. (Citation2021) proposed an efficient new method called Attention-based Overall Enhance Network (ABOEN) for measuring semantic text similarity.
In terms of concrete operations, Asghar et al. (Citation2017) integrated emojis, modifiers and specific vocabularies to analyze online community comments and implemented it on the SentiWordNet basic dictionary. In order to analyze the problem of the shared sentiment on social network, Wani et al. (Citation2018) constructed a MoodBook emotion dictionary based on EmoLex lexicon and Empath lexicon for determining the emotions reflected by users’ posts. Shin (Citation2020) extended an existing emotion dictionary by collecting new words and slang related to emotions on social media. Song et al. (Citation2022) used topic analysis and time series analysis to study consumer behavior, where a lexicon-based sentiment analysis method was used to determine consumer attitudes.
1.2. Personalized recommendation algorithms
Personalized recommendation algorithms collect historical behavioral data of users and information about current popular products to build a model to evaluate the preference of individuals for generating personalized recommendation. In various mainstream fields, personalized recommendation algorithms are widely used.
1.2.1. Traditional recommendation algorithms
Content-based recommendation algorithm was firstly proposed and applied. According to the information of purchased products, the algorithm calculates the similarity between specific products and others, which is a criterion for evaluating users’ preferences. The content-based recommendation algorithm has great interpretability, no cold-start and data sparsity problems, and its recommendation result is simple and intuitive. How to accurately extract the features of items and mining users’ potential interest is the key to improving recommendation efficiency.
The collaborative filtering recommendation algorithm can be divided into two categories, namely, user-based collaborative filtering recommendation algorithm and item-based collaborative filtering recommendation algorithm. The collaborative filtering recommendation algorithm calculates similarity to obtain the k nearest neighbors that are most similar to the user or item, and then to predict the user’s preference for a certain item by using the nearest neighbor information (Gong, Citation2010; Zhao et al., Citation2021).
Compared to the content-based recommendation algorithm, the collaborative filtering recommendation algorithm focuses on the user-item rating matrix. For this reason, it is also suitable for semi-structured or unstructured data, where items’ features are difficult to extract. Nowadays, collaborative filtering recommendation algorithm is the most used recommendation algorithm.
However, collaborative filtering recommendation algorithms still have the problems on data sparseness, cold-start, difficulty in balancing timeliness and recommendation quality. This paper introduces a time impact function to address the balancing problem between timeliness and quality of recommendation.
For data sparseness, similarity calculation, content filling and matrix dimension reduction are three main approaches to solve the problem. Nilashi et al. (Citation2014) corrected cosine similarity through weighted Jaccard co-efficient, which alleviated the data sparseness to a certain extent. Sanjeevi et al. (Citation2015) proposed a collaborative filtering approach based on biclustering (CBE-CF), which was used to identify dense modules of the scoring matrix and measure the similarity between new users and dense modules through information entropy. Wu et al. (Citation2021) developed a sparse cosine similarity calculation method, which categorized users into high-relevance and low-relevance users, and further proposed differentiated numerical similarity calculation methods for different types of users. Zhang et al. (Citation2021) designed a hybrid collaborative filtering recommendation algorithm, where a slope algorithm was used to fill in the unscored items in the original score matrix. The Singular Value Decomposition (SVD) technology was applied to perform singular value decomposition on the filled score matrix to modify the predicted score.
Content-filling methods could mitigate sparseness by filling the matrix with fixed values; however, they are poorly controllable and difficult to guarantee the recommendation quality. The dimension reduction methods sacrifice some valuable information to decrease the original accuracy of the algorithm. In this regard, Hong and Yu (Citation2019) analyzed the correlation between items and further suggested a model that could predict ratings, which was used in the collaborative filtering algorithm with higher accuracy.
For the cold-start problem, similarity calculation is also a critical breakthrough. Bag et al. (Citation2019) developed a new similarity model, in which correlated Jaccard similarity and Jaccard mean square distance were two new similarity measures. With respect to traditional similarity metrics in the item-based collaborative filtering recommendation algorithm (I-CF), Ajaegbu (Citation2021) introduced a balance factor and combined it with three existing traditional metrics to successfully address the cold-start problem.
Moreover, for data recommendation in distributed systems, considering users’ data privacy of the platform, Liu et al. (Citation2021) proposed modified locality sensitive hashing (LSH) to facilitate users’ point of interest (POI) recommendation with homomorphic encryption technology.
1.2.2. Hybrid recommendation algorithms
Due to the combined strengths of multiple algorithms to enhance recommendation efficiency, the hybrid recommendation algorithms are popular in research. Various hybrids have been explored, including weighted, mixed, switching, feature combination, Cascading, and feature augmentation.
Inan et al. (Citation2018) combined content-based recommendation with item-based collaborative filtering recommendation by adding movie features such as actors, directors, and movie genres to accurately recommend their favorite movies to movie-goers. Y. Wang and Chen (Citation2020) integrated content and collaborative matrix decomposition technology and developed a hybrid recommendation algorithm, effectively alleviating the sparseness of data and improving recommendation accuracy. Darvishy et al. (Citation2020) proposed a hybrid personalized news recommendation system, where the evaluation index (F1 Score) was improved by 81.56% compared to the original recommendation system. H. Li and Han (Citation2021) developed a user preference model based on the time impact factor to achieve a hybrid of content-based and collaborative filtering recommendations.
Previous studies have shown that under the same conditions, the hybrid recommendation algorithms could better alleviate some prominent problems such as data sparseness and cold-start than single algorithms to improve recommendation accuracy to a greater extent. Combining a content-based recommendation algorithm with a collaborative filtering recommendation algorithm to generate recommendations has become a popular direction of current recommendation systems. Based on the emerging field of research on green food, from the dynamic perspective that user’ preference changes over time, this paper proposes a new hybrid recommendation algorithm, which is a combination of an improved user-based collaborative filtering recommendation algorithm and a content-based recommendation algorithm.
