
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Whether the post-categorical, semantic properties of task-irrelevant speech are processed has been a source of debate between two central accounts. The first, a structural account, proposes that the semantic content of irrelevant speech is filtered out early on, and thus remains unprocessed. The second account proposes that the semantic content of speech is, in fact, processed and can influence later behavior. The present research offers a resolution between these two prominent accounts by examining whether semantic processing of task-irrelevant speech occurs despite explicit instructions to ignore it. During a visual-verbal serial recall paradigm, participants were auditorily presented with non-dominant homophones plus their close associates, or close associates without the homophone itself and asked to ignore this irrelevant speech containing these semantic primes. In a subsequent “unrelated” phase, we assessed whether the spelling of homophones was influenced by the irrelevant speech that had occurred earlier in the serial recall phase. We found evidence of semantic priming in conditions wherein the homophone was present, as well as conditions wherein only associates of the homophone were present. Regardless of whether they were presented, homophones were more likely to be spelt in accordance with their non-dominant meaning, and most participants did not report awareness of this fact. We suggest that semantic processing of irrelevant speech occurs even when there is an explicit direction to ignore it and does not result in any material disruptive effect on serial recall performance.
Introduction
The capacity to direct attention to a subset of incoming information that is relevant to one’s current goals while simultaneously ignoring goal-irrelevant information is a common everyday occurrence. This capacity to ignore task-irrelevant stimuli contributes extensively to the performance of many everyday cognitive tasks (Marsh et al., Citation2021; for reviews see Banbury et al., Citation2001; Beaman, Citation2005). For example, you may be attempting to read the words within this document and comprehend their integrated meaning while ignoring background voices and sounds. In contrast to vision, the cognitive system is inherently open to sound; sound is processed omnidirectionally regardless of where attention is currently focused and there is no autonomous means through which the sense of hearing can be shut-off. While task-irrelevant stimuli from many modalities can interfere with focal task performance, this is particularly the case for task-irrelevant sound due to the ineluctable nature of hearing.
The disruptive impact of background sound on cognition has typically been studied in the context of the visual-verbal serial recall paradigm (Colle & Welsh, Citation1976; Salame & Baddeley, Citation1982 wherein the maintenance of visual-verbal information (sequences of 6–9 sequentially presented digits, letters or words) is disrupted by the mere presence of to-be-ignored sounds (the “irrelevant sound effect”; for disruption of auditory-verbal serial recall by task-irrelevant sound see, e.g., Nicholls & Jones, Citation2002). This irrelevant sound paradigm shares some functional characteristics with the classic task used to investigate selective attention and the extent of processing of unattended sound – the dichotic listening task (Broadbent, Citation1958). Here, participants repeat back (shadow) a message presented to one ear whilst ignoring a second message presented to the other ear. Like the dichotic listening task, the irrelevant sound paradigm requires the attentionally-demanding verbatim recall of to-be-attended material and requests that participants ignore auditory material. However, a principal difference is that, in the case of the irrelevant sound paradigm, the primary task is visual rather than auditory. This unique feature means that, unlike dichotic listening, the visual-verbal task does not involve the separation of two auditory messages. Thus, the irrelevant sound paradigm may minimize the propensity for attentional switches to occur toward the task-irrelevant sound (Jones, Citation1999). Unlike dichotic listening, the irrelevant sound paradigm does not probe participants with questions about whether they noticed changes in the unattended channel and participants are not given explicit or implicit memory tests. Rather, participants are instructed to deliberately ignore auditory material and instead the key variable is the extent to which task-irrelevant sound impairs focal visual-verbal serial recall performance.
Much work in this area has sought to determine the characteristics of to-be-ignored sounds that disrupt visual-verbal serial recall. Generally, the disruption produced by task-irrelevant sound does not appear to depend on whether participants comprehend the sound: similar magnitudes of disruption have been observed from prose in a familiar or unfamiliar language, played forward or backward (Jones et al., Citation1990), or from words as compared with meaningless non-words (Salame & Baddeley, Citation1982. Furthermore, the similarity between the meaning of to-be-remembered items and to-be-ignored items has little, if any, influence on the magnitude of disruption to visual-verbal serial recall (Bridges & Jones, Citation1996; Buchner et al., Citation1996; LeCompte & Shaibe, Citation1997; Neely & LeCompte, Citation1999).
At first glance, this failure to demonstrate disruption attributable to the semanticity of task-irrelevant sound coheres with the notion of the operation of a filter system at an early juncture in the processing stream. Specifically, the filter concept refers to a set of discrete processing stages that allows only information pertaining to pre-categorical physical properties of sensory information (e.g., pitch, timbre, intensity, spatial location) to pass through to capacity limited processing stages (e.g., Broadbent, Citation1958, Citation1971). On this view, the semanticity of sound is not processed or is largely attenuated (Treisman, Citation1964; Treisman & Geffen, Citation1968), possibly due to its processing being blocked at subcortical levels (Guerreiro et al., Citation2010), and so cannot disrupt visual-verbal serial recall.
However, a second possibility is that the semantic properties of sound are processed but do not interfere with visual-verbal serial recall because they do not conflict with the processing of relevant information (Marsh et al., Citation2009; Meng et al., Citation2020). Furthermore, for scenarios in which the focal task is not cognitively demanding, semantic properties of task-irrelevant sound can be processed simultaneously without causing disruption to focal task performance. Visual-verbal serial recall requires little by way of semantic processing that could render it susceptible to disruption via the semantic properties of sound: typically digits or letters are used as stimuli and drawn from a small well-known set so that processing the semantic identities as opposed to the order of the items is largely unnecessary. It is also useful to point out here that when semantic processing becomes a pre-requisite for efficient task processing (such as in free recall, categorization, reading, or problem solving), then the semantic properties of sound assume disruptive potential because this processing comes into conflict with the semantic processing of primary task material (Jones et al., Citation2012; Marsh et al., Citation2008, Citation2009, Citation2021; Meng et al., Citation2020). For example, Chinese participants experience disruption of Chinese sentence processing from meaningful task-irrelevant speech when the reading task requires a semantic acceptability judgment but not when it requires noncharacter detection (Meng et al., Citation2020).
The present experiment addresses the thematic focus of the special issue on theoretical advancement in auditory distraction research, including progress toward a deeper understanding of the factors that affect auditory distraction (i.e., task parameters, types of sounds and the role of cognitive control). Although the special issue focuses particularly on varieties of distraction, our reported research extends this scope by exploring the consequences of sound processing in the absence of distraction that are attributable to the properties of the sound of interest (e.g., semantics as compared to acoustics). In this article we explore the notion that semantic processing of task-irrelevant sound occurs even if its capacity to disrupt visual-verbal serial recall is negligible or absent. Further, we suggest that semantic priming will occur during the presentation of task-irrelevant speech, and that this can be observed via indirect measures post task.
Semantic Processing of Irrelevant Sound
Several recent studies have provided evidence for semantic processing of task-irrelevant sound. For example, Vachon et al. (Citation2020) demonstrated that a categorical change in the content of to-be-ignored auditory sequences (e.g., apple, pear, orange, banana, goat, peach, lemon, strawberry) produced additional disruption of visual-verbal serial recall, compared to a sequence without a categorical deviation, despite the fact it was personally non-significant to participants. To detect a categorical change, it is suggested that semantic processing of task-irrelevant sound may have taken place without conscious awareness (Vachon et al., Citation2020). Further, Röer et al. (Citation2017a) demonstrated semantic processing of task-irrelevant sound in the absence of any impact on visual-verbal serial recall. In a design within which the meaning of speech was manipulated between-participants, they showed that category-exemplars presented in a forward direction, and hence meaningful, were no more disruptive to visual-verbal serial recall than those presented in reverse direction and hence meaningless to participants. Crucially, however, participants in a serial recall task who subsequently performed an ostensibly unrelated category-exemplar task, produced category-exemplars with a higher probability than those within a matched set of previously non-presented category-exemplars. This finding coheres with the notion that distractor words are semantically processed to the extent that they can influence behavior on a “priming task” regardless of whether they exert any disruptive effect on ongoing task performance.
The aforementioned findings undermine the view that the semantic properties of task-irrelevant sound do not influence task performance because they are filtered out at an early processing stage (Broadbent, Citation1958; Treisman, Citation1964, p. 1969). Rather, they are consistent with the view that semantic processing of task-irrelevant sound always occurs to some degree even if it does not produce attentional capture such as in the case when stimuli have self-relevance (e.g., one’s own name; Röer et al., Citation2017b).
