
ABSTRACT
Diversity of vocabulary knowledge and quantity of language exposure prior to literacy are key predictors of reading development. However, diversity and quantity of exposure are difficult to distinguish in behavioural studies, and so the causal relations with literacy are not well known. We tested these relations by training a connectionist triangle model of reading that learned to map between semantic; phonological; and, later, orthographic forms of words. The model first learned to map between phonology and semantics, where we manipulated the quantity and diversity of this preliterate language experience. Then the model learned to read. Both diversity and quantity of exposure had unique effects on reading performance, with larger effects for written word comprehension than for reading fluency. The results further showed that quantity of preliteracy language exposure was beneficial only when this was to a varied vocabulary and could be an impediment when exposed to a limited vocabulary.
Introduction
Acquisition of reading skills is time-consuming, is effortful, and exhibits vast variation in children’s ability to learn (Seidenberg, Citation2017). Determining the factors that contribute to this variation is critically important before effective interventions can be established. Although socioeconomic status of children (Locke, Ginsborg, & Peers, Citation2002) and teacher knowledge (Cunningham, Perry, Stanovich, & Stanovich, Citation2004; Cunningham, Zibulsky, & Callahan, Citation2009) contribute substantially to literacy outcomes, there is now abundant evidence that children’s oral language skills are also key predictors of literacy development (Curtis, Citation1980; Lee, Citation2011; Muter, Hulme, Snowling, & Stevenson, Citation2004; Nation & Snowling, Citation1998, Citation2004; Ouellette, Citation2006; Ouellette & Beers, Citation2010; Ricketts, Nation, & Bishop, Citation2007; Snow, Burns, & Griffin, Citation1998).
According to the Simple View of Reading (SVR; Gough & Tunmer, Citation1986), reading comprehension skills are a combination of word recognition, reflected in reading fluency (Adlof, Catts, & Little, Citation2006), and oral language abilities. A series of longitudinal studies have demonstrated the dependencies between these skills. The relative contribution of word recognition and oral language on reading comprehension varies with literacy development (Adlof et al., Citation2006; Foorman, Herrera, Petscher, Mitchell, & Truckenmiller, Citation2015; Storch & Whitehurst, Citation2002), supported by intervention studies that indicate that oral vocabulary has a causal relationship with reading comprehension (Clarke, Snowling, Truelove, & Hulme, Citation2010; Fricke, Bowyer-Crane, Haley, Hulme, & Snowling, Citation2013). However, the relationship for reading fluency is less clear (Dickinson, McCabe, Anastasopoulos, Peisner-Feinberg, & Poe, Citation2003; Duff, Reen, Plunkett, & Nation, Citation2015).
Regardless of how vocabulary size promotes literacy development, a key practical issue is how to promote these oral language skills, such as vocabulary knowledge, in children prior to formal literacy training. As the language gap is present during preschool years and remains evident throughout both primary (Biemiller, Citation2005; von Hippel, Workman, & Downey, Citation2017) and secondary school years (Reardon, Citation2013), it is important to help children develop their vocabulary knowledge in early childhood. A key message in UK preschool educational settings is to maximise the exposure that children have to language (Bercow, Citation2008; Social Mobility Commission, Citation2017), and numerous studies have shown that quantity of children’s oral language exposure (the sheer amount of language input) relates to their vocabulary size (Bornstein, Haynes, & Painter, Citation1998; Bornstein & Tamis-LeMonda, Citation1995; Cartmill et al., Citation2013; Hart & Risley, Citation1992, Citation1995; Hoff & Naigles, Citation2002; Hurtado, Marchman, & Fernald, Citation2008; Huttenlocher, Haight, Bryk, Seltzer, & Lyons, Citation1991; Huttenlocher, Waterfall, Vasilyeva, Vevea, & Hedges, Citation2010; Kamil & Hiebert, Citation2005; Pearson, Fernandez, Lewede, & Oller, Citation1997; Rowe, Citation2012). The lexical diversity, or the range of vocabulary, of speech to children has also been assessed against children’s language development (Bornstein et al., Citation1998; Demir-Vegter, Aarts, & Kurvers, Citation2014; Hoff & Naigles, Citation2002; Huttenlocher et al., Citation2010; Pan, Rowe, Singer, & Snow, Citation2005; Rowe, Citation2012).
Quantity of exposure is likely to result in greater quality of representations for those words experienced and so may contribute independently, or interact with, lexical diversity. Quantity of exposure has been assumed to result in greater fidelity of representation of meaning and pronunciation of words (Perfetti, Citation2007), which reflects vocabulary depth, which has been operationalised in terms of ability to define words and produce synonyms (Ouellette, Citation2006). Diversity of exposure, on the other hand, can result in greater breadth of vocabulary, measured in either word recognition (Ouellette, Citation2006) or word production (Rowe, Citation2012). This distinction between vocabulary depth and breadth was measured in a study of oral language skills in Grade 4 children by Ouellette (Citation2006). He found that concurrent measures of both vocabulary size and depth were independent predictors of reading accuracy and reading comprehension scores (see also Ouellette & Beers, Citation2010). Tannenbaum, Torgesen, and Wagner (Citation2006) found a similar effect in Grade 3 readers.
Jones and Rowland (Citation2017) recently developed a computational model of vocabulary acquisition to explore how quantity and diversity of exposure relates to acquisition of the child’s oral vocabulary. The model’s ability to acquire additional words was improved by both lexical diversity and quantity of input, but quantity is important early and diversity is more important later for oral vocabulary learning, consistent with behavioural findings (Rowe, Citation2012). However, the effects of diversity and quantity of exposure on literacy development have not yet been demonstrated, except in concurrent studies of oral vocabulary and literacy skills (Ouellette, Citation2006).
The model of reading that we explore in this article is based on the triangle model of reading (Harm & Seidenberg, Citation2004; Plaut, McClelland, Seidenberg, & Patterson, Citation1996; Seidenberg & McClelland, Citation1989), which comprises phonological, semantic, and orthographic representations of words, with interconnections that are trained during the course of language and reading development (). A key feature of the model’s performance is that it incrementally learns relations between each of the representations as a consequence of experience with the language. The triangle model has been successful in simulating a wide range of key behaviours in proficient readers (Chang, Furber, & Welbourne, Citation2012; Harm & Seidenberg, Citation1999; Plaut et al., Citation1996; Seidenberg & McClelland, Citation1989), and processes involved in reading development (Monaghan, Chang, Welbourne, & Brysbaert, Citation2017; Monaghan & Ellis, Citation2010), as well as extensions to nonalphabetic orthographic systems (Chang, Welbourne, & Lee, Citation2016; Yang, McCandliss, Shu, & Zevin, Citation2009).
Figure 1. The architecture of the model. Note. Numbers in the different layers indicate the number of units in that layer. Arrows show connections between layers.
