
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
In the field of neurobiology of language, neuroimaging studies are generally based on stimulation paradigms consisting of at least two different conditions. Designing those paradigms can be very time-consuming and this traditional approach is necessarily data-limited. In contrast, in computational and corpus linguistics, analyses are often based on large text corpora, which allow a vast variety of hypotheses to be tested by repeatedly re-evaluating the data set. Furthermore, text corpora also allow exploratory data analysis in order to generate new hypotheses. By drawing on the advantages of both fields, neuroimaging and computational corpus linguistics, we here present a unified approach combining continuous natural speech and MEG to generate a corpus of speech-evoked neuronal activity.
Introduction
Contemporary linguistic research is characterised by a great variety of methodological approaches. In particular, in the fields of psycholinguistics and neurobiology of language a vast number of different methods are applied in order to investigate the neural and mental processing principles of language acquisition, representation, comprehension and production (De Groot & Hagoort, Citation2017). Besides functional magnetic resonance imaging (fMRI) studies (Deniz et al., Citation2019; Huth et al., Citation2016; Spitzer et al., Citation1998), electrophysiological measurements, i.e. magnetoencephalography (MEG) (Hämäläinen et al., Citation1993) and electroencephalography (EEG) (Files, Citation2011; Millett, Citation2001), are widely used in neurolinguistics to investigate the neural and mental correlates underlying language processing in the human brain (Bambini et al., Citation2016; Lai et al., Citation2019; Pulvermüller & Shtyrov, Citation2008; Pulvermüller et al., Citation2009; Schmidt-Snoek et al., Citation2015; Tomasello et al., Citation2019).
However, most of the experimental studies on language processing conducted so far have focused on one aspect of linguistic information at a time. For instance, neurocognitive studies have explored the neural responses of words compared to pseudo words (Craddock et al., Citation2015; Pulvermüller et al., Citation1994), between different conceptual semantic categories (Moseley et al., Citation2013), complex against simple grammatical sentences (Friederici et al., Citation2006), or during pragmatic processing of different communicative actions (Tomasello et al., Citation2019). Although, all these studies shed light on the correlates of language processing in the human brain, it is still not fully understood whether similar brain responses during single words or sentence understanding also emerge during perception of natural speech, similar to everyday experience. However, recently a growing number of approaches address this issue (Brodbeck et al., Citation2018; Broderick et al., Citation2018; Deniz et al., Citation2019; Ding & Simon, Citation2012; Silbert et al., Citation2014).
Furthermore, traditional experimental designs typically consist of at least two different conditions studied under carefully controlled circumstances (Bambini et al., Citation2016; Lai et al., Citation2019; Schmidt-Snoek et al., Citation2015). The measured data are then pre-processed, i.e. referenced, filtered, epoched and averaged, and finally contrasted according to the different stimulation conditions (De Groot & Hagoort, Citation2017). To obtain a good signal to noise ratio (SNR) of the acquired brain responses, each of these conditions must contain dozens of different items or stimulus repetitions.
For instance, the evaluation of event-related potentials (ERPs) from the EEG data, or, in the case of MEG, event-related fields (ERFs), requires a relatively large number of stimuli (40–120 trials) per condition to achieve high SNR and ensure sufficient statistical power. This is due to the fact that the signal of a specific condition remains constant across multiple repetitions while the noise signal which is assumed to be randomly distributed, is reduced when large number of time-locked stimuli are pooled together (Coles & Rugg, Citation1995; Handy, Citation2005; Luck, Citation2014; Pfurtscheller & Da Silva, Citation1999; Woodman, Citation2010).
However, creating a large number of stimuli to increase SNR is associated with a serious drawback. It is well known that repeated presentation of a stimulus causes a diminished neural activation, a phenomenon for which the term repetition suppression has been coined (Arnaud et al., Citation2013; Grill-Spector et al., Citation2006; Henson, Citation2003; Mayrhauser et al., Citation2014; Summerfield et al., Citation2008). In fMRI, repetition suppression is observed as a reduced blood oxygen-level-dependent (BOLD) response elicited by a repeated stimulus, also called fMRI adaptation (Grill-Spector & Malach, Citation2001); for a recent review, see also (Segaert et al., Citation2013). The underlying neuronal mechanisms are still a matter of debate, and range from neuronal fatigue (Grill-Spector et al., Citation2006), or neuronal sharpening (Martens & Gruber, Citation2012), through neuronal facilitation (Grill-Spector et al., Citation2006) as relatively automatic bottom-up mechanisms, to predictive coding (Friston, Citation2005). There, top-down backward influences from higher to lower cortical layers modulate processing in case of a correct prediction of the upcoming stimulus. Hence, repetition suppression reflects a smaller prediction error for expected stimuli, i.e. decreased activation for repeated stimuli. Thus, in order to prevent repetition suppression, it is necessary to design a certain number of different stimuli from each condition to avoid repetition, which is often very challenging or even impossible. One strategy is to focus on single-item ERPs/ERFs, but in such cases it is necessary to compensate by testing more participants to obtain stable signals (Laszlo & Federmeier, Citation2011).
Here, we present an alternative approach to overcome the aforementioned limitations of the electrophysiological assessment of language processing and to open up the possibility of investigating different levels of linguistic information during natural speech comprehension within a single experiment. In particular, in the present study, we investigated brain responses elicited during listening to the audio book edition of a German-language novel by means of MEG measurements (for similar approaches, see Huth et al., Citation2016; Wehbe et al., Citation2014). Repetition suppression is not expected to occur here, as the same linguistic utterance is not repeatedly presented among a few stimuli types, and if repetition happens, it does in different linguistic contexts (i.e. it possibly occurs with different linguistic units) and also more sparsely.
Other previously published papers describe the use of continuously written stimuli in reading studies while recording EEG/MEG (Barca et al., Citation2011; Cornelissen et al., Citation2009; Dalal et al., Citation2009; Laine et al., Citation2000). Remarkably, it turned out that the representation of semantic information across human cerebral cortex during listening versus reading is invariant to stimulus modality (Deniz et al., Citation2019). Since listening to an audio book during the 1-h measurement session seems to be less strenuous for the participants than reading for the same period of time, we chose acoustic stimulation rather than visual stimulation.
Using computational corpus linguistics (CCL) (Sinclair, Citation2004; Souter & Atwell, Citation1993) applied to the analyses of large text corpora, which usually consist of hundreds of thousands or even billions of tokens (Aston & Burnard, Citation1998; Davies, Citation2010; Ide & Suderman, Citation2004; Michel et al., Citation2011; Schäfer & Bildhauer, Citation2012; Trinkle et al., Citation2016), offers the opportunity to test a vast number of hypotheses by repeatedly re-analysing the data (Evert, Citation2005) and to deploy modern machine learning techniques on such datasets (Koskinen & Seppä, Citation2014). Furthermore, text corpora also allow for exploratory data analyses in order to generate new hypotheses (Leech, Citation2014). In our approach, we can generate a large database of neuronal activity in a single measurement session, corresponding to the comprehension of several thousands of words of continuous speech similarly to everyday language. However, for later studies, the data set has to be split into multiple parts (e.g. development/training/test or training/validation/test) in analogy to standard machine learning data sets as MNIST (50,000 training images, 10,000 test images (Bottou et al., Citation1994)), as hypothesis generation and checking for statistical significance have to be done in two disjoint steps, in order to prevent HARKing (hypothesising after the results are known) (Kerr, Citation1998). In such cases, inferential statistical analysis is not valid and applicable (Munafò et al., Citation2017). Thus, this approach is only possible with a large dataset.
Here, we provide the proof-of-principle of this approach by calculating ERFs and normalised power spectra of word onsets and offsets overall as well as for the group of content words (nouns, verbs, adjectives) and for the group of function words (determiners, prepositions, conjunctions), which are known to differ semantically to a substantial extent. Hence, greater activation for content compared to function words can be expected, as reported in previous studies (e.g. Diaz & McCarthy, Citation2009; Pulvermüller et al., Citation1995).Footnote1 Furthermore, we check for consistency of the data, by comparing intra-individual differences of neural activity in different brain regions and we perform non-parametric cluster permutation tests to determine significant differences between conditions.
Methods
Human participants
Participants were 15 (8 females and 7 males) healthy right-handed (augmented laterality index: ,
) and monolingual native speakers of German aged 20–42 years. They had normal hearing and did not report any history of neurological illness or drug abuse. They were paid for their participation after signing an informed consent form. Ethical permission for the study was granted by the ethics board of the University Hospital Erlangen (registration no. 161-18 B). For the questionnaire-based assessment and analysis of handedness, we used the Edinburgh Inventory (Oldfield, Citation1971).
Speech stimuli and natural language text data
As natural language text data, we used the German novel Gut gegen Nordwind by Daniel Glattauer (@ Deuticke im Paul Zsolnay Verlag, Wien 2006) which was published by Deuticke Verlag. As speech stimuli, we used the corresponding audio book which was published by Hörbuch Hamburg. Both the novel and the audio book are available in stores, and the respective publishers gave us permission to use them for the present and future scientific studies.
Book and audio book consist of a total number of 40,460 tokens (number of words) and 6117 types (number of unique words). The distribution of single word classes and bi-gram word class combinations occurring in the (audio) book were analysed and compared to a number of German reference corpora (Goldhahn et al., Citation2012), and in addition, other German novels, by applying part-of-speech (POS) tagging (Jurafsky & Martin, Citation2014; Màrquez & Rodríguez, Citation1998; Ratnaparkhi, Citation1996) as implemented in the python library spaCy (Explosion, Citation2017). The similarities or dissimilarities, respectively, of all distributions are visualised using multi-dimensional scaling (MDS) (Cox & Cox, Citation2008; Kruskal, Citation1964, Citation1978; Torgerson, Citation1952).
The total duration of the audio book is approximately 4.5 h. For our study, we only used the first 40 min of the audio book, divided into 10 parts of approximately 4 min (,
). This corresponds to approximately 6000 words, or 800 sentences, respectively, of spoken language, where each sentence consists on average of 7.5 words and has a mean duration of 3 s.
