
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Heterogeneous hardware other than a small-core central processing unit (CPU) such as a graphics processing unit (GPU), field-programmable gate array (FPGA), or multi-core CPU is increasingly being used. However, to use heterogeneous hardware, programmers must have sufficient technical skills to utilize OpenMP, CUDA, and OpenCL. On the basis of this, we have proposed an environment-adaptive software that enables automatic conversion, configuration, and high-performance operation of once written code, in accordance with the hardware to be placed. However, no techniques have been developed to properly and automatically offload applications in the mixed offloading destination environment such as GPU, FPGA, and multi-core CPU. In this paper, for a new element of environment-adaptive software, we study a method for offloading applications properly and automatically in an environment where the offloading destination is a mix of GPU, FPGA, and multi-core CPU. We evaluate the effectiveness of the proposed method in multiple applications.
PUBLIC INTEREST STATEMENT
To use heterogeneous hardware such as GPU or FPGA, programmers must have sufficient technical skills such as CUDA or OpenCL. On the basis of this, I have proposed environment-adaptive software that enables automatic conversion, configuration, and high performance operation of once written code. However, no considerations have been done to offload applications in the mixed offloading destination environment. This paper is a new element of environment-adaptive software. I propose a method for offloading applications properly and automatically in an environment where the destination is a mix of GPU, FPGA, and multi-core CPU. The method firstly measures performances for each destination device, then it secondly measures performances with multiple destination devices combination. I evaluate the effectiveness of the proposed method in multiple applications, and more than 6 times performances of the evaluated application using appropriate devices for each computation part.
1. Introduction
As Moore’s Law slows down, the central processing unit’s (CPU’s) transistor density cannot be expected to double every 1.5 years. To compensate for this, more systems are using heterogeneous hardwares, such as graphics processing units (GPUs), field-programmable gate arrays (FPGAs), and multi-core CPUs. For example, Microsoft’s search engine Bing uses FPGAs (Putnam et al., Citation2014), and Amazon Web Services (AWS) provides GPU and FPGA instances using cloud technologies (e.g., (Sefraoui et al., Citation2012; Yamato, Citation2015, Citation2016).
However, to properly utilize devices other than small-core CPUs in these systems, configurations and programs must be made that consider device characteristics, such as Open Multi-Processing (OpenMP; Sterling et al., Citation2018), Open Computing Language (OpenCL; Stone et al., Citation2010), and Compute Unified Device Architecture (CUDA; Sanders & Kandrot, Citation2010). Therefore, for most programmers, skill barriers are high. In addition, Internet of Things (IoT) technologies (e.g., (Hermann et al., Citation2016)-(Evans & Annunziata, Citation2012) are increasingly being used in the system, and the required skills are also increasing.
The expectations for applications using heterogeneous hardware are becoming higher; however, the skill hurdles are currently high for using them. To surmount these hurdles, application programmers should only need to write logics to be processed, and then software should adapt to the environments with heterogeneous hardware to make it easy to use such hardware. Java (Gosling et al., Citation2005), which appeared in 1995, caused a paradigm shift in environment adaptation that allows software written once to run on another CPU machine. However, no consideration was given to the application performance at the porting destination.
Therefore, we previously proposed environment-adaptive software that effectively runs once-written applications by automatically executing code conversion and configurations so that GPUs, FPGAs, multi-core CPUs, and so on can be appropriately used in deployment environments. For an elemental technology for environment-adaptive software, we also proposed a method for automatically offloading loop statements and function blocks for applications to GPUs or FPGAs (Yamato, Citation2019; Yamato, Citation2021).
The purpose of this paper is to automatically offload applications with high performances in mixed offloading destination environments in which various devices of GPU, FPGA, and multi-core CPU exist. First, we propose a method that automatically offloads to a single device of GPU, FPGA, or multi-core CPU. Next, we propose a method for appropriate offloading in mixed offloading destination environments with various devices. We evaluate the effectiveness of the proposed method in existing applications.
For offloading to a mixed environment, the previously proposed methods of loop statements offloading to GPU, FPGA (Yamato, Citation2019; Yamato, Citation2021) and function block offloading (Yamato, Citation2020) are also used as elemental technologies. The target of this paper is appropriate offloading to a mixed environment using previous individual device offloading technologies. The contributions of this paper, excluding previous proposals, are as follows.
- Proposal of offload method for multi-core CPU of loop statement as an elemental technology.
- Proposal of overall offload flow by single migration verification and combination of multiple offloads in mixed environment.
- Proposal of a method for pursuing high speed by combining multiple offloads to the same node.
- Confirmation of the proposed method's effectiveness by offload verification to a mixed environment of multiple actual applications.
The rest of this paper is organized as follows. In Section 2, we review the technologies on the market and our previous proposals. In Section 3, we present the proposed automatic offloading method for mixed offloading destination environments with various devices. In Section 4, we explain its implementation. In Section 5, we discuss its performance evaluation and the results. In Section 6, we describe related work, and in Section 7, we conclude the paper.
2. Existing technologies
2.1. Technologies on the market
Java is an example of environment-adaptive software. In Java, using a virtual execution environment called Java Virtual Machine, written software can run even on machines that use different operating systems (OSes) without more compiling (Write Once, Run Anywhere). However, whether the expected performance could be attained at the porting destination was not considered, and there was too much effort involved in performance tuning and debugging at the porting destination (Write Once, Debug Everywhere).
CUDA is a major development environment for general purpose GPUs (GPGPUs) that use GPU computational power for more than just graphics processing. To control heterogeneous hardware uniformly, the OpenCL specification and its software development kit (SDK) are widely used. CUDA and OpenCL require not only C language extension but also additional descriptions such as memory copy between GPU or FPGA devices and CPUs. Because of these programming difficulties, there are few CUDA and OpenCL programmers.
SYCL is a single-source programming model for heterogeneous hardware (SYCL web site, Citation2020). In OpenCL, the host and device code are written separately, but in SYCL, they can be written in a single source. DPC++ is a SYCL compiler. Both OpenCL and SYCL require a new program to use heterogeneous hardware. SYCL targets a single code to run on multiple devices such as GPUs and FPGAs, but the single code is created by the programmer.
For easy heterogeneous hardware programming, there are technologies that specify parallel processing areas by specified directives, and compilers transform these directives into device-oriented codes on the basis of specified directives. Open accelerators (OpenACC; Wienke et al., Citation2012) and OpenMP are examples of directive-based specifications, and the Portland Group Inc. (PGI) compiler (Wolfe, Citation2010) and gcc are examples of compilers that support these directives.
In this way, CUDA, OpenCL, SYCL, OpenACC, OpenMP, and others support GPU, FPGA, or multi-core CPU offload processing. Although processing on devices can be done, sufficient application performance is difficult to attain. For example, when users use an automatic parallelization technology, such as the Intel compiler (Su et al., Citation2002) for multi-core CPUs, possible areas of parallel processing such as “for” loop statements are extracted. However, naive parallel execution performances with devices are not high due to the overheads of CPU and device memory data transfer. To achieve high application performance with devices, CUDA, OpenCL, or so on needs to be tuned by highly skilled programmers, or an appropriate offloading area needs to be searched for by using the OpenACC compiler or other technologies.
In addition, the polyhedral model is one of the models used when performing automatic parallelization by a compiler, and performs dependency expression, analysis, scheduling, and parallelization based on algebra. However, in the polyhedral model, only the loop part that can accurately express the dependency is handled so there are some constraints when applying it, and only the simple loop parts such as matrix calculation can be handled.
Therefore, users without skills in using GPU, FPGA, or multi-core CPU will have difficulty attaining high application performance. Moreover, if users use automatic parallelization technologies to obtain high performance, much effort is needed to determine whether each loop statement is parallelized.
