 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Teaching students statistical programming languages while simultaneously teaching them how to debug erroneous code is challenging. The traditional programming course focuses on error-free learning in class while students’ experiences outside of class typically involve error-full learning. While error-free teaching consists of focused lectures emphasizing correct coding, error-full teaching would follow such lectures with debugging sessions. We aimed to explore these two approaches by conducting a pilot study of 18 graduate students who voluntarily attended a SAS programming seminar held weekly from September 2018 through November 2018. Each seminar had a 10-min error-free lecture, 15-min programming assignment, 5-min break, 10-min error-full lecture, and 15-min programming assignment. We examined student performance and preference. While four students successfully completed both assignments and ten students did not successfully complete either assignment, one student successfully completed only the first assignment that directly followed the error-free lecture and three students successfully completed only the second assignment that directly followed the error-full lecture. Of the 15 students who responded, twelve (80%) preferred error-full to error-free learning. We will evaluate error-full learning on a larger scale in an introductory SAS course. Supplemental files are available online for this article.
1 Introduction
1.1 The Challenge to be Addressed
For some students, learning a computer programming language is a challenge; learning statistics is a challenge; and learning a statistical computer programming language is a nightmare. During an in-class lecture for instance, the instructor may present error-free code that generates a dataset or statistical output with a clean log every single time. Replicating such code independently in a new setting, however, may prove to be challenging for students who lack experience with computer programming. Diagnosis and correction of errors is, therefore, an inherent part of the development of effective programming skills. The instructor can teach students good programming principles in an environment without errors. Students can also be shown how to diagnose and correct erroneous code. Teaching both simultaneously, however, creates new challenges because correct code does not generate errors, yet all programmers must learn to debug errors. Learning correct code and debugging present complementary challenges.
Our study aimed to investigate ways that students can become more comfortable with programming through guided exposure to erroneous code to enhance their confidence and to better develop their ability to work through problems independently. In doing so, a series of seminars were developed to investigate student preferences toward an error-free versus an error-full teaching environment.
The error-free teaching environment attempts to mimic what we view as a more traditional way of teaching programming. Here, exercises in the classroom focus on learning correct code from the beginning. While students are taught the basic rules of debugging, the emphasis of the exercise is on successful completion of the given task. If a student does not encounter an error in their code, it may not be discussed as part of their learning experience. This teaching method exposes students to error handling in a more unstructured manner that has, in our experiences, been intimidating to students who lack confidence in their abilities a-priori. As such, students are likely to spend more of their time in directionless trial-and-error debugging on their own. The increased anxiety and frustration associated with this process likely has a deleterious effect on their learning experience, which we aim to ameliorate.
In contrast, the ideal error-full teaching approach we would like to implement in a classroom setting would specifically dedicate classroom time to both learning correct code and learning about how to identify, interpret, and correct errors. Structured lessons that introduce common errors would be built into lectures each week to ensure that students are exposed to them. We refer to this identification, interpretation, and correction of errors as a guided debugging session. Thus, when working through assignments outside of class, students will have already been exposed to specific error handling in a more formal manner, and they would be expected to more readily be able to apply the lessons learned to avoid or correct such common errors. In doing so, this approach would ideally reduce anxiety and frustration and empower students to be able to solve problems on their own without having to resort to office hours, extensive email questions, or seemingly infinite loops of trial-and-error debugging.
While numerous papers have been written on debugging SAS programs (Hayes Citation1995; Lee and Wu Citation1999; DiIorio Citation2001; Staum Citation2002; Delwiche and Slaughter Citation2003; Jolley and Stroupe Citation2009; Fahmy Citation2010; Russell and Tyndall Citation2010; Lafler Citation2013), only a few texts include excerpts or chapters devoted to debugging SAS programs (SAS Institute Inc. Citation2015, chap. 23–25; Delwiche and Slaughter Citation2019, chap. 11) or have been written entirely on the subject (Burlew Citation2001; Cody Citation2017). As such, the ideal error-full teaching environment would involve (i) a more focused version of the error-free lecture followed by (ii) guided and interactive debugging sessions. While the “guided” sessions would be led by the instructor, the “interactive” sessions would be driven by the students.
Our study investigated whether students learning a new statistical programming language such as SAS in a seminar setting perform better in an error-free or a modified version of the error-full teaching environment (due to time constraints) and whether students prefer to learn in an error-free or this modified error-full teaching environment. We describe this modified error-full approach that we implemented in the seminars (and reasons for doing so) in detail in Section 2.2.
1.2 The Course that Motivated this Study
Use of SAS for Data Management and Data Analysis is a 15-week (one-semester) graduate-level introductory statistical programming course in which students explore data management and data analysis techniques using SAS® software, which is one of the most widely used database management systems and statistical analysis software packages. Class sizes have ranged from forty to seventy students. In this course, students create, subset, merge, and concatenate datasets; create and manipulate variables; and implement common statistical methods such as Student’s t-test, chi-squared tests, linear regression, and logistic regression using data from public health and biomedical studies.
We have traditionally offered this course in person using the “error-free” approach described above. Assignments consist of answering multiple-choice questions and writing SAS programs from scratch to complete data management and data analysis tasks. Since being able to do something right also means being able to recognize when something is wrong, we also ask students to debug prewritten erroneous programs. Through these debugging exercises, we expect students to apply their knowledge of correct programming to recognize when a program is incorrect and to identify and resolve the errors.
Each week, students attend a three-hour lecture delivered by the course director and an additional two-hour lab session led by teaching assistants (TAs) and/or instructional assistants (IAs). These lab sessions provide students with “one-on-one” access to experienced SAS users who can clarify the material presented during the lecture and answer specific questions related to their homework assignments.
From the first time this class was taught, it was clear that students may not write error-free programs on the first try when working through their assignments on their own outside of class. Diagnosing errors in the log can be challenging for students, especially if they have little prior programming experience. Even those students who successfully execute their programs without error exhibit some level of uncertainty and frustration at the amount of time and energy they invested to get there.
