
Abstract
Objective: The Dutch digits-in-noise test (NL DIN) and the American-English version (US DIN) are speech-in-noise tests for diagnostic and clinical usage. The present study investigated differences between NL DIN and US DIN speech reception thresholds (SRTs) for a group of native Dutch-speaking listeners. Design: In experiment 1, a repeated-measures design was used to compare SRTs for the NL DIN and US DIN in steady-state noise and interrupted noise for monaural, diotic, and dichotic listening conditions. In experiment 2, a subset of these conditions with additional speech material (i.e. US DIN triplets without inter-digit coarticulation/prosody) was used. Study sample: Experiment 1 was conducted with 16 normal-hearing Dutch students. Experiment 2 was conducted with nine different students. Results: No significant differences between SRTs measured with the NL DIN and US DIN were found in steady-state noise. In interrupted noise the US DIN SRTs were significantly better in monaural and diotic listening conditions. Experiment 2 demonstrated that these better SRTs cannot be explained by the combined effect of inter-digit coarticulation and prosody in the American-English triplets. Conclusions: The NL DIN and US DIN are highly comparable and valuable tests for measuring auditory speech recognition abilities. These tests promote across-language comparisons of results.
Introduction
Traditionally, the ability to recognize speech in noise is tested with nonsense syllables, monosyllabic words (Wilson, Citation2003; Wilson & Burks, Citation2005), or sentences (Kalikow et al, Citation1977; Plomp & Mimpen, Citation1979; Bench et al, Citation1979; Nilsson et al, Citation1994; Killion et al, Citation2004). The use of redundant sentences as speech material is often advocated for its high face validity. Speech-in-noise testing with digit-triplet speech material has become increasingly popular during the last decade, primarily as a screening tool for hearing loss (Smits et al, Citation2004, Citation2005; Ozimek et al, Citation2009a; Jansen et al, Citation2010; Watson et al, Citation2012; Zokoll et al, Citation2012; Williams-Sanchez et al, Citation2014). Smits et al (Citation2004) reported a strong correlation (r = 0.85) between their bandwidth-limited digit-triplet speech-in-noise screening test (the Dutch National Hearing Test, a self-administered test available by telephone) and the most commonly used Dutch speech-in-noise test (a sentences-in-noise test with highly redundant sentences; Plomp & Mimpen, Citation1979). Supported by these results, Smits et al (Citation2013) developed a broadband Dutch digit-triplet speech-in-noise test for diagnostic and clinical usage, called the Digits-in-noise (DIN) test. The DIN test uses digit triplets in steady-state speech noise to assess primarily the auditory, or bottom-up, speech recognition abilities in noise. The test measures the speech reception threshold (SRT) via an adaptive procedure. Smits et al (Citation2013) determined the criterion validity of the DIN test by comparing results on the test with results on the Dutch sentences-in-noise test (Plomp & Mimpen, Citation1979). After correction for the standard error of measurement of both tests, the correlation coefficient between SRTs measured with both tests equaled 0.96. They found that the vowels, consonants, and word-length of the digit-triplet stimuli were important for the recognition task in the DIN test. Watson et al (Citation2012) developed a US version of the digit-triplet screening test. Subsequently, Watson and colleagues developed a new version (Feeney et al, Citation2013) with a broader bandwidth (US DIN), quite similar to the Dutch DIN test (NL DIN). However, the NL DIN and the US DIN differ in several respects. Equivalance of the results of the NL DIN and US DIN, despite these differences, would further promote these DIN tests as clinical speech-in-noise tests because it would provide clinicians in different countries with tests that measure the same aspect of hearing despite language differences between subjects. When there exists a systematic difference between results of the NL DIN and US DIN, then a correction factor could be applied to achieve equivalence of the results. Because the importance of specific signal-cues for recognition of NL DIN and US DIN digit triplets may differ for listening conditions (e.g. monaural, binaural), equivalence for one condition would not necessarily mean equivalence for other conditions, and a single correction factor could be insufficient.
The aim of the current study was to determine the group differences between results of the NL DIN and the US DIN for normal-hearing Dutch listeners. Only highly educated university students were included as subjects to minimize possible effects of English proficiency on the results. Comparisons were done for several listening conditions, including monaural, diotic, and dichotic presentation in steady-state noise as well as interrupted noise.