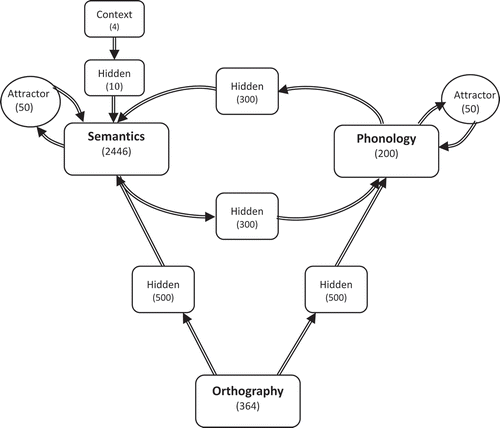
The triangle model is consistent with key aspects of the SVR (Gough & Tunmer, Citation1986), as it includes mappings and representations that reflect oral language skills, reading fluency, and reading comprehension. Reading fluency (or decoding skills) in the SVR is operationalised in the triangle model as mapping from orthography to phonology, written word comprehension as mapping from orthography to semantics, and oral language skills as mapping between phonology and semantics. However, the triangle model is less constrained than the SVR in that connections between all representations are present in the triangle model. The role of pathways within the triangle model is thus not architecturally constrained but is instead a matter of degree of engagement, which is determined by the difficulty of the mappings to be acquired.
For investigating preliteracy language development, it is vital that the triangle model be exposed to oral language prior to literacy onset, such that preliteracy language experience can then be assessed for its impact on reading development. In this oral language experience, the model learns to map from words’ sounds to meanings, as well as learning to produce words’ sounds from meanings. Implementing these preliteracy language skills in a model, and then testing the literacy development of the same model, enables us to test the direct relation between preliteracy language skills and literacy development in a theoretical framework of reading. Furthermore, the language experience of the model can be controlled to determine the contributions to literacy development of both the variety and the quantity of preliteracy language experience, where, behaviourally, it is often difficult to distinguish their separate contributions due to the high correlation between variation in vocabulary and quantity of exposure (Rowe, Citation2012).
In this article, we addressed four main research questions. First, in line with behavioural studies, we predicted that both variety of exposure and quantity would contribute to literacy development (Jones & Rowland, Citation2017; Ouellette, Citation2006; Rowe, Citation2012). This would be due to the greater fidelity of phonological and meaning representations of words consequent on quantity and diversity of exposure, which should support acquisition of mappings from orthography onto phonology and meaning.
The second research question related to how quantity and diversity of preliterate language exposure might interact and how the pattern might change across reading development. The effects of diversity and quantity could be additive. Alternatively, diversity and quantity could affect each other. For instance, greater diversity may mitigate constraints that derive from limited exposure due to broader training on phonotactic probabilities of the vocabulary (e.g., Storkel, Citation2001), or limited exposure to a diverse vocabulary might result in poorer learning of all words due to fewer opportunities to acquire clear phonological or meaning representations of each word (Perfetti, Citation2007), and thus impair reading acquisition. Regarding the pattern across reading development, exposure could be more important early in literacy, with diversity becoming increasingly important, akin to oral vocabulary development (Rowe, Citation2012). Alternatively, diversity might be more important than exposure, consistent with processes involved in later oral vocabulary development (Jones & Rowland, Citation2017).
The third research question related to the differential contribution of exposure and diversity of oral language experience on written word comprehension and word reading fluency. In line with Ouellette’s (Citation2006) behavioural study, we predicted that exposure and variation would both be more important for development of written word comprehension than reading fluency. This is a consequence of the type of mappings to be learned between representations. In English, the mapping between meaning representations and written forms is an almost entirely arbitrary relation (Monaghan, Shillcock, Christiansen, & Kirby, Citation2014), but with some exceptions relating to morphology (Seidenberg & Gonnerman, Citation2000) and historical orthographic properties that have preserved distinctions of meaning (Aronoff, Berg, & Heyer, Citation2016). Acquiring arbitrary mappings is computationally extremely expensive and learning such associations is therefore slow. However, for generating spoken forms from written forms, the mapping is quasi-regular in English and can be acquired with fewer resources and greater speed (Duff et al., Citation2015; Plaut et al., Citation1996). Thus, for the easier quasi-regular mapping task involved in reading fluency, generalisations can be constructed relatively quickly, and from a smaller vocabulary, than that required to produce meaning representations from written forms, as in written word comprehension.
The final research question determined the alignment of the triangle model of reading with the SVR, by quantifying the role of decoding skills (mappings from orthography to phonology) and the role of oral vocabulary (mappings from phonology to semantics) on written word comprehension. We tested the extent to which the triangle model was effective in simulating the division of labour predicted by the SVR that reading comprehension would be served by both oral vocabulary and decoding skills (Adlof et al., Citation2006; Curtis, Citation1980; Gough & Tunmer, Citation1986; Nation & Snowling, Citation2004; Ouellette & Beers, Citation2010; Ricketts et al., Citation2007; Storch & Whitehurst, Citation2002; Tomblin & Chang, Citation2006). The SVR and the triangle model differ somewhat in their conceptions of the directionality of mappings between phonology and semantics. The SVR focuses on mappings from phonology to semantics, whereas the triangle model contends that semantics to phonology may also be involved for reading fluency. Thus we also tested the extent to which oral language and written word comprehension affected reading fluency, by investigating the contribution of indirect mappings from orthography to phonology, via semantics.
A computational model of preliteracy effects on literacy development
The computational model was an implementation of the triangle model (Harm & Seidenberg, Citation2004) in English. Previously, this model has been applied mostly to simulate reading behaviours in proficient readers; however, it has not investigated the influence of oral language skills on literacy development. Here we systematically controlled and varied the model’s preliteracy training to determine the effect on later literacy development while inheriting the explanatory strength of the triangle model approach in accounting for reading phenomena.
Method
Architecture
The architecture of the model is shown in . The model consisted of three key processing layers (orthographic, phonological, and semantic) and five intervening layers to form interconnections between the processing layers.
Attractor layers, which contained 50 units, were connected to and from the phonological and semantic layers. These attractor layers helped the model develop stable and high-fidelity phonological and semantic representations of words where partial or noisy degraded activation patterns can move toward familiar representations (Harm & Seidenberg, Citation2004). In addition, there were four context units connecting to the semantic layer through a set of 10 hidden units. These units enabled the model to disambiguate homophones (e.g., hear, here) by using broad information about the context in which the word occurred. One context unit was active for each homophone, with the context unit assigned to each word meaning selected at random at the beginning of training. In this way, each context unit was almost equally active across the training corpus. For nonhomophones, none of the context units were active.
The semantic layer was connected to the phonological layer through a set of 300 hidden units, and the phonological layer was connected back to the semantic layer through another set of 300 hidden units. These hidden units provided resources for the model to learn the mappings between representations. The orthographic layer was connected to both the phonological and semantic layers through different sets of 500 hidden units. All units in one layer were connected with all units in the next layer. For all of the hidden layers in the model, the numbers of units were selected through pilot testing as the minimum required for reliable accurate mappings to be acquired.
Representations
The representations of orthography, phonology, and semantics were similar to those used by Harm and Seidenberg (Citation2004). The training corpus comprised all 6,229 monosyllabic words in English for which semantic (from Wordnet; Miller, Citation1990) and phonological (from CELEX; Baayen, Piepenbrock, & van Rijn, Citation1993) representations were available. This corpus was identical to that used in Harm and Seidenberg (Citation2004) but also included all inflected forms of words, some of which were originally omitted. Frequency, derived from the Wall Street Journal corpus (Marcus, Santorini, & Marcinkiewicz, Citation1993), was log-compressed prior to training of the model.
