
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Background
Estrogen receptors (ERs) are nuclear transcription factors that are involved in the regulation of many complex physiological processes in humans. ERs have been validated as important drug targets for the treatment of various diseases, including breast cancer, ovarian cancer, osteoporosis, and cardiovascular disease. ERs have two subtypes, ER-α and ER-β. Emerging data suggest that the development of subtype-selective ligands that specifically target ER-β could be a more optimal approach to elicit beneficial estrogen-like activities and reduce side effects.
Methods
Herein, we focused on ER-β and developed its in silico quantitative structure-activity relationship models using machine learning (ML) methods.
Results
The chemical structures and ER-β bioactivity data were extracted from public chemogenomics databases. Four types of popular fingerprint generation methods including MACCS fingerprint, PubChem fingerprint, 2D atom pairs, and Chemistry Development Kit extended fingerprint were used as descriptors. Four ML methods including Naïve Bayesian classifier, k-nearest neighbor, random forest, and support vector machine were used to train the models. The range of classification accuracies was 77.10% to 88.34%, and the range of area under the ROC (receiver operating characteristic) curve values was 0.8151 to 0.9475, evaluated by the 5-fold cross-validation. Comparison analysis suggests that both the random forest and the support vector machine are superior for the classification of selective ER-β agonists. Chemistry Development Kit extended fingerprints and MACCS fingerprint performed better in structural representation between active and inactive agonists.
Conclusion
These results demonstrate that combining the fingerprint and ML approaches leads to robust ER-β agonist prediction models, which are potentially applicable to the identification of selective ER-β agonists.
Introduction
Estrogen receptors (ERs) are nuclear transcription factors and hormone-regulated modulators of intracellular signaling and gene expression.Citation1–Citation4 There are two subtypes of ERs, ER-α and ER-β. ER-α is encoded by the ESR1 gene on chromosome 6, and ER-β is encoded by the ESR2 gene on chromosome 14.Citation5 Both ER-α and ER-β are widely distributed in many kinds of cells and tissues, and modulate biological functions in several organ systems, such as endocrine, reproductive, skeletal, cardiovascular, and central nervous systems. ER-α is predominantly expressed in mammary gland, ovary, uterus, male reproductive organs (testes and epididymis), prostate, liver, heart, bone, adipose tissue, vascular system, and brain. ER-β is mainly expressed in mammary gland, ovary (granulosa cells), bladder, prostate (epithelium), adipose tissue, immune system, colon, heart, vascular system, lung, and brain.Citation6,Citation7 The ER-α subtype has a more prominent role in the mammary gland, uterus, the preservation of skeletal homeostasis, and the regulation of metabolism. The ER-β subtype has a more profound effect on the immune and central nervous systems. What is more, ER-β generally counteracts the ER-α promoted cell hyper-proliferation in tissues such as breast and uterus.Citation4,Citation8
Abnormal ER signaling leads to development of a variety of diseases including osteoporosis. Estradiol replacement therapy is used in the clinic for the treatment of osteoporosis. However, estradiol replacement therapy often leads to an increased risk of breast and endometrial cancers, and thromboembolism due to the ER-α promoted cell hyper-proliferation.Citation4 Selective estrogen receptor modulators (SERMs) are a class of drugs that act on the ER. A characteristic that distinguishes these substances from pure ER agonists and antagonists (that is, full agonists and silent antagonists) is that their action is different in various tissues, thereby granting the possibility to selectively inhibit or stimulate estrogen-like action in various tissues.Citation9,Citation10 Following tamoxifen, the first SERM, a number of other anti-estrogens have been developed. Good SERMs would display antagonist activity in the mammary gland and uterus, and agonist activity in cardiovascular, skeletal, and central nervous systems.Citation9,Citation11,Citation12 Emerging data suggest that ER-β subtype-selective ligands could be used to elicit beneficial estrogen-like activities and reduce side effects.Citation4,Citation13–Citation15 These results inspired the medical researchers to discover selective ER-β agonists. Roberts et al found sulfonamides as selective ER-β agonists.Citation16 Paterni et al identified a series of new salicylketoxime derivatives that display unprecedentedly high levels of ER-β selectivity, and one compound was further proved to be active in an in vivo xenograft model of human glioma.Citation17
Computational approaches in medicinal chemistry provide important tools for lead discovery and lead optimizations. Machine learning methods are widely applied in computer aided drug design, particularly in the ligand based virtual screening. Zang et al developed binary classification models using a large collection of environmental chemicals from ER assays by quantitative structure-activity relationship (QSAR) and machine learning methods.Citation18 Ng et al developed a classification model using decision forest to predict environmental chemicals binding to ER.Citation19 However, previous QSAR studies mainly focused on toxicity or endocrine disruption activity predictions for environmental chemicals. Furthermore, there had been rare reports focusing on the subtype-selective ER agonist prediction.
