
ABSTRACT
Most models of word recognition assume that a letter’s identity and position are conjointly encoded. This means that in words with repeated letters (e.g. “radar”), each instance of the same letter is coded as a separate object. Here we tested an alternative scenario, according to which the brain employs configurational representations (e.g. recognition of three units in the configuration 12321 activating “radar”). Such representations explain why one sees similarities between “radar” and “tenet”, and would offer an efficient way to compute letter repetitions. In two experiments, target word recognition was tested as a function of different-symbol primes that were configurationally congruent (“kgegk”—“radar”) or not (“kggke”—“radar”). We reasoned that if the brain indeed engages configuration codes, congruent primes should facilitate target recognition compared to incongruent primes. However, Bayesian statistical analyses provided strong evidence for the null-hypothesis. We surmise that the brain does not engage configuration codes in word recognition.
1. Introduction
For multiple reasons you may experience a sense of similarity between the words “mom” and “dad”. The most obvious reason is the semantic relationship. Additionally, although the two words consist of completely different letters, there are orthographic similarities: both words comprise two different letters whereby an instance of one letter is flanked by two instances of the other letter. Likewise, you may have a sense of similarity between “dad” and “wow”, between “radar” and “tenet” or between “deed” and “boob”. Might this sense of similarity inform us about mechanisms involved in visual word recognition? In the present article, we investigate the possibility that the brain employs configurational codes, which represent item occurrences (and notably, item repetitions) irrespective of the item’s identity. As will be explained in due course, this idea has played a part in prior theorising about the reading brain—and, notably, its evidencing would constitute a challenge to several contemporary models of word recognition.
The field has spawned various models that effectively account for many phenomena (e.g. Coltheart et al., Citation2001; Davis, Citation2010; Gomez et al., Citation2008; Grainger & Jacobs, Citation1996; Grainger & van Heuven, Citation2003; McClelland & Rumelhart, Citation1981; Snell et al., Citation2018a; Whitney, Citation2001). Although these models vary in their specifics, most do adhere, in one way or another, to the core principle that the identity and position of a letter are conjointly encoded—and more specifically, that positional information is encoded strictly in conjunction with item information. However, in consequence, it has remained unclear how the brain deals with letter repetitions. For instance, take the Open Bigram model of Grainger and van Heuven (Citation2003), in which strings of letters activate bigram representations—i.e. letter pairs such as “ab”, “ac”, “bc”—that convey the relative positions of letters. Here, the word “radar” would provide equal activation of the bigrams “ar” and “ra”, as well as “rd” and “dr”. In consequence, the string “radar” would provide a good amount of erroneous evidence for “ardra”.
Alternatively, following a classic slot-based scheme (e.g. McClelland & Rumelhart, Citation1981) wherein separate sets of letter detectors are available to each letter position, each instance of the same letter is encoded as a separate object (e.g. “radar” activates the “r” detector in the first slot and the “r” detector in the fifth slot). But such models do not fit a wide range of behavioural phenomena without adopting positional noise (whereby the “d” in “radar” does not only activate the “d” detector at the central slot but also surrounding slots; e.g. Gomez et al., Citation2008). Consequently, according to this approach words with repeated letters should generate a lot of ambiguity: e.g. the string “dad” provides strong evidence for a “d” at the central slot. There is indeed some evidence to suggest that words with repeated letters are slightly harder to recognise than words that solely comprise unique letters—and specifically so when the repeating letters are non-adjacent (such that the repetition of “e” hampers recognition of “tenet” but not “teen”; Trifonova & Adelman, Citation2019, Citation2022). On the other hand, Schoonbaert and Grainger (Citation2004) found that target words with letter repetitions (e.g. “balance”) were primed to equal extents by a version of the target that was missing a repeated letter (“balnce”) as a version that was missing a unique letter (“balace”), whereas a noisy slot-based scheme predicts stronger priming of the former than the latter prime.
More generally, returning to the start of this introduction, none of the existing models explain the perceived similarity between the words “dad” and “wow”. Indeed, as these words comprise entirely different letters, the only similarity between these words is a configurational one. A possibility, therefore, is that the brain employs configurational codes in order to handle letter repetitions in the word recognition process (e.g. recognition of three different units in the configuration 12321 leading to activation of “radar”). The aim of the present study is to test this scenario.
1.1 Why the brain may encode configurations
As noted above, a core assumption in the field has been that letter identity and position are conjointly encoded. At the same time, there is evidence that the identities of letters are to some extent coded irrespective of position (e.g. Grainger et al., Citation2014; Snell et al., Citation2018b; Treisman & Souther, Citation1986). More generally, given that item identity and location information are largely processed by different regions of the brain (with key roles for the temporal and parietal cortex, respectively), it appears sensible that at some level of representation, each dimension is encoded irrespective of the other. Although the configurational representation would not be entirely independent of item information (as knowledge must exist about the number of unique letter identities), the representation in itself would nonetheless be purely configurational in nature (e.g. “a letter flanked by two instances of another letter”).
