
Abstract
This meta-analysis examines the methodological tendencies of scientific research about political communication on Twitter published in journals based on Spanish-speaking countries between 2019 and 2021. It covers all the journals indexed in the JCR and the two first quartiles of Scopus index, producing a universe of 1.233 articles, of which 51 addressed political communication on Twitter. The focus is set on the following methodological parameters: sample types and construction, time periods, geographical areas, methodologies, multimedia analysis, general research themes and approaches, and software resources. The aim is to provide a map of recent research in the Spanish-speaking scientific community and to identify widespread methodological trends. A significant trend of software dependency was identified, i.e. published research often consists of the mere application of a certain software to a certain dataset, without enough discussion on the possible biases introduced by the software and the sampling methods.
1. Introduction
The public sphere has undergone deep alterations during the last two decades, under the influence of globalization and digitalization, particularly after the rise of social media and their impact on traditional media and politics (Van Dijck, Citation2013). Twitter is one of the most used social media not only by citizens, but also by institutions, social leaders, media, or corporations (Bruns & Burgess, Citation2011, pp. 1–3; Fuchs, Citation2014, pp. 100–102). Its specific approach to microblogging, designed for microposts that will trigger a public debate, instead of sharing everyday personal happenings, as on other platforms, has made it the political online social medium par excellence (Hermida Citation2013, pp. 295–297). Twitter is increasingly influencing the processes of creation, operation, marketing and consumption of all kinds of communications, from newspapers to videogames, from television to literature, with special strength in the case of industries that play a role in newsmaking and political communication (Deller, Citation2011, p. 222; Hermida, Citation2010, pp. 299–301). Nowadays, many media brands hire qualified professionals for managing their presence on Twitter. Simultaneously, different voices, from professors to responsibles for national security, are expressing concerns or even taking measures to prevent Twitter’s potential threat to sovereignty and the democratic processes (Bradshaw & Howard, Citation2019, p. 21; Cadwalladr, Citation2017, pp. 1–2). In 2010, the Arab Spring was even known as The Twitter Revolution, due to the use of Twitter to mobilise and sustain the demonstrations that toppled oppressive regimes in Egypt and Tunisia (Nyoka & Tembo, Citation2022, p. 2). But Twitter can either enhance or degrade democracy depending on how its users use it in democratic process (Akerele-Popoola et al., Citation2022). To advance knowledge about its political uses is of vital importance, due to its potential to influence perceptions with very few (if any) gatekeepers to edit or verify accuracy allowing for the self-interested leverage of a network’s properties to manipulate the beliefs and behaviours of its users (McHugh & Perrault, Citation2022, p. 2).
Coherently with this social importance, the interest in researching political communication through Twitter is large. Considering scientific production in Spanish, for example, the amount of research published about political communication on Twitter is clearly higher than for any other digital platform. Following a boolean search in Dialnet, the largest data-base for scientific production in Spanish, we retrieve 333 results about political communication on Twitter, including scientific journal articles, monographies, book chapters and PhD theses. Contributions about political communication on other platforms are far less frequent (e.g., 126 for Facebook, 55 for Instagram, 52 for YouTube, 13 for WhatsApp, 8 for TikTok, 3 for Telegram, 2 both for Linked-in and Snapchat, 1 for WeChat, and 0 for Pinterest; on 5 August 2022). The same happens in the Scopus database, where 577 articles on political communication using Twitter have been indexed since 2008, while only 331 using Facebook (Arroyo Barrigüete et al., Citation2022, p. 6). The greater interest generated by Twitter is likely due to the public orientation of this medium, which on the one hand facilitates access to contents (as it is not necessary to be “friend” or “follower” of an account, in most cases, to be able to access their posts) and on the other to the greater political relevance of its contents (not aimed for private or interpersonal uses, as on other platforms).
Specifically in the field of political communication, online social media have become the setting for important events that have attracted the interest of researchers, such as the largely unpredicted results of the British vote for Brexit or the triumph of Donald Trump in 2016 (Bessi & Ferrara, Citation2016, pp. 10–11; Howard & Kollany, Citation2016, pp. 1, 5). Both were strongly influenced by Cambridge Analytica’s use of a Facebook security fault (Ur Rehman, Citation2019, pp. 4–6) that allowed them to massively access private user data to conduct micro-segmentation electoral campaigns and discourage opponent votes, -a political-communication strategy which until then not only had been unheard of but actually was technically impossible. Also, very significant have been the efforts by the government of Russia to influence and intervene in the democratic processes of third countries (Splidsboel-Hansen et al., Citation2018, pp. 1–2, 21, 26, 29). These developments have taken politics and political communication on the Internet to a new level. As a result, the amount of scientific literature about the use of Twitter for political communication has been rising during the last decade (Campos-Domínguez, Citation2017, p. 785; Casero-Ripollés, Citation2018, p. 965). It is thus vital to enlarge and deepen knowledge about Twitter and Twitter-based research all around the world, which is at the same time an aim hard to accomplish, because, among other reasons, subcultures in Twitter are language-dependent, and the uses and receptions of online discourses vary largely among countries and cultures.
In consequence, meta-analyses about uses of Twitter in political communication need to restrict their focus to meaningful entities such as the Ibero-american Cultural Space (in Spanish, Espacio Cultural Iberoamericano, and from this point forward, ECI). The ECI is a concept that refers to the network of cultural, historical, and linguistic relationships between Spanish and Portuguese-speaking countries in Latin America, the Iberian peninsula, and other territories deeply influenced by Spanish language (Bustamante, Citation2018; Grynspan, Citation2021, pp. 2–8). This space is characterized by a high diversity of cultures sharing linguistic and cultural roots, and common socio-political and religious matrices. It presents high levels of interaction and exchange between these nations, in fields like politics, education, economy, cultural cooperation, arts, literature, film industry, or social trends (Bustamante, Citation2019, pp. 118–124; Sánchez Zuluaga, Citation2017, pp. 218–238 y 270–320). The ECI has been a recurring topic both for cultural research and politics, for example in every Ibero-American Summit of Heads of State and Government, since it was officially acknowledged in the Statement of Guadalajara, in 1991, as an initiative to strengthen cultural ties between the countries of this cultural space. It has been the theoretical framework for many research and cultural cooperation programs. The idea behind the ECI is that the cultural diversity of Ibero-America is a source of wealth and that, through dialogue and collaboration, the ties between the countries can be strengthened and human and social development can be promoted.
In consequence, this meta-analysis will focus on research about the uses of Twitter in political communication, published within the cultural region of the ECI, assuming that the digital cultures that express themselves through this medium, although increasingly global and interconnected, maintain characteristics of their cultural matrices that provide essential keys in understanding and interpreting communication in general, and political communication in particular. Thus, we analyse the methodological tendencies of scientific research about political communication on Twitter appearing in top-level Ibero-american journals, published both in Spanish or English, regardless of the nationality of authors.
2. State of the art
Twitter was first released in 2006 and, although it was not until 2010 that the Spanish version was published, Twitter soon became very popular in Spain after its massive use during the historic mobilizations of 15 May 2011 (Fernández-Planells et al., Citation2013, p. 125; López Abellán, Citation2012, p. 72). Since then, Twitter regularly appeared as a main study object of research on political communication in the ECI (Del Río et al., Citation2019; Marín Dueñas et al., Citation2019; Olmedo-Neri, Citation2021). Social scientists needed to learn about the structure of Twitter’s interactions and social networks, and how the micro-blogging platform was being used by citizens, prominent figures and institutions.
