
ABSTRACT
We conducted three experiments to analyze the respective roles of the joint influence account and the word production architecture account within the cross-modal Stroop effect. We utilized a varied time course of targets and distractors and investigated the possible asymmetry of visual and auditory targets to determine the underlying mechanism of interference. In Experiment 1, we used color patches as the visual target. We found color-word Stroop asymmetry that supported the word-production architecture account; there was a Stroop interference effect when participants named visual but not auditory targets. In Experiment 2, we used printed words as the color carrier instead of color patches. The size of interference in visual targets in Experiment 2 was still greater than in auditory targets and was driven by additive interference from the visual distractor dimension, which supported the joint influence account. In Experiment 3, which was a replication of Experiment 2 that removed the integrated incongruent visual distractor, we concluded that target and distractor integration played a key role in moderating the size of the interference effect, and that the lesser interference after removing the incongruent visual distractor supported the joint influence account. In almost every possible combination of conditions, we detected color-word Stroop asymmetry, and while the results were consistent with both the joint influence and word production architecture account when color patches were used as the color carrier, the joint influence account could more completely explain the findings regardless of the color carrier. Further research should be done to establish how target and distractor integration operates within and across modalities, as well as the contexts in which the word production architecture account applies.
One of the most widely studied tasks in psychology, listed with over 20,000 citations on Google Scholar, is the Stroop color-word task (Stroop, Citation1935; for a review, see, MacLeod & MacDonald, Citation2000). The traditional Stroop task involves naming the ink color of a color word, and each ink color compared to the color word will either be congruent (e.g., the word “blue” presented in blue) or incongruent (e.g., the word “blue” presented in green). Participants typically experience increased difficulty, as measured by lower accuracy and longer response times, in color naming performance during incongruent trials compared to congruent trials. This task and its variations have been widely studied because they allow psychologists to explore selective attention in terms of how much control we truly have over what we process. In applied contexts, this task helps researchers to have a better understanding of how much or how little we can avoid irrelevant information that can distract us from a task.
Within the traditional Stroop paradigm, participant responses tend to follow a general pattern that is known as the Stroop effect and has two components: Stroop interference and Stroop facilitation (MacLeod & MacDonald, Citation2000; Roelofs, Citation2005). As mentioned above, Stroop interference is found when participants generally perform slower and less accurately on incongruent color naming trials than control trials. Conversely, Stroop facilitation is found when participants perform faster and more accurately on congruent trials than control trials. In addition, there is also an interesting pattern known as Stroop asymmetry (e.g., MacLeod & MacDonald, Citation2000; Stroop, Citation1935) in that when instructions are reversed such that participants must name the printed word and ignore the color of the text, there is no interference. This difference in interference based on whether the target is a color and the distractor is a word (i.e., interference) or vice-versa (i.e., no interference) has been utilized as a tool for understanding the underlying mechanisms of interference in the traditional paradigm. While this pattern of findings has been demonstrated in the visual version of the task, much less research exists on the asymmetry of the cross-modal variant of the Stroop task (Roelofs, Citation2005).
The Stroop effect has been explored beyond the traditional paradigm through the cross-modal Stroop task (e.g., Cowan & Barron, Citation1987). Compared to the traditional Stroop task which utilizes the same modality for both targets and distractors, the cross-modal Stroop variant uses a visual target that is typically a color patch and an auditory distractor that is typically a spoken color word, although other modality combinations are possible as well (e.g., Razumiejczyk et al., Citation2015). Congruent trials consist of the visual target matching the auditory distractor, while incongruent trials consist of a visual target and auditory distractor mismatch. Research by Roelofs (Citation2005) and Francis et al. (Citation2017) have investigated the cross-modal variation of the paradigm in terms of its asymmetry and time course, and the joint influence of multiple stimuli, respectively. One overarching goal of cross-modal Stroop research in general is to understand selective attention by exploring how Stroop task interference effects differ in visual versus auditory contexts, and in unimodal versus cross-modal contexts. The current research continues this aim by using the empirical signatures of the effects of asymmetry and time course on the size of the cross-modal Stroop effect to understand the underlying mechanism(s) of interference.
Stroop Asymmetry and the Importance of Stimulus Timing
Stroop asymmetry is of particular interest because it allows for comparisons between unimodal and cross-modal Stroop interference effects, and tests for the way distractors are causing interference. There have been three major accounts for the causes behind color-word Stroop asymmetry. The first two, which are similar in nature, are the relative pathway strength account (Cohen et al., Citation1990) and the dimension discriminability account (Melara & Algom, Citation2003). The relative pathway strength account states that inadvertent activation of the stronger pathway interferes with the use of the weaker pathway, and not the other way around. Word naming typically has a stronger pathway than ink color naming given our greater practice at reading, which is reflected by response times in the literature. This account explains why distractor words disrupt color naming in the Stroop effect but not the other way around. This account could also generate predictions regarding experimental designs using stimulus-onset asynchronies (SOAs), which refer to the amount of time between the presentations of the target and distractor. The relative pathway strength account would predict that distractor-first SOA’s should have the most interference, but behavioral data have shown that they do not (Glaser & Glaser, Citation1982).
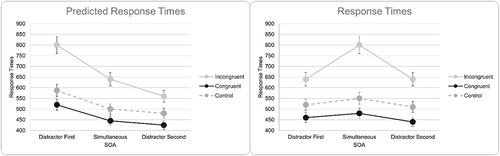
The dimension discriminability account is similar to the relative pathway strength account but substitutes pathway strength with discriminability. In the Stroop literature, target stimuli comprising words have been established as having more dimension discriminability (i.e., the ease with which a stimulus can be distinguished along a dimension such as color, as measured by response time) in control conditions than with color target stimuli. The dimension discriminability account states that the more discriminable dimension should interfere with the less discriminable dimension when the two are at odds with each other, but not the other way around. In the Stroop effect, words are easier to discriminate meaning color target stimuli with word distractors should have a greater Stroop effect than word target stimuli with color distractors, which seems to be the case (Melara & Algom, Citation2003). However, like the previous account, this account suffers from incorrectly predicting that distractor-first SOAs will have the most interference when they do not. Examples of how the two accounts would predict Stroop task performance in experimental designs using SOAs are shown in on the left. Examples of typical performance as observed in the literature (e.g., Elliott et al., Citation1998; Roelofs, Citation2005) are shown in on the right.
Figure 1. Predicted time courses for mean naming latencies (left) and typical empirical time courses for mean naming latencies (right) for color naming incongruent, congruent, and control spoken color word distractors. The time courses on the left are predicted by the relative pathway strength and the dimension discriminability accounts.
The third account of the Stroop color-word asymmetry is the word production architecture account (Roelofs, Citation1992). This account states that words have priority for pronunciation while pictures have priority for meaning. This applies to the Stroop task because colors are analogous to pictures in that they almost demand meaning to process: color naming requires controlled mapping through the selection of a “lemma,” which is a syntactic entity that mediates between word form and word meaning. On the contrary, word pronunciation can simply be completed with shallow form-to-form mapping (i.e., mapping the written or spoken word to a mental word form) and this does not require lemma selection or processing of meaning. Controlled mapping is only necessary when the speaker intends to name the color and lemma selection is needed to process some meaning. This difference in architectures for word production and color processing is consistent with simultaneous stimulus and distractor presentations generally having the greatest interference (Roelofs, Citation2003) while distractor-first SOA’s do not because regardless of preexposure, the different architectures and their associated mapping methods remain the same. A major example in support of the word production architecture account is a four-part study exploring Stroop asymmetry in the cross-modal Stroop task involving written-word, spoken-word, and color naming (Roelofs, Citation2005).
