
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Identification, segmentation and counting of stained in vitro cell colonies play a vital part in biological assays. Automating these tasks by optical scanning of cell dishes and subsequent image processing is not trivial due to challenges with, e.g. background noise and contaminations. Here, we present a machine learning procedure to amend these issues by characterising, extracting and segmenting inquired cell colonies using principal component analysis, -means clustering and a modified watershed segmentation algorithm to automatically identify visible colonies. The proposed segmentation algorithm was tested on two data sets: a T-47D (proprietary) cell colony and a bacteria (open source) data set. High
scores (
for T-47D and
for bacterial images), along with low absolute percentage errors (
for T-47D and
for bacterial images), underlined good agreement with ground truth data. Our approach outperformed a recent state-of-the-art method on both data sets, demonstrating the usefulness of the presented algorithm.
1. Introduction
Clonogenic assay or colony formation assay serves as a means to assess viable, growing cell colonies (Franken et al. Citation2006) and plays imperative roles in radiobiology (Moiseenko et al. Citation2007), microbiology (Krastev et al. Citation2011) and immunology (Junkin and Tay Citation2014). Manual identification of colonies (conglomerations composed of cells) is time-consuming with potentially large inter-observer variations. High-pass optical image scanners, digital cameras or other imaging systems introduces a new field of image processing solutions. However, digital assessment of inspected colonies depends on several factors such as background noise, clustering of cells/colonies, spatially varying illumination, contaminants in the suspension medium, variable colony confluency and colony-specific features including size and circularity. Therefore, it is essential to have a robust and adaptive approach that takes these discernments into consideration and that provides accurate, fast, objective and reliable segmentation of colonies.
We propose a versatile automated segmentation method with an image analysis pipeline consisting of signal decomposition of the raw input image, foreground-background separation, segmentation of the colonies and post-segmentation correction. In essence, the segmentation procedure relies on three key techniques performed in sequence:
(1) Principal component analysis (PCA) – of image channels to convert information stored in the colour channels into different contrast intensity planes, whereby automated channel selection is performed by spatial texture analysis using the grey-level co-occurence matrix (GLCM),
(2) k-Means clustering – for distinguishing connected cell colonies (foreground pixels) from acquisition artefacts and cell containers (background pixels),
(3) Multi-threshold-based watershed segmentation – to further segment the extracted features into colonies by incorporating fuzzy logic.
In the present study, we show the applicability of each separate method as to supply linked information downstream of the image analysis pipeline. Hence, the collective integration of these techniques to assess the colony viability yields a novel approach that is presently evaluated. Specifically, PCA is an effective way to suppress redundant information and amass one composite principal component (PC) channel that contains inherent information on the colonies from the initial multichannel (colour) data. The goal is to find a special linear combination of the colour channel images that retains the colony intensity – the scene variance of the colonies – and discard objects with different texture and colour features, such as cell dish border, shadows, dust and contaminants in the medium. A conventional greyscale image of the input data would be sensitive to such objects and include them further downstream in the segmentation pipeline. Furthermore, the PC channel that contains explicit depiction of the colonies is automatically selected by a GLCM texture assessment. This selection is used as a basis for the watershed segmentation procedure, which has not been addressed previously. Subsequent segmentation optimisation takes into account cell colony characteristics, such as, circularity and size through adaptive fuzzy logic consensus for each individual image. By forming a fuzzy mathematical description of the selection space for each feature, aggregate colony feature scores are computed to objectively choose the optimal watershed segmentation outcome. The performance of this approach is evaluated against a state-of-the-art method, as well as manual cell colony count on a selection of data sets showing different characteristics.
1.1. Background
Automated cellular and bacterial colony counters have been an abiding topic of interest (Mansberg Citation1957). There are currently commercial solutions available, but these are proprietary tools that require purchase of respective imaging stations and may be cost-prohibitive. In addition, these products are running segmentation algorithms that are undisclosed, making them restrictive and hard to interpret for the user.
Several free and open-source colony segmentation methods are accessible for the user as they are supported on common operating systems. Applications within this category include circular Hough image transform algorithms (Bewes et al. Citation2008; Militello et al. Citation2017), such as CHiTA, and NIST’s Integrated Colony Enumerator (NICE) (Clarke et al. Citation2010). CHiTA identifies cell colonies by intensity gradient field discrimination. However, the utilisation of the circular Hough transform makes the program prone to neglect more elongated segments. NICE represents a helpful enumeration tool that operates by combining extended-minima transform and thresholding algorithms. The extended-minima analysis is used to find the centre of the bacteria colonies and to distinguish adjacent colonies. Nonetheless, this segmentation approach does not take different colony shapes, sizes or variable staining into account, which could render the following intensity threshold faulty, and has not been tested on human cells.
OpenCFU is a popular, cross-platform and C++ based open-source software, made freely available (Geissmann Citation2013). It declares to be faster, more accurate and more robust to the presence of artefacts compared to NICE. The study utilised a high-definition camera for image acquisition and the application is operated via an intuitive graphical user interface (GUI) which is also extensively described in a user manual. Although the program is able to initiate a batch acquisition and exclude anomalous objects, the selection method is restricted to circular objects. In fact, the OpenCFU algorithm recursively thresholds an annotation of circular regions in a greyscale image to generate a score-map to assess both the isoperimetric quotient and the aspect ratio of each detected object and then exclude regions that are morphologically unlikely to be colonies. This could be a concern when processing cell lines with non-circular colony phenotype.
CellProfiler is another popular, free, open-source program that addresses a variety of biological features, including standard and complex morphological assays (e.g. cell count, size, cell/organelle shape, protein staining) (Carpenter et al. Citation2006). The program uses either standardised pipelines or individual modules that can be customised to specific tasks. Other macro-based colony detection algorithms implemented as ImageJ (Schindelin et al. Citation2012) plugins have also been proposed, such as IJM (Cai et al. Citation2011), Cell Colony Edge (Choudhry Citation2016) and CoCoNut (Siragusa et al. Citation2018). However, due to the sequential order of the modules, the performance of the cumulative operations may not be optimal on images from different experiments. Furthermore, a machine learning procedure has been combined with pipelines in CellProfiler to solve segmentation tasks – ilastik (Sommer et al. Citation2011). It uses a random forest classifier (Breiman Citation2001) in the training phase in order to assign each pixel’s neighbourhood into classes by interactive pixel labelling.