It may be noted that this scenario invokes the traditional Gestalt’s principle of perceptual grouping by similarity (e.g. Wagemans et al., Citation2012), whereby item repetitions lead to the perception of a pattern irrespective of the item itself (see ). A modern take on this is the feature-location routine as proposed by Huang and Pashler (Citation2007), which is “a mechanism that takes as an input a featural value and outputs a Boolean map describing all the locations at which that feature is present” (Huang, Citation2015, p. 1368). Applying this to visual word recognition, letter identities would constitute the featural values, and configurational representations would constitute the Boolean maps. Thus, although “mom” and “dad” provide different featural input, the Boolean maps for these words would be identical. Can such Boolean maps be revealed in the realm of visual word recognition?
Figure 1. Perceptual grouping by similarity. In the classic example (A), both visuals spark the same percept of a unique object located in the centre of a diamond-shaped arrangement, irrespective of the identities of individual items. Analogously, in word recognition (B), both strings would activate the same configurational representation, irrespective of letter identity.
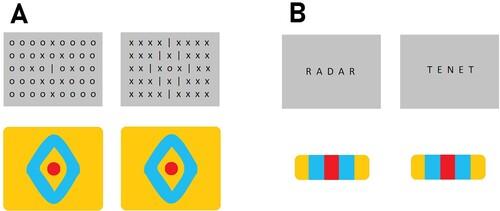
Importantly, prior theorising about how the brain handles letter repetitions has already sparked a construct that is strongly reminiscent of the Boolean map. In his SOLAR model, Davis (Citation1999) described the concept of a so-called latch-field, with the specific purpose of encoding single letters at multiple positions. The SOLAR model comprises only one node per letter identity, but each letter node is connected to its own latch-field, which controls the timing of information transfer from the sequential letter input to spatial orthographic codes (i.e. word representations). The latch-field itself comprises multiple latch-nodes that handle each individual occurrence of the letter. As such, the word “BANANA” would be represented by nodes B1, A1, N1, A2, N2, and A3; meaning that this six-letter word is represented by only three letter nodes and their respective latch-fields.
A difference between Davis’ latch-fields and the Boolean map as hypothesised here, is that the latch-fields are letter-specific (i.e. different letters always connect to their own respective latch-fields) whereas the Boolean map would be letter-aspecific (i.e. it can take various featural values, in line with the overarching theory of visual processing proposed by Huang and Pashler (Citation2007)). A benefit of the latter assumption is that it allows for more flexibility: upon learning new features or objects (letters, symbols, et cetera), the system can continue to rely on the same mechanism, without having to instantiate new Boolean maps for every new object it encounters.
Notably, if we were indeed to evidence configurational codes in word recognition, this would impose considerable constraints on current theory. Specifically, the concept of a configurational code can be harmonised with absolute position-coding models (e.g. the Overlap model of Gomez et al. (Citation2008)), as the code represents occurrences of a given item in space. On the contrary, configuration codes are at apparent odds with relative position-coding models (e.g. the Open-Bigram model of Grainger and van Heuven (Citation2003) or SERIOL by Whitney (Citation2001)) according to which letters aren’t encoded for their absolute positions in space. Indeed, even if a relative position-coding model successfully recognises a word with repeated letters (e.g. recognising the word “dad” through activated bigrams “da”, “ad” and “dd”), it would by no means predict that those bigrams prime “wow” too.
Before outlining the present study, we must highlight a few important lines of research. Some evidence has been reported for a role of consonant-vowel (CV-) structures during visual word recognition (whereby “radar” would be represented as CVCVC). Such a representation could be regarded as a semi-independent positional code, as its constituents would merely convey a binomial categorisation rather than complete identity information. Using a Stroop task, Berent and Marom (Citation2005) found that readers were quicker to utter the print colour of a letter string if the letters formed the same CV-structure as the utterance (e.g. “red” would be uttered quicker for the string CVC) compared to a string with an incongruent CV-structure (e.g. the string CCVCC depicted in red colour). However, incongruent strings always had a different length, which constituted a confound in this study. Further, effects could have been driven by an impact of phonological congruency on speech production.Footnote1
Relatedly, Perea et al. (Citation2018) investigated the potential role of CV-structures in a masked priming lexical decision task. Target words were recognised faster when preceded by a prime with the same CV-structure (e.g. “paesaje”—“paisaje”) compared to a prime with a different CV-structure (“parsaje”—“paisaje”). However, this effect was only observed in trials where the target’s consonants were preserved in the congruent prime (“psj” in prime “paesaje”), and not in trials where the congruent prime had different consonants (e.g. “alusno”—“alumno”). The authors took this as evidence that the reading system puts emphasis on the processing of consonant identities, rather than CV-structures.
