Abstract
Assessing the completeness of topic coverage in medical curricula is difficult to establish as no universal standard for completeness has been agreed upon. However, the United States Medical Licensing Examination (USMLE) Step 1 Exam Content Outline may provide a beginning framework. This project developed a computer-based tool that matched ArizonaMed curriculum content (Tucson track) against a modified USMLE content outline. The project involved three phases: (1) the USMLE Step 1 content outline was deconstructed and translated using equivalent Medical Subject Heading (MeSH) terms; (2) a report was made of all MeSH terms used to identify the content in the ArizonaMed curriculum database, compared to the MeSH-modified USMLE outline, and the resulting matches are graphically expressed. The frequency with which each MeSH term appeared across the years also was reported; and (3) a retreat was held with faculty and others to ensure the MeSH-translated outline was accurate and complete. Faculty were able to visualize how content was being expressed among instructional blocks across the first two years. Results also assured faculty and students that all subjects contained in the USMLE content outline were covered in the curriculum. The success of this effort is leading to improvements in content-tracking capability for the ArizonaMed database.
Introduction
Evaluating the scope of medical knowledge content taught within medical school curricula has been a challenge as each school mounts its own interpretation of what constitutes the knowledge appropriate to the basic education of physicians. Today, it is broadly accepted that medical knowledge is a fluid and changing construct and that integrating categories of knowledge provide a flexible way to engage that content (Bordage & Harris Citation2011; LCME standard ED-11 2011). Thus, as an ‘interdisciplinary’ principle is applied to curricular design, broad subject areas (e.g., organ systems) may be imposed, but without predetermining the topic relationships within each area (Harden Citation1998). By this organizing principle, learning is optimized as the most instructive relationships of knowledge are allowed to emerge.
As organization-by-discipline dissolves, content oversight becomes institutionally complex. An informed balance must be established between the interests of multiple departments and broad educational goals in the design and delivery of integrated courses (D’Eon & Crawford Citation2005). Effective evaluation practices provide the means to know if the intent to deliver broadly integrated content is being played out in practice. One evaluation tool that can help is a useful content map of the curriculum.
In educational literature, the concept of ‘curriculum mapping’ is often applied to a comprehensive plan for an instructional program. The characteristics of the plan that give it a ‘mapping’ quality are that the elements of the plan are linked by way of explanatory relationships and outcome objectives. For this type of map, the functional relationships of curricular components become as important as the components themselves. The value of mapping comes in that all participants, including students, are informed of the ‘big picture’ for the curriculum, and can then locate their own work within that context (Harden Citation2001).
A map that charts the presence and location of curricular content across time is one aspect of curriculum mapping. Content maps depict what instructional topics are being covered, the distribution of that coverage, the depth of coverage, and finally the temporal sequence and pace of coverage. This is the primary function of the mapping tool we developed. Using a graphical format, the map provides a means by which the overall continuum of learning can be quickly understood and assessed for continuity. Relationships between sequential as well as concurrent topics are readily apparent when depicted graphically, as are unintended gaps or redundancies. With this information revealed, deeper investigations can be made toward assessing relationships of content with instructional methods, and how those relationships may affect learning outcomes (Kelley et al. Citation2008). For evaluation purposes, mapping can help ensure that the inclusion and interrelationships of content no longer occur by happenstance (Britton et al. Citation2008). This article addresses the processes and experiences of The University of Arizona College of Medicine in its effort to create and use a computer-aided tool by which the expression of medical knowledge in integrated years I and II curriculum could be mapped, reported, and discussed.
Designing the arizona medical knowledge ontology
Starting with what was working
The ability of computers to work effectively with text-based data is critical to the construction of a curriculum content map. Although text-string searching and Boolean operators (i.e., AND, OR, and NOT) were once fine tools for the analysis of words and documents, relational databases and linkable metadata are now the functional norm. Linkable metadata requires humans to assess entries and make taxonomic decisions about which terms should signify knowledge concepts, and how those terms should relate to each other. Whole vocabularies of taxonomically ordered terms have been created in this effort, e.g., The National Library of Medicine's Medical Subject Heading® (MeSH) and the Unified Medical Language System® Metathesaurus®. The Association of American Medical Colleges (AAMC) Curriculum Management Information Tool uses MeSH term metadata to identify topics. It was the first nationally based relational database to provide an analysis of medical curricula for purposes of institutional management (Salas et al. Citation2003).