In the research by Roelofs (Citation2005), distractor onset varied in a range between 300 milliseconds before to 300 milliseconds after target onset. Results showed that in color naming with spoken word distractors (Expt. 1), spoken color word naming with written color-word distractors (Expt. 3), and written color word naming with spoken distractors (Expt. 4), Stroop interference was found. The only experiment without significant Stroop interference was spoken color-word naming with color-patch distractors (Expt. 2). These results were interpreted as support for the word production architecture account. This is because words, written and spoken, showed priority for pronunciation (i.e., naming) while colors did not. Further, the largest interference effects were found when the SOA was at 0 milliseconds, which is a typical pattern (see, ) in line with the word production architecture account, but not the relative pathway strength or dimension discriminability accounts that would predict the largest interference at distractor-first SOAs (see, ). Overall, while this research supports the word production architecture account over the relative pathway and the dimension discriminability accounts, this support is based on one study so we were seeking to expand on it.
Stimuli Modalities and the Importance of Integration versus Separation
One of the benefits of the Stroop effect is it allows researchers to examine how selective attention differs when stimuli are presented in one or more modalities. Stroop interference effects can be explored through the comparison of target stimulus integration (as is typically the case in the unimodal version) and separation (as is the case in cross-modal version). For example, in the unimodal version of the Stroop task, one line of questioning has explored whether the presence of two visual distractors increases interference. Studies have found that two incongruent visual distractors which were either consistent or inconsistent with each other generally did not increase interference compared to one incongruent visual distractor (Kahneman & Chajczyk, Citation1983; MacLeod & Bors, Citation2002; Yee & Hunt, Citation1991). One explanation of this finding has been the capture account, which argues the first distractor captures so much attention that second distractor is not attended to enough to impact interference (Kahneman & Chajczyk, Citation1983). However, this account has since been challenged by the finding that when a congruent distractor was mixed with an incongruent distractor, the incongruent distractor’s interference effect was reduced (MacLeod & Bors, Citation2002). MacLeod and Bors (Citation2002) explained this finding with a joint influence account, which proposed that every stimulus during a trial is attended to and impacts processing. During their study, the word dimension continued to be monitored during multiple word ink color naming. One natural progression from learning that the word dimension continued to be monitored after the first Stroop stimulus was to consider if auditory distractors would continue to be monitored in the same fashion. In the cross-modal version of the Stroop task, findings from the limited work on this topic have been mixed. For example, Cowan and Barron (Citation1987) presented multiple stimuli, such as an incongruent pairing of a written color word in a different color font with the presence of an auditory color word as a distractor and found that auditory and visual distractor words had additive interference effects. However, Elliott et al. (Citation2014) did not find the same pattern of results, though the difference in outcomes between those two studies might be attributed to methodological differences in stimuli timing. A more recent study addressed these discrepancies in findings regarding cross-modal Stroop and investigated whether a pattern of joint influence truly exists between the visual and auditory modality (Francis et al., Citation2017).
Francis et al. (Citation2017) found that interference effects were stronger when two distractors were present rather than one distractor, regardless of consistency with each other (e.g., seeing and hearing the word “blue” resulted in a greater interference effect as compared to a red colored word than a visual or auditory distractor by itself). Further, auditory and visual distractors as different words independently contributed to interference regardless of integration, and the interference from two visual distractors was greater during integrated visual distractors compared to spatially separated ones. These findings were interpreted as consistent with the joint influence account, especially when considering that two different irrelevant words on the same trial resulted in greater interference; an explanation that does not align with the capture account.
Comparisons between the Models of the Stroop Effect
Thus far, support has been provided within the existing literature for both the word production architecture account and the joint influence account; however, different variables were manipulated in those separate streams of research. Insights on how multiple sources of distractors affect Stroop interference over the time course, and whether functional differences in architecture affecting word naming and color naming remain the same under this context, would be important for advancing both accounts. However, it is difficult to directly compare the primary studies for both the word production architecture and joint influence accounts due to methodological differences (i.e., SOA’s only used within the word production architecture account research and multiple sources of interference only used within the joint influence account research). One goal of the present study was to resolve this methodological problem by using experimental manipulations of both SOAs and multiple sources of interference to compare and further characterize the word production architecture and joint influence accounts.
Experiment 1
This experiment consisted of two parts, a baseline portion (Part A) and an experimental portion (Part B). In Part A, participants named the color of squares and repeated auditory color words without distractors in separate sets of trials to determine the rate of responding for the auditory and visual channels. This design provided a baseline for the control conditions in the two modalities during the experimental portion, without the potentially biasing context of having distracting stimuli present. In Part B, participants named the color of squares while attempting to ignore spoken color word distractors, and repeated spoken color words while attempting to ignore color square distractors. Comparing subject performance when given visual color squares and auditory words in both the target and distractor capacities allowed us to explore the differences between each in terms of Stroop asymmetry while including the time course helped to test the word production architecture account. There are two hypotheses for Part B. The word-production architecture account predicts that there should be Stroop asymmetry: no Stroop interference effect in the Auditory Targets condition when color patches are used as distractors, and a Stroop interference effect in the Visual Targets condition when spoken distractor words are used as distractors. The word-production architecture account also predicts that maximal interference should occur at the simultaneous SOA. Overall, Experiment 1 is an attempted replication of Experiments 1 and 2 of Roelofs (Citation2005) but instead of having separate experiments, we combined them into one design.
Method
Participants
Sixty-eight Louisiana State University undergraduates were tested for course or extra credit (age M = 20.32, SD = 1.93). Participants were not eligible to participate if they reported abnormal hearing, color vision, mind-altering medications, or a first language other than English. Four participants were excluded from all analyses for not fulfilling these requirements. Two participants were removed due to data collection errors (final N = 62). This experiment was a replication of prior work that involved much fewer subjects (N = 14; Roelofs, Citation2005) and we selected the sample size by increasing our sample to more than twice the original sample size in each of our between-participants groups (N = 31 in each task order).
Materials
All experimental manipulations, except for task order, were within subjects. Part A consisted of two tasks, which were counterbalanced: Naming Colors and Repeating Colors. In Naming Colors, participants named the color of a square as quickly and accurately as possible. Squares were chosen based on their usage in several prior studies; however, the choice of visual stimulus does not significantly influence the size of the interference observed (Lutfi-Proctor et al., Citation2014). In Repeating Colors, participants repeated an auditory color word as quickly and accurately as possible. The auditory words were a recorded female voice presented through headphones at a subjectively equal and comfortable volume. In both tasks, only the colors red, blue, and green were used. The auditory color words were 280 ms (blue), 270 ms (green), and 340 ms (red) in duration, and the colors were presented randomly, an equal number of times. Before starting the study, participants were instructed to name the color of the target as quickly and accurately as possible, and not to wait for the distractor to finish. This part of the instruction is most relevant to the Visual Targets task because they are paired with auditory distractors that, unlike the targets, unfold over time due to their modality.
Part B, again, consisted of two tasks, which were also counterbalanced: Auditory Targets and Visual Targets. In Auditory Targets, participants repeated spoken color words while seeing color squares which were incongruent or congruent to the spoken word, a blank screen, or visual catch trial (a black circle). Catch trials were included to ensure that participants were looking at the screen during the Auditory Targets task. To equate the two tasks, this condition was also included in the Visual Targets version. In Visual Targets, participants named the color of squares while hearing incongruent and congruent words, silence, and catch trials (the word “tall”). The Part B tasks are titled Visual Targets and Auditory Targets, as opposed to Repeating Colors and Naming Colors in Part A, because the purpose of Part B was to assess selective attention for targets in the presence of distractors rather than establish baselines. To summarize, there were 4 different congruency conditions: congruent (dimensions matched), incongruent (dimensions mismatched), neutral (the visual or auditory dimension was presented alone) and catch (they were asked to attend to the opposite modality of the task for a trial). For both tasks, the SOA was varied so that the auditory stimulus was presented 500 ms before (+500 ms or sound first), simultaneously with (0 ms or simultaneous), and 500 ms after (−500 ms or visual first) the visual stimulus (see, ). An SOA of 500 was chosen to allow the spoken word to be completely presented. This manipulation led to a 3 (SOA: +500 ms, 0 ms, −500 ms) x 4 (congruency: incongruent, congruent, control, catch) repeated-measures design for both tasks. The experiment was presented using E-Prime 2.10 software on a Dell Dimension desktop computer with a 17-inch monitor (Psychology Software Tools, Pittsburgh, PA). A headset microphone connected to a response box logged the vocalization onsets and recorded the participants’ response times. The task was completed in approximately 30 minutes.