In addition, Rezaeimehr et al. (Citation2018) and Ahmadian et al. (Citation2018, Citation2022a) considered the effect of time on user preferences to improve algorithms by identifying overlapping community structures among users with clustering. However, their focus is on ratings whereas the proposed hybrid algorithms are the combination of traditional recommendation algorithms and text sentiment analysis. Based on a data-driven approach, we consider a time impact function to improve traditional recommendation algorithms and achieve more accurate recommendations for green food.
1.2.3. Application of sentiment analysis in recommender systems
Users’ text contents are full of potentially valuable information. In order to better meet individuals’ needs, the combination of recommendation algorithm and text sentiment analysis technique has become a popular topic (Jiang et al., Citation2016). Song et al. (Citation2021) constructed an emotion dictionary based on users’ reviews of viral food and quantified the degree of sentiments, while portraying users’ preferences. A hybrid recommendation approach was proposed from content-based and user-based perspectives, and the obtained sentiment values were used to build a user-viral food rating matrix to improve the recommendation accuracy. Y. L. Zhang and Zhang (Citation2022) used Latent Dirichlet Allocation (LDA) to obtain relevant topics of movie reviews, and identified a sentiment tendency based on Bidirectional Encoder Representations from Transformer (BERT), where the diversity of recommendation lists was improved.
For the purpose of more accurately reflecting users’ existing preferences, this paper considers a time impact factor in the user-based collaborative filtering recommendation algorithm. It is a weighting factor introduced in the inter-user similarity calculation. The application of time impact function could adjust the influence of reviews’ sentiment values at different review times on the predicted preference of the unpurchased food.
The application of text sentiment analysis in recommender systems could drive personalized recommendations to a higher level and has a wide practical implication. Now it is mostly used in areas such as movie recommendation and news recommendation on social media platforms. In view of the unique advantages of hybrid recommendation combined with text sentiment analysis and the public’s rising enthusiasm for healthy consumption, this paper further analyzes the problem of personalized recommendations for green food based on reviews’ sentiment measure and food label information. It innovatively develops a time impact function to accurately portray users’ preferences with review text and review time. A constructed emotion dictionary of green food is used to quantify sentiments of review texts. A content-based recommendation algorithm combined with an improved user-based collaborative filtering recommendation algorithm in a linearly weighted manner is proposed. The performance of the proposed hybrid recommendation algorithm is verified and compared to other algorithms in an experiment.
The main contributions of our study are as follows:
It fills the significant literature gap in the research of green food recommendations on e-commerce websites. Currently, there is limited research on mixed recommendations combined with sentiment analysis, especially in the field of green food. As a growing field of research on green food, how to quickly and accurately matching consumers’ preferences with desired green food items has significant practical implications.
Our model could lead to a better understanding of actual consumers’ behavior regarding their preferences. Specifically, users tend to prefer a product less over time, and typically old reviews are less indicative of the current consumers’ preferences than new ones. The paper considers the influence of review time on preferences by developing a time impact function and introducing it into the user-based collaborative filtering recommendation algorithm. It reduces the actual deviation of reviews’ sentiment values. Although Rezaeimehr et al. (Citation2018) and Ahmadian et al. (Citation2018, 2022) also consider the impact of time on the reviews, they focus on ratings but not text reviews. The advantage of Rezaeimehr et al. (Citation2018) is to identify overlapping community structure among users, which alleviates the sparsity effect and improves the performance of the recommendation system. The advantage of Ahmadian et al. (Citation2022b) is to consider health in developing recommendation systems for food items. The disadvantage is not to consider rich information from text reviews, which might further improve their recommendation systems. The advantage of Ahmadian et al. (Citation2022a) is to develop a reliability measure to enhance ratings to solve the data sparsity problem in time-aware recommendation systems. The disadvantage is not to utilize the relationship among the reviewers in improving the recommendation system. The advantage of Ahmadian et al. (Citation2018) is to take a temporal clustering approach in developing a social recommendation system. The disadvantage is not to consider health in recommending food items.
Finally, our results could bring some positive values to consumers, e-commerce platforms and green food enterprises. Consumers could locate their favorite green food with less time and efforts and a higher probability. E-commerce platforms could achieve a higher transaction rate and increase their operating income from green food sales. It would lead to a greater support for distribution channels of green food. Moreover, the precise recommendation could improve the economic benefits of green food enterprises, reduce ineffective marketing and word-of-mouth maintenance costs. They could spend more resources on producing more and better green food.
The rest of the paper is organized as follows: Section 2 proposes a hybrid recommendation model based on review text and review time. A field emotion dictionary is constructed to calculate sentiment values of users ’ reviews and a time impact factor is considered to improve the user-based collaborative filtering algorithm. Section 3 presents an empirical analysis of the proposed hybrid recommendation algorithm and compares its performance with three other algorithms. Section 4 summarizes the work of this paper and discusses some limitations and future directions.
2. A proposed hybrid recommendation algorithm
2.1. Description of the framework
The paper proposes a hybrid recommendation model based on the quantification of review sentiments, using green food as an example. In order to construct the model, the primary task is to obtain sentiment values of users’ reviews for green food.
Firstly, through the integration of three existing emotion dictionaries, namely, NTUSD (Chen et al., Citation2021), HowNet (Github.com, Citation2022), Tsinghua (a Chinese commendatory (OSCHINA, Citation2018) and derogatory lexicon) and a lexicon of field words constructed by Semantic Orientation Pointwise Mutual Information (SO-PMI) algorithm (H. J. Chen et al., Citation2017), a domain emotion dictionary of green food is built. Then, a user-green-food rating matrix is created by calculating sentiment values of sample reviews. Meanwhile, the green food 0–1 feature matrix is constructed through users’ reviews and green food labels on the website. In combination of the two recommendation algorithms, based on the two matrixes obtained in the previous step, we analyze the similarity between green food items by cosine similarity to predict other food, which the users probably like.