Very recently, near human-quality natural-language-based concept mapping by computers arrived. IBM's Watson® triumphed in the quiz show Jeopardy! as a demonstration of the latest capability of computers to independently develop and use machine-based meta-ordering of natural language text. This functionality has been in development among medical schools for a number of years. Notable for the accuracy of its natural-language analysis engines is the Vanderbilt University School of Medicine's KnowledgeMap (KM) program (Denny et al. Citation2005). The KM system employs computer-based algorithms that allow curricular materials to be electronically parsed for knowledge concepts. It then applies metadata ‘tags’ to those it uncovers. As tags are added, linkages are built between them, which form the terms-to-concepts scaffold onto which the instructional material is mapped. The more concepts the computer learns to map, the more accurate its resource of metadata relationships become. In this way, the KM system identifies content and relationships between topics as it exists in a curriculum.
The obvious value of having a computer apply natural-language algorithms to map content is speed. What would take a person days to accomplish can be completed in seconds. But more importantly, computers do not suffer the human effects of subjectivity, fatigue, or inadequate preparation when determining appropriate metadata tags. These human limitations can have profound consequences on the accuracy of content maps. Computer-generated maps must be assessed for accuracy to ensure the algorithms are adequate to the task. But when output reliability is established, as has been demonstrated with KM, human effort (and subjectivity) is enormously reduced as topic identification and metadata coding becomes automated (Denny et al. Citation2003).
The database software in use at The University of Arizona College of Medicine does not feature the advanced natural-language capabilities of KM. Moreover, we wanted to develop a reporting function that depicted the location and relationships of content in the curriculum. Consequently, our requirements resulted in a different approach to mapping than that for a system such as KM. Instead of computer algorithms determining metadata identifiers, our curricular software relies on an operator (faculty, educational expert, etc.) to select code words or terms that signify the content covered in each instructional session. The database search engine can then find and provide reports of content based on those coded terms. As a result, the accuracy of any map we produce is a direct reflection on the time spent poring through materials and tagging topics. This is an increasingly difficult task as medical knowledge is further integrated. Because an electronic curriculum database has become a necessity for schools in the health professions, the personnel resources spent on coding efforts must be maximally exploited. Despite the limitations of our database, coding content has been ongoing for a number of years; we wanted to extend the use of that valuable resource.
How the map is constructed
We used a simple method to construct our map (): (1) create a reference list of topics we seek; (2) organize the reference list of terms into a structure of meaningful relationships (an ontology of terms); (3) adjust the vocabulary of the ontology so that it employs the exact same terms as are used in the curriculum dataset (MeSH terms); (4) collect the dataset of MeSH terms used to identify topics in our curriculum; and (5) match the dataset against the ontology and display the correlates, associated to the course in which the match occurred. Each of these steps is described in more detail in the subsequent sections.
Table 1. Illustrative definition of a content map
Determining the mapping vocabulary
The ArizonaMed curriculum is designed as instructional blocks of integrated systems (organ and physiological) for the first two years. Each block is composed of individual instructional sessions. The curricular dataset allows different types of metadata ‘tags’ to be associated (coded) to each instructional session. The tags signify the topics being covered in that session. While it is possible to perform open word searches of the database, it is impossible to control for the use of synonyms, jargon, or abbreviations when using them. Thus, open searches cannot be used to provide encompassing reports of curricular content. What is required for mapping purposes is a set of terms that can be assured to be found in the dataset, and which are widely accepted to represent curricular content.
To that end, the MeSH terms, a taxonomy of medical and scientific terms developed by United States National Library of Medicine, were selected for our mapping purposes (http://www.nlm.nih.gov/mesh/meshhome.html). The MeSH classification scheme creates ‘Descriptor Data’ for each term. That data includes the principal term (identified as the ‘MeSH Heading’) along with notes about its meaning and use. The descriptor data also includes other ‘Entry Terms’, which can be considered synonyms of the MeSH heading. Our database allows only the MeSH heading terms to be entered as metadata; the use of related MeSH ‘Entry Terms’ is not allowed by the system. In this way, the need to control for synonym use is automatically maintained.