Finally, relevant results have been reported by Mariol et al. (Citation2008). Using a lexical decision task and measuring response times as well as event-related potentials (ERPs), these authors found that responses to pseudowords were affected by letter legality manipulations both in terms of identity (i.e. the legal double consonant “ss”, versus the illegal double consonant “hh”) and in terms of position (i.e. aforementioned double consonants being presented at the word edge, versus inner-positioned double consonants). In the ERPs, additive effects of identity and position were observed in early time windows (N200), whereas an interaction of the two factors was observed in the later P300 window. The authors took this as evidence for early independent coding of letter identity and position, and conjoined coding at later stages. The configurational codes that we hypothesise here would as such operate relatively early in the processing stream.
However, the positional manipulation in the study of Mariol et al. was such that the double consonants were outer- versus inner letters, meaning that the design suffered from a confound in crowding. Specifically, outer letters are perceived better due to reduced crowding (e.g. Bouma, Citation1970; Loomis, Citation1977; Marzouki & Grainger, Citation2014), and so the effect of perceiving illegal letter identities will likely be enhanced at the illegal, outer positions. Due to these shortcomings, direct evidence for positional representations independent from identity information is as of yet lacking.
1.2 The present study
Here we report two priming lexical decision experiments that tested for effects of prime-target configurational congruency on target word recognition. In both experiments, the constituents of a congruent prime had the same relative positions as those of the target (e.g. “mstsm”—“radar”) whereas this was not the case for incongruent primes (“mmsst” —“radar”). Crucially, however, primes and targets always consisted of completely different symbols, while the two prime types comprised the exact same set of symbols. Hence, if differences were found between prime conditions, this could solely be attributed to configurational information.
In Experiment 1, primes were presented briefly (60 ms) and were preceded by a forward mask (“######”). Prior research has shown that this is a robust and effective technique for investigating the influence of various sub-lexical orthographic manipulations on target word recognition speed (e.g. Davis & Bowers, Citation2006; Forster et al., Citation1987; Heuven et al., Citation2001; Moor & Brysbaert, Citation2000). In Experiment 2, primes comprised digits rather than letters and were presented for 1500 ms, with the aim to maximise the prime’s potential for impacting target word recognition (see Section 3).
2. Experiment 1
2.1 Methods
Twenty-four students of the VU University Amsterdam participated in this study for course credit or monetary compensation of €10 per hour. All participants reported to be native to the Dutch language and non-dyslexic and to have normal or corrected-to-normal vision. All participants gave informed consent prior to their participation.
We devised a stimulus set comprising 96 Dutch target words with a length ranging between four and six letters. Our inclusion criterion was that words had to comprise at least one letter that occurred at least twice in the word (e.g. “kerker” [dungeon], in which the “k”, “e” and “r” all occur twice; “eerder” [earlier], in which the “e” and “r” occur three and two times, respectively). This was done to allow for the creation of congruent versus incongruent primes.Footnote2 For each target word, a configurationally congruent prime was devised that consisted of completely different letters (e.g. for “kerker” we devised prime “apoapo”). Primes and targets had no congruent CV-structures. Next, an incongruent prime was created by shuffling the congruent prime’s letters (e.g. “aappoo”), whereby we made sure that there was no congruency in relative letter positions or CV-structure. We verified that the overall bigram frequency across both types of prime was equal (∼2*10−3 ppm). Lastly, for each target word, we also created a nonword equivalent by substituting a letter identity (e.g. for “kerker” the nonword was “kirkir”). Nonwords were used to induce the lexical decision task. The complete stimulus set is provided in the Appendix.
The experiment followed a 2 × 2 factorial design with configurational congruency (Congruent versus Incongruent) and target lexicality (Word versus Nonword) as factors. All word and nonword targets were shown in both prime conditions to all participants, meaning that the experiment comprised 384 trials per participant. Trials were presented in random order.
The experiment was implemented with OpenSesame (Mathôt et al., Citation2012) and adminstered on a 22-inch, 1680*1050-pixel, 120-Hz display in a dimly lit testing room of the VU University in Amsterdam. Participants were seated at 70 cm from the display, so that each letter subtended 0.30 degrees of visual angle.
