
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Past studies demonstrated that interlocutors mutually affect each other’s vocal behavior in joint speech situations. However, findings on exactly how and when these adaptive processes occur are inconsistent. We propose a novel experimental paradigm, the ‘One-Voice Professor’ game, that explicitly separates content matching (“saying the same thing”) from simultaneity (“speaking at the same time”), in an effort to systematically investigate different joint speech conditions. In our first experiment, we analyzed the vocal characteristics of 96 participants who engaged in joint speech with a recorded voice, in a 2-by-2 experimental design. Results indicate significant effects on the fundamental vocal frequency (f0), with the strongest f0 adaptation in the alternating-and-matching condition, and f0 divergence in the simultaneous-and-matching condition. Since these effects could have been impacted by the fact that speakers could not mutually adapt with the recorded voice, we applied the same paradigm in our second experiment to an interactive joint speech situation. Same-gendered dyads (n = 66) improvised speech together in interviews designed to separate matching from simultaneity. The results show main effects of the conditions, with matching leading to stronger f0 adaptation and simultaneity to divergence on secondary voice characteristics (f1, f2, and harmonics-to-noise ratio (HNR)). These findings confirm the hypothesis that simultaneity and matching of speech influence phonetic adaptation differently.
Introduction
Though not a body-part in the usual sense of the word, the voice has been described as an “auditory face,” closely linked to our perception of self and others (Belin et al., Citation2004). However, this does not mean that the vocal profile is a fully unique and stable feature of our individual identity. Research in phonetics and phonology in the last decades convincingly demonstrates that speakers flexibly adapt their vocal characteristics in interaction with others (Borrie et al., Citation2019; Coles-Harris, Citation2017; Nguyen & Delvaux, Citation2015; Pardo et al., Citation2013). Some adaptation may be temporary but in other cases, the effects of interacting with a particular speaker may have longer-lasting effects (Pardo et al., Citation2012). Experimental studies of speech adaptation, als sometimes referred to as “imitation” or “phonetic convergence,” show that it is expressed using various phonetic features, including pitch (Gijssels et al., Citation2016), speech rate (Cohen Priva et al., Citation2017), rhythm (Borrie et al., Citation2019; Reichel et al., Citation2018), speech formants (Pardo et al., Citation2010) and other speech properties (Garrod & Pickering, Citation2004). In some joint speech scenario’s, phonetic divergence is known to take place as well (Levitan & Hirschberg, Citation2011). However, a large-scale comparison of different measures of phonetic convergence showed that the effects tend to be subtle, variable, and inconsistent over different studies (Pardo et al., Citation2017).
In general, the extent of mutual adaptation seems to depend on speaker characteristics (Postma-Nilsenová & Postma, Citation2013) and contextual cues (Lewandowski & Jilka, Citation2019), such as the form of joint speech itself (Mantell & Pfordresher, Citation2013). In particular, speech interactions themselves can be matching in content (when speakers repeat each other’s utterances, as often happens in confirmatory statements) or differing in content (when the utterances do not match each-other, as in the case of questions and answers). Another dimension is that of alternating speech (when the speakers are not talking simultaneously but wait for their turn) or simultaneous (as in the moments when speakers overlap their turns or finish each other’s sentences). In some interactions, like singing, chanting, or reading together, joint vocal behavior can be both matching and simultaneous by design (Cummins, Citation2002; Wiltermuth & Heath, Citation2009).
The simultaneous occurrence of matching sensory feedback can be described as synchronicity. Existing research seems to support the conclusion that this synchronicity can have a positive impact on mutual feelings of affiliation, rapport, and social bonding (Kirschner & Tomasello, Citation2010; Kreutz, Citation2014; Pearce et al., Citation2015, Citation2016). When examined as separate concepts, however, simultaneity and matching may differ in their potential effect on blurring self-other boundaries (Rombout et al., Citation2018; Tarr et al., Citation2018). For example, simultaneous physical activities (including singing) that have been linked to elevated β-endorphin levels (Pearce et al., Citation2015) lead to synchronization of breath and heart rhythms. This is not necessarily the case for matching but not simultaneously occurring physical activities.
Vocal synchronization is a complex, interactive process between speakers (Cummins, Citation2003, Citation2009). However, past studies on phonetic adaptation did not disentangle the individual effects of these two dimensions of synchronicity (simultaneous/alternating behavior versus matching/differing content). In fact, in most joint speech research, the experimental design involves close speech shadowing, dialogue, or both of these compared (Chistovich et al., Citation1966; Cummins, Citation2002; Kreutz, Citation2014; Marslen-Wilson, Citation1985; Pardo et al., Citation2018), which does not allow for measuring the impact of matching and simultaneity separately or in detail. Close shadowing tasks can range from simultaneous to more alternating speaking depending on how they are set up (Pardo et al., Citation2017), but the exact effect of this has not been closely explored.
Research on phonetic adaptation is not just of great interest to the field of linguistic but also from the point of view of human-machine interaction and the development of simulated environments in virtual reality (VR). Speaking is a complex multi-sensory process, with several feedback loops within and between motor and sensory systems (Postma, Citation2000). Adaptation itself is thus likely to be influenced by additional visual information about speech articulation, showing its potential multi-sensory nature (Dias & Rosenblum, Citation2016). Interestingly, studies on embodiment in VR consider the impact of actions and multi-sensory signals (including those in speech production and perception) on the awareness of the self-other boundary (Kalckert & Ehrsson, Citation2014). Multi-sensory integration (Kilteni et al., Citation2015; Tsakiris, Citation2017) can give rise to embodiment illusions, where, for example, a rubber hand can be integrated in the body-scheme (Botvinick & Cohen, Citation1998). Embodiment illusions acting on the voice (“envoicement”; Banakou & Slater, Citation2014; Zheng et al., Citation2011) might occur accidentally or as a feature of social interaction where synchronicity plays a role, which could explain some of the effects of synchronous vocal behavior (Rombout & Postma-Nilsenová, Citation2019) through the social context it creates (Coles-Harris, Citation2017). Blurring of the self-other boundary through synchronicity of vocal utterances could therefore be potentially modulated by individual differences in susceptibility to embodiment illusions (Tajadura-Jiménez et al., Citation2017). In particular, perceptual sensitivity to different signals – sensory input, but also motor feedback – plays a role in how susceptible individuals are to different types of embodiment illusions (Suzuki et al., Citation2013). These signals can be divided in categories (Seth, Citation2013), commonly identified as interoception (everything happening inside of the body), exteroception (everything outside of the body), and proprioception (the position of the body in space) (. Including the concept of perceptual sensitivity in phonetic adaptation studies could shed more light on the underlying mechanisms and potentially account for the individual differences that have been observed in the past.
