
ABSTRACT
The presence of phonological neighbours facilitates word-form learning, suggesting that prior phonological knowledge supports vocabulary acquisition. We tested whether prior semantic knowledge similarly benefits word learning by teaching 7-to-10-year-old children (Experiment 1) and adults (Experiment 2) pseudowords assigned to novel concepts with low or high semantic neighbourhood density according to feature norms. Form recall, definition recall, and semantic categorisation tasks were administered immediately after training, the next day, and one week later. Across sessions, pseudowords assigned to low-density (versus high-density) semantic neighbourhood concepts elicited better word-form recall (for adults) and better meaning recall (for children). Exploratory cross-experiment analyses demonstrated that the neighbourhood influence was most robust for recalling meanings. Children showed greater gains in form recall than adults across the week, regardless of links to semantic knowledge. While the results suggest that close semantic neighbours interfere with word learning, we consider alternative semantic dimensions that may be beneficial.
Our ability to learn new words remains important across the lifespan, enabling us to communicate about new things we experience. Encountering an unfamiliar food from a different cuisine or a rare animal at the zoo, for instance, requires us to learn its association with a new combination of sounds, encode its key features, and determine how it relates to concepts that we already know. For example, we might learn that a pomelo is a type of fruit that is similar to a grapefruit, but larger and sweeter. In using what we know about grapefruits to support new learning, we bring a broader understanding of citrus fruit features—inferring that a pomelo likely has a waxy peel, pips, and juicy flesh. However, the availability of this related knowledge will vary across new concepts we encounter, and it is not clear the extent to which it helps or hinders memory for the new word. We addressed this question by examining how children’s and adults’ learning of novel concepts is affected by the density of associated semantic neighbourhoods. Determining the role of prior knowledge has important implications for theories of word learning, as well as for understanding how word learning changes as semantic knowledge accumulates across development.
The role of prior knowledge in new word acquisition can be examined both in terms of the initial learning of a new word and its long-term retention in vocabulary, as dissociated within a complementary learning systems framework (Davis & Gaskell, Citation2009; McClelland et al., Citation1995). According to this model, vocabulary knowledge is stored in a distributed manner in neocortical regions of the brain, permitting efficient language processing and communication (Gaskell & Marslen-Wilson, Citation1997). For a new word to become part of this system, it must do so in such a way to avoid disrupting existing connections. The complementary learning systems model proposes that initial lexical representations are formed using the hippocampal memory system, with the new form-meaning mapping not yet fully integrated with existing neocortical vocabulary (Davis & Gaskell, Citation2009). This system allows knowledge of a new word to be acquired rapidly without disrupting existing connections, and the new representation can then support slower integration of the new word into neocortical-based networks.
The strengthening of neocortical connections is proposed to result from repeated reactivations of the hippocampal representation, which can occur “offline” during sleep. In line with this, increased competition is observed between new and familiar words in lexical processing tasks following sleep but not wake in both adults (Dumay & Gaskell, Citation2007) and children (Henderson et al., Citation2012), suggesting that sleep enhances integration with neocortical vocabulary. These sleep-associated consolidation processes are further associated with improved accuracy and efficiency in recalling the new word-forms (Ashworth et al., Citation2014; Gais et al., Citation2006; James et al., Citation2020a; Tamminen et al., Citation2010). Deliberate retrieval practice may also enhance recall of new word knowledge (e.g. Hulme & Rodd, Citation2021), proposed to operate via similar principles of hippocampal reactivation (Antony et al., Citation2017). These findings converge on the importance of memory reactivation processes in supporting vocabulary acquisition, and highlight the importance of understanding factors that influence this longer-term consolidation of new word knowledge as well as those that support initial encoding.
One factor proposed to support lexical consolidation is the learner’s prior linguistic knowledge (James et al., Citation2017). Recent progress in complementary learning systems theory has examined how the speed of neocortical learning may be influenced by memory schema (e.g. Kumaran et al., Citation2016; McClelland, Citation2013; McClelland et al., Citation2020), driven by evidence that new information related to existing knowledge becomes integrated into neocortical networks very rapidly (Tse et al., Citation2007). For example, McClelland (Citation2013) demonstrated that a neural network trained with structured knowledge of birds and their semantic properties (e.g. grow, move, fly) showed more rapid learning of a typical new example that shared these properties (a cardinal) than an atypical example (a penguin, which cannot fly but can swim). This model demonstrates how information that capitalises upon existing knowledge can be integrated into neocortical networks without requiring repeated hippocampal reactivations (Tse et al., Citation2007). From a language learning perspective then, it follows that individuals with rich lexical networks will likely have more relevant structures to draw upon to support new word learning, and thus consolidation into neocortical networks is proposed to proceed more rapidly. Capitalising upon existing knowledge may be one means by which individuals with good vocabulary knowledge acquire new vocabulary at faster pace than those with weak vocabulary, thereby increasing the “vocabulary gap” in performance across development (James et al., Citation2017). However, the nature of this lexical support is not well-specified, and it is not clear how word learning might be influenced by different aspects of linguistic knowledge.
One way of examining the influence of prior knowledge on word learning is to manipulate the psycholinguistic properties of the to-be-learned words. By quantifying the similarities between new items and real words that would be known to the learner in different ways, we can examine whether these relationships predict memory for new words before and/or after opportunities for consolidation. In examining word-form similarity, many studies have demonstrated that novel words with many phonological neighbours (i.e. words that differ by a single sound) are more readily learned than words with fewer phonological neighbours. This benefit has been found for pre-school children (Hoover et al., Citation2010; Storkel, Citation2009; Storkel et al., Citation2013), school-aged children (James et al., Citation2019; van der Kleij et al., Citation2016), and adults (James et al., Citation2019; Storkel et al., Citation2006), suggesting that individuals can access prior knowledge to support learning across the lifespan (although note that this support may be less apparent in incidental word learning; James et al., Citation2020b). From a complementary learning systems perspective, James et al. (Citation2019) found that this early benefit from phonological neighbours was reduced one week later, once words with fewer neighbours had opportunities to benefit from offline consolidation processes. These findings support the proposal that items related to prior word-form knowledge may be integrated into neocortical systems more rapidly, and are therefore less dependent on offline reactivation processes to support long-term memory.
In this study, we turn our attention towards semantic neighbours to develop a broader understanding of how different aspects of prior knowledge influence memory for new vocabulary. Learning the meaning of a new word is a crucial part of vocabulary acquisition itself, and also supports the long-term retention of new word-form knowledge (Henderson et al., Citation2013). However, while psycholinguistic measures that capture semantic neighbourhoods have well-documented influences on the processing of known words (see Pexman, Citation2020, for a recent review), they have received relatively little attention in experimental studies of word learning. Network approaches to modelling language acquisition support that semantic neighbours broadly predict vocabulary growth, finding that new words are more likely to be acquired when they are highly connected to known ones (Engelthaler & Hills, Citation2017; Hills et al., Citation2009), although semantically distinct words may be acquired earlier (Engelthaler & Hills, Citation2017). Yet only two studies to our knowledge have examined the learning and retention processes that might underlie these influences: Tamminen et al. (Citation2013) in a study of sleep-associated consolidation in adults, and Storkel and Adlof (Citation2009) in a study of preschool children. In contrast to the benefits seen for word-form neighbours, the findings of both studies point towards interference from related semantic knowledge when learning new words.
Tamminen et al. (Citation2013) taught adults pseudowords as names for novel concepts with either sparse or dense semantic connections. These novel concepts were created from existing concepts with either low- or high-density semantic neighbourhoods, as quantified by the number of associates provided in free association norms (Nelson et al., Citation2004). To make each concept novel, they added a novel feature (e.g. bee whose sting feels pleasant, crab that has a beak). Participants were tested on their knowledge of the new pseudowords immediately after learning, the next day, and one week later—allowing for an assessment of the influence of prior knowledge before and after opportunities for consolidation. Across all test sessions, participants had poorer performance for high- versus low-density concepts in a synonym judgement task, which required them to identify which of three familiar words was associated with the trained word. This perhaps indicates that participants experienced interference from existing knowledge in learning the new concepts. However, there was no influence of the density of prior semantic knowledge on explicit recall of the new word-forms or their meanings, suggesting that this interference might arise from lexical processing during the synonym judgement task rather than during learning per se. In line with this, responses only slowed to high-density novel items in a speeded semantic categorisation task one week later, suggesting that a longer period of consolidation enhanced competition between new and known concepts as they became better integrated in memory (similar to the way in which lexical competition was observed following sleep in the studies described above). Thus, dense existing semantic knowledge elicited interference when processing the novel concepts in the context of familiar words, but there was no evidence that memory for the new words themselves was affected by links to semantic knowledge.
However, evidence of semantic interference in establishing new word representations comes from a study with children. Storkel and Adlof (Citation2009) quantified semantic set sizes of non-objects by collecting free associations from presented line drawings. In a subsequent word-learning task, preschool children were more accurate in identifying nonwords associated with objects from small semantic set sizes, suggesting that—at least in young children—connections to existing semantic knowledge can interfere in learning and/or remembering new information. In this study, the effect only emerged at a delayed test one week later, offering further support to the hypothesis that offline processes enhance engagement of the new words with existing semantic knowledge.