Properties of the NL DIN and US DIN
Details of the NL DIN and US DIN are described in Smits et al (Citation2013), Watson et al (Citation2012), and Feeney et al (2013). The DIN tests use digit-triplets in steady-state noise, with the same spectrum as the long-term spectrum of the digits, to determine the signal-to-noise ratio (SNR) at which a listener recognizes 50% of the triplets correctly (i.e. the SRT). An adaptive procedure (1-up 1-down, with a 2-dB step size) without feedback is used to determine the SRT. The NL DIN uses 24 triplets per list (Smits et al, Citation2013), the US DIN uses 30 triplets per list. provides an overview of some relevant properties of the DIN tests. The NL DIN includes all digits from 0 to 9 (/nyl/, /en/, /twe/, /dri/, /vir/, /vɛif/, /zɛs/, /zevɘn/, /ɑχt/, /nexɘn/) including the disyllabic digits, whereas the US DIN does not. Differences in speaking rate, articulation and intonation may also exist, which can have an effect on the recognition probability. The Dutch and English digits are phonetically different, which may have an effect on their recognition as well. Other prominent differences between the NL DIN and US DIN are the gender of the speaker and the methods of recording the triplets. The US DIN triplets are naturally spoken three-digit sequences uttered by a female speaker. The NL DIN triplets were created by concatenating single digits uttered by a male speaker. Thus, the NL DIN triplets have no coarticulation between digits and no prosody. Coarticulation is defined as a change in the acoustic-phonetic content of a speech segment due to a nearby segment. In the current paper inter-digit coarticulation refers to coarticulation between digits, which is present in the US DIN but not present in the NL DIN. Coarticulation within words is present in both DIN tests. The digits from the NL DIN were concatenated with silent periods before the first digit, between the digits and after the final digit to form the digit-triplet stimuli. All the silent periods were enlarged or reduced randomly to make the start of each digit unpredictable. Smits et al (Citation2013) defined the speech level as the average level of the individual digits, whereas Watson et al (Citation2012) defined the speech level as the average level of the triplets. That is, the speech level of the US DIN includes the natural silences between the digits but the NL DIN does not. This introduces a fundamental difference in the definition of SNR and SRT between the tests. To determine a correction factor for this difference, Adobe Audition (Adobe Systems Inc., v3.0.1) was used to remove the silences from the digit-triplet files (note that the original stimuli with silences in place were used in all listening experiments). Several settings of the ‘Delete Silence’ function were tested. Although a more strict definition of ‘silence’ or ‘audio’ changed the total duration of silences, the effect of different settings on the RMS level of the US DIN triples differed less than 0.13 dB from the effect on the NL DIN triplets. shows the RMS level of the digit-triplet sound files relative to the RMS of the noise soundfile for the original files and for the corrected files (i.e. after removal of the silences). These numbers can be used to determine the corrected SRTs for comparing US DIN and NL DIN results more precisely.
Table 1. Properties of the NL DIN and US DIN.
The noise tokens in the original US DIN were time-locked to the triplets, thus creating a specific noise fragment for each triplet. In the NL DIN a fresh noise token is taken from a longer noise file for each stimulus. During the development of the US DIN it was decided to use time-locked noise tokens when equalizing the triplets. The use of random noise tokens instead of time-locked noise tokens could have an effect on the homogeneity of the triplets which may effect the standard error of measurement (Smits & Houtgast, Citation2006). An effect on the SRT is not expected. In the current experiments we use random noise tokens in all experiments because no time-locked noise tokens exist for the US DIN in interrupted noise nor for the NL DIN.
Experiment 1: Comparison of the NL DIN and US DIN SRTs
The aim of Experiment 1 was to compare the NL DIN and US DIN SRTs for Dutch normal-hearing adult listeners. It was decided to use a within-subjects repeated measures design to control for confounding variables like age, hearing threshold, attention etc. The disadvantage of this design is the possible effect of non-nativeness of the listeners on the performance on the US DIN. However, the effect of non-nativeness on the NL DIN is small (Kaandorp et al, Citation2015). All the listening conditions that are currently in use for the NL DIN were included (monaural, diotic, and dichotic presentations in steady-state noise and interrupted noise).
Methods
Subjects
Sixteen adult subjects (fourteen female, two male) participated. Pure-tone thresholds were better than 20 dB HL for all octave frequencies from 250 to 8000 Hz, except for three subjects with a threshold of 25 dB HL at one frequency in one ear. Subjects ranged in age from 19 to 25 years, with an average age of 22 years. All participants were University students with Dutch as their native language and good to very good English proficiency. They were taught in English from the age of 10.
Stimuli
Dutch and American-English triplets from the NL DIN and US DIN were used. A new list of triplets was chosen for each SRT estimate. Each list consisted of 24 triplets randomly chosen from the set of 120 available Dutch triplets or 50 available American-English triplets. An equal number of presentations was chosen for the NL DIN and US DIN to make a well-balanced study design and comparison of the results possible. Williams-Sanchez et al (2015) showed that the number of triplets per list can be reduced to approximately 25 without reducing the reliability of the SRT estimate. Therefore it was decided to use the standard number of 24 triplet presentations from the NL DIN for the US DIN as well. All triplets were unique in each list, but could be chosen again in the next list. A noise fragment was randomly taken from a noise file to create a fresh noise token for each triplet. The sampling rate of the stimuli was 44.1 kHz. Interrupted noises (16-Hz block-modulated, 50% duty cycle, 15 dB modulation depth) were created from the original NL DIN and US DIN steady-state noises. The level of the interrupted noise was defined as the level of the noise after modulation of the steady-state noise. Software was developed to present the Dutch speech and noise stimuli or English speech and noise stimuli monaurally (left or right ear), diotic (identical signals to both ears), or dichotic (antiphasic speech, SπN0).