Then, based on Pearson’s correlation similarity analysis (Batyrshin, Citation2015), the first K neighboring users are used to predict the other green food that they may like. In the meantime, a time impact factor is added into the latter collaborative filtering recommendation algorithm to correct predicted scores. Finally, the recommendation results of the two recommendation algorithms are weighted to generate the top N green food, which is selected and recommended based on the predicted scores. The technical framework of this paper is shown in .
Figure 1. General technical route.
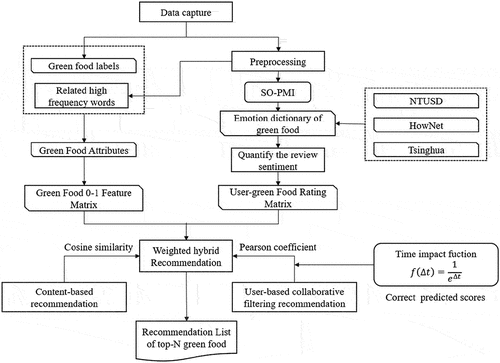
2.2. Quantifying reviews’ sentiments
2.2.1. Construction of emotion dictionary for green food
The green food involves two aspects: food and green health. The related emotional words have strong particularity, while the dictionaries with strong universality often have low particularity. In order to achieve higher accuracy of sentiment analysis on green food reviews, SO-PMI algorithm is used to explore existing dictionaries and a domain emotion dictionary based on green food online reviews is built.
The process in could be described in detail in the following steps.
Figure 2. Flow chart of construction of green food field dictionary.
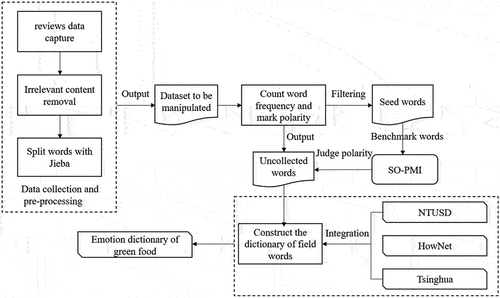
Step 1: Crawl reviews under the homepage of several green food items from JD.COM (a major Chinese e-commence platform in China) to form the original dataset. Then, we correct text and delete some irrelevant contents.
Step 2: Split words through the open-source library. Then, we delete stop words in the splitting sequence according to a list of stop words.
Step 3: Count the frequency of each word and select words, whose frequencies are more than or equal to N. Then, we manually select n positive and n negative seed words, and the rest of the words are used to form a lexicon.
Step 4: Determine the sentiment tendency of the remaining words with the assistance of the SO-PMI algorithm. We merge them with the seed words to construct a lexicon of domain words.
Step 5: Combine the three basic emotion dictionaries of NTUSD, HowNet and Tsinghua with the lexicon of domain words to construct the emotion dictionary of green food.
2.2.2. Calculation of reviews’ sentiment value
Based on the emotion dictionary of green food, the corresponding sentiment word is matched by the splitting sequence and its position in the sequence is marked. In the meantime, it is needed to determine whether there is a negative or an adverb of degree. If there is, the position and number need to be counted. The sentiment value of the entire review is calculated by combining the weights of the words.
The process in could be described in detail in the following steps.
Figure 3. Chart flow of user-green food sentiment value calculation.
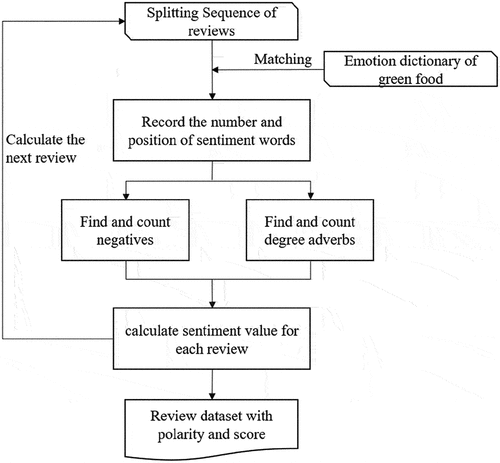
Step 1: Read the splitting sequence of each review and match it with the sentiment words in the domain dictionary. Then, we record the position and number of sentiment words in the sentence one by one.
Step 2: Determine whether there are degree adverbs or negatives. If there is a negative word, multiply −1. If there is an adverb of degree, multiply the weight of it.
Step 3: Calculate the sum of each sentiment phrase to obtain the sentiment value of the review.
Step 4: Quantify the sentiment of the next review following the steps above and obtain a review dataset with determined polarity and scores.
2.3. Combination of recommendation algorithms
As a content-based recommendation algorithm and a user-based collaborative filtering recommendation algorithm could complement each other’s strengths, a weighted hybrid of the two recommendation algorithms is adopted in the paper. A time impact factor is established to modify the results of the collaborative filtering recommendation algorithm in order to reflect the changes of preferences and further optimize the recommendation efficacy. The flow chart of implementation of the hybrid recommendation is shown in .
Figure 4. Flow chart of implementation of hybrid recommendation.
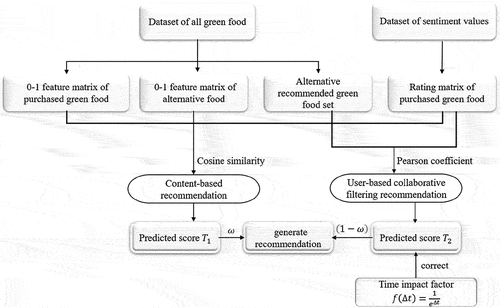
The entire model could be divided into three steps: data description, individual recommendation model construction, and hybrid recommendation. The data includes a set of reviews’ sentiment values and label information of green food.
After data preparation, the 0–1 feature matrixes of alternative recommended green food and purchased green food by all users to describe the food are constructed. Then, a user-green-food rating matrix is constructed based on the reviews’ sentiment values. The matrixes are used to complete the portrayal of green food features and user preferences.