In view of the teaching challenges we have faced, we find applicable Arthur Ashe’s famous quotation, “Success is a journey, not a destination. The doing is often more important than the outcome” (Arthur Ashe Learning Center Citation2020). To be a successful programmer, one must not only arrive at the correct answer but also be confident and efficient along the way. We believe that confidence typically breeds perseverance in students, which will lead to a greater patience in working through debugging. Our goal in conducting this study was to learn new ways to reduce student frustration and to help them become more confident and efficient programmers.
Having identified a reason to redesign the course, we needed a new design and concrete data to suggest whether we could improve student satisfaction. Lee and Wu (Citation1999) suggested a DebugIt approach to teaching undergraduate and high school students enrolled in introductory Pascal courses, which did improve their programming and debugging skills over those enrolled in the more traditional error-less teaching courses. In our experience, however, some students may not know what to do from the start, suggesting that such an approach may not be fruitful if used alone. Researchers have found that people who struggle with problem-solving tend to struggle the most when learning new programming languages (Dalbey and Linn Citation1985, Deek and McHugh Citation1998). Some of the authors’ students have verbally expressed how they learned more in a 30-min office hour debugging session than a three-hour error-free lecture. On the end-of-semester course evaluations, one student commented, “Office hours helped me recognize errors and [the professor] explained why the errors occurred followed with constructive ways to resolve them” (anonymous). As such, we hypothesized that it may be a combination of both problem-solving focused error-free lectures followed by guided and interactive debugging exercises that will result in the most fruitful student experience.
Problem-solving skills are essential when debugging programs that executed without generating errors but yielded output that differed from what was expected. For example, a programmer may use the wrong column numbers when reading raw data arranged in fixed fields as shown in .
Fig. 1 SAS program with incorrect column numbers. This is the SAS Enhanced Editor window containing an example of a DATA step that compiled and executed without generating any error messages in the log but did not yield the desired output SAS dataset.
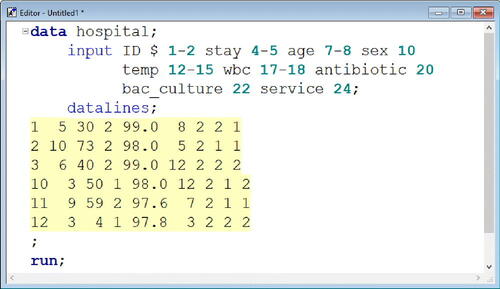
Although the program compiled and executed without generating any error messages in the log (), the variable values in the output dataset are incorrect (). Note that the column numbers in the INPUT statement should have instead been specified as 1-2, 3-5, 6-8, 9-10, 11-15, 16-18, 19-20, 21-22, and 23-24 to correctly read the data. It is incumbent on the programmer to recognize this through other means, such as spot checking for incorrect data values in the dataset or looking for inconsistencies in the log that may be due to invalid data.
Fig. 2 SAS Log window. This is the SAS log, which generates messages about the execution of the program. This log indicates the program in executed successfully and created a new SAS dataset containing 6 observations and 9 variables.
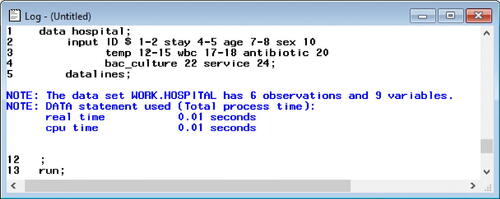
Fig. 3 VIEWTABLE window showing the contents of hospital SAS dataset. These are the values of the variables in the hospital SAS dataset. Notice that some values of all variables (except ID) are incorrect since the wrong columns were specified in the INPUT statement.
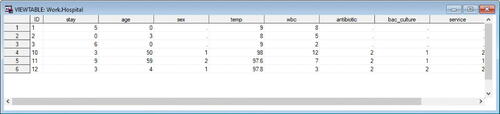
In viewing the data in the output dataset “hospital” through the VIEWTABLE window (), it is clear the variable values do not match the raw data recorded in the data lines. Such spot checking is an important next step that students should be taught as a routine of good programming practice.
2 Methods
2.1 Study Design
This was a pilot study. Participants were graduate students at a school of public health within a private university in Washington, D.C. who voluntarily attended at least one of ten one-hour SAS programming seminars offered in person weekly from September 2018 through November 2018. Each seminar consisted of a 10-min traditional error-free lecture, 15-min programming assignment, 5-min break, 10-min error-full lecture, and 15-min programming assignment. The 5-min break was intended to control for fatigue-related bias.
The seminar announcements emailed to all graduate students in the school clearly specified that the seminars were part of a research study to test out a new teaching method, emphasized that participation was voluntary, and highlighted that consent had to be given to participate in the study. Any students could attend the seminar. Students interested in participating in the study read the consent form, participated in the lectures, completed the assignments, and filled out the questionnaire and evaluation. No identifiable information was collected during this process.
The error-free lecture was based on the traditional lectures currently delivered in the programming course. For the error-full lecture, the instructor presented a program in a focused error-free lecture and then, due to time constraints, specific errors were incorporated into the program one-by-one to demonstrate the process students should follow when debugging their own programs. Doing so allowed the instructor to control which issues were discussed and resolved within a limited time. Students were able to subsequently focus on linking specific error messages (or incorrect output) directly to known errors in the program. Given practical limitations, we suggest some potential improvements to this study design in Section 4.4.
The major distinction between the teaching methods was the approach in which the material was presented (i.e., teaching only correct code with the error-free method or adding additional guided error interpretation sessions with the error-full method). The assignments for error-free and error-full approaches took on the exact same format where students were asked to write a SAS program from scratch to complete a task.
2.2 Description of Lectures and Assignments
We designed five unique SAS programming seminars. Each seminar was delivered twice, on two different days of the week, to avoid scheduling conflicts for students. Each seminar consisted of two different but comparable topics that could be used for the error-free and the error-full portions. One instructor designed and delivered the materials for the first, third, and fifth seminars, while another instructor designed and delivered the materials for the second and fourth seminars. Both instructors reviewed each other’s materials for consistency. The seminar topics increased in complexity from the first seminar, which focused on creating SAS datasets by reading raw data from in-stream data lines, to the fifth seminar, which focused on the SAS macro language. We illustrate the error-free and error-full approaches in the following sections using the first seminar as an example.