Figure 2. a) Experiment 1 visual targets where participants must name the color of the patch; b) Experiment 1 auditory targets where participants must name the auditory stimulus.

Procedure
Every trial in Part A began with a fixation cross in the center of the screen, which remained for 500 ms. For Naming Colors, the visual targets were then presented on the screen and remained until the microphone detected a response. The experimenter used the keyboard to answer three questions: the response the participant gave, whether a false start occurred (the microphone was triggered with an incomplete response), and whether the experimenter made an error in answering the previous questions. The Repeating Colors task was identical except participants heard a color word after the fixation cross and the screen remained blank until the microphone was triggered. Each task began with 6 practice trials with each of the colors presented twice, and then 45 experimental trials with each color presented 15 times followed.
In Part B, each trial began with a fixation cross in the center of the screen for 500 ms. Depending on the SOA condition, the auditory and visual stimuli were then either presented simultaneously, with the auditory stimulus being heard and then the visual stimulus appearing, or with the visual stimulus present on screen followed by the auditory stimulus.
For each task, incongruent, congruent, and control trials were presented an equal number of times, and the 6 possible incongruent combinations were shown the same number of times (9): red-blue, red-green, blue-red, blue-green, green-red, and green-blue. The same was true of the congruent trials (18): red-red, blue-blue, and green-green, and control trials. Both conditions – SOA and congruency – were intermixed and randomly presented.
Participants completed 9 practice trials involving both the visual and auditory stimuli with varying SOAs, and then 171 experimental trials. Each SOA condition (0 ms, 500 ms, and −500 ms) was presented 57 times, contained 3 catch trials, and 18 trials of each congruency condition. The numbers for each type of trial were held constant for both the Visual and Auditory Targets Tasks.
In the Auditory Targets task, participants heard a spoken color word while seeing a colored stimulus, a blank screen, or a black circle. Participants were told to repeat the word they heard as quickly and accurately as possible except when they saw a black circle, when their task was to say “circle” instead of the spoken word. Catch trials were included to ensure that participants were looking at the screen during the Auditory Targets task. To equate the two tasks, this condition was also included in the Visual Targets version.
In the Visual Targets task, participants named the color of a visual stimulus while hearing spoken words, silence, or a non-color word (“tall”). Participants were told to name the color of the stimulus as quickly and accurately as possible except for when they heard the word “tall” (catch trial) when they would say “tall” instead of the color of the visual stimulus.
Results
ANOVAs were used to analyze the means of medians of response times, which were used in all the following experiments,Footnote1 the count of inaccurate trials, and the effect of the counterbalance order. For Part A (color naming and repeating baseline), a total of 0.86% trials were removed due to response errors, 0.73% because of false starts, and 0.02% for experimenter errors. For Part B (Visual Targets and Auditory Targets), a total of 1.98% trials were removed due to inaccurate responses, 0.92% because of false starts, and 0.03% for experimenter errors. Catch trials were not included in any of the RT and error analyses (this is consistent across all three experiments; see Appendix A for means and standard deviations).Footnote2 All error analyses are reported for all experiments in Appendix B.
For all analyses across the three experiments α = .05, and the Bonferroni correction was used for follow-up tests. In cases where sphericity was violated and the results were significant, the Greenhouse-Geisser correction was used. All analyses also focused on response times instead of accuracy because response times were most helpful with informing theoretical predictions, partially due to low task difficulty resulting in very high accuracy results.
Part A: Color Naming and Color Repeating Baseline
ANOVAs were used to analyze the effect of the counterbalance order (between-subjects) on the response times for the two tasks (within-subjects).
There was a main effect of task on response times, F (1, 60) = 138.43, p < 0.01, ηp2 = 0.70, with participants taking significantly longer to repeat an auditory word, M = 671.54 (SD = 137.32) than to name a color, M = 514.71 (SD = 85.71). However, there was no significant main effect of task order nor a significant task and task order interaction.
Part B: Visual Targets and Auditory Targets
Separate 2 (task order) x 2 (task) x 3 (congruency) x 3 (SOA) ANOVAs were used to analyze the effect of the counterbalance order (between-subjects) on response times for the two tasks.
Task order did influence response times; however, due to the results from both tasks being affected similarly (it was the magnitude of the effects which differed), task order was removed from all further analyses. A 2 (task) x 3 (SOA) x 3 (congruency) repeated-measures ANOVA was then conducted on response times. The three-way interaction between task, SOA, and congruency was significant, F (3.07, 187.11) = 15.82, p < 0.01, η2 p = 0.21. In order to analyze the significant three-way interaction among task, SOA, and congruency, separate repeated-measures ANOVAs were then run for each task.
For Auditory Targets, there was a main effect of SOA, F (1.57, 95.49) = 7.49, p < 0.01, ηp2 = 0.11, with response times for trials with simultaneous onsets > sound first = visual first (p < 0.001), simultaneous onsets = visual first (p = 0.053), and no statistically significant difference between sound first and visual first (p = 1). There was also a significant main effect of congruency, F (1.57, 95.78) = 39.66, p < 0.01, ηp2 = 0.39, with response times for control trials > congruent (p < 0.001), control ≥ incongruent (p < 0.001), and no statistically significant difference between congruent and incongruent trials (p = 0.535; see, ). The interaction was not significant.
Figure 3. Means of median response times with standard error bars for Experiment 1.
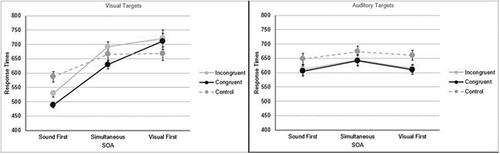
For Visual Targets, the main effect of congruency was also significant (congruent < incongruent = control), F (1.44, 87.86) = 12.00, p < 0.01, ηp2 = 0.17, as was the main effect of SOA (sound first < simultaneous < visual first), F (1.25, 75.97) = 78.80, p < 0.01, ηp2 = 0.56, and the interaction, F (2.70, 164.09) = 19.04, p < 0.01, ηp2 = 0.24 (see, ). The pattern of results was similar to those in Auditory Targets when the sound was first, congruent < incongruent < control, all p’s < 0.01. When the visual item was first, control < congruent (p = 0.01), and control < incongruent (p < 0.01), while the congruent and incongruent conditions did not differ significantly (p = 1). During simultaneous onsets, the pattern was congruent < incongruent (p < 0.001) while the other two comparisons were not statistically significantly different (congruent < control, p = 0.059; control < incongruent p = 0.224).
Discussion
The results provided evidence for color-word Stroop asymmetry (i.e., there was an absence of a Stroop interference effect when the target was an auditorily-presented word) and supported the hypothesis that, based on the word production architecture account, we would detect maximal interference during the simultaneous SOA. These findings also lend support to the word production architecture account because there was a moderate Stroop interference effect for spoken color word distractors (i.e., the Visual Targets condition) but not color patch distractors (i.e., the Auditory Targets condition), which is predicted by the account due to higher priority for written and spoken words than color patches. However, the overall pattern of response times across the SOAs was not the same as Roelofs (Citation2005).