While the priming study of Röer et al. (Citation2017a) appears to offer compelling evidence for semantic processing of task-irrelevant sound, there are two features of the study that require addressing. First, because only quiet and meaningful trials were presented, it is not possible to rule out the explanation that meaningful speech may be more salient overall (as compared to no sound at all), thus more likely to be processed and influence priming. A within-subject comparison with meaningful speech, meaningless speech and a quiet condition, like the one we propose here, would allow for a direct test of this. Second, it cannot be determined unequivocally whether the priming observed arose due to priming the identities of category-exemplars or through their semantic relationship to one another. That is, the accessibility of category-exemplars within the category-exemplar production task could be facilitated due to processing the specific identity of items during earlier exposure, regardless of their shared categorical membership. A stronger demonstration of semantic priming would be observed via a test of whether extraction of meaning from a word can be influenced by the presentation of task-irrelevant words that alter its semantic interpretation. A homophone spelling task is suitable for this purpose (Eich, Citation1984; Wood et al., Citation1997).
The Fate of the Unattended: Is Irrelevant Speech Semantically Processed?
One challenge of work at the attention-memory interface relates to whether nonconscious semantic processing can occur in the absence of attention for sequences of two words (or more; see Greenwald, Citation1992). The semantic priming observed by Röer et al., Citation2017b) does not necessarily reflect processing of the shared semantic membership between two or more words because primed retrieval of category-exemplars could be achieved merely by processing the individual identities of words even if elicited by a category cue (e.g., vegetables). The categorical deviation effect observed by Vachon et al. (Citation2020) is suggestive of automatic processing of shared categorical membership, but more work is required to determine whether this effect is also underpinned by an attentional capture mechanism (see Labonté et al., Citation2021; Littlefair et al., Citation2022). Further, the disruption produced by a semantic mismatch – an unexpected sentence-end word – in task-irrelevant speech, suggests the occurrence of some semantic integration of sentential material preceding the mismatch (Röer et al., Citation2021).
However, recent work (Hughes & Marsh, Citation2020) questions whether this latter effect is driven in part by a diversion of attention to the content of single, isolated, linguistically meaningful sentences due to curiosity or interest on the part of the participants. Therefore, extraction of the meaning of a two-word+ sequence in this setting may not be produced by attentionless unconscious cognition (e.g., automatic semantic processing). Perhaps a more convincing demonstration would be to observe priming that is not simply driven by the identities of items presented as irrelevant sound, but of non-presented items that are semantically associated to irrelevant speech material. One way to achieve this is to present words that are semantically associated to the non-dominant meaning of homophones and investigate the probability with which the non-dominant version of the homophone is later spelt in the context of an “unrelated” task.
The use of homophones for the purpose of addressing priming via task-irrelevant speech is not a new method of investigation. For example, in the context of a dichotic listening task, Eich (Citation1984) requested participants to shadow (or repeat) a word or prose presented to one ear while a list of word pairs was presented to the other ear. The word pairs presented to the “unattended” ear were repeatedly presented and comprised a homophone and a word (e.g., taxi) that denoted the non-dominant (less common) of the two potential meanings (fare as compared with fair). Following the shadowing task, when asked to spell auditorily-presented homophones, participants produced the non-dominant spelling – consistent with the context that it appeared in within the to-be-ignored auditory channel – more frequently for previously presented, compared to newly encountered, homophones. Further, in a surprise recognition test for the homophones (in the absence of the descriptor words) participants failed to demonstrate explicit memory for the earlier encountered homophones. Eich (Citation1984) concluded that participants demonstrated implicit memory (as measured via the spelling task) but not explicit memory for unattended words (homophones) in the absence of attention to the unattended auditory words.
Determining whether semantic processing of task-irrelevant sound occurs in the absence of voluntary shifts of attention away from the focal task to the irrelevant task requires careful experimental control. In dichotic listening, participants are often periodically required to report any changes presented in the non-shadowed ear (for an overview, see, Holender, Citation1986) and the nature and frequency of such reports may distort estimates of the degree to which the unattended material is processed (Jones, Citation1999). Further, requesting reports of a change or event within the unattended message may falsely increase estimates of the degree of obligatory processing due to participants – particularly those with a history of participating in such studies – deliberately switching attention to the unattended message.
Another factor that may influence the frequency of attentional shifts to an unattended channel is the rate of presentation of the shadowing task materials. Indeed, Wood et al. (Citation1997) revisited the study of Eich (Citation1984) and failed to replicate Eich’s findings when words in the attended channel were presented twice as fast (170 words per minute) as in the original study, yet they replicated the implicit memory for the to-be-ignored words at the original slower rate of presentation (85 words per minute). In contrast, however, Wood et al. (Citation1997) demonstrated that participants had explicit memory for words in the unattended channel when presented at the faster rate. They argue that the greater explicit memory for non-dominant homophones presented at faster rates reflects increments in data-driven processing due to the greater repetition of stimuli within the faster repetition rates (Wood et al., Citation1997). Clearly then, the methodological variations between Eich’s original study and that of Wood et al. (Citation1997) requires further investigation in future work. It is possible, for example, that doubling the rate of presentation reduces or eliminates homophone priming due to contextual effects (Besken & Mulligan, Citation2010) rather than factors attributable to attentional switching. Therefore, the conclusion that the extensive semantic processing claimed by Eich (Citation1984) was the result of voluntary attentional switches to the “unattended” channel, requires further consideration.
Although Eich’s (Citation1984) study was very much geared to understanding whether two-word priming could occur from task-irrelevant speech (the homophone and its de-contextualizing word were presented together), the current study goes beyond this to also investigate whether automatic semantic processing can spread beyond the presented words to semantically associated words. Thus, we investigate whether priming of the non-dominant versions of homophones can emerge when semantic associates of the weaker version are presented even in the absence of the homophone itself.
Current Study
The present study sought to determine whether participants are primed by task irrelevant sound in the absence of attentional switches to the “to-be-ignored” channel. As such, our research offers a resolution between two prominent accounts, the early filter account (Broadbent, Citation1958) and a position consistent with the late filter account (Röer et al., Citation2013), by using a visual-verbal serial recall paradigm within which semantic primes are presented as either meaningful or meaningless irrelevant speech. The latter position suggests that semantic processing of to-be-ignored speech can occur even in the absence of awareness of any disruption to serial recall. Thus, by including some questions concerning explicit memory we can, at least in part, determine the extent of irrelevant sound processing, even in the absence of – or only weak evidence of – disruption to visual-verbal serial recall that is attributable to the semantic features of the to-be-ignored material.
To summarize, we investigate whether semantic priming can emerge via the presentation of the homophone together with primes of its non-dominant (i.e., less commonly produced) meaning as irrelevant speech. Since the non-dominant version is less likely to be reported than its dominant pair, an increase in reports of the non-dominant version indicates a priming effect via a previous encounter. Furthermore, we investigate whether such homophone priming can occur even when semantic associates of the homophone are presented in the absence of the homophone itself.
Method
Design
The study involved a repeated measures design, which incorporated two phases. In Phase 1, participants undertook a visual-verbal serial recall task while being presented with either meaningful or meaningless irrelevant speech, or while working in a quiet control condition. The two meaningful speech conditions entailed either the presentation of a homophone plus its associates (meaningful – homophone present) or the associates alone without the homophone (meaningful – homophone absent). The two meaningless speech conditions involved the same word sequences played in reverse (meaningless – homophone present; meaningless – homophone absent). In sum, the independent variable was sound condition with five levels and the dependent variable was serial recall performance.
Phase 2 involved a homophone spelling task that was used to measure whether priming occurred from the irrelevant speech presented in Phase 1. The dependent variable was the extent of semantic priming that arose from the meaningful, versus meaningless and quiet conditions, as reflected in participants’ choice of homophone spellings.
Participants
Ninety-six participants were recruited using the participant recruitment service Prolific Academic. Prolific Academic is an online participation site which recruits a broad sample of participants from all over the word. This sample can be filtered to meet the inclusion criteria for an experiment. In our case, participants were screened such that the sample would yield participants who were at least 18 years old, right-handed, self-reported normal or corrected-to-normal vision and normal hearing, and who spoke English as their first language.
In our final sample, participants were aged between 18–30 years, and included 37 males and 59 females with a mean age of 24 years (SD = 4). They were compensated with £5, which is Prolific Academic’s recommended rate for 30 minutes of participation. Sample size was based on a power analysis using GPower (Faul et al., Citation2007), which indicated that 96 participants would be sufficient to detect a medium effect (.30) with 80% power using an F test with alpha at .05. Ethical approval was granted by the University of Central Lancashire Ethics Committee, which adheres to the British Psychological Society Code of Ethics.
Apparatus
The program was completed within labjs, which is a graphical interface for creating JavaScript experiments (Henninger et al., Citation2019). The experiment was presented online via OpenLab (https://open-lab.online/).
Materials
In the current article we refer to “homophone dominance” as the extent to which one of two words with the same pronunciation but with different meaning and spelling is more frequently produced (higher dominance) when participants are, for example, asked to spell the word following its auditory presentation. For auditory distracter material, 40 homophone pairings were sampled from the White and Abrams (Citation2004) norms. Each pairing consisted of a dominant (i.e., more likely to be produced) homophone and a non-dominant (i.e., less likely to be produced) homophone, such as cereal (dominant) versus serial (non-dominant, see Appendix 1).