For orthography, each word was represented by 14 letter slots, permitting all words in the corpus to be represented. Each slot comprised 26 units, one for each of the 26 letters of the alphabet. Words were positioned with their first vowel aligned on the fifth slot. For words having two adjacent vowels, the second vowel was placed on the sixth slot. Consonants preceding or following the vowel were positioned in adjacent slots to the two vowel slots. Further vowels that were nonadjacent to the first vowel also occurred in adjacent slots after the first two vowel slots.Footnote1 This maximised the model’s ability to detect similarities between pronunciation of letter combinations by reducing the problem of dispersion (Plaut et al., Citation1996).Footnote2
For phonology, each word was represented by eight phoneme slots, allowing all words in the corpus to be represented. Pronunciation of each word was positioned with the vowel at the fourth phoneme slot. The first three slots were for onset consonants and the last four slots were for coda consonants, enabling the probabilities of mappings between particular letters and phonemes to be detected.Footnote3 Each phoneme was encoded by a binary vector of 25 phonological features (including, e.g., voice, nasal, labial, palatal, round, etc.), taken from Chomsky and Halle’s (Citation1968) phoneme feature matrix and exactly the same as in Harm and Seidenberg (Citation2004).
The semantic representation for each word derived from Wordnet (Miller, Citation1990) comprised 2,446 semantic features, in accordance with those used in Harm and Seidenberg (Citation2004). The presence of semantic features was encoded as 1, and the absence of semantic features was encoded as 0. For example, a dog has legs but cannot fly, so the leg feature for dog is 1 and the fly feature for dog is 0. Comprehension in the model relates to reproduction of the semantic features of a word; we therefore refer to the model’s performance as written word comprehension, to distinguish the task from text comprehension.
Training procedure
The training process had two phases. In preliteracy training, the model learned the mappings between phonology and semantics, mimicking the language skills that children have developed before learning to read. In reading training, the model learned mappings from orthography to phonology and to semantics.
To investigate the effect of exposure and diversity in preliterate language experience on reading performance, the model was trained with six vocabulary sizes in the preliteracy training: 1,000, 2,000, 3,000, 4,000, 5,000, and 6,000 words. The set of words in each vocabulary size was selected from the whole training corpus (i.e., 6,229 words) based on frequency, such that the most frequent 1,000 words in the language composed the 1,000 vocabulary size condition, the most frequent 2,000 words for the 2,000 word vocabulary condition, and so on. This simulated the relation between frequency of words and the likelihood of their occurrence in language exposure (Kuperman & van Dyke, Citation2013).Footnote4
In preliteracy training, the model was trained on both a speaking task (mappings from semantic to phonological representations) and a hearing task (mappings from phonological to semantic representations). The model also learned to develop stable phonological representations (mappings from phonological to phonological representations) via the phonological attractor units, and stable semantic representations (mappings from semantic to semantic representations) via the semantic attractors. The model learned to produce representations over several time steps. For both the speaking and hearing tasks, the input pattern of each word was presented constantly for eight time steps, and in the last two time steps, the model was required to reproduce the target pattern of the word. For both the phonological and semantic attractors, the input pattern of each word was presented constantly for six time steps. For Time Steps 7 and 8, the model had to reproduce the target pattern of the word. The input from the context units was provided only for the hearing task.
Following Harm and Seidenberg (Citation2004), the four training tasks were interleaved, with 40% of trials for the speaking task, 40% of trials for the hearing task, 10% of trials for the phonological attractor training, and the remaining 10% for the semantic attractor training. These ratios were selected to ensure that all tasks were learned effectively.Footnote5 Which word was presented to the model was determined by sampling according to the words’ log-frequencies.
The model learned by adjusting weight connections between units based on the back-propagation through time algorithm (Pearlmutter, Citation1989, Citation1995; Plaut et al., Citation1996). The weight connections were incrementally adjusted to reduce this error between the actual and target representations. A typical learning rate of 0.05 was used to ensure that changes to weights were made gradually, preventing the model being unduly affected by individual learning trials. The difference between the actual and target representation for each word was measured in terms of the divergence between these representations (cross-entropy; Plaut et al., Citation1996, Equation 4). The model was trained on the oral language skills with varying amounts of exposure, either sampling words 400,000 times from the vocabulary, or 800,000, 1.2 million, 1.6 million, or 2 million times.
After preliteracy training, the model was trained on the literacy tasks, learning the mappings from orthography to semantics and to phonology. The same literacy training procedure was applied to each of the 30 preliteracy simulations of the model (6 vocabulary conditions × 5 exposure conditions). The orthographic representation of a word along with the context layer representation was presented constantly for 12 time steps. For Time Steps 7–12, the model was required to produce the phonological and semantic representations for that word. All the other training parameters remained the same as in the preliteracy training.
Four versions of each model, with different randomised starting parameters and different random sampling from the training vocabularies, were run to ensure that these random parameters did not adversely affect the simulations.Footnote6
Testing procedure
After preliteracy training, the model was tested on the speaking and hearing tasks. For the speaking task, the semantic representation of each word was presented and the activation of units in the phonological layer at the end of the eight time steps was recorded. Error score was measured by the sum of the squared differences between the activation of each input unit and its target activation, and accuracy was computed by measuring for each phoneme slot the closest phoneme to the model’s actual production, and determining whether they were the same for all phoneme slots. The error score and the accuracy are closely related, but error score provides a more nuanced measure of how close the model’s production is to the target representation. Thus, if the model produced an incorrect phoneme, the error score would be high. However, if the model produced phonological representations that were closer to the target phoneme in each position but individual phonological features were less accurately represented, then the error score could still be higher than a phonological representation where all phonological features were accurately reproduced.
For the hearing task, the phonological representation of each word was presented and the activation of units in the semantic layer at the end of the eight time steps was recorded. Error score was measured by the sum of squared differences over the semantic layer. Accuracy was measured by computing the Euclidean distance between the model’s actual semantic representation and the semantic representation of each word in the training corpus. If the smallest distance was to the target representation, then the model was judged to be correct. Again, error scores provide a more sensitive measure than accuracy, as two words could be accurately represented in semantics (in terms of being closer to the target set of meaning features) but diverge in terms of how close individual meaning features are to their target activation.
At the end of reading training, the model’s reading performance was tested on all words in the corpus, by presenting the orthographic representation of a word and measuring error score and accuracy for both semantic and phonological output at Time Step 12 in the same way as for the preliteracy training phase.
Results
Preliteracy training performance
We measured the model’s ability to acquire the oral vocabularies with different amounts of exposure. shows the preliteracy performance of the model for the speaking task, mapping from semantics to phonology, and the hearing task, mapping from phonology to semantics, across training up to 2 million word exposures for the six vocabulary sizes. By 2 million words, accuracy scores were greater than 88% of the vocabulary for both tasks. Both exposure and vocabulary size had an overall positive influence on vocabulary size in the model. illustrates the percentage correct of the set of words that the model is exposed to. Thus, the model trained on a diverse vocabulary of 6,000 words has a larger vocabulary than the model trained on 1,000 words if its proportion correct exceeds one sixth that of the 1,000-word model. Note that the literacy models with different exposure conditions were trained at points that preceded the end of the 2 million words training.