The color-word Stroop asymmetry replicated the findings in Roelofs (Citation2005) in terms of the Stroop interference effect. In Visual Targets, we found a condition by SOA interaction and evidence that incongruent trials were slower than congruent trials during simultaneous and Sound First SOA’s, but not Visual First SOA’s. In Auditory Targets, we found that there was no condition by SOA interaction, and that the main effect of condition was not due to a difference between congruent and incongruent trials, but instead due to slower control trials. Specifically, Roelofs (Citation2005) also found a condition by SOA interaction and slower incongruent than congruent trials during simultaneous and Sound First SOA’s in visual targets (his Experiment 1), and neither a condition by SOA interaction nor differential effects between congruent and incongruent trials at any SOA in auditory targets (his Experiment 2).
While our major results in terms of the Stroop effect were consistent with Roelofs (Citation2005), there were differences in the individual patterns of trial types. For example, for auditory targets in his Experiment 2, Roelofs found a slowing of response times across SOA going from distractor-first to simultaneous to target-first SOA’s, which we did not replicate in our own auditory target condition. We did not replicate trends in response times across SOA that Roelofs found for visual targets in his Experiment 1, either. One explanation for differences between the current study and the work of Roelofs is methodological in nature. Firstly, the current study had N = 62 compared to N = 14 from Roelofs (Citation2005). Secondly, our time course maxed at −500 and +500 ms rather than −300 and +300 ms. Thirdly, our pre-trial screens used fixation crosses rather than blank screens. Finally, our catch trials consisted of “tall” and black circles while Roelofs (Citation2005) replaced some visual stimuli with crosses randomly as visual attention checks that required participants to press a button upon cross detection to proceed.
To better understand similarities and differences between the current Experiment 1 and the work of Roelofs, Experiment 2 was conducted. We planned to examine our findings across two experiments, to do a within-lab conceptual replication of our Experiment 1, as well as to examine the joint-influence account discussed in the introduction.
Experiment 2
Experiment 2 was comparable to Experiment 1 in the overall design; however, some changes were made. In past literature on the traditional Stroop effect, it has been found that having multiple, visual distractors in a trial lessens the magnitude of the Stroop effect (Cho et al., Citation2006; Kahneman & Chajczyk, Citation1983; Yee & Hunt, Citation1991). This finding is typically referred to as dilution and is attributed to additional stimuli lessening the amount of attention directed toward the actual target (the color; Chajut et al., Citation2009; Mitterer et al., Citation2003). This finding has been described by a capture account, which states that whichever distractor gets attended to first captures attention and causes the other(s) to not be processed sufficiently enough to contribute to interference (Kahneman & Chajczyk, Citation1983). On the other hand, Francis et al. (Citation2017) found distractors in both the visual and auditory modalities were stronger when there were multiple distractors compared to single distractors. Different distractors independently contributed to interference regardless of integration, but the interference was greater when the distractor was integrated or in the same modality with the target, as opposed to spatially separated. These findings were interpreted as consistent with the joint influence account, especially when considering that two different irrelevant words on the same trial resulted in greater interference; an explanation that does not align with the capture account. Our hypothesis in this experiment was that the presence of multiple visual and auditory distractions per trial would result in increased interference effects compared to Experiment 1, given that the joint influence account has previously been supported in the cross-modal version over the capture account.
Thus, to examine the effects of additional stimuli and the impact of joint interference, we manipulated SOA, congruency, and whether participants responded to the auditory or visual modality, as in Experiment 1, but we changed the type of visual target from a color square to a color-carrying color word. The participants’ task was to name the font color of the word while they have to ignore the written color word. The joint influence account predicts that this experiment should display greater interference than Experiment 1 because of the presence of multiple distractors.
This experiment was a replication and extension of Roelofs (Citation2005), our own Experiment 1, and of the work of Francis et al. (Citation2017). As mentioned, Experiment 2 was similar to Experiment 1 but with a greater scope that addressed the designs of Roelofs (Citation2005) and Francis et al. (Citation2017) simultaneously and allowed for comparison. Roelofs also replaced color patches with color words in his Experiments 3 and 4. However, what extended our experiment from Roelofs was that our color words were not in plain text. The color word stimuli themselves had color, which was the case in Francis et al. (Citation2017). To provide a more direct comparison to Roelofs (Citation2005), we changed the SOAs from a 500 ms timing schedule to a 300 ms timing schedule. This change also allowed the unfolding of the auditory word to be closer to the presentation of the visual item when the sound was presented first.
Methods
Participants
Participants consisted of 60 Louisiana State University undergraduates who participated for course or extra credit. Participants were unable to participate if they did not meet the same requirements listed in Experiment 1. Five participants were removed from all analyses for not fulfilling the requirements; furthermore, one student was removed due to poor accuracy overall (Final N = 54). This experiment was a replication of prior work by Francis et al. (Citation2017) that had N = 50, which we surpassed.
Materials and Procedure
The experiment consisted of a 2 (task) x 3 (SOA) x 4 (congruency) within-subjects design. Once again, participants either responded to the color of a visual target (Visual Targets) or an auditory color word (Auditory Targets). These two tasks were identical to those in Experiment 1 with a few exceptions. As mentioned above, in this experiment SOA was shortened to 300 ms. In addition, the visual dimension now consisted of colored color words (e.g., the written word blue in blue ink). Participants were asked to name the color of the ink in the Visual Targets task and to name the auditory stimulus in the Auditory Targets task (see, ). In this experiment, the printed color word and the color of the ink were matched except for incongruent trials. The purpose of the match was to be more comparable to original and cross-modal Stroop where there is typically only one different, semantically related distractor (see, Lutfi-Proctor et al., Citation2014 for an examination of a non-semantically related visual distractor in cross-modal Stroop). The written word, ink color, and auditory word never matched on incongruent trials (see, ). Therefore, there were six incongruent combinations (the color listed corresponds to the auditory word, ink color, and written word respectively): blue-green-red, blue-red-green, green-blue-red, green-red-blue, red-green-blue, and red-blue-green.
Figure 4. a) Experiment 2 visual targets where participants must name the ink color of the visual targets, b) Experiment 2 auditory targets where participants must name the auditory stimulus.
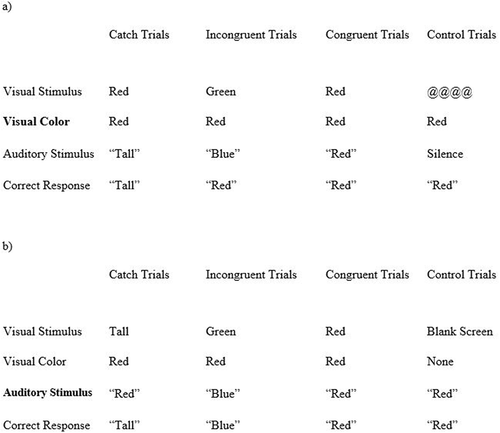
In Auditory Targets, participants repeated an auditory color word while seeing colored color words, a screen with a fixation cross, or the word “tall” in an ink color congruent to the auditory word. Their task was to repeat the auditory word as quickly and accurately as possible unless they saw the catch word “tall” in which case they were told to read the word instead of repeating what they had heard (see, ). Once again, catch trials were included to ensure that participants were looking at the screen during Auditory Targets and not boosting performance by looking elsewhere, and this condition was adapted for Visual Targets as well.
During Visual Targets, participants named the color of the ink of written color words or a row of four @ symbols (control trials) while hearing spoken color words, silence, or the word “tall.” They were told to name the color of the ink as quickly and accurately as possible except for when they heard the word “tall” in which case they should repeat the word “tall” instead of naming the color (see, ).
Results
Approximately 0.23% of trials were removed due to an experimenter error, 2.29% of trials due to a false start, and 1.09% of trials for containing an incorrect answer (not including catch trials). Inaccurate trials were removed from all response time analyses.