These homophone pairings were divided into four sets of 10, ensuring that dominance was equivalent between sets (see Appendix1), F(3, 39) = 0.001, p = 1.00: Dominance – Set A [M = 13.60, SD = 15.13], Set B [M = 13.60, SD = 22.04], Set C [M = 13.60, SD = 16.13], Set D [M = 13.20, SD = 13.93]. The number of syllables was likewise equivalent between sets, F(3, 39) = 1.00, p = .404: Number of Syllables – Set A [M = 1, SD = 0.00], Set B [M = 1, SD = .00], Set C [M = 1, SD = 0.00], Set D [M = 1.20, SD = 0.63]. Establishing four sets of tightly controlled homophone pairings paved the way toward the creation of irrelevant speech materials (described in more detail below) that could be systematically deployed across the experimental conditions.
Once the sets of homophone pairings were established, four associates of the non-dominant meaning of each homophone were retrieved from the White and Abrams (Citation2004) norms. Meaningful speech conditions were then created that included either the homophone and its top three associates, wherein the homophone was presented first followed by its associates in decreasing order of strength, or else the four top associates of the homophone in decreasing order of strength but without the preceding homophone. To create the meaningless speech conditions, the item sequences in the meaningful speech conditions were time reversed. This was achieved by reversing each of the four sequences using the “reverse” function in Audacity. Playing each sequence backwards in this way rendered the speech entirely meaningless.
Within each sequence, the items were presented twice in the same order. Each word was digitally recorded using text-to-speech software in a female voice (Amazon Alexa) at 16 bit, 44.1 kHz. All sequences were eight words long (four words repeated twice) and were eight seconds in duration. Words were presented at a rate of one per second. Due to the words being of different length, the offset to onset of words varied but the onset to onset of each word was 1 second. The complete set of homophones with output dominance can be found in Appendix 1.
Procedure
After the screening procedure, participants were told what would be required of them and that they could withdraw from the study at any time without penalty. Upon consent, we asked participants to close any other applications on their device and to silence their phone. We advised participants of the importance of minimizing any distractions in their environment so as to be able to concentrate on their task. Upon pressing the spacebar to continue, a prompt appeared asking participants to adjust the volume of the sound to a comfortable listening level and they were asked to put on their headphones. Participants were requested not to take off their headphones during the study and not to adjust the volume from the set level until the study had been completed.
Calibration Task
Participants were next presented with the calibration task (Woods et al., Citation2017), which involved six trials comprised of three tones per trial. For each trial a participant’s objective was to discern which of the three tones was the quietest once the trial had ended and to denote their selection by pressing a key that mapped onto the sequence of the presented tones (e.g., 1, 2 or 3). To pass this calibration test and proceed, participants had to respond correctly on five out of the six trials. If this criterion was not met, a screen appeared that said, “Sorry! Your system does not provide the audio fidelity needed to complete this study. We are very sorry, but you cannot continue.” Participants who did not meet the criterion exited the program and those who met criterion advanced to the next task.
Phase 1. Serial Recall
In this phase, participants were told, “In this study you will be presented with digits that you have to memorise in order. You will also be presented, sometimes, with sounds over your headphones that you are required to ignore.” Next, they were told they would see eight out of nine digits from the range 1 to 9, without repetition, and that they needed to remember the sequence of numbers in the order of presentation. Further, they were asked to concentrate on the digits, but not to say the digits aloud. On each trial within the serial recall task, the set of eight numbers were pseudo-randomly presented due to the constraint that no repeats of a given digit could occur within a sequence and that runs of more than two items were avoided. The digits were presented in black, 72-point Arial font at a rate of 1 per second (800 ms on, 200 ms off).
At the onset of the presentation of the to-be-remembered digits, participants were auditorily presented with an irrelevant speech stream. There were 20 meaningful speech trials, 20 meaningless speech trials and 10 quiet trials. Half of the meaningful speech trials (n = 10) contained the homophone and three associates, whereas the other half (n = 10) contained four associated alone. Likewise, half of the meaningless speech trials (n = 10) contained the homophone and associates, albeit reversed, whereas the other half (n = 10) contained just the reversed associates. Items from the four matched homophone sets were systematically rotated across the four meaningful and meaningless speech conditions (i.e., meaningful – homophone present, meaningful – homophone absent, meaningless – homophone present, meaningless – homophone absent), with each condition thereby drawing upon items from a separate set in a fully counterbalanced manner across participants. Each participant received their full complement of 50 experimental trials in an independently randomized order.
To begin this phase, participants first did three practice trials in quiet. Next, the irrelevant speech sequences began with the onset of the first to-be-remembered digits, with items in each irrelevant speech sequence being spoken at a rate of one word per second, therefore lasting eight seconds in total. The speech was presented binaurally across headphones. After each trial, the set of digits (1–9) appeared on the screen in canonical order. Participants were instructed to select the digits that they had just seen in the correct order of presentation using a mouse-driven pointer. Clicking on a digit caused the digit to disappear from the screen. No accuracy feedback was given. Participants were only able to click on each digit once, thus no revision of the to-be-remembered sequence was allowed. The next trial began after participants selected all eight items.
After all experimental trials had been completed, participants heard a series of three repeated letters, and were asked to type the last letter that they heard. This final manipulation served as the “catch trial” to ensure that participants had kept their headphones on during the duration of the experiment. This whole phase of the experiment lasted approximately 20 minutes.
Filler Task – Arithmetic
To control for any recency effects, a filler task was employed whereby participants were given a series of simple math calculations in the form of 30 double-digit addition problems (e.g., 46 + 82 = __). Participants were told to do as many of the problems as they could in 2 minutes.
Phase 2. Homophone Spelling Task
Participants were told that this next part of the study was unrelated to the first two parts. They were reminded to minimize any distractions in their environment and to concentrate on the task. Participants were presented auditorily with 40 homophones, 10 of which had been presented along with associates of their non-dominant meaning, and 10 of which had their non-dominant associates presented alone in Phase 1. The other 20 presented homophones were controls that participants had not previously encountered as they were presented as part of the meaningless (homophone present, homophone absent) conditions.
The homophones were presented over headphones one at a time in a random order. Participants were told that they would hear a beep followed by a spoken word (the homophone) and that their task was to spell that word in the text box appearing on the screen. They were asked to respond with the first spelling that came to mind and to type it and then press “Done” to listen to the next word. On entering their response, or after an allotted period of 45 sec, the next homophone was auditorily presented. Phase 2 took approximately 10 min to complete.
Post-experimental Phase
Once all trials in Phase 2 were completed, participants were asked a series of questions to probe for awareness. First, they were asked if they had noticed any relationship between the spelling task and the earlier digit recall task and if so, could they describe the relationship. Second, they were asked if they were aware that some of the to-be-spelt items from Phase 2 had been heard in Phase 1 and if they had intentionally tried to remember them. Participants were also asked a series of questions to assess their general compliance with task instructions and their motivation (see, Elliott et al., Citation2022). Lastly, participants were thanked and thoroughly debriefed.
Results
Phase 1. Serial Recall Task
A strict serial recall criterion was applied to the data such that responses were only scored as correct if the digits were reproduced in the same serial position as they had been presented previously. For analysis, means were computed by collapsing data across serial position.
demonstrates evidence of an irrelevant sound effect: participants’ performance was more error-prone when irrelevant speech was presented as compared to a quiet control condition. To verify this pattern of results, a one-way, repeated measures analysis of variance (ANOVA) was initially conducted to test for the presence of an irrelevant sound effect. This showed a main effect of sound condition with a large effect size (Cohen, 1998), F(4, 380) = 21.858, MSE = 0.007, p < .001, = 0.187, and follow-up pairwise comparisons demonstrated that performance in quiet was significantly better than performance in meaningful – homophone present (p < .001, 95% CI [0.070, 0.124]), meaningful – homophone absent (p < .001, 95% CI [0.066, 0.123]), meaningless – homophone present (p < .001, 95% CI [0.056, 0.107]), and meaningless – homophone absent (p < .001, 95% CI [0.049, 0.103]) conditions, thereby establishing an irrelevant speech effect.
Table 1. Mean proportion serial recall performance according to sound condition in phase 1 of the experiment.
To explore whether the semanticity of the irrelevant speech produced additional disruption, a 2 (Meaning: Meaningful Speech vs. Meaningless Speech) × 2 (Homophone Presence: Homophone Present vs. Homophone Absent) ANOVA was undertaken on the serial recall scores. This revealed a main effect of meaning with a medium effect size, F(1, 95) = 4.189, MSE = 0.007, p = .043, = 0.042, but no main effect of homophone presence, F(1, 95) = 0.309, MSE = 0.005, p = .580,
= 0.003, and no interaction between these variables, F(1, 95) = 0.022, MSE = .005, p = .884,
= 0.000.