Procedure
Following pure-tone audiometry the subjects were seated in another sound booth in front of a computer and received detailed instructions. Stimuli were presented in a within-subjects repeated-measures design in two sessions (test and retest) with a short break between. Each session consisted of a block with the Dutch stimuli and a block with English stimuli. Half of the subjects started with the Dutch stimuli and the other half started with the English stimuli. Within each block, all measurements in steady-state noise and interrupted noise were grouped and measurement conditions were counterbalanced according to a Latin square. One training list preceded the Dutch stimuli and one training list preceded the English stimuli. The test was made fully automatic, thus subjects could perform the test without the help of an experimenter. The subjects entered the response on the computer keyboard after each triplet was presented. Signals were presented using a sound card (Soundblaster Audigy 2, Creative Technology Ltd.) and delivered through headphones (Sennheiser HDA200). The overall level of speech and noise was kept at 65 dBA. A 1-up 1-down adaptive procedure with a fixed step size of 2 dB was used to determine the SRT (Plomp & Mimpen, Citation1979). The SRT was calculated by averaging the last 21 SNRs In the procedure, a response is considered correct only when all three digits in a triplet are identified correctly. A total of 34 SRTs per subject were measured: 2 DIN test versions (NL, EN) × 2 noises (steady-state, interrupted noise) × 4 conditions (monaural left, monaural right, diotic, dichotic) × 2 tests (test, retest) + 2 training lists.
Statistical analyses
All statistical analyses were conducted using SPSS (IBM SPSS; v 20.0.0). The data were analysed with repeated-measures analysis of variance (ANOVA). In cases where the sphericity assumptions were violated, the Greenhouse-Geisser correction was used. Post-hoc tests were conducted using the Bonferroni adjustment for multiple comparisons 1. A significance level of .05 was used. Box plots were generated using Sigmaplot (Systat software; v 10.0) to present the SRT data for the different conditions. Each box shows the lower and upper quartile values, and the black line inside the box indicates the median value. The whiskers represent the 5th and 95th percentiles.
Results
SRTs
shows the average SRTs for the NL DIN and US DIN for steady-state noise and interrupted noise. The standard error of the mean (SE), reflecting the precision of the average SRT, was calculated from the averaged test and retest results, and the standard error of measurement (SEM), reflecting the measurement error of a SRT estimate, was derived from the test and retest differences 2.
Table 2. Average SRT (uncorrected SRTs, with corrected values between brackets) for the DIN tests, standard error of the mean (SE), and standard error of measurement (SEM). Data from experiment 1.
, upper panels, shows boxplots of the test-retest SRT averages of the original DIN test results (i.e. with speech and noise levels as defined in the original papers of Smits et al, Citation2013, and Watson et al, 2012) for steady-state noise (left) and interrupted noise (right). A repeated measures ANOVA was conducted to compare the effects of DIN test version (i.e. NL DIN vs. US DIN), noise type (i.e. steady-state noise vs. interrupted noise), and condition (i.e. left, right, diotic, and dichotic). The original DIN test results show significant effects for DIN test version F(1,15) = 239.19, p <0.001, noise type F(1,15) = 5570.31, p <0.001, and condition F(3,45) = 1170.69, p <0.001. Some interactions were also significant but these will be considered when comparing results for the corrected SRTs (see below).
Figure 1. Top panels show boxplots of the test-retest SRT averages of the original DIN test results (i.e. with speech and noise levels as defined in the original papers). Results for the NL DIN are shown with filled boxes, results for the US DIN with unfilled boxes. The left panel shows the results for steady-state noise and the right panel for interrupted noise. Bottom panels show the same data but with corrected SRTs.
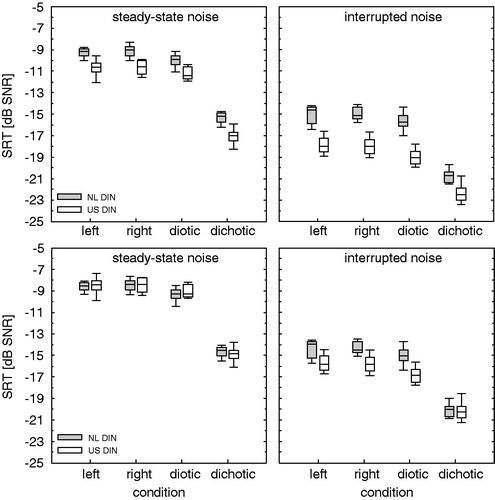
Because of the difference in definition of the speech level (with silences for the US DIN and without silences for the NL DIN) all SRTs were corrected for the difference (see ). The lower panels of show the results for the corrected SRT averages.
