
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Discrimination and fairness are major concerns in algorithmic models. This is particularly true in insurance, where protected policyholder attributes are not allowed to be used for insurance pricing. Simply disregarding protected policyholder attributes is not an appropriate solution as this still allows for the possibility of inferring protected attributes from non-protected covariates, leading to the phenomenon of proxy discrimination. Although proxy discrimination is qualitatively different from the group fairness concepts discussed in the machine learning and actuarial literature, group fairness criteria have been proposed to control the impact of protected attributes on the calculation of insurance prices. The purpose of this paper is to discuss the relationship between direct and proxy discrimination in insurance and the most popular group fairness axioms. We provide a technical definition of proxy discrimination and derive incompatibility results, showing that avoiding proxy discrimination does not imply satisfying group fairness and vice versa. This shows that the two concepts are materially different. Furthermore, we discuss input data pre-processing and model post-processing methods that achieve group fairness in the sense of demographic parity. As these methods induce transformations that explicitly depend on policyholders' protected attributes, it becomes ambiguous whether direct and proxy discrimination is, in fact, avoided.
1. Introduction
1.1. Problem context
For legal and societal reasons, there are several policyholder attributes that are not allowed to be used in insurance pricing (Avraham et al., Citation2014; Chibanda, Citation2021; European Commission, Citation2012; European Council, Citation2004; Prince & Schwarcz, Citation2020); for instance European law does not allow the use of information on sex in insurance pricing. Furthermore, ethnicity is a critical attribute that is typically viewed as a protected characteristic. In the actuarial and insurance literature, Charpentier (Citation2022), Frees and Huang (Citation2022) and Xin and Huang (Citation2021) give extensive overviews on the potential use (direct or indirect) of policyholders' protected attributes and the implications for insurance prices, while Avraham et al. (Citation2014), Prince and Schwarcz (Citation2020) and Maliszewska-Nienartowicz (Citation2014) provide legal viewpoints on this topic. Closely related is the recent report of the European Insurance and Occupational Pension Authority (EIOPA) (EIOPA, Citation2021), which discusses governance principles towards an ethical and trustworthy use of artificial intelligence in the insurance sector.
A critical observation from this literature is that just ignoring (being unaware of) protected information does not guarantee a lack of discrimination in pricing. In the presence of statistical associations between covariates used in pricing, it can occur that protected attributes are inferred from non-protected covariates, which thus act as undesirable proxies for, e.g. sex or ethnicity. As a result, the calculated insurance prices are subject to proxy discrimination; for a wide-ranging overview of this idea see (Tschantz, Citation2022).
Defining, identifying and addressing proxy discrimination presents a number of interrelated challenges and here we outline but a few. First, such discrimination need not be intentional, as the inference of protected attributes can take place implicitly through the fitting procedure of a predictive model. The complexity of models often used in insurance pricing can make this inference process quite opaque to the user. Second, the non-protected covariates implicitly used as proxies cannot just be removed from models, as, besides their proxying effect, they are typically considered legitimate predictors of policyholders' risk (e.g. smoking status can correlate with sex, while at the same time having a clear and established link to health outcomes). Third, proxy discrimination relates to the way that prices are calculated and does not necessarily imply adverse outcomes for any protected demographic group – in fact, in some situations proxy discrimination can mask rather than exacerbate demographic disparities (see Remark 9 in Lindholm et al. (Citation2022).)
The third challenge above can be a source of confusion when discussing indirect discriminatory effects, as it relates to the complex relation between proxy discrimination and notions of group fairness, which place requirements on the joint statistical behaviour of insurance prices, protected attributes and actual claims (for example, independence between prices and protected attributes is known as demographic parity). Common definitions of indirect discrimination appear to require – and maybe even conflate with each other – both the proxying of protected attributes and an adverse impact on protected groups; see (Maliszewska-Nienartowicz, Citation2014), but also the broader discussion of Barocas et al. (Citation2019), Chapter 4.
There have been several approaches to prevent proxy discrimination, including restrictions in the use of covariates, discussed in Section 6 of Frees and Huang (Citation2022). More technical approaches and price adjustments include: a counter factual approach drawing from causal inference, see see (Araiza Iturria et al., Citation2022; Charpentier, Citation2022; Kusner et al., Citation2017); the probabilistic approach of Lindholm et al. (Citation2022) focussing specifically on implicit inferences; and the projection method of Frees and Huang (Citation2022). The latter approach finds itself within in a broader literature which considers adjustments to covariates, which produce independence of protected attributes from non-protected covariates; see also (Grari et al., Citation2022). On the face of it, this seems an attractive proposition: by breaking the dependence between protected attributes and their potential proxies, proxy discrimination is prevented. In other words: satisfying a group fairness perspective may also have the additional beneficial effect of addressing proxy discrimination. In the sequel, we will take a critical perspective to this particular rationale.
1.2. Aims and outline of the paper
In this paper, we aim to investigate the relationship between proxy discrimination – and the requirement to avoid it – and notions of group fairness. In particular, we will focus on the question of whether standard notions of group fairness (namely: demographic parity, equalized odds, and predictive parity) are consistent with avoiding proxy discrimination. This is a pertinent question, not least in the context of literature advocating the former as a solution to the latter.
In Section 2, we provide a technical definition of avoiding proxy discrimination as an individual fairness property. Individual fairness, broadly, requires that policyholders with the same characteristics receive the same premium (Charpentier, Citation2022; Dwork et al., Citation2012). In our context, we require that whether or not policyholder profiles are treated as equivalent should not hinge upon the dependence structure between protected attributes and non-protected covariates. We show through examples how standard unawareness pricing, arising from optimal claims prediction by ignoring protected information, leads to proxy discrimination, and how this issue can be addressed by the approach of Lindholm et al. (Citation2022).
Then, we turn our attention to the compatibility of the individual fairness property of avoiding proxy discrimination with standard group fairness properties. We show that avoiding proxy discrimination does not imply satisfying any of the three group fairness properties considered. Conversely, satisfying demographic parity does not imply avoiding proxy discrimination. These results indicate that neither of the two requirements of group fairness or avoiding proxy discrimination is strictly stronger then the other; hence the former cannot be viewed as a quick fix for the latter. As these results are negative, they are derived by designing concrete (counter-)examples that demonstrate potential trade-offs and incompatibilities.
In Section 3, we discuss in more detail the impact that strategies to effect group fairness have on insurance prices, focussing specifically on demographic parity. The theory of optimal transport has recently been promoted to make statistical models fair, via its application in input pre-processing and model post-processing methods, see (Chiappa et al., Citation2020; del Barrio et al., Citation2019); an early application of these ideas in an insurance context w.r.t. creating gender-neutral policies in life insurance using mean-field approximations can be found in Example 5.1 of Djehiche and Lofdahl (Citation2016). We study these pre- and post-processing methods, and conclude that they may be helpful tools for achieving fairness objectives in insurance pricing. Specifically, model post-processing, which is more frequently used in machine learning, is simpler to apply and allows for optimal modelling choices from the perspective of predictive accuracy. However, model post-processing can lead to results that are not easily explainable to insurance customers and policymakers. In addition, the adjustments made by these methods depend on the statistical relations between protected attributes and non-protected covariates. As these relations are often driven by portfolio composition rather than causal relations, their strength and direction remains portfolio-specific. This means that any adjustments (e.g. to model inputs) in order to achieve group fairness will have to be different from insurer to insurer. Such arbitrariness is hard to imagine in practice, for both regulatory and commercial reasons.
Furthermore, the extent to which the resulting prices can be considered free of discrimination is a matter of interpretation. Focusing on the case where model inputs are transformed to achieve independence, these adjustments are explicit functions of protected attributes and hence subject to direct discrimination. Unless the transformed inputs have an interpretation that is justifiable in its own right, we would end up in a paradoxical situation where proxy discrimination appears addressed (by independence between transformed protected and unprotected attributes), at the price of introducing direct discrimination. But this of course does not make sense, since the whole idea of avoiding proxy discrimination is conceptually predicated on the lack of direct discrimination.
In Section 4, we discuss our overall conclusions and further aspects of the problem. Mathematical results are proved in Appendix 1.
1.3. Relation to the machine learning literature
The issues we address in this paper from an insurance perspective are closely related to extensive discussions in the machine learning literature; for wide overviews of those discussions see (Barocas et al., Citation2019; Mehrabi et al., Citation2019; Tschantz, Citation2022). One particular difference of the discussions of fairness in the insurance pricing and machine learning contexts is that, in the former, responses of predictive models are discrete numerical or continuous, while in the latter they are typically binary/categorical. This means that one cannot assume that proofs and technical arguments developed in the machine learning literature on the relation between different notions of fairness necessarily transfer to the insurance context. Furthermore, the regulatory emphasis in insurance is more on avoiding direct and indirect (or proxy) discrimination, rather than comparing the outcomes on different demographic groups (European Commission, Citation2012; European Council, Citation2004).
We consider proxy discrimination as a type of individual fairness – since its focus is on the way similar policyholders should be treated – and we introduce a suitable notion of similarity. Our perspective on proxy discrimination is essentially the same as omitted variable bias; see (Mehrabi et al., Citation2019; Tschantz, Citation2022). We note that a substantial variety of alternative notions of proxy discrimination exist and these are typically formulated via the rich framework of causal inference, e.g. (Kilbertus et al., Citation2017; Kusner et al., Citation2017; Qureshi et al., Citation2016). In contrast, we make no assumptions regarding causality. There are three reasons for this. First, our focus is on indirect inference of protected attributes and this is an issue of statistical association, rather than causality. Second, the statistical relations between covariates are often not the result of any causal relations, but instead artefacts of the composition of insurance portfolios. Third, any causal relations that do exist between covariates are not necessarily well understood in practice, particularly in high-dimensional insurance pricing applications. Hence our approach is motivated by a mix of conceptual and pragmatic arguments that apply in the insurance context.