Defining a baseline reference for content
Our challenge was to determine what could constitute a reference list on which to build our map. Initially, the list would need to encompass topics broad enough to represent years I and II content. However, simply identifying a comprehensive set of terms to represent areas of content is insufficient for mapping purposes. To be meaningful as a map, those terms must be arranged into relationships of content (an ontology of terms) that all users can accept and understand (Noy & McGuinness 2001; Willet & Marshall 2008). Happily, the United States Medical Licensing Examination (USMLE) Step 1 Content Outline provides just such a structure for curricular topics (USMLE Citation2011). As a framework for organizing curricular content, the USMLE content outline is widely known and accepted by administrators, faculty, and students. It is organized by organ system, which is adaptable to our modified organ-system curriculum without undue difficulty. We need to stress that the Step I outline was not used to constrain the content we mapped. It merely provided the framework for organizing content, which was needed in order to produce a meaningful map.
The Step 1 content outline is just as advertised: an outline. It needed considerable modification to be usable in our computer-based process. We first deconstructed its basic organization of headings, sections, and subsection phrases to produce a hierarchy of terms with four levels of specificity. Referring to as an example, the first three levels of the original USMLE outline (‘I. General Principles, a. DNA Structure; b. DNA Replication; c.; etc.) were expanded into four.
Figure 1. Illustration of how the USMLE Step I subjects outline was developed into a content ontology. Stage 1 shows deconstruction of the outline's phrases into four increasingly-detailed subject levels. Stage 2 illustrates the population of Level 5 with MeSH terms that are computer-readable and representative of medical knowledge content.

To complete the reference list, MeSH terms were used to populate a fifth and most specific level of the framework. We endeavored to retain much original wording so that a direct reference back to the unmodified Step 1 outline was possible. With the framework for the reference list defined, we began populating it with MeSH terms. When sufficiently complete, the modified USMLE outline was renamed the ‘ArizonaMed Medical Knowledge Ontology’ (AMKO). The Ontology and the curriculum dataset of terms were then comparable by computer, both drawn from the same MeSH-term source. In total, some 1550 different MeSH terms were used in the AMKO, and can be matched against the more than 6000 different MeSH terms coded into the ArizonaMed database.
Maximizing the effective resolution of the AMKO
In database theory, ‘granularity’ can be understood as the encompassing power of terms, one relative to others (Willett Citation2008). In a hierarchical taxonomy, a term of coarse granularity will encompass subordinate terms of finer granularity beneath it. We reasoned that if we were to use terms of very coarse granularity (e.g., pathology, physiology, biochemistry, etc.), the resolution of our map would be too imprecise to be of value. Likewise, using too fine a term (e.g., 2,3-diphosphoglycerate and colipases) would make it difficult to map content beyond the one or two sessions to which those terms would be assigned. From experience with our database, we could reasonably trust that the subject matter identified for a session is likely taught to completeness by our faculty when a mid-granularity MeSH term encompassing that content has been coded into the instructional record. The assumption was made from the outset that if mid-granularity subject terms were adopted for the ontology, we were confident that those terms, when mapped, denoted instruction of finer-level concepts and processes. For this reason, fine-granularity terms would not be included in the ontology. Subsequent testing of this assumption is allowed by back-tracking any MeSH term matched to its originating session's learning objectives. An added benefit for using mid-level terms in the ontology is that support staff with good familiarity of curricular content can usually identify the appropriate term for coding as metadata. The project had no impact on how or where fine-granularity MeSH terms were coded in the database, and these remain available for searches of highly specific content.
Developing accuracy for analysis and reporting
As the AMKO was being expanded with terms, we gained an understanding of how the overall organization of the AMKO was affected when curricular data was applied to it. To reduce ambiguity in the map, it became evident that the AMKO could not contain duplicate terms. Any MeSH term has potential to be coded to multiple sessions across multiple blocks in the curriculum. Therefore, if a MeSH term were to be included more than once in the AKMO, the resulting map would be artificially inflated as duplicates in the ontology would be multiplied by the number of times it appeared in the database.