2.2. Previous proposals
On the basis of the above background, to adapt software to an environment, we previously proposed environment-adaptive software (Yamato, Citation2019), the processing flow of which is shown in . The environment-adaptive software is achieved with an environment-adaptation function, test-case database (DB), code-pattern DB, facility-resource DB, verification environment, and production environment.
Figure 1. Processing flow of environment-adaptive software.
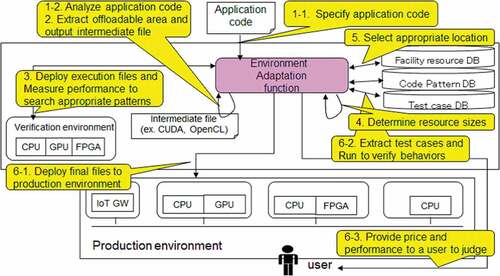
Step 1: Code analysis
Step 2: Offloadable-part extraction
Step 3: Search for suitable offload parts
Step 4: Resource-amount adjustment
Step 5: Placement-location adjustment
Step 6: Execution-file placement and operation verification
Step 7: In-operation reconfiguration
In Step 1, input code is analyzed using parsing library to grasp code structures such as loops. In Step 2, offloadable parts of loops and function blocks are extracted to create intermediate language files such as OpenCL. In Step 3, intermediate files are deployed to measure performances on verification environments. From the performance results, more appropriate offloadable parts are extracted in Step 2. Steps 2 and 3 are reclusively performed to extract and convert appropriate code suitable for GPU, FPGA or multi-core CPU. After code conversion, Step 4 is to decide the amount of resources needed to operate the application, Step 5 is to decide the location to be deployed, and Step 6 is to perform verification tests before starting actual use. In Step 7, code or resource amounts or locations are re-configured during operation based on production data to reflect current usage. In Steps 1–7, the processing flow conducts code conversion, resource-amount adjustment, placement-location adjustment, and in-operation reconfiguration for environment adaptation. However, depending on the user, there may be cases where only code conversion is required; thus, in such cases, only Step 1–3 should be performed.
We will summarize this section. Since most offloading to heterogeneous devices is currently done manually, we proposed the concept of environment-adaptive software and automatic offloading to heterogeneous hardware. Regarding GPU offloading example, various types of loops are automatically offloaded to GPU using evolutionary computation (Yamato, Citation2019). The aim of our research is to make it possible to automatically run existing code on heterogeneous hardware with high performance, instead of a new programming model, and we think this approach is novel.
However, the offloading destination is a single device so far, and mixed offloading destination environments with various devices of GPU, FPGA, and multi-core CPU are not considered yet. Therefore, in this paper, we focus on automatic offloading when the offloading destination is a mixed environment with various devices. This is a significantly different point from our previous papers.
3. Proposal of automatic offloading to mixed offloading destination environment with various devices
To realize environment-adaptive software, we have proposed a method to automatically offload program loop statements to GPU and FPGA and program function blocks to GPU and FPGA. Based on these elemental technologies, this section describes the basic idea for various devices and offloading to each device and proposes a method to automatically offload to a mixed offloading destination environment.
3.1. Basic ideas for offloading to various devices
The offloading destination environments covered in this paper are the GPU, FPGA, and multi-core CPU. GPUs and FPGAs have been used as heterogeneous hardware for a long time, and there are many cases of speed up by manual offloading using CUDA and OpenCL. Multi-core CPUs with 16 or more cores can be purchased for a few hundred dollars, and more core CPUs with 32 to 64 are also available, and parallelization is performed using technical specifications such as OpenMP. In many cases, the speed is improved by manual tuning.
To automatically offload at high-speed, we gradually search for high-speed offload patterns with evolutionary calculation by measuring the performance of a physical machine in a verification environment. This is the same as in the case of GPU offload, which has been proposed so far. The reason for this is that the performance varies greatly with not only the code structure but also the actual processing contents, such as the specifications of the processing hardware, the data size, and the number of loops. Therefore, the performance is difficult to predict statically, and dynamic measurements should be conducted. On the market, there is an automatic parallelizing compiler such as (Su et al., Citation2002) that finds loop statements and parallelizes them at the compile stage. However, performance often needs to be measured because parallelization of parallelizable loop statements often results in low speed.
Regarding dynamic measurement, the proposed method is able to execute it recursively. It does not generalize the way of optimizing. For example, in the case of stencil calculation, there is know-how to optimize, but our method cannot extract know-how. A major feature of the proposed method is that it actually executes and measures the performance of all migration destination candidates using the data used by the user and selects a high-speed pattern.
For the objects to be offloaded, we focus on the loop statement and function block of the program. This is the same as in the case of GPU and FPGA offload, which have been proposed so far. Loop statements are the first target for offloading because most processing of programs that take a long time is spent in loops. On the other hand, with regard to function blocks, when speeding up specific processing, an algorithm suitable for the processing content and processing hardware is often used so there is a case where processing can be greatly speeded up compared with offloading individual loop statements. Performance is improved by replacing frequently used function blocks such as Fourier transform with the processing implemented on the basis of appropriate algorithms suitable for device characteristics.
Regarding code pattern, there are some studies that impose restrictions such as the type of loop, but this research does not have any particular restrictions on the code pattern. In this research, all patterns of code are tried for function block offload and loop statement offload to multi-core CPU, GPU, and FPGA.
3.2. Automatic offloading to each offloading device
We describe automatic offloading for three offloading destinations (GPU, FPGA, and multi-core CPU) using two methods (loop statement and function block offloading). Regarding GPU and FPGA offloading, we refer to our previous papers.
3.2.1. Automatic multi-core CPU offloading of loop statements
We propose an automatic multi-core CPU offloading method for loop statements.
Like GPUs, multi-core CPUs utilize many computational cores and parallelize processing to speed up. Unlike the GPU, the multi-core CPU has a common memory so there is no need to consider the overhead due to data transfer between the CPU and the GPU memory, which is often a problem with offloading to the GPU. In addition, the OpenMP specification is frequently used for parallelizing program processing on a multi-core CPU. OpenMP is a specification that specifies parallel processing and other processing for a program with directives such as #pragma omp parallel for. The OpenMP programmer is responsible for parallelizing the processing in OpenMP. When an attempt is made to parallelize the processing that cannot be parallelized, the compiler does not output an error and the calculation result becomes wrong.
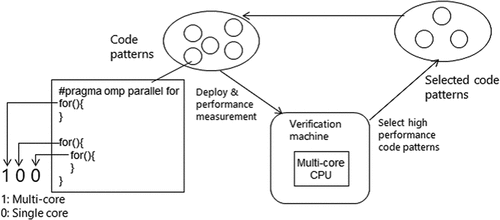
On the basis of the above, in this paper, we take the approach of the genetic algorithm (GA) method (Holland, Citation1992) that gradually accelerates the offload patterns for automatically offloading loop statements to multi-core CPUs. Code optimization using GA on GPU is detailed in our previous papers (Yamato, Citation2019). The difference from the GPU is that the #pragma omp parallel for of OpenMP is used instead of the #pragma acc kernels of OpenACC to instruct multi-core CPU execution of the loop statements. Specifically, multiple patterns are created that specify whether loops are processed in parallel or not with OpenMP #pragma directives, and the actual performance measurement is repeated in the verification environment. Here, a PGI compiler which is used for automatic GPU offload outputs an error when parallelization is impossible. However, OpenMP compilers such as gcc do not output such errors. Therefore, to automate error output, the processing performed by the OpenMP directive is simplified to only whether the loop statement is processed in parallel by the multi-core CPU. Only the pattern that produces the correct calculation result remains in the evolutionary calculation by checking whether or not the final calculation result is correct for each measurement.