Substantial literature exists on the incompatibility of different notions of fairness, see for example the seminal contribution of Kleinberg et al. (Citation2016) and the related discussion by Hedden (Citation2021). Our contribution to this literature thus consists of demonstrating incompatibility of avoiding proxy discrimination with group fairness notions, from an insurance perspective. In a sense, such incompatibility is not particularly surprising, given the rather different scope of individual and group fairness. The potential conflict between those two classes of fairness criteria is discussed in Binns (Citation2020) and Friedler et al. (Citation2016), using, respectively, discursive and technical arguments but reaching consistent conclusions: that such conflicts demonstrate the need to clarify ideas about justice and the particular types of harm that should be prevented in specific contexts. While we do not examine the moral foundations of the technical fairness criteria, this is a conclusion we support. More practically, trade-offs between individual and group fairness are operationalized by reflecting them within model fitting processes, see for example (Awasthi et al., Citation2020; Lahoti et al., Citation2019; Zemel et al., Citation2013), noting that these papers do not specifically consider proxy discrimination as a type of individual (un)fairness.
Finally, the applications of methods from Optimal Transport has received prominence both in the machine learning literature, see (Chiappa et al., Citation2020; del Barrio et al., Citation2019), and more recently in actuarial science, e.g. (Charpentier et al., Citation2023). Our contribution to this strand of literature is primarily conceptual. We show how the incompatibility between avoiding proxy discrimination and group fairness manifests through the generation of directly discriminatory prices, when optimal transport methods are deployed to achieve demographic parity in insurance. Furthermore, we highlight the communication challenges associated with the transformations of model inputs and outputs.
2. Discrimination and fairness in insurance pricing
2.1. Proxy discrimination
To set the stage, we fix a probability space with
describing the real world probability measure. We consider the random triplet
on this probability space. The response variable Y describes the insurance claim that we try to predict (and price). The vector
describes the non-protected covariates (non-discriminatory characteristics), and
describes the protected attributes (discriminatory characteristics). We assume that the partition into non-protected covariates
and protected attributes
is given exogenously, e.g. by law or by societal norms and preferences. We use the distribution
to describe an insurance portfolio and its claims, in particular, the random selection of a policyholder from the insurance portfolio, based on their characteristics, is given by the distribution
. Different insurance companies may have different insurance portfolio distributions
, and this insurance portfolio distribution typically differs from the overall population distribution in a given society because the insurance penetration is not uniform across the entire population. For simplicity, in this paper, we assume that the protected attributes
are discrete and finite, only taking values in a finite set
.
In our context, concern for proxy discrimination arises from the understanding that even when the protected attributes are not used explicitly in pricing, they may still be used implicitly, because the pricing mechanisms deployed may include inference of
from the non-protected covariates
. Hence, we require that insurance prices do not depend on the conditional distribution
, such that a modification of that conditional distribution does not impact the individual prices. To formalize this concern, we first note that the distribution
is specific to a particular portfolio and insurance company. Let
be the set of all distributions over
, such that any alternative insurance portfolio can be identified with a distribution
; one may think of
as a modification of the portfolio distribution
or as another portfolio in the same idealized insurance market. Further, assume that
takes values in a set
, i.e.
for all
. To start with, we consider proxy discrimination as a property of pricing functionals, defined as follows.
Definition 2.1
A pricing functional π is a mapping , such that for a portfolio
, a policyholder with non-protected covariates
is charged the insurance price
.
Note that, by construction, a pricing functional as defined above avoids direct discrimination since is not an explicit input to it. Avoiding proxy discrimination is a more stringent requirement, given as follows.
Definition 2.2
A pricing functional π on avoids proxy discrimination if for any two portfolios
that satisfy
,
and
, we have
(1)
(1)
Definition 2.2 of (lack of) proxy discrimination requires that in comparable insurance portfolios, prices should be identical. Comparability means that the portfolio distributions and
should be identical in all aspects apart from the dependence structure between
and
, which is precisely the source of potential proxy discrimination. We may thus view the property of avoiding proxy discrimination as a particular form of individual fairness. That is, broadly, the requirement that policyholders with similar profiles regarding non-protected covariates
, receive in similar circumstances the same premium (Charpentier, Citation2022; Dwork et al., Citation2012). In the current context ‘similar circumstances’ refers to the insurance portfolios having the same structure, except for the dependence between the protected attributes
and the non-protected covariates
. This dependence is insurance company specific and originates from the specific structure of the insurance portfolio.
In Definition 2.2 no specific pricing (or predictive) model is assumed – the definition can be applied to any functional of non-protected covariates and portfolio distribution. We note that a pricing functional violating (Equation1(1)
(1) ) in general does not allow us to conclude that such violations will be material in the context of a specific portfolio. To talk about materiality of proxy discrimination we need to consider a reference portfolio structure
that is comparable to
. By convention, we will choose
such that under that measure
are independent.
Definition 2.3
Proxy discrimination is material for the pricing functional π and the portfolio , if, for the measure
with
it holds that
(2)
(2)
The positive probability in (Equation2(2)
(2) ) is calculated with respect to the distribution of
which is the same under
and
. This formulation aims to avoid assigning materiality to scenarios where
for policies with
that do not actually occur in the portfolio.
Our aim is to examine standard types of insurance prices from the perspective of proxy discrimination.
2.2. Discrimination-free insurance prices
Best-estimate price: For insurance pricing, one aims at designing a regression model that describes the conditional distribution of Y, given the explanatory variables . Moreover, the main building block for technical insurance prices is the conditional expectation of claims, given the policyholder characteristics. This motivates the following definition.
Definition 2.4
For a portfolio the best-estimate price of Y, given full information
, is given by
(3)
(3)
This price is called ‘best-estimate’ because it has minimal mean squared error (MSE), i.e. it is the most accurate predictor for Y, given , in the
-sense; for simplicity, we assume that all considered random variables are square-integrable with respect to
.
In general, the best-estimate price directly discriminates because it uses the protected attributes as an input, see (Equation3
(3)
(3) ). As such, it does not provide a pricing functional in the sense of Definition 2.1.
Unawareness prices : The simplest response to the direct discrimination of best-estimate prices is to obtain a pricing functional by conditioning on the non-protected covariates only. This approach corresponds to the concept of fairness through unawareness (FTU) in machine learning, motivating the following definition.
Definition 2.5
For a portfolio the unawareness price of Y, given
, is defined by
(4)
(4)
The unawareness price does not directly discriminate because it does not use protected attributes as explicit inputs. However, the unawareness price is generally not free from proxy discrimination, as it allows implicit inference of
through the tower property
(5)
(5) From Equation (Equation5
(5)
(5) ) it is apparent that a modification of the conditional distribution
would generally impact the calculation of
and Equation (Equation1
(1)
(1) ) will not generally be satisfied. If there is statistical dependence (association) between
and
with respect to
, unawareness prices implicitly use this dependence for inference of
from
; in Example 2.12, below, we illustrate this inference on an explicit example.
Nonetheless, in practice one still needs to establish whether, under the unawareness price and for a specific portfolio distribution , proxy discrimination is material. Hence, we need to compare
, given in (Equation5
(5)
(5) ), to the corresponding formula under
, given by
(6)
(6) The comparison of formulas (Equation5
(5)
(5) ) and (Equation6
(6)
(6) ) highlights that there are two necessary conditions for proxy discrimination becoming material for
; note that
by assumption. First, we need to have, for some
, a conditional probability
(7)
(7) i.e. we need to have dependence between
and
that allows us to (partly) infer the protected attributes
from the non-protected covariates
, such that
is used as a proxy for
. Second, the functional
needs to have a sensitivity in
, otherwise, if
(8)
(8) the inference potential from
to
is not exploited in the construction of
, and there is no proxy discrimination, see (Equation5
(5)
(5) ). In fact, under property (Equation8
(8)
(8) ) we may choose any portfolio distribution
and we receive equal unawareness and best-estimate prices. In that case, there cannot be any material proxy discrimination because
is sufficient to compute the best-estimate price (Equation3
(3)
(3) ). As an example, we suppose that (non-protected) telematics data
makes gender information
superfluous to predict automobile claims Y. This would imply a (causal) graph
, which means that
does not carry any additional information to predict claims Y, given
. Therefore, (Equation8
(8)
(8) ) holds in this telematics data example.
We summarize this discussion in the following proposition.
Proposition 2.6
The unawareness price µ on
is a pricing functional that generally does not avoid proxy discrimination.
For the unawareness price µ and a given portfolio
The previous proposition gives a necessary condition for proxy discrimination to be material. Note that in the binary case this necessary condition is also sufficient, but in the general case this may not be true.
Discrimination-free insurance price : In order to address the issue of proxy discrimination, Lindholm et al. (Citation2022) proposed to break the inference potential in (Equation5(5)
(5) ), to arrive at what they term a discrimination-free insurance price. The idea is to replace the conditional distribution
in (Equation5
(5)
(5) ) by a (marginal) pricing distribution
, which thus breaks the statistical association between
and
.
Definition 2.7
For a portfolio , a discrimination-free insurance price (DFIP) of Y, given
, is defined by
(9)
(9) where the distribution
is dominated by
.
It follows directly from the construction of Definition 2.7 that the DFIP avoids proxy discrimination.
Proposition 2.8
Let be either exogenously given or, alternatively,
. In either of these cases, the DFIP
on
is a pricing functional that avoids proxy discrimination.
Remarks 2.9
A number of observations regarding Definition 2.7 and Proposition 2.8 apply.
The price (Equation9
Under (Equation8
Under additional assumptions on causal graphs, the DFIP (Equation9
Motivated by the observation that the DFIP can be understood as an expectation under a change of probability measure, we note that we may then view as the
-optimal
-measurable price of Y in a model where
and
are independent. Following this argument, the DFIP can be represented according to the following proposition.
Proposition 2.10
Let , such that
Then, the DFIP of (Equation9
(9)
(9) ) can be represented as
for
-almost every
.
The proof of Proposition 2.10 is given in Appendix 1.
Remark 2.11
The DFIPs (Equation9(9)
(9) ) require the knowledge of
, hence they require collection and modelling of protected attributes
, a form of ‘fairness through awareness’, see (Dwork et al., Citation2012). When data on protected attributes are only partially available, then calculation of
is challenging; see (Lindholm et al., Citation2023) for a technical solution to this issue. Proposition 2.10 gives us a different means of addressing this problem, as it implies that we can estimate the DFIP directly from an i.i.d. sample
of
, without going via the best-estimate price. Let us consider here the case that
, and assume that we have access to (estimated) population probabilities
and
. Then, we can find an estimate for the DFIP by solving the weighted square loss problem
(10)
(10) where
is a restricted class of regression functions on
(e.g. GLMs); the solution
estimates the DFIP
. Naturally, this approach requires reliable estimation of the conditional distribution,
, using a partial but representative sample – otherwise it may introduce a different kind of bias and discrimination.