The USMLE somewhat solves this problem in their content outline by collapsing across-systems content into ‘General Principles’; the remaining sections of the USMLE outline reflect discrete organ and physiological systems. However, across those systems sections, the USMLE retains the use of some identical subsection topics. For example, the USMLE includes ‘Normal Processes: embryonic development, fetal maturation, and perinatal changes’ within the skin, musculoskeletal, nervous system (etc.) sections of the outline.
We discovered that without a way to control for in-common topics, a number of the MeSH terms coded to our blocks (e.g., cell differentiation; embryonic development; etc.) would be duplicated within multiples of systems subheadings. To eliminate having to make a choice about where a commonly-used term should be placed among the many possible subsections in the outline, we simply extended the convention already used by USMLE and created other ‘General Principles’ headings to contain those multiple-system-use terms. To date, we have added general principle sections of ‘Embryonic Development’, ‘Structure and Function of Basic Tissue Components’, and ‘Pharmacological Agents’. We also expanded each system section in the outline to include a subheading for ‘Signs and Symptoms.’
Quality Assurance Review of the Map and the Ontology
When it was decided that the first iteration of the AMKO was sufficiently complete and that the initial mapping routine functioned appropriately, we sought an initial review by the faculty. Early in this project, we decided that the role of faculty was best to critique the AMKO for quality assurance, rather than use faculty to construct a map. One reason is that as integrative curricula lose their discipline-based structure, it becomes very difficult for individual faculty to know where and how their areas of expertise are expressed across the whole of curricular content (Huber et al. Citation2004). Moreover, knowledge is organized differently among academics for reasons of personal understandings and disciplinary frameworks. For these reasons, it would have been a difficult and lengthy exercise to create an ontology of essential curricular content out of faculty committee work. However, we also recognized that faculty are the key to the accuracy of the map. We theorized that when the ontology was mapped against curricular data, we could then rely on faculty to recognize their own content and confirm the correctness of both the ontology and the descriptive map that emerged from its use (Amundsen et al. Citation2008).
A Saturday retreat was called for all course directors, course coordinators, and other key curriculum administrators and evaluators to assess the accuracy of the ontology against their knowledge of the curriculum. Using the first iteration of the AMKO, a comparison against all MeSH terms used in years I and II of the curriculum was made and the graphical map produced. Retreat participants were subdivided into groups to examine that section of the map, which best corresponded with their content expertise. During their sessions, the faculty compared what was indicated on the map against their knowledge of curriculum content. Any discrepancies they found were noted and incorporated, or corrected in the next iteration of the AMKO.
All participants then reconvened to discuss what changes needed to be made to the ontology, to the coding of session metadata (curricular dataset), and to content coverage in the curriculum itself. As a general conclusion from the retreat, the participants were assured the curriculum thoroughly covered the subjects contained in the USMLE Step 1 content outline, and this outcome was reported to the medical students. Comments noted during the retreat, guided subsequent iterations of the AMKO and of the protocols by which MeSH metadata are assigned to session records.
The need to bring consistency to metadata coding resulted in the development of over-all guidelines for coding content. We now have a system by which faculty and block coordinators may enter any desired MeSH codes for their sessions regardless of granularity level, but a ‘not-yet-reviewed’ field has been added to these records. That field is marked ‘reviewed’ only by the curriculum librarian and other key coders who assess the breadth and depth of the codes supplied. In this way, faculty are not constrained to use particular MeSH terms, yet continuity is assured because the session is ultimately reviewed by those most familiar with the mid-granularity vocabulary required for the map.
Producing the AMKO map
Software tools
Our mapping and reporting is accomplished using the Microsoft Excel® spreadsheet program. The completed AMKO was entered into the spreadsheet to serve as the reference list for comparative analysis routines. To plot a map, the ArizonaMed database is queried for every MeSH term used to code the block in question. The resulting report also includes a frequency-of-use for each term for that block. This list is pasted into the spreadsheet where a filter routine strips the frequency count from the text string and reserves it in another column for subsequent use.