Phase 2. Homophone Spelling Task
Spellings for each homophone were categorized as: (1) the non-dominant spelling of the homophone; (2) the dominant spelling of the homophone; and (3) an error. Errors were misperceived words or illegible responses. The proportion of errors was very small (< .03 within each sound condition) and therefore not subject to formal statistical analysis.
The crucial question in relation to Phase 2 of the study is whether the production of non-dominant homophone spellings was higher (and dominant homophone spellings lower) when semantic associates of the non-dominant meaning of the homophone had been presented (either with, or without the homophone) in Phase 1 of the study, compared to the production of non-dominant homophones when the homophone and/or its semantic associates had not previously been encountered as irrelevant speech. demonstrates the mean proportion of non-dominant spellings of homophones produced in Phase 2 as a function of sound condition. Mean production rates appear to be greater for non-dominant spellings of homophones when participants had prior exposure to the homophone and/or non-dominant associates of it as irrelevant speech in Phase 1 of the study. Further, the greater production of the non-dominant spelling of the homophone did not appear to depend on whether the homophone was presented: the same pattern arose from prior exposure to only its semantic associates as irrelevant speech.
Figure 1. Mean proportion of non-dominant homophone spellings according to sound condition in phase 2. error bars represent standard errors of the means.
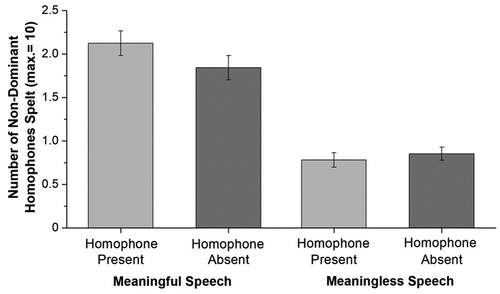
To determine the presence of a priming effect, a 2 (Meaning: Meaningful Speech vs. Meaningless Speech) × 2 (Homophone Presence: Homophone Present vs. Homophone Absent) ANOVA was undertaken on the proportion data for non-dominant homophone spellings. This demonstrated a main effect of Meaning with a medium effect size, F(1, 95) = 113.020, MSE = 0.012, p < .001, = 0.543, confirming the presence of homophone priming from meaningful irrelevant speech. However, there was no main effect of Homophone Presence, F(1, 95) = 0.896, MSE = 0.012, p = .346,
= 0.009, nor a two-way interaction between Meaning and Homophone Presence, F(1, 95) = 2.414, MSE = 0.012, p = .124,
= 0.025. This indicates that the magnitude of priming did not increase with the inclusion of the homophone as a distracter within the irrelevant speech, although there was a numerical tendency for greater priming following the inclusion of the homophone.
To determine whether the magnitude of homophone priming was related to individual differences in susceptibility to disruption via the meaning of irrelevant speech, difference scores were computed. Mean scores from the two meaningful speech conditions were averaged (MOverall = 0.615; SD = 0.172) and subtracted from the average of the two meaningless (reversed) speech conditions (MOverall = .632, SD = 0.167) in Phase 1 to create an index of susceptibility to disruption on the serial recall task via the meaning of irrelevant speech (MOverall = 0.017, SD = 0.081). This index was then correlated with the non-dominant homophone spelling scores in the meaningful – homophone present and meaningful – homophone absent conditions in Phase 2. The resulting Pearson’s correlation test revealed the absence of a significant correlation between susceptibility scores and priming when the homophone was present, r(96) = .096, p = .350, or not present, r(96) = .004, p = .969, within the meaningful speech.
To test whether there was a stronger effect of priming for those susceptible to disruption via meaningful speech, we categorized people as either susceptible to disruption via the meaning of background sound (n = 60), or invulnerable to disruption via this property (n = 34), regardless of the magnitude of that disruption. This was achieved by averaging the means for the two conditions within which meaningless speech was presented, and also averaging the means for the two conditions within which meaningful speech was presented. We then subtracted the new mean for meaningful speech from the new mean for meaningless speech. Participants classified as susceptible to disruption via meaningful speech had a positive mean score, whereas people who were more disrupted by meaningless speech had a negative mean score. Note that two people had identical mean scores in meaningful and meaningless speech conditions and were grouped into the invulnerable to disruption category.
A 2 (Meaning: Meaningful speech vs. Meaningless speech) × 2 (Homophone Presence: Homophone Present vs. Homophone Absent) × 2 (Susceptibility to Distraction via Meaning: Yes, No) ANOVA revealed no interactions between this susceptibility categorization and the within-participant variables: Meaning, F(1, 94) = 0.152, MSE = 0.012, p = .697, = 0.002, Homophone Presence, F(1, 94) = 0.405, MSE = 0.012, p = .526,
= 0.013, and Meaning × Homophone Presence, F(1, 94) = 0.680, MSE = 0.013, p = .412,
= 0.007. There was also no between-participants main effect of susceptibility categorization, F(1, 94) = 2.586, MSE = 0.014, p = .111,
= 0.027. There does not appear to be a relationship between susceptibility to distraction via the meaning of irrelevant speech and the magnitude of priming from the contents of irrelevant speech. This suggests that it is unlikely that priming is a consequence of attentional switches to the task-irrelevant material.
Based on whether participants responded that they noticed a relationship between the spelling task and the serial recall task (yes vs. no) and provided an accurate description of that relationship (e.g., “some words from the digit recall task were also read out to be spelled”), participants were categorized as aware (n = 16) or unaware (n = 80). To determine whether awareness was related to the magnitude of homophone priming, a 2 (Meaning: Meaningful Speech vs. Meaningless Speech) × 2 (Homophone Presence: Homophone Present vs. Homophone Absent) x 2 (Awareness: Aware vs. Unaware) mixed ANOVA was undertaken on the proportion of non-dominant homophones spelt in Phase 2. This demonstrated that Awareness did not interact with Meaning, F(1, 94) = 0.007, MSE = 0.012, p = .933, = 0.000, or Homophone Presence, F(1, 94) = 2.632, MSE = 0.011, p = .108,
= 0.027. Further, it did not interact with Meaning and Homophone Presence, F(1, 94) = 0.480, MSE = 0.013, p = .490,
= 0.005. However, the between-participants main effect of Awareness was significant, F(1, 94) = 5.925, MSE = 0.013, p = .017,
= 0.059. Participants classified as aware produced a higher proportion of non-dominant homophones than those classified as unaware (M = 0.172, SD = 0.688, SE = 0.014, aware, M = 0.134, SD = 1.199, SE = 0.006, unaware; 95% CI [.007, .069]).
To investigate whether awareness was related to susceptibility to disruption via the meaning of irrelevant speech in the earlier serial recall task, a 2 (Meaning: Meaningful Speech vs. Meaningless Speech) × 2 (Homophone Presence: Homophone Present vs. Homophone Absent) × 2 (Participant Awareness: Aware vs. Unaware) mixed ANOVA was undertaken on the serial recall data from Phase 1. This revealed no interactions between awareness and any of the within-participant variables: Meaning, F(1, 94) = 1.687, MSE = 0.007, p = .197, = 0.018, Homophone Presence, F(1, 94) = 0.087, MSE = 0.005, p = .769,
= 0.004, Meaning and Homophone Presence, F(1, 94) = 1.564, MSE = 0.005, p = .214,
= 0.016. There was no between-participants main effect of awareness, F(1, 94) = 0.079, MSE = 0.110, p = .779,
= 0.001. Therefore “awareness” did not appear to be linked to susceptibility to distraction via meaning in Phase 1.
Participants were also asked whether they deliberately tried to recall words that had been presented earlier during the serial recall task; seven answered yes, and 89 answered no. Participants responded further as to the extent to which they felt that they were deliberately recalling the words that they heard during the serial recall task while spelling words (1 = not at all, 2 = rarely, 3 = sometimes, 4 = often). The ensuing mean ratings demonstrated that participants judged that they were not deliberately retrieving previously presented words during the serial recall task when spelling auditorily presented words (M = 1.202, SD = 0.480, SE = 0.05, participants responding yes; M = 1.202, SD = 0.535, SE = 0.18, participants responding no).
Discussion
This study was undertaken to advance an understanding of the extent to which the cognitive system processes task-irrelevant sound when attention is focused on a primary task. To address this, we presented participants with meaningful and meaningless irrelevant speech while they undertook a visual-verbal serial recall task. The meaningful speech comprised homophones with associates of their non-dominant meaning (homophone-present condition), or associates of their non-dominant meaning presented alone (homophone-absent condition). The extent to which semantic processing of task-irrelevant speech occurred was assessed via an ostensibly unrelated homophone spelling task that participants completed after engaging in a filler task (cf., Eich, Citation1984).
Our results provide compelling evidence of semantic processing by demonstrating the occurrence of semantic priming via irrelevant meaningful speech in both homophone-present and homophone-absent conditions, with a marginally stronger effect of priming for the homophone-present condition. As expected, there was no evidence of semantic priming when participants heard semantically meaningless (i.e., reversed) speech. However, participants who heard, and ignored, either the non-dominant homophone and its associates, or heard only associates of the non-dominant homophone, were significantly more likely to produce the non-dominant version in a subsequent spelling task.