In order to determine the influence of the order of the tasks on response times, 2 (task order) x 2 (task) x 3 (congruency: congruent, incongruent, and control) x 3 (SOA) ANOVAs were used. As there were no significant main effects of task order and none of the interactions with task order were significant, task order was removed, and 2 (task) x 3 (congruency) x 3 (SOA) repeated-measures ANOVAs were used to analyze the results and are reported below.
The 2 (task) x 3 (congruency) x 3 (SOA) repeated-measures ANOVA on response times yielded a significant three-way interaction among task, SOA, and congruency, F (3.19, 168.97) = 52.00, p < 0.01, ηp2 = 0.50. In order to examine this interaction, separate 3 (SOA) x 3 (congruency) repeated-measures ANOVAs were run for each task.
For Auditory Targets, there was a main effect of congruency, F (2, 104) = 43.04, p < 0.01, ηp2 = 0.45, congruent < incongruent = control, a main effect of SOA, F (2, 104) = 97.71, p < 0.01, ηp2 = 0.65, visual first < simultaneous < sound first, and a significant congruency by SOA interaction, F (3.34, 173.79) = 13.50, p < 0.001, ηp2 = 0.21. With a simultaneous onset, congruent < incongruent and congruent < control (p’s < 0.001) while incongruent = control (p = 1). When the visual was first, congruent < incongruent < control (all p’s < 0.001), and when the sound was first, congruent < incongruent (p < 0.001) and congruent < control (p = 0.028) while incongruent = control (p = 0.403; see, ).
Figure 5. Means of median response times with standard error bars for Experiment 2.
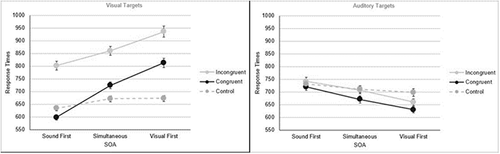
For Visual Targets, there was also a significant main effect of congruency, F (1.56, 81.25) = 228.91, p < 0.01, ηp2 = 0.82, control < congruent < incongruent, and a significant main effect of SOA, F (1.57, 81.55) = 177.20, p < 0.01, ηp2 = 0.77, sound first < simultaneous < visual first. Once again, there was a significant congruency by SOA interaction, F (3.38, 175.56) = 42.70, p < 0.01, ηp2 = 0.45. At the simultaneous and visual first onsets, there was a control < congruent < incongruent pattern (all p’s < 0.001), while at the sound first onset, the pattern was congruent < control < incongruent (all p’s < 0.001; see, ).
Discussion
We did not observe the same patterns of findings across the two types of targets in Experiment 2 that was observed in Experiment 1. The response time results revealed that both visual and auditory targets had main effects of congruency and SOA. These main effects were qualified by a significant three-way interaction among task, SOA, and congruency. Visual and auditory target trials were different in that response times increased from sound first to simultaneous to visual first SOAs for visual targets, while they decreased along that same pattern for auditory targets, which suggested that task demands were affecting the outcome. The visual target condition also had significantly greater incongruent response times compared to auditory targets, which suggested that joint influence was strongest when the task was to name the ink color of an incongruent color word in the presence of an incongruent auditory distractor. This combination was a multidimensional Stroop effect: there were different colors competing from three different dimensions (i.e., the visual target, the visual distractor, and the auditory distractor). Regarding the word production architecture account, the asymmetry results were consistent with its prediction of higher priority for written and spoken color words than color patches: a large Stroop interference effect was obtained when written and spoken color words were used as distractors (i.e., the Visual Targets condition) while a lesser Stroop interference effect was obtained when written color words and color patches were used as distractors (i.e., the Auditory Targets condition). However, neither visual nor auditory targets followed the SOA pattern that would be predicted by the word production architecture account (i.e., simultaneous SOAs showing the greatest interference).
Experiment 2 did not reveal a definite color-word Stroop asymmetry as in Experiment 1, in which there was a clear interference effect for visual but not auditory targets, and instead revealed interference effects for both types of targets. However, comparing the sizes of the two interference effects suggested a similar pattern to Experiment 1; there was greater Stroop interference in visual targets than for auditory targets. Additionally, response times overall were much slower during Experiment 2, which lends support to the joint influence account. To further explore the joint influence account and the word production architecture account, we needed to tease apart their relative contributions when multidimensional Stroop was not intensifying interference effects in one of the two tasks.
Experiment 3
As in Experiment 2, we manipulated SOA, congruency, and whether participants responded to the auditory or visual modality. However, we changed the design: in Experiment 3 the written word and ink color always matched, while in Experiment 2 the written word and ink color could differ. The joint influence account predicts that there should be a smaller magnitude of cross-modal Stroop interference in the Visual Targets task than what was observed in Experiment 2 due to participants no longer experiencing multidimensional Stroop (i.e., instances where there are three different colors competing from three different dimensions) during incongruent trials. This prediction was specific to the Visual Targets task because in both Experiment 2 and the current Experiment 3, there was no modality integration in the Auditory Targets task because there was never an auditory distractor paired with an auditory target.
Method
Participants
Fifty-eight Louisiana State University undergraduates participated for course or extra-credit. Students were not eligible to participate if they did not meet the same requirements listed for Experiment 1. As such, three participants were removed for not fulfilling the requirements and one more was removed due to a data collection error (Final N = 54). This experiment was a variation on Experiment 2, which was a replication of work by Francis et al. (Citation2017) that had a sample size of N = 50.
Materials and Procedure
The experiment consisted of a 2 (task) x 3 (SOA) x 4 (congruency) within-subjects design. Once again, participants either responded to the color of a visual target (Visual Targets) or an auditory color word (Auditory Targets). These two tasks were identical to those in Experiment 2 except this time the written word and ink color always matched during incongruent trials. This design change removed incongruent visual target integration.
During Visual Targets, participants named the color of the ink of written color words or a row of four @ symbols (control trials) while hearing spoken color words, silence, or the word “tall.” There were told to name the color of the ink as quickly and accurately as possible except for when they heard the word “tall” in which case they should repeat the word “tall” instead of naming the color.
In Auditory Targets, participants repeated an auditory color word while seeing colored color words, a screen with a fixation cross, or the word “tall” in an ink color congruent to the auditory word. The task was to repeat the auditory word as quickly and accurately as possible unless they saw the word “tall” in which case they were told to read the word instead of repeating what they had heard.
Results
Approximately 0.10% of trials were removed due to an experimenter error and 2.39% of trials due to a false start, while 1.82% of trials contained an incorrect answer. Inaccurate trials were removed from all RTs analyses.
To determine the influence of the order of the tasks on response times – catch trials were analyzed separately – 2 (task order) x 2 (task) x 3 (congruency: congruent, incongruent, and control) x 3 (SOA) mixed-model ANOVAs were used. As there were no significant main effects of task order and none of the interactions with task order were significant, task order was removed, and 2 (task) x 3 (congruency) x 3 (SOA) repeated-measures ANOVAs were used to analyze the results and are reported below.
The three-way interaction between task, SOA, and congruency was significant, F (2.60, 137.56) = 46.56, p < 0.01, ηp2 = 0.47. To examine the three-way interaction, separate 3 (congruency) x 3 (SOA) repeated-measures ANOVAs were then run for each task.
For Auditory Targets there was a main effect of congruency, F (2, 106) = 23.86, p < 0.01, ηp2 = 0.31, congruent < incongruent = control, a main effect of SOA, F (1.84, 97.43) = 93.93, p < 0.01, ηp2 = 0.64, visual first < simultaneous < sound first, and a significant congruency by SOA interaction, F (2.28, 120.88) = 7.26, p < 0.01, ηp2 = 0.12. With a simultaneous onset, congruent < incongruent and congruent < control (p’s < 0.001) while incongruent and control did not differ significantly (p = 0.610). When the visual was first, congruent < incongruent < control (all p’s < 0.05), and when the sound was first, congruent < incongruent (p = .016) and control was not different from either (p = 1 and 0.154, respectively; see, ).