2.2.1 Implementing the Error-Free Approach
The first seminar began with an error-free lecture on using column and formatted input to read hypothetical standard and nonstandard raw data values aligned in fixed fields (or specific columns) from in-stream data lines within the DATA step ().
Fig. 4 Error-free lecture SAS program. This is the SAS Enhanced Editor window containing one of the DATA steps used during the error-free lecture. Only a subset of the data lines is shown to conserve space.
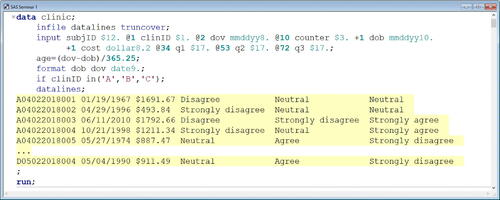
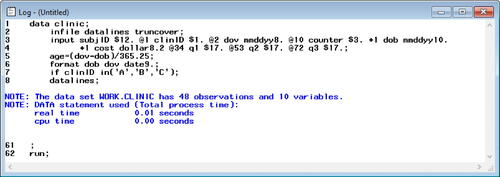
After the program was run (or submitted), SAS generated a log (). As shown in , the log provided information on the execution of the program. The error-free code, as expected, did not generate any errors.
Fig. 5 Error-free lecture SAS log. This is the SAS log, which generates messages about the execution of the program. This log indicates the program in executed successfully and created a new SAS dataset containing 48 observations and 10 variables.
Following the lecture, the students were given up to 15 min to complete an assignment related to the error-free lecture, which we refer to as the error-free assignment simply because it followed the error-free lecture. Specifically, they were given standard and nonstandard raw data values aligned in fixed fields along with a table describing the variable attributes and asked to write a DATA step that creates a temporary SAS dataset by reading the data directly from in-stream data lines. One possible solution is shown in , and the corresponding log is shown in . The complete lecture and assignment materials have been provided as supplementary material.
Fig. 6 Error-free assignment solution. This is the SAS Enhanced Editor window containing a solution to the error-free assignment. Only a subset of the data lines is shown to conserve space.
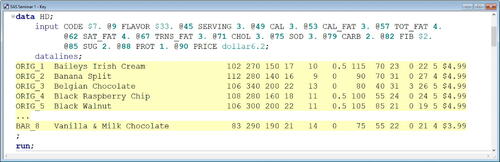
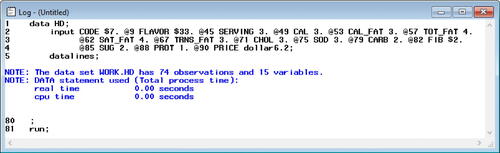
Fig. 7 Error-free assignment SAS log. This is the SAS log, which generates messages about the execution of the program. This log indicates the program in executed successfully and created a new SAS dataset containing 74 observations and 15 variables.
2.2.2 Implementing the Error-full Approach
The second half of the first seminar continued with an error-full lecture focused on using list or modified list input to read hypothetical standard and nonstandard raw data values arranged in a free format from in-stream data lines within the DATA step. This lecture began with an error-free presentation on this topic ().
Fig. 8 Error-full lecture SAS program. This is the SAS Enhanced Editor window containing one of the DATA steps used during the error-full lecture. Only a subset of the data lines is shown to conserve space.
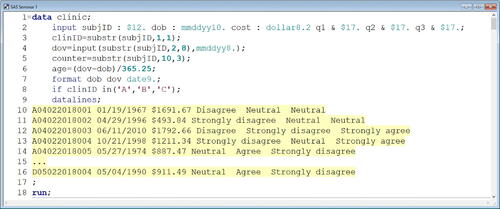
After the program was run (or submitted), SAS generated a log (). As shown in , the log provided information on the execution of the program. The error-free code, as expected, did not generate any errors.
Fig. 9 Error-full lecture SAS log. This is the SAS log, which generates messages about the execution of the program. This log indicates the program in executed successfully and created a new SAS dataset containing 48 observations and 10 variables.
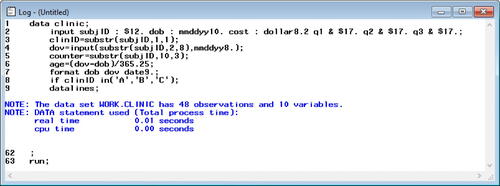
The instructor then guided students through an error interpretation session to demonstrate the process one should follow when debugging programs. Students followed along as the instructor modified the code in the Enhanced Editor () to generate specific errors in the log one-by-one. We present four examples of varying complexity using errors that resulted in (1) red text in the Enhanced Editor, (2) red error messages in the log, (3) suspicious blue notes in the log, or (4) no indication of an issue at all.
For example (1), the instructor moved the “;” appearing on line 17 of to line 16 and drew everyone’s attention to line 16, which now appeared as:
The instructor reminded students to pay attention to the color-coding of text in the Enhanced Editor, as this is the first way SAS provides clues that a program contains an error. If the correction was not obvious, they were encouraged to rerun the program and examine their log.
The instructor then clearly explained the resulting error messages generated in the log () and reminded students how to correct the error. Since this last observation would have been excluded because of the IF statement anyway, it appears as though the SAS dataset was created correctly with 48 observations and 10 variables (note that the data lines include 52 observations, but the four from clinic D were not to be written to the SAS dataset “clinic”). If a student ignored this error this time and later repeated the same mistake in a program with a different set of data lines, they still would not capture the last record and may end up excluding data unintentionally.
Fig. 10 Error-full lecture SAS log with error (1). This is the SAS log, which generates messages about the execution of the program. This log indicates the program did not execute successfully. While the new SAS dataset “clinic” was created with 48 observations and 10 variables, the last row of data was not processed as part of the DATA step. Instead, SAS encountered an invalid statement and execution stopped.