Furthermore, notice that calculation of the DFIP via (Equation9(9)
(9) ), that is, by first estimating
and then averaging out
, is a form of model-post processing. On the other hand, estimating DFIP via (Equation10
(10)
(10) ), is an in-process adjustment of the model, since proxy discrimination is removed as part of the estimation process. In Section 3, we will see how model pre- and post-processing is used to address a different criterion, demographic parity.
Examples
To illustrate the ideas of this section, and to set the stage for concepts discussed in later sections, we introduce two examples. First, we consider a situation where we have a response variable Y whose conditional expectation is fully described by the non-protected covariates , and the protected attributes
do not carry any additional information about the mean of the response Y. Therefore, for this model, proxy discrimination is immaterial and the best-estimate price is identical with the unawareness price and the DFIP, as discussed in the second item of Remarks 2.9. Moreover, this model is simple enough to be able to calculate all quantities of interest, and, even if it is unrealistic in practice, it allows us to gain intuition about the relationship between proxy discrimination and the group fairness concepts that will be introduced in the sequel.
Note that from now on, we will drop the dependence of various functionals on when there is no danger of confusion, e.g.
and
.
Example 2.12
No discrimination despite dependence of
Assume we have two-dimensional covariates having a mixture Gaussian portfolio density
(11)
(11) with
,
,
,
,
, and where we set
Thus, D is a Bernoulli random variable taking the values 0 and 1 with probability 1/2, and X is conditional Gaussian, given D = d, with mean
and variance
. Below, we make explicit choices for
and
which are kept throughout all examples. To make our examples more concrete, here and in subsequent sections, let X be the age of the policyholder, and D the gender of the policyholder with D = 0 for women and D = 1 for men.
For the response Y we assume conditionally, given ,
(12)
(12) That is, the mean of the response does not depend on the protected attributes
, but only on the non-protected covariates
. This means that
is sufficient to describe the mean of Y and Proposition 2.6 directly tells us that the corresponding unawareness prices are not subject to proxy discrimination. In fact, the best-estimate, unawareness, and discrimination-free insurance prices coincide in this example and they are given by
(13)
(13) Therefore, in this example, we do not have proxy discrimination and the best-estimate price is itself discrimination-free, see second item of Remarks 2.9.
In Figure (lhs) we give an explicit example for model (Equation11(11)
(11) ). This plot shows the conditional Gaussian densities of X, given
; we select
, age gap
(providing
), and
. We can easily calculate the conditional probability of D = 0 (being woman), given age X,
(14)
(14) Figure (middle) shows these conditional probabilities as a function of the age variable X = x. For small X we have likely a woman, D = 0, and for large X a man, D = 1. Figure (rhs) shows the Gaussian densities of the claims Y at the given age X = 40 and for both genders D = 0, 1. The vertical dotted line shows the resulting means (Equation13
(13)
(13) ). These means coincide for both genders D = 0, 1, and the protected attribute D only influences the width of the Gaussian densities, see (Equation12
(12)
(12) ).
We give some general remarks on Example 2.12.
Figure 1. (lhs) Conditional Gaussian densities for
; (middle) conditional probability
as a function of
; (rhs) densities of claims Y for age X = 40 and genders D = 0, 1.
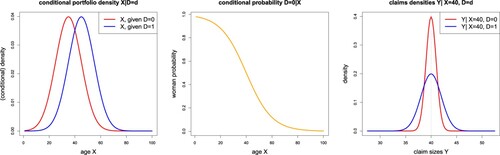
Remarks 2.13
A crucial feature of Example 2.12 is that the non-protected covariates
A situation where protected attributes
We now present a variation of the previous example, where the dependence of leads to proxy discrimination, which requires correction in the sense of Equation (Equation9
(9)
(9) ).
Example 2.14
Proxy discrimination and DFIP
We again assume two-dimensional covariates having the same mixture Gaussian distribution as in (Equation11
(11)
(11) ). For the response variable Y we now assume that conditionally, given
,
(15)
(15) For Y representing health claims, the interpretation of this model is that female policyholders (D = 0) between ages 20 and 40 generate higher costs due to a potential pregnancy,Footnote1 and male policyholders generally have lower costs.
The resulting best-estimate prices, illustrated in Figure by the red and blue dotted lines, are given by
Hence, the above best-estimate prices have a sensitivity in
and
, and Proposition 2.6 directly tells us that the corresponding unawareness prices are subject to proxy discrimination. Another crucial difference of these best-estimate prices compared to the ones in Example 2.12 is that we do not have monotonicity in
for women, e.g. there is not a unique age x that leads to the best-estimate price
. This feature will become important later, when in Example 3.6 we apply output Optimal Transport methods to the same model.
We calculate the unawareness price
where we have used (Equation14
(14)
(14) ). This unawareness price is illustrated in orange colour in Figure . Not surprisingly, it closely follows the best-estimate prices for woman policyholders for small ages and men for large ages, because we can infer the gender D from the age X quite well, see Figure (middle). Thus, except in the age range from 20 to 60, we almost charge the best-estimate price to the corresponding genders, except to a few ‘mis-allocated’ men at small ages and women at high ages. This is precisely proxy discrimination and, in our understanding, consistent with what is described in paragraph 5 of Section 2 of Maliszewska-Nienartowicz (Citation2014), and can be interpreted as generating a disproportionate impact on (woman) policyholders.
Figure 2. Best-estimate, unawareness and discrimination-free insurance prices in Example 2.14.
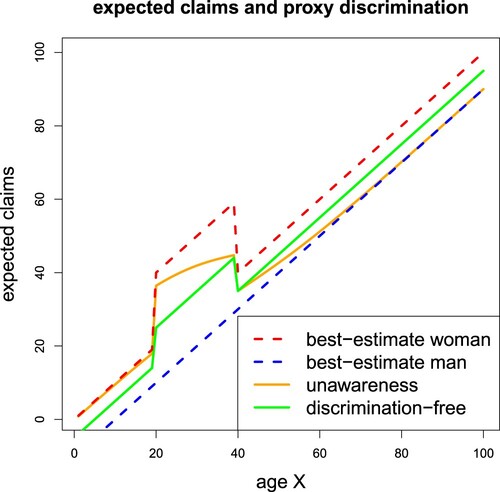
Subsequently, the DFIP, using the choice , is shown in green colour in Figure and reads as
The price
exactly interpolates between the two best-estimate prices for women and men. As a result we have a cost reallocation between different ages which leads to a loss of predictive power and to cross-financing of claim costs within the portfolio.
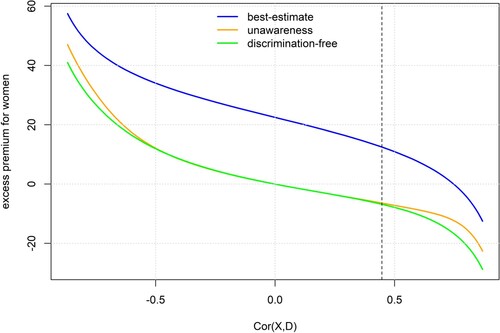
We now turn our attention to the differential outcomes for each gender, under each of the pricing mechanisms considered. Specifically, we calculate the ‘excess premium’ for women, as the difference of the average price for women (prices conditional on D = 0, minus the average price for men (prices conditional on D = 1). Furthermore, we consider how this excess premium varies in the correlation , which we can control via the model parameter δ (age gap) and plot the results in Figure . We observe that, as correlation increases, there is a sharper distinction between older male and younger female policyholders, which, given the effect of age on claims, reduces the excess premium for women. Furthermore, as expected, the excess premium is reduced by switching from best-estimate (blue) to either unawareness prices (green) or DFIP (orange). Furthermore, for all correlation values, the excess premium for the unawareness price dominates that for the DFIP, since the proxying of gender by age (more pronounced for correlation close to
), increases prices for women. However, this does not mean that using the DFIP produces more equal outcomes for each gender. Specifically, for high correlation values we see that the excess premium for
is the highest in absolute value.
Figure 3. Average excess premium for women D = 0 compared to men D = 1, in Example 2.14, as a function of . The dashed vertical line corresponds to the baseline scenario of
,
.
Finally, it is also of interest to establish how the different pricing functionals we consider perform as predictors of Y. Let Π be a random variable, representing the statistical behaviour under of insurance prices derived by a given pricing functional. For example, if
is the unawareness price,
. Then, the performance of the price Π as a predictor of Y can be measured by the mean squared error (MSE), given by
. We also consider a potential bias by providing the average prediction
of the prices, over the portfolio distribution. We calculate the resulting MSEs using Monte Carlo simulation with a pseudo-random sample of size 1 million. The results in Table show the negative impact of deviating from the optimal predictors, based on
and
, respectively. This is the price we pay for avoiding proxy discrimination with respect to the protected attributes
. Our pricing measure choice
produces a bias as can be seem from the last column of Table .
2.3. Group fairness axioms
As discussed in Section 2.1, the property of avoiding proxy discrimination can be understood as an individual fairness property, in the sense that it requires that similar policyholders, in the sense specified by Definition 2.2, be treated similarly. This has implications on how the pricing functionals (Equation9(9)
(9) ) avoiding proxy discrimination are constructed, without exploiting the dependence structure of
and
. On the other hand, as demonstrated in Example 2.14, Figure , addressing proxy discrimination does not consider at all the statistical properties of DFIPs; for example, for
, it will generally hold that
(16)
(16) such that different demographic groups, on average, are charged different premiums.
Table 1. MSEs and average prediction of the different prices in Example 2.14.
To address concerns about the implications of using any pricing method for the outcomes for different demographic groups, we need to consider the resulting prices as random variables. As an example, the right-hand side of (Equation16(16)
(16) ) uses the random selection of an insurance policy
and its related price
, respectively, from the insurance portfolio, conditioned on selecting an insurance policy with protected attributes
. Throughout this section, we denote the prices in an insurance portfolio by the random variable Π. We may interpret
as the price for a policyholder with profile
,
. If π is a pricing functional, then we can set
, such that Π is
-measurable; note however that the definitions of the group fairness properties below do not rely on such a measurability condition on Π.