A repeated measures ANOVA was also conducted on the corrected SRTs (lower panels of ). There was a significant main effect for DIN test version F(1,15) = 17.22, p <0.001, noise type F(1,15) = 5579.74, p <0.001, and condition F(3,45) = 1171.43, p <0.001. There were significant interactions for DIN test version × noise F(1,15) = 49.43, p <0.001, condition × noise F(1.92, 28.81) = 12.53, p <0.001, and DIN test version × condition × noise F(3,45) = 12.77, p <0.001. Separate repeated measures ANOVAs were conducted for the average SRTs in steady-state noise and interrupted noise to compare the effects of DIN test version and condition. For steady-state noise there was a significant main effect for condition F(3,45) = 818.31, p <0.001. Neither the main effect for DIN test version nor the interaction for condition × DIN test version was significant. These results suggest that the DIN test version has no significant effect on the corrected SRT in steady-state noise. Post-hoc comparisons with Bonferroni correction showed significant differences between all conditions except for the difference between monaural-left and monaural-right (mean difference of 0.08 dB, p = 1.00).
For interrupted noise there was a significant main effect for DIN test version F(1,15) = 42.45, p <0.001, and condition F(3,45) = 191.41, p <0.001. There was a significant interaction for DIN test version × condition F(3,45) = 9.56, p <0.001. Post-hoc comparisons with Bonferroni correction showed significantly lower US DIN SRTs than NL DIN SRTs in interrupted noise for left (1.3 dB) right (1.4 dB), and diotic presentation (1.8 dB). There was no significant difference between the NL DIN SRT and the US DIN SRT for the dichotic condition. These results suggest that the DIN test version has a significant effect on the corrected SRT in interrupted noise for all conditions except for the dichotic condition.
Speech recognition functions
The speech recognition functions (i.e. mean proportion correct as a function of SNR) for the monaural, diotic, and dichotic conditions were determined for steady-state noise and interrupted noise. Data from the monaural-left and monaural-right conditions were aggregated. A cumulative normal distribution was fitted to the raw data. The slope, S, of this function represents the slope at 50% correct. In addition, the data from the individual subjects were corrected for the estimated SRT (thus aligning the SRTs) and then fitted with a cumulative normal distribution. The ‘true’ slope of the speech recognition function lies within those two values (Smits & Houtgast, Citation2006). Results are presented in . Significantly steeper slopes for the NL DIN than for the US DIN speech recognition functions were found for the monaural condition in steady-state noise (Wald chi-square = 8.173, p <0.005), and the dichotic condition in steady-state noise (Wald chi-square = 4.618, p <0.05). No significant differences were found for the other conditions.
Table 3. Slope (S) of the fitted speech recognition functions; standard error (SE) between brackets. Slope values were determined from a maximum likelihood fit to the raw data and from fit to the raw data after correction for the individual SRT.
Experiment 2: The effects of inter-digit coarticulation and prosody
Experiment 1 showed no significant differences between NL DIN SRTs and US DIN SRTs for steady-state noise and for the dichotic condition in interrupted noise. The better SRTs for the US DIN for the monaural and diotic condition in interrupted noise suggest that specific cues are available for recognition of the US DIN triplets in these conditions, but that these cues are not available for the NL DIN triplets. Because the differences arise only in the conditions with interrupted noise it may be that these are relatively low-amplitude cues that are only audible in the gaps. We hypothesized that inter-digit coarticulation and prosody, present in the US DIN but not present in the NL DIN, could provide those cues. The purpose of experiment 2 was to determine if the differences in SRTs between the NL DIN and US DIN disappear following disruption of the natural inter-digit coarticulation and prosody in the US DIN.
Methods
Subjects
Nine adult subjects (six female, three male) participated. Pure-tone thresholds were better than 20 dB HL for all octave frequencies from 250 to 8000 Hz except for one subject with a threshold of 25 dB HL at 8000 Hz in one ear. Subjects ranged in age from 19 to 23 years, with an average age of 21 years. All participants were University students with Dutch as their native language and good to very good English proficiency.
Stimuli
The Dutch and American-English triplets from the NL DIN and US DIN (as in experiment 1) were used. Steady-state noise and interrupted noise were similar to those in experiment 1.
A new set of 50 triplets without inter-digit coarticulation/prosody was constructed from the US DIN triplets. We used the procedure from Lyzenga & Smits (Citation2011) to create triplets without inter-digit coarticulation and prosody from the original speech material. The positions of the individual digits in each triplet were changed to disturb the natural coarticulation and prosody. The word boundaries were determined acoustically and visually, but are, to a certain extent, still arbitrary. Triplets with digit order 1-2-3 were changed to digit order 1-3-2, 2-1-3, or 3-2-1. The F0-contour was therefore disrupted and the inter-digit coarticulation disturbed, but the level of the triplets remained unchanged with this procedure.
