
Figures & data
Figure 1. A pipeline to identify scFv thermostability using deep learning. (a) The biological challenge of antibody thermostability prediction from sequences. Antibody thermostability can determine the manufacturability of antibodies in downstream processes. The biological question that we AIM to tackle is whether we can predict the thermal characteristics of an scFv, given its sequence. Available data for this challenge can comprise of the amino acid sequences, structures and calculated energetics. Leveraging antibodies with pre-determined temperature characteristics is paramount, however, the availability is scarce for such a dataset. (b) Thermostability data generation. To generate a dataset of scFv sequences with known temperature-specific features, we determined the loss of target binding of the scFv post high temperature stress to obtain a TS50 measurement. (c) Training a classification network for predicting TS50 bins. One of the approaches is transfer learning with unsupervised models (top branch). We utilized pre-trained BERT-like models (such as ESM1-b, ESM1-v, etc) to make (1) Zero-shot predictions and (2) Fine-tuned predictions with the labeled TS50 dataset. Another approach is to train a supervised model with calculated thermodynamic energies (bottom branch). We used sequence and structure-based features for supervised learning using simple convolutional models to train a classifier. The outcome of such trained ML models can be employed either for predicting thermostability of generated antibody sequences or to computationally validate experimental designs.
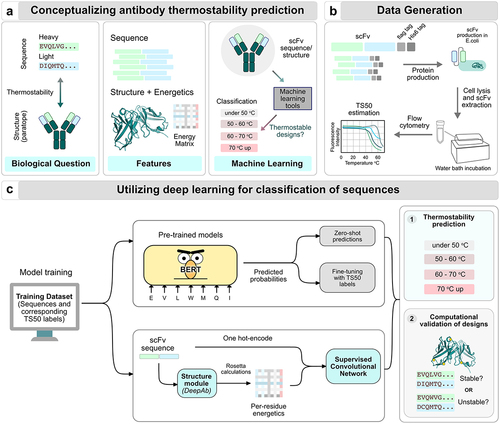
Figure 2. Fine-tuning over pre-trained unsupervised models improves correlation on withheld targets. (a) Zero-shot and (b) Fine-tuned sequence scoring methods for thermostability prediction. (c) Zero-shot likelihood-based predictions with pre-trained models do not correlate strongly with the TS50 datasets. (d) Fine-tuning the pre-trained models on TS50 data from targets significantly improves correlation on the held-out target. (e) Zero-shot likelihood-based predictions on blind test sets. (f) Models fine-tuned on TS50 data do not generalize well to blind test sets.
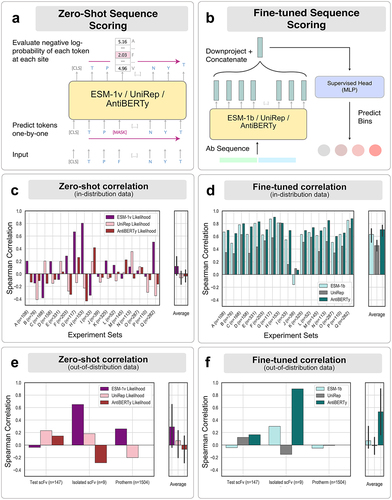
Figure 3. Energy features can extract ’generalizable’ information of thermostability. (a) The supervised convolutional network architecture for classification of antibody sequences. The input scFv sequences pass a structure-generation module with DeepAb followed by Rosetta-based evaluation to estimate per-residue energies for each amino acid residue in the scFv structure. The sequences are one-hot encoded (top branch) and the energetic features, represented as an i-j matrix(bottom branch), are provided to the network. The output from the sequence branch and the energy branch are passed through a dense-layer to generate the probabilities of the sequence to lie in each of the temperature bins. (b) t-stochastic neighbor embeddings from the energetics-only model colored by the temperature bins. (c) Receiver-operating characteristic curve to demonstrate the classification of the test sequences for the above-70 bin with the energetics-only model. Note that Test scFv and Isolated scFv have a smaller sample size, explaining the relatively less rugged nature of the curves. (d) The model’s performance metrics for the classification task on completely blind test scFv sequences is reported with the Spearman's correlation coefficient.
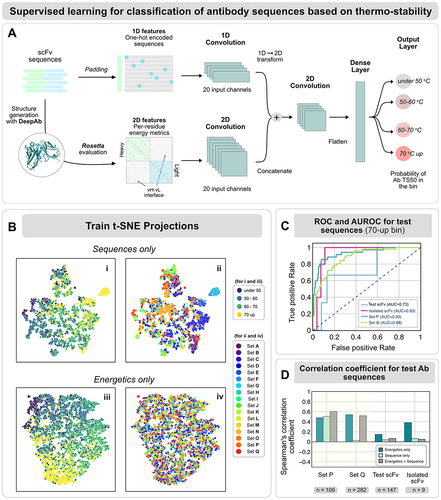
Figure 4. Computational deep mutational scan of an antibody variable fragment shows agreement with experimental thermal denaturation data. Validating all the point mutants with our SCNN and ESM-1b finetuned models for anti-VEGF antibody (PDB ID: 2FJG(bound) and PDB ID: 2FJF (unbound)), we observed synergies in mutants predicted in the over-70°C bin and the experimental thermal denaturation data available from prior work.Citation10,Citation33 Spheres indicate the experimentally validated mutants that improved Tm; pink indicates predictions from the network with the same residue position, but different amino acid mutation; red indicates the predictions matching experimental data and gray indicates mutations which were not observed in computational predictions. Thumbnails highlight the mutations in agreement with experiments and potential interactions. The table illustrates the comparison with the experimental and computational predictions.
Supplemental Material
Download PDF (10.5 MB)Data availability statement
The source code for TherML (zero-shot, fine-tuned and supervised models) is available at https://github.com/AmeyaHarmalkar/therML for non-commercial use only. The experimental thermostability data and sequences are from internal antibody engineering studies and cannot be made available as the sequences are an intellectual property of Amgen. Any additional information required to reanalyze the data reported in this paper is available from the lead author upon request.