Thus, unlike for word-form neighbours, it appears from the existing research that connections to semantic knowledge may interfere with new word acquisition. However, semantic relationships can be conceptualised along several different dimensions (Hameau et al., Citation2019), and different measures have been shown to contribute unique variance in predicting performance in speeded word recognition tasks (Pexman et al., Citation2008). Tamminen et al. (Citation2013) derived their measures of semantic neighbourhood from free-association norms, which were created by asking participants to produce the first word that came to mind when presented with the target (Nelson et al., Citation2004). Free-association norms are considered a language-based measure that typically reflects the co-occurrence of concepts in spoken and/or written language, and can be broadly distinguished from object-based metrics that draw upon the content of the concepts themselves (Buchanan et al., Citation2001). For example, feature production norms are collected by asking participants to list features of target concepts (McRae et al., Citation2005), producing measures of semantic richness (i.e. the number of features produced) and common features between concepts. Semantic neighbourhoods conceptualised in this way may arguably be more beneficial to a new learner than linguistic co-occurrence. For example, the target “bird” leads to “cat” as a more frequent lexical associate than “robin” (Nelson et al., Citation2004), yet knowledge of birds is intuitively more useful when learning about a robin than a cat. In this study, we test the hypothesis that semantic prior knowledge defined by object-based similarities will facilitate word learning and consolidation.
This proposal garners support from studies of early language learning that capture the variability in knowledge that preschool children bring to the task. For example, Borovsky et al. (Citation2016) demonstrated that infants were more able to learn and recognise new words from categories that they had more knowledge about compared to categories for which they had lower levels of existing knowledge. Similarly, Perry et al. (Citation2016) found that preschool children with larger shape-based noun vocabularies were more likely to remember object shapes during word learning. These studies support the proposal that semantic knowledge relevant to a new concept’s properties may aid acquisition, although they cannot address questions of longer-term memory as children were only tested on the same day as learning.
The present study
We used a similar design to Tamminen et al. (Citation2013), but instead drew upon shared features as an object-based measure of semantic relationships to test whether semantic neighbourhood density can benefit word learning (rather than the associative measure used previously). We taught participants pseudowords and associated definitions, formed by adding a novel feature to known concepts from low and high feature density neighbourhoods. We tested explicit recall of the pseudowords and definitions immediately after learning, the next day, and one week later, to examine the influence of existing knowledge on word learning before and after opportunities for consolidation. We also used a speeded semantic categorisation task to index integration of the new words into neocortical vocabulary, capitalising on previous findings that known words with high semantic neighbourhood density are responded to more quickly in this task than words with low semantic density (Mirman & Magnuson, Citation2008). Tamminen et al. (Citation2013) found that implicit semantic neighbourhood effects for trained pseudowords emerged only after a period of consolidation, consistent with other studies that have found implicit semantic activation to emerge after one/more periods of sleep (Clay et al., Citation2007; Tham et al., Citation2015).
One motivation for understanding the role of semantic prior knowledge is to understand how word learning might change across development. The studies described above span a broad age range from preschool children to adults, yet there is a lack of direct developmental comparisons. A study of known words taken from linguistic corpora suggested that young infants start by learning words from sparse semantic neighbours but increasingly benefit from dense neighbours across the preschool years (Storkel, Citation2009). However, these developmental differences have not been tested experimentally, and no studies to our knowledge have considered the influence of semantic neighbours in school-aged children. There are two possibilities here: first, school-aged children may show smaller semantic density effects than adults given that our selected measure is based on adult norms, and children may not have yet acquired rich enough knowledge about concepts to have such extreme differences in low- versus high-density items. Speaking to this proposal, Pexman and Yap (Citation2018) found that adults with better existing vocabulary knowledge showed more sensitivity to semantic neighbourhood density in speeded responses during a semantic categorisation task compared to adults with lower vocabulary knowledge, suggesting that the knowledge learners bring to the task is highly relevant. Alternatively, children might show larger semantic density effects under the possibility that an underdeveloped system may be more sensitive to the influence of existing knowledge. For example, Davies et al. (Citation2017) showed that effects of psycholinguistic variables on lexical processing decline across the lifespan as the lexical system accumulates experience and maximises learning efficiency. We present two experiments to explore these possibilities across children aged 7–10 years (Experiment 1) and adults (Experiment 2). While the developmental studies described above typically assessed semantic prior knowledge influences in pre-school children, selecting a school-aged group allowed us to use the same experimental tasks for children and adults, thus facilitating developmental comparisons. Further, these age groups overlap with those that have been examined in studies of phonological neighbours in word learning (James et al., Citation2019; James et al., Citation2020b), allowing comparisons with different types of prior knowledge influence.
Our main research questions were as follows: First, is explicit memory for novel words helped or hindered by links to existing semantic knowledge during word learning, as defined by object-based norms? Second, can newly trained concepts acquire the lexical properties of their neighbours, benefiting from rich semantic connections in speeded reaction time tasks? Third, what is the time course of this engagement with semantic knowledge? By using both explicit and implicit measures of new word knowledge, we aimed to capture initial encoding processes and those that indicate integration with existing knowledge, proposed to require periods of offline consolidation. Finally, across experiments we also explored whether children and adults are differently influenced by semantic knowledge during word learning, reflecting differences in the amount of prior knowledge or their sensitivity to it during learning. In the first experiment with children, we thus tested three experimental hypotheses: 1) A large number of shared features will facilitate explicit aspects of word learning, as demonstrated by superior performance in recall and recognition tasks; 2) Novel concepts that share lots of features with existing concepts should show a reaction time advantage when compared to novel concepts that share fewer features, in a speeded semantic categorisation task; and 3) Across tasks, effects of neighbourhood density (i.e. better recall/recognition for high density items; a density effect in speeded semantic categorisation) will emerge only after a night’s sleep (24-hour test) or longer period of consolidation (week follow-up test).
Experiment 1
Experiment 1 can be considered exploratory in the sense that it was not pre-registered, and that the sample size was determined opportunistically (school availability within the timeframe of the study). However, our analysis plan and key hypothesis tests were consistent with a pre-registered adult study being conducted in parallel (Experiment S1, http://osf.io/3vnsg; detailed below).
Experiment 1 methods
Participants
Two whole classes of children took part in the study, recruited via two schools in North Yorkshire. The resulting sample included 51 children (25 male) aged 7–10 years (M = 8.67 years). One additional child was excluded from analyses due to hearing difficulties. Two of the included children were absent on the second day of testing, and thus only contributed data for two out of the three follow-up tests.
The study was approved by the Research Ethics Committee of the Department of Psychology, University of York. Consent was obtained from the school head teachers. Parents were fully informed about the study and were given the opportunity to opt their child out of taking part.
Design and procedure
Children completed a single training session in a whole-class setting, which lasted approximately 45 min. Test sessions were then conducted individually in a quiet setting outside the classroom at three time points: the same day (T1), the next day (T2), and one week later (T3). Standardised assessments of vocabulary and nonverbal ability (matrix reasoning) from the Wechsler Abbreviated Scale of Intelligence II (Wechsler, Citation2011) were also collected during these sessions for descriptive purposes. The mean t-scores were within the average range for both matrix reasoning (M = 46.53, SD = 9.73) and vocabulary (M = 59.71, SD = 11.92).
Stimuli
Pseudowords were initially selected using the English Lexicon Project (Balota et al., Citation2007) according to the following criteria: 5–6 letters long, no orthographic neighbours, and a nonword rejection Z-score of −0.45 to 0.45 (i.e. an average range response time for rejection in a lexical decision task). These criteria were used to ensure that the word-forms were well-matched across conditions, and to minimise alternative sources of variability in the speeded semantic categorisation task. Twenty-four bisyllabic pseudowords were selected in total such that each began with different vowels or consonant clusters and were judged to be easily pronounceable (Appendix 1), and these were split into two lists matched on length, number of orthographic neighbours, and bigram frequency (Marian et al., Citation2012).Footnote1 A subset of 16 pseudowords were selected for Experiment 1 with children.
Novel concepts were created by taking an existing base concept and adding an additional feature (further details below). For example, a gorilla (base concept) that has green skin (added feature). Half of the base concepts were animals, for purposes of the semantic categorisation task. Critically, the base concepts were selected for having high (n = 12) or low (n = 12) semantic neighbourhood density according to the McRae et al. (Citation2005) feature norms.Footnote2 In this first step towards examining feature-based semantic neighbourhoods in word learning, we took a broad approach to defining semantic neighbourhood density. First, we selected for the number of features of each item (also termed semantic richness), as has consistently been shown to facilitate lexical processing (Pexman, Citation2020). Second, we considered the density of the semantic neighbourhood by selecting for low versus high intercorrelational feature density—the extent to which the listed features co-occurred in other normed concepts. This metric is described in detail within the database documentation (McRae et al., Citation2005): pairs of features are considered significantly correlated if they share ≥ 6.5% of their variance within the database (i.e. they often co-occur together in the 541 normed concepts), and the proportion of significantly correlated feature pairs is calculated for each concept. We predicted that this co-occurrence would also support learning, being indicative of many shared features that could support processing (Grondin et al., Citation2009) and representing many existing connections between concepts.