A significant number of meta-studies covers the research about the uses of Twitter in education (Lytras et al., Citation2018; Rodríguez-Hoyos et al., Citation2015), career construction (Gerber & Lynch, Citation2017), public health (Edo-Osagie et al., Citation2020; Sinnenberg et al., Citation2017), security corporate communication (Walby & Gumieny, Citation2020), second language learning (Hattem & Lomicka, Citation2016) and other specific areas, but very few meta-studies focus on a methodological review about political or even institutional communication (Campos-Domínguez, Citation2017; Casero-Ripollés, Citation2018; Montero Corrales, Citation2018). None of these are specific to the Spanish-speaking political culture or scientific community. Several software reviews address programs for examining Twitter conversations (notably Yu & Muñoz-Justicia, Citation2020b) and some original empirical work includes notable methodological proposals, but not based on meta-studies (e.g. Percastre-Mendizábal et al., Citation2017). Furthermore, existing meta-analyses were generally interested in comparing the results of various original studies (Campos-Domínguez, Citation2017; Montero Corrales, Citation2018), and did not focus on comparing methodologies.
The above-mentioned studies, as many other international meta-studies of a broader scope, may be considered out-of-date, given their dependency on Twitter’s API interface, after the release of the updated version (V2.0) in May 2022, which included new limits to automated sample construction. The limits and biases produced by Twitter’s prior interfaces had been acknowledged and documented (Antonakaki et al., Citation2021; Driscoll, Citation2014; Morstatter et al., Citation2014; Pfaffenberger, Citation2016; Weller, Citation2014), but the newly introduced limits require reviewing any conclusion achieved for the prior versions.
Campos-Domínguez (Citation2017) conducted a brief but dense map of the evolution of topics and approaches worldwide, concluding that research on political communication on Twitter,
has followed Gartner’s over-expectation cycle: after the launch, when the first technical studies appeared, there was some research posing oversized expectations about the possibility of discussion and interaction on Twitter. This was followed by a stage of disappointment, when academic papers began to dismantle the expectations created and prove that political engagement was very low. The consolidation phase coincided with the stage which analysed the contents of the discussions and their impact on the public sphere, the platform’s possibilities for heterodox uses such as activism and construction of a new communication reality in the hybrid space, concluding with a normalization phase, characterised by the subversion of traditional political roles by social movements and populisms.
In another meta-study, Casero-Ripollés (Citation2018) analysed Twitter’s impact on the production, distribution, and consumption of political information, ultimately pointing out nine challenges to be resolved in order to achieve better understanding of digital political communication in the ECI:
1. Predominance of studies aimed at a single country. 2. Most studies focusing on a single platform. 3. Most studies refer to electoral campaigns. 4. Predominance of platforms based on the one-to-many communication models versus those one-to-one. 5. Poor analysis of political influence in the digital environment. 6. Need for studies on the changes in professional profiles of political communication players. 7. Need to introduce a critical view. 8. Need for methodological creativity, and 9. Encourage progress of theory in this field.
Montero Corrales (Citation2018) focused on the study of advertising on Facebook and Twitter, providing a map of interests for fifteen international journals (including six in Spanish) which organised the research into “five possible approaches”: 1) social media and learning; 2) social media vs. broadcast media; 3) content management in social media; 4) social media audiences; 5) markets and social media (Montero Corrales, Citation2018, p. 49).
Bibliometric meta-studies, such as that by Noor et al. (Citation2020) or by Yu and Muñoz-Justicia (Citation2020a), are of great use and acknowledge very comprehensively the many dimensions of the scientific literature in political communication in Twitter. Yu and Muñoz-Justicia (Citation2020a) analysed annual production, main sources, most productive authors, most cited publications and most relevant keywords, and provided a map of collaborations between countries (Asians collaborate frequently with Americans, while Europeans tend to collaborate with each other) as well as a valuable thematic analysis by time periods, concluding that the main research topics on Twitter
are primarily related to business (including marketing, advertising, etc.), communication (including political communication, new media studies, etc.), disaster management, scientometrics and computing
Over time, interest has shifted from the business area to disaster management and crisis communications, and, more recently, towards automated learning and automated analysis of emotions, through increasingly powerful computational methods (Yu & Muñoz-Justicia, Citation2020a). With a different categorization, Noor et al. (Citation2020, p. 89) identified the main six topics in Twitter research as: event detection, analysis of emotions, education, public health, politics and crisis management.
All these meta-studies addressing at least some methodological angle were conducted prior to the publication of the new API V2 and none of them clearly aimed at methodologies. Yet other international contributions have done so, although more as a proposal than as an observation. Stieglitz et al. (Citation2018, p. 166) compiled those which, in their view, are the “main challenges and difficulties which researchers face during the research steps of social media prior to data analysis: discovery, collection and preparation”, for which they propose specific solutions summarised in a logical three-phase research method and six prior questions, which require predicting the necessary volume of data, such as recognizing the most relevant areas, the infrastructure to process and interpret the whole corpus, as well as the working formats and structures. Separately, bibliometric studies focusing on methods (Karami et al., Citation2020, p. 67709), have concluded that research on Twitter (not only on political communication) based on, in this order: 1) analysis of emotions, 2) analysis of social connections, 3) Big Data mining, 4) thematic analysis, and 5) content analysis.
In conclusion, meta-studies about political communication published in Spanish or Spain via Twitter are still scarce and increasingly outdated. Specifically, a meta-study focusing on high-level research that could provide an initial map on the methodological trends in this field for the Spanish-speaking scientific community was not yet provided. In order to achieve progressive research maturity, it is necessary to conduct new systematic reviews of current research trends to be able to detect recurring objects of study, sampling methods, supporting software, geographical areas paid most and least attention to, or shared categorizations that could help to compare the results found. Previous meta-studies have presented certain flaws and challenges still to be addressed in the research on political communication in Spanish via Twitter (Campos-Domínguez, Citation2017, p. 789; Casero-Ripollés, Citation2018, pp. 969–971; Montero Corrales, Citation2018, pp. 48–49). The aim of this study is to produce a more complete and updated panoramic view of the current status of this field, and to check to what degree flaws and challenges are being addressed. This will contribute to understanding the evolution of academic research about political communication.
3. Research questions
The focus of this meta-analysis is set on the following methodological parameters: sample types and constructions, time periods, geographical areas, methodologies, multimedia analysis, general research themes and approaches, and the software being used.
Specifically, the research questions guiding the analyses of this contribution include:
RQ1: Which relevant journals are devoting more/less space to the object of study, that is political communication via Twitter, within the field of communication studies?
RQ2: How many articles on this topic have been published each year between 2019 and 2021 in each journal?
RQ3: Which geographical areas receive the most/least attention? How often are regions outside the ECI being researched by ECI researchers?
RQ4: Which types of time-periods are most frequently researched?
RQ5: Are multimedia contents of Tweets (videos, images, GIFs) being taken into account?
RQ6: Which proportion of the research focuses on electoral campaigns communication (vs. outside campaign time periods)?
RQ7: Which methodological research approaches are most frequently carried out?
RQ8: Which sample sizes are used in this research corpus? How are samples constructed or processed?
RQ9: Which software is used and how?
RQ10: Which deficits, blind spots, or other challenges emerge for the future?
The working hypotheses for this meta-analysis, connected with these research questions, are
H1: Most top-level journals devote increasing space to research about political communication via Twitter.
H2: Electoral campaigns are still the phenomenon receiving most attention in political communication research.
H3: Spain receives more attention than other countries with larger GDP or population in the ECI.
H4: Visual content (such as videos or pictures) are frequently disregarded.
H5: Research in this field frequently faces problems of representativeness of the samples.
H6: Research in this field tends to rely excessively on analytic software capabilities, often underestimating the possible bias and limits introduced by that software.