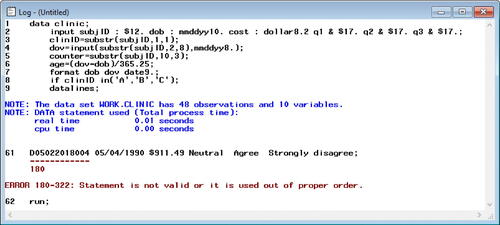
Another common mistake of beginner programmers is attempting to interchange SAS statements that perform the same task but in different ways. For example (2), the instructor replaced “IF” with “WHERE” in line 8 of so that it now appeared as:
They reran the program and then clearly explained the resulting error and warning messages generated in the log (). Specifically, the red error message in the log indicates that there are “no input datasets available for WHERE statement,” because the WHERE statement applies to all datasets listed in preceding SET, MERGE, MODIFY, or UPDATE statements of which there are none. Thus, as the warning tells us (), the SAS dataset “clinic” has 10 variables but 0 observations. The instructor then reminded students how to correct the error.
Fig. 11 Error-full lecture SAS log with error (2). This is the SAS log, which generates messages about the execution of the program. This log indicates the program did not execute successfully. The DATA step created a new SAS dataset containing 0 observations and 10 variables, which was not the desired output dataset. Execution stopped due to an error in line 8.
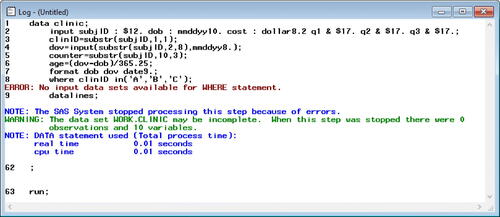
Another common mistake is failing to delimit formats appropriately. For example (3), the instructor deleted the period “.” from “date9.” in line 7 of so it appeared as:
They reran the program and examined the notes generated in the log (). At first glance, the DATA step appears to have executed successfully. However, if one looks more closely, they see a blue note indicating that the “variable “date9” is uninitialized” because no variable with that name was created during the compilation phase before its use in the FORMAT statement. SAS also cannot find a format in the FORMAT statement, so the variables “dob” and “dov” remain unformatted in the SAS dataset “clinic.” Note that “date9” was never intended to be a variable; however, leaving off the period fools SAS into thinking it is supposed to be a variable. So, this causes two errors: (i) the “variable not initialized” error and (ii) the fact that the date9 format was never applied. Again, “date9” should have been delimited with a period “.” to indicate it is a format to be applied to the “dov” and “dob” variables.
Fig. 12 Error-full lecture SAS log with error (3). This is the SAS log, which generates messages about the execution of the program. This log indicates the program executed successfully, but it also provides a note hinting there may be an issue. While the new SAS dataset “clinic” was created with 48 observations and 10 variables, the “date9” format was not applied to the variables “dob” and “dov”.
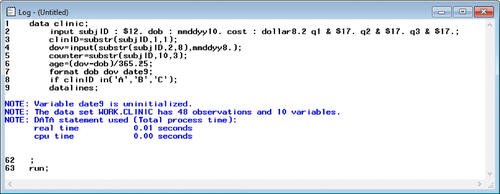
Another common mistake among students is improper specification of the order of operations in calculations. For example (4), the instructor deleted the parentheses ‘(‘and ’)’ from the expression in line 6 of so it appeared as:
They reran the program and examined the log (). As shown in , the resulting notes generated in the log look identical to those generated from the error-free program (). As mentioned in Section 1.2, errors like this can be more difficult to identify and diagnose as the log does not give any indication something went wrong.
Fig. 13 Error-full lecture SAS log with error (4). This is the SAS log, which generates messages about the execution of the program. This log indicates the program executed and created a new SAS dataset containing 48 observations and 10 variables. However, the values for the numeric variable “age” were calculated incorrectly because of missing parentheses.
The instructor then reminded the students to spot check for incorrect data values in the dataset. They printed the first five observations in the dataset “clinic” to the output window and directed everyone’s attention to the values for the variable “age” (). After pointing out “age” (in years) was calculated incorrectly (), the instructor reminded students how to use parentheses appropriately in calculations to control the order of operations.
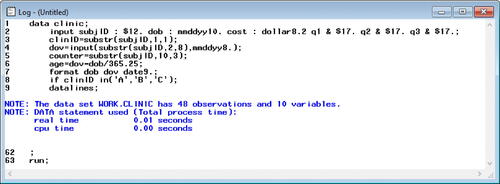
Fig. 14 Subset of SAS dataset “clinic.” These are the first five observations of the SAS dataset “clinic.” In examining the data closely, it is obvious that the values for the variable “age” (in years) were calculated incorrectly.
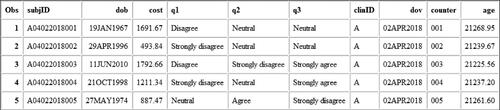
Following this error interpretation session, the students were given up to 15 min to complete an assignment related to the error-full lecture, which we refer to as the error-full assignment simply because it followed the error-full lecture. Specifically, they were given standard and nonstandard raw data values arranged in a free format along with a table describing the variable attributes and asked to write a DATA step that creates a temporary SAS dataset by reading the data directly from in-stream data lines. One possible solution is shown in , and the corresponding log is shown in . The complete lecture and assignment materials have been provided as supplementary material.
Fig. 15 Error-full assignment solution. This is the SAS Enhanced Editor window containing a solution to the error-full assignment. Only a subset of the data lines is shown to conserve space.
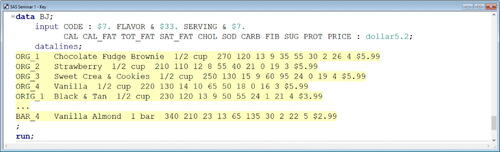
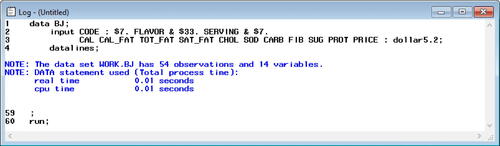
Fig. 16 Error-full assignment SAS log. This is the SAS log, which generates messages about the execution of the program. This log indicates the program in executed successfully and created a new SAS dataset containing 54 observations and 14 variables.