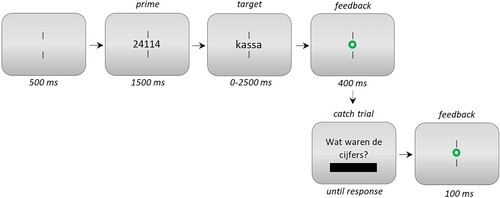
The trial procedure is shown in . Vertical fixation bars were presented above and below the centre of the display throughout the experiment. 600 ms after the start of each trial, a mask consisting of hashmarks was shown for 500 ms, and was followed by a prime for 60 ms. The prime was then replaced by the target, which stayed onscreen until a response was given. Participants used their left or right hand to provide a keyboard button press for “nonword” or “word”, respectively. They were instructed to do this as quick and accurate as possible. Feedback was provided by means of a green or red dot (for correct and incorrect responses, respectively), which stayed onscreen for 350 ms. Prior to the 384 experimental trials, participants were offered eight practice trials for which we did not collect data. Participants were also offered a break halfway through the experiment. The complete experiment lasted approximately 15 min.
Figure 2. Experiment 1 trial procedure. The size of stimuli relative to the screen is exaggerated in this example.

2.2 Results
To gauge word recognition performance across conditions, we analysed response times (RTs) and error rates. RT analyses included only correctly answered trials with a word as target item (as nonwords were merely used to induce the task).Footnote3 Trials with RTs beyond 2.5 SDs from the grand mean (∼3% of all trials) were removed from the analyses of RTs and errors.
Data were analysed with linear mixed-effect models (LMMs) in the R statistical computing environment. Models included Configurational Congruency as experimental factor, and by-item and by-participant slopes and intercepts as random effects. Effects were deemed reliable if | t | > 1.96 (or | z | > 1.96 in the case of generalised LMMs with which we analysed error rates). In case of a null-effect, we employed Bayesian statistics to establish direct evidence for the null hypothesis. This was done using the open-source statistical software program JASP (JASP Team, Citation2023).
Based on our hypothesis that the brain engages configurational representations, we expected shorter RTs as compared to the incongruent condition. As it turns out, our analysis revealed no effect of congruency on RTs: the difference in RTs between the incongruent condition (M = 755 ms) and the congruent condition (M = 757 ms) was not significant, with b = −2.02, SD = 6.93, t = −0.29. For the Bayes Factor computation, we assigned a prior distribution of r = 0.71, based on Berent and Marom (Citation2005). Computations returned BF10 = 0.027 and BF01 = 37.63, respectively, meaning that the null hypothesis is 38 times more likely than the alternative hypothesis based on Experiment 1 results.
In line with the results of RT analysis, the analysis of the error rates did not reveal any significant difference between the congruent and the incongruent condition either, with a mean accuracy of 91% in both conditions (b = .01, SD = 0.01, z = −1.01).
3. Interim Discussion
Here we investigated whether the word recognition process engages configurational representations irrespective of item identity (driving, for instance, a sense of similarity among “bee”, “911” and “zoo”). Using the well-established masked priming paradigm (Grainger, Citation2008, for a review), we obtained evidence againstFootnote4 configurational coding in word recognition. The size of our Bayes factor (BF01 = 37.63) reflects abundant statistical power, and the straightforward design of our experiment leaves little room for an account of why no effects were observed here if pure position coding were true. We may nonetheless raise a few challenges against our own results.
Foremost, there is a possibility that positional information impacts the word recognition process at a relatively late point in time, and that our prime durations were too short. On the other hand, previous masked priming experiments have robustly shown that subtle manipulations of letter identity and position (e.g. transposed-letter priming) are picked up by the system in spite of brief prime durations (e.g. Grainger, Citation2008, for a review). If conjoint processing of identity and position can be revealed with such brief exposures, it is difficult to see how configurational coding could not.
Alternatively, an argument could be made that the coding of letter identity bears much more prominence than the coding of letter positions (for empxlae, tihs sntenece can be raed tankhs to teh itednteitis rthaer tahn the pstnoiios of lttrees). The detrimental effect of having a complete mismatch between prime and target letter identities might somehow have negated any transfer of positional information from the prime to the target. Then again, one might argue that such degrees of item-dependence would call into question the hypothesised role of configurational codes in the first place.
Although the above considerations do not invalidate the evidence for an absence of configuration coding in Experiment 1, we nonetheless carried out a second experiment in which we endeavoured to optimise the prime’s potential to impact target word processing. In other words, Experiment 2 was geared at maximising our confidence in a null-result. Our first methodological augmentation for Experiment 2 was the use of digit primes instead of letter primes. This choice was driven by the finding that non-alphabetic primes cause less interference than do different-letter primes (Peressotti & Grainger, Citation1999), and further relies on the notion that position codes—insofar as they are observed outside the realm of orthographic processing—are domain-general (e.g. van de Cavey & Hartsuiker, Citation2016). We further employed longer and unmasked prime exposures, hence taking into account the off-chance that the absence of configurational congruency effects in Experiment 1 was caused by too brief prime durations. Lastly, a portion of the trials was catch trials in which the participant was asked to report the prime identity after having made the lexical decision. This was done to motivate participants to pay close attention to the prime stimulus, hence increasing the prime’s potential to impact target word processing.