Current Study
Matching versus differing and simultaneous versus alternating speech forms the basis of the two studies described in this paper. Explicitly matching speech enforces adaptation of speech content, and leads to similarities in the motor and auditory feedback of the interlocutors. Simultaneity ensures that these feedback loops are activated at the same moment. These can be combined in four different ways (see ) to create different levels and types of synchronicity.
Figure 1. The one-voice professor: all combinations of matching/differing and simultaneous/alternating joint speech.
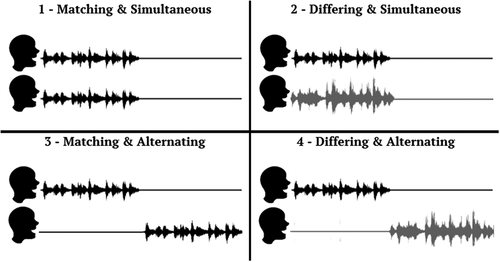
In the first study we create these four different scenarios with a participant and a recorded voice, comparable to speech-shadowing manipulations. We additionally explore the blurring of self-other boundaries, as well as the influence of perceptual sensitivity (whereby we distinguish between interoception, exteroception and proprioception). To explore simultaneity and matching in a scenario allowing for mutual adaptation, we then adapted a theatrical game called “The One-Voice Expert” (Keith, Citation1979), in which two or more actors improvise speech together as if they are one person. The original game results in joint speech that is matching (saying the same thing) as well as simultaneous (speaking at the same time; Cummins, Citation2002; Pardo et al., Citation2018). We adapted it into ’The One-Voice Professor’, to also fit the other three possible combinations of these features for the second study.
In terms of vocal characteristics, we measure the fundamental frequency (f0), an important pathway for conveying social information (Babel & Bulatov, Citation2012; Gregory et al., Citation2001), and a phonetic feature to which interlocutors frequently adapt. Additionally, we measure secondary voice characteristics, namely the formant frequencies f1 and f2 (the two lowest frequency formants arising from the resonance of the vocal tract), and the harmonics-to-noise-ratio (HNR, the additive noise in the speech signal; Awan & Frenkel, Citation1994), which have also been associated with social factors such as identity and affect (Amin et al., Citation2013; Goudbeek et al., Citation2009; Schweitzer & Lewandowski, Citation2014).
Speakers have been shown to adapt f0 and f1 in non-interactive, matching and alternating speech, both spontaneously and when explicitly instructed to imitate (Sato et al., Citation2013). Convergence of f0 also occurred with matching and simultaneous speech (Bradshaw et al., Citation2021). However, in an interactive and alternating scenario where content was only partly matched, f0 was unaffected (Lelong & Bailly, Citation2011). In a conversation situation, with speech that is different and alternating, interlocutors converged on HNR (Levitan & Hirschberg, Citation2011), but only after an adjustment period, and showed very diverse patterns of divergence and convergence on f1 and f2 (Pardo et al., Citation2012; J. S. Pardo, Citation2010). By contrast, pitch (as a function of f0) was in this type of scenario also affected, but the strongest convergence happened during back-channels, so much more immediate (Heldner et al., Citation2010). To our knowledge, there are no studies on phonetic convergence after simultaneous yet alternating speech, and no comparisons that fully separate these two dimensions from each-other.
Our research questions are:
RQ1 – How does matching of speech content and simultaneity of vocal behavior influence phonetic adaptation?
RQ2 – Does perceptual sensitivity play a role in phonetic adaptation?
We hypothesize that phonetic adaptation will be most prominently present in the conditions with matching speech content and simultaneous vocal behavior and least in conditions with different content. In fact, if simultaneous speaking is combined with differing utterances, we hypothesize that divergence might even take place to maintain stronger vocal control and avoid slurring of speech (Liu et al., Citation2009).
Additionally, we expect individual speakers who score high on perceptual sensitivity to be less likely to adapt their speech patterns in interaction due to the fact that they are well equipped to distinguish between sources of sensory feedback (internal vs. external sources; Suzuki et al., Citation2013).
Experiment 1 – Recorded Voice
In our first experiment, participants engaged in joint speech with a gender-matched recorded voice, reading out texts presented on a screen. We created four experimental conditions for each combination of matching and simultaneity (see ).
Methods
Ninety-six participants (65 female, 31 male, average age 22.2 years (SD = 3.59)) were recruited and randomly allocated to N = 24 for the matching/simultaneous condition (C1), N = 24 for differing/simultaneous (C2), N = 24 for matching/alternating (C3), and N = 24 for differing/alternating (C4)).
Participants had no self-reported speech or hearing issues. All participants were English speaking university students from international origin (27 different native languages, most commonly including Dutch (43 participants) and/or English (6 participants)), gathered from the participant pool of a university in the southern Netherlands. They were rewarded with study credits. Participation was voluntary and informed consent was obtained from all participants. The study was approved by the Research Ethics and Data Management Committee of the school.
Conditions and the Joint-Speech-Paradigm
The study used a 2 (synchronicity: synchronous vs. alternating) x 2 (content: matching vs. differing) between-groups design. Participants were engaged in a joint speaking task in English, speaking along with a gender matched recorded voice. The recorded stimuli were natural voices, recorded from native English speakers with similar (American English) accents.
Ten sentences were displayed on a screen one by one. A beep indicated the start and end of the recorded sentence. In condition 1 (matching/simultaneous) participants were instructed to read the sentences aloud at the same time as the recorded voice, as if they were reciting the sentence together. In condition 2 (different/simultaneous) participants spoke at the same time as well, but were presented with different sentences of approximately the same length as the recorded sentence. They were instructed to try to match the pace of the recorded voice. In condition 3 (matching/alternating) participants read the same sentence as the recorded voice, but only after the recorded voice was done speaking. Finally in condition 4 (different/alternating) participants read different sentences after the recorded voice was done speaking. See also . All sentences were presented twice.
Measurements
Vocal Characteristics
Before and after the reading task, participants recorded 30 common short English words starting with a consonant and ending in a vowel, categorized based on their phonemic transcription in the English pronunciation system, which resulted in 6 categories of vowel-sounds (see ). The use of common English words increased the chance of correct vowel pronunciation by the international participant group, while the ending vowel ensured a long majority vowel sound in every recording, from which audio characteristics could be easily extracted.
