
ABSTRACT
Participants judged whether a letter-string created a word when a single letter was added to the end indicated by a hyphen. Unique final fragments were easier to reconstruct when corresponding to the body of a word, having no onset (e.g. laugh from –augh) than when the second consonant of a two-letter onset was also included (e.g. blind from –lind). Conversely, unique initial fragments were easier to reconstruct when including the first consonant of a two-letter coda (e.g. drink from drin–) than when corresponding to an “antibody”, having no coda (e.g. claim from clai–). Such results cannot be explained by any account of orthographic processing based purely on the identity and position of the component letters while ignoring their function as an onset, coda, or vowel. Instead, the results are compatible with a model such as the proposed Subsyllabic Processing (SSP) account where subsyllabic structures are hierarchically represented.
When reading a linear alphabetic script such as English, it would be expected that the part of the word that is encountered first would be the starting point for recognising that word. That is, orthographic information at the beginning of a word would be expected to provide a more effective avenue to accessing the word in lexical memory than would any other orthographic information. This is not only true at the perceptual stages of visual word recognition, where initial letters are more visible than final letters (e.g. Marzouki & Grainger, Citation2014; Scaltritti & Balota, Citation2013), but also at the lexical processing stage. For example, words embedded at the beginning of a nonword (e.g. fur in furb) are more detectable than words embedded at the end (e.g. lid in clid), as determined by the interference they generate when making nonword classification responses (e.g. Taft et al., Citation2017).
The mere position in which the orthographic information appears, however, is not the full story. Taft et al. (Citation2017) showed that the interference generated by an initially embedded monosyllabic word depends on the subsyllabic orthographic structure of that word. When the embedded word has a consonant following its vowel (i.e. a “coda”, such as the r of fur embedded in furb), interference is greater than when the embedded word does not have a coda and hence ends in a vowel (e.g. tea embedded in teaf). Such a finding indicates that subsyllabic structure pays an important role in the processing of visually presented words, something that is lacking in the two most prominent accounts of the early stages of orthographic processing, namely, models that incorporate open bigrams or spatial coding of letters.
According to open bigram accounts, (e.g. Grainger & van Heuven, Citation2003; Grainger & Whitney, Citation2004; Grainger & Ziegler, Citation2011; Schoonbaert & Grainger, Citation2004; Whitney, Citation2001, Citation2008; Whitney & Cornelissen, Citation2008), the lexical representation of a visually presented word is activated via units corresponding to the correctly ordered pairs of letters (i.e. bigrams), both adjacent and non-adjacent, that make up that word. For example, leaf would be coded at the bigram level as le, la, lf, ea, ef, and af (as well as initial position #l and final position f#, where # indicates the edge of the word: see Marzouki & Grainger, Citation2014; Whitney & Cornelissen, Citation2008). So, the orthographic coding that takes place is based solely on pairings of the component letters, with no consideration given to the role of these letters as a consonant or vowel.
In the spatial coding account (e.g. Davis, Citation2010; Davis & Bowers, Citation2004, Citation2006, Citation2017; Davis & Bowers, Citation2006), a word is coded in terms of nodes representing its individual letters, and the amount of activation generated within each of these is determined by its position, with the highest activation for initial letters and the lowest for final letters. For example, the lexical representation for leaf will be maximally responsive when the l unit is most strongly activated by the letter-string, the e unit is the next most strongly activated, and so on. Again, the role of these letters as a consonant or vowel is entirely irrelevant to the way in which they are processed.
In contrast, the Sub-Syllabic Processing (SSP) account maintained by Taft et al. (Citation2017) allows some letters to go together more closely than others, with the status of the letter as a vowel or consonant playing a central role (see also Lee & Taft, Citation2009; Taft & Krebs-Lazendic, Citation2013). Research has suggested that, in English at least, syllables (hence monosyllabic words) are analysed into an onset and body (e.g. Bowey, Citation1990; Patterson & Morton, Citation1985; Taraban & McClelland, Citation1987; Treiman et al., Citation1995; Treiman & Chafetz, Citation1987). The “onset” refers to any consonant or consonants that precede the vowel (e.g. the cr of crouch), while the “body” refers to the rest of the syllable (e.g. the ouch of crouch) which, in turn, is composed of the vowel (ou) followed by an optional consonantal coda (ch).Footnote1 As discussed by Treiman et al. (Citation1995), the combining of letters into body units increases the consistency with which orthographic subunits correspond to their pronunciation. For example, although ea can be pronounced as /i:/ or /ε/, the latter pronunciation is more constrained when the coda is considered because it never occurs for certain bodies (e.g. eap, eal, ean) and is the dominant pronunciation for others (e.g. ead, ealth). So, there may be a phonological basis for analysing syllables orthographically into their subcomponents, though that does not mean that this phonological information is itself required for activating lexical information. Visual word recognition may well be achieved purely on an orthographic basis, at least for proficient adult readers (e.g. Taft & van Graan, Citation1998) even if the orthographic sub-structures that are used were originally set up in correspondence with phonological sub-structures. The SSP model captures these sub-structures by proposing the existence of orthographic units that correspond to onsets and bodies.