4. Methods
This meta-analysis aims at analysing the characteristics and tendencies of scientific research about political communication on Twitter in the ECI, appearing in top-level Latin-American and Spanish journals, and published both in Spanish or English, between 2019 and 2021. The nationality of the journals, as they are the main vehicle for scientific research, was chosen as selection criterion instead of the nationality of the authors, in order to focus on their editorial policy as a key factor in the configuration of research trends, frameworks and quality standards, above and beyond the individual decisions made by researchers. Scientific journals and their editorial policies play a key role in deciding main topics, common methodologies, blindspots or quality standards of scientific research, for any given scientific community.
The universe of our sample includes every journal published in Spain or Latin-America (both in English or Spanish) indexed in the JCR (2021 edition, the latest available when this meta-analysis began) or in the two first quartiles of Scopus index (SJR-2021 edition) under the category of “Communication”. Within the ECI, this study limits its scope to Spanish speaking-countries. That resulted in selecting seven journals: 1) Communication and Society (Univ. of Navarra, Spain) - España); 2) Comunicación y Sociedad (University of Guadalajara, México); 3) Comunicar (Univ. of Huelva, Spain); 4) Cuadernos.info (Pontif. Catholic Univ. of Chile); 5) El Profesional de la Información (Univ. Complutense of Madrid, Spain) ; 6) Revista de comunicación (Univ. of Piura, Perú); 7) Revista Latina de Comunicación Social (Univ. of La Laguna, Spain).
The procedure results in a universe of 1,233 papers (the total number of articles published by those seven journals between 2019 and 2021). From this universe, only the papers that research political communication via Twitter were selected. This generated a final sample of 51 papers about political communication via Twitter, on which we applied our analysis. The selection was carried out by reading the abstract, keywords, aims and scopes descriptions of each paper, together with performing an automated search for the keyword “Twitter” within the complete version of all the articles. The codification process was carried out in parallel by two of the authors, following a common definition of political communication as the “interactive process concerning the transmission of information among politicians, the news media, and the public” (Norris, Citation2015), where “news media” in this case was restricted to Twitter. The codifications achieved a level of discrepancy of±0.24% (three cases out of 1,233; one of them was finally included in the sample, and two excluded). When coding the methodologies, geographical areas, topics or software being used by the research articles reviewed, the authors of this paper registered the literal description declared by the analysed articles whenever possible, even when we disagree with the consideration of a concrete label as a theory or a methodology, for example. When a methodology was not clearly stated, we coded it into a category following the most common, well-established, and uncontroversial definitions within communication studies.
5. Results
In response to RQ1 and RQ2, the study found the number of publications per journal and year shown in Table .
Table 1. Articles in each journal and year (source: own production)
Contrary to the H1 hypothesis, most journals have not increased the amount of papers published on this topic from year to year, nor has the total number of articles published per year increased: 12 articles were registered in 2019 (23.5%), 23 in 2020 (45.1%), and 16 in 2021 (31.4%). The journal showing most interest in political communication via Twitter are EPI with 16 articles (31.4% of the sample) and Communication and Society, with 15 (29.4%), followed at a significant distance by Cuadernos.info and Revista Latina, with 6 articles each (11.8%). The least space was dedicated by Comunicación y Sociedad, with just one article (2.0%).
5.2. Sample sizes and types
In response to RQ8, the study found, as expected, that sample sizes chosen by researchers are very different among the articles analysed, because they address very different research objectives. Most studies analyse tweets and interactions (72.5%). In these cases, the average size of the sample was 19,813 tweets, with a median of 995. As for the remaining cases, 17.6% did not analyse tweets, but rather other types of contents such as patterns of profile followers, or surveys and interviews conducted among Twitter users, and 7.8% did not specify any sample at all. Among these studies, it is remarkable that one of them (Salgado Andrade, Citation2021) considered a sample of 8 memes (out of a universe of 58) about the COVID-19 pandemic whose collection and selection was not justified by any criteria. Also a single case (2.0%) was found without any kind of sample, as it was a purely theoretical reflection.
5.3. Sampling methods
In relation to RQ7 and RQ10, one of the most interesting elements of this meta-study is understanding how samples destined for the analysis of political communication on Twitter are being constructed. Therefore, we have looked at the criteria defined to delimit the samples of cases (i.e., Tweets, interactions and/or profiles, see Figure ). These selection criteria vary and, frequently (23.5%), studies apply more than one strategy for delimitation. The most common approach (68.6%) is to construct a set of profiles to be analysed, and then retrieve a certain amount of their tweets. Selecting hashtags instead of profiles was the criterion in 21.6% of articles. Selecting search terms or keywords to identify topics occurred in 9.8% while selecting data by their virality, in 7.8%. A 5.9% decided to sample data by account mentioning. Other criteria appeared on only one occasion, like geolocalisation, appearance of tweets on the front pages of certain newspapers, or collecting memes from 4 different politicians whose selection was not justified. One article did not specify any selection criteria, and three did not analyse Twitter data (one was a theoretical reflection and two produced data through surveys or interviews with Twitter users).
Figure 1. Sample search criteria (source: own production).
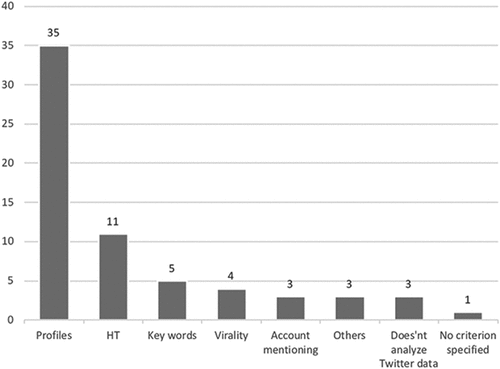
Of all the studies analysed, only 35.3% distinguish between the universe and the sample, detailing each concept. All other quantitative studies do not make this distinction, leaving in the dark how they accomplish data screening, that is the process of determining the final sample of analysis departing from an initial universe. Discussions about the complex screening processes from the initial set of tweets collected until ending up with the reduced sample finally analysed are often missing, even where a distinction between universe and sample of analysis was made. In cases that did not conduct screening at all, researchers relied on software (e.g., Twitonomy, see below), or a Boolean search delimited by time ranges through Twitter’s API or search form, to compile a sample, with no discussion on the difficulties of further screening.
5.4. Number of accounts analysed
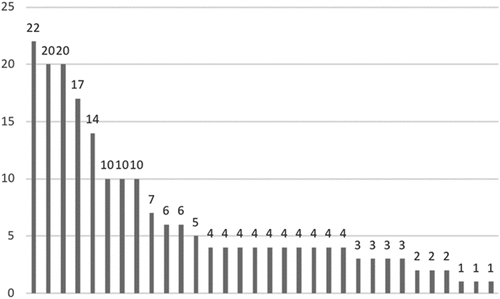
Out of the 66.6% of studies that built their analytical sample based on a limited set of user accounts, up to 57.1% did so with four or fewer Twitter accounts. In fact, four is the most frequent value for the size of user account samples (28.6%). This is because analyses focusing on profiles from four political leaders, or parties, or newspapers, are very frequent, achieving a minimum plurality of different voices or achieving a diversity that allows making some comparisons. Only three studies analysed more than 25 profiles: one study analysed 42, another 87 and a third study, 5,001 profiles. The three cases were excluded from Figure displaying the number of accounts.
Figure 2. Number of accounts analysed (source: own production).