Our selected low-density base concepts had fewer features listed in the norms (≤ 16), and fewer of these listed features (≤ 14%) co-occurred in other normed concepts. High-density base concepts had more features overall (≥ 18) and more of these (≥ 25%) also co-occurred in other concepts. The two groups of stimuli were otherwise well matched on measures of frequency, age of acquisition, imageability, concreteness and word length (). A pilot study of these base concepts with adults supported a reaction time benefit for high-density concepts in a semantic categorisation task (mean difference = 14 ms; t(70) = 2.56, p = .01).
Table 1. Properties of stimuli in the low and high semantic neighbourhood density conditions.
The added features that made each concept novel were also selected from the McRae et al. (Citation2005) norms, and each occurred only once in the norms to minimise the influence of additional semantic neighbourhoods. The features were drawn from a range of perceptual, behavioural and functional categories, which were matched in type across low- and high-density base concepts (Appendix 1). To ensure that these combinations of base concepts and features did not differ in plausibility across low- and high-density conditions, 58 adults completed online ratings of how plausible they would find each item in a children’s storybook. High- and low-density items did not differ in plausibility (ps >.2). A subset of 16 items (8 per density condition) were selected for Experiment 1. A single fixed set of pseudoword-concept pairings was used for Experiment 1 (with counterbalancing of pseudowords across density conditions introduced in Experiment 2).
Training tasks
The training tasks were conducted with the class as a whole. Children were given workbooks to support their learning, and were guided through a number of tasks using a PowerPoint presentation projected at the front of the classroom (see ). The first three tasks were completed for each item in turn (form and definition repetition, drawing), followed by the meaning matching task for all items. In total, children heard each new word-form nine times, and each definition six times.
Figure 1. Schematic of the training tasks used in the learning phase.
Note: For each item, children first repeated the new word aloud twice and wrote it down, before repeating the definition twice. They were given 30 s to draw a picture of the new concept. After completing these learning tasks for all items, children completed two rounds of multiple choice quizzes.
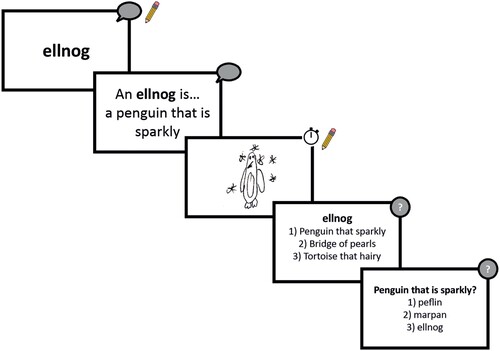
Form repetition
Children heard each new word-form spoken by the experimenter, with its orthographic form projected on the PowerPoint at the front of the classroom. They repeated the pseudoword aloud twice, and subsequently copied it into their workbooks.
Definition repetition
Children were introduced to the definition of each pseudoword, and again repeated it aloud twice.
Drawing task
Children were given 30 s per item to draw a picture of the new concept, designed to help them to engage with its different features. These were not scored or analysed further.
Meaning matching
After the workbooks had been collected, further learning and feedback took place via a multiple choice quiz. In the first round, a pseudoword and three possible options for its definition were presented on screen, and children had to show their answer by raising one, two or three fingers. In the second round, the definition was presented and the children had to choose the correct word-form to match. Each item was presented once in each round, with the correct answer provided after each one.
Test tasks
Children completed the test tasks individually with the experimenter. There were four test tasks to assess different aspects of word knowledge. All test tasks were presented using DMDX software v5.1.3.4 (Forster & Forster, Citation2003), with item order randomised. The tasks were presented in the following fixed order.
Cued form recall
Children were presented with the first consonant(s) and vowel of the word (both aurally and visually), and were asked to speak the remainder of the word. Children were encouraged to attempt partial responses even if they were not sure of the answer, and the experimenter transcribed the responses for scoring on the basis of whole word accuracy (0, 1).
Form recognition
Children were presented with auditory and orthographic presentations of the pseudoword alongside a corresponding foil in which the final vowel was changed (see Appendix 1). Both of the written stimuli remained on screen for up to 7 s, or until the child had selected their answer with a key press response.
Speeded semantic categorisation
Children were presented with each word-form visually and auditorily, and were asked to make speeded judgements about whether or not the concept was an animal using a key press response. They were asked to respond as quickly and accurately as possible, and each trial terminated after a response or 7 s. To allow for adjustment to the task and response format, the experimental task was preceded by 24 practice trials using existing English words, providing feedback for erroneous responses. We analysed both the accuracy (0, 1) and the response time (ms) for correct trials.
Cued meaning recall
Children were given an auditory and visual presentation of each word-form, and asked to provide as much of the definition as they could remember. Verbal responses were transcribed by the experimenter. A total of two points could be awarded per item for correctly recalling the base concept and the added feature.
Analyses
Data were analysed in R (R Core Team, Citation2015), using lme4 (Bates et al., Citation2015b) and ordinal (Christensen, Citation2015) to fit mixed effects models. For each dependent variable, we initially fitted a model with fixed effects of test session, semantic density, and their interaction. Fixed effects were deviance coded to enable interpretation of each predictor in relation to the overall mean. Test session is a three-level factor, and we set two orthogonal contrasts to interpret the data: delay1 tested for differences in memory performance without versus with opportunities for consolidation (T1 vs. T2&T3); delay2 tested for continued changes across the week (T2 vs. T3). For models with discrete dependent variables, Wald’s Z was used to determine statistical significance. For reaction times, we report significance computed using the lmerTest package (Kuznetsova et al., Citation2017).
In light of earlier convergence issues in attempting to fit maximal models (Barr et al., Citation2013), we adopted a parsimonious modelling approach for these experiments (Bates et al., Citation2015a). We first fitted a model with our fixed effects of interest and random intercepts for participants and items, and then pruned away the interaction if not contributing to model fit (p < .2). We then used a forward “best-path” approach to test for the inclusion of appropriate random slopes (Barr et al., Citation2013). The results presented are from the most complex model supported by the data. The data and analysis scripts are available on the OSF (https://osf.io/35ftn). Figures were made using ggplot2 (Wickham, Citation2009).
Experiment 1 results
Cued form recall
Children recalled a mean proportion of .20 (SD = .40) of the word-forms at T1, and performance improved substantially over tests (A; delay1: β = 0.95, SE = 0.05, Z = 21.10, p <.001). Recall continued to improve between T2 (M = .51, SD = .50) and T3 (M = .80, SD = .40; delay2: β = 0.91, SE = 0.07, Z = 13.35, p <.001). There was no influence of semantic neighbourhood density in recall of word-forms, alone or in interaction with test session (ps > .6; ).
Figure 2. Explicit recall performance by semantic neighbourhood condition and test session.
Note: Proportion correct for (A) Form recall in Experiment 1; (B) Form recall in Experiment 2; (C) Meaning recall in Experiment 1; and (D) Meaning recall in Experiment 2. Individual points mark average participant recall for each condition for each test session. Error bars denote 95% confidence intervals.
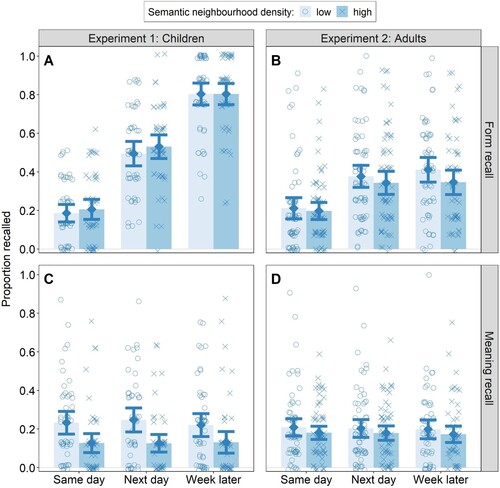
Table 2. Final analysis models for Experiment 1: Form tasks.
Form recognition
Children could successfully recognise the new word-forms at above chance levels at T1 (M = .83, SD = .38), and improved at subsequent tests (T2: M = .92, SD = .28; T3: M = .94, SD = .24). This effect of test session was statistically significant across both contrasts (delay1: β = 0.39, SE = 0.05, Z = 8.07, p < .001; delay2: β = 0.21, SE = 0.10, Z = 2.08, p = .037), again demonstrating significant improvements in form knowledge across the week. As with the recall of word-forms, there was no influence of semantic neighbourhood density on their recognition (ps > .18; ).
Cued meaning recall
Children scored an average of .36 out of a maximum of 2 points for each item at T1 (SD = .76). There were no significant changes in performance across test sessions (ps > .36; ), but there was a significant difference in memory for words from different semantic neighbour conditions (β = −0.48, SE = 0.18, Z = −2.62, p = .009). Children were better at recalling definitions with low semantic neighbourhood density (M = .47, SD = .84) than high semantic neighbourhood density (M = .26, SD = .67; C). There was no evidence of an interaction between test session and semantic neighbourhood density (pruned from the final model; p = .687).