In order to avoid cutting the text in the middle of a sentence or even in the middle of a word, we manually cut at paragraph boundaries, which resulted in more meaningful interruptions of the text. For the present study, only the first three sections (roughly 12 min of continuous speech) of the recordings and the corresponding measurements were analysed.
Stimulation protocol
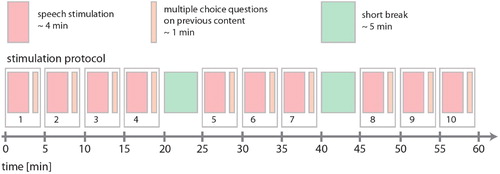
The continuous speech from the audio book was presented in 10 subsequent parts (cf. above) at a sensory level of approximately 30–60 dB SPL. The actual loudness varied from participant to participant. It was chosen individually to ensure good intelligibility during the entire measurement but also to prevent it from being unpleasant. Simultaneously with auditory stimulation, a fixation cross at the centre of the screen was presented all the time to minimise artefacts from eye movements. After each audio book part, three multiple-choice questions on the content of the previously presented part were presented on the screen in order to test the participants' attention. Participants had to answer the questions by pressing previously defined keys on a MEG-compatible keyboard. MEG recording was stopped during the question blocks, since these short breaks were also used to allow participants to move and make themselves comfortable again. Furthermore, stimulation was interrupted for a short break of approximately 5 min after audio book parts number 4 and 7. The total duration of the protocol is approximately 1 h. The complete stimulation protocol is shown in .
Figure 1. Stimulation protocol. The total duration of the protocol was approximately 1 h. The audio book was presented in 10 subsequent parts with an average duration of 4 min. After each part, three multiple-choice questions on the content of the previous part of the audio book were presented. After audio book parts number 4 and 7, stimulation was interrupted for a short break of approximately 5 min.
Generation of trigger pulses with forced alignment
In order to automatically create trigger pulses for both, the synchronisation of the speech stream with the MEG recordings, and to mark the boundaries of words, phonemes, and silence for further segmentation of the continuous data streams, forced alignment (Katsamanis et al., Citation2011; Moreno et al., Citation1998; Yuan & Liberman, Citation2009) was applied to the text and recording. For this study, we used the free web service WebMAUS (Kisler et al., Citation2017; Schiel, Citation1999). It takes a wave file containing the speech signal, and a corresponding text file as input and gives three files as output: the time tags of word boundaries, a phonetic transcription of the text file, and the time tags of phone boundaries. Even though forced alignment is a fast and reliable method for the automatic phonetic transcription of continuous speech, we carried out random manual inspections in order to ensure that the method actually worked correctly. Although forced alignment is not reliable, manual spot checks found no errors in our alignment. Of course, the high-quality recording of an audio book is among the best possible inputs for such software.
For simplicity, we only used the time tags of word boundaries in this study. However, a more fine grained analysis on the level of speech sounds could easily be performed retrospectively, since the time tags of beginning and ending of a given word correspond to the beginning of the word's first phone and the ending of the word's last phone, respectively. Thus, the two lists containing the time tags of the word and phoneme boundaries can easily be aligned with each other.
Speech presentation and synchronisation with MEG
The speech signal was presented using a custom-made setup (). It consists of a stimulation computer connected to an external USB sound device (Asus Xonar MKII, 7.1 channels) providing five analogue outputs. The first and second analogue outputs are connected to an audio amplifier (AIWA, XA-003), where the first output is connected in parallel to an analogue input channel of the MEG data logger in order to enable an exact alignment of the presented stimuli and the recorded MEG signals (cf. (a)). In addition, the third analogue output of the sound device is used to feed the trigger pulses derived from forced alignment into the MEG recording system via another analogue input channel. In doing so, our setup prevents temporal jittering of the presented signal caused by multi-threading of the stimulation PC's operating system, for instance. For an overview of the wiring scheme of all devices, see (a).
Figure 2. Setup configuration. (a) Wiring scheme of the different devices. (b) The speech sound is transmitted into the magnetically shielded chamber via a custom-made construction consisting of two loudspeakers (1) which are coupled to silicone funnels and (2) each connected to a flexible tube. (c) Through a small whole in the magnetically shielded chamber (1), speech sound is transmitted via the two flexible tubes (2).
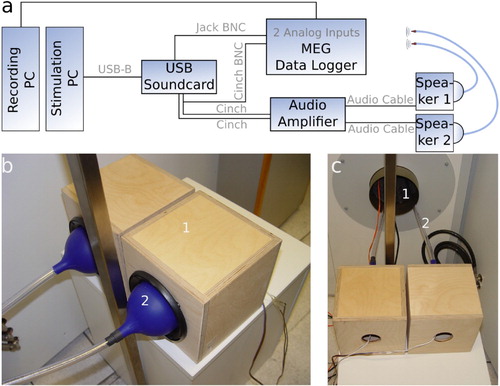
The speech sound was transmitted into the magnetically shielded MEG chamber to the participants' ears via a custom-made device consisting of two loudspeakers (Pioneer, TS-G1020F) which are coupled to silicone funnels each connected to a flexible tube of length and with an inner diameter of
((b)). These tubes are led through a small hole in the magnetically shielded chamber to prevent artefacts produced by interfering magnetic fields generated by the loudspeakers ((c)). We carried out calibration tests to ensure that the acoustical distortions caused by the tube system do not affect speech intelligibility. Furthermore, due to the length of the tubes and the speed of sound, there is a constant time delay from the generation of sound to the arrival of the sound at the participant of
, which we took into account for the alignment described below.
The stimulation software is implemented using the programming language Python 3.6, together with Python's sound device library, the PsychoPy library (Peirce, Citation2007, Citation2009) for the stimulation protocol, and the NumPy library for basic mathematical and numerical operations.
Magnetoencephalography and data processing
MEG data (248 magnetometers, 4D Neuroimaging, San Diego, CA, USA) were recorded (1017.25 Hz sampling rate, filtering: 0.1–200 Hz analogue band pass, supine position, eyes open) during speech stimulation. Positions of five landmarks (nasion, LPA, RPA, Cz, inion) were acquired using an integrated digitiser (Polhemus, Colchester, Vermont, Canada). MEG data were corrected for environmental noise using a calibrated linear weighting of 23 reference sensors (manufacturers algorithm, 4D Neuroimaging, San Diego, CA, USA).
Further processing was performed using the Python library MNE (Gramfort et al., Citation2013, Citation2014). Data were digitally filtered offline (1–10 Hz bandpass for ERF analyses; 50 Hz notch on for power spectra analysis) and downsampled to a sampling rate of 1000 Hz. MEG sensor positions were co-registered to the ICBM-152 standard head model (Fuchs et al., Citation2002) and atlas 19–21 (Evans et al., Citation2012), as individual MRI data sets for the participants were not available. Furthermore, recordings were corrected for eye blinks and electrocardiography artefacts based on signal space projection of averaged artefact patterns, as implemented in MNE (Gramfort et al., Citation2013, Citation2014).
Additionally, we performed an independent component analysis (ICA) and deleted the first two independent components of the data, to further improve data quality. However, it appears that this processing step does not affect the observed differences of neural responses to function and content words (Figures and S8).
Trials with amplitudes higher than T would have been rejected, as they were supposed to arise from artefacts. However, none of the trials fit this condition, and hence no trail was rejected.
For this study, we restricted our analyses to sensor space, and did not perform source localisation in analogy to other ERF studies (Hauk et al., Citation2006; Højlund et al., Citation2019; Shtyrov & Pulvermüller, Citation2007).
Alignment, segmentation and tagging
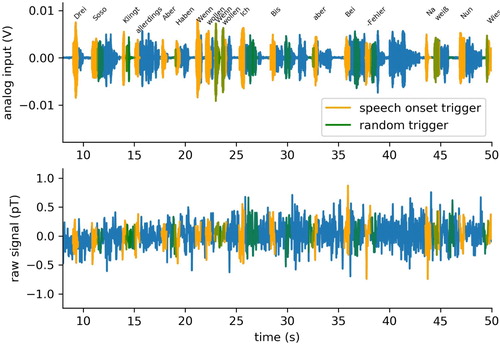
Since we have both, the original audio book wave file together with the time tags of word boundaries from forced alignment ((a)), and the corresponding recordings of two analogue auxiliary channels of the MEG ((b)), all 248 MEG recording channels could easily be aligned offline with the speech stream ((c)). Subsequently, the continuous multi-channel MEG recordings were segmented using the time tags as boundaries and labelled with the corresponding types, in our case individual words (). Note that, in principle, the process of segmentation can also be performed at different levels of granularity. For instance, using the time tags of phone boundaries would result in a more fine-grained segmentation, whereas grouping several words together to n-grams with appropriate labels to larger linguistic units (i.e. collocations, phrases, clauses, sentences) would result in a more coarse-grained segmentation.
Figure 3. Alignment of speech stream and MEG signal. (a) Sample audio book wave file together with time tags of word boundaries from forced alignment. (b) Corresponding recordings of two analogue auxiliary channels of the MEG. (c) Alignment of data streams from a and b, together with one sample MEG channel.
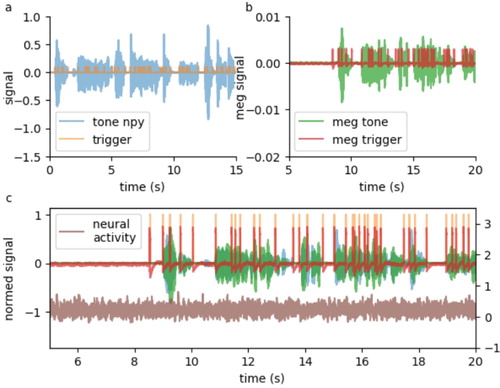
Figure 4. Segmentation of speech stream and MEG signal. After alignment, the continuous wave file (top panel) and multi-channel MEG recordings (bottom panel) are segmented using the time tags from forced alignment as boundaries and labelled with the corresponding types, i.e. words.