Next, the content-based recommendation model and the user-based collaborative filtering recommendation model are constructed. The degree of similarity between green food is then determined by cosine similarity, and the degree of similarity between the user to be recommended and other users is determined by Pearson coefficients. Then, the users’ scores ,
for each type of alternative green food are predicted, considering the changes of user preferences over time by adding a time impact function
to
.
Based on the two matrixes obtained, the similarity between green food items analyzed by cosine similarity is used for predicting the other green food to be recommended. Based on Pearson’s correlation similarity analysis, the first K neighboring users are used to predict the other green food that they may like. In the meantime, a time impact factor is introduced to the latter collaborative filtering recommendation to correct the predicted scores. Finally, the recommendation results of the algorithms are weighted to recommend the top N green food with high scores.
Finally, the two single recommendation models are linearly mixed with weight parameters ω and (1-ω) to form a hybrid recommendation model for green food. The combined scores are sorted in descending order and then the top N green food is the output to generate recommendations.
The relevant algorithms covered in this paper are abbreviated in Table S1 in the Supplement, and the corresponding abbreviations represent the corresponding algorithms. In particular, Time_HR stands for the hybrid recommendation algorithm with time impact; HR stands for the hybrid recommendation algorithm without time impact; CB stands for the content-based recommendation algorithm; and User_CF stands for the user-based collaborative filtering recommendation algorithm.
Users are customers, who have purchased and rated green food on an e-commerce platform. The label features of green food are selected from the product description field on the product page of the platform and supplemented by reviews. Based on the constructed user-green-food rating matrix, the similarity between users could be calculated and then the first K neighboring users could be found. Based on the assumption that the users’ preferences for food would be affected by time changes, subject to a forgetting curve, a time impact function is defined as in EquationEquation (1)(1)
(1) .
denotes the difference between the current time (the time when green food is recommended to the user) and the user’s review time. For the convenience of calculation, the year difference is considered and the time is simplified. For example, the current year is 2022, a user’s review time is taken in 2021 and
.
The function value set as a weight is used to adjust the predicted score and could reduce the impact of the users’ preferences for food purchased at earlier time on the overall recommendation, which in turn relatively increase the impact of the users’ preferences for food purchased more recently on the recommendation. The new predicted score with the time impact factor can be calculated according to EquationEquation (2)(2)
(2) .
User is one of the
neighbouring users of User
and User
is the user to be recommended. The CB and User_CF are combined in a linearly weighted manner to recommend the top N green food items to the user to be recommended according to the combined score, which is shown in EquationEquation (3)
(3)
(3) .
denotes the predicted score generated by CB, and
denotes the predicted score generated by User_CF.
3. Algorithm application and result analysis
3.1. Data collection and preprocessing
In this paper, user reviews and food labels of 50 food products from JD.COM 28,428 reviews are obtained. Each review data includes contents such as username, review text, food attributes and review time, which spans from years 2011 to 2022. The data that is obviously irrelevant to the product and has a low sentiment value is removed. The texts with cumbersome expressions and incorrect punctuation are manually modified. After that, there are 9,777 valid data left, which forms a dataset used in the research. Jieba word separation system that is powerful and easy-to-use is applied to separate these reviews into words.
3.2. Sentiment analysis of users’ reviews
3.2.1. Construction of an emotion dictionary for green food
Firstly, three popular dictionaries, namely, HowNet, Tsinghua and NTUSD are merged to construct the basic emotion dictionary, which includes 11,684 negative words and 7,854 positive words. The number of each split word is calculated, from which words with a frequency of no less than 10 are selected. After that, some objective and neutral words are removed. Compared to the basic emotion dictionary, a lexicon consisting of 176 uncollected words is obtained. Using the number of significant negative sentiment words in the lexicon as an upper limit, a total of 30 positive and negative sentiment words with strong relevance to the green food field as seed words are selected. Table S2 in the Supplement shows some seed words.
Based on the set of seed words obtained above, the SO-PMI algorithm is then used to calculate SO-PMI values of the remaining 116 words, and the sentiment polarity of the words is evaluated. Table S3 in the Supplement shows the SO-PMI values and polarities of some words. The emotion dictionary for green food is constructed by expanding the existing lexicon with new sentiment words. These new words are identified by the SO-PMI algorithm.
3.2.2. Calculation of reviews’ sentiment values
In order to quantify the sentiment degree of reviews, except for the base emotion dictionary, a negation dictionary and a dictionary of degree adverbs are also needed. Based on the results of splitting words and commonly used negation words, a negative dictionary with 24 words that each word’s weight is −1 is built. For degree adverbs, the words are selected from HowNet. The corresponding weights for the specific levels are shown in Table S4 in the Supplement.
The negative sentiment words are given a weight of −1 and positive sentiment words are given a weight of 1. For the dataset, the sentiment values of the reviews based on five different emotion dictionaries are separately calculated with Python language. It is known that a sentiment value larger than 0 corresponds to a positive sentiment polarity, and the value smaller than 0 corresponds to a negative sentiment polarity. If a sentiment value equals to 0, the review’s sentiment polarity is neutral. Based on a random collection of 1,000 reviews from the dataset, the performances of the constructed green food field dictionary, combined popular dictionary, HowNet, NTUSD and Tsinghua are compared in .
Table 1. Performance comparisons of five emotion dictionaries.
It is shown that the green food field dictionary has the best recognition performance for reviews’ sentiment in Recall and F1 indices. Therefore, the sentiment values calculated by the constructed emotion dictionary are more suitable to reflect users’ emotions toward green food.
3.2.3. Standardization of sentiment values
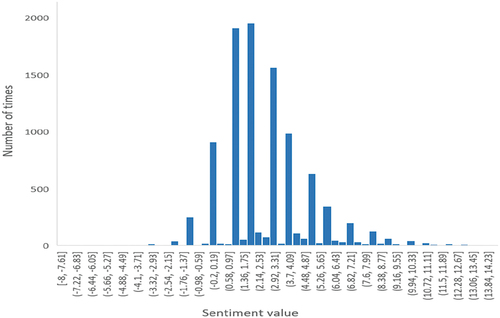
shows the distribution of sentiment values, where the values are concentrated in the range of (−0.2, 5.26), accounting for 84.86% of all values. Further statistics show that most of the sentiment values lie within the [−5, 5] range, with a total of 8,684 reviews, accounting for 88.82%. Therefore, we need to standardize the sentiment values in order to facilitate the calculation of the subsequent algorithm. For example, a sentiment value less than −5 is directly set as −5, a sentiment value greater than 5 is directly set as 5, and sentiment values within the [−5, 5] range remain unchanged.