Figure 6. Means of median response times with standard error bars for Experiment 3.
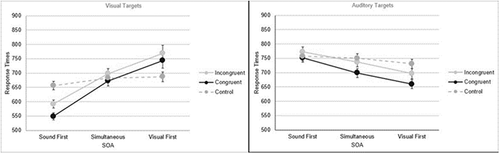
For Visual Targets, there was also a significant main effect of congruency, F (1.65, 87.22) = 6.99, p < 0.01, ηp2 = 0.12, congruent < incongruent with control trials not significantly different from either, and a significant main effect of SOA, F (1.19, 62.87) = 89.93, p < 0.01, ηp2 = 0.63, sound first < simultaneous < visual first. Once again, there was a significant congruency by SOA interaction, F (2.31, 122.32) = 50.82, p < 0.01, ηp2 = 0.49. With a simultaneous onset, congruent < incongruent (p = 0.006) with control trials not being different from either p = 0.945 and 0.554, respectively. When the sound was first, congruent < incongruent < control (p’s < 0.001), and when the visual was first, control < congruent (p = 0.002), control < incongruent (p < 0.001) and congruent < incongruent (p = 0.039; see, ).
Discussion
Experiment 3 was designed as a replication of Experiment 2 without incongruent visual target integration. This experiment provided a greater understanding of joint influence particularly when it was no longer masked by multidimensional Stroop, or instances when three different colors were competing from three dimensions (i.e., the written color word, the ink color of the word, and the auditory color word). The purpose of this experiment was to isolate the contribution of multidimensional Stroop in Experiment 2, particularly because of the idea that it was the main cause of the peak interference effects in the Visual Targets condition. The joint influence account predicts that by removing multidimensional Stroop from incongruent trials in Experiment 3, there should be a smaller sized cross-modal Stroop effect in the Visual Targets task. The current results supported that prediction: with the replacement of incongruent target integration in the Visual Targets task with congruent target integration, there was smaller cross-modal Stroop interference in the Visual Targets task. The findings of this experiment supported the joint influence account because they suggest we are attending to all dimensions, and the joint influence account is the only account mentioned that can handle this. On the other hand, the findings also conflicted with the word production architecture account. Even after multidimensional Stroop was removed, this task design did not show the color-word Stroop asymmetry between visual and auditory target naming that was observed in Experiment 1 when color patches were used as the visual targets. Further, the peak of the slowest response times did not appear at the simultaneous SOA condition. These were the main two predictions of the word production architecture account: color-word Stroop asymmetry and slowest responding at the simultaneous SOA. Similarly to Experiment 2, the results of Experiment 3 also supported the word production architecture account’s prediction about distractor type priority, but not its prediction about SOAs.
General Discussion
This three-experiment study compared two models of the cross-modal Stroop effect: the word production architecture account and the joint influence account. There has been support in the literature for both models when examined separately; however, different manipulations in prior studies made it difficult to compare the two models. The current study reconciled that problem by using experimental manipulations featured in both (e.g., SOAs for the word production architecture account and multiple stimuli for the joint influence account) in order to explore both models at once. Though methodological differences between Experiment 1 and Experiments 2–3 make it difficult to draw extensive direct comparisons (i.e., different visual stimuli led to different levels of overall difficulty in the two experiments), the results still revealed much about the mechanisms of cross-modal Stroop interference.
Firstly, in Experiment 1, the Sound First SOA facilitated responding across conditions for visual targets and for auditory targets and led to faster responding than the simultaneous onset SOA. This pattern persisted in Experiments 2–3 with visual targets, but not with auditory targets, and suggested that the Sound First SOA may be used as a warning to facilitate responding when the target task was in a different modality (Elliott et al., Citation1998). Secondly, Experiment 1 overall replicated the color-word Stroop asymmetry demonstrated in Roelofs (Citation2005), though we detected differences in the individual patterns of trial types. The results of Experiment 2–3 replicated findings from Francis et al. (Citation2017; increased interference by multiple distractors). In terms of color-word Stroop asymmetry, the Experiment 2–3 results replicated Francis et al. (Citation2017) in that we too found that multiple distractors led to greater Stroop interference, and that integration (i.e., word and color information being combined on the same target stimulus in the same physical location) led to substantially more interference (e.g., the Experiment 2 visual target condition demonstrated the largest interference across all the experiments reported here). This finding was supported by our isolation of the effect of incongruent target integration from that visual target condition in Experiment 3.
We were able to disentangle the interference effects in Experiment 2 by conducting the third experiment. In Experiment 3, the design was comparable to Experiment 1 in the sense that there was always a “single” Stroop effect, or two colors competing for attention at most, so it allowed us to understand what components of Experiment 2 were being driven by the traditional visual Stroop effect. When we removed multidimensional Stroop in Experiment 3 by always matching the written word and ink color during incongruent trials (i.e., always having congruent target integration), as opposed to written word and ink color always mismatching during incongruent trials in Experiment 2, the substantially greater interference effect in the Visual Targets condition was removed as well. This finding suggested that joint influence’s effect was influenced by the visual target integration.
Though there was support for the word production architecture account (Roelofs, Citation2005), the overall interpretation of the SOA findings challenged it. According to the word production architecture account, word pronunciation architecture consists of shallow, form-to-form mapping where a written or spoken word easily maps onto a mental word form. Color naming architecture is more involved because it demands lemma selection to process meaning on a certain level. Thus, words have priority for pronunciation while pictures and colors have priority for meaning. This account leads to two predictions (Roelofs, Citation2005). The first prediction is that word distractors should cause Stroop interference while visual color distractors should not, due to the priority of words for pronunciation. This prediction was supported by the present series of experiments where spoken and written color word distractions overall had greater Stroop interference effects than color patch distractors. This account could also explain the difference between the visual targets conditions of Experiments 2 and 3 in terms of an “inadvertent reading hypothesis” (MacLeod & MacDonald, Citation2000). In Experiment 2, the participants’ task was to name the color patches, which was a difficult task that could be vulnerable to written and spoken color word interference. In Experiment 3, when the written color word was always congruent with the to-be named color of the word, the decreased Stroop effect could be attributed to the fact that reading a color word is easier than naming the color of the word. The second prediction is that Stroop interference should be greatest during the simultaneous SOA because the architecture difference between words and colors remains the same regardless of stimulus timing. We only observed maximal color-naming latencies at simultaneous presentations in Experiment 1 during the auditory target condition. Roelofs (Citation2005) also found maximal color-naming latencies at simultaneous presentations in one condition as well, though they were in the visual target condition. Overall, support for the word production architecture account in the current work was mixed: while our patterns of color-word Stroop asymmetry were consistent with the account, future research is needed to completely understand the SOA results, which challenged the account.
Our findings were more consistent with the joint influence account (Francis et al., Citation2017). This account states that interference effects are stronger when multiple distractors are involved due to their independent contributions to interference. There was a clear joint influence in visual targets, with the incongruent trials showing significantly longer response times throughout the time course in Experiments 2–3 compared to Experiment 1. The congruent condition also had slower response times whenever joint influence was involved, especially in visual targets. It is important to note that Experiments 2–3 did not display color-word Stroop asymmetry. This finding suggested that color-word Stroop asymmetry was more likely to appear, as it did in Experiment 1 and Roelofs (Citation2005), with single as opposed to multiple distractors.
As we consider our study in light of both Roelofs (Citation2005) and Francis et al. (Citation2017), it is important to compare methodologies. Francis et al. (Citation2017) used our same stimuli with the addition of purple. Francis et al. (Citation2017) considered multiple stimuli due to their joint influence emphasis while only Roelofs (Citation2005) used SOA due to his time course emphasis. Lastly, our controls differed between silence in the current study and Roelofs (Citation2005), and tone in Francis et al. (Citation2017). While different Stroop control conditions have been compared (MacLeod, Citation1991), there does not seem to be consensus on one best control condition.