Deep learning models have also become popular. For instance, a convolutional neural network (CNN) has been suggested for bacteria colony counting on blood agar plate (Ferrari et al. Citation2017). The model works as a CNN-based patch classifier and assigns colony segments into classes depending on the number of colonies it contains, from 1 to 6. Segments containing more than 6 colonies or including contaminants on the agar are labelled as outliers and discarded. However, this method is merely able to handle experiments with limited confluency as more training data is required to handle confluent cell areas. Hence, the CNN performance and prediction accuracy, in general, are strongly dependent on the availability of large amounts of high-quality and problem-specific training data. A recent deep learning technique has been proposed that effectively mitigate this limitation by exploiting models trained for other tasks (Albaradei et al. Citation2020). In that framework, a deep learning model designed and trained to count people in congested crowd scenes is transformed into a specialised cell colony counting model by partially retraining it using a smaller data set. Although the feasibility of this approach was demonstrated, more data collection and further validations are required to assess to which extent the model can generalise across different experiments. Several other deep learning models have also been reported (Akram et al. Citation2016; Ronneberger et al. Citation2015; Sadanandan et al. Citation2017; Xie et al. Citation2018; Falk et al. Citation2019). However, these CNN-based models are fine-tuned for individual cell nucleus detection and classification in microscopic digital pathology images such as fluorescent, haematoxylin and eosin staining and immunohistochemistry imaging, making them ineligible for cell colony segmentation problems (Albaradei et al. Citation2020). Furthermore, a binary classifier in quantum-like machine learning has also been proposed for clonogenical assay evaluation (Sergioli et al. Citation2021).
AutoCellSeg, a current state-of-the-art method, utilises adaptive multi-thresholding to extract connected cell colony conglomerations of interest and automatic feedback-based watershed segmentation to further partition the conglomerations into separate colonies (Khan et al. Citation2018). This algorithm was applied on images of four different types of bacterial species, where the results were tested against established ground truths (GTs) showing greater accuracy performance than OpenCFU and CellProfiler. However, it is usable in different operation modes and enables the user to select object features interactively for supervised image segmentation method via the GUI, implying that AutoCellSeg is not fully automated.
With the presented methodology, we circumvent drawbacks of the discussed algorithms such as basic one-dimensional thresholding by using PCA on the decomposed multichannel data and subsequent -means clustering, disregard of geometrical shape by using Fuzzy logic to evaluate the multi-threshold watershed segmentation. The necessity of high amounts of training data is another drawback amended by the presented method. As will become evident, our colony segmentation method – the automated colony counting (ACC) algorithm – accurately maps cell colonies and yields quantitative estimates of number, localisation and density. Moreover, since the AutoCellSeg method was reported to outperform other methodologies, our current ACC procedure was chosen to be benchmarked against this approach.
2. Methods
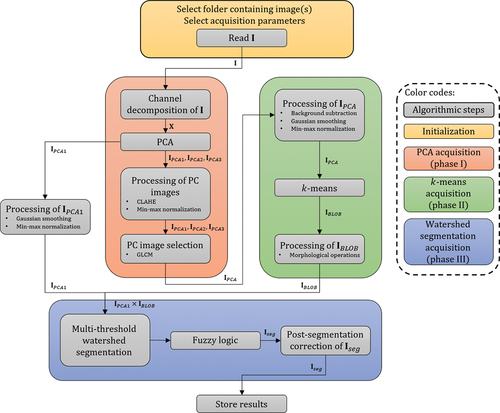
The image analysis pipeline is mainly composed of three cardinal phases (see ). Initially, the image,
, is read from the selected folder, where segmentation parameters are chosen by the user in the initialisation. Phase I: the colour components of
are decomposed into a matrix,
, before performing PCA on the input data. The PC images,
,
and
, of the
input sample are then processed, by means of contrast-limited adaptive histogram equalisation (CLAHE), prior to texture analysis via GLCM computation. Phase II: from the GLCM-analysis, the channel with minimum contrast is selected,
, and supplied to the
-means analysis phase. The raw PC image is processed in order to augment the foreground information from the background, while restraining background information. Performing
-means yields a binary image of the merged colonies,
. Phase III: multiplying
by the first PC image of
,
, masks out the relevant intensity regions in preparation for watershed segmentation. Multiple intensity-thresholds are imposed on each inquired region, where respective colony features are evaluated using fuzzy logic providing a segmented binary image of
,
. Finally,
is corrected post-segmentation before the conclusive results (colony count, features, etc.) are saved as .csv files.
Figure 1. Overview of the image processing pipeline showing the main steps.
2.1. Phase I: principal component analysis (PCA)
2.1.1. Image channel decomposition
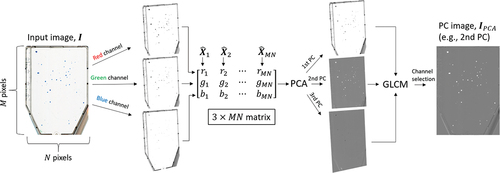
We apply a decomposition method to the multivariate data composed of the colour channels. The idea is to identify the information about cell colonies and separate it from cell flask, shadows and noise. Originally, all of these signals are distributed across the three channels of the true colour image resulting from an optical scan of a cell flask containing stained colonies (see subsection 3.3). The proposed algorithm de-mixes the signal via a linear combination of sources using PCA. With this approach, we map colony information on a single plane by bundling the information from all colour channels (Lay et al. Citation2020).
Let denote the observation vector in
comprising the red (
), green (
) and (
) colour components of the
th pixel in the
input image,
. By rearranging the multichannel components, the matrix of observations,
, is then defined to be a matrix of the form
The mean-deviation form matrix of
is introduced as
, for
, where
is the sample mean of the observation matrix
. Consequently,
is introduced as
2.1.2. Principal component analysis (PCA)
PCA is a popular method for extracting relevant information from multivariate data, mainly focusing on dimensionality reduction (Wold et al. Citation1987; Abdi and Williams Citation2010). It aims to transform input variables linearly into PCs, sorted by their explained variance in a descending order. The main idea is that a high percentage of the total variance of the input data is covered by the first output PCs.
Technically, PCA describes the change of variable for each observation vector of by,
where the orthogonal matrix consists of the unit eigenvectors (or PCs) of the co-variance matrix of
,
, determined via singular value decomposition (SVD) of
. Since
is an invertible matrix, a linear combination of the original variables in
determines the new PC pixel values – the intensity variation of each composite
pixel – by the variable transformation,
where ,
and
are the entries in the first, second and third PC vector,
,
and
respectively, while the new variables
,
and
represent the first, second and third PC pixel values given by
from Equationequation (3)
(3)
(3) . This projects an image in the first, second and third dimension of the PCA space –
,
and
respectively – reflecting the triplet colour variation of the inquired image (see ).