An Excel ‘lookup’ function then matches all the MeSH terms used in that block against the entire AMKO list and records ‘hits’ for every match (). As each hit is recorded, it is also summed with its frequency-of-use number. That frequency of hits is highlighted using conditional formatting to a unique color associated for each block. In the spreadsheet, color-coded hits are cross referenced to each MeSH term in the ontology by the block in which they appear. Reports are run for every block, as well as for the entire years I and II curriculum. The AMKO mapping application has been developed to the point that an operator must only copy the raw data from the ArizonaMed database MeSH report and paste it into the appropriate Excel spreadsheet page then click a single button. It takes approximately two minutes for a trained operator to create a basic map for any block (approximately 15 minutes for the entire years I and II curriculum), although filtering and sorting the worksheet in order to express the map in various ways (discussed below) requires some additional time.
Figure 2. Excerpted from the complete AMKO map, column headings depict the 10 blocks (courses) in chronological sequence for the preclinical curriculum. Rows represent subject heading levels and 11 of 1550 MeSH terms included in the reference ontology (see Level 5 in ). The number in each cell reveals how many instructional sessions in a block (column) feature the specific content signified by that MeSH term (row).
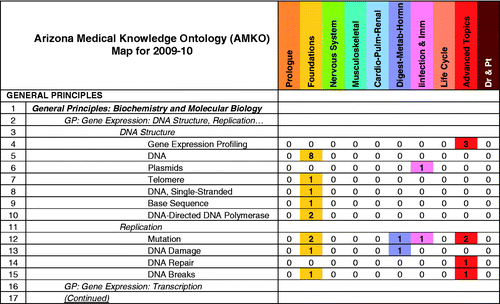
Working with the AMKO map
represents the first portion of the basic map, showing only the initial subject headings and 11 of the 1550+ MeSH terms available in the reference ontology. Where a match occurs between the AMKO and a block MeSH term, the intersecting cell assumes the color assigned to that block. The number of times that a particular MeSH term is used in that block is displayed in that colored cell. Different colors help make the expression of hits per block easily recognized at a glance. Each block maintains its identifying color for all the map reports.
Spreadsheet functions allow the number of hits by blocks to be filtered and summed for any subheading level of the AMKO. By summing, patterns of content relationships are better revealed. For example, collapsing the full report to Level 3 (e.g., Gene Expression: DNA Structure, Replication, Exchange and Epigenetics; Gene Expression: Transcription, etc.) results in a map of 260+ broader subject areas ().
Figure 3. The AMKO map has been collapsed to sum all hits within a set of Level 3 subject headings. This figure is the same format as ; however, rows now include only Level 3 subject headings (see Level 3 in ) and the numbers are the sum of all hits under those headings.
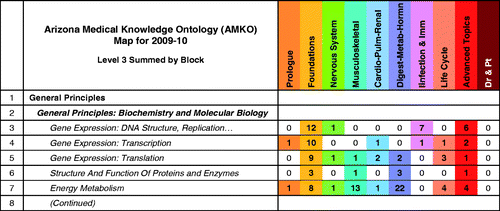
In , the numbers by block for each subheading represent how many different MeSH terms for that subheading matched to the AMKO. For example, in row 3 under ‘Foundations,’ the number 12 indicates 12 different terms within that broader subject area were matched. This count provides some ability to infer the breadth of coverage for that subject area by block.
Aside from collapsing the map to show general patterns of integration, rows and columns can also be sorted and filtered to address other types of questions about curricular content. For example, the counts of individual MeSH terms can be sorted by frequency-of-use across blocks, illustrating at a glance what individual MeSH identifiers () are most or least frequently applied.
Figure 4. The AMKO map can be filtered to identify the most-to-least frequently mapped content areas. Formatted similarly to , the rows are summed and ranked by frequency of hits across all blocks (last column to the right).