We now introduce the three most popular group fairness properties in the machine learning literature, which are essentially properties of the joint distribution of . The properties we consider here are demographic parity, equalized odds and predictive parity; we refer to Barocas et al. (Citation2019), Xin and Huang (Citation2021) and Charpentier (Citation2022). In the next section, we show that the DFIP of Example 2.12, given in Equation (Equation13
(13)
(13) ), violates all three of these group fairness axioms. These three notations of group fairness are collected next definition.
Definition 2.15
The prices Π, in the context of portfolio distribution , satisfy:
Demographic parity, if Π and
Equalized odds, if Π and
Predictive parity, if Y and
We comment on each of the three group fairness notions of Definition 2.15 below, focussing on the conditions needed for pricing mechanisms to satisfy them and whether they can be realistically expected to hold within insurance portfolios. We note that in the fairness and machine learning literature, see, e.g. (Barocas et al., Citation2019), the equalized odds and predictive parity properties are primarily used for binary responses, which is of less relevance for actuarial pricing applications.
Remarks 2.16
Demographic parity (Agarwal et al., Citation2019; also: statistical parity, independence axiom) is the simplest notion to interpret. If Π satisfies demographic parity, this directly implies
Moreover, we may have two different insurance companies with portfolio distributions
Equalized odds (Hardt et al., Citation2016; also: disparate mistreatment, separation axiom) implies that within groups of policyholders that produce the same level claims, the prices are independent of protected attributes. In general, independence between
The notion of predictive parity (Barocas et al., Citation2019; also: sufficiency axiom) can be motivated by the definition of a sufficient statistic in statistical estimation theory. We can interpret
Regardless of the actuarial relevance of the fairness notions of Definition 2.15 it is clear that rather special conditions are needed in order for all of them to hold jointly. The following proposition provides such a sufficient condition:
Proposition 2.17
Assume that the prices Π, in the context of portfolio distribution , satisfy
The prices Π then satisfies fairness notions (i)–(iii) from Definition 2.15.
The proof is given in Appendix 1.
2.4. Discrimination-free vs. fair insurance prices
In Example 2.14 and Section 2.3, we discussed how avoiding proxy discrimination and achieving outcomes across demographic groups that satisfy a group fairness criterion are rather different requirements. We now formalize this insight via the following two propositions.
Proposition 2.18
Consider the pricing functional π and the respective prices . If π avoids proxy discrimination, it is not implied that Π satisfies any of demographic parity, equalized odds or predictive parity.
Proposition 2.19
Consider the pricing functional π and the respective prices . If Π satisfies demographic parity, it is not implied that π avoids proxy discrimination.
A particular implication of Propositions 2.18 and 2.19 is that avoiding proxy discrimination is generally not a stronger requirement than avoiding group fairness notions (and vice versa). As both propositions are negative results, they can be proved by counter-examples. For Proposition 2.18 this is Example 2.12. In that example, the DFIP produces violations of all three group fairness properties considered here. The required derivations to show this are somewhat laborious and, thus, are delegated to Appendix 1. As the DFIP in that example is identical to the unawareness price, one cannot claim that these violations are specific to the construction of . The crucial feature of Example 2.12 is that the non-protected covariates
are sufficient for describing the conditional expectation of the response Y, but they are not sufficient to describe the full conditional distribution of Y, given
.
To prove Proposition 2.19, a suitable counter-example is given in Example 2.20, below; here we provide a situation where the unawareness price does not materially avoid proxy discrimination, while at the same time it satisfies demographic parity. Furthermore, in an additional Example 2.21, below, we offer a situation which produces prices that satisfy all of demographic parity, equalized odds and predictive parity, but which directly discriminate, in the sense that they are explicit functions of protected attributes . Of course, if such direct discrimination takes place, one cannot meaningfully say that proxy discrimination is avoided.
Remark that in the following examples, we consider a real-valued Gaussian distributed protected attribute . This is in contrast to assuming that
is finite, see Section 2.1. The reason for this different choice is a computational one because in a multivariate Gaussian setting all quantities of interest can be calculated explicitly. In the examples the protected attribute
and the non-protected covariates will be positively correlated, which allows inferring one from the other.
Example 2.20
Demographically fair prices that produce proxy discrimination
We choose three-dimensional Gaussian covariates
(20)
(20) For the response variable we assume
This gives us the best-estimate price
(21)
(21) A standard result on multivariate Gaussian random variables tells us, see, e.g. Corollary 4.4 in Wüthrich and Merz (Citation2015),
This allows us to calculate the unawareness price by
(22)
(22) which is different to the DFIP,
. We know that the unawareness price in general does not avoid proxy discrimination. Since the best-estimate price has a sensitivity in D and because there is dependence between
and D, proxy discrimination is material; recall Proposition 2.6. In fact, not considering non-protected covariates
leads to a prediction of the protected attribute D of
. Since
and D are positively correlated, we can (partly) infer D from
by using the (informed) prediction
, e.g. if both
and
take positive values, we get a positive predicted value for D, given
.
The random vector is two-dimensional Gaussian with independent components because
This implies that the unawareness price
is independent of D, hence, it satisfies demographic parity. This also proves Proposition 2.19.
We now give an example that satisfies all three group fairness criteria of demographic parity, equalized odds and predictive parity, but at the same time directly discriminates.
Example 2.21
Group fair prices that directly discriminate
Assume the non-protected covariates and the protected attribute
are real-valued. We choose a three-dimensional Gaussian distribution
with fixed covariance parameter
. The best-estimate is given by
(23)
(23) this uses again Corollary 4.4 of Wüthrich and Merz (Citation2015). This best-estimate price directly discriminates because it uses D as an input. We now show that
satisfies all three notions of group fairness. For this, we derive the joint distribution of
. Note that
Hence,
This shows that
and D are independent, which is precisely the sufficient condition presented in Proposition 2.17. As a result, all three group fairness axioms above are fulfilled for the best-estimate price
. On the other hand, this best-estimate directly discriminates as can be seen from (Equation23
(23)
(23) ).
We now give some additional remarks on Propositions 2.18 and 2.19 and Example 2.21.
Remarks 2.22
Propositions 2.18 and 2.19 indicate that avoiding proxy discrimination and satisfying group fairness are rather different concepts, and, in general, one does not imply the other. For this reason, satisfying simultaneously both is more restrictive than just complying with one of them – and sometimes even impossible if one wants to have a non-trivial predictor. Currently, many regulators focus on proxy discrimination, though corresponding legislation leaves room for interpretation. Therefore, constraining pricing models with group fairness criteria does not seem to solve this particular regulatory problem.
Proxy discrimination is caused by two factors that need to hold simultaneously, namely, (1) there needs to be a dependence between the non-protected covariates
Focusing on the example of demographic parity fairness, this notion solely relates to the independence of the resulting prices Π and protected attributes
If we wanted all participants in an insurance market to comply with demographic parity, we would need to choose projections
A crucial feature of Example 2.20 is that independence between
Examples 2.20 and 2.21 use multivariate Gaussian distributions, since these make all relevant calculations straightforward. This is not a limitation, as similar examples can be constructed with discrete protected attributes
3. Achieving demographic parity by optimal transport methods
3.1. Rationale
In Section 2, we formalized our view of direct and proxy discrimination, and we discussed pricing functionals that avoid them. Furthermore, we established that group fairness concepts are not generally consistent with the requirement of avoiding direct and proxy discrimination; essentially they provide answers to different problems. Next, we focus on methods to create pricing functionals that satisfy group fairness and discuss their implications for both direct and proxy discrimination.
In this section, we will specifically focus on demographic parity as a group fairness concept. The reason for this is three-fold:
Let us take as a starting point the need to avoid proxy discrimination. We have noted that in the special case where
Demographic parity is a much simpler concept to explain to stakeholders, including policyholders. While no form of group fairness is mandated by regulators, insurers will remain sensitive to reputational risk, which itself derives from those violations of group fairness that are most easily monitored; see, e.g. the Citizens Advice report (Cook et al., Citation2022). We do not envisage that insurance companies will or indeed should aim to satisfy demographic parity and, in fact, we argue against this in the sequel. But companies may be motivated to monitor demographic disparities and in some cases partially smooth out these effects, e.g. using the methods of Grari et al. (Citation2022).
As argued in Remarks 2.16, demographic parity may sometimes be achieved by a careful selection of the policyholders in the portfolio (aiming to have
In the rest of this Section, we will use the theory of optimal transport (OT) for input pre-processing and output post-processing, see (Chiappa et al., Citation2020; del Barrio et al., Citation2019), with the aim of achieving demographic parity. By using these techniques it will also be possible to relate the price deformations needed in order to achieve demographic parity to the construction of DFIPs. For both types of OT, independence of prices from protected attributes is achieved by a -dependent transformation of the non-protected covariates
. An important difference between input pre-processing and model post-processing is that the former transforms the inputs
, and retains the dimension of the original non-protected covariates
. In fact, up to technical conditions (continuity), the OT input transformation
is one-to-one (for given
) which allows us to reconstruct the original features
from the pre-processed ones
. Model post-processing, using an OT map, transforms the (one-dimensional) regression output
, by making
independent of the protected attributes
. We have already seen in Example 2.21 a situation where the best-estimate price
is independent of
, hence satisfies demographic parity. In that example the best-estimate price can be identified with
and the OT output map is the identity map.
3.2. Input (data) pre-processing
A sufficient way to make an insurance price satisfy demographic parity is to pre-process the non-protected covariates such that the transformed version
becomes independent of the protected attributes
under
. First, we emphasize that this pre-processing is only performed on the input data
(and using
), but it does not consider the response Y. Second, independence between
and
is a sufficient condition for satisfying demographic parity with respect to
, but not a necessary one, see Example 2.20.
One method of input pre-processing is to apply an OT map to obtain a covariate distribution that is independent of the protected attributes; for references see (Chiappa et al., Citation2020; del Barrio et al., Citation2019). More specifically, for given , we change the conditional distribution
(24)
(24) to an unconditional distribution
for the non-protected covariates
(25)
(25) meaning that the transformed covariates
are independent of
. Intuitively, to minimally change the predictive power by this transformation from (Equation24
(24)
(24) ) to (Equation25
(25)
(25) ), the unconditional distribution
should be as similar as possible to the conditional ones
, for all
; we come back to this in Remark 3.4, below. In this approach, the covariates
and
preserve their meanings because they live on the same covariate space, but the OT map locally perturbs the original covariate values
, based on
.