The proposed method behaves as follows (). When the code is input, the syntax is analyzed using parsing library such as Clang, and the loop statement is determined. Here, the gene pattern is set to 1 when parallel processing is performed on the multi-core CPU and 0 when it is not. If the value is 1, the proposed method adds #pragma omp parallel for to the loop statement, OpenMP code that specifies parallel processing is created. The proposed method compiles the prepared multiple OpenMP files with an OpenMP compiler such as gcc and measures the performance of a verification environment machine equipped with a multi-core CPU. As a result of performance measurement, the pattern of high-speed processing is set to high goodness of fit and the pattern of low-speed processing is set to low goodness of fit, and next-generation patterns are created by processing, such as elite selection, crossover, and mutation of GA. Here, in the performance measurement, the fact that the final calculation result is the same as that without parallel processing is compared with the case where the original code is processed with a single core of CPU. If the difference is unacceptably large, the goodness of fit of the pattern is set sufficiently low so that it will not be selected for the next generation.
Figure 2. Automatic multi-core CPU offloading method for loop statements.
3.2.2. Automatic GPU offloading of loop statements
We previously proposed (Yamato, Citation2019) an automatic GPU offloading method for loop statements. We use it in this paper. Automatic offload is enabled by extracting appropriate loop statements using the GA and by reducing CPU-GPU memory data transfer. It is also necessary to reduce the communication delay between CPU and GPU to improve performance. In (Yamato, Citation2019) and other papers, we consider transferring variables as high as possible in a nested loop, and also consider transferring variables in a batch.
3.2.3. Automatic FPGA offloading of loop statements
We previously proposed (Yamato, Citation2021) an automatic FPGA offload method for loop statements. We use it in this paper. The candidate loop statements are narrowed down by using the arithmetic intensity, the number of loops, and the amount of resources. After narrowing down, the performance of multiple patterns in the verification environment is measured to enable automatic offloading.
3.2.4. Automatic offloading of function blocks
We previously proposed (Yamato, Citation2020) an automatic offloading method for function blocks. We use it in this paper. The method was verified for GPU and FPGA, but the processing is the same to detect function blocks that can be offloaded by name matching and similarity detection, so it can be adopted in the multi-core CPU as well. We used abstract syntax tree similarity matching of Deckard (Deckard web site, Citation2021) for function block offloading. However, it is not always enough to offload function blocks, and not all the function blocks can be offloaded. The expansion of function block similarity detection is the subject of another paper.
3.3. Automatic offloading for mixed offloading destination environment
Based on the basic ideas and individual device offloading methods, we study automatic offloading in a mixed offloading destination environment. The major difference in simultaneous migration to a mixed environment from single device migration is that when there are multiple high-speed offload patterns at the same node, the combination is tried (3.3.2).
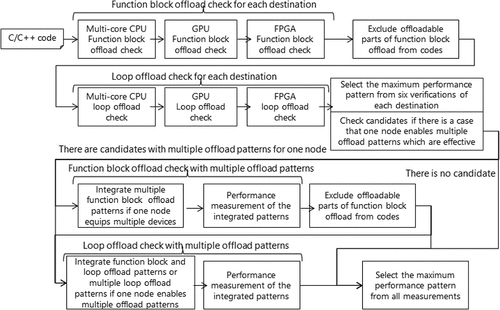
3.3.1. Verification order of each device offloading
Even if the program code is the same, the performance depends on the specifications of the processing hardware and the processing contents (data size, number of loops, etc.). Therefore, actual performance measurements are needed. Since there are three types of offloading devices (multi-core CPU, GPU, and FPGA) and two methods of offloading focus points (loop statement and function block), at least six (3*2) offload verifications are needed.
Compared to loop statements and function blocks, function block offloading can be faster if there are offloadable functions. Compared to verification times for one pattern, verification time is multi-core CPU = GPU < FPGA. Currently, FPGA requires several hours for circuit implementations, and measuring its performance takes time.
On the basis of the above, we propose the following order of verification with six offloads: multi-core CPU function block offload, GPU function block offload, FPGA function block offload, multi-core CPU loop statement offload, GPU loop statement offload, and FPGA loop statement offload. Offload verifications are performed in this order to search for high-performance patterns. The target codes of the former three and the latter three may be different. Specifically, if function block offloading is possible in the former three, the latter three types of loop statement offloading are verified in the code without the function block part that is offloadable. In the offload verifications, the user can specify the target performance, and if a sufficiently fast offload pattern is found in the former of six verifications within the range specified by the user, the subsequent verifications will not be performed.
The reason for this is that function block offloading can be faster, so verification will be performed in advance. Also, when performing automatic offloading, high-speed pattern search is expected to be performed as quickly as possible. Therefore, the FPGA that requires long verification time is the last. In addition, FPGA verification is not performed if a pattern that satisfies the user requirements is found in the previous stage. Multi-core CPU and GPU differ little in terms of verification time, but multi-core CPU is more similar to small-core CPU than to GPU, which has a separate memory space. Therefore, the verification order follows the above description. If a pattern that sufficiently satisfies the user requirements is found in the multi-core CPU ahead, GPU verification will not be performed.
3.3.2. Evaluating combinations with multiple offload patterns
Next, the final pattern is determined. If there is one pattern that is faster than the single core of CPU in the six offload verifications, the proposed method prepares an executable file with that pattern. When preparing the executable file, we may select not only the pattern with the highest performance but also the pattern with the most cost-efficient performance in accordance with the price of the acceleration device used. Here, we examine the final pattern when multiple patterns can be speeded up in six verifications.
When offloading to another node, technical specifications such as message passing interface (MPI) are required, and speed up is difficult due to communication overhead. In general server machine configuration, there are machines with multi-core CPUs and GPUs, machines with multi-core CPUs and FPGAs, but few machines with multi-core CPUs, GPUs, and FPGAs. If multiple devices can be accelerated, offloading to the same node is a necessary condition in this paper. For example, the multi-core CPU and GPU on the same node can be candidates, but the GPU and FPGA on another node cannot.
We study a combination of function block offload. The following rules apply to function block offload. A) If the same function block can be offloaded to multiple devices, the proposed method selects the offload destination with the highest performance improvement. B) If different function blocks can be offloaded to different devices but not to the same node, the function block with the highest performance improvement is targeted for offload. C) If different function blocks can be offloaded to different devices and to the same node, those function blocks are targeted for offload.
Note that processing or function blocks that are frequently used may be offloaded with high priority. In that case, the six offload verifications should be performed with a sample test that measures performance with emphasis on high-priority processing.
Then, we study a combination of loop statement offloads.
When the function block can be offloaded, the loop statement is offloaded to the code excluding the function block part that was able to be offloaded. If the loop statement can be offloaded only to a different node from the destination in function block offloading, and the performance improvement is small, the loop statement is not offloaded. For example, when the fast Fourier transform (FFT) processing is offloaded by a function block and the FPGA can process 1 second from 100 seconds, the speed of the remaining loop statements can be processed 30 seconds from 100 seconds with the GPU, offload is not performed for the GPU from another node. If it can be offloaded to the same node, the proposed method checks the speed up for the pattern in which both function blocks and loop statements are offloaded to the node.
The following rules apply to loop statement offload. D) If the same loop statement group can be offloaded to multiple devices, the proposed method selects the offload destination with the highest performance improvement. E) If different loop statement groups can be offloaded to different devices but not to the same node, the loop statement group with the highest performance improvement is targeted for offload. F) If different loop statement groups can be offloaded to different devices and to the same node, the loop statement group with the highest performance improvement is preferentially offloaded, and the remaining loop statement groups are offloaded to the offload destination with low-performance improvement.
When offloading to multiple devices at the same node such as in C) and F), offloading to multiple devices at the same time may not necessarily speed up the process. Therefore, it is necessary to offload to multiple devices at the same time and perform performance verification to determine whether it is faster than offloading to one device.
shows the flow of the proposed method.