According to the model, letters are initially assigned to slots in letter-banks that represent the onset, vowel, and coda positions. illustrates the architecture of the SSP model using the word drink as an example. When letters are assigned to a slot, activation is generated in the corresponding form units that represent existing onsets, vowels, and codas respectively. Pre-lexical information is available with regard to which letters correspond to a vowel, with any other letters corresponding to a consonant and, hence, being part of an onset or coda. So, the i of the letter-string drink activates a vowel unit via the vowel bank, the d and r combine to activate an onset unit via the onset bank, and the n and k combine to activate a coda unit via the coda bank. Importantly, combined activation in the vowel and coda units activates a corresponding body unit (here, ink) which, in turn, combines with the onset (dr) to activate the lexical representation (drink).
Figure 1. The way in which the word drink would be represented and accessed according to the Subsyllabic Processing (SSP) model. See the text for a full description.
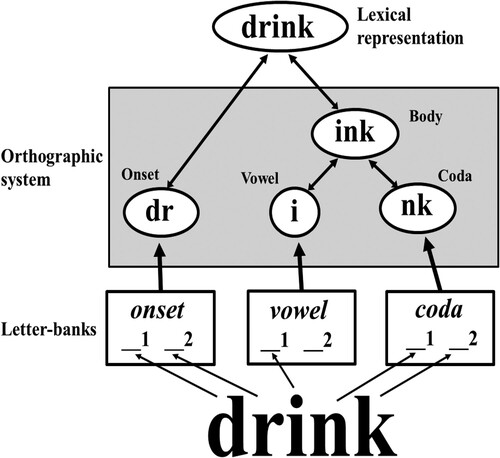
Models that focus on the early stages of orthographic processing, such as the open bigram and spatial coding accounts, are largely motivated by the fact that lexical representations can be activated even when letters are transposed, especially medial letters (e.g. drnik or dirnk being confused with drink). A word and its transposed version either share many open bigrams or have a very similar spatial coding pattern. The way in which the SSP model handles the fact that a word can be activated from its transposed version is by incorporating imprecise assignment of letters to slots (see Lee & Taft, Citation2009; Taft & Krebs-Lazendic, Citation2013). More importantly for present purposes, the SSP model readily explains the finding that interference to nonword classification responses arises when an initially embedded word ends in a coda (e.g. fur in furb), but not when it ends in a vowel (e.g. tea in teaf). Taft et al. (Citation2017) propose that the units representing the coda and body of furb (i.e. rb and urb respectively) experience competition from the partially activated units representing the coda and body of the embedded word fur (i.e. r and ur respectively) which, combined with the onset (i.e. f), activate the lexical representation of fur. In contrast, the existence of the embedded word tea does not lead to competition with the coda and body of teaf (i.e. f and eaf respectively) because the vowel ea contributes to the activation of eaf rather than competes with it.
In addition, there is minimal interference when a word is embedded at the end of a nonword (e.g. lid in clid) because, according to Taft et al. (Citation2017), the only competition that arises is from partial activation of the onset of the embedded word (l competing with cl) in contrast to the two different units being activated in the case of initially embedded words (i.e. coda and body units). Moreover, since it is likely that the first letter of a word provides the greatest weight in activating lexical information, being the first letter encountered when reading from left-to-right, competition from the cl of clid will be stronger against l than will competition from the rb of furb against r. So, when clid is presented, the activation of words beginning with cl is likely to overwhelm the partial activation of words beginning with l (including the embedded word lid).
The central feature of the SSP model is that it captures the internal structure of a word by postulating the existence of specific sub-syllabic orthographic units. Such an idea lends itself to the possibility that words can be re-constructed from some sub-syllabic fragments more easily than from others. Consider the case of monosyllabic words that are missing their initial letter or their final letter (e.g. lind from blind and drin from drink respectively). There is only one word that can be generated when a letter is added to the beginning of lind or to the end of drin, but the former should be harder to establish than the latter. The body of the presented fragment –lind (with its missing letter being indicated by a hyphen) will fully activate the body ind, which provides the pathway to the target word blind, but also to the competing words that share that body (e.g. mind, kind, grind, etc.). In addition, the partially activated onset unit for bl will experience competition from the other onsets that are also partially activated (cl, gl, pl, etc.). There may even be competition from words beginning with l, despite the existence of the hyphen, given how much input the initial letter of a letter-string provides. In contrast, drin– will activate the target word drink through the combination of its matching onset dr and the body unit for ink that has been activated via the vowel unit for i and the partially activated coda unit for nk. While there will be competition between the partially activated body unit ink and the other partially activated bodies (int, ind, ing, etc.), this should be readily overcome by the fact that the presented fragment includes the all-important onset of the target word.