For the analysis of function and content words, we additionally applied POS tagging (Jurafsky & Martin, Citation2014; Màrquez & Rodríguez, Citation1998; Ratnaparkhi, Citation1996) using spaCy (Explosion, Citation2017) to assign word classes (e.g. nouns, verbs, adjectives, conjunctions, determiners, prepositions) to the individual words. According to Ortmann et al. (Citation2019), spaCy's accuracy for POS tagging of German texts is 92.5%. This value could be confirmed by two German native speakers who cross-checked a random sample of sentences that have been POS tagged using spaCy. However, the most frequent errors observed in spaCy are confusions of nouns and proper names, adverbs and adverbial adjectives, and of different verb forms (Ortmann et al., Citation2019). Since all these word classes belong to the domain of content words, these confusions are irrelevant for the classification in function and content words analysed in this study. So that the accuracy for this distinction is expected to be much higher.
Event-related fields
In order to provide the proof-of-principle of our approach, we analysed event-related fields (ERF) evoked by word onsets (Figure ). Since the continuous MEG signals of all 248 channels are already segmented according to word boundaries, we can compute ERFs of word onsets for each channel by simply averaging the pre-processed signals over the word tokens in our database. Here, we included only those words that follow a short pause, instead of using all words occurring in the data set. Thus, there is a short period of silence, ranging from approximately 50 ms to 1.5 s, before the actual word onsets which improves signal quality, yet with the drawback that only a fraction of all tokens can be used. However, there were still 291 remaining events, baseline corrected, within the first three parts of the audio book, corresponding to approx. 12 min of continuous speech, that fit this condition.
In addition, we also analysed ERFs evoked by prototypical content words (nouns, verbs, adjectives) and compared them with ERFs evoked by function words (determiners, prepositions, conjunctions) (). Again, we included only those words that follow a short interval of silence, instead of using all words occurring in the data set. Within the first three parts of the audio book, this resulted in 81 remaining events for the content word condition and 106 events for the function word condition.Footnote2
Permutation test
We performed intra-individual permutation tests (Maris & Oostenveld, Citation2007) to estimate the p-value for the ERF comparison between content and function words. Thus, the ERF was cut into four subsequent time frames, each with a duration of 250 ms, and the root-mean-square amplitude (RMS) was calculated ((e)):
, with the signal values within a 250 ms interval
, the total number of values within a 250 ms interval
ms, and the sampling rate
Hz.
10,000 different random permutations of content word and function word labels were generated. For each of these samples the four RMS amplitudes for the different time frames were calculated based on the baseline correctedFootnote3 single trials, resulting in a distribution of amplitudes for each time frame ((f)). The amplitude values corresponding to the true labelling are compared with amplitudes derived from random permutations in order to estimate the statistical significance, i.e. the p-values for content and function words and
, respectively, in (f).
Normalised power spectra
Using Fourier transformation, we also analysed the averaged normalised power spectra (alpha, beta and gamma frequency range) for words in contrast to pauses and for function and content words. The frequency bands were defined as follows : Hz,
Hz,
Hz. The epoch length for this analysis was 400 ms for both, short periods of silence and word onsets. Furthermore, we projected the resulting values to the corresponding spatial position of the sensors. This was done by the usage of the plot_psd_topomap function of the MNE library with Python interface (Gramfort et al., Citation2013, Citation2014).
Results
The general idea of our approach was to perform MEG measurements of participants listening to an audio book. By synchronising the continuous speech stream with the ongoing multi-channel neuronal activity and subsequently automatically segmenting the data streams according to word boundaries derived from forced alignment, we generated a database of annotated speech evoked neuronal activity. This corpus may then be analysed offline by applying the full range of methods from statistics, natural language processing, and computational corpus linguistics. In order to demonstrate the feasibility of our approach, we restricted our analyses to sensor space and did not perform any kind of source localisation (cf. Methods). More specifically, we calculate averaged ERFs for word onsets, and normalised power spectra for onsets of both, words and short pauses. In addition, we compare averaged ERFs for content and function words, and the corresponding normalised power spectra and discuss the results in the light of existing studies.
Distribution of word classes
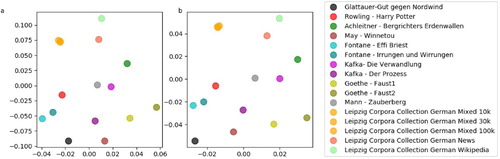
We analysed the distributions of word classes and word class combinations in the audio book and compared them with five different German corpora (German mixed 10k, 30k, and 100k; German news 30k; German Wikipedia 30k) taken from the Leipzig Corpora Collection (Goldhahn et al., Citation2012), and in addition with a number of other German novels. A sample of the resulting distribtuions is provided in . It turns out that Gut gegen Nordwind seems to have a very typical word class distribution ((a,b)), especially in comparison to other German novels ((c–h)). In contrast, in the German mixed corpus, there seem to be an under representation of pronouns ((i,j)) compared to all analysed novels. Using multi-dimensional scaling (MDS), we visualise the mutual (dis-)similarities between all word class distributions ((a)), and distributions of word class combinations ((b)). We find that Gut gegen Nordwind is closer, i.e. more similar, to the German novels than to the German corpora. The five corpora seem to cluster apart from the novels. In particular, the distributions of the German mixed corpora of three different sizes (10k, 30k, 100k words) are almost indistinguishable, and hence the corresponding MDS projections are overlapping. Furthermore, it remarkably turns out, that different novels from the same author are closer, i.e. more similar in terms of word class and word class combination distributions, than novels from different authors.
Figure 5. Distributions of word classes and bi-gram word classes. (a,c,e,g,i) Distribution of word classes according to POS tagging. Adjectives (ADJ), adverbs (ADV), nouns (NOUN), proper nouns (PROPN), verbs (VERB), adpositions (ADP), auxiliary verbs (AUX), determiners (DET), particles (PART), pronouns (PRON), subordinating conjunctions (SCONJ). (b,d,f,h,j) Distribution of word classes of 2-word sequences. Rows: word class of first word. Columns: word class of second word.
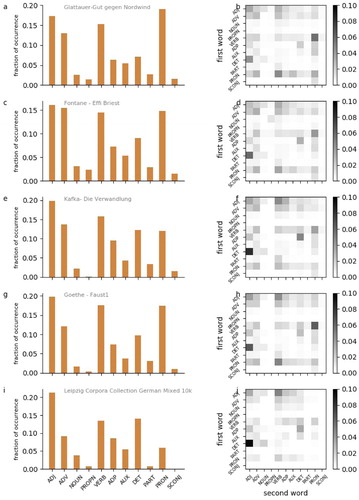
Figure 6. MDS projection of word class distributions. (a) MDS projection of distributions of single word classes. (b) MDS projection of distributions of bi-gram word classes combinations.
Event-related fields of word onsets
For a first proof of concept and to determine clear neurophysiological brain responses from continuous speech, we analysed event-related fields (ERFs) for word onsets (irrespective of their word classes) from different topographical sides.
(a) shows one example of the resulting ERFs averaged over the aforementioned 291 events corresponding to word onsets for one participant (subject 2 of 15) and parts number 1 to 3 of the audio book and (b) shows a projection of the spatial distribution of the ERF amplitudes at 350 ms after word onset. The largest amplitudes occur in channels located at temporal and frontal areas of the left hemisphere known to be associated with language processing (Friederici & Gierhan, Citation2013). The ERFs of those channels with the largest ERF amplitudes are shown in (c). Furthermore, we see a clear N400 component for the word onset condition, indicating language associated processing (cf. Broderick et al., Citation2018; Friederici et al., Citation1993; Hagoort & Brown, Citation2000; Kutas & Federmeier, Citation2011; Lau et al., Citation2009; Strauß et al., Citation2013).
Figure 7. Event–related fields for word onset. Shown are exemplary data of book parts number 1–3 of 10 from subject 2 of 15. (a) Summary of ERFs of all 248 recording channels averaged over 291 trials. (b) Spatial distribution of ERF amplitudes at 350 ms after word onset. (c) The largest amplitudes occur in channels located at temporal and frontal areas of the left hemisphere. (d) The corresponding channels at the right hemisphere show clearly smaller ERF amplitudes. (e) The same is true for occipital channels. (f) Same channels as in c, but averaged over randomly chosen triggers instead of word onset triggers. Also in this control condition, the resulting amplitudes are smaller than those for the word onset condition.
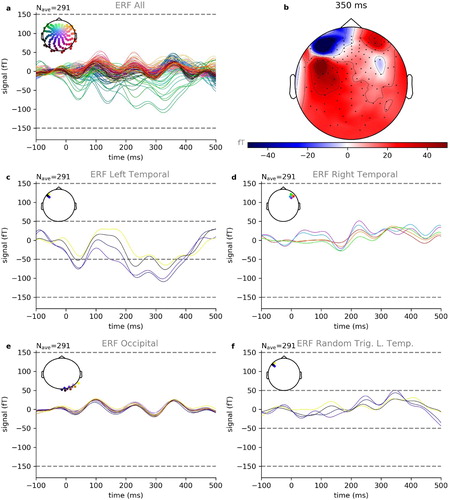
In order to exclude random effects, we compare these channels with the corresponding channels located at the right hemisphere – where we expect less activation due to the asymmetric lateralisation of speech in the brain – ((d)), and with some occipital channels ((e)). In both cases, the resulting ERF amplitudes are clearly smaller than those of the left temporal and frontal channels ((c)). In addition, we calculate control ERFs for the same channels shown in (c), but instead of word boundaries we used randomly chosen time tags for segmentation. Also in this control condition, the resulting ERF amplitudes are smaller than those for the word onset condition ((f)). This result, in particular, demonstrates that even though there are no or only relatively short inter-stimulus intervals, leading to overlapping effects of late and early responses of subsequent words, there is still enough signal left in the individual trials.