This latter finding, that spelling of the non-dominant homophone is more likely even when associates of the homophone are presented alone, supports theories of spreading-activation in semantic networks (Anderson, Citation1983; Collins & Loftus, Citation1975; Kenett & Faust, Citation2019). Such theories propose that words that are semantically related to each other are represented in the form of a network of nodes, and that activation can spread through this network from presented words to non-presented words. In this way, spreading activation occurs from the presented words to other related concept nodes in the network (i.e., other semantic associates or category members; Marsh et al., Citation2021). In the case of our study, semantic activation of the associates of homophones converges on the semantic nodes representing the non-dominant homophone even when the homophone itself is not presented.
Our results are consistent with a previous study by Bentin et al. (Citation1995), who demonstrated that participants committed more false positives to lures (new words, e.g., “cat”) that were semantically related to “old” words (e.g., “dog”) regardless of whether they had been presented in the attended or unattended channel. The current study, like that of Bentin et al. (Citation1995) demonstrates that semantic activation of task-irrelevant words is possible without attention and that such activation can spread beyond the presented material to semantically associated information within memory. In this way, the spreading activation mechanism offers a ready explanation for how nonconscious processing can occur for sequences of two or more words in the absence of attention (cf., Greenwald, Citation1992).
Our pattern of results supports a position aligned with a late filter account (e.g., Röer et al., Citation2017b) and suggests that semantic priming may be an attentionless process, achieved via spreading activation that has no direct influence on the focal task. In support of this assertion, no differential priming effects were found that related to participants’ performance on the serial-recall task or self-report measures of awareness. There was a small, but significant effect for increased spelling of the non-dominant homophone for those participants who reported awareness of the overlap between the irrelevant speech and homophone spelling task, but this was not more evident for the conditions wherein the non-dominant homophones had been primed by the irrelevant speech.
Our results are at odds with the view taken by proponents of an early filter account who propose that the semantic properties of task-irrelevant speech are filtered out at an early stage due to a limited-capacity cognitive system (Broadbent, Citation1958, Citation1971). In this account, the filter allows information relating to the physical properties of speech (e.g., pitch, intensity) to pass through to limited capacity stages of processing but prevents the intrusion of semantic properties of speech. This model has been criticized due to logical errors embedded in the assumptions of an early-filter account (Allport, Citation1989; Neumann, Citation1996; Van der Heijden, Citation1992). Specifically, the notion of limited capacity rests upon an inference that (a) evidence of unattended information failing to interfere with focal task performance indicates that (b) this unattended information must be blocked from being processed and is therefore (c) evidence for a limited processing capacity (Röer et al., Citation2021). Logically, this argument is incorrect and is an example of the “fallacy of affirming the consequent” (Popper, Citation1959; Van der Heijden, Citation1992). The notion of “selective-processing-therefore-limited-capacity” does not legitimately follow from “limited-capacity-therefore-selective-processing” because limited capacity is an a priori theoretical assumption: selective processing is what is observed. Within limited resource approaches it is never clear why resources (or capacity) become(s) limited in the first place (Anderson et al., Citation1994; Neumann, Citation1987). As such, our results offer a resolution between the early-filter account and a more recent account that aligns with the late-filter view (e.g., Röer et al., Citation2021). Consistent with the notion of late-filtering, we show semantic priming of to-be-ignored speech without any disruption to visual-serial recall.
In addition, the results of the current study (see also, Röer et al., Citation2017a, Citation2017b) suggest that processing may happen without conscious awareness as the type of processing applied to the sound was unrelated to the type of processing applied to the focal task. These results undermine the notion that the semantic processing of to-be-ignored sounds depends on the amount of attention paid to the semantic properties of to-be-remembered items (Meade & Fernandes, Citation2016). The attentional control settings for visual-verbal serial recall are arguably not semantically based and are therefore incompatible with the semantic properties of the task-irrelevant material (cf. Meade & Fernandes, Citation2016). As such, it is unlikely that any contingency between the to-be-recalled and to-be-ignored material drove our observed semantic priming effect through top-down mechanisms. Further, the fact that the semantic properties of sound had very little impact on performance on the serial-recall task suggests that any contingency (i.e., semantic relationship) between the to-be-recalled and to-be-ignored material (cf. Meade & Fernandes, Citation2016) was unlikely to be driving semantic processing of to-be-ignored sound. The semantic priming effect observed in our study therefore seems to demonstrate that the semantic characteristics of irrelevant sound are represented in the absence of a focal task that requires semantic analysis. Therefore, the results favor an explanation based on priming produced by automaticity of semantic processing that is task-process invariant (for related arguments see, Vachon et al., Citation2020).
Although there was a marginally significant effect for meaningful, against meaningless, speech on visual-verbal serial recall, this effect was small in magnitude at 1.7%. This supports the view that pre-categorical acoustic factors, rather than post-categorical semantic factors, are chiefly responsible for the irrelevant sound effect. On the interference-by-process account (Jones & Tremblay, 2000), the serial representation of sound, as conveyed through token-to-token acoustic complexity, conflicts with the serial ordered representation of the to-be-remembered visual-verbal material to manifest the irrelevant sound (or changing-state) effect (for similar discussion see, Jones, Citation1999). A small effect of meaning from sequences comprising forward as compared to reversed words has been shown previously. LeCompte and Shaibe (Citation1997) demonstrated that an irrelevant sequence comprising four words presented in a forward direction produces marginally greater disruption of serial recall than four words presented in reverse. Although speculative, it is possible that the small additional disruption produced by forward against reverse words is not, in fact, attributable to semantics: within sequences of a small number of words, the reduction in abrupt onsets and sharp transitions in acoustic energy that arises as a function of reversing speech could reduce the acoustical complexity of the speech stream. Since token-to-token acoustic variability yields cues for segmentation that drive an (acoustic) interference-by-process, the slightly diminished disruption produced by reversed as compared to forward speech, could be attributable to a reduction in acoustic complexity, or to phonetic or phonological factors, rather than to semantic factors (for a similar line of reasoning see, Tremblay et al., Citation2001). Further research is required to provide insight into these apparent nuances. Given the finding that the magnitude of priming is the same for participants who report being aware versus those who do not report such awareness, it is unlikely that the semantic priming observed in the current study is related to the degree of susceptibility to disruption via the meaning of task-irrelevant speech.
It is important to consider whether the disruptive power of task-irrelevant sound observed in the current study is less pronounced in our online experiment compared to typical experiments in the laboratory. In auditory distraction experiments, there are various challenges that make it difficult to predict whether online data collection yields a similar magnitude of effect to laboratory-based research. These challenges tend to be related to a lack of experimental control, including issues related to the quality of headphones used or the quality of sound presentation as well as the potential use of smart-phones, laptops or desktop computers that may affect the presentation and timing of stimuli. Furthermore, researchers have less control over participant behavior, their compliance with instructions and their motivation (Jensen & Thomsen, Citation2014). We attempted to control for these acoustic differences as far as possible via a stringent headphone calibration and check prior to the onset of the study. It is also reassuring to note that Elliott et al. (Citation2022) successfully replicated the irrelevant sound effect in a cross-laboratory, face-to-face and online comparison with similar effect sizes. Although they report relatively smaller effect sizes for the online Prolific sample, the researchers attribute this to the sample demographics rather than to differences in the online versus laboratory administration of the experiment. Specifically, these differences in the magnitude of the effect are attributed to participant experience (i.e., potential practice effects) in the Psychology student sample. Despite the slightly smaller interference effects in our experiment, it is reassuring that we nevertheless find evidence of semantic priming. We also note the potential bias in our sample. For example, it is possible that our online participants were more technologically savvy as compared to an average population, which could have implications for their susceptibility to distraction or to the effects of semantic primes (e.g., such individuals might be more adept at maintaining concentration in the face of distraction). Future research should take care to eliminate such potential biases wherever possible by a careful consideration of the differences that might exist in specific types of samples.
Only 16 out of 96 participants (17%) noticed a relationship between the words presented as irrelevant speech during the serial recall task and the words to-be-spelt. This percentage of “aware” participants is much smaller than typically reported for studies of dichotic listening wherein the participant’s name is presented in the unattended channel (Conway & Kane, Citation2001, p. 29% reported by Röer & Cowan, Citation2021, p. 33% reported by Moray, Citation1959, p. 35% reported by Wood & Cowan, Citation1995). It is also smaller than the 96% of participants who reported noticing their own name when it was presented as irrelevant speech in the context of a visual-verbal serial recall task (Röer et al., Citation2013). The difference in these awareness ratings could be related to the nature of presentation. For instance, in the case of the own-name effect in the context of visual-verbal serial recall (e.g., Röer et al., Citation2013), a participant’s own-name is the first item presented within the irrelevant sequence, which increases its salience and opportunity for semantic processing. Further, in the case of semantic mismatches (e.g., Röer et al., Citation2019), the sentence end-word is typically the last word presented and is thereby also salient.