Now, it is probably the case that almost any account of early orthographic processing can handle results where fragment completion is easier for initial than final fragments (i.e. drin– versus –lind). As long as greater weight is placed on initial than final letters and/or an element of serial processing is introduced (e.g. if a phonological representation were to be generated when carrying out the task), open bigram and spatial coding models would be able to account for an advantage for initial fragments over final ones (see Taft et al., Citation2017, for discussion of amendments of this type to those models). However, unlike the open bigram and spatial coding models, the SSP account crucially predicts that such a result will not be found for all types of initial and final fragments. In particular, the existence of body units in the system leads to the prediction that the advantage of initial over final fragments will be lost (and potentially reversed) when the initial fragment has no coda (e.g. clai-) and the final fragment has no onset (e.g. –augh). Both of these types of fragment will be referred to as “open syllables”, where the latter is the body of the target word (e.g. augh is the body of laugh), and the former is the “antibody” of the target word (i.e. its onset plus vowel, such as the clai of claim; see Forster & Taft, Citation1994).
For either type of open syllable there is only one word that can be created when adding a single letter, yet according to the SSP account, there should be no advantage for the initial fragment (e.g. clai–) over the final one (e.g. –augh). Even though the initial fragment has the onset of the target word intact and the final fragment does not, the latter corresponds to a unique body and therefore generates little in the way of competing lexical representations. That is, laugh is the only word to be activated through the body augh, and the absence of any onset information within the fragment means that there is no competition from other words activated through an onset unit. When it comes to the fragment clai–, on the other hand, the onset cl contributes to the activation of the target word claim, but the fact that there is no coda information at all means that the body unit for aim is only weakly supported. Whether this means that a final fragment will actually be harder to complete than an initial fragment when the former is an antibody and the latter is a body (clai– vs –augh) will depend on the weighting placed on having the full onset intact (cl) relative to having only a partial body (ai). However, what can at least be clearly predicted is that the ease of fragment completion for initial and final fragments should interact with syllable openness. For example, any advantage in generating the target word from drin– relative to –lind (to be referred to as the “Part Coda” and “Part Onset” conditions respectively) should not be observed for clai– relative to –augh (i.e. the “Antibody” vs “Body” conditions).
A more straightforward way to envisage this predicted interaction, and the orientation that will be adopted here, is to consider the comparison of fragments that come from the same position in the target word. Such an approach controls for the relative ease of adding a letter to the beginning of a fragment compared to the end. The predicted interaction is that final fragments should be harder to complete when they include a part onset (e.g. –lind) than when they do not (e.g. –augh), but initial fragments should be no harder to complete when they include a part coda (e.g. drin-) than when they do not (e.g. clai-). This is because –lind will not only suffer competition from words beginning with l, but also from other words that share the body ind, whereas –augh will suffer neither onset nor body competition. While drin– and clai– both share the onset of their target word, the ease of accessing that word will depend on the amount of competition arising from having a body unit activated via its vowel plus part of its coda (e.g. the in of drink) relative to being activated via its vowel alone (e.g. the ai of claim). Since the former conveys more information about the body of the target word, it might provide an advantage over the latter in accessing the target word from the fragment. If so, the outcome would actually be a cross-over interaction between syllable openness and fragment position. That is, if an initial fragment is harder to reconstruct when there is no coda information than when there is (e.g. clai– versus drin–), this would contrast with the situation for final fragments which should be easier to reconstruct when there is no onset information than when there is (e.g. –augh versus –lind).
The likelihood of observing such an interaction in the fragment completion task is bolstered by findings previously obtained in a variety of other tasks. For example, in a priming study, Taraban and McClelland (Citation1987) observed that the pronunciation given to a nonword target was more influenced by the pronunciation of the matched body of a word prime (e.g. jead being pronounced to rhyme with the prime head) than the pronunciation of the matched antibody of the same prime (e.g. heam being pronounced with the same vowel as head). Treiman and Chafetz (Citation1987) showed that a monosyllabic word could be reconstituted from its components more easily when those components corresponded to onset and body (e.g. sp and ill or spr and ay) than when they corresponded to antibody and coda (e.g. spi and ll) or when the onset was broken up (e.g. sp and ray). In addition, the naming of monosyllabic word targets was shown by Bowey (Citation1990) to be facilitated when they were preceded by their body (e.g. eap priming heap), but not when preceded by a unit composed of their body and part of their onset (e.g. rin not priming grin). So, from these studies it appears that the body has a special role to play in visual word recognition, and that partial onset information does nothing to enhance this.
In order to assess the predictions of the SSP model, an experiment was conducted where two initial fragment conditions were included, Part Coda (e.g. drin–) and Antibody (e.g. clai–), as well as two final fragments conditions, Part Onset (e.g. –lind) and Body (e.g. –augh). The task was fragment decision (“Does this letter-string create a real word when a single letter is added in the indicated space”). A single dash was used to indicate the position in which the letter should be added. The initial and final fragments were presented in two separate blocks so that the position was consistent across all trials within the block. The fragment decision task was chosen over a task where the target word was to be identified from the fragment by naming it, because the latter would have allowed articulatory preparation on the basis of the first few letters of an initial fragment, hence potentially concealing any effect of subsyllabic structure for initial fragments and disadvantaging responses to final fragments.