4. Experiment 2
4.1 Methods
Twenty-eight students, none of whom participated in the previous experiment, were recruited for Experiment 2 following the same criteria as those of Experiment 1.
The set of 96 word targets and 96 nonword targets from Experiment 1 was also used in Experiment 2. This time around, primes were not devised beforehand, but were instead generated during the experiment, prior to the start of each trial. All of our target words consisted of no more than four different letter identities. Therefore, when generating the congruent prime display, each of the target’s letter identities was randomly coupled to one of the digits “1”, “2”, “3” and “4”, so that, for instance, for the target “klok” the prime could be “1431” for one participant, and “2132” for another participant. In positionally incongruent trials, primes were generated using the same procedure but based on the incongruent prime stimulus used in Experiment 1. By randomly assigning digits to letter identities per trial, we avoided the possibility that effects would be driven by similarities or learned associations between digits and letters.
The reason why we only used the digits 1–4 is because the prime stimulus was to be recalled on a portion of trials. During pilot testing, we determined that performance on these catch trials would rapidly deteriorate upon an increasing variety of digits. We additionally reasoned that when repeatedly encountering the same identities, more emphasis may be put on the processing of positional information.
Experiment 2 used the same 2 × 2 factorial design as Experiment 1. The prime stimulus was probed on 55 randomly selected trials (i.e. one out of seven trials), immediately after the participant’s lexical decision. The procedure was equal to that used in Experiment 1, save for the extended prime exposure (1500 ms), and the occasional prime recall display in the case of a catch trial (). The prime recall display showed the question “What were the digits?” in Dutch. Participants were instructed to use the keyboard to type the digits in response. Digits appeared onscreen as the participant typed, and the backspace key could be used to modify the answer if so desired. Answers were finalised with a press on the return key. Feedback was provided after catch trial responses.
Figure 3. Overview of the trial procedure in Experiment 2. Catch trials occurred in one out of seven trials (“Wat waren de cijfers?” is Dutch for “What were the digits?”). The size of stimuli relative to the screen is exaggerated in this example.
4.2 Results
Our data exclusion criteria and methods of analysis were equal to those used in Experiment 1.Footnote5 Our analysis again revealed no effect of congruency on RTs: the difference in RTs between the incongruent condition (M = 818 ms) and the congruent condition (M = 819 ms) was not significant, with b = −1.62, SD = 7.35, t = −0.22. Bayes Factor computations returned BF10 = 0.021 and BF01 = 46.93, respectively, meaning that the null hypothesis is 47 times more likely than the alternative hypothesis based on Experiment 2 results.
To determine whether results varied as a function of the degree to which participants processed the prime, we established the overall catch trial accuracy per participant, and included these scores as covariate in the model. The analysis revealed no significant interaction of subject accuracy and congruency (b = −8.65, SD = 26.93, t = −0.32) nor a significant effect of catch trial accuracy (b = 6.70, SD = 85.96, t = 0.08). The effect of congruency remained insignificant (b = 2.61, SD = 13.58, t = 0.19).
The analysis of the error rates did not reveal any significant difference between conditions either, with a mean accuracy of 89% in the congruent and 90% in the incongruent condition (b = 0.00, SD = 0.01, z = 0.14). Again, no interaction effect was obtained after reanalysing the data with catch trial accuracy as a covariate (b = 0.02, SD = 0.03, z = 0.58). The effects of catch trial accuracy and congruency remained insignificant as well (respectively b = 0.13, SD = 0.10, z = 1.27, and b = −0.01, SD = 0.02, z = −0.36).
Lastly, we ran a post-hoc analysis to investigate whether there was an influence of the proportion of repeated letters. Here, proportions were calculated by checking for each of the target’s letters whether it also appeared elsewhere (e.g. in “dad”, 67% of letters are repeated, whereas 100% of letters are repeated in “deed”). When adding the proportion of repeated letters to the model, we observed, in line with prior research (Schoonbaert & Grainger, Citation2004; Trifonova & Adelman, Citation2019; Adelman & Trifonova, Citation2022), that words with a higher proportion of repeated letters yielded longer RTs: b = 73.72, SE = 26.21, t = 2.81.