5.5. Time periods and campaign centrality
As for the time periods analysed (in response to RQ4), the range varied from 5 years to 48 hours, among those which selected tweets by time elapsed. No study analysed time periods of under 24 hours. Even if they focused on a television program such as the electoral debates, or the publication of a leak, the period was extended to the 24 hours prior and/or after the event. Half of the studies (51.0%, 26 papers) focused on periods between 48 hours and up to one month, and only five of them (9.8%) analysed periods of one year and more. The average period studied was 115.6 days, with the mode being one month (30 days) and the median 30.5 days.
In response to RQ6, and confirming hypothesis H2, electoral campaigns continue playing a key role in political communication studies on Twitter, with almost half of the research (45.0%) observing this time period, whether the full period or events occurring during the campaign, such as electoral debates, reflection days, voting days or other specific events. All other studies covered time periods outside the campaign, or periods of one year or longer, therefore they did not focus on campaign developments, even if they included some in their sample.
5.6. Geographical areas
In response to RQ3, the study found that most papers published analysed the Spanish digital public sphere (56.9%, 29 papers), as predicted by hypothesis H3. Of these, 23 analysed the national public sphere (45.1% of the total). Six analysed regional phenomena (11.8% of the total): three about Catalonia, one about the Community of Madrid, one about eight regions and another one about Andalusia. Except for the latter, which addressed only Andalusian political spokespersons, the rest of the studies did not limit their analysis by geo-localization, but rather took into account the debate generated about regional topics considering participants from anywhere. This is at least partly due to the dearth of the geolocation service of Twitter messages or users, which can be easily tricked and furthermore is infrequently used by Twitter users, who tend not to specify their geolocation in their messages or profiles.
Outside Spain, the regions of greatest interest are Latin America and European Union countries (15.7% each). Two cases analysed political phenomena located in the United States (Figure ). Table shows the distribution of areas of greatest interest.
Figure 3. Geographical areas (source: own production).
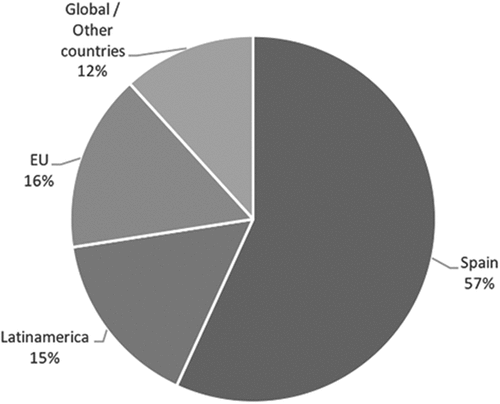
Table 2. Geographical areas (source: own production. n = 52 because one of the papers analysed both the United States and the United Kingdom)
5.7. Software used and how it is employed
In response to RQ9, the analysis registered up to 35 software programs mentioned by the researchers in 51 articles. Most notable among them are statistical analysis programs such as SPSS and R (used in 33.3% of the cases), the application Twitonomy, that compiles samples, analyse units and displays the data (19.6%) or directly accessing Twitter’s API (13.7%) for, essentially, extracting data (Figure ).
Figure 4. Software used (source: own production).
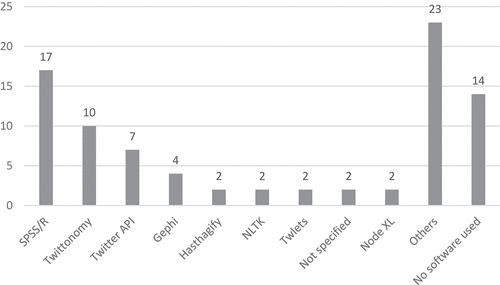
The complete list of software used and specified is, in alphabetical order: AdaBoost, Chorus Tweet Catcher, Decision Tree, Doccano, FanPage Kharma, Gephi, Google Knowledge Graph, Hashtagify, Keras, Machines, Maxqda, NLTK, Node XL, Nvivo, Orange, Pajek, QSR Nvivo, R, Random Forest, Rstudio, Rtuit, SciKit-Learn, SPSS, Support Vector, TensorFlow, TinEye, Tweepy, Twitonomy, Twitter Archiver, Twitter Capture and Analysis Toolset, Twitter Search, Twlets, Vicinitas and Wordle.
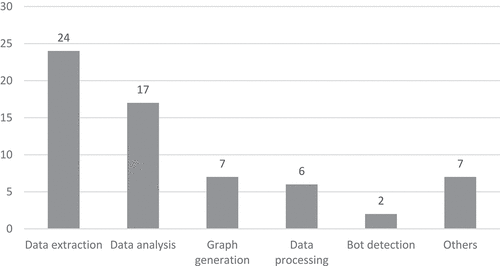
The most frequently mentioned uses of these applications were data extraction (24 cases), data analysis (17), chart generation (7) and data processing (6) (Figure ).
Figure 5. Software’s purpose (sources: own production).
5.8. Research methodologies
As can be seen in Figure , the most frequently quoted research method was, by far, content analysis (both quantitative and qualitative), applied in 76.5% of the cases (39 papers). It was followed by the Social Network Analysis, or SNA, used 54.9% of the cases (28 papers), the analysis of emotions 25.5% (13 cases) and the discourse analysis 13.7% (7 cases).
Figure 6. Methodologies used (source: own production).
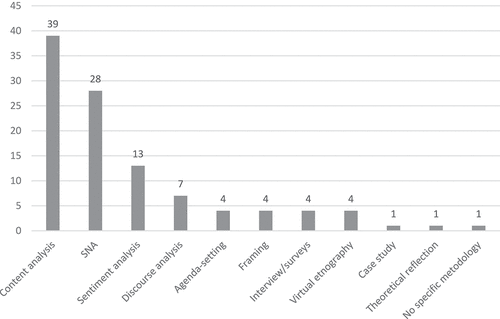
There is also a repetition of well-established methodologies such as agenda-setting, framing, in-depth interviews, surveys, and virtual ethnography, all with an occurrence of 7.8% (four cases each). In addition, one paper used a case study of a brief intentional sample (González-Oñate et al., Citation2020), another paper presented a purely theoretical dissertation (Guerrero-Solé et al., Citation2020) and another one mentioned no specific methodology (Haman & Školník, Citation2021).
5.9. Multimedia analysis
In response to RQ5, the study found that, within all the studies analysed, only 29.4% (15 cases) took into account the audiovisual contents of Tweets (videos, images, GIFs, sounds, etc.) and specified them in their methodology constructions and/or results. Thus, hypothesis H4 is verified. The remaining 70.6% (36 studies) did not specifically address this issue, or did not mention it at all, despite the importance of images in political communication on Twitter, very frequently used as a rhetorical device, and very often exclusively. This generates problems of representativeness (as predicted by hypotheses H5) and/or comprehensiveness for a significant amount of the studies analysed, in which some method of analysis is applied—partially automated—, to text fragments whose meaning is altered if separated from their accompanying image not apt for automated semantic analysis. Only two of the studies specifically focused on the use of images as a key issue.
5.10. Topics and general approaches
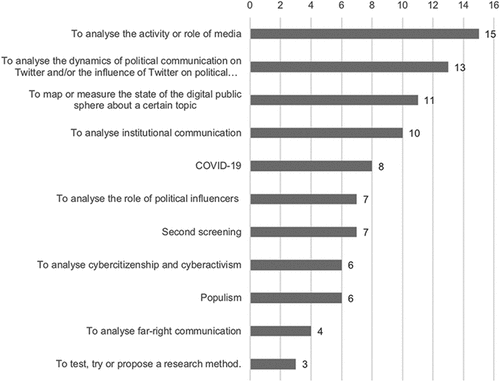
As for the purpose of the papers analysed, we identified eleven main thematic lines (cfr. Figure ), here listed in order of frequency (62.7% of the papers presented several topics, so the total of the following percentages is more than 100):
To analyse the activity or role of media: 24.5%
To analyse the dynamics of political communication on Twitter and/or the influence of Twitter on political processes: 25.5%
To map or measure the state of the digital public sphere about a certain topic: 24.6%
To analyse institutional communication: 19.6%
Management of the COVID-19 crisis: 15.7%
To analyse the role of political influencers: 13.7%
Second screening: 13.7%
To analyse cybercitizenship and cyberactivism: 11.8%
Populism: 11.8%
To analyse far-right communication: 7.8%
To test, try or propose a research method: 5.88%
Figure 7. Topics and general approaches (source: own production).