The primary result predicted by the SSP model, in contrast to the other proposed models of early orthographic processing, is an interaction between fragment position (final vs initial; i.e. Body/Part Onset vs Antibody/Part Coda) and syllable openness (open syllable vs closed syllable; i.e. Body/Antibody vs Part Onset/Part Coda). When a body uniquely defines a word when combined with a one-letter onset (e.g. –augh), there is no competition when activating the target word via the body representation. In contrast, a final fragment that has a body shared with other words, but is narrowed down to a single target word by virtue of the existence of the second letter of the two-letter onset of the target (e.g. –lind), will generate competition not only from the words that share their body (e.g. kind, mind, grind, etc.), but also from other words whose onset has the same second letter (e.g. cl, gl, pl, etc.) and possibly from words that begin with the onset of the fragment (l). Therefore, words should be harder to reconstruct from a final fragment that has a partial onset than a final fragment that has no onset. However, the equivalent result should not hold for initial fragments. An Antibody and a Part Coda fragment (e.g. clai– and drin– respectively) both include the complete onset of the target word, but the former provides no information about the coda while the latter does. Therefore, it should be no easier to reconstruct the target word from the former than from the latter, and indeed the reverse might be true.
Method
Participants
Participants were 114 undergraduate students from the University of New South Wales (UNSW Sydney) who received course credit for their participation. All were English monolinguals with normal or corrected to normal vision.
Materials
Each of the four conditions included 24 monosyllabic fragments of 3–5 letters (see Appendix). Only one word could be created from each fragment by adding a single letter to either the beginning or the end as indicated by a hyphen. Two of the conditions comprised final fragments. These were a Body condition consisting of word bodies that could only create a single word (i.e. the target) when a one-consonant onset was added at the beginning (e.g. –augh, –eil, –ounge, from laugh, veil, and lounge respectively), and a Part Onset condition where items were composed of a body preceded by the second consonant of the two-consonant onset of the target word (e.g. –lind, –rin, –welve, from blind, grin, and twelve respectively).
There were also two conditions comprising initial fragments. Antibody items were composed of an onset and vowel which created only a single word with the addition of a one-consonant coda (e.g. clai–, hau–, screa–, from claim, haul, and scream respectively). The other initial fragment condition comprised Part Coda items which included the onset of the target along with its vowel and the first consonant of its two-consonant coda (e.g. drin–, haw–, knigh–, from drink, hawk, and knight respectively).
The four conditions were matched overall (all p's > 0.38) on fragment length (with a mean of 3.72, 3.76, 3.76, and 3.80 letters for the Body, Part Onset, Antibody, and Part Coda conditions respectively), as well as frequency of the target word (with mean log frequencies of 1.38, 1.35, 1.39, and 1.37). In addition, a few of the fragments, if pronounced regularly (i.e. according to grapheme-phoneme conversion rules, see e.g. Coltheart et al., Citation2001), would have a different pronunciation to their target, and there were 6 of these in each condition. For example, the regular pronunciation of the or of –orld is /ɔ:/ rather than the /ɜ:/ of the target word world, the regular pronunciation of the o of –ront is /ɔ/ rather than the /ʌ/ of front, the regular pronunciation of the ea of grea– is /i:/ rather than the /eɪ/ of great, and the regular pronunciation of the n of drin– is /n/ rather than the /ŋ/ of drink.
Another potentially important consideration was the fact that each condition included cases where possible competing completions existed if the hyphen were not processed as it was supposed to be. That is, in the Body and Antibody conditions, there were fragments where words could be created by adding more than a single letter (e.g. scrounge in the case of the Body fragment –ounge, and haunt in the case of the Antibody fragment hau–) while in the Part Onset and Part Coda conditions there were fragments where a word could be generated if a letter were added at the wrong end (e.g. rind in the case of the Part Onset fragment –rin, and thaw in the case of the Part Coda fragment haw–). In fact, such cases of potentially competing completions were very infrequent, with a mean of < 1 in each condition, and there was no significant difference between the conditions on this factor (p's > .50).
The final and initial fragments were presented in separate blocks, with each block also including a set of 48 letter-strings that were not fragments of real words, hence requiring a “no” response. Half of these distractors in the final-fragment block corresponded to the Body condition, being a non-existing body (e.g. –eale, –enk, –oanch), and half corresponded to the Part Onset condition with a body preceded by a consonant that could potentially be the second letter of an onset (e.g. –rale, –lep, –hetch). A similar setup was used in the initial-fragment block, with half of the distractors corresponding to the Antibody condition (e.g. froo–, goi–, shroa–), and the other half to the Part Coda condition (e.g. veas–, der–, sloun–).