Interestingly, this time around, we also observed our hypothesised effect of Configurational Congruency, whereby congruent primes yielded shorter RTs than incongruent primes (b = −80.00, SE = 27.12, t = −2.91). However, we also found an interaction between Configurational Congruency and proportion of repeated letters (b = 112.61, SE = 37.00, t = 3.05), and the nature of this interaction was such that the beneficial effect of configurational congruency was there for targets with relatively few repeated letters, while it was reversed for targets with many repeated letters; (hence the null effects reported earlier).Footnote6 This particular pattern speaks against our theory: if configurational codes exist, then these should have a larger impact on words with a high proportion of repeated letters, as a higher proportion of letter locations is covered by the configurational code. At any rate, our theory would under no circumstance lead to predict a detrimental effect of configurational congruency for words with many repeated letters. We therefore do not consider these particular results to be evidence for our theory.
5. General discussion
In the realm of visual perception, it has been suggested that the brain employs Boolean maps, which, for a given featural input, represent the locations in space where that feature appears (e.g. Huang & Pashler, Citation2007; Huang, Citation2015). Here we asked whether these Boolean maps may also operate in visual word recognition, constituting a way for the brain to encode configurations of repeating letters. Matching configurational codes between words such as “radar” and “tenet” may explain the experienced similarity between these words.
We employed the priming lexical decision task, long established as an effective tool for gauging the ease of word recognition as a function of the identities and positions of individual letters (Grainger, Citation2008, for a review). Our straightforward experiments, wherein target words were preceded by different-symbol primes in a configurationally congruent versus incongruent configuration, provide clear-cut evidence that bottom-up lexical activation does not rely on configurational representations. These findings suggest that the well-established word recognition models were correct in assuming that positional information is encoded strictly in conjunction with letter identity information.
Interestingly, when including the proportion of repeated letters as covariate in our analysis, we did find our hypothesised effect of Configurational Congruency. But this came alongside an interaction between Configurational Congruency and proportion of repeated letters, such that our hypothesised effect was specifically there for words with few repeated letters, while the reversed pattern was found for words with many repeated letters (see Section 4.2). If our hypothesis were true, then we would have expected an opposite interaction, with a larger benefit of configurational congruency for words with many repeated letters; (indeed, we can conceive of no theoretical explanation as to why “deer” would be primed by “abbc” while “deed” is not primed by “abba”—or at least no explanation that would involve configurational codes).
The general absence of “purely positional” representations (when disregarding the proportion of repeated letters) is at apparent odds with evidence that the identities of letters are to some extent encoded independent from their positions (e.g. Grainger et al., Citation2014; Snell et al., Citation2018b). If Boolean maps guide visual perception, then why do they not impact word recognition? One answer would be that explicit encoding of positional information is not strictly necessary. Letter position coding relies on phonotactic constraints: that is, certain orderings of letters within words are more probable than others (e.g. Vitevitch & Luce, Citation1999). A reader may “know”, for instance, that a “t” is positioned to the right of a “p”, simply because “tp” is unlikely to occur (in English). Such implicitly learned patterns would thus convey positional information through the identities rather than the actual positions of letters. This conception ties in with principles of statistical learning and entropy as it pertains to language comprehension (e.g. Levy et al., Citation2009; McDonald & Shillcock, Citation2003; Romberg & Saffran, Citation2010).
From an entropy point of view, it could be argued that configurational representations do not contribute much to statistical probability distributions in word recognition, given that many words encountered in everyday life consist of all-different letters. That is, many words share the same configurational structure (e.g. “rock”, “read” and “fish” all have the configuration 1234) and thus one cannot dissociate one word from the other based on configurational information alone. Letter identity information, on the other hand, provides so much constraint that one may even disregard position information entirely, allowing one to interpret jumbled letter sentences with relative ease (e.g. the example in the Interim Discussion).
In short, whereas configurations may bear a significant amount of entropy in other realms of visual perception (e.g. Huang & Pashler, Citation2007), this does not seem to be the case in visual word recognition. Returning, then, to the question posed at the outset of this paper—what causes the sense of similarity between “mom” and “dad”—the present results and above considerations compel to believe that this sense of similarity is a product of the visual system in general, rather than the orthographic processing system in specific.
In sum, our results provide strong evidence that, within the realm of word recognition, the brain does not engage configurational representations.
Supplemental Material
Download MS Word (22.5 KB)Acknowledgement
This research was funded by the European Research Council, grant H2020-MSCA-IF-2018 833223 awarded to Joshua Snell.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
Notes
1 Notably, all vowels share the property that there is no obstruction of airflow, whereas all consonants to some extent imply an obstruction of airflow. Congruent CV-structures may therefore facilitate speech production, even if primes comprise completely different letters.
2 One may realize that words with solely unique letters (e.g., “rock”) will always have positionally congruent different-letter primes (e.g., “dsnt”). A positionally incongruent prime could be devised (e.g., “dssn”), but such a prime would never consist of the exact same set of letters as the congruent prime, hence creating a potential confound.
3 No effects were observed for nonwords: b = −5.01, SD = 7.33, t = −0.68 for RTs and b = 0.01, SD = 0.01, t = 1.59 for error rates.