2.3 The Types of Errors
During the error interpretation portion of the error-full lectures, students were presented with a variety of syntax and semantic errors that occurred during the compilation phase, as well as execution-time and data errors that occurred during the execution phase. Syntax errors included misspelled keywords, missing or invalid punctuation, and invalid statements or DATA step options. Semantic errors included specifying the wrong number of arguments for a function, using a variable name with invalid type for the application, and using a library reference that had not yet been assigned. Execution-time errors included specifying variables in the INPUT statement that did not match the data lines, illegal math operators (e.g., dividing by zero), failing to sort observations before submitting a BY statement, and specifying incorrect arguments to functions. Data errors included specifying numeric variables in the INPUT statement when reading character data. With all errors, students were reminded to check the log from the top down as corrections to earlier parts of the code could have caused subsequent errors to disappear.
2.4 Data Collection and Descriptive Analysis
We collected data to examine whether the students performed better in an error-free or an error-full SAS programming environment and whether students preferred to learn in an error-free or an error-full SAS programming environment. All data were de-identified to maintain the confidentiality of the students. Students also reported their level of SAS experience (none, SAS user without formal training, completed an introductory SAS course, completed an advanced SAS course, experienced SAS user).
To examine student performance, the questionnaire asked students to record whether they successfully completed the assignment (yes, no, I do not know). To explore student satisfaction, the questionnaire also asked students to select their preferred teaching method (error-free, error-full) and enter additional comments in an open-ended field to let us know their thoughts on the error-free and/or error-full teaching methods. All data were self-reported. Frequencies were obtained for all quantitative demographic, performance, and satisfaction variables. Open-ended questions were summarized.
3 Results
Eighteen students participated in the study. The level of SAS experience varied widely with one student having no SAS experience, one student being an experienced SAS user, and the remaining 15 students falling somewhere in between. Eight of these students attended multiple seminars, but only data from their first seminar attended were summarized along with those who attended only one seminar.
All 18 students worked through (i.e., completed) both assignments. Successfully completing the assignment, however, required a program that accomplished the tasks correctly without any errors in the log. While four students successfully completed both assignments and ten students did not successfully complete either assignment, one student successfully completed only the first assignment that directly followed the error-free lecture and three students successfully completed only the second assignment that directly followed the error-full lecture.
Of 15 students who responded, 12 (80%) preferred the error-full to the error-free method. In general, students left positive feedback for both the error-free and error-full portions of the seminars, with seven students commenting that the seminars were “enjoyable,” “helpful,” or “informative.” A few others did express that the material was “way over my head.” One student nicely summarized our intention with the error-full approach by specifically commenting that “ErrorFULL learning allows me to better learn the techniques due to the chance to see incorrect code, the errors that it produces and the solutions.”
Some students who did not select a preference were more focused on evaluating the seminar itself as opposed to assessing the methods, one simply commenting “I didn’t like it.” Their feedback expressed confusion and frustration at not being able to complete the requested tasks. This supports our point made earlier that dissatisfied students tend to give up.
4 Discussion
Through our study, we learned that students appreciated the addition of a guided error interpretation session following a traditional error-free lecture when learning statistical programming. This finding motivates us to implement error-full teaching in the classroom and assess student performance and satisfaction on a larger scale. As we prepare to design an ideal error-full learning environment, we reflect on the motivation, strengths, and weaknesses of this study. We also explore future considerations by examining reputable teaching techniques in comparable fields of study.
4.1 Error-free versus Error-full Learning
In searching for the most efficient learning environment, psychologists Ferster and Skinner (Citation1957) introduced the concept of error-free (i.e., errorless) learning in the mid-twentieth century. Others have further developed the errorless learning approach agreeing with Skinner that “errors are not necessary for learning to occur” (Skinner Citation1953; Barnes and Underwood Citation1959; Terrace Citation1963; Bandura Citation1986).
While multiple studies have shown that adults with impaired memory perform better under error-free learning approaches, other studies have shown that individuals with unimpaired memory may learn better under error-full methods (Cyr and Anderson Citation2011; Middleton and Schwartz Citation2012; Faran et al. Citation2017; Śmigórska et al. Citation2019). In reviewing the literature, Metcalfe (Citation2017) found evidence that error-full learning followed by corrective feedback was beneficial to learning among “neurologically typical students.” She emphasized the importance of corrective feedback and evaluation of the decision-making process that resulted in the error, which our programming students could get from the SAS log and instructor (Metcalfe Citation2017). In surveying undergraduate students and instructors at three large public North American universities, Pan et al. (Citation2020, p. 1) discovered that these students and instructors “avoid generating errors but prioritize learning from them when they occur.” They, too, argued that the “deliberate generation of errors, followed by feedback, should be considered as a viable learning technique” (Pan et al. Citation2020, p. 16).
Lacking in the literature are comparisons of such error-free and error-full teaching techniques in graduate-level programming courses. These approaches motivated our redesign of the SAS course with appropriate error-free and error-full material so we can begin to fill this void.
4.2 Study Strengths
This study allowed us to explore an error-full teaching method in an ungraded environment where students could participate without the influence of performance anxiety. Students also had the opportunity to learn new SAS techniques and to strengthen their existing skills. Since all students experienced both the error-free and error-full teaching approaches, they were able to select their preferred method of choice and give us their feedback on advantages and disadvantages of both.
4.3 Study Limitations
Our study was limited by the small sample size. While more than fifty students attended at least one seminar, only 18 agreed to enroll in the study by participating in the survey. Since attendance was voluntary, and students could choose not to submit their work, our sample is limited by a lack of representativeness of the general student population. Additionally, the data were self-reported by students, which affected the reliability of assessing outcomes such as whether they successfully completed the assignment. The one-hour time constraint placed on the seminars limited not only the time that could be spent on assignments but also the amount of material that could be covered. Advertisement as a workshop instead of as a seminar may have better emphasized the expectation of hands-on participation.
Since the error-full approach is an extension of the error-free approach that includes a discussion and demonstration of erroneous code, we did not rotate the order of the error-free and the error-full lectures. We did present two different topics at similar difficulty levels, where the latter would require different knowledge than the former, but there is a possibility that students could have performed better on the second assignment having learned more material. The students had different levels of SAS experience, so some students had already been exposed to more errors and debugging techniques than others prior to the seminar. In addition to this learning effect, we were not able to account for a fatigue effect, where students could have been less focused during the second portion of the seminar.