Table 3. Final analysis model for Experiment 1: Cued meaning recall.
Semantic categorisation
Accuracy
Performance was very low on the semantic categorisation task (M = .59, SD = .49). Neither test session nor semantic neighbourhood density influenced accuracy on this task (all ps > .4; Table A2-1).
Reaction time
We were cautious in analysing the RT data considering that performance accuracy was so low in this task, and removed participants who were at/below chance performance (n = 11). This left 40 participants in the analysis, who ranged from .52-.83 in categorisation accuracy (M = .63). The data were log-transformed to remediate issues of skewness in model fitting. We also removed responses < 200 ms or that were ≥ 2.5 standard deviations above each participant’s condition mean. We analysed RTs to correct responses only, leaving 49.05% of original trials.
Responses were slowest at T1 (M = 2154 ms, SD = 1211 ms) compared to later test points (β = −0.07, SE = 0.01, t = −7.66, p < .001), but the decrease in response times between the T2 (M = 1833ms, SD = 1150 ms) and T3 (M = 1696 ms, SD = 977 ms) tests were not statistically significant (β = −0.03, SE = 0.02, t = −1.84, p = .066). There was no influence of semantic neighbourhood density on reaction times (ps > .14; Table A2-2).
Experiment 1 discussion
Experiment 1 examined how children learn and remember pseudowords paired with novel concepts. Children recalled 20% of the pseudowords on the same day as learning, but showed substantial improvements across the week: averaging 51% and 80% at the day and week follow-up tests, respectively. However, they were much poorer at learning the word meanings: they showed low accuracy in both the meaning recall (18%) and semantic categorisation (59%) tasks, which neither improved nor declined with repeated tests. This increase in recall for word-forms is consistent with previous findings of an offline consolidation and/or retrieval practice benefit for this aspect of word knowledge, and adds to growing evidence that definition recall does not benefit from the same opportunities for reactivation (James et al., Citation2020a; Tamminen et al., Citation2012; Tamminen & Gaskell, Citation2013). However, participants may also have benefited from opportunities to re-encode the word-forms (but not meanings) during repeated tests in this study, facilitating improvements in this aspect of word knowledge across the week.
Our primary research questions related to the new words’ engagement with existing semantic knowledge, as indicated by performance differences related to semantic neighbourhood density. We found that existing semantic knowledge can influence new vocabulary acquisition in school-aged children: they were better at recalling novel semantic concepts from low- versus high-density semantic neighbourhoods. However, recall of word-forms appeared unaffected by these semantic manipulations. Thus, in line with the processing interference observed for language-based neighbourhoods previously in adults (Tamminen et al., Citation2013), dense feature-based semantic neighbourhoods also appear to elicit interference observable in children’s learning of new concepts. This hindrance was observed at the immediate test and did not change at the delayed tests. High- relative to low-density semantic knowledge activated during encoding may thus interfere in forming the new representation, and/or could make the novel concept harder to retrieve amongst its competitors at test.
In Experiment 2, we examined the contribution of semantic neighbourhood density to word learning in adults. In an adult study carried out in parallel to Experiment 1, we found no influence of semantic neighbourhood density in a comparable word learning experiment (Experiment S1, available on the OSF at https://osf.io/ksdfu/). Specifically, adults did not show interference from dense semantic neighbourhoods in recalling the word meanings, as we observed for children. However, adults showed much higher levels of recall performance than children, and different training tasks were used across the two experiments. To facilitate developmental comparisons, we repeated the experiment with adults using the same training procedures as Experiment 1, but we reduced the number of exposures during training to ensure comparable levels of performance between age groups.
Experiment 2
Three hypotheses were pre-registered on the Open Science Framework (http://osf.io/yk3d5): 1) Cued recall for word-forms will improve over time, consistent with Experiment 1 (and Experiment S1), and with extant evidence supporting strengthening of novel word-forms by delayed tests; 2) Where a neighbourhood density effect emerges, we predict that low-density items will be better learned than high-density items—consistent with our findings from Experiment 1 (and non-significant numerical differences in Experiment S1); and 3) If the absence of a density effect in the definitions task for adults in Experiment S1 was driven by their higher performance, then we would expect a neighbourhood density effect to emerge at lower performance levels in this task.Footnote3 However, if the absence of the density effect is driven by adults’ learning efficiency (relative to the enhanced sensitivity of developing learners to semantic competitors), we would expect no effect of density in the definitions task for adults regardless of performance levels.
Experiment 2 methods
Participants
70 participants were recruited via the University of York Psychology Department participant pool according to the following criteria: native monolingual English speakers, aged 18-35, with normal or corrected-to-normal hearing and vision, and no reading or language disorders. Three participants did not complete more than one of the three follow-up sessions, and were excluded from analyses. Thus, the final sample consisted of 67 participants (14 male), with a mean age of 20.33 years (SD = 2.54). Nine participants contributed only partial data (2/3 sessions) having missed the final session.
Participants received either £10 or course credit for their time. The study was approved by the Department of Psychology Research Ethics Committee at the University of York.
Design and procedure
To make Experiment 2 as comparable as possible to Experiment 1, we conducted training in a group setting lasting approximately 45 min. Three test sessions were then completed online according to the same schedule: the same day (T1), next day (T2), and one week later (T3). Participants were asked to complete the first test session within 2 h of training, and complete each subsequent session at a similar time (by 6pm at the latest). All sessions completed on the correct day were included in the analyses. Although we did not implement specific attention checks in the online tests, inspection of task performance confirms that participants were engaged with the activities (i.e. recognition task performance was always well above chance, ≥ 67%). No standardised assessments were collected for Experiment 2.
Stimuli
The full set of 24 items were used for the adults. We additionally incorporated two elements of counterbalancing for this experiment to ensure that idiosyncratic differences in the stimuli were not responsible for the neighbourhood density effects. The two versions of the stimuli altered the set of pseudowords and novel features assigned to each density condition.
Training tasks
The training tasks were identical to Experiment 1, except with form and definition repetitions reduced to one per item. Only one round of meaning matching was administered, presenting each definition once with three options for its word-form on each occasion. This meant that participants had five exposures to the new word-forms in total, and only two exposures to the definitions, intended to reduce adults’ performance levels in line with children. Participants circled their meaning matching answers (1, 2, or 3) in an additional training booklet.
Test tasks
The four test tasks were programmed for participants to complete online from home, in the same fixed order described above. Adults were provided with only the written cues, and gave typed responses for the recall task. Given that we were most interested in vocabulary learning (rather than orthographic learning specifically), answers were scored according to whether they read as phonologically correct (e.g. attee or atty instead of attie; chiypod instead of chipod). The form and definition recall tasks were hosted online using Qualtrics (Qualtrics, Citation2014). A link within the survey took participants to the form recognition and semantic categorisation tasks, which were programmed using Testable (Rezlescu, Citation2015) to enable response time recordings.
Analyses
Analyses were conducted as in Experiment 1.
Experiment 2 results
Cued form recall
The proportion of word-forms recalled on the same day of learning (M = .21, SD = .40) was highly comparable to Experiment 1 (M = .20, SD = .40), suggesting a similar level of difficulty for children and adults. Recall improved significantly at the delayed tests (delay1: β = 0.39, SE = 0.03, Z = 13.32, p < .001; B), but continued improvements between T2 (M = .36, SD = .48) and T3 (M = .38, SD = .49) were not statistically significant (p = .122; ).
Table 4. Final analysis models for Experiment 2: Form tasks.
There was a small but statistically significant effect of density (β = −0.11, SE = 0.05, Z = −2.254, p = .025): word-forms associated with low neighbourhood density concepts were better recalled (M = .33, SD = .47) than those associated with high-density concepts (M = .29, SD = .46). This density effect did not change over time, and the interaction was pruned from the final model (p = .383).
Form recognition
A technical issue meant that T1 form recognition and semantic categorisation data from the first set of participants was not saved from Testable (n = 9), and this issue also affected a later session for two participants. Unfortunately it was not possible to replace these participants due to timing constraints, and our main hypotheses related to the explicit recall measures for this experiment. We removed any participants who did not have data from at least two of the three sessions, leaving 65 participants for these analyses.
Recognition of the new word-forms was much higher than participants’ ability to recall them. Performance was lowest at the first test point (M = 0.91, SD = 0.29; delay1: β = 0.11, SE = 0.04, Z = 2.59, p = .010), but there were no further changes in performance between the day (M = .94, SD = .24) and week (M = .93, SD = .26; p = .578) tests. There was a small but significant effect of neighbourhood density (β = 0.21, SE = 0.11, Z = 1.97, p = .049): performance was slightly higher for high-density items (M = .93, SD = .26) than low-density (M = .92, SD = .27). However, there was no evidence of an interaction with test session (pruned from final model; p = .951; ).
Cued meaning recallFootnote4
Participants scored an average of 0.39 (SD = 0.78) points per item at the first test, which did not change over time (ps > .7; D; ). Whilst this level of performance was highly comparable to Experiment 1 (M = .36, SD = .76), recall of meanings was not affected by the semantic neighbourhood density of the concepts in adult participants (p = .704).