Table 1. The stimuli words and the associated English pronunciation symbol for their vowel sound
The fundamental frequency and selected secondary vocal characteristics of these recordings were then compared to the same recordings of the stimulus voice. Both were analyzed using the Soundgen library in R (Anikin et al., Citation2018; R Core Team, Citation2013), with PitchFloor = 50 Hz and PitchCeiling = 500 Hz, extracting the values for f0, f1, f2 and harmonics-to-noise ratio (HNR) from every recording. Vocal adaptation per word was calculated by taking the difference of the before value from the participant (p), and that of the recorded voice (r), and subtracting from this the difference of the after value of the participant and the value of the recorded voice:
where
and
Voice-Recognition Task
The 30 recordings, intended to extract vocal characteristics, were additionally normalized to −5 decibel, and background noise was removed. These cleaned recordings were then used in two voice-recognition tasks, both before and after the reading task. We based the task on facial recognition tasks commonly used in enfacement studies (Sforza et al., Citation2010) to measure any shifts in the boundary between self and other. In this timed forced-choice task participants were faced with a binary choice of whether they heard their own voice or someone else. Each of the two voice-recognition tasks consisted of 15 own-voice and 15 recorded voice samples presented in a random order. Samples were randomized over the two tasks.
Envoicement
To measure the experienced embodiment over the recorded voice, common embodiment questions (Botvinick & Cohen, Citation1998; Longo et al., Citation2008) were adapted in such a way that all statements referred to the voice (7-point Likert scale, see ).
Table 2. Envoicement questionnaire
Affiliation Questions
Based on similar questions commonly used in enfacement research (Sforza et al., Citation2010), participants indicated on a 7-point Likert scale how attractive they thought the recorded voice was and whether they considered it similar to their own in terms of pitch, timbre and rhythm.
Perceptual Sensitivity
Interoceptive, proprioceptive and exteroceptive sensibility were measured through questionnaires. For interoception, the short form of the Body Perception Questionnaire (Porges, Citation1993) was used, the body awareness part only (BPQ, 26 items, 6 point Likert scale). For exteroception we used a Perception of Surroundings Questionnaire (5 items, 6 point Likert scale) based on the same format as the BPQ (Porges, Citation1993), and for proprioception a similar Body-Posture Perception Questionnaire (5 items, 6 point Likert scale), and a Behavioral Self-Assessment Questionnaire (5 items, 6 point Likert scale), which was based on third-party report questionnaires (Blanche et al., Citation2012; Miller-Kuhaneck et al., Citation2007).
Interoceptive accuracy was measured with a Multi-interval Heartbeat Detection Task (Brener et al., Citation1994). A flashing circle appeared on a screen accompanied by a beep, and participants were asked to judge whether these indicators were simultaneous with their own heartbeat or not. The interval between actual, measured heartbeat and the indicators was randomized and counterbalanced over trials. There were 4 intervals: 0 ms, 150 ms, 300 ms, and 450 ms, and 30 trials per interval, resulting in 120 trials total. After each trial, participants were also asked to indicate their confidence in their answer on a 10-point scale. This confidence measurement functioned as a second indication of interoceptive sensibility.
Proprioceptive accuracy was measured through joint position reproduction (Han et al., Citation2016). Participants were seated behind a table with a piece of paper on it, and placed a marker in the middle of this. They were then asked to close their eyes, raise their hand as high as they could, and then place the marker back, as close to the original spot as possible. This was repeated with their other hand. The distance between the spots was used as an inverted accuracy measurement.
Exteroceptive accuracy was not measured as most existing tasks target somatosensation, the classification of which is uncertain. Developing a new task fell outside of the scope of this study.
Procedure
The experiments were conducted on a desktop computer and a Sennheiser headset with microphone. The experimental manipulation and all questionnaires were conducted in the OpenSesame software. The interoceptive accuracy test was conducted in a custom program on a laptop with a Grove Seeed studio ear-clip sensor, and the proprioceptive accuracy test used markers and paper.
Participants started by answering demographic questions, as well as doing the perceptual sensitivity questionnaires and tasks. Then, the 30 word-recordings were made, and the first voice-recognition test performed.
The second step of the experiment was the reading task. Ten sentences appeared on the screen one by one, and the participants read them out loud, while hearing the recorded voice through their headphones. Each participant read the sentences according to the condition they were randomly assigned to.
Participants then completed another voice-recognition test, the envoicement questionnaire and affiliation questions, and a few general manipulation-check questions. Lastly, they recorded the same 30 words again.
Results
The sound recordings were compromised for one participant, leaving N = 95 for the reaction time and voice characteristics measurements (resulting in N = 23 for condition 4). We used an alpha-level of .05 for all statistical tests, and all assumptions were met unless otherwise indicated.
Vocal Characteristics
The selected vocal characteristics (f0, f1, f2 and HNR) were analyzed separately. The six vowel sound categories (see ), together with gender, were taken into consideration as fixed effects in the linear mixed effect analysis (Bates et al., Citation2015; R Core Team, Citation2013), with intercepts for the participants. Combined with the interaction between matching and simultaneity, this resulted in the following model:
Likelihood ratio tests indicated a significant effect of simultaneity on f0 (χ2 = 4.59, p = .032), with the interaction between matching and simultaneity approaching significance (χ2 = 3.49, p = .061) (see also ). The strongest f0 adaptation to the recorded voice occurred in the matching/alternating condition, whereas there was f0 divergence in the matching/simultaneous condition (see and ). There were no significant effects on the selected secondary vocal characteristics (f1, f2 and HNR). Additionally, adaptation on f1 was strongly correlated with adaptation on f2 (see ).
Figure 2. Adaptation of f0, f1, f2 and HNR per condition.
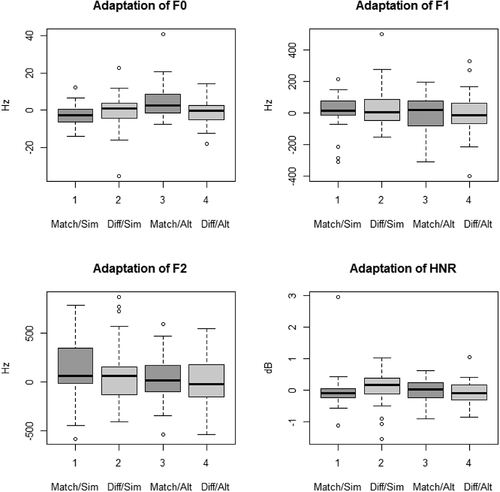
Table 3. Summary of mixed effects models; p < 0.05 indicated with an asterisk. Effect size d based on Brysbaert and Stevens (Citation2018) and Westfall et al. (Citation2014)
Table 4. Descriptive statistics. For matching, 0 = differing content, 1 = matching content. For simultaneity, 0 = alternating speech, 1 = simultaneous speech
Table 5. Pearson correlations, p < 0.05 indicated with an asterisk
Voice Recognition Task
Changes in reaction time and number of mistakes between the first and second voice recognition task were not significantly affected by the interaction between matching and simultaneity. Reaction time and amount of mistakes were inversely correlated (see ).
Envoicement & Affiliation
We found no significant effects of the conditions on envoicement or the affiliation questions. Envoicement and likeness scores were correlated (see ). Likeness was also weakly and inversely correlated with adaptation on HNR.