The discrepancy between the awareness ratings for studies of the own-name effect and the current study suggest that the underpinnings of the two effects may be different. The disruption produced by semantically significant material such as one’s own name or valent distracters may be undergirded by attentional capture or diversion, whereas the priming effects we observe are more suggestive of the legacy of semantic activation in the absence of attentional switches. Based on the results in the context of the current study, however, we cannot rule out that the homophones or their associates were encoded without attention. The homophone (when presented) and its associates were not preceded by an unrelated set of “buffer” sounds. Rather, the homophone or a strong associate was the first item to be encountered within an irrelevant sequence and was arguably salient. However, in support of an account of processing without awareness, we found a similar magnitude of priming when only the associates were presented without the homophone, even when the homophone itself was not salient due to its absence. In addition, unlike the own-name effect, there is arguably nothing that is personally significant about the homophone or its associates that would produce attentional capture and thereafter lead to awareness for the words. Analysis demonstrated that individuals who were aware as opposed to unaware of the relationship between the auditory distracters and the to-be-spelt words were no more susceptible to disruption via the meaning of irrelevant speech. This suggests that serial recall performance measures, unlike dichotic listening performance (e.g., particularly shadowing errors), may not index awareness of the content of irrelevant speech. Moreover, there was no indication that meaningful speech produced a greater number of attentional shifts than meaningless speech, as indicated by only a small effect of meaningful versus meaningless speech and equivalent priming for those participants demonstrating greater disruption for meaningful versus meaningless speech.
Recent advances in relation to research on auditory distraction have included the reconceptualization of an early filter. The “new early filter account” (Marsh et al., Citation2018, p. Citation2019, Citation2016) constitutes a development from the early filter assumption of Broadbent’s (Citation1958) model that there is a capacity limitation in how the human mind processes information. Broadbent (Citation1958) localized this bottleneck to the cochlear nuclei. This filter selects some information for further processing to the exclusion of other information. By contrast to Broadbent (Citation1958), Marsh et al.’s (Citation2016) new early filter assumption entails that prior contextual information (stored and processed by a working memory network) determines an attentional expectancy. Accordingly, corticotectal-corticofugal loops (Campbell & Marsh, Citation2019) – which are under cholinergic control by the basal forebrain via the prefrontal cortex within that working memory network (Campbell & Marsh, Citation2019) – control the early filtering of auditory information.
The homophone priming effect found in the current study accords with a new early filter that is wide open by default, thereby allowing the semantic analysis of to-be-ignored sound. The predictive-selectivity assumption of the new early filter model stipulates that when the incoming stimulation pattern is predictable, the filter narrows to exclude more information in preference to that predicted from attentional expectancy. The model thus predicts a reduction in the homophone priming effect when homophones are embedded within sentences, thereby rendering those words more predictable. As such, the new early filter model exhibits sufficient explanatory adequacy with respect to the present investigation’s findings. Further, the account assumes that individuals with higher working memory capacity (WMC) have better prefrontal control of the corticopetal-corticofugal loops via the cortical cholinergic system (Beaman, Citation2005; Gisselgård et al., 2002; 2004). An intriguing prediction of the new early filter model, which remains to be tested, is thus that there is a reduced homophone priming effect for participants with higher WMC, particularly when linguistic predictability is high.
Future Research
To determine whether the semantic priming effects we observe do indeed occur in the absence of conscious awareness, future research should explore whether priming effects are susceptible to top-down control. For example, previous research has demonstrated that increasing focal task (or cognitive) engagement promotes top-down cognitive control (Marsh et al., Citation2015; Halin et al., Citation2014; Hughes et al., Citation2013; Sörqvist & Marsh, Citation2015). This increase in control is thought to reduce or eliminate the disruptive effects of irrelevant sound that are attributable to auditory attentional capture (Hughes et al., Citation2013), attentional diversion (e.g., produced by valent words; Marsh et al., Citation2018), or similarity in meaning to semantically processed focal task material (Marsh et al., Citation2015).
It has been argued that increasing active task-engagement shields against distraction via two mechanisms. The first is through promoting a steadfast locus of attention, thereby preventing attentional switches to sound (Halin et al., Citation2014; Sörqvist & Marsh, Citation2015), and the second mechanism works by reducing the peripheral processing of irrelevant sound (e.g., Halin et al., Citation2014; Marsh et al., Citation2016; Sörqvist et al., Citation2016, Citation2012). These mechanisms suggest that increasing focal task engagement by, for example, increasing the encoding difficulty of the to-be-recalled material (Hughes et al., Citation2013; see also Parmentier, Citation2014) should help prevent attentional slippage to irrelevant sound (and thus attentional encoding of semantic meaning). Further, promoting focal task engagement through reducing peripheral processing of sound should also prevent processing of semantic meaning within irrelevant speech.
Recent work (Vachon et al., Citation2020), however, provides evidence that semantic processing of irrelevant sound occurs regardless of the level of engagement required by the focal task. For example, visually degrading to-be-recalled materials does not modulate the disruption of visual-verbal serial recall produced by a categorical deviant (e.g., the digit 9 in the following sequence: HKMQ9XZB). Further, Working Memory Capacity (WMC) measurements, which reflect stable dispositions for attentional control, are also unrelated to the categorical deviation effect (see Labonté et al., Citation2021). Since visual-degradation and WMC measurements are related to the disruption produced by an acoustic irregularity (Hughes et al., Citation2013; Labonté et al., Citation2021) and the detection of one’s own name in an unattended channel in dichotic listening (more individuals with low vs. high WMC detect their own name), the latter finding suggests that some semantic processing of irrelevant speech occurs regardless of top-down cognitive control and is, therefore, unrelated to attentional capture (see Labonté et al., Citation2021; Vachon et al., Citation2020).
Our results lend support to an account of automatic spreading activation given that the semantic material (i.e., homophones) were always presented in a to-be-ignored channel. In future research, finding that the presence, or magnitude, of semantic priming of homophones by irrelevant speech is not amenable to manipulations of top-down cognitive control would add weight to the notion that it occurs through automatic spreading activation (cf., Vachon et al., Citation2020). To determine whether an effect can be viewed as automatic, future research should also consider other key criteria (e.g., unintentional, goal-independent, uncontrollable, autonomous, efficient and fast; Moors & De Houwer, Citation2006) that are used to denote automaticity. For example, to test whether priming is goal independent, research could employ a design whereby homophones are encountered when participants perform a serial recall task that minimizes attention toward the semantic properties of the to-be-remembered items (Meade & Fernandes, Citation2016). This could be achieved by changing the focal task so that it denotes use of verbal encoding strategies (e.g., the use of the spatial dots task; Vachon et al., 2022).
Another way in which the automaticity of semantic processing has been addressed is to compare implicit with explicit tests of memory. In Eich’s (Citation1984) dichotic listening study, participants were given a surprise auditory recognition test and asked to decide whether each word was “old” or “new.” Eight of the homophones were old and eight were new and there were also 16 filler items. Participants demonstrated no explicit memory for the homophones even though in the implicit memory test they spelt the homophones in accordance with the meaning promoted by unattended speech. Assuming that explicit memory tests reveal evidence of the attentional encoding of words following attentional shifts to the unattended channel, if priming was associated with explicit memory, this might indicate that attention shifted to unattended words. However, this picture is clouded by the finding that in their replication of Eich (Citation1984), Wood et al. (Citation1997) reported enhanced explicit memory for homophones presented in the unattended channel with faster presentation rates, for which the authors argue there is less likelihood of attentional shifts. In contrast, at fast presentation rates, Wood et al. (Citation1997) failed to observe enhanced implicit memory through the spelling test. Rather than propose a semantic or conceptual basis for superior explicit memory for the unattended homophones, the authors argue that increased data-driven processing may explain this effect, owing to multiple presentations of each homophone. Again, further research is required to understand the boundary conditions that influence the effect of attentional processes on observed priming effects.
Conclusion
A lively historical debate that continues to the present day concerns the extent to which unattended input is processed. Early filter (or early selection) accounts assume that only the pre-categorical, acoustic properties of task-irrelevant sound are extracted and influence concurrent task performance. On this account, the post-categorical properties of task-irrelevant sound, such as semanticity, are prevented from accessing further processing stages. At first glance, support for such an assumption was derived from the lack of disruptive effects attributable to irrelevant sound meaning. However, the argument that semantic content is not processed does not follow from its impotency to produce disruption. In the present study, we demonstrate evidence for semantic processing regardless of its capability to disrupt a concurrent task or its relationship to focal task material. This non-contingent semantic priming hints at a late filtering account of semantic processing of material that is not personally significant (Röer et al., Citation2021; see, also Vachon et al., Citation2020) but further research is required to understand the nuances of the effect. Nevertheless, the current findings provide insight into the cognitive mechanisms that inform accounts of auditory distraction (e.g., Hughes, Citation2014; Bell et al., Citation2019; Hughes et al., Citation2013).