We revisit Examples 2.12 and 2.14 illustrated in Figure , and we give two different proposals for in Figure . The plot on the left hand side shows the average density
of the two Gaussian densities
, given
, i.e. we have a Gaussian mixture for
on the left hand side of Figure . The plot on the right hand side shows the Gaussian density for
, that averages the means
and
; we also refer to (Equation31
(31)
(31) )–(Equation32
(32)
(32) ), below. For the moment, it is unclear which of the two choices for
gives a better predictive model for Y; we also refer to Remark 3.4, below.
Assume we have selected an unconditional distribution to approximate
,
, and we would like to optimally transform the random variable
to its unconditional counterpart
. This is precisely where OT comes into play. Choose a distance function ϱ on the covariate space. The (2-)Wasserstein distance between
and
w.r.t. ϱ is defined by
(26)
(26) where
is the set of all joint probability measures having marginals
and
, respectively. The Wasserstein distance (Equation26
(26)
(26) ) measures the difference between the two probability distributions
and
by optimally coupling them. Colloquially speaking, this optimal coupling means that we try to find the (optimal) transformation
such that we can perform this change of distribution at a minimal effort;Footnote2 this optimal transformation
is called an OT map or a push forward. Under additional technical assumptions, determining the OT map
is equivalent to finding the optimal coupling
.
Figure 4. Example 2.14, revisited: conditional densities , for
, and two different choices for
,
; for a formal definition we refer to (Equation31
(31)
(31) )–(Equation32
(32)
(32) ).
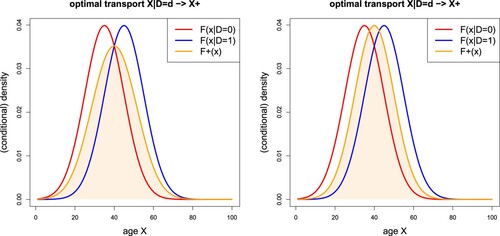
Remarks 3.1
The input OT approach can also be thought of in relation to context-sensitive covariates. For example, the European Commission (European Commission, Citation2012), footnote 1 to Article 2.2(14) – life and health underwriting – mentions the waist-to-hip ratio as a non-protected (useful) context-sensitive covariate for health prediction. Note that the waist-to-hip ratio is gender-, age- and race- dependent. Furthermore the impact of the waist-to-hip ratio on predictions of health outcomes depends specifically on factors like gender, age, and race, that is, the same value should be interpreted differently depending on the demographic group the policyholder belongs to. This means that a
Applying an OT map will modify the waist-to-hip ratio such that it has the same distribution for both genders, which can then be treated coherently as an input to a predictive model. However, this does not mean that the transformed variable will reflect health impacts in a demographic-group-appropriate way, if the OT map produces a transformation specifically with the aim of removing dependence between
In many situations the OT map
The Wasserstein distance (Equation26
In general, this OT map should be understood as a local transformation of the covariate space, so that the main structure remains preserved, but the local assignments are perturbed differently for different realizations of
Assume we have a (one-dimensional) real-valued non-protected covariate
We emphasize that (Equation28
Next, we state that the OT input pre-processed version of the non-protected covariates satisfies demographic parity and avoids proxy discrimination with respect to the transformed inputs . Also, interestingly, these notions do not touch the response Y, but it is sufficient to know the best-estimate price
. The proof of the next proposition is straightforward.
Proposition 3.2
OT input pre-processing
Consider the triplet and choose the OT maps
,
, with
being independent of
(under
). The unawareness price
avoids proxy discrimination with respect to
and satisfies demographic parity.
We emphasize that Proposition 3.2 makes a statement about the transformed input and not about the original covariates
. Hence, whether we can consider the price
to be truly discrimination-free depends on the interpretation we attach to the transformed inputs
, see the first bullet in Remarks 3.1. Moreover, Proposition 3.2 applies to any transformation
,
that makes
independent of
, and which does not add more information to
with respect to the prediction of Y; this is what we use in the last equality statement.
Now, we consider one-dimensional OT in the context of our Example 2.14. The method is similar to the (one-dimensional) proposals in Section 4.3 of Xin and Huang (Citation2021), called there ‘debiasing variables’. However, the OT approach works in any dimension, and also takes care of the dependence structure within , given
. Nevertheless, we consider a one-dimensional example for illustrative purposes.
Example 3.3
Application of input OT
We apply the OT input pre-processing to the situation of Example 2.14, which considered age- and gender-dependent costs, including excess costs for women between ages 20 and 40. Our aim is to obtain an insurance price that both satisfies demographic parity and avoids proxy discrimination (with respect to the transformed inputs). In this set-up we have a real-valued non-protected covariate , and we can directly apply the one-dimensional OT formulations (Equation27
(27)
(27) ) and (Equation28
(28)
(28) ). The conditional distributions satisfy for d = 0, 1 and for given
and
, see (Equation11
(11)
(11) ),
(30)
(30) where Φ denotes the standard Gaussian distribution. For the transformed distribution
we select the two examples of Figure ; the first one is given by
(31)
(31) and the second one by
(32)
(32) Selections (Equation31
(31)
(31) ) and (Equation32
(32)
(32) ) are two possible choices by the modeller, but any other choice for
which does not depend on D is also possible. The first choice is the average of the two conditional distributions (Equation30
(30)
(30) ), the second one is their Wasserstein barycenter; we refer to Proposition 3.8 and Remarks 3.4 and 3.9, below.
We start by calculating the Wasserstein distances (Equation27(27)
(27) ) using Monte Carlo simulation and a discretized approximation to
in the case of the Gaussian mixture distribution (Equation31
(31)
(31) ). The results are presented in Table . We observe that the second option (Equation32
(32)
(32) ) is closer to the conditional distributions
, d = 0, 1, in Wasserstein distance; in fact, in this second option we have
for all
, and there is no randomness involved in the calculation of the expectation in (Equation27
(27)
(27) ).
Table 2. Wasserstein distances for the two examples (Equation31
(31)
(31) )–(Equation32
(32)
(32) ) for
.
Figure shows the OT maps (Equation28(28)
(28) ) for the two choices of
given by (Equation31
(31)
(31) )–(Equation32
(32)
(32) ). We observe that in the second option we generally make women older by
years, and we generally make men younger by
years, so that the distributions
of the OT transformed ages
coincide for both genders d = 0, 1. The first option (Equation31
(31)
(31) ) leads to an age dependent transformation. If we focus on the y-axis in Figure , we can identify the ages of women and men that are assigned to the same age cohort. For instance, following the horizontal grey dotted line at level
, we find for the second option (Equation32
(32)
(32) ) that women of age 35 and men of age 45 will be in the same age cohort (and hence same price cohort). This seems a comparably large age shift which may be difficult to explain to customers. However, in real insurance portfolios we expect more similarity between women and men so that we need smaller age shifts. Additionally, this picture will be superimposed by more non-protected covariates which will require the multi-dimensional OT map framework.
Based on this OT input transformed data, we construct a regression model . In this (simple) one-dimensional problem
we simply fit a cubic spline to the data
using the locfit package in R; see (Loader et al., Citation2022).
Figure 5. OT maps for examples (Equation31
(31)
(31) )–(Equation32
(32)
(32) ) of
with the original age X on the x-axis and the transformed ages
on the y-axis; the black dotted line is the 45
diagonal.
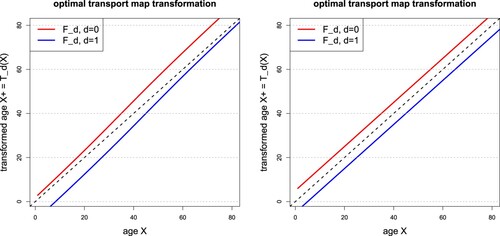
Table presents the prediction accuracy of the OT input transformed models. At first sight it is surprising that the input OT transformed model has a better predictive performance than the unawareness price model
. However, by considering the details of the true model, this is not that surprising. Women have generally higher costs than men at the same age
under model assumption (Equation15
(15)
(15) ), and considering the age shifts of the OT maps makes women and men more similar with respect to claim costs in this example. The MSE of the unawareness price
is calculated as
The first term on the right hand side is the MSE of the best-estimate predictor
based on all information
, and the second term corresponds to the loss of accuracy by using the unawareness price
. The OT maps (Equation31
(31)
(31) ) and (Equation32
(32)
(32) ) make women older and men younger, and as a result their risk profiles with respect to the transformed inputs
become more similar in this example. This precisely leads, in this case, to a smaller MSE of
over
. Namely, we have
(33)
(33) with the last term being smaller than the last one in the unawareness price case because the
-dependent transformation
makes
more similar to
compared to
. This is specific to our example which can be better understood by discussing Figure . Figure illustrates the OT input transformed model prices
for choices (Equation31
(31)
(31) )–(Equation32
(32)
(32) ) for
. For Figure we map these prices back to the original features
, separated by gender
. This back-transformation can be done because the OT maps
are one-to-one under continuous non-protected covariates
, and for given
, see Remarks 3.1. Figure then evaluates the prices
, where we consider
as a function of age
for fixed gender
. The right hand side shows choice (Equation32
(32)
(32) ) for
, which leads to parallel shifts for the transformed age assignments
, see Figure (rhs). As a consequence, the excess pregnancy costs of women with ages in
are shared with men having ages in
in our example, see orange and cyan lines in Figure (rhs). This should be contrasted to the DFIP
(green line in Figure ) which shares the excess pregnancy costs within the age class
for both genders. The transformation for choice (Equation31
(31)
(31) ) for
leads to a distortion along the age cohorts as we do not have parallel shifts, see Figures (lhs) and (lhs).
Coming back to (Equation33(33)
(33) ) and focusing on choice (Equation32
(32)
(32) ) for
, which corresponds to Figure (rhs), we observe that the age shifts of 5 years lead to OT input transformed prices
that rather perfectly match the best-estimates
. In fact, the age shifts of 5 years exactly compensate the term
in (Equation15
(15)
(15) ), and the only difference between women and men (after the age shifts) are the pregancy related costs. This explains the good MSE results of input OT in Table , but this is very model specific here, as can be verified by switching the age profiles (i.e. by setting
and
) and keeping everything else unchanged.