Figure 2. The pretraining performance of the model on the hearing task (phonology to semantics) and speaking task (semantics to phonology) with six vocabulary sizes (1,000 to 6,000). Note. K = thousand; M = million.
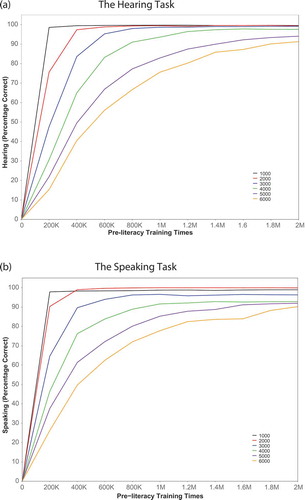
Figure 3a. The reading fluency performance of the model trained with six vocabulary sizes (1,000 to 6,000), with each panel illustrating the five amounts of exposure (400K, 800K, 1.2M, 1.6M, and 2M). Note. K = thousand; M = million.
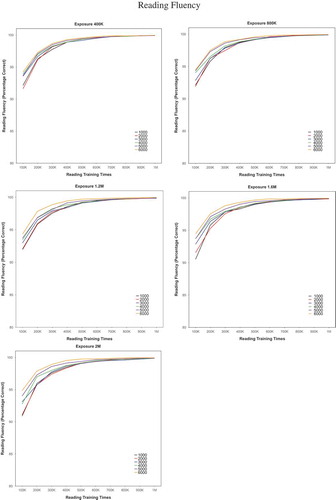
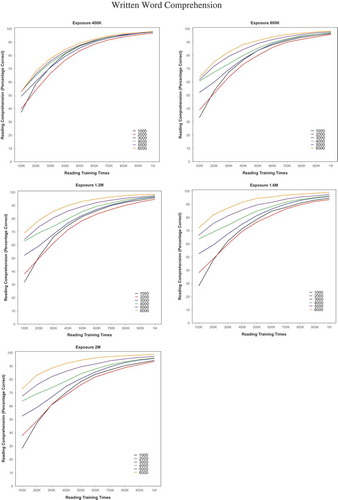
Figure 3b. The written word comprehension performance of the model trained with six vocabulary sizes (1,000 to 6,000), with each panel illustrating the five amounts of exposure (400K, 800K, 1.2M, 1.6M, and 2M). Note. K = thousand; M = million.
Exploring relations between preliteracy language exposure and reading development
The model’s performance was measured every 100,000 reading trials from 100,000, up to 1 million exposures as shown in for reading fluency and for written word comprehension. To investigate how vocabulary size and amount of exposure affected the model’s accuracy at different reading times for both reading fluency and written word comprehension, we conducted generalised linear mixed-effect models on each of these measures. Simulation run (one to four) and word item were random factors, and vocabulary size (1,000, …, 6,000), amount of preliteracy language exposure (400,000, …, 2 million), and reading time (100,000, …, 1 million) were fixed factors. Reading time was log-transformed prior to the analyses ( and demonstrate that performance across reading experience was not linear). All the variables were scaled because the range of each variable was very different.
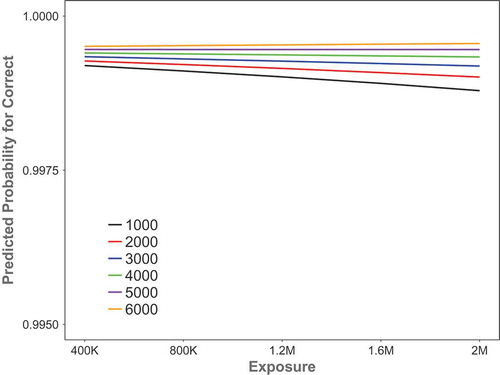
For reading fluency (orthography-to-phonology mappings), both amount of preliteracy exposure and vocabulary size were significant predictors (β = −0.05, p < .001, and β = 0. 25, p < .001, respectively). Log reading time also made a significant contribution (β = 1.45, p < .001). Thus, amount of exposure, vocabulary size, and log reading time all had significant effects on literacy outcomes in the model. There was a significant two-way interaction between exposure and vocabulary size (; β = 0.06, p < .001). The interaction graph is plotted on the basis of predictions of the generalised linear mixed-effects models, measured in predicted probabilities for accurate reading. As can be seen in , when vocabulary sizes were greater than 3,000, literacy acquisition of the model was not affected by amount of exposure, but performance decreased then with amount of exposure: for combined performance from 1,000 to 3,000 vocabulary size, exposure was significant (β = −0.09, p < .001), but for combined performance from 4,000 to 6,000 vocabulary size, exposure was not significant (β = −0.002, p = .66).
Figure 4. Two-way interaction between exposure and vocabulary for reading fluency. Note. K = thousand; M = million.
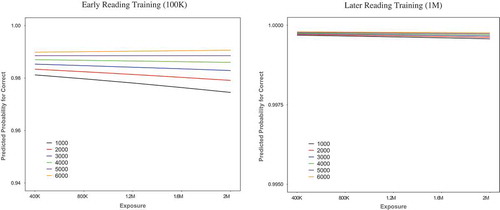
In addition, the three-way interaction between exposure, vocabulary size, and log reading time also reached significance (β = 0.008, p = .014). Further analyses at different training times () showed that at early reading time 100,000, both the effects of exposure (β = −0.041, p < .001) and of vocabulary size (β = 0.28, p < .001) were significant. The interaction between vocabulary size and exposure was also significant (β = 0.047, p < .001). Whereas at later reading time 1 million, both exposure (β = −0.079, p < .05) and vocabulary size (β = 0.174, p < .001) were significant predictors but the interaction was not (p = .58). These results indicated that vocabulary size had a positive and stronger influence on reading fluency at early compared to later reading time, whereas exposure had a negative influence and the effect increased with reading training.
Figure 5. The interaction between vocabulary and exposure for reading fluency at early reading (100K) and later reading (1M). Note. K = thousand; M = million.
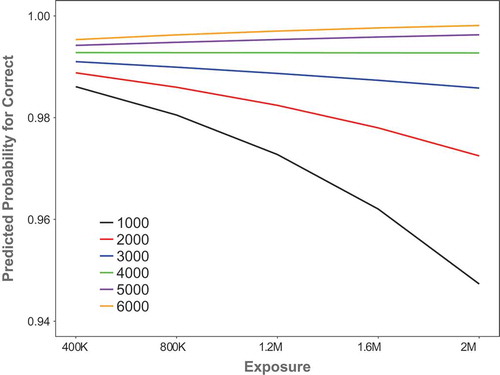
Similarly, for written word comprehension (orthography-to-semantics mappings), both exposure (β = −0.08, p < .001) and vocabulary size (β = 0.77, p < .001) were significant predictors, as was log reading time (β = 2.14, p < .001). There was a significant two-way interaction between exposure and vocabulary size (β = 0.27, p < .001), as shown in . When vocabulary sizes were greater than 3,000, literacy acquisition accuracy of the model increased with amount of exposure (β = 0.26, p < .001), but a reverse pattern was observed for vocabulary sizes smaller than 3,000 (β = −0.3, p < .001).