Procedure
The procedure, stimulus levels, and equipment were similar to those in experiment 1. Stimuli were presented in a within-subjects repeated-measures design in two sessions (test and retest) with a short break in between. In contrast to experiment 1, each session consisted of three blocks: the Dutch stimuli, the original English stimuli, and the modified English stimuli (mEN). Measurement conditions were randomized. One training list preceded each of the Dutch stimuli, the English stimuli, and the modified English stimuli lists. Only the two binaural conditions were measured. A total of 27 SRTs per subject were measured: 3 sets of stimuli (NL, EN, mEN) × 2 noises (steady-state, interrupted noise) × 2 conditions (diotic, dichotic) × 2 tests (test, retest) + 3 training lists.
Results
SRTs
shows the average SRTs for the three stimuli for steady-state noise and interrupted noise. shows boxplots of the test-retest SRT averages of the corrected DIN test results for steady-state noise (left) and interrupted noise (right). Filled boxes show results for the NL DIN, unfilled boxes show the results for the US DIN with the original stimuli, and the dotted boxes represent the results for the US DIN with the modified stimuli.
Figure 2. Boxplots of the corrected test-retest SRT averages for the NL DIN, US DIN, and US DIN with modified stimuli (i.e. disturbed natural coarticulation and prosody). The left panel shows the results for steady-state noise and the right panel for interrupted noise.
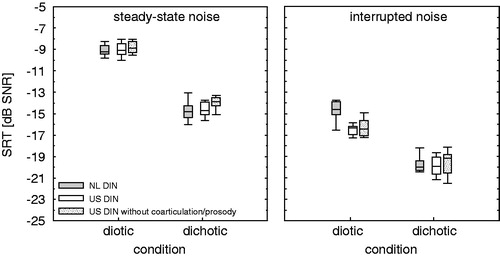
Table 4. Average SRT (uncorrected SRTs, with corrected values between brackets) for the DIN tests and standard error of the mean (SE). Data from experiment 2.
A repeated measures ANOVA was conducted to compare the results of experiment 1 and experiment 2. Only the conditions that were used in both experiment 1 and experiment 2 were included. Noise, DIN test version, and condition were entered as within-subject factors, experiment as a between-subjects factor. Results of experiment 2 did not differ significantly from the results of experiment 1, where identical stimuli were used.
A repeated measures ANOVA was conducted to compare the effects of coarticulation/prosody, noise type, and condition for the US DIN. There was a significant main effect for coarticulation/prosody F(1,8) = 86.224, p <0.001, noise type F(1,8) = 5064.74, p <0.001, and condition F(1,8) = 2408.73, p <0.001. There was a significant interaction for condition × noise F(1,8) = 258.02, p <0.001. The interactions for coarticulation/prosody × noise and coarticulation/prosody × condition were not significant. These results suggest that there is an effect of coarticulation/prosody on the US DIN SRT, but the effect is similar for steady-state noise and interrupted noise, and not affected by the listening condition. The average SRT for the US DIN with inter-digit coarticulation/prosody is 0.34 dB better (lower) than for the US DIN without inter-digit coarticulation/prosody. The better US DIN SRTs than NL DIN SRTs for the monaural and diotic condition in interrupted noise cannot be attributed to the natural inter-digit coarticulation and prosody in the US DIN triplets.
Discussion and Conclusions
The steady-state noise SRTs for the NL DIN and US DIN are not significantly different for normal-hearing Dutch university students when the speech level is corrected for silences. The monaural NL DIN SRTs are similar to the previously reported normal-hearing SRTs of −8.8 to −8.9 dB SNR for the TDH-39 headphones and −9.9 dB SNR for Sony MDRV-900 headphones (Smits et al, Citation2013). The monaural US DIN SRTs for the non-native listeners in the current study correspond very well to the SRTs for native American listeners (Feeney et al, Citation2013; mean SRT was −10.1 dB SNR in that study, personal communication). This finding is in line with the results of Kaandorp et al (Citation2015) who showed that the results on the NL DIN are hardly affected by the linguistic abilities of the listeners. They even included listeners with a much broader range of linguistic abilities than in the current study where only listeners with a good proficiency in English were tested.
Watson et al (Citation2012) defined the speech level as the average level including natural pauses between the digits, which follows the definition of the SII standard (ANSI, Citation1997). Smits et al (Citation2013) concatenated digits to form the triplets and they defined the speech level as the level of the digits without the inserted silences between the digits. Jansen et al (Citation2010) developed a French digit-triplet test and they also defined the speech level as the average level of the digits without silences. They reported an average monaural SRT of −10.2 dB SNR for normal-hearing adults using the same headphones as in the current study (Sennheiser HDA 200). Although their results are very similar to ours, strong conclusions cannot be drawn because the properties of the noise may be different. The speech noises for the NL DIN and US DIN were created by filtering Gaussian noise whereas Jansen et al (Citation2010) superimposed digits to create the speech noise with the same spectrum as the digits. Although both procedures can result in speech noise with a Gaussian amplitude distribution, the latter does not necessarily give uncorrelated noise (also see and Footnote 4 in Ozimek et al, Citation2009b).