Figure 6. OT input transformed model prices for examples (Equation31
(31)
(31) )–(Equation32
(32)
(32) ) of
.
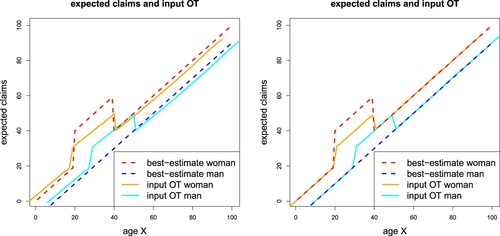
Table 3. MSEs and average prediction of the different prices in Example 2.14.
Figure shows the results of the switched age profile case, with women having a higher average age, , than men,
. This leads to the opposite behaviour for the conditional probabilities
, see Figure (lhs), and, equivalently, for the unawareness price, see Figure (middle). On the other hand, the DFIP is not affected by this change as we do not infer D from X (we do not proxy discriminate in the DFIP). Figure (rhs) shows the resulting OT input transformed prices
for example (Equation32
(32)
(32) ) of
. These OT input transformed prices now provide a worse MSE (Equation33
(33)
(33) ) compared to the unawareness price, see also Table . This also verified by Figure . Figure and Table may not be in support of using OT input transformation generally, however, we emphasize that the OT map
is selected solely based on the inputs
and not considering the response Y. As a result, we can receive a predictive model that is either better or worse than the unawareness price model. This is, however, not surprising, since input OT targets demographic parity, not predictive performance. In fact, the selection of the OT map is not even allowed to consider the response Y, otherwise it may (and will) imply a sort of indirect model selection discrimination.
The prices depicted in Figures and (rhs) satisfy demographic parity and avoid proxy discrimination with respect to , see Proposition 3.2. As discussed in Remarks 3.1, whether one considers these prices desirable in relation to direct and proxy discrimination depends on whether the transformed age
can be interpreted/justified as a valid covariate in its own right. If it is seen as just an artefact of the dependence structure of
, stakeholders may be more interested in discrimination with respect to the original covariates
. From such a perspective it is clear that the prices of Figures and (rhs) are subject to even direct discrimination, given the different dashed lines for women and for men on the original scale.
Figure 7. Changed age profiles with (women) and
(men): (lhs) conditional probability
as a function of
; (middle) best-estimate, unawareness and discrimination-free insurance prices; (rhs) OT input transformed model prices
for example (Equation32
(32)
(32) ) of
.
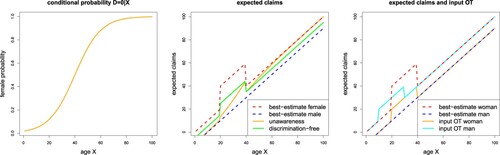
Table 4. Changed role of ages of women and men, setting and
.
An important difference between the DFIP and the OT map transformed prices
is that the latter always provide a (statistically) unbiased model, if the chosen regression class is sufficiently flexible. In fact,
may not only satisfy the balance property, but even the more restrictive auto-calibration property; see (Wüthrich & Ziegel, Citation2024).
Finally, we build a best-estimate model on the transformed information
. We do this by separately fitting two cubic splines to the women data
and the men data
, respectively. The results are presented on the last line of Table . Up to estimation error, we rediscover the true model, but on the transformed input data, as the MSE only contains the noise part (irreducible risk) of the response Y. Thus, as expected, this one-to-one OT map (in the continuous case), for given gender, does not involve a loss of information, and the predictive performance in the parametrizations
and
coincides (up to estimation error).
Remark 3.4
For OT input tranformation we need to select an unconditional distribution , see (Equation25
(25)
(25) ). In Example 3.3 we have provided two natural choices (Equation31
(31)
(31) )–(Equation32
(32)
(32) ), but we have not discussed a systematic way of choosing this unconditional distribution
. Intuitively, the OT transformed covariates
should be as close as possible to
, and at the same time they should be independent from
under
, i.e.
. This is a problem studied in Delbaen and Majumdar (Citation2023):
(34)
(34) for the
-distance function
under
. Theorems 5–7 of Delbaen and Majumdar (Citation2023) show that such a minimum can be found by solving a related problem involving the Wasserstein distance (Equation26
(26)
(26) ) with the Euclidean distance for ϱ. Unfortunately, this is still only a mathematical result and no efficient algorithm is currently known to calculate this solution in higher dimensions.
From an actuarial viewpoint, it is not fully clear whether (Equation34(34)
(34) ) solves the right problem, as this may depend on the chosen class of regression functions. e.g. if we work with GLMs then certain real-valued covariates may be considered on the original scale and others on the log-scale, which may/should impact the choice of the objective function in (Equation34
(34)
(34) ). Moreover, categorical covariates may pose further challenges in defining suitable objective functions. Concluding, the problem of selecting the OT input transformation in a systematic way is still an open problem that requires more research which goes beyond the scope of this article.
3.3. Model post-processing
Model post-processing to achieve fairness works on the outputs, and not on the inputs like data pre-processing. From a purely technical viewpoint, both methods work in a similar manner. A main difference is that input pre-processing usually is multi-dimensional and (regression) model post-processing is one-dimensional. Assume, in a first step, we have fitted a best-estimate price model . Model post-processing applies transformations to these best-estimate prices
such that the transformed price
fulfils a fairness axiom. Focusing on demographic parity, the transformed price
should be independent of
under
. Note that any of the following steps could equivalently be applied to any other pricing functional, such as the unawareness price
.
If we apply an OT output transformation, we modify (Equation24(24)
(24) ) and (Equation25
(25)
(25) ) as follows. For
, we change the conditional distributions
on
(35)
(35) to an unconditional distribution
for the prices
(36)
(36) In particular, this means that the real-valued random variable
is independent of
. Based on these choices we look for OT maps
, given
, providing the corresponding distribution. Since everything is one-dimensional here, we can directly work with versions (Equation28
(28)
(28) ) and (Equation29
(29)
(29) ), respectively, depending on whether our price functionals
have continuous marginals
or not. Thus, in the continuous case we have OT maps
(37)
(37) for
. The resulting Wasserstein distance is given by (Equation27
(27)
(27) ) with
replaced by
. With this procedure, since the distribution
does not depend on
, the OT transformed price
fulfills demographic parity. The remaining question is how to choose
, this is discussed below.
Remark 3.5
is a real-valued random variable, and one should not get confused by the multi-dimensional covariate
in this expression; also the OT transformed price
is a real-valued random variable, independent of
. Often, one wants to relate this price
to the original covariates
. In the continuous case we can do this using the OT maps (Equation37
(37)
(37) ), namely, we have a measurable map
(38)
(38) Formula (Equation38
(38)
(38) ) gives the OT transformed price
of a given insurance policy with covariates
, and (Equation37
(37)
(37) ) describes the distribution of this price, if we randomly select an insurance policy from our portfolio
, for given protected attributes
.
Example 3.6
Application of output OT
We revisit Examples 2.14 and 3.3, but now, instead of input pre-processing, we apply model post-processing to the best-estimate . These best-estimates are illustrated in red and blue colour in Figure . As density
we simply choose the average of the two conditional densities
(39)
(39) Note that the distributions of
are absolutely continuous, therefore their densities
exist. Figure illustrates the density
and the resulting distribution
, respectively.
Figure 8. OT output post-processing density and distribution
.
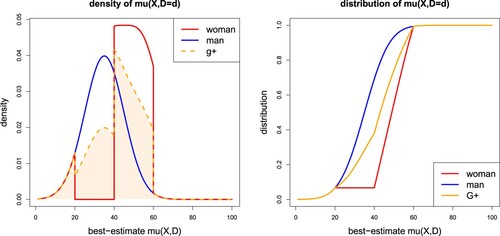
Table presents the results of the OT output post-processed best-estimate prices using density (Equation39(39)
(39) ) for
. The resulting MSE is smaller than the corresponding value of the input OT version, see Table . This is generally expected for suitable choices of
because the fairness debiasing only takes place in the last step of the (estimation) procedure, and all previous steps deriving the best-estimate price uses full information
. Input OT already performs the debiasing procedure in the first step and, therefore, all subsequent steps are generally non-optimal in terms of full information
. OT output post-processing directly acts on the best-estimate prices
. These best-estimate prices can be understood as price cohorts, and for OT output post-processing the specific (multi-dimensional) value of the non-protected covariates, say
, does not matter as long as they belong to the same price cohort
. In case of non-monotone best-estimate prices, this can lead to price distortions that are not easily explainable to customers and policymakers. In Figure (top) we express the output post-processed prices
as a function of the original age variable
, separated by gender
, we also refer to (Equation38
(38)
(38) ). We observe that for women
, the best-estimate prices
coincide (red dots in Figure , top), but the underlying risk factors for these high costs are completely different ones. Women at age 30 have high costs because of pregnancy, and women at age 50 have high costs because of aging (women at age 50 are assumed to not be able to get pregnant). Using OT output post-processing, these two age classes (being in the same price cohort) are treated completely equally and obtain the same fairness debiasing discount (orange dot in Figure , top). But this discount for women at age 50 cannot be justified if we believe that fairness (or anti-discrimination) should compensate for the excess pregnancy costs which only applies to women but not to men between ages 20 and 40. In fact, this is precisely how the excess pregnancy costs are treated in the DFIP
, see green line in Figure (bottom-rhs), and in the OT input pre-processing price
, see Figure (bottom-lhs); the plots at the bottom of Figure are repeated from Examples 2.14 and 3.3 for ease of comparison.
Remark 3.7
From Example 3.6, we conclude that output post-processing should be used with great care. The price functional typically leads to a large loss of information (this can be interpreted as a projection), and insurance policies with completely different risk factors may be assigned to the same price cohort by this projection. Therefore, it is questionable if model post-processing should treat different covariate cohorts
with equal best-estimate prices equally (which precisely happens in OT output post-processing) or whether we should look for another way of correcting. Of course, one may similarly object to the case of input OT, particularly that excess pregnancy costs of women at age 20-40 are shared specifically with men of age 30–50. Nonetheless, at least, the results of input OT, Figure (bottom-lhs), are easier to interpret compared to Figure (top). Note though that when policyholder features
are highly granular, it becomes difficult to assign policies into homogeneous groups. In such circumstances we may find that the new rating classes induced by input OT are also hard to interpret.