Figure 6. Two-way interaction between exposure and vocabulary for written word comprehension. Note. K = thousand; M = million.
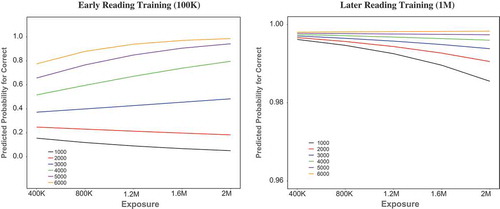
In addition, the three-way interaction between exposure, vocabulary, and log reading time also made a significant contribution (β = −0.01, p < .001). shows the interaction patterns at different training times. At reading time 100,000, both exposure (β = 0.31, p < .001) and vocabulary (β = 1.72, p < .001) were significant predictors, and the interaction was also significant (β = 0.51, p < .001). At reading time 1 million, both exposure (β = −0.21, p < .001) and vocabulary (β = 0.48, p < .001) were significant predictors, and the interaction was also significant (β = 0.18, p < .001). The results showed that exposure had a positive effect in early reading training, whereas a negative effect in later reading training. Vocabulary size, on the other hand, had a positive effect at both early and later reading times, albeit the effect became smaller. For the interaction between vocabulary size and exposure, the beta values (0.51 vs. 0.18) were much larger in early reading than in later reading, suggesting that the effects were still persistent through reading development, though more reading experience resulted toward a converging of performance.
Figure 7. The interaction between vocabulary and exposure for written word comprehension at early reading (100K) and later reading (1M). Note. K = thousand; M = million.
To test whether the effects of vocabulary size, exposure, and log reading time were different for written word comprehension and reading fluency, we included reading task as a fixed effect in a combined analysis. The results showed that the interaction between task, exposure, and vocabulary size was significant (β = 0.19, p < .001). The four-way interaction between task, log reading time, exposure, and vocabulary size was also significant (β = −0.09, p < .001). These results confirmed our hypothesis that there are stronger effects of vocabulary size and exposure for written word comprehension compared to reading fluency and that the effects of oral language on written word comprehension are sustained to a greater extent through reading development than for reading fluency in the model.
Effects of oral language and reading fluency on written word comprehension
The SVR predicts contributions to reading comprehension from both oral language and reading fluency. To determine the extent to which these effects are observed in the triangle model of reading, we repeated the linear mixed-effects models with written word comprehension accuracy as the dependent variable, and oral language (resulting from preliteracy oral language exposure and diversity) as predictors, but we also added reading fluency as a predictor. We found that, as demonstrated in latent variable models of behavioural data on reading comprehension (e.g., Adlof et al., Citation2006), oral language indexed by exposure (β = −0.02, p < .001) and vocabulary size (β = 0.86, p < .001) contributed significantly to written word comprehension in the model, and reading fluency was also related (β = 0.81, p < .001); thus, the model’s performance was consistent with the SVR in predicting written word comprehension.
Effects of oral language and written word comprehension on reading fluency
To test the possible contribution of both oral language skills and written word comprehension in affecting reading fluency, we conducted linear mixed-effects models on reading fluency with oral language (exposure and vocabulary size) and written word comprehension as predictors. Written word comprehension (β = 1.19, p < .001) predicted significant variance in reading fluency in addition to the oral language measures of vocabulary size (β = 0.17, p < .001) and exposure (β = −0.04, p < .001), indicating that both oral language skills and written word comprehension are impacting on the model’s reading fluency, and not only effects from fluency on comprehension as constrained by the SVR.
Discussion
In behavioural studies of preliteracy language influences on learning to read, distinguishing individual predictors and determining their causal relations are a challenge. However, theoretical proposals for the effect of oral language on learning to read can be tested for their adequacy in computational modelling of reading. We here implemented the triangle model of reading (Harm & Seidenberg, Citation2004) but crucially investigated the model’s learning, both prior to literacy onset, as well as during reading acquisition.
In relating the triangle model to the SVR, the simulation results demonstrated that both oral language and reading fluency contributed to written word comprehension, consistent with the SVR and with behavioural studies of reading development (Adlof et al., Citation2006; Curtis, Citation1980; Gough & Tunmer, Citation1986; Nation & Snowling, Citation2004; Ouellette & Beers, Citation2010; Ricketts et al., Citation2007; Storch & Whitehurst, Citation2002; Tomblin & Zhang, Citation2006). The contribution of (at least) two skills in predicting reading development in the model are shown to emerge from the computational requirements of the task to learn mappings between orthographic, phonological, and semantic representations. In addition, the triangle model also demonstrated that there were effects on reading fluency of written word comprehension as well as the measures of oral language skills. These results are consistent with the behavioural findings of semantic influences on reading fluency (Nation & Snowling, Citation2004; Ouellette, Citation2006; Ricketts et al., Citation2007; Share, Citation1995) and highlight the importance of bidirectional influences between reading fluency and reading comprehension.
A further influence on the reading system in the triangle model is the direct mappings between orthography and semantics, which becomes of increasing importance as reading acquisition develops (Nation, Citation2009; Nation & Snowling, Citation2004; Taylor, Duff, Woollams, Monaghan, & Ricketts, Citation2015).
Regarding the relative contributions of oral language on reading fluency and written word comprehension, the computational modelling demonstrates that oral language has an impact on reading fluency only in early reading development, whereas the differential effects of exposure and diversity remain, though somewhat reduced, for written word comprehension. According to Storch and Whitehurst’s (Citation2002) data, in early literacy development, oral language directly influences reading accuracy, whereas this direct effect is not observed by Grade 3 readers, which is instead primarily influenced by reading accuracy in previous years. In contrast, oral language continues to influence performance for reading comprehension by Grade 3, and a growing distinction between reading accuracy and reading comprehension appears to be observed as children’s literacy develops (Adlof et al., Citation2006; Foorman et al., Citation2015; Pentimonti, O’Connell, Justice, & Cain, Citation2015; Tomblin & Zhang, Citation2006), with the latter influenced more by oral language skills.
The computational model also enabled us to distinguish between different contributors of exposure and diversity of preliteracy language experience in their effect on later development of reading. The modelling results showed that both vocabulary size and amount of exposure had unique effects on the reading performance, for both written word comprehension and reading fluency. As predicted based on behavioural results (Ouellette, Citation2006) and the computational properties of the mappings to be learned (Taylor et al., Citation2015), the effect of preliteracy oral language was substantially greater for written word comprehension than for reading fluency. For reading fluency, acquiring the mapping between orthography and phonology is easier than learning the mapping from orthography and semantics, and so the latter mapping is likely to be mediated to a greater degree by the preliteracy oral language system, via mappings from phonology to semantics (Harm & Seidenberg, Citation2004; Monaghan, Chang, & Welbourne, Citation2017). Furthermore, there was a larger effect on reading from vocabulary diversity than exposure. This suggests that variation in language exposure, rather than quantity of language exposure, ought to be the primary message for preliteracy language exposure and drives to enhance children’s range of language experience, such as in shared reading (Cameron-Faulkner & Noble, Citation2013), rather than sheer quantity of exposure may best promote later development of reading skills.