Procedure
The fragment decision experiment was administered using the DMDX computer display programme (Forster & Forster, Citation2003). All letter-strings were presented in lowercase 20-point Arial font, and remained on the screen until the participant responded (with a 4000 ms time-out), followed 1000 ms later by the presentation of the next item. Items were individually randomised for each participant. Initial and final fragments were presented in two separate blocks, with the order of blocks being counterbalanced across participants. The instructions for the block of initial fragments was the following: “In this experiment, you will see a series of word fragments. Press YES if a proper English word can be created when a single letter is added to the end of each of these fragments. Otherwise press NO”. The instructions for the block of final fragments was the same, but with the word “beginning” replacing the word “end”. Participants were asked to respond as quickly but as accurately as possible by pressing a key designated “yes’ or “no” on the keyboard. Each block was preceded by 10 practice trials that were of a similar structure to the fragments used in the experiment. Feedback was given in the practice trials in relation to accuracy, but not in the test trials.
Results
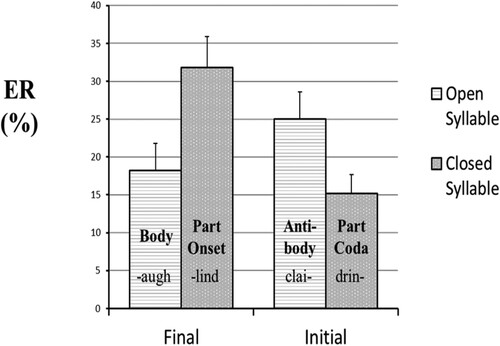
The RT data were trimmed by removing responses that were faster than 200 ms and longer than 2000ms. Two participants were removed because they made more than 50% errors in one of the blocks. Mean response times are presented in and error rates in .
Figure 2. Adjusted condition means for RT (in ms) based on the final LME model. Error bars represent standard error.
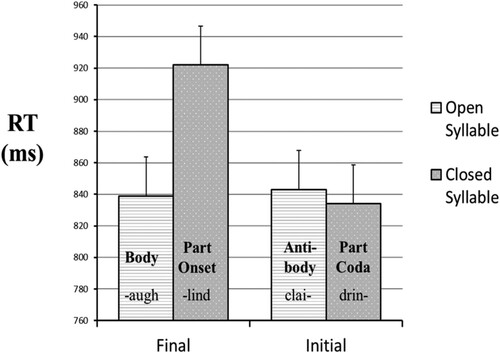
Figure 3. Adjusted condition means for % error rate based on the final LME model. Error bars represent standard error.
The results of the initial and final fragment blocks were analysed separately, along with the interaction between block (i.e. fragment position) and syllable openness. The results were analysed via linear mixed effects modelling, using the lme4 package in R (Baayen et al., Citation2008). Fixed and random factors were included in the model if the chi-squared tests indicated that they improved the model's goodness of fit, which was assessed using a step-wise model selection procedure. In the separate analyses of the initial and final blocks, the fixed factor of interest was syllable openness, with the covariates being response time on the previous trial, fragment length, frequency of the target word, and number of possible competing completions. These variables were centred according to their respective means and all but the last one was retained in the final model because they improved the model's goodness of fit. The analysis across the two blocks also included the fixed factor of fragment position and the interaction between fragment position and syllable openness.
The random effects included the random intercepts for subjects and items. The effects of subject-related variance on the fixed factors of interest were assessed via by-subject random slopes, but these were omitted from the final model as they did not improve its fit. For the response time measure, inverse RTs were used as the DV (i.e. –1000/RT) to minimise the impact of positive skew in the RT distribution. Values for p were obtained by using the R package lmerTest (Kuzentsova et al., Citation2014). The analyses of error rates (ER) followed the same logic, but with ERs being entered as a binary variable using the glmer function in the lme4 package, and p values being generated using the Wald z statistic for the fixed factors.
Both the accuracy and speed measures revealed a significant interaction between fragment position and syllable openness, z = 3.70, p < 0.001 and t = 2.45, p < 0.02, respectively. The analyses of the final fragments revealed fewer errors for open syllables (i.e. the Body condition, e.g. –augh) than for closed syllables (i.e. the Part Onset condition, e.g. –lind), z = 2.72, p < 0.01, as well as shorter RTs, t = 3.34, p = 0.001. In contrast, the analyses of the initial fragments revealed more errors for open syllables (i.e. the Antibody condition, e.g. clai-) than for closed syllables (i.e. the Part Coda condition, e.g. drin-), z = 2.56, p = 0.01, with no significant effect on RTs, t = 0.39, p > 0.1.