Figure 2. Schematic PCA procedure for an input image, . The multichannel colour image is firstly decomposed into a
matrix,
, where each column,
, represents a composite, centred
pixel. Through PCA, a linear combination of the colour channels is obtained to compose the PC images,
,
and
. Dimensionality reduction is then automatically achieved by using a GLCM contrast criteria that optimally selects a single PC image for colony feature characterisation,
.
2.1.3. Grey-level co-occurrence matrix (GLCM)
In our application, the PC images (,
,
) include variance information about the cell colonies, cell container, shadows and noise. Among the PC images, we assume that only one of the images offers a reliable and selective depiction of the colonies, whereas the two remaining PC images contain (variance) information representing other image contributions.
The GLCM is a statistical approach for analysing texture (Haralick et al. Citation1973; Haralick and Shapiro Citation1992). We will use image contrast, as defined from the GLCM, to identify and select the optimal PC image with respect to cell colony depiction. In a single input channel image (representing in our case one PC image), , the co-occurrence matrix,
, is defined as the frequency of pixel-pairs along a particular distance and direction in
of
grey-levels:
where and
denotes the
th entry in the co-occurrence matrix and normalised co-occurrence matrix, respectively. The GLCM describes the relative frequency between the pixel-pair
and
separated by a specified displacement
and angle
– offset – with grey-level intensity
and
, respectively, in the domain
.
Next, the Haralick feature (Haralick et al. Citation1973) for contrast is computed from the GLCM as a statistical measure to describe colony texture characteristic and is used for PC selection
It returns a measure of the intensity contrast repetition rate for a pixel-pair across the whole image. This statistic ranges in the interval , where it is 0 for a constant image. Therefore, low contrast entails an image that features low spatial frequencies.
The PC selection criterion involves choosing the PC image with the lowest contrast statistic. As either ,
or
expresses the colour variation of solely the colonies, the most suitable PC image is composed of pixel values that are insensitive to and suppress the presence of various high-contrast artefacts such as contaminants/residue in the suspension medium, inevitable shadow artefacts due to imaging/scanning procedures, inherent background noise emanated from the image/scan acquisition and the cell container boundary. Hence, the spatial frequency of local colour variations depicting merely the colonies is minimised in the PC image characterising the colonies relative to the remaining two PCs depicting all other elements. Hence, the PC channel with the lowest contrast results in the PC image selection describing the colonies optimally (see ):
Prior to GLCM contrast estimation, each PC image is enhanced by applying CLAHE (Zuiderveld Citation1994) to aid the selection criterion in Equationequation (10)(10)
(10) . Through dividing an image into a grid of rectangular regions, the histogram of the contained pixels for each region is computed. The contrast of each region is locally optimised by redistributing the pixel intensity according to a transform function, where a uniform histogram equalisation distribution is used here. Then, by imposing a clip limit (or contrast factor) as a maximum on the computed histograms, over-saturation of particularly homogeneous areas (characterised by high peaks in the contextual histograms) is reduced, which prevents over-enhancement of, e.g. noise and edge-shadowing effect derived from an unlimited adaptive histogram equalisation (AHE).
2.2. Phase II: k-means clustering
To distinguish the conglomerate cell colonies characterised in from background, we deploy
-means clustering (Lloyd Citation1982) on the raw
to produce a binary mask of the cell colonies. After subtracting the background through opening–closing by reconstruction in order to augment foreground recognition and min-max normalisation of the values to 0–1 in
, we construct a feature matrix
by aggregating the
th pixel value,
, with its 8-connected neighbours,
. We obtain a
matrix,
where each pixel cluster ,
, is assigned to either background,
, or foreground,
, through squared Euclidean distance (ED) minimisation
where denotes to the centroid of the class assigned to pixel
. Hence, finding the optimal distance by
-means (
) creates a binary mask,
, containing contiguous colony components denoted as Binary Large OBjects (BLOBs),
, where
is the total number of BLOBs. The BLOB extraction is therefore made independent of geometrical shape as all sizes and shapes with adequate pixel intensity are masked out by
-means (see ).
Figure 3. Schematic -means procedure for a PC image,
. The image is used to construct a
matrix,
, where each column,
, represents a pixel value,
, with its 8-connected neighbours,
. Then, considering each
, pixel
is assigned to nearest cluster centroid
(background) or
(foreground) by minimising the ED. This results in a binary image containing appurtenant BLOBs,
.
![Figure 3. Schematic k-means procedure for a PC image, IPCA. The image is used to construct a 9×MN matrix, Z, where each column,Zi, represents a pixel value, pi, with its 8-connected neighbours, pi(1),…,pi(8). Then, considering each Zi, pixel pi∈[0,1] is assigned to nearest cluster centroid c0=0,…,0T (background) or c1=1,…,1T (foreground) by minimising the ED. This results in a binary image containing appurtenant BLOBs, IBLOB.](/cms/asset/0a4dce7d-d0e1-4bab-a8a6-4c1684624a49/tciv_a_2035822_f0003_oc.jpg)
2.3. Phase III: topological multi-threshold watershed segmentation
We further apply the watershed algorithm following Khan et al. (Citation2016) and Khan et al. (Citation2018), which we modify and expand to handle colony confluency. Here, distance transformation along multi-threshold-based watershed is consolidated with quality criteria to recursively subdivide the BLOBs of interest into distinct colonies through catchment basin and watershed line formulation (Gonzalez and Woods Citation2018).
The established BLOBs in are divided into individual colonies by the watershed algorithm. Watershed segmentation relies on a topographic (intensity) information across two spatial coordinates,
and
, reflecting the colony number in each BLOB. This information is obtained from
which conveys principally greyscale measure of colony intensity. Thus, by multiplying
with
, a topographic surface is provided where the background is masked out. However, erroneous over-segmentation may result from direct application of the watershed algorithm due to noise and local irregularities in the intensity distribution. This may accordingly lead to the formation of overwhelming amounts of basin regions. Therefore, we utilise extended-minima transform to avoid the tendency to include regional minima. All regional minima are identified as connected pixels with intensities that differ more than a specified threshold,
, relative to neighbouring pixels, while the remaining local minima whose depths are too shallow are suppressed. The definition of the extended-minima operator for a given
,
, produces a desired binary mask of the pronounced basins,
where denotes reconstruction by erosion of
from
to suppress all shallow minima and
represents the regional minima operator of corresponding erosion.