We thus showed that quantity and diversity of language exposure relate not only to vocabulary acquisition (Jones & Rowland, Citation2017) but also to learning to read. Quantity of exposure appears to contribute more positively in early compared to later reading time (although it has overall a negative influence on reading fluency). Similarly, lexical diversity also has a larger influence early in reading development. This is partially consistent with the work of Jones and Rowland (Citation2017), who showed that exposure is more important early in vocabulary learning and lexical diversity is more important later. Note that however the effects of vocabulary size and exposure were not additive in terms of the model’s performance. The significant interaction between vocabulary size and amount of exposure suggests that the link between vocabulary knowledge and literacy was modulated by quantity of exposure to vocabulary, which was not always useful, particularly if increased exposure was drawn from a limited vocabulary.
So why is increased exposure harmful to later development of reading skills if drawn from a limited vocabulary? Within the model, this can be explained in terms of plasticity of the reading system. With more exposure, the model is able to represent the experienced vocabulary with a higher degree of fidelity (Perfetti, Citation2007) but becomes less flexible in incorporating new information (Monaghan & Ellis, Citation2010). So when the model is trained on a small vocabulary, its representation of that small vocabulary is highly accurate, but the model is then less able to expand to the vocabulary it experiences while learning to read. Then the newly experienced words are less effectively included into the oral vocabulary processing within the model, and greater reliance must be made on the direct orthography to phonology and orthography to semantics routes within the model. The simulation results further showed that this interaction pattern started from early literacy training and continued over the time course of learning to read, suggesting that extended reading experience does not completely mitigate the differences. The implication of this finding is that when children have limited oral vocabulary, it is more important to increase the diversity rather than quantity of their oral vocabulary, consistent with the observations of Rowe (Citation2012) that breadth of oral vocabulary acquisition is ideally accomplished by promoting an increased vocabulary range after a core vocabulary has been acquired.
However, there are some limitations to the modelling study. Word reading in the model is characterised by exposure to monosyllabic words. Although the majority of words that children start to learn are monosyllabic, the average number of syllables in words increases constantly throughout the school years (Zeno, Ivens, Hillard, & Duvvuri, Citation1995). The skills that children learn for monosyllabic words cannot apply in exactly the same way to polysyllabic words (Toste, Williams, & Capin, Citation2017) due to their morphological complexity. Future work can be extended to develop a model of reading that has a fully representative vocabulary. This would also allow for the exploration of how morphological and syntactic structures of words might affect learning to read (Tomblin & Zhang, Citation2006), as polymorphemic words are more likely to be polysyllabic.
Another consideration is the operationalisation of reading only single words in the model. Tomblin and Zhang (Citation2006) showed that grammar and vocabulary become distinct components of reading comprehension with literacy development, and Pentimonti et al. (Citation2015) showed that discourse comprehension also fragments from other comprehension skills with development of reading. In our current modelling framework, we have included context units that relate to the semantic representations of individual words and included properties of the semantics that relate to grammatical distinctions. Clearly, implementing a richer context, and examining performance for sequences of words rather than isolated words, on the model’s performance would be required to simulate this greater richness of literacy development.
A further limitation in the model is that once the reading tasks were introduced, further experience of oral vocabulary in the model ended so that we could isolate the role of early language exposure on reading development in the model. But children’s oral vocabulary continues to develop during learning to read, and the structure of language skills may well then change as a consequence (Monaghan, Chang, & Welbourne, Citation2017). So, later-acquired oral vocabulary may influence reading performance differently, and this would be an interesting topic for further investigation.
How the evident division of labour in the model with regard to reading development extends to other languages would further define the interactions between oral language skills and literacy across cultures. The extent to which a combination of decoding and oral language skills are involved in written word comprehension is likely to vary according to the ease with which the decoding of orthography to phonology occurs. In very regular alphabetic languages, such as Italian (Pagliuca & Monaghan, Citation2010), the role of both decoding and oral language in comprehension is likely to be more enhanced than in languages where acquiring orthography to phonology is as arbitrary as acquiring direct orthography to semantics mappings, such as in Chinese (Yang et al., Citation2009).
In conclusion, we have shown that theoretical models of relations between oral vocabulary skills and learning to read can be implemented in a computational model of reading, enabling a test of the explanatory adequacy of hypotheses about the causal relations between different language skills. We have further shown that such models can distinguish different aspects of preliteracy language experience—vocabulary size and amount of exposure—and determine their independent and combined influences on later development of learning to read. The model demonstrates that such relations are not straightforward and that under some circumstances, increasing quantity of language experience without ensuring vocabulary breadth may be detrimental to later development of reading skills.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
Notes
1. For instance, the word strengths was represented as _ s t r e _ n g t h s _ _ _, great was represented as _ _ g r e a t _ _ _ _ _ _ _, and tide was represented as _ _ _ t i_ d e _ _ _ _ _ _.
2. Many vowels in English words are represented by two adjacent vowels (as in great). Without two orthographic slots reserved for vowels, the model would learn less effectively the mapping between these two orthographic vowels and the phonological vowel.
3. For instance, the word strengths was represented as s t r E n g T s and great was _ g r eI t _ _ _.
4. Monaghan, Chang, Welbourne, and Brysbaert (Citation2017) demonstrated that restricting training to the most frequent 1,000 words affected reading performance in the same way as randomly selecting 1,000 words across the frequency range, so that the particular characteristics of the higher frequency vocabulary were unlikely driving performance.
5. Note that the attractor training requires an identity mapping to be formed, which is computationally substantially easier than mapping between phonology and semantics, which is largely an arbitrary relation.
6. Altogether there were 120 simulation runs of the model with varied quantity and diversity of preliteracy language experience. As the four random versions of each model resulted in little variation in performance, we determined that additional simulation runs would not alter the patterns of results observed.
References
- Adlof, S. M., Catts, H. W., & Little, T. D. (2006). Should the SVR include a fluency component? Reading and Writing, 19(9), 933–958. doi:10.1007/s11145-006-9024-z
- Aronoff, M., Berg, K., & Heyer, V. (2016). Some implications of English spelling for morphological processing. The Mental Lexicon, 11, 164–185. doi:10.1075/ml
- Baayen, R. H., Piepenbrock, R., & van Rijn, H. (1993). The celex lexical database (cd-rom). Philadelphia, PA: Linguistic Data Consortium, University of Pennsylvania.
- Bercow, J. (2008). The Bercow report: A review of service for children and young people (0–19) with speech, language and communication needs (SLCN). London, UK: DCSF.
- Biemiller, A. (2005). Size and sequence in vocabulary development: Implications for choosing words for primary grade vocabulary instruction. In E. H. Hiebert & M. L. Kamil (Eds.), Teaching and learning vocabulary: Bringing research to practice (pp. 223–242). Mahwah, NJ: Lawrence Erlbaum Associates.
- Bornstein, M. H., Haynes, M. O., & Painter, K. M. (1998). Sources of child vocabulary competence: A multivariate model. Journal of Child Language, 25, 367–393.
- Bornstein, M. H., & Tamis-LeMonda, C. S. (1995). Language and nonlanguage factors in development of prelinguistic vocalization to linguistic communication. In G. Konopczynski (Ed.), Is early language performance predictive of later language development? (pp. 81–102). Calais, France: Ortho-Editions.