As we acknowledged in Section 2.1, we needed to modify the debugging session for the seminar, which we would not need to do in the classroom. As we reflect on our delivery of the error interpretation portion during our seminars, we acknowledge there was a better way to do it. More importantly this led us to what we believe is a better way to implement it in the classroom, which we describe in Section 4.4.
4.4 Examining the Error-full Approach in a Programming Course
In this section, we discuss our proposed improvements to the study. Our pilot study was conducted to test the error-full approach and identify areas for improvement before implementing it in the classroom. Although the design and delivery of our seminar was imperfect, valuable information was gained that will enable us to improve the error-full approach before classroom implementation.
Our original idea for the error-full approach included only interactive debugging sessions following the error-free lecture. However, to fit within the time constraints of the seminar, we modified the debugging sessions to be guided by the instructor. Whether errors were accidentally made live by the student or generated by virtue of intentional display of a common mistake, discussion regarding error interpretation would have proceeded equivalently. Given the time constraint, the latter approach was used in lieu of waiting for students to generate the erroneous code for discussion.
These experiences helped us to make improvements. We believe that, in the future, we should first teach students the right way in an error-free lecture, next teach them how to fix erroneous code in a guided debugging session, and then let them practice debugging in an interactive debugging session. So, the error-full approach we propose includes both guided debugging sessions led by the instructor followed by interactive debugging sessions driven by the students. Some of our motivation for these ideas comes from the work of Dweck (Citation2008), who promoted a “growth mindset” in which intelligence grows as students learn from their mistakes. We believe that students can learn from mistakes in general, regardless of their genesis. Also, Lemov and Atkins (Citation2015) suggested, “great teachers make it safe to be wrong. They build a Culture of Error that respects, normalizes, and values learning from errors” (p. 57).
Additionally, some problems existed in our original study with respect to the necessity of trying to fit the debugging session into the seminar setting. During the error-full portion of the seminars, we showed the students correct code, then showed students the errors, and finally ran the program to show and discuss clues one should look for when interpreting the error (basically walking them through the debugging process). In retrospect, we should have started with incorrect code (where only the instructor knows the error) and guided the students blinded to the error through the debugging process (to be that voice in their head telling them what to look for, how to interpret it, and what to do next). However, time was limited for students to do the debugging themselves. In the classroom, the additional time available will enable students to participate during this part of class.
We plan to evaluate the error-full method in the Use of SAS for Data Management and Data Analysis course. Implementing the error-full approach in a weekly three-hour class over 14 weeks gives us more flexibility and will allow us to better evaluate student performance than in a single one-hour seminar. We typically enroll approximately sixty students in the class. Each week, all students will attend the same one-hour error-free lecture.
After the lecture, the students will break out into two different lab groups (with approximately 30 students in each) for a one-hour guided session followed by a one-hour interactive session. Each student will be randomized to one of these lab groups at the beginning of the semester and remain in that lab group for the entire semester. For ethical reasons, all students must have some instruction on error interpretations since they will be graded on debugging erroneous programs.
In lab group 1, the instructor, TA, or IA will first guide their students through an error interpretation session in line with what we did in the seminar. For the interactive session, these students will then be given a practice exercise that consists of a partially written error-free program that they need to add to in order to complete a set of given tasks. The lab instructors will assist as the students work through the exercise by focusing on writing the correct code, avoiding generating any errors in the log, and producing the desired result.
In lab group 2, the instructor, TA, or IA will first guide students through a debugging session where they will identify, interpret, and correct errors (only known to the instructor). For the interactive session, these students will then be given a practice exercise that consists of a partially written error-full program that they need to edit and add to in order to complete the same set of tasks given to those in lab group 1. While the need to diagnose a program containing multiple errors is common in practice, this can be tricky for novice programmers. The lab instructors will assist as the students work through the exercise by locating the error message in the log, explaining the meaning of the error message, and showing how to correct the error. Reminding the students to check the log from the top down is important as subsequent errors may disappear and new ones may emerge. The same error (e.g., a missing semicolon) may result in different log messages because of preceding errors, and the error message itself may not be directly indicative of the underlying problem. In those instances where the log does not exhibit any errors but the code does not generate the desired result (as illustrated with the example presented in ), students will focus on explaining the issue, searching for clues to identify the error in the code, and communicating how to correct and hopefully avoid such issues in the future.
It is important to emphasize that during the guided sessions for both lab groups, the students will be presented with the same errors in different ways. In lab group 1, students will observe as the instructor sabotages correct code. However, in lab group 2, students will be presented with erroneous code where only the instructor will be aware of the error(s) in advance. The students will then participate and/or observe as the instructor walks them through the thought process they should use as they debug programs. In doing so, the instructor would assume the role of a student trying to solve the problem as they encounter errors while trying to successfully accomplish a task. For example, in lab group 1, the instructor could have the students remove the period from a format in a FORMAT statement. In lab group 2, however, the period would already be missing from the provided code. Common errors will be chosen for both lab groups based on the instructor’s experience and the expectations for the class session.
We believe that the approach in lab group 2 reflects the intent and motivation for the development of our error-full method. The primary tasks for lab group 1 will focus on error interpretation of known errors having witnessed the sabotage of correct code, which places less emphasis on independent problem-solving skills. These students will be observing during the guided sessions and attempting to correctly code during the interactive sessions. On the other hand, the tasks for lab group 2 will put a greater emphasis on independent problem solving during both the guided and interactive sessions by identifying, interpreting, and correcting errors (unknown to them), which is our main goal in developing the error-full method of teaching.
For graded course assignments (including the final exam), students will be given a combination of multiple-choice and fill-in-the-blank questions, a series of tasks to write a program from scratch, and a debugging-type assessment in which they are asked to edit a poorly written program until it executes without error.