Owing to the significance of the selective ER-β agonists, as discussed above, we proposed a protocol to predict selective ER-β agonists using a machine learning approach (). Due to the difficulty in developing a regression model for a large structural diverse dataset, binary classification approaches were used here. In this work, we collected a dataset of selective ER-β agonists from an open database (ChEMBL, www.ebi.ac.uk/chembl) and performed the dataset analysis using principal component analysis (PCA) and distance analysis. Then we constructed the prediction models using various molecular fingerprints and machine learning approaches. The accuracies and robustness of the prediction models were further validated, and the performance of the machine learning methods and the molecular fingerprints was compared. These models could be useful in the discovery of selective ER-β agonists.
Figure 1 The data analysis and machine learning schema.
Abbreviations: ER, estrogen receptor; SVM, support vector machine; ROC, receiver operating characteristic; PCA, principal component analysis.
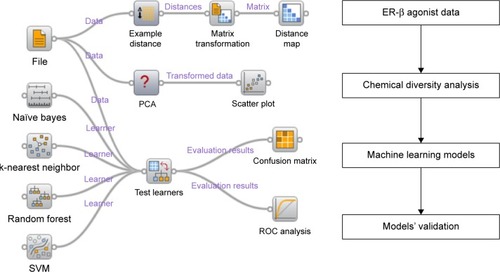
Materials and methods
Dataset
The ER-β bioactive agonists were downloaded from ChEMBL database (ChEMBL 20 release). Duplicates and salts were removed using Open Babel.Citation20 Compounds with unclear EC50 data, for example <1,000 nM, were removed. The active ER-β agonist was defined as having an EC50 less than 10 μM. The inactive agonist was defined as having an EC50 more than 10 μM. Finally a dataset was constructed which contained 356 active agonists and 107 inactive agonists. The balancing of the dataset is important for developing a robust model. Machine learning approaches are likely to perform poorly in situations with data imbalance between the classes.Citation21,Citation22 In order to balance the dataset, we generated a decoy dataset (249 compounds) using the DUD-E online automated tool.Citation23 Finally, a dataset with 356 active compounds and 356 inactive compounds was obtained.
Molecular fingerprints
Molecular fingerprints are representations of chemical structures originally developed for substructure and similarity searching, but later widely used for descriptors in QSAR studies.Citation24 Four popular fingerprint generation methods in chemoinformatics including Chemistry Development Kit extended fingerprint (ExtFP, 1024 bits), MACCS fingerprint (MACCSFP, 166 bits), PubChem fingerprint (PubChemFP, 881 bits), and 2D atom pairs (AP2D, 780 bits) were used in this study. All the fingerprints were generated using the PaDEL-Descriptor software.Citation25
Naïve Bayesian (NB) classification
The NB classification method is a simple classification method based on the Bayes’ theorem as described below:
The prior probability can be estimated from the training set, while the marginal probability can be ignored. The details of NB classifier building have been described elsewhere.Citation26,Citation27 NB classification can process large amounts of data, learn fast, and noise data tolerance. The NB classifiers were developed in Orange with default settings. Laplace method was used for probability estimation.
k-nearest neighbor (KNN)
KNN classifier can predict a test sample based on the closest training examples. The nearness is measured by similarity or distance based on vectors in a multidimensional feature space. In the classification process, “k” was a user-defined value, and an unlabeled vector was classified by assigning the label that was most frequent in the k-nearest training samples. The KNN classifiers were developed in Orange using Euclidean distance and the value of “k” was set to three.
Random forest (RF)
The RF was first proposed by Breiman.Citation28 The RF method is based upon an ensemble of decision trees, from which the prediction of a continuous variable is provided as the average of the predictions of all trees. The advantages of RF in QSAR include high accuracy of prediction, built-in descriptor selection, and a method for evaluating the importance of descriptors in the QSAR model. The details of training procedures are described elsewhere.Citation29 The RF classifiers were developed in Orange and the number of trees in forest was set to ten, splitting was stopped in RF with nodes of five or fewer instances.