Perceptual Sensitivity
We present the results on the perceptual sensitivity questionnaires and tasks here on an exploratory basis. Within perceptual sensitivity, there was a correlation between interoceptive and proprioceptive sensibility. Additionally, proprioceptive sensibility was weakly correlated with envoicement, and exteroceptive sensibility with adaptation on f2 (see ).
Discussion
Experiment 1 indicated that simultaneity might influence vocal adaptation of f0, with more adaptation when participants were not speaking at the same time. Some divergence occurred in the matching-simultaneous condition, indicating that adaptation could be suppressed in a situation where the voices can be easily confused with one another. The inverse correlation between likeness and adaptation on HNR could point to a similar effect – adapting to a voice that already sounds close to one’s own may lead to confusion and slurring of speech.
Perceptual sensitivity does not appear to be related to the other variables in this paradigm, with only a slightly positive correlation between proprioceptive sensibility and envoicement, and similarly between exteroceptive sensibility and adaptation of f2. These findings contradict our hypothesis that a higher perceptual sensitivity may be linked to less adaptation.
Answers on the envoicement questionnaire seem to be related to how alike the recorded voice is to the own-voice, but not significantly influenced by the conditions in this experimental paradigm. As the recorded voice is not interactive, and unresponsive to changes in the own-voice, this could influence adaptation through embodiment effects. The chance of embodiment might be reduced because the recorded voice will not become more like the own-voice over time. Therefore, we aimed to replicate the setup in an actual dialogue situation, with the potential for mutual adaptation.
Additionally, the international nature of the participant group has the potential to introduce confounding variables in pronunciation and adaptation, although the recordings might have limited this effect somewhat as there was always one native English voice present in the joint speech. To reduce pronunciation differences in the more interactive second experiment, we conducted it in Dutch and limited the participants to native Dutch speakers.
Experiment 2 – Joint Speech
In our second experiment, participants engaged in joint speech in gender-matched dyads, improvising speech together in response to question prompts. This setup allows for mutual adaptation and a less rigid structure of utterance content. A collaborative joint speech task requires speakers to work together toward a shared goal.
Since perceptual sensitivity did not appear to play a significant role in the first experiment, we replaced these tasks and questionnaires with measurements of affect and closeness, to more broadly address the social nature of the interaction. We kept the embodiment questionnaire in to account for potentially stronger blurring of self-other boundaries in the more interactive paradigm.
We adapted a theatrical game called “The One-Voice Expert” (Keith, Citation1979), in which actors improvise matching and simultaneous speech together as if they are one person, an expert answering questions on a made-up topic of expertise. From this basis, four experimental paradigms for each combination of matching and simultaneity were created, collectively termed “The One-Voice Professor.” These novel paradigms allow for interactive mutual adaptation while matching and simultaneity can be studied separately.
Methods
Sixty-six participants (40 female, 26 male, average age 23 years (SD = 3.20)) formed 33 same-gender dyads, randomly counterbalanced over N = 16 for the matching/simultaneous condition (C1), N = 18 for differing/simultaneous (C2), N = 16 for matching/alternating (C3), and N = 16 for differing/alternating (C4)).
Participants had no self-reported speech or hearing issues. All were native Dutch speaking university students. They were rewarded with study credits. Participation was voluntary and informed consent was obtained from all participants. The study was approved by the Research Ethics and Data Management Committee of the school.
Conditions and the interview-paradigm
The study used a 2 (synchronicity: synchronous vs. alternating) x2 (content: matching vs. differing) between-groups design. Each dyad went through two interview scenarios in Dutch. To avoid reliance on preconceived ideas, the subject of the interviews was made up and the dyads were asked open-ended questions about “catching spears” and “eating habits of odd ducks,” such as “What is the most peculiar eating habit of odd ducks?” and “What happened the last time you went out to catch spears?.”
Depending on the experimental condition, the instructions for answering these questions varied. All dyads were asked to speak slowly and in complete sentences, repeating the questions as part of their answer. In condition 1 (matching/simultaneous) dyads answered as if they were a single speaker, at the same time and without anyone taking the lead. In condition 2 (differing/simultaneous), the participants tried to match the length of their answers, speaking at the same time, but taking care to each say something different. In condition 3 (matching/alternating), participants spoke after one another, switching between first and second place with each question (as indicated by the experimenter). The second speaker was instructed to repeat the first as exactly as possible. Finally, in condition 4 (differing/alternating), participants spoke after one another in the same way, but gave different answers, though again of about the same length. The interviews lasted around 3 to 5 minutes each.
Measurements
Vocal Characteristics
Before and after the two interviews, the participants recorded 30 syllables made up of a consonant and a vowel sound (“Foo,” “Kaa”). All syllables were sounds common in Dutch but with no particular meaning by themselves.
The syllable recordings were analyzed with the Soundgen library in R (Anikin et al., Citation2018), with PitchFloor = 50 Hz and PitchCeiling = 500 Hz, extracting values for f0, f1, f2 and HNR from every recording. Vocal adaptation per syllable was calculated by taking the difference between the before value from the participant (p1) and their dyad counterpart (p2), and subtracting from this the difference of the after value of the participant and the before value of their dyad counterpart:
where
and
Voice-Recognition Task
The 30 recordings, intended to extract vocal characteristics, were additionally normalized to −5 decibel, and background noise was removed. These cleaned recordings were then used in three voice-recognition tasks, before, after, and in between the two interviews. The tasks consisted of 10 samples of one participant in the dyad and 10 samples of the other, presented in a random order. Samples were randomized over the tasks.
Envoicement
To measure the experienced embodiment over the voice of the other person in the dyad, embodiment questions (Botvinick & Cohen, Citation1998; Longo et al., Citation2008) were adapted in such a way that all statements referred to the voice (7-point Likert scale). See also , with “other person’s voice” replacing all instances of ’recorded voice’, and the addition of a seventh statement: “(7) It seemed like my own voice came from the mouth of the other person.”
Affiliation Questions
Based on similar questions commonly used in enfacement research (Sforza et al., Citation2010), participants indicated (7-point Likert scale) how attractive they thought the other person’s voice was and whether they considered it similar to their own in terms of pitch, timbre and rhythm, as well as how well they thought the collaboration went.
Closeness and Affect
Additionally, social closeness was measured using the Inclusion of Other in the Self (IOS) scale (Woosnam, Citation2010), and affect (valence, arousal and dominance) with the AffectButton (Broekens & Brinkman, Citation2013).
Procedure
The experiments were conducted in two soundproof booths with two desktop computers and two Sennheiser headsets with microphones. All questionnaires, voice recordings and tasks were run using OpenSesame software. The interviews took place in the voice-chat program TeamSpeak.
Participants started by answering demographic questions, as well as recording the syllables and performing the first voice-recognition test. They then were instructed to switch to the voice-chat program for the first interview, where written questions appeared on the screen. The dyads could hear each other speak through their headphones while they were answering the questions out loud according to the condition they were randomly assigned to.