Finally, we evaluated the re-test reliability of our results using three-fold sub-sampling by separately averaging only over events belonging to the same part of the the audio book (Figures S1–S3). Again, the largest ERF amplitudes were found in the same channels as before and all results show very similar patterns to those shown in . In addition, we provide exemplary results of two further participants in the Supplements section (Figures S4 and S5).
Event-related fields of content and function words
As a further validity test of the present study, we analysed and compared the brain responses of different word classes. As an example, the resulting ERFs averaged over the respective events (content words: n = 81, function words: n = 106) for one participant (subject 2 of 15) and parts number 1 to 3 of the audio book are shown in (a,c) and a projection of the spatial distribution of the ERF amplitudes at after word onset is provided in (b,d). Again, we see a clear N400 component for both conditions, indicating language associated processing (cf. Broderick et al., Citation2018; Friederici et al., Citation1993; Hagoort & Brown, Citation2000; Kutas & Federmeier, Citation2011; Lau et al., Citation2009; Strauß et al., Citation2013).
Figure 8. Event-related fields for function and content words. Shown are exemplary data of book parts number 1–3 of 10 from subject 2 of 15. (a) Averaged ERFs for content words (n = 81 trials) with largest amplitudes. (b) Spatial distribution of ERF amplitudes at 550 ms after word onset for content words. (c) Averaged ERFs for function words (n = 106 trials) with largest amplitudes. (d) Spatial distribution of ERF amplitudes at 550 ms after word onset for function words. (e) ERF with the largest amplitude for content words and function words, together with ERFs derived from permutation test. (f) Distribution of ERF amplitudes derived from permutation test within four subsequent time frames: 0–250 ms (upper left), 250–500 ms (upper right), 500–750 ms (lower left) and 750–1000 ms (lower right).
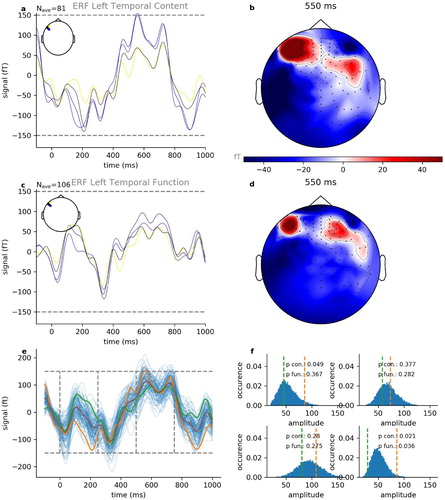
Furthermore, we found that content words ((a,b) elicited greater activation than function words ((c,d)), especially in temporal and frontal areas of the left hemisphere. Since content parts of speech have been shown to differ semantically from function parts of speech (Kemmerer, Citation2014; Pulvermüller, Citation2003), these findings are in line with previous studies (Diaz & McCarthy, Citation2009).
In addition, we compared the two conditions for the channel yielding the largest ERF amplitude and performed a permutation test (Maris & Oostenveld, Citation2007) independently for four subsequent time frames each with a duration of 250 ms ((e,f)). We found that the averaged ERFs for the two conditions (content and function words, intra-individual) are significantly (p < 0.05) different within the first (0 –250 ms) and third (500 –750 ms), but not within the second (250 –500 ms) and fourth (750 –1000 ms) time frame ((f)). These results are consistent across all subjects (cf. e.g. Figures S6 and S7 for two further subjects), and are in line with previously reported results (Keurs et al., Citation1995).
Averaged normalised power spectra
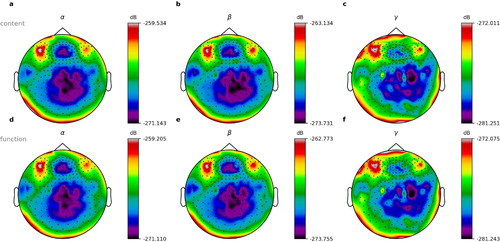
In our analysis of the averaged normalised power spectra, we were unable to find significant differences between the conditions of word onset and of silence onset () and neither between content words and function words (). See discussion section for possible reasons.
Figure 9. Normalised power spectra for words and silence. Shown are exemplary data of book parts number 1–3 of 10 from subject 2 of 15. (a–c) Power spectra for word offset, i.e. silence. (d–f) Power spectra for word onsets. (a,d) Alpha frequency range. (b,e) Beta frequency range. (c,f) Gamma frequency range.
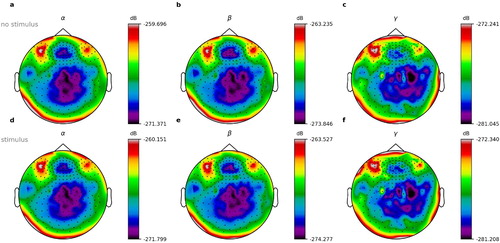
Figure 10. Normalised power spectra for content and function words. Shown are exemplary data of book parts number 1–3 of 10 from subject 2 of 15. (a–c) Power spectra for content words. (d–f) Power spectra for function words. a,d: Alpha frequency range. (b,e) Beta frequency range. (c,f) Gamma frequency range.
Discussion
In this study, we presented an approach where we combine electrophysiological assessment of neuronal activity with computational corpus linguistics, in order to create a corpus as defined in Jurafsky and Martin (Citation2014) of continuous speech-evoked neuronal activity. We demonstrated that using an audio book as natural speech stimulus, and simultaneously performing MEG measurements led to a relatively large number of analysable events (word onsets: n=291, silence onsets: n = 187, content words: n = 81, function words: n = 106), yet within a relatively short measurement time of . We further provided the proof-of-principle that, in contrast to common study designs, even though our stimulus trials were not presented in isolation, i.e. with appropriate inter-stimulus intervals of a few seconds, averaging over all respective events of a certain condition results in ERFs in left temporal and frontal channels with increased amplitudes compared to those of several control channels (e.g. at right hemisphere or at occipital lobe). The same is true with respect to comparison with control conditions (e.g. random trigger times). These results are well in line with previously published findings (Friederici & Gierhan, Citation2013).
Furthermore, we analysed ERFs for different categories of words. Although, a frequently investigated and contrasted pair of word classes is that of nouns and verbs (Damasio & Tranel, Citation1993; Preissl et al., Citation1995; Pulvermüller et al., Citation1999, Citation1996; Tsigka et al., Citation2014; Vigliocco et al., Citation2011), for the present study, we opted for the distinction between function words, defined as determiners, prepositions and conjunctions, and content words, defined as nouns, verbs and adjectives. These lexical categories are also frequently used in neuroimaging studies on the neurobiology of language (Bell et al., Citation2009; Bird et al., Citation2002; Diaz & McCarthy, Citation2009; Keurs et al., Citation1995; Mohr et al., Citation1994; Pulvermüller et al., Citation2009). In addition, they differ greatly in the semantic domain, and cover more fully the the totality of the words than the categories of nouns and verbs, since nouns and verbs are both included in the content word category. We found a clear N400 component (cf. ) especially in left hemispheric frontal regions for both function and content words and a positive component from 400-700 ms which is in line with Brennan et al.'s findings (Brennan & Pylkkänen, Citation2012, Citation2017). Additionally, we found that content words elicit greater activation than function words, especially in temporal and frontal areas of the left hemisphere. Due to their substantial semantic differences (Kemmerer, Citation2014; Pulvermüller, Citation2003), this finding is in line with previous studies (Diaz & McCarthy, Citation2009).
With respect to the average normalised power spectra, it was found that presentation of speech stimuli was associated with an increase in broadband gamma and a decrease in alpha over auditory cortex, while alpha power was increased in domain unspecific cortical areas (Archila-Meléndez et al., Citation2018; Müller & Weisz, Citation2012; Weisz et al., Citation2011). One reason could be that, since we analysed only very short periods of silence, i.e. between two words, our two conditions of word onset and silence onset can be considered basically, at a larger time scale, to be the same condition, i.e. continuous speech stimulation. This may explain why we found no differences in frequency power here. Even though it has been proposed that in human language networks linguistic information of different types is transferred in different oscillatory bands – in particular attention is assumed to correlate with an increase in gamma and a decrease in alpha band power (Bastiaansen & Hagoort, Citation2006) – the role of different spectral bands in mediating cognitive processes is still not fully understood. Therefore, it remains unclear, whether these findings extend to content and function words. Whether our approach is too insensitive to see differences here remains to be seen and further studies should look more closely at this issue.
As mentioned above, in contrast to traditional studies that are limited to testing only a small number of stimuli or word categories, the present approach opens the possibility to explore the neuronal correlates underlying different word meaning information across a large range of semantic categories (Huth et al., Citation2016), and syntactic structures (Kaan & Swaab, Citation2002). This is because the ongoing natural speech used here contains both, a large number of words from different semantic domains (Wehbe et al., Citation2014) and a large number of sentences at all levels of linguistic complexity (Bates, Citation1999).
On the other hand, one may argue that stimulation with ongoing natural speech has, compared to traditional approaches, the drawback that there are virtually no inter-stimulus intervals between the single words. This, of course, introduces a mixture of effects at different temporal scales, e.g. early responses to the actual word are confounded with late responses of the previous word. However, all these effects may be averaged out, as demonstrated by other studies (Brodbeck et al., Citation2018; Broderick et al., Citation2018; Deniz et al., Citation2019; Ding & Simon, Citation2012; Silbert et al., Citation2014) and also by our results.
In a follow-up study, it will have to be validated whether our approach also works for linguistic units of different complexity other than single words. For instance, smaller linguistic units such as phonemes and morphemes, but also larger linguistic units like collocations, phrases, clauses, sentences, or even beyond, could be investigated. For instance, we might be able to determine what neural correlates of the different association measures used in research on collocation look like (see Evert et al., Citation2017 for an overview and further references). Furthermore, more abstract linguistic phenomena need to be analysed, e.g. argument structure constructions (Goldberg, Citation1995, Citation2003, Citation2006) or valency (Herbst, Citation2011, Citation2014; Herbst & Schüller, Citation2008). Finally, our speech-evoked neural data may also be grouped, averaged, and subsequently contrasted according to male and female voice, looking at gender-specific differences (see e.g. Özçalışkan & Goldin-Meadow, Citation2010; Proverbio et al., Citation2014).