4 Note that the null-hypothesis was directly confirmed not by the non-significant statistic returned by our linear mixed-effect model, but rather by our Bayesian statistical analyses.
5 Note that again no effects were observed for nonwords: b = −3.16, SD = 6.25, t = −0.51 for RTs and b = −0.00, SD = 0.01, z = −0.11 for error rates.
6 When isolating targets with a proportion of repeated letters below the median, there was a trend towards a beneficial effect of configurational congruency: b = −23.12, SE = 13.89, t = −1.66. When isolating targets with a proportion of repeated letters above the median, there was a trend towards a detrimental effect of configurational congruency: b = 18.60, SE = 10.08, t = 1.85.
References
- Adelman, J., & Trifonova, V. (2022). Orthographic priming from unrelated primes: Heterogeneous feedforward inhibition predicted by associative learning. Journal of Memory and Language, 127, 104372. https://doi.org/10.1016/j.jml.2022.104372
- Berent, I., & Marom, M. (2005). Skeletal structure for printed words: Evidence from the Stroop task. Journal of Experimental Psychology: Human Perception and Performance, 31(2), 328–338. https://doi.org/10.1037/0096-1523.31.2.328
- Bouma, H. (1970). Interaction effects in parafoveal letter recognition. Nature, 226(5241), 177–178. https://doi.org/10.1038/226177a0
- Cavey, V. D. C., & Hartsuiker, R. (2016). Is there a domain-general cognitive structuring system? Evidence from structural priming across music, math, action descriptions, and language. Cognition, 146, 172–184. https://doi.org/10.1016/j.cognition.2015.09.013
- Coltheart, M., Rastle, K., Perry, C., Ziegler, J., & Langdon, R. (2001). DRC: Dual route cascaded model of visual word recognition and reading aloud. Psychological Review, 108(1), 204–256. https://doi.org/10.1037/0033-295X.108.1.204
- Davis, C. (1999). The self-organising lexical acquisition and recognition (SOLAR) model of visual word recognition [Unpublished doctoral dissertation]. University of New South Wales.
- Davis, C. (2010). The spatial coding model of visual word identification. Psychological Review, 117(3), 713–758. https://doi.org/10.1037/a0019738
- Davis, C., & Bowers, J. (2006). Contrasting five different theories of letter position coding: Evidence from orthographic similarity effects. Journal of Experimental Psychology: Human Perception and Performance, 32(3), 535–557. https://doi.org/10.1037/0096-1523.32.3.535
- Forster, K., Davis, C., Schoknecht, C., & Carter, R. (1987). Masked priming with graphemically related forms: Repetition or partial activation? The Quarterly Journal of Experimental Psychology Section A, 39(2), 211–251. https://doi.org/10.1080/14640748708401785
- Gomez, P., Ratcliff, R., & Perea, M. (2008). The overlap model: A model of letter position coding. Psychological Review, 115(3), 577. https://doi.org/10.1037/a0012667
- Grainger, J. (2008). Cracking the orthographic code: An introduction. Language and Cognitive Processes, 23(1), 1–35. https://doi.org/10.1080/01690960701578013
- Grainger, J., & Jacobs, A. M. (1996). Orthographic processing in visual word recognition: A multiple read-out model. Psychological Review, 103(3), 518–565. http://doi.org/10.1037/0033-295X.103.3.518
- Grainger, J., Mathôt, S., & Vitu, F. (2014). Test of a model of multi-word reading: Effects of parafoveal flanking letters on foveal word recognition. Acta Psychologica, 146, 35–40. https://doi.org/10.1016/j.actpsy.2013.11.014
- Grainger, J., & van Heuven, W. (2003). Modeling letter position coding in printed word perception. In P. Bonin (Ed.), The mental lexicon: Some words to talk about words (pp. 1–23). Nova Science.
- Heuven, V. W., Dijkstra, T., Grainger, J., & Schriefers, H. (2001). Shared neighbourhood effects in masked orthographic priming. Psychonomic Bulletin and Review, 8(1), 96–101. https://doi.org/10.3758/BF03196144
- Huang, L. (2015). Grouping by similarity is mediated by feature selection: Evidence from the failure of cue combination. Psychonomic Bulletin and Review, 22(5), 1364–1369. https://doi.org/10.3758/s13423-015-0801-z
- Huang, L., & Pashler, H. (2007). A Boolean map theory of visual attention. Psychological Review, 114(3), 599–631. https://doi.org/10.1037/0033-295X.114.3.599
- JASP Team. (2023). JASP (Version 0.17).