Figure 5. Statistical chart of sentiment value distribution.
3.3. Implementation and analysis of the algorithm
3.3.1. Data description
A feature matrix is constructed based on 50 green foods and their label features in terms of the content-based recommendation. Some of the foods and their features are shown in Table S5 in the Supplement.
In terms of the user-based collaborative filtering recommendation algorithm with a time effect, the usernames in our dataset are set with uniform numbers to replace original IDs shown in Table S6 in the Supplement. Based on the set of sentiment values, a rating matrix of all customers for the purchased green food is constructed as shown in Table S7 in the Supplement.
3.3.2. Implementation of the algorithm
In terms of the hybrid recommendation algorithm, to fit the model and verify its performance, a partition of 3/4 and 1/4 of the dataset is selected, corresponding to the training set and the testing set, respectively.
The Mean Absolute Error (MAE) and F1 are set as indices to evaluate the performance of the recommendation algorithms. The difference between the true and predicted scores is used to assess the performance of the algorithm. The MAE calculation method is shown in EquationEquation (4)(4)
(4) . The smaller MAE is, the better the performance of the algorithm is.
The index that combines Precision and Recall is F1, which is often used to evaluate the accuracy of the model. Its calculation method is shown in EquationEquation (5)(5)
(5) . The higher F1 is, the higher accuracy of the algorithm and the better performance is.
Since the number of neighboring users, K, could affect the performance of User_CF, it is needed to find an optimal value. Its initial value is set as 2, and the step size is 2. Figure S1 in the Supplement shows the influence of the value K on the MAE value. When K equals 4, the MAE value is the lowest, which indicates that the prediction result is the most accurate.
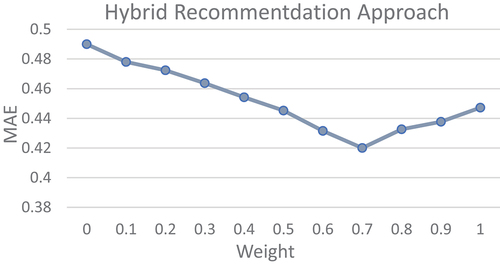
shows the different MAE values of the hybrid recommendation approach at different weights. The weight, W, represents the weight assigned to the CB, and the weight assigned to the User_CF is 1-W. It shows that when the weight is 0.7, the recommendation of the hybrid approach is the best.
Figure 6. MAE values of the hybrid recommendation approach under different weights.
shows MAE and F1 values corresponding to the 4 recommendation approaches, including Time_HR, HR, CB and User_CF based on the same dataset. It shows that in terms of prediction accuracy, compared to the other three recommendation algorithms, the hybrid recommendation model Time_HR has the lowest MAE, followed by HR, CB, and User_CF. In terms of the evaluation index F1, Time_HR has the highest score, followed by HR, CB, and User_CF. Based on the two indices, the hybrid recommendation algorithm with the time impact (Time_HR) has the best performance.
Table 2. Comparison of MAE and F1 of different recommendation approaches.
In our dataset, the number of green foods that is purchased by most users is concentrated in 5 or less categories. Due to the limited data, the similarity calculated between users is not very high, limiting the performance improvement of Time_HR. Although the performance improvement of Time_HR is not notable as compared to HR, Time_HR does consider the relationship between consumers and green food from a dynamic perspective, and portray user preferences in multiple dimensions. More importantly, Time_HR does improve the recommendation efficiency, which suggests that it could be useful to consider the influence of review time on green food recommendations. In addition, users’ reviews are more realistic than star scores on e-commerce platforms, and could provide more nuanced feedback of how much consumers like or dislike a type of green food.
In all, the experiments demonstrate that the proposed hybrid recommendation algorithm based on quantified sentiment values of online reviews and review time is feasible. It has the best performance for personalized recommendations of green food.
3.4. Empirical analysis from the consumers’ perspective
We compare and analyze the superiority of the algorithm proposed in this paper based on two evaluation indices. From the consumer’ perspective, we illustrate how consumers could benefit from the algorithm when shopping for green food online. It is mainly divided into two steps: explaining the principle of the algorithm based on the user’s food purchase behavior; and comparing and analyzing the user’s actual purchase records and prediction results of the algorithm.
Figure S2 in the Supplement shows that user 1 likes “a” and “b”. Both foods “a” and “b” have characteristics: sweet, sour and dried fruit. Since food “d” has these characteristics that are similar to “a” and “b”, the algorithm indicates that user 1 will like green food “d”, and the food “d” is recommended to user 1.
Figure S3 in the Supplement shows that user 1 likes green food “a”, green food “b”, and green food “c”, and user 3 likes green food “a” and “c”. The algorithm judges that the preferences of users 3 and 1 are the most similar. Therefore, the algorithm predicts that user 3 would like green food “b”, where food “b” is recommended to user 3.
The hybrid algorithm sorts the green food to be recommended according to their scores. The platform predicts consumers’ preferences based on consumers’ previous browsing and purchase records, and then presents the foods that they may like on the recommended homepage or the additional segments added to their browsed web pages. When consumers buy food on the platform, if the recommended content matches the user’s preference, it might drive consumers to place an order directly. As an example, from the green food dataset, three users are randomly selected and labeled as Users 1, 2, and 3. We further apply the algorithm to predict the purchase decisions of the three users. Compared with the actual purchase records, partial results are shown in Table S8 in the Supplement.