Figure 9. (Top) OT output post-processed prices expressed in their original features
and separated by gender
, see (Equation38
(38)
(38) ); (bottom-lhs) OT input pre-processing taken from Figure ; (bottom-rhs) unawareness price and DFIP taken from Figure .
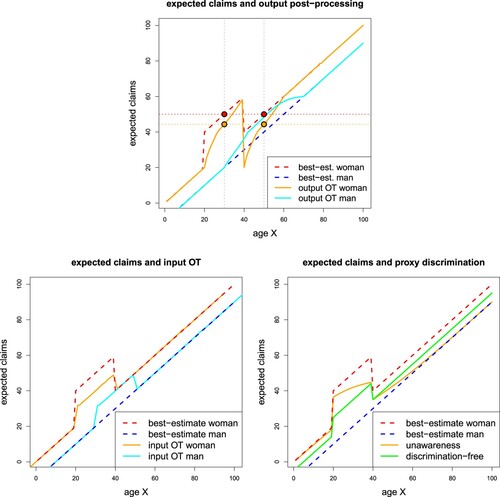
Table 5. MSEs and average prediction of the different prices in Example 2.14.
If, despite the last criticism, we would like to hold on to OT model post-processing, we may ask the question about the optimal OT transform in (Equation37(37)
(37) ) and (Equation36
(36)
(36) ), respectively, to receive maximal predictive power of
for Y. This is the same question as discussed in Remark 3.4 for OT input pre-processing. The question of optimal maps for input OT pre-processing could not be generally answered because of potential high-dimensionality, non-linearity and computational complexity, see Remark 3.4. However, for optimal (one-dimensional) model post-processing with OT we can rely on (simpler) analytical results in one-dimensional OT. In particular, Theorem 2.3 of Chzhen et al. (Citation2020) states the following.
Proposition 3.8
Assume are absolutely continuous for all
. Consider
(40)
(40) Then,
is the
-measurable and demographic parity fair predictor of Y that has minimal MSE.
Remarks 3.9
The big round brackets in (Equation40
In (Equation40
4. Conclusions and discussion
We have shown that direct and proxy discrimination and group fairness are materially different concepts. We can have discrimination-free insurance prices that do not satisfy any of the group fairness axioms, and, vice versa, we can have, e.g. prices that satisfy demographic parity but are subject to material proxy discrimination and even direct discrimination. In particular, in Example 2.21 we gave an example of a price that satisfies demographic parity, equalized odds and predictive parity, but directly discriminates from an insurance regulation view. This clearly questions the direct application of group fairness axioms to insurance pricing, as they do not provide a quick fix for (and may even conflict with) mitigating direct and proxy discrimination.
In a next step, we presented OT input pre-processing and OT output post-processing. These methods can be used to make distributions of non-protected characteristics independent of protected attributes. Input pre-processing locally perturbs the non-protected covariates such that the resulting conditional distributions become independent of the protected attributes
. If we only work with these transformed covariates, we receive prices that satisfy demographic parity and avoid proxy discrimination; however note that there will generally be direct discrimination with respect to the original covariates, as depicted in Figure . Output post-processing is different as it acts on the real-valued best-estimates
, which should be seen as a summary statistic for pricing that already suffers from a loss of information, i.e. we can no longer fully distinguish the underlying risk factors that lead to these best-estimate prices. This may make output post-processing problematic because we may receive a fairness debiasing that cannot be explained to customers and policymakers.
The following table compares the crucial differences between discrimination-free insurance pricing and group fairness through OT input pre-processing.
Table
We list further points that require a careful consideration in any attempt to regulate insurance prices with reference to non-discrimination and group fairness concepts:
One difficulty in this field is that there are many different terms that do not have precise (mathematical) definitions or, even worse, their definitions contradict. Therefore, it would be beneficial to have a unified framework and consistent definitions, e.g. for terms such as disparate effect, disparate impact, disproportionate impact, etc.; see, e.g. (Chibanda, Citation2021). Some of these terms are already occupied in a legal context. We hope that our formalization of proxy discrimination in Section 2 and its disentanglement from notions of group fairness is a step in that direction.
Adverse selection and unwanted economic consequences of non-discriminatory pricing should be explored; see, e.g. (Shimao, Citation2022). The DFIP typically fails to fulfil the auto-calibration property which is crucial for having accurate prices on homogeneous risk classes. However, the OT input pre-processed data allows for auto-calibrated regression models, for auto-calibration see (Wüthrich & Merz, Citation2023).
All considerations above have been based on the assumption that we know the true model. Clearly, in statistical modelling, there is model uncertainty which may impact different protected classes differently because, e.g. they are represented differently in historical data (statistical and historical biases). There are several examples of this type in the machine learning literature; see, e.g. (Barocas et al., Citation2019; Mehrabi et al., Citation2019; Pessach & Erez Shmueli, Citation2022).
Our considerations so far presented a black-and-white picture of direct and proxy discrimination or group unfairness either taking place or not. Nonetheless, especially in the context of a possible regulatory intervention, it is important to quantify the materiality of those potential problems within a given insurance portfolio. Such an approach requires the use of discrimination and unfairness metrics, pointing more towards formalizing notions like disproportional and disparate impacts, respectively.
We have been speaking about (non-)discrimination of insurance prices. These insurance prices are actuarial or statistical prices (technical premium), i.e. they directly result as an output from a statistical procedure. These prices are then modified to commercial prices, e.g. administrative costs are added, etc. An interesting issue is raised in Thomas (Citation2012) and Thomas (Citation2022), namely, by converting actuarial prices into commercial prices one often distorts these prices with elasticity considerations, i.e. insurance companies charge higher prices to customers who are (implicitly) willing to pay more. This happens, e.g. with new business and contract renewals that are often priced differently, though the corresponding customers may have exactly the same risk profile – a situation that can also be understood as unfair, see FCA (Financial Conduct Authority, Citation2021), and which is also known as price walking, see EIOPA (EIOPA, Citation2023). In the light of discrimination and fairness one should clearly question such practice of elasticity pricing as this leads to discrimination that cannot be explained by risk profiles (no matter whether we consider protected or non-protected information).
Given all the above arguments, in general we maintain that demographic fairness is not a reasonable requirement for insurance portfolios. Nonetheless a word of caution is needed. Consider the use of individualized data (e.g. wearables, telematics) for accurate quantification of the risk of insurance policies. Using such data may diminish the contribution of protected attributes to predictions, effectively leading to a lack of sensitivity of best-estimate prices in
Acknowledgments
The authors thank the Editor and two anonymous reviewers for constructive comments that substantially improved the paper. We also thank Benjamin Avanzi, Arthur Charpentier, Freddy Delbaen, Christian Furrer, Munir Hiabu, Fei Huang, Gabriele Visentin, and Ruodu Wang for stimulating conversations. An earlier shorter version of this manuscript by the same authors, with the title ‘A discussion of discrimination and fairness in insurance pricing’, is available on SSRN, manuscript ID 4207310.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes
1 For simplicity of this exposition, we conflate biological sex and gender such that by ‘woman’/‘female’ we identify policyholders who can potentially be pregnant.
2 The common explanation relates a probability distribution to a pile of soil: a (minimal) effort can then be understood by transforming this pile of soil of a certain shape into a pile of soil of a given different shape.
References
- Agarwal, A., Dudik, M., & Wu, Z. S. (2019). Fair regression: Quantitative definitions and reduction-based algorithms. arXiv: 1905.12843.
- Araiza Iturria, C. A., Hardy, M., & Marriott, P. (2022). A discrimination-free premium under a causal framework (SSRN Manuscript ID 4079068).
- Avraham, R., Logue, K. D., & Schwarcz, D. B. (2014). Understanding insurance anti-discrimination laws. Southern California Law Review, 87(2), 195–274.
- Awasthi, P., Cortes, C., Mansour, Y., & Mohri, M. (2020). Beyond individual and group fairness. arXiv: 2008.09490.
- Barocas, S., Hardt, M., & Narayanan, A. (2019). Fairness and machine learning: Limitations and opportunities. https://fairmlbook.org/
- Binns, R. (2020). On the apparent conflict between individual and group fairness. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency (pp. 514–524). Association for Computing Machinery.
- Buolamwini, J., & Gebru, T. (2018). Gender shades: Intersectional accuracy disparities in commercial gender classification. In Conference on Fairness, Accountability and Transparency. Proceedings of Machine Learning Research (Vol. 81, pp. 77–91). PMLR.
- Charpentier, A. (2022). Insurance: Discrimination, biases & fairness. In Institut Louis Bachelier, Opinions & Débates, No25, July 2022.
- Charpentier, A., Hu, F., & Ratz, P. (2023). Mitigating discrimination in insurance with Wasserstein barycenters. arXiv: 2306.12912.
- Chiappa, S., Jiang, R., Stepleton, T., Pacchiano, A., Jiang, H., & Aslanides, J. (2020). A general approach to fairness with optimal transport. In Proceedings of the 34th AAAI Conference on Artificial Intelligence (Vol. 34, No. 04). AAAI-20 Technical Tracks 4 .
- Chibanda, K. F. (2021). Defining discrimination in insurance. In CAS research papers: A special series on race and insurance pricing. https://www.casact.org/publications-research/research/research-paper-series-race-and-insurance-pricing
- Chzhen, E., Denis, C., Hebiri, M., Oneto, L., & Pontil, M. (2020). Fair regression with Wasserstein barycenters. Advances in Neural Information Processing Systems, 33, 7321–7331.
- Cook, T., Greenall, A., & Sheehy, E. (2022). Discriminatory pricing: Exploring the ‘ethnicity penalty’ in the insurance market. Citizens Advice. https://www.citizensadvice.org.uk/Global/CitizensAdvice/Consumer%20publications/Report%20cover/Citizens%20Advice%20-%20Discriminatory%20Pricing%20report%20(4).pdf
- Cuturi, M., & Doucet, A. (2014). Fast computation of Wasserstein barycenters. In Proceedings of the 31st International Conference on Machine Learning. PMLR.