- Cameron-Faulkner, T., & Noble, C. (2013). A comparison of book text and child directed speech. First Language, 33(3), 268–279. doi:10.1177/0142723713487613
- Cartmill, E., Armstrong, B. F., Gleitman, L. R., Goldin-Meadows, S., Medinac, T. N., & Trueswell, J. C. (2013). Quality of early parent input predicts child vocabulary 3 years later. Proceedings of the National Academy of Sciences, 110, 11278–11283. doi:10.1073/pnas.1309518110
- Chang, Y. N., Furber, S., & Welbourne, S. (2012). “Serial” effects in parallel models of reading. Cognitive Psychology, 64(4), 267–291. doi:10.1016/j.cogpsych.2012.01.002
- Chang, Y.-N., Welbourne, S., & Lee, C.-Y. (2016). Exploring orthographic neighborhood size effects in a computational model of Chinese character naming. Cognitive Psychology, 91, 1–23. doi:10.1016/j.cogpsych.2016.09.001
- Chomsky, N., & Halle, M. (1968). The sound pattern of English. New York, NY: Harper & Row.
- Clarke, P. J., Snowling, M. J., Truelove, E., & Hulme, C. (2010). Ameliorating children’s reading comprehension difficulties: A randomised controlled trial. Psychological Science, 21, 1106–1116. doi:10.1177/0956797610378686
- Cunningham, A. E., Perry, K. E., Stanovich, K. E., & Stanovich, P. J. (2004). Disciplinary knowledge of K-3 teachers and their knowledge calibration in the domain of early literacy. Annals of Dyslexia, 54(1), 139–167. doi:10.1007/s11881-004-0007-y
- Cunningham, A. E., Zibulsky, J., & Callahan, M. D. (2009). Starting small: Building preschool teacher knowledge that supports early literacy development. Reading and Writing, 22, 487–510. doi:10.1007/s11145-009-9164-z
- Curtis, M. E. (1980). Development of components of reading skill. Journal of Educational Psychology, 72(5), 656–669. doi:10.1037/0022-0663.72.5.656
- Demir-Vegter, S., Aarts, R., & Kurvers, J. (2014). Lexical richness in maternal input and vocabulary development of Turkish preschoolers in the Netherlands. Journal of Psycholinguistic Research, 43, 149–165. doi:10.1007/s10936-013-9245-7
- Dickinson, D. K., McCabe, A., Anastasopoulos, L., Peisner- Feinberg, E. S., & Poe, M. D. (2003). The comprehensive language approach to early literacy: The interrelationship among vocabulary, phonological sensitivity, and print knowledge among preschool-aged children. Journal of Educational Psychology, 95, 465–481. doi:10.1037/0022-0663.95.3.465
- Duff, F. J., Reen, G., Plunkett, K., & Nation, K. (2015). Do infant vocabulary skills predict school-age language and literacy outcomes? Journal of Child Psychology and Psychiatry, 56(8), 848–856. doi:10.1111/jcpp.12378
- Foorman, B. R., Herrera, S., Petscher, Y., Mitchell, A., & Truckenmiller, A. (2015). The structure of oral language and reading and their relation to comprehension in kindergarten through grade 2. Reading and Writing, 28(5), 655–681. doi:10.1007/s11145-015-9544-5
- Fricke, S., Bowyer-Crane, C., Haley, A. J., Hulme, C., & Snowling, M. J. (2013). Efficacy of language intervention in the early years. Journal of Child Psychology and Psychiatry, 54, 280–290. doi:10.1111/jcpp.12010
- Gough, P. B., & Tunmer, W. E. (1986). Decoding, reading, and reading disability. Remedial and Special Education, 7(1), 6–10. doi:10.1177/074193258600700104
- Harm, M. W., & Seidenberg, M. S. (1999). Phonology, reading and dyslexia: Insights from connectionist models. Psychological Review, 106, 491–528.
- Harm, M. W., & Seidenberg, M. S. (2004). Computing the meanings of words in reading: Cooperative division of labor between visual and phonological processes. Psychological Review, 111(3), 662–720. doi:10.1037/0033-295X.111.3.662
- Hart, B., & Risley, T. (1995). Meaningful differences in the everyday experience of young American children. Baltimore: Paul H Brookes Publishing.
- Hart, B., & Risley, T. R. (1992). American parenting of language-learning children: Persisting differences in family-child interactions observed in natural home environments. Developmental Psychology, 28(6), 1096–1105. doi:10.1037/0012-1649.28.6.1096
- Hoff, E., & Naigles, L. R. (2002). How children use input to acquire a lexicon. Child Development, 73, 418–433. doi:10.1111/cdev.2002.73.issue-2
- Hurtado, N., Marchman, V. A., & Fernald, A. (2008). Does input influence uptake? Links between maternal talk, processing speed and vocabulary size in Spanish-learning children. Developmental Science, 11, F31–F39. doi:10.1111/desc.2008.11.issue-6
- Huttenlocher, J., Haight, W., Bryk, A., Seltzer, M., & Lyons, T. (1991). Early vocabulary growth: Relation to language input and gender. Developmental Psychology, 27, 236–248. doi:10.1037/0012-1649.27.2.236
- Huttenlocher, J., Waterfall, H., Vasilyeva, M., Vevea, J., & Hedges, L. V. (2010). Sources of variability in children’s language growth. Cognitive Psychology, 61, 343–365. doi:10.1016/j.cogpsych.2010.08.002
- Jones, G., & Rowland, C. F. (2017). Diversity not quantity in caregiver speech: Using computational modeling to isolate the effects of the quantity and the diversity of the input on vocabulary growth. Cognitive Psychology, 98, 1–21. doi:10.1016/j.cogpsych.2017.07.002
- Kamil, M., & Hiebert, E. (2005). Teaching and learning vocabulary: Perspectives and persistent issues. In E. H. Hiebert & M. L. Kamil (Eds.), Teaching and learning vocabulary: Bringing research to practice (pp. 1–23). Mahwah, NJ: Lawrence Erlbaum.
- Kuperman, V., & Van Dyke, J. A. (2013). Reassessing word frequency as a determinant of word recognition for skilled and unskilled readers. Journal of Experimental Psychology: Human Perception and Performance, 39(3), 802–823. doi:10.1037/a0030859
- Lee, J. (2011). Size matters: Early vocabulary as a predictor of language and literacy competence. Applied Psycholinguistics, 32, 69–92. doi:10.1017/S0142716410000299
- Locke, A., Ginsborg, J., & Peers, I. (2002). Development and disadvantage: Implications for the early years and beyond. International Journal of Language & Communication Disorders, 37(1), 3–15. doi:10.1080/13682820110089911
- Marcus, M. P., Marcinkiewicz, M. A., & Santorini, B. (1993). Building a large annotated corpus of English: The Penn treebank. Computational Linguistics, 19(2), 313–330.
- Miller, G. A. (1990). WordNet: An on-line lexical database. International Journal of Lexicography, 3, 235–312. doi:10.1093/ijl/3.4.235
- Monaghan, P., Chang, Y. N., & Welbourne, S. (2017). Different processes for reading words learned before and after onset of literacy. Proceedings of the 39th Cognitive Science Society Conference, London.