Also, analyses based on source space need to be tested, as well as more sophisticated analyses taking advantage of the multi-dimensionality of the data, such as, for instance, multi-dimensional cluster statistics (Krauss, Metzner, et al., Citation2018; Krauss, Schilling, et al., Citation2018). In addition, state-of-the-art deep learning approaches may be used as a tool for analysing brain data, e.g. for creating so-called embeddings of the raw data (Krauss et al., Citation2020). Moreover, as proposed by Kriegeskorte and Douglas (Citation2018), our neural corpus can serve to test (Schilling et al., Citation2018) computational models of brain function (Krauss et al., Citation2017, Citation2016; Krauss, Tziridis, et al., Citation2018; Schilling, Tziridis, et al., Citation2020), in particular models based on neural networks (Krauss, Prebeck, et al., Citation2019; Krauss, Schuster, et al., Citation2019; Krauss, Zankl, et al., Citation2019) and machine learning architectures (Gerum et al., Citation2020; Schilling, Gerum, et al., Citation2020), in order to iteratively increase biological and cognitive fidelity (Kriegeskorte & Douglas, Citation2018).
Due to the corpus-like features of our data, all additional analyses mentioned may be performed on the existing database, and without the need for designing new stimulation paradigms, or carrying out additional measurements.
However, in order to avoid statistical errors due to HARKing (Kerr, Citation1998; Munafò et al., Citation2017) – defined as generating scientific statements exclusively based on the analysis of huge data sets without previous hypotheses – and to guarantee consistency of the data, it is necessary to apply e.g. re-sampling techniques such as sub-sampling as shown above and described in detail in Schilling et al. (Citation2019). Furthermore, the approach presented here allows us to apply the well-established machine learning practice of data set splitting, i.e. to split the dataset into multiple parts before the beginning of the evaluation, where the one part is used for generating new hypotheses, and another part for subsequently testing these hypotheses (or split again into training and testing data). However, since we recorded a whole story, possible order effects should be taken into account for dataset splitting. Hence, instead of splitting the data set according to the chronological order, e.g. using the first parts of the audio book as training, and the subsequent parts as test dataset, it should better be split randomly.
To conclude, there are two major reasons why we think the study of the neurobiology of language can benefit tremendously from the introduction of corpus-linguistic methodology.
The first is that we can base our research on naturally occurring language, which should make them more ecologically valid than the more artificial stimuli used in carefully balanced and controlled experiments. Of course, even though audio books are frequently used in similar studies (Brodbeck et al., Citation2018; Broderick et al., Citation2018; Deniz et al., Citation2019; Ding & Simon, Citation2012; Silbert et al., Citation2014), one may also discuss whether audio books actually can be considered natural speech. One could argue that the fact that highly trained professional speakers and actors are usually employed to read audio books, who may use specific intonational patterns to paint a more vivid image of the situation, may lead to unnaturalness and thus possibly to unusual arousal patterns in the hearer. However, this argument is flawed. People spend large portions of their days listening to language produced by such professional speakers for radio, television news and drama, online videos, and podcasts. While probably not predominant for most people, it corresponds to a perfectly normal, everyday type of language experience. Even if we expect deviations from spoken interaction in such stimuli, we could even exploit this to study brain responses to creative language use (see Uhrig, Citation2018, Citation2020 and the sources cited there for linguistic studies of creativity). Of course, further studies using recordings of everyday dialogues between untrained subjects, e.g. describing what they have done during the day, should be designed to obtain a more comprehensive picture and more robust results, because, as Kriegeskorte and Douglas pointed out that “as we engage all aspects of the human mind, our tasks will need to simulate natural environments” (Kriegeskorte & Douglas, Citation2018). Still, purely receptive task such as the one used in this study is one type of natural environment, and one that can be studied without too much interference compared to, say, spontaneous interaction.
The second reason is the fact that measurements can be re-used if they form part of a large corpus of neuroimaging results. Let us look at a few numbers: In the present study, we stimulated 15 participants with 40 min of audio each. Test time spent in the MEG was 60 min due to the questions and pauses mentioned above. With 30 min of preparation, we used the MEG lab for a total of 22.5 h during experimentation. In that period of time, we gathered measurements for roughly 6000 words perceived by 15 participants, totalling 90,000 sets of brain responses to words. These correspond to roughly 35 GB of measurements (4 bytes per value, 1000 per second, 248 channels, 40 min per participant, 15 participants). For this study, we only looked at a tiny fraction of the data (words preceded by a short pause of at least 50 ms in the first 12 min) and already managed to confirm certain patterns found by previous studies with a strict experimental design. If we assume that pauses are equally distributed across the corpus, we can expect to find roughly 1000 such events, with 15 participants for each, i.e. 15,000 data points alone for words preceded by silence. Having these plus all the other words in their immediate linguistics contexts without pauses opens many more avenues for interesting research question at no added laboratory costs. Once we start looking at all words, we expect that the noise introduced through not being able to control for a variety of factors will be counterbalanced by the sheer size of data sets constructed using the methodology presented.
By that, we agree with the view of Hamilton and Huth that “natural stimuli offer many advantages over simplified, controlled stimuli for studying how language is processed by the brain”, and that “the downsides of using natural language stimuli can be mitigated using modern statistical and computational techniques” (Hamilton & Huth, Citation2020).
Supplementary Material
Download PDF (8.6 MB)Acknowledgements
The authors are grateful to the publishers Deuticke Verlag and Hörbuch Hamburg for the permission to use the novel and corresponding audio book Gut gegen Nordwind by Daniel Glattauer for the present and future studies. The authors thank Martin Kaltenhäuser for technical assistance, and Stefan Rampp for useful discussion. Finally, the authors wish to thank the anonymous reviewers for their remarks and advice which significantly increased the value of our work. P. K. and A. S. designed the study. A. S., P. K., A. Z. and V. K. prepared the stimulation and processed the audio book. A. S., P. K., V. K. and M. H. performed the experiments. A. S. and P. K. analysed the data. A. S., P. K., A. M., A. Z. and K. S. analysed the text of the novel. A. S., P. K., R. T., M. R. H. S., A. M. and P. U. discussed the results. P. K., A. S., R. T., M. R. H. S. and P.U. wrote the manuscript.
Data availability statement
Data will be made available to other researches on reasonable request.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes
1 We follow the categorisation of these studies and thus only include the content and function word classes listed above in our study.
2 The numbers do not add up to the total of 291 words because only the word classes listed in the introduction were included in the analysis of content and function words.
3 Following the suggestions published by Alday, instead of traditional baseline correction, we performed strong high-pass filtering with a cutoff frequency of 0.1 Hz, since traditional baseline correction eventually reduces signal-to-noise ratio and seems, therefore, to be statistically unnecessary or even undesirable (Alday, Citation2019).
References
- Alday, P. M. (2019). How much baseline correction do we need in ERP research? Extended GLM model can replace baseline correction while lifting its limits. Psychophysiology, 56(12), e13451. https://doi.org/10.1111/psyp.v56.12 doi: 10.1111/psyp.13451
- Archila-Meléndez, M. E., Kranen-Mastenbroek, V. H., Valente, G., Correia, J., Gommer, E. D., Jansma, B. M., Rouhl, R. P., & Roberts, M. J. (2018). S09. The role of oscillatory activity in attentive speech perception: An Ecog study in epilepsy patients. Clinical Neurophysiology, 129, e145. https://doi.org/10.1016/j.clinph.2018.04.369
- Arnaud, L., Sato, M., Ménard, L., & Gracco, V. L. (2013). Repetition suppression for speech processing in the associative occipital and parietal cortex of congenitally blind adults. PLoS One, 8(5), e64553. https://doi.org/10.1371/journal.pone.0064553
- Aston, G., & Burnard, L. (1998). The BNC handbook: Exploring the British national corpus with SARA. Capstone.
- Bambini, V., Bertini, C., Schaeken, W., Stella, A., & Di Russo, F. (2016). Disentangling metaphor from context: An ERP study. Frontiers in Psychology, 7, 559. https://doi.org/10.3389/fpsyg.2016.00559
- Barca, L., Cornelissen, P., Simpson, M., Urooj, U., Woods, W., & Ellis, A. W. (2011). The neural basis of the right visual field advantage in reading: An MEG analysis using virtual electrodes. Brain and Language, 118(3), 53–71. https://doi.org/10.1016/j.bandl.2010.09.003
- Bastiaansen, M., & Hagoort, P. (2006). Oscillatory neuronal dynamics during language comprehension. Progress in Brain Research, 159, 179–196. https://doi.org/10.1016/S0079-6123(06)59012-0
- Bates, E. (1999). Processing complex sentences: A cross-linguistic study. Language and Cognitive Processes, 14(1), 69–123. https://doi.org/10.1080/016909699386383
- Bell, A., Brenier, J. M., Gregory, M., Girand, C., & Jurafsky, D. (2009). Predictability effects on durations of content and function words in conversational english. Journal of Memory and Language, 60(1), 92–111. https://doi.org/10.1016/j.jml.2008.06.003
- Bird, H., Franklin, S., & Howard, D. (2002). ‘Little words’ – not really: Function and content words in normal and aphasic speech. Journal of Neurolinguistics, 15(3-5), 209–237. https://doi.org/10.1016/S0911-6044(01)00031-8
- Bottou, L., Cortes, C., Denker, J. S., Drucker, H., Guyon, I., Jackel, L. D., LeCun, Y., Muller, U. A., Sackinger, E., Simard, P., & Vapnik, V. (1994). Comparison of classifier methods: A case study in handwritten digit recognition. Proceedings of the 12th IAPR international conference on Pattern Recognition, Vol. 3-conference C: Signal Processing (Cat. No. 94CH3440-5) (Vol. 2, pp. 77–82). IEEE.