Acknowledgments
This research was supported by internal funds from the School of Psychology and Computer Science at the University of Central Lancashire awarded to Beth H. Richardson and John E. Marsh. Correspondence concerning this article should be addressed to Beth H. Richardson, School of Psychology and Computer Sciences, Darwin Building, Marsh Lane, Preston, Lancashire, UK, PR21HE. Email: [email protected].
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Allport, A. (1989). Visual attention. In M. I. Posner (Ed.), Foundations of cognitive science (pp. 631–682). The MIT Press.
- Anderson, J. R. (1983). A spreading activation theory of memory. Journal of Verbal Learning and Verbal Behavior, 22(3), 261–295. https://doi.org/10.1016/S0022-5371(83)90201-3
- Anderson, M. C., Bjork, R. A., & Bjork, E. L. (1994). Remembering can cause forgetting: Retrieval dynamics in long-term memory. Journal of Experimental Psychology. Learning, Memory, and Cognition, 20(5), 1063–1087. https://doi.org/10.1037/0278-7393.20.5.1063
- Banbury, S. P., Macken, W. J., Tremblay, S., & Jones, D. M. (2001). Auditory Distraction and Short-Term Memory: Phenomena and Practical Implications. Human Factors, 43(1), 12–29. https://doi.org/10.1518/001872001775992462
- Beaman, C. P. (2005). Auditory distraction from low‐intensity noise: A review of the consequences for learning and workplace environments. Applied Cognitive Psychology, 19(8), 1041–1064. doi:10.1002/acp.1134.
- Bell, R., Röer, J. P., Lang, A.-G., & Buchner, A. (2019). Distraction by steady-state sounds: Evidence for a graded attentional model of auditory distraction. Journal of Experimental Psychology. Human Perception and Performance, 45(4), 500–512. https://doi.org/10.1037/xhp0000623
- Bentin, S., Kutas, M., & Hillyard, S. A. (1995). Semantic processing and memory for attended and unattended words in dichotic listening: Behavioural and electrophysiological evidence. Journal of Experimental Psychology. Human Perception and Performance, 21(1), 54–67. https://doi.org/10.1037/0096-1523.21.1.54
- Besken, M., & Mulligan, N. W. (2010). Context effects in auditory implicit memory. Quarterly. Journal of Experimental Psychology, 63(10), 2012–2030. https://doi.org/10.1080/17470211003660501
- Bridges, A. M., & Jones, D. M. (1996). Word dose in the disruption of serial recall by irrelevant speech: Phonological confusions or changing state? The Quarterly Journal of Experimental Psychology: Section A, 49(4), 919–939. doi:10.1080/027249896392360
- Broadbent, D. E. (1958). Perception and communication. Pergamon Press. https://doi.org/10.1037/10037-000
- Broadbent, D. E. (1971). Cognitive psychology: Introduction. British Medical Bulletin, 27(3), 191–194. https://doi.org/10.1093/oxfordjournals.bmb.a070851
- Buchner, A., Irmen, L., & Erdfelder, E. (1996). On the irrelevance of semantic information for the “Irrelevant Speech” effect. The Quarterly Journal of Experimental Psychology: Section A, 49(3), 765–779. https://doi.org/10.1080/713755633
- Campbell, T. A., & Marsh, J. E. (2019). On corticopetal–corticofugal loops of the new early filter. NeuroReport, 30(3), 202–206. https://doi.org/10.1097/WNR.0000000000001184
- Cohen, J. (1988). Statistical power analysis for the behavioural sciences (2nd ed.). Hillside, NJ: Lawrence Erlbaum Associates.
- Colle, H. A., & Welsh, A. (1976). Acoustic masking in primary memory. Journal of Verbal Learning and Verbal Behavior, 15(1), 17–31. https://doi.org/10.1016/s0022-5371(76)90003-7
- Collins, A. M., & Loftus, E. F. (1975). A spreading-activation theory of semantic processing. Psychological Review, 82(6), 407–428. https://doi.org/10.1037/0033-295X.82.6.407
- Conway, A. R. A., & Kane, M. J. (2001). Capacity, control and conflict: An individual differences perspective on attentional capture. Advances in Psychology, 133, 349–372. https://doi.org/10.1016/s0166-4115(01)80016-9
- Eich, E. (1984). Memory for unattended events: Remembering with and without awareness. Memory & Cognition, 12(2), 105–111. https://doi.org/10.3758/bf03198423
- Elliott, E. M., Bell, R., Gorin, S., Robinson, N., & Marsh, J. E. (2022). Auditory distraction can be studied online! A direct comparison between in-person and online experimentation. Department of Psychology, Louisiana State University. Manuscript submitted for publication
- Faul, F., Erdfelder, E., Lang, A.-G., & Buchner, A. (2007). G*Power 3: A flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behavior Research Methods, 39(2), 175–191. https://doi.org/10.3758/bf03193146
- Greenwald, A. G. (1992). New Look 3: Unconscious cognition reclaimed. American Psychologist, 47(6), 766–779. doi:10.1037/0003-066X.47.6.766.
- Guerreiro, M. J., Murphy, D. R., & Van Gerven, P. W. (2010). The role of sensory modality in age-related distraction: A critical review and a renewed view. Psychological Bulletin, 136(6), 975–1022. https://doi.org/10.1037/a002073
- Halin, N., Marsh, J. E., Hellman, A., Hellström, I., & Sörqvist, P. (2014). A shield against distraction. Journal of Applied Research in Memory and Cognition, 3(1), 31–36. https://doi.org/10.1016/j.jarmac.2014.01.003
- Henninger, F., Shevchenko, Y., Mertens, U. K., Kieslich, P. J., & Hilbig, B. E. (2019). lab.js: A free, open, online study builder. Behavior Research Methods, 54(2), 556–573. https://doi.org/10.3758/s13428-019-01283-5
- Holender, D. (1986). Semantic activation without conscious identification in dichotic listening, parafoveal vision, and visual masking: A survey and appraisal. Behavioral and Brain Sciences, 9(1), 1–23. https://doi.org/10.1017/s0140525x00021269
- Hughes, R. W. (2014). Auditory distraction: A duplex-mechanism account. PsyCh Journal, 3(1), 30–41. https://doi.org/10.1002/pchj.44
- Hughes, G., Desantis, A., & Waszak, F. (2013). Attenuation of auditory N1 results from identity-specific action-effect prediction. European Journal of Neuroscience, 37(7), 1152–1158. https://doi.org/10.1111/ejn.12120
- Hughes, R. W., & Marsh, J. E. (2020). When is forewarned forearmed? Predicting auditory distraction in short-term memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 46(3), 427–442. https://doi.org/10.1002/pchj.44
- Jensen, C., & Thomsen, J. P. (2014). Self-Reported cheating in web surveys on political knowledge. Quality & Quantity, 48(6), 3343–3354. https://doi.org/10.1007/s11135-013-9960-z
- Jones, D. (1990). Recent advances in the study of human performance in noise. Environment International, 16(4–6), 447–458. https://doi.org/10.1016/0160-4120(90)90013-V
- Jones, D. (1999). The cognitive psychology of auditory distraction: The 1997 BPS Broadbent Lecture. British Journal of Psychology, 90(2), 167–187. https://doi.org/10.1348/000712699161314
- Jones, D. M., Marsh, J. E., & Hughes, R. W. (2012). Retrieval from memory: Vulnerable or inviolable? Journal of Experimental Psychology. Learning, Memory, and Cognition, 38(4), 905–922. https://doi.org/10.1037/a0026781
- Kenett, Y. N., & Faust, M. (2019). A semantic network cartography of the creative mind. Trends in Cognitive Sciences, 23(4), 271–274. https://doi.org/10.1016/j.tics.2019.01.007
- Labonté, K., Marsh, J. E., & Vachon, F. (2021). Distraction by auditory categorical deviations is unrelated to working memory capacity: Further evidence of a distinction between acoustic and categorical deviation effects. Auditory Perception & Cognition, 4(3–4), 139–164. https://doi.org/10.1080/25742442.2022.2033109
- LeCompte, D. C., & Shaibe, D. M. (1997). On the irrelevance of phonological similarity to the irrelevant speech effect. The Quarterly Journal of Experimental Psychology: Section A, 50(1), 100–118. doi:10.1080/713755679.