The interrupted noise SRTs are systematically lower (better) for the US DIN than for the NL DIN except for the diotic listening condition. Apparently, the effect of the interruptions on speech recognition in noise is different for the American-English triplets compared to the Dutch triplets. Listeners benefit from the interruptions in the noise because they can effectively use the short periods of favorable SNR (so-called ‘dip-listening’). More speech information becomes audible in these short periods; an effect which occurs for American-English and Dutch triplets in the current experiments. It was hypothesized that specific low-amplitude speech cues might become audible and useful for speech recognition as well. Some of these cues are present in the US DIN but not in the NL DIN. The triplets in the US DIN were uttered with natural coarticulation and prosody. If the inter-digit coarticulation and/or natural prosody facilitate recognition of triplets then this might improve the US DIN SRT in interrupted noise, where the coarticulation and/or prosody could be audible in the short periods of high SNR. These cues might be inaudible in steady-state noise resulting in the observed difference between the NL DIN and US DIN for the two types of noise. Fernandes et al (Citation2007) showed that coarticulatory cues are very sensitive to masking noise. They reported that coarticulatory cues were no longer available at a SNR of 10 dB. This implies that coarticulatory cues are not available in any of our conditions because the SRTs are low (approximately −15 dB SNR) and the modulation depth of the interrupted noise is 15 dB. Thus, even without considering forward and backward masking, the local SNRs are much lower than 10 dB SNR in the gaps. The results in Experiment 2 showed no significant difference between SRTs for the US DIN without and with coarticulation/prosody in any of the conditions or noises. Lyzenga & Smits (Citation2011) reported a non-significant difference of 0.34 dB between the original, natural spoken triplets from the Dutch National Hearing Test and those triplets without coarticulation/prosody. With our experimental method it is not possible to distinguish between a positive effect of natural prosody, a negative effect of unnatural prosody, disrupted F0-contour, or each of these effects, but our results suggest that these effects do not exist or are small. The local SNR in the gaps is much more favorable in the diotic listening condition than in the dichotic listening condition because the SRTs are much lower in the dichotic listening condition. Because the difference between the NL DIN and US DIN in interrupted noise was not present in the dichotic listening condition this may suggest that the better results for the US DIN in interrupted noise are indeed related to the more favorable SNR in the gaps.
Experiment 2 demonstrated that the difference between the NL DIN and US DIN in interrupted noise is not caused by the combined effect of inter-digit coarticulation and natural prosody in the US DIN. Thus other factors must be considered. It is plausible that the gender difference between the talkers causes the difference in SRTs for interrupted noise. Rhebergen et al (Citation2008) measured SRTs in steady-state noise and 8-Hz interrupted noise for Dutch sentences spoken by a male or female talker. In steady-state noise the SRTs were almost identical: −4.5 dB for the male speaker and −4.6 dB for the female speaker. However, in interrupted noise the SRTs were −15.9 dB for the male speaker and −17.4 dB for the female speaker. The lower SRTs in interrupted noise for the female talker are in agreement with the results of the current study. Wang & Humes (Citation2010) studied the effect of interrupted speech on the recognition of CVC words in quiet. They found that interrupted speech from the female talker was significantly more intelligible than interrupted speech from the male talker. One reason for the differences between male and female speech in those studies could be the difference in fundamental frequency, which is approximately twice as high for female talkers. Bradlow et al (Citation1996) analysed speech recognition data in quiet from different talkers and found higher speech recognition scores for female speech than for male speech, but no correlation between F0 and speech recognition scores within the group of male or female talkers. Wang and Humes (Citation2010) hypothesized that the higher number of pitch periods in a glimpse might facilitate integration of the speech fragments, but from an analysis of their data they concluded that other factors must be responsible for the difference. Manipulating the F0 contour as we did in experiment 2 may decrease speech recognition in noise. Miller et al (Citation2010) manipulated (flattened, exaggerated, inverted, and sinusoidally modulated) the F0 contour of sentences and found worse speech recognition scores for sentences in noise. Binns and Culling (Citation2007) measured SRTs in steady-state noise and against an interfering talker. They reported a decrease in SRT when decreasing the F0 modulation or inversing the F0 contour, with a much larger effect with an interfering talker as masker. Laures and Bunton (Citation2003) reported worse speech recognition scores in white noise and multitalker babble after flattening the F0 contour. These studies show that disrupting the F0 contour can decrease speech recognition scores in noise, which may be the reason for the higher SRTs in Experiment 2 for the American-English triplets without coarticulation/prosody. The better SRTs for the US DIN than the NL DIN in interrupted noise may be related to the gender of the speaker but other factors cannot be ruled out. The difference may be linked more to a precise articulation or pronunciation of the triplets than to the higher F0 of the speaker. Also the importance of consonants and vowels for the recognition of the digits could be different for these languages and could interact with the type of noise. Further research to explore these possibilities could help to understand the differences in SRTs that were found in the current study. For instance, the effect of manipulating speech features like the F0 of the speaker, speaking rate, or articulation on the SRT can be examined.