5.11. Key findings
The key finding of this meta-analysis are:
(1) Twitter is still the online social network generating the greatest research interest regarding political communication among the Spanish-speaking scientific community. In particular, just in relation to this specific interest, studies on said platform have represented 4.1% of all JCR, and Scopus Q1 and Q2 publications under the category of Communication in the last three years.
(2) In general, samples are large in relation to the time periods analysed (median 995 Tweets/one month) and well justified (usually according to the activity of accounts of influential figures during a period of special relevance, or the activity generated around a hashtag). Nonetheless, in response to RQ10:
There are cases of studies published in high impact journals with insufficient samples and/or arbitrary criteria for building samples, as predicted by hypotheses H5.
A high number of studies (35%) do not distinguish between universe and sample, and donot include any discussion whatsoever on the lack of unbiased access to the totalinformation on Twitter, or on the risks of bias induced by the sample collection and datascreening methods.
In other words, there is a tendency to extract and analyse a set of data just by applyingsome software and then to present the outcome.
(3) The most common number of accounts analysed is low (57.1% of the studies analysed four or fewer Twitter accounts, out of the 66.6% of studies that built their analytical sample based on a certain set of user accounts). In fact, four is the most frequent sample size for user accounts (28.6%), which indicates a research trend towards the analysis of local communication phenomena, more focused on communication strategies of prominent figures than on studying the response of citizens or large digital communities.
(4) The most common value for time periods is one month, often coinciding with the last month of a campaign prior to elections. In parallel to all the above points, this also shows a research trend towards specific and intense periods, instead of towards longer processes with a broader scope. In particular, the most common criterion was to study campaign periods. Accordingly, the academic view prioritises politics as an electoral phenomenon rather than a parliamentary, institutional or an activism-related one.
(5) The geographical area most intensely researched is Spain (57%), followed at a big distance by the European Union and Latin America (16% each).
(6) There is a very widespread use of software (73%), with a large variety of programs (up to 35 different applications registered) to analyse political communication on Twitter. The most used ones are for statistical analysis (R or SPSS, 33.3%), followed by Twitonomy (19.6%) and direct access to Twitter’s own API interface through ad-hoc scripts (13.7%). Generally, software is used for data extraction (47%) and analysis (33%). A high number of software-dependent studies are restricted by the limitations of the software used, but restrictions are mostly not taken into account or poorly discussed (cfr. Discussion below).
(7) Contents analysis and social network analysis stand out, by far, as the most widespread methodologies (76% and 55% respectively). Also relatively common are the analysis of emotions (25%) and the analysis of discourse (14%).
(8) Although multimedia contents are a key element of communication on Twitter, at times essential in the case of political communication, only 29% of the studies consider it analysis material and only 4% focus specifically on its analysis. There is a certain overestimation of the importance of written contents, or rather, an underestimation of image contents. This may be due to the fact that text is often the input for Computer Assisted Text Analysis software, while multimedia contents require human analysis and, therefore, go beyond the capabilities of any software dependent study.
(9) The most common sampling method is to construct a set of profiles to be analysed, and then retrieve a certain amount of their tweets (66.6%). Selecting hashtags instead of profiles was the criterion in 21.6% of articles, and selecting search terms or keywords to identify topics or selecting posts by their virality occurred both in 7.8% of the cases.
(10) Most journals have not increased the amount of papers published on this topic from year to year, nor has the total number of articles published per year increased.
(11) While hypothesis H1 has been disproved, H2, H3 and H4 have been validated. Hypothesis H5 and H6 were at least partially confirmed, raising concerns about a frequent problem of representativeness and software-dependency in the research on political communication via Twitter, and calling for further specific attention to this problem (see next section, Discussion).
6. Discussion
After this meta-analysis, a series of notable elements for improving academic research criteria in the specific field and topic of political communication research on Twitter could be identified.
6.1. Software dependency and software-induced biases
Firstly, cases with very small and arbitrary samples were found. These were isolated cases, yet their presence in high impact journals is concerning.
Not distinguishing between universe and sample and not reporting the applied data screening strategy (i.e., how to achieve the sample of analysis from the universe of potential cases) is, on the other hand, a very common practice. This appears to indicate, together with the lack of discussion on the difficulties of building samples, a certain unawareness of the potential biases due to unspecified data screening. As predicted by hypothesis H6, software applications were often used in those cases without discussion whatsoever on the difficulty of data screening. A common practice is that, by specifying a certain set of user accounts or search terms, a data package is automatically extracted from Twitter, which is then entered into a program that automatically performs the analyses. The results provided by the software are the ones presented in the study, with minimum or none interpretation. However, the capability of the software used for data extraction is far from collecting all the tweets for keywords, hashtags, accounts or time periods, as generally stated in the instructions of use. This is the case for programs such as Twitonomy, Chorus Tweet Catcher, FanPage Kharma, Hashtagify, Node XL, Tweepy, Twitter Archiver, Twitter Capture and Analysis Toolset, Twitter Search, Twlets or Vicinitas, among others, therefore any study which merely presents samples built with these programs, and the resulting data from automatic processing, lacking any discussion on the limits of the sample construction and/or screening, are in fact having clear problems with the representativeness of their samples, as stated in hypothesis H5 and H6. This is what we call software-dependent methodologies. This phenomenon, although frequently unnoticed by Twitter researchers, was however pointed out already at the start of the studies on said platform. Back in 2011, investigators Bruns and Burgess highlighted that Twitter imposes strong technical restrictions we will not list here for lack of space, but which refer to the age and comprehensiveness of the set of Tweets that can be consulted with their official APP or search form, concluding that this “prevents any academic study that aims to monitor activities or interests with representative samples” (Bruns & Burgess, Citation2011).
The vast majority of the studies analysed use, either directly or through other software, Twitter APIs to access their data. Since the current API (v2.0) is dated May 2022, the studies included in this meta-analysis are based on API 1.0 and 1.1, when Twitter distinguished three types of access: 1) Streaming API, to query the tweet stream in near real time, with a maximum limit of 50 tweets per second (of the approximately 7600 tweets published every secondFootnote1); 2) Search API, to retrieve tweets less than 7 days old (limited to 18,000 tweets every 15 minutes, i.e. 20 tweets per second); and 3) Restore API, to retrieve tweets less than 7 days old (limited to 18,000 tweets every 15 minutes, i.e. 20 tweets per second). In the new API v2, the nomenclature and limits have changed slightly, and a distinction has been made between free or essential access (0.5 M tweets per month), business or commercial access (2 M tweets/month) and academic access (the least limited, with 10 M tweets per month, out of the 19,700 M tweets published per month).Footnote2 Therefore, it would be of interest if researchers always specified which API was used in each case (or which API uses the software they are employing) to account for the specific sampling limits. However, regardless of the API version in use, the conclusion is the same: the APIs used in academic research do not actually provide access to the full set of tweets in real time, nor to 100% of those in the historical archive, and the way in which Twitter selects the subset offered is unknown. Therefore, the problem of representativeness of the sample still occurs. Moreover, in the official documentation of its APIs, Twitter warns2:
In addition to rate limits, we also have Tweet caps that limit the number of Tweets that any Project can retrieve from certain endpoints in a given month, which is based on your access level. […] Users’ rate limits are shared across all Apps that they have authorised. […] Some application features that you may want to provide are simply impossible in light of rate-limiting, especially around the freshness of results.