Table 5. Final analysis model for Experiment 2: Cued meaning recall.
Semantic categorisation
Accuracy
Accuracy was generally very low (M = .57, SD = .50), and did not change across the course of the week (ps > .35). There was also no significant effect of neighbourhood density (p = .508; Table A2-3).
Reaction time
At this low level of performance, 16 participants were excluded from RT analyses on the basis of chance-level performance (note that this exclusion was not specified in the pre-registration due to an oversight). This left 49 participants in the analysis, who ranged from .51-.74 in categorisation accuracy (M = .60). Only 44.98% of the data was retained after data trimming (as above), and so caution is needed in interpreting these data. Modelling was carried out on the log-transformed data, and showed only a decrease in reaction time across test sessions: participants were slowest at the first test (M = 1202 ms, SD = 495 ms; delay1: β = −0.08, SE = 0.01, t = −6.45, p < .001), and continued to improve between the day (M = 1017 ms, SD = 430 ms) and week (M = 911 ms, SD = 403 ms) memory tests (delay2: β = −0.05, SE = 0.02, t = −2.71, p = .010). There was no effect of neighbourhood density (p = .344; Table A2-4).
Experiment 2 discussion
In Experiment 2, we examined whether semantic neighbourhood density influences adults’ word learning. To draw comparisons with children in Experiment 1, we used more items and fewer exposures to the new stimuli to create a similar level of task difficulty between the two groups. Adults recalled a comparable proportion of the stimuli across the different tasks to children, but note that the overall information learned was still higher for adults as they were provided with more items (24 vs. 16). Consistent with the results of Experiment 1, memory for new word-forms improved over repeated tests distributed across the week, whereas definition knowledge remained stable.
Like children, adults were influenced by semantic neighbourhood density in recalling the new items. However, while children had been influenced by the semantic manipulation in recalling the word meanings, adults showed this effect in recalling the word-forms—despite no explicit demands on accessing semantic knowledge in these tasks. For word-form recall, the effects of semantic neighbourhood density were similar in direction to those observed Experiment 1, demonstrating a disadvantage for high-density items. However, this was also accompanied by a small benefit for recognising high-density items. In contrast to children, adults were not influenced by semantic density in recalling the novel meanings.
Additional exploratory analyses
The results suggest that both children and adults experienced interference from high-density semantic neighbourhoods, but there were group differences in how this interference manifested in the different measures of word learning. We conducted additional exploratory analyses to assess whether these patterns of performance for explicit recall of word-forms and meanings were statistically different between the two experiments.
For each of the two recall measures, we fitted a mixed effects model with fixed effects of session, density, and group (children versus adults), with all interaction terms. Random effects were specified as above, and the full model tables can be found in Appendix 2 (Tables A2-5 and A2-6). For the word-form recall task, there were main effects of test session (delay1: β = 0.68, SE = 0.03, Z = 25.07, p < .001; delay2: β = 0.50, SE = 0.04, Z = 12.10, p < .001), reflecting the improvements seen across the week in each experiment. There was also a main effect of group (β = −0.58, SE = 0.16, Z = −3.55, p < .001), with adults performing worse than children, but this was in the context of significant interactions with test session (group*delay1: β = −0.29, SE = 0.03, Z = −10.98, p < .001; group*delay2: β = −0.43, SE = 0.04, Z = −10.44, p < .001). Pairwise contrasts for each test session showed that the two groups did not differ at the first test point (p = .942), but that children increasingly outperformed adults in their likelihood of recalling the word-forms at T2 (β = −0.88, SE = 0.33, Z = −2.62, p = .009) and T3 (β = −2.60, SE = 0.34, Z = −7.60, p < .001). There was no effect of density, alone or in interaction with any other variable.
For the meaning recall task, only the main effect of density was statistically significant (β = −0.27, SE = 0.12, Z = −2.22, p = .027), showing a benefit for recalling meanings associated with low-density semantic neighbourhoods. There was no effect of age group, alone or in interaction with any other variable.
General discussion
The two experiments showed that semantic prior knowledge influences new word learning. We used an object-based metric to test the hypothesis that more shared features could facilitate learning, in contrast to previous studies that found semantic interference from language-based measures of relatedness. However, this was not the case: both children and adults showed interference from dense feature-based neighbourhoods in recalling the new items. This semantic interference emerged for the task drawing upon meaning knowledge for children and form knowledge in adults, although cross-experiment analyses indicated that these task differences may not be robust. In the following discussion, we focus first on the nature of semantic influences during word learning, before considering possible developmental differences and implications for word learning more broadly.
The influence of semantic neighbours during word learning
The results are consistent with the few previous studies that have manipulated the availability of semantic neighbours during word learning, finding that memory for new words can be hindered by links to denser semantic neighbourhoods (Storkel & Adlof, Citation2009; Tamminen et al., Citation2013). Our findings add two key contributions to the literature here: first, that school-aged children are similarly affected by semantic neighbours as preschool children and adults; and second, that feature-based conceptualisations of semantic neighbourhoods influence learning as well as associative (language-based) metrics. Counter to predictions that semantic influences would emerge at delayed tests—following increased opportunities for the new representations to integrate with existing knowledge (Davis & Gaskell, Citation2009; McClelland et al., Citation1995)—the effects emerged immediately after training for tasks assessing explicit knowledge of the new forms and/or meanings, and did not change across the week. This early influence of existing knowledge may be due to the nature of the training task, given that related concepts were explicitly incorporated during encoding (i.e. the base concepts were named in the definitions, and participants used their prior knowledge of these concepts to draw the items). A key question for future studies is thus whether the time course of semantic influence would differ if these similarities were not made explicit during encoding, requiring learners to infer similarity with known concepts using images or feature descriptions alone.
Why then do dense semantic networks lead to poorer memory performance for new concepts in this context? One possible explanation is that the co-activation of multiple related concepts during encoding leads to competition or interference in processing. Recent findings from the lexical processing literature indicate that the high-density disadvantage may relate to the specific metrics we chose when designing our stimuli. We selected base concepts that varied in both semantic richness (the number of reported features) and density (the co-occurrence of those features in other concepts), based on early evidence that shared features facilitate lexical processing (Grondin et al., Citation2009). Since then, several studies have demonstrated that our selected measures might have opposing influences, particularly in studies of word production (Hameau et al., Citation2019; Lampe et al., Citation2022; Rabovsky et al., Citation2016). According to Lampe et al. (Citation2022), an abundance of semantic features leads to stronger lexical activation that supports faster and more accurate responses during picture naming tasks, whereas high intercorrelational density more strongly activates related concepts that cause interference. Applied to the present findings, the co-activation of a large number of related concepts when learning the high-density items may have led to interference in establishing the new semantic representation and/or when performing the recall tasks, with further research required to pinpoint the locus of this effect.
An alternative (not mutually exclusive) possibility is that a dense network of co-occurring features makes it more challenging to integrate the highly distinctive feature that made each concept novel (i.e. the new concept is relatively more atypical of existing knowledge). Framed in this way, our stimuli perhaps more closely align with computational models of learning atypical category exemplars (McClelland et al., Citation2020): across both conditions, learners had the same amount of new information—a single feature—to integrate with existing knowledge. However, when the known concept comes from a dense neighbourhood, this additional feature can be considered more atypical of existing concepts. Thus, it becomes more challenging to integrate this novel information than when there are fewer related concepts, requiring more extensive opportunities for learning and reactivation than were offered by the present study.
A third possibility for the density disadvantage relates to the way in which the feature norms themselves were derived, and the extent to which they capture relevant semantic relationships for supporting learning. Feature norms are created by asking participants to list features of different concepts, but these reports are biased towards salient and distinctive features; participants are less likely to report the ordinary features that they share with many other concepts. Thus, the metrics we used to define semantic neighbourhood density may not capture the vast array of highly familiar features known and shared for certain concepts, which may be beneficial when learning new related concepts. To explore this possibility further, we conducted some additional analyses (Appendix 3) using an alternative metric from the McRae et al. (Citation2005) feature norms as a predictor of performance across experiments: the proportion of distinctive features (i.e. the proportion of the base concept’s listed features that were not listed for other concepts). This metric was not significantly correlated to either the number of features reported or the percentage of correlated features used in initial selection of the stimuli, suggesting that it captures a different semantic dimension. The results showed that items with high feature distinctiveness were slightly harder to recall (66%) than items with fewer distinctive features (71%), suggesting that atypicality may hinder concept memory. Thus, there may be a benefit for semantic prior knowledge in word learning that was not well-captured by our design.
It is not possible to dissociate between these possible theoretical explanations with the present results, but they highlight two important aspects to consider for future studies: first, that multiple semantic dimensions should be examined simultaneously to understand their influences on learning (similar to recent analyses for word recognition, e.g. Lampe et al., Citation2022); and second, the need to distinguish between the availability of existing knowledge (here, the base concept) and the ease at which new information can be incorporated into existing networks (the novel feature). Speaking to this distinction, studies that do not require the integration of new semantic information find the opposite pattern of results to those presented here: pseudowords are more readily remembered when paired with existing concepts from higher density semantic networks (Mak & Twitchell, Citation2020). Thus, both the availability of semantic knowledge and the need to integrate new information are key considerations in understanding how prior knowledge can influence new word learning.