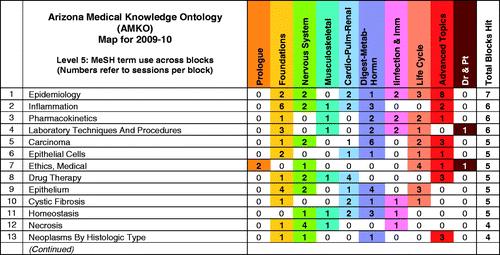
The results can be interesting. For example, in , ‘Epidemiology’ and ‘Inflammation’ (rows 1 and 2) are expected to be covered across many blocks, as the curriculum was intentionally designed to have them widely expressed. However, ‘cystic fibrosis’ (row 10) appears as the only named disease among broader topics across five blocks. Was this result an issue of coding, or is the disease appropriately covered in this many blocks? One might also ask of this result, why not ‘Diabetes’? The map allows us to recognize this type of content-representation issue and investigate it.
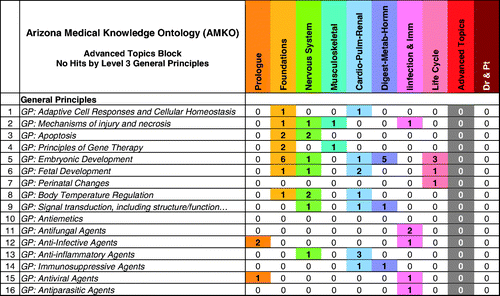
Focus can be given to the vertical axis (curriculum blocks) using sorting and filtering. For example, we can filter Level 3 subject headings for zero hits by block (see the block named Advanced Topics in ). With this information, we can review those subject areas not represented in a given block while noting those blocks in which they are covered. Assessments can then be made to ensure the distribution is desirable. Conversely, we can filter blocks by ‘topics hit’ and note in which blocks that content is not being covered, then assess whether changes may be needed.
Figure 5. The AMKO map can be filtered by block to reveal unrepresented content. The ‘General Principles’ section of the AMKO map was filtered to show all Level 2 subject headings with zeros for the advanced topics block. The subject areas with zero hits for the advanced topics block can be assessed across the row to ensure coverage in other blocks.
Other selections and sorts are possibly related to specific subject areas. For example, if we wish to look at all immune system content, we can tally for all subsections of immune system in the AMKO (). Expected patterns emerge as the Foundations block, and the Infection and Immunity blocks are more heavily represented with 30 and 56 entries, respectively.
Figure 6. The pattern of content coverage is depicted across all blocks for a broad, comprehensive subject area. Rows represent content headings at Level 2, and the numbers signify the total hits for that level by block. The circle highlights the particular pattern of coverage for the Level 2 heading ‘Immune systems’ across a set of blocks as discussed in the text.
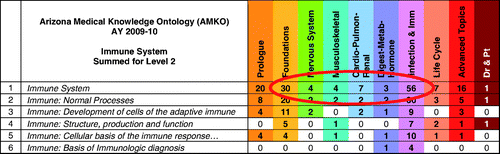
The map also reveals relatively few hits within the blocks for nervous system; musculoskeletal; cardiopulmonary and renal; and digestion, metabolism and hormones. With this information, faculty are alerted to the variance and can decide if this distribution is appropriate.
Limitations
The AMKO is limited by its use of MeSH terms. The MeSH vocabulary does not fully cover some types of content related to clinical knowledge or clinical skills. For example, each of the organ or physiologically-organized systems contained in the AMKO includes a subheading for ‘Drug-induced adverse effects’. This content is covered in the curriculum, but very few specific drug-induced adverse effects by organ system have been assigned their own MeSH terms. Adverse effects seem more commonly as signs or symptoms (e.g., ‘Pemphigus’ for drug-induced skin blisters). For this reason, the ‘Drug-induced…’ subheading was demoted one level to reside under ‘Signs and Symptoms’ for each system section.
MeSH terms do not thoroughly express social and behavioral content. The AMKO contains the subheading of ‘Gender, Ethnic, Emotional, and Social Factors’ within each of the system headings. Because of the limited MeSH descriptors available, curricular content is underreported for these areas, and this limitation is apparent in the maps generated (). Efforts are underway to devise a locally-controlled vocabulary of social and behavioral terms, which can be added to the curriculum dataset and to AMKO. With this addition, modifications to the project will be made so that this underreporting is eliminated. The faculty are aware of this limitation and take it into consideration when reviewing the curriculum map.