Employing on
yields varying outcomes for different thresholds,
. To account of this, multiple
,
, are sequentially applied on each
, for
, to create a manifold of candidate segmentation outcomes in the form of binary masks. Additionally, to withstand high cell confluency and achieve a proper segmentation, ED transform is conducted on each mask from every
. Then, the optimal transformation is selected that maximises the quality segmentation criterion,
, which incorporates fuzzy logic,
where ,
and
are fuzzy spline-based pi-shaped membership functions (MFs) given by
for evaluation of colony area, circularity or expected colony count, , respectively, represented by the variable
. Hence, each segmented candidate colony will have its property set
for all points
graded according to the MF (16) such that
. The parameters
,
,
and
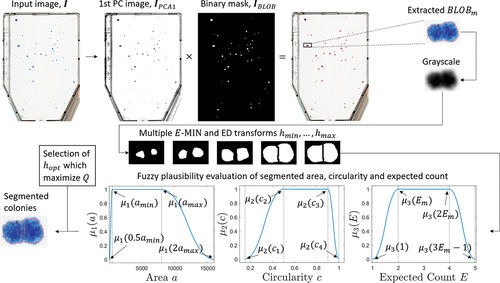
are adjustable and correspond to the pi-shaped edges, which form the selection space (see ).
Figure 4. Schematic watershed processing pipeline for a single iterated BLOB, . The BLOB is extracted by the multiplication between the first PC image conversion of the input image,
, and the generated BLOB mask,
. Having the intensity representation of the conglomeration extracted, several
operators and ED transforms are applied, where each transformation yields segmented colonies. The validity of each segmentation outcome is subsequently graded using fuzzy pi-shaped MF
for a fuzzy set
representing colony area, circularity and expected count.
For , the corners of the area distribution are
where and
are minimum and maximum user specified colony sizes, respectively. For
, the circularity parameters are flexible
, where
with circularity value 1 for a perfect circle. For the expected count distribution
, the function edges are defined as
, where
,
is the area of
and
is the median area of
. Thus, the multi-feature fuzzy logic presented is utilised to assess the geometrical shapes of subdivided colonies within an iterated
after each successive watershed segmentation. This is performed in order to objectively select the segmented outcome that attains colonies of coherent geometrical characteristics. Ultimately, the segmentation procedure yields an appropriate binary image representing the final feature-endorsed colonies,
.
3. Experimental set-up and data acquisition
3.1. Parameter selection
The images are loaded in the ACC algorithm and the parameters are manually tuned as listed in for each data set. During the PCA acquisition (phase I), the PC images are firstly processed using CLAHE in preparation for the GLCM contrast selection criterion. The contrast enhancement is performed by partitioning each image into regions with a clip limit factor of
. For the computation of the co-occurrence matrix,
, in Equationequation (8)
(8)
(8) the spatial dependence between neighbouring pixels was evaluated at
grey-levels. Further, the GLCM is highly dependent on the parameters
and
. Thus, applying Equationequation (8)
(8)
(8) , several matrices were obtained for each change in direction
. This was defined by four different offset vectors;
(
),
(
),
(
),
(
), where the displacement
(in pixels) is set to examine merely adjacent pixels in
(the PC images). The co-occurrence matrix and thereby the contrast statistic was readily computed for each offset and then averaged. The choice of
is justified as a pixel is more likely to be correlated to closely located pixels than those further away.
Table 1. Parameter selection in the automated colony counting (ACC) method for image segmentation of the different clonogenic species. The Gaussian smoothing filter size, , specified as a 2-element vector of positive numbers in terms of the standard deviation,
, of the Gaussian distribution, is applied on
and
. The radius of the disk-shaped structuring element in the morphological opening-closing by reconstruction,
, is given in pixels. Minimum and maximum user specified colony areas,
and
respectively, are given in pixels.
For the -means acquisition (phase II), the processing stage of
included morphological opening–closing by reconstruction using a disk-shaped structuring element with a radius of
(in pixels), before smoothing using a filter with a 2D Gaussian kernel of size
(see ). These operations were used for background suppression and to smooth the varying spatial image intensity for outliers, respectively. Here,
should conform with areas size of the BLOBs as it should be exceedingly greater, whereas
should reduce evident noise over smaller spatial regions. In the processing step of
, various morphological operations were applied on the binary mask such as dilation and flood-filling of holes.
was also processed prior to the watershed segmentation: 2D Gaussian filtering (to avoid over-segmentation of the BLOBs) was employed, where the enhanced image was min-max normalised (see ). The Gaussian smoothing on
is set to directly affect the forthcoming segmentation of the extracted BLOBs as the filtering is performed on regions in
masked out by
. Depending on the image dpi, area size of the actual colonies and colony confluency, the standard deviation of the Gaussian blur of the BLOB greyscale intensities should be chosen accordingly.
During the watershed segmentation (phase III), each masked having an area
and circularity
was further separated through the multi-threshold segmentation. These condition limits for segmentation were kept fixed. Enforcing this, we chose
with incremental steps
as a search space for all data sets. The size of this watershed search space has a pronounced influence on the runtime; even though a smaller range and/or larger
would yield a shorter computation time, doing so may not ensure optimal segmentation results. Thus, a high colony density necessitates a large search span by lowering the
value to eventuate a finer segmentation of BLOBs, while choosing a very large
value may not be cost-effective. The pi-shaped MF parameters for the area and circularity distributions were fixed to
and
, respectively, where
and
(in pixels) are provided by the user (see ). The edges for the expected colony count within each iterated
,
, are adaptively computed throughout the segmentation process. Subsequent segmented colonies were recursively divided until the criterion
was met.
3.2. Cell culture and manual counting
Human breast ductal cell carcinoma cells of the T-47D line were cultured in RPMI medium (Lonza), supplemented with 10% FBS (Biochrom), 1% penicillin/streptomycin (Lonza) and 200 units per litre insulin (Gibco), at 37°C in air with 5% CO2. The cells were kept in exponential growth by reculturing twice per week with one additional medium change per week. The seeded number of cells was low which consequently formed sparsely populated colonies in each T25 culture flask (25 cm2 cell culture area; Nunclon, Denmark). For more information on the cell culture and colony formation assay used in the current work, see e.g. Edin et al. (Citation2012).