Finally, it is important to consider that the initial challenge of learning concepts from high-density neighbourhoods may yet translate to longer-term processing benefits over time and further exposures. Although we originally set out to examine semantic integration with the semantic categorisation tasks, we later reduced the number of stimulus exposures in the adults’ learning phase to aid in interpreting differences in semantic influences between children and adults when performing at a similar level of difficulty. Thus, perhaps unsurprisingly, we did not see any influence of semantic neighbourhood density on speeded processing as we initially had predicted (and as was observed by Tamminen et al., Citation2013). We consider that the present results thus reflect a relatively early stage of new word knowledge, and that the new word meanings were not well-consolidated into vocabulary during the course of the experiment. With additional learning opportunities, dense semantic neighbourhoods may yet provide a beneficial role in new word knowledge. In line with this possibility, Mak et al. (Citation2021) demonstrated that words encountered across semantically diverse texts are more poorly learned than those encountered in a single semantic context in the first instance, but that diversity comes to benefit word knowledge after an initial period of stabilisation has occurred. Thus, with more opportunities for training over a longer period of time, the disadvantages seen for learning high-density concepts in the present study may translate to a longer-term processing benefit for the new words, in line with the lexical processing advantage observed for the base concepts themselves.
Developmental differences in semantic influences
We tested children and adults using the same experimental paradigm, providing an insight into the influence of semantic knowledge on word learning across development. It was clear that both groups accessed related semantic knowledge during the experiment, marked by superior recall of items associated with low- versus high-density semantic neighbourhoods. Yet there was some indication of a developmental difference in how these neighbourhood effects manifest in task performance. In Experiment 1, children were influenced by neighbourhood density only in their recall of meanings and not word-forms. For adults in Experiment 2 however (and non-significantly in Experiment S1), neighbourhood density effects were most apparent in the form recall measure—despite no requirement for semantic knowledge to be retrieved for task success. These task differences were not anticipated and may be spurious—indeed, it is important to stress that the cross-experiment analyses did not find clear evidence of developmental differences in neighbourhood effects. However, we can consider that perhaps only the mature lexical-semantic system activates semantic knowledge so automatically during learning that it affects the resources available to encode or retrieve associated word-forms, given that this activation is experience-dependent (Pexman, Citation2020). On the converse, strengths in explicit learning may mean that adults can overcome semantic competition in the definitions task. These possibilities warrant further investigation in studies designed and powered to examine developmental differences.
Encoding and consolidation processes in word learning
Moving beyond the influence of semantic neighbours, the results are consistent with previous studies demonstrating improvements in word-form knowledge with repeated tests across a week period (e.g. Henderson et al., Citation2013; James et al., Citation2019; Storkel, Citation2001; Tamminen et al., Citation2010). These improvements are consistent with the hypothesis that new word knowledge is strengthened “offline”, via opportunities for hippocampal reactivation during sleep (Davis & Gaskell, Citation2009; McClelland et al., Citation1995), and/or that performance improves with repeated retrieval practice (Goossens et al., Citation2014). A first notable finding here is that participants demonstrated clear gains in word-form knowledge but not meaning knowledge, despite comparably low initial performance in these tasks. A likely key factor in this difference in gains is that participants were re-exposed to the word-forms at each test point (i.e. in the form recognition task, and as a cue for the definition recall task), whereas there was no further re-exposure to the novel meanings. With further opportunities for (re-)encoding the word-forms, it is perhaps no surprise that such impressive gains were seen across the course of the week.
However, we also consider the possibility that differences in gains are additionally influenced by the extent to which different aspects of new word knowledge can build on existing representations, in line with a complementary learning systems perspective. That is, this discrepancy is similarly observed in studies that equate opportunities to re-encode form and meaning aspects of new word knowledge, suggesting that repeated exposures may not be the only contributing factor. For example, the repeated tests in James et al. (Citation2020a) incorporated a single re-exposure of the word-form (as a cue for meaning recall) and training image (as a cue for a picture naming task) at three test points over 24 h. While word-form recall improved after sleep, definition recall remained stable across periods of wake and sleep despite repeated opportunities to re-encode semantic features. In the context of the present experiment, the word-forms represented a relatively arbitrary combination of sounds, proposed to be dependent on the hippocampal system at encoding and thus most reliant on reactivation to support neocortical consolidation (James et al., Citation2019). On the converse, the word meanings created for this experiment were novel variants of known concepts, directly building on existing representations in both semantic neighbourhood conditions. Recent computational studies have conceptualised the neocortical system as being prior knowledge-dependent (Kumaran et al., Citation2016; McClelland, Citation2013; McClelland et al., Citation2020), indicating that neocortical learning can occur rapidly in the context of existing knowledge without requiring hippocampal reactivation. Thus, while semantic aspects of new word knowledge may sometimes benefit from offline consolidation (e.g. McGregor et al., Citation2013), the scope for capitalising upon existing semantic connections may render this effect less robust across studies than the benefits observed for word-form memory. Whether this explanation would hold beyond the confound of repeated word-form tests within the present design remains an open question, which could be better addressed by using a between-subjects manipulation of test delay.
The second notable finding is that children showed greater improvements in word-form knowledge across the week than adults. We emphasise caution in interpreting this result: first because it was the result of an exploratory analysis, and second because of some methodological differences between the two experiments (i.e. the spoken versus written modality of the recall test). However, superior long-term retention of word-forms in children has been demonstrated across several previous studies (James et al., Citation2019; Smalle et al., Citation2018), including those using identical training and test paradigms across the two groups (James et al., Citation2020b). A valuable contribution of the present study is that interpretation of these group differences is often confounded by adults’ relative strength in initial encoding: do children benefit more by delayed tests because of developmental differences in memory processes, or is it simply that there is more scope for improvement when initial learning is weak? We found here that children continue to show delayed benefits relative to adults even when matched for initial difficulty in the first test session. This benefit is in line with evidence suggesting an enhanced role for sleep in children’s memory consolidation (Peiffer et al., Citation2020; Wilhelm et al., Citation2012; Wilhelm et al., Citation2013), linked to a higher proportion of the slow neural oscillations that are associated with memory consolidation processes. However, other studies have also found superior memory retention in children across shorter periods that do not contain sleep (Bishop et al., Citation2012; Smalle et al., Citation2018), suggesting that multiple mechanisms may contribute to enhanced vocabulary consolidation during this period. Indeed, it could be that children benefit more than adults from the retrieval practice or re-encoding opportunities at each test point. A valuable next step here will be to examine whether developmental differences remain when the test delay is a between-subjects manipulation, with different groups completing only a single test either the same day, the next day, and one week later. Understanding these developmental differences in longer-term memory processes, and whether we can capitalise upon them to support vocabulary development, presents an exciting avenue for future research.
Conclusions
It is well-established that prior knowledge affects new learning. This study built upon previous studies of phonological knowledge in vocabulary learning to show that semantic neighbours also affect the acquisition of new words. Further, these semantic influences can be captured by object-based metrics, as well as the associative semantic dimensions used in previous studies (Storkel & Adlof, Citation2009; Tamminen et al., Citation2013). We found that by training pseudowords and associated novel concepts with close semantic neighbours (i.e. differing in a single feature), children and adults found it harder to learn and/or remember new words associated with dense feature neighbourhoods. Given that these findings somewhat contradict the semantic density benefits observed in studies of known words, we propose that time and/or experience, semantic dimension, and semantic distance should each be thoroughly examined to understand the role that prior semantic knowledge plays in vocabulary acquisition.
Supplemental Appendix
Download MS Word (24.6 KB)Acknowledgment
An earlier version of this manuscript was published in the first author's PhD thesis, and we would like to thank Professor Dorothy Bishop for suggesting further exploratory analyses.
Data availability statement
All materials, data, and analyses are available at https://osf.io/35ftn/.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes
1 Experiment S1 used original items selected from the English Lexicon Project. Due to experimenter error, slight variants of four of the items were used in Experiment 1 (i.e., attie, bryat, shamal, vorgol instead of attay, bryet, shimal, vorgal). However, we recomputed orthographic neighbourhood density and bigram frequency based on the new set to confirm that these did not differ between word lists, and retained the amended version for both Experiment 1 and 2 here to facilitate developmental comparisons.
2 Only 18 of the 24 items were also entries in the Florida Free Association Norms. These indicated that the two sets would likely differ in semantic neighbourhood density by this measure, with high-density concepts having more associates (M = 17.33) than low-density concepts (M = 12.22; p = .05).
3 Note that the pre-registration refers to a significant effect of semantic neighbourhood density for cued form recall in an initial adult experiment (Experiment S1). This was due to an error in which test session was entered into analyses as a continuous rather than categorical predictor.