- Monaghan, P., Chang, Y. N., Welbourne, S., & Brysbaert, M. (2017). Exploring the relations between word frequency, language exposure, and bilingualism in a computational model of reading. Journal of Memory and Language, 93, 1–21. doi:10.1016/j.jml.2016.08.003
- Monaghan, P., & Ellis, A. W. (2010). Modeling reading development: Cumulative, incremental learning in a computational model of word naming. Journal of Memory and Language, 63(4), 506–525. doi:10.1016/j.jml.2010.08.003
- Monaghan, P., Shillcock, R. C., Christiansen, M. H., & Kirby, S. (2014). How arbitrary is language? Philosophical Transactions of the Royal Society B, 369, 20130299. doi:10.1098/rstb.2013.0299
- Muter, V., Hulme, C., Snowling, M. J., & Stevenson, J. (2004). Phonemes, rimes, vocabulary, and grammatical skills as foundations of early reading development: Evidence from a longitudinal study. Developmental Psychology, 40(5), 665–681. doi:10.1037/0012-1649.40.5.665
- Nation, K. (2009). Form–Meaning links in the development of visual word recognition. Philosophical Transactions of the Royal Society B: Biological Sciences, 364, 3665–3674. doi:10.1098/rstb.2009.0119
- Nation, K., & Snowling, M. (2004). Beyond phonological skills: Broader language skills contribute to the development of reading. Journal of Research in Reading, 27, 342–356. doi:10.1111/jrir.2004.27.issue-4
- Nation, K., & Snowling, M. J. (1998). Semantic processing and the development of word-recognition skills: Evidence from children with reading comprehension difficulties. Journal of Memory and Language, 39(1), 85–101. doi:10.1006/jmla.1998.2564
- Ouellette, G., & Beers, A. (2010). A not-so-SVR: How oral vocabulary and visual-word recognition complicate the story. Reading and Writing, 23, 189–208. doi:10.1007/s11145-008-9159-1
- Ouellette, G. P. (2006). What’s meaning got to do with it: The role of vocabulary in word reading and reading comprehension. Journal of Educational Psychology, 98(3), 554–566. doi:10.1037/0022-0663.98.3.554
- Pagliuca, G., & Monaghan, P. (2010). Discovering large grain-sizes in a transparent orthography: Insights from a connectionist model of reading aloud for Italian. European Journal of Cognitive Psychology, 22, 813–835. doi:10.1080/09541440903172158
- Pan, B. A., Rowe, M. L., Singer, J. D., & Snow, C. E. (2005). Maternal correlates of growth in toddler vocabulary production in low-income families. Child Development, 76, 763–782.
- Pearlmutter, B. A. (1989). Learning state space trajectories in recurrent neural networks. Neural Computation, 1(2), 263–269. doi:10.1162/neco.1989.1.2.263
- Pearlmutter, B. A. (1995). Gradient calculations for dynamic recurrent neural networks – A survey. IEEE Transactions on Neural Networks, 6(5), 1212–1228. doi:10.1109/72.410363
- Pearson, B. Z., Fernandez, S. C., Lewedeg, V., & Oller, D. K. (1997). The relation of input factors to lexical learning by bilingual infants. Applied Psycholinguistics, 18, 41–58. doi:10.1017/S0142716400009863
- Pentimonti, J., O’Connell, A., Justice, L., & Cain, K. (2015). The dimensionality of language ability in young children. Child Development, 86(6), 1948–1965. doi:10.1111/cdev.12450
- Perfetti, C. (2007). Reading ability: Lexical quality to comprehension. Scientific Studies of Reading, 11, 357–383. doi:10.1080/10888430701530730
- Plaut, D. C., McClelland, J. L., Seidenberg, M. S., & Patterson, K. (1996). Understanding normal and impaired word reading: Computational principles in quasi-regular domains. Psychological Review, 103(1), 56–115.
- Reardon, S. F. (2013). The widening income achievement gap. Educational Leadership, 70(8), 10–16.
- Ricketts, J., Nation, K., & Bishop, D. (2007). Vocabulary is important for some, but not all reading skills. Scientific Studies of Reading, 11, 235–257. doi:10.1080/10888430701344306
- Rowe, M. L. (2012). A longitudinal investigation of the role of quantity and quality of child-directed speech in vocabulary development. Child Development, 83, 1762–1774. doi:10.1111/j.1467-8624.2012.01805.x
- Seidenberg, M. (2017). Language at the speed of sight: How we read, why so many can’t, and what can be done about it. New York, NY: Basic Books.
- Seidenberg, M. S., & Gonnerman, L. M. (2000). Explaining derivational morphology as the convergence of codes. Trends in Cognitive Sciences, 4(9), 353–361.
- Seidenberg, M. S., & McClelland, J. L. (1989). A distributed, developmental model of word recognition and naming. Psychological Review, 96, 523–568.
- Share, D. L. (1995). Phonological recoding and self-teaching: Sine qua non of reading acquisition. Cognition, 55(2), 151–218.
- Snow, C. E., Burns, M. S., & Griffin, P. (Ed.). (1998). Preventing reading difficulties in young children. Washington, DC: National Academy Press: Wiley Subscription Services, Inc. .
- Social Mobility Commission. (2017). Social mobility in Great Britain: Fifth state of the nation report. London: UK Government.
- Storch, S. A., & Whitehurst, G. J. (2002). Oral language and code-related precursors to reading: Evidence from a longitudinal structural model. Developmental Psychology, 38(6), 934–947.
- Storkel, H. L. (2001). Learning new words: Phonotactic probability in language development. Journal of Speech, Language and Hearing Research, 44, 1321–1337. doi:10.1044/1092-4388(2001/103)
- Tannenbaum, K. R., Torgesen, J. K., & Wagner, R. K. (2006). Relationships between word knowledge and reading comprehension in their-grade children. Scientific Studies of Reading, 10, 381–398. doi:10.1207/s1532799xssr1004_3
- Taylor, J. S. H., Duff, F. J., Woollams, A., Monaghan, P., & Ricketts, J. (2015). How word meaning influences word reading. Current Directions in Psychological Science, 24, 322–328. doi:10.1177/0963721415574980
- Tomblin, J. B., & Zhang, X. (2006). The dimensionality of language ability in school-age children. Journal of Speech, Language, and Hearing Research, 49(6), 1193–1208. doi:10.1044/1092-4388(2006/086)
- Toste, J. R., Williams, K. J., & Capin, P. (2017). Reading big words: Instructional practices to promote multisyllabic word reading fluency. Intervention in School and Clinic, 52(5), 270–278. doi:10.1177/1053451216676797
- von Hippel, P., Workman, J., & Downey, D. B. (2017). Inequality in reading and math skills comes mainly from early childhood: A replication, and partial correction, of ‘Are schools the great equalizer?’ SSRN working paper 3036094.
- Yang, J., McCandliss, B. D., Shu, H., & Zevin, J. D. (2009). Simulating language-specific and language-general effects in a statistical learning model of Chinese reading. Journal of Memory and Language, 61(2), 238–257. doi:10.1016/j.jml.2009.05.001
- Zeno, S. M., Ivens, S. H., Hillard, R. T., & Duvvuri, R. (1995). The educator’s word frequency guide. Brewster, NJ: Touchstone Applied Science Associates.