To validate the quality of the presented ACC segmentation algorithm, we compared the ACC number to the number produced by the recently published method AutoCellSeg (Khan et al. Citation2018) (both proprietary and open-source data), as well as to the manual colony counting (MCC) facilitated by three trained human observers (only proprietary data). Here the observers were independent meaning that no subject could know the results of any other before counting. Additionally, an extra independent observer established a GT by manual counting during a microscopic analysis of the culture dishes for comparison (proprietary data).
3.3. Data description
The ACC algorithm was applied to the images of the cell culture flasks containing fixed and stained cell colonies. We conducted experiments on both proprietary and open-source data.
Proprietary data (data set 1) were obtained from a flatbed laser scanner (Epson Perfection V850 Pro), providing images with a resolution of 2125
2985, 1200 dots per inch (dpi), 21.17µm/pixel spatial resolution and 48-bit depth. No prior filtering nor adjustments were performed on the captured images during scanning with the scanner software (EPSON Scan v3.9.3.3). Data set 1, including respective MCC and GT data, is publicly available in Zenodo’s repository (Arous et al. Citation2021). An example of cell colony image is provided in . The cell flask contains cell colonies, as well as background structures (e.g. shadows) and outer contours of the T25 cell flask. The segmentation suggested by the ACC is delineated in red. The full data set consists of 16 cell culture flasks used for a colony formation assay of the T-47D (breast) cancer cell line.
Figure 5. Example image from data set 1. The segmentation suggested by the automated colony counting (ACC) algorithm is outlined in red.

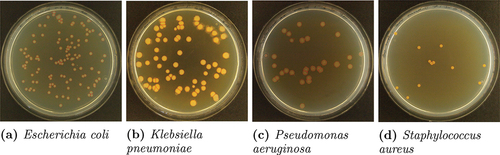
Open-source images (data set 2) of colour representation, 4032
3024 resolution, 314 dpi, 80.89
m/pixel spatial resolution and 24-bit depth, with accompanying GT delineations, were obtained from the publicly available AutoCellSeg’s GitHub repository (https://github.com/AngeloTorelli/AutoCellSeg/tree/master/DATA/Benchmark). The data set contained 12 images of four bacterial species (3 images each), including Escherichia coli (E. coli), Klebsiella pneumoniae (Klebs. pn.), Pseudomonas aeruginosa (Pseud. ae.) and Staphylococcus aureus (Staph. au.) cultured in Petri dishes. The GT colony delineations were produced by the authors Torelli et al. using Adobe Photoshop before being converted into binary masks. Delineations obtained for this data set using the ACC algorithm are shown in .
Figure 6. Example images from data set 2. The segmentation suggested by the automated colony counting (ACC) algorithm is outlined in red.
3.4. Hardware
The segmentation using the ACC procedure was implemented in MATLAB (MathWork, Natick, MA, USA) and executed on an Intel Core i7-8565 U CPU @ 1.80 GHz with 16 GB RAM. The average runtime of the proposed algorithm was 114 seconds per image, which is adequate when considering the software as a fully automated batch throughput solution for large data sets. However, runtime optimisation and parallelisation are not in the scope of this work and will be considered in future projects. The AutoCellSeg results were obtained by installing and utilising the freely available AutoCellSeg software (https://github.com/AngeloTorelli/AutoCellSeg), which is based on the open-source implementation by Torelli et al., and run on a partially automated mode via the GUI with similar processing parameters as in our own pipeline.
3.5. Statistical analysis
In addition to cell colony counts, we investigated the spatial information associated with the detected cell colonies in the images. Hence, further provides binary classification metrics for both ACC and AutoCellSeg using a region-wise definition of the confusion matrix. Given the segmentation of ACC or AutoCellSeg, respectively, as well as one centralised coordinate point per colony representing the GT (GT mark), we considered a colony as detected if at least one GT mark was within the delineated area. Such regions were denoted as true positives (). We denoted a cell colony as false positive (
) if the delineated region did not contain any GT mark. Finally, false negative (
) regions were obtained from those GT marks which were either located outside the delineated areas (not detected by the algorithm) or in a delineated region together with other GT marks (merged with other colonies by the algorithm). The
score was chosen as a binary classification metric to measure the spatial accuracy of the detected colonies made by the observers and the ACC. Here the
score is the harmonic mean between the precision and recall:
Table 2. Statistical results for 16 T-47D cell flask images (data set 1) presented as mean standard deviation [min, max], obtained from our automated colony counting (ACC) procedure, the AutoCellSeg method, as well as manual colony counting (MCC), when compared to the ground truth (GT).
where the precision is a measure of exactness (the ratio of cases to the total predicted positive cases,
), while recall is a measure of completeness (the ratio of
cases to the total actual positives cases,
).
4. Results
4.1. Data set 1
shows an overview on the results from ACC, AutoCellSeg and MCC, as well as their respective values compared to the GT on data set 1. Even though both MCC and GT were obtained from manual counting, the former was based on manual counting on the same images that were presented to the algorithm, whereas the GT is more reliable due to the in-depth information from the microscopy. For each image, the average MCC is shown along with its mean absolute deviation between the observers. As shown in , both ACC and AutoCellSeg have tendencies to underestimate the number of colonies. Corresponding statistical measures of colony count, precision, recall, score and absolute percentage error (APE) are listed in . From , the values of precision, recall and
score of the proposed system are greater than the AutoCellSeg method, while the APE where comparable between the two methods; 11.5% and 11.3% for ACC and AutoCellSeg, respectively. However, MCC resulted in 3.7% APE.
Figure 7. Relationship between the counts for the three methods – automating colony counting (ACC) (circle), AutoCellSeg (square), manual colony counting (MCC) (triangle) – and ground truth (GT) counts for data set 1 (T-47D colonies). Mean MCC is shown along with its standard deviation between the 3 observers. The stippled line is the identity line.
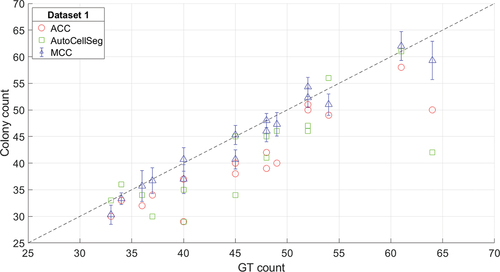
The counts obtained from all methods achieve similar results and do not show a clear winner: our proposed ACC method produced a root-mean-square error (RMSE) of 14% with a tendency to underestimate the GT count. AutoCellSeg showed similar characteristics with an RMSE of 17%. Although the MCC had a similar RMSE (ACC errors are within the error bounds associated with MCC), the manual observers slightly overestimated the colony number: in all except for three images, the mean MCC was higher than the GT count (see ).