Therefore, it would be a good research practice if each methodological framework clearly indicated the access level being used, the way it is dealing with the limits of such level, or with the fact that we do not know how Twitter chooses which posts enter a sample and which ones it leaves out, once its limitations by volume, date or level of access have been reached. The representativeness of any sample of tweets can never be assumed in an undiscussed way. As Ruiz-Soler points out (Ruiz-Soler, Citation2017, p. 27)
Most research using [Twitter’s] Stream or Search APIs to gather data will not be able to compare the results with those provided by the Firehose API, so it is impossible to know how big the population of tweets really is. In other words, not having any previous information about the tweets’ population size when using public APIs implies a structural uncertainty about the validity of the sample.
Moreover, Campan et al. (Citation2018, p. 3638) have found that
concurrent collections of Tweets will likely miss the same Tweets. Also, even the unfiltered sampling process is missing the same Tweets at a significantly higher rate. The process Twitter is using to eliminate Tweets (with or without filtering) is likely deterministic, and guided by a limit size. Such a sample cannot be considered a random sample. […] Using Twitter data is useful for academic research, in particular for keywords that are not very popular, however with caution. Tweets collected using trendy keywords can also be useful if a random sample is not necessary for such a study.
Along the same lines, the conclusions of Pfeffer et al. (Citation2018, p. 1) go even a little further:
we demonstrate that, due to the nature of Twitter’s sampling mechanism, it is possible to deliberately influence these samples, the extent and content of any topic, and consequently to manipulate the analyses of researchers, journalists, as well as market and political analysts trusting these data sources. Our analysis also reveals that technical artifacts can accidentally skew Twitter’s samples. Samples should therefore not be regarded as random.
As can be seen, this is a phenomenon widely known in computer sciences (Campan et al., Citation2018; Carvalho et al., Citation2017, pp. 374–376; Morstatter et al., Citation2014; Pfeffer et al., Citation2018; Ruiz-Soler, Citation2017, pp. 21–26; Tromble et al., Citation2017; Tufekci, Citation2014), and yet, as demonstrated in this meta-study, it is largely ignored within the social sciences, especially in the scientific community researching political communication in Spanish-speaking Twitter.
At the same time, software oriented towards Twitter research often warns of these limitations, in addition to its own. For example, NodeXL, in its documentation, warns thatFootnote3:
Moreover, Twitter’s public free API has many limits. NodeXL Basic and Pro are both affected by these limits. Data is available only for 8–9 days. Queries cannot return more than 18,000 tweets. The follower network is further restricted: the rate at which queries about who follows who can be asked is low.
However, research based on NodeXL often does not discuss the effects of such limitations on their sample building methods. On the other hand, sample screening tasks are fundamental, as Congosto et al. (Citation2017) point out:
Currently, it is possible to select a set of tweets by one of these three forms: 1.Keywords; 2. By users; 3. By geo localization; These three options are mutually excluding; it is not possible to look for more than one option simultaneously. When it is necessary to monitor users and keywords, the developer has to resort to solutions that process in parallel, fusing, and eliminating duplicated messages later. For instance, this case is relatively frequent in the tracking of electoral campaigns in which it is interesting to know the conversation around the candidates (users) and the mottos for the campaign (represented as a set of keywords).”
But these recommendations, as demonstrated, are not always being considered in research on political communication with a high impact factor. This observation is particularly serious if we take into account warnings such as the one summarised by Tufekci (Citation2014):
Almost all of Twitter (and other social media) analyses depend on access to samples. Twitter does not reveal in detail how data sampling is handled. The API has to be regarded as an unavoidable “black box”, which is sitting between the researcher and the data source. Consequently, the use of Twitter data is regarded as highly problematic, especially in the social sciences. Because sampling is so prevalent, we need to question its validity and better understand platform mechanisms and possible biases in the resulting data […] In this paper we will prove that the sampling mechanism of Twitter’s Sample API is highly vulnerable to manipulation and is prone to creating sampling artifacts that can jeopardise representativeness of accessible data. Therefore, the samples from the Sample API cannot be regarded as random.
Other studies, which are not meta-studies, coincide in different ways with the conclusions drawn from the research presented here, through purely technical analyses of the characteristics of Twitter’s API v1.0 (Bruns & Burgess, Citation2011) and API v1.1 (Pfeffer et al., Citation2018).
6.2. Scarcity of multimedia analysis
Twitter is a platform where multimedia contents are a key element of communication, from photographs and memes to videos and GIFs. For example, when they are employed ironically, expressing the opposite of the words that accompany them, which is a very common use. However, the academic studies we have analysed most often ignore this and analyse only the written contents. On the one hand, this is an omission that is difficult to justify, given the importance of the audio-visual contents. On the other hand, it points, again, towards the above mentioned problem of software dependency or software-induced bias, predicted by hypothesis H6. The software programs can analyse the written contents of large packages of Tweets, providing both results on the words they use or the relations they express (like answers, mentions, retweets or quotes). But the multimedia analysis cannot easily be delegated to a program. Thus, software dependent tactics seldom take multimedia contents into account.
7. Recommendations for future research
Taking into account the key findings of this this meta-study and their discussion, and giving special emphasis to the two problems discussed above, three major recommendations may be offered for scientific production on political communication on Twitter:
Sampling methods should be clearly explained and discussed, paying attention to any source of bias, and specifically to software-induced bias. The preparation and screening of the data samples must follow well-defined criteria, which in turn must be explained, and not left at the mercy of automatic extraction conducted by any software. As explained, computer programs cannot access all the data published via Twitter. Not considering these difficulties will produce biased samples and lead to probable over-extrapolations: the risk of presenting results as representative when they are not.
Given the importance of multimedia contents for communication on Twitter, it will be useful to pay more attention to elements other than text in order to understand how information, trends of thought and public opinion are being generated on said platform.
Research about political communication can benefit from greater autonomy and variation in data analysis instead of excessively relying on automated analyses provided by various computer programs.
8. Limitations
At this point, this research project has not been able to transcend the limits of the ECI cultural space, it has left outside non-Spanish speaking countries, and is limited to the last three years. A wider scope would of course be useful, including other cultural spaces like the anglo-saxon, or European or Arab countries, and ideally reaching the whole world and the time period of the last decade, which of course would require a vast amount of resources.
Not all relevant research on the selected topic was included, as the focus was set on journals based on the Spanish-speaking countries of the ECI.
Therefore, an appropriate way to continue this research would be to include Portuguese-speaking countries, to enlarge the time period until six or more years, and to compare the described research trends with the ones presented by journals based outside the ECI (on the very same research topic).
Our meta-analysis is limited to only one online social network, the most clearly oriented to political communication. A comparison with the research trends on other platforms will be very useful.
Acknowledgments
This work was supported by the Volkswagen Foundation under Grant 99685.
Authors express their gratitude to the reviewers for their thoughtful comments and efforts towards improving this manuscript.
Disclosure statement
The authors declare that they have no known competing financial interests to disclose or personal relationships that could have appeared to influence the work reported in this paper, and that no situation of real, potential or apparent conflict of interest is known to them.