- Littlefair, Z., Vachon, F., Ball, L. J., Robinson, N., & Marsh, J. E. (2022). Acoustic and categorical deviation effects are produced by different mechanisms: Evidence from additivity and habituation. Auditory Perception & Cognition, 5(1–2), 1–24. https://doi.org/10.1080/25742442.2022.2063609
- Marsh, J. E., Campbell, T. A., John, J. P., Mehrotra, S., & Kutty, B. M. (2016). Processing complex sounds passing through the rostral brainstem: The new early filter model. Frontiers in Neuroscience, 10(136), 1–33. https://doi.org/10.3389/fnins.2016.00136
- Marsh, J. E., Hughes, R. W., & Jones, D. M. (2008). Auditory distraction in semantic memory: A process-based approach. Journal of Memory and Language, 58(3), 682–700. https://doi.org/10.1016/j.jml.2007.05.002
- Marsh, J. E., Hughes, R. W., & Jones, D. M. (2009). Interference by process, not content, determines semantic auditory distraction. Cognition, 110(1), 23–38. https://doi.org/10.1016/j.cognition.2008.08.003
- Marsh, J. E., Hughes, R. W., Sörqvist, P., Beaman, C. P., & Jones, D. M. (2015). Erroneous and veridical recall are not two sides of the same coin: Evidence from semantic distraction in free recall. Journal of Experimental Psychology: Learning, Memory, and Cognition, 41(6), 1728–1740. https://doi.org/10.1037/xlm0000121
- Marsh, J. E., Threadgold, E., Barker, M. E., Litchfield, D., Degno, F., & Ball, L. J. (2021). The susceptibility of compound remote associate problems to disruption by irrelevant sound: A window onto the component processes underpinning creative cognition? Journal of Cognitive Psychology, 33(6–7), 793–822. https://doi.org/10.1080/20445911.2021.1900201
- Marsh, J. E., Yang, J., Qualter, P., Richardson, C., Perham, N., Vachon, F., & Hughes, R. W. (2018). Post-categorical auditory distraction in short-term memory: Insights from increased task load and task type. Journal of Experimental Psychology. Learning, Memory, and Cognition, 44(6), 882–897. https://doi.org/10.1037/xlm0000492
- Meade, M. E., & Fernandes, M. A. (2016). The role of semantically related distractors during encoding and retrieval of words in long-term memory. Memory, 24(6), 801–811. doi:10.1080/09658211.2015.1053491.
- Meng, Z., Lan, Z., Yan, G., Marsh, J. E., & Liversedge, S. P. (2020). Task demands modulate the effects of speech on text processing. Journal of Experimental Psychology. Learning, Memory, and Cognition, 46(10), 1892–1905. https://doi.org/10.1037/xlm0000861
- Moors, A., & De Houwer, J. (2006). Automaticity: A theoretical and conceptual analysis. Psychological Bulletin, 132, 297–326. https://doi.org/10.1037/0033-2909.132.2.297
- Moray, N. (1959). Attention in dichotic listening: Affective cues and the influence of instructions. Quarterly Journal of Experimental Psychology, 11(1), 56–60. https://doi.org/10.1080/17470215908416289
- Neely, C. B., & LeCompte, D. C. (1999). The importance of semantic similarity to the irrelevant speech effect. Memory & Cognition, 27(1), 37–44. https://doi.org/10.3758/bf03201211
- Neumann, O. (1987). Beyond capacity: A functional view of attention. In H. Heuer & A. F. Sanders (Eds.), Perspectives on perception and action. Erlbaum. 361–394.
- Neumann, O. (1996). Theories of attention. In O. Neumann & A. F. Sanders (Eds.), Handbook of perception and action (Vol. 3, pp. 389–446). Elsevier. https://doi.org/10.1016/s1874-5822(96)80027-2.
- Nicholls, A. P., & Jones, D. M. (2002). The sandwich effect reassessed: Effects of streaming, distraction, and modality. Memory & Cognition, 30(1), 81–88. https://doi.org/10.3758/bf03195267
- Parmentier, F. B. R. (2014). The cognitive determinants of behavioral distraction by deviant auditory stimuli: A review. Psychological Research, 78(3), 321–338. doi:10.1007/s00426-013-0534-4.
- Popper, K. R. (1959). The propensity interpretation of probability. The British Journal for the Philosophy of Science, 10(37), 25–42. https://doi.org/10.1093/bjps/x.37.25
- Röer, J. P., Bell, R., & Buchner, A. (2013). Self-relevance increases the irrelevant sound effect: Attentional disruption by one’s own name. Journal of Cognitive Psychology, 25(8), 925–931. https://doi.org/10.1080/20445911.2013.828063
- Röer, J. P., Bell, R., Buchner, A., Saint-Aubin, J., Sonier, R. P., Marsh, J. E., & Arnström, S. (2021). A multilingual preregistered replication of the semantic mismatch effect on serial recall. Journal of Experimental Psychology, 48(7) . Learning, Memory, and Cognition. https://doi.org/10.1037/xlm0001066
- Röer, J. P., Bell, R., Körner, U., & Buchner, A. (2019). A semantic mismatch effect on serial recall: Evidence from interlexical processing of irrelevant speech. Journal of Experimental Psychology. Learning, Memory, and Cognition, 45(3), 515–525. https://doi.org/10.1037/xlm0000596
- Röer, J. P., & Cowan, N. (2021). A preregistered replication and extension of the cocktail party phenomenon: One’s name captures attention; unexpected words do not. Journal of Experimental Psychology. Learning, Memory, and Cognition, 47 (2), 234–242. https://doi.org/10.1037/xlm0000874
- Röer, J. P., Körner, U., Buchner, A., & Bell, R. (2017a). Attentional capture by taboo words: A functional view of auditory distraction. Emotion, 17(4), 740–750. https://doi.org/10.1037/emo0000274
- Röer, J. P., Körner, U., Buchner, A., & Bell, R. (2017b). Semantic priming by irrelevant speech. Psychonomic Bulletin & Review, 24(4), 1205–1210. https://doi.org/10.3758/s13423-016-1186-3
- Salame, P., & Baddeley, A. (1982). Disruption of short-term memory by unattended speech: Implications for the structure of working memory. Journal of Verbal Learning and Behavior, 21(2), 150–164. doi:10.1016/S0022-5371(82)90521-7.
- Sörqvist, P., Dahlström, Ö., Karlsson, T., & Rönnberg, J. (2016). Concentration: The neural underpinnings of how cognitive load shields against distraction. Frontiers in Human Neuroscience, 10 (221), 1–10. https://doi.org/10.3389/fnhum.2016.00221
- Sörqvist, P., & Marsh, J. E. (2015). How concentration shields against distraction. Current Directions in Psychological Science, 24 (4), 267–272. https://doi.org/10.1177/0963721415577356
- Sörqvist, P., Stenfelt, S., & Rönnberg, J. (2012). Working memory capacity and visual–verbal cognitive load modulate auditory–sensory gating in the brainstem: Toward a unified view of attention. Journal of Cognitive Neuroscience, 24(11), 2147–2154. https://doi.org/10.1162/jocn_a_00275
- Treisman, A. M. (1964). Selective attention in man. British Medical Bulletin, 20(1), 12–16. doi:10.1093/oxfordjournals.bmb.a070274.
- Treisman, A., & Geffen, G. (1968). Selective attention and cerebral dominance in perceiving and responding to speech messages. Quarterly Journal of Experimental Psychology, 20(2), 139–150. https://doi.org/10.1080/14640746808400142
- Tremblay, K., Kraus, N., McGee, T., Ponton, C., & Otis, B. (2001). Central auditory plasticity: Changes in the N1-P2 complex after speech-sound training. Ear and Hearing, 22 (2), 79–90. https://doi.org/10.1097/00003446-200104000-00001
- Vachon, F., Marsh, J. E., & Labonté, K. (2020). The automaticity of semantic processing revisited: Auditory distraction by a categorical deviation. Journal of Experimental Psychology. General, 149(7), 1360–1397. doi:10.1037/xge0000714.
- Van der Heijden, A. H. C. (1992). Selective attention in vision. Routledge and Kegan Paul.
- White, K. K., & Abrams, L. (2004). Free associations and dominance ratings of homophones for young and older adults. Behavior Research Methods, Instruments and Computers, 36(3), 408–420. https://doi.org/10.3758/BF03195589
- Wood, N., & Cowan, N. (1995). The cocktail party phenomenon revisited: How frequent are attention shifts to one’s name in an irrelevant auditory channel? Journal of Experimental Psychology. Learning, Memory, and Cognition, 21(1), 255–260. doi:10.1037/0278-7393.21.1.255.
- Woods, K. J. P., Siegel, M. H., Traer, J., & McDermott, J. H. (2017). Headphone screening to facilitate web-based auditory experiments. Attention, Perception & Psychophysics, 79(7), 2064–2072. https://doi.org/10.3758/s13414-017-1361
- Wood, N. L., Stadler, M. A., & Cowan, N. (1997). Is there implicit memory without attention? A re-examination of Eich’s procedure. Memory & Cognition, 25 (6), 772–779. https://doi.org/10.3758/bf03211320
Appendix 1:
Homophone sets and their dominance. dominance refers to the meaning that comes to mind first when the word is heard (i.e., dominance was calculated by giving participants pairs of homophones and asking then to rate which was more dominant).