Response times between Experiment 1 and Experiments 2–3 differed in one major way: Experiment 2–3 response times were much slower, which is consistent with the inadvertent reading hypothesis. This finding was demonstrated clearly in the control conditions, as response times generally rose from Experiment 1 to Experiments 2–3 between both auditory and both visual conditions. Overall, multiple distractors elicited greater interference than a single distractor, and most of the time this was true regardless of whether the two distractors were congruent or not. Joint influence was especially notable in visual targets, where the incongruent trials in Experiment 2 had considerably greater response times compared to the rest of the trials in the current study.
Joint influence is the general idea that multiple distractors each interfere with responding (Francis et al., Citation2017; MacLeod & Bors, Citation2002). We propose a clear definition of joint influence as: “the effect of multiple distractors, which is moderated by integration of a distractor into the target, and further by whether such integration is congruent or not with the target.” It is important to note that this study examined integration in terms of modality, and that in the literature, integration can also take the form of spatial location (Francis et al., Citation2017). An example of this is that a computerized visual target can have a visual distractor elsewhere on the screen: while there is modality integration, there is no spatial integration (Cho et al., Citation2006). Thus, our study alone does not completely disentangle integration in terms of modality and spatial location, and how they relate to congruency. While there is limited research on this topic, such as work by Lutfi-Proctor et al. (Citation2018) that paired visual targets with auditory distractors that were manipulated to change their perceived spatial locations around participants, further research needs to be done to completely disentangle integration of modality and physical location (e.g., auditory targets with auditory distractors).
In conclusion, the current study reconciled the word production architecture (Roelofs, Citation2005) and the joint influence accounts (Francis et al., Citation2017) within the cross-modal Stroop paradigm using methodologies unique to both: SOA’s and multiple distractors. In Experiment 1 with single distractors, a Stroop effect was found in Visual Targets but not Auditory Targets. This result was consistent with the color-word Stroop asymmetry pattern found in Roelofs (Citation2005). We also found a case of maximal interference at the simultaneous SOA in Auditory Targets, a pattern also predicted by the word production architecture account. In Experiments 2–3, multiple distractors showed greater interference effects than single distractors, which was consistent with Francis et al. (Citation2017). Experiment 3 isolated the effect of incongruent visual target integration in Experiment 2 and found that with only congruent visual target integration, the size of the Stroop interference decreased, which was also consistent with Francis et al. (Citation2017). Given this series of findings, we agree that target and distractor integration played an essential role in the size of the interference effects observed in the current research and in the work of Francis et al. Overall, the joint influence account explained the relatively slower response times in Experiments 2–3 as compared to Experiment 1.
Implications of These Findings
A key manipulation that we introduced was the temporal relationship between the target and distractor(s). While we focused on testing predictions of two theoretical accounts based on cross-modal Stroop effects, it is worth noting that we observed specific patterns of the stimuli time course on performance depending on whether the target was visual or auditory. We acknowledge that there is an implication here apart from asymmetry. Specifically, it is possible that the sensory modality of the target plays a fundamental role in this temporal relationship.Footnote3 In Experiments 1 and 3, we observed evidence that the auditory distractors in the Sound First condition could serve as a warning cue for the upcoming visual target; however, this warning benefit was negated by the incongruent printed word in the Sound First, Visual Target condition of Experiment 2. We feel this pattern supports the joint influence account and provides further evidence of the distinctions between the two modalities. Future research is needed to investigate whether visual distractors can serve as a warning cue for auditory targets.
Beyond the sensory modality of targets, another implication of the current work is about auditory distractions. This relates to the Special Issue for Auditory Perception & Cognition, titled “On Theoretical Advancement in Auditory Distraction Research,” for two reasons. Firstly, our work is contextualized in the cross-modal Stroop task, which is at heart an auditory distraction paradigm: the standard version of the task uses a visual target that is typically a color patch and an auditory distractor that is typically a spoken color word. Secondly, though we extend the paradigm to examine both visual and auditory targets/distractions, the importance of our results lies within the auditory distractions. In Experiment 1, we detected interference with visual targets and auditory distractions but not vice-versa. In Experiments 2–3, the size of interference was greater for visual targets and visual/auditory distractions than for auditory targets with visual distractions. Whenever auditory distractions were involved, there was more overall interference. Future research can help explore the mechanisms responsible for auditory distractions within this context. Auditory distractions are critical to understand due to their prevalence in daily life as well as the nature of the auditory system: the auditory system is always “on” so distractors in this modality are harder to avoid than those in the visual modality, which can be avoided by averting one’s gaze or closing one’s eyes.
Within the broader context of the Stroop effect, we believe that the Stroop task is so widely studied because it allows psychologists to explore attention in terms how much control we have over what we process. The cross-modal version of the Stroop task in the present study, combined with our novel approach involving both multiple stimuli and the varied time course, helped to contribute to a better understanding of selective attention in terms of both the visual and auditory modalities. The applied importance of these findings is that we seem vulnerable to what we process in multiple ways. In Experiment 1, control over disregarding irrelevant information was dictated by the form of the targets and distractors (i.e., color-word Stroop asymmetry). In Experiments 2–3, the introduction of both multiple distractions and integrated distractions each contributed to interference, as participants were unable to ignore the additional irrelevant information. These findings suggested that protecting our focus from distractions may be more dependent on control over our environments, rather than on how we perceive the environment’s influence on us. Proactive awareness on decreasing potential distractors may be a more effective strategy at improving focus, given how little we control over what we do process.
Disclosure Statement
No potential conflict of interest was reported by the author(s).
Notes
1. Due to experiment programming for both experiments, the response times for the visual first Auditory Targets trials had to be corrected. Response times started recording as soon as the square appeared; however, participants were instructed to give their response when the auditory word sounded. Thus, either 500 ms (Experiment 1) or 300 ms (Experiment 2) was subtracted from each visual-first Auditory Targets trial. From this corrected raw data, all trials with an RT less than 200 ms were dropped and the median for each person calculated. This correction enabled a more direct comparison to the other trial types, which started recording as soon as the target item appeared.
2. Catch trials were analyzed with repeated-measures ANOVAs for all experiments and these analyses are available on our OSF page at https://osf.io/f6z4x/