Discussion
It is apparent from the results that internal subsyllabic structure has an impact on the ease of reconstructing a target word when it is missing one letter. In particular, it is easier to restore an onset when it is entirely absent (e.g. –augh) than when it is partly present (e.g. –lind), whereas it is easier to restore a coda when it is partly present (e.g. drin–) than when it is entirely absent (e.g. clai–). Such a finding is incompatible with any model of orthographic processing that does not incorporate the involvement of onset-body structure, such as the open bigram account (e.g. Grainger & van Heuven, Citation2003; Grainger & Whitney, Citation2004; Grainger & Ziegler, Citation2011; Schoonbaert & Grainger, Citation2004; Whitney, Citation2001, Citation2008; Whitney & Cornelissen, Citation2008) or the spatial coding account (e.g. Davis, Citation2010; Davis & Bowers, Citation2004, Citation2006, Citation2017; Davis & Bowers, Citation2006). According to these models, the only characteristic of a letter that is taken into consideration is its identity and position in the word, which means that all unique initial fragments should be equally predictive of the target word, as should all unique final fragments. There is no opportunity for the internal structure of the word to have any impact, yet that is what has been demonstrated in this study. Thus, the open bigram and spatial coding models are found wanting in contrast to the SSP framework (e.g. Lee & Taft, Citation2009; Taft et al., Citation2017; Taft & Krebs-Lazendic, Citation2013) where the function of consonants as onset or coda plays a role in visual word recognition, as does the combination of the coda and vowel as a body.
According to the SSP account (see ), it will be relatively easy to access the target word from a Body fragment (e.g. –augh) because it fully overlaps with a sublexical representation that provides the pathway to only one word (except in those few cases where there is potential competition from another word that has an onset of more than one letter, such as scrounge competing with lounge). In contrast, a Part Onset fragment (e.g. –lind) will fully activate the sublexical representation of a body that, in most cases, provides the pathway to several competing lexical representations (e.g. mind, kind, grind, etc., competing with blind). Moreover, the partially activated onset of the intended word (bl) will experience competition from the other onset units that are also partially activated (e.g. cl, fl, gl). In line with this is the post-hoc finding that the number of possible single-letter onset completions of a Part Onset item correlated with both RT (r = 0.49, p < 0.02) and ER (r = 0.57, p < 0.01) when partialing out word frequency. In addition, because the first letter of a word plays such an important role in lexical access, it is quite possible that the initial consonant of the fragment will activate competing words that have that consonant as their onset (i.e. words beginning with l in the case of –lind), despite the presence of the hyphen at the beginning. It can therefore be clearly seen why Body fragments were more easily reconstructed than Part Onset fragments despite both of them having only a single completion.
Turning to the initial fragments, both the Part Coda and Antibody items (e.g. drin– and clai– respectively) will activate the unit corresponding to their complete onset (dr and cl respectively), and both will partially activate the body of the target word (ink and aim respectively) along with other possible bodies (i.e. ind, ing, int, etc. in the case of drin–, and ait, ail, ain, etc. in the case of clai–). Nevertheless, there was a significant advantage for the Part Coda condition over the Antibody condition in terms of accuracy, and this can be potentially explained by assuming that body activation is stronger when there is a contribution from both the vowel and coda units, rather than just the vowel alone. That is, the coda of the target word in the Part Coda condition (e.g. the nk of drink) will be partially activated by the coda of the presented fragment (i.e. n), which then provides more input to the body level than is the case for the Antibody condition where no coda is activated at all.
From the above explanation for the results of the initial fragments, one might expect that the more possible coda completions that exist for the Part Coda items, the greater the competition with the correct coda. That is, the fact that l occurs as the first letter in many two-letter codas (i.e. lb, ld, lt, lm, lf, etc) might be expected to make it harder to think of the missing letter in fiel– than in deat– where the correct completion (th) is the only option. In the event, however, the number of possible coda completions did not correlate with either RT or ER when partialing out word frequency (r < /0.1/, in each case). Moreover, the number of possible bodies that could be formed by adding another letter (e.g. ind, ing, int, etc. in the case of drin– ) only showed a very weak indication that it correlated with RT and ER when partialing out word frequency (r = 0.28 and r = 0.26, respectively, p’s > 0.1). It is, therefore, not so clear what the basis is for completion of initial fragments. What can be concluded, though, is that it is harder to reinstate a full coda than a partial coda, presumably because there are far more options available for what the coda might be when there are zero consonants provided than when there is one.
Note that there are also far more options available for what the onset might be for a Body fragment (e.g. –augh) than for a Part Onset fragment (e.g. –lind), yet the former is easier to reconstruct than the latter. Such a contrast with the findings for initial fragments emphasises the fact that letter coding takes the internal structure of the word into account, which is the critical point being drawn from this research. A model like SSP handles the impact of fragment position by incorporating hierarchical structure into the form representation, with onset/body structure being central to the account. The other models are unable to explain the different response patterns for initial and final fragments.