- Brennan, J. R., & Pylkkänen, L. (2012). The time-course and spatial distribution of brain activity associated with sentence processing. Neuroimage, 60(2), 1139–1148. https://doi.org/10.1016/j.neuroimage.2012.01.030
- Brennan, J. R., & Pylkkänen, L. (2017). Meg evidence for incremental sentence composition in the anterior temporal lobe. Cognitive Science, 41, 1515–1531. https://doi.org/10.1111/cogs.2017.41.issue-S6 doi: 10.1111/cogs.12445
- Brodbeck, C., Presacco, A., & Simon, J. Z. (2018). Neural source dynamics of brain responses to continuous stimuli: Speech processing from acoustics to comprehension. NeuroImage, 172, 162–174. https://doi.org/10.1016/j.neuroimage.2018.01.042
- Broderick, M. P., Anderson, A. J., Di Liberto, G. M., Crosse, M. J., & Lalor, E. C. (2018). Electrophysiological correlates of semantic dissimilarity reflect the comprehension of natural, narrative speech. Current Biology, 28(5), 803–809. https://doi.org/10.1016/j.cub.2018.01.080
- Coles, M. G., & Rugg, M. D. (1995). Event-related brain potentials: An introduction. Oxford University Press.
- Cornelissen, P. L., Kringelbach, M. L., Ellis, A. W., Whitney, C., Holliday, I. E., & P. C. Hansen (2009). Activation of the left inferior frontal gyrus in the first 200 ms of reading: Evidence from magnetoencephalography (MEG). PloS One, 4(4), e5359. https://doi.org/10.1371/journal.pone.0005359
- Cox, M. A., & Cox, T. F. (2008). Multidimensional scaling. In C.-h. Chen, W. Härdle, & A. Unwin (Eds.), Handbook of data visualization (pp. 315–347). Springer.
- Craddock, M., Martinovic, J., & Müller, M. M. (2015). Early and late effects of objecthood and spatial frequency on event-related potentials and gamma band activity. BMC Neuroscience, 16(1), 6. https://doi.org/10.1186/s12868-015-0144-8
- Dalal, S. S., Baillet, S., Adam, C., Ducorps, A., Schwartz, D., Jerbi, K., Bertrand, O., Garnero, L., Martinerie, J., & Lachaux, J. -P. (2009). Simultaneous MEG and intracranial EEG recordings during attentive reading. Neuroimage, 45(4), 1289–1304. https://doi.org/10.1016/j.neuroimage.2009.01.017
- Damasio, A. R., & Tranel, D. (1993). Nouns and verbs are retrieved with differently distributed neural systems. Proceedings of the National Academy of Sciences, 90(11), 4957–4960. https://doi.org/10.1073/pnas.90.11.4957
- Davies, M. (2010). The corpus of contemporary american english as the first reliable monitor corpus of english. Literary and Linguistic Computing, 25(4), 447–464. https://doi.org/10.1093/llc/fqq018
- De Groot, A. M., & Hagoort, P. (2017). Research methods in psycholinguistics and the neurobiology of language: A practical guide (Vol. 9). Wiley.
- Deniz, F., A. O. Nunez-Elizalde, Huth, A. G., & Gallant, J. L. (2019). The representation of semantic information across human cerebral cortex during listening versus reading is invariant to stimulus modality. Journal of Neuroscience, 39(39), 7722–7736. https://doi.org/10.1523/JNEUROSCI.0675-19.2019
- Diaz, M. T., & McCarthy, G. (2009). A comparison of brain activity evoked by single content and function words: An FMRI investigation of implicit word processing. Brain Research, 1282, 38–49. https://doi.org/10.1016/j.brainres.2009.05.043
- Ding, N., & Simon, J. Z. (2012). Neural coding of continuous speech in auditory cortex during monaural and dichotic listening. Journal of Neurophysiology, 107(1), 78–89. https://doi.org/10.1152/jn.00297.2011
- Evans, A. C., Janke, A. L., Collins, D. L., & Baillet, S. (2012). Brain templates and atlases. Neuroimage, 62(2), 911–922. https://doi.org/10.1016/j.neuroimage.2012.01.024
- Evert, S. (2005). The statistics of word cooccurrences: Word pairs and collocations [PhD thesis]. University of Stuttgart.
- Evert, S., Uhrig, P., Bartsch, S., & Proisl, T. (2017). E-VIEW-alation – a large-scale evaluation study of association measures for collocation identification. In I. Kosem, C. Tiberius, M. Jakubíçek, J. Kallas, S. Krek, & V. Baisa (Eds.), Proceedings of the eLex 2017 conference on Electronic Lexicography in the 21st Century (pp. 531–549). Lexical Computing.
- Explosion, A. (2017). spacy-industrial-strength natural language processing in python. https://spacy.io.
- Files, B. (2011). An introduction to EEG. Perception.
- Friederici, A. D., Fiebach, C. J., Schlesewsky, M., Bornkessel, I. D., & Von Cramon, D. Y. (2006). Processing linguistic complexity and grammaticality in the left frontal cortex. Cerebral Cortex, 16(12), 1709–1717. https://doi.org/10.1093/cercor/bhj106
- Friederici, A. D., & S. M. Gierhan (2013). The language network. Current Opinion in Neurobiology, 23(2), 250–254. https://doi.org/10.1016/j.conb.2012.10.002
- Friederici, A. D., Pfeifer, E., & Hahne, A. (1993). Event-related brain potentials during natural speech processing: Effects of semantic, morphological and syntactic violations. Cognitive Brain Research, 1(3), 183–192. https://doi.org/10.1016/0926-6410(93)90026-2
- Friston, K. (2005). A theory of cortical responses. Philosophical Transactions of the Royal Society B: Biological Sciences, 360(1456), 815–836. https://doi.org/10.1098/rstb.2005.1622
- Fuchs, M., Kastner, J., Wagner, M., Hawes, S., & Ebersole, J. S. (2002). A standardized boundary element method volume conductor model. Clinical Neurophysiology, 113(5), 702–712. https://doi.org/10.1016/S1388-2457(02)00030-5
- Gerum, R. C., Erpenbeck, A., Krauss, P., & Schilling, A. (2020). Sparsity through evolutionary pruning prevents neuronal networks from overfitting. Neural Networks, 128, 305–312. https://doi.org/10.1016/j.neunet.2020.05.007
- Goldberg, A. E. (1995). Constructions: A construction grammar approach to argument structure. University of Chicago Press.
- Goldberg, A. E. (2003). Constructions: A new theoretical approach to language. Trends in Cognitive Sciences, 7(5), 219–224. https://doi.org/10.1016/S1364-6613(03)00080-9
- Goldberg, A. E. (2006). Constructions at work: The nature of generalization in language. Oxford University Press on Demand.
- Goldhahn, D., Eckart, T., & Quasthoff, U. (2012). Building large monolingual dictionaries at the leipzig corpora collection: From 100 to 200 languages. Proceedings of the Eighth International Conference on Language Resources and Evaluation (LREC'12), Istanbul, Turkey (Vol. 29, pp. 31–43).
- Gramfort, A., Luessi, M., Larson, E., Engemann, D. A., Strohmeier, D., Brodbeck, C., Goj, R., Jas, M., Brooks, T., Parkkonen, L., & Hämäläinen, M. S. (2013). MEG and EEG data analysis with MNE-python. Frontiers in Neuroscience, 7, 267. https://doi.org/10.3389/fnins.2013.00267
- Gramfort, A., Luessi, M., Larson, E., Engemann, D. A., Strohmeier, D., Brodbeck, C., Parkkonen, L., & Hämäläinen, M. S. (2014). MNE software for processing MEG and EEG data. Neuroimage, 86, 446–460. https://doi.org/10.1016/j.neuroimage.2013.10.027
- Grill-Spector, K., Henson, R., & Martin, A. (2006). Repetition and the brain: Neural models of stimulus-specific effects. Trends in Cognitive Sciences, 10(1), 14–23. https://doi.org/10.1016/j.tics.2005.11.006
- Grill-Spector, K., & Malach, R. (2001). FMR-adaptation: A tool for studying the functional properties of human cortical neurons. Acta Psychologica, 107(1–3), 293–321. https://doi.org/10.1016/S0001-6918(01)00019-1
- Hagoort, P., & Brown, C. M. (2000). Erp effects of listening to speech: Semantic ERP effects. Neuropsychologia, 38(11), 1518–1530. https://doi.org/10.1016/S0028-3932(00)00052-X
- Hämäläinen, M., Hari, R., Ilmoniemi, R. J., Knuutila, J., & Lounasmaa, O. V. (1993). Magnetoencephalography – theory, instrumentation, and applications to noninvasive studies of the working human brain. Reviews of Modern Physics, 65(2), 413. https://doi.org/10.1103/RevModPhys.65.413
- Hamilton, L. S., & Huth, A. G. (2020). The revolution will not be controlled: Natural stimuli in speech neuroscience. Language, Cognition and Neuroscience, 35(5), 573–582. https://doi.org/10.1080/23273798.2018.1499946
- Handy, T. C. (2005). Event-related potentials: A methods handbook. MIT Press.
- Hauk, O., Davis, M. H., Ford, M., Pulvermüller, F., & Marslen-Wilson, W. D. (2006). The time course of visual word recognition as revealed by linear regression analysis of erp data. Neuroimage, 30(4), 1383–1400. https://doi.org/10.1016/j.neuroimage.2005.11.048
- Henson, R. N. (2003). Neuroimaging studies of priming. Progress in Neurobiology, 70(1), 53–81. https://doi.org/10.1016/S0301-0082(03)00086-8
- Herbst, T. (2011). The status of generalizations: Valency and argument structure constructions. Zeitschrift für Anglistik und Amerikanistik, 59(4), 347–368.
- Herbst, T. (2014). The valency approach to argument structure constructions. In T. Herbst, H.-J. Schmid, & S. Faulhaber (Eds.), Constructions–collocations–patterns (pp. 167–216). Mouton de Gruyter.
- Herbst, T., & Schüller, S. (2008). Introduction to syntactic analysis: A valency approach. Narr Francke Attempto Verlag.