The check marks in the “Reality” column represent the actual purchases made by the three users, indicating their preferences. The red check marks in the table represent prediction results by the model. From this comparison, we can see that the hybrid recommendation algorithm has a high accuracy.
4. Conclusions and future directions
The boom in online transactions for green food is demonstrating the shift in the manner how individuals purchase green food. With privacy mechanisms protecting basic personal information, consumers’ behavioral records become readily available and important data to portray their interests in green food. A hybrid recommendation algorithm is proposed to make the best use of the existing data and then to recommend green food to customers with clear preferences or potential needs. Its application could promote the prosperous development of the green food industry and people’s healthy consumption. Based on users’ reviews and review time, the algorithm is constructed by an emotion dictionary of green food to quantify the sentiment in reviews instead of star scores (i.e. ratings). A time impact factor is considered to reflect customer preference changes from a dynamic perspective. Finally, based on a dataset consisting of 50 green foods and corresponding reviews from JD.COM (a major Chinese e-commence platform in China), the performance of the algorithm is compared with three other recommendation algorithms to verify the feasibility and superiority.
According to the results, our main work and conclusions are as follows:
Based on the SO-PMI algorithm, an emotion dictionary of green food using a large number of reviews is constructed, and the high accuracy of the constructed dictionary is determined based on recall rate and F1 score. Instead of star ratings, sentiment values of the reviews calculated by the emotion dictionary enhance the objectivity of recommendations based on mere ratings, which not only avoid the unreliability of star scores but also facilitate the achievement of high-quality green food recommendations.
Based on the forgetting curve and logistic function, a time impact function is developed to consider the changes of consumer interests in green food over time. Combining it with the similarities among users distinguishes the impacts of previous scores in different periods on the predicted scores.
Through a set of experiments with the dataset, it is found that the optimal number of neighboring users for user-based collaborative filtering recommendation algorithm is 4. By linearly weighting the content-based recommendation algorithm and the user-based collaborative filtering recommendation algorithm with different weights, it is found that when the proportion of the content-based recommendation algorithm accounts for 70% of the recommendation, the proposed hybrid algorithm has the best performance.
It shows that the proposed algorithm performs better than three other algorithms in terms of evaluation indices: F1 Score and MAE. In addition, compared with the hybrid recommendation algorithm without a time impact, there is less performance improvement.
Due to the dataset’s size and the platform’s privacy protection mechanism, the recommendation efficiency of the hybrid recommendation algorithm with a time impact has not achieved a greater breakthrough. However, it considers the sentiment intensity and review time, which makes more efficient use of the available data and could generate recommendations more objectively.
E-commerce websites could benefit from this paper. Given consumers’ sharing behavior and the dynamics of their preferences, administrators of e-commerce platforms should pay attention to the emotional representation and timeliness of users’ reviews in the process of personalized recommendations. As our results show, compared with the traditional single recommendation algorithm, our hybrid recommendation model considering time could more accurately recommend favorite green food to consumers. In this case, a virtuous cycle could be formed among consumers, e-commerce platforms and green food enterprises.
When users are successfully recommended their favorite green food, their satisfaction would be improved, which could lead to increases in the transaction rate of the platform and the operating income of the enterprise. Then, it could promote the upgrading of the marketing strategy of the enterprise and the production capability of green food. More importantly, the healthy development of the green economy would be promoted. In contrast, if less effective recommendation algorithms were adopted, consumers might not be able to find their desired green food and thus start that virtuous cycle.
The hybrid algorithm proposed in this paper still has some aspects to be improved and could be further explored in the following ways.
We could expand the scale of data on food categories and user reviews. The larger the number of reviews and the wider the range of food items, the clearer the portrayal of customers’ preferences would be. The dataset used in this paper is limited. The number of food items purchased by most users is small, and the time span between purchases is large. These limit the proposed algorithm’s effectiveness to a certain extent.
Automatic recognition of irrelevant reviews such as obvious duplications could be explored. Most reviews in e-commerce platforms have a strong tendency to use colloquial expressions and there are a large number of fake good reviews that are bought by merchants. These result in a heavy workload before sentiment analysis, which is costly and ineffective. Automated recognition would significantly improve the efficiency and quality of sentiment analysis.
We could revise the emotion dictionary based on the products’ domain to consider more types of words and special sentences. In fact, many reviews consist of multiple sentences, where the connectives and inflections between sentences have a great impact on the overall text sentiment. Once these could be incorporated into the dictionary, the quantification of sentiments would be more accurate.
We could compare the results of multiple similarity combinations. There are more than a few approaches to calculate similarity, and the corresponding results vary. It is interesting to combine the different methods in a few manners to find the most effective similarity combination by comparing them.
We could attempt to improve the time impact function. This paper uses the forgetting curve and logistic function to specify the time impact function. The representation of the function could be further improved based on practical application scenarios.
Supplemental Figures
Download MS Word (93.7 KB)Supplemental Tables
Download MS Word (41 KB)Disclosure statement
No potential conflict of interest was reported by the author(s).
Supplementary data
Supplemental data for this article can be accessed online at https://doi.org/10.1080/19476337.2023.2215844.
Additional information
Funding
References
- Ahmadian, S., Joorabloo, N., Jalili, M., Meghdadi, M., Afsharchi, M., & Ren, Y. (2018, August). A temporal clustering approach for social recommender systems. In 2018 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), Barcelona, Spain (pp. 1139–1144). IEEE.