Figure 3. Automatic offloading method for mixed offloading destination environment.
4. Implementation
4.1. Tools to use
In this section, we explain the implementation of the proposed method. To evaluate the method’s effectiveness, we use C/C++ language applications.
To control the GPU, we use PGI compiler 19.10, which is an OpenACC compiler for C/C++ languages. This PGI compiler can also use CUDA libraries such as cuFFT.
To control the FPGA, we use Intel Acceleration Stack 1.2 (Intel FPGA SDK for OpenCL 17.1.1, Quartus Prime Version 17.1.1). The Intel FPGA SDK for OpenCL is a high-level synthesis tool (HLS) that compiles #pragma directives in addition to the standard OpenCL.
To control multi-core CPU, we use gcc 10.1. Gcc supports many functions and also supports OpenMP specification.
For C/C++ language program parsing, we use parsing libraries of LLVM/Clang 6 libClang Python binding.
We use Deckard v2.0 (Deckard web site, Citation2021) as a similarity-detection tool. It determines the similarity between the partial code to be verified and the code for comparison registered in the code-pattern DB to detect offloadable functions by using an abstract syntax tree technique.
We use MySQL8.0 as the code-pattern DB. It holds the record for searching a library or IP core that can be speeded up, using the calling library name as a key. At the same time, the correspondence with the comparison code for detecting the library or IP core by the similarity detection technology is also retained.
We use ROSE framework 0.9 (ROSE compiler framework web site, Citation2022) to analyze arithmetic intensity. ROSE calculates arithmetic intensity for each loop on the basis of calculation frequency and data size. Loops with high value may become candidates for FPGA offloading.
We use the profiling tool gcov to analyze loop count. A loop statement with a large number of loops during execution is selected as a candidate for loop statement FPGA offload.
We implemented the method with Perl 5 and Python 2.7. Perl controls GA processes, and Python controls other processes such as parsing.
4.2. Implementation behavior
The operation outline of the implementation is explained here. The implementation analyzes the code using Clang when there is a request to offload the C/C++ application. Next, offload verifications for each device are performed in order by six methods. For function block offload, the same search is performed for multi-core CPUs, GPUs, and FPGAs. If function block offloading is possible in the first three, the three types of loop statement offloading in the latter half are verified for the code without the function block that was offloadable. Regarding loop statement offload, for multi-core CPUs and GPUs, a loop optimization search is performed with GA processes, and for FPGAs, ROSE and gcov are used to narrow down to high-load loops for verifications because circuit implementation takes a long time. If two or more speed up methods can be used in six offload verifications, the implementation tries combinations of different function blocks and loop statements if they can be offloaded to the same node. If not, the implementation selects the best performance from six verifications.
4.2.1. Function block offload verifications
The implementation parses the program structures such as the library being called, the defined classes, and structures.
Next, the implementation detects the GPU library, FPGA IP core, or so on that can speed up the called library. With the library being called a key, the executable file and OpenCL that can be speeded up are acquired from the records registered in the code pattern DB. When a replacement function that can speed up is found, the implementation creates the executable file. In the case of a multi-core CPU or GPU library, the original part is deleted and replaced so that the replacement library (CUDA library, etc.) is called. In the case of an IP core for FPGA, the acquired OpenCL code is replaced with the kernel code after deleting the original part from the host code. After each replacement, the implementation compiles with gcc for multi-core CPU, the PGI compiler for GPU, and Intel Acceleration Stack for FPGA.
The previous paragraph describes the case of calling the library. The processing is also performed in parallel when a similarity detection tool is used. The implementation uses Deckard to detect the similarity between the partial code such as the detected class and the comparison code registered in the DB, and it discovers the function block whose similarity exceeds the threshold and the corresponding GPU or multi-core CPU library or FPGA IP core. In particular, if the replacement source code and the interface of the replacement library or IP core such as arguments, return values, and types are different, the implementation changes the interface in accordance with the replacement destination library or IP core after confirming that the user does not mind. After replacement, the implementation creates an execution file.
Here, an execution file is created that can measure performance with the multi-core CPU, GPU, or FPGA in the verification environment. For function block offloading, we will measure the performance of each replacement function block and determine whether it can be speeded up.
4.2.2. Loop statement offload verifications for multi-core CPU and GPU
The implementation analyzes the code of the C/C++ application, discovers the loop statement, and grasps the program structure such as the variable data used in the loop statement.
Since loop statements that cannot be processed by the offload device itself need to be eliminated, the implementation tries inserting directives to be processed by the GPU for each loop statement and excludes loop statements that generate errors from the GA process. Here, if the number of loop statements with no error is A, then A is the gene length.
Next, as an initial value, the implementation prepares genes with a specified number of individuals. Each value of the gene is created by randomly assigning 0 and 1. Depending on the prepared gene value, if the value is 1, a directive is inserted into the C/C++ code that specifies GPU or multi-core CPU processing for the corresponding loop statements.
For GPU offload, data transfer is also specified. On the basis of the reference relation of variable data, the implementation instructs the data transfer for GPU. If the variables set and defined on the CPU program side and the variables referenced on the GPU program side overlap, the variables need to be transferred from the CPU to the GPU. Moreover, if the variables set on the GPU program side and the variables referenced, set, and defined on the CPU program side overlap, the variables need to be transferred from the GPU to the CPU. Among these variables, if variables can be transferred in batches before and after GPU processing, the implementation inserts a directive that specifies variables to be transferred in batches.
The implementation compiles the C/C++ code in which the directives are inserted with a PGI compiler or gcc. It deploys the compiled executable files and measures the performances. In the performance measurement, along with the processing time, the implementation checks whether the calculation result is valid or not. For example, the PCAST function of the PGI compiler can check the difference in calculation results. If the difference is large and not allowable, the implementation sets the processing time to a huge value.
After measuring the performance of all individuals, the goodness of fit of each individual is set in accordance with the processing time. The individuals to be retained are selected in accordance with the set values. GA processings, such as crossover, mutation, and copy, are performed on the selected individuals to create next-generation individuals.
For the next-generation individuals, directive insertion, compilation, performance measurement, goodness of fit setting, selection, crossover, and mutation processing are performed. After completing the specified number of generations of GA, the C/C++ code with directives that correspond to the highest performance gene is taken as the solution.
4.2.3. Loop statement offload verifications for FPGA
The implementation holds information of the loop statement and the program structure such as the variable data used in the loop statement.
The implementation executes ROSE to obtain the arithmetic intensity of each loop statement. Similarly, gcov is used to obtain the number of loops for each loop statement.
Next, the implementation generates FPGA offloaded OpenCL code for each loop statement with high arithmetic intensity and high loop count. The OpenCL code is obtained by dividing the loop statement as an FPGA kernel and the rest as a CPU host program.
By using the created OpenCL codes, the implementation pre-compiles them by Intel FPGA SDK for OpenCL and calculates the amount of resources such as Flip Flop to be used. The used resource amount is displayed as a ratio of the total resource amount. Here, a loop statement with a high arithmetic intensity, a high loop count, and a low resource amount is selected from loops that have arithmetic intensity, loop count, and resource amount information.
The implementation then creates patterns to measure using the selected loop statements as candidates and compiles them. The performance is measured when the selected loop statements are offloaded to FPGA one by one, and whether the performance can be improved is determined. As a result, if multiple patterns can be speeded up, OpenCL for that combination is also created, and the performance is measured, and it is determined whether the performance can be improved compared with patterns with single-loop statement offload. However, FPGA has a limited amount of resources, so it is not created if the amount of resources does not fall within the upper limit during multiple loops offload.
The implementation finally selects the maximum offloading performance pattern from several measured patterns.