- Højlund, A., Gebauer, L., McGregor, W. B., & Wallentin, M. (2019). Context and perceptual asymmetry effects on the mismatch negativity (MMNM) to speech sounds: An MEG study. Language, Cognition and Neuroscience, 34(5), 545–560. https://doi.org/10.1080/23273798.2019.1572204
- Huth, A. G., De Heer, W. A., Griffiths, T. L., Theunissen, F. E., & Gallant, J. L. (2016). Natural speech reveals the semantic maps that tile human cerebral cortex. Nature, 532(7600), 453. https://doi.org/10.1038/nature17637
- Ide, N., & Suderman, K. (2004). The American national corpus first release. Proceedings of the Fourth Language Resources and Evaluation Conference (LREC), Lisbon (pp. 1681–1684).
- Jurafsky, D., & Martin, J. H. (2014). Speech and language processing (Vol. 3). Pearson.
- Kaan, E., & Swaab, T. Y. (2002). The brain circuitry of syntactic comprehension. Trends in Cognitive Sciences, 6(8), 350–356. https://doi.org/10.1016/S1364-6613(02)01947-2
- Katsamanis, A., Black, M., Georgiou, P. G., Goldstein, L., & Narayanan, S. (2011, January 28–31). Sailalign: Robust long speech-text alignment. Proceedings of the workshop on New Tools and Methods for Very Large Scale Research in Phonetic Sciences.
- Kemmerer, D. (2014). Cognitive neuroscience of language. Psychology Press.
- Kerr, N. L. (1998). Harking: Hypothesizing after the results are known. Personality and Social Psychology Review, 2(3), 196–217. https://doi.org/10.1207/s15327957pspr0203_4
- Keurs, M. t., Brown, C., Hagoort, P., Praamstra, P., & Stegeman, D. (1995). ERP characteristics of function and content words in Broca's aphasics with agrammatic comprehension.
- Kisler, T., Reichel, U., & Schiel, F. (2017). Multilingual processing of speech via web services. Computer Speech & Language, 45, 326–347. https://doi.org/10.1016/j.csl.2017.01.005
- Koskinen, M., & Seppä, M. (2014). Uncovering cortical MEG responses to listened audiobook stories. Neuroimage, 100, 263–270. https://doi.org/10.1016/j.neuroimage.2014.06.018
- Krauss, P., Metzner, C., Joshi, N., Schulze, H., Traxdorf, M., Maier, A., & Schilling, A. (2020). Analysis and visualization of sleep stages based on deep neural networks. bioRxiv.
- Krauss, P., Metzner, C., Schilling, A., Schütz, C., Tziridis, K., Fabry, B., & Schulze, H. (2017). Adaptive stochastic resonance for unknown and variable input signals. Scientific Reports, 7(1), 1–8. https://doi.org/10.1038/s41598-016-0028-x
- Krauss, P., Metzner, C., Schilling, A., Tziridis, K., Traxdorf, M., Wollbrink, A., Rampp, S., Pantev, C., & Schulze, H. (2018). A statistical method for analyzing and comparing spatiotemporal cortical activation patterns. Scientific Reports, 8(1), 1–9. https://doi.org/10.1038/s41598-017-17765-5
- Krauss, P., Prebeck, K., Schilling, A., & Metzner, C. (2019). Recurrence resonance in three-neuron motifs. Frontiers in Computational Neuroscience, 13, 64. https://doi.org/10.3389/fncom.2019.00064
- Krauss, P., Schilling, A., Bauer, J., Tziridis, K., Metzner, C., Schulze, H., & Traxdorf, M. (2018). Analysis of multichannel EEG patterns during human sleep: A novel approach. Frontiers in Human Neuroscience, 12, 121. https://doi.org/10.3389/fnhum.2018.00121
- Krauss, P., Schuster, M., Dietrich, V., Schilling, A., Schulze, H., & Metzner, C. (2019). Weight statistics controls dynamics in recurrent neural networks. PloS One, 14(4), e0214541. https://doi.org/10.1371/journal.pone.0214541
- Krauss, P., Tziridis, K., Metzner, C., Schilling, A., Hoppe, U., & Schulze, H. (2016). Stochastic resonance controlled upregulation of internal noise after hearing loss as a putative cause of tinnitus-related neuronal hyperactivity. Frontiers in Neuroscience, 10, 597. https://doi.org/10.3389/fnins.2016.00597
- Krauss, P., Tziridis, K., Schilling, A., & Schulze, H. (2018). Cross-modal stochastic resonance as a universal principle to enhance sensory processing. Frontiers in Neuroscience, 12, 578. https://doi.org/10.3389/fnins.2018.00578
- Krauss, P., Zankl, A., Schilling, A., Schulze, H., & Metzner, C. (2019). Analysis of structure and dynamics in three-neuron motifs. Frontiers in Computational Neuroscience, 13, 5. https://doi.org/10.3389/fncom.2019.00005
- Kriegeskorte, N., & Douglas, P. K. (2018). Cognitive computational neuroscience. Nature Neuroscience, 21(9), 1148–1160. https://doi.org/10.1038/s41593-018-0210-5
- Kruskal, J. B. (1964). Nonmetric multidimensional scaling: A numerical method. Psychometrika, 29(2), 115–129. https://doi.org/10.1007/BF02289694
- Kruskal, J. B. (1978). Multidimensional scaling (Vol. 11). Sage.
- Kutas, M., & Federmeier, K. D. (2011). Thirty years and counting: Finding meaning in the n400 component of the event-related brain potential (ERP). Annual Review of Psychology, 62, 621–647. https://doi.org/10.1146/annurev.psych.093008.131123
- Lai, V. T., Howerton, O., & Desai, R. H. (2019). Concrete processing of action metaphors: Evidence from ERP. Brain Research, 1714, 202–209. https://doi.org/10.1016/j.brainres.2019.03.005
- Laine, M., Salmelin, R., Helenius, P., & Marttila, R. (2000). Brain activation during reading in deep dyslexia: An MEG study. Journal of Cognitive Neuroscience, 12(4), 622–634. https://doi.org/10.1162/089892900562381
- Laszlo, S., & Federmeier, K. D. (2011). The n400 as a snapshot of interactive processing: Evidence from regression analyses of orthographic neighbor and lexical associate effects. Psychophysiology, 48(2), 176–186. https://doi.org/10.1111/psyp.2011.48.issue-2 doi: 10.1111/j.1469-8986.2010.01058.x
- Lau, E., Almeida, D., Hines, P. C., & Poeppel, D. (2009). A lexical basis for n400 context effects: Evidence from MEG. Brain and Language, 111(3), 161–172. https://doi.org/10.1016/j.bandl.2009.08.007
- Leech, G. (2014). The state of the art in corpus linguistics. In K. Aijmer & B. Altenberg (Eds.), English corpus linguistics (pp. 20–41). Routledge.
- Luck, S. (2014). An introduction to the event-related potential technique (2nd ed.). MIT Press.
- Maris, E., & Oostenveld, R. (2007). Nonparametric statistical testing of EEG-and MEG-data. Journal of Neuroscience Methods, 164(1), 177–190. https://doi.org/10.1016/j.jneumeth.2007.03.024
- Màrquez, L., & Rodríguez, H. (1998). Part-of-speech tagging using decision trees. In European conference on machine learning (pp. 25–36). Springer.
- Martens, U., & Gruber, T. (2012). Sharpening and formation: Two distinct neuronal mechanisms of repetition priming. European Journal of Neuroscience, 36(7), 2989–2995. https://doi.org/10.1111/j.1460-9568.2012.08222.x
- Mayrhauser, L., Bergmann, J., Crone, J., & Kronbichler, M. (2014). Neural repetition suppression: Evidence for perceptual expectation in object-selective regions. Frontiers in Human Neuroscience, 8, 225. https://doi.org/10.3389/fnhum.2014.00225
- Michel, J.-B., Shen, Y. K., Aiden, A. P., Veres, A., Gray, M. K., Pickett, J. P., Hoiberg, D., Clancy, D., Norvig, P., Orwant, P., Pinker, S., M. A. Nowak, & Aiden, E. L. (2011). Quantitative analysis of culture using millions of digitized books. science, 331(6014), 176–182. https://doi.org/10.1126/science.1199644
- Millett, D. (2001). Hans berger: From psychic energy to the EEG. Perspectives in Biology and Medicine, 44(4), 522–542. https://doi.org/10.1353/pbm.2001.0070
- Mohr, B., Pulvermüller, F., & Zaidel, E. (1994). Lexical decision after left, right and bilateral presentation of function words, content words and non-words: Evidence for interhemispheric interaction. Neuropsychologia, 32(1), 105–124. https://doi.org/10.1016/0028-3932(94)90073-6
- Moreno, P. J., Joerg, C., Thong, J. -M. V., & Glickman, O. (1998). A recursive algorithm for the forced alignment of very long audio segments. Fifth International Conference on Spoken Language Processing, Sydney, Australia.
- Moseley, R. L., Pulvermüller, F., & Shtyrov, Y. (2013). Sensorimotor semantics on the spot: Brain activity dissociates between conceptual categories within 150 ms. Scientific Reports, 3, 1928. https://doi.org/10.1038/srep01928
- Müller, N., & Weisz, N. (2012). Lateralized auditory cortical alpha band activity and interregional connectivity pattern reflect anticipation of target sounds. Cerebral Cortex, 22(7), 1604–1613. https://doi.org/10.1093/cercor/bhr232
- Munafò, M. R., Nosek, B. A., Bishop, D. V., Button, K. S., Chambers, C. D., N. P. Du Sert, Simonsohn, U., Wagenmakers, E. -J., Ware, J. J., & Ioannidis, J. P. (2017). A manifesto for reproducible science. Nature Human Behaviour, 1(1), 0021. https://doi.org/10.1038/s41562-016-0021
- Oldfield, R. C. (1971). The assessment and analysis of handedness: The Edinburgh inventory. Neuropsychologia, 9(1), 97–113. https://doi.org/10.1016/0028-3932(71)90067-4
- Ortmann, K., Roussel, A., & Dipper, S. (2019). Evaluating off-the-shelf NLP tools for German. Proceedings of the 15th Conference on Natural Language Processing (KONVENS 2019).