3. We thank an anonymous reviewer for this suggestion.
References
- Chajut, E., Schupak, A., & Algom, D. (2009). Are spatial and dimensional attention separate? Evidence from Posner, Stroop, and Eriksen tasks. Memory & Cognition, 37(6), 924–934. https://doi.org/https://doi.org/10.3758/MC.37.6.924
- Cho, Y. S., Lien, M. C., & Proctor, R. W. (2006). Stroop dilution depends on the nature of the color carrier but not on its location. Journal of Experimental Psychology: Human Perception and Performance, 32 (4) , 826–839. https://doi.org/https://doi.org/10.1037/0096-1523.32.4.826
- Cohen, J. D., Dunbar, K., & McClelland, J. L. (1990). On the control of automatic processes: A parallel distributed processing account of the Stroop effect. Psychological Review, 97(3), 332–361. https://doi.org/https://doi.org/10.1037/0033-295X.97.3.332
- Cowan, N., & Barron, A. (1987). Cross-modal, auditory-visual Stroop interference and possible implications for speech memory. Perception and Psychophysics, 41(5), 393–401. https://doi.org/https://doi.org/10.3758/BF03203031
- Elliott, E. M., Cowan, N., & Valle-Inclan, F. (1998). The nature of cross-modal, color-word interference effects. Perception and Psychophysics, 60(5), 761–767. https://doi.org/https://doi.org/10.3758/BF03206061
- Elliott, E. M., Morey, C. C., Morey, R. D., Eaves, S. D., Shelton, J. T., & Lutfi-Proctor, D. A. (2014). The role of modality: Auditory and visual distractors in Stroop interference. Journal of Cognitive Psychology, 26(1), 15–26. https://doi.org/https://doi.org/10.1080/20445911.2013.859133
- Francis, W. S., MacLeod, C. M., & Taylor, R. S. (2017 Joint influence of visual and auditory words in the Stroop task. Attention, Perception, and Psychophysics. https://doi.org/https://doi.org/10.3758/s13414-016-1218-0
- Glaser, M. O., & Glaser, W. R. (1982). Time course analysis of the Stroop phenomenon. Journal of Experimental Psychology: Human Perception & Performance, 8(6), 875–894. https://doi.org/https://doi.org/10.1037/0096-1523.8.6.875
- Kahneman, D., & Chajczyk, D. (1983). Tests of the automaticity of reading: Dilution of Stroop effects by color-irrelevant stimuli. Journal of Experimental Psychology: Human Perception and Performance, 9 (4) , 497–509. https://doi.org/https://doi.org/10.1037/0096-1523.9.4.497
- Lutfi-Proctor, D. A., Elliott, E. M., & Cowan, N. (2014). The role of visual stimuli in cross-modal Stroop interference. PsyCh Journal, 3(1), 17–29. https://doi.org/https://doi.org/10.1002/pchj.51
- Lutfi-Proctor, D. A., Elliott, E. M., & Golob, E. J. (2018). Spatial integration and the underlying mechanisms of cross-modality interference. Journal of Cognition, 2(1), 2. https://doi.org/https://doi.org/10.5334/joc.5
- MacLeod, C. M. (1991). Half a century of research on the Stroop effect: An integrative review. Psychological Bulletin, 109(2), 163–203. https://doi.org/https://doi.org/10.1037/0033-2909.109.2.163
- MacLeod, C. M., & Bors, D. A. (2002). Presenting two color words on a single Stroop trial: Evidence for joint influence, not capture. Memory & Cognition, 30(5), 789–797. https://doi.org/https://doi.org/10.3758/BF03196434
- MacLeod, C. M., & MacDonald, P. A. (2000). Interdimensional interference in the Stroop effect: Uncovering the cognitive and neural anatomy of attention. Trends in Cognitive Sciences, 4(10), 383–391. https://doi.org/https://doi.org/10.1016/S1364-6613(00)01530-8
- Melara, R. D., & Algom, D. (2003). Driven by information: A tectonic theory of Stroop effects. Psychological Review, 110(3), 422–471. https://doi.org/https://doi.org/10.1037/0033-295X.110.3.422
- Mitterer, H., La Heij, W., & Van der Heijden, A. H. C. (2003). Stroop dilution but not word-processing dilution: Evidence for attention capture. Psychological Research, 67(1), 30–42. https://doi.org/https://doi.org/10.1007/s00426-002-0108-3
- Razumiejczyk, E., Macbeth, G., Marmolejo-Ramos, F., & Noguchi, K. (2015). Crossmodal integration between visual linguistic information and flavour perception. Appetite, 91, 76–82. https://doi.org/https://doi.org/10.1016/j.appet.2015.03.035
- Roelofs, A. (1992). A spreading-activation theory of lemma retrieval in speaking. Cognition, 42(1–3), 107–142. https://doi.org/https://doi.org/10.1016/0010-0277(92)90041-F
- Roelofs, A. (2003). Goal-referenced selection of verbal action: Modeling attentional control in the Stroop task. Psychological Review, 110(1), 88. https://doi.org/https://doi.org/10.1037/0033-295X.110.1.88
- Roelofs, A. (2005). The visual-auditory color-word Stroop asymmetry and its time course. Memory & Cognition, 33(8), 1325–1336. https://doi.org/https://doi.org/10.3758/BF03193365
- Stroop, J. R. (1935). Studies of interference in serial verbal reactions. Journal of Experimental Psychology, 18(6), 643–662. https://doi.org/https://doi.org/10.1037/h0054651
- Yee, P. L., & Hunt, E. (1991). Individual differences in Stroop dilution: Tests of the attention-capture hypothesis. Journal of Experimental Psychology: Human Perception and Performance, 17(3), 715. https://doi.org/https://doi.org/10.1037/0096-1523.17.3.715
Appendix A
Table A1. Error rate percentages in the catch trials in experiments 1–3
Appendix B
Error Analyses for Experiments 1–3
Experiment 1: Part A
There was a significant main effect of task, F (1, 60) = 19.13, p < 0.01, ηp2 = 0.24. Participants made more errors when naming the color of a square than when repeating a color word. While there was no significant main effect of order, there was a significant task and task order interaction, F (1, 60) = 4.66, p < 0.05, ηp2 = 0.07. Participants produced more errors on the second task; however, this increase was largest when they named colors first and repeated words second.
Experiment 1: Part B
Once again, the 2 (task order) x 2 (task) x 3 (congruency) x 3 (SOA) ANOVA produced a three-way interaction among task, congruency, and task order. Two repeated-measures ANOVAS were run for each task to examine this interaction. Unlike for response times, the pattern of results was not identical across the two tasks when task order was considered; therefore, we examined the errors from the first task only for each person and ran a 2 (task: between subjects) x 3 (congruency: within subjects) x 3 (SOA: within subjects) ANOVA with task as a between-subjects variable.
There was a main effect of congruency, F (1.50, 89.77) = 7.61, p < 0.01, ηp2 = 0.11 with congruent = neutral < incongruent. There was a main effect of task, F (1, 60) = 5.80, p < 0.05, ηp2 = 0.09 with Visual Targets > Auditory Targets. The SOA by task interaction was not significant, nor was the congruency by SOA interaction. However, the congruency, SOA, and task interaction was significant, F (4, 240) = 2.60, p < 0.05, ηp2 = 0.04. In order to examine this interaction, we ran separate 3 (congruency) x 3 (SOA) repeated-measures ANOVAs for each task. In Visual Targets, there was a main effect of congruency, F (2, 58) = 7.20, ηp2 = 0.20 with congruent = neutral < incongruent. The congruency by SOA interaction was significant, F (4, 116) = 3.38, p < 0.05, ηp2 = 0.07 with congruent = control < incongruent at simultaneous and sound first SOA’s. In Auditory Targets, there were no main effects or interactions (see, ).
Table B1. Error Rates: Experiment 1
Experiment 2
In order to examine the significant three-way interaction among task, congruency, and SOA, F (1.83, 96.93) = 9.24, p < 0.01, ηp2 = 0.15, separate 3 (congruency) x 3 (SOA) repeated-measures ANOVAs were run on errors for each task.
For Auditory Targets there was a main effect of congruency, F (1.46, 75.90) = 17.50, p < 0.01, ηp2 = 0.25, incongruent > congruent = control, and a main effect of SOA, F (2, 104) = 7.71, p < 0.01, ηp2 = 0.13, visual first = simultaneous > sound first; however, the congruency by SOA interaction was not significant.
For Visual Targets, there was also a significant main effect of congruency, F (1.06, 55.10) = 27.90, p < 0.01, ηp2 = 0.35, incongruent > congruent = control, and a significant main effect of SOA, F (1.56, 80.90) = 10.56, p < 0.01, ηp2 = 0.17, sound first > simultaneous = visual first. There was also a significant congruency by SOA interaction, F (1.76, 91.69) = 9.32, p < 0.01, ηp2 = 0.15. At every SOA, incongruent > congruent = control; however, while SOA had no impact on control and congruent trials overall, it did impact incongruent trials with sound first > simultaneous = visual first (see, ).
Thus, errors were highest in the visual targets task in the incongruent condition when the sounds came first.
Table B2. Error Rates: Experiment 2
Experiment 3
For Auditory Targets, there was a main effect of congruency, F (1.02, 54.86) = 4.16, p = 0.02, ηp2 = 0.07, congruent = control < incongruent. There were no other significant main effects or interactions for accuracy (see, ).
Table B3. Error Rates: Experiment 3