Support vector machine (SVM)
SVM is a general data modeling methodology, originally developed by Vapnik, aimed at minimizing the structural risk under the frame of Vapnik Chervonenkis theory.Citation30 The principle of SVM is to find a hyperplane in a high dimensional space to separate the positives and negatives.Citation31 In this work, the radial basis function kernel function was used and the cost was set to 1.00. SVM models were developed using Orange.
Model validation
Cross validation method was employed to test the model performance and robustness. In 5-fold cross validation, the dataset was divided into five subsets, four subsets were chosen as training sets which left one subset as test set in each run. After five runs, each subset was used as test set and the entire dataset was predicted. The quality of the model was evaluated by the quantity of true positives (TP), true negatives (TN), false positives (FPos), and false negatives (FN). Then the sensitivity (SE), the specificity (SP), the classification accuracy (CA) and the Matthews correlation coefficient (MCC) were calculated using the following equations. Furthermore, the receiver operating characteristic (ROC) curve was plotted and the area under the ROC curve (AUC) was calculated. The values of AUC range from 0–1.0, and 1.0 indicates a perfect model, 0.5 indicates a random model, and >0.8 indicates a good model.
Results and discussion
Chemical diversity analysis
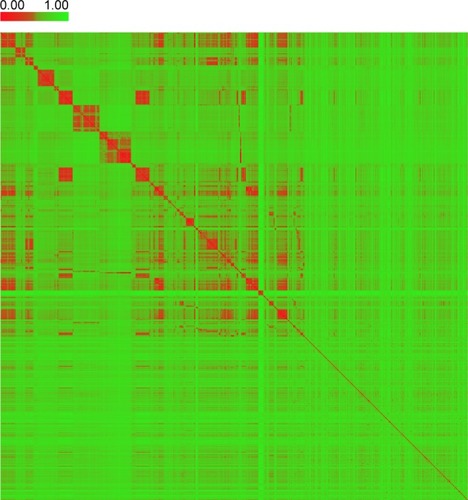
The diversity is important when building a QSAR model.Citation32 The PCA was performed here to explore the chemical space of the dataset, which contained 356 active agonists and 356 inactive agonists. For each molecule, four types of fingerprints (ExtFP 1024 bits, MACCSFP 166 bits, PubChemFP 881 bits, and AP2D 780 bits) were calculated as descriptors. Each compound is represented by a multidimensional vector, the dimension of which is equal to the bit-length of a fingerprint. A reducing dimension calculation was processed in the PCA. The top two principal components were preserved and plotted as illustrated in . Each node represents a molecule of the entire dataset. The actives and inactives were rendered in black and gray color, respectively. The actives and the inactives cover the same chemical space, suggesting the diversity of this collected dataset and the reasonability of the decoy generation methods. The distance of the compounds in this dataset was calculated using Euclidean distance based on the ExtFP. A distance matrix (712×712) was generated and plotted with a heat map. The distance values were normalized to interval 0–1. One represents the largest distance (green) and suggests the structural dissimilarity. As shown in , most areas in the heat map were green, indicating the chemical diversity of this dataset.
Figure 2 Principal component analysis (PCA) of the dataset.
Abbreviations: Ext, extended; AP2D, 2D atom pairs; FP, fingerprints.
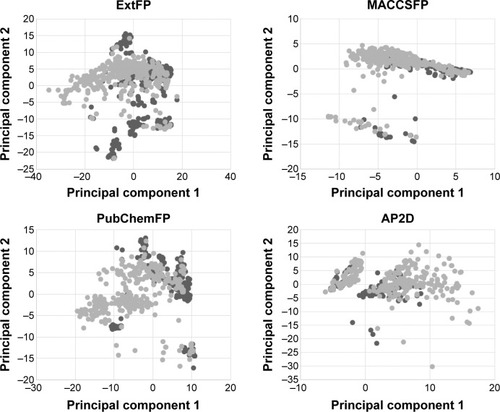
Figure 3 The heat map of distance matrix for the compounds in the collected dataset.