- Özçalışkan, Ş., & Goldin-Meadow, S. (2010). Sex differences in language first appear in gesture. Developmental Science, 13(5), 752–760. https://doi.org/10.1111/desc.2010.13.issue-5 doi: 10.1111/j.1467-7687.2009.00933.x
- Peirce, J. W. (2007). Psychopy – psychophysics software in python. Journal of Neuroscience Methods, 162(1-2), 8–13. https://doi.org/10.1016/j.jneumeth.2006.11.017
- Peirce, J. W. (2009). Generating stimuli for neuroscience using psychopy. Frontiers in Neuroinformatics, 2, 10.
- Pfurtscheller, G., & Da Silva, F. L. (1999). Event-related EEG/MEG synchronization and desynchronization: Basic principles. Clinical Neurophysiology, 110(11), 1842–1857. https://doi.org/10.1016/S1388-2457(99)00141-8
- Preissl, H., Pulvermüller, F., Lutzenberger, W., & Birbaumer, N. (1995). Evoked potentials distinguish between nouns and verbs. Neuroscience Letters, 197(1), 81–83. https://doi.org/10.1016/0304-3940(95)11892-Z
- Proverbio, A. M., Calbi, M., Manfredi, M., & Zani, A. (2014). Comprehending body language and mimics: An ERP and neuroimaging study on italian actors and viewers. PLoS One, 9(3https://doi.org/10.1371/journal.pone.0091294
- Pulvermüller, F. (2003). The neuroscience of language: On brain circuits of words and serial order. Cambridge University Press.
- Pulvermüller, F., Lutzenberger, W., & Birbaumer, N. (1995). Electrocortical distinction of vocabulary types. Electroencephalography and Clinical Neurophysiology, 94(5), 357–370. https://doi.org/10.1016/0013-4694(94)00291-R
- Pulvermüller, F., Lutzenberger, W., & Preissl, H. (1999). Nouns and verbs in the intact brain: Evidence from event-related potentials and high-frequency cortical responses. Cerebral Cortex, 9(5), 497–506. https://doi.org/10.1093/cercor/9.5.497
- Pulvermüller, F., Preißl, H., Eulitz, C., Pantev, C., Lutzenberger, W., Feige, B., Elbert, T., & Birbaumer, N. (1994). Gamma-band responses reflect word/pseudoword processing. In Oscillatory event-related brain dynamics (pp. 243–258). Springer.
- Pulvermüller, F., Preissl, H., Lutzenberger, W., & Birbaumer, N. (1996). Brain rhythms of language: Nouns versus verbs. European Journal of Neuroscience, 8(5), 937–941. https://doi.org/10.1111/ejn.1996.8.issue-5 doi: 10.1111/j.1460-9568.1996.tb01580.x
- Pulvermüller, F., & Shtyrov, Y. (2008). Spatiotemporal signatures of large-scale synfire chains for speech processing as revealed by MEG. Cerebral Cortex, 19(1), 79–88. https://doi.org/10.1093/cercor/bhn060
- Pulvermüller, F., Shtyrov, Y., & Hauk, O. (2009). Understanding in an instant: Neurophysiological evidence for mechanistic language circuits in the brain. Brain and Language, 110(2), 81–94. https://doi.org/10.1016/j.bandl.2008.12.001
- Ratnaparkhi, A. (1996). A maximum entropy model for part-of-speech tagging. Conference on Empirical Methods in Natural Language Processing, Philadelphia, PA.
- Schäfer, R., & Bildhauer, F. (2012). Building large corpora from the web using a new efficient tool chain. In N. C. C. Chair, K. Choukri, T. Declerck, M. U. Doğan, B. Maegaard, J. Mariani, A. Moreno, J. Odijk, & S. Piperidis (Eds.), Proceedings of the eight international conference on language resources and evaluation (LREC'12) (pp. 486–493). European Language Resources Association (ELRA).
- Schiel, F. (1999). Automatic phonetic transcription of non-prompted speech. Proceedings of the ICPhS, San Francisco, CA (pp. 607–610).
- Schilling, A., Gerum, R. C., Krauss, P., Metzner, C., Tziridis, K., & Schulze, H. (2019). Objective estimation of sensory thresholds based on neurophysiological parameters. Frontiers in Neuroscience, 13, 481. https://doi.org/10.3389/fnins.2019.00481
- Schilling, A., Gerum, R., Zankl, A., Schulze, H., Metzner, C., & Krauss, P. (2020). Intrinsic noise improves speech recognition in a computational model of the auditory pathway. bioRxiv.
- Schilling, A., Metzner, C., Rietsch, J., Gerum, R., Schulze, H., & Krauss, P. (2018). How deep is deep enough? – quantifying class separability in the hidden layers of deep neural networks. Preprint. arXiv:1811.01753.
- Schilling, A., Tziridis, K., Schulze, H., & Krauss, P. (2020). The stochastic resonance model of auditory perception: A unified explanation of tinnitus development, zwicker tone illusion, and residual inhibition. bioRxiv.
- Schmidt-Snoek, G. L., Drew, A. R., Barile, E. C., & Agauas, S. J. (2015). Auditory and motion metaphors have different scalp distributions: An ERP study. Frontiers in Human Neuroscience, 9, 126. https://doi.org/10.3389/fnhum.2015.00126
- Segaert, K., Weber, K., de Lange, F. P., Petersson, K. M., & Hagoort, P. (2013). The suppression of repetition enhancement: A review of FMRI studies. Neuropsychologia, 51(1), 59–66. https://doi.org/10.1016/j.neuropsychologia.2012.11.006
- Shtyrov, Y., & Pulvermüller, F. (2007). Early MEG activation dynamics in the left temporal and inferior frontal cortex reflect semantic context integration. Journal of Cognitive Neuroscience, 19(10), 1633–1642. https://doi.org/10.1162/jocn.2007.19.10.1633
- Silbert, L. J., Honey, C. J., Simony, E., Poeppel, D., & Hasson, U. (2014). Coupled neural systems underlie the production and comprehension of naturalistic narrative speech. Proceedings of the National Academy of Sciences, 111(43), E4687–E4696. https://doi.org/10.1073/pnas.1323812111
- Sinclair, J. (2004). Trust the text. In Trust the text (pp. 19–33). Routledge.
- Souter, C., & Atwell, E. (1993). Corpus-based computational linguistics Brill.
- Spitzer, M., Kischka, U., Gückel, F., Bellemann, M. E., Kammer, T., Seyyedi, S., Weisbrod, M., Schwartz, A., & Brix, G. (1998). Functional magnetic resonance imaging of category-specific cortical activation: Evidence for semantic maps. Cognitive Brain Research, 6(4), 309–319. https://doi.org/10.1016/S0926-6410(97)00020-7
- Strauß, A., Kotz, S. A., & Obleser, J. (2013). Narrowed expectancies under degraded speech: Revisiting the n400. Journal of Cognitive Neuroscience, 25(8), 1383–1395. https://doi.org/10.1162/jocn_a_00389
- Summerfield, C., Trittschuh, E. H., J. M. Monti, Mesulam, M.-M., & Egner, T. (2008). Neural repetition suppression reflects fulfilled perceptual expectations. Nature Neuroscience, 11(9), 1004. https://doi.org/10.1038/nn.2163
- Tomasello, R., Kim, C., Dreyer, F. R., Grisoni, L., & Pulvermüller, F. (2019). Neurophysiological evidence for rapid processing of verbal and gestural information in understanding communicative actions. Scientific Reports, 9(1), 1–17. https://doi.org/10.1038/s41598-018-37186-2
- Torgerson, W. S. (1952). Multidimensional scaling: I. Theory and method. Psychometrika, 17(4), 401–419. https://doi.org/10.1007/BF02288916
- Trinkle, D. A., Auchter, D., Merriman, S. A., & Larson, T. E. (2016). The history highway: A 21st-century guide to internet resources. Routledge.
- Tsigka, S., Papadelis, C., Braun, C., & Miceli, G. (2014). Distinguishable neural correlates of verbs and nouns: A MEG study on homonyms. Neuropsychologia, 54, 87–97. https://doi.org/10.1016/j.neuropsychologia.2013.12.018
- Uhrig, P. (2018). I don't want to go all yoko ono on you – creativity and variation in a family of constructions. Zeitschrift für Anglistik und Amerikanistik, 66(3), 295–308. https://doi.org/10.1515/zaa-2018-0026
- Uhrig, P. (2020). Creative intentions: The thin line between ‘creative’ and ‘wrong’. Cognitive Semiotics, 13(1). doi: 10.1515/cogsem-2020-2027
- Vigliocco, G., Vinson, D. P., Druks, J., Barber, H., & Cappa, S. F. (2011). Nouns and verbs in the brain: A review of behavioural, electrophysiological, neuropsychological and imaging studies. Neuroscience & Biobehavioral Reviews, 35(3), 407–426. https://doi.org/10.1016/j.neubiorev.2010.04.007
- Wehbe, L., Murphy, B., Talukdar, P., Fyshe, A., Ramdas, A., & Mitchell, T. (2014). Simultaneously uncovering the patterns of brain regions involved in different story reading subprocesses. PloS One, 9(11), e112575. https://doi.org/10.1371/journal.pone.0112575
- Weisz, N., Hartmann, T., Müller, N., & Obleser, J. (2011). Alpha rhythms in audition: Cognitive and clinical perspectives. Frontiers in Psychology, 2, 73. https://doi.org/10.3389/fpsyg.2011.00073
- Woodman, G. F. (2010). A brief introduction to the use of event-related potentials in studies of perception and attention. Attention, Perception, & Psychophysics, 72(8), 2031–2046. https://doi.org/10.3758/BF03196680
- Yuan, J., & Liberman, M. (2009). Investigating/l/variation in English through forced alignment. Tenth Annual Conference of the International Speech Communication Association, Brighton, UK.