With regard to spatial information, ACC obtained superior scores compared to AutoCellSeg, although the absolute ranges for both procedures were on a very high level (
score mostly
%). This indicates that ACC can outperform the current state-of-the method. Analysing the metrics in detail revealed that in most cases, both precision and recall could be improved by ACC. In few cases, we observe that ACC obtains a higher
score, although the error with respect to absolute colony counts is higher compared to AutoCellSeg. This anomaly might be caused by a mutual compensation of different error types in AutoCellSeg, such as dividing one cell colony into multiple regions and neglecting others at the same time. This will decrease the
score, but remain undisclosed when comparing overall colony counts.
4.2. Data set 2
In addition to the results obtained from the proprietary T-47D cell data set, we used both algorithms, ACC and AutoCellSeg, on publicly available open-source data sets. The data sets differ from data set 1 in colouring, shape of the cell dish, size of the investigated cell colonies, image resolution and background. Evaluation is made in the same way as for data set 1, except for that no manual counting from different observers was available for evaluation.
From , ACC demonstrated a slightly better performance compared to AutoCellSeg. This conforms with the overall statistical results in , where the experiment conducted on data set 2 demonstrates that ACC is able to outperform AutoCellSeg with respect to precision, recall, score and APE. In fact, ACC is superior to AutoCellSeg in 9 out of 12 cases with respect to
scores and performs equally well in 2 cases, whereas AutoCellSeg scored higher on only 1 case. Indirectly, the presented results can be compared to experiments from (Khan et al. Citation2018) on the same data sets, where other recent methods are evaluated. Unlike for data set 1, the single images in this experiment show more variability, hence the high-quality results underline the flexibility of the presented algorithm.
Figure 8. Relationship between the counts for the two methods – automating colony counting (ACC) (circle), AutoCellSeg (square) – and ground truth (GT) counts for data set 2 (bacterial colonies). Data for Escherichia coli (E. coli) (red), Klebsiella pneumoniae (Klebs. pn.) (green), Pseudomonas aeruginosa (Pseud. ae.) (blue) and Staphylococcus aureus (Staph. au.) (cyan) are presented. The stippled line is the identity line.
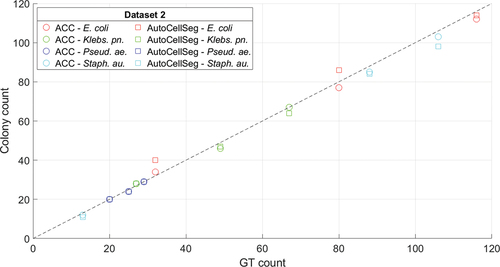
Table 3. Statistical results for 12 bacterial colony Petri dish images (data set 2).
5. Discussion
A clear benefit of the proposed ACC algorithm is the saving of resources in terms of time and manual effort. Remarkably, the algorithm matches manual observation techniques not only in terms of speed but also delivers robust and objective results.
Our experiments demonstrated that the proposed algorithm is capable of solving the automated cell counting problem and serves as a valid alternative to manual procedures with a competitive quality. Herein, the PC image containing the colour variability of the colonies offers a reliable and selective depiction of the colonies when compared to the traditional greyscale image, , of
. Without PCA, feature extraction from
is liable to include and segment falsely detected objects with similar greyscale intensities as colonies. Also, the results are superior to those obtained from the AutoCellSeg state-of-the-art method and in the range of human inter-observer variance. Thus, further refinement is hardly possible unless more accurate reference data are available. In particular, the flexibility of our presented ACC algorithm, taking different cell dish geometries, background, image resolution and colouring into account, proved its high value.
We discovered a small bias between the human observers and the automated counts, particularly on data set 1. In this case, the algorithm tends to provide lower estimates. A manual evaluation showed that particularly small and sparsely populated cell regions with low contrast to the background were neglected by the automated algorithm in specific cases, but identified as colonies by human observers. Such errors can be reduced by parameter tuning, particularly those related to watershed segmentation. However, the fact that the results from different human observers are not always consistent (in particular when judging such small regions) shows the challenges of the task. Following the definition of cell colonies as conglomerations of more than typically 50 cells, this threshold can solely be verified by microscopy. Enhanced parameter tuning procedures to fit different problem set-ups will be investigated in the future work when reliable GT information is available for a larger amount of data.
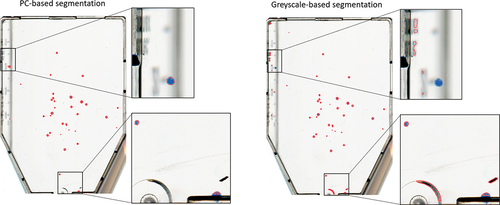
In order to substantiate the significance of the PCA (phase I), a comparison in colony segmentation performance delivered by ACC was done when feeding rather than
into the
-means procedure (phase II). A demonstration is shown in . Estimates of precision, recall and
score were
,
and
, respectively. Thus, the precision decreases significantly, i.e. it delivers many
s as shadow and cell container segments get thresholded and included further downstream in the pipeline.
Figure 9. Demonstration of colony segmentation performance on an image from data set 1 when PCA (left) versus conventional greycale conversion (right) of the input image is used in the pipeline. The segmentation suggested by the automated colony counting (ACC) algorithm is outlined in red.
A similar automated colony segmentation procedure has been proposed, using an ad-hoc image capture system for Petri dishes (Chiang et al. Citation2015). The image processing pipeline employed PCA to convert acquired colour images into intensity, Otsu’s method (Otsu Citation1979) to extract E. coli K12 bacterial colonies and distance transform along with watershed to separate clustered colonies. Although the mean values of precision, recall and score are all reported to be 0.96 with 3.37% mean absolute percentage error, the colony counting results rely solely on images captured in the built hardware apparatus that provides sufficient back lighting. Therein, it is unclear as to which PC channel is exploited. Also, the segmentation was only tested on a single bacteria colony strain, leaving features of colonies with different colours and opacity uninvestigated. Contrarily, our proposed algorithm has been proved on images of various colony strains with different characteristics (size, shape, contrast, colouration) acquired by a general-purpose flatbed scanner.