Basing the structure of the AMKO on the format for the USMLE Step I content outline was both helpful and limiting. A content map must express some categorization of knowledge in order to provide context and meaning. Approaches to categorization are as varied as the individuals who do the categorizing. By using the USMLE as the starting framework of our map, we avoided most criticism that our ontology was organized on arbitrary decisions about content relationships. The downside for using this strategy has been that it can be difficult to explain that ontological structure and ontological content are related, but different issues. We have been questioned about using the USMLE as the starting point for the AMKO by those who believe the limitations of the Step 1 outline may somehow limit the expression of topic areas contained in the AMKO, and thus may constrain reports of content included in the curriculum. We find there is no danger of that outcome. Where the map may overstate or understate content, those instances are readily reported by faculty.
A further limitation of producing AMKO maps is related to the processes involved. Subjective judgment must be employed about which terms to include in the ontology and where those terms are to be located in its hierarchy. Judgment must also be employed when deciding what content in the curriculum to code into the database and which MeSH identifier to use. For example, a block coordinator may consider certain content ancillary to the development of a session's main topic and decide not to identify it with a MeSH term. On the other hand, it might be coded, but is in fact of very minor importance to the session topic. Thus, a recorded ‘hit’ signifies content presence, but without inference that the content is appropriate to its curricular location (however, any hit can be traced back to its source and investigated). Although coding guidelines have been established, this judgment requires review by faculty and other educational experts.
Discussion
The conception and development of the Excel-based mapping function was the work of one curriculum support specialist. The requisite Excel functions were programmed and tested over the span of 2 or 3 months, ancillary to regular duties. The development of the AMKO took longer. The deconstruction of the USMLE outline and rebuilding it by MeSH terms was initiated by the same specialist, but the curriculum librarian and two faculty members provided assistance to help refine the organization of the ontology and then select the foundational set of MeSH terms. It took a year of discussing taxonomic strategies and field testing the evolving set of MeSH terms to develop the AMKO to the point where its first application was adequate for broader evaluation by the block directors and faculty. A benefit drawn from that year, however, was the increased accuracy and consistency of MeSH coding that was entered into the database.
Spin-offs of the project have been the adaptation of the Excel spreadsheet to provide other types of curriculum maps. The mapping function has been adapted for use with lists of custom search terms, at two levels of hierarchy. The lists may reflect a query of a single topic, or the interrelationships of multiple topics. With this development, it has become possible to produce graphical maps of instructional materials such as syllabi and transcribed lecture slides. The results are mapped to individual instructional sessions and their respective instructional blocks. In addition to providing a more detailed look at content, the results have served to double-check the accuracy of the AMKO and the coding of the database with MeSH terms. The mapping application has also been used to analyze the ‘Bloom's Taxonomy’ level of ‘action verbs’ that form the stem of learning objectives (Bloom et al. Citation1956; Krathwohl Citation2002). The patterns of use for lower-order (i.e., recall-type objectives) to higher-order verbs (i.e., concept synthesis and integration-type objectives) can now be plotted for each block (Phillips et al. 2006). This is useful information because a design principle for the ArizonaMed program establishes that instruction should increasingly challenge students’ problem-solving and critical thinking skills over time.
The original concept for the map included the idea that individual faculty would use it themselves to locate and assess the content they teach. However, the need to manipulate data between two computer applications (ArizonaMed database and Excel) has required the tool to be centrally maintained within the office of educational support services. Faculty ask for maps on topics and topic relationships (e.g., immunology, hematology, nutrition, etc.) and those are then produced for them by a trained operator. The resulting maps are delivered to the individual, or committee with an orientation on how to read them, and on other ways the data can be manipulated to their needs. With faculty use, the quality of the AMKO and the accuracy of the maps it produces are increased by their participation as content experts.
This curriculum mapping project has proved valuable in a number of ways:
Initial results assured faculty and students that all subjects contained in the USMLE list are accounted for in the curriculum.
Systematic content evaluation by faculty is more efficient when starting with a concrete example of what content integration might look like. Without an example in hand, our experience of committee work has been that discussing content integration often devolves into pondering ‘how to get the faculty to talk about integration’. A graphical representation of integration helps frame these discussions.