4 One participant did not complete 2/3 definitions tests, and was excluded from this analysis.
References
- Antony, J. W., Ferreira, C. S., Norman, K. A., & Wimber, M. (2017). Retrieval as a fast route to memory consolidation. Trends in Cognitive Sciences, 21(8), 573–576. https://doi.org/10.1016/j.tics.2017.05.001
- Ashworth, A., Hill, C. M., Karmiloff-Smith, A., & Dimitriou, D. (2014). Sleep enhances memory consolidation in children. Journal of Sleep Research, 23(3), 304–310. https://doi.org/10.1111/jsr.12119
- Baayen, R. H., Piepenbrock, R., & Gulikers, L. (1995). The CELEX lexical database (release 2). Distributed by the Linguistic Data Consortium, University of Pennsylvania.
- Balota, D. A., Yap, M. J., Hutchison, K. A., Cortese, M. J., Kessler, B., Loftis, B., Neely, J. H., Nelson, D. L., Simpson, G. B., & Treiman, R. (2007). The English lexicon project. Behavior Research Methods, 39(3), 445–459. https://doi.org/10.3758/BF03193014
- Barr, D. J., Levy, R., Scheepers, C., & Tily, H. J. (2013). Random effects structure for confirmatory hypothesis testing: Keep it maximal. Journal of Memory and Language, 68(3), 255–278. https://doi.org/10.1016/j.jml.2012.11.001
- Bates, D., Kliegl, R., Vasishth, S., & Baayen, H. (2015a). Parsimonious mixed models. arXiv Preprint ArXiv, 1506, 04967. https://doi.org/10.48550/arXiv.1506.04967
- Bates, D., Maechler, M., Bolker, B., & Walker, S. (2015b). Fitting linear mixed-effects models using lme4. Journal of Statistical Software, 67(1), 1–48. https://doi.org/10.18637/jss.v067.i01
- Bishop, D. V., Barry, J. G., & Hardiman, M. J. (2012). Delayed retention of new word-forms is better in children than adults regardless of language ability: A factorial two-way study. PloS one, 7(5), e37326. https://doi.org/10.1371/journal.pone.0037326
- Borovsky, A., Ellis, E. M., Evans, J. L., & Elman, J. L. (2016). Lexical leverage: Category knowledge boosts real-time novel word recognition in 2-year-olds. Developmental Science, 19(6), 918–932. https://doi.org/10.1111/desc.12343
- Brysbaert, M., Warriner, A. B., & Kuperman, V. (2014). Concreteness ratings for 40 thousand generally known English word lemmas. Behavior Research Methods, 46(3), 904–911. https://doi.org/10.3758/s13428-013-0403-5
- Buchanan, L., Westbury, C., & Burgess, C. (2001). Characterizing semantic space: Neighborhood effects in word recognition. Psychonomic Bulletin & Review, 8(3), 531–544. https://doi.org/10.3758/BF03196189
- Christensen, R. H. B. (2015). Ordinal-Regression models for ordinal data. R Package Version 2015.6-28. http://www.cran.r-project.org/package=ordinal.
- Clay, F., Bowers, J. S., Davis, C. J., & Hanley, D. A. (2007). Teaching adults new words: The role of practice and consolidation. Journal of Experimental Psychology: Learning, Memory, and Cognition, 33(5), 970. https://doi.org/10.1037/0278-7393.33.5.970
- Coltheart, M. (1981). The MRC psycholinguistic database. The Quarterly Journal of Experimental Psychology Section A, 33(4), 497–505. https://doi.org/10.1080/14640748108400805
- Davies, R. A., Arnell, R., Birchenough, J. M., Grimmond, D., & Houlson, S. (2017). Reading through the life span: Individual differences in psycholinguistic effects. Journal of Experimental Psychology: Learning, Memory, and Cognition, 43(8), 1298. https://doi.org/10.1037/xlm0000366
- Davis, M. H., & Gaskell, M. G. (2009). A complementary systems account of word learning: Neural and behavioural evidence. Philosophical Transactions of the Royal Society B: Biological Sciences, 364(1536), 3773–3800. https://doi.org/10.1098/rstb.2009.0111
- Dumay, N., & Gaskell, M. G. (2007). Sleep-associated changes in the mental representation of spoken words. Psychological Science, 18(1), 35–39. https://doi.org/10.1111/j.1467-9280.2007.01845.x
- Engelthaler, T., & Hills, T. T. (2017). Feature biases in early word learning: Network distinctiveness predicts age of acquisition. Cognitive Science, 41, 120–140. https://doi.org/10.1111/cogs.12350
- Forster, K. I., & Forster, J. C. (2003). Dmdx: A windows display program with millisecond accuracy. Behavior Research Methods, Instruments, & Computers, 35(1), 116–124. https://doi.org/10.3758/BF03195503
- Gais, S., Lucas, B., & Born, J. (2006). Sleep after learning aids memory recall. Learning & Memory, 13(3), 259–262. https://doi.org/10.1101/lm.132106
- Gaskell, M. G., & Marslen-Wilson, W. D. (1997). Integrating form and meaning: A distributed model of speech perception. Language and Cognitive Processes, 12(5-6), 613–656. https://doi.org/10.1080/016909697386646
- Goossens, N. A., Camp, G., Verkoeijen, P. P., & Tabbers, H. K. (2014). The effect of retrieval practice in primary school vocabulary learning. Applied Cognitive Psychology, 28(1), 135–142. https://doi.org/10.1002/acp.2956
- Grondin, R., Lupker, S. J., & McRae, K. (2009). Shared features dominate semantic richness effects for concrete concepts. Journal of Memory and Language, 60(1), 1–19. https://doi.org/10.1016/j.jml.2008.09.001
- Hameau, S., Nickels, L., & Biedermann, B. (2019). Effects of semantic neighbourhood density on spoken word production. Quarterly Journal of Experimental Psychology, 72(12), 2752–2775. https://doi.org/10.1177/1747021819859850
- Henderson, L. M., Weighall, A., & Gaskell, G. (2013). Learning new vocabulary during childhood: Effects of semantic training on lexical consolidation and integration. Journal of Experimental Child Psychology, 116(3), 572–592. https://doi.org/10.1016/j.jecp.2013.07.004
- Henderson, L. M., Weighall, A. R., Brown, H., & Gaskell, M. G. (2012). Consolidation of vocabulary is associated with sleep in children. Developmental Science, 15(5), 674–687. https://doi.org/10.1111/j.1467-7687.2012.01172.x
- Hills, T. T., Maouene, M., Maouene, J., Sheya, A., & Smith, L. (2009). Longitudinal analysis of early semantic networks. Psychological Science, 20(6), 729–739. https://doi.org/10.1111/j.1467-9280.2009.02365.x
- Hoover, J. R., Storkel, H. L., & Hogan, T. P. (2010). A cross-sectional comparison of the effects of phonotactic probability and neighborhood density on word learning by preschool children. Journal of Memory and Language, 63(1), 100–116. https://doi.org/10.1016/j.jml.2010.02.003
- Hulme, R. C., & Rodd, J. M. (2021). Learning new word meanings from story reading: The benefit of immediate testing. PeerJ, 9, e11693. https://doi.org/10.7717/peerj.11693
- James, E., Gaskell, M. G., & Henderson, L. M. (2019). Offline consolidation supersedes prior knowledge benefits in children's (but not adults’) word learning. Developmental Science, 22(3), e12776. https://doi.org/10.1111/desc.12776
- James, E., Gaskell, M. G., & Henderson, L. M. (2020a). Sleep-dependent consolidation in children with comprehension and vocabulary weaknesses: It’ll be alright on the night? Journal of Child Psychology and Psychiatry, 61(10), 1104–1115. https://doi.org/10.1111/jcpp.13253
- James, E., Gaskell, M. G., Pearce, R., Korell, C., Dean, C., & Henderson, L.-M. (2020b). The role of prior lexical knowledge in children's and adults’ incidental word learning from illustrated stories. Journal of Experimental Psychology: Learning, Memory, and Cognition, 47(11), 1856–1869. https://doi.org/10.31234/osf.io/vm5ad
- James, E., Gaskell, M. G., Weighall, A., & Henderson, L. (2017). Consolidation of vocabulary during sleep: The rich get richer? Neuroscience & Biobehavioral Reviews, 77, 1–13. https://doi.org/10.1016/j.neubiorev.2017.01.054
- Kumaran, D., Hassabis, D., & McClelland, J. L. (2016). What learning systems do intelligent agents need? Complementary learning systems theory updated. Trends in Cognitive Sciences, 20(7), 512–534. https://doi.org/10.1016/j.tics.2016.05.004
- Kuperman, V., Stadthagen-Gonzalez, H., & Brysbaert, M. (2012). Age-of-acquisition ratings for 30,000 English words. Behavior Research Methods, 44(4), 978–990. https://doi.org/10.3758/s13428-012-0210-4
- Kuznetsova, A., Brockhoff, P. B., & Christensen, R. H. (2017). lmerTest package: Tests in linear mixed effects models. Journal of Statistical Software, 82(13), 1–26. https://doi.org/10.18637/jss.v082.i13
- Lampe, L. F., Hameau, S., & Nickels, L. (2022). Semantic variables both help and hinder word production: Behavioral evidence from picture naming. Journal of Experimental Psychology: Learning, Memory, and Cognition, 48(1), 72–97. https://doi.org/10.1037/xlm0001050