4.2.4. Verification of combinations with multiple offload patterns
Of the six offload verifications, if only one pattern is faster than single-core processing of CPU, the implementation selects it. However, if there are multiple cases, the following performance verifications are added, and when those performances are higher than those of six offload verifications, the highest performance is selected.
For a combination of function block offload, there are three cases of A), B), and C) described in the previous section. For C), the additional performance verification is conducted by offloading different function blocks to multiple devices at the same node, and the implementation checks if the performance is faster than in other cases.
If the loop statement can be offloaded to a different node from the function block offload, and the performance improvement effect is smaller than in the function block offload, the loop statement is not offloaded. If loop statements can be offloaded to the same node with function block offload, both are offloaded to the node, and an additional performance verification is conducted.
For a combination of loop statement offload, there are three cases of D), E), and F) described in the previous section. For F), the additional performance verification is conducted by offloading different loop groups to multiple devices of the same node, and the implementation checks if the performance is faster than in other cases. In loop statement offload combination verifications, the loop statements defined in the same file are restricted so that the processing is not divided into different devices. This is to avoid an increase in complexity due to different processing devices for closely related loop statements in the same file.
Because individual device offloads were previous proposals, many tools were used from them. However, the tools and implementation behaviors are described in detail in this section to confirm and reproduce the proposals of this paper.
5. Evaluation
Since the automatic offload of loop statements to GPU and FPGA is evaluated by Yamato (Citation2019); Yamato (Citation2021), and the automatic offload of function blocks to GPU and FPGA is evaluated by (Yamato, Citation2020), this paper demonstrates that applications can be offloaded to appropriate devices in a mixed offloading destination environment. We do not evaluate the effect of offloading to each device.
5.1. Evaluation method
5.1.1. Evaluated applications
On the basis of the implementation, we evaluate applications of matrix calculation, a block tridiagonal solver, signal processing, and a combination of matrix calculation and a block tridiagonal solver for the usage of assumed areas such as IoT.
Simple matrix calculation is used in many types of analysis such as machine-learning analysis. Since matrix calculation is used not only on cloud sides but also on device sides due to the spread of IoT and artificial intelligence (AI), various applications need automatic performance improvements. For an experiment, we use polybench 3 mm (3 matrix multiplications) in which three matrix multiplications are calculated with a size of 1024*1024 (STANDARD_DATASET: NI = 1024, NJ = 1024, NK = 1024, NL = 1024, NM = 1024; Polybench 3mm web site, Citation2012).
The block tridiagonal solver is a numerical solution of partial differential equations. There are various kinds and implementations of numerical calculations, but we use NAS.BT (NASA Block Tridiagonal Solver; NAS.BT web site, Citation2022) as an example of a medium-sized numerical calculation application with more than 100 loop statements. The parameters are CLASS A settings with a 64*64*64 grid size, 200 iterations, and 0.0008 time step.
Within signal processing, the time-domain finite-impulse response filter performs processing in a finite time on the output when an impulse function is input to the system. When considering applications that transfer signal data from devices over the network to reduce network costs, signal processing such as signal filters is assumed to be conducted on device sides, thus signal processing offloading is important. We use MIT Lincoln laboratory’s high performance embedded computing (HPEC) Challenge Benchmark C code for the time-domain finite-impulse response filter (tdFIR; Time domain finite impulse response filter web site, Citation2020). HPEC’s sample test processing is carried out with 64 filters and 4096 lengths of input/output vectors.
5.1.2. Experimental conditions
In this experiment, the implementation receives offload application codes and verifies offloading of function blocks and loop statements for three offloading destinations of GPU, FPGA, and multi-core CPU. On the basis of six verifications, the implementation selects or creates a high-performance pattern and measures the performance. We evaluate the degree of improvement compared with the case where all processing is done by a single core of CPU without offloading. At the same time, we show that the appropriate device is selected.
The experimental conditions are as follows.
Offload applications and loop statements number: Matrix multiplication 3 mm that has 20 loops, block tridiagonal solver NAS.BT that has 179 loops, time-domain finite-impulse response filter tdFIR that has 6 loops and a script that executes 3 mm and NAS.BT sequentially and has 199 loops.
The experimental conditions of function block offload are as follows.
Offload targets: Intel sample OpenCL of time-domain finite-impulse response filter. In this evaluation, we prepare one function block offload target because we only need to determine the appropriate device and method selection.
Function block offloading method: The code of the offload source application tdFIR calls the corresponding method on the code side and is discovered by DB name matching and by Deckard. A function block with C language code of tdFIR is replaced and offloaded with the OpenCL code for FPGA. C language code and OpenCL code are registered in DB. Since function block offloading itself is evaluated in Yamato (Citation2020), this experiment uses function block offloading to tdFIR only .
The experimental conditions of the GA for GPU and multi-core CPU loop statement offload are as follows.
Gene length: Number of GPU and multi-core CPU processable loop statements. 18 for 3 mm, 120 for NAS.BT, and 6 for tdFIR.
Number of individuals M: No more than the gene length. 16 for 3 mm, 20 for NAS.BT, and 6 for tdFIR.
Number of generations T: No more than the gene length. 16 for 3 mm, 20 for NAS.BT, and 6 for tdFIR.
Goodness of fit: (Processing time) . When the processing time becomes shorter, the goodness of fit becomes larger. By setting the power of (−1/2), we prevent the narrowing of the search range due to the goodness of fit being too high for specific individuals with short processing times. If the performance measurement does not complete in 3 minutes, a timeout is issued, and the processing time is set to 1000 seconds to calculate the goodness of fit. If the calculation result is largely different from the result of the original codes, the processing time is also set to 1000.
Selection algorithm: Roulette selection and Elite selection. Elite selection means that one gene with maximum goodness of fit must be reserved for the next generation without crossover or mutation.
Crossover rate Pc: 0.9
Mutation rate Pm: 0.05
The experimental conditions of FPGA loop statements offload were as follows.
Narrowing down using arithmetic intensity: Narrow down to the top five loop statements of arithmetic intensity.
Narrowing down using resource efficiency: Narrow down to the top three loop statements in resource efficiency analysis. The implementation selects the top three loop statements with high arithmetic intensity/resource amount in this verification.
Number of measured offload patterns: 4. In the first measurement, the top three loop statement offload patterns were measured. Then, the second measurement was conducted with the combination pattern of two loop statement offloads that were high performance in the first measurement.
5.1.3. Experimental environment
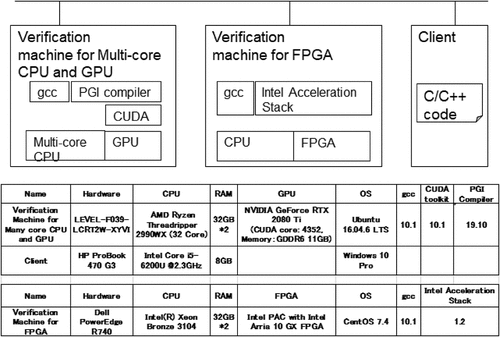
We use AMD Ryzen Threadripper 2990WX as a multi-core CPU device. Gcc 10.1 processes OpenMP for multi-core CPU control. We use GeForce RTX 2080 Ti as a GPU device. PGI compiler 19.10 and CUDA toolkit 10.1 process OpenACC for GPU control. Ryzen CPU and GeForce GPU are equipped on the same node. We use Intel Arria 10 GX FPGA as an FPGA device. Intel Acceleration Stack 1.2 process OpenCL to control FPGA that is installed on DELL EMC PowerEdge R740. shows the experimental environment and its specifications. A client note PC specifies the C/C++ application codes, which are converted and verified on verification machines. For commercial use, the final codes are deployed in running environments for users after verifications.
Figure 4. Experimental environment.
5.2. Performance results
We evaluated the performance improvements of applications with mixed offloading destination environments.