For curriculum governance efforts, having a graphical representation of content integration is a valuable tool. Maps illustrate broad patterns of integration, which can evoke deeper questions to be asked of content gaps, redundancies, relationships, location, and instructional method. For evaluation purposes, the map can provide concrete information about content for governance committees. This information is important when exploring their intent to define and deliver an integrative curriculum. For purposes of accreditation, the maps can help to quickly find and answer questions about the presence of critical content and the breadth and depth to which that content is covered.
Continual debate about curricular content is essential if an integrative curriculum is to remain vital and responsive. A good graphical map can contribute toward this organizational premise by providing both information about integration and a framework with which to engage discussion.
Acknowledgments
This work was conducted in the Office of Medical Student Education, University of Arizona College of Medicine. All authors are employed at the Office of Medical Student Education, University of Arizona College of Medicine.
Declaration of interest: The authors report no declarations of interest.
References
- Amundsen C, Weston C, McAlpine L. Concept mapping to support university academics’ analysis of course content. Stud Higher Educ 2008; 33(6)633–652
- Bloom BS, Englehart M, Furst E, Hill W, Krathwohl D. Taxonomy of educational objectives, the classification of educational goals – Handbook I: Cognitive domain. McKay, New York 1956
- Bordage G, Harris I. Making a difference in curriculum reform and decision-making processes. Med Educ 2011; 45(1)87–94
- Britton M, Letassy N, Medina M, Er N. A curriculum review and mapping process supported by an electronic database system. Am J Pharm Educ 2008; 72(5)99
- D'Eon M, Crawford R. The elusive content of the medical-school curriculum: A method to the madness. Med Teach 2005; 27(8)699–703
- Denny JC, Smithers JD, Armstrong B, Miller RA, Spickard A, III. “Understanding” medical school curriculum content using knowledgeMap. J Am Med Inform Assoc 2003; 10(4)351–361
- Denny JC, Smithers JD, Armstrong B, Spickard A, III. “Where do we teach what?” Finding broad concepts in the medical school curriculum. J Gen Intern Med 2005; 20: 943–946
- Harden RM. Integrated teaching – What do we mean? A proposed taxonomy. Medical Education AMSE Meeting Abstracts – 1997 Med Educ 1998; 32: 216–217
- Harden RM. AMEE Guide No. 21: Curriculum mapping: A tool for transparent and authentic teaching and learning. Med Teach 2001; 23(2)123–137
- Huber MT, Hutchings P, Association of American Colleges and Universities, Washington, DC. 2004. Integrative learning: Mapping the terrain. The Academy in Transition. New York: Carnegie Foundation for the Advancement of Teaching
- Kelley KA, McAuley JW, Wallace LJ, Frank SG. Curricular mapping: Process and product. Am J Pharm Educ 2008; 72(5)100
- Krathwohl DR. A revision of Bloom's taxonomy: An overview. Theory Practice 2002; 41(4)212–218
- Noy NF, McGuinness DL, 2001. Ontology development 101: A guide to creating your first ontology. Technical Report SMI-2001-0880, Stanford Medical Informatics
- Phillip J, Vuchetich PJ, Hamilton WR, Ahmad SO, Makoid MC. Analyzing course objectives: Assessing critical thinking in the pharmacy curriculum. J Allied Health 2006; 35(4)e253–e275
- Salas AA, Anderson MB, LaCourse L, Allen R, Candler CS, Cameron T, Lafferty D. CurrMIT: A tool for managing medical school curricula. Acad Med 2003; 78(3)275–279
- United States Medical Licensing Examination® 2011 Step 1 Content Description and General Information. Federation of State Medical Boards of the United States, Inc. and the National Board of Medical Examiners® (NBME®). 2010. Available from http://www.usmle.org/Examinations/step1/step1_content.html
- Willett TG. Current status of curriculum mapping in Canada and the UK. Med Educ 2008; 42(8)786–793
- Willett TG, Marshall KC, Broudo M, Clarke M. It's about TIME: A general-purpose taxonomy of subjects in medical education. Med Educ 2008; 42(4)432–438