Participants then performed a second voice-recognition test, and switched programs again for the second interview, after which they did the third and last voice-recognition test. They then filled out the IOS scale, AffectButton, affiliation questions, envoicement questionnaire, and a few general manipulation-check questions. Lastly, they recorded the same 30 syllables again.
Results
For 4 participants, the sound recordings were compromised, leaving N = 62 for the reaction time and voice characteristics measures (resulting in N = 16 for C1, N = 16 for C2, N = 14 for C3, and N = 16 for C4). We used an alpha-level of .05 for all statistical tests, and all assumptions were met unless otherwise indicated.
Vocal Characteristics
We performed a linear mixed effects analysis (Bates et al., Citation2015; R Core Team, Citation2013) on the relationship between adaptation of vocal characteristics (f0, f1, f2 and HNR) and the conditions, looking separately at matching and simultaneity, as well as their interaction. Gender was added as a fixed effect, and participants, dyads and syllables as intercepts. This resulted in the following model:
Utterance matching had a significant effect on f0 adaptation, with more adaptation when participants were not saying the same thing. Simultaneity influenced the secondary vocal characteristics, with stronger f1 and f2 adaptation in the alternating conditions, but stronger HNR adaptation in the simultaneous conditions. See also , and .
Figure 3. Adaptation of f0, f1, f2 and HNR per condition.
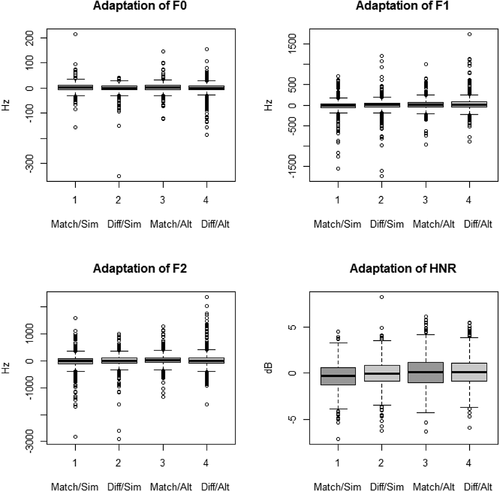
Table 6. Summary of mixed effects models, p < 0.01 indicated with double asterisk, p < 0.05 with one asterisk. Effect size d based on Brysbaert and Stevens (Citation2018) and Westfall et al. (Citation2014)
Table 7. Descriptive statistics. For matching, 0 = differing content, 1 = matching content. For simultaneity, 0 = alternating speech, 1 = simultaneous speech
Voice Recognition Task
We found no significant effects of the conditions on the voice recognition task scores measured before and after each interview. Over the three tasks participants became faster (F(1, 57) = 35.10, p < .001, η2 = .381), but there was no interaction effect between time and condition. During the task after the first interview, significantly more mistakes were made in the simultaneous conditions (F(1,60) = 5.23, p = .026), and the participants were significantly quicker in the synchronous conditions (F(1,59) = 4.69, p = .034).
Other Measurements
We found no significant differences between conditions on the difference between before and after the intervention on the valence, arousal and dominance scores. Neither were there significant differences in the IOS score, on the envoicement questionnaire, or on the affiliations questionnaires. The subjective experience of the collaboration was however affected by both similarity and matching. Alternating resulted in higher collaboration ratings than speaking at the same time (F(46,35) = 24.53, p < .001), and so did matching versus differing (F(19,14) = 10.13, p = .002), with the highest average rating after the matching/alternating condition.
Discussion
The results of experiment 2 confirm the influence of simultaneity on adaptation. In this interactive situation, this occurs in a different way compared to the non-interactive, recorded voice paradigm. In this experiment, we mainly find the divergence on the secondary vocal characteristics, specifically f1 and f2. This could again point to a suppression of adaptation when the voices overlap. However, we see the opposite effect for HNR. Additionally, f0 also shows a different pattern – matching utterances lead to less divergence in this paradigm. Again, no effect on the subjective measurement of envoicement was found.
The differences between the results of the two experiments could be due to the mutual adaptation possible between the dyads, but also to other elements such as a potential higher sense of collaboration with the dyad partner, or the improvisation of speech versus reading given sentences out loud.
General Discussion and Conclusion
The goal of this study was to develop an innovative experimental paradigm to study vocal adaptation, separating matching of speech content and simultaneity of vocal behavior. We expected adaptation to occur mainly after matching speech, and especially when in combination with simultaneity, to support successful interaction. Conversely, we hypothesized that the combination of simultaneous speaking with differing utterances would lead to phonetic divergence to strengthen the boundary between self and other.
Experiment 1 showed that during joint speech with a recorded voice, the ensuing f0 adaptation is influenced by simultaneity. Divergence occurs mainly in the condition where the speech is matching and simultaneous. Experiment 2 compared the same conditions in a collaborative task that allowed for mutual adaptation, showing similar effects of simultaneity on f1 and f2 adaptation, but the inverse for HNR. In these circumstances, f0 seems to be mainly influenced by the matching of utterances, showing less divergence.
This pattern, a combination of divergence and convergence in different circumstances, has been well-documented in previous joint speech research, but is often mainly described as a social effect (Pardo et al., Citation2012). These differences in outcome due to the changed parameters of the tasks again confirm how phonetic adaptation is influenced by many complex circumstances of the joint speech scenario, and slight changes can lead to large differences in results (Pardo, Citation2013). These experiments show that simultaneity and matching of utterances are two important factors contributing to this complexity, and influence vocal characteristics differently.
Contradictory to our hypothesis, simultaneity seemed to be the deciding factor in most cases, and not matching. Only in experiment 2, on f0, did our hypothesis that matching would lead to the strongest adaptation hold. This is partly in accordance with previous research, where f0 adaptation did occur after both matching and differing speech content, but simultaneity is less often a factor (Lelong & Bailly, Citation2011; Sato et al., Citation2013). The formants f1 and f2 are affected in the second experiment in a similar way, which might help explain some of the very mixed results in previous studies, where simultaneity was often not explicitly taken into account and might have inadvertently differed between dyads (Pardo et al., Citation2012; Pardo, Citation2010). We found convergence on HNR mainly after simultaneity, which might be considered in contrast to a previous study finding convergence after matching and alternating speech, but there it was not compared to a simultaneous scenario (Levitan & Hirschberg, Citation2011).
Neither of the experiments uncovered significant differences of the subjective envoicement measurement between conditions. It is possible that the effect of a nonvisual envoicement illusion influenced adaptation but simply did not rise to conscious awareness (Rombout & Postma-Nilsenová, Citation2019). In future experiments, this question could be addressed by the addition of visual articulation feedback (Dias & Rosenblum, Citation2016). We indeed find little to no effect of the conditions on any of the subjective measurements. Several perceptual sensitivity measurements are positively correlated with adaptation in experiment 1, which contradicts our hypothesis that higher sensitivity might lead to less adaptation but the relationships found are statistically weak.