Students have been afraid to explore the unknown for fear of seeing red. They often ask, “Can I do this in SAS?” or “Will SAS let me do this?” Our response has been, “Let us try it and find out together.” We aim to create a learning environment in which students are not afraid to make mistakes. Instead, they should view mistakes as a learning moment. We want to encourage them, when in doubt, to try and err, rather than immediately run to an instructor for help. So, as part of their assignments, students will be asked to clearly document the errors they generated/encountered and describe how they corrected/resolved them. At the end of the semester, these errors can be compiled anonymously into a large document that all students can use as a reference and learn from one another’s mistakes. This addition to the assignments was inspired by Metcalfe (Citation2017), who noted that error tolerance encouraged students’ active, exploratory, generative engagement. Metcalfe (Citation2017) argued that “allowing students to self-generate [errors as well as correct responses] induces one of the strongest beneficial effects on learning in the cognitive literature” (p. 479). Several studies have found that such learning was optimized when students made mistakes, received supportive, corrective feedback, and redid the questions having learned from the errors (Dweck Citation2008; Yang et al. Citation2017).
At the end of the semester, we will compare final course grades and scores on each of the course assignments between the students in the two lab groups. We will also conduct a qualitative analysis of the student evaluations, with specific questions related to the introduction of errors or lack thereof in the lab portion of class.
4.5 Thinking Beyond the Syntax
Proponents agree that most students sitting in a statistics class feel as if they are sitting in a foreign language class (Lalonde and Gardner Citation1993). The same can be said for students sitting in a computer programming class. So, students enrolled in a statistical programming course that combines data management and data analysis enter the classroom feeling like they have been hit with a double whammy. They must be reminded that the software exists to simplify their job, so they do not have to conduct these methods manually. It should not be an impediment. When it comes to programming statistics, the syntax should be the easy part so more attention can be devoted to the other tasks at hand.
Training students to become successful statistical programmers requires more than just teaching them syntax. Programming is not just about memorizing and applying syntax, rather it requires students to think in a different way than that to which they are accustomed. Steve Jobs once said, “Everybody should learn how to program a computer, because it teaches you how to think” (Cringely 2012). Students must develop a basic understanding of the theory behind statistical methods and know when to apply these methods, how to execute those properly using statistical programming languages, how to interpret the generated results, and how to communicate their findings to a statistical and a non-statistical audience. Even seasoned practitioners have been known to avoid statistical methods and results sections of research articles for fear of not being able to interpret what has been presented (Brown Citation1991, Citation1992; Johnston Citation2002). Teaching this skill early on is critical to counter this tendency.
In guiding students along this path, we must find the right balance between error-free and error-full techniques in all aspects, not just the syntax. Afterall, the most challenging errors are those that result in a clean log but do not yield the expected result. In such instances, being able to think beyond the syntax is key.
As Bers (Citation2019) acknowledges, computer programming is the language of the 21st century. It is our responsibility to ensure our students gain the skills they need to continue to grow these communication lines error-free.
5 Conclusion
Students in our study preferred to learn statistical programming in an error-full learning environment with focused lectures emphasizing correct coding followed by error interpretation sessions. We will implement error-full teaching in an introductory SAS course to evaluate it on a larger scale. This will allow students to learn how to resolve (and hopefully avoid) their own SAS problems. What is learned from these studies can facilitate improvement of educational programming at our university and elsewhere.
Conference Presentations
This research was presented as a poster presentation at the following conferences: GW’s Scholarship of Teaching and Learning poster session on September 27, 2018 and on September 27, 2019, Association of Schools and Programs of Public Health Annual Meeting in Arlington, Virginia on March 21, 2019, The Joint Statistical Meetings in Denver, Colorado on July 29, 2019, GWSPH Teaching Fellows panel presentation on April 26, 2019.
Financial Disclosure
The authors declare that they have no financial relationship relevant to this article to disclose.
Software
SAS and all other SAS Institute Inc. product or service names are registered trademarks or trademarks of SAS Institute Inc. in the USA and other countries. ® indicates USA registration.
Supplemental Material
Download Zip (417.1 KB)Acknowledgments
We thank all the students who participated in the seminars and contributed data for this study. We would also like to thank the GW Milken Institute School of Public Health’s Academy of Master Teachers for granting us a Fellowship Award and encouraging us to conduct this research. We also thank the editors and reviewers for their helpful commentary in outlining our proposed study.
Conflict of Interest
The authors declare that they have no potential conflicts of interest relevant to this article to disclose.
Data Sharing
In the IRB application, we declared that all data would be aggregated/summarized in all publications, and no individual-level results would be communicated to protect the students’ privacy and confidentiality.
Additional information
Funding
References
- Arthur Ashe Learning Center. (2020), The Arthur Ashe Legacy [online]. Available at: https://arthurashe.ucla.edu/black-history-month-2014-2009-in-his-words/.
- Bandura, A. (1986), Social Foundations of Thought and Action: A Social Cognitive Theory, Englewood Cliffs, NJ: Prentice-Hall.
- Barnes, J. M. and Underwood, B. J. (1959), “Fate of First-List Associations In Transfer Theory,” Journal of Experimental Psychology, 58, 97– 105. DOI: https://doi.org/10.1037/h0047507.
- Bers, M. U. (2019), “Coding as Another Language: A Pedagogical Approach for Teaching Computer Science in Early Childhood,” Journal of Computers in Education, 6, 499–528. DOI: https://doi.org/10.1007/s40692-019-00147-3.
- Brown, J. (1991), “Statistics as a Foreign Language: Part 1: What to Look for in Reading Statistical Language Studies,” TESOL Quarterly, 25, 569–586. DOI: https://doi.org/10.2307/3587077.
- Brown, J. (1992), “Statistics as a Foreign Language: Part 2: More Things to Consider in Reading Statistical Language Studies,” TESOL Quarterly, 26, 629–664. DOI: https://doi.org/10.2307/3586867.
- Burlew, M. M. (2001), Debugging SAS® Programs: A Handbook of Tools and Techniques, Cary, NC: SAS Institute Inc.
- Cody, R. (2017), Cody’s Data Cleaning Techniques Using SAS® (3rd ed.), Cary, NC: SAS Institute Inc.
- Cringely, R. X. (Writer), Sen, P., Gau, J., and Segaller, S. (Producers), Sen, P. (Director). (2012), Steve Jobs: The Lost Interview, [Video]. Furnace, Oregon Public Broadcasting, Public Broadcasting Service (PBS).