For three applications, shows the processing time by a single core of CPU, which device and which method were used for offloading, the offload processing time, the degree of performance improvement, and the results of offloading to another device. The degree of performance improvement shows how much the processing time of applications was improved. 1 means the same processing time when a sample test is processed by a single core of CPU on the offload destination machine after gcc or PGI compiler compiles.
Figure 5. Results of offloading to mixed offloading destination environment.
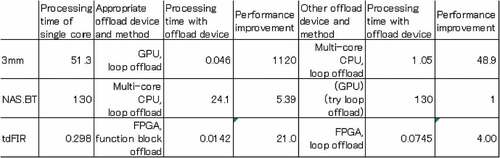
For 3 mm, our method added the #pragma acc kernels of OpenACC and the #pragma omp parallel for of OpenMP as the offload to GPU and to multi-core CPU of loop statements. These instructions of OpenACC and OpenMP are similar. For 3 mm, the processing time with a single core was 51.3 seconds, but by GPU with loop statement offload, it was processed in 0.046 seconds, and the improvement was 1120 times. After offloading loop statements to a multi-core CPU, 3 mm was processed in 1.05 seconds and the improvement was 44.5 times, and a higher performance GPU offloading was selected. For NAS.BT, our method added the #pragma omp parallel for of OpenMP as the offload of loop statements to a multi-core CPU. However, similar instructions using #pragma acc kernels with OpenACC could not be accelerated. For NAS.BT, the processing time with a single core was 130 seconds, but by multi-core CPU with loop statement offload, it was processed in 24.1 seconds, and the improvement was 5.39 times. When the implementation tried to offload loop statements to GPU, the processing time exceeded 130 seconds, so the result was 130-second processing by a single core of CPU without any offload. For tdFIR, our method used the OpenCL commands to offload function blocks and loop statements to FPGA, but tdFIR could not be accelerated on other devices. For tdFIR, the processing time in a single core was 0.298 seconds, but by FPGA with function block offload, it was processed in 0.0142 seconds, and the improvement was 21.0 times. Since the function block offloading was possible, the loop statement offloading of the remaining part where the function block was removed was not attempted. However, when the function block offloading was not performed and the looping statement offloading was performed by FPGA, the improvement was only 4.00 times.
In this experiment, 3 mm is a simple iterative calculation, NAS.BT is a slightly complicated block diagonal solver calculation, and tdFIR is signal processing, covering multiple types of applications used in assumed areas such as IoT. There is a risk that it may not be possible to speed up an application that is not suitable for offload, but for three applications it was possible to speed up on any of three devices with common ways such as GA of the proposed method.
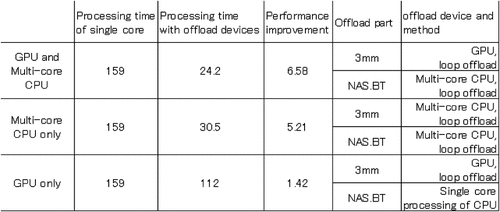
For 3 mm and NAS.BT combination application, shows the processing time by a single core of CPU, the total processing time, the total performance improvement, the offload part, and which device and which method were used for offloading. Even though it is clear that 3 mm performs best when offloaded to GPU and NAS.BT performs best when offloaded to multi-core CPU, it is not clear whether 3 mm offloaded to GPU and NAS.BT offloaded to multi-core CPU will achieve the best performance when they are combined. The proposed method automatically measures the combination performance, but this time, for evaluation, we also show the results when both processes are performed with only one device. The implementation processes 3 mm offloaded to GPU and NAS.BT offloaded to multi-core CPU. The total processing time, which was 159 seconds when only a single core was used, was 24.2 seconds and the improvement was 6.58 times. When both processes were performed on the multi-core CPU, the processing time was 30.5 seconds and the improvement was 5.21 times. In the case of the GPU, only 3 mm was offloaded to GPU, which had improved performance, and the processing time was 112 seconds and the improvement was 1.42 times. In this way, by properly using devices of the same node, processing can be performed faster than using a single device. This is a big effect of combination offloading of 3.3 and cannot be achieved by previous single device offloading.
Figure 6. Results of offloading to multiple devices on one node.
For three of the function block offloads in the six measurements, the search only takes a few minutes, but when using FPGA, implementing the replaced codes takes about 3 hours. For three of the loop statement offloads in the six measurements, FPGA verifications take half a day because it takes 3 hours for one pattern, and searching by a GA with a multi-core CPU or GPU takes about 6 hours each. For offload to multiple devices at the same node, the measurement itself takes a few minutes. As a result, all measurements take about a day.
5.3. Discussion
In our previous study on loop statement offloading to GPUs, we used a method of measuring the performances of multiple offloading patterns in a verification environment and searching for high-performance patterns automatically. For example, even large applications with more than 100 loop statements, such as Darknet, are automatically offloaded to GPUs and triple in performance. Because there are various applications, it is not always possible to speed up just by offloading loop statements to the GPU. Therefore, to use a heterogeneous device for more general purposes, it is necessary to speed up even if the offloading destinations are diverse. In this paper, the proposed method performs more than three times better, using mixed offload destination environments with GPU, FPGA, and multi-core CPU.
Regarding the offloading effect with costs, multi-core CPU chips, GPU boards, or FPGA boards cost about 1,000–4,000 USD. Therefore, a server with multi-core CPU, GPU, or FPGA costs about two to three times as much as that for only small-core CPU. In data center systems such as cloud systems, hardware, development, and verification costs are about 1/3 of the total cost; electricity and operation/maintenance costs are another 1/3; and other expenses, such as service orders, are the other 1/3. The data center cost comes from a public cloud of NTT. Therefore, we think automatically improving application performance by more than 3 times will have a sufficiently positive cost effect even though the hardware cost is about two to three times higher.
Regarding the time to start production services, in this verification example, verification took about 6 hours for the multi-core CPU, 6 hours for the GPU, and 12 hours for the FPGA. As for FPGA, it takes about 3 hours to set the actual circuit implementation from OpenCL, and the total time depends on the number of FPGA verification patterns. When we provide production services, we provide the first day for free and try to speed up using the verification environment during the first day, and from the second day, we provide the production service with multi-core CPUs, GPUs, and FPGAs. Typical service orders, such as cloud provisioning of a public cloud of NTT, take 1 day, thus, we think 1-day verification is acceptable. If the user wants to use a service immediately, on the basis of the verification order of the proposal, the user may use the service after completing the verification with only the function block offload or with multi-core CPU and GPU.
To offload function blocks, it is necessary to pre-register the libraries and IP cores commonly used by many applications in the DB. In addition to general-purpose processing such as FFT and matrix multiplication, functions are assumed to be registered in specific fields such as machine learning and signal processing. Code similarity detection is a technology for code maintenance in software engineering. Deckard checks similarities between the abstract syntax trees, but in software engineering there are line-based detection, lexical unit-based detection, program-dependent graph-based detection, metric and fingerprint-based detection, and so on. Therefore, it is conceivable to add a lexical unit-based that seems to be appropriate for function block offloading, or to use deep learning, which is currently making remarkable progress for code similarity detection.
For code similarity detection, Deckard looks for offloadable function blocks, but the code to be replaced is separate for multi-core CPUs, GPUs, and FPGAs, and it is unlikely that they are all ready. Therefore, it is assuming that there are many function blocks that cannot be offloaded to a specific destination, function block offload is used in combination with loop statement offload. If the same function block can be offloaded to multiple devices on multi-core CPUs, GPUs, and FPGAs, our method verifies for multiple destinations and selects a faster one.