A recent alternative solution for cell colony detection employs the assumption that there is a strict proportionality between area of the dish covered by the colonies and the number of colonies, rather than quantifying the exact count of colonies directly (Militello et al. Citation2020). Within this area-based approach, multi-feature fuzzy clustering is leveraged by considering local entropy and standard deviation in the input colour images, where colony formation was chosen as the main quantity of interest. Albeit yielding colony counts that correlate well with manual measurements on four human cell lines, the method does however not provide further segmentation of the extracted merged areas from the background.
In addition, identification of the centroid coordinates of each colony listed together with information about respective colony ID, area, circularity and mean/standard deviation of intensity (colour, greyscale and PCs) distribution as well as colony count are saved for further analysis upon completion of our segmentation procedure. Moreover, a binary mask containing fully filled areas representing the segmented colonies is also saved for each image. Thus, the culminated output from the algorithm could open for new applications with colony formation assays beyond regular colony counting. This is useful for users who, for instance, wish to evaluate the colony size of a distinct cell population with respect to treatment efficacy of, e.g. irradiation or a drug.
Compared to other contemporary problems in digital image processing and computer vision, the available amount of training and test data is very limited and the GT is not completely unbiased. Hence, complex models such as CNNs are hardly applicable. Instead, the presented algorithm is unsupervised and overcomes the limitations imposed from the training data by building on well-established and easy-to-train components. An extension with other architectures will be evaluated when more training data are available in the future. Moreover, translating the proposed algorithm into other languages such as Python, R, etc. is also valuable as it allows for more flexibility to extend the program in various programming languages with their complementary packages or modules.
6. Conclusion
We presented a novel algorithm to segment cell colonies on images of cell dishes from colony formation experiments. Our ACC procedure is based upon a tailored pipeline with three major components: PCA bundles the information content from the colour channels,
-means clustering identifies conglomerate areas of cell colonies and a fuzzy statistics modification of the watershed algorithm splits them into separate cell colonies.
Our experiments were conducted on a breast cancer cell line as well as publicly available images from other cell types. In our analyses, the method was evaluated against both a recent state-of-the-art method and manual counting by human experts. The experiments demonstrated that the proposed algorithm is able to beat the benchmark, as well as it meets the expectations by obtaining results of similar quality as the manual observers.
Acknowledgments
We would like to thank Julia Marzioch, Olga Zlygosteva and Magnus Børsting from the Department of Physics at the University of Oslo for conducting the manual counting of the cell colonies.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors
Delmon Arous
Delmon Arous is a PhD fellow in the Department of Physics at the University of Oslo, section of Biophysics and Medical Physics, where he received a Master’s degree in physics in the same section. His work focuses specifically on Monte Carlo simulations of radiation transport, dosimetry and quantitative image analysis for facilitating, among other, in vivo studies of radiation effects in the head and neck of mice.
Stefan Schrunner
Stefan Schrunner received his PhD degree in computer science from Graz University of Technology, Austria, in 2019. He is currently a post-doctoral fellow in data science at the Norwegian University of Life Sciences. His research interests are machine learning and applied statistics, including time series analysis, image processing, pattern recognition and Bayesian models.
Ingunn Hanson
Ingunn Hanson received her MSc degree in Nanotechnology from the Norwegian University of Science and Technology in 2018. She is currently working on her PhD project in Radiobiology at the Section of Medical Physics and Biophysics, University of Oslo. Her work focuses on chemical radioprotection and radio-mitigation on the cellular and organism-wide level.
Nina Frederike Jeppesen Edin
Nina Frederike Jeppesen Edin has a PhD in physics. She works as associate professor and head of Section for Biophysics and Medical Physics at University of Oslo.
Eirik Malinen
Eirik Malinen holds a PhD in biophysics and is professor at the Department of Physics, University of Oslo, Norway. He is engaged in radiation physics research as well as preclinical and clinical investigations utilising ionising radiation.
Related Research Data
References
- Abdi H, Williams LJ. 2010. Principal component analysis. Wiley Interdiscip Rev Comput Stat. 2(4):433–459. doi:10.1002/wics.101.
- Akram SU, Kannala J, Eklund L, and Heikkilä J. 2016. Cell segmentation proposal network for microscopy image analysis. In: Deep learning and data labeling for medical applications. New York (NY): Springer; p. 21–29.
- Albaradei SA, Napolitano F, Uludag M, Thafar M, Napolitano S, Essack M, Bajic VB, Gao X. 2020. Automated counting of colony forming units using deep transfer learning from a model for congested scenes analysis. IEEE Access. 8:164340–164346. doi:10.1109/ACCESS.2020.3021656.
- Arous D, Schrunner S, Hanson I, FJ Edin N, and Malinen E. 2021. Cell colony image segmentation dataset 1 for T-47D breast cancer cells. doi:10.5281/zenodo.4593510.
- Bewes J, Suchowerska N, McKenzie D. 2008. Automated cell colony counting and analysis using the circular Hough image transform algorithm (chita). Phys Med Biol. 53(21):5991. doi:10.1088/0031-9155/53/21/007.
- Breiman L. 2001. Random forests. Mach Learn. 45(1):5–32. doi:10.1023/A:1010933404324.
- Cai Z, Chattopadhyay N, Liu WJ, Chan C, Pignol JP, Reilly RM. 2011. Optimized digital counting colonies of clonogenic assays using ImageJ software and customized macros: comparison with manual counting. Int J Radiat Biol. 87(11):1135–1146. doi:10.3109/09553002.2011.622033.
- Carpenter AE, Jones TR, Lamprecht MR, Clarke C, Kang IH, Friman O, Guertin DA, Chang JH, Lindquist RA, Moffat J, et al. 2006. Cellprofiler: image analysis software for identifying and quantifying cell phenotypes. Genome Biol. 7(10):R100. doi:10.1186/gb-2006-7-10-r100.
- Chiang PJ, Tseng MJ, He ZS, Li CH. 2015. Automated counting of bacterial colonies by image analysis. J Microbiol Methods. 108:74–82. doi:10.1016/j.mimet.2014.11.009.
- Choudhry P. 2016. High-throughput method for automated colony and cell counting by digital image analysis based on edge detection. PloS one. 11(2):e0148469. doi:10.1371/journal.pone.0148469.
- Clarke ML, Burton RL, Hill AN, Litorja M, Nahm MH, Hwang J. 2010. Low-cost, high-throughput, automated counting of bacterial colonies. Cytometry Part A. 77A(8):790–797. doi:10.1002/cyto.a.20864.