- Cyr, A., and Anderson, N. D. (2011), “Trial-and-Error Learning Improves Source Memory Among Young and Older Adults,” Psychology and Aging, 27, 429–439. DOI: https://doi.org/10.1037/a0025115.
- Dalbey, J., and Linn, M. (1985), “The Demands and Requirements of Computer Programming: A Literature Review,” Journal of Educational Computing Research, 1, 253–274. DOI: https://doi.org/10.2190/BC76-8479-YM0X-7FUA.
- Deek, F. P., and McHugh, J. A. (1998), “A Survey and Critical Analysis of Tools for Learning Programming,” Computer Science Education, 8, 130–178. DOI: https://doi.org/10.1076/csed.8.2.130.3820.
- Delwiche, L. D., and Slaughter, S. J. (2019), Chap. 6, “Debugging Your SAS Programs,” in The Little SAS® Book: A Primer (6th ed.), Cary, NC: SAS Institute Inc.
- Delwiche, L. D., and Slaughter, S. J. (2003), “Errors, Warnings and Notes (Oh My) A Practical Guide to Debugging SAS® Programs,” in Proceedings of the 2003 SAS Users Group International (SUGI) Conference, Seattle, Washington, March 30-April 2, paper 1468–2014.
- DiIorio, F. (2001), “The SAS® Debugging Primer,” in Proceedings of the Twenty-Sixth Annual SAS® Users Group International Conference, paper 54-26. Available at: http://www2.sas.com/proceedings/sugi26/p054-26.pdf.
- Dweck, C. S. (2008), Mindset: The New Psychology of Success, New York: Ballantine Books.
- Fahmy, A. (2010), “Logging the Log Magic: Pulling the Rabbit out of the Hat,” in Proceedings of the 2010 PharmaSUG Conference, Benchworkzz, Austin, Texas, USA.
- Faran, Y., Osher, Y., Sofen, Y., and Shalom, D. B. (2017), “Errorful and Errorless Learning in Preschoolers: At What Age Does the Errorful Advantage Appear?” Cognitive Development, 44, 150–156. DOI: https://doi.org/10.1016/j.cogdev.2017.10.002.
- Ferster, C. B., and Skinner, B. F. (1957), Schedules of Reinforcement, New York: Appleton-Century-Crofts.
- Hayes, B. (1995), “Debugging Myself,” American Scientist, 83, 404–408.
- Johnston, L. E. (2002), “Statistics as a Second Language: A Brief Overview for the Wary Clinician.” Seminars in Orthodontics, 8, 54–61. DOI: https://doi.org/10.1053/sodo.2002.32072.
- Jolley, L., and Stroupe, J. (2009), “Fifty Ways to Lose Your Data (and How to Avoid Them),” in Proceedings of SAS Global Forum 2009, Washington, DC, March 22-25, paper 134-2009.
- Lafler, K. P. (2013), “Strategies and Techniques for Debugging SAS® Program Errors and Warnings,” in Proceedings of the 2013 MidWest SAS Users Group (MWSUG) Conference. Spring Valley, CA: Software Intelligence Corporation.
- Lalonde, R. N., and Gardner, R. C. (1993), “Statistics as a Second Language? A Model for Predicting Performance in Psychology Students,” Canadian Journal of Behavioural Science, 25, 1, 108–125. DOI: https://doi.org/10.1037/h0078792.
- Lee, G. C., and Wu, J. C. (1999), “Debug It: A Debugging Practicing System,” Computers and Education, 32, 165–179. DOI: https://doi.org/10.1016/S0360-1315(98)00063-3.
- Lemov, D., and Atkins, N. (2015), Teach Like a Champion 2.0: 62 Techniques That Put Students on the Path to College (2nd ed.), San Francisco, CA: Jossey-Bass.
- Metcalfe J. (2017), “Learning From Errors,” Annual Review of Psychology, 68, 465–489. DOI: https://doi.org/10.1146/annurev-psych-010416-044022.
- Middleton, E. L., and Schwartz, M. F. (2012), “Errorless Learning in Cognitive Rehabilitation: A Critical Review,” Neuropsychological Rehabilitation, 22, 138–168. DOI: https://doi.org/10.1080/09602011.2011.639619.
- Pan, S. C., Sana, F., Samani, J., Cooke J., and Kim, J. A. (2020), “Learning From Errors: Students’ and Instructors’ Practices, Attitudes, and Beliefs,” Memory, 28, 1105–1122. DOI: https://doi.org/10.1080/09658211.2020.1815790.
- Russell, K., and Tyndall, R. (2010), “SAS® System Options: The True Heroes of Macro Debugging,” in Proceedings of the 2010 NorthEast SAS Users Group (NESUG) Conference. Cary, NC: SAS Institute Inc.
- SAS Institute Inc. (2015), “Debugging SAS Programs,” Step-by-Step Programming With Base SAS® 9.4 (2nd ed.), Cary, NC: SAS Institute Inc.
- Skinner B. F. (1953), Science and Human Behavior, New York: MacMillan.
- Śmigórska A., Śmigórski K., and Rymaszewska J. (2019), “Errorless Learning as a Method of Neuropsychological Rehabilitation of Individuals Suffering From Dementia in the Course of Alzheimer’s Disease,” Psychiatria Polska, 53, 1, 117–127. DOI: https://doi.org/10.12740/pp/81104.
- Staum, R. (2002), “To Err is Human: To Debug Divine,” in Proceedings of the Twenty-Seventh Annual SAS Users Group International Conference, Orlando, Florida from April 14-17, paper 64–27.
- Terrace, H. S. (1963), “Discrimination Learning With and Without Errors,” Journal of the Experimental Analysis of Behavior, 6, 1–27. DOI: https://doi.org/10.1901/jeab.1963.6-1.
- Yang, C., Potts, R., and Shanks, D. R. (2017), “Metacognitive Unawareness of the Errorful Generation Benefit and Its Effects on Self-Regulated Learning,” Journal of Experimental Psychology: Learning, Memory, and Cognition, 43, 1073–1092. DOI: https://doi.org/10.1037/xlm0000363.