Regarding loop statement offload to multi-core CPUs and GPUs, to search for the offload part in a shorter time, the performance can be measured in parallel for multiple verification machines. In addition, although the crossover rate Pc is set to a high value of 0.9 and a wide range is searched to find a certain performance solution early, parameter tuning is also conceivable. For higher speeds, the difficulty of automation increases, but it is conceivable to appropriately perform memory processing such as proper use of multiple memories.
Regarding loop statement offload to FPGA, to search for the offload part in a shorter time, the performance can be measured in parallel by multiple verification machines. It is also possible to tune parameters such as the number of narrowed down verifications. For faster speed, common speed-up methods of local memory cache, stream processing, multiple instantiations, loop statement expansion, nested loop statement integration, memory interleaving, and so on can be used when OpenCL is created. Multiple instantiations may speed up depending on the resource amount, and an appropriate value can be set in consideration of the available resource amount.
The proposed method is based on the fact that the data actually used by the user vary widely and the actual device verification is performed on each device to select a high-performance pattern. However, depending on the device characteristics, some degree of static distribution can be considered for the GPU and multi-core CPU offloading. Since the GPU has a large number of calculation cores but a different memory from the CPU, data transfer between CPU and GPU often becomes a bottleneck. Additionally, the index of arithmetic intensity is calculated by calculation frequency/data size. Therefore, it can be inferred that the loop statement with high arithmetic intensity is suitable for GPU, and the loop statement with moderate arithmetic intensity is suitable for multi-core CPU. It is assumed that GPU is suitable for loop statement processing that has a small data size and high calculation frequency to avoid a bottleneck of data transfer. From the performance results of 5.2, simple processing such as 3 mm is suitable for GPU offload, slightly complicated calculation such as NAS.BT is suitable for multi-core CPU, and signal processing is suitable for FPGA, but in production use, we think it is necessary to actually measure and confirm the performance by the proposed method.
Regarding Step 7 of environment-adaptive software, we study various reconfigurations of in-operation. If the sample data specified by the user used for optimization are ambiguous, it is assumed that re-optimization will be performed using the actual data in operation and reconfigured. There is a case that the iteration number and data size may not be decided unless it is in operation, but in such a case, it is conceivable to perform optimization calculation again during operation according to the actual usage data. We also study how to consider communication overhead by appropriate positioning with offloading in Steps 7 and 5 of environment-adaptive software.
6. Related work
GPU offloading areas were searched, and the GA was also used to search for them automatically in (Tomatsu et al., Citation2010). However, its target applications are limited, and a huge number of tunings are needed, such as calculations for 20 individuals and 200 generations. Chen et al. (Chen et al., Citation2012) used metaprogramming and just in time (JIT) compilation for GPU offloading of C++ expression templates, Bertolli et al. (Bertolli et al., Citation2015) and Lee et al. (Lee et al., Citation2009) investigated offloading to GPUs using OpenMP. There have been few studies on automatically converting existing code to a GPU. Our previous method (Yamato, Citation2019), which we also use in this paper, aims to complete the GA process in a short time.
Generally, CUDA and OpenCL control intra-node parallel processing and message passing interface (MPI) controls inter-node or multi-node parallel processing. However, MPI also requires high technical skills in parallel processing. Thus, MPI concealment technology has been developed that virtualizes devices of outer nodes as local devices and enables such devices to be controlled by only OpenCL (Shitara et al., Citation2011). When we select multi-nodes for offloading destinations, we plan to use this MPI concealment technology.
Even if an appropriate offloading area can be extracted, application performance may not be high when the resource balance of a CPU and devices is not appropriate. For example, a CPU takes 100 seconds and GPU 1 second when one task is processed so a CPU becomes a bottleneck. Shirahata et al. (Shirahata et al., Citation2010) attempted to improve the total application performance by distributing map tasks with the same execution times of a CPU and GPU in MapReduce processing. Referring to their paper, we investigate how to deploy functions with appropriate resource amounts to avoid bottlenecking any device processing.
Regarding FPGA offloading, Liu et al. (Liu et al., Citation2015) proposed a technology that offloads nested loops to FPGAs. The nested loops can be offloaded with an additional 20 minutes of manual work. Alias et al. (Alias et al., Citation2013) proposed a technology in which an HLS configures an FPGA by specifying C language code and loop tiling, and so on using Altera HLS C2H. Sommer et al. (Sommer et al., Citation2017) proposed a technology that can interpret OpenMP code and execute FPGA offloading. Putnum et al. (Putnam et al., Citation2008) used a CPU-FPGA hybrid machine to speed up a program with a slightly modified standard C language. There have been many studies on FPGA offloading, but instructions need to be manually added, such as which parts to parallelize using OpenMP or other specifications.
There are many reports on improving performance by offloading to GPU, FPGA, and multi-core CPU, but most approaches involve manually adding an instruction such as which part to parallelize like OpenMP directives. Few methods automatically offload existing codes. In addition, most methods consider only one type of device as an offloading destination, and few methods offload to mixed environments of GPU, FPGA, and multi-core CPU, which is the subject of this paper.
7. Conclusion
For a new element of our environment-adaptive software, we proposed an automatic offloading method for mixed offloading destination environments with various devices of graphics processing unit (GPU), field-programmable gate array (FPGA), and multi-core central processing unit (CPU). Environment-adaptive software adapts applications to the environments to use heterogeneous hardwares such as GPUs and FPGAs appropriately.
First, for preparation, we proposed an automatic offload method for loop statements for a multi-core CPU as one of various offloading destination environments, with reference to the evolutionary computation method for a GPU. Next, we studied the order of offload trials for each offloading device and the speed-up method when there were multiple offload candidates with one node. Specifically, the function block offload for multi-core CPU, the function block offload for GPU, the function block offload for FPGA, the loop statement offload for multi-core CPU, the loop statement offload for GPU, and the loop statement offload for FPGA are verified in this order. This is because function block offloading can be faster than loop statement offloading, and FPGA verifications take longer time to measure performance. Next, as a result of six offload verifications, if there are multiple offload candidates that can be accelerated, the implementation checks whether these candidates are at the same node. When different processes can be offloaded to different devices at the same node, these processes are offloaded to the devices, and the performance is measured. If the performance is higher than those for the other patterns, the offloading pattern is adopted. If it is not possible to offload to the same node, the fastest pattern is adopted among the six offload verifications of each device.
We implemented the proposed method, evaluated its automatic offloading in several applications to mixed offloading destination environments, and demonstrated its effectiveness. In the future, we will evaluate more applications with mixed environments to confirm the advantages and disadvantages of the proposed method. Furthermore, we will study how to improve its cost-effectiveness by adjusting the amount of processing resources of CPU, GPU, and FPGA in mixed offloading destination environments.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors

Yoji Yamato
Yoji Yamato received a B.S. and M.S. in physics, and a Ph.D. in general systems studies from the University of Tokyo in 2000, 2002, and 2009. He joined NTT in 2002, where he has been conducting developmental research on a cloud computing platform, an IoT platform and a technology of environment-adaptive software. Currently, he is a distinguished researcher at NTT Network Service Systems Laboratories. Dr. Yamato is a senior member of IEEE and IEICE, and a member of IPSJ.
References
- Alias, C., Darte, A., & Plesco, A. (2013, March). Optimizing remote accesses for offloaded kernels: Application to high-level synthesis for FPGA. 2013 Design, Automation and Test in Europe (DATE), 575–23. https://doi.org/10.7873/date.2013.127
- Bertolli, C., Antao, S. F., Bercea, G. T., Jacob, A. C., Eichenberger, A. E., Chen, T., Sura, Z., Sung, H., Rokos, G., Appelhans, D., & O’Brien, K., “Integrating GPU support for OpenMP offloading directives into Clang,” ACM Second Workshop on the LLVM Compiler Infrastructure in HPC (LLVM’15), November. 2015.