- Delbaen, F., & Majumdar, C. (2023). Approximation with independent random variables. Frontiers of Mathematical Finance, 2/2, 141–149. https://doi.org/10.3934/fmf.2023011
- del Barrio, E., Gamboa, F., Grodaliza, P., & Loubes, J.-P. (2019). Obtaining fairness using optimal transport theory. In Proceedings of the 36st International Conference on Machine Learning, Long Beach, California. Proceedings of Machine Learning Research (Vol. 97, pp. 2357–2365). PMLR.
- Djehiche, B., & Löfdahl, B. (2016). Nonlinear reserving in life insurance: Aggregation and mean-field approximation. Insurance: Mathematics & Economics, 69, 1–13.
- Dwork, C., Hardt, M., Pitassi, T., Reingold, O., & Zemel, R. (2012). Fairness through awareness. In Proceedings of the 3rd Innovations in Theoretical Computer Science Conference (pp. 214–226). Association for Computing Machinery.
- EIOPA (2021). Artificial intelligence governance principles: Towards ethical and trustworthy artificial intelligence in the European insurance sector (A report from EIOPA's Consultative Expert Group on Digital Ethics in Insurance).
- EIOPA (2023). EIOPA supervisory statement takes aim at unfair ‘price walking’ practices. March 16, 2023. https://www.eiopa.europa.eu/eiopa-supervisory-statement-takes-aim-unfair-price-walking-practices-2023-03-16_en
- European Commission (2012). Guidelines on the application of COUNCIL DIRECTIVE 2004/113/EC to insurance, in the light of the judgment of the Court of Justice of the European Union in Case C-236/09 (Test-Achats). Official Journal of the European Union (Vol. C11, pp. 1–11).
- European Council (2004). COUNCIL DIRECTIVE 2004/113/EC – implementing the principle of equal treatment between men and women in the access to and supply of goods and services. Official Journal of the European Union (Vol. L 373, pp. 37–43).
- Financial Conduct Authority (2021). General insurance pricing practices market study: Feedback to CP20/19 and final rules (Policy Statement PS21/5).
- Frees, E. W. J., & Huang, F. (2022). The discriminating (pricing) actuary. North American Actuarial Journal, 27(1), 2–24. https://doi.org/10.1080/10920277.2021.1951296
- Friedler, S., Scheidegger, C., & Venkatasubramanian, S. (2016). On the (im)possibility of fairness. arXiv: 1609.07236.
- Grari, V., Charpentier, A., Lamprier, S., & Detyniecki, M. (2022). A fair pricing model via adversarial learning. arXiv: 2202.12008v2.
- Hardt, M., Price, E., & Srebro, N. (2016). Equality of opportunity in supervised learning. In Advances in neural information processing systems (pp. 3315–3323). Curran Associates.
- Hedden, B. (2021). On statistical criteria of algorithmic fairness. Philosophy & Public Affairs, 49(2), 209–231. https://doi.org/10.1111/papa.v49.2
- Kilbertus, N., Rojas Carulla, M., Parascandolo, G., Hardt, M., Janzing, D., & Schölkopf, B. (2017). Avoiding discrimination through causal reasoning. In Proceedings of the International Conference on Advances in Neural Information Processing Systems (pp. 656–666). Curran Associates.
- Kleinberg, J., Mullainathan, S., & Raghavan, M. (2016). Inherent trade-offs in the fair determination of risk scores. arXiv: 1609.05807.
- Kusner, M. J., Loftus, J., Russell, C., & Silva, R. (2017). Counterfactual fairness. In Advances in neural information processing systems (pp. 4066–4076). Curran Associates.
- Lahoti, P., Gummadi, K. P., & Weikum, G. (2019). iFair: Learning individually fair data representations for algorithmic decision making. In IEEE 35th International Conference on Data Engineering (pp. 1334–1345).
- Lindholm, M., Richman, R., Tsanakas, A., & Wüthrich, M. V. (2022). Discrimination-free insurance pricing. ASTIN Bulletin, 52(2), 55–89. https://doi.org/10.1017/asb.2021.23
- Lindholm, M., Richman, R., Tsanakas, A., & Wüthrich, M. V. (2023). A multi-task network approach for calculating discrimination-free insurance prices. European Actuarial Journal. https://doi.org/10.1007/s13385-023-00367-z
- Loader, C., Sun, J., & Liaw, A., & Lucent Technologies (2022). locfit: Local regression, likelihood and density estimation. https://cran.r-project.org/web/packages/locfit/index.html
- Maliszewska-Nienartowicz, J. (2014). Direct and indirect discrimination in European union law – how to draw a dividing line?. International Journal of Social Sciences, III(1), 41–55.
- Mehrabi, N., Morstatter, F., Sexana, N., Lerman, K., & Galstyan, A. (2019). A survey on bias and fairness in machine learning. arXiv: 1908.09635v3.
- Pearl, J. (2009). Causality: Models, reasoning, and inference (2nd ed.).Cambridge University Press.
- Pessach, D., & Erez Shmueli, E. (2022). A review on fairness in machine learning. ACM Computing Survey, 55(3), Article 51. https://doi.org/10.1145/3494672
- Prince, A. E. R., & Schwarcz, D. (2020). Proxy discrimination in the age of artificial intelligence and big data. Iowa Law Review, 105(3), 1257–1318.
- Qureshi, B., Kamiran, F., Karim, A., & Ruggieri, S. (2016). Causal discrimination discovery through propensity score analysis. arXiv: 1608.03735.
- Ravfogel, S., Elazar, Y., Gonen, H., Twiton, M., & Goldberg, Y. (2020). Null it out: Guarding protected attributes by iterative nullspace projection. arXiv: 2004.07667.
- Ravfogel, S., Twinton, M., Goldberg, Y., & Cotterell, R. (2022). Linear adversarial concept erasure. arXiv: 2201.12091.
- Shimao, H., & Huang, F. (2022). Welfare cost of fair prediction and pricing in insurance market (SSRN Manuscript ID 4225159).
- Thomas, R. G. (2012). Non-risk price discrimination in insurance: Market outcomes and public policy. Geneva Papers on Risk and Insurance – Issues and Practice, 37, 27–46. https://doi.org/10.1057/gpp.2011.32
- Thomas, R. G. (2022). Discussion on ‘The discriminating (pricing) actuary’, by E. W. J. Frees and F. Huang. North American Actuarial Journal, in press.
- Tschantz, M. C. (2022). What is proxy discrimination? In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency (pp. 1993–2003). Association for Computing Machinery.
- Vallance, C. (2021). Legal action over alleged Uber facial verification bias. BBC News. Retrieved April 28, 2023, from https://www.bbc.co.uk/news/technology-58831373.
- Wüthrich, M. V., & Merz, M. (2015). Stochastic claims reserving manual: Advances in dynamic modeling (SSRN Manuscript ID 264905).
- Wüthrich, M. V., & Merz, M. (2023). Statistical foundations of actuarial learning and its applications. Springer. https://doi.org/10.1007/978-3-031-12409-9
- Wüthrich, M. V., & Ziegel, J. (2024). Isotonic recalibration under a low signal-to-noise ratio. Scandinavian Actuarial Journal, in press.
- Xin, X., & Huang, F. (2021). Anti-discrimination insurance pricing: Regulations, fairness criteria, and models (SSRN Manuscript ID 3850420).
- Zemel, R., Wu, Y., Swersky, K., Pitassi, T., & Dwork, C. (2013). Learning fair representations. In Proceedings of the 30th International Conference on Machine Learning, PMLR (Vol. 28, No. 3, pp. 325–333). PMLR.
Appendices
Appendix 1.
Mathematical proofs
We prove the mathematical results in this appendix.
Proof of Proposition 2.18.
We start with demographic parity (the independence axiom). Since the conditional distribution of , given
, explicitly depends on the realization of the protected attribute D = d (we have a mixture Gaussian distribution for X), the independence axiom fails to hold, see also (Equation14
(14)
(14) ).
Sufficiency (Equation19(19)
(19) ) of
implies that
(A1)
(A1)
We calculate the right hand side of (EquationA1
(A1)
(A1) )
where we have used (Equation14
(14)
(14) ). Next, we calculate the left hand side of (EquationA1
(A1)
(A1) )
Thus, these two conditional variances have a disjoint range, a.s., and we cannot have sufficiency of
.
Finally, there remains to prove the failure of the separation axiom. We aim at proving
(A2)
(A2) for
. We start by analysing the left hand side of (EquationA2
(A2)
(A2) ). We have
The joint density of
is given by
This gives for the conditional density of X, given
,
This is a Gaussian density, and we have
This implies for
, for simplicity we set d = 0 but the same arguments hold for d = 1,
On the other hand,
The latter inequality holds because by assumption
and
for all
. This proves (EquationA2
(A2)
(A2) ) and that the separation axiom does not hold.
Proof of Proposition 2.10.
We can rewrite the DFIP as follows
where we have defined the distribution (this breaks the dependence between
and
)
Classical square loss minimization then provides us with
This completes the proof.
Proof of Proposition 2.17.
In the statement of the proposition it is assumed that
(A3)
(A3) holds, and by marginalizing w.r.t. Y this directly gives us that (i) from Definition 2.15 holds, i.e.
. Analogously, by instead marginalising w.r.t. Π yields that
.
Item (ii) of Definition 2.15 holds follows from
The proof of (iii) of Definition 2.15 follows by repeating the steps used in the proof of part (ii) when switching the positions of Y and Π and replacing the application of
with
.
This completes the proof.
Appendix 2.
Non-Gaussian example
The counter-examples used to prove Propositions 2.18 and 2.19 are based on multivariate Gaussian distributions. If we limit the focus to demographic parity and avoiding proxy discrimination, it is easy to construct analogous non-Gaussian counter-examples.
Concerning Example 2.12, you can just remove the Gaussian assumption and keep everything else, and the claim follows.
Example A.1
Non-Gaussian version of Example 2.20
Let and assume that
, but that
. Assume in addition that
where a is a constant. Further, assume that
and that
where
, independent of
. That is, D can be thought of as a noisy version of
, and it holds that
Hence, if
it follows that
and
satisfies demographic parity, i.e. (i) from Definition 2.15 holds.
On the other hand, by the above construction it is clear that
Hence the unawareness price
satisfies demographic parity, while being materially different to the DFIP
.