Performance of cross validation
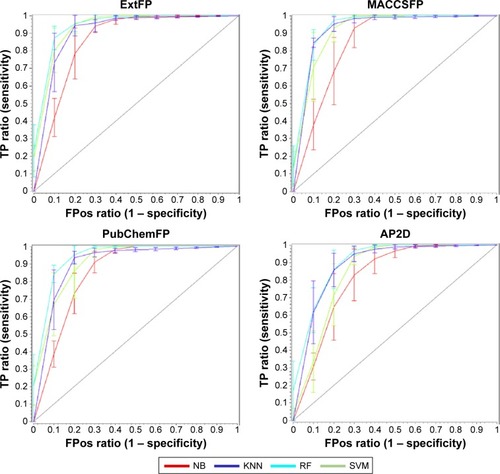
In order to evaluate the performance of models, 5-fold cross validation was employed here. We developed 16 models based on four types of fingerprints and four classifiers. The CA, SE, SP, AUC, and MCC values are listed in . The ranges of CA, SE, SP, AUC, and MCC were 0.7710–0.8834, 0.8146–0.9410, 0.6938–0.8820, 0.8151–0.9475, and 0.5487–0.7698, respectively. The ROC curves of the 16 models are illustrated in . The AUC values of all models were greater than 0.8, indicating the good performance of the constructed models. The excellent models (MCC >0.75) were SVM combined with ExtFP, and RF combined with ExtFP. SVM-ExtFP achieved performances of CA 0.8834 and MCC 0.7698. RF-ExtFP achieved a performance of CA 0.8750 and MCC 0.7501. Ten-fold cross validation method was also employed and the model performances were evaluated and are listed in . Compared with 5-fold cross validation results, 10-fold cross validation results tended to be a bit more optimistic and showed a similar trend. In the following study, the 5-fold cross validation results were used. For comparison, we developed models using true inactive agonists that do not include decoys. The 5-fold cross validation model performance is listed in . The mean value of the MCC for the 16 models is 0.3518, this indicates a poor performance of the imbalanced dataset when compared with the balanced dataset, which achieved a mean value of MCC 0.6881.
Table 1 Model performances of 5-fold cross validation
Figure 4 The ROC curves of the 5-fold cross validation models based on four types of fingerprints (FP) and four machine learning approaches.
Abbreviations: ROC, receiver operating characteristic; NB, Naïve Bayesian; KNN, k-nearest neighbor; RF, random forest; SVM, support vector machine; Ext, extended; AP2D, 2D atom pairs; TP, true positives, FPos, false positives.
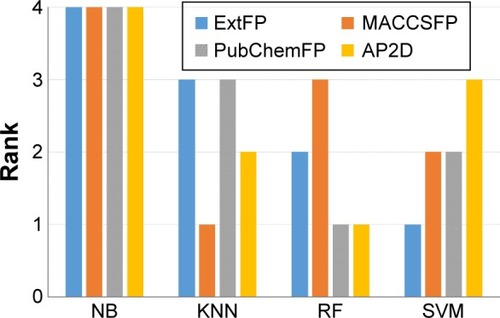
In order to compare the performances of different machine learning methods, we ranked the performances of the models with the same fingerprint using the values of MCC. The rank results are shown in . NB ranked fourth with each type of fingerprint. KNN ranked first with the MACCSFP. RF ranked first with PubChemFP and AP2D. SVM ranked first with ExtFP. These results suggest the model performance varies with different combinations of machine learning approaches and molecular fingerprints. Taken together, NB performs worst compared with KNN, RF, and SVM. RF and SVM are superior to other methods for the classification of ER-β agonists. In Zang et al’s binary classification models of a large collection of environmental chemicals from ER assays, they obtained the best model using SVM.Citation18 This consistency suggests SVM is a suitable machine learning method for this target.
Figure 5 Performance ranking of machine learning methods with various fingerprints (FP).
Abbreviations: NB, Naïve Bayesian; KNN, k-nearest neighbor; RF, random forest; SVM, support vector machine; Ext, extended; AP2D, 2D atom pairs.