We found several scenario’s where voice characteristics diverged. Divergence may occur to avoid sensory feedback confusion and potential slurring of speech (Liu et al., Citation2009). We expected this suppression mainly in the simultaneous and differing condition, but the effect occurred in all simultaneous conditions. When speaking with a recorded voice, this effect is more pronounced on the fundamental frequency, potentially because there are no considerations of collaboration or overt social expectations. In our interactive scenario the divergence is reserved for secondary vocal characteristics, possibly allowing more room in the f0 modulation for other objectives, such as affect and other social intentions. It remains to be seen if this effect remains the same in even more natural dialogue situations, where content matching and simultaneity are generally less intentional and social considerations may differ.
The negative influence of subjective likeness on HNR adaptation could stem from the same mechanism of avoiding confusion – subjective vocal similarity is positively correlated with embodiment, and yet this result points to the suppression of adaptation in circumstances where the voices already resemble each-other. Further research is needed to test this claim further and identify the mechanisms behind this potential “suppression” of adaptation.
The results found in our study appear to be in line with the Communication Accommodation Theory, according to which convergence and divergence are used to manage social distance (Giles et al., Citation1991). However, the Communication Accomodation theory operates on a social, inter-relational level, while our framework derives from a sensory, embodiment level. As described above, social considerations might have played a role in the differences between the results of the two experiments. It seems likely that multiple elements on several levels affect convergence and divergence of speech, leading to the complex patterns generally observed in speech adaptation studies (J. S. Pardo, Citation2010).
Another possible explanation, that should be mentioned here, is that divergence could be the result of compensation behavior. Previous research has shown that when people hear real-time but pitch-shifted auditory feedback of their own voice, they modulate their voice to compensate (Burnett et al., Citation1997). If they believe another voice is their own, the same effect might occur. This would mean that due to the nature of a simultaneous speaking interaction, the effect is opposite from envoicement studies. In a social joint speaking scenario where body-boundaries expand, a speaker could subconsciously attempt to influence the other voice by modulating their own, thus compensating for any differences in the “wrong” direction. This explanation is highly speculative, and further research is needed to identify whether this mechanism does in fact occur.
We conclude that separately taking into account matching of speech content and simultaneity of vocal behavior can provide a new understanding of why interlocutors choose to adapt to each other in some, but not other contexts. The novel paradigm explored in this study provides new perspectives on the shape that joint speaking scenarios can take and which elements can be manipulated to uncover the sources of phonetic adaptation.
Disclosure Statement
No potential conflict of interest was reported by the author(s).
References
- Amin, T. B., German, J. S., & Marziliano, P. (2013). Detecting voice disguise from speech variability: Analysis of three glottal and vocal tract measures. Proceedings of Meetings on Acoustics, 20, 060005.
- Anikin, A., Dong, Y., & Yu, X. (2018). Soundgen: An open-source tool for synthesizing nonverbal vocalizations. Behavior Research Methods, 50(1), 1–15. https://doi.org/https://doi.org/10.3758/s13428-017-1001-8
- Awan, S. N., & Frenkel, M. L. (1994). Improvements in estimating the harmonics-to-noise ratio of the voice. Journal of Voice, 8(3), 255–262. https://doi.org/https://doi.org/10.1016/S0892-1997(05)80297-8
- Babel, M., & Bulatov, D. (2012). The role of fundamental frequency in phonetic accommodation. Language and Speech, 55(2), 231–248. https://doi.org/https://doi.org/10.1177/0023830911417695
- Banakou, D., & Slater, M. (2014). Body ownership causes illusory self-attribution of speaking and influences subsequent real speaking. Proceedings of the National Academy of Sciences, 111(49), 17678–17683. https://doi.org/https://doi.org/10.1073/pnas.1414936111
- Bates, D., Maechler, M., Bolker, B., & Walker, S. (2015). Fitting Linear Mixed-Effects Models Using lme4. Journal of Statistical Software 67 1 1–48 doi:https://doi.org/https://doi.org/10.18637/jss.v067.i01 . http://CRANR-projectorg/package=lme4
- Belin, P., Fecteau, S., & Bedard, C. (2004). Thinking the voice: Neural correlates of voiceperception. Trends in Cognitive Sciences, 8(3), 129–135. https://doi.org/https://doi.org/10.1016/j.tics.2004.01.008
- Blanche, E. I., Reinoso, G., Chang, M. C., & Bodison, S. (2012). Proprioceptive processing difficulties among children with autism spectrum disorders and developmental disabilities. The American Journal of Occupational Therapy, 66(5), 621–624. https://doi.org/https://doi.org/10.5014/ajot.2012.004234
- Borrie, S. A., Barrett, T. S., Willi, M. M., & Berisha, V. (2019). Syncing up for a good conversation: A clinically meaningful methodology for capturing conversational entrainment in the speech domain. Journal of Speech, Language, and Hearing Research, 62(2), 283–296. https://doi.org/https://doi.org/10.1044/2018_JSLHR-S-18-0210
- Botvinick, M., & Cohen, J. (1998). Rubber hands ‘feel’ touch that eyes see. Nature, 391(6669), 756. https://doi.org/https://doi.org/10.1038/35784
- Bradshaw, A. R., McGettigan, C., & Kempe, V. (2021). Convergence in voice fundamental frequency during synchronous speech. PloS One, 16(10), e0258747. https://doi.org/https://doi.org/10.1371/journal.pone.0258747
- Brener J, Ring C and Liu X. (1994). Effects of data limitations on heartbeat detection in the method of constant stimuli. Psychophysiology, 31(3), 309–312. https://doi.org/https://doi.org/10.1111/j.1469-8986.1994.tb02219.x
- Broekens, J., & Brinkman, W.-P. (2013). Affectbutton: A method for reliable and valid affective self-report. International Journal of Human-Computer Studies, 71(6), 641–667. https://doi.org/https://doi.org/10.1016/j.ijhcs.2013.02.003
- Brysbaert, M., & Stevens, M. (2018). Power analysis and effect size in mixed effects models: A tutorial. Journal of Cognition, 1(1 9). https://doi.org/https://doi.org/10.5334/joc.10
- Burnett, T. A., Senner, J. E., & Larson, C. R. (1997). Voice f0 responses to pitch-shifted auditory feedback: A preliminary study. Journal of Voice, 11(2), 202{211. https://doi.org/https://doi.org/10.1016/S0892-1997(97)80079-3
- Chistovich, L., Fant, G., de Serpa-Leitao, A., & Tjernlund, P. (1966). Mimicking of synthetic vowels (Quarterly Progress and Status Report, Speech Transmission Lab). Royal Institute of Technology, 2, 1–18.