- Mak, M. H., Hsiao, Y., & Nation, K. (2021). Anchoring and contextual variation in the early stages of incidental word learning during reading. Journal of Memory and Language, 118, 104203. https://doi.org/10.1016/j.jml.2020.104203
- Mak, M. H., & Twitchell, H. (2020). Evidence for preferential attachment: Words that are more well connected in semantic networks are better at acquiring new links in paired-associate learning. Psychonomic Bulletin & Review, 27(5), 1059–1069. https://doi.org/10.3758/s13423-020-01773-0
- Marian, V., Bartolotti, J., Chabal, S., & Shook, A. (2012). Clearpond: Cross-linguistic easy-access resource for phonological and orthographic neighborhood densities. PloS one, 7(8), e43230. https://doi.org/10.1371/journal.pone.0043230
- McClelland, J. L. (2013). Incorporating rapid neocortical learning of new schema-consistent information into complementary learning systems theory. Journal of Experimental Psychology: General, 142(4), 1190. https://doi.org/10.1037/a0033812
- McClelland, J. L., McNaughton, B. L., & Lampinen, A. K. (2020). Integration of new information in memory: New insights from a complementary learning systems perspective. Philosophical Transactions of the Royal Society B: Biological Sciences, 375(1799), 20190637. https://doi.org/10.1098/rstb.2019.0637
- McClelland, J. L., McNaughton, B. L., & O'Reilly, R. C. (1995). Why there are complementary learning systems in the hippocampus and neocortex: Insights from the successes and failures of connectionist models of learning and memory. Psychological Review, 102(3), 419. https://doi.org/10.1037/0033-295X.102.3.419
- McGregor, K. K., Licandro, U., Arenas, R., Eden, N., Stiles, D., Bean, A., & Walker, E. (2013). Why words are hard for adults with developmental language impairments. Journal of Speech, Language, and Hearing Research, 56(6), 1845–1856. https://doi.org/10.1044/1092-4388(2013/12-0233)
- McRae, K., Cree, G. S., Seidenberg, M. S., & McNorgan, C. (2005). Semantic feature production norms for a large set of living and nonliving things. Behavior Research Methods, 37(4), 547–559. https://doi.org/10.3758/BF03192726
- Mirman, D., & Magnuson, J. S. (2008). Attractor dynamics and semantic neighborhood density: Processing is slowed by near neighbors and speeded by distant neighbors. Journal of Experimental Psychology: Learning, Memory, and Cognition, 34(1), 65. https://doi.org/10.1037/0278-7393.34.1.65
- Nelson, D. L., McEvoy, C. L., & Schreiber, T. A. (2004). The University of south florida free association, rhyme, and word fragment norms. Behavior Research Methods, Instruments, & Computers, 36(3), 402–407. https://doi.org/10.3758/BF03195588
- Peiffer, A., Brichet, M., De Tiège, X., Peigneux, P., & Urbain, C. (2020). Re-epithelialization and immune cell behaviour in an ex vivo human skin model. Scientific Reports, 10(1), 1–9. https://doi.org/10.1038/s41598-019-56847-4
- Perry, L. K., Axelsson, E. L., & Horst, J. S. (2016). Learning what to remember: Vocabulary knowledge and children's memory for object names and features. Infant and Child Development, 25(4), 247–258. https://doi.org/10.1002/icd.1933
- Pexman, P. M. (2020). How does meaning come to mind? Four broad principles of semantic processing. Canadian Journal of Experimental Psychology/Revue Canadienne de Psychologie Expérimentale, 74(4), 275–283. https://doi.org/10.1037/cep0000235
- Pexman, P. M., Hargreaves, I. S., Siakaluk, P. D., Bodner, G. E., & Pope, J. (2008). There are many ways to be rich: Effects of three measures of semantic richness on visual word recognition. Psychonomic Bulletin & Review, 15(1), 161–167. https://doi.org/10.3758/PBR.15.1.161
- Pexman, P. M., & Yap, M. J. (2018). Individual differences in semantic processing: Insights from the calgary semantic decision project. Journal of Experimental Psychology: Learning, Memory, and Cognition, 44(7), 1091. https://doi.org/10.1037/xlm0000499
- Qualtrics (2014). Qualtrics [software]. Provo, UT, USA: Qualtrics.
- Rabovsky, M., Schad, D. J., & Rahman, R. A. (2016). Language production is facilitated by semantic richness but inhibited by semantic density: Evidence from picture naming. Cognition, 146, 240–244. https://doi.org/10.1016/j.cognition.2015.09.016
- R Core Team. (2015). R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. http://www.R-project.org/.
- Rezlescu, C. (2015). Testable: The web-based platform for creating, running and sharing behavioural experiments. Association for Psychological Science Teaching institute conference, New York, 21–24 May.
- Smalle, E. H., Page, M. P., Duyck, W., Edwards, M., & Szmalec, A. (2018). Children retain implicitly learned phonological sequences better than adults: A longitudinal study. Developmental Science, 21(5), e12634. https://doi.org/10.1111/desc.12634
- Storkel, H. L. (2001). Learning new words. Journal of Speech, Language, and Hearing Research, 44(6), 1321–1337. https://doi.org/10.1044/1092-4388(2001/103)
- Storkel, H. L. (2009). Developmental differences in the effects of phonological, lexical and semantic variables on word learning by infants. Journal of Child Language, 36(02), 291–321. https://doi.org/10.1017/S030500090800891X
- Storkel, H. L., & Adlof, S. M. (2009). The effect of semantic set size on word learning by preschool children. Journal of Speech, Language, and Hearing Research, 52(2), 306–320. http://jslhr.pubs.asha.org/data/Journals/JSLHR/929279/jslhr_52_2_306.pdf. https://doi.org/10.1044/1092-4388(2009/07-0175)
- Storkel, H. L., Armbrüster, J., & Hogan, T. P. (2006). Differentiating phonotactic probability and neighborhood density in adult word learning. Journal of Speech, Language, and Hearing Research, 49(6), 1175–1192. https://doi.org/10.1044/1092-4388(2006/085)
- Storkel, H. L., Bontempo, D. E., Aschenbrenner, A. J., Maekawa, J., & Lee, S.-Y. (2013). The effect of incremental changes in phonotactic probability and neighborhood density on word learning by preschool children. Journal of Speech, Language, and Hearing Research, 56(5), 1689–1700. https://doi.org/10.1044/1092-4388(2013/12-0245)
- Tamminen, J., Davis, M. H., Merkx, M., & Rastle, K. (2012). The role of memory consolidation in generalisation of new linguistic information. Cognition, 125(1), 107–112. https://doi.org/10.1016/j.cognition.2012.06.014
- Tamminen, J., & Gaskell, M. G. (2013). Novel word integration in the mental lexicon: Evidence from unmasked and masked semantic priming. Quarterly Journal of Experimental Psychology, 66(5), 1001–1025. https://doi.org/10.1080/17470218.2012.724694
- Tamminen, J., Lambon Ralph, M. A., & Lewis, P. A. (2013). The role of sleep spindles and slow-wave activity in integrating new information in semantic memory. The Journal of Neuroscience, 33(39), 15376–15381. https://doi.org/10.1523/JNEUROSCI.5093-12.2013
- Tamminen, J., Payne, J. D., Stickgold, R., Wamsley, E. J., & Gaskell, M. G. (2010). Sleep spindle activity is associated with the integration of new memories and existing knowledge. Journal of Neuroscience, 30(43), 14356–14360. https://doi.org/10.1523/JNEUROSCI.3028-10.2010
- Tham, E. K., Lindsay, S., & Gaskell, M. G. (2015). Markers of automaticity in sleep-associated consolidation of novel words. Neuropsychologia, 71, 146–157. https://doi.org/10.1016/j.neuropsychologia.2015.03.025
- Tse, D., Langston, R. F., Kakeyama, M., Bethus, I., Spooner, P. A., Wood, E. R., Witter, M. P., & Morris, R. G. (2007). Schemas and memory consolidation. Science, 316(5821), 76–82. https://doi.org/10.1126/science.1135935
- van der Kleij, S. W., Rispens, J. E., & Scheper, A. R. (2016). The effect of phonotactic probability and neighbourhood density on pseudoword learning in 6- and 7-year-old children. First Language, 36(2), 93–108. https://doi.org/10.1177/0142723715626064
- Wechsler, D. (2011). WASI-II: Wechsler Abbreviated Scale of intelligence. Pearson.
- Wickham, H. (2009). Ggplot2: Elegant graphics for data analysis. Springer Science & Business Media.
- Wilhelm, I., Prehn-Kristensen, A., & Born, J. (2012). Sleep-dependent memory consolidation – what can be learnt from children? Neuroscience & Biobehavioral Reviews, 36(7), 1718–1728. https://doi.org/10.1016/j.neubiorev.2012.03.002
- Wilhelm, I., Rose, M., Imhof, K. I., Rasch, B., Büchel, C., & Born, J. (2013). The sleeping child outplays the adult's capacity to convert implicit into explicit knowledge. Nature Neuroscience, 16(4), 391-393. https://doi.org/10.1038/nn.3343