Additional information
Funding
Notes on contributors
Miguel Álvarez-Peralta
Miguel Álvarez-Peralta has been a professor and researcher at the Faculty of Communication of the University of Castilla-La Mancha since 2012. He has taught Political Communication, Media System Structure, Economic Journalism and Semiotics of Mass Communication, in UCLM, Complutense University of Madrid (UCM), the National University of Distance Education (UNED), the Menéndez Pelayo International University (UIMP), the University of Bologna (Italy) and Harvard University (Cambridge, USA), where he worked as a Fellow Researcher (2012-2013). He has lectured as well at other universities in the United States, United Kingdom, Greece, Mexico, Argentina, Chile, Portugal and Italy.
Raúl Rojas-Andrés
Raúl Rojas-Andrés is professor and researcher at the Faculty of Communication of the University of Castilla-La Mancha, teaching Political Communication. He focuses his investigation on the study of the Spanish left-wing culture, its relations with cultural distinction and how the communication of culture and knowledge influences the construction of popular identities around ideologies. He is graduated in Philosophy, master in Sociology and PhD in Journalism and Communication.
Svenne Diefenbacher
Svenne Diefenbacher is lecturer and researcher at the Department of Social Psychology at Ulm University since October 2011, graduated in Social Sciences at the Humboldt University of Berlin and with a Master’s degree in Research Methodology in Social Sciences of the Complutense University of Madrid. Their research focuses on determinants of behaviour, behaviour change and habit formation with applications in health promotion and infection prevention in private and professional settings (e.g., hospitals and health-care workers, early-child education and care institutions).
Notes
1. According to Domo’s “Data Never Sleeps 5.0” report (Marr, Citation2018).
2. Twitter’s API official documentation, available at: developer.twitter.com/en/docs/twitter-api.
3. NodeXL official Documentation, FAQs, available at www.smrfoundation.org/nodexl/faq/.
References
- Akerele-Popoola, O. E., Azeez, A. L., & Adeniyi, A. (2022). Twitter, civil activisms and EndSARS protest in Nigeria as a developing democracy. Cogent Social Sciences, 8(1), 2095744. https://doi.org/10.1080/23311886.2022.2095744
- Antonakaki, D., Fragopoulou, P., & Ioannidis, S. (2021). A survey of Twitter research: Data model, graph structure, sentiment analysis and attacks. Expert Systems with Applications, 164, 114006. https://doi.org/10.1016/j.eswa.2020.114006
- Arroyo Barrigüete, J. L., Barcos, L., Bellón, C., & Corzo, T. (2022). One year of European premiers leadership and empathy in times of global pandemic: A Twitter sentiment analysis. Cogent Social Sciences, 8(1), 2115693. https://doi.org/10.1080/23311886.2022.2115693
- Bessi, A., & Ferrara, E. (2016). Social bots distort the 2016 US Presidential election online discussion. First Monday, 21(11–7). https://doi.org/10.5210/fm.v21i11.7090
- Bradshaw, S., & Howard, P. N. (2019). The global disinformation order: 2019 global inventory of organised social media manipulation. University of Oxford.
- Bruns, A., & Burgess, J. E. (2011septiembre8) New methodologies for researching news discussion on Twitter. In The Future of Journalism Cardiff University. http://eprints.qut.edu.au/46330/
- Bustamante, E. (2018). Informe sobre el estado de la Cultura en España. España y el espacio cultural iberoamericano. Libros de la Catarata: ISBN 978-84-9097-466-7
- Bustamante, E. (2019). La construcción del espacio iberoamericano de comunicación y cultura. Integraciones y des-integraciones. TSN Transatlantic Studies Network: Revista de Estudios Internacionales, 5(8), 117–19.
- Cadwalladr, C. (2017). The great British Brexit robbery: How our democracy was hijacked. The Guardian, 7.
- Campan, A., Atnafu, T., Truta, T. M., & Nolan, J. (2018). Is data collection through Twitter streaming API useful for academic research? 2018 IEEE International Conference on Big Data (Big Data), 3638–3643. https://doi.org/10.1109/BigData.2018.8621898
- Campos-Domínguez, E. (2017). Twitter y la comunicación política. El profesional de la información, 26(5), 785. https://doi.org/10.3145/epi.2017.sep.01
- Carvalho, J. P., Rosa, H., Brogueira, G., & Batista, F. (2017). MISNIS: An intelligent platform for twitter topic mining. Expert Systems with Applications, 89, 374–388. https://doi.org/10.1016/j.eswa.2017.08.001
- Casero-Ripollés, A. (2018). Research on political information and social media: Key points and challenges for the future. El profesional de la información, 27(5), 964. https://doi.org/10.3145/epi.2018.sep.01
- Congosto, M., Basanta-Val, P., & Sanchez-Fernandez, L. (2017). T-Hoarder: A framework to process Twitter data streams. Journal of Network and Computer Applications, 83, 28–39. https://doi.org/10.1016/j.jnca.2017.01.029
- Deller, R. A. (2011). Twittering on: Audience research and participation using Twitter. Participations, 8(1), 216–245.
- Del Río, M. A. C., Pullaguari-Zaruma, K. P., & Prada-Espinel, O. A. (2019). Comparativa de la competencia mediática en comunicación política vía Twitter durante las campañas electorales de candidatos presidenciales en España, Ecuador y Colombia. Contratexto, 32(032), 41–70. https://doi.org/10.26439/contratexto2019.n032.4606
- Driscoll, K. (2014). Working Within a Black Box: Transparency in the Collection and Production of Big Twitter Data. 20.
- Edo-Osagie, O., De La Iglesia, B., Lake, I., & Edeghere, O. (2020). A scoping review of the use of Twitter for public health research. Computers in Biology and Medicine, 122, 103770. https://doi.org/10.1016/j.compbiomed.2020.103770
- Fernández-Planells, A., Feixa Pampols, C., & Figueroas-Maz, M. (2013). 15-M en España: diferencias y similitudes en las prácticas comunicativas con los movimientos previos. Última década, 21(39), 115–138. https://doi.org/10.4067/S0718-22362013000200006
- Fuchs, C. (2014). Social media: A Critical Introduction. SAGE Publications.
- Gerber, H. R., & Lynch, T. L. (2017). Into the Meta: Research methods for moving beyond social media surfacing. TechTrends, 61(3), 263–272. https://doi.org/10.1007/s11528-016-0140-6
- González-Oñate, C., Jiménez-Marìn, G., & Sanz-Marcos, P. (2020). Consumo televisivo y nivel de interacción y participación social en redes sociales: análisis de las audiencias millennials en la campaña electoral de España. Profesional de la información, 29(5). https://revista.profesionaldelainformacion.com/index.php/EPI/article/view/78304/62583
- Grynspan, R. (2021). «La Cumbre Iberoamericana de Jefes de Estado y de Gobierno y la cooperación del Espacio Cultural Iberoamericano». Monograma. Monograma Revista Iberoamericana de Cultura y Pensamiento, 9(9), 51–58. https://doi.org/10.36008/monograma.2021.09.2009
- Guerrero-Solé, F., Suárez-Gonzalo, S., Rovira, C., & Codina, L. (2020). Social media, context collapse and the future of data-driven populism. Profesional de la información, 29(5). https://doi.org/10.3145/epi.2020.sep.06
- Haman, M., & Školník, M. (2021). Politicians on social media. The online database of members of national parliaments on Twitter. Profesional de la información, 30(2). https://doi.org/10.3145/epi.2021.mar.17
- Hattem, D., & Lomicka, L. (2016). What the Tweets say: A critical analysis of Twitter research in language learning from 2009 to 2016. E-Learning and Digital Media, 13(1–2), 5–23. https://doi.org/10.1177/2042753016672350
- Hermida, A. (2010). Twittering the news: The emergence of ambient journalism. Journalism Practice, 4(3), 297–308. https://doi.org/10.1080/17512781003640703
- Hermida A. (2013). Journalism: Reconfiguring journalism research about Twitter, one tweet at a time. Digital Journalism, 1(3), 295–313. https://doi.org/10.1080/21670811.2013.808456
- Howard, P. N., & Kollany, B. (2016). Bots, #strongerin and #brexit: Computational Propaganda during the UK-EU Referendum. Social Science Research Network.