- Chen, J., Joo, B., Watson, W., III, & Edwards, R., “Automatic offloading C++ expression templates to CUDA enabled GPUs,” 2012 IEEE 26th International Parallel and Distributed Processing Symposium Workshops & PhD Forum, pp.2359–2368, May 2012.
- Deckard web site. 2021. http://github.com/skyhover/Deckard
- DPC++ web site 2021. https://www.intel.com/content/www/us/en/developer/tools/oneapi/dpc-library.html#gs.flx6xq
- Evans, P. C., & Annunziata, M., “Industrial internet: Pushing the boundaries,” Technical report of General Electric (GE) (General Electric), November. 2012.
- Gosling, J., Joy, B., & Steele, G. (2005). The Java language specification, third edition. Addison-Wesley. ISBN-10: 0-321-24678-0
- Hermann, M., Pentek, T., & Otto, B. (2016). Design principles for industrie 4.0 scenarios. 2016 49th Hawaii international conference on system sciences (HICSS), 3928–3937. https://doi.org/10.1109/hicss.2016.488
- Holland, J. H. (1992). Genetic algorithms. Scientific American, 267(1), 66–73. https://doi.org/10.1038/scientificamerican0792-66
- Lee, S., Min, S. J., & Eigenmann, R., “OpenMP to GPGPU: A compiler framework for automatic translation and optimization,” 14th ACM SIGPLAN symposium on Principles and practice of parallel programming (PPoPP’09), 2009.
- Liu, C., Ho-Cheung, N., & Kwok-Hay So, H., “Automatic nested loop acceleration on FPGAs using soft CGRA overlay,” Second International Workshop on FPGAs for Software Programmers (FSP 2015), 2015.
- NAS.BT web site. 2022. https://www.nas.nasa.gov/publications/npb.html
- Polybench 3mm web site. 2012. https://web.cse.ohio-state.edu/pouchet.2/software/polybench/
- Polytope model web site. https://www.infosun.fim.uni-passau.de/cl/loopo/doc/loopo_doc/node3.html
- Putnam, A., Bennett, D., Dellinger, E., Mason, J., Sundararajan, P., & Eggers, S., “CHiMPS: A C-level compilation flow for hybrid CPU-FPGA architectures,” IEEE 2008 International Conference on Field Programmable Logic and Applications, pp.173–178, September. 2008.
- Putnam, A., Caulfield, A. M., Chung, E. S., Chiou, D., Constantinides, K., Demme, J., Esmaeilzadeh, H., Fowers, J., Gopal, G. P., Gray, J., Haselman, M., Hauck, S., Heil, S., Hormati, A., Kim, J.-Y., Lanka, S., Larus, J., Peterson, E., Pope, S., … Burger, D., “A reconfigurable fabric for accelerating large-scale datacenter services,” Proceedings of the 41th Annual International Symposium on Computer Architecture (ISCA’14), pp.13–24, June 2014.
- ROSE compiler framework web site. 2022. http://rosecompiler.org/
- Sanders, J., & Kandrot, E. (2010). CUDA by example: An introduction to general-purpose GPU programming. Addison-Wesley. ISBN: 9780132180160
- Sefraoui, O., Aissaoui, M., & Eleuldj, M. (2012). OpenStack: Toward an open-source solution for cloud computing. International Journal of Computer Applications, 55(3), 38–42. https://doi.org/10.5120/8738-2991
- Shirahata, K., Sato, H., & Matsuoka, S., “Hybrid map task scheduling for GPU-based heterogeneous clusters,”IEEE Second International Conference on Cloud Computing Technology and Science (CloudCom), pp.733–740, December. 2010.
- Shitara, A., Nakahama, T., Yamada, M., Kamata, T., Nishikawa, Y., Yoshimi, M., & Amano, H., “Vegeta: An implementation and evaluation of development-support middleware on multiple OpenCL platform,” IEEE Second International Conference on Networking and Computing (ICNC 2011), pp.141–147, 2011.
- Sommer, L., Korinth, J., & Koch, A., “OpenMP device offloading to FPGA accelerators,” 2017 IEEE 28th International Conference on Application-specific Systems, Architectures and Processors (ASAP 2017), pp.201–205, July 2017.
- Sterling, T., Anderson, M., & Brodowicz, M. (2018). High performance computing: Modern systems and practices. Morgan Kaufmann.
- Stone, J. E., Gohara, D., & Shi, G. (2010). OpenCL: A parallel programming standard for heterogeneous computing systems. Computing in Science & Engineering, 12(3), 66–73. https://doi.org/10.1109/MCSE.2010.69
- Su, E., Tian, X., Girkar, M., Haab, G., Shah, S., & Petersen, P., “Compiler support of the workqueuing execution model for Intel SMP architectures,” In Fourth European Workshop on OpenMP, September. 2002.
- SYCL web site. 2020. https://www.khronos.org/sycl/
- Time domain finite impulse response filter Intel sample web site. https://www.intel.com/content/www/us/en/programmable/support/support-resources/design-examples/design-software/opencl/td-fir.html
- Time domain finite impulse response filter web site. 2020. http://www.omgwiki.org/hpec/files/hpec-challenge/tdfir.html
- Tomatsu, Y., Hiroyasu, T., Yoshimi, M., & Miki, M. (2010, August). gPot: Intelligent compiler for GPGPU using combinatorial optimization techniques. The 7th Joint Symposium between Doshisha University and Chonnam National University. Doshisha University and Chonnam National University.
- Wienke, S., Springer, P., Terboven, C., & an Mey, D. (2012). OpenACC-first experiences with real-world applications. Euro-Par 2012 Parallel Processing, 859–870. https://doi.org/10.1007/978-3-642-32820-6_85
- Wolfe, M., “Implementing the PGI accelerator model,” ACM the 3rd Workshop on General-Purpose Computation on Graphics Processing Units, pp.43–50, March. 2010.
- Yamato, Y. (2015, October). Automatic system test technology of virtual machine software patch on IaaS cloud. IEEJ Transactions on Electrical and Electronic Engineering, 10(S1), 165–167. https://doi.org/10.1002/tee.22179
- Yamato, Y., Fukumoto, Y., & Kumazaki, H., “Analyzing machine noise for real time maintenance,” 2016 8th International Conference on Graphic and Image Processing (ICGIP 2016), October. 2016.
- Yamato, Y., “Proposal of optimum application deployment technology for heterogeneous IaaS cloud,” 2016 6th International Workshop on Computer Science and Engineering (WCSE 2016), pp.34–37, June 2016.
- Yamato, Y., Fukumoto, Y., & Kumazaki, H., “Security camera movie and ERP data matching system to prevent theft,” IEEE Consumer Communications and Networking Conference (CCNC 2017), pp.1021–1022, January. 2017.
- Yamato, Y., “Proposal of vital data analysis platform using wearable sensor,” 5th IIAE International Conference on Industrial Application Engineering 2017 (ICIAE2017), pp.138–143, March. 2017a.
- Yamato, Y., “Experiments of posture estimation on vehicles using wearable acceleration sensors,” The 3rd IEEE International Conference on Big Data Security on Cloud (BigDataSecurity 2017), pp.14–17, May 2017b.
- Yamato, Y. (2019). Study of parallel processing area extraction and data transfer number reduction for automatic GPU offloading of IoT applications. Journal of Intelligent Information Systems, Springer, 54(3), 567–584. https://doi.org/10.1007/s10844-019-00575-8
- Yamato, Y., “Proposal of automatic offloading for function blocks of applications,” The 8th IIAE International Conference on Industrial Application Engineering 2020 (ICIAE 2020), pp.4–11, March. 2020.
- Yamato, Y. (2021). Automatic offloading method of loop statements of software to FPGA. International Journal of Parallel, Emergent and Distributed Systems, Taylor and Francis, 36(5), 482–494. https://doi.org/10.1080/17445760.2021.1916020