- Cohen Priva, U., Edelist, L., & Gleason, E. (2017). Converging to the baseline: Corpus evidence for convergence in speech rate to interlocutor’s baseline. The Journal of the Acoustical Society of America, 141(5), 2989–2996. https://doi.org/https://doi.org/10.1121/1.4982199
- Coles-Harris, E. H. (2017). Perspectives on the motivations for phonetic convergence. Language and Linguistics Compass, 11(12), e12268. https://doi.org/https://doi.org/10.1111/lnc3.12268
- Cummins, F. (2002). On synchronous speech. Acoustics Research Letters Online, 3(1), 7–11. https://doi.org/https://doi.org/10.1121/1.1416672
- Cummins, F. (2003). Practice and performance in speech produced synchronously. Journal of Phonetics, 31(2), 139–148. https://doi.org/https://doi.org/10.1016/S0095-4470(02)00082-7
- Cummins, F. (2009). Rhythm as entrainment: The case of synchronous speech. Journal of Phonetics, 37(1), 16–28. https://doi.org/https://doi.org/10.1016/j.wocn.2008.08.003
- Dias, J. W., & Rosenblum, L. D. (2016). Visibility of speech articulation enhances auditory phonetic convergence. Attention, Perception, & Psychophysics, 78(1), 317–333. https://doi.org/https://doi.org/10.3758/s13414-015-0982-6
- Garrod, S., & Pickering, M. J. (2004). Why is conversation so easy? Trends in Cognitive Sciences, 8(1), 8–11. https://doi.org/https://doi.org/10.1016/j.tics.2003.10.016
- Gijssels, T., Casasanto, L. S., Jasmin, K., Hagoort, P., & Casasanto, D. (2016). Speech accommodation without priming: The case of pitch. Discourse Processes, 53(4), 233–251. https://doi.org/https://doi.org/10.1080/0163853X.2015.1023965
- Giles, H., Coupland, N., & Coupland, J. (1991 Accommodation theory: Communication, context, and consequence). . Contexts of Accommodation: Developments in Applied Sociolinguistics, (Cambridge: Cambridge University Press)978-0-521-36151-4 .
- Goudbeek, M., Goldman, J. P., & Scherer, K. R. (2009). Emotion dimensions and formant position. Tenth Annual Conference of the International Speech Communication Association.
- Gregory, S. W., Jr, Green, B. E., Carrothers, R. M., Dagan, K. A., & Webster, S. W. (2001). Verifying the primacy of voice fundamental frequency in social status accommodation. Language & Communication, 21(1), 37–60. https://doi.org/https://doi.org/10.1016/S0271-5309(00)00011-2
- Han J., Waddington G., Adams R., Anson J. and Liu Y. (2016). Assessing proprioception: A critical review of methods. Journal of Sport and Health Science, 5(1), 80–90. https://doi.org/https://doi.org/10.1016/j.jshs.2014.10.004
- Heldner, M., Edlund, J., & Hirschberg, J. B. (2010). Pitch similarity in the vicinity of backchannels. Proceedings of Interspeech.
- Kalckert, A., & Ehrsson, H. H. (2014). The moving rubber hand illusion revisited: Comparing movements and visuotactile stimulation to induce illusory ownership. Consciousness and Cognition, 26 1 , 117–132. https://doi.org/https://doi.org/10.1016/j.concog.2014.02.003
- Keith, J. (1979). Impro: Improvisation and the theatre Keith, J. In Londen. Faber and Faber Ltd 978-0-87830-117-1 .
- Kilteni, K., Maselli, A., Kording, K. P., & Slater, M. (2015). Over my fake body: Body ownership illusions for studying the multisensory basis of own-body perception. Frontiers in Human Neuroscience, 9, 141. https://doi.org/https://doi.org/10.3389/fnhum.2015.00141
- Kirschner, S., & Tomasello, M. (2010). Joint music making promotes prosocial behavior in 4-year-old children. Evolution and Human Behavior, 31(5), 354–364. https://doi.org/https://doi.org/10.1016/j.evolhumbehav.2010.04.004
- Kreutz, G. (2014). Does singing facilitate social bonding? Music and Medicine, 6(2), 51–60. https://doi.org/https://doi.org/10.47513/mmd.v6i2.180
- Lelong, A., & Bailly, G. (2011). Study of the phenomenon of phonetic convergence thanks to speech dominoes. Analysis of Verbal and Nonverbal Communication and Enactment, the Processing Issues 6800 , 273–286 doi:https://doi.org/https://doi.org/10.1007/978-3-642-25775-9_26.
- Levitan, R., & Hirschberg, J. B. (2011). Measuring acoustic-prosodic entrainment with respect to multiple levels and dimensions. Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics.
- Lewandowski, N., & Jilka, M. (2019). Phonetic convergence, language talent, personality and attention. Frontiers in Communication, 4, 18. https://doi.org/https://doi.org/10.3389/fcomm.2019.00018
- Liu, H., Xu, Y., & Larson, C. R. (2009). Attenuation of vocal responses to pitch perturbations during mandarin speech. The Journal of the Acoustical Society of America, 125(4), 2299–2306. https://doi.org/https://doi.org/10.1121/1.3081523
- Longo, M. R., Schüür, F., Kammers, M. P., Tsakiris, M., & Haggard, P. (2008). What is embodiment? A psychometric approach. Cognition, 107(3), 978–998. https://doi.org/https://doi.org/10.1016/j.cognition.2007.12.004
- Mantell, J. T., & Pfordresher, P. Q. (2013). Vocal imitation of song and speech. Cognition, 127(2), 177–202. https://doi.org/https://doi.org/10.1016/j.cognition.2012.12.008
- Marslen-Wilson, W. D. (1985). Speech shadowing and speech comprehension. Speech Communication, 4(1–3), 55–73. https://doi.org/https://doi.org/10.1016/0167-6393(85)90036-6
- Miller-Kuhaneck, H., Henry, D.A., Glennon, T.J., Mu, K. (2007 Development of the Sensory Processing Measure–School: Initial studies of reliability and validity.). . The American Journal of Occupational Therapy 61 2 170–175 doi:https://doi.org/https://doi.org/10.5014/ajot.61.2.170 (:).
- Nguyen, N., & Delvaux, V. (2015). Role of imitation in the emergence of phonological systems. Journal of Phonetics, 53 1 , 46–54. https://doi.org/https://doi.org/10.1016/j.wocn.2015.08.004
- Pardo, J. S., Jay, I. C., & Krauss, R. M. (2010). Conversational role influences speech imitation. Attention, Perception, & Psychophysics, 72(8), 2254–2264. https://doi.org/https://doi.org/10.3758/BF03196699
- Pardo, J. S. (2010 Expressing oneself in conversational interaction. Morsella, E.). . Expressing oneself/expressing One’s Self: Communication, Cognition, Language, and Identity (Psychology Press), 183–196 978-1-84872-886-8 .