- Ahmadian, S., Rostami, M., Jalali, S. M. J., Oussalah, M., & Farrahi, V. (2022a). Healthy food recommendation using a time-aware community detection approach and reliability measurement. International Journal of Computational Intelligence Systems, 15(1), 1–24. https://doi.org/10.1007/s44196-022-00168-4
- Ahmadian, S., Joorabloo, N., Jalili, M., & Ahmadian, M. (2022b). Alleviating data sparsity problem in time-aware recommender systems using a reliable rating profile enrichment approach. Expert Systems with Applications, 187, 115849. https://doi.org/10.1016/j.eswa.2021.115849
- Ajaegbu, C. (2021). An optimized item-based collaborative filtering algorithm. Journal of Ambient Intelligence and Humanized Computing, 12(12), 10629–10636. https://doi.org/10.1007/s12652-020-02876-1
- Alharbi, A. S. M., & de Doncker, E. (2019). Twitter sentiment analysis with a deep neural network: An enhanced approach using user behavioral information. Cognitive Systems Research, 54, 50–61. (2017). https://doi.org/10.1016/j.cogsys.2018.10.001
- Asghar, M. Z., Khan, A., Ahmad, S., Qasim, M., & Khan, I. A. (2017). Lexicon-enhanced sentiment analysis framework using rule-based classification scheme. PLos One, 12(2), e0171649. https://doi.org/10.1371/journal.pone.0171649
- Bag, S., Kumar, S. K., & Tiwari, M. K. (2019). An efficient recommendation generation using relevant Jaccard similarity. Information Sciences, 483, 53–64. https://doi.org/10.1016/j.ins.2019.01.023
- Batyrshin, I. Z. (2015). On definition and construction of association measures. Journal of Intelligent & Fuzzy Systems: Applications in Engineering and Technology, 29(6), 2319–2326. https://doi.org/10.3233/IFS-151930
- Chen, H. J., Dai, Y. H., & You, B. (2017). Construction of affective education in mobile learning: The study based on learner’s interest and emotion recognition. Computer Science & Information Systems, 14(3), 685–702. https://doi.org/10.2298/CSIS170110023C
- Chen, C. C., Huang, H. H., & Chen, H. H. (2021). NTUSD-Fin: A market sentiment dictionary for financial social media data applications.
- Chen, Z. S., Liu, X. L., Chin, K. S., Pedrycz, W., Tsui, K.-L., & Skibniewski, M. J. (2021). Online-review analysis based large-scale group decision-making for determining passenger demands and evaluating passenger satisfaction: Case study of high-speed rail system in China. Information Fusion, 69, 22–39. https://doi.org/10.1016/j.inffus.2020.11.010
- Chen, Z. S., Zhang, X., Rodriguez, R. M., Pedrycz, W., Martinez, L., & Skibniewski, M. J. (2022). Expertise-structure and risk-appetite-integrated two-tiered collective opinion generation framework for large scale group decision making. IEEE Transactions on Fuzzy Systems, 30(12), 5496–5510. https://doi.org/10.1109/TFUZZ.2022.3179594
- China Internet Network Information Center. (2022). The 49th statistical report on the development status of the internet in China. https://www.cnnic.cn/gywm/xwzx/rdxw/20172017_7086/202202/t20220225_71725.htm
- Darvishy, A., Ibrahim, H., Sidi, F., & Mustapha, A. (2020). HYPNER: A hybrid approach for personalized news recommendation. IEEE Access, 8, 46877–46894. https://doi.org/10.1109/ACCESS.2020.2978505
- Dashtipour, K., Gogate, M., Adeel, A., Larijani, H., & Hussain, A. (2021). Sentiment analysis of Persian movie reviews using deep learning. Entropy, 23(5), 596. https://doi.org/10.3390/e23050596
- Github.com. (2022). vacing/Chinese_Corpus. Retrieved March, 2022, from https://github.com/vacing/Chinese_Corpus
- Goel, A., Gautam, J., & Kumar, S. (2016). Real time sentiment analysis of tweets using Naive Bayes. In Proceedings on 2016 2nd International Conference on Next Generation Computing Technolo- gies, New York (Vol. 2016, pp. 257–261). IEEE.
- Gong, S. (2010). A collaborative filtering recommendation algorithm based on user clustering and item clustering. Journal of Software, 5(7), 745–752. https://doi.org/10.4304/jsw.5.7.745-752
- He, J., Wang, X., Vandenbosch, M. B., & Nault, B. R. (2020). Revealed preference in online reviews: Purchase verification in the tablet market. Decision Support Systems, 132, 113281. https://doi.org/10.1016/j.dss.2020.113281
- Hong, B., & Yu, M. C. (2019). A collaborative filtering algorithm based on correlation coefficient. Neural Computing & Applications, 31(12), 8317–8326. https://doi.org/10.1007/s00521-018-3857-7
- Inan, E., Tekbacak, F., & Ozturk, C. (2018). More opt: A goal programming based movie recommender system. Journal of Computational Science, 28, 43–50. https://doi.org/10.1016/j.jocs.2018.08.004
- Jiang, Z., & Jin, Y. (2016). Research on recommendation algorithm combined with review sentiment analysis. Application Research of Computers, 5(33), 1312–1314. (In Chinese). http://dx.doi.org/10.3969/j.issn.1001-3695.2016.05.007
- Kim, Cheon, Kim, J., Yun-Ki, S., & Jin, Z. (2020). Performance comparison of sentiment Lexicons in predicting American citizen’s sentiment for the apartment rents. Journal of the Korean Society of Cadastre, 36(1), 15–32. https://doi.org/10.1007/s42952-019-00016-w
- Li, L. (2021). Research on green food consumption behavior and its influencing factors from the perspective of Internet public opinion. Contemporary Economy, 6, 114–118. (In Chinese). http://dx.doi.org/10.3969/j.issn.1007-9378.2021.06.025
- Li, W. (2010). Sentiment analysis and cognition. Computer Science, 37(7), 11–15. (In Chinese). http://dx.doi.org/10.3969/j.issn.1002-137X.2010.07.003
- Li, H., & Han, D. Z. (2021). A novel time-aware hybrid recommendation scheme combining user feedback and collaborative filtering. IEEE Systems Journal, 15(4), 5301–5312. https://doi.org/10.1109/JSYST.2020.3030035