The results of the current study show differences in SRT between the US DIN and the NL DIN for normal-hearing listeners. A single correction factor that would be effective to compensate for a systematic difference is not possible because of the interaction between DIN version and noise type. Differences in slope values of the US DIN and NL DIN speech recognition functions were also found (see ). These differences have an impact on the amount of SNR loss measured for hearing-impaired listeners, especially when other target points (e.g. 80% correct instead of 50% correct) are chosen (Smits & Festen, Citation2011,Citation2013). Although our results show no significant difference in corrected SRT between the NL DIN and US DIN for normal-hearing listeners in steady-state noise, it does not mean that a similar result would be found for hearing-impaired listeners. Further research is needed to generalize our conclusions. One approach would be the analyses of existing datasets from hearing-impaired listeners, but an experimental design with normal-hearing listeners who listen to filtered stimuli (both US DIN and NL DIN stimuli) to simulate hearing-loss might be a better approach because it eliminates the confounding of linguistic skills and other top-down factors.
In summary, the first experiment in this study showed no significant differences between SRTs measured with the NL DIN and US DIN in steady-state noise for monaural, diotic, or dichotic listening conditions in a group of normal-hearing Dutch listeners. In interrupted noise, the US DIN SRTs were significantly better in monaural and diotic listening conditions. Results of the second experiment indicated that these better SRTs cannot be explained by the combined effect of coarticulation and prosody in the naturally spoken American-English triplets. The NL DIN and US DIN are valuable tools for measuring auditory speech recognition abilities in noise and make comparisons of measurements in steady-state noise across language possible. The difference in the definition of speech level (i.e. with or without silences) needs to be taken into account when comparing absolute values.
Declaration of interest
CDT, Inc. holds the copyright to the US DIN test and may benefit by sales or licensing of that test.
| Abbreviations | ||
| DIN test | = | Digits-in-noise test |
| NL DIN | = | Dutch DIN test |
| S | = | Slope; |
| SE | = | Standard error |
| SEM | = | Standard error of measurement |
| SNR | = | Signal-to-noise ratio |
| SRT | = | Speech reception threshold |
| US DIN | = | American-English DIN test |
Acknowledgement
Support for the development of the US DIN was provided by the US National Institutes of Health/National Institute on Deafness and Other Communication Disorders (NIH/NIDCD) Grant R43 DC009719, by Indiana University, and by Communication Disorders Technology, Inc.
Note
Notes
1. The analyses were also conducted without a Bonferroni correction (LSD). All the differences that were not significant remained not significant when omitting the Bonferroni correction.
2. The standard error of measurement, SEM, was derived from the standard deviation of the test-retest differences by SEM = SDdiff/√2.
Related Research Data
References
- ANSI (1997) ANSI S3.5-1997, American National Standard Methods for the Calculation of the Speech Intelligibility Index, American National Standards Institute, New York.
- Bench J., Kowal A. & Bamford J. 1979. The BKB (Bamford-Kowal-Bench) Sentence Lists for partially-hearing children. Br J Audiol, 13, 108–112.
- Binns C. & Culling J.F. 2007. The role of fundamental frequency contours in the perception of speech against interfering speech. J Acoust Soc Am, 122, 1765–1776.
- Boersma P. & Weenink D. 2013. Praat: Doing Phonetics by Computer [Computer Program]. Version 5.3.41.,
- Bradlow A.R., Torretta G.M. & Pisoni D.B. 1996. Intelligibility of normal speech I: Global and fine-grained acoustic-phonetic talker characteristics. Speech Commun, 20, 255–272.
- Feeney M.P., Folmer R.L., Vachhani J., McMillan G.P., Watson C.S. & Kidd G.R. 2013. Test performance of a computer version of the Digits-In-Noise test for adult hearing screening. Poster Presented at the 36th Annual Midwinter Meeting of the Association for Research in Otolaryngology.
- Fernandes T., Ventura P. & Kolinsky R. 2007. Statistical information and coarticulation as cues to word boundaries: a matter of signal quality. Percept Psychophys, 69, 856–864.
- Jansen S., Luts H., Wagener K.C., Frachet B. & Wouters J. 2010. The French digit triplet test: a hearing screening tool for speech intelligibility in noise. Int J Audiol, 49, 378–387.