- Levy, R., Bicknell, K., Slattery, T., & Rayner, K. (2009). Eye movement evidence that readers maintain and act on uncertainty about past linguistic input. Proceedings of the National Academy of Sciences, 106(50), 21086–21090. https://doi.org/10.1073/pnas.0907664106
- Loomis, J. (1977). Lateral masking in foveal and eccentric vision. Vision Research, 18(3), 335–338. https://doi.org/10.1016/0042-6989(78)90168-2
- Mariol, M., Jacques, C., Schelstraete, M. A., & Rossion, B. (2008). The speed of orthographic processing during lexical decision: Electrophysiological evidence for independent coding of letter identity and letter position in visual word recognition. Journal of Cognitive Neuroscience, 20(7), 1283–1299. https://doi.org/10.1162/jocn.2008.20088
- Marzouki, Y., & Grainger, J. (2014). Effects of stimulus duration and inter-letter spacing on letter-in-string identification. Acta Psychologica, 148, 49–55. https://doi.org/10.1016/j.actpsy.2013.12.011
- Mathôt, S., Schreij, D., & Theeuwes, J. (2012). OpenSesame: An open-source, graphical experiment builder for the social sciences. Behavior Research Methods, 44(2), 314–324. https://doi.org/10.3758/s13428-011-0168-7
- McClelland, J., & Rumelhart, D. (1981). An interactive activation model of context effects in letter perception: I. An account of basic findings. Psychological Review, 88(5), 375–407. https://doi.org/10.1037/0033-295X.88.5.375
- McDonald, S., & Shillcock, R. (2003). Eye movements reveal the on-line computation of lexical probabilities during reading. Psychological Science, 14(6), 648–652. https://doi.org/10.1046/j.0956-7976.2003.psci_1480.x
- Moor, D. M., & Brysbaert, M. (2000). Neighborhood-frequency effects when primes and targets are of different lengths. Psychological Research Psychologische Forschung, 63(2), 159–162. https://doi.org/10.1007/PL00008174
- Perea, M., Marcet, A., & Acha, J. (2018). Does consonant-vowel skeletal structure play a role early in lexical processing? Evidence from masked priming. Applied Psycholinguistics, 39(1), 169–186. https://doi.org/10.1017/S0142716417000431
- Peressotti, F., & Grainger, J. (1999). The role of letter identity and letter position in orthographic priming. Perception and Psychophysics, 61(4), 691–706. https://doi.org/10.3758/BF03205539
- Romberg, A., & Saffran, J. (2010). Statistical learning and language acquisition. Wiley Interdisciplinary Reviews: Cognitive Science, 1(6), 906–914. https://doi.org/10.1002/wcs.78
- Schoonbaert, S., & Grainger, J. (2004). Letter position coding in printed word perception: Effects of repeated and transposed letters. Language and Cognitive Processes, 19(3), 333–367. https://doi.org/10.1080/01690960344000198
- Snell, J., Bertrand, D., & Grainger, J. (2018b). Parafoveal letter-position coding in reading. Memory & Cognition, 46(4), 589–599. https://doi.org/10.3758/s13421-017-0786-0
- Snell, J., van Leipsig, S., Grainger, J., & Meeter, M. (2018a). OB1-reader: A model of word recognition and eye movements in text reading. Psychological Review, 125(6), 969–984. https://doi.org/10.1037/rev0000119
- Treisman, A., & Souther, J. (1986). Illusory words: The roles of attention and top-down constraints in conjoining letters to form words. Journal of Experimental Psychology: Human Perception and Performance, 12(1), 3–17. https://doi.org/10.1037/0096-1523.12.1.3
- Trifonova, I. V., & Adelman, J. S. (2019). A delay in processing for repeated letters: Evidence from megastudies. Cognition, 189, 227–241. https://doi.org/10.1016/j.cognition.2019.04.005
- Trifonova, I. V., & Adelman, J. S. (2022). Repeated letters increase the ambiguity of strings: Evidence from identifcation, priming and same-different tasks. Cognitive Psychology, 132, 101445. https://doi.org/10.1016/j.cogpsych.2021.101445
- Vitevitch, M. S., & Luce, P. A. (1999). Probabilistic phonotactics and neighborhood activation in spoken word recognition. Journal of Memory and Language, 40(3), 374–408. https://doi.org/10.1006/jmla.1998.2618
- Wagemans, J., Elder, J., Kubovy, M., Palmer, S., Peterson, M., Singh, M., & von der Heydt, R. (2012). A century of Gestalt psychology in visual perception: I. Perceptual grouping and figure–ground organization. Psychological Bulletin, 138(6), 1172–1217. https://doi.org/10.1037/a0029334
- Whitney, C. (2001). How the brain encodes the order of letters in a printed word: The SERIOL model and selective literature review. Psychonomic Bulletin & Review, 8(2), 221–243. doi:10.3758/BF03196158