- Liu, D., Shan, L., Wang, L., Yin, S., Wang, H., & Wang, C. (2021). P3OI-MELSH: Privacy protection target point of interest recommendation algorithm based on multi-exploring locality sensitive hashing. Frontiers in Neurorobotics, 15, 660304. https://doi.org/10.3389/fnbot.2021.660304
- Machova, K., Mach, M., & Vasilko, M. (2022). Comparison of machine learning and sentiment analysis in detection of suspicious online reviewers on different type of data. Sensors, 22(1), 155. https://doi.org/10.3390/s22010155
- Nilashi, M., Bin Ibrahim, O., & Ithnin, N. (2014). Multi-criteria collaborative filtering with high accuracy using higher order singular value decomposition and Neuro-Fuzzy system. Knowledge-Based Systems, 60, 82–101. https://doi.org/10.1016/j.knosys.2014.01.006
- OSCHINA. (2018). THUOCL. https://www.oschina.net/informat/thuocl
- Pang, B., Lee, L., & Vaithyanathan, S. (2002, July). Thumbs up sentiment classification using machine learning techniques. Proceedings of Conference on Empirical Methods in Natural Language Processing (EMNLP), Philadophia (pp. 79–86). https://doi.org/10.3115/1118693.1118704
- Rahim, A. I. A., Ibrahim, M. I., Chua, S., & Musa, K. I. (2021). Hospital Facebook reviews analysis using a machine learning sentiment analyzer and quality classifier. Healthcare, 9(12), 1679. https://doi.org/10.3390/healthcare9121679
- Rezaeimehr, F., Moradi, P., Ahmadian, S., Qader, N. N., & Jalili, M. (2018). TCARS: Time-and community-aware recommendation system. Future Generation Computer Systems, 78, 419–429. https://doi.org/10.1016/j.future.2017.04.003
- Sanjeevi, S. G., Grandhe, S., & Shrivastav, H. (2015).An adaptive clustering and incremental learning solution to cold start problem in recommendation systems. In Proceedings of the International Scientific Academy of Engineering and Technology (ISAET) Conference Proceeding, Dubai, UAE.
- Shin, P. (2020). Emotional analysis system for social media using sentiment dictionary with newly-created words. Journal of the Korea Society of Computer and Information, 25(4), 133–140.
- Song, C., Yu, Q., Jose, E., Zhuang, J., & Geng, H. (2021). A hybrid recommendation approach for viral food based on online reviews. Foods, 10(8), 1801. https://doi.org/10.3390/foods10081801
- Song, C., Zheng, L., & Shan, X. (2022). An analysis of public opinions regarding Internet-famous food: A 2016–2019 case study on Dianping. British Food Journal, 124(12), 4462–4476. ahead-of-print. https://doi.org/10.1108/BFJ-05-2021-0510
- Ullah, M. A., Marium, S. M., Begum, S. A., & Dipa, N. S. (2020). An algorithm and method for sentiment analysis using the text and emoticon. ICT Express, 6(4), 357–360. https://doi.org/10.1016/j.icte.2020.07.003
- Wang, Y., & Chen, Y. (2020). Hybrid recommendation algorithm integrating content and matrix decomposition. Application Research of Computers, 37(5), 1359–1363. (In Chinese).
- Wang, A., Zhang, Q., Zhao, S., Lu, X., & Peng, Z. (2020). A review-driven customer preference measurement model for product improvement: Sentiment-based importance–performance analysis. Information Systems and E-Business Management, 18(1), 61–88. https://doi.org/10.1007/s10257-020-00463-7
- Wani, M. A., Agarwal, N., Jabin, S., & Hussain, S. Z. (2018). User emotion analysis in conflicting versus noncon- flicting regions using online social networks. Telematics and Informatics, 35(8), 2326–2336. https://doi.org/10.1016/j.tele.2018.09.012
- WeAreSocial. (2021). The latest insights into the ‘state of digital’. https://wearesocial.com/uk/blog/2021/01/digital-2021-the-latest-insights-into-the-state-of-digital
- Wu, S., Dong, Y., Guiying, W., & Gao, X. (2021). Research on user similarity calculation of collaborative filtering for sparse data. Journal of Frontiers of Computer Science and Technology, 16(5), 1043–1052. (In Chinese). https://doi.org/10.3778/j.issn.1673-9418.2011062
- Xiao, L., Chen, Z. S., Govindan, K., & Skibniewski, M. J. (2022). Effects of online consumer reviews on a dual-channel closed-loop supply chain with trade-in. IEEE Transactions on Engineering Management, 1–16. https://doi.org/10.1109/TEM.2022.3167160
- Xiao, S., Wei, C. -P., & Dong, M. (2015). Crowd intelligence: Analyzing online product reviews for preference measurement. Information & Management, 53(2), 169–182. https://doi.org/10.1016/j.im.2015.09.010
- Zhang, L., Wang, S., & Liu, B. (2018). Deep learning for sentiment analysis: A survey. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 8(4), e1253. https://doi.org/10.1002/widm.1253
- Zhang, C., Xiao, J., & Zhou, L. (2021). Research on hybrid collaborative filtering recommendation algorithm based on matrix filling. Mathematics in Practice and Knowledge, 51(10), 81–89. (In Chinese).
- Zhang, Y. L., & Zhang, L. L. (2022). Movie recommendation algorithm based on sentiment analysis and LDA. Procedia computer science, 199, 871–878. https://doi.org/10.1016/j.procs.2022.01.109
- Zhang, H., Zhang, H. X., Lu, X. Y., & Gao Q. (2021). Attention-based overall enhance network for Chinese semantic textual similarity measure. Journal of Applied Science and Engineering, 25(2), 287–295. http://dx.doi.org/10.6180/jase.202204_25(2).0005
- Zhao, W., Zeng, Y., & He, Y. (2021). Collaborative filtering via factorized neural networks. Applied Soft Computing, 109, 107484. https://doi.org/10.1016/j.asoc.2021.107484
- Zhu, Q., Li, Y., Geng, Y., & Qi, Y. (2013). Green food consumption intention, behaviors and influencing factors among Chinese consumers. Food Quality & Preference, 28(1), 279–286. https://doi.org/10.1016/j.foodqual.2012.10.005