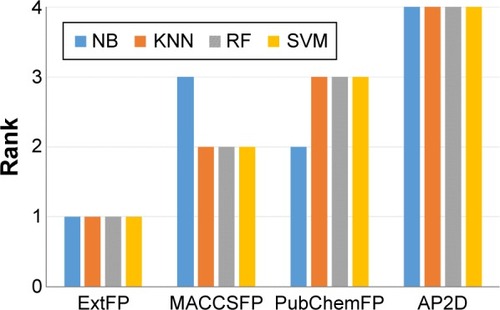
We further compared the performances of the fingerprints. Model performances with various fingerprints and the same machine learning methods were ranked, as shown in . As is obvious from the figure, ExtFP performed best and AP2D performed worst. ExtFP ranked first for any machine learning method mentioned here. In contrast, AP2D ranked last. ExtFP had 1024-bit length and AP2D had 780-bit length. Usually, the length of the fingerprints may affect the performance. However, MACCSFP with only 166-bit length, ranked second in KNN, RF, and SVM models, and ranked third in NB models. These results suggest that the model’s performance is not dependent on the length of the fingerprints but the structural representation methods. Furthermore, MACCSFP is a good fingerprint generation method for capturing the structural patterns of ER-β agonists.
Figure 6 Performance ranking of fingerprints (FP) in various machine learning methods.
Abbreviations: NB, Naïve Bayesian; KNN, k-nearest neighbor; RF, random forest; SVM, support vector machine; Ext, extended; AP2D, 2D atom pairs.
Performance of test set
To further evaluate the robustness of the model and to prove the observations in the cross validations, the test set was randomly split from the original dataset. The ratio of training set against test set was 2:1. The model performances for the test set are summarized in . For machine learning methods, RF ranked first with MACCSFP and PubChemFP. NB ranked last with any fingerprints. For fingerprints, ExtFP ranked first in NB and SVM. MACCSFP ranked first in KNN and second in RF and SVM. MACCSFP showed good performance and AP2D performed worst. This is in agreement with the previous observation in the cross validation.
Table 2 Model performances of test set
We further collected an external test dataset from two literature sources,Citation17,Citation33 which included eleven ER-β selective agonists. We added eleven decoys to obtain a dataset with 22 compounds in total. We trained models using compounds from ChEMBL and predicted the external test dataset. The models’ performances are summarized in . All those models showed a good performance in classifying agonists and non-agonists.
Table 3 Model performances of external test set
Conclusion
Emerging data suggest that ER-β subtype-selective ligands could be used to elicit beneficial estrogen-like activities and reduce side effects. There have been rare reports focusing on the subtype-selective ER agonist prediction. Owing to the significance of the selective ER-β agonists, in this work, we collected a dataset of selective ER-β agonists and performed the dataset analysis using PCA and distance analysis. Subsequently, we constructed the classification models of selective ER-β agonists using multiple machine learning methods and various molecular fingerprints. The models were validated through cross validation methods and test set validations. The range of classification accuracies was 77.10% to 88.34%, and the range of AUC values was 0.8151 to 0.9475, evaluated by the 5-fold cross validation. Comparison analysis suggests that both the RF and the SVM are superior to other machine learning methods for the classification of selective ER-β agonists. Chemistry Development Kit ExtFP and MACCSFP performed better in structural representation between active and inactive agonists. These models are robust and accurate, and could be applied in the virtual screening of large chemical libraries to identify selective ER-β agonists.
Supplementary materials
Table S1 Ten-fold cross validation model performance
Table S2 Five-fold cross validation model performance using experimental inactive agonists
Disclosure
The authors report no conflicts of interest in this work.