- Edin NJ, Olsen DR, Sandvik JA, Malinen E, Pettersen EO. 2012. Low dose hyper-radiosensitivity is eliminated during exposure to cycling hypoxia but returns after reoxygenation. Int J Radiat Biol. 88(4):311–319. doi:10.3109/09553002.2012.646046.
- Falk T, Mai D, Bensch R, Çiçek Ö, Abdulkadir A, Marrakchi Y, Böhm A, Deubner J, Jäckel Z, Seiwald K, et al. 2019. U-net: deep learning for cell counting, detection, and morphometry. Nat Methods. 16(1):67–70. doi:10.1038/s41592-018-0261-2.
- Ferrari A, Lombardi S, Signoroni A. 2017. Bacterial colony counting with convolutional neural networks in digital microbiology imaging. Pattern Recognit. 61:629–640. doi:10.1016/j.patcog.2016.07.016.
- Franken NA, Rodermond HM, Stap J, Haveman J, Van Bree C. 2006. Clonogenic assay of cells in vitro. Nat Protoc. 1(5):2315. doi:10.1038/nprot.2006.339.
- Geissmann Q. 2013. Opencfu, a new free and open-source software to count cell colonies and other circular objects. PloS one. 8(2):e54072. doi:10.1371/journal.pone.0054072.
- Gonzalez RC, Woods RE. 2018. Digital image processing. New York (NY): Pearson.
- Haralick RM, Shanmugam K, Dinstein IH. 1973. Textural features for image classification. IEEE Trans Syst Man Cybern. 6(6):610–621. doi:10.1109/TSMC.1973.4309314.
- Haralick RM, and Shapiro LG. 1992. Computer and robot vision. Vol. 1. Boston (MA): Addison-wesley Reading.
- Junkin M, Tay S. 2014. Microfluidic single-cell analysis for systems immunology. Lab Chip. 14(7):1246–1260. doi:10.1039/c3lc51182k.
- Khan AUM, Mikut R, Reischl M. 2016. A new feedback-based method for parameter adaptation in image processing routines. PloS one. 11(10):e0165180. doi:10.1371/journal.pone.0165180.
- Khan A.u.M, Torelli A, and Wolf I, et al. 2018. AutoCellSeg: robust automatic colony forming unit (CFU)/cell analysis using adaptive image segmentation and easy-to-use post-editing techniques. Sci Rep. 8(1):1–10. doi:10.1038/s41598-017-17765-5.
- Krastev DB, Slabicki M, Paszkowski-Rogacz M, Hubner NC, Junqueira M, Shevchenko A, Mann M, Neugebauer KM, Buchholz F. 2011. A systematic RNAi synthetic interaction screen reveals a link between p53 and snornp assembly. Nat Cell Biol. 13(7):809–818. doi:10.1038/ncb2264.
- Lay DC, Lay SR, McDonald J. 2020. Linear algebra and its applications. Boston (MA): Pearson.
- Lloyd S. 1982. Least squares quantization in pcm. IEEE Trans Inf Theory. 28(2):129–137. doi:10.1109/TIT.1982.1056489.
- Mansberg H. 1957. Automatic particle and bacterial colony counter. Science. 126(3278):823–827. doi:10.1126/science.126.3278.823.
- Militello C, Rundo L, Conti V, Minafra L, Cammarata FP, Mauri G, Gilardi MC, Porcino N. 2017. Area-based cell colony surviving fraction evaluation: a novel fully automatic approach using general-purpose acquisition hardware. Comput Biol Med. 89:454–465. doi:10.1016/j.compbiomed.2017.08.005.
- Militello C, Rundo L, Minafra L, Cammarata FP, Calvaruso M, Conti V, Russo G. 2020. Mf2c3: multi-feature fuzzy clustering to enhance cell colony detection in automated clonogenic assay evaluation. Symmetry. 12(5):773. doi:10.3390/sym12050773.
- Moiseenko V, Duzenli C, Durand RE. 2007. In vitro study of cell survival following dynamic MLC intensity-modulated radiation therapy dose delivery. Med Phys. 34(4):1514–1520. doi:10.1118/1.2712044.
- Otsu N. 1979. A threshold selection method from gray-level histograms. IEEE Trans Syst Man Cybern. 9(1):62–66. doi:10.1109/TSMC.1979.4310076.
- Ronneberger O, Fischer P, and Brox T 2015. U-net: convolutional networks for biomedical image segmentation. In: International Conference on Medical image computing and computer-assisted intervention, 2015 Munich, Germany. Springer. p. 234–241 doi:10.1007/978-3-319-24574-4_28.
- Sadanandan SK, Ranefall P, Le Guyader S, Wählby C. 2017. Automated training of deep convolutional neural networks for cell segmentation. Sci Rep. 7(1):1–7. doi:10.1038/s41598-017-07599-6.
- Schindelin J, Arganda-Carreras I, Frise E, Kaynig V, Longair M, Pietzsch T, Preibisch S, Rueden C, Saalfeld S, Schmid B, et al. 2012. Fiji: an open-source platform for biological-image analysis. Nat Methods. 9(7):676–682. doi:10.1038/nmeth.2019.
- Sergioli G, Militello C, Rundo L, Minafra L, Torrisi F, Russo G, Chow KL, Giuntini R. 2021. A quantum-inspired classifier for clonogenic assay evaluations. Sci Rep. 11(1):1–10. doi:10.1038/s41598-021-82085-8.
- Siragusa M, Dall’Olio S, Fredericia PM, Jensen M, Groesser T. 2018. Cell colony counter called coconut. PloS one. 13(11):e0205823. doi:10.1371/journal.pone.0205823.
- Sommer C, Straehle C, Koethe U, and Hamprecht FA 2011. Ilastik: interactive learning and segmentation toolkit. In: 2011 IEEE international symposium on biomedical imaging: From nano to macro, 2011 Chicago (IL). IEEE. p. 230–233 doi:10.1109/ISBI.2011.5872394.
- Wold S, Esbensen K, Geladi P. 1987. Principal component analysis. Chemometrics and Intelligent Laboratory Systems. 2(1–3):37–52. doi:10.1016/0169-7439(87)80084-9.
- Xie W, Noble JA, Zisserman A. 2018. Microscopy cell counting and detection with fully convolutional regression networks. Computer methods in biomechanics and biomedical engineering. Imaging & Visualization. 6(3):283–292.
- Zuiderveld K. 1994. Contrast limited adaptive histogram equalization. Graphics Gems. 474–485.