- Pardo, J., Gibbons, R., Suppes, A., & Krauss, R. M. (2012). Phonetic convergence in college roommates. Journal of Phonetics, 40(1), 190–197. https://doi.org/https://doi.org/10.1016/j.wocn.2011.10.001
- Pardo, J. (2013). Measuring phonetic convergence in speech production. Frontiers in Psychology, 4, 559. https://doi.org/https://doi.org/10.3389/fpsyg.2013.00559
- Pardo, J. S., Jordan, K., Mallari, R., Scanlon, C., & Lewandowski, E. (2013). Phonetic convergence in shadowed speech: The relation between acoustic and perceptual measures. Journal of Memory and Language, 69(3), 183–195. https://doi.org/https://doi.org/10.1016/j.jml.2013.06.002
- Pardo, J., Urmanche, W., Wilman, Wiener, S., & Wiener, J. (2017). Phonetic convergence across multiple measures and model talkers. Attention, Perception, & Psychophysics, 79(2), 637–659. https://doi.org/https://doi.org/10.3758/s13414-016-1226-0
- Pardo, J., Urmanche, A., Wilman, S., Wiener, J., Mason, N., Francis, K., & Ward, M. (2018). A comparison of phonetic convergence in conversational interaction and speech shadowing. Journal of Phonetics, 69 1 , 1–11. https://doi.org/https://doi.org/10.1016/j.wocn.2018.04.001
- Pearce, E., Launay, J., & Dunbar, R. I. (2015). The ice-breaker effect: Singing mediates fast social bonding. Royal Society Open Science, 2(10), 150221. https://doi.org/https://doi.org/10.1098/rsos.150221
- Pearce, E., Launay, J., van Duijn, M., Rotkirch, A., David-Barrett, T., & Dunbar, R. I. (2016). Singing together or apart: The effect of competitive and cooperative singing on social bonding within and between sub-groups of a university fraternity. Psychology of Music, 44(6), 1255–1273. https://doi.org/https://doi.org/10.1177/0305735616636208
- Porges, S. (1993). Body perception questionnaire Kolacz, J. In Laboratory of developmental assessment. University of Maryland.
- Postma, A. (2000). Detection of errors during speech production: A review of speech monitoring models. Cognition, 77(2), 97–132. https://doi.org/https://doi.org/10.1016/S0010-0277(00)00090-1
- Postma-Nilsenová, M., & Postma, E. (2013). Auditory perception bias in speech imitation. Frontiers in Psychology, 4, 826. https://doi.org/https://doi.org/10.3389/fpsyg.2013.00826
- R Core Team (2013). R: A language and environment for statistical computing. Vienna, Austria http://www.R-project.org/
- Reichel, U. D., Beňuš, Š., & Mády, K. (2018). Entrainment profiles: Comparison by gender, role, and feature set. Speech Communication, 100 1 , 46–57. https://doi.org/https://doi.org/10.1016/j.specom.2018.04.009
- Rombout, L. E., Atzmueller, M., & Postma-Nilsenová, M. (2018). Towards estimating collective motor behavior: Aware of self vs. aware of the other. Proceedings of the Workshop on Affective Computing and Context Awareness in Ambient Intelligence.
- Rombout, L. E., & Postma-Nilsenová, M. (2019). Exploring a voice illusion. Proceedings of the 8th international conference on affective computing and intelligent interaction (ACII), 711–717.
- Sato, M., Grabski, K., Garnier, M., Granjon, L., Schwartz, J.-L., & Nguyen, N. (2013). Converging toward a common speech code: Imitative and perceptuo-motor recalibration processes in speech production. Frontiers in Psychology, 4, 422. https://doi.org/https://doi.org/10.3389/fpsyg.2013.00422
- Schweitzer, A., & Lewandowski, N. (2014). Social factors in convergence of f1 and f2 in spontaneous speech. Proceedings of the 10th International Seminar on Speech Production, 391–394.
- Seth, A. K. (2013). Interoceptive inference, emotion, and the embodied self. Trends in Cognitive Sciences, 17(11), 565–573. https://doi.org/https://doi.org/10.1016/j.tics.2013.09.007
- Sforza, A., Bufalari, I., Haggard, P., & Aglioti, S. M. (2010). My face in yours: Visuo-tactile facial stimulation influences sense of identity. Social Neuroscience, 5(2), 148–162. https://doi.org/https://doi.org/10.1080/17470910903205503
- Suzuki, K., Garfinkel, S. N., Critchley, H. D., & Seth, A. K. (2013). Multisensory integration across exteroceptive and interoceptive domains modulates self-experience in the rubber hand illusion. Neuropsychologia, 51(13), 2909–2917. https://doi.org/https://doi.org/10.1016/j.neuropsychologia.2013.08.014
- Tajadura-Jiménez, A., Banakou, D., Bianchi-Berthouze, N., & Slater, M. (2017). Embodiment in a child-like talking virtual body inuences object size perception, self-identification, and subsequent real speaking. Scientific Reports, 7(1), 1–12. https://doi.org/https://doi.org/10.1038/s41598-017-09497-3
- Tarr, B., Slater, M., & Cohen, E. (2018). Synchrony and social connection in immersive virtual reality. Scientific Reports, 8(1), 1–8. https://doi.org/https://doi.org/10.1038/s41598-018-21765-4
- Tsakiris, M. (2017). The multisensory basis of the self: From body to identity to others. The Quarterly Journal of Experimental Psychology, 70(4), 597–609. https://doi.org/https://doi.org/10.1080/17470218.2016.1181768
- Westfall, J., Kenny, D. A., & Judd, C. M. (2014). Statistical power and optimal design in experiments in which samples of participants respond to samples of stimuli. Journal of Experimental Psychology: General, 143(5), 2020. https://doi.org/https://doi.org/10.1037/xge0000014
- Wiltermuth, S. S., & Heath, C. (2009). Synchrony and cooperation. Psychological Science, 20(1), 1–5. https://doi.org/https://doi.org/10.1111/j.1467-9280.2008.02253.x
- Woosnam, K. M. (2010). The inclusion of other in the self (IOS) scale. Annals of Tourism Research, 37(3), 857–860. https://doi.org/https://doi.org/10.1016/j.annals.2010.03.003
- Zheng, Z. Z., MacDonald, E. N., Munhall, K. G., Johnsrude, I. S., & Sirigu, A. (2011). Perceiving a stranger’s voice as being one’s own: A ‘rubber voice’ illusion? PloS One, 6(4), e18655. https://doi.org/https://doi.org/10.1371/journal.pone.0018655