References
- JiaMDahlman-WrightKGustafssonJAEstrogen receptor alpha and beta in health and diseaseBest Pract Res Clin Endocrinol Metab201529455756826303083
- KatzenellenbogenBSChoiIDelage-MourrouxRMolecular mechanisms of estrogen action: selective ligands and receptor pharmacologyJ Steroid Biochem Mol Biol200074527928511162936
- EversNMvan den BergJHWangSCell proliferation and modulation of interaction of estrogen receptors with coregulators induced by ERα and ERβ agonistsJ Steroid Biochem Mol Biol201414337638524923734
- PaterniIGranchiCKatzenellenbogenJAMinutoloFEstrogen receptors alpha (ERα) and beta (ERβ): subtype-selective ligands and clinical potentialSteroids201490132924971815
- NilssonSKoehlerKFGustafssonJADevelopment of subtype-selective oestrogen receptor-based therapeuticsNat Rev Drug Discov2011101077879221921919
- DrummondAEFullerPJThe importance of ERbeta signalling in the ovaryJ Endocrinol20102051152320019181
- TaylorAHAl-AzzawiFImmunolocalisation of oestrogen receptor beta in human tissuesJ Mol Endocrinol200024114515510657006
- HeldringNPikeAAnderssonSEstrogen receptors: how do they signal and what are their targetsPhysiol Rev200787390593117615392
- JordanVCGapsturSMorrowMSelective estrogen receptor modulation and reduction in risk of breast cancer, osteoporosis, and coronary heart diseaseJ Natl Cancer Inst200193191449145711584060
- RiggsBLHartmannLCSelective estrogen-receptor modulators – mechanisms of action and application to clinical practiceN Engl J Med2003348761862912584371
- DhingraKSelective estrogen receptor modulation: the search for an ideal hormonal therapy for breast cancerCancer Invest200119664965911486708
- MaximovPYLeeTMJordanVCThe discovery and development of selective estrogen receptor modulators (SERMs) for clinical practiceCurr Clin Pharmacol20138213515523062036
- MinutoloFMacchiaMKatzenellenbogenBSKatzenellenbogenJAEstrogen receptor beta ligands: recent advances and biomedical applicationsMed Res Rev201131336444219967775
- HinscheOGirgertREmonsGGrundkerCEstrogen receptor β selective agonists reduce invasiveness of triple-negative breast cancer cellsInt J Oncol201546287888425420519
- MarzioniMTorriceASaccomannoSAn oestrogen receptor β-selective agonist exerts anti-neoplastic effects in experimental intrahepatic cholangiocarcinomaDig Liver Dis201244213414221782536
- RobertsLRArmorDBarkerCSulfonamides as selective oestrogen receptor β agonistsBioorg Med Chem Lett201121195680568321885279
- PaterniIBertiniSGranchiCHighly selective salicylketoxime-based estrogen receptor β agonists display antiproliferative activities in a glioma modelJ Med Chem20155831184119425559213
- ZangQRotroffDMJudsonRSBinary classification of a large collection of environmental chemicals from estrogen receptor assays by quantitative structure-activity relationship and machine learning methodsJ Chem Inf Model201353123244326124279462
- NgHWDoughtySWLuoHDevelopment and Validation of Decision Forest Model for Estrogen Receptor Binding Prediction of Chemicals Using Large Data SetsChem Res Toxicol201528122343235126524122
- O’BoyleNMBanckMJamesCAMorleyCVandermeerschTHutchisonGROpen Babel: An open chemical toolboxJ Cheminform201133321982300
- KleinKHennigSPaulSKA Bayesian Modelling Approach with Balancing Informative Prior for Analysing Imbalanced DataPloS One2016114e015270027070549
- DattaSDasSNear-Bayesian Support Vector Machines for imbalanced data classification with equal or unequal misclassification costsNeural Netw201570395226210983
- MysingerMMCarchiaMIrwinJJShoichetBKDirectory of useful decoys, enhanced (DUD-E): better ligands and decoys for better benchmarkingJ Med Chem201255146582659422716043
- RogersDHahnMExtended-connectivity fingerprintsJ Chem Inf Model201050574275420426451
- YapCWPaDEL-descriptor: an open source software to calculate molecular descriptors and fingerprintsJ Comput Chem20113271466147421425294
- ChenLLiYZhaoQPengHHouTADME evaluation in drug discovery. 10. Predictions of P-glycoprotein inhibitors using recursive partitioning and naive Bayesian classification techniquesMol Pharm20118388990021413792
- SunHA naive bayes classifier for prediction of multidrug resistance reversal activity on the basis of atom typingJ Med Chem200548124031403915943476
- BreimanLRandom forestsMachine Learning2001451532
- SvetnikVLiawATongCCulbersonJCSheridanRPFeustonBPRandom forest: a classification and regression tool for compound classification and QSAR modelingJ Chem Inf Comput Sci20034361947195814632445
- ChengFYuYShenJClassification of cytochrome P450 inhibitors and noninhibitors using combined classifiersJ Chem Inf Model2011515996101121491913
- HeikampKBajorathJSupport vector machines for drug discoveryExpert Opin Drug Discov2014919310424304044
- XuCChengFChenLIn silico prediction of chemical Ames mutagenicityJ Chem Inf Model201252112840284723030379
- ChenLWuDBianHPSelective ligands of estrogen receptor β discovered using pharmacophore mapping and structure-based virtual screeningActa Pharmacol Sin201435101333134125176400