- Karami, A., Lundy, M., Webb, F., & Dwivedi, Y. K. (2020). Twitter and research: A systematic literature review through text mining. Institute of Electrical and Electronics EngineersAccess, 8, 67698–67717. https://doi.org/10.1109/ACCESS.2020.2983656
- López Abellán, M. (2012). Twitter como instrumento de comunicación política en campaña: Elecciones Generales de 2011. Cuadernos de Gestión de Información, 2(2), 69–84.
- Lytras, M. D., Visvizi, A., Daniela, L., Sarirete, A., & Ordonez De Pablos, P. (2018). Social networks research for sustainable smart education. Sustainability, 10(9), 2974. https://doi.org/10.3390/su10092974
- Marín Dueñas, P. P., Simancas González, E., & Berzosa Moreno, A. (2019). Uso e influencia de Twitter en la comunicación política: el caso del Partido Popular y Podemos en las elecciones generales de 2016. Cuadernos info, 45(45), 129–144. https://doi.org/10.7764/cdi.45.1595
- Marr, B. (2018, may 21). How much data do we create every day? Forbes, https://www.forbes.com/sites/bernardmarr/2018/05/21/how-much-data-do-we-create-every-day-the-mind-blowing-stats-everyone-should-read/
- McHugh, P., & Perrault, E. (2022). Of supranodes and socialwashing: Network theory and the responsible innovation of social media platforms. Cogent Social Sciences, 8(1), 2135236. https://doi.org/10.1080/23311886.2022.2135236
- Montero Corrales, L. (2018). Facebook y Twitter: Un recorrido por las principales líneas de investigación. Revista Reflexiones, 97(1), 39. https://doi.org/10.15517/rr.v97i1.33283
- Morstatter, F., Pfeffer, J., & Liu, H. (2014). When is it biased?: Assessing the representativeness of twitter’s streaming API. Proceedings of the 23rd International Conference on World Wide Web - WWW ’14 Companion, 555–556. https://doi.org/10.1145/2567948.2576952
- Noor, S., Guo, Y., Shah, S. H. H., Nawaz, M. S., & Butt, A. S. (2020). Research synthesis and thematic analysis of twitter through bibliometric analysis. International Journal on Semantic Web and Information Systems, 16(3), 88–109. https://doi.org/10.4018/IJSWIS.2020070106
- Norris, P. (2015). Political Communication. In E. J. D. Wright (Ed.), International Encyclopedia of the Social & Behavioral Sciences (Second Edition) (pp. 342–349). Elsevier. https://doi.org/10.1016/B978-0-08-097086-8.95025-6
- Nyoka, P., & Tembo, M. (2022). Dimensions of democracy and digital political activism on Hopewell Chin’ono and Jacob Ngarivhume Twitter accounts towards the July 31st demonstrations in Zimbabwe. Cogent Social Sciences, 8(1), 2024350. https://doi.org/10.1080/23311886.2021.2024350
- Olmedo-Neri, R. A. (2021). La comunicación política en Internet: el caso de #RedAMLO en México. Universitas-XXI, Revista de Ciencias Sociales y Humanas, 34(34), 109–130. https://doi.org/10.17163/uni.n34.2021.05
- Percastre-Mendizábal, S., Pont-Sorribes, C., & Codina, L. (2017). A sample design proposal for the analysis of Twitter in political communication. El profesional de la información, 26(4), 579. https://doi.org/10.3145/epi.2017.jul.02
- Pfaffenberger, F. (2016). Twitter als Basis wissenschaftlicher Studien. Springer Fachmedien Wiesbaden. https://doi.org/10.1007/978-3-658-14414-2
- Pfeffer, J., Mayer, K., & Morstatter, F. (2018). Tampering with Twitter’s Sample API. EPJ Data Science, 7(1), 50. https://doi.org/10.1140/epjds/s13688-018-0178-0
- Rodríguez-Hoyos, C., Salmón, I. H., & Fernández-Díaz, E. (2015). Research on SNS and education: The state of the art and its challenges. Australasian Journal of Educational Technology, 31(1), Article 1 https://doi.org/10.14742/ajet.995.
- Ruiz-Soler, J. (2017). Twitter research for social scientists: A brief introduction to the benefits, limitations and tools for analysing Twitter data. Dígitos Revista de Comunicación Digital, 1(3). Art. 3. https://doi.org/10.7203/rd.v1i3.87.
- Salgado Andrade, E. (2021). Memes y procesos de semiosis de la pandemia en México. Comunicación y sociedad, 18. https://doi.org/10.32870/cys.v2021.7906
- Sánchez Zuluaga, U. H. (2017). Identificación de las condiciones para la promoción del mercado común iberoamericano de la cultura en el sector de las industrias creativas dentro del marco de la creación del Espacio Cultural Iberoamericano. Tesis doctoral. Universidad Rey Juan Carlos de Madrid. http://hdl.handle.net/10115/14824
- Sinnenberg, L., Buttenheim, A. M., Padrez, K., Mancheno, C., Ungar, L., & Merchant, R. M. (2017). Twitter as a tool for health research: A systematic review. American Journal of Public Health, 107(1), e1–8. https://doi.org/10.2105/AJPH.2016.303512
- Splidsboel-Hansen, F., van der Noordaa, R., Bogen, Ø., & Sundbom, H. (2018). Kremlin Trojan Horses: Russian Influence in Denmark. Atlantic Council.
- Stieglitz, S., Mirbabaie, M., Ross, B., & Neuberger, C. (2018). Social media analytics – Challenges in topic discovery, data collection, and data preparation. International Journal of Information Management, 39, 156–168. https://doi.org/10.1016/j.ijinfomgt.2017.12.002
- Tromble, R., Storz, A., & Stockmann, D. (2017). We don’t know what we don’t know: When and how the use of twitter’s public APIs biases scientific inference. Social Science Research Network Electronic Journal. https://doi.org/10.2139/ssrn.3079927
- Tufekci, Z. (2014). Big questions for social media big data: Representativeness, validity and other methodological pitfalls. ICWSM ’14: Proceedings of the 8th International AAAI Conference on Weblogs and Social Media. https://doi.org/10.48550/ARXIV.1403.7400
- Ur Rehman, I. (2019). Facebook-Cambridge analytica data harvesting: What you need to know. Library Philosophy and Practice, 2019(8), 1–11. https://doi.org/10.12968/sece.2019.8.11
- Van Dijck, J. (2013). The culture of connectivity: A critical history of social media. Oxford University Press.
- Walby, K., & Gumieny, C. (2020). Public police’s philanthropy and Twitter communications in Canada. Policing: An International Journal, 43(5), 755–768. https://doi.org/10.1108/PIJPSM-03-2020-0041
- Weller, K. (2014). What do we get from twitter—and what not? A close look at twitter research in the social sciences. KNOWLEDGE ORGANIZATION, 41(3), 238–248. https://doi.org/10.5771/0943-7444-2014-3-238
- Yu, J., & Muñoz-Justicia, J. (2020a). A bibliometric overview of twitter-related studies indexed in web of science. Future Internet, 12(5), 91. https://doi.org/10.3390/fi12050091
- Yu, J., & Muñoz-Justicia, J. (2020b). Free and low-cost twitter research software tools for social science. Social Science Computer Review, 40(1), 124–149. https://doi.org/10.1177/0894439320904318