- Kaandorp M.W., de Groot A.M., Festen J.M., Smits C. & Goverts S.T. 2016. The influence of lexical-access ability and vocabulary knowledge on measures of speech recognition in noise. Int J Audiol, 55, 157-167.
- Kalikow D.N., Stevens K.N. & Elliott L.L. 1977. Development of a test of speech intelligibility in noise using sentence materials with controlled word predictability. J Acoust Soc Am, 61, 1337–1351.
- Killion M.C., Niquette P.A., Gudmundsen G.I., Revit L.J. & Banerjee S. 2004. Development of a quick speech-in-noise test for measuring signal-to-noise ratio loss in normal-hearing and hearing-impaired listeners. J Acoust Soc Am, 116, 2395–2405.
- Laures J.S. & Bunton K. 2003. Perceptual effects of a flattened fundamental frequency at the sentence level under different listening conditions. J Commun Disord, 36, 449–464.
- Lyzenga J. & Smits C. 2011. Effects of Coarticulation, Prosody, and Noise Freshness on the Intelligibility of Digit Triplets in Noise. J Am Acad Audiol, 22, 215–221.
- Miller S.E., Schlauch R.S. & Watson P.J. 2010. The effects of fundamental frequency contour manipulations on speech intelligibility in background noise. J Acoust Soc Am, 128, 435–443.
- Nilsson M., Soli S.D. & Sullivan J.A. 1994. Development of the Hearing in Noise Test for the measurement of speech reception thresholds in quiet and in noise. J Acoust Soc Am, 95, 1085–1099.
- Niquette, P., Arcaroli, J., Revit, L., Parkinson, A., Staller, S.,. et al. 2003. Development of the BKB-SIN Test. Paper Presented at the Annual Meeting of the American Auditory Society, Scottsdale, AZ.
- Ozimek E., Kutzner D., Sek A. & Wicher A. 2009a. Development and evaluation of Polish digit triplet test for auditory screening. Speech Comm, 51, 307–316.
- Ozimek E., Kutzner D., Sek A. & Wicher A. 2009b. Polish sentence tests for measuring the intelligibility of speech in interfering noise. Int J Audiol, 48, 433–443.
- Plomp R. & Mimpen A.M. 1979. Improving the reliability of testing the speech reception threshold for sentences. Audiology, 18, 43–52.
- Rhebergen K.S., Versfeld N.J. & Dreschler W.A. 2008. Learning effect observed for the speech reception threshold in interrupted noise with normal hearing listeners. Int J Audiol, 47, 185–188.
- Smits C. & Festen J.M. 2011. The interpretation of speech reception threshold data in normal-hearing and hearing-impaired listeners: Steady-state noise. J Acoust Soc Am, 130, 2987–2998.
- Smits C. & Festen J.M. 2013. The interpretation of speech reception threshold data in normal-hearing and hearing-impaired listeners: II fluctuating noise. J Acoust Soc Am, 133, 3004–3015.
- Smits C., Kapteyn T.S. & Houtgast T. 2004. Development and validation of an automatic speech-in-noise screening test by telephone. Int J Audiol, 43, 15–28.
- Smits C. & Houtgast T. 2005. Results from the Dutch speech-in-noise screening test by telephone. Ear Hear, 26, 89–95.
- Smits C. & Houtgast T. 2006. Measurements and calculations on the simple up-down adaptive procedure for speech-in-noise tests. J Acoust Soc Am, 120, 1608–1621.
- Smits C., Goverts S.T. & Festen J.M. 2013. The digits-in-noise test: Assessing auditory speech recognition abilities in noise. J Acoust Soc Am, 133, 1693–1706.
- Wang X. & Humes L.E. 2010. Factors influencing recognition of interrupted speech. J Acoust Soc Am, 128, 2100–2111.
- Watson C.S., Kidd G.R., Miller J.D., Smits C. & Humes L.E. 2012. Telephone screening tests for functionally impaired hearing: current use in seven countries and development of a US version. J Am Acad Audiol, 23, 757–767.
- Williams-Sanchez V., McArdle R.A., Wilson R.H., Kidd G.R., Watson C.S. & Bourne A.L. 2014. Validation of a Screening Test of Auditory Function using the Telephone. J Am Acad Audiol, 25, 937–951.
- Wilson R.H. 2003. Development of a speech in multitalker babble paradigm to assess word-recognition performance. J Am Acad Audiol, 14, 453–470.
- Wilson R.H. & Burks C.A. 2005. Use of 35 words for evaluation of hearing loss in signal-to-babble ratio: a clinic protocol. J Rehabil Res Dev, 42, 839–852.
- Zokoll M.A., Wagener K.C., Brand T., Buschermöhle M. & Kollmeier B. 2012. Internationally comparable screening tests for listening in noise in several European languages: the German digit triplet test as an optimization prototype. Int J Audiol, 51, 697–707.