Finally, something needs to be said about the use of the fragment completion task and whether there are possible confounds arising from that task that could explain the obtained results. The first potential concern that can be raised is that participants are not asked to explicitly identify the target word when performing the task and that it is therefore possible that the full word is not actually accessed. If this is an issue, however, it needs to be assumed that it is possible to differentiate an existing fragment from a non-existing fragment on a basis other than the fact that the former is part of a real word and the latter is not. To sustain such an argument, the non-fragments would need to systematically violate the rules of English word structure, hence allowing them to be differentiated from the real fragments prior to any access to lexical representations. In addition, the number of such violations would need to be greater in some conditions than in others in order to explain the obtained pattern of results. For example, it would be easy to discriminate existing Body fragments from non-existing Body fragments if most of the latter were like –iwb, where i is never followed by a semi-vowel in English and wb is a non-existing coda. However, it is very hard to see what sort of rules might have been violated within the non-fragments used in the present experiment. Even if some of them might be considered to have an unusual structure, especially amongst the Body distractors (e.g. –oanch, –oultz, or –oip), they are not obviously different in structure to some of the bodies that do exist in a real word such as the –oung of young, the –acht of yacht, or the –oap of soap. Therefore, it is hard to sustain the argument that the reason for the pattern of results observed in the experiment was that the conditions differed in their ease of discrimination from the non-fragments.
The fact that more monosyllabic words begin with a consonant than a vowel raises another potential concern. Part Onset fragments can be considered more word-like than Body fragments, given that the former always begin with a consonant and the latter always begin with a vowel, and it might be argued that the more word-like the fragment is, the harder it is to treat it as a fragment rather than as a non-existing word. Such an inhibitory impact on making the response could therefore explain the advantage of Body fragments over Part Onset fragments. The problem with such an idea, however, is that monosyllabic words are also more likely to end in a consonant than a vowel (apart from final silent e), and that means that Part Coda fragments would also have to be considered more word-like than Antibody fragments. Yet responses were easier to make for the former than the latter. Therefore, an explanation in terms of the word-likeness of the fragments seems untenable.
A third possible concern with the fragment decision task is that there exists a strategy that might have been adopted that did not tap into the internal structure of the target words. In particular, participants might have run through the alphabet in order to try out the possible completions of the fragment until a lexical representation was activated. The possible use of such a strategy, however, does not contradict the SSP account. It is simply an extra procedure that might come into play when the fragment initially fails to activate any lexical information. It cannot be the sole strategy adopted in the experiment since it would not explain the differences found between the conditions. Indeed, as pointed out earlier, there were fewer viable options to try out for the Part Onset fragments than the Body fragments, yet the former were harder to reconstruct than the latter. So, the adoption by some participants of a strategy beyond that assumed by the SSP account can simply be seen as an additional way try to find the target word when other approaches are unsuccessful. That means that, if such a strategy were adopted for some of the items, it would simply be a reflection of the difficulty in reconstructing the target from that fragment and, therefore, would only serve to add variability to the RTs.
Conclusion
The reported experiment clearly demonstrates that the letters that make up a word are structured within the lexical retrieval system in terms of their status as consonant and vowel. Moreover, the function of the consonants as onset or coda plays an important role, with the proposed account incorporating a hierarchical representation where activation in units corresponding to the vowel and coda combine to activate a unit representing the word body. Any account of orthographic representation and processing that fails to incorporate a role for onsets and bodies would have difficulty explaining the pattern of results obtained in the fragment completion task reported here.
Supplementary Material
Download MS Word (21.2 KB)Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes
1 The term "body" is typically referred to in linguistic studies as the "rime". However, those studies are almost always talking about a phonological unit. When it comes to orthographic units in reading, the tendency is to refer to the orthographic equivalent of the rime as the "body", as is done here. It should be noted, however, that linguistic studies often use the term "body" to refer to the phonological onset-plus-vowel unit, which is therefore potentially confusing.
References
- Baayen, R. H., Davidson, D. J., & Bates, D. M. (2008). Mixed-effects modeling with crossed random effects for subjects and items. Journal of Memory and Language, 59(4), 390–412. http://doi.org/10.1016/j.jml.2007.12.005
- Bowey, J. A. (1990). Orthographic onsets and rimes as functional units of reading. Memory & Cognition, 18(4), 419–427. https://doi.org/10.3758/BF03197130
- Coltheart, M., Rastle, K., Perry, C., Langdon, R., & Ziegler, J. (2001). DRC: A dual route cascaded model of visual word recognition and reading aloud. Psychological Review, 108(1), 204–256. https://doi.org/10.1037/0033-295X.108.1.204
- Davis, C. J. (2010). The spatial coding model of visual word identification. Psychological Review, 117(3), 713–758. https://doi.org/10.1037/a0019738
- Davis, C. J., & Bowers, J. S. (2004). What do letter migration errors reveal about letter position coding in visual word recognition? Journal of Experimental Psychology: Human Perception and Performance, 30(5), 923–941. https://doi.org/10.1037/0096-1523.30.5.923
- Davis, C.J., & Bowers, J.S. (2006). Contrasting five different theories of letter position coding: Evidence from orthographic similarity effects. Journal of Experimental Psychology: Human Perception and Performance, 32(3), 535–557. https://doi.org/10.1037/0096-1523.32.3.535
- Davis, C. J., & Bowers, J. S. (2017). A backwards glance at words: Using reversed-interior masked primes to test models of visual word identification. Journal of Experimental Psychology: Human Perception and Performance, 32(3), 535–557. https://doi.org/10.1037/0096-1523.32.3.535
- Forster, K. I., & Forster, J. C. (2003). DMDX: A Windows display program with millisecond accuracy. Behavior Research Methods, Instruments, & Computers, 35(1), 116–124. http://doi.org/10.3758/BF03195503
- Forster, K. I., & Taft, M. (1994). Bodies, antibodies, and neighborhood-density effects in masked form priming.. Journal of Experimental Psychology: Learning, Memory, and Cognition, 20(4), 844–863. https://doi.org/10.1037/0278-7393.20.4.844
- Grainger, J., & van Heuven, W. J. B. (2003). Modeling letter position coding in printed word perception. In P. Bonin (Ed.), Mental lexicon: “Some words to talk about words” (pp. 1–23). Nova Science.
- Grainger, J., & Whitney, C. (2004). Does the huamn mnid raed wrods as a wlohe? Trends In Cognitive Sciences, 8(2), 58–59. https://doi.org/10.1016/j.tics.2003.11.006
- Grainger, J., & Ziegler, J. C. (2011). A dual-route approach to orthographic processing. Frontiers in Psychology, 2, 54. https://doi.org/10.3389/fpsyg.2011.00054
- Kuznetsova, A., Brockhoff, P., & Christensen, R. (2014). LmerTest: Tests for random and fixed effects for linear mixed effect models. R package, version 2.0-3.
- Lee, C. H., & Taft, M. (2009). Are onsets and codas important in processing letter position? A comparison of TL effects in English and Korean. Journal of Memory and Language, 60(4), 530–542. https://doi.org/10.1016/j.jml.2009.01.002
- Marzouki, Y., & Grainger, J. (2014). Effects of stimulus duration and inter-letter spacing on letter-in-string identification. Acta Psychologica, 148, 49–55. https://doi.org/10.1016/j.actpsy.2013.12.011
- Patterson, K. E., & Morton, J. (1985). From orthography to phonology: An attempt at an old interpretation. In K. E. Patterson, J. C. Marshall, & M. Coltheart (Eds.), Surface Dyslexia (pp. 335–359). Lawrence Erlbaum Associates Limited.
- Scaltritti, M., & Balota, D. A. (2013). Are all letters really processed equally and in parallel? Further evidence of a robust first letter advantage. Acta Psychologica, 144(2), 397–410. https://doi.org/10.1016/j.actpsy.2013.07.018
- Schoonbaert, S., & Grainger, J. (2004). Letter position coding in printed word perception: Effects of repeated and transposed letters. Language and Cognitive Processes, 19(3), 333–367. https://doi.org/10.1080/01690960344000198
- Taft, M., & Krebs-Lazendic, L. (2013). The role of orthographic syllable structure in assigning letters to their position in visual word recognition. Journal of Memory and Language, 68(2), 85–97. https://doi.org/10.1016/j.jml.2012.10.004
- Taft, M., & van Graan, F. (1998). Lack of phonological mediation in a semantic categorization task. Journal of Memory and Language, 38(2), 203–224. https://doi.org/10.1006/jmla.1997.2538
- Taft, M., Xu, J., & Li, S. (2017). Letter coding in visual word recognition: The impact of embedded words. Journal of Memory and Language, 92, 14–25. https://doi.org/10.1016/j.jml.2016.05.002
- Taraban, R., & McClelland, J. L. (1987). Conspiracy effects in word pronunciation. Journal of Memory and Language, 26(6), 608–631. https://doi.org/10.1016/0749-596X(87)90105-7
- Treiman, R., & Chafetz, J. (1987). Are there onset- and rime-like units in printed words. In M. Coltheart (Ed.), Attention and performance, XII (pp. 281-298). Lawrence Erlbaum Associates Limited.
- Treiman, R., Mullennix, J., Bijeljac-Babic, R., & Richmond-Welty, E. D. (1995). The special role of rimes in the description, use, and acquisition of English orthography. Journal of Experimental Psychology: General, 124(2), 107–136. https://doi.org/10.1037/0096-3445.124.2.107
- Whitney, C. (2001). How the brain encodes the order of letters in a printed word: The SERIOL model and selective literature review. Psychonomic Bulletin & Review, 8(2), 221–243. https://doi.org/10.3758/BF03196158
- Whitney, C. (2008). Comparison of the SERIOL and SOLAR theories of letter-position encoding. Brain and Language, 107(2), 170–178. https://doi.org/10.1016/j.bandl.2007.08.002
- Whitney, C., & Cornelissen, P. (2008). SERIOL reading. Language and Cognitive Processes, 23(1), 143–164. https